Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Multivariate Statistische Verfahren
Diskriminanzanalyse Universität Mainz Institut für Psychologie SoSe 2013 Uwe Mortensen

2
Einführung I Es soll entschieden werden, ob ein Schulkind unter ADHS leidet oder nur eine situativ bedingte Verhaltensabweichung vorliegt. Ein Bewerber für eine leitende Position für diese Position geeignet ist oder nicht. der Schatten auf dem Röntgen-Foto ein Tumor oder nur eine harmlose Variation im Gewebe ist, Ein Gemälde aus der Zeit Rembrandts von der Hand des Meisters oder von der eines Epigonen ist,

3
Einführung II In jedem Fall müssen Symptome oder Merkmale von Personen oder Objekten so interpretiert werden, dass sie möglichst fehlerfrei klassifiziert werden. Viele Symptome (Kopfweh, Bauchweh, etc) zeigen sich bei völlig ver- schiedenen Erkrankungen. Viele Fähigkeiten sind wichtig für eine leitende Position, ohne dabei auf eine spezifische Fähigkeit für eine bestimmte leitende Funktion zu weisen. Merkmale auf Röntgen-Fotos, die bei Tumoren zu beobachten sind, treten auch bei harmlosen Gewebeveränderungen auf Merkmale von Rembrandt-Bildern können auch bei Bildern gefunden werden, die nicht von Rembrandt gemalt wurden.
 zeigen sich bei völlig ver- schiedenen Erkrankungen. Viele Fähigkeiten sind wichtig für eine leitende Position, ohne dabei auf eine spezifische Fähigkeit für eine bestimmte leitende Funktion zu weisen. Merkmale auf Röntgen-Fotos, die bei Tumoren zu beobachten sind, treten auch bei harmlosen Gewebeveränderungen auf. Merkmale von Rembrandt-Bildern können auch bei Bildern gefunden werden, die nicht von Rembrandt gemalt wurden.")
4
Einführung III Im Allgemeinen muss nur zwischen einer endlichen Menge von alternativen Klassen entschieden werden. Der Ansatz von Fisher (1936): Die Symptome (Indikatoren, Prädiktoren) müssen so gewichtet werden, dass die Zuordnung einer Person oder eines Objekts zu einer Klasse möglichst fehlerfrei ist. Dazu müssen die Personen/Objekte so auf einer noch zu konstruierenden Skala abgebildet werden, dass sie möglichst eng beieinander auf der Skala liegen, wenn sie zur gleichen Klasse gehören, und möglichst weit separiert werden, wenn sie zu verschiedenen Klassen gehören. Aufgabe: finde die optimalen Gewichte und die Skala oder die Skalen, die eine Klassifikation mit minimalem Fehler erlauben.
: Die Symptome (Indikatoren, Prädiktoren) müssen so gewichtet werden, dass die Zuordnung einer Person oder eines Objekts zu einer Klasse möglichst fehlerfrei ist. Dazu müssen die Personen/Objekte so auf einer noch zu konstruierenden Skala abgebildet werden, dass sie möglichst eng beieinander auf der Skala liegen, wenn sie zur gleichen Klasse gehören, und möglichst weit separiert werden, wenn sie zu verschiedenen Klassen gehören. Aufgabe: finde die optimalen Gewichte und die Skala oder die Skalen, die eine Klassifikation mit minimalem Fehler erlauben.")
5
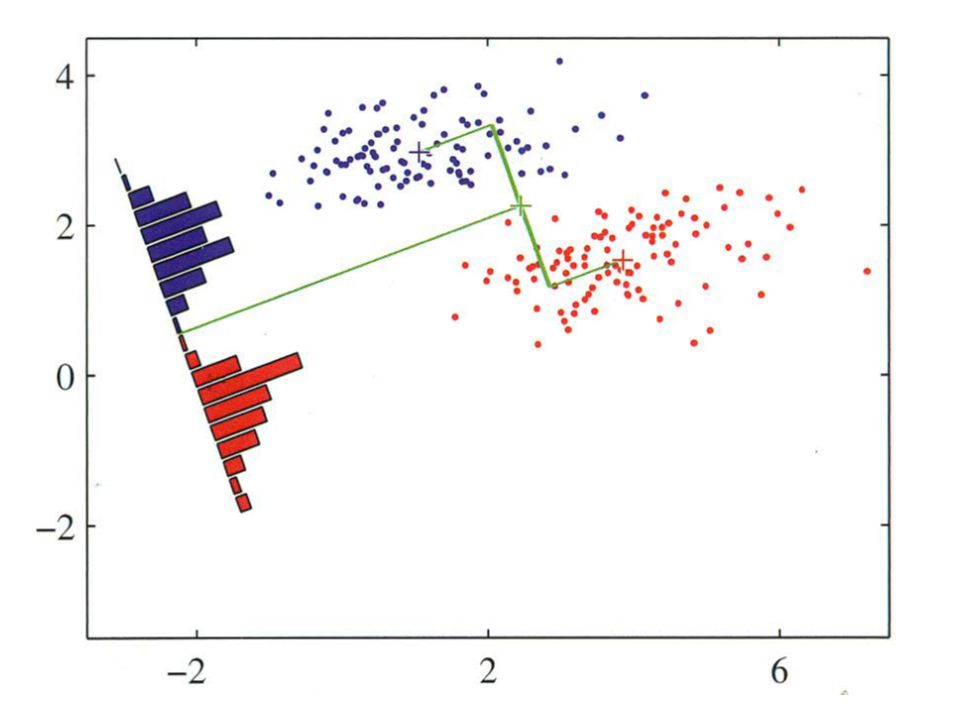
Spezifizierung der Idee
(Y = Kanonische Variable, Diskriminanzfunktion) Maximale Diskriminierbarkeit bezüglich Y Zu bestimmende „Gewichte“ der Prädiktoren (hier: Bildpunkte)
 Maximale Diskriminierbarkeit bezüglich Y. Zu bestimmende „Gewichte der Prädiktoren (hier: Bildpunkte)")
8
Umsetzung der Idee I Intuitive Einführung: Erinnerung an die Varianzanalyse: Die Gesamtvarianz der Daten wird in eine Varianzkomponente „innerhalb“ der Gruppen und in eine Varianzkomponente „zwischen“ den Gruppen aufgeteilt. Beide Komponenten werden für eine Schätzung der Fehlervarianz herangezogen. Ist die Schätzung auf der Basis der „Zwischen“-Komponente zu groß, wird die Nullhypothese („Es gibt keine Effekte der experimentellen Variablen“) verworfen. Fishers Idee: Die Prädiktoren (entsprechend den unabhängigen Variablen der Varianzanalyse) werden so gewichtet, dass die Varianz „zwischen“ den Klassen relativ zu der „innerhalb“ der Klassen maximal wird.
 verworfen. Fishers Idee: Die Prädiktoren (entsprechend den unabhängigen Variablen der Varianzanalyse) werden so gewichtet, dass die Varianz „zwischen den Klassen relativ zu der „innerhalb der Klassen maximal wird.")
9
Diskriminanzkriterium
Umsetzung der Idee II Diskriminanzkriterium Kanon. Variable Daten - Prädiktoren Kategorien, Gruppen

10
Die Quadratsummen I

11
Die Quadratsummen II

12
Die Quadratsummen III Zur Quadratsumme „innerhalb“:

13
Die Quadratsummen IV

14
Die Lösung Matrix der Varianzen und Kovarianzen „zwischen“:

15
Die Lösung Wie entscheidet man, in welche Klasse eine Person oder ein Objekt fällt?

16
Die Mahalanobis-Distanz

18
Beispiel 1: Nach Amthauer (1970) erhalten Ärzte, Juristen und Pädagogen in den Untertests Analogien (AN), Figurenauswahl (FA) und Würfelaufgaben (WÜ) des IST (Intelligenz-Struktur-Test) die folgenden mittleren Scores: mit der Varianz-Kovarianz-Matrix (und ihrer Inversen)
 erhalten Ärzte, Juristen und Pädagogen in den Untertests Analogien (AN), Figurenauswahl (FA) und Würfelaufgaben (WÜ) des IST (Intelligenz-Struktur-Test) die folgenden mittleren Scores: mit der Varianz-Kovarianz-Matrix (und ihrer Inversen)")
19
Beispiel 1 (Fortsetzung):
Ein Abiturient hat in diesen Untertests die Scores 108 (AN), 112 (FA) und 101 (WÜ) erzielt. Welche Berufswahl ist für ihn optimal? Für die Gruppe der Ärzte findet man die Distanz d.h. d1 = Für die Juristen findet man d2 = und für die Pädagogen d3 = Die kleinste Distanz bzw. die größte Nähe findet man zu den Medizinern, also sollte er Medizin studieren.
, 112 (FA) und 101 (WÜ) erzielt. Welche Berufswahl ist für ihn optimal Für die Gruppe der Ärzte findet man die Distanz. d.h. d1 = Für die Juristen findet man d2 = und für die Pädagogen d3 = Die kleinste Distanz bzw. die größte Nähe findet man zu den Medizinern, also sollte er Medizin studieren.")
20
Annahme: die multivariate Gauss-Verteilung
Bei der Fisherschen Diskriminanzanalyse wird (zunächst) keine Annahme über die Verteilung der Prädiktoren gemacht, - insofern ist das Verfahren verteilungsfrei. Kann man annehmen, dass die Prädiktoren multivariat normalverteilt sind, so können weitere Entscheidungskriterien eingeführt werden sowie bestimmte statistische Tests durchgeführt werden.
 keine Annahme über die Verteilung der Prädiktoren gemacht, - insofern ist das Verfahren verteilungsfrei. Kann man annehmen, dass die Prädiktoren multivariat normalverteilt sind, so können weitere Entscheidungskriterien eingeführt werden sowie bestimmte statistische Tests durchgeführt werden.")
21
Multivariate Gauss-Verteilung und Klassifikation I
a posteriori Dichte Likelihood A priori Wahrscheinlichkeit

22
Multivariate Gauss-Verteilung und Klassifikation II
Zur Entscheidung zwischen zwei Klassen: Für gleiche a priori-Wahrscheinlichkeiten der Klassen hat man Und der Vergleich der a posteriori-Wahrscheinlichkeit entpricht einer Entscheidung nach dem Likelihodd-Quotienten.

23
Multivariate Gauss-Verteilung und Klassifikation III
Spezielle Entscheidungsregeln:

24
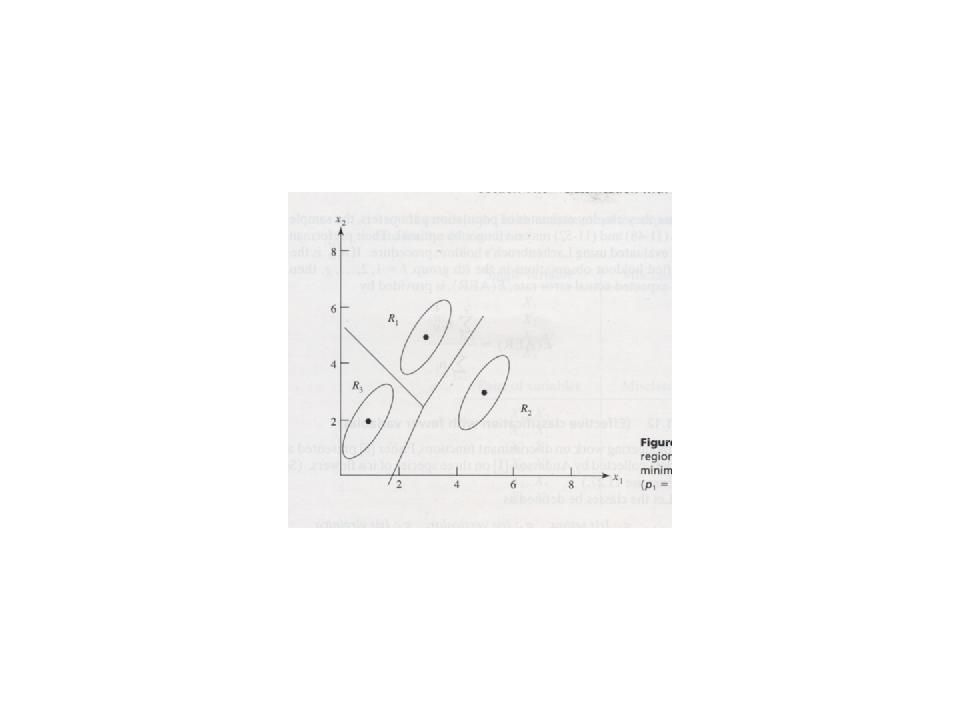
Multivariate Gauss-Verteilung und Klassifikation IV
Die Form der Trennflächen hängt davon ab, ob die Varianz-Kovarianz- Matrizen für die verschiedenen Klassen gleich oder ungleich sind.

25
Multivariate Gauss-Verteilung und Klassifikation V

26
Multivariate Gauss-Verteilung und Klassifikation VI

27
Multivariate Gauss-Verteilung und Klassifikation VII
Klassenbereiche im Falle homogener Varianz-Kovarianz-Matrizen und gleicher a priori-Wahrscheinlichkeiten:

28
Multivariate Gauss-Verteilung und Klassifikation VII
Statistische Tests:

29
Beispiel 2: Klassifikation von Geweben (Cervix-Krebs) I
Optical Coherence Tomography (OCT)-Bild Luminanzprofil
-Bild. Luminanzprofil.")
30
Beispiel 2: Klassifikation von Geweben (Cervix-Krebs) II
Aufgabe: Klassifiziere ein OCT-Bild in eine von 6 CIN-Klassen: (CIN = Cervical Intraepithelial Neoplasia = abnormale Erscheinungsform von Zellen im Cervixepithel) 00 = gesund 10 = Entzündung 21 22 = verschiedene Schweregrade 23 30 = Krebs Wahrer Befund: Histologie/Pathologie Visuelle Klassifikation durch ExpertIn – wie weit stimmen Pathologen und ExpertIn überein, existieren systematische Unterschiede? Enthalten die Luminanzprofile die gesamte relevante Information? Implizieren Wartezeiten bis zur pathologischen Untersuchung (oh bis 4h) Veränderungen im Gewebe, die für die Diagnose relevant sind? Gibt es prä- und postoperative Unterschiede?
 00 = gesund. 10 = Entzündung = verschiedene Schweregrade = Krebs. Wahrer Befund: Histologie/Pathologie. Visuelle Klassifikation durch ExpertIn – wie weit stimmen Pathologen und ExpertIn überein, existieren systematische Unterschiede Enthalten die Luminanzprofile die gesamte relevante Information Implizieren Wartezeiten bis zur pathologischen Untersuchung (oh bis 4h) Veränderungen im Gewebe, die für die Diagnose relevant sind Gibt es prä- und postoperative Unterschiede")
31
Beispiel 2: Zur Problematik von Diskriminanzanalysen – Anzahl der Prädiktoren und Anzahl der „Fälle“ (Beobachtungen, hier: Profile) Es werden zur Klassifikation nur Profile verwendet, die unmittelbar während der Operation (0h) gewonnen wurden: N = 152, - aber nur 150 Prädiktoren (= Anzahl der Bildpunkte). Können die Klassifikationen anhand der OCT-Bilder einerseits und anhand der histologischen Befunde andererseits aufgrund der Profile vorausgesagt werden? Wenn ja: sollte die Konfiguration der CIN-Klassen in beiden Fällen identisch sein, und was bedeutet es, wenn die Konfiguration nicht identisch ist?
 gewonnen wurden: N = 152, - aber nur 150 Prädiktoren (= Anzahl der Bildpunkte). Können die Klassifikationen anhand der OCT-Bilder einerseits und anhand der histologischen Befunde andererseits aufgrund der Profile vorausgesagt werden Wenn ja: sollte die Konfiguration der CIN-Klassen in beiden Fällen identisch sein, und was bedeutet es, wenn die Konfiguration nicht identisch ist")
32
Beispiel 2: Zur Problematik von Diskriminanzanalysen – Anzahl der Prädiktoren und Anzahl der „Fälle“ (Beobachtungen, hier: Profile) Die Klassifikationen scheinen in beiden Fällen perfekt zu sein: es gibt keine Streuung der individuellen Profile um die Kategorienmittelpunkte OCT-Klassifikationen und Klassifikationen auf der Basis pathologischer Befunde sind ähnlich, aber auch deutlich verschieden, -- wie ist dieser Befund zu deuten? Oder sind die perfekten Klassifikationen Artefakte?

33
Beispiel 2: Zur Problematik von Diskriminanzanalysen – Anzahl der Prädiktoren und Anzahl der „Fälle“ (Beobachtungen, hier: Profile) Generell gilt: Ist die Anzahl der „Beobachtungen“ (hier: Profile) relativ zur Anzahl der Prädiktoren (hier: Bildpunkte) zu „klein“ und/oder sind die Korrelationen zwischen den Prädiktoren zu groß – die Matrix der Prädiktorwerte ist „ill conditioned“ – kommt es zu Artefakten. Im hier vorliegenden Fall kommt es zu perfekt erscheinenden Klassifikationen, über die ein weiteres Nachdenken aber gar nicht lohnt! (Faust-)Regel: man sollte mindestens 2.5- bis 3-mal so viele Beobachtungen wie Prädiktoren haben!
 relativ zur Anzahl der Prädiktoren (hier: Bildpunkte) zu „klein und/oder sind die Korrelationen zwischen den Prädiktoren zu groß – die Matrix der Prädiktorwerte ist „ill conditioned – kommt es zu Artefakten. Im hier vorliegenden Fall kommt es zu perfekt erscheinenden Klassifikationen, über die ein weiteres Nachdenken aber gar nicht lohnt! (Faust-)Regel: man sollte mindestens 2.5- bis 3-mal so viele Beobachtungen wie Prädiktoren haben!")
34
Beispiel 2: Klassifikation von Geweben (Cervix-Krebs) IV: Existieren Unterschiede im Gewebe in Abhängigkeit von der Wartezeit bis zur histologischen Untersuchung? Beispiele für Profile: 0h bis 4h (I)
")
35
Beispiel 2: Klassifikation von Geweben (Cervix-Krebs) V
Es existieren Unterschiede im Mikrobereich, allerdings scheinen sie nicht systematischer Natur zu sein!

36
Beispiel 2: Klassifikation von Geweben (Cervix-Krebs) VI
Diskriminanzanalyse in Bezug auf die zeitlichen Abstände bis zur histologischen Untersuchung (0h, 1h, 2h, 3h und 4h): lassen sich die Profile nach dem zeitlichen Abstand klassifizieren? (Statt der Punkte kann man die Nummer des Profils anzeigen lassen und so überprüfen, ob es wenigstens einen Ansatz zur Klassenbildung gibt: Befund = negativ!) Es sind keine den Zeitpunkten entsprechenden Cluster erkennbar, d.h. die Daten korrespondieren zur Nullhypothese, nach der die Zeitpunkte keinen systematischen Einfluss auf die Profile haben.
: lassen sich die Profile nach dem zeitlichen Abstand klassifizieren (Statt der Punkte kann man die Nummer des Profils anzeigen lassen und so überprüfen, ob es wenigstens einen Ansatz zur Klassenbildung gibt: Befund = negativ!) Es sind keine den Zeitpunkten entsprechenden Cluster erkennbar, d.h. die Daten korrespondieren zur Nullhypothese, nach der die Zeitpunkte keinen systematischen Einfluss auf die Profile haben.")
37
Beispiel 2: Klassifikation von Geweben (Cervix-Krebs) VI
Folgerung: da es keine systematischen Unterschiede zwischen den Untersuchungszeitpunkten zu geben scheint, können alle Profile zu einer Stichprobe zusammengefasst werden. Statt nur 152 Profile können nun 464 Profile untersucht werden! Dazu werden zunächst die mittleren Profile für jede CIN-Klasse und die zugehörigen Standardabweichungen der Luminanzwerte pro Bildpunkt betrachtet. Die Form der mittleren Profile könnte sich von CIN-Klasse zu CIN-Klasse unterscheiden.

38
Beispiel 2: Klassifikation von Geweben (Cervix-Krebs) VII
Mittlere Profile pro Klasse, wie anhand der OCT-Bilder klassifiziert: Kommentar: Die mittleren Verläufe erscheinen spezifisch für die Kategorien, sind aber insbesondere für CIN = 10, 21, 22, 23 gering.

39
Beispiel 2: Klassifikation von Geweben (Cervix-Krebs) VIII
Standardabweichungen der Profile pro Klasse (Klassifikation anhand der OCT-Bilder) Kommentar: Auch die Standardabweichungen haben charakteristische Verläufe. Keine Homogenität bezüglich der Bildpunkte!
 Kommentar: Auch die Standardabweichungen haben charakteristische Verläufe. Keine Homogenität bezüglich der Bildpunkte!")
40
Beispiel 2: Klassifikation von Geweben (Cervix-Krebs) IX
OCT-Klassifikation Pathologie Mittl. Prof. Stand ‘abw.

41
Plots der mittleren Profile 1h, 2h, 3h, und 4h versus 0h
Der Befund korrespondiert zu dem, dass keine h-spezifische Kategorisierung der Profile möglich zu sein scheint. Aber man kann von derartigen Beziehungen nicht auf die Unmöglichkeit von Klassifikationen schließen!

42
Plots der Standardabweichungen 1h, 2h, 3h, und 4h versus 0h

43
Beispiel 2: Klassifikation von Geweben (Cervix-Krebs) X
Die mittleren Profile in den Klassen sind einander ähnlich, aber Die Standardabweichungen sind relativ groß – kann dies zu unterschiedlichen Klassifikationen anhand der OCT-Bilder einerseits und der pathologischen Befunde andererseits kommen?

44
Diskriminanzanalysen zur Zuordnung von Profilen zu CIN-Kategorien (i) auf der Basis von OCT-Bildern und (ii) auf der Basis pathologischer Befunde (464 Profile, 151 Bildpunkte als Prädiktoren) I Kan. Var. 1: p = .000 Kan. Var. 2: p = .065 Kan. Var. 1: p = .000 Kan. Var. 2: p = .152

45
Diskriminanzanalysen für OCT und Histolog.
(464 Profile, 151 Bildpunkte als Prädiktoren) II Mittlere Positionen der Profile für die einzelnen CIN-Klassen, (i) für die OCT-Beurteilungen, (ii) für die histologischen Beurteilungen. Bis auf die Klassen 22 und 23 stimmen die mittleren Positionen gut überein.
 II. Mittlere Positionen der Profile für die einzelnen CIN-Klassen, (i) für die OCT-Beurteilungen, (ii) für die histologischen Beurteilungen. Bis auf die Klassen 22 und 23 stimmen die mittleren Positionen gut überein.")
46
Übereinstimmung von Klassifikation und prognostizierter (DA-Klassifikation)
")
47
Beispiel 2: Klassifikation von Geweben (Cervix-Krebs) III
Chi-Quadrat = df =16, p = .000

48
Prä- und Post-Op-Daten:
Existieren spezifische Prä- und Post-Cluster? Die Profile werden alle auf einen von zwei möglichen, jeweils sehr kleinen Bereich einer Diskriminanzfunktion (Kanonische Variable) Abgebildet: ca – 25 für post-op-Profile, + 25 für prä-op-Profile! Allerdings gibt es nur 78 Profile, bei 151 Prädiktoren. In diesem Fall erzeugt die DA eine perfekte Klassifikation auch bei rein zufälligen Helligkeitswerten, d.h. die gezeigte Klassifikation muß als Artefakt betrachtet werden! S ist sehr wahrscheinlich,dass keinerlei Prä-Post-Unterschiede existieren!
 Abgebildet: ca – 25 für post-op-Profile, + 25 für prä-op-Profile! Allerdings gibt es nur 78 Profile, bei 151 Prädiktoren. In diesem Fall erzeugt die DA eine perfekte Klassifikation auch bei rein zufälligen Helligkeitswerten, d.h. die gezeigte Klassifikation muß als Artefakt betrachtet werden! S ist sehr wahrscheinlich,dass keinerlei Prä-Post-Unterschiede existieren!")
49
Mittlere Prä- und Post-Profiles sowie Standardabweichungen
Die mittleren Profile sind sich extrem ähnlich (allerdings: die Steigung sollte gleich 1 und die add. Konstante sollte gleich Null sein! Analog: Standardabweichungen:

50
Beispiel 2: Gibt es Unterschiede zwischen prä- und postoperativem Gewebe?

51
Prä-Post-Op Partielle LDAs, II

52
Probleme der praktischen Anwendung der linearen Diskriminanzanalyse, I
Die partiellen DAs zeigen, dass eine Prä-Post-Klassifizierung schon bei wenigen Prädiktoren erfolgt. Dieser Sachverhalt spiegelt aber nicht eine besondere Leistungsfähigkeit der DA (oder LDA = Lineare DA) wieder, sondern eher eine Begrenzung ihrer Möglichkeiten: Der Stichprobenumfang (hier: die Anzahl der Profile) sollte stets mindestens um den Faktor 3 größer als die Anzahl der Prädiktoren sein (hier: 151), und Die Korrelationen zwischen den Prädiktoren sollten möglichst nahe bei Null sein. Wie Simulationen mit zufälligen Helligkeitswerten (allgemein: mit zufälligen Prädiktorwerten) zeigen, können schon perfekte Kategorisierungen vorgenommen werden, wenn die Anzahl der Profile kleiner als die Anzahl der Prädiktoren ist. Diese Klassifikationen sind, wegen der Zufälligkeit der Prädiktorwerte, reine Artefakte.
 wieder, sondern eher eine Begrenzung ihrer Möglichkeiten: Der Stichprobenumfang (hier: die Anzahl der Profile) sollte stets mindestens um den Faktor 3 größer als die Anzahl der Prädiktoren sein (hier: 151), und. Die Korrelationen zwischen den Prädiktoren sollten möglichst nahe bei Null sein. Wie Simulationen mit zufälligen Helligkeitswerten (allgemein: mit zufälligen Prädiktorwerten) zeigen, können schon perfekte Kategorisierungen vorgenommen werden, wenn die Anzahl der Profile kleiner als die Anzahl der Prädiktoren ist. Diese Klassifikationen sind, wegen der Zufälligkeit der Prädiktorwerte, reine Artefakte.")
53
Probleme der praktischen Anwendung der linearen Diskriminanzanalyse, II
Hohe Korrelationen zwischen den Prädiktoren erzeugen in jedem Fall kaum interpretierbare Gewichte u1, …, up, deren Absolutwerte im Allgemeinen zu groß ausfallen. Die Schätzungen dieser Gewichte führen zu Fehleinschätzungen der Rolle der einzelnen Prädiktoren. Es werden eine Reihe von Verfahren zur Reduktion des Fehlers bei den Parameterschätzungen (der Bestimmung der Gewichte) vorgeschlagen. Im Wesentlichen bestehen diese Korrekturen in der Addition von Konstanten, die von den u1, …, up abhängen, zu den Diagonalwerten der Varianz-Kovarianz-Matrizen; man spricht dann von einer ‚Regularisierung‘. Auf die Details kann hier nicht eingegangen werden, es soll nur auf diese Möglichkeit hingewiesen werden. In Statistikprogrammen wie R werden Module für die Regularisierte Diskriminanzanalyse angeboten.
 vorgeschlagen. Im Wesentlichen bestehen diese Korrekturen in der Addition von Konstanten, die von den u1, …, up abhängen, zu den Diagonalwerten der Varianz-Kovarianz-Matrizen; man spricht dann von einer ‚Regularisierung‘. Auf die Details kann hier nicht eingegangen werden, es soll nur auf diese Möglichkeit hingewiesen werden. In Statistikprogrammen wie R werden Module für die Regularisierte Diskriminanzanalyse angeboten.")
54
Danke für Ihre Aufmerksamkeit!

55
Fishersche Diskriminanzanalyse
(Y = Kanonische Variable, Diskriminanzfunktion) Illustration für p = 2: Maximale Diskriminierbarkeit bezüglich Y Zu bestimmende „Gewichte“ der Prädiktoren (hier: Intensität/Bildpunkt) Projektion auf maximal diskriminierende Skala Verteilungen der Profile auf der maximal diskriminierenden Skala
 Illustration für p = 2: Maximale Diskriminierbarkeit bezüglich Y. Zu bestimmende „Gewichte der Prädiktoren (hier: Intensität/Bildpunkt) Projektion auf maximal diskriminierende Skala. Verteilungen der Profile auf der maximal diskriminierenden Skala.")
Ähnliche Präsentationen