Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Achtung Terminänderung !!!
Klausur am 6. August 2008 nicht am 9:00 – 13:00 Uhr Hörsaal Löfflerstraße Hörsaal Makarenkostraße

2
Statistische Methoden II SS 2008
Vorlesung: Prof. Dr. Michael Schürmann Zeit: Freitag (Pause: ) Ort: Hörsaal Makarenkostraße (Kiste) Übungen Gruppe 2: Hermann Haase Di SR 222 Gruppe 1: Hermann Haase Di SR 222 Gruppe 5: Svenja Schützhold Di SR 222 Gruppe 7: Sebastian Grapenthin Di 14: :00 HS 11 Gruppe 8: Svenja Schützhold Di 16: :00 SR 5 Gruppe 4: Sabine Storandt Mi SR 222 Gruppe 3: fällt weg Mi SR 222 Gruppe 6: Sebastian Grapenthin Mi SR 3 SR : Fleischmannstraße 6 SR : Loefflerstraße 70 HS : Domstraße 9a (Hist. Institut)
 Ort: Hörsaal Makarenkostraße (Kiste) Übungen. Gruppe 2: Hermann Haase Di SR 222. Gruppe 1: Hermann Haase Di SR 222. Gruppe 5: Svenja Schützhold Di SR 222. Gruppe 7: Sebastian Grapenthin Di 14: :00 HS 11. Gruppe 8: Svenja Schützhold Di 16:00 -18:00 SR 5. Gruppe 4: Sabine Storandt Mi SR 222. Gruppe 3: - fällt weg - Mi SR 222. Gruppe 6: Sebastian Grapenthin Mi SR 3. SR 222 : Fleischmannstraße 6. SR : Loefflerstraße 70. HS 11 : Domstraße 9a (Hist. Institut)")
3
Statistische Methoden I WS 2007/2008
Einleitung: Wie schätzt man die Zahl der Fische in einem See? Zur Geschichte der Statistik I. Beschreibende Statistik 1. Grundlegende Begriffe 2. Eindimensionales Datenmaterial 2.1. Der Häufigkeitsbegriff 2.2. Lage- und Streuungsparameter 2.3. Konzentrationsmaße (Lorenz-Kurve) 3. Mehrdimensionales Datenmaterial 3.1. Korrelations- und Regressionsrechnung 3.2. Indexzahlen 3.3. Saisonbereinigung
 3. Mehrdimensionales Datenmaterial Korrelations- und Regressionsrechnung Indexzahlen Saisonbereinigung.")
4
II. Wahrscheinlichkeitstheorie
1. Laplacesche Wahrscheinlicheitsräume 1.1. Kombinatorische Formeln 1.2. Berechnung von Laplace-Wahrschein- lichkeiten 2. Allgemeine Wahrscheinlichkeitsräume 2.1. Der diskrete Fall 2.2. Der stetige Fall 2.3. Unabhängigkeit und bedingte Wahrscheinlichkeit 3. Zufallsvariablen 3.1. Grundbegriffe 3.2. Erwartungswert und Varianz 3.3. Binomial- und Poisson-Verteilung 3.4. Die Normalverteilung und der Zentrale Grenzwertsatz

5
4. Markov-Ketten 4.1. Übergangsmatrizen 4.2. Grenzverhalten irreduzibler Markov-Ketten 4.3. Gewinnwahrscheinlichkeiten 4.4. Beispiel „Ruin der Spieler“ 4.5. Anwendungen

6
III. Induktive Statistik
1. Schätztheorie 1.1. Grundbegriffe, Stichproben 1.2. Maximum-Likelihood-Schätzer 1.3. Erwartungstreue Schätzer 1.4. Konfidenzintervalle 1.5. Spezialfall Binomial-Verteilung 2. Spezialfall Normalverteilung 2.1. Student- und Chi-Quadrat-Verteilung 2.2. Konfidenzintervalle

7
3. Tests 3.1. Grundbegriffe 3.2. Tests einfacher Hypothesen (Neyman-Pearson-Test) 3.3. Tests zusammengesetzter Hypothesen 3.4. Vergleich zweier unabhängiger Stichproben 3.5. Chi-Quadrat-Tests 3.6. Kolmogorov-Smirnov-Test 3.7. Einfache Varianzanalyse

8
Statistische Methoden I
WS 2007/2008 Literatur 1) G. Bamberg, F. Baur: Statistik. Oldenbourg 2) G. Bamberg, F. Baur: Statistik-Arbeitsbuch. Oldenbourg 3) L. Fahrmeir, R. Künstler, I. Pigeot, G. Tutz: Statistik. Springer 4) J. Schira: Statistische Methoden der VWL und BWL. Pearson Education 5) H. Haase: Stochastik für Betriebswirte. Shaker 6) J. Hartung: Statistik. Oldenbourg 7) R. Schlittgen: Einführung in die Statistik. Oldenbourg 8) A. Quatember: Statistik ohne Angst vor Formeln. Pearson Studium 9) H.-D. Radke: Statistik mit Excel. Markt + Technik
 G. Bamberg, F. Baur: Statistik. Oldenbourg. 2) G. Bamberg, F. Baur: Statistik-Arbeitsbuch. Oldenbourg. 3) L. Fahrmeir, R. Künstler, I. Pigeot, G. Tutz: Statistik. Springer. 4) J. Schira: Statistische Methoden der VWL und BWL. Pearson Education. 5) H. Haase: Stochastik für Betriebswirte. Shaker. 6) J. Hartung: Statistik. Oldenbourg. 7) R. Schlittgen: Einführung in die Statistik. Oldenbourg. 8) A. Quatember: Statistik ohne Angst vor Formeln. Pearson Studium. 9) H.-D. Radke: Statistik mit Excel. Markt + Technik.")
10
Die wichtigsten Tabellen

11
Übersicht I Konfidenzintervalle für den Erwartungswert

12
Übersicht II Konfidenzintervalle für die Varianz

13
Test für den Erwartungswert
Fall Normalverteilung Test für den Erwartungswert Varianz bekannt

14
Test für den Erwartungswert
Fall Normalverteilung Test für den Erwartungswert Varianz unbekannt

15
Übersicht Chi-Quadrat-Tests

16
Test auf Unabhängigkeit
Faustregeln Chi-Quadrat-Tests Test auf Anpassung Test auf Unabhängigkeit Test auf Homogenität

17
Weitere nützliche Übersichten
in den Powerpoint-Präsentationen der Vorlesung!

18
Beschreibende Statistik

19
Zentrale Themen Darstellung von Daten (Stem-Leaf-Diagramm, Box-Plot)
(praktischer Teil) Darstellung von Daten (Stem-Leaf-Diagramm, Box-Plot) Absolute und relative Häufigkeiten Empirische Verteilungsfunktion Lageparameter (arithmetisches Mittel, Median, Quantile, Quartile) Streuungsparameter (Varianz, emp. Varianz, Streuung) Lorenz-Kurve, Gini-Koeffizient Kovarianz Korrelationskoeffizient nach Bravais-Pearson Regressionsrechnung (lineare Regression, Regressionsgerade, Bestimmtheitsmaß) Peisindex nach Laspeyres und nach Paasche
 Darstellung von Daten (Stem-Leaf-Diagramm, Box-Plot) Absolute und relative Häufigkeiten. Empirische Verteilungsfunktion. Lageparameter (arithmetisches Mittel, Median, Quantile, Quartile) Streuungsparameter (Varianz, emp. Varianz, Streuung) Lorenz-Kurve, Gini-Koeffizient. Kovarianz. Korrelationskoeffizient nach Bravais-Pearson. Regressionsrechnung (lineare Regression, Regressionsgerade, Bestimmtheitsmaß) Peisindex nach Laspeyres und nach Paasche.")
20
Wahrscheinlich- keitstheorie Beschreibende Statistik
(= Deskriptive Statistik) Beschreibung von Datenmaterial 1. Semester Wahrscheinlich- keitstheorie 1. Semester Schließenden Statistik (= Induktive Statistik) Analyse von Datenmaterial, Hypothesen, Prognosen 2.Semester
 Beschreibung von Datenmaterial. 1. Semester. Wahrscheinlich- keitstheorie. 1. Semester. Schließenden Statistik. (= Induktive Statistik) Analyse von Datenmaterial, Hypothesen, Prognosen. 2.Semester.")
27
Häufigkeiten Gegeben ist eine Datenliste (Urliste)
(hier z. B. die Klausur-Noten von 50 Studenten) Hier die geordneten Daten
 Hier die geordneten Daten")
28
Kumulierte relative Häufigkeiten
Absolute Häufigkeiten h(1) = 0.1 h(2) = 0.12 h(3) = 0.36 h(4) = 0.3 h(5) = 0.12 Relative Häufigkeiten F(1) = 0.1 F(2) = 0.22 F(3) = 0.58 F(4) = 0.88 F(5) = 1 Kumulierte relative Häufigkeiten
 = 0.1. h(2) = h(3) = h(4) = 0.3. h(5) = Relative Häufigkeiten. F(1) = 0.1. F(2) = F(3) = F(4) = F(5) = 1. Kumulierte relative Häufigkeiten.")
29
Berechnung der Winkel für ein Kreisdiagramm
Fakultäten EMAU Berechnung der Winkel für ein Kreisdiagramm T: Theologische RSW: Rechts- und Staatswiss. Med: Medizinische Phil: Philosophische MathNat: Mathematisch-Naturwiss. K: Studienkolleg, ... h(T) = 0.011 h(RSW) = 0.22 h(Med) = 0.164 h(Phil) = 0.309 h(MathNat) = 0.273 h(K) = 0.022 3.96 Grad Grad 59.04 Grad Grad 98.28 Grad 7.92 Grad
 = h(RSW) = h(Med) = h(Phil) = h(MathNat) = h(K) = Grad Grad Grad Grad Grad Grad.")
30
Kreisdiagramm Fakultäten EMAU

32
Stabdiagramm „Zähne“

33
Histogram „Zähne“

34
Empirische Verteilungsfunktion
„Zähne“

35
Stem-Leaf-Diagramm Bei diesem Diagramm werden meist (siehe aber Aufgabe 3) nur die beiden führenden Ziffern berücksichtigt. Die erste Ziffer wird links von einer senkrecht gezogenen Linie eingetragen. Damit hat man den Stamm. Die zweiten Ziffern - die Blätter - werden rechts davon notiert, und zwar zeilenweise aufsteigend geordnet. Dabei muss jeder Wert des Datensatzes durch eine zweite Ziffer (ggf. Null!) repräsentiert werden. Kaltmieten
 repräsentiert werden. Kaltmieten.")
37
Charakterisierung von Merkmalen
Unterscheidung zwischen qualitativen quantitativen Merkmalen quantitative: Merkmale unterscheiden sich nach der Größe qualitative: Merkmale unterscheiden sich nach der Art Unterscheidung nach der zugrundeliegenden Werteskala Nominal- Ordinal- metrische Skala

38
Nominal: keine Rangordnung
Ordinal: Rangordnung, aber Zwischenwerte nicht interpretierbar metrisch: Rangordnung, Werte zwischen 2 Werten erlauben eine Interpretation Unterscheidung nach diskreten stetigen Merkmalen diskret: Menge der Werte abzählbar (evtl. abzählbar unendlich) stetig: Menge der Werte kontinuierlich, (z.B. reelle Zahlen oder ein Intervall reeller Zahlen)
 stetig: Menge der Werte kontinuierlich, (z.B. reelle Zahlen. oder ein Intervall reeller Zahlen)")
39
Ordinal, diskret

40
metrisch, diskret

41
metrisch, stetig

42
Ordinal, diskret

43
Arithmetisches Mittel
Merkmal Datensatz

44
Median Merkmal Geordneter Datensatz
n ungerade: Wert, der in der Mitte steht n gerade: arithmetisches Mittel der beiden Werte, die in der Mitte stehen

45
Aufgabe 1

46
Aufgabe 2

47
Quantile

51
Boxplot Ober-, Untergrenze der „Box“: oberes, unteres Quartil
„dicker Strich“ in der Box: Median Ausreißer nach oben: Werte > oberes Quartil Quartilsabstand Ausreißer nach unten: Werte < unteres Quartil Quartilsabstand Jeder Ausreißer wird mit einem Symbol gesondert einge- tragen. Antennen: größter und kleinster Wert in der Datenliste, der kein Ausreißer ist

52
Aufgabe 3

53
Aufgabe 4

54
Mittelwert oder Median
Grobe Faustregeln Metrische Skalierung Mittelwert Ordinale Skalierung Median Ausreißer wahrscheinlich Median Wenn sich die Werte „irdendwie“ gegeneinander ausgleichen Mittelwert

55
Streuungsparameter Median Mittlere Abweichung vom Median
Die Ungleichung gilt für jede Konstante c.

56
Streuungsparameter Mittelwert Varianz
Die Ungleichung gilt für jede Konstante c.

57
Rechenregeln für Mittelwert, Varianz und Streuung

58
Rechenregeln für Mittelwert, Varianz und Streuung

59
Rechenregeln für Mittelwert, Varianz und Streuung

60
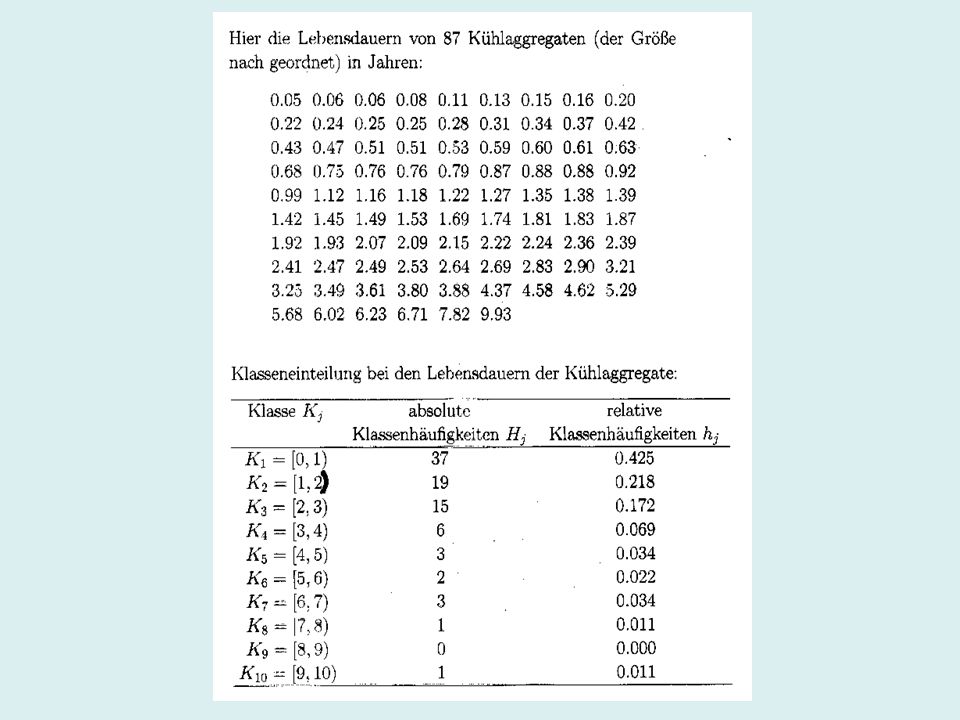
Berechnung von Streuungsparametern an einem einfachen Beispiel

Ähnliche Präsentationen











>")

 Ort:Hörsaal Makarenkostraße (Kiste)>")



 Ort:Hörsaal Makarenkostraße (Kiste)>")
 Ort:Hörsaal Loefflerstraße Übungen.>")


 Konzentrationsmaße Kennwert für die wirtschaftliche Konzentration Typische Beispiele: Verteilung des.>")


 wird auf den 4. Juni (Mittwoch) vorverlegt ! 14 – 16 Zeit:>")




 Ort:Hörsaal Makarenkostraße (Kiste)>")