Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Deskriptive Statistik und Wahrscheinlichkeitstheorie
Termin7 Tutorat Deskriptive Statistik und Wahrscheinlichkeitstheorie Kai Vogt

2
Heute: Kurze Wiederholung (Aufgabenblatt) Hypothesenprüfung
Hypothesenformulierung Alpha- und Beta-Fehler Einflussgrößen des Beta-Fehlers

3
Wichtiges aus Termin 6 Kombinatorik Stichprobentheorie Schätzungen
Wann wird was verwendet? Einfache Beispiele rechnen bzw. einsetzen. Stichprobentheorie Zufallsauswahl vs. Nicht-zufallsgesteuerte Auswahlverfahren (Welche gibt es jeweils? Pros & Contras) Schätzungen Punktschätzung vs. Intervallschätzung Standardfehler Was ist das? Konfidenzintervall (Definition, einfache Berechnungen & Interpretationen, Mutungs- vs. Vertrauensintervalle) 3
 Schätzungen. Punktschätzung vs. Intervallschätzung. Standardfehler Was ist das Konfidenzintervall (Definition, einfache Berechnungen & Interpretationen, Mutungs- vs. Vertrauensintervalle) 3.")
4
Arbeitsblatt Stichprobentheorie
Die Varianz ist ein erwartungstreuer Schätzer Das Effizienzkriterium fordert, dass die Streuung des Schätzers möglichst gering sein soll Laut Konsistenzkriterium spielt die Stichprobengröße keine Rolle Die Varianz erfüllt das Kriterium der Exhaustivität nicht

5
Man unterscheidet zwischen zufallsgesteuerten und nicht-zufallsgesteuerten Verfahren der Stichprobengewinnung Zufallsauswahl ist immer besser als eine nicht- zufallgesteuerte Auswahl Die Quotenauswahl ist ein nicht-zufallsgesteuertes Auswahlverfahren Die Klumpenauswahl ist ein zufallsgesteuertes Verfahren

6
Bei der uneingeschränkten Zufallsauswahl unterscheidet sich die Wahrscheinlichkeit in die Stichprobe aufgenommen zu werden je nach Personengruppe Die geschichtete Zufallsauswahl hat keine Voraussetzungen Die Klumpenauswahl hat mit der mehrstufigen Zufallsauswahl nichts zu tun Eine Stichprobe computergestützt zufällig aus einem Register zu ziehen ist ein Beispiel für eine Ad-hoc Auswahl

7
Bei der geschichteten Zufallsauswahl wird nicht davon ausgegangen, dass sich die Teilpopulationen systematisch unterscheiden Bei einer Quotenauswahl lässt sich streng genommen kein Standardfehler bestimmen Bei der geschichteten Zufallsauswahl wird von einem systematischen Unterschied der Teilstichproben ausgegangen Am Bertoldsbrunnen die ersten zehn Leute zu befragen ist ein Beispiel für die Ad-hoc Auswahl

8
Ein Mutungsintervall schätzt, in welchem Bereich ein Populationsparameter liegt.
Ein Konfidenzintervall schätzt, in welchem Bereich ein Anteil der Stichprobe/Population liegt Der zentrale Grenzwertsatz postuliert keine Zusammenhänge zwischen der Anzahl der Stichproben und der Verteilungskurve der gewonnen Mittelwerte Die Streuung der Mittelwerteverteilung ist die Standardabweichung

9
Hypothesenprüfung

10
Grundlegende Idee Anhand von Stichprobenkennwerten werden Hypothesen für die Population getestet Dabei soll die Bedeutsamkeit einer Mittelwertsdifferenz oder Relevanz eines Zusammenhangs, einer Korrelation getestet werden Wie groß muss mein gefundener Mittelwertunterschied sein, damit keiner sagen kann, er sei zufällig entstanden? Ab wann ist er statistisch bedeutsam?

11
Vorgehen bei statistischen Tests:
Formulierung der Hypothesen (gerichtet oder ungerichtet). Berechnung eine empirischen Werts (z.B. t, r,…) Vergleich von empirischem Wert mit kritischem Wert (Tabelle) Der kritische Wert hängt ab von den Freiheitsgraden und der Art der Hypothese Je nachdem ob der emprische über oder unter dem kritischen Wert liegt wird die H0 aufrechterhalten oder verworfen (=H1 angenommen) heute!
. Berechnung eine empirischen Werts (z.B. t, r,…) Vergleich von empirischem Wert mit kritischem Wert (Tabelle) Der kritische Wert hängt ab von den Freiheitsgraden und der Art der Hypothese. Je nachdem ob der emprische über oder unter dem kritischen Wert liegt wird die H0 aufrechterhalten oder verworfen (=H1 angenommen) heute!")
12
Nullhypothese & Alternativhypothese
Nullhypothese (H0): Diese “Negativhypothese” behauptet immer, dass es keine Mittelwertsunterschiede, beziehungsweise keine Zusammenhänge in der Population gibt. Alternativhypothese (H1): Diese besagt, dass ein Unterschied oder ein Zusammenhang in der Population existiert. Die Alternativhypothese sollte immer aus einem Theoriegebäude, aus Vorstudien und der Literatur abgeleitet sein.
: Diese Negativhypothese behauptet immer, dass es keine Mittelwertsunterschiede, beziehungsweise keine Zusammenhänge in der Population gibt. Alternativhypothese (H1): Diese besagt, dass ein Unterschied oder ein Zusammenhang in der Population existiert. Die Alternativhypothese sollte immer aus einem Theoriegebäude, aus Vorstudien und der Literatur abgeleitet sein.")
13
Grundlegende Idee (Reloaded)
Anhand von Stichprobenkennwerten werden Hypothesen für die Population getestet Dabei soll die Bedeutsamkeit einer Mittelwertsdifferenz oder Relevanz eines Zusammenhangs, einer Korrelation getestet werden. Grundlage beim Hypothesentesten ist immer die H0. Statistisch wird die Wahrscheinlichkeit für gefundene Mittelwertsdifferenzen (Effekte) erhoben. Wenn die Gültigkeit der H0 aufgrund der gefundenen Stichprobenergebnisse sehr unwahrscheinlich ist, wird die Gültigkeit der H1 angenommen (ansonsten wird die H0 beibehalten.)
 erhoben. Wenn die Gültigkeit der H0 aufgrund der gefundenen Stichprobenergebnisse sehr unwahrscheinlich ist, wird die Gültigkeit der H1 angenommen (ansonsten wird die H0 beibehalten.)")
14
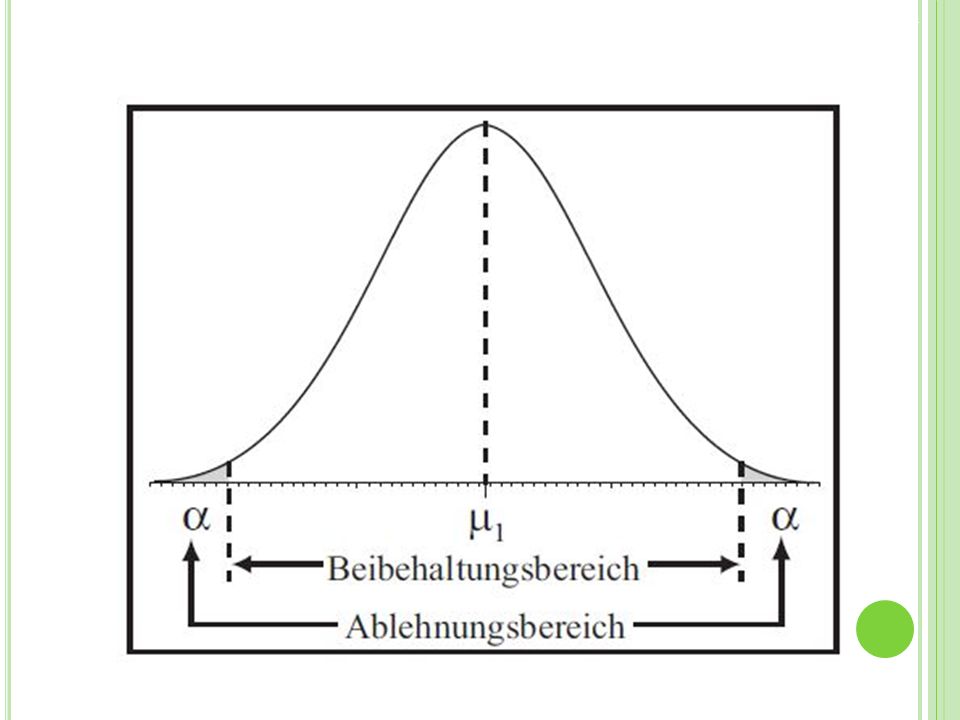
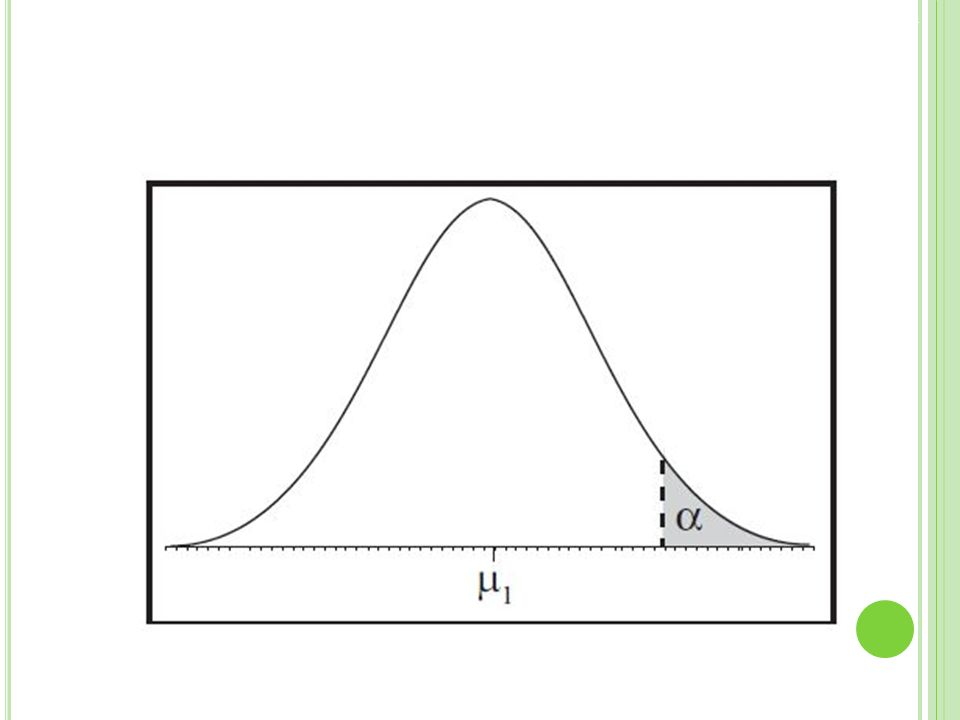
Das alpha-Niveau Das alpha-Niveau wird immer vor der Untersuchung festgelegt (und darf danach nicht mehr verändert werden). Meistens liegt es bei 5% (selten bei 1% oder 0,1%) Es legt in Abhängigkeit von Stichprobengröße und zugrunde liegender theoretischer Verteilung den Grenzwert für ein Konfidenzintervall fest. Umgangssprachlich: „Es legt die Größe des Konfidenzintervalls fest und damit die Grenze für die Wahrscheinlichkeit eines alpha- Fehlers“. Liegt der empirisch ermittelte Kennwert einer erhobenen Stichprobe außerhalb dieses Intervalls so wird die Ho verworfen und die H1 angenommen. Es liegt ein signifikanter Mittelwertsunterschied vor…
 Es legt in Abhängigkeit von Stichprobengröße und zugrunde liegender theoretischer Verteilung den Grenzwert für ein Konfidenzintervall fest. Umgangssprachlich: „Es legt die Größe des Konfidenzintervalls fest und damit die Grenze für die Wahrscheinlichkeit eines alpha- Fehlers . Liegt der empirisch ermittelte Kennwert einer erhobenen Stichprobe außerhalb dieses Intervalls so wird die Ho verworfen und die H1 angenommen. Es liegt ein signifikanter Mittelwertsunterschied vor…")
15
Die (heilige) Signifikanz
Liegt die Wahrscheinlichkeit für das Auftreten eines gefundenen Mittelwertunterschieds unter der Bedingung der H0, unterhalb des alpha- Niveaus, handelt es sich um einen signifikanten (bedeutsamen) Mittelwertsunterschied.
 Mittelwertsunterschied.")
16
Statistische Formulierung von Hypothesen
Es sei μ1 das mittlere (…) in der Population der (...) und es sei μ2 die mittlere (...) in der Population der (...). Dann gilt: H0 : μ1 = μ2 und H1 : μ1 ≠ μ2 bei einem alpha-Niveau von 5%. zweiseitige bzw. ungerichtete Testung
 in der Population der (...) und es sei μ2 die mittlere (...) in der Population der (...). Dann gilt: H0 : μ1 = μ2 und H1 : μ1 ≠ μ2 bei einem alpha-Niveau von 5%. zweiseitige bzw. ungerichtete Testung")
19
Statistische Formulierung von Hypothesen
Es sei μ1 das mittlere (…) in der Population der(...) und es sei μ2 die mittlere (...) in der Population der (...). Dann gilt: H0 : μ1 ≤ μ2 und H1 : μ1 > μ2 bei einem alpha-Niveau von 5%. einseitige bzw. gerichtete Testung Oder : H0 : μ1 ≥ μ2 und H1 : μ1 < μ2
 in der Population der(...) und es sei μ2 die mittlere (...) in der Population der (...). Dann gilt: H0 : μ1 ≤ μ2 und H1 : μ1 > μ2 bei einem alpha-Niveau von 5%. einseitige bzw. gerichtete Testung Oder : H0 : μ1 ≥ μ2 und. H1 : μ1 < μ2.")
21
Fehler beim Hypothesentesten
Aufgrund von Unsicherheiten bei der Stichprobenziehung besteht die Gefahr eines falschen Schlusses auf die Population. Es wird zwischen zwei möglichen Fehlern bei der Testung einer Hypothese unterschieden.

22
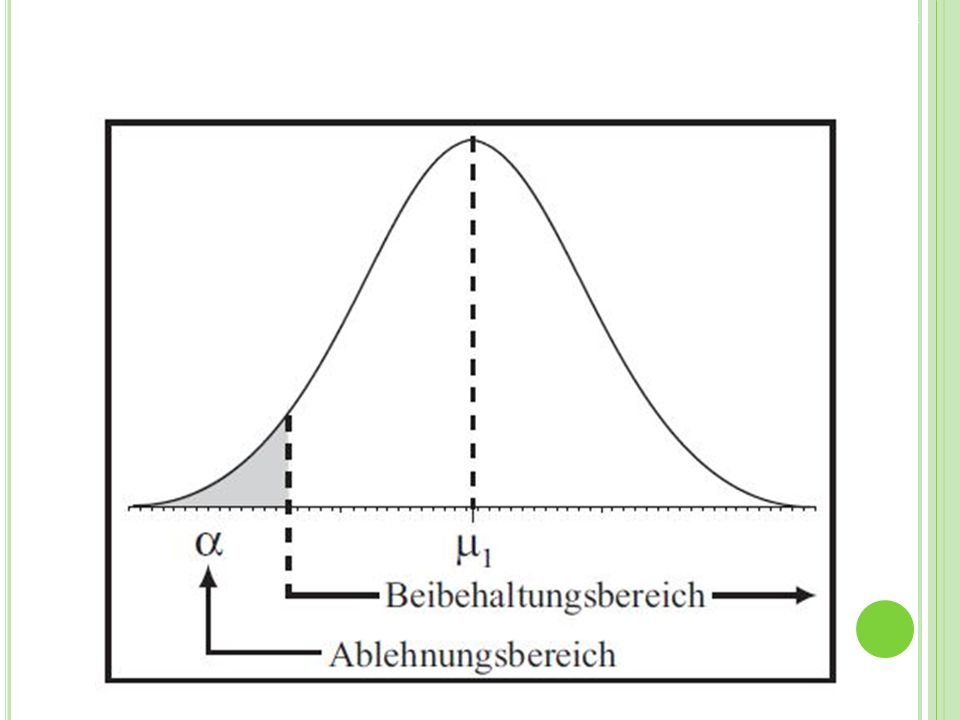
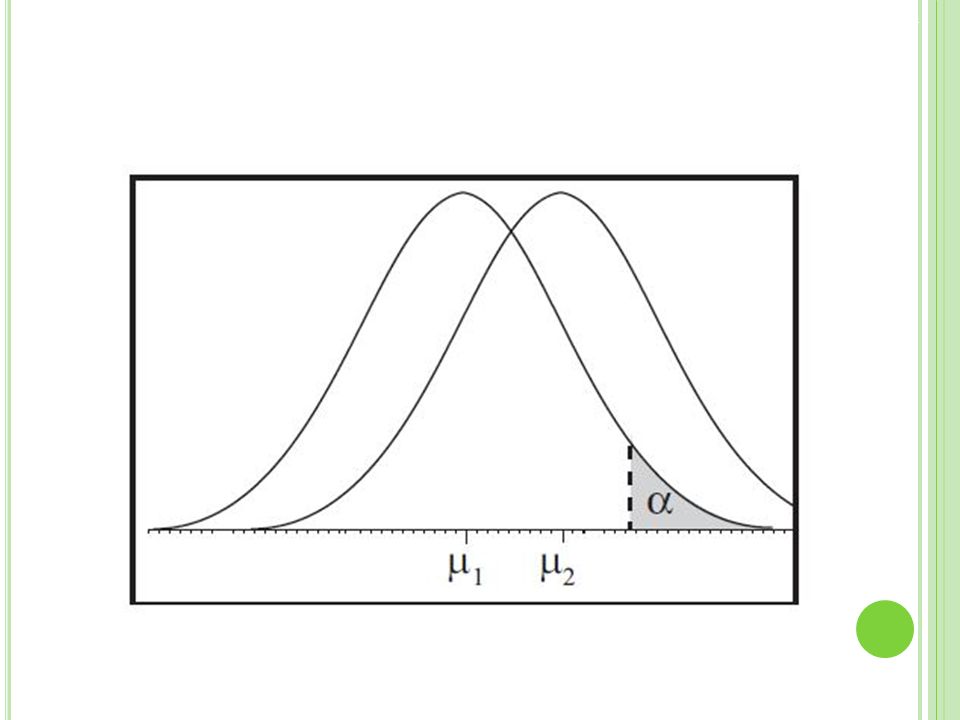
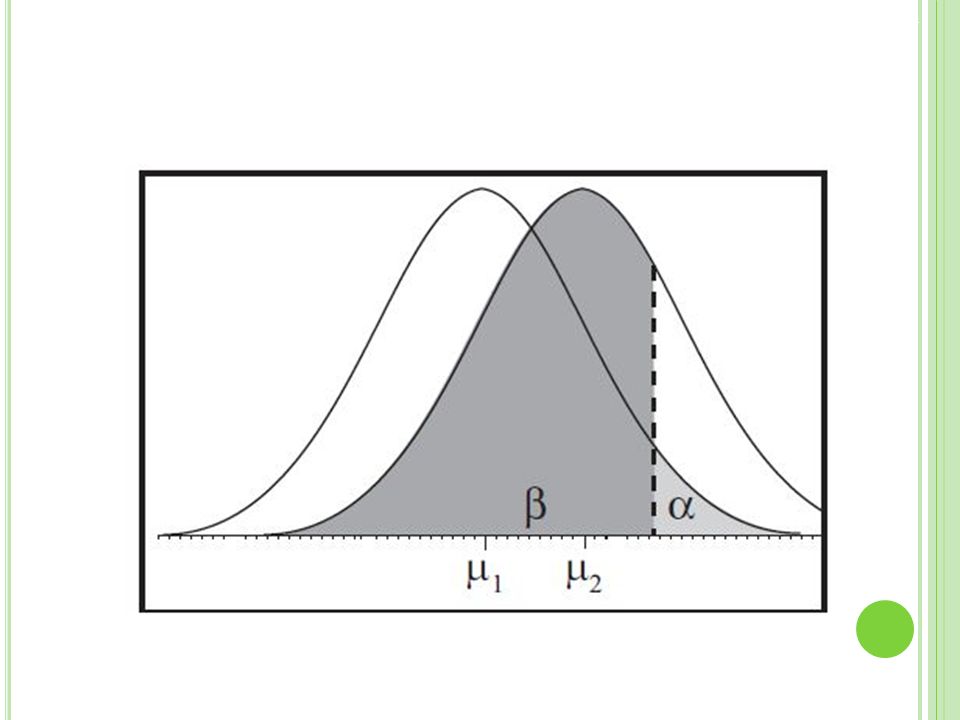
Zwei mögliche Fehler: alpha-Fehler: Ablehnung der “richtigen” Nullhypothese bei gültiger Nullhypothese (Fehler erster Art). Umgangssprachlich: „Ein Effekt wird angenommen dabei gibt es diesen nicht.“ beta-Fehler: Beibehaltung der “falschen” Nullhypothese bei gültiger Alternativhypothese (Fehler zweiter Art). Umgangssprachlich: „Ein Effekt wird nicht entdeckt obwohl dieser eigentlich existiert.“
. Umgangssprachlich: „Ein Effekt wird nicht entdeckt obwohl dieser eigentlich existiert.")
23
Teststärke Die Teststärke ist die Wahrscheinlichkeit, dass ein in der Population vorhandener Unterschied bei statistischer Testung entdeckt wird. Sie berechnet sich mit T= 1 - β Umgangssprachlich: „Wahrscheinlichkeit dafür, dass ein existierender Effekt auch gefunden wird.“

24
Zur Übersicht: ? ?

28
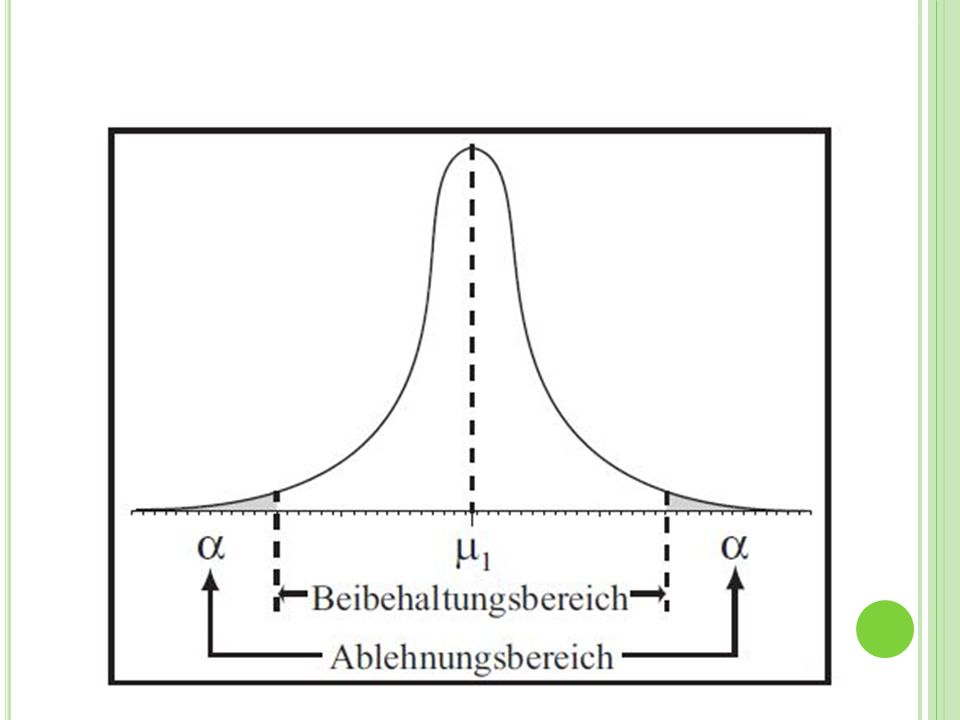
Was beeinflusst den Beta-Fehler?
Höhe des alpha-Niveaus Ein- oder zweiseitige Testung Homogenität der Merkmalsverteilung (=Streuung des Merkmals) Stichprobenumfang Größe des statistischen Effekts Abhängige versus unabhängige Stichproben Teststärke (1 − beta-Fehler)
 Stichprobenumfang. Größe des statistischen Effekts. Abhängige versus unabhängige Stichproben. Teststärke (1 − beta-Fehler)")
29
WICHTIGES AUS TERMIN 7 Einführung: Hypothesenprüfung
Nullhypothese (H0) vs. Alternativhypothese (H1) Was ist eine H1 bzw. eine H0? Verständnis für die grundlegende Idee des Hypothesentestens (Es wird von der H0 ausgegangen wenn H0 zu unwahrscheinlich dann wird die H1 angenommen.) Alpha-Niveau und Signifikanz Hypothesen formulieren (gerichtet & ungerichtet) Alpha-Fehler, Beta-Fehler & Teststärke (T=1-ß) Definitionen (Was ist Fehler erster bzw. zweiter Ordnung? Was versteht man unter der Teststärke) Einzeichnen der beiden Fehler in Verteilungsformen. Wie lassen sich die beiden Fehler beeinflussen? (alpha-Fehler a posteriori überhaupt nicht mehr…)
 vs. Alternativhypothese (H1) Was ist eine H1 bzw. eine H0 Verständnis für die grundlegende Idee des Hypothesentestens (Es wird von der H0 ausgegangen wenn H0 zu unwahrscheinlich dann wird die H1 angenommen.) Alpha-Niveau und Signifikanz. Hypothesen formulieren (gerichtet & ungerichtet) Alpha-Fehler, Beta-Fehler & Teststärke (T=1-ß) Definitionen (Was ist Fehler erster bzw. zweiter Ordnung Was versteht man unter der Teststärke) Einzeichnen der beiden Fehler in Verteilungsformen. Wie lassen sich die beiden Fehler beeinflussen (alpha-Fehler a posteriori überhaupt nicht mehr…)")
30
Vielen Dank für eure Aufmerksamkeit!
Bis nächste Woche… Schreibt euch Fragen auf wenn ihr welche habt… Fragen an Vielen Dank für eure Aufmerksamkeit!

Ähnliche Präsentationen


















 1.>")
