Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Statistiken und Tabellen
Referat am von Maria Wieländer

2
Gliederung Datensatz Statistiken Tabellen Vergleich mit Excel
Zusammenfassung

3
Datensatz Amerikanische DNNB – Umfrage von 1998
Religiosität von Personen verschiedener Schichten Kategorien: Häufigkeit der Kirchenbesuche Fundamentalismus als Gefahr Bedeutung von Religion im eigenen Leben Alter Kinder Stadt – Land Bildung Bildung des Ehepartners Region der Umfrage Einkommen

4
Arbeiten mit dem Datensatz
Datensatz in R laden: „File -> Load Datafile“ >BowlAl1998 <- read.table("C:/Dokumente und Einstellungen/Maria/Desktop/Testprogramme/BowlAl1998.txt",header=T,sep="\t", quote="");attach(BowlAl1998) Zuordnen von Abkürzungen: > C<-CHURCH > A<-AGE > CHI<-CHILDREN > E<-EDUC
;attach(BowlAl1998) Zuordnen von Abkürzungen: > C<-CHURCH. > A<-AGE. > CHI<-CHILDREN. > E<-EDUC.")
5
Kritik Wenn „attach“ nicht aktiviert ist, ist es sehr kompliziert, mit dem Datensatz in R zu arbeiten (C<-BowlAl1998$CHURCH)
")
6
Statistiken

7
Arithmetisches Mittel
Allgemein: > t<-c(7,8,4,1,5,0,9,8,9,3) > mean(t) [1] 5.4 Datensatz: > mean(A) [1]
 > mean(t) [1] 5.4. Datensatz: > mean(A) [1]")
8
Median 50% der Werte liegen unterhalb des Medians und 50% der Werte oberhalb Allgemein: > w<-c(4,6,2,8,0,9,7,3,4,4) > median(w) [1] 4 Datensatz: > median(A) [1] 45
 [1] 4. Datensatz: > median(A) [1] 45.")
9
Minimum und Maximum Allgemein: > min(4,4,7,3,3,8,9,1,6,9) [1] 1
[1] 9 > range(4,4,7,3,3,8,9,1,6,9) [1] 1 9 Datensatz: > min(A) [1] 18 > max(A) [1] 92 > range(A) [1] 18 92
![Minimum und Maximum Allgemein: > min(4,4,7,3,3,8,9,1,6,9) [1] 1](http://slideplayer.org/slide/642152/1/images/9/Minimum+und+Maximum+Allgemein%3A+%3E+min%284%2C4%2C7%2C3%2C3%2C8%2C9%2C1%2C6%2C9%29+%5B1%5D+1.jpg "[1] 9. > range(4,4,7,3,3,8,9,1,6,9) [1] 1 9. Datensatz: > min(A) [1] 18. > max(A) [1] 92. > range(A) [1]")
10
Quantile Allgemein: > p<-c(2,4,6,7,9,8,1,4,7,8) Datensatz:
> quantile(p,0.25) 25% 4 > quantile(p,0.75) 75% 7.75 Datensatz: > quantile(A,0.25) 25% 35 > quantile(A,0.75) 75% 60
 25% 4. > quantile(p,0.75) 75% Datensatz: > quantile(A,0.25) 25% 35. > quantile(A,0.75) 75% 60.")
11
Standardabweichung Allgemein: > u<-c(4,6,3,6,3,1,9,0,7,4)
> sd(u) [1] Datensatz: > sd(A) [1]
 [1] Datensatz: > sd(A) [1]")
12
Varianz Allgemein: > e<-c(5,3,6,9,2,1,6,8,4,6) > var(e)
[1] Datensatz: > var(A) [1]
 [1]")
13
Einfacher Allgemein: > d<-c(4,8,4,1,4,2,9,0,5,4) > summary(d)
Min. 1st Qu. Median Mean 3rd Qu. Max. Datensatz: > summary(A) Min. 1st Qu. Median Mean 3rd Qu. Max
 Min. 1st Qu. Median Mean 3rd Qu. Max")
14
Statistiken nach Klassen
Datensatz: >tapply(A,C,mean) >tapply(A,C,median)
 >tapply(A,C,median)")
15
tapply(A,C,summary) $`1` Min. 1st Qu. Median Mean 3rd Qu. Max.
$`2` Min. 1st Qu. Median Mean 3rd Qu. Max. $`3` Min. 1st Qu. Median Mean 3rd Qu. Max. $`4 Min. 1st Qu. Median Mean 3rd Qu. Max. $`5` Min. 1st Qu. Median Mean 3rd Qu. Max. $`6` Min. 1st Qu. Median Mean 3rd Qu. Max. $`7`

16
Auswertung Positives: Kritik:
Schnelle Ergebnisse auch bei großen Datensätzen Kritik: Viele Befehle nicht leicht zu erschließen, Handbuch wäre nötig „c“ nötig bei per Hand eingegebenen Zahlen (z.B. mean(c(1,2,3,4)) statt mean(1,2,3,4)) Unübersichtliches Layout
) statt mean(1,2,3,4)) Unübersichtliches Layout.")
17
Tabellen

18
Tabellen mit einer Variablen
Kirchenbesuche: > table(C) C Alter: > table(A) A
 C Alter: > table(A) A")
19
Tabellen mit zwei Variablen
Kirchenbesuche und Bildung: > table(C,E) E C
 E. C")
20
Alter und Kirchenbesuche:
> table(A,C) C A
 C. A")
21
Bilden von Klassen Ermitteln von Minimum und Maximum:
> range(A) [1] 18 92 Klasseneinteilung: > table(cut(A,breaks=c(17,25,35,40,50,60,70,80,92))) (17,25] (25,35] (35,40] (40,50] (50,60] (60,70] (70,80] (80,92]
 [1] Klasseneinteilung: > table(cut(A,breaks=c(17,25,35,40,50,60,70,80,92))) (17,25] (25,35] (35,40] (40,50] (50,60] (60,70] (70,80] (80,92]")
22
Tabellen mit drei Variablen
Kinder, Kirchenbesuch, Bildung > table(C,E,CHI) , , CHI = 0 E C , , CHI = 1 E C
 , , CHI = 0. E. C , , CHI = 1. E. C")
23
Fehlende Werte im Datensatz
Summe der fehlenden Werte: > fC<-is.na(C) > sum(fC) [1] 40 Tabelle mit den fehlenden Werten: > ftC<-table(C,exclude=0) > ftC C <NA>
 > sum(fC) [1] 40. Tabelle mit den fehlenden Werten: > ftC<-table(C,exclude=0) > ftC. C <NA>")
24
Prozentangaben Kirchenbesuche: In Prozent: > pC<-100*tC/sum(tC)
> tC<-table(C) > tC C In Prozent: > pC<-100*tC/sum(tC) > pC Gerundet: > round(pC,2)
 > tC. C In Prozent: > pC<-100*tC/sum(tC) > pC Gerundet: > round(pC,2)")
25
Zusammenfügen der Tabellen: > tt<-rbind(tC,pC)
tC pC

26
Tabellen in Prozent: >t<- table(C,E) >t E C 1 2 3 4 5 6
> pt<-round(100*t/sum(t),2) > pt E C
,2) > pt. E. C")
27
Zeilen- und Spaltensummen
Tabelle: > t<-table(C,E) > t E C Tabelle mit fehlenden Werten: > ee<-table(C,E,exclude=c(0)) > ee E C <NA> <NA>
 > t. E. C Tabelle mit fehlenden Werten: > ee<-table(C,E,exclude=c(0)) > ee. E. C <NA> <NA>")
28
Anfügen der Gesamtsumme:
Zeilensumme: > l<-table(C,exclude=0) > l C <NA> Spaltensumme: > e<-table(E,exclude=0) > e E <NA> Gesamtsumme: > s<-sum(e) > s [1] 3350 Anfügen der Gesamtsumme: > gs<-c(e,s) > gs <NA>
 > l. C <NA> Spaltensumme: > e<-table(E,exclude=0) > e. E <NA> Gesamtsumme: > s<-sum(e) > s. [1] Anfügen der Gesamtsumme: > gs<-c(e,s) > gs <NA>")
29
Anfügen der Zeilensummen: Anfügen derSpaltensummen:
> v<-cbind(ee,l) > v <NA> l <NA> Anfügen derSpaltensummen: > w<-rbind(v,gs) > w <NA> l <NA> gs
 > v <NA> l <NA> Anfügen derSpaltensummen: > w<-rbind(v,gs) > w <NA> l <NA> gs")
30
Auswertung Positives: Kritik:
einfache Tabellen können schnell erstellt werden Kritik: gerade bei großen Tabellen unübersichtlich, da keine Linien Tabellen mit Klassenbildung zu aufwändig fehlende Daten tauchen nur bei gesondertem Befehl auf kein expliziter Befehl für Prozentangaben Bildung von Tabellen mit angefügten Zeilen- und Spaltensummen sehr umständlich

31
Vergleich mit Excel

32
Laden des Datensatzes in Excel

34
Auswählen der Funktion
Statistiken Auswählen der Funktion

35
Angeben des Datenbereiches

36
Alternativ

37
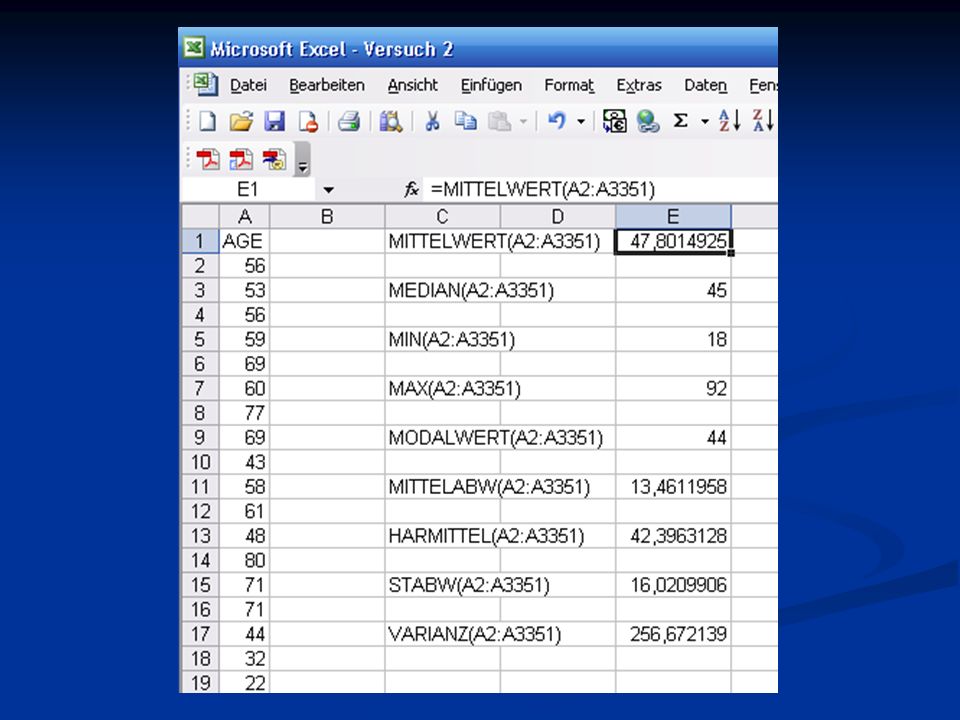
Ergebnis

39
Erstellen von Tabellen
Einfügen von Einsern

40
Tabellenfunktion

41
Auswählen der Kategorien und Ziehen von x in den Datenfelderbereich

42
Tabelle

43
Auswertung Befehle für Statistiken in Excel leichter zu finden, da schon vorgegeben Aber Excel gibt nur das Ergebnis zurück, ohne konkrete Benennung Summary - Funktion in R nützlich Tabellen in Excel einfacher zu erstellen und übersichtlicher, aber wenn Einser nicht eingefügt, werden nicht immer alle Werte berücksichtigt

44
Fazit Positives: Kritik: Einsatz von R bei großen Datensätzen sinnvoll
Besonders bei Statistiken hilfreich Kritik: R für Tabellen weniger geeignet Befehle müssen den Schülern vorgegeben werden Handbuch mit den für die Schule wichtigen Befehlen nötig

Ähnliche Präsentationen






>")

Media Landesanstalt für Kommunikation Baden-Württemberg (LFK) Landeszentrale für Medien und Kommunikation.>")









>")

