Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Vorlesung: Vorverarbeitung von Affymetrix-Daten

2
? ! Vorverarbeitung von Microarray Daten: Beispiel: Affymetrix
Biologie Diagnostik Therapie ... ? Experiment- Design Experiment (Microarray) Bildverarbeitung ! Rohe Intensitätswerte Vom “Tiff” zum Expressions Level Biologische Verifikation Normalisierung Expressions Level Analyse: Clustering; Class Discovery; Klassifikation; Differentielle Gene; ....
 Bildverarbeitung. ! Rohe Intensitätswerte. Vom Tiff zum Expressions Level. Biologische Verifikation. Normalisierung. Expressions Level. Analyse: Clustering; Class Discovery; Klassifikation; Differentielle Gene; ....")
3
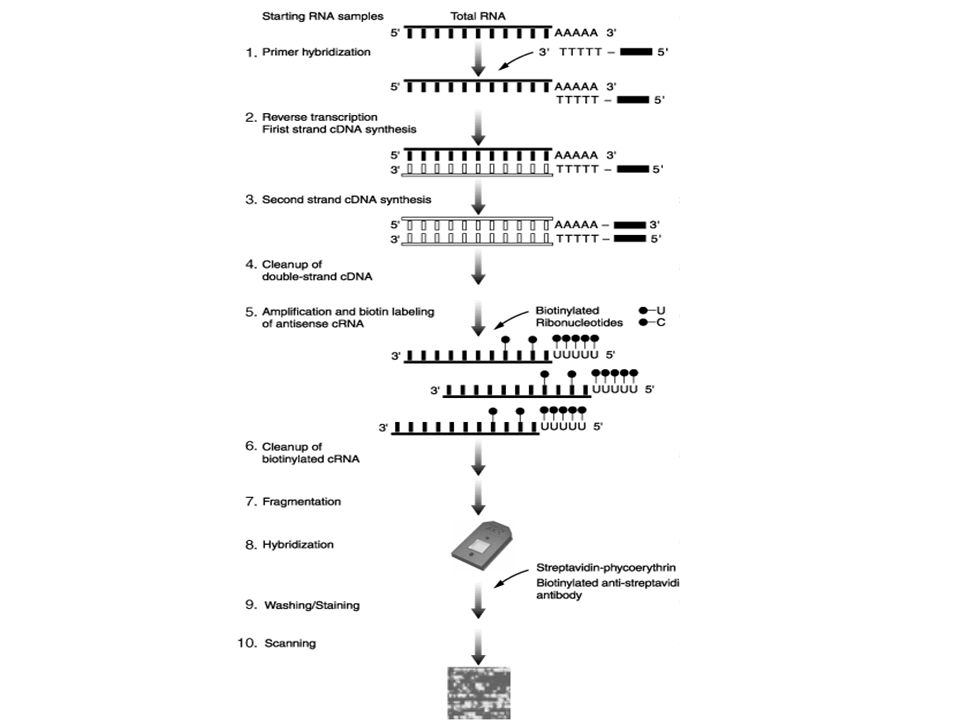
Bild eines hybridisierten Arrays
Vorverarbeitung von Microarray Daten: Beispiel: Affymetrix * GeneChip Probe Array Single stranded, labeled RNA target Oligonucleotide probe 18µm copies of a specific oligonucleotide probe per feature 1.28cm >450,000 different probes Bild eines hybridisierten Arrays Compliments of D. Gerhold

4
Extraktion der Poly-A - RNA
Chip-hybridisierung Zellpool aus Gewebeproben oder Zellkulturen Amplifikation und Markierung der RNA Auslesen des Fluoreszenzsignals Chipzelle Oligonukleotid

6
Vorverarbeitung von Microarray Daten: Beispiel: Affymetrix
... TGTGATGGTGGGAATGGGTCAGAAGGACTCCTATGTGGGTGACGAGGCC TTACCCAGTCTTCCTGAGGATACACCCAC TTACCCAGTCTTGCTGAGGATACACCCAC probe cell probe pair ... PM MM probe set PM MM Bildzelle Oligopaar Saturierte Zelle (A) (B)
 (B)")
7
Vorverarbeitung von Microarray Daten: Beispiel: Affymetrix
Lokalisation Intensität Annotation PM-MM Sequenz ...

8
Vorverarbeitung von Microarray Daten: Probleme
(1) Hintergrund (2) PM / MM (perfect match / mismatch) (3) “Summary statistics” ? ... PM MM
 Hintergrund. (2) PM / MM (perfect match / mismatch) (3) Summary statistics ... PM. MM")
9
Vorverarbeitung von Microarray Daten:
Beispiele: MAS 5.0 (Affymetrix Microarray Suite, Affymetrix Software) Li/Wong: PNAS 2001 vol 98 (1), pp31-36 RMA: Robust Multiarray Analysis, Irizarry/Bolstad/Speed (NAR, (4), e15)
 Li/Wong: PNAS 2001 vol 98 (1), pp RMA: Robust Multiarray Analysis, Irizarry/Bolstad/Speed (NAR, (4), e15)")
10
Vorab: Was ist Tukeys Biweight ?
Angabe der Tendenz Maß für den Mittelwert sehr robust gegenüber Ausreißern Vektor: X = (x1,...,xn) Berechne Tukey´s Biweight von X: T(X) Berechne die absolute Distanz von jedem Datenpunkt zum Median Berechne S = Median der absoluten Abweichungen (MAD) Definiere u = (Datenpunkt-Median(Datenpunkte) )/(Konstante*S + ) Konstante = 5; = Gewichtsfunktion: w(u) = (1 - u2)2 for |u| <= 1 0 else T(x) = i w(u) xi / i w(u)
 Berechne Tukey´s Biweight von X: T(X) Berechne die absolute Distanz von jedem Datenpunkt zum Median. Berechne S = Median der absoluten Abweichungen (MAD) Definiere u = (Datenpunkt-Median(Datenpunkte) )/(Konstante*S + ) Konstante = 5; = Gewichtsfunktion: w(u) = (1 - u2)2 for |u| <= 1. 0 else. T(x) = i w(u) xi / i w(u)")
11
x x x x x x Vorab: Was ist Tukeys Biweight ? X = 1,2,3,2,4,20
x x x x x x X = 1,2,3,2,4,20 Median 2.5 Mittelwert 5.3 Tukeys Biweight 2.3

12
Vorverarbeitung von Microarray Daten: Beispiel 1: MAS 5.0
k = 16 (zB) Kontrollzellen und leere Spots werden nicht weiter beachtet
 Kontrollzellen und leere Spots werden nicht weiter beachtet.")
13
Vorverarbeitung von Microarray Daten: Beispiel 1: MAS 5.0
Alle Zellen eines Sub-Arrays (=Zone) werden der Größe nach geordnet Jeder Zelle wird ein Rang zugeordnet C1 C2 C3 C4 … Cn Definition von Hintergrund eines Sub- Arrays: Zbg = niedrigsten 2% des jeweiligen Subarrays .
 werden der Größe nach geordnet. Jeder Zelle wird ein Rang zugeordnet. C1. C2. C3. C4. … Cn. Definition von Hintergrund eines Sub- Arrays: Zbg = niedrigsten 2% des jeweiligen Subarrays. .")
14
Vorverarbeitung von Microarray Daten: Beispiel 1: MAS 5.0
Problem: Bei dieser Definition von Hintergrund (Zbg) gibt es “scharfe” Grenzen zwischen den einzelnen “Subarrays” Lösung: Glättung der Übergänge
 gibt es scharfe Grenzen zwischen den einzelnen Subarrays Lösung: Glättung der Übergänge.")
15
Vorverarbeitung von Microarray Daten: Beispiel 1: MAS 5.0
Glättung der Übergänge dk(x,y) = Distanz vom Mittelpunkt (.) des k-ten Segments zu einem Punkt mit den Koordinaten (x,y) Gewichtung: wk(x,y)=1/(dk2 + s) (default s=100) . .
 = Distanz vom Mittelpunkt (.) des k-ten Segments zu einem Punkt mit den Koordinaten (x,y) Gewichtung: wk(x,y)=1/(dk2 + s) (default s=100) . .")
16
Vorverarbeitung von Microarray Daten: Beispiel 1: MAS 5.0
Neuer Hintergrund: b(x,y) = k wk(x,y) Zbg / k wk(x,y) . .
 = k wk(x,y) Zbg / k wk(x,y) . .")
17
Vorverarbeitung von Microarray Daten: Beispiel 1: MAS 5.0
Perfect match und Mismatch (PM MM) ... PM MM Definitionen: Adjustierte Intensität: A(x,y) = maxInt(x,y) – b(x,y) | NoiseFrac * n(x,y) NoiseFrac = 0.5 default n(x,y) = 1 / w(x,y) * (w(x,y) n Zk) n Zk = Standardabweichung (niedrigste 2% Intensitäten) Int(x,y) = max Int(x,y) , 0.5
 ... PM. MM. Definitionen: Adjustierte Intensität: A(x,y) = maxInt(x,y) – b(x,y) | NoiseFrac * n(x,y) NoiseFrac = 0.5 default. n(x,y) = 1 / w(x,y) * (w(x,y) n Zk) n Zk = Standardabweichung (niedrigste 2% Intensitäten) Int(x,y) = max Int(x,y) , 0.5 ")
18
Vorverarbeitung von Microarray Daten: Beispiel 1: MAS 5.0
Perfect match und Mismatch (PM MM) ... PM MM Definitionen: Idealer Mismatch: IM i,j = PM i,j / 2 Sbi MM i,j > PM i,j ; Sbi > MM i,j MM i,j < PM i,j PM i,j / 2 a MM i,j > PM i,j ; Sbi <= a = / (1+(( -Sbi)/ ’))) = 0.03 ’ = 10 Sbi = biweight specific background
 ... PM. MM. Definitionen: Idealer Mismatch: IM i,j = PM i,j / 2 Sbi MM i,j > PM i,j ; Sbi > MM i,j MM i,j < PM i,j. PM i,j / 2 a MM i,j > PM i,j ; Sbi <= a = / (1+(( -Sbi)/ ’))) = ’ = 10. Sbi = biweight specific background.")
19
Vorverarbeitung von Microarray Daten: Beispiel 1: MAS 5.0
Perfect match und Mismatch (PM MM) ... PM MM Definitionen: Neuer Signalwert (Intensität): i = 1,…,n probe pair j = 1,…,m array probe set V i,j = max(PM i,j - IM i,j , ) = 2 –20 PV i,j = log(V i,j) für alle j Neuer Signalwert = Tbi (PV i1, … , PV in )
 ... PM. MM. Definitionen: Neuer Signalwert (Intensität): i = 1,…,n probe pair. j = 1,…,m array probe set. V i,j = max(PM i,j - IM i,j , ) = 2 –20. PV i,j = log(V i,j) für alle j. Neuer Signalwert = Tbi (PV i1, … , PV in )")
20
Vorverarbeitung von Microarray Daten: Beispiel 2: Li/Wong
Li/Wong (PNAS 2001 vol 98 (1), pp31-36) Modell: MMij = j + i j + PMij = j + i j + i j + j Baseline i Expression eines Gens in der i ten Probe j Anstiegsrate: MM im j ten “probe pair” j zuätzliche Anstiegsrate im korrespondierenden PM Wert Zufälliger Fehler
, pp31-36) Modell: MMij = j + i j + PMij = j + i j + i j + j Baseline. i Expression eines Gens in der i ten Probe. j Anstiegsrate: MM im j ten probe pair j zuätzliche Anstiegsrate im korrespondierenden PM Wert. Zufälliger Fehler.")
21
Vorverarbeitung von Microarray Daten:
Beispiel 2: Li/Wong Vorab: Was ist “Least Square Fit” (= Methode kleinster Fehlerquadrate)
")
22
Vorverarbeitung von Microarray Daten: Beispiel 2: Li/Wong
Vorab: Was ist “Least Square Fit” (= Methode kleinster Fehlerquadrate) Summe der Fehlerquadrate ist minimal
 Summe der Fehlerquadrate ist minimal.")
23
Vorverarbeitung von Microarray Daten: Beispiel 2: Li/Wong
Vorab: Was ist “Least Square Fit” (= Methode kleinster Fehlerquadrate) X=(1,2,3,4,5) Y=(1,1,2,2,4)
 X=(1,2,3,4,5) Y=(1,1,2,2,4)")
24
Vorab: Was ist “Least Square Fit” (= Methode kleinster Fehlerquadrate)
X=(1,2,3,4,5); Y=(1,1,2,2,4) Y= ß0+ ß1*x Es werden ß1 und ß0 so geschätzt, daß die Summe der Quadrate der Residuen minimal werden: Min
; Y=(1,1,2,2,4) Y= ß0+ ß1*x. Es werden ß1 und ß0 so geschätzt, daß die Summe der Quadrate der Residuen minimal werden: Min.")
25
Vorab: Was ist “Least Square Fit” (= Methode kleinster Fehlerquadrate)
xi yi (xi)2 xi * yi 1 2 … n x1 x2 xn y1 y2 yn y12 y22 yn2 x1y1 x2y2 xnyn xi yi (xi)2 xi * yi
2. xi * yi … n. x1. x2. xn. y1. y2. yn. y12. y22. yn2. x1y1. x2y2. xnyn. xi. yi. (xi)2. xi * yi.")
26
Vorab: Was ist “Least Square Fit” (= Methode kleinster Fehlerquadrate)
xi yi (xi)2 xi * yi 1 2 3 4 5 9 16 25 6 8 20 xi = 15 yi = 10 (xi)2 = 55 xi * yi = 37
2. xi * yi xi = 15. yi = 10. (xi)2 = 55. xi * yi = 37.")
27
Vorab: Was ist “Least Square Fit”
(= Methode kleinster Fehlerquadrate)
")
28
Vorverarbeitung von Microarray Daten: Beispiel 2: Li/Wong
Modell: MMij = j + i j + PMij = j + i j + i j + => PMij - MMij = i j + ij Angenommen: ij ~ N(0,2) Least Square Fit von PMij - MMij = i j + ij
 Least Square Fit von PMij - MMij = i j + ij.")
29
unspezifische Bindung
Vorverarbeitung von Microarray Daten: Beispiel 3: RMA RMA: Irizarry/Bolstad/Speed (NAR, (4), e15) Modellannahme: Signal PM = Hintergrund + Signal = hg + s = = Optisches Rauschen + unspezifische Bindung Hintergrund Korrektur: B(PM) = E(s|PM) s ~ exponential hg ~ normal
, e15) Modellannahme: Signal PM = Hintergrund + Signal = hg + s = + = Optisches Rauschen. + unspezifische Bindung. Hintergrund Korrektur: B(PM) = E(s|PM) s ~ exponential. hg ~ normal.")
30
Vorverarbeitung von Microarray Daten: Beispiel 3: RMA
PM, MM: “Forget about MM” Grund: was immer da auch gemessen wird; momentan laesst sich das nicht sinnvoll in biologische Interpretationen fassen ev. kann man in der Zukunft die Hintergrundkorrektur etwas besser durchführen, indem man die MM-Werte benutzt.

31
Vorverarbeitung von Microarray Daten: Beispiel 3: RMA
Summary Statistic: Yijn = jn + jn + ijn i=1,...,I (chips) j=1,...,J (probes) n=1,...,n (probe set) jn “probe affinity effect” jn “log scale expression level” ijn error iid N(0, 2) j j= 0 n -> median polish
 j=1,...,J (probes) n=1,...,n (probe set) jn probe affinity effect jn log scale expression level ijn error iid N(0, 2) j j= 0 n. -> median polish.")
32
Vorverarbeitung von Microarray Daten: Beispiel 3: RMA
Was ist “Median Polish”: An eine Matrix M wird ein additives Modell gefittet: Konstante + Spalten + Zeilen. Im Algorithmus werden abwechselnd Zeilen- bzw Spalten Mediane entfernt und wird solange durchgefuehrt, bis die proportionale Reduktion in der Summe der absoluten Residuen kleiner epsilon ist oder bis zu einem Max von Iterationsschritten.

33
Macht es etwas aus, welche Methode ich wähle?
all spots Av Diff pm only “MAS 5.0” Li/Wong pm only bgMAS+Av Diff pm only Li/Wong pm-mm RMA Av Diff pm - mm

34
Macht es etwas aus, welche Methode ich wähle?
Reference distribution is normal for the log fold change from: Terry Speed, Summarizing and comparing GeneChip data

35
Vergleich von mehreren Proben
cDNA Arrays Oligonucleotide Arrays

36
Vergleich von mehreren Proben
Patient Kontrolle Patient G C A Kontrolle G C A G C A G C A

37
Vergleich von mehreren Proben
Affymetrix in MAS5.0: - nicht einzeln auswerten der Chips sondern direkter paarweiser Vergleich: “Balancing factors” Wilcoxon Ranksummen Test

38
Software Open source-open development software Projekt seit 2001
erste Bioconductor software release, May 2002 R basiert

40
Software library(affy)
x = ReadAffy(celfile.path="/project/gene_expression/spikein/") data.rma = express ( x, subset = NULL , bg.correct = bg.correct.rma , pmcorrect.method="pmonly" , summary.stat = medianpolish , normalize=F , verbose = TRUE )
 data.rma = express ( x, subset = NULL , bg.correct = bg.correct.rma , pmcorrect.method= pmonly , summary.stat = medianpolish , normalize=F , verbose = TRUE )")
Ähnliche Präsentationen






 = 5n 3 + n + 1000 für alle n a)Geben sie eine obere Schranke O(g(n)) an. b)Beweisen.>")


 library(lme4)>")


 Wege Prof. Dr. Th. Ottmann.>")
 Prof. Dr. Th. Ottmann.>")





