Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Agrar- und Ernährungspolitik III
Vorlesung 11. März 2009 Statistik und Modellierung auf Grundlage einzelbetrieblicher Daten Martin Kniepert

2
Übersicht Auswahl einzelbetrieblicher Daten Buchhaltungsdaten
Auswahlrahmen Stichprobenbestimmung (Streuungsplan) Konfidenzintervalle Hochrechnungen
 Konfidenzintervalle. Hochrechnungen.")
3
Zur Berechnung von Einkommen in der Agrarwirtschaft
Marktorientierte Ansätze insbesondere die LGR (=> spätere Vorlesung) Unmittelbar betriebsorientierte Ansätze – Auswertung von Buchhaltungsergebnissen landwirtschaftlicher Betriebe Problem: Die Betriebe können nicht insgesamt erhoben werden. Lösung: Stichprobenerhebung aus der Grundgesamtheit
 Unmittelbar betriebsorientierte Ansätze – Auswertung von Buchhaltungsergebnissen landwirtschaftlicher Betriebe. Problem: Die Betriebe können nicht insgesamt erhoben werden. Lösung: Stichprobenerhebung aus der Grundgesamtheit.")
4
Exkurs: NACE 01 bis 05 Pflanzlich gem. Tier Jagd Lohn Forst Fisch

5
Exkurs: Urlaub auf dem Bauernhof
Die Betriebe in ihrer Mischstruktur abzubilden kommt dabei auch dem agrarpolitischen Verständnis entgegen, die Multifunktionalität der Agrarproduktion im Auge zu behalten. Möglichkeiten zur Kombination von touristischem Angebot mit Landwirtschaft (Urlaub auf dem Bauernhof; Direktvermarktung die NitNils) Tourismus Land-wirtschaft
 Tourismus. Land-wirtschaft.")
6
Agrarregister Registrierung aller landwirtschaftlichen Betriebe mit Sitz in Österreich Stammdaten Betriebsnummer, Adresse, Name Bewirtschafterin Erhebungsspezifische Daten Eckdaten Fläche Eckdaten Nutztierbestand … Standarddeckungsbeitrag (SDB)
")
7
Strukturerhebungen Betriebliche Erhebungen
Die Agrarstrukturerhebung (AS, als Vollerhebung: 1995, 1999, 2010, als Stichprobe 2003, 2005, 2007, 2013, 2016; für AT) Anbau auf dem Ackerland (jährlich; dient auch als Grundlage für die Agrarstrukturerhebung) Weingartenerhebung Etc. Rechtliche Grundlagen sind Voraussetzungen In der Umsetzung enge Verzahnung verschiedener Verwaltungsdaten (insbesondere Mehrfachantrag der AMA) und sonstiger Erhebungen Anbau auf dem Ackerland Allgemeine Viehzählung, die ihrerseits wieder verschiedene Datenbestände integriert
 Anbau auf dem Ackerland (jährlich; dient auch als Grundlage für die Agrarstrukturerhebung) Weingartenerhebung. Etc. Rechtliche Grundlagen sind Voraussetzungen. In der Umsetzung enge Verzahnung verschiedener Verwaltungsdaten (insbesondere Mehrfachantrag der AMA) und sonstiger Erhebungen. Anbau auf dem Ackerland. Allgemeine Viehzählung, die ihrerseits wieder verschiedene Datenbestände integriert.")
8
Strukturerhebung (2) Jeweils Vergleichbarkeit von Daten überprüfen!
Erfassungsuntergrenzen unterschiedlich nach Jahren, Betriebsformen etc. Bspw. AS 1995: 1 ha Gesamtfläche; Bspw. AS 1999: 1 ha landwirtschaftliche genutzte Fläche etc. Veränderte Erhebungsmethoden Viehzählung über die Gemeinden => Rinderdatenbank (seit… Geflügelzählung über Gemeinden => QGV Jeweils Vergleichbarkeit von Daten überprüfen!

9
Exkurs: Datenerhebung
Nicht aus wissenschaftlichem Interesse Bspw. Veränderte Erhebungsmethoden Viehzählung über die Gemeinden => Rinderdatenbank (seit… Geflügelzählung über Gemeinden => (Östereichische Qualitätsgeflügelvereinigung (QGV) etc. Jeweils Vergleichbarkeit von Daten überprüfen!
 etc. Jeweils Vergleichbarkeit von Daten überprüfen!")
10
Das INLB (1) Das Informationsnetz Landwirtschaftlicher Buchführung (INLB; engl.: FADN, frz.: RICA) Basierend auf EU-Verordnungen Weiter zu Rechtsgrundlagen... INLB: „ ... die einzige Quelle mikroökonomischer Daten (..), die harmonisiert sind, d. h. die Buchhaltungsgrundsätze sind in allen Ländern gleich.“ [Anspruch] RI/CC 882 Rev.7.0
, die harmonisiert sind, d. h. die Buchhaltungsgrundsätze sind in allen Ländern gleich. [Anspruch] RI/CC 882 Rev.7.0.")
11
Das INLB (2) Für das INLB wird eine Stichprobe aus Gesamtzahl der lw. Betriebe gezogen. Die Stichprobe bezieht sich auf Betriebe in einem bestimmten Auswahlrahmen Die Auswahl der Betriebe erfolgt nicht nach dem Zufallsprinzip, sondern gezielt nach ausgewählten Kriterien. [Berücksichtigt werden für Österreich übrigens bestimmte Aspekte, die für die EU insgesamt weniger wichtig sind; streng genommen ist das INLB eine Sonderauswertung der österreichischen Ergebnisse der lw. Buchführung.]

12
Der Auswahlrahmen in Österreich (1)
6.000 € > StDB > € Betriebe > 200 ha Wald bleiben ausgeschlossen Betriebe mit > 25% Gartenbauanteil bleiben ausgeschlossen => Konzentrationsprinzip (vgl. Kromrey 1994:203) Auswahl-rahmen Bäuerlich Betriebe insg. % Bäuerliche Betriebe Betriebe insgesamt Anzahl 54 Fläche (ha) 85 ... GVE 92 GSDB 83 Quelle: Grüner Bericht 2004
 Auswahl-rahmen. Bäuerlich Betriebe insg. % Bäuerliche. Betriebe. Betriebe insgesamt. Anzahl Fläche (ha) GVE GSDB Quelle: Grüner Bericht")
13
Der Auswahlrahmen in Österreich (2)
Kleinstbetriebe Großbetriebe Auswahlrahmen Buchführungsergebnisse Gartenbau, große Forstbetriebe

14
Reine Zufallsstichprobe vs. „repräsentative“ Stichprobe
Mindestens Betriebe entspr. 1,96 % der Gesamtzahl des Auswahlrahmens ( ) Repräsentationsrelevante Merkmale Stichprobe als verkleinertes Abbild einer Grundgesamtheit Grad der Homogenität der Grundgesamtheit wichtig für die „Stichhaltigkeit“ der Stichprobe. Stichprobenumfang n von Grundgesamtheit N Hochrechnung des Stichprobenergebnisses y auf die Grundgesamtheit: Y = y/n * N Je homogener die Grundgesamtheit ist, desto kleiner kann die Stichprobe sein, im theoretischen Grenzfall ist n = 1
 Repräsentationsrelevante Merkmale. Stichprobe als verkleinertes Abbild einer Grundgesamtheit. Grad der Homogenität der Grundgesamtheit wichtig für die „Stichhaltigkeit der Stichprobe. Stichprobenumfang n von Grundgesamtheit N. Hochrechnung des Stichprobenergebnisses y auf die Grundgesamtheit: Y = y/n * N. Je homogener die Grundgesamtheit ist, desto kleiner kann die Stichprobe sein, im theoretischen Grenzfall ist n = 1.")
15
Inhomogenität der Grundgesamtheit
Gerade die Unterschiede in einer Grundgesamtheit können Gegenstand der Untersuchung sein (Strukturentwicklung) Gut konstruierte Streuungspläne erlauben die Verringerung der Erhebungsbedarfs => Repräsentativität. Kostenersparnis Größere Sorgfalt bei Einheiten der Stichprobe möglich Kleinere Stichproben möglicherweise vorteilhafter gegenüber großen!
 Gut konstruierte Streuungspläne erlauben die Verringerung der Erhebungsbedarfs => Repräsentativität. Kostenersparnis. Größere Sorgfalt bei Einheiten der Stichprobe möglich. Kleinere Stichproben möglicherweise vorteilhafter gegenüber großen!")
16
Geschichtete Stichproben (1)
Vorteile: Größere Genauigkeit bei geringerem Aufwand; Repräsentativität Nachteil: Mit den Schichtungskriterien werden gleichzeitig die Auswertungsmöglichkeiten festgelegt: Die Repräsentativität gilt in Bezug auf Schichtungskriterien Auswertungen mit Blick bspw. auf biologische Landwirtschaft/konventionelle Landwirtschaft können sich nicht auf die gleiche Repräsentativität stützen

17
Geschichtete Stichproben (2)
Trotzdem: Die erhobenen Daten können entsprechend anderer Kriterien neu gewichtet hochgerechnet werden. Vorraussetzung: Ausreichende Anzahl von Betrieben für einen statistisch signifikanten Stichprobenumfang. Handicap: Die Betriebe wurden unter anderen Gesichtspunkten ausgewählt, das Zufallsprinzip ist insofern nicht eingehalten.

18
Streuungsplan der lw. Buchführung
70 „Schichten“ (vgl. Tab. A2, LBG 2001) Disproportional geschichtet (Hochrechnung mit Gewichten für einzelnen Schichten) Jede Schicht in der Stichprobe wird als repräsentativ für die entsprechende Schicht in der Grundgesamtheit zusammengestellt Die einzelnen Schichten (S) werden gewichtet, um auch für den Auswahlrahmen insgesamt repräsentativ zu sein Bezugsgröße: Familienarbeitskräfte, ha RLN, Größen die in der Stichprobe und in der Grundgesamtheit vorliegen.
 Disproportional geschichtet (Hochrechnung mit Gewichten für einzelnen Schichten) Jede Schicht in der Stichprobe wird als repräsentativ für die entsprechende Schicht in der Grundgesamtheit zusammengestellt. Die einzelnen Schichten (S) werden gewichtet, um auch für den Auswahlrahmen insgesamt repräsentativ zu sein. Bezugsgröße: Familienarbeitskräfte, ha RLN, Größen die in der Stichprobe und in der Grundgesamtheit vorliegen.")
19
Kriterien für den Streuungsplan (1)
4 Größenklassen (6-12 tsd tsd. €) [noch bis 2002: 8 Größenklassen] Bis 2002: Gebiet explizit im Streuungsplan alpine Lagen mittlere Höhenlagen Flach- und Hügelland zusätzlich und genauer für Österreich: Erschwerniszonen, Höhe, Hangneigung) Betriebstypen entsprechend Strukturerhebung (siehe Folgeblatt)
 [noch bis 2002: 8 Größenklassen] Bis 2002: Gebiet explizit im Streuungsplan. alpine Lagen. mittlere Höhenlagen. Flach- und Hügelland. zusätzlich und genauer für Österreich: Erschwerniszonen, Höhe, Hangneigung) Betriebstypen entsprechend Strukturerhebung (siehe Folgeblatt)")
20
Kriterien für den Streuungsplan (2)
Betriebstypen im Einzelnen Betriebe mit hohem Forstanteil (>50%) Betriebe mit 25 bis 50% Forstanteil Futterbaubetriebe (Milchkühe, sonst. Rinder, Schafe, Ziegen, Pferde u.a.) Landwirtschaftliche Mischbetriebe Marktfruchtbetriebe (Getreide, Zuckerrüben, Erdäpfel, Ölfrüchte, Alternativen, Tabak, sonst. marktfähige Produkte) Dauerkulturen (Obst- und Weinbau) Veredelung (Schweine, Geflügel)
 Betriebe mit 25 bis 50% Forstanteil. Futterbaubetriebe (Milchkühe, sonst. Rinder, Schafe, Ziegen, Pferde u.a.) Landwirtschaftliche Mischbetriebe. Marktfruchtbetriebe (Getreide, Zuckerrüben, Erdäpfel, Ölfrüchte, Alternativen, Tabak, sonst. marktfähige Produkte) Dauerkulturen (Obst- und Weinbau) Veredelung (Schweine, Geflügel)")
21
Flächen einer Normalverteilung N(μ,σ)
y 0,4 0,3 0,2 0,1 -z z μ-4σ μ-3σ μ-2σ μ-σ μ μ+σ μ+2σ μ+3σ μ+4σ 68,27% 95,45% 99,73% 99,99%

22
Standardnormalverteilung N(0,1)
Jede beliebige Normalverteilung N(μ,σ) kann durch Standardisierung in eine einheitliche Standardnormalverteilung N(0,1) transformiert (d.h. mit z multipliziert) werden. Für N(0,1) sind Flächenanteile (also Wahrscheinlich-keiten) „austabelliert“.
 kann durch Standardisierung in eine einheitliche Standardnormalverteilung N(0,1) transformiert (d.h. mit z multipliziert) werden. Für N(0,1) sind Flächenanteile (also Wahrscheinlich-keiten) „austabelliert .")
23
Flächen einer Standard-Normalverteilung N(0,1)
y 0,4 0,3 0,2 0,1 -z z -4 -3 -2 -1 1 2 3 4 68,27% 95,45% 99,73% 99,99%

24
Konfidenzintervall Das Konfidenzintervall (Δkrit) für Mittelwerte (μ) berechnet sich folgendermaßen: Für n > 30 kann diese Formel genutzt werden:

25
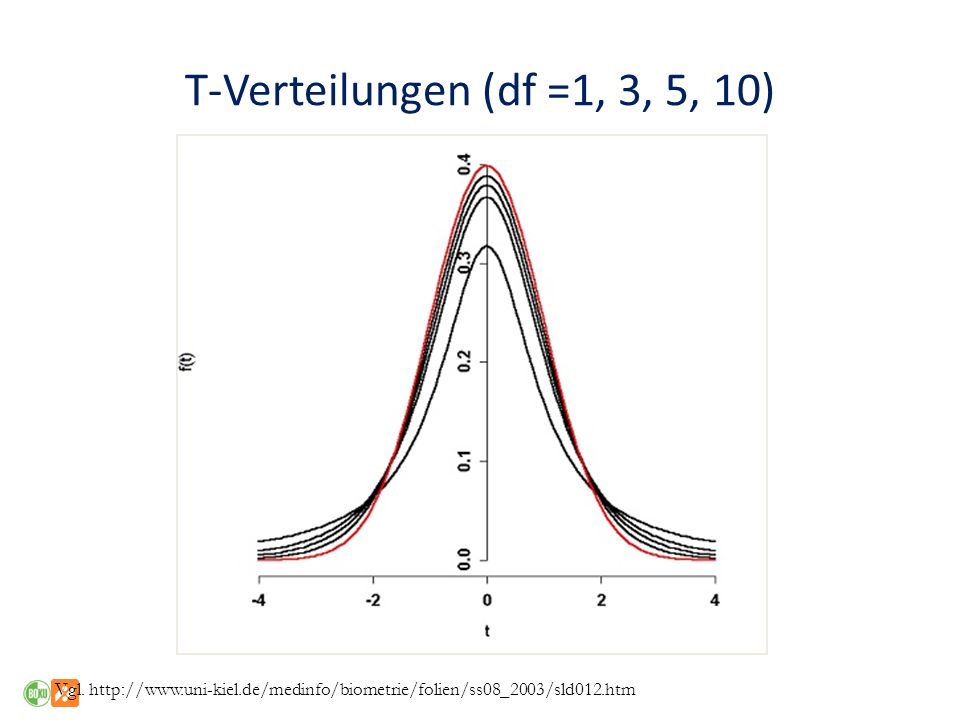
T-Verteilungen (df =1, 3, 5, 10) Vgl.
26
t-Verteilung df p 0,900 p 0,975 p 0,990 p 0,995 1 3,078 12,706 31,821 63,656 2 1,886 4,303 6,965 9,925 3 1,638 3,182 4,541 5,841 4 1,533 2,776 3,747 4,604 ... 10 1,372 2,228 2,764 3,169 30 1,310 2,042 2,457 2,750 1000 1,282 1,962 2,330 2,581

27
Zur Hypothesenbildung
Nullhypothese H0: Ein Zusammenhang zwischen zwei untersuchten Größen besteht nicht! Alternativhypothese H1: In der Regel die Forschungshypothese Ein Zusammenhang zwischen zwei untersuchten größen wird unterstell bzw. soll nachgewiesen werden.

28
Zur Hypothesenbildung (1)
Nullhypothese H0: Ein Zusammenhang zwischen zwei untersuchten Größen besteht nicht! (bspw. Steuer auf Inputverbrauch) Ein Grenzwert wird nicht überschritten, höchstens erreicht Alternativhypothese H1: In der Regel die Forschungshypothese Ein Zusammenhang zwischen zwei untersuchten Größen wird unterstellt, soll nachgewiesen werden. Ein Grenzwert wird überschritten
 Ein Grenzwert wird nicht überschritten, höchstens erreicht. Alternativhypothese H1: In der Regel die Forschungshypothese. Ein Zusammenhang zwischen zwei untersuchten Größen wird unterstellt, soll nachgewiesen werden. Ein Grenzwert wird überschritten.")
29
Zur Hypothesenbildung (2)
Nullhypothese H0 und Alternativhypothese H1 schließen sich gegenseitig aus. Bspw. H0: Pestizidbelastung <= 3 g je / kg H1 : Pestizidbelastung > 3 g je / kg Eine dritte Möglichkeit neben diesen Hypothesen bleiben nicht. Im Beispiel (3 g je / kg ) wird eine Annahmegrenze (cA) präzisiert. Der kritische Wert (c) beläuft sich auf 3 g bei einem Stichprobenumfang von 1 kg.
 wird eine Annahmegrenze (cA) präzisiert. Der kritische Wert (c) beläuft sich auf 3 g bei einem Stichprobenumfang von 1 kg.")
30
Begriffe Im Beispiel (3 g je / kg ) wird eine Annahmegrenze (cA) präzisiert. Der kritische Wert (c) beläuft sich auf 3 g bei einem Stichprobenumfang von 1 kg. Signifikanzniveau α0:
 beläuft sich auf 3 g bei einem Stichprobenumfang von 1 kg. Signifikanzniveau α0:")
31
Bestätigung? Fehler 1. und 2. Art
Wenn eine Hypothese bestätigt werden kann, gilt die andere automatisch als verworfen. Eine dritte Möglichkeit neben diesen Hypothesen bleiben nicht. Fehler 1. Art: H0 wird verworfen, obwohl H0 richtig ist. Fehler 2. Art: H0 wird angenommen, obwohl H0 falsch ist. In beiden Fällen erweist sich die Stichprobe als gewissermaßen nicht stichhaltig.

32
Beispiel Pestizid Nullhypothese H0 und Alternativhypothese H1 schließen sich gegenseitig aus. Bspw. H0: Pestizidbelastung <= 3 g je / kg H1 : Pestizidbelastung > 3 g je / kg Eine dritte Möglichkeit neben diesen Hypothesen bleiben nicht.

33
Lese- und Lernempfehlungen
Zu Signifikanztests, Konfidenzintervall etc. Sachs, Lothar (1999), Angewandte Statistik, Neunte Überarbeitete Auflage, Berlin, Heidelberg [Lehrbuchsammlung der BOKU A, insb. S. 97ff) Bortz, J., Döring, N. (1995), Forschungsmethoden und Evaluation, 2. Auflage, Berlin et al. ([Lehrbuchsammlung der BOKU A, insbes. Seite ] Erben, Wilhelm (1998), Statistik mit Excel 5 oder 7, (Buch mit Diskette), [Lehrbuchsammlung der BOKU ] Zur den Buchaltungsdaten LBG-Wirtschaftstreuhand, Buchführungsergebnisse aus der österreichischen Landwirtschaft (jährlich), Wien BMLFUW (Hg), Grüner Bericht (jährlich, Wien) ( Diverse Internet-Angebote unter Stichworten wie „Konfidenzintervall“, „Standardfehler“ etc. mit Java-Applets zur Manipulation von Parametern etc.
, Angewandte Statistik, Neunte Überarbeitete Auflage, Berlin, Heidelberg [Lehrbuchsammlung der BOKU A, insb. S. 97ff) Bortz, J., Döring, N. (1995), Forschungsmethoden und Evaluation, 2. Auflage, Berlin et al. ([Lehrbuchsammlung der BOKU A, insbes. Seite ] Erben, Wilhelm (1998), Statistik mit Excel 5 oder 7, (Buch mit Diskette), [Lehrbuchsammlung der BOKU ] Zur den Buchaltungsdaten. LBG-Wirtschaftstreuhand, Buchführungsergebnisse aus der österreichischen Landwirtschaft (jährlich), Wien. BMLFUW (Hg), Grüner Bericht (jährlich, Wien) ( Diverse Internet-Angebote unter Stichworten wie „Konfidenzintervall , „Standardfehler etc. mit Java-Applets zur Manipulation von Parametern etc.")
Ähnliche Präsentationen













 1.>")





