Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Betrieb von Datenbanken Marco Skulschus & Marcus Wiederstein Datenmanipulation Lehrbuch, Kapitel 4

2
Seminar-Inhalt Grundlagen Einfache Abfragen Komplexe Abfragen Datenmanipulation Grundlagen T-SQL Programm-Module in der DB Administration

3
Modul-Inhalt 1.Datenstrukturen anlegen 2.Daten bearbeiten

4
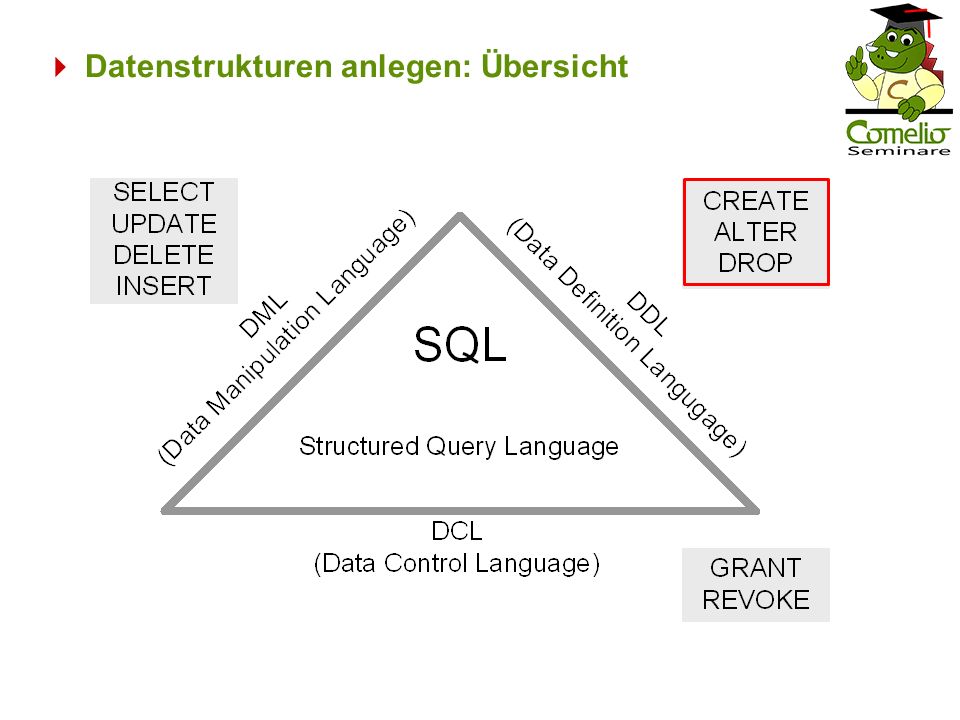
Datenstrukturen anlegen: Übersicht

6
Datenstrukturen anlegen: Tabellen

7
Datenstrukturen anlegen: Spalten

8
Datenstrukturen anlegen: Schlüssel Varianten der Definition von Primär- und Fremdschlüsseln: –Bei der Spaltendefinition –Am Ende der Tabellendefinition außerhalb der Spalten –Außerhalb der Tabellendefinition in einem ALTER-Befehl

9
Datenstrukturen anlegen: Änderungen

10
Datenstrukturen anlegen: Sichten Sichten stellen gespeicherte Abfragen dar. Sie wirken in ihrer Funktionsweise und Benutzung wie gewöhnliche Tabellen. Sichten sind eine hervorragende Möglichkeit, um komplexe Datenstrukturen für den Abruf zu vereinfachen, in dem die Sichtdefinition bereits benötigte Umrechnungen, Funktionsaufrufe und natürlich Verknüpfungen sowie Filter enthält. –Strukturen: Durch die Erstellung einer Sicht ist es möglich, bspw. mehrere Tabellen zu verknüpfen und dadurch die Komplexität von sehr weit und damit sehr gut normalisierten Datenmodellen wieder zu vereinfachen. –Daten: Durch die Erstellung einer Sicht ist es möglich, die Daten bereits soweit zu filtern, dass ein Benutzer gerade nicht alle Daten sehen kann, sondern nur einen Teil.

11
Datenstrukturen anlegen: Sichten

12
Datenstrukturen anlegen: Index Für die Optimierung von Abfragen, d.h. für ihre beschleunigte Ausführung, kann man Indizes (Singular: Index) für eine Tabelle angeben. –Mit einem so genannten Clustered Index ordnet man die Reihen der Tabelle nach der angegebenen Sortierung physikalisch, d.h. auf der Festplatte, bereits in der benötigten Reihenfolge. Da die Daten nur einmal physikalisch geordnet werden können, ist auch nur ein solcher Index pro Tabelle zulässig. Sofern die Tabelle einen Primärschlüssel besitzt, wird dieser Clustered Index automatisch erstellt. –Im Gegensatz dazu kann man auch einen Non-Clustered Index erstellen. Er betrifft nicht die physikalische Speicherung bzw. Sortierung der Daten. Stattdessen befindet sich die Sortierung in einer zusätzlichen Baumstruktur, die wie die schon erwähnten Techniken Lexikon, Wörterbuch oder Stichwortverzeichnis fungieren.
 für eine Tabelle angeben. –Mit einem so genannten Clustered Index ordnet man die Reihen der Tabelle nach der angegebenen Sortierung physikalisch, d.h. auf der Festplatte, bereits in der benötigten Reihenfolge. Da die Daten nur einmal physikalisch geordnet werden können, ist auch nur ein solcher Index pro Tabelle zulässig. Sofern die Tabelle einen Primärschlüssel besitzt, wird dieser Clustered Index automatisch erstellt. –Im Gegensatz dazu kann man auch einen Non-Clustered Index erstellen. Er betrifft nicht die physikalische Speicherung bzw. Sortierung der Daten. Stattdessen befindet sich die Sortierung in einer zusätzlichen Baumstruktur, die wie die schon erwähnten Techniken Lexikon, Wörterbuch oder Stichwortverzeichnis fungieren..")
13
Fragen...

14
Modul-Inhalt 1.Datenstrukturen anlegen 2.Daten bearbeiten

15
Daten bearbeiten: Übersicht

16
Daten bearbeiten: Einfügen INSERT [ INTO] { | rowset_function_limited [ WITH ( [...n ] ) ] } { [ ( column_list ) ] { VALUES ( { DEFAULT | NULL | expression } [,...n ] ) | derived_table | execute_statement } | DEFAULT VALUES
![Daten bearbeiten: Einfügen INSERT [ INTO] { | rowset_function_limited [ WITH ( [...n ] ) ] } { [ ( column_list ) ] { VALUES ( { DEFAULT | NULL | expression } [,...n ] ) | derived_table | execute_statement } | DEFAULT VALUES](http://images.slideplayer.org/3/897919/slides/slide_16.jpg "Daten bearbeiten: Einfügen INSERT [ INTO] { | rowset_function_limited [ WITH ( [...n ] ) ] } { [ ( column_list ) ] { VALUES ( { DEFAULT | NULL | expression } [,...n ] ) | derived_table | execute_statement } | DEFAULT VALUES")
17
Daten bearbeiten: Aktualisieren UPDATE { | rowset_function_limited } SET { column_name = { expression | DEFAULT | NULL } | { udt_column_name.{ { property_name = expression | field_name = expression } | method_name ( argument [,...n ] ) } } | @variable = expression | @variable = column = expression [,...n ] } [,...n ] [ FROM{ } [,...n ] ] [ WHERE { | { [ CURRENT OF { { [ GLOBAL ] cursor_name } | cursor_variable_name } ] } } ]
![Daten bearbeiten: Aktualisieren UPDATE { | rowset_function_limited } SET { column_name = { expression | DEFAULT | NULL } | { udt_column_name.{ { property_name = expression | field_name = expression } | method_name ( argument [,...n ] ) } } = expression = column = expression [,...n ] } [,...n ] [ FROM{ } [,...n ] ] [ WHERE { | { [ CURRENT OF { { [ GLOBAL ] cursor_name } | cursor_variable_name } ] } } ]](http://images.slideplayer.org/3/897919/slides/slide_17.jpg "Daten bearbeiten: Aktualisieren UPDATE { | rowset_function_limited } SET { column_name = { expression | DEFAULT | NULL } | { udt_column_name.{ { property_name = expression | field_name = expression } | method_name ( argument [,...n ] ) } } = expression = column = expression [,...n ] } [,...n ] [ FROM{ } [,...n ] ] [ WHERE { | { [ CURRENT OF { { [ GLOBAL ] cursor_name } | cursor_variable_name } ] } } ]")
18
Daten bearbeiten: Löschen DELETE [ FROM ] { | rowset_function_limited [ WITH ( [...n ] ) ] } [ FROM [,...n ] ] [ WHERE { | { [ CURRENT OF { { [ GLOBAL ] cursor_name } | cursor_variable_name } ] } ]
![Daten bearbeiten: Löschen DELETE [ FROM ] { | rowset_function_limited [ WITH ( [...n ] ) ] } [ FROM [,...n ] ] [ WHERE { | { [ CURRENT OF { { [ GLOBAL ] cursor_name } | cursor_variable_name } ] } ]](http://images.slideplayer.org/3/897919/slides/slide_18.jpg "Daten bearbeiten: Löschen DELETE [ FROM ] { | rowset_function_limited [ WITH ( [...n ] ) ] } [ FROM [,...n ] ] [ WHERE { | { [ CURRENT OF { { [ GLOBAL ] cursor_name } | cursor_variable_name } ] } ]")
19
Fragen...

Ähnliche Präsentationen




>")
>")


 Datenbank mit PHP.>")








![IS: Datenbanken, © Till Hänisch 2000 CREATE TABLE Syntax: CREATE TABLE name ( coldef [, coldef] [, tableconstraints] ) coldef := name type [länge], [[NOT]NULL],](/1/649894/big_thumb.jpg "IS: Datenbanken, © Till Hänisch 2000 CREATE TABLE Syntax: CREATE TABLE name ( coldef [, coldef] [, tableconstraints] ) coldef := name type [länge], [[NOT]NULL],>")

