Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Wikis in Unternehmen Tools & Research Hans-Jörg Happel Max Völkel © 2007 FZI, Creative Commons Share-Alike

2
LS Gronau, Uni Potsdam

4
Was wünscht das Online-Volk?
Why?

5
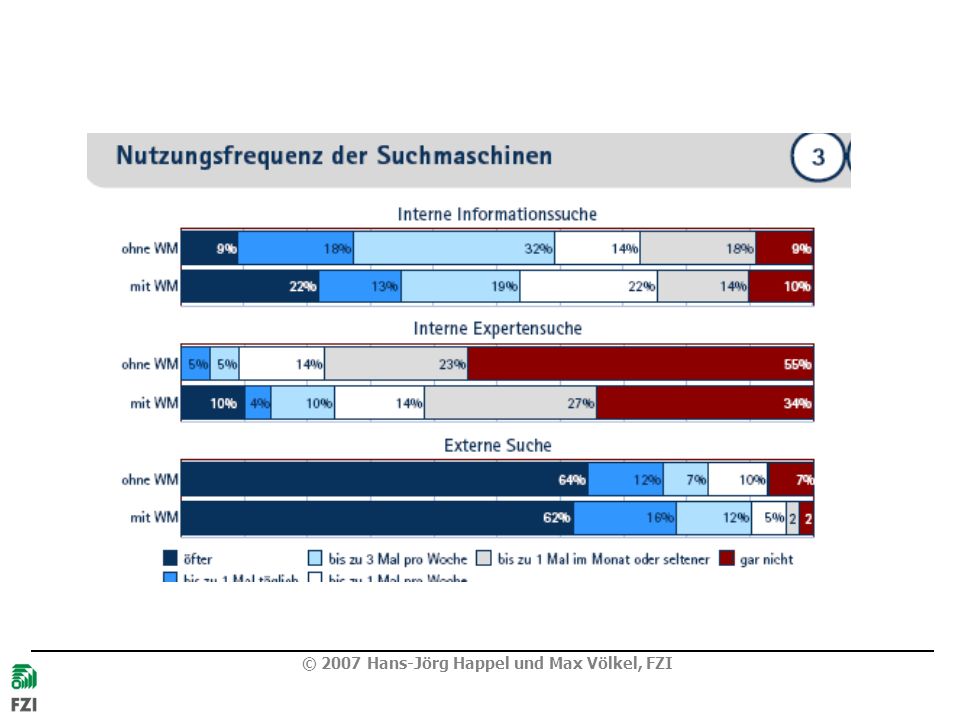
Social Software im Mittelstand?
Unternehmenskultur passt nicht zum Wiki-Ansatz Worin besteht der konkrete Mehrwert? Wie argumentiert man? Welche Technologie ist die richtige? Wikis, Blogs, Tagging, … Einführung und Akzeptanz Integration in bestehende IT-Infrastruktur Wiki oder Intranet-Portal? Aggregation von Informationen mit Wikis?

6
Woogle Idee Vorteile Interne Suche & Wiki Funktionalität verbinden
Austausch der Nutzer über Suche ermöglichen Eine Wiki-Seite für jeden Suchbegriff Vorteile Verzeichnis von Suchbegriffen „Social Did you mean“ Sofort neue Inhalte erstellen Wiki-Akzeptanz steigern Unternehmens-Brille über Internet Project X Index Query „Project X“ G Wiki

7
Kontakt: voelkel@fzi.de
JWiki + WIF Problem: Migration von Wikis Migration von X nach Wiki Migration von Wiki nach Y JWiki: Open-source Java library für Extraktion von Wikiseiten aus bestehenden Wikis Bisher: JSPWiki, MediaWiki WIF XHTML-basiertes Standardformat für Austausch von Wikiseiten Wiki-Syntax nach Wahl kann per XSLT erzeugt werden Kontakt:

8
SemFS – ein semantisches Dateisystem
Interpretation Pfadangabe als Suchanfrage Dateien in einem Ordner als Suchergebnisse Unterordner als vorgeschlagene Such-Verfeinerungen Zugriff Window: per WebDAV Unter Linux per fuse (user-level file system)
")
9
Comparison File system: partition of the adress space Tagging: overlapping sets /a /a/b /a/b/c /a/c /a/c/b /c /c/b /c/b/a /c/a /c/a/b /b /b/a /b/a/c /b/c /b/c/a a a a+b b b /a /a/b /a/c a+b+c c a+c b+c c

10
What is a file system? Organising files …
An address given as path expression := Letter “:“ (“\“ name)* dir! response files folders name metadata File System metadata
* dir! response. files. folders. name. metadata. File System. metadata.")
11
What is a semantic file system
What is a semantic file system? Organising files and managing binary data. Flexible implementation. Unified metadata unified search op Semantic File System metadata data X Flickr CMS File System

12
Zugriff auf „beliebige“ Daten per Windows-Explorer
SemFS Zugriff auf „beliebige“ Daten per Windows-Explorer Such-Verfeinerung kann intuitiv genutzt werden Passt gut zum Tagging-Paradigme Kann auch geteilt genutzt werden (WebDAV) Kontakt: (Projekt ist eine Kooperation von FZI, AIFB, Uni Koblenz)
 Kontakt: (Projekt ist eine Kooperation von FZI, AIFB, Uni Koblenz)")
13
WAVES

14
MindMeister

15
Personal Ontology-based
Nepomuk means… Networked P2P-technology for efficient on-the-fly exchange Environment for existing applications can be interlinked Personal Ontology-based every user maintains own structures shared semantics emerge, like folksonomies Management of Unified Knowledge knowledge is connected across desktop borders semantically enhanced browsing and searching

16
Service registry and middleware
User Interface components (mapping, wiki, search interface, ontology browser) Service registry and middleware Services (search, text analysis, adaptors) Local storage (RDF know- ledge base) NEPOMUK consists of partly independent modules and services -- entfernt Peer-to-Peer storage
 Service registry and middleware. Services (search, text analysis, adaptors) Local storage (RDF know- ledge base) NEPOMUK consists of partly independent modules and services -- entfernt. Peer-to-Peer storage.")
17
Social Semantic Desktop
Desktop: Help to manage personal knowledge/information (documents, files, , bookmarks, notes) Semantic: Make content available to automated processing Social: Enable exchange across individual boundaries person event friend Topic acquaintance person website document colleague image Personal Semantic Web: a semantically enlarged Social protocols NEPOMUK enabled intimate supplement to memory and distributed search peers
 Semantic: Make content available to automated processing. Social: Enable exchange across individual boundaries. person. . event. friend. Topic. acquaintance. person. website. document. colleague. image. Personal Semantic Web: a semantically enlarged. Social protocols. NEPOMUK enabled. intimate supplement to memory. and distributed search. peers.")
18
Vernetzen von Applikationsobjekten auf dem Desktop
NEPOMUK Ziele: Vernetzen von Applikationsobjekten auf dem Desktop Z.B. Outlook-Kontakt mit Word-Datei Z.B. Excel-File mit Tags Z.B. Tags mit Personen Semantische Desktop-Suche Zeige mit alle Fotos, die in Italien gemacht wurden und auf denen Hans-Jörg drauf ist! Einfacheres Teilen von Informationen (P2P Einfacheres erstellen strukturierter Informationen 2. Teil Kontakt:

19
Mash-Up: Beispiel

20
„Aus zwei (webseiten) mach eins“ Programmableweb.com: 1535 web-APIs
Mash-Ups „Aus zwei (webseiten) mach eins“ Craigs List: Google Maps und Immobilien-Inserate Programmableweb.com: 1535 web-APIs Amazon Delicious Flickr Google GoogleMaps Technorati Yahoo YouTube Zahlen Wer kennt was?
 mach eins Craigs List: Google Maps und Immobilien-Inserate. Programmableweb.com: 1535 web-APIs. Amazon. Delicious. Flickr. Google. GoogleMaps. Technorati. Yahoo. YouTube. Zahlen. Wer kennt was")
21
Mash-Up: Zukunft 1. Yahoo Pipes 2. Semantic Web

22
Siehe auch http://wiki.ontoworld.org
Semantic Wikipedia DEMO: Show wiki: ganz normal Show a city page with geo coord. Show Elbe page Canned query: lists city names + link to article + city size (sort by size?) @denny macht query @max crawl: Show info bix Show geo coord. Show wiki syntax Liegt in transitiv machen Siehe auch

23
Semantic Wikipedia: Vorteile
Strukturiertes Wissen wird exportiert (im RDF-Standard) Neue Web 2.0 Anwendungen möglich Wie IMDB, CDDB, Amazon, Wikipedia-Daten im Mediaplayer Wiederverwendung von Wissen über Sprachgrenzen hinweg Berlin, Einwohner, = Berlin, population, Aggregierte Suche über mehrere Seiten Liste aller Filme, die einen gebürtigen Italiener als Regisseur haben? Welche Städte in Europa haben mehr als 1 Mio Einwohner? Listen können automatisch generiert werden Qualität: Finden von Fehlern und Widersprüchen Hat jedes Land eine Hauptstadt? Wird jede Person geboren bevor sie stirbt? Passen die Geburtstagsjahreslisten zu den Geburtstagen der Personen? Passt die Bevölkerungsdichte zu Bevölkerung und Fläche? Offene Fragen Benutzungsschnittstellen zum Formulieren der strukturierten Anfragen
 Neue Web 2.0 Anwendungen möglich. Wie IMDB, CDDB, Amazon, Wikipedia-Daten im Mediaplayer. Wiederverwendung von Wissen über Sprachgrenzen hinweg. Berlin, Einwohner, = Berlin, population, Aggregierte Suche über mehrere Seiten. Liste aller Filme, die einen gebürtigen Italiener als Regisseur haben Welche Städte in Europa haben mehr als 1 Mio Einwohner Listen können automatisch generiert werden. Qualität: Finden von Fehlern und Widersprüchen. Hat jedes Land eine Hauptstadt Wird jede Person geboren bevor sie stirbt Passen die Geburtstagsjahreslisten zu den Geburtstagen der Personen Passt die Bevölkerungsdichte zu Bevölkerung und Fläche Offene Fragen. Benutzungsschnittstellen zum Formulieren der strukturierten Anfragen.")
24
Semantic Wiki = Wiki + Semantic Web
Semantic MediaWiki Erweiterung der MediaWiki-Software (Technik der Wikipedia) Syntaxerweiterung erlaubt getypte Links Seite Karlsruhe Bisher: … liegt im Süden von [[Deutschland]] … Neu: … liegt im Süden von [[liegt in::Deutschland]] … Syntaxerweiterung erlaubt annotieren von Werten Bisher: … hat eine Bevölkerung von 280,000 Einwohnern. … Neur: … hat eine Bevölkerung von [[Bevölkerung:=280000]] Einwohnern. Architektur
 Syntaxerweiterung erlaubt getypte Links. Seite Karlsruhe. Bisher: … liegt im Süden von [[Deutschland]] … Neu: … liegt im Süden von [[liegt in::Deutschland]] … Syntaxerweiterung erlaubt annotieren von Werten. Bisher: … hat eine Bevölkerung von 280,000 Einwohnern. … Neur: … hat eine Bevölkerung von [[Bevölkerung:=280000]] Einwohnern. Architektur.")
25
Semantic MediaWiki

26
What is located in California?

27
[[Category:Country]] [[located in::Africa]]
Inline queries <ask> [[Category:Country]] [[located in::Africa]] [[population:=>1,000,000]] [[population:=<10,000,000]] [[population:=*]] [[area:=*km²]] [[borders::*]] </ask> Other thing: the stated knowledge can also be reused inside the wiki, in form of inline queries. This is an example.
![[[Category:Country]] [[located in::Africa]]](http://slideplayer.org/slide/1273519/3/images/27/%5B%5BCategory%3ACountry%5D%5D+%5B%5Blocated+in%3A%3AAfrica%5D%5D.jpg "Inline queries. <ask> [[Category:Country]] [[located in::Africa]] [[population:=>1,000,000]] [[population:=<10,000,000]] [[population:=*]] [[area:=*km²]] [[borders::*]] </ask> Other thing: the stated knowledge can also be reused inside the wiki, in form of inline queries. This is an example.")
28
Inline query results Run on ontoworld, it would look like this.

31
Fazit Semantic MediaWiki
Stabile Erweiterung der MediaWiki software Neue Browse-Möglichkeiten (Simple Semantic Search) Neue Suchmöglichkeiten (Aggregation von Informationen über mehrere Seiten hinweg mit Inline-Queries) Kontakt:
 Neue Suchmöglichkeiten (Aggregation von Informationen über mehrere Seiten hinweg mit Inline-Queries) Kontakt:")
32
Social Software im Mittelstand?
Unternehmenskultur passt nicht zum Wiki-Ansatz Worin besteht der konkrete Mehrwert? Wie argumentiert man? Welche Technologie ist die richtige? Wikis, Blogs, Tagging, … Einführung und Akzeptanz Woogle Integration in bestehende IT-Infrastruktur JWiki + WIF SemFS NEPOMUK Benutzbarkeit WAVES Rich client wiki + Refactoring iMapping Wiki oder Intranet-Portal? Aggregation von Informationen mit Wikis? Mash-Ups Semantic MediaWiki

33
Enterprise 2.0 Martin Koser

34
Zuviele unstrukturierte Daten
Struktur und Suche Zuviele unstrukturierte Daten Nur Volltextsuche Erstellung „hochwertiger Daten“ ist teuer Lösung: Weicherer Übergang

35
Persönliches Wissensmanagement

36
Wikiseek

37
Web.de SmartSearch

38
Semantic Web Idee: Webseiten angereichert mit maschinenlesbaren Annotationen Suche über eindeutige Konzepte statt ambige Stichworte Bsp: Bank (Finanzinstitut) statt „Bank“ Strukturierte Suche statt nur Stichwortsuche Bsp: <*, liegt in, Europa> statt „Stadt Europa“ Inferenz findet auch nicht explizites Wissen Bsp: <Karlsruhe, liegt in, Deutschland> und <Deutschland, liegt in, Europa> <Karlsruhe, liegt in, Europa> Stand der Technik: Austauschformate RDF, OWL sind W3C-Standards (HTML, CSS, XML) RDF & OWL Tools incl. Inferenz vorhanden Beispiel: Friend-of-a-Friend (FOAF) „semantische Visitenkarte“
 statt „Bank Strukturierte Suche statt nur Stichwortsuche. Bsp: <*, liegt in, Europa> statt „Stadt Europa Inferenz findet auch nicht explizites Wissen. Bsp: <Karlsruhe, liegt in, Deutschland> und <Deutschland, liegt in, Europa> <Karlsruhe, liegt in, Europa> Stand der Technik: Austauschformate RDF, OWL sind W3C-Standards (HTML, CSS, XML) RDF & OWL Tools incl. Inferenz vorhanden. Beispiel: Friend-of-a-Friend (FOAF) „semantische Visitenkarte")
39
Semantic Web + Web 2.0 = Web 3.0? Web 2.0 Web 3.0 Tagging
annotieren mit ambigen Stichwörtern Singular/Plural-Problem Synonyme Keinerlei Intelligenz annotieren mit eindeutigen Stichwörtern Inferenz (Tag „Hund“ folgert Tag „Tier“) Rekombination von Daten verschiedener Quellen Mesh-Ups vorab von Hand programmiet Spontan durch End-Nutzer (siehe Piggybank) Suche Stichwortsuche oder Tag-Suche findet Dokumente Strukturierte Suche kombiniert Daten und erzeugt Dokumente Zeithorizont 2007 – 2010
 Rekombination von Daten verschiedener Quellen. Mesh-Ups vorab von Hand programmiet. Spontan durch End-Nutzer (siehe Piggybank) Suche. Stichwortsuche oder Tag-Suche findet Dokumente. Strukturierte Suche kombiniert Daten und erzeugt Dokumente. Zeithorizont –")
40
Von Dokumenten zu Wissensmodellen

41
Technological Developments
accelerated distribution by many orders of magnitude lower costs Analog Digital Communication speed internet printing press cost written language time

42
Cost of Communication Data transmission is cheap now
Total cost of communication to send content to n people: | choosing relevant parts of the personal model | + | encoding of model parts in document parts | + | order document parts strictly linear/hierarchical | + n ·( | data transmission | | linear reading of the document | | decoding of model parts from document parts | | creating a networked model out of model parts | | integrate new model to existing model | )
")
43
Cost of Communication Where can we save, if n is small?
Total cost of communication to send content to n people: | choosing relevant parts of the personal model | + | encoding of model parts in document parts | + | order document parts strictly linear/hierarchical | + n ·( | data transmission | | linear reading of the document | | decoding of model parts from document parts | | creating a networked model out of model parts | | integrate new model to existing model | )
")
44
Total cost of communication to send content to n people:
| choosing relevant parts of the personal model | + | encoding of model parts in document parts | + | order document parts strictly linear/hierarchical | + n ·( | data transmission | | linear reading of the document | | decoding of model parts from document parts | | creating a networked model out of model parts | | integrate new model to existing model | )
")
45
Current process – culture is document-centric
Sender Recipient(s) Cost
 Cost.")
46
Sender Recipient(s) Cost
Ideal process - What if not documents, but knowledge models would be exchanged between people? Sender Recipient(s) Cost
 Cost.")
47
Realistic (improved) process – use both
Sender Recipient(s) manage knowledge digitally refine it step-by-step into a document-like artefact export a part of the personal knowledge model as a document Cost
 manage knowledge digitally. refine it step-by-step into a document-like artefact. export a part of the personal knowledge model as a document. Cost.")
48
Von Dokumenten zu Wissensmodellen
A document consists of information atoms (words) Packaging – establishes a context Reference-ability – reference to a published document can act as a placeholder for the content expressed within. Process metadata – should be sent along such as authors, audience, goal Document Author, audience, goal
 Packaging – establishes a context. Reference-ability – reference to a published document can act as a placeholder for the content expressed within. Process metadata – should be sent along. such as authors, audience, goal. Document. Author, audience, goal.")
49
Dokumente enthalten bereits eine Menge (impliziter) Struktur
A document is a knowledge artefact consisting of several layers: Content Semantics – content means something. Building upon logical and argumentative structure, the author encodes statements about a domain within the content. Argumentative Structure – to convey its content to the reader. Argumentative structures appear on all scales. A typical structure is the “Introduction - Related work – Contribution - Conclusion”-pattern of scientific articles. On smaller scales, patterns like “claim-proof” and “question-answer” are used. Logical Structure – can reference smaller parts within a document i.e. paragraphs, headlines, footnotes, citations, and title Not all documents have all layers Visual Structure – guides the reader informally type-setting (i.e. bold, italics, different font styles and size), placement of figures, pages – carries additional information Linearity – defined order for navigating through all information items
, placement of figures, pages – carries additional information. Linearity. – defined order. for navigating through all information items.")
50
Trend zu kleineren Content-Einheiten

51
Conceptual Data Structures
Conceptual Data Structures Die 4 Grund-Relationen zur Wissensstrukturierung context detail before after target source annotation member annotation Item M. Völkel and H. Haller: Conceptual Data Structures (CDS) - Towards an Ontology for Semi-Formal Articulation of Personal Knowledge In Proc. of the 14th International Conference on Conceptual Structures Aalborg University - Denmark, July 2006.
 - Towards an Ontology for Semi-Formal Articulation of Personal Knowledge In Proc. of the 14th International Conference on Conceptual Structures Aalborg University - Denmark, July")
52
iMapping: a graphical approach to semi-structured knowledge modelling
examples like a pinboard Freely place any information items on an infinite canvas iMapping core principles Max Heiko simplicity spatial layout nesting, zooming graphical authoring allow vague structures capture implicit semantics minimize cognitive overhead use Conceptual Data Structures optionale all-in-one-Folie anstatt all den vorhergehenden iMapping-Folien works_for works_for Rudi

53
Zusammenfassung des Ausblicks
Trend: Persönliches Wissensmanagement Struktur und Suche Zuviele unstrukturierte Daten Nur Volltextsuche Erstellung „hochwertiger Daten“ ist teuer Lösung: Weicherer Übergang & Schrittweise Verfeinerung Von Dokumenten zu Wissensmodellen Woogle Semantic MediaWiki iMapping Semantische Wissensmodelle CDS

54
Fazit

55
- Jeder hat sein persönliches Wiki - Mash-Ups enttäuschen
Thesen - Jeder hat sein persönliches Wiki - Mash-Ups enttäuschen - Von Dokumenten zu Wissensmodellen - Semantic Web + Web 2.0 Web 3.0

Ähnliche Präsentationen



![Webinar für [Name der Gruppe] [Name des Institutes]](/1/204123/big_thumb.jpg "Webinar für [Name der Gruppe] [Name des Institutes]>")

>")













