Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
1 Physikalische Datenorganisation RecordDatensatz fester oder variabler Länge mit Feldern bestimmten Typs BlockSpeichereinheit im Hintergrundspeicher (2 9 - 2 12 Bytes) FileMenge von Blöcken Pinned recordBlockadresse + Offset Unpinned recordBlockadresse + Recordschlüssel Blockadresse + Index (Tupelidentifikator)
 FileMenge von Blöcken Pinned recordBlockadresse + Offset Unpinned recordBlockadresse + Recordschlüssel Blockadresse + Index (Tupelidentifikator)")
2
2 Tupelidentifikator: Verschieben innerhalb der Seite 47112 5001 Grundzüge... 5041 Ethik... TID 123 Seite 4711 4052 Logik... 4052 Mathematische Logik...

3
3 Tupelidentifikator: Verdrängen auf andere Seite 4052 Mathematische Logik... 47112 5001 Grundzüge... 5041 Ethik... TID 123 Seite 4711 123 Seite 4812 4052 Mathematische Logik für Informatiker... 4812 3 4052 Mathematische Logik

4
4 Implementierung des E-R-Modells pro Entity ein Record mit den Attributen als Datenfelder pro Relationship ein Record mit den TIDs der beteiligten Entities

5
5 INSERT: Einfügen eines Records DELETE: Löschen eines Records MODIFY: Modifizieren eines Records LOOKUP: Suchen eines Records Speicher-Operationen

6
6 Heap-File INSERT: Record am Ende einfügen DELETE: Lösch-Bit setzen MODIFY: Record überschreiben LOOKUP: Gesamtes File durchsuchen

7
7 Hashing alle Records sind auf Buckets verteilt ein Bucket besteht aus einer verzeigerten Liste von Blöcken Bucketdirectory enthält Einstiegsadressen Hashfunktion (angewandt auf Schlüssel) liefert zuständige Liste Bei N Buckets bildet die Hashfunktion einen Schlüssel auf eine Zahl zwischen 0 und N-1 ab. Pro Datenrecord ein Frei/Belegt-Bit

8
8 10 11 11 11 Peter Thomas Melanie Ute Kurt Fritz Susanne Eberhard Karl Beate 10Eva 0 1 2 3 4 1110 Beispiel für Hashorganisation (|v| mod 5)
")
9
9 Beispiel für Hash-Funktion Sei N die Anzahl der Buckets. Fasse den Schlüssel v als k Gruppen von jeweils n Bits auf. Sei d i die i-te Gruppe als natürliche Zahl interpretiert: dkdk d k-1 d2d2 d1d1 h(v) = (d k + d k-1 +... + d 2 + d 1 ) mod N
 = (d k + d k d 2 + d 1 ) mod N.")
10
10 Hash-Operationen für Schlüssel v LOOKUP: Berechne h(v) = i. Lies den für i zuständigen Directory-Block ein, und beginne bei der für i vermerkten Startadresse mit dem Durchsuchen aller Blöcke. MODIFY: Falls Schlüssel beteiligt: DELETE und INSERT durchführen. Andernfalls: LOOKUP durchführen und dann überschreiben. INSERT: Zunächst LOOKUP durchführen. Falls Satz mit v vorhanden: Fehler. Sonst: Freien Platz im Block überschreiben und ggf. neuen Block anfordern. DELETE: Zunächst LOOKUP durchführen. Bei Record Löschbit setzen.

11
11 10 11 11 11 Peter Thomas Melanie Ute Kurt Fritz Susanne Eberhard Karl Beate 10Eva 0 1 2 3 4 1110 Paul einfügen Hashorganisation: Ausgangslage h(s) = |s| mod 5
 = |s| mod 5")
12
12 10 11 11 11 Peter Thomas Melanie Ute Kurt Fritz Susanne Eberhard Karl Beate 10Eva 0 1 2 3 4 1110 10Paul Hashorganisation: nach Einfügen von Paul Kurt umbenennen nach Curdt

13
13 Peter 10 11 11 01 Thomas Melanie Ute Fritz Susanne Eberhard Karl BeateCurdt 10Eva 0 1 2 3 4 1111 10Paul Hashorganisation: nach Umbenennen von Kurt in Curdt

14
14 Probleme beim Hashing durch dynamisch sich ändernden Datenbestand: Blocklisten werden immer länger Reorganisation erforderlich

15
15 Erweiterbares Hashing Hashfunktion liefert Binärstring verwende geeigneten Prefix des Binärstring als Adresse

16
16 Beispiel für erweiterbares Hashing MatNrNameHashwert 2125Sokrates101100100001 2126Russel011100100001 2127Kopernikus111100100001 2129Descartes100010100001 Hashwert = umgekehrte Binärdarstellung von Matrikelnummer Ein Datenblock enthalte zwei Records

17
17 Beispiel für erweiterbares Hashing x 2125 2126 2127 1 01100100001 0 11100100001 1 11100100001 d p h(x) 0 (2126, Russel, C4, 232) (2125, Sokrates, C4, 226) (2127, Kopernikus, C3, 310) 1 t = 1 t´= 1 2125Sokrates101100100001 2126Russel011100100001 2127Kopernikus111100100001 2129Descartes100010100001 Sokrates, Russel, Kopernikus einfügen Descartes einfügenBucket 1 läuft überSetze globale Tiefe t:=2
 0 (2126, Russel, C4, 232) (2125, Sokrates, C4, 226) (2127, Kopernikus, C3, 310) 1 t = 1 t´= Sokrates Russel Kopernikus Descartes Sokrates, Russel, Kopernikus einfügen Descartes einfügenBucket 1 läuft überSetze globale Tiefe t:=2")
18
18 Beispiel für erweiterbares Hashing x 2125 2126 2127 2129 10 1100100001 01 1100100001 11 1100100001 10 0010100001 d p h(x) 00 (2126, Russel, C4, 232) (2125, Sokrates, C4, 226) (2127, Kopernikus, C3, 310) 01 t´= 2 t´= 1 t = 2 10 11 (2129, Descartes, C3, 312) t´= 2 2125Sokrates101100100001 2126Russel011100100001 2127Kopernikus111100100001 2129Descartes100010100001
 00 (2126, Russel, C4, 232) (2125, Sokrates, C4, 226) (2127, Kopernikus, C3, 310) 01 t´= 2 t´= 1 t = (2129, Descartes, C3, 312) t´= Sokrates Russel Kopernikus Descartes")
19
19 Defizite beim Hashing Keine Sortierung Keine Bereichsabfragen

20
20 ISAM (Index sequential access method) Index-Datei mit Verweisen in die Hauptdatei. Index-Datei enthält Tupel, sortiert nach Schlüsseln. Liegt in der Index-Datei, so sind alle Record-Schlüssel im Block, auf den a zeigt, größer oder gleich v.

21
21 ISAM-Operationen für Record mit Schlüssel v LOOKUP (für Schlüssel v): Suche in Index-Datei den letzten Block mit erstem Eintrag v 2 v. Suche in diesem Block das letzte Paar (v 3, a) mit v 3 v. Lies Block mit Adresse a und durchsuche ihn nach Schlüssel v. MODIFY: Zunächst LOOKUP. Falls Schlüssel an Änderung beteiligt: DELETE + INSERT. Sonst: Record ändern, Block zurückschreiben. INSERT: Zunächst LOOKUP. Falls Block noch Platz für Record hat: einfügen. Falls Block voll ist: Nachfolgerblock oder neuen Block wählen und Index anpassen. DELETE: Analog zu INSERT
 mit v 3 v. Lies Block mit Adresse a und durchsuche ihn nach Schlüssel v. MODIFY: Zunächst LOOKUP. Falls Schlüssel an Änderung beteiligt: DELETE + INSERT. Sonst: Record ändern, Block zurückschreiben. INSERT: Zunächst LOOKUP. Falls Block noch Platz für Record hat: einfügen. Falls Block voll ist: Nachfolgerblock oder neuen Block wählen und Index anpassen. DELETE: Analog zu INSERT.")
22
22 Manfred einfügen Index-Organisation: Ausgangslage

23
23 Index-Organisation: nach Einfügen von Manfred

24
24 Sekundär-Index Sekundärindex besteht aus Index-File mit Einträgen der Form.

25
25 Sekundär-Index für Gewicht 6871727883

26
26 Beispiel zur physikalischen Speicherung Gegeben seien 300.000 Records mit folgenden Angaben: Die Blockgröße betrage 1024 Bytes. AttributBytes AttributBytes Pers-Nr.15 Vorname15 Nachname15 Straße25 PLZ 5 Ort25 Platzbedarf pro Record: 100 Bytes.

27
27 Fragen zur Zahl der Records Wieviel Daten-Records passen in einen zu 100% gefüllten Datenblock? 1024 / 100 = 10 Wieviel Daten-Records passen in einen zu 75% gefüllten Datenblock? 10 * 0,75 = 7-8 Wieviel Schlüssel / Adresspaare passen in einen zu 100% gefüllten Indexblock? 1.024 / (15+4) = 53 Wieviel Schlüssel / Adresspaare passen in einen zu 75% gefüllten Indexblock? 1.024 / (15+4)*0,75 40
 = 53 Wieviel Schlüssel / Adresspaare passen in einen zu 75% gefüllten Indexblock / (15+4)*0,")
28
28 Heapfile versus ISAM Welcher Platzbedarf entsteht beim Heapfile? 300.000 / 10 = 30.000 Blöcke Wieviel Blockzugriffe entstehen im Mittel beim Heapfile? 30.000 / 2 = 15.000 Welcher Platzbedarf entsteht im Mittel bei ISAM? 300.000 / 7,5 40.000 zu 75% gefüllte Datenblöcke + 40.000 / 40 1.000 zu 75% gefüllte Indexblöcke Wieviel Blockzugriffe entstehen im Mittel bei ISAM? log 2 (1.000) + 1 11 Blockzugriffe
 Blockzugriffe.")
29
29 B*-Baum Jeder Weg von der Wurzel zu einem Blatt hat dieselbe Länge. Jeder Knoten außer der Wurzel und den Blättern hat mindestens k Nachfolger. Jeder Knoten hat höchstens 2 k Nachfolger. Die Wurzel hat keinen oder mindestens 2 Nachfolger.

30
30 B*-Baum-Adressierung Ein Knoten wird auf einem Block gespeichert Ein Knoten mit j Nachfolgern (j 2k) speichert j Paare von Schlüsseln und Adressen (s 1, a 1 ),..., (s j, a j ). Es gilt s 1 s 2... s j. Eine Adresse in einem Blattknoten führt zum Datenblock mit den restlichen Informationen zum zugehörigen Schlüssel Eine Adresse in einem anderen Knoten führt zu einem Baumknoten

31
31 Einfügen in B*Baum eingefügt werden soll: 45 312217 774217 7977474742 61 53

32
32 Einfügen in B*Baum eingefügt werden soll: 45 Block anfordern 312217 774217 7977474742 61 53 Überlaufblock verteilen

33
33 Einfügen in B*Baum eingefügt werden soll: 45 Vorgänger korrigieren 312217 774217 7977474742 6153

34
34 Einfügen in B*Baum eingefügt wurde: 45 312217 53421777 7977454542 6153 4747

35
35 27 55 12 94 37 88 72 39 25 88 74 58 64 Sequenz für B*-Baum mit k=2

36
36 27

37
37 27 27 55

38
38 27 55

39
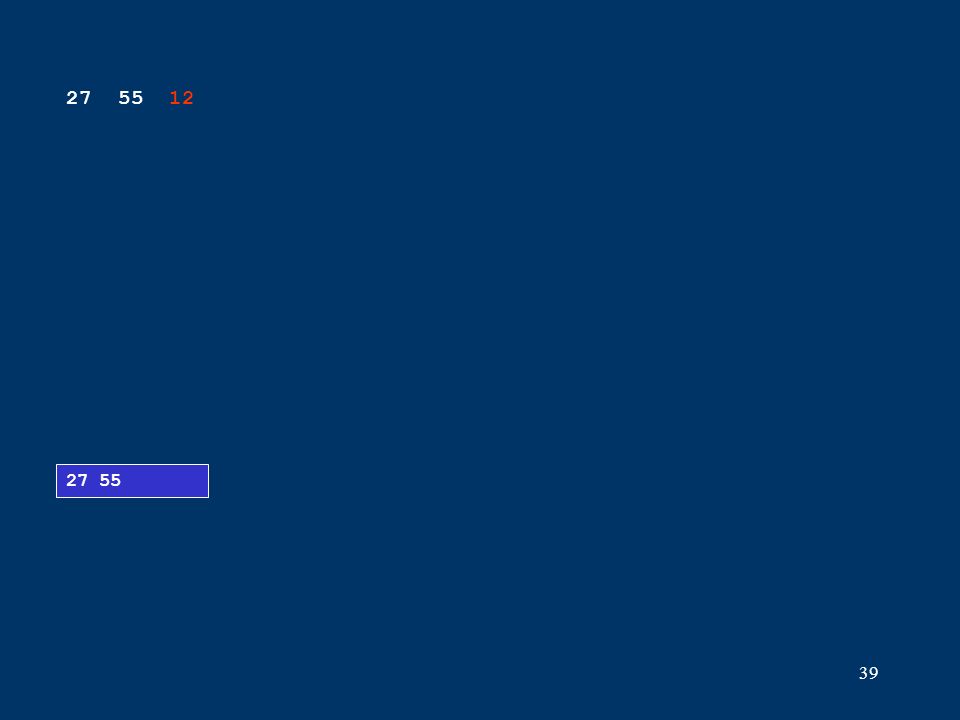
39 27 55 27 55 12
40
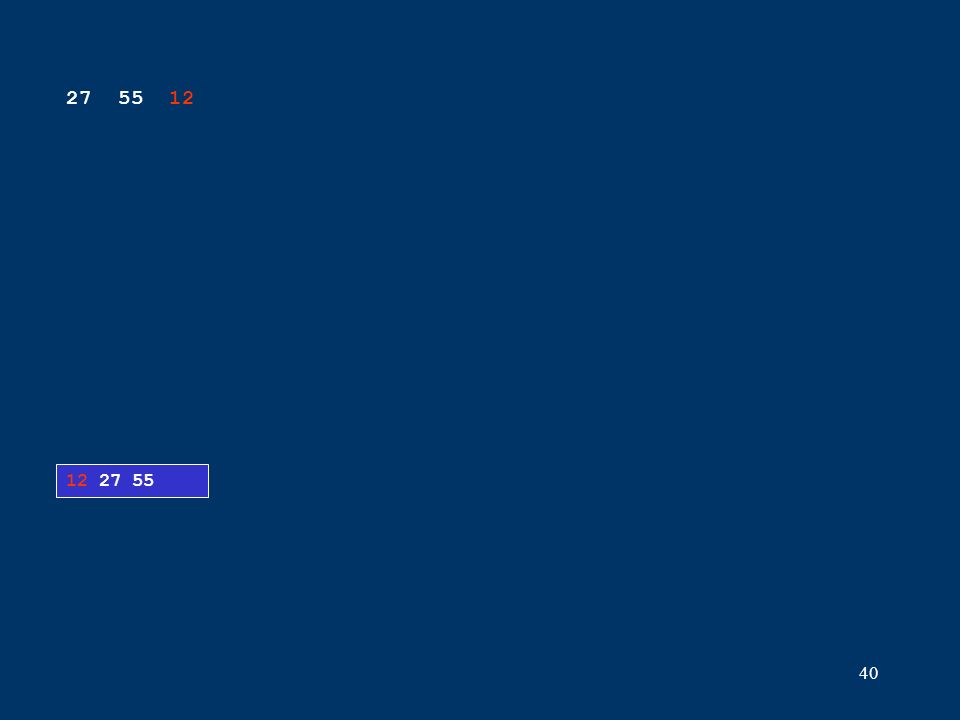
40 12 27 55 27 55 12
41
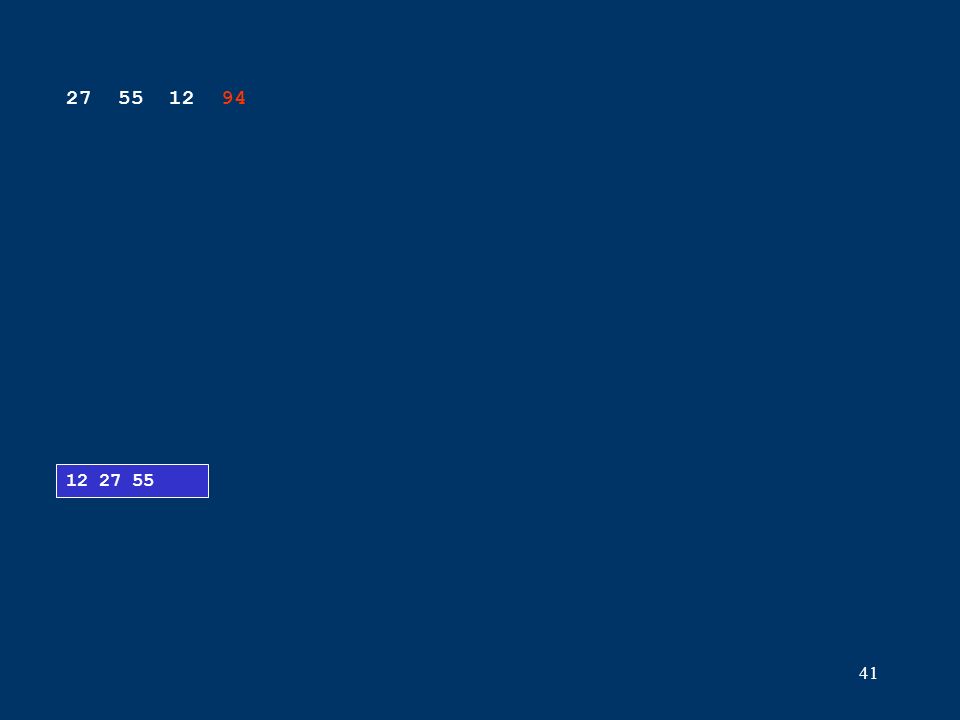
41 12 27 55 27 55 12 94
42
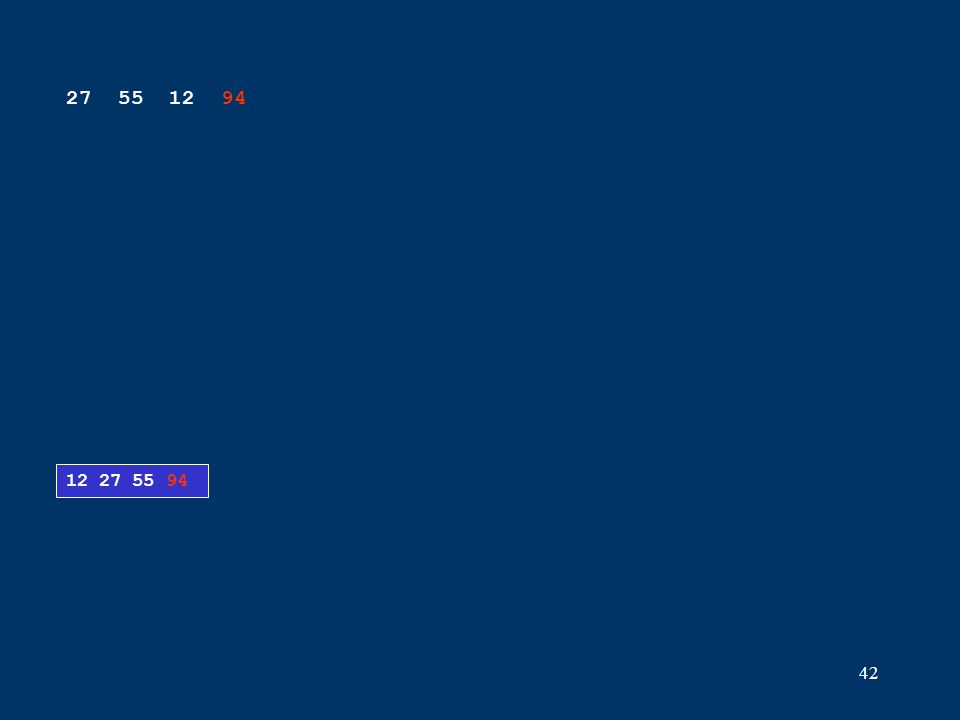
42 12 27 55 94 27 55 12 94
43
43 12 27 55 94 27 55 12 94 37

44
44 12 27 55 94 27 55 12 94 37
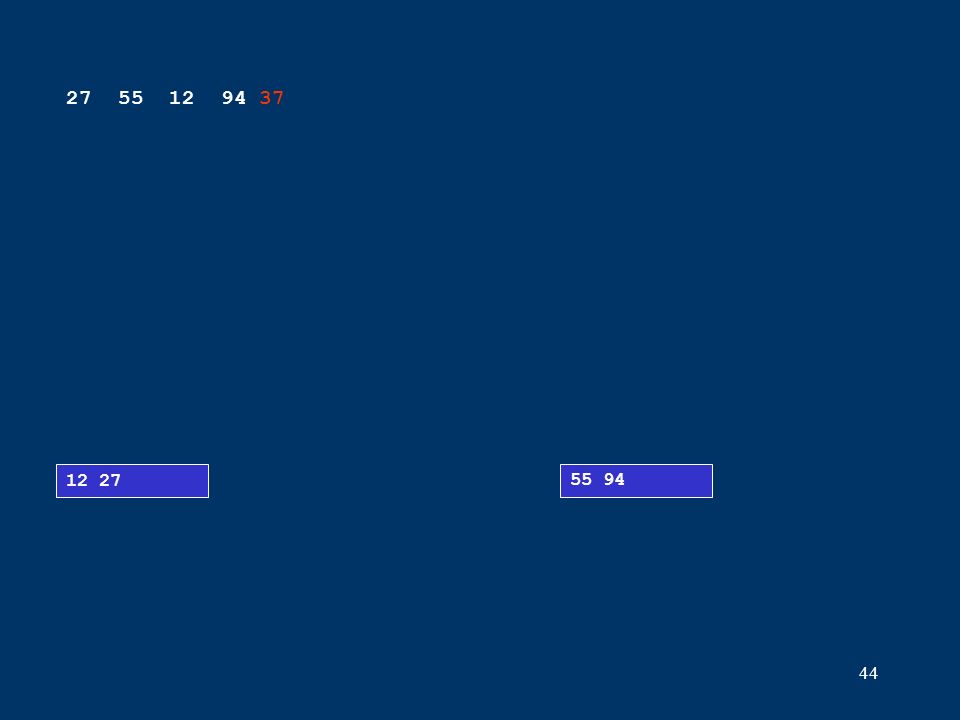
45
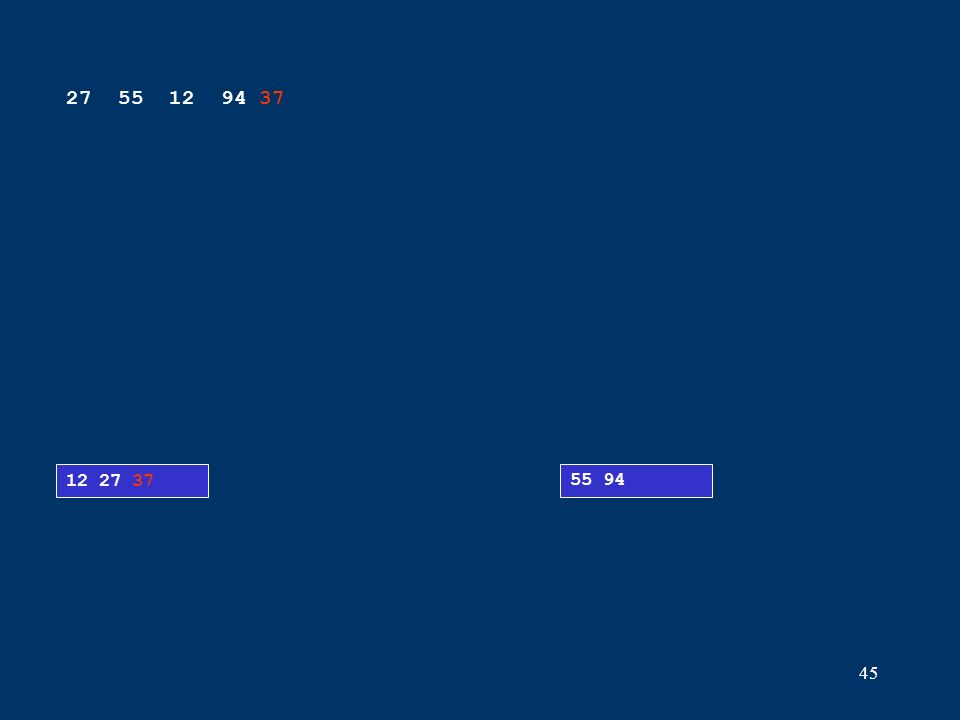
45 12 27 3755 94 27 55 12 94 37
46
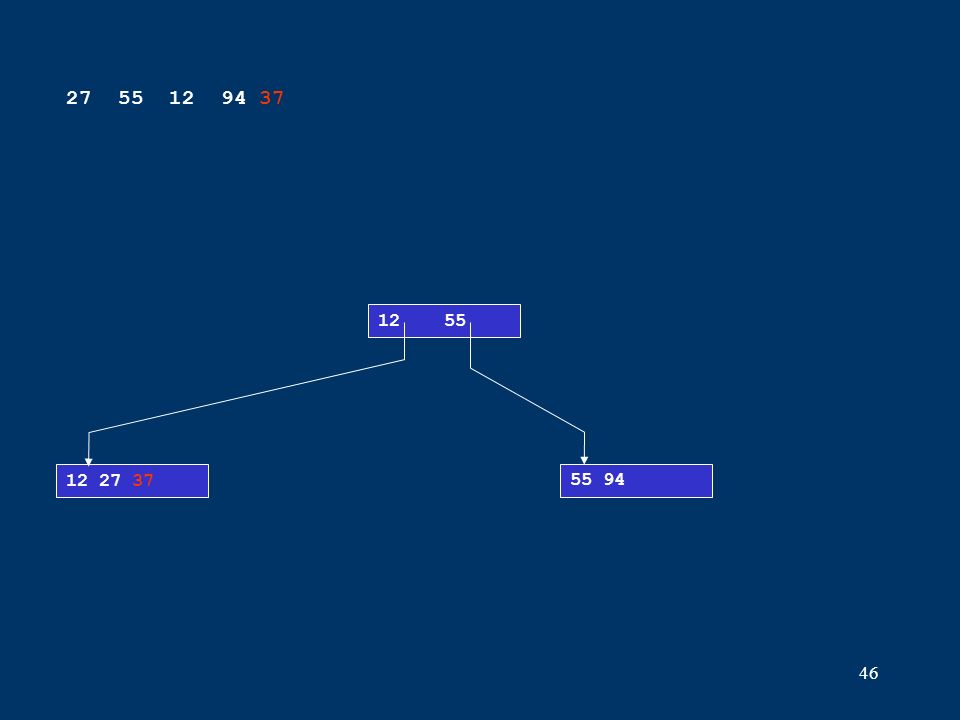
46 12 27 3755 94 12 55 27 55 12 94 37
47
47 12 27 3755 94 12 55 27 55 12 94 37 88

48
48 12 27 3755 88 94 12 55 27 55 12 94 37 88

49
49 12 27 3755 88 94 12 55 27 55 12 94 37 88 72

50
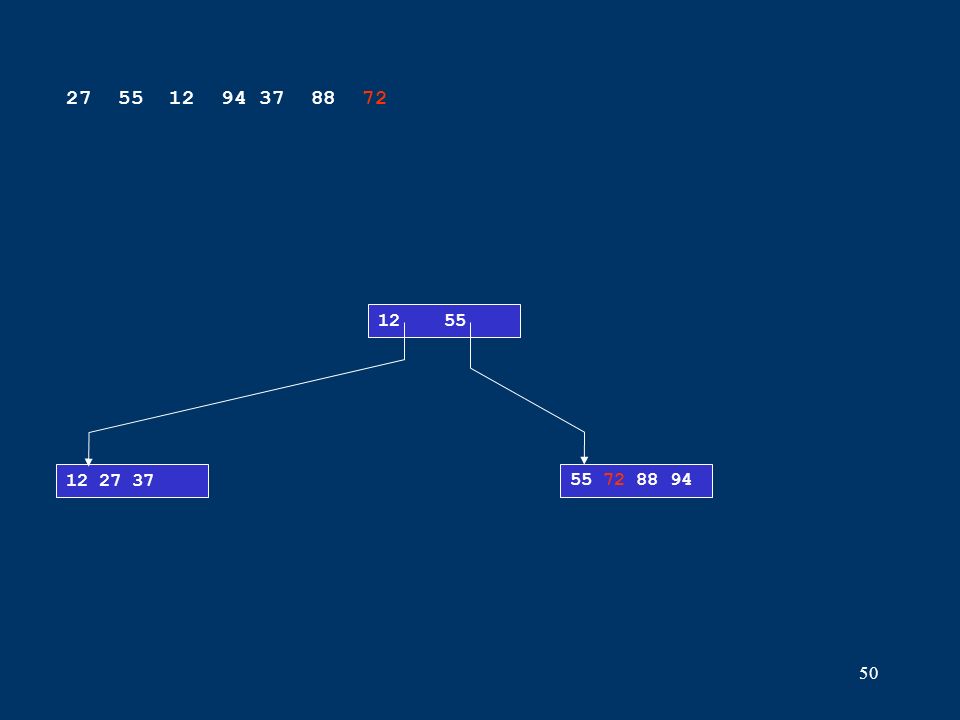
50 12 27 3755 72 88 94 12 55 27 55 12 94 37 88 72
51
51 12 27 3755 72 88 94 12 55 27 55 12 94 37 88 72 39
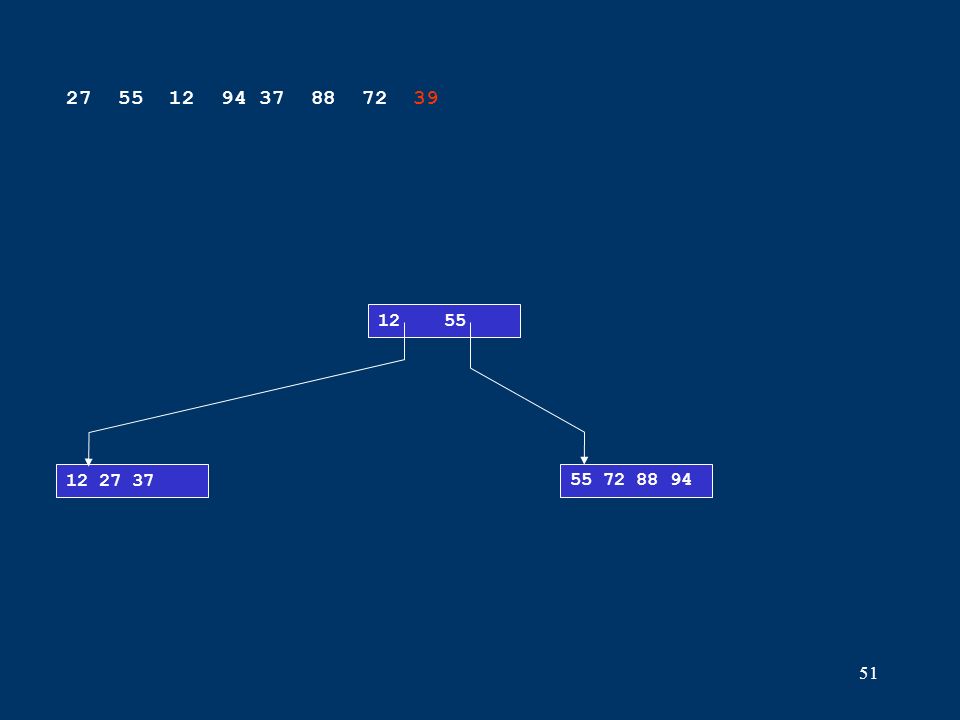
52
52 12 27 37 3955 72 88 94 12 55 27 55 12 94 37 88 72 39
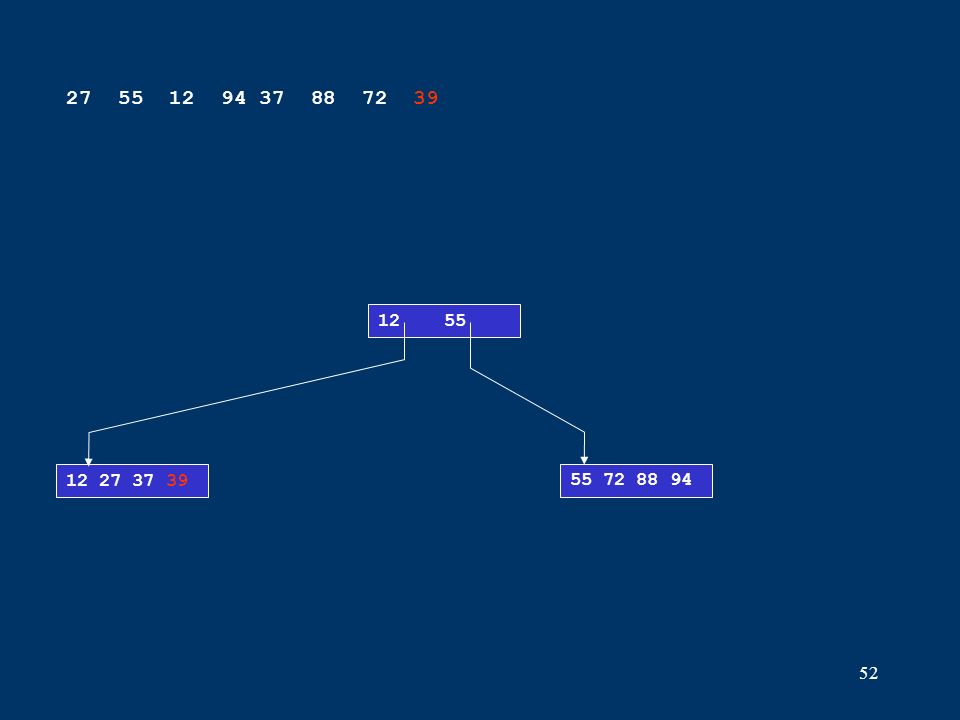
53
53 12 27 37 3955 72 88 94 12 55 27 55 12 94 37 88 72 39 25
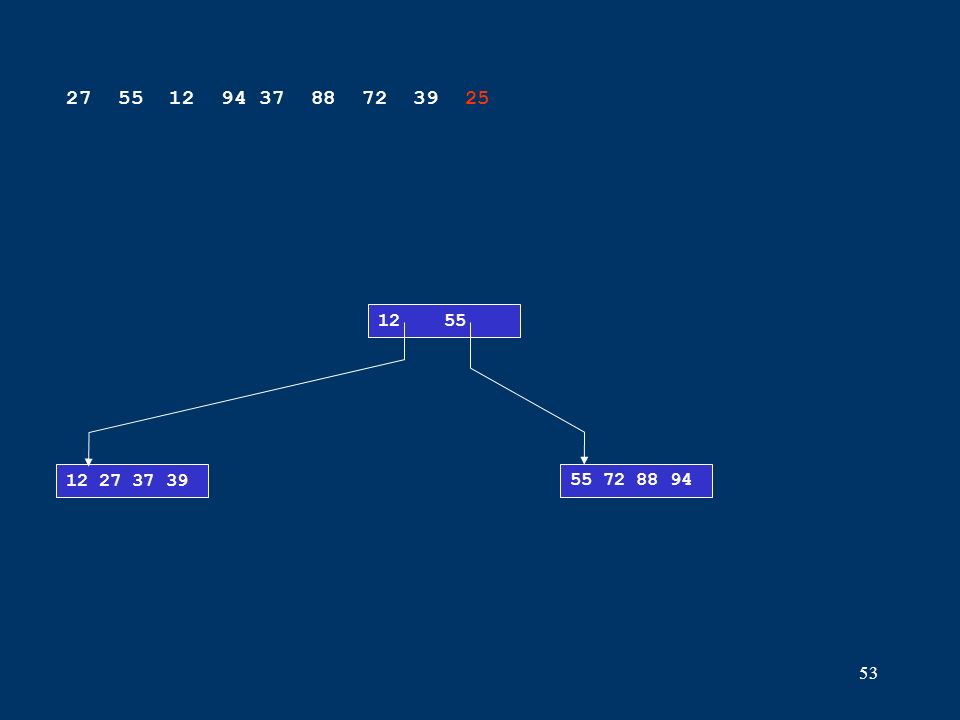
54
54 12 2737 3955 72 88 94 12 37 55 27 55 12 94 37 88 72 39 25
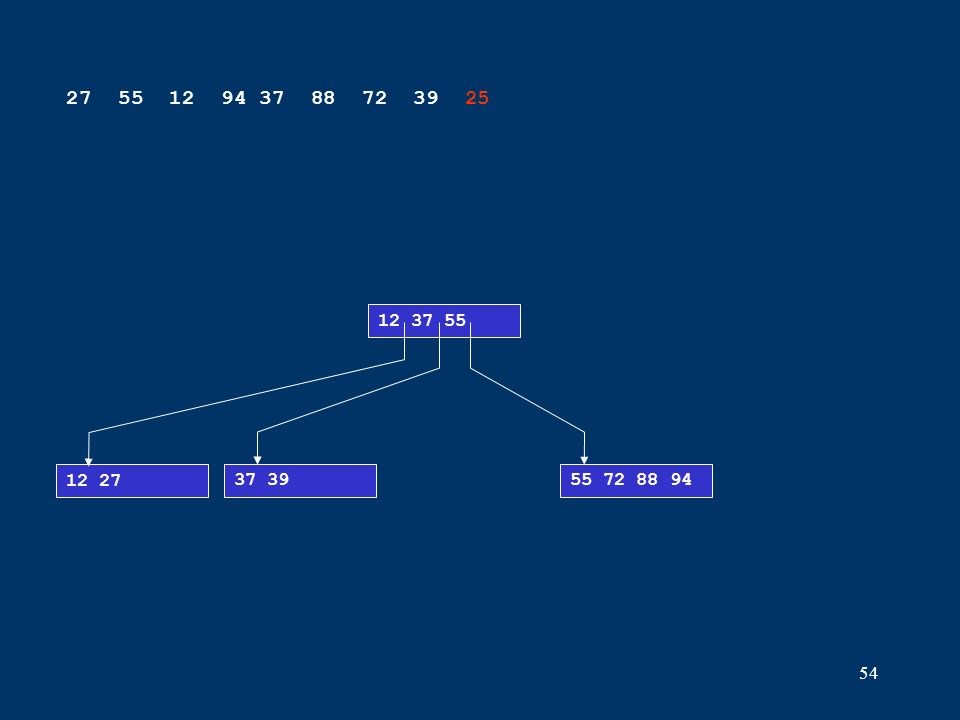
55
55 12 25 2737 3955 72 88 94 12 37 55 27 55 12 94 37 88 72 39 25
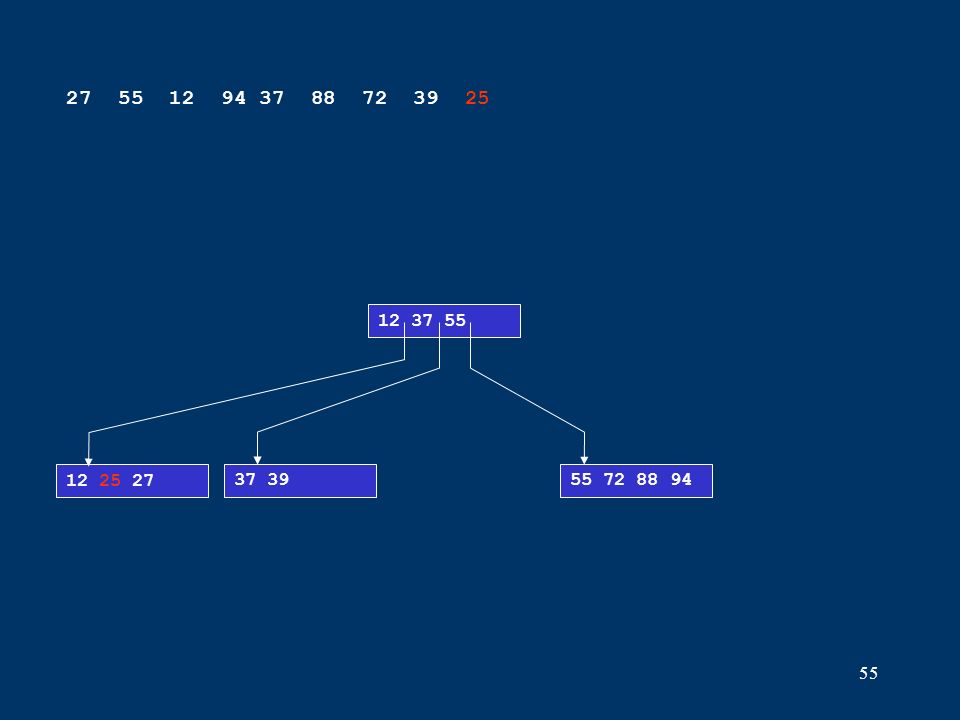
56
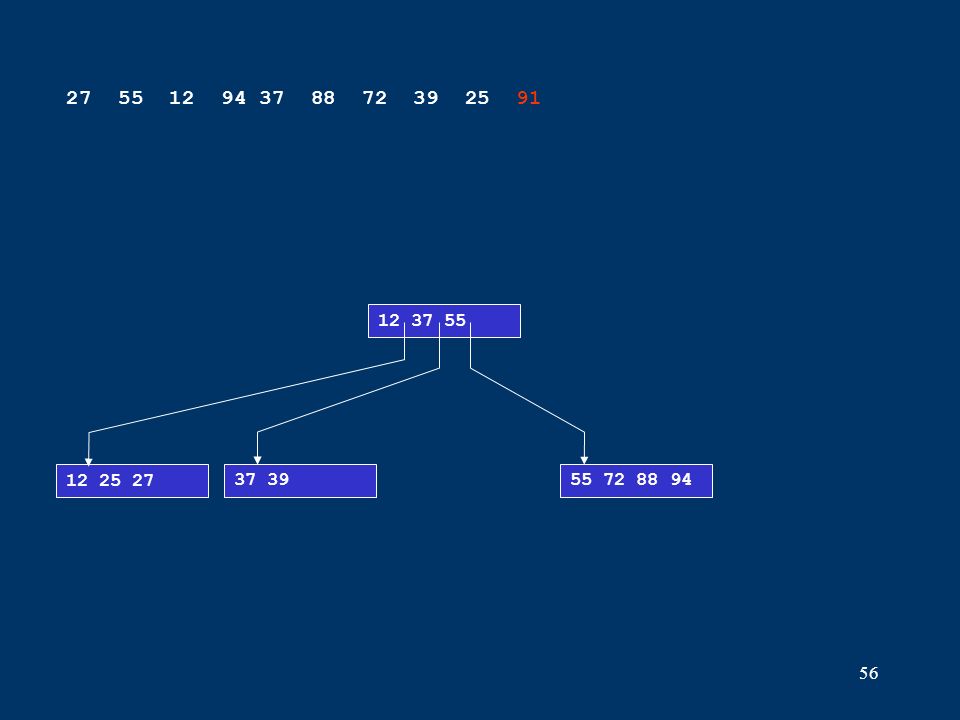
56 12 25 2737 3955 72 88 94 12 37 55 27 55 12 94 37 88 72 39 25 91
57
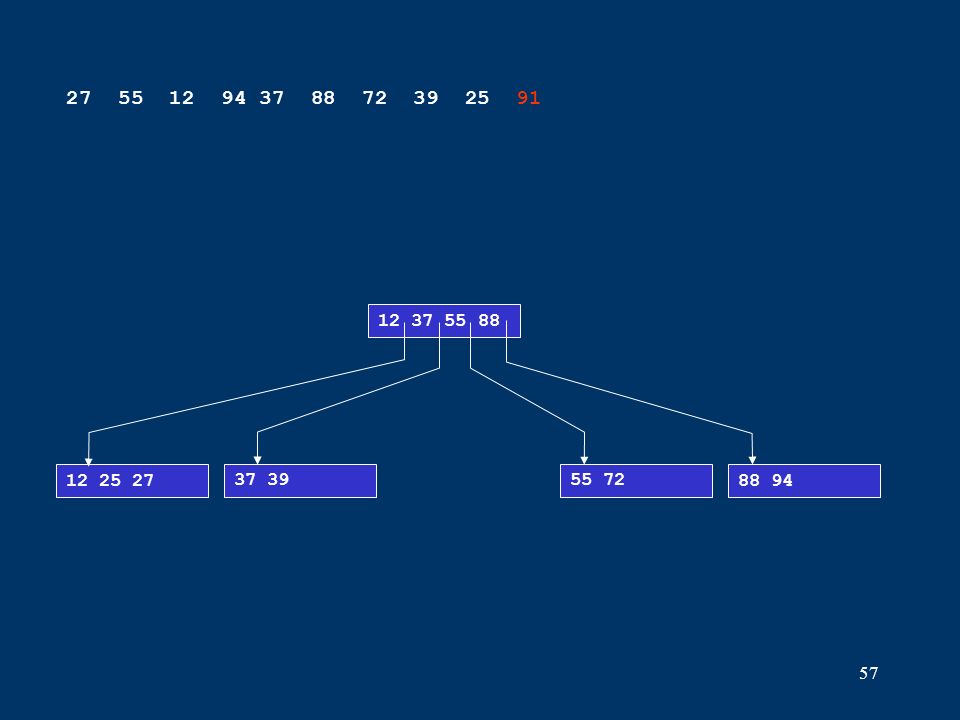
57 12 25 2737 3955 7288 94 12 37 55 88 27 55 12 94 37 88 72 39 25 91
58
58 12 25 2737 3955 7288 91 94 12 37 55 88 27 55 12 94 37 88 72 39 25 91

59
59 12 25 2737 3955 7288 91 94 12 37 55 88 27 55 12 94 37 88 72 39 25 91 74

60
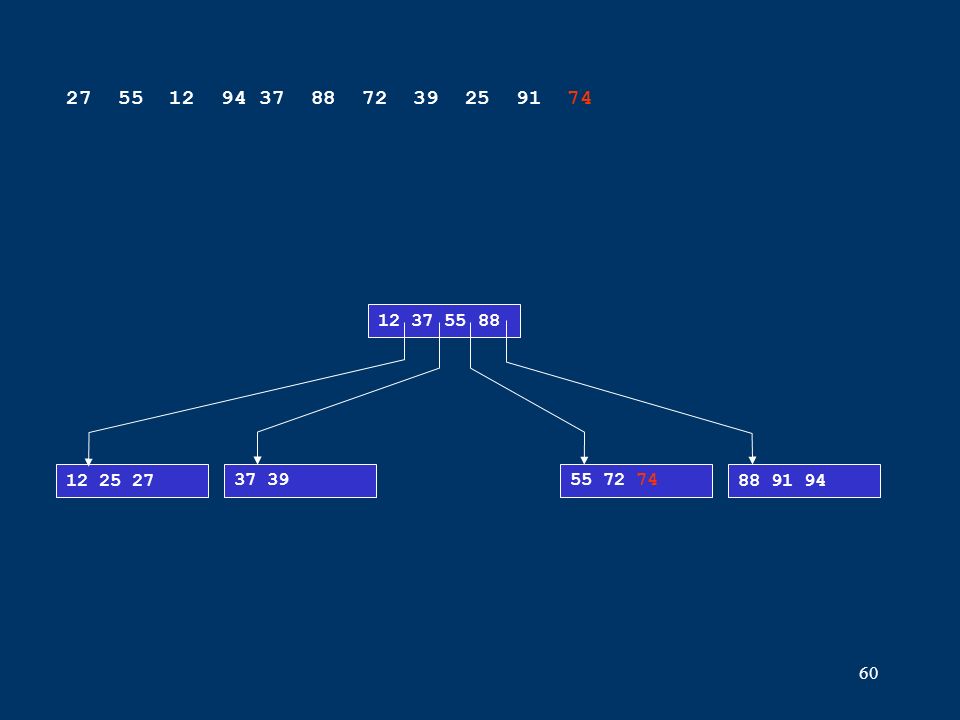
60 12 25 2737 3955 72 7488 91 94 12 37 55 88 27 55 12 94 37 88 72 39 25 91 74
61
61 12 25 2737 3955 72 7488 91 94 12 37 55 88 27 55 12 94 37 88 72 39 25 88 74 58
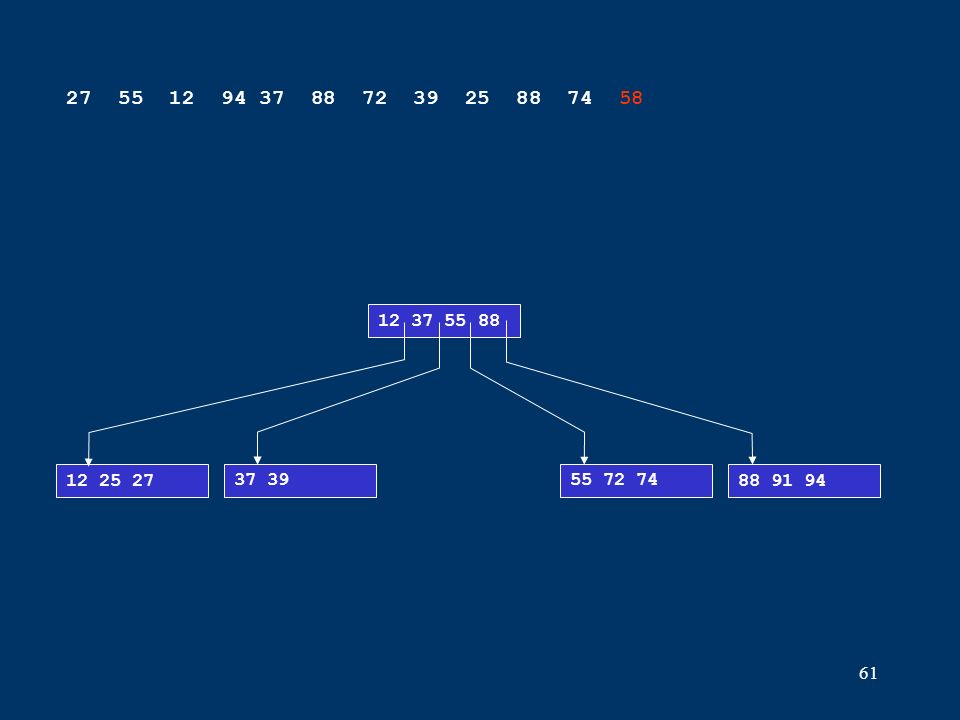
62
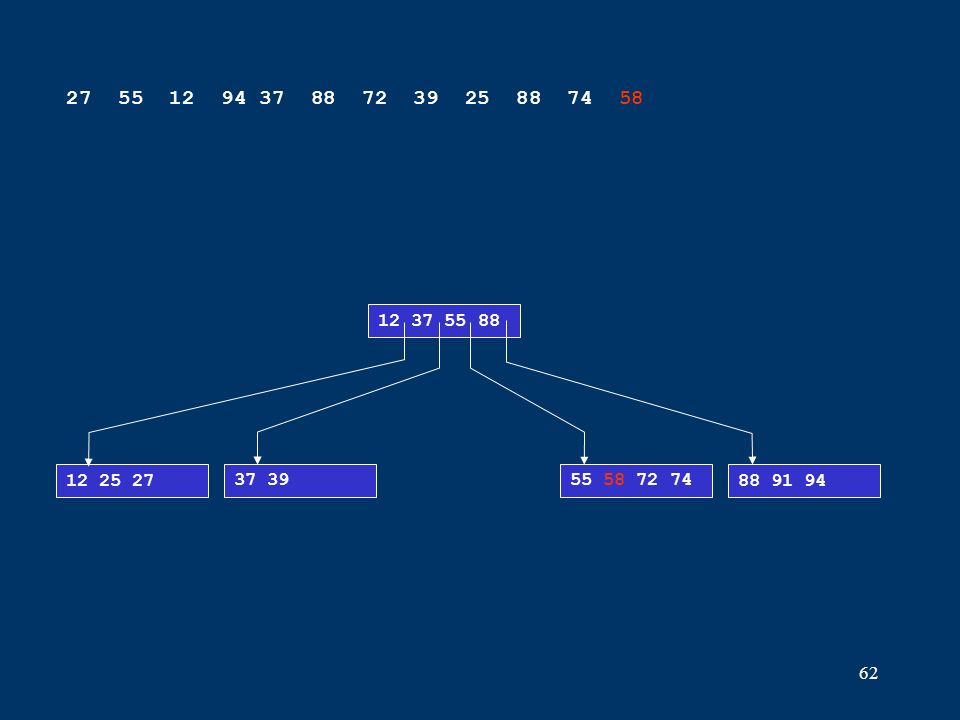
62 12 25 2737 3955 58 72 7488 91 94 12 37 55 88 27 55 12 94 37 88 72 39 25 88 74 58
63
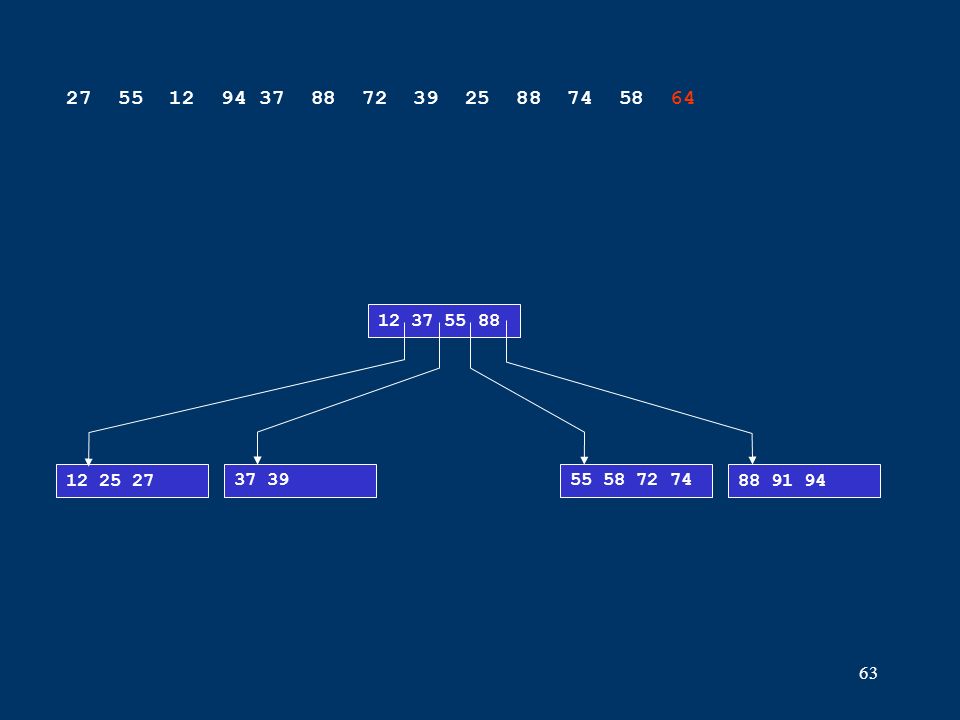
63 12 25 2737 3955 58 72 7488 91 94 12 37 55 88 27 55 12 94 37 88 72 39 25 88 74 58 64
64
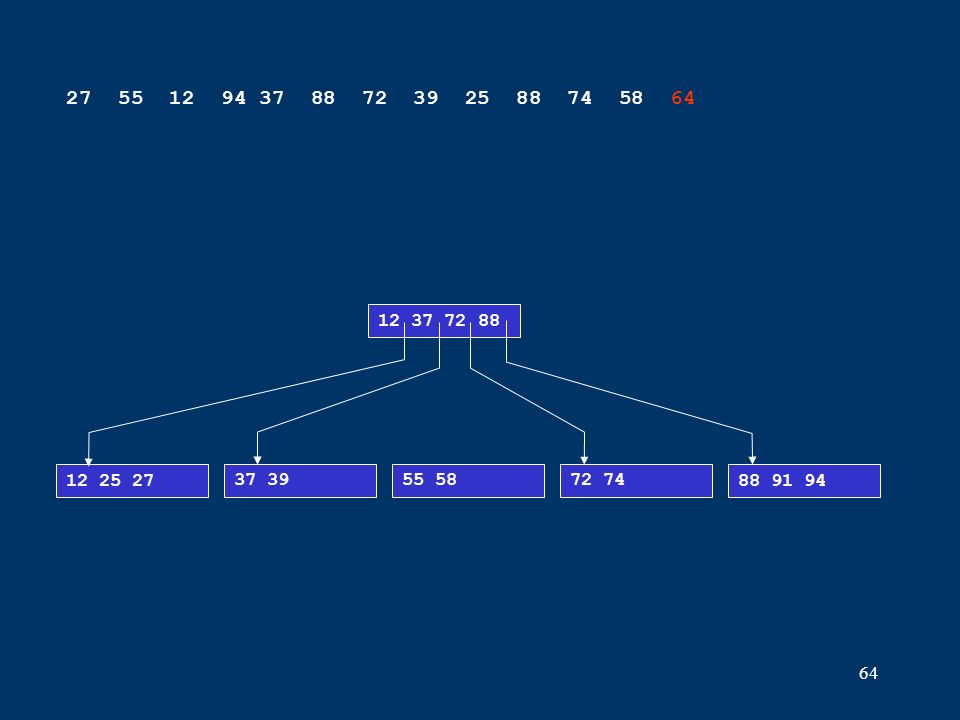
64 12 25 2737 3972 7488 91 94 12 37 72 88 27 55 12 94 37 88 72 39 25 88 74 58 64 55 58
65
65 12 25 2737 3972 7488 91 94 12 37 72 88 27 55 12 94 37 88 72 39 25 88 74 58 64 55 58 64
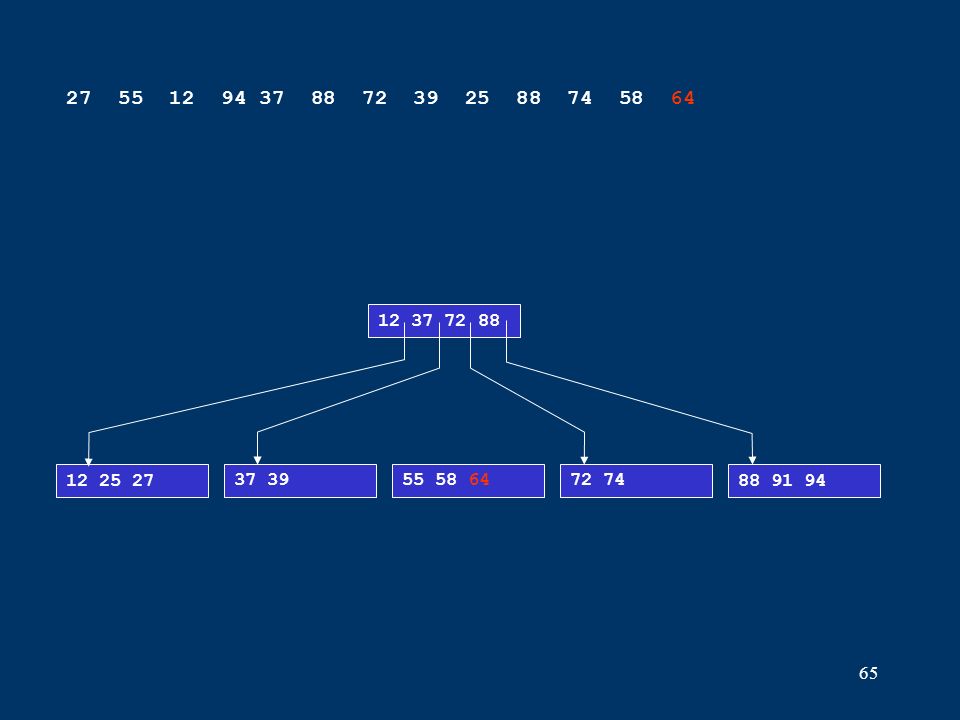
66
66 12 25 27 12 37 37 3955 58 6472 7488 91 94 55 72 88 27 55 12 94 37 88 72 39 25 88 74 58 64
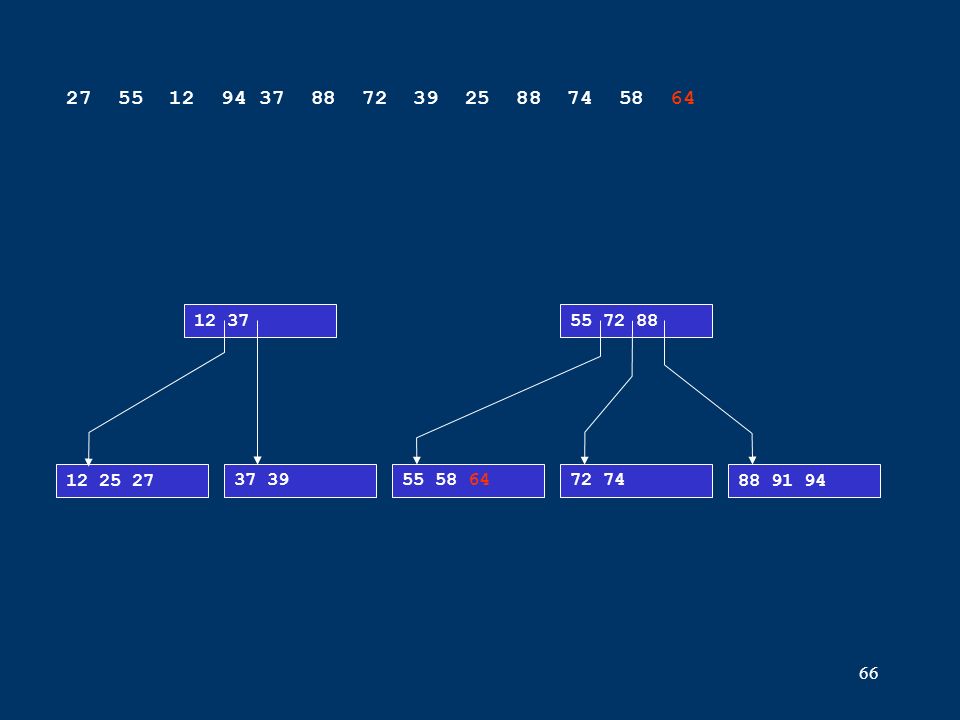
67
67 12 25 27 12 37 37 3955 58 6472 7488 91 94 55 72 88 12 55 27 55 12 94 37 88 72 39 25 88 74 58 64

68
68 12 25 27 12 37 37 3955 58 6472 7488 91 94 55 72 88 12 55 27 55 12 94 37 88 72 39 25 88 74 58 64 Sequenz eingefügt

69
69 Löschen in B*Baum 312217 774217 797753474261 Entferne 53

70
70 Löschen in B*Baum 312217 774217 7977614742 Entferne 79

71
71 Löschen in B*Baum 2217 613117 77614731 Entferne 47

72
72 Löschen in B*Baum 312217 77 17 7977 Entferne 77

73
73 Löschen in B*Baum 2217 31 17 7931 Entferne 22

74
74 Löschen in B*Baum 793117

75
75 Fragen zum B*Baum Wie groß ist k ? Blockgröße / (Schlüssel / Adresspaar-Größe) = 1024 / (15+4) / 2 = 26 Wieviel Söhne hat eine zu 50 % gefüllte Wurzel ? 26 Wieviel Söhne hat ein zu 75 % gefüllter Knoten ? 39 Wieviel zu 75 % gefüllte Datenblöcke sind erforderlich ? 300.000 / 7,5 40.000
 = 1024 / (15+4) / 2 = 26 Wieviel Söhne hat eine zu 50 % gefüllte Wurzel . 26 Wieviel Söhne hat ein zu 75 % gefüllter Knoten . 39 Wieviel zu 75 % gefüllte Datenblöcke sind erforderlich / 7,")
76
76 Platzbedarf B*Baum Wieviel Blöcke belegt der B*Baum ? HöheKnotenZeiger aus Knoten 0126 12626 * 39 = 1.014 226*3926*39*39 = 39.546 drei Ebenen reichen aus Platzbedarf = 1 + 26 + 26*39 + 39.546 40.000 Blöcke Wieviel Blockzugriffe sind erforderlich ? 4

77
77 Hashing versus B*Baum Welcher Platzbedarf entsteht beim Hashing, wenn dieselbe Zugriffszeit erreicht werden soll wie beim B*Baum? 4 Blockzugriffe = 1 Directory-Blockzugriff + 3 Datenblockzugriffe. Buckets bestehen im Mittel aus 5 Blöcken. von 5 Blöcken sind 4 voll und der letzte halb voll. 4,5 * 10 = 45 Records pro Bucket 300.000 / 45 = 6666 Buckets erforderlich 6666 / (1024 / 4) = 26 Directory-Blöcke Platzbedarf = 26 + 5 * 6.666 = 33.356
 = 26 Directory-Blöcke Platzbedarf = * =")
78
78 B*Baum versus Hashing B*BaumHashing VorteileDynamischSchnell Sortierung möglichplatzsparend NachteileSpeicheroverheadkeine Sortierung kompliziertNeuorganisation

79
79 Mehrdimensionale Suchstrukturen Alterzwischen 20 und 30 Einkommenzwischen 2000 und 3000 PLZzwischen 40000 und 50000

80
80 Query-Rechteck y2y2 y1y1 y x x1x1 x2x2 E D C B G F HI K A J

81
81 k-d-Baum zur Verwaltung von mehrdimensionalen Datenpunkten Verallgemeinerung des binären Suchbaums mit k-dimensionalem Sortierschlüssel Homogene Variante: Baumknoten enthält Datenrecord + Zeiger Inhomogene Variante: Baumknoten enthält Schlüssel + Zeiger Blätter enthalten Zeiger auf Datenrecord Ebene i modulo k diskriminiert bzgl. Dimension i x y z

82
82 2-d-Baum Im 2-dimensionalen Fall gilt für Knoten mit Schlüssel [x/y]: im linken Sohnim rechten Sohn Auf ungerader Ebenealle Schlüssel xalle Schlüssel > x Auf gerader Ebenealle Schlüssel yalle Schlüssel > y
![82 2-d-Baum Im 2-dimensionalen Fall gilt für Knoten mit Schlüssel [x/y]: im linken Sohnim rechten Sohn Auf ungerader Ebenealle Schlüssel xalle Schlüssel > x Auf gerader Ebenealle Schlüssel yalle Schlüssel > y](http://images.slideplayer.org/1/665965/slides/slide_82.jpg "82 2-d-Baum Im 2-dimensionalen Fall gilt für Knoten mit Schlüssel [x/y]: im linken Sohnim rechten Sohn Auf ungerader Ebenealle Schlüssel xalle Schlüssel > x Auf gerader Ebenealle Schlüssel yalle Schlüssel > y")
83
83 2-d-Baum 1 2 3 4 5 6 7 8 910111213141516 1 2 3 4 5 6 7 8 9 10 A C B D E F G H

84
84 Beispiel für 2-d-Baum D 6/2H8/5 C 9/4 B14/3 B A 5/6 G1/8 F 12/7 E 7/9 bzgl. y kleiner bzgl.x kleiner bzgl. y kleiner bzgl. y grösser bzgl. y grösser bzgl.x grösser bzgl.x grösser Ebene 0

85
85 Beispiel für 2-d-Baum D 6/2H8/5 C 9/4 B14/3 B A 5/6 G1/8 F 12/7 E 7/9 bzgl. y kleiner bzgl.x kleiner bzgl. y kleiner bzgl. y grösser bzgl. y grösser bzgl.x grösser bzgl.x grösser Insertz.B. füge Record [3/9] I 3/9

86
86 Beispiel für 2-d-Baum D 6/2H8/5 C 9/4 B14/3 B A 5/6 G1/8 F 12/7 E 7/9 bzgl. y kleiner bzgl.x kleiner bzgl. y kleiner bzgl. y grösser bzgl. y grösser bzgl.x grösser bzgl.x grösser Exact Matchz.B. finde Record [15/5]

87
87 Beispiel für 2-d-Baum D 6/2H8/5 C 9/4 B14/3 B A 5/6 G1/8 F 12/7 E 7/9 bzgl. y kleiner bzgl.x kleiner bzgl. y kleiner bzgl. y grösser bzgl. y grösser bzgl.x grösser bzgl.x grösser Partial Matchz.B. finde alle Records [x/y] mit x=7

88
88 Beispiel für 2-d-Baum D 6/2H8/5 C 9/4 B14/3 B A 5/6 G1/8 F 12/7 E 7/9 bzgl. y kleiner bzgl.x kleiner bzgl. y kleiner bzgl. y grösser bzgl. y grösser bzgl.x grösser bzgl.x grösser Range-Queryz.B. finde alle Records [x/y] mit 8 x 13, 5 y 8

89
89 Beispiel für 2-d-Baum D 6/2H8/5 C 9/4 B14/3 B A 5/6 G1/8 F 12/7 E 7/9 bzgl. y kleiner bzgl.x kleiner bzgl. y kleiner bzgl. y grösser bzgl. y grösser bzgl.x grösser bzgl.x grösser Best Matchz.B. finde nächsten Nachbarn zu [7/3]

90
90 2-d-Baum 1 2 3 4 5 6 7 8 910111213141516 1 2 3 4 5 6 7 8 9 10A C B D E F G H

91
91 Inhomogene Variante

92
92 Partitionierungen

93
93 Gitterverfahren mit konstanter Gittergröße

94
94 Grid File Alternative zu fester Gittergröße 1981 vorgestellt von Hinrichs & Nievergelt 2-Platten-Zugriffsgarantie Bei k-dimensionalen Tupeln: k Skalen zum Einstieg ins Grid-Directory (im Hauptspeicher) Grid Directory zum Finden der Bucket-Nr. (Hintergrundspeicher) Bucket für Datensätze (Hintergrundspeicher)
 Bucket für Datensätze (Hintergrundspeicher).")
95
95 Grid File im 2-dimensionalen Fall Alle Records der roten Gitterzelle sind im Bucket mit Adresse G[1,2] 0 y[i],i=0,.. max_y 3030 2500 2050 800 y 304085120 x x x[i],i=0,.. max_x 0304085120 y 0800205025003030 Region:benachbarte Gitterzellen Gitterzelle: rechteckiger Teilbereich Bucket:speichert Records einer Region
![95 Grid File im 2-dimensionalen Fall Alle Records der roten Gitterzelle sind im Bucket mit Adresse G[1,2] 0 y[i],i=0,..](http://images.slideplayer.org/1/665965/slides/slide_95.jpg "max_y y x x x[i],i=0,.. max_x y Region:benachbarte Gitterzellen Gitterzelle: rechteckiger Teilbereich Bucket:speichert Records einer Region.")
96
96 Bucket Directory 0 30 40 85 120 0 1 2 3 4 4321043210 3030 2500 2050 800 0 Suche Record [35 / 2400] Befrage Skalen asp07nk99jh056509 aasdf0cß03j400d0v 9v8asßfimo98csi98a dxcvß98dspa0s9fxc0 wi00808ß3jsßsa9ßß Lade G[1,2] vom Bucketdirectory Lade Datenblock
![96 Bucket Directory Suche Record [35 / 2400] Befrage Skalen asp07nk99jh aasdf0cß03j400d0v 9v8asßfimo98csi98a dxcvß98dspa0s9fxc0 wi00808ß3jsßsa9ßß Lade G[1,2] vom Bucketdirectory Lade Datenblock](http://images.slideplayer.org/1/665965/slides/slide_96.jpg "96 Bucket Directory Suche Record [35 / 2400] Befrage Skalen asp07nk99jh aasdf0cß03j400d0v 9v8asßfimo98csi98a dxcvß98dspa0s9fxc0 wi00808ß3jsßsa9ßß Lade G[1,2] vom Bucketdirectory Lade Datenblock")
97
97 1.000.000 Datenrecords 4 Datenrecords passen in ein Bucket X-Achse und Y-Achse habe 500 Unterteilungen 250.000 Einträge im Bucketdirectory 4 Bytes pro Adresse + 1.024 Bytes pro Block 250 Zeiger pro Directory-Block 1.000 Directory-Blöcke i 249: G[i,j] befindet sich auf Block 2*j als i-te Adresse i > 249: G[i,j] befindet sich auf Block 2*j+1 als (i-250)-te Adresse Beispiel für Bucket Directory..................................... 0 249 499........................................210...210 G[280,2] auf Block 5 an Position 30.....................................
![Datenrecords 4 Datenrecords passen in ein Bucket X-Achse und Y-Achse habe 500 Unterteilungen Einträge im Bucketdirectory 4 Bytes pro Adresse Bytes pro Block 250 Zeiger pro Directory-Block Directory-Blöcke i 249: G[i,j] befindet sich auf Block 2*j als i-te Adresse i > 249: G[i,j] befindet sich auf Block 2*j+1 als (i-250)-te Adresse Beispiel für Bucket Directory](http://images.slideplayer.org/1/665965/slides/slide_97.jpg "G[280,2] auf Block 5 an Position")
98
98 Bucket-Überlauf Eine Zelle in Region Mehrere Zellen in Region

99
99 Aufspalten der Regionen 8 6 4 2 2468101214 Insert A = [5 / 6]
![99 Aufspalten der Regionen Insert A = [5 / 6]](http://images.slideplayer.org/1/665965/slides/slide_99.jpg "99 Aufspalten der Regionen Insert A = [5 / 6]")
100
100 Aufspalten der Regionen 8 6 4 2 2468101214 A A Insert B = [14 / 3]
![100 Aufspalten der Regionen A A Insert B = [14 / 3]](http://images.slideplayer.org/1/665965/slides/slide_100.jpg "100 Aufspalten der Regionen A A Insert B = [14 / 3]")
101
101 Aufspalten der Regionen 8 6 4 2 2468101214 A B A B Insert C = [9 / 4]
![101 Aufspalten der Regionen A B A B Insert C = [9 / 4]](http://images.slideplayer.org/1/665965/slides/slide_101.jpg "101 Aufspalten der Regionen A B A B Insert C = [9 / 4]")
102
102 Aufspalten der Regionen 8 6 4 2 2468101214 A C B B C A Insert D = [6 / 2]
![102 Aufspalten der Regionen A C B B C A Insert D = [6 / 2]](http://images.slideplayer.org/1/665965/slides/slide_102.jpg "102 Aufspalten der Regionen A C B B C A Insert D = [6 / 2]")
103
103 Aufspalten der Regionen 8 6 4 2 2468101214 A C B B C A D D Insert E = [7 / 9]
![103 Aufspalten der Regionen A C B B C A D D Insert E = [7 / 9]](http://images.slideplayer.org/1/665965/slides/slide_103.jpg "103 Aufspalten der Regionen A C B B C A D D Insert E = [7 / 9]")
104
104 Aufspalten der Regionen Insert F = [12 / 7]
![104 Aufspalten der Regionen Insert F = [12 / 7]](http://images.slideplayer.org/1/665965/slides/slide_104.jpg "104 Aufspalten der Regionen Insert F = [12 / 7]")
105
105 Aufspalten der Regionen Insert G = [1 / 8]
![105 Aufspalten der Regionen Insert G = [1 / 8]](http://images.slideplayer.org/1/665965/slides/slide_105.jpg "105 Aufspalten der Regionen Insert G = [1 / 8]")
106
106 Aufspalten der Regionen B C 8 6 4 2 2468101214 E A C B F F D G A E D G Insert A = [5 / 6]
![106 Aufspalten der Regionen B C E A C B F F D G A E D G Insert A = [5 / 6]](http://images.slideplayer.org/1/665965/slides/slide_106.jpg "106 Aufspalten der Regionen B C E A C B F F D G A E D G Insert A = [5 / 6]")
107
107 Dynamik des Grid Directory 300 200 10 50 Insert A=[12 / 280] 3 Datenrecords pro Bucket
![107 Dynamik des Grid Directory Insert A=[12 / 280] 3 Datenrecords pro Bucket](http://images.slideplayer.org/1/665965/slides/slide_107.jpg "107 Dynamik des Grid Directory Insert A=[12 / 280] 3 Datenrecords pro Bucket")
108
108 Dynamik des Grid Directory 10 50 300 200 A 10 50 300 200 300 200 10 50 Insert B=[25 / 220]
![108 Dynamik des Grid Directory A Insert B=[25 / 220]](http://images.slideplayer.org/1/665965/slides/slide_108.jpg "108 Dynamik des Grid Directory A Insert B=[25 / 220]")
109
109 Dynamik des Grid Directory 10 50 300 200 A B 10 50 300 200 300 200 10 50 Insert C=[45 / 270]
![109 Dynamik des Grid Directory A B Insert C=[45 / 270]](http://images.slideplayer.org/1/665965/slides/slide_109.jpg "109 Dynamik des Grid Directory A B Insert C=[45 / 270]")
110
110 Dynamik des Grid Directory 10 50 300 200 A B C 10 50 300 200 300 200 10 50 Insert D=[22 / 275]
![110 Dynamik des Grid Directory A B C Insert D=[22 / 275]](http://images.slideplayer.org/1/665965/slides/slide_110.jpg "110 Dynamik des Grid Directory A B C Insert D=[22 / 275]")
111
111 Dynamik des Grid Directory 300 200 10 30 50 300 200 A B C 10 50 300 200 D 10 30 50 Insert E=[24 / 260]
![111 Dynamik des Grid Directory A B C D Insert E=[24 / 260]](http://images.slideplayer.org/1/665965/slides/slide_111.jpg "111 Dynamik des Grid Directory A B C D Insert E=[24 / 260]")
112
112 Dynamik des Grid Directory 250 200 C 300 10 30 50 A B 10 50 300 200 D 10 30 50 300 200 E 250 Insert F=[26 / 280]
![112 Dynamik des Grid Directory C A B D E 250 Insert F=[26 / 280]](http://images.slideplayer.org/1/665965/slides/slide_112.jpg "112 Dynamik des Grid Directory C A B D E 250 Insert F=[26 / 280]")
113
113 Dynamik des Grid Directory 10 30 50 300 200 30 50 10 20 30 250 200 A B C D 10 30 50 300 200 E 250 300 F 250 200 300 Directory Block vergröbern

114
114 Dynamik des Grid Directory 10 20 30 250 200 A B C 10 30 50 300 200 D 10 30 50 300 200 E 250 300 F 30 50 300 200

115
115 Vereinigung von Regionen bei zu geringer Bucketauslastung: Benachbarte Regionen vereinigen Vereinigung muß Rechteck ergeben Vereinigung wird ausgelöst wenn Bucket < 30 % Auslastung wenn vereinigtes Bucket < 70 % Auslastung

116
116 Nearest Neighbor Q P R

117
117 Verwaltung von geometrischen Objekten Grid File unterstützt Range-Query bisher:k Attribute Jetzt:k-dimensionale Punkte

118
118 Verwaltung von Intervallen 1 2 3 4 5 6 7 8 9 1011121314 15 1 2 3 4 5 E A B C D F A [Anfang / Ende] E A B C D F Besser: [Mittelpunkt / halbe Länge]
![118 Verwaltung von Intervallen E A B C D F A [Anfang / Ende] E A B C D F Besser: [Mittelpunkt / halbe Länge]](http://images.slideplayer.org/1/665965/slides/slide_118.jpg "118 Verwaltung von Intervallen E A B C D F A [Anfang / Ende] E A B C D F Besser: [Mittelpunkt / halbe Länge]")
119
119 Query-Punkt gegen Intervall Punkt p liegt im Intervall mit Mitte m und halber Länge d m-d p m+d m-d m+d m

120
120 Query-Punkt gegen Intervall 1 2 3 4 5 6 7 8 9 1011121314 15 1 2 3 4 5 E A B C D F E A B C D F Punkt p liegt im Intervall mit Mitte m und halber Länge d m-d p m+d p=5 m-d 5 m+d

121
121 Query-Intervall gegen Intervall Intervall mit Mitte s und halber Länge t schneidet Intervall mit Mitte m und halber Länge d m-d s+t und s-t m+d m-dm+d s+ts-t

122
122 Query-Intervall gegen Intervall 1 2 3 4 5 6 7 8 9 1011121314 15 1 2 3 4 5 E A B C D F E A B C D F Intervall mit Mitte s und halber Länge t schneidet Intervall mit Mitte m und halber Länge d m-d s+t und s-t m+d s=10, t=1 m-d 11 und 9 m+d

123
123 Query-Rechteck gegen Rechteck Stelle Rechteck durch vierdimensionalen Punkt dar

Ähnliche Präsentationen
>")


>")



>")

 U N I V E R S I T Ä T H A M B U R G November 2011.>")
 U N I V E R S I T Ä T H A M B U R G November 2011.>")
Media Landesanstalt für Kommunikation Baden-Württemberg (LFK) Landeszentrale für Medien und Kommunikation.>")




 Prof. Th. Ottmann.>")


