Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

 Ort:Hörsaal Makarenkostraße (Kiste)")
 Konzentrationsmaße Kennwert für die wirtschaftliche Konzentration Typische Beispiele: Verteilung des.")




 Konzentrationsmaße Kennwert für die wirtschaftliche Konzentration Typische Beispiele: Verteilung.")

1
Statistische Methoden I
WS 2002/2003 Zur Geschichte der Statistik I. Beschreibende Statistik 1. Grundlegende Begriffe 2. Eindimensionales Datenmaterial 2.1. Der Häufigkeitsbegriff 2.2. Lage- und Streuungsparameter 2.3. Konzentrationsmaße (Lorenz-Kurve) 3. Mehrdimensionales Datenmaterial 3.1. Korrelations- und Regressionsrechnung 3.2. Indexzahlen 3.3. Saisonbereinigung
 3. Mehrdimensionales Datenmaterial Korrelations- und Regressionsrechnung Indexzahlen Saisonbereinigung.")
2
II. Wahrscheinlichkeitstheorie
1. Laplacesche Wahrscheinlicheitsräume 1.1. Kombinatorische Formeln 1.2. Berechnung von Laplace-Wahrschein- lichkeiten 2. Allgemeine Wahrscheinlichkeitsräume 2.1. Der diskrete Fall 2.2. Der stetige Fall 2.3. Unabhängigkeit und bedingte Wahrscheinlichkeit 3. Zufallsvariablen 3.1. Grundbegriffe 3.3. Erwartungswert und Varianz

3
III. Induktive Statistik
1. Schätztheorie 1.1. Grundbegriffe, Stichproben 1.2. Maximum-Likelihood-Schätzer 1.3. Erwartungstreue Schätzer 1.4. Konfidenzintervalle 1.5. Spezialfall Binomial-Verteilung 2. Spezialfall Normalverteilung 2.1. Student- und Chi-Quadrat-Verteilung 2.2. Konfidenzintervalle

4
3. Tests 3.1. Grundbegriffe 3.2. Tests einfacher Hypothesen (Neyman-Pearson-Test) 3.3. Tests zusammengesetzter Hypothesen 3.4. Vergleich zweier unabhängiger Stichproben 3.5. Chi-Quadrat-Tests 3.6. Kolmogorov-Smirnov-Test 3.7. Einfache Varianzanalyse

6
Beschreibende Statistik

7
Wahrscheinlich- keitstheorie Beschreibende Statistik
(= Deskriptive Statistik) Beschreibung von Datenmaterial 1. Semester Wahrscheinlich- keitstheorie 1. Semester Schließenden Statistik (= Induktive Statistik) Analyse von Datenmaterial, Hypothesen, Prognosen 2.Semester
 Beschreibung von Datenmaterial. 1. Semester. Wahrscheinlich- keitstheorie. 1. Semester. Schließenden Statistik. (= Induktive Statistik) Analyse von Datenmaterial, Hypothesen, Prognosen. 2.Semester.")
14
Häufigkeiten Gegeben ist eine Datenliste (Urliste)
(hier z. B. die Klausur-Noten von 50 Studenten) Hier die geordneten Daten
 Hier die geordneten Daten")
15
Kumulierte relative Häufigkeiten
Absolute Häufigkeiten h(1) = 0.1 h(2) = 0.12 h(3) = 0.36 h(4) = 0.3 h(5) = 0.12 Relative Häufigkeiten F(1) = 0.1 F(2) = 0.22 F(3) = 0.58 F(4) = 0.88 F(5) = 1 Kumulierte relative Häufigkeiten
 = 0.1. h(2) = h(3) = h(4) = 0.3. h(5) = Relative Häufigkeiten. F(1) = 0.1. F(2) = F(3) = F(4) = F(5) = 1. Kumulierte relative Häufigkeiten.")
16
Berechnung der Winkel für ein Kreisdiagramm
Fakultäten EMAU Berechnung der Winkel für ein Kreisdiagramm T: Theologische RSW: Rechts- und Staatswiss. Med: Medizinische Phil: Philosophische MathNat: Mathematisch-Naturwiss. K: Studienkolleg, ... h(T) = 0.011 h(RSW) = 0.22 h(Med) = 0.164 h(Phil) = 0.309 h(MathNat) = 0.273 h(K) = 0.022 3.96 Grad Grad 59.04 Grad Grad 98.28 Grad 7.92 Grad
 = h(RSW) = h(Med) = h(Phil) = h(MathNat) = h(K) = Grad Grad Grad Grad Grad Grad.")
17
Kreisdiagramm Fakultäten EMAU

19
Stabdiagramm „Zähne“

20
Histogram „Zähne“

21
Empirische Verteilungsfunktion
„Zähne“

22
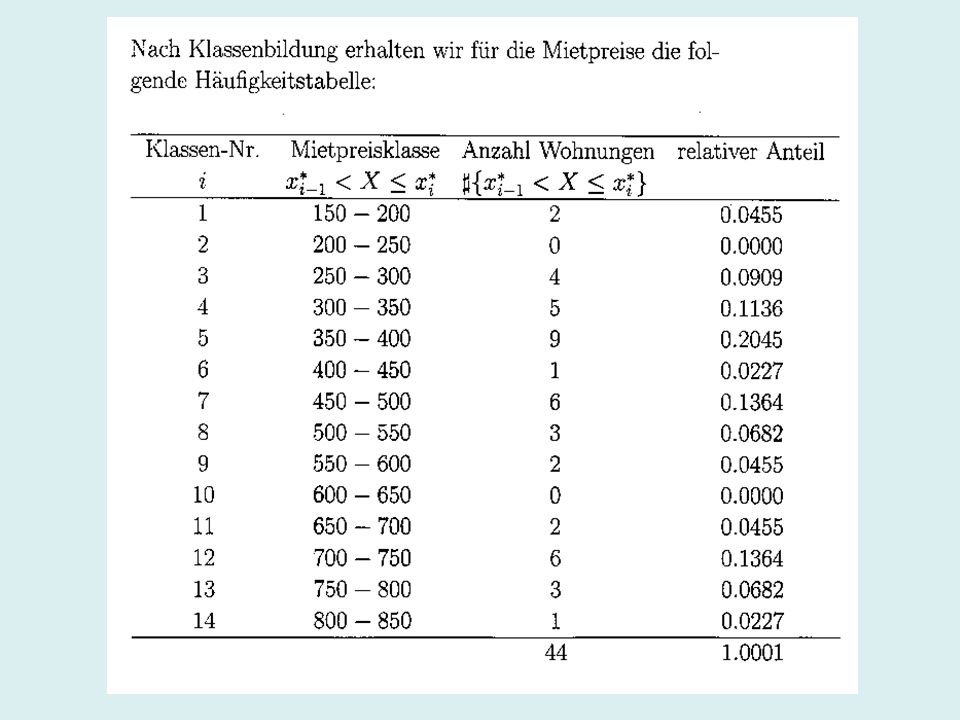
Stem-Leaf-Diagramm Bei diesem Diagramm werden meist nur die beiden führen- den Ziffern berücksichtigt. Die erste Ziffer wird links von Einer senkrecht gezogenen Linie eingetragen. Damit hat man den Stamm. Die zweiten Ziffern - die Blätter - werden rechts davon notiert, und zwar zeilenweise aufsteigend geordnet. Dabei muss jeder Wert des Datensatzes durch eine zweite Ziffer (ggf. Null!) repräsentiert werden. Kaltmieten
 repräsentiert werden. Kaltmieten.")
24
Charakterisierung von Merkmalen
Unterscheidung zwischen qualitativen quantitativen Merkmalen quantitative: Merkmale unterscheiden sich nach der Größe qualitative: Merkmale unterscheiden sich nach der Art Unterscheidung nach der zugrundeliegenden Werteskala Nominal- Ordinal- metrische Skala

25
Nominal: keine Rangordnung
Ordinal: Rangordnung, aber Zwischenwerte nicht interpretierbar metrisch: Rangordnung (Reihenfolge), Werte zwischen 2 Werten erlauben eine Interpretation Unterscheidung nach diskreten stetigen Merkmalen diskret: Menge der Werte abzählbar (evtl. abzählbar unendlich) stetig: Menge der Werte kontinuierlich, (z.B. reelle Zahlen oder ein Intervall reeller Zahlen)
, Werte zwischen 2 Werten. erlauben eine Interpretation. Unterscheidung nach. diskreten. stetigen. Merkmalen. diskret: Menge der Werte abzählbar (evtl. abzählbar unendlich) stetig: Menge der Werte kontinuierlich, (z.B. reelle Zahlen. oder ein Intervall reeller Zahlen)")
26
Ordinal, diskret

27
metrisch, diskret

28
metrisch, stetig

29
Ordinal, diskret

30
Arithmetisches Mittel
Merkmal Datensatz

31
Median Merkmal Geordneter Datensatz
n ungerade: Wert, der in der Mitte steht n gerade: arithmetisches Mittel der beiden Werte, die in der Mitte stehen

32
Achtung Aufgabe!

33
Achtung noch eine Aufgabe!

34
Quantile

38
Boxplot Ober-, Untergrenze der „Box“: oberes, unteres Quartil
„dicker Strich“ in der Box: Median Ausreißer nach oben: Werte > oberes Quartil Quartilsabstand Ausreißer nach unten: Werte < unteres Quartil Quartilsabstand Jeder Ausreißer wird mit einem Symbol gesondert einge- tragen. Antennen: größter und kleinster Wert in der Datenliste, der kein Ausreißer ist

39
Achtung Aufgabe!

40
Achtung noch eine Aufgabe!

41
Mittelwert oder Median
Grobe Faustregeln Metrische Skalierung Mittelwert Ordinale Skalierung Median Ausreißer wahrscheinlich Median Wenn sich die Werte „irdendwie“ gegeneinander ausgleichen Mittelwert

42
Streuungsparameter Median Mittlere Abweichung vom Median
Die Ungleichung gilt für jede Konstante c.

43
Streuungsparameter Mittelwert Varianz
Die Ungleichung gilt für jede Konstante c.

44
Rechenregeln für Mittelwert, Varianz und Streuung

45
Rechenregeln für Mittelwert, Varianz und Streuung

46
Rechenregeln für Mittelwert, Varianz und Streuung

47
Berechnung von Streuungsparametern an einem einfachen Beispiel

48
Konzentrationsmaße (Gini-Koeffizient, Lorenz-Kurve) Konzentrationsmaße
Kennwert für die wirtschaftliche Konzentration Typische Beispiele: Verteilung des Geldvermögens unter den einzelnen Bevölkerungsgruppen Verteilung von Marktanteilen Aufteilung der landwirtschaftlichen Nutzflächen in einer Region

49
Ein Markt wird von 5 Unternehmen beliefert.
Die folgende Tabelle beschreibt die Aufteilung der Marktanteile:

50
Daraus ergeben sich die folgenden Werte für die Punkte
auf der Lorenz-Kurve:

51
Dazu die Lorenz-Kurve:

52
Berechnung des Gini-Koeffizienten

53
Achtung Aufgabe!

54
Achtung noch eine Aufgabe!

55
Landwirtschaftlich genutzte Fläche einer Region

56
Dazu die Lorenz-Kurve:

57
Datenmatrix

58
Datentabelle für 2 Merkmale

59
Kontingenztafel der absoluten Häufigkeiten

60
Kontingenztafel der relativen Häufigkeiten

61
Betriebe und hinterzogene Steuer
Kontingenztabelle X: Art des Betriebes 1 = Handelsbetriebe 2 = Freie Berufe (Leistungsbetriebe) 3 = Fertigungsbetriebe Y: Art der hinterzogenen Steuer 1 = Lohnsteuer 2 = Einkommenssteuer 3 = Umsatzsteuer 4 = Sonstiges
 3 = Fertigungsbetriebe. Y: Art der hinterzogenen Steuer. 1 = Lohnsteuer. 2 = Einkommenssteuer. 3 = Umsatzsteuer. 4 = Sonstiges.")
62
Kovarianz Merkmal Datensatz Merkmal Datensatz

63
Korrelationskoeffizient
nach Bravais-Pearson Eigenschaften X und Y unabhängig

64
X größer Y größer X größer Y kleiner

65
Positiver strikter Zusammenhang
Negativer strikter Zusammenhang

66
Korrelationskoeffizient bei verschiedenen Konstellationen
von Ausprägungen

67
Korrelationskoeffizient: 1.00

68
Korrelationskoeffizient: 0.52

69
Korrelationskoeffizient: 0.00

70
Korrelationskoeffizient: -0.62

71
Achtung Aufgabe!

72
Achtung noch eine Aufgabe!

73
Mögliche Funktionenklassen
für die Regressionsrechnung

74
Lineare Funktionen Polynome Exponentialfunktionen (Exponentielles Wachstum; x ist die Zeit) Gompertz-Kurven Logistische Funktionen

75
Prinzip der kleinsten Quadrate (Kleinst-Quadrat-Schätzung)
Man sucht in der betrachteten Klasse diejenige Funktion f, so dass die Summe der Abweichungsquadrate minimiert wird: Bestimme f, so dass minimal !!

76
Aufgaben der Regressionsrechnung
1. Extrapolation Stellt man sich für den Moment x als die Zeit vor, so möchte man die beobachteten Werte auf die „Zukunft“ extrapolieren. Man erstellt eine „Prognose“. Dazu bedient man sich der gefundenen Funktion f, um für eine „Zeit“ x der „Zukunft“ den Wert y = f(x) zu schätzen.
 zu schätzen.")
77
2. Interpolation Man interessiert sich für den Wert von y = f(x) Für
Zwischenwerte von x, d. h. für Werte x, die zwischen 2 beobachteten Werten liegen: Wieder bedient man sich der Funktion f, um eine Interpolation der Werte durchzuführen.

78
Lineare Regression Finde reelle Zahlen a und b,so dass der Wert von
minimal wird! Mit anderen Worten: Finde den „Punkt“ (a ,b), an dem die Funktion ihr Minimum annimmt!
, an dem die Funktion. ihr Minimum annimmt!")
79
Steigung der Regressionsgeraden
Schnitt der Regressionsgeraden mit der y-Achse bei

80
Bestimmtheitsmaß Maß für die Güte der Anpassung der
Daten an die Regressionsfunktion Dabei ist

81
In einem Kaufhauskonzern mit 10 Filialen
soll die Wirkung von Werbeausgaben auf die Umsatzsteigerung untersucht werden. Die Daten sind: X: Werbeausgaben in 1000 Euro Y: Umsatzsteigerung in Euro

82
Demonstrationsbeispiel
Lineare Regression Varianzen Mittelwerte Kovarianz

83
Steigung der Regressionsgeraden
Schnitt der Regressionsgeraden mit der y-Achse bei

84
Achtung Aufgabe!

85
Achtung noch eine Aufgabe!

86
Statistische Maßzahlen
Bisher: Mittelwert Median Quantile (Quartile) Lagemaße Varianz Standardabweichung Kovarianz Korrelation Streuungsmaße Konzentrationsmaße Gini-Koeffizient
 Lagemaße. Varianz. Standardabweichung. Kovarianz. Korrelation. Streuungsmaße. Konzentrationsmaße. Gini-Koeffizient.")
87
Verhältniszahlen Index- zahlen Gliederungs- zahlen Beziehungs- zahlen

88
Warenkorb N Güter (Mengen und Preise) in der Basisperiode 0
Berichtsperiode t

89
Preise in der Basisperiode 0 Preise in der Berichtsperiode t Mengen in der Basisperiode 0 Mengen in der Berichtsperiode t

90
Preisindex nach Laspeyres
Preisindex nach Paasche Laspeyres: Bezug auf den alten Warenkorb Paasche: Bezug auf den neuen Warenkorb

91
Formeln für die Preisindizes nach Laspeyres und nach Paasche

92
Aggregatform

93
Wegen der besseren Übersichtlichkeitdefinieren wir uns
einen sehr kleinen Warenkorb bestehend aus: Zigaretten Bier Kaffee In den Jahren 1950 bis 1953 werden für den Jahres- verbrauch pro Einwohner und für die Preise die folgenden Daten zu Grunde gelegt:

94
Index 0 1950 Index 1 1951 Index 2 1952 Index 3 1953

95
Achtung Aufgabe!

Ähnliche Präsentationen















 Ort:Hörsaal Makarenkostraße (Kiste)>")
 Ort:Hörsaal Loefflerstraße Übungen.>")

 Konzentrationsmaße Kennwert für die wirtschaftliche Konzentration Typische Beispiele: Verteilung des.>")






 nicht nach Außerhalb tragen. Die Weitergabe an Dritte (d. h. an Personen, die nicht Hörer der Vorlesung.>")


 Ort:Hörsaal Loefflerstraße.>")

