Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
beobachteten und erwarteten Anzahlen
Wie lässt sich die Stärke eines Zusammenhanges bei kategorialen Werten (nominalskalierten Werten) auf Basis einer Kreuztabelle, Kontingenz- tafel bewerten? Mit Hilfe der Differenz zwischen beobachteten und erwarteten Anzahlen
 auf Basis einer Kreuztabelle, Kontingenz- tafel bewerten Mit Hilfe der. Differenz zwischen. beobachteten und erwarteten Anzahlen.")
2
Erkrankt Nicht-erkrankt
Brunnen A Brunnen B

3
Vier Felder Matrix Mädchen und gut schlecht Junge

4
Mädchen und gut 345 schlecht 2 Junge 8 366 Mädchen 347 Jungen 374

5
721 = 353 374 = ? 353 mal 374 = 183 721 Eine Dreisatzaufgabe:
Wenn von 721 Schülerinnen und Schülern 353 gut sind, wie viele müssten dann von 374 (Jungen) gut sein? 721 = 353 374 = ? 353 mal 374 = 183 721
 gut sein 721 = = 353 mal 374. =")
6
Mädchen und gut 345 schlecht 2 Junge 8 [erwartet 183] 366 Mädchen 347 Jungen 374 N = 721 gut = 353 schlecht = 368
![Mädchen und. gut schlecht. 2. Junge. 8 [erwartet 183] 366. Mädchen Jungen](http://slideplayer.org/slide/637260/1/images/6/M%C3%A4dchen+und.+gut+schlecht.+2.+Junge.+8+%5Berwartet+183%5D+366.+M%C3%A4dchen+Jungen.jpg "N = 721. gut = 353. schlecht = 368.")
7
Gibt es einen Zusammenhang zwischen den Leistungen in den Fächern Geographie und Grammatik?
Gerechnet wird: 32 mal 40 = 1280 geteilt durch 80 = 16 Sie können diese Berechnung selbstverständlich auch als Dreisatz formulieren: von 80 (Gesamt) sind in Gram gut 32 von (Gesamt in Geo gut) sind in Geo gut X
 sind in Gram gut 32 von 40 (Gesamt in Geo gut) sind in Geo gut X.")
8
Die Stärke des Zusammenhangs ergibt sich logisch aus der Größe der Differenz zwischen erwartet und beobachtet. Berechnet werden kann diese Stärke bspw. durch das sog. Chi-Quadrat.

9
Konvention über den Aufbau: abhängige Variable in die Spalte, unabhängige in Zeile

10
Summary Table: Expected Frequencies (Titanic) Marked cells have counts > 10 Pearson Chi-square: 190,401, df=3, p=0,00000 class survival - Survival survival - Missing Row - Totals First Class 104,9864 220,014 325,000 Second Class 92,0650 192,935 285,000 Third Class 228,0627 477,937 706,000 Crew 285,8860 599,114 885,000 All Grps 711,0000 1490,000 2201,000

11
Berechnet werden die Zahlen „Erwartet“ wie folgt:
In der ersten Zeile wurden 203 Gerettete beobachtet. Die Gesamtzahl der Passagiere in der ersten Klasse betrug 325. Ingesamt wurden 711 Personen gerettet, an Bord waren insgesamt 2201 Personen. Die Rechnung lautet jetzt: mal 325 = , geteilt durch 2201 macht 104,98 (~ 105) Sie können diese Berechnung selbstverständlich auch als Dreisatz formulieren: von 2201 (Gesamt) überlebten 711 von (erste Klasse) überlebten X
 Sie können diese Berechnung selbstverständlich auch als Dreisatz formulieren: von 2201 (Gesamt) überlebten 711 von 325 (erste Klasse) überlebten X.")
12
Der „Chi-Quadrat-Test“ zur Überprüfung der Unabhängigkeit von zwei Variablen
Mit diesem Test kann die Unabhängigkeit von zwei Variablen, und damit indirekt auch die Größe des Zusammenhangs zwischen zwei Variablen geprüft werden. Von Bedeutung ist dieser Test bspw. wenn der Frage nachgegangen werden soll, ob – um bei dem Beispiel der Titanic zu bleiben – das Alter oder das Geschlecht eine größere Rolle bei der Frage des Überlebens gespielt hat. Dazu rufen wir wieder die Dialogbox „Kreuztabelle“ auf und setzen wieder, wie auf der nächsten Folie ersichtlich, „class“ in die Zeile und „survival“ in die Spalte. Jetzt klicken wir das Fenster „Statistik“ an und erhalten die folgende Dialogbox. ∑ („Wert beobachtet“ – „Wert erwartet“)2 Chi-Quadrat = „Wert erwartet“
2. Chi-Quadrat = „Wert erwartet")
15
Chi-Quadrat

16
Betrachten wie nun die Tabellen und Werte des Chi-Quadrats:
Damit haben wir für die Variablen „Überleben/Klasse“ einen Chi-Quadrat-Test Wert von ,401 und für die Variablen „Überleben/Alter“ einen Wert von ,956 Was sagen diese Werte aus?

17
Um diese Frage zu beantworten soll erläutert werden, wie die Werte errechnet werden. Aus der Kreuztabelle werden die Werte für „Beobachtet“ und „Erwartet“ jeder Zeile wie in der unteren Tabelle zu sehen voneinander abgezogen. Beobachtet B Erwartet E B-E (B-E) ² (B-E)² /E 203 105 98 9604 91,46 122 220 -98 43,65 118 92 26 676 7,34 167 193 -26 3,50 178 228 -50 2500 10,01 528 478 50 5,23 212 286 -74 5476 19,15 673 599 74 9,14 ∑ 189,48 Anschließend wird dieser Wert quadriert, (um nur positive Werte zu erhalten) und durch die „erwarteten Werte“ dividiert. Diese Werte werden schließlich aufaddiert und wir erhalten den Wert des Chi-Quadrat-Tests!
 ². (B-E)² /E , , , , , , , ,14. ∑ 189,48. Anschließend wird dieser Wert quadriert, (um nur positive Werte zu erhalten) und durch die „erwarteten Werte dividiert. Diese Werte werden schließlich aufaddiert und wir erhalten den Wert des Chi-Quadrat-Tests!")
18
∑ 190,32 Einige Lehrbücher berechnen den Wert so:
Um diese Frage zu beantworten soll erläutert werden, wie die Werte errechnet werden. Aus der Kreuztabelle werden die Werte für „Beobachtet“ und „Erwartet“ jeder Zeile wie in der unteren Tabelle zu sehen voneinander abgezogen. Anschließend wird die Wurzel aus dem Wert E gezogen, denn B-E durch die Wurzel E geteilt und schließlich wird das Ganze quadriert (um nur positive Werte zu erhalten). Diese Werte werden schließlich aufaddiert und wir erhalten den Wert des Chi-Quadrat-Tests! Beobachtet B Erwartet E B-E SQRT(E) B-E/SQRT(E) (B-E/SQRT (E))² 203 105 98 10,24 9,57 91,58 122 220 -98 14,83 -6,60 43,56 118 92 26 9,59 2,71 7,34 167 193 -26 13,89 -1,87 3,49 178 228 -50 15,09 -3,31 10,95 528 478 50 21,86 2,28 5,19 212 286 -74 16,91 -4,37 19,09 673 599 74 24,47 3,02 9,12 ∑ 190,32
. Diese Werte werden schließlich aufaddiert und wir erhalten den Wert des Chi-Quadrat-Tests! Beobachtet B. Erwartet E. B-E. SQRT(E) B-E/SQRT(E) (B-E/SQRT (E))² ,24. 9,57. 91, ,83. -6,60. 43, ,59. 2,71. 7, ,89. -1,87. 3, ,09. -3,31. 10, ,86. 2,28. 5, ,91. -4,37. 19, ,47. 3,02. 9,12. ∑ 190,32.")
19
Um einen Aspekt zu verstehen, der diesem Wert entnommen werden kann, verdeutlichen wir uns einmal den Fall, bei dem der beobachtetet Wert nahezu dem erwarteten Wert entspricht: Beobachtet B Erwartet E B-E SQRT(E) B-E/SQRT(E) (B-E/SQRT (E))² 243 242 1 15,58 0,064 0,00411 Anschließend den Wert, der einer maximal möglichen Abweichung entspricht: Beobachtet B Erwartet E B-E SQRT(E) B-E/SQRT(E) (B-E/SQRT (E))² 1 243 -242 15,58 -15,53 241,18 Dieser Vergleich zeigt (hoffentlich) deutlich (einen der) hier zugrunde liegenden Aspekte: Je höher der Chi-Quadrat-Test Wert, desto größer der Zusammenhang zwischen den betrachteten Variablen. Zurück zu der gestellten Frage ergibt sich folglich, dass die Variablen „Klasse“ mit dem Chi-Quadrat-Test Wert von 190,401 einen höheren Zusammenhang zwischen dieser Variablen und dem Überleben aufweist, als die Variable „Alter“ mit einem Wert von nur 20,956. Kurz: Mit Hilfe des Chi-Quadrat-Test Wertes kann die Stärke des Zusammen- hang zwischen verschiedenen Variablen vergleichend beurteilt werden.
 B-E/SQRT(E) (B-E/SQRT (E))² ,58. 0,064. 0, Anschließend den Wert, der einer maximal möglichen Abweichung entspricht: Beobachtet B. Erwartet E. B-E. SQRT(E) B-E/SQRT(E) (B-E/SQRT (E))² , , ,18. Dieser Vergleich zeigt (hoffentlich) deutlich (einen der) hier zugrunde liegenden Aspekte: Je höher der Chi-Quadrat-Test Wert, desto größer der Zusammenhang zwischen den betrachteten Variablen. Zurück zu der gestellten Frage ergibt sich folglich, dass die Variablen „Klasse mit dem Chi-Quadrat-Test Wert von 190,401 einen höheren Zusammenhang zwischen dieser Variablen und dem Überleben aufweist, als die Variable „Alter mit einem Wert von nur 20,956. Kurz: Mit Hilfe des Chi-Quadrat-Test Wertes kann die Stärke des Zusammen- hang zwischen verschiedenen Variablen vergleichend beurteilt werden.")
20
Es ist auch möglich, um eine weitere Variante zu zeigen, sich die Chi- Quadrat-Werte geschichtet anzeigen zu lassen – eine ggf. übersichtlichere Darstellungsform. Es zeigt sich, dass von den hier vorliegenden Variablen die Kombination „Female/Adult“ den größten Einfluss auf die Frage „Überleben“ oder „Nicht-Überleben“ hatte.

21
Mit Hilfe des sog. Korrelationskoeffizienten
Wie lässt sich die Stärke eines Zusammenhanges bei numerischen Werten (intervallskalierten Werten) auf Basis einer Korrelationsanalyse bewerten? Mit Hilfe des sog Korrelationskoeffizienten
 auf Basis einer Korrelationsanalyse bewerten Mit Hilfe des sog. Korrelationskoeffizienten.")
22
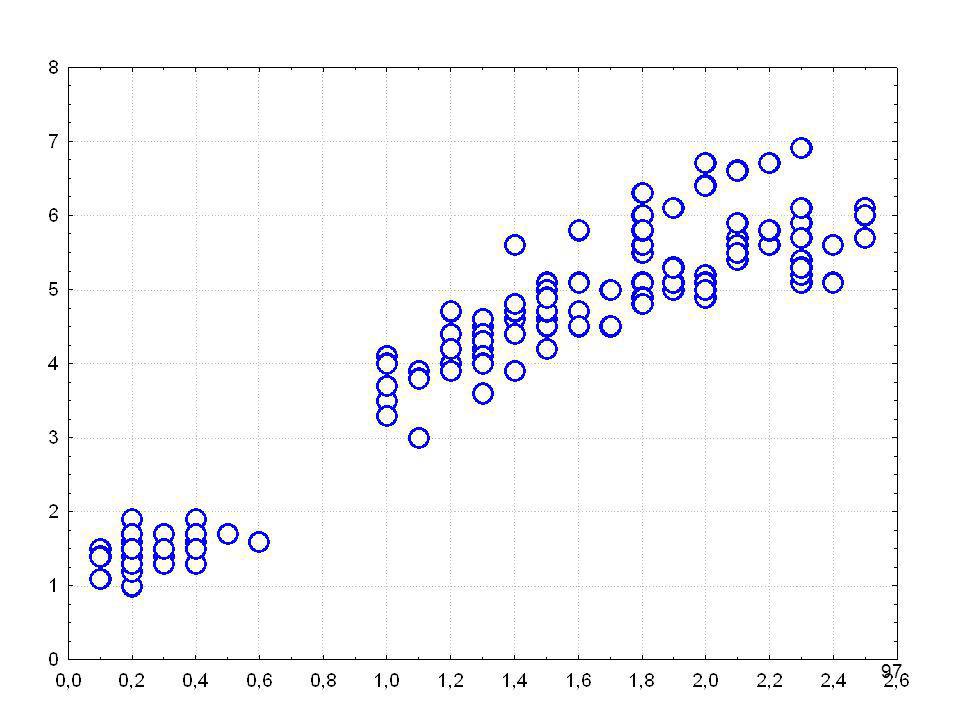
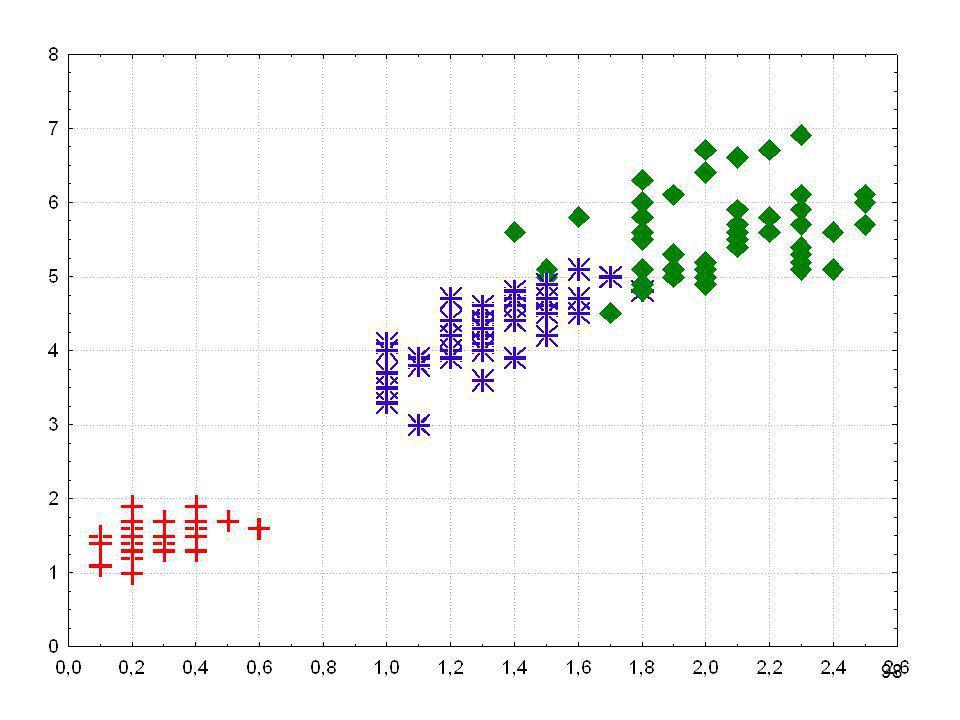
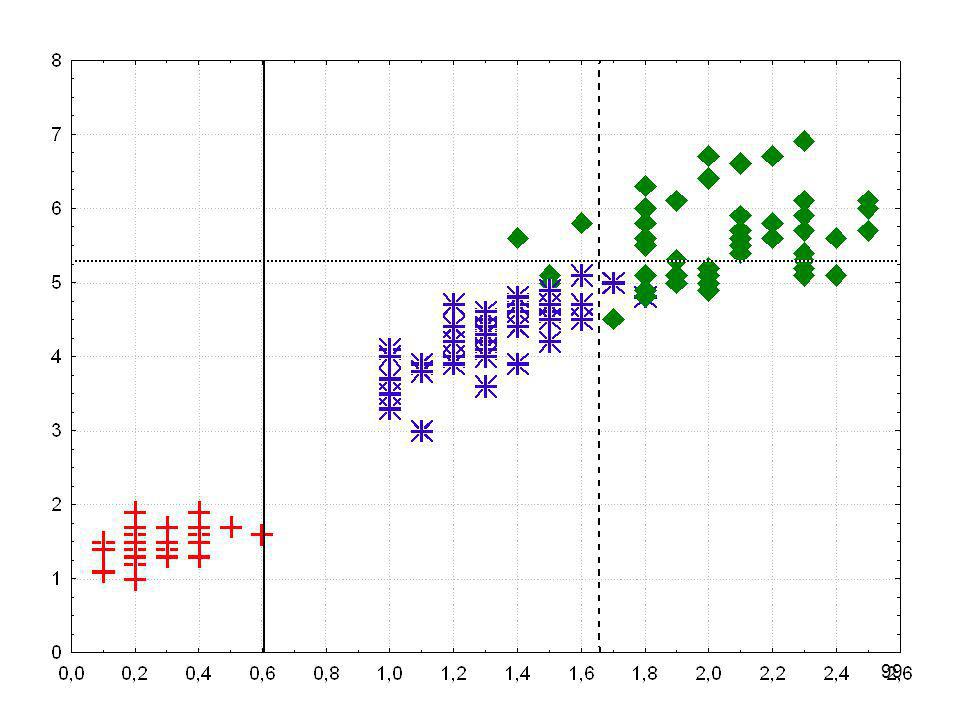
Ausgangspunkt: Ein Streudiagramm oder Scatterplot
Für jede Person, jedes Objekt wird ein Wert erhoben oder gemessen und am Schnittpunkt der beiden Werte wird eine Markierung eingetragen Körperlänge Gewicht

23
Ausgangspunkt: Ein Streudiagramm oder Scatterplot
Körperlänge Gewicht

24
Ausgangspunkt: Ein Streudiagramm oder Scatterplot
Körperlänge Gewicht

25
Ausgangspunkt: Ein Streudiagramm oder Scatterplot
Körperlänge Sog. Regressionsgrade Gewicht

26
Ausgangspunkt: Ein Streudiagramm oder Scatterplot
Körperlänge Summe der kleinsten Quadrate Gewicht

27
Ausgangspunkt: Ein Streudiagramm oder Scatterplot Korrelation: Je kleiner die Summe der kleinsten Quadrate, desto stärker der Zusammenhang Körperlänge Summe der kleinsten Quadrate Gewicht

28
Einzelwerte für Variable B
Einzelwerte für Variable A Korrelationskoeffizient 0

29
Korrelationskoeffizient hoch, positiv
Einzelwerte für Variable B Einzelwerte für Variable A

30
Korrelationskoeffizient hoch, negativ
Einzelwerte für Variable B Einzelwerte für Variable A

31
Positiver korrelativer Zusammenhang: „Je mehr, desto mehr“
Korrelationskoeffizient +1.0 Negativer korrelativer Zusammenhang: „Je mehr, desto weniger“ Korrelationskoeffizient -1.0

32
Verlauf über die Zeit Leistungen in Klasse A und in Klasse B A A A A A

33
Verlauf über die Zeit Leistungen in Klasse A und in Klasse B A A A A A

34
Verlauf über die Zeit Leistungen in Klasse A und in Klasse B A A A B A
Ausreißer A Leistungen in Klasse A und in Klasse B B A B A B B B A B B B B A B B B A A B Verlauf über die Zeit

35
Leistungen in Klasse B Leistungen in Klasse A A A A Böse Falle Null:
Missing Value: Für eine Person liegen keine Angaben zu der Leistung in Klasse B vor A A Leistungen in Klasse B A A A A A A A Leistungen in Klasse A

36
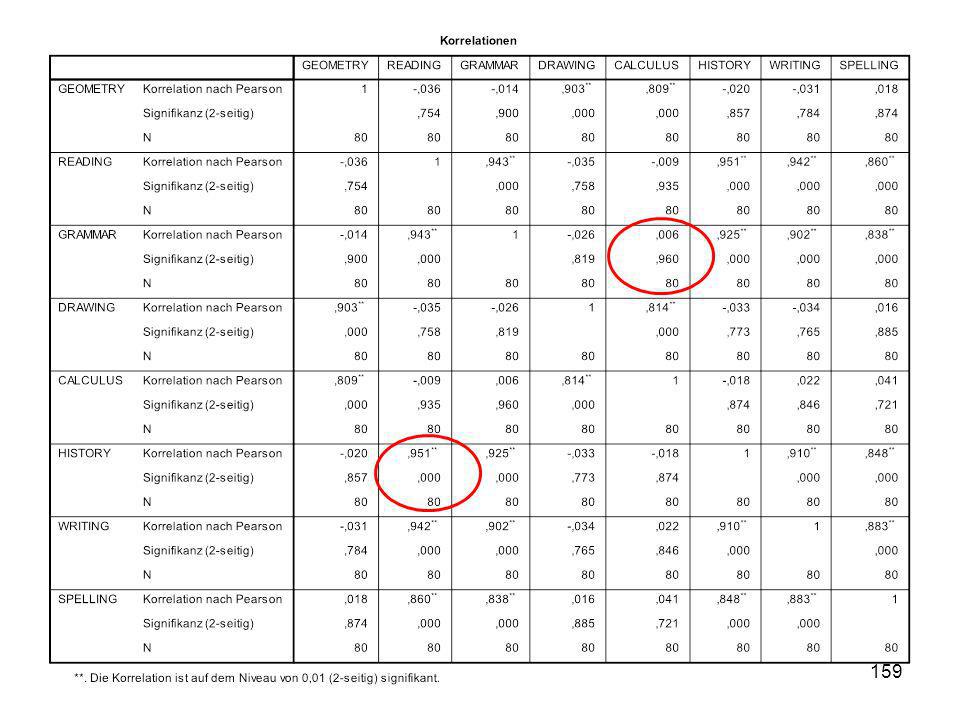
Scores of 12th graders on standardized tests (index for average: 100 pts)
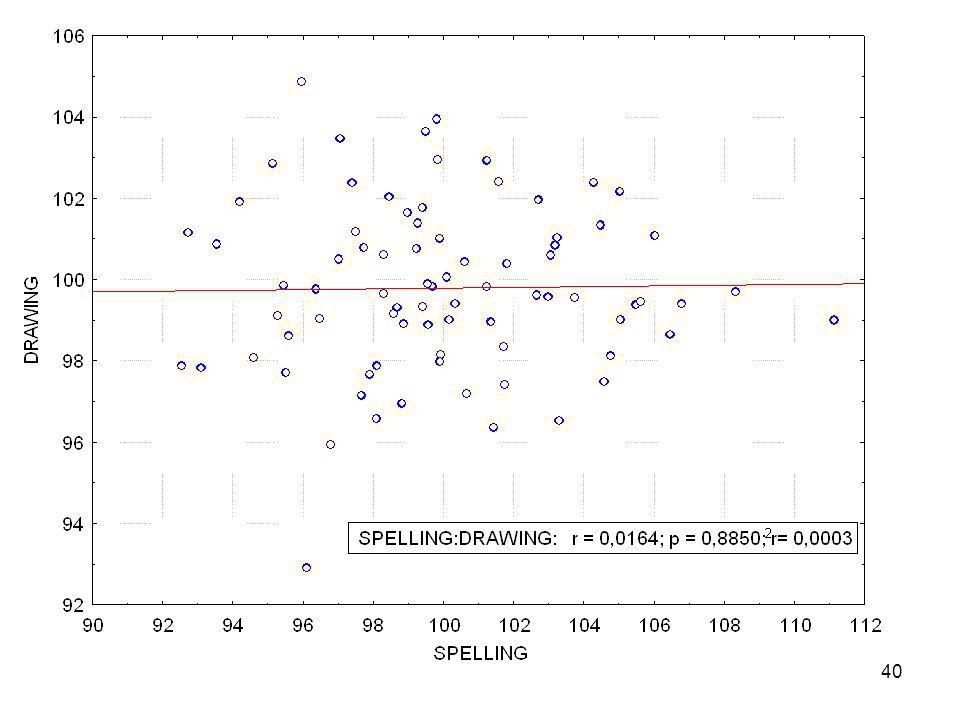
GEOMETRY READING GRAMMAR DRAWING CALCULUS HISTORY WRITING SPELLING 1 98,655 98,483 98,094 99,163 97,853 99,987 96,858 98,583 2 98,701 100,394 98,870 97,872 100,313 103,135 100,480 98,112 3 98,399 97,799 98,822 96,949 96,796 101,657 96,900 98,823 4 98,032 100,207 101,876 98,151 99,570 102,063 101,035 99,924 5 97,962 99,147 98,886 99,318 100,372 101,457 98,850 98,691 6 98,981 102,662 103,544 98,116 98,054 102,774 102,450 104,772 7 94,024 98,124 97,377 92,904 92,288 101,826 98,890 96,106 8 99,410 106,941 108,109 98,651 99,025 107,434 104,996 106,469 9 100,327 98,228 97,282 101,636 102,193 100,004 97,964 98,979 10 99,014 99,284 99,634 98,339 98,468 101,214 100,687 101,721 11 102,358 99,548 99,599 103,473 103,778 102,091 99,776 97,062 12 98,470 99,212 98,047 97,710 99,047 99,465 97,632 95,526 13 97,689 103,773 104,649 96,524 95,386 105,934 103,168 103,302 14 102,657 96,935 98,332 102,945 103,428 97,203 98,076 99,835 15 101,586 94,367 94,817 100,865 102,702 95,990 96,305 93,534 16 102,202 97,450 99,258 101,766 102,481 100,471 96,756 99,404 17 101,536 100,455 99,534 100,060 99,558 103,421 100,778 100,099 18 98,469 100,804 99,322 97,412 97,612 103,925 99,504 101,752 19 102,980 99,128 102,023 103,068 102,579 98,051 98,455 20 99,450 103,106 103,938 100,844 99,197 106,890 102,378 103,188 21 100,607 103,657 103,662 101,333 100,136 105,343 103,572 104,477

37
Beachten Sie den Korrelationsquotienten!

38
Beachten Sie den Korrelationsquotienten!

39
Welche Möglichkeiten des Umgangs mit fehlenden Werten gibt es?
Y X Y X Bei kategorialen Merkmalen häufigste Ausprägung der k nächsten Nachbarn Bei metrischen Merkmalen durchschnittlicher Wert der k nächsten Nachbarn Aber auch: Missing Values rauswerfen!

41
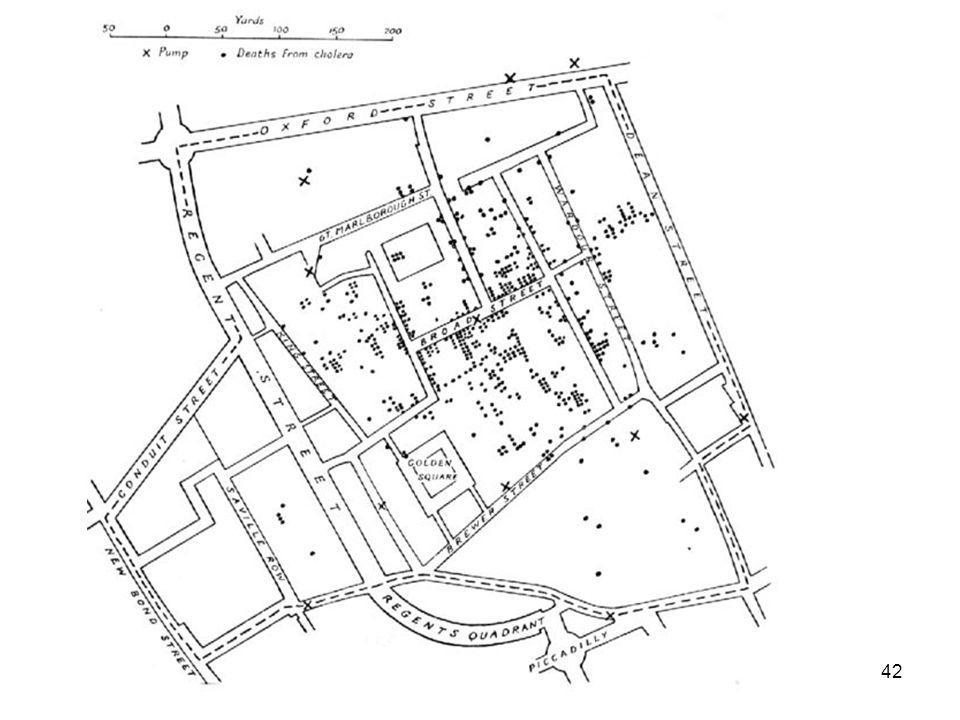
Wie kann der Befund von Snow transformiert werden und wozu?
Um Vergleiche zwischen den Stärken des Effekts möglich zu machen Um die wirkungsvollsten Interventionsansatz zu bestimmen Um die Wirkungen von Interventionen abschätzen zu können … ..

43
„Snow“ enthält kategoriale Daten:
Brunnen An Cholera Verstorbene Wie ließen sich diese kategorialen Daten in numerische übertragen?

44
Beispiel:

45
Distanz Anzahl der Erkrankten

46
Distanz Anzahl der Erkrankten

47
Distanz Anzahl der Erkrankten

48
Distanz „Schwelle“ Anzahl der Erkrankten

49
Distanz Anzahl der Erkrankten

54
„schlecht“ „gut“

55
Unterschiede messen Median ist der Punkt, bei dem die eine Hälfte der Werte oberhalb und die andere unterhalb dieses Punktes liegt Median Mean Der Mittelwert wird berechnet durch die Summe aller Werte geteilt durch die Anzahl der Werte

56
∑ ∑ Mathematisch wird die Berechnung des Mittelwertes so dargestellt:
X = ∑ xi n X ausgesprochen: X Strich oder x quer ist das Symbol für den Mittelwert ∑ dies ist der griechische Großbuchstabe für Sigma und das sog. Summenzeichen, d.h. alle Messwerte müssen addiert werden xi dieses Zeichen steht für sämtliche Einzelmesswerte n und n steht schließlich für die Anzahl der durchgeführten Messungen

57
Unterschiede messen Zwei weit verbreite, einfache Methoden:
Zwischen zwei Klassen unterscheiden: Gut ↔ Schlecht Zwischen vier (oder einer anderen Anzahl von) Perzentilen unterscheiden
 Perzentilen unterscheiden.")
58
Unterschiede messen Keine Variation vorhanden

59
Erste Ebene: Spannbreite (R für range)
Unterschiede messen In welchem Maß ist Variation vorhanden? Erste Ebene: Spannbreite (R für range) R = Xmax – Xmin
 R = Xmax – Xmin.")
60
Zweite Ebene: Summe der quadrierten Fehler (Abweichungen)
Unterschiede messen In welchem Maß ist Variation vorhanden? Zweite Ebene: Summe der quadrierten Fehler (Abweichungen) ∑ ( ) 2 xi - X σ² = n - 1 Mean
 ∑ ( ) 2. xi. - X. σ² = n - 1. Mean.")
61
Dritte Ebene: Standardabweichung
Unterschiede messen In welchem Maß ist Variation vorhanden? Dritte Ebene: Standardabweichung √ ∑ ( ) 2 xi - X σ = n - 1 Mean
 2. xi. - X. σ = n - 1. Mean.")
62
z = σx xi Unterschiede messen In welchem Maß ist Variation vorhanden?
Vierte Ebene: z-Transformation Abstand jeder Messung zum Mittelwert, geteilt durch die Standardabweichung xi - X z = σx Mean 0 Mean 0 Alle Mittelwerte werden Null, die Abstände werden standardisiert; die relative Lage jeder Messung kann verglichen werden

64
(leicht hinkender Vergleich)
Sie wollen verschieden formatige, verschieden große Bilder auf eine Seite bringen

65
(leicht hinkender Vergleich)
Sie wollen verschieden formatige, verschieden große Bilder auf eine Seite bringen

66
Mittelwerte: 64, ,26 Std.-Abw.: 11, ,831

67
Wirkung der Z-Transformation:

68
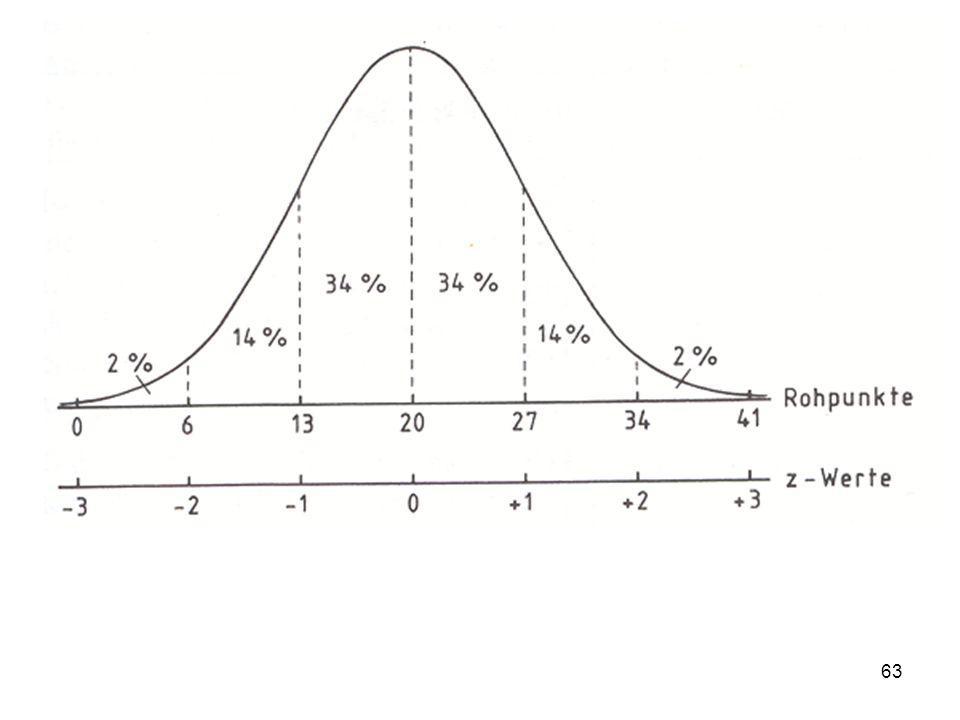
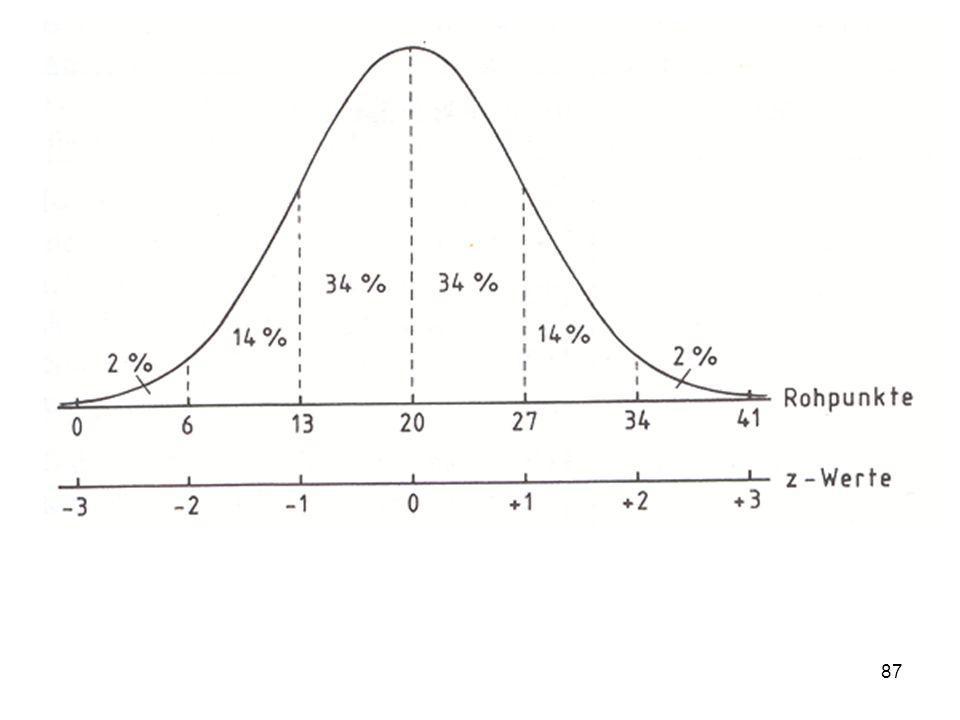
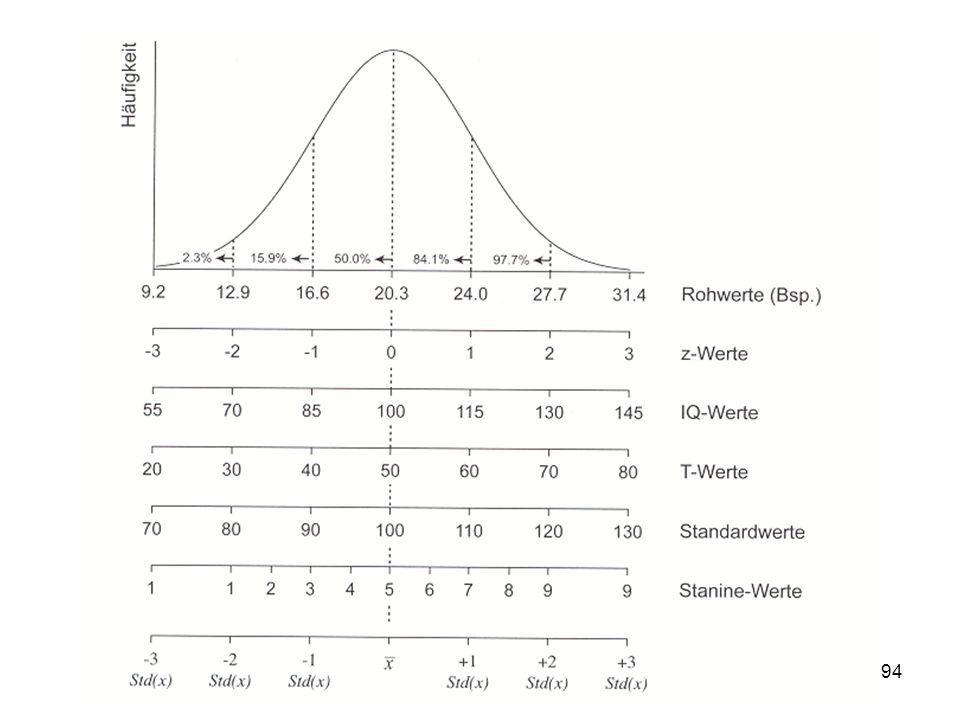
Mit Hilfe dieser Grafik wird erkennbar, was die Prozentränge im Unterschied zu den Z-standardisierten Werten angeben: Am linken Rand sind die Rohwerte abgetragen, am oberen Rand die Prozentränge und am unteren Rand die z-standardisierten Werte. Wie ersichtlich, hat der höchste Rohwert den Prozentrang 100 und den Z-Wert +3. Der niedrigste Rohwert hingegen den Prozentrang 1,25 und den Z-Wert -2.

69
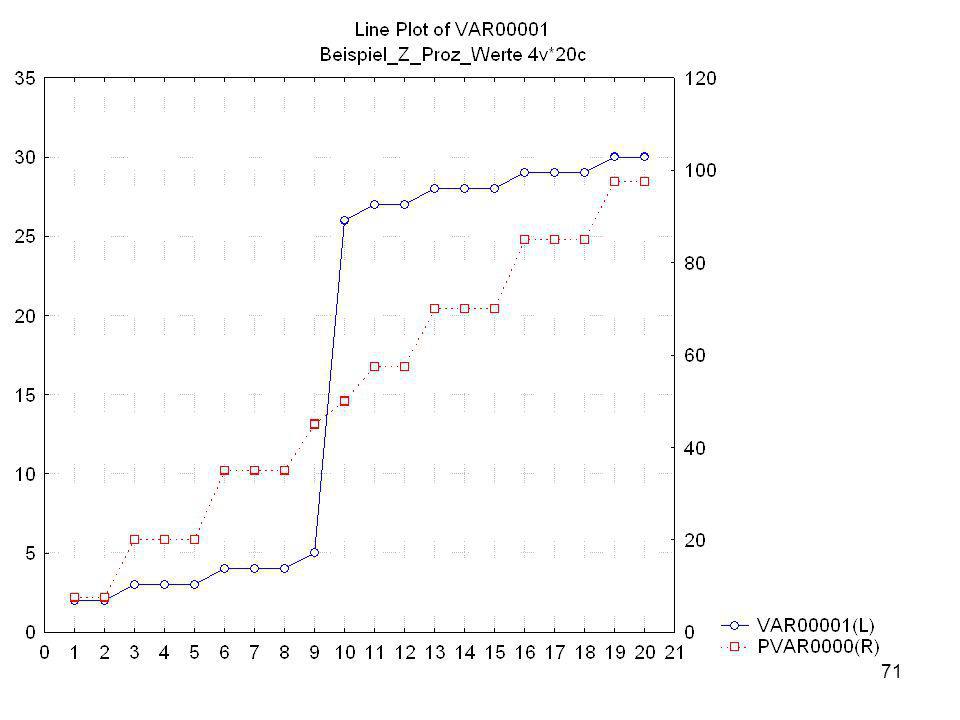
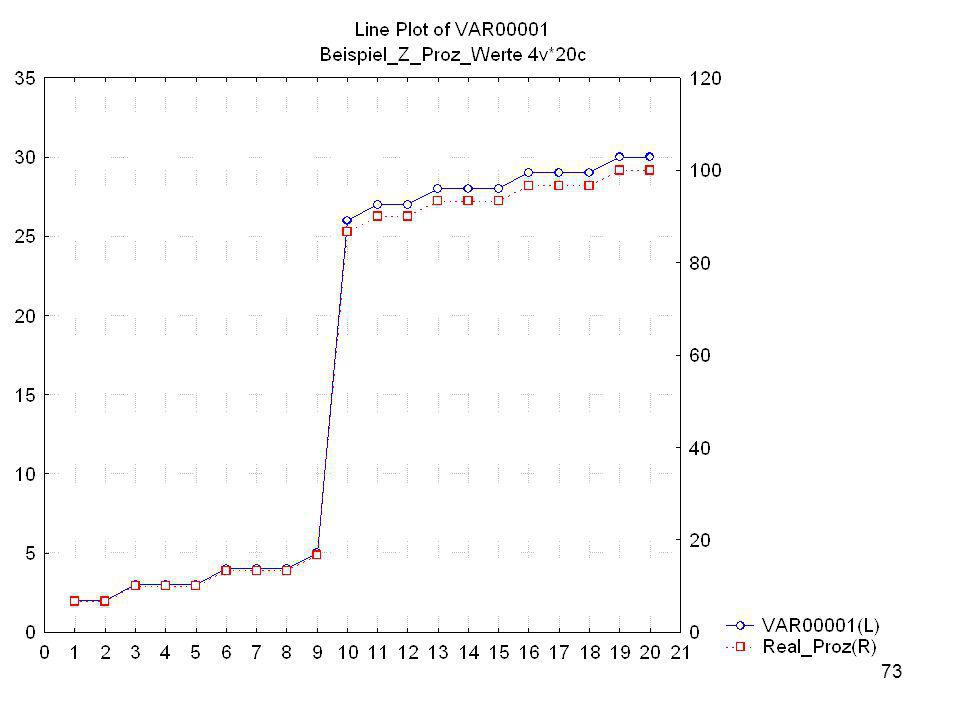
Prozentränge cum f cum f % = 100 N (N = 300) Rohwert Fälle f cum f
80 .. 5 25 98 4 18 73 24,3 24 3 19 55 18,3 2 15 36 12,0 12 1 21 7,0 7 9 3,0 300 = 100 % 9 = x %

70
sog. ‚Absoluter Rangwert‘: 1. Rang + 2. Rang/2 = 1,5
Werte mal 100/Max-Wert: 2*100 = 200/30 = 6,66666 Relative Rangfolge in %: 20 = 100 % 1,5 = x % Z-Transformation

83
Einfache Aussage über Reihenfolge
1 Rangreihe: Einfache Aussage über Reihenfolge Hohe Reliabilität, etwa durch Paarvergleich Keine Informationen über Abstände Vergleichbarkeit nur bei identischen N‘s 2 3 4 5 6 7 8

84
Grobe Aussage über die Stellung in einer Reihe
Quartile: Grobe Aussage über die Stellung in einer Reihe Hohe Reliabilität, weil recht ‚simpel‘ Sehr grobe Informationen über Abstände Einfache Vergleichbarkeit über verschiedene Bereiche hinweg 1 I. Quartil 2 3 II. Quartil 4 5 III. Quartil 6 7 VI. Quartil 8

85
Werte Quartil Prozentrang 30 4 100,00 28 90,00 21 3 80,00 16 70,00 12 60,00 11 2 50,00 6 40,00 5 30,00 1 20,00 10,00 Prozentrang: Aussage über die Stellung in einer Reihe Reliabilität von der Messung abhängig Keine Informationen über Abstände Einfache Vergleichbar- keit über verschiedene Bereiche hinweg

86
Relativer Prozentrang
Werte Relativer Prozentrang 30 100,00 28 93,33 21 70,00 16 53,33 12 40,00 11 36,67 6 20,00 5 16,67 1 3,33 ,00 Relativer Prozentrang: (100*Wert)/MaxWert Genaue Aussage über die Stellung in einer Reihe Reliabilität von der Messung abhängig Informationen über Abstände Einfache Vergleichbar- keit über verschiedene Bereiche hinweg
/MaxWert. Genaue Aussage über die Stellung in einer Reihe. Reliabilität von der Messung abhängig. Informationen über Abstände. Einfache Vergleichbar- keit über verschiedene Bereiche hinweg.")
88
Werte Rel. % Z-Werte Note 30 100,00 1,59844 2 28 93,33 1,41039 21 70,00 ,75221 3 16 53,33 ,28208 12 40,00 -,09403 4 11 36,67 -,18805 6 20,00 -,65818 5 16,67 -,75221 1 3,33 -1,12831 ,00 -1,22234

89
Umwandlung eines numerischen Wertes in einen kategorialen Wert

90
Deskriptive Statistik (School perfomance)
Gült. N Mittelw. Median Minimum Maximum Stdabw. WRITING 80 99,82004 99,56863 93,51375 109,1118 3,377652 Deskriptive Statistik (School perfomance)
")
91
Mittelwert: Arithmetisches Mittel = Summe aller beobachteten Merkmalswerte dividiert durch die Anzahl der Beobachtungen Median (auch Zentral- oder 50% Wert): Der Median ist der Wert für den gilt, dass 50% aller Werte größer oder gleich sind. Der Median halbiert die Stichprobenverteilung
: Der Median ist der Wert für den gilt, dass 50% aller Werte größer oder gleich sind. Der Median halbiert die Stichprobenverteilung.")
92
Deskriptive Statistik (School perfomance)
Gült. N Mittelw. Median Minimum Maximum Stdabw. WRITING 90 121,5067 100,1944 93,51375 410,0000 66,48269 Deskriptive Statistik (School perfomance)
")
93
Gült. N Mittelw. Median Minimum Maximum Stdabw. WRITING 80 99,82004 99,56863 93,51375 109,1118 3,377652 Gült. N Mittelw. Median Minimum Maximum Stdabw. WRITING 90 121,5067 100,1944 93,51375 410,0000 66,48269

95
Gruppenzugehörigkeit: A
Gruppenzugehörigkeit: B Gruppenzugehörigkeit: C

96
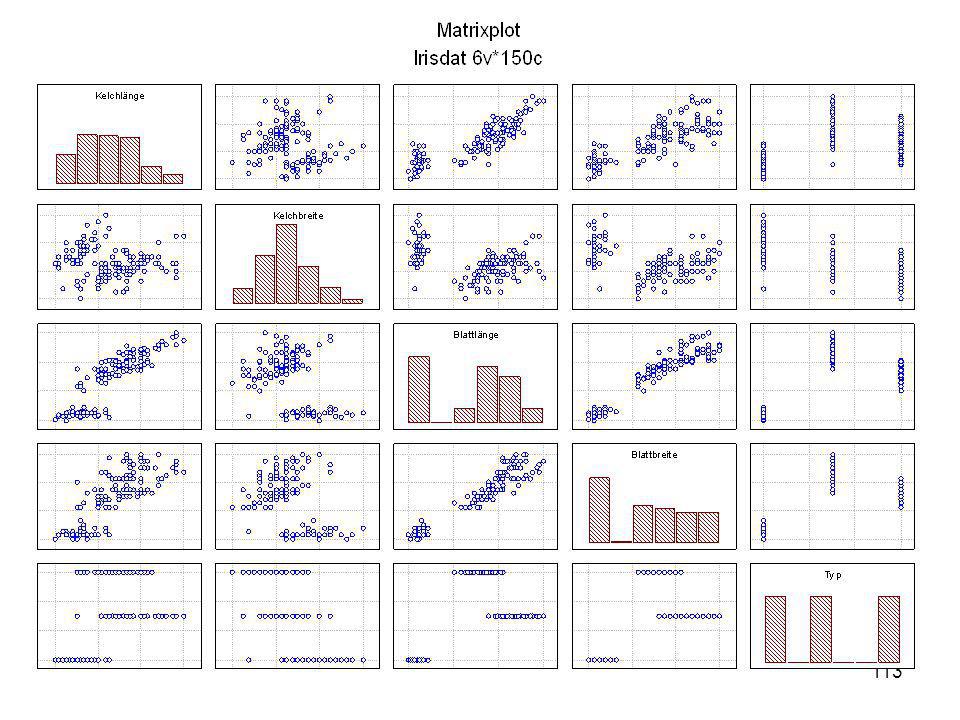
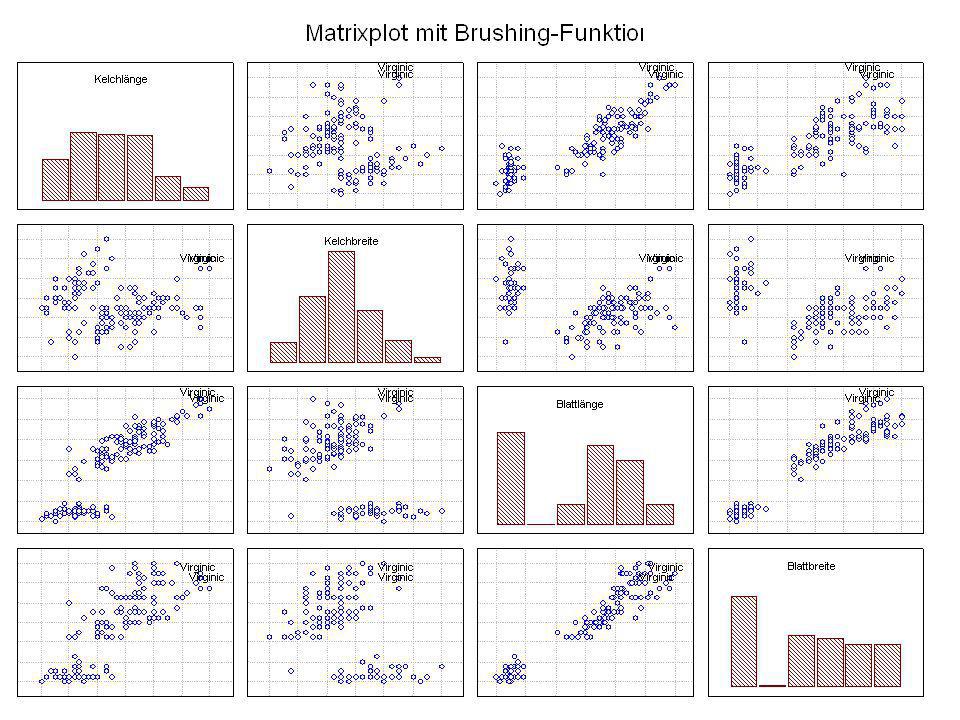
Gibt es „Muster“ in der Verteilung?

100
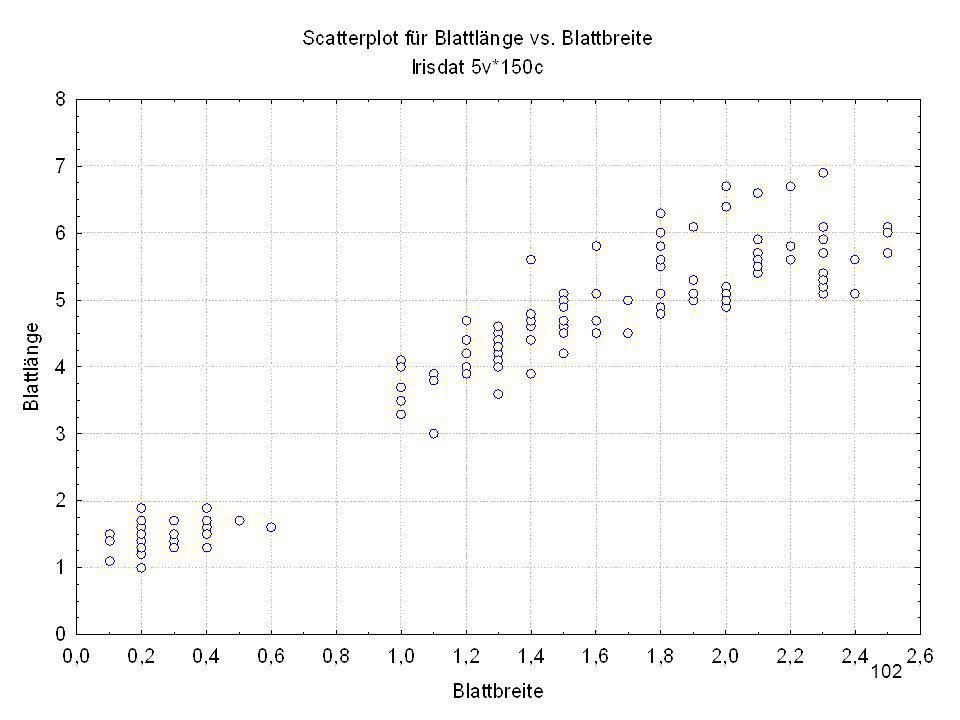
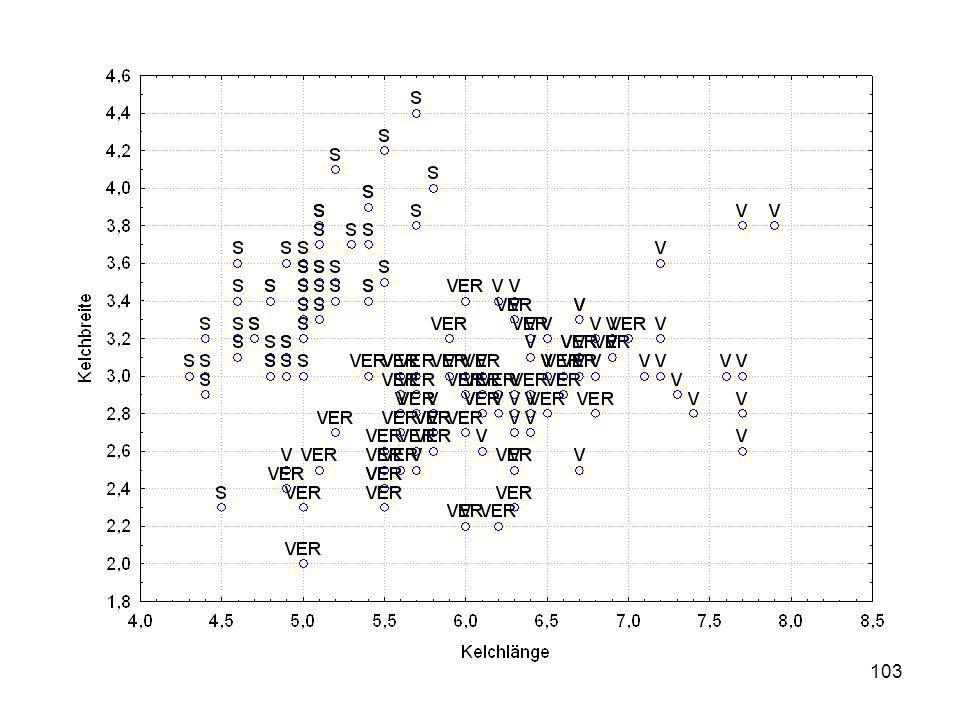
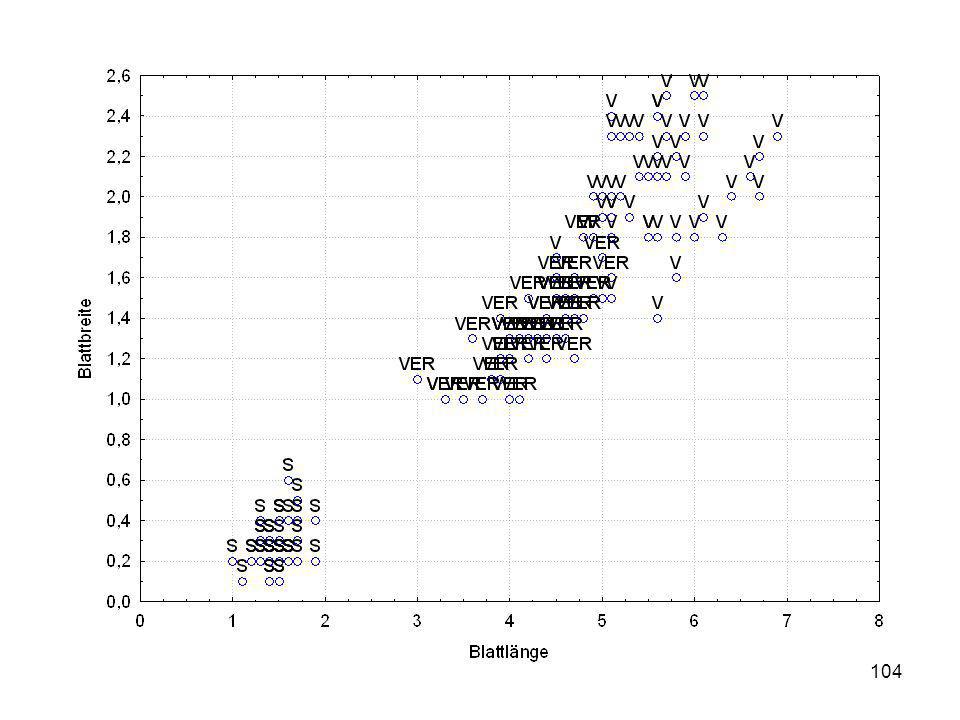
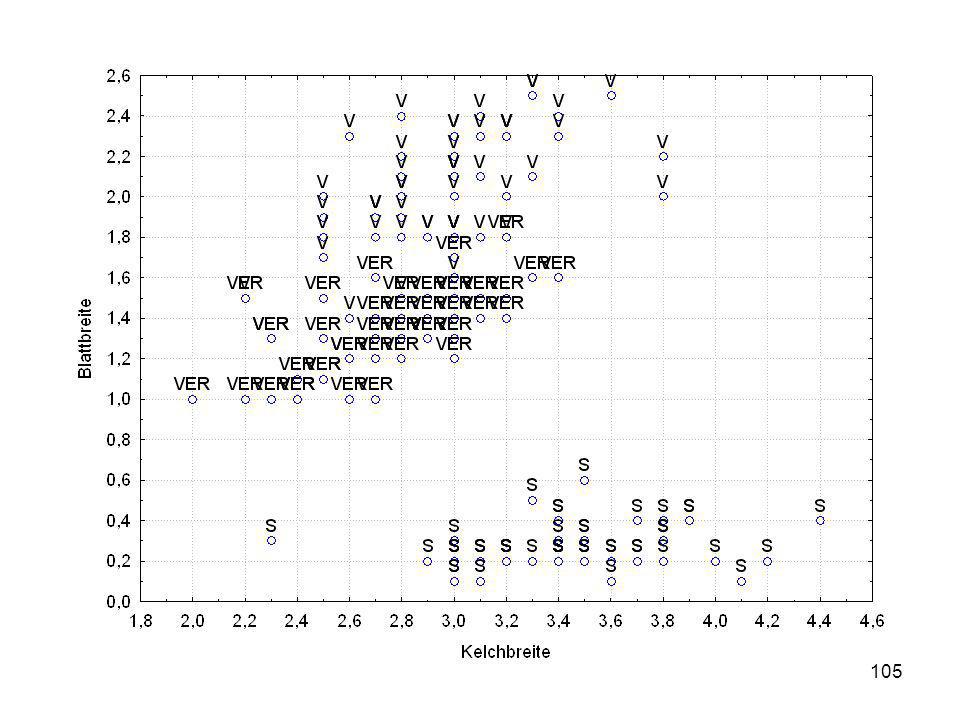
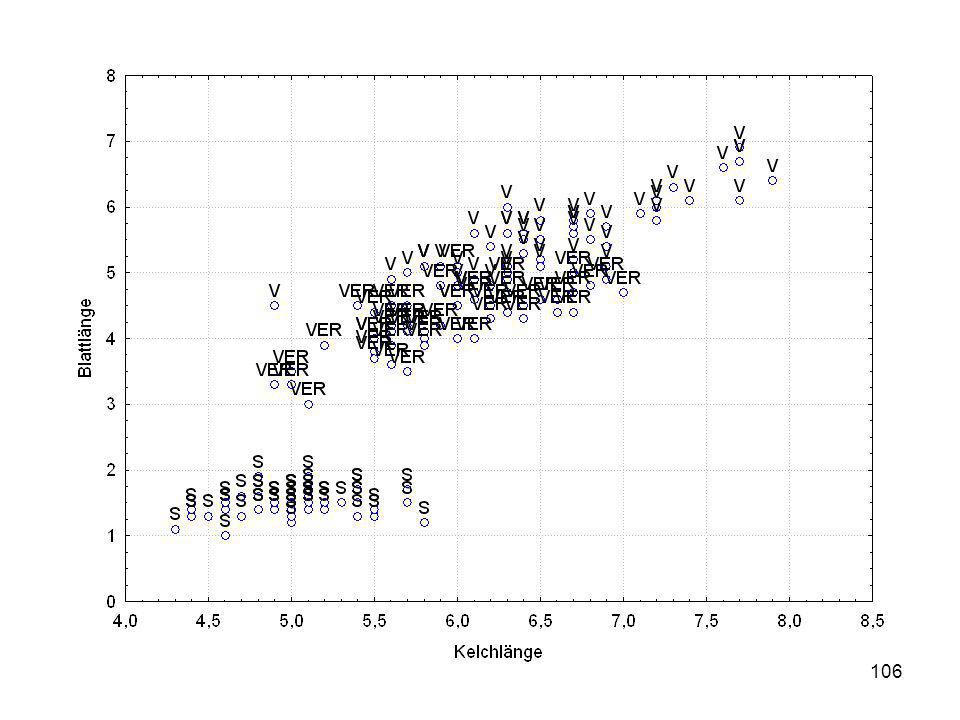
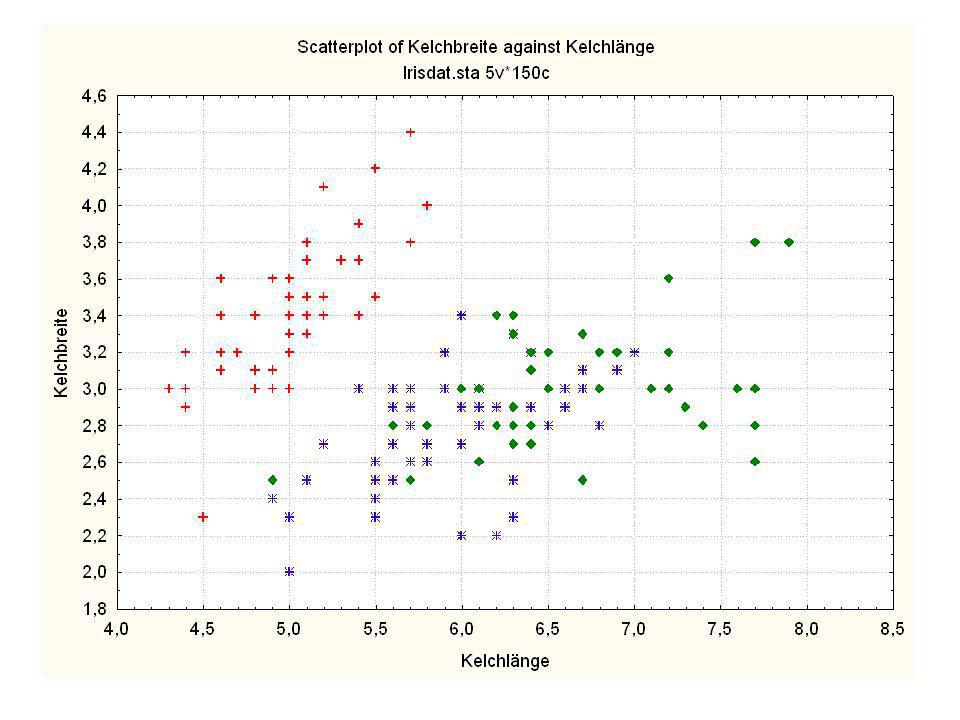
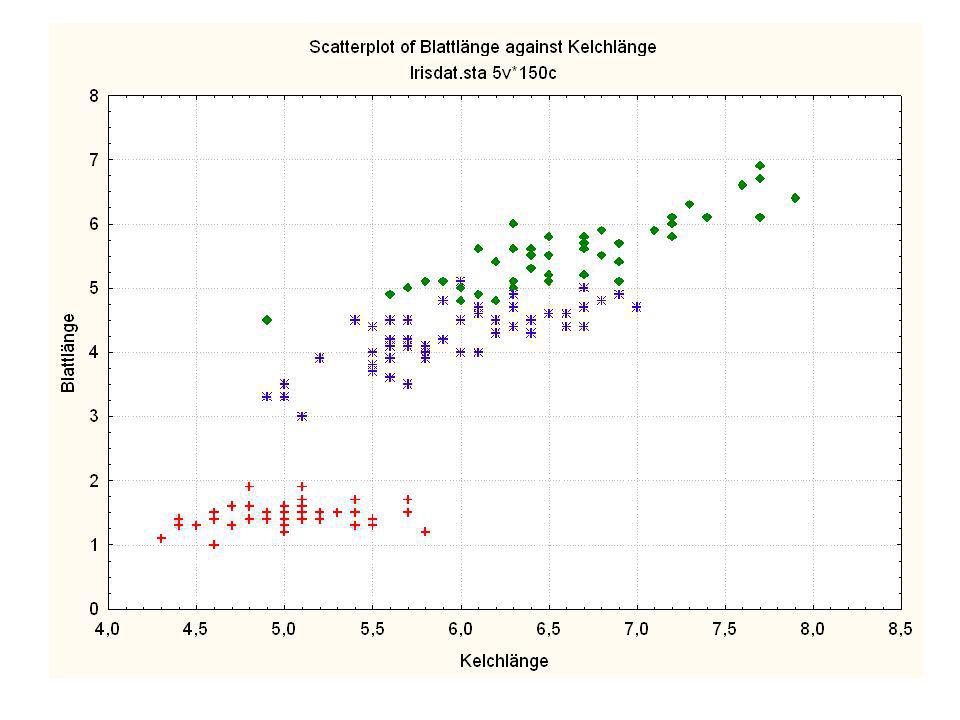
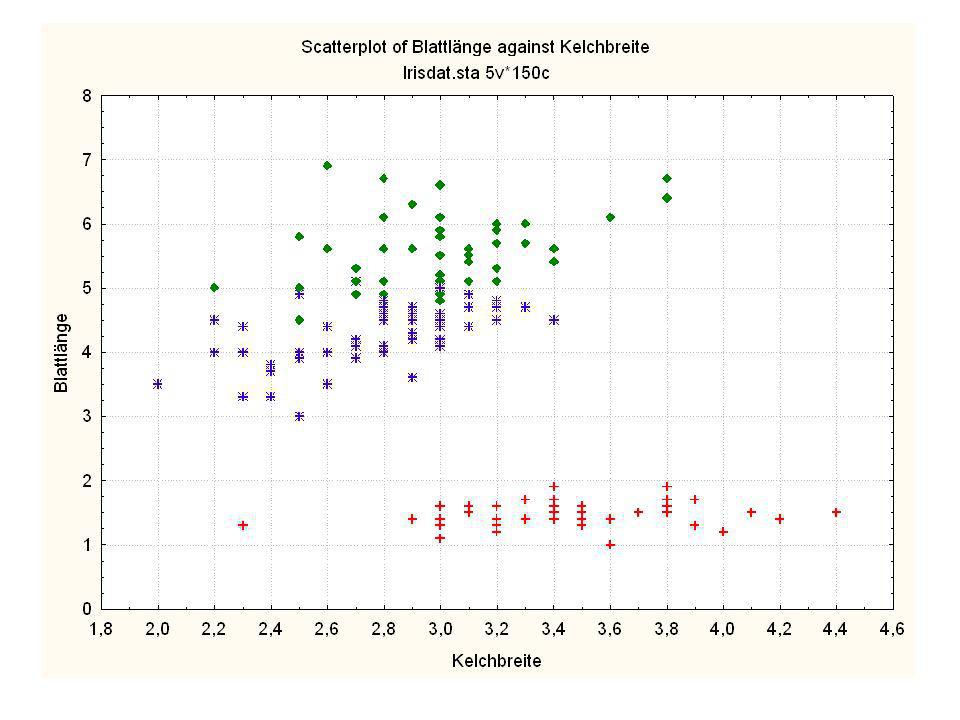
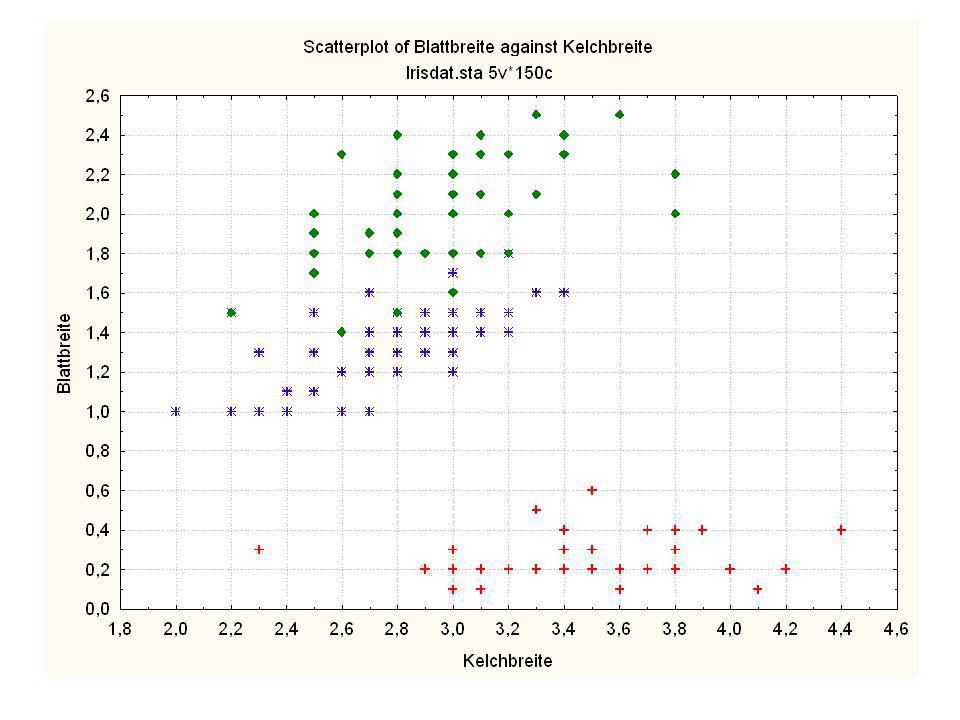
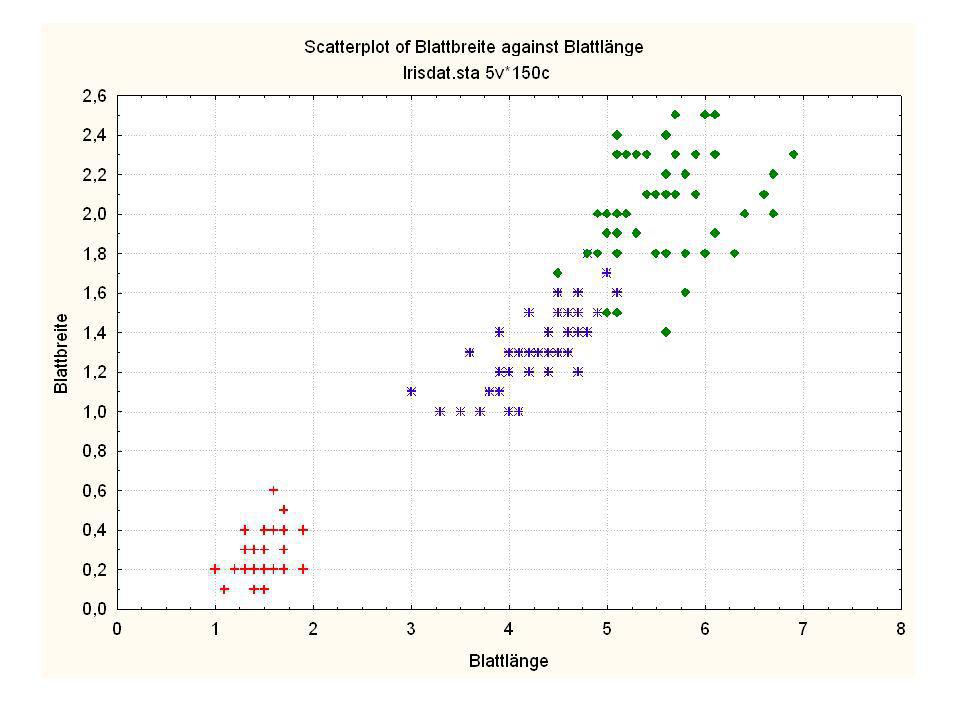
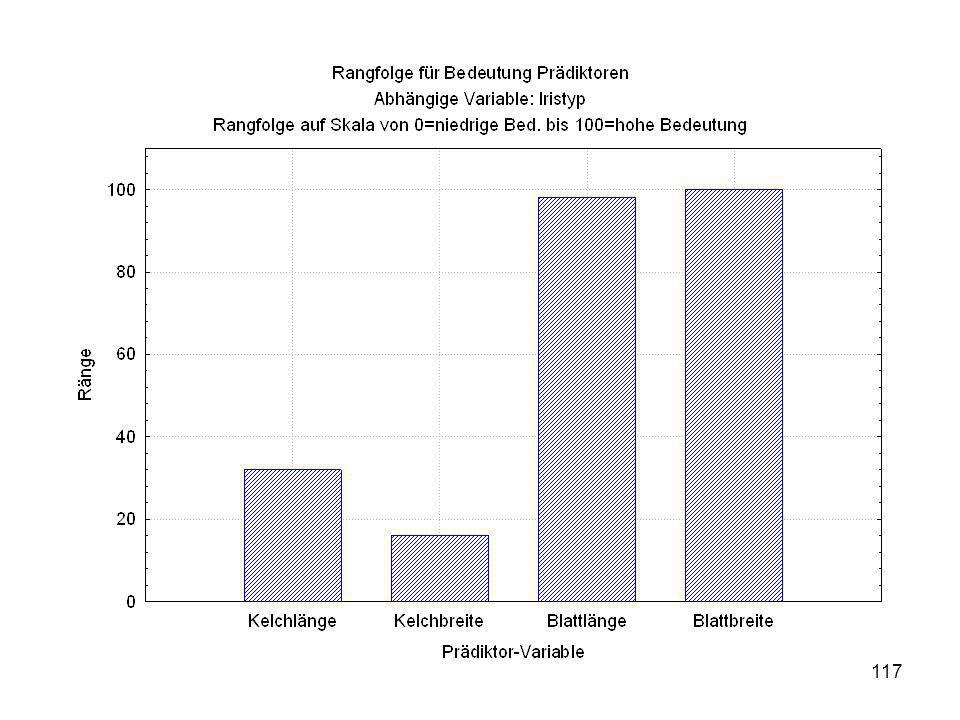
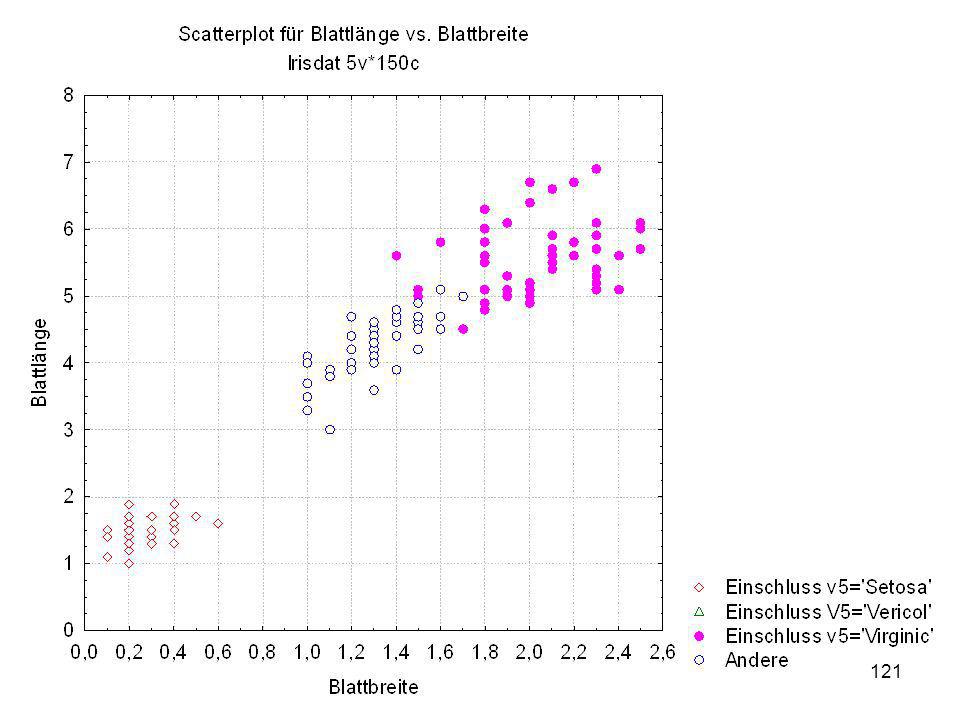
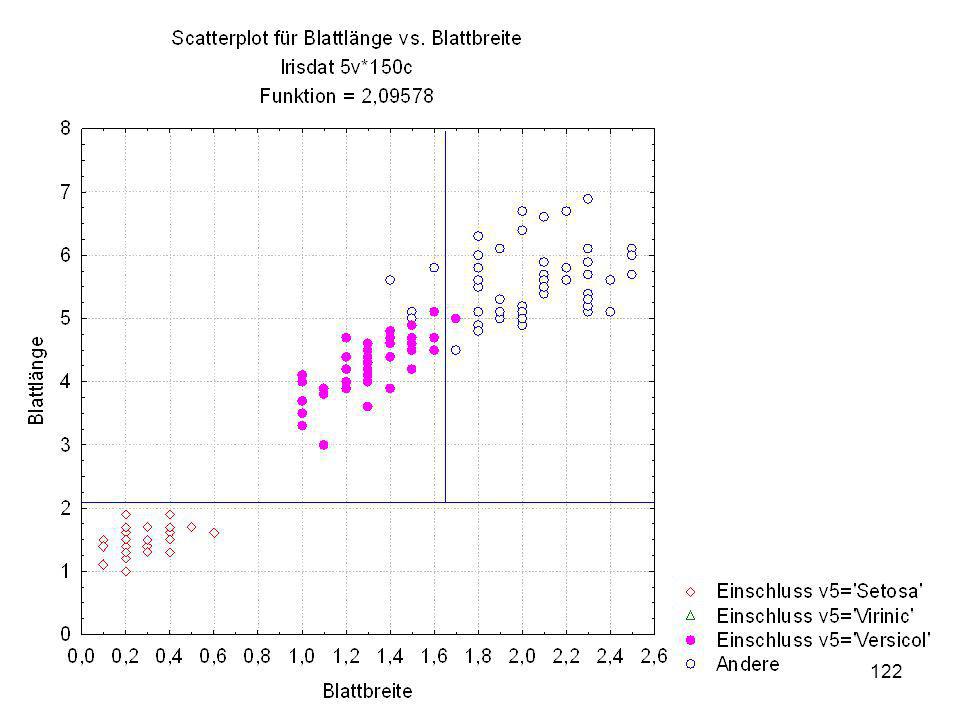
Durch was unterscheiden sich die drei Iristypen?
Kelchlänge Kelchbreite Blattlänge Blattbreite Iristyp 1 5 3,3 1,4 0,2 Setosa 2 6,4 2,8 5,6 2,2 Virginic 3 6,5 4,6 1,5 Versicol 4 6,7 3,1 2,4 6,3 5,1 6 3,4 0,3 7 6,9 2,3 8 6,2 4,5 9 5,9 3,2 4,8 1,8 10 3,6 11 6,1 12 2,7 1,6 13 5,2 14 2,5 3,9 1,1 15 5,5 16 5,8 1,9 17 6,8 18 1,7 0,5 19 5,7 1,3 20 5,4 21 7,7 3,8 22 4,7 23 24 7,6 6,6 2,1 25 4,9 Fisher (1936) Irisdaten: Länge und Breite von Blättern und Kelchen für 3 Iristypen Durch was unterscheiden sich die drei Iristypen?
 Irisdaten: Länge und Breite von Blättern und Kelchen für 3 Iristypen. Durch was unterscheiden sich die drei Iristypen")
101
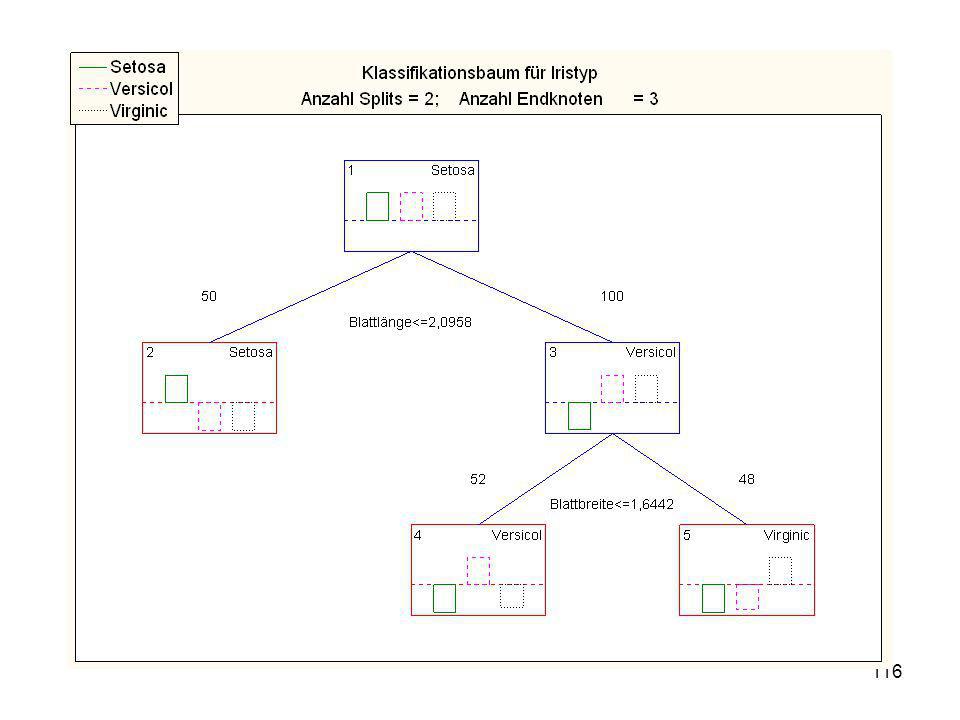
CART (classification and regression trees)
Kategoriale Werte (gut/schlecht) Metrische Werte (1, 2, 3, 4, ..) [Nominale, Ordinale Werte] CART (classification and regression trees) Split: Welche Variable trennt am besten bei welchem Wert?
 Metrische Werte (1, 2, 3, 4, ..) [Nominale, Ordinale Werte] CART (classification and regression trees) Split: Welche Variable trennt am besten bei welchem Wert")
118
Fehlklassifikationsmatrix Lernstichprobe (Irisdat) Matrix progn
Fehlklassifikationsmatrix Lernstichprobe (Irisdat) Matrix progn. (Zeile) x beob. (Spalte) Lernstichprobe N = 150 Klasse - Setosa Klasse - Versicol Klasse - Virginic Setosa Versicol 4 Virginic 2 Prognost. Klasse x Beob. Klasse n's (Irisdat) Matrix progn. (Zeile) x beob. (Spalte) Lernstichprobe N = 150 Klasse - Setosa Klasse - Versicol Klasse - Virginic Setosa 50 Versicol 48 4 Virginic 2 46
 Matrix progn. (Zeile) x beob. (Spalte) Lernstichprobe N = 150. Klasse - Setosa. Klasse - Versicol. Klasse - Virginic. Setosa. Versicol. 4. Virginic. 2. Prognost. Klasse x Beob. Klasse n s (Irisdat) Matrix progn. (Zeile) x beob. (Spalte) Lernstichprobe N = 150. Klasse - Setosa. Klasse - Versicol. Klasse - Virginic. Setosa. 50. Versicol Virginic")
119
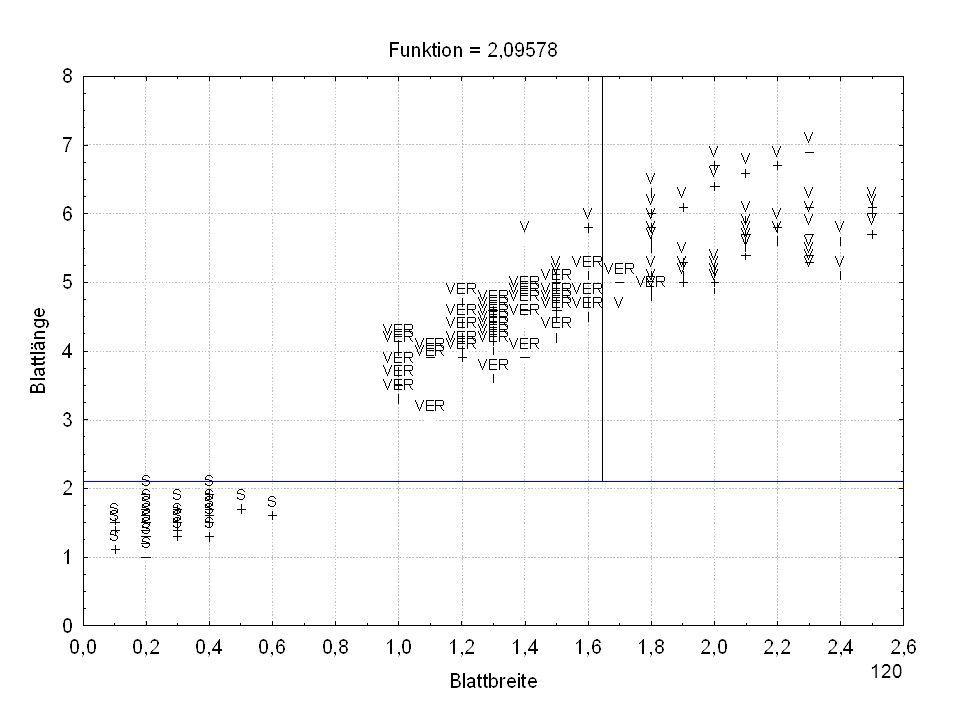
Split-Bedingung (Irisdat) Split-Bedingung je Knoten
Split - Konst. Split - Variable 1 -2,09578 Blattlänge 2 3 -1,64421 Blattbreite

123
Zwei, von vielen Problemen:
Feature Choise Overfitting, Underfitting

124
Zwei, von vielen Problemen:
Feature Choise Overfitting, Underfitting

125
Kategoriale Splits Bivariate Splits Multivariate Splits a b < 0,5
> 0,5 Multivariate Splits < 0,5 > 0,5, < 1,8 > 1,8

126
Analyse und Modellbildung
Wie kann man dieses Problem lösen? Etwa mit Hilfe einer sog. „Kreuzvalidierung“: Alle Daten Teilmenge Anwendung auf andere Teilmenge Analyse und Modellbildung

127
Daten Trainings-daten Daten teilen Validierungs-daten Modell- bewertung

128
Vierter Schritt: Wovon ist „gut“ oder „schlecht“ abhängig
Vierter Schritt: Wovon ist „gut“ oder „schlecht“ abhängig? Güte der erreichten Aufklärung überprüfen

130
Practical Significance
Statistical Significance

131
Was, wenn kein Zusammenhang?
Practical Significance 50% Datensatz Datensatz Modell/Zusammenhang 50% Datensatz Statistical Significance Modell/Zusammenhang = Zufall? Zufall Modell/Zusammenhang >/< Zufall? Was, wenn kein Zusammenhang?

132
Zusammenfassung der behandelten methodischen Ansätze:
Eine bislang unbehandelte Frage lautet: Wie aussagekräftig sind die jeweils gewonnenen Befunde?

133
H0 Person A besitzt keine hellseherischen Fähigkeiten
Folgende Hypothese soll geprüft werden: H0 Person A besitzt keine hellseherischen Fähigkeiten H1 Person A verfügt über hellseherische Fähigkeiten Unter welchen Bedingungen kann H0 bestätigt/verworfen werden? Unter welchen Bedingungen kann H1 bestätigt/verworfen werden? Es gibt Konventionen, die als Grundlage der Entscheidung genutzt werden können/sollten: Das Signifikanzniveau. Irrtumswahrscheinlichkeit Bedeutung Symbolisierung p > 0,05 nicht signifikant ns p <= 0,05 signifikant * p <= 0,01 sehr signifikant ** p <= 0,001 höchst signifikant ***

134
Wie groß ist die Wahrscheinlichkeit dreimal „Kopf“ zu erhalten, wenn drei mal eine Münze geworfen wird? Dazu müssen wir uns die Möglichkeiten vor Augen führen: (K = Kopf; W = Wappen) WWW, WWK, WKW, KWW, WKK, KWK, KKW und KKK Wir haben folglich 8 Möglichkeiten, davon erfüllt eine unsere Bedingung. Die Wahrscheinlichkeit p ist demnach 1/8 oder 0,125.
 WWW, WWK, WKW, KWW, WKK, KWK, KKW und KKK. Wir haben folglich 8 Möglichkeiten, davon erfüllt eine. unsere Bedingung. Die Wahrscheinlichkeit p ist demnach 1/8 oder 0,125.")
135
Wahrscheinlichkeit p bei drei Würfen

136
Wie groß ist die Wahrscheinlichkeit viermal „Kopf“ zu erhalten, wenn vier mal eine Münze geworfen wird? Dazu erneut die Möglichkeiten: (K = Kopf; W = Wappen) W W W W K K K K W W K K K W K W W W W K K K K W W K K W W K W K W W K W K K W K K K W W W K W W K W K K K W W K K W W W W K K K Wir haben folglich 16 Möglichkeiten, davon erfüllt eine unsere Bedingung. Die Wahrscheinlichkeit p ist demnach 1/16 oder 0,0625.
 W W W W K K K K W W K K K W K W. W W W K K K K W W K K W W K W K. W W K W K K W K K K W W. W K W W K W K K K W W K K W W W W K K K. Wir haben folglich 16 Möglichkeiten, davon erfüllt eine. unsere Bedingung. Die Wahrscheinlichkeit p ist demnach 1/16 oder 0,0625.")
137
Signifikanzstufen Irrtumswahrscheinlichkeit Bedeutung Symbolisierung
p > 0,05 nicht signifikant ns p <= 0,05 signifikant * p <= 0,01 sehr signifikant ** p <= 0,001 höchst signifikant ***

138
„Ein Wert von p = 0.05 besagt unter der Annahme, dass kein Effekt existiert, dass – vereinfacht aus- gedrückt, puristische Methodiker mögen mit der Stirn runzeln – bei dieser Stichprobengröße ein mindestens so großer Effekt nur in 5% aller vergleichbar angelegter Studien beobachtet werden kann.“ Rost 2007, 81

139
Irrtumswahrscheinlichkeit: Ein p = 0,03 bedeutet:
Die Wahrscheinlichkeit, dass unter der Annahme, die Nullhypothese sei richtig, das gegebene Untersuchungsergebnis oder ein noch extremeres auftritt, beträgt 0,03 oder 3%. Signifikanzstufen p <= 0,05 signifikant * p <= 0,01 sehr signifikant ** p <= 0,001 höchst signifikant ***

140
Partner Partnerin Vorzeichen + - =
Ergebnis einer hypothetischen Studie, in der die Ausbildung von Paaren verglichen wird (aus: Sedlmeier & Renkewitz 2008, 370): Partner Partnerin Vorzeichen Studium Realschule + Gymnasium - = Es finden sich somit 7 positive Vorzeichen. Ist das Ergebnis auf dem 5% Niveau signifikant? Wie hoch ist die Wahrscheinlichkeit für 0, 1, 2 etc. positive Vorzeichen? Vorzeichentest nach Fischer
: Partner. Partnerin. Vorzeichen. Studium. Realschule. + Gymnasium. - = Es finden sich somit 7 positive Vorzeichen. Ist das Ergebnis auf dem 5% Niveau. signifikant Wie hoch ist die Wahrscheinlichkeit für 0, 1, 2 etc. positive Vorzeichen Vorzeichentest nach Fischer.")
142
Wenn, wie im vorliegenden Fall, von zehn Paaren sieben ein positives Vorzeichen aufweisen (Bildungsabschluss des männlichen Partners höher als der des weiblich), dann liegt die Wahrscheinlichkeit dafür: 0,1 % + 1,0 % + 4,4 % + 11,7 % = 17,2 % Es wäre gemäß der Konvention also falsch, daraus irgendwelche Schlussfolgerungen zu ziehen.

143
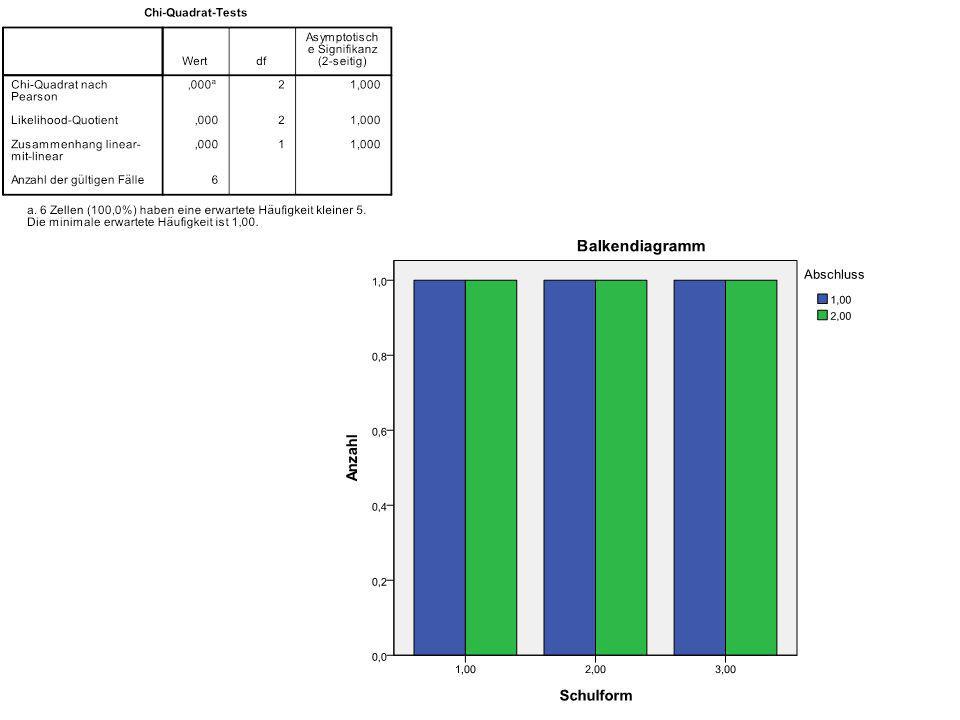
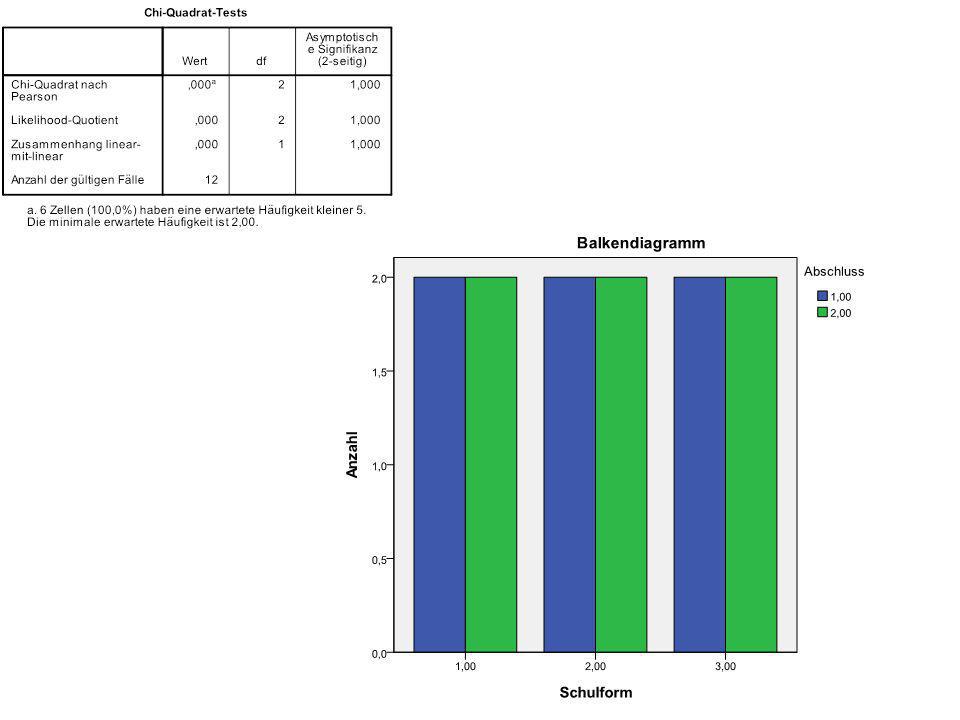
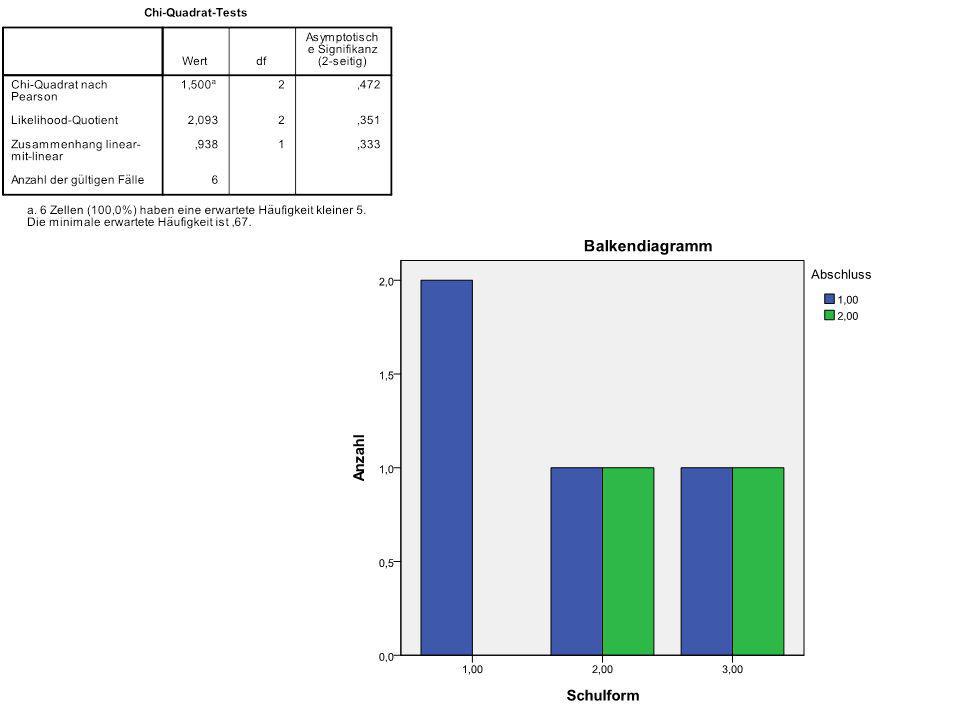
Erstellen einer einfachen Probedatei mit folgendem Inhalt:

144
Bei zwei Beobachtungen pro Schulform ergeben sich damit 3 mal 8 = 24 Kombinationsmöglichkeiten:
№ Schulform Abschluss 1 2 3 4 5 6 7 8

145
Die Wahrscheinlichkeit p ist demnach für eine ‚Abweichung‘ von
einem Fall bei sechs Beobachtungen 01/06 entspricht der Wahrscheinlichkeit vom 8/ p = 0,33333

155
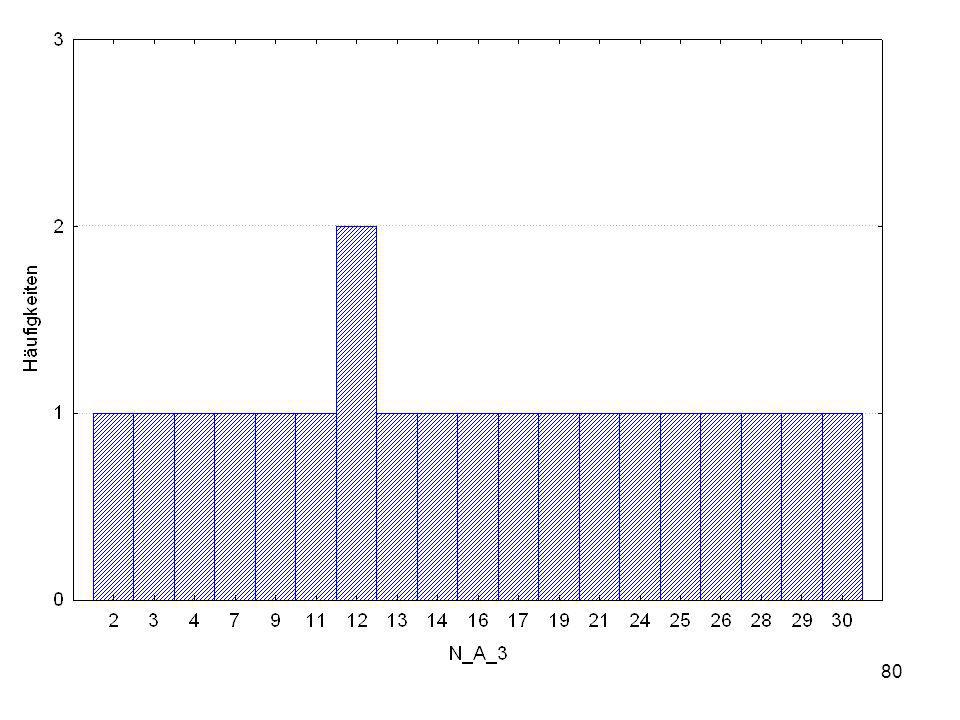
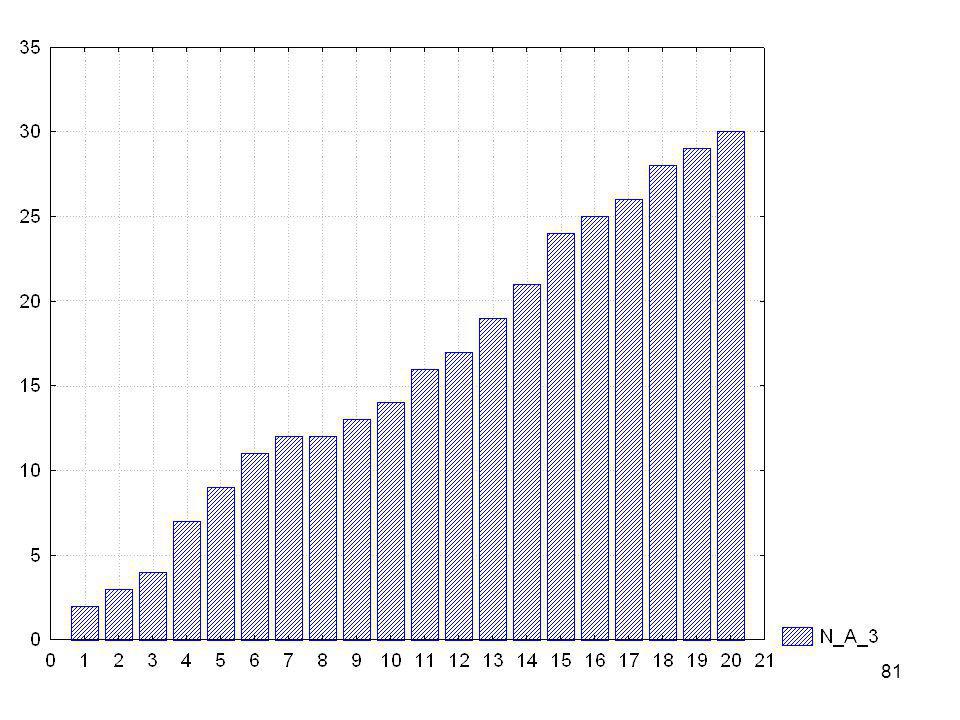
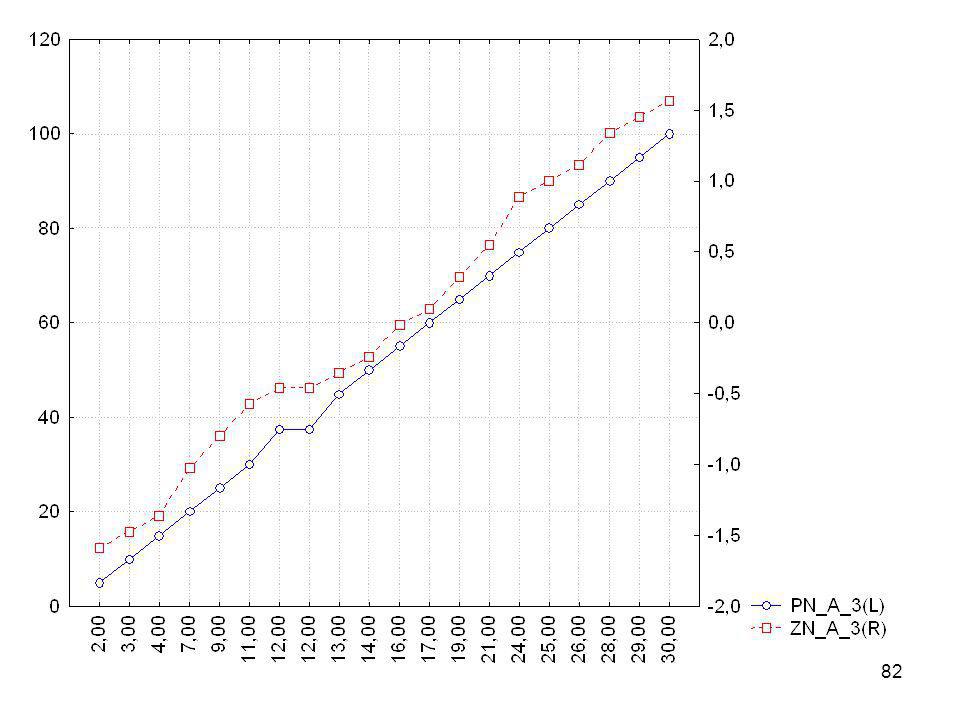
N = 80

156
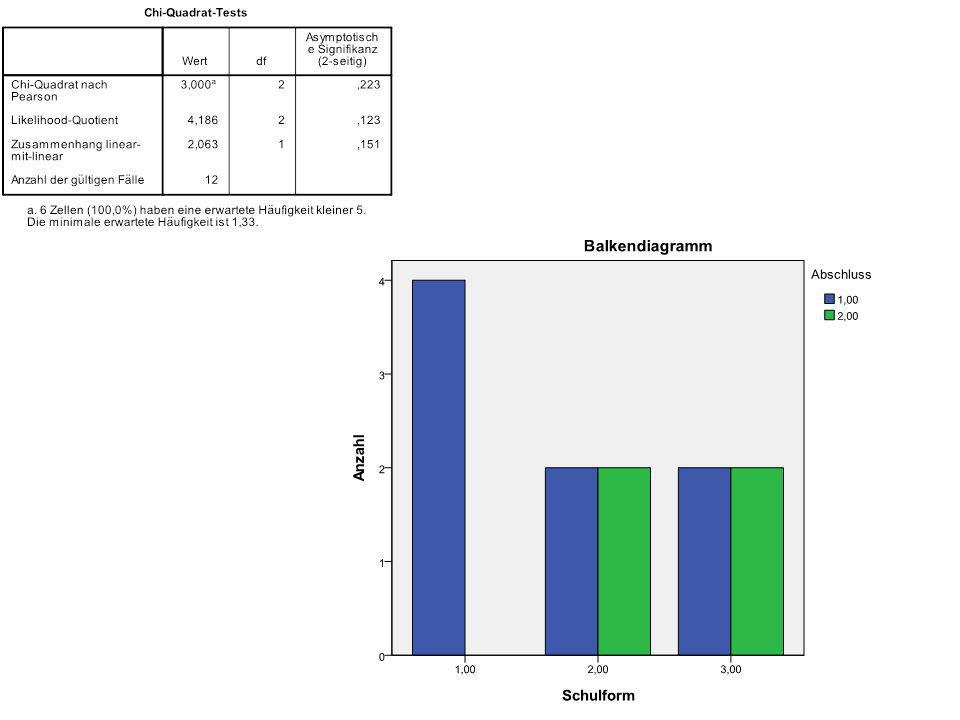
N = 4

157
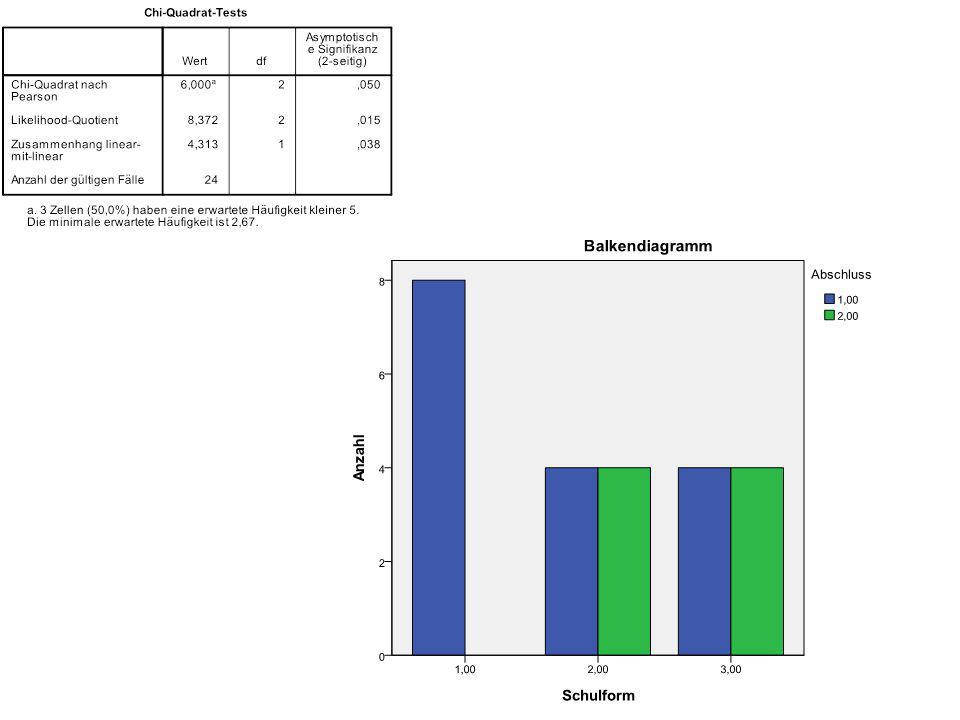
N = 8

158
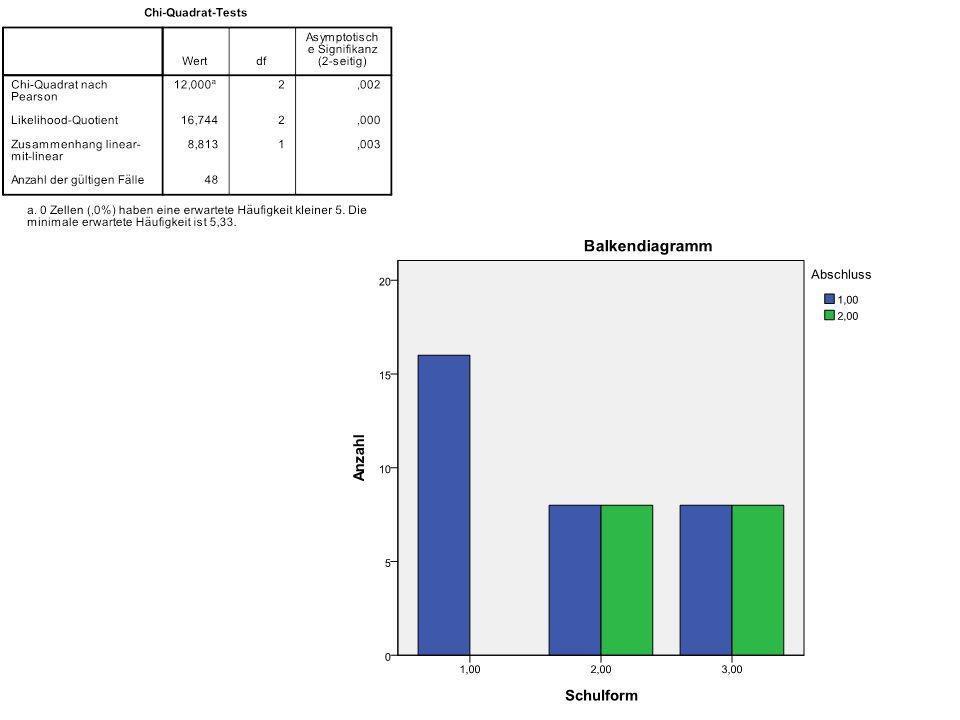
N = 16

160
N = 80

161
N = 4

162
N = 4

163
N = 8

164
N = 16

Ähnliche Präsentationen













>")
>")


Media Landesanstalt für Kommunikation Baden-Württemberg (LFK) Landeszentrale für Medien und Kommunikation.>")










