Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Seminar, Übung, Schulung:
Umgang mit komplexen und umfangreichen Datensätzen Stichworte: Zu zahlreichen Fragestellungen und Forschungsthemen existieren umfangreiche Datenbestände Beispiel: PISA, SOEP (Socio-Economic-Panel), Daten über den Studienverlauf/die Benotungen, Statistisches Bundesamt Es bedarf besonderer Techniken, um mit derartig umfangreichen Datenbeständen angemessen umzugehen, nicht in den Mengen zu versinken: Syntax Macros Data-Mining Automatisierung von Abläufen, Erzeugung von Routinen
, Daten über den Studienverlauf/die Benotungen, Statistisches Bundesamt. Es bedarf besonderer Techniken, um mit derartig umfangreichen Datenbeständen angemessen umzugehen, nicht in den Mengen zu versinken: Syntax. Macros. Data-Mining. Automatisierung von Abläufen, Erzeugung von Routinen.")
2
Eine bekannte Daumenregel im Analysegeschäft lautet:
Etwa 80% der Arbeit liegt in der Datenbereinigung und -aufbereitung! Ungeachtet dieser Erkenntnis dominieren in der Wissensvermittlung Einführungen in deskriptiver Statistik und multivariaten Verfahren, die meist „saubere“ und entsprechend aufbereitete Daten voraussetzen. Fragen der Datenqualität und ihrer Auswirkung werden hingegen kaum thematisiert. Das Seminar setzt genau an diesem Missverhältnis an.

3
In diesem Seminar, Übung, Schulung werden basale Techniken zu diesem Thema vorgestellt und eingeübt.
Dazu sollten wir uns über eine dafür geeignete Form der Vermittlung verständigen! Der geplante grobe inhaltliche Ablauf: Einführung in die Thematik Einlesen von verschiedenen Datensätzen Syntax und Macro-Prozeduren zum Einlesen Zusammenstellen unterschiedlichster Variablensätze Generieren neuer Variablen Makroskopischen Analysen Techniken der EDA (Explorative Daten Analyse), Data-Mining
, Data-Mining.")
4
Datenmanagement ist die Grundlage jeder Datenverarbeitung.
Datenmanagement bedeutet u.a.: Transponieren Bilden von Subsets Bilden von Subsets über Filter/Bedingungen Bilden neuer Variablen oder Werte über Umkodieren oder arithmetische Operationen Zusammenfügen von Datensätzen Bereinigen der Datensätze (Missing values, Ausreißer, Anpassungen bei Nicht-Normalverteilung)
")
5
Start: Information, Planung, Abstimmung Einführung in die Thematik Kurzeinführung SPSS Syntax und Makros in SPSS Einlesen von Daten mit Syntax + Makro Schleifen Berechnung neuer Variablen Fortsetzung: Berechnung neuer Variablen, Auswahl und Zusammenstellung spezifischer Datensätze Statistika und StatSoft Data Miner: Kurzeinführung in die Funktionen und die Werkzeuge Aufbau einfacher Analysen Späterer Termin Fortsetzung: Arbeiten mit dem Data Miner Mo Betreute Eigenarbeit: Bearbeitung von vorgegebenen Aufgaben Di Zeiten, Blöcke, Inhalte!!??

6
Die Phasen im Data Mining Prozess
Transformation Interpretation Selektion Vorverarbeitung Data Mining Selektierte Daten Vorbereitete Daten Transformierte Daten Wissen/ Modelle Daten Muster

7
Was ist die generelle Idee, das generelle hier behandelte Konzept?
Es gibt selbstverständlich eine ganze Reihe höchst unterschiedlicher Fragestellungen. Ich behandele mit Ihnen eine Form wie bspw.: Was unterscheidet Schüler mit hoher und mit niedriger Leistung? Wann wird viel, wann wird wenig Kaffee verkauft und wovon ist dies abhängig? Wie lassen sich Kunden mit einem hohen Kreditrisiko von denen mit geringem Kreditrisiko unterscheiden? Wo liegen die Gründe eines schnellen, erfolgreichen Studiums? Wovon ist bei einem Schiffsuntergang das Überleben abhängig? Betrachten wir zunächst kategoriale Daten:

8
Ihnen liegt bspw. Ein Datensatz von 2201 Personen vor, die auf der Titanic unterwegs waren. Sie haben Angaben zu: Kabinenklasse Altersgruppe Geschlecht Überlebt/Vermisst (siehe Tabelle) Wie können Sie der eben gestellten Frage nachgehen?
 Wie können Sie der eben gestellten Frage nachgehen")
9
Durch die Berechnung von sog
Durch die Berechnung von sog. Klassifikationsbäumen können Sie der Frage so nach- gehen: Sie sehen, welcher Faktor der wichtigste ist und können weitere Abhängigkeiten erkennen:

10
Was ist die generelle Idee, das generelle hier behandelte Konzept?
Betrachten wir jetzt metrische Daten: Erster Schritt: Verteilung anschauen, Daten inspizieren

11
Ggf. Daten verändern, hier als ein Beispiel: alle Werte in absolute Werte umrechnen. Sie müssen „etwas sehen“!!

12
Zweiter Schritt: Unterteilungen vornehmen, Bewertungen vornehmen

13
Dritter Schritt: Wovon ist „gut“ oder „schlecht“ abhängig
Dritter Schritt: Wovon ist „gut“ oder „schlecht“ abhängig? Dazu nach den Variablen suchen, die zwischen diesen beiden Kategorie trennen

15
Vierter Schritt: Wovon ist „gut“ oder „schlecht“ abhängig
Vierter Schritt: Wovon ist „gut“ oder „schlecht“ abhängig? Hierarchie aller „gut“ „schlecht“ beeinflussenden Faktoren betrachten

16
Vierter Schritt: Wovon ist „gut“ oder „schlecht“ abhängig
Vierter Schritt: Wovon ist „gut“ oder „schlecht“ abhängig? Güte der erreichten Aufklärung überprüfen

17
„Wie geht Erkenntnisgewinn?“ Ein erster, flüchtiger Blick
Transformation Interpretation Data Mining Vorbereitete Daten Transformierte Daten Wissen/ Modelle Muster

18
Kelchlänge Kelchbreite Blattlänge Blattbreite Iristyp 1 5 3,3 1,4 0,2 Setosa 2 6,4 2,8 5,6 2,2 Virginic 3 6,5 4,6 1,5 Versicol 4 6,7 3,1 2,4 6,3 5,1 6 3,4 0,3 7 6,9 2,3 8 6,2 4,5 9 5,9 3,2 4,8 1,8 10 3,6 11 6,1 12 2,7 1,6 13 5,2 14 2,5 3,9 1,1 15 5,5 16 5,8 1,9 17 6,8 18 1,7 0,5 19 5,7 1,3 20 5,4 21 7,7 3,8 22 4,7 23 24 7,6 6,6 2,1 25 4,9 Fisher (1936) Irisdaten: Länge und Breite von Blättern und Kelchen für 3 Iristypen
 Irisdaten: Länge und Breite von Blättern und Kelchen für 3 Iristypen.")
19
CART (classification and regression trees)
Kategoriale Werte (gut/schlecht) Metrische Werte (1, 2, 3, 4, ..) [Nominale, Ordinale Werte] CART (classification and regression trees) Split: Welche Variable trennt am besten bei welchem Wert?
 Metrische Werte (1, 2, 3, 4, ..) [Nominale, Ordinale Werte] CART (classification and regression trees) Split: Welche Variable trennt am besten bei welchem Wert")
31
Fehlklassifikationsmatrix Lernstichprobe (Irisdat) Matrix progn
Fehlklassifikationsmatrix Lernstichprobe (Irisdat) Matrix progn. (Zeile) x beob. (Spalte) Lernstichprobe N = 150 Klasse - Setosa Klasse - Versicol Klasse - Virginic Setosa Versicol 4 Virginic 2 Prognost. Klasse x Beob. Klasse n's (Irisdat) Matrix progn. (Zeile) x beob. (Spalte) Lernstichprobe N = 150 Klasse - Setosa Klasse - Versicol Klasse - Virginic Setosa 50 Versicol 48 4 Virginic 2 46
 Matrix progn. (Zeile) x beob. (Spalte) Lernstichprobe N = 150. Klasse - Setosa. Klasse - Versicol. Klasse - Virginic. Setosa. Versicol. 4. Virginic. 2. Prognost. Klasse x Beob. Klasse n s (Irisdat) Matrix progn. (Zeile) x beob. (Spalte) Lernstichprobe N = 150. Klasse - Setosa. Klasse - Versicol. Klasse - Virginic. Setosa. 50. Versicol Virginic")
32
Split-Bedingung (Irisdat) Split-Bedingung je Knoten
Split - Konst. Split - Variable 1 -2,09578 Blattlänge 2 3 -1,64421 Blattbreite

38
Daten Trainings-daten Daten teilen Validierungs-daten Modell- bewertung

39
Disagreement table for observed variable (Compute Best Predicted Classification from all Models) Observed variable: Kreditwürdigkeit PMML_GDA3Pred for Kreditwürdig-keit - % Incorrect PMML_CTrees4Pred for Kreditwürdig-keit - % Incorrect PMML_CCHAID5Pred for Kreditwürdig-keit - % Incorrect VotedPrediction for Kreditwürdig-keit - % Incorrect Nein 8,40401 15,11180 9,17502 11,71935 Ja 21,50350 11,80070 24,82517 17,91958

42
Eine Alternative: ROC Kurven
(Receiver Operating Characteristic) Richtig Positive Sensitivität t = Richtig Positive + Falsch Negative Richtig Negative Spezifität = Richtig Negative + Falsch Positive
 Richtig Positive. Sensitivität t = Richtig Positive + Falsch Negative. Richtig Negative. Spezifität = Richtig Negative + Falsch Positive.")
43
Kriterium Prediktor 50 50 50 50 „richtig positiven“ „falsch negative“
erfolgreich 50 50 50 50 nicht-erfolgreich „falsch positiven“ „richtig negative“ abgelehnt angenommen Prediktor

44
Nachdenken, was die erzielten Ergebnisse bedeuten!!

45
Vorbereitung: Zunächst müssen wir gemeinsam unsere Rechner vorbereiten, um die Einstellungen des SPSS so zu konfigurieren, dass der automatisch generierte Programmiercode auch gefunden und genutzt werden kann. Zugleich benötigt jeder von Ihnen einen eigenen Ordner im Verzeichnis „Komplexe Daten“ auf dem Laufwerk ‚N:\‘. Diese beiden Einstellungen müssen wir nun vornehmen.

46
Sie können alle im Programm auf der Windows-Oberfläche durchgeführten Arbeiten in einem ‚Journal‘ aufzeichnen lassen. Dazu stehen zwei Optionen zur Verfügung. ‚Überschreiben‘ oder ‚Anhängen‘ Der Speicherort des Syntax- Journals finden Sie unter: Bearbeiten Optionen/Options File Locations

47
Erster Teil: Selektion Vorverarbeitung Selektierte Vorbereitete Daten
Es gibt verschiedene Möglichkeiten: Datenbanken, Abfrage und Zusammenstellung mit SQL (Structured Query Language) Nutzung von Syntax- und Macro-Prozeduren, bspw. aus SPSS heraus Die Vorteile/Nachteile: SQL ist oft schneller, mächtiger. Hat aber Einschränkungen, weniger Transparenz Syntax, Macros erlauben mehr Operationen, geben Einblick in Zwischenresultate; sind entsprechend aufwändiger und (etwas) langsamer, erfordern Zwischenschritte
 Nutzung von Syntax- und Macro-Prozeduren, bspw. aus SPSS heraus Die Vorteile/Nachteile: SQL ist oft schneller, mächtiger. Hat aber Einschränkungen, weniger Transparenz. Syntax, Macros erlauben mehr Operationen, geben Einblick in Zwischenresultate; sind entsprechend aufwändiger und (etwas) langsamer, erfordern Zwischenschritte.")
50
Syntax- und Macro-Prozeduren
Die hier favorisierte Alternative, Variante: Zusammenführen und -fügen der Arbeitsdatensätze mit Hilfe von Syntax- und Macro-Prozeduren aus verschiedenen Datensätzen Selektion Vorverarbeitung Syntax- und Macro-Prozeduren Selektierte Daten Vorbereitete Daten Daten Selektion & Vorverarbeitung Selektierte Daten Vorbereitete Daten Daten

51
Einige Vorteile dieser Variante:
Größere Übersichtlichkeit, die Ergebnisse der Arbeits- schritte lassen sich einfach überprüfen Die Makros können als eine Art von Projekt abgespeichert werden Verschiedenste Bearbeitungen lassen sich recht einfach kopieren und in für andere Zwecke einfügen Der Umfang an Berechnungs- und Editieroptionen ist in (nahezu) allen Fällen größer
 allen Fällen größer.")
52
Schritte im Datenmanagement:
Daten integriert? Struktur geeignet? Werte korrekt? Daten vollständig? Verteilung passend? Datenmenge geeignet? Doch bitte beachten: Nicht alle dieser Schritte können im Rahmen dieser Veranstaltung behandelt werden!!

53
Ziel für (nahezu) alle Tabellen ist folgendes Format, folgende Struktur:
Case Variable_01 (Prädiktor1) Variable_02 (Prädiktor2) Variable_03 (Prädiktor3) Variable_04 (Prädiktor4) .. Abhängige Variable(n) Jede Zeile stellt einen Fall dar
 Variable_02. (Prädiktor2) Variable_03. (Prädiktor3) Variable_04. (Prädiktor4) .. Abhängige Variable(n) Jede Zeile stellt einen Fall dar.")
54
Aufbau der Datenmatrix, um einen Kausalbaum, eine Kreuztabelle zu erstellen:
V1 V2 V3 V4 V5 V6 Person/Bedingung Vgut_schlecht 345 232 234 336 767 787 A G 564 887 236 454 B 665 897 C S 789 123 567 D 459 456 E 981 F 438 341 657 656 H 447 I

55
Aufbau der Datenmatrix, um eine Korrelationsanalyse zu erstellen:
V1 V2 V3: Gefahrene Kilometer V4: Gartengröße V5: Wohnraum V6: Gehalt 345 232 234 336 767 787 564 887 236 454 665 897 789 123 567 459 456 981 438 341 657 656 447

56
Ein (sehr) kurzer Blick auf einige Probleme:
Probleme aufgrund von Missing Data (MD) Viele statistische und Data-Mining-Verfahren benötigen vollständige Daten, etwa die Korrelations- und Regressionsanalyse oder Neuronale Netze MD vermindern die Datenbasis und damit die statistische Aussagekraft der Ergebnisse Bei systematischen MD werden Ergebnisse verfälscht bzw. verzerrt Beim Einsatz von Filterfunktionen müssen die als Filter genutzten Werte vollständig sein ……
 Viele statistische und Data-Mining-Verfahren benötigen vollständige Daten, etwa die Korrelations- und Regressionsanalyse oder Neuronale Netze. MD vermindern die Datenbasis und damit die statistische Aussagekraft der Ergebnisse. Bei systematischen MD werden Ergebnisse verfälscht bzw. verzerrt. Beim Einsatz von Filterfunktionen müssen die als Filter genutzten Werte vollständig sein. ……")
57
Verlauf über die Zeit Leistungen in Klasse A und in Klasse B A A A A A

58
Verlauf über die Zeit Leistungen in Klasse A und in Klasse B A A A A A

59
Verlauf über die Zeit Leistungen in Klasse A und in Klasse B A A A B A
Ausreißer A Leistungen in Klasse A und in Klasse B B A B A B B B A B B B B A B B B A A B Verlauf über die Zeit

60
Leistungen in Klasse B Leistungen in Klasse A A A A Böse Falle Null:
Missing Value: Für eine Person liegen keine Angaben zu der Leistung in Klasse B vor A A Leistungen in Klasse B A A A A A A A Leistungen in Klasse A

61
Beachten Sie den Korrelationsquotienten!

62
Beachten Sie den Korrelationsquotienten!

63
Welche Möglichkeiten des Umgangs mit fehlenden Werten gibt es?
Y X Y X Bei kategorialen Merkmalen häufigste Ausprägung der k nächsten Nachbarn Bei metrischen Merkmalen durchschnittlicher Wert der k nächsten Nachbarn Aber auch: Missing Values rauswerfen!

64
FILE='N:\Daten\D_Zwei\Daten-Mi-10.sav'.
Ein erster Schritt: Dateien öffnen: Der Befehl sieht wie folgt aus GET FILE='N:\Daten\D_Zwei\Daten-Mi-10.sav'. Wichtig sind die Anführungszeichen! Wichtig ist der Punkt am Schluss!! Wenn Sie nicht alle Variablen des Datensatzes einlesen möchten – was sehr oft vorteilhaft ist – können Sie folgende Zusatzbefehle einfügen: FILE='N:\Daten\D_Zwei\Daten-Mi-10.sav‘ /KEEP = var001, var002 . Oder /DROP = var009, var010 .

65
Command Syntax Reference GET FILE
Ausschnitt aus: Hilfe SPSS Command Syntax Reference GET FILE GET GET FILE='file' [LOCK={YES**}] {NO } [/KEEP={ALL** }] [/DROP=varlist] {varlist} [/RENAME=(oldvarnames=newvarnames)...] [/MAP] **Default if the subcommand is omitted. Release History Release 17.0 LOCK keyword introduced on the FILE subcommand. Example GET FILE='/data/empl.sav'.
...] [/MAP] **Default if the subcommand is omitted. Release History. Release LOCK keyword introduced on the FILE subcommand. Example. GET FILE= /data/empl.sav .")
66
Ausschnitt aus: Hilfe SPSS Command Syntax Reference GET DATA

67
Ein Beispiel für einen ‚einfach‘ unvollständigen Datensatz: Es wurde nur einmal am Anfang jeden Falles der Name, das Datum, die Zeit und eine Id eingegeben

68
Auf die ‚dumme‘ Art: Jede Variable ‚in die Hand nehmen‘
Wie lassen sich in solchen Fällen die fehlenden Werte für jeden Fall einfügen? Auf die ‚dumme‘ Art: Jede Variable ‚in die Hand nehmen‘ Auf die ‚kluge‘ Art: ein kleines Programm schreiben Dazu beginnen wir zunächst mit dem Einlesen der Datei Daten-Mi-10.sav Um ohne Wissen über die Programmiersprache diese Aufgabe lösen zu können, laden wir die Datei ‚per Maus‘ und schauen dann in die Journal-Aufzeichnung

69
Wichtig ist es jetzt, sich so genau wie nur möglich über die Aufgabenstellung Gedanken zu machen:
In jede leere Zeile der Variable ‚ID‘ soll der Wert eingetragen werden, der am Anfang eines Falles steht. Dabei muss beachtet werden, wo und wie ein neuer ID-Fall anfängt, bzw. wo ein alter aufhört!

70
Dazu ist es wichtig, die Funktionen Lag und Lead einzuführen: Bitte schauen Sie sich die folgende Darstellung genau an. In der Tabelle sind Werte einer Variable X eingetragen. Daneben sehen Sie das sog. Lag und das sog. Lead von X. Das Lag gibt immer den vor dem Wert in der Reihe stehenden Wert wieder; das Lead den jeweils nachfolgenden Wert. Bitte beachten Sie, dass für den ersten Wert der Variable X kein Lag berechnet werden kann und ein sog. Missing Value (.) produziert wird!! X Lag Lead 198 . 220 305 470
 produziert wird!! X. Lag. Lead")
71
CREATE y = LAG(x, 1) . EXECUTE .
Lassen Sie uns den Befehl einmal ausprobieren! Öffnen Sie dazu bitte eine neue Datei, geben Sie einer Variable den Namen X und tragen Sie einfach ein paar Werte ad libitum ein. Jetzt müssen Sie, falls nicht bereits geschehen, eine neu Syntax öffnen und dort den folgenden Befehl eingeben: CREATE y = LAG(x, 1) . EXECUTE .
 . EXECUTE .")
72
Sie haben gesehen, wie der Befehl funktioniert
Sie haben gesehen, wie der Befehl funktioniert. Um mit diesem Befehl unsere Aufgaben zu lösen, müssen noch zwei Probleme angegangen werden: Das Programm muss mit der ersten Zeile etwas anfangen können Dem Programm muss vorgeben werden, bei einem neuen Fall auch den dann neue ID-Wert zu nehmen Das Programm führt keine Berechnungen aus, wenn in den Spalten Missing Values stehen

73
Erläuterung: die sog. Caseummer, in der Befehlssyntax als ‚$casenum‘ ansprechbar

74
Diese Probleme lösen wir wie folgt:
RECODE ID (MISSING=0) . EXECUTE . IF ((Zeile > 0) & ($casenum > 1)) Id = Id + Lag(Id, 1) . Mit dem ersten Befehl Recodieren wir alle Werte der Variable ID, die ein Missing Value beinhalten, in den Wert 0. Mit dem zweiten Befehl erstellen wir eine konditionale Bedingung an die Berechnung des LAGs Id: Nur wenn der Wert der Variable Zeile größer als Null ist und der Case (Fall) größer als Eins.
 . EXECUTE . IF ((Zeile > 0) & ($casenum > 1)) Id = Id + Lag(Id, 1) . Mit dem ersten Befehl Recodieren wir alle Werte der Variable ID, die ein Missing Value beinhalten, in den Wert 0. Mit dem zweiten Befehl erstellen wir eine konditionale Bedingung an die Berechnung des LAGs Id: Nur wenn der Wert der Variable Zeile größer als Null ist und der Case (Fall) größer als Eins.")
75
Exkurs I

76
Irrtumswahrscheinlichkeit: Ein p = 0,03 bedeutet:
Die Wahrscheinlichkeit, dass unter der Annahme, die Nullhypothese sei richtig, das gegebene Untersuchungsergebnis oder ein noch extremeres auftritt, beträgt 0,03. Signifikanzstufen p <= 0,05 signifikant * p <= 0,01 sehr signifikant ** p <= 0,001 höchst signifikant ***

77
Partner Partnerin Vorzeichen + - =
Ergebnis einer hypothetischen Studie, in der die Ausbildung von Paaren verglichen wird (aus: Sedlmeier & Renkewitz 2008, 370): Partner Partnerin Vorzeichen Studium Realschule + Gymnasium - = Es finden sich somit 7 positive Vorzeichen. Ist das Ergebnis auf dem 5% Niveau signifikant? Wie hoch ist die Wahrscheinlichkeit für 0, 1, 2 etc. positive Vorzeichen? Vorzeichentest nach Fischer
: Partner. Partnerin. Vorzeichen. Studium. Realschule. + Gymnasium. - = Es finden sich somit 7 positive Vorzeichen. Ist das Ergebnis auf dem 5% Niveau. signifikant Wie hoch ist die Wahrscheinlichkeit für 0, 1, 2 etc. positive Vorzeichen Vorzeichentest nach Fischer.")
80
Variablenspezifikation, Zusammenstellen, Variablenmodifikation eines
Daten im *.txt - Format Daten im *.sav - Format Daten im *.sta - Format Daten im *.dat - Format Einlesen, Variablenspezifikation, Zusammenstellen, Variablenmodifikation eines neuen, auf die Fragestellung zugeschnittenen Datensatzes

81
Öffnen Sie dazu bitte unter „Datei“ „Textdaten einlesen“, markieren Síe die Datei „School performence Klasse_A“ und Sie erhalten diese Dialogbox

82
Besonders wichtig ist diese Dialogbox
Besonders wichtig ist diese Dialogbox. Hier muss gut durchdacht und überlegt werden, welche Trennungszeichen die Werte der einzelnen Variablen trennen. In dem gezeigten Beispiel ist „Leerzeichen“ und „Komma“ markiert, was zu einer Trennung bspw. des Wertes „98,655“ in zwei verschiedene Variablen führt. Um dies zu verhindern wählen Sie die auf der folgenden Seite gezeigte Einstellung ►

83
Sie können jetzt erkennen, dass der Wertes „98,655“ durch die Markierung der Trennungszeichen „Tabulator“ und „Leerzeichen“ nun richtig einer einzigen Variablen zugewiesen wird.

84
/* Syntax zum Einlesen der Beispieldateien
GET DATA /TYPE = TXT /FILE = ‚N:\Komplexe Daten\School performance_Klasse_A.txt' /DELCASE = LINE /DELIMITERS = "\t " /ARRANGEMENT = DELIMITED /FIRSTCASE = 1 /IMPORTCASE = ALL /VARIABLES = V1 F7.2 V2 F7.2 V3 F7.2 V4 F7.2 V5 F7.2 V6 F7.2 V7 F7.2 V8 F7.2 . CACHE. EXECUTE. SAVE OUTFILE=‚N:\Komplexe Daten\School performance_Klasse_A.sav' /COMPRESSED. EXECUTE . So sieht die dabei im Hintergrund erzeugte Syntax des Einlesens dieser Daten aus

85
Variablen für School performance Klassen A/B/C
GEOMETRY READING GRAMMAR DRAWING CALCULUS HISTORY WRITING SPELLING Wie lassen sich diese Variablennamen in den Datensatz einlesen?

86
/* Syntax zum Einlesen der Beispieldateien
GET DATA /TYPE = TXT /FILE = ‚N:\Komplexe Daten\School performance_Klasse_A.txt' /DELCASE = LINE /DELIMITERS = "\t " /ARRANGEMENT = DELIMITED /FIRSTCASE = 1 /IMPORTCASE = ALL /VARIABLES = V1 F7.2 V2 F7.2 V3 F7.2 V4 F7.2 V5 F7.2 V6 F7.2 V7 F7.2 V8 F7.2 . CACHE. EXECUTE. RENAME VARIABLES (V1=GEOMETRY) (V2=READING) (V3=GRAMMAR) (V4=DRAWING) (V5=CALCULUS) (V6=HISTORY) (V7=WRITING) (V8=SPELLING) . EXECUTE . SAVE OUTFILE=‚N:\Komplexe Daten\School performance_Klasse_A.sav' /COMPRESSED. Neue Befehlszeile! Mit diesen Befehlen werden die Variablen- namen V1 etc. in GEOMETRY etc. umbenannt
 (V2=READING) (V3=GRAMMAR) (V4=DRAWING) (V5=CALCULUS) (V6=HISTORY) (V7=WRITING) (V8=SPELLING) . EXECUTE . SAVE OUTFILE=‚N:\Komplexe Daten\School performance_Klasse_A.sav /COMPRESSED. Neue Befehlszeile! Mit diesen Befehlen werden die Variablen- namen V1 etc. in GEOMETRY etc. umbenannt.")
87
Das sind die variablen Teile des Programms
/* Syntax zum Einlesen der Beispieldateien GET DATA /TYPE = TXT /FILE = 'C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE'+ '_Komplexe_Daten\School performance_Klasse_A.txt' /DELCASE = LINE /DELIMITERS = "\t " /ARRANGEMENT = DELIMITED /FIRSTCASE = 1 /IMPORTCASE = ALL /VARIABLES = V1 F7.2 V2 F7.2 V3 F7.2 V4 F7.2 V5 F7.2 V6 F7.2 V7 F7.2 V8 F7.2 . CACHE. EXECUTE. SAVE OUTFILE='C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\School performance_Klasse_A.sav' /COMPRESSED. EXECUTE . Das sind die variablen Teile des Programms

88
Bitte erstellen Sie nun die folgende Kreuztabelle mit den Daten aus der Datei Titanic.sav:
Sie sehen die Abhängigkeit des Überlebens von der gebuchten Schiffskabinen-Klasse. Bitte öffnen Sie jetzt das Syntax- Journal-Fenster und kopieren Sie den Inhalt in Bezug auf die Erstellung dieser Kreuztabelle in Ihr Syntax-Fenster.

89
FILE=‚N:\Komplexe Daten\Titanic.sav'.
DATASET NAME DatenSet1 WINDOW=FRONT. CROSSTABS /TABLES=class BY survival /FORMAT= AVALUE TABLES /STATISTIC=CHISQ /CELLS= COUNT EXPECTED ROW COLUMN TOTAL /COUNT ROUND CELL . Die Datei enthält noch weitere Variablen mit den kategorialen Werten zu age gender Setzen Sie jetzt bitte diese Variablen-Namen an die Stelle von „class“ und starten Sie die Syntax mit dem Befehl „EXECUTE .“

90
Ein Makro macht nun nichts anderes, als – einfach gesprochen – an die Stelle der Platzhalter in Listen eingetragene Werte oder Zeichen in das Programm einzusetzen. Der große Vorteil besteht bei ihrem Einsatz darin, dass „nur“ noch neue oder veränderte Listen an das Programm übergeben werden müssen, der Ablauf erfolgt dann in rasender Geschwindig- keit mit allen in den Listen genannten Zeichen/Werten. Damit sind verschiedene Einsatzzwecke gegeben: Automatisierung von Routineanalysen Aufzeichnung aller für eine Analyse durchgeführten Schritte, die sich jederzeit – mit Veränderungen – wiederholen lassen Besonders interessant ist der Makroeinsatz, wenn aus einer Vielzahl von Datensätzen mit bestimmten Abschnitte, Variablen vergleichende Analysen gerechnet werden sollen

91
SPSS Makros: Allgemeiner Aufbau
Makroprogramm und erster Aufruf DEFINE !freq1 () . descriptives var = alter fameink . !ENDDEFINE !freq1 . Mit diesem Aufruf kann immer wieder an beliebigen Stellen in einem Syntax-Programm das gesamte Makroprogramm in Gang gesetzt werden
 . descriptives var = alter fameink . !ENDDEFINE . !freq1 . Mit diesem Aufruf kann immer wieder an beliebigen Stellen in einem Syntax-Programm das gesamte Makroprogramm in Gang gesetzt werden.")
92
SPSS Makros Struktur Makro(grob)struktur Bedeutung, Funktion DEFINE !freq1 () . Anfang der Makrodefinition mit Name „!FREQ1“ und Argument „()“ . descriptives Makroinhalt var = alter fameink . !ENDDEFINE . Ende der Makrodefinition !freq Makroaufruf
 . Anfang der Makrodefinition mit Name „!FREQ1 und Argument „() . descriptives Makroinhalt var = alter fameink . !ENDDEFINE . Ende der Makrodefinition !freq1 . Makroaufruf.")
93
Die variablen Teile des Programms werden in einem Makro durch „Platzhalter“ markiert und am Ende des Programms wird in der sog. Makroexpansion festgelegt, welche Werte die „Platzhalter“ in dem jeweiligen Programmdurchlauf annehmen sollen. /* MAKRO zum Einlesen der Beispieldateien DEFINE !EINLESENUEBUNGSTXT (PFAD = !charend ('§')/KLASSE = !charend('§')/PLATZ = !charend ('§') ) . GET DATA /TYPE = TXT /FILE = !QUOTE (!PFAD) /DELCASE = LINE /DELIMITERS = "\t " /ARRANGEMENT = DELIMITED /FIRSTCASE = 1 /IMPORTCASE = ALL /VARIABLES = V1 F7.2 … Name des Makros: MAKRO_Einlesen_UebungsDateien.sps
/KLASSE = !charend( § )/PLATZ = !charend ( § ) ) . GET DATA /TYPE = TXT. /FILE = !QUOTE (!PFAD) /DELCASE = LINE. /DELIMITERS = \t /ARRANGEMENT = DELIMITED. /FIRSTCASE = 1. /IMPORTCASE = ALL. /VARIABLES = V1 F7.2. … Name des Makros: MAKRO_Einlesen_UebungsDateien.sps.")
94
An Ende des Programmaufrufs werden die Werte, die durch „Platzhalter“ beim Programmdurchlauf einnehmen sollen definiert. !ENDDEFINE . !EINLESENUEBUNGSTXT PFAD = C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\School performance_Klasse_A.txt § KLASSE = 'A' § PLATZ = C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\School performance_Klasse_A.sav § . Name des Makros: MAKRO_Einlesen_UebungsDateien.sps

95
Was bedeutet „TOKENS“? (engl. „Zeichen)
Mit der Option !TOKENS werden die nächsten n Tokens im Makroaufruf dem Argument bzw. den Argumenten zugewiesen. Als Elemente zählen Variablen, Zahlen, Strings usw.: Beschreibung Beispiele Anzahl Tokens und Erläuterungen Variablenliste Var1 Var2 Var3 3 (jeder Variablenname zählt als ein einzelnes Token) Werteliste 4 (jede Zahl zählt als einzelnes Token) Zeichenliste und Kommas A , b 3 (ein Komma wird als separates Token gezählt; Groß-/Kleinschreibung ist unerheblich)
 Werteliste (jede Zahl zählt als einzelnes Token) Zeichenliste und Kommas. A , b. 3 (ein Komma wird als separates Token gezählt; Groß-/Kleinschreibung ist unerheblich)")
96
Bei !TOKENS sind das Ausrufezeichen und die Anzahl n in einer Klammer wichtig. n entspricht positiven ganzzahligen Werten. Die Option !TOKENS-Option ist also nützlich, wenn die Anzahl der Token bekannt und konstant ist. Bei der Festlegung der Anzahl der Token sind Besonderheiten bei der „Zählweise“ von Token zu berücksichtigen: Beschreibung Beispiele Anzahl Tokens und Erläuterungen Anführungs-zeichen „Alter ..“ ‚cc 00 cd‘ 2 (Inhalte zwischen paarigen Anführungszeichen bzw. Hoch-kommatas zählen als ein Token) Zeichen-kombinationen 11A 2 (Zahl vor String) A11 1 (String vor Zahl)
 Zeichen-kombinationen. 11A. 2 (Zahl vor String) A11. 1 (String vor Zahl)")
97
In dem Beispiel Makro MACRO_Einfaches_Beispiel wird nach den Namensargumenten Var1 und Var2 unmittelbar nach einem notwendigen =-Zeichen die Option !TOKENS(1) angegeben. Während der sog. Makro- expansion greift !AUSWERTUNG auf die Vorgaben zurück, die durch dieses Argument festgelegt wurden, nämlich eine Variable Var1 und eine Variable Var2 bereitzustellen. Die Information „ein Zeichen“ wird daher mit der Zu- weisung zur gleichen Anzahl an Variablen zum Argument im Makroaufruf für die Analyse verknüpft.

98
Ein Beispiel: Name des Macros: MACRO_Einfaches_Beispiel
/* Einfaches erstes Beispiel für eine Makro-Programmierung DEFINE !Auswertung (VAR1 = !TOKENS(1)/ VAR2 = !TOKENS(1)) . GET FILE='C:\Programme\SPSS\1993 US Sozialerhebung (Teilmenge).sav'. EXECUTE . GRAPH /SCATTERPLOTT(BIVAR)= !VAR1 WITH !VAR2 . !ENDDEFINE . !AUSWERTUNG VAR1=alter VAR2= kinder . !AUSWERTUNG VAR1=alter VAR2= zeitung . !AUSWERTUNG VAR1=einkom91 VAR2= alter . /* GRAPH /* /SCATTERPLOT(BIVAR)=alter WITH kinder /* /MISSING=LISTWISE . Name des Macros: MACRO_Einfaches_Beispiel
/ VAR2 = !TOKENS(1)) . GET. FILE= C:\Programme\SPSS\1993 US Sozialerhebung (Teilmenge).sav . EXECUTE . GRAPH. /SCATTERPLOTT(BIVAR)= !VAR1 WITH !VAR2 . !ENDDEFINE . !AUSWERTUNG VAR1=alter VAR2= kinder . !AUSWERTUNG VAR1=alter VAR2= zeitung . !AUSWERTUNG VAR1=einkom91 VAR2= alter . /* GRAPH. /* /SCATTERPLOT(BIVAR)=alter WITH kinder. /* /MISSING=LISTWISE . Name des Macros: MACRO_Einfaches_Beispiel.")
99
In diesem Makro „MACRO_Einfaches_Beispiel“ wird oben fest- gelegt, dass den beiden Platzhaltern VAR1 und VAR2 Zeichen im Umfang von einem Zeichen zugeordnet werden. In den Befehl zum Erstellen eines Scatterplotts werden dann keine Variablennamen, sondern nur die Platzhalter gesetzt. /* Einfaches erstes Beispiel für eine Makro-Programmierung DEFINE !Auswertung (VAR1 = !TOKENS(1)/ VAR2 = !TOKENS(1)) . GET FILE='C:\Programme\SPSS\1993 US Sozialerhebung (Teilmenge).sav'. EXECUTE . GRAPH /SCATTERPLOTT(BIVAR)= !VAR1 WITH !VAR2 . !ENDDEFINE . !AUSWERTUNG VAR1=alter VAR2= kinder . !AUSWERTUNG VAR1=alter VAR2= zeitung . !AUSWERTUNG VAR1=einkom91 VAR2= alter . /* GRAPH /* /SCATTERPLOT(BIVAR)=alter WITH kinder /* /MISSING=LISTWISE . Was an Stelle der Platzhalter bei jedem Durchlauf gesetzt werden soll, wird an dieser Stelle fest- gelegt.
/ VAR2 = !TOKENS(1)) . GET. FILE= C:\Programme\SPSS\1993 US Sozialerhebung (Teilmenge).sav . EXECUTE . GRAPH. /SCATTERPLOTT(BIVAR)= !VAR1 WITH !VAR2 . !ENDDEFINE . !AUSWERTUNG VAR1=alter VAR2= kinder . !AUSWERTUNG VAR1=alter VAR2= zeitung . !AUSWERTUNG VAR1=einkom91 VAR2= alter . /* GRAPH. /* /SCATTERPLOT(BIVAR)=alter WITH kinder. /* /MISSING=LISTWISE . Was an Stelle der Platzhalter bei jedem Durchlauf gesetzt werden soll, wird an dieser Stelle fest- gelegt.")
100
!CHAREND („Zeichen“) – Listen durch ein einzelnes Zeichen
Mittels !CHAREND werden alle Tokens bis zu einem explizit festzulegenden Zeichen in einem Makroaufruf dem Argument zugewiesen und ausgeführt. Bei diesem Zeichen muss es sich um ein einzelnes Zeichen (String mit der Länge 1) handeln, das zwischen Hochkommata und in Klammern steht. Im Prinzip kann jedes beliebige Zeichen als Trennzeichen eingesetzt werden. Die SPSS Command Syntax Reference (2004) verwendet z.B. einen sog. Slash ‚/‘, um eine Trennung zu signalisieren. Dieser Slash hat also nichts mit dem Trennungszeichen zu tun, das zwischen zwei Argumentdefinitionen stehen muss; um eine Verwechslung zu vermeiden, wird empfohlen, als Zeichen keinen Slash, sondern ein beliebiges anderes Zeichen zu nehmen, bspw. ‚§‘.
 handeln, das zwischen Hochkommata und in Klammern steht. Im Prinzip kann jedes beliebige Zeichen als Trennzeichen eingesetzt werden. Die SPSS Command Syntax Reference (2004) verwendet z.B. einen sog. Slash ‚/‘, um eine Trennung zu signalisieren. Dieser Slash hat also nichts mit dem Trennungszeichen zu tun, das zwischen zwei Argumentdefinitionen stehen muss; um eine Verwechslung zu vermeiden, wird empfohlen, als Zeichen keinen Slash, sondern ein beliebiges anderes Zeichen zu nehmen, bspw. ‚§‘.")
101
Bei !CHAREND-Trennungszeichen ist ihre richtige Position absolut entscheidend. Eine falsche Position führt dazu, dass diese Positions- oder auch Namensargumente beim Aufruf des Makros falsche Token-Zusammenstellungen an SPSS über- geben. !CHAREND-Optionen sind v.a. bei positionalen Argumenten nützlich, können jedoch auch bei Namens- argumenten eingesetzt werden. DEFINE !Beispiel1 (key1 = !CHAREND (‚§‘) / key2 = !CHAREND (‚§‘) ). frequencies var = !key1 . descriptives var = !key2 . !ENDDEFINE . !Beispiel1 KEY1=familienstand ausbild abschluss geschl § KEY2=alter § .
 / key2 = !CHAREND (‚§‘) ). frequencies var = !key1 . descriptives var = !key2 . !ENDDEFINE . !Beispiel1 KEY1=familienstand ausbild abschluss geschl § KEY2=alter § .")
102
Ein Beispiel dazu: Name des Macros: MACRO_Einfaches_Beispiel2
/* Einfaches zweites Beispiel für eine Makro-Programmierung DEFINE !Auswertung1 (VAR1 = !TOKENS(1)/ VAR2 = !TOKENS(1)/VAR3 =TOKENS(1)) . GET FILE='C:\Programme\SPSS\1993 US Sozialerhebung (Teilmenge).sav'. EXECUTE . CROSSTABS /TABLES= !VAR1 BY !VAR2 BY !VAR3 /FORMAT= AVALUE TABLES /CELLS= COUNT EXPECTED ROW COLUMN TOTAL /COUNT ROUND CELL . !ENDDEFINE . !AUSWERTUNG1 VAR1= famstand VAR2 = leben VAR3 = ethgr . Name des Macros: MACRO_Einfaches_Beispiel2
/ VAR2 = !TOKENS(1)/VAR3 =TOKENS(1)) . GET. FILE= C:\Programme\SPSS\1993 US Sozialerhebung (Teilmenge).sav . EXECUTE . CROSSTABS. /TABLES= !VAR1 BY !VAR2 BY !VAR3. /FORMAT= AVALUE TABLES. /CELLS= COUNT EXPECTED ROW COLUMN TOTAL. /COUNT ROUND CELL . !ENDDEFINE . !AUSWERTUNG1 VAR1= famstand VAR2 = leben VAR3 = ethgr . Name des Macros: MACRO_Einfaches_Beispiel2.")
103
Eine weitere Möglichkeit die hier Erwähnung finden soll ist die Verwendung sog. positionaler Argumente. Dabei wird, wie in dem folgenden Beispiel gezeigt, durch den Befehl !POS und dem Zusatz !TOKENS die Möglichkeit geschaffen, durch die Benennung der Platzhalter in Form von !1 oder !2 etc. das Programm anzuweisen, den ersten Wert (durch !1), den zweiten Wert (durch !2) etc. aus der Reihe der aufgelisteten Tokens in das Programm aufzunehmen.
, den zweiten Wert (durch !2) etc. aus der Reihe der aufgelisteten Tokens in das Programm aufzunehmen.")
104
Name des Macros: MACRO_Einfaches_Beispiel3
/* Ein drittes Beispiel für eine Makro-Programmierung DEFINE !Auswertung1 (!POS = !TOKENS(1)/ !POS = !TOKENS(1)/!POS = !TOKENS(1)) . GET FILE='C:\Programme\SPSS\1993 US Sozialerhebung (Teilmenge).sav'. EXECUTE . CROSSTABS /TABLES= !1 BY !2 BY !3 /FORMAT= AVALUE TABLES /CELLS= COUNT EXPECTED ROW COLUMN TOTAL /COUNT ROUND CELL . !ENDDEFINE . !AUSWERTUNG1 famstand leben ethgr . !AUSWERTUNG1 famstand todesstr ethgr . !AUSWERTUNG1 famstand todesstr sternzei . Name des Macros: MACRO_Einfaches_Beispiel3
/ !POS = !TOKENS(1)/!POS = !TOKENS(1)) . GET. FILE= C:\Programme\SPSS\1993 US Sozialerhebung (Teilmenge).sav . EXECUTE . CROSSTABS. /TABLES= !1 BY !2 BY !3. /FORMAT= AVALUE TABLES. /CELLS= COUNT EXPECTED ROW COLUMN TOTAL. /COUNT ROUND CELL . !ENDDEFINE . !AUSWERTUNG1 famstand leben ethgr . !AUSWERTUNG1 famstand todesstr ethgr . !AUSWERTUNG1 famstand todesstr sternzei . Name des Macros: MACRO_Einfaches_Beispiel3.")
105
Die bislang vorgestellten Optionen erforderten es, dass die Anzahl und/oder Stellung der Platzhalter in der Definition festlag und bekannt war. Eine oft sehr nützliche Alternative zu dieser Option stellt der Befehl !CHAREND dar. Ein Beispiel für diesen bereits erläuterten Befehls folgt in dem nächsten Makro. Das besondere und neue an diesem nächsten Beispiel ist jedoch die Einführung von einer Schleife, einem sog. Loop. Was bewirken bzw. können solche Loops? Während in den bisherigen Beispielen für jeden Durchlauf des gestarteten Makros die dabei einzusetzenden Variablenwerte festgelegt werden mussten, werden bei einem Loop, genauer mit Hilfe eines sog. List-Processing-Loops eine (nahezu unbegrenzte) Menge von Werten vorgegeben, die dann auto- matisch der Reihe nach eingesetzt werden.
 Menge von Werten vorgegeben, die dann auto- matisch der Reihe nach eingesetzt werden.")
106
Schematisch lässt sich das Ganze so darstellen: Am Anfang eines solchen Loops steht der Befehl !DO gefolgt von der Bezeichnung des Platzhalters der einzusetzenden Variablen, bspw. !VAR, dann folgt der Befehl !IN und schließ- lich wird der Platz angegeben, an dem die einzusetzenden Werte oder Zeichen stehen, bspw. (LISTE). Das Ende der Schleife, des Loops wird durch den Befehl !DOEND ange- geben: !DO !VAR !IN (LISTE) Befehle – !DOEND
 Befehle – !DOEND.")
107
!DO !VAR !IN (LISTE) Select if (ALTER > !VAR) CROSSTABS /TABLES= Gehalt BY Hausbesitz /FORMAT= AVALUE TABLES /CELLS= COUNT EXPECTED ROW COLUMN TOTAL /COUNT ROUND CELL . !DOEND LISTE = In dieser schematischen Darstellung würden also alle vier Werte aus der „Liste“ automatisch nacheinander in die Berechnung ein- gesetzt werden.

108
/* Ein fünftes Beispiel für eine Makro-Programmierung mit einer Schleife
/* SET PRINTBACK=ON MPRINT=ON . DEFINE !Auswertung3 (LISTE1 = !CHAREND ('/')/ VAR1 = !TOKENS(1)) . GET FILE='C:\Programme\SPSS\1993 US Sozialerhebung (Teilmenge).sav'. EXECUTE . !DO !WERT1 !IN (!LISTE1) . CROSSTABS /TABLES= !WERT1 BY !VAR1 /FORMAT= AVALUE TABLES /CELLS= COUNT EXPECTED ROW COLUMN TOTAL /COUNT ROUND CELL . !DOEND . !ENDDEFINE . !AUSWERTUNG3 LISTE1 = famstand beschäft partei sternzei / VAR1 = todesstr . Name des Macros: MACRO_Einfaches_Beispiel5
/ VAR1 = !TOKENS(1)) . GET. FILE= C:\Programme\SPSS\1993 US Sozialerhebung (Teilmenge).sav . EXECUTE . !DO !WERT1 !IN (!LISTE1) . CROSSTABS. /TABLES= !WERT1 BY !VAR1. /FORMAT= AVALUE TABLES. /CELLS= COUNT EXPECTED ROW COLUMN TOTAL. /COUNT ROUND CELL . !DOEND . !ENDDEFINE . !AUSWERTUNG3 LISTE1 = famstand beschäft partei sternzei / VAR1 = todesstr . Name des Macros: MACRO_Einfaches_Beispiel5.")
109
Name des Macros: MACRO_Einfaches_Beispiel5a
/* Ein fünftes Beispiel für eine Makro-Programmierung mit einer Schleife /* SET PRINTBACK=ON MPRINT=ON . DEFINE !Auswertung3 (LISTE1 = !CHAREND ('/')/ VAR1 = !TOKENS(1)) . GET FILE='C:\Programme\SPSS\1993 US Sozialerhebung (Teilmenge).sav'. EXECUTE . !DO !WERT1 !IN (!LISTE1) . CROSSTABS /TABLES= !WERT1 BY !VAR1 /FORMAT= AVALUE TABLES /CELLS= COUNT EXPECTED ROW COLUMN TOTAL /COUNT ROUND CELL . !DOEND . !ENDDEFINE . !AUSWERTUNG3 LISTE1 = famstand beschäft partei sternzei alterhei geschw kinder alter gebmonat sternzei ausbild abschlus vaterab mutterab geschl ethgr einkom91 einkbefr region ort einwohn partei wahl92 einstell todesstr waffen gras religion leben kindid pille sexualkd prügel sterbehi zeitung tvstunde bigband blugrass country blues musicals klassik folk jazz opern rap hvymetal sport kultur tvshows tvnews tvpbs wissen4 partner sexfreq wohnen soi gebjahr fameink schulab altergr politik region4 verheira classic3 jazz3 rap3 blues3 /VAR1 = todesstr . Name des Macros: MACRO_Einfaches_Beispiel5a
/ VAR1 = !TOKENS(1)) . GET. FILE= C:\Programme\SPSS\1993 US Sozialerhebung (Teilmenge).sav . EXECUTE . !DO !WERT1 !IN (!LISTE1) . CROSSTABS. /TABLES= !WERT1 BY !VAR1. /FORMAT= AVALUE TABLES. /CELLS= COUNT EXPECTED ROW COLUMN TOTAL. /COUNT ROUND CELL . !DOEND . !ENDDEFINE . !AUSWERTUNG3 LISTE1 = famstand beschäft partei sternzei alterhei. geschw kinder alter gebmonat sternzei ausbild abschlus vaterab mutterab geschl ethgr einkom91 einkbefr region. ort einwohn partei wahl92 einstell todesstr waffen gras religion leben kindid pille sexualkd prügel sterbehi zeitung. tvstunde bigband blugrass country blues musicals klassik folk jazz opern rap hvymetal sport kultur tvshows tvnews. tvpbs wissen4 partner sexfreq wohnen soi gebjahr fameink schulab altergr politik region4 verheira classic3 jazz3 rap3 blues3. /VAR1 = todesstr . Name des Macros: MACRO_Einfaches_Beispiel5a.")
110
Was zunächst sehr kompliziert zu klingen scheint ist jedoch in den meisten Fällen eher einfach und sehr nützlich: Es lassen sich (nahezu) unbegrenzt viele Schleifen miteinander verschachteln: Das nächste Makro demonstriert diese Möglichkeit. Zuerst wird das erste Zeichen der Liste1 eingesetzt, dann das erste Zeichen der Liste2, dann das zweite Zeichen der Liste2 usw. Sind alle Zeichen der Liste2 durch, wird das zweite Zeichen der Liste1 eingesetzt usw. usw. LOOP II LOOP I

111
Name des Macros: MACRO_Einfaches_Beispiel4
/* Ein viertes Beispiel für eine Makro-Programmierung mit zwei ineinander /* verschachtelten Schleifen /* SET PRINTBACK=ON MPRINT=ON . DEFINE !Auswertung3 (LISTE1 = !CHAREND ('/')/ LISTE2 = !CHAREND ('§')) . GET FILE='C:\Programme\SPSS\1993 US Sozialerhebung (Teilmenge).sav' . EXECUTE . !DO !WERT1 !IN (!LISTE1) . !DO !WERT2 !IN (!LISTE2) . CROSSTABS /TABLES= !WERT1 BY !WERT2 /FORMAT= AVALUE TABLES /CELLS= COUNT EXPECTED ROW COLUMN TOTAL /COUNT ROUND CELL . !DOEND . !DOEND . !ENDDEFINE . !AUSWERTUNG3 LISTE1 = famstand beschäft partei / LISTE2 = todesstr sternzei § . Name des Macros: MACRO_Einfaches_Beispiel4
/ LISTE2 = !CHAREND ( § )) . GET. FILE= C:\Programme\SPSS\1993 US Sozialerhebung (Teilmenge).sav . EXECUTE . !DO !WERT1 !IN (!LISTE1) . !DO !WERT2 !IN (!LISTE2) . CROSSTABS. /TABLES= !WERT1 BY !WERT2. /FORMAT= AVALUE TABLES. /CELLS= COUNT EXPECTED ROW COLUMN TOTAL. /COUNT ROUND CELL . !DOEND . !DOEND . !ENDDEFINE . !AUSWERTUNG3 LISTE1 = famstand beschäft partei / LISTE2 = todesstr sternzei § . Name des Macros: MACRO_Einfaches_Beispiel4.")
112
Eine weitere Möglichkeit der Schleifenkonstruktion ist die eines sog
Eine weitere Möglichkeit der Schleifenkonstruktion ist die eines sog. Index-Loop. Beim Index-Loop wird bei einem Zähler mit dem Wert 1 gestartet und im Allgemeinen in n+1-Schritten solange wiederholt, bis ein bestimmter (Index-) Wert erreicht ist. !DO !var = (Anfang) !TO (Ende) [optional: !BY (Schritt)] Befehle - !DOEND Das folgende Makro zeigt ein Beispiel für einen solchen Index- Loop, mit dem sechs zusätzliche Variablen mit den Namen neu1var bis neu6var generiert werden: Im Anschluss an dieses Beispiel wird der bislang noch nicht eingeführte Befehl !CONCAT erläutert.
 Wert erreicht ist. !DO !var = (Anfang) !TO (Ende) [optional: !BY (Schritt)] Befehle - !DOEND. Das folgende Makro zeigt ein Beispiel für einen solchen Index- Loop, mit dem sechs zusätzliche Variablen mit den Namen neu1var bis neu6var generiert werden: Im Anschluss an dieses Beispiel wird der bislang noch nicht eingeführte Befehl !CONCAT erläutert.")
113
/* Ein sechstes Beispiel für eine Makro-Programmierung mit einer Index-Schleife
/* SET PRINTBACK=ON MPRINT=ON . DEFINE !LOOP1 (key1 = !TOKENS(1)/key2 = !TOKENS(1)) . !DO !i = !KEY1 !TO !KEY2 . COMPUTE !CONCAT (neu, !i, var) = normal (1) . !DOEND . !ENDDEFINE . !LOOP1 Key1 = 1 Key2 = 6 . Name des Macros: MACRO_Einfaches_Beispiel6
/key2 = !TOKENS(1)) . !DO !i = !KEY1 !TO !KEY2 . COMPUTE !CONCAT (neu, !i, var) = normal (1) . !DOEND . !ENDDEFINE . !LOOP1 Key1 = 1 Key2 = 6 . Name des Macros: MACRO_Einfaches_Beispiel6.")
114
Stringfunktionen und einige ihrer Variationsmöglichkeiten
Syntax für Strings Funktion, Rückmeldung und Beispiel !LENGTH (String) Länge des angegebenen Strings. Bsp.: !LENGTH(Hello). Ergebnis: 5 !CONCAT (String1, String2, …) Aneinanderkettung der zusammenzu- führenden Strings. Bsp.: !CONCAT(hel, lo). Ergebnis: Hello !QUOTE (String) Das Argument wird in Anführungs- zeichen gesetzt. Bsp.: !QUOTE(Hello). Ergebnis: „Hello“ !SUBSTR (String, FROM, [Länge]) Abschnitt des Strings, der ab FROM startet und bei nicht festgelegter Länge bis zum Stringende geht Bsp.: !SUBSTR(Hello, 3) Ergebnis: „LLO“
 Länge des angegebenen Strings. Bsp.: !LENGTH(Hello). Ergebnis: 5. !CONCAT (String1, String2, …) Aneinanderkettung der zusammenzu- führenden Strings. Bsp.: !CONCAT(hel, lo). Ergebnis: Hello. !QUOTE (String) Das Argument wird in Anführungs- zeichen gesetzt. Bsp.: !QUOTE(Hello). Ergebnis: „Hello !SUBSTR (String, FROM, [Länge]) Abschnitt des Strings, der ab FROM startet und bei nicht festgelegter Länge bis zum Stringende geht. Bsp.: !SUBSTR(Hello, 3) Ergebnis: „LLO")
115
Das Zusammenführen von ausgesuchten Variablen
Eine weitere Anwendung von Makros: Das Zusammenführen von ausgesuchten Variablen aus verschiedenen Dateien: Dazu müssen die einzelnen Dateien nacheinander aufgerufen werden Dabei werden nur die Variablen geladen, die von Interesse sind Die Auswahl der Variablen wird in einer (Zwischen-)Datei abgelegt Der nächste Datensatz wird aufgerufen, die Variablen ausgesucht etc. Der Datensatz wird mit den Daten in der Zwischendatei verbunden Wenn alle Datei „durchkämmt“ sind, ist der Datensatz „fertig“ Beispiel:
Datei abgelegt. Der nächste Datensatz wird aufgerufen, die Variablen ausgesucht etc. Der Datensatz wird mit den Daten in der Zwischendatei verbunden. Wenn alle Datei „durchkämmt sind, ist der Datensatz „fertig Beispiel:")
116
Name des Macros: MACRO_Einfaches_Beispiel7
/* Ein siebentes Beispiel für eine Makro-Programmierung zum Zusammenfügen verschiedener Datensätze /* SET PRINTBACK=ON MPRINT=ON . GET FILE='C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\1991 US Sozialerhebung.sav' /KEEP = kinder . EXECUTE . COMPUTE YEAR = FORMATS YEAR (F 1.0) . SAVE OUTFILE='C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\SPEICHER01.sav' . DEFINE !Zusammen1 (PFAD = !CHAREND ('/')/ WERT1 = !CHAREND ('§')) . FILE= !QUOTE(!PFAD) COMPUTE YEAR = !WERT1 . ADD FILES /FILE=* /* Alternative: MATCH /FILE='C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\SPEICHER01.sav' . SAVE OUTFILE='C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\SPEICHER01.sav' . !ENDDEFINE . !Zusammen1 PFAD = C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\1993 US Sozialerhebung (Teilmenge).sav / WERT1 = 1993 § . PFAD = C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\Mehl Fake.sav / WERT1 = 2000 § . Name des Macros: MACRO_Einfaches_Beispiel7
 . SAVE OUTFILE= C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\SPEICHER01.sav . DEFINE !Zusammen1 (PFAD = !CHAREND ( / )/ WERT1 = !CHAREND ( § )) . FILE= !QUOTE(!PFAD) COMPUTE YEAR = !WERT1 . ADD FILES /FILE=* /* Alternative: MATCH. /FILE= C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\SPEICHER01.sav . SAVE OUTFILE= C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\SPEICHER01.sav . !ENDDEFINE . !Zusammen1. PFAD = C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\1993 US Sozialerhebung (Teilmenge).sav / WERT1 = 1993 § . PFAD = C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\Mehl Fake.sav / WERT1 = 2000 § . Name des Macros: MACRO_Einfaches_Beispiel7.")
117
/* Ein achtes Beispiel für eine Makro-Programmierung zum Berechnen des Mittelwertes
/* SET PRINTBACK=ON MPRINT=ON . GET FILE='C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\SPEICHER01.sav' . EXECUTE . SELECT IF (YEAR = 2000) . COMPUTE Fall = 1 . CREATE SUMFall = CSUM(Fall) . CREATE SUMChild = CSUM(Kinder) . SORT CASES BY SUMfall (D) . SELECT IF ($casenum = 1) . COMPUTE MEANChild = SUMChild/SUMFall . RENAME VARIABLES (MEANChild = MEANChild2000) . SAVE OUTFILE='C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\SPEICHER02.sav' / KEEP= MEANChild /* HIER BEGINNT DAS MAKRO !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! Name des Macros: MACRO_Einfaches_Beispiel8; Fortsetzung nächste Seite ↓
 . COMPUTE Fall = 1 . CREATE SUMFall = CSUM(Fall) . CREATE SUMChild = CSUM(Kinder) . SORT CASES BY SUMfall (D) . SELECT IF ($casenum = 1) . COMPUTE MEANChild = SUMChild/SUMFall . RENAME VARIABLES (MEANChild = MEANChild2000) . SAVE OUTFILE= C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\SPEICHER02.sav / KEEP= MEANChild /* HIER BEGINNT DAS MAKRO !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! Name des Macros: MACRO_Einfaches_Beispiel8; Fortsetzung nächste Seite ↓")
118
DEFINE !Mittelwerte1 (LISTE1 = !CHAREND ('/')) .
!DO !Jahr !IN (!LISTE1) . GET FILE='C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\SPEICHER01.sav' . EXECUTE . SELECT IF (YEAR = !Jahr) . COMPUTE Fall = 1 . CREATE SUMFall = CSUM(Fall) . CREATE SUMChild = CSUM(Kinder) . SORT CASES BY SUMFall (D) . SELECT IF ($casenum = 1) . COMPUTE MEANChild = SUMChild/SUMFall . RENAME VARIABLES (MEANChild = !CONCAT(MEANChild, !Jahr)) . MATCH FILES /FILE=* /FILE='C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\SPEICHER02.sav' /DROP = Fall, SUMFall, SUMChild, YEAR, Kinder . SAVE OUTFILE='C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\SPEICHER02.sav' . !DOEND . !ENDDEFINE . !Mittelwerte1 LISTE1 = / .
 . GET. FILE= C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\SPEICHER01.sav . EXECUTE . SELECT IF (YEAR = !Jahr) . COMPUTE Fall = 1 . CREATE SUMFall = CSUM(Fall) . CREATE SUMChild = CSUM(Kinder) . SORT CASES BY SUMFall (D) . SELECT IF ($casenum = 1) . COMPUTE MEANChild = SUMChild/SUMFall . RENAME VARIABLES (MEANChild = !CONCAT(MEANChild, !Jahr)) . MATCH FILES /FILE=* /FILE= C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\SPEICHER02.sav /DROP = Fall, SUMFall, SUMChild, YEAR, Kinder . SAVE OUTFILE= C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\SE_Komplexe_Daten\SPEICHER02.sav . !DOEND . !ENDDEFINE . !Mittelwerte1 LISTE1 = / .")
119
Ursprungs-Datei Ziel-Datei Datei als Zwischenablage Match Add
Die schematische Logik dieser Variante: Ursprungs-Datei Auswahl relevanter Variablen Berechnungen Auswahl relevanter Variablen Berechnungen Auswahl relevanter Variablen Berechnungen Match Datei als Zwischenablage Add Ziel-Datei

120
∑ aller Werte : Anzahl der Werte
Wie lassen sich nun aus diese Art und Weise zusammengestellte Dateien weiterverarbeiten? Eine Möglichkeit, die ausführlicher, d.h. nicht mit der maximal möglichen Eleganz vorgestellt wird (weil noch zu komplex), ist das Berechnen von Mittelwerten: ∑ aller Werte : Anzahl der Werte Dazu ist es wichtig, die Funktionen Lag und Lead einzuführen: X Lag Lead 198 . 220 305 470
, ist das Berechnen von Mittelwerten: ∑ aller Werte : Anzahl der Werte. Dazu ist es wichtig, die Funktionen Lag und Lead einzuführen: X. Lag. Lead")
121
Name der Syntax: Syntaxbeispiel_Zählen_Sortieren_Auswählen
Anmerkungen: Bitte vergleichen mit „create“ „$casenum“ verweist auf die Fallnummern am linken Rand der Datenmaske Lag(XYZ, 1) = die Zahl gibt den Abstand an: 1 = nächste Zeile; 2 = übernächste Zeile „D“ = down „A“ = up Setzt in eine Variable Anzahl_2 die Anzahl der Werte ‚2‘ der Variable var001 ein (siehe auch Syntax Befehlsdefinitionen) COMPUTE Fall = 1 . EXECUTE . /* ALTERNATIVE: COMPUTE Fall = $casenum . /* SELECT IF (Kinder = 4) . IF ($casenum >1) Fall = Lag(Fall, 1) + Fall . SORT CASES BY Fall (D) . /* ALTERNATIV: (A) SELECT IF ($casenum = 1) . COUNT Anzahl_2 = var (2) .
 = die Zahl gibt den Abstand an: 1 = nächste Zeile; 2 = übernächste Zeile. „D = down „A = up. Setzt in eine Variable Anzahl_2 die Anzahl der Werte ‚2‘ der Variable var001. ein. (siehe auch Syntax Befehlsdefinitionen) COMPUTE Fall = 1 . EXECUTE . /* ALTERNATIVE: COMPUTE Fall = $casenum . /* SELECT IF (Kinder = 4) . IF ($casenum >1) Fall = Lag(Fall, 1) + Fall . SORT CASES BY Fall (D) . /* ALTERNATIV: (A) SELECT IF ($casenum = 1) . COUNT. Anzahl_2 = var001 (2) .")
122
Häufigkeiten zählen mit dem Befehl „COUNT“:
Allgemeine Syntax: COUNT Zielvariable = Quellvariable(n) (Werteliste) Zu zählende Werte Beschreibung Einzelwerte Alle fehlenden Werte missing Systemdefinierte fehlende Werte sysmis Wertebereiche: … bis … 5 thru 10 Wertebereiche: kleinster bis … lowest thru 0 Wertebereiche: … bis größter Wert 100 thru highest
 (Werteliste) Zu zählende Werte. Beschreibung. Einzelwerte Alle fehlenden Werte. missing. Systemdefinierte fehlende Werte. sysmis. Wertebereiche: … bis … 5 thru 10. Wertebereiche: kleinster bis … lowest thru 0. Wertebereiche: … bis größter Wert. 100 thru highest.")
123
ACHTUNG, ganz WICHTIG!!! CREATE bezieht sich wie folgt auf die Spalten: CREATE Function keywords: CSUM Cumulative sum DIFF Difference FFT Fast Fourier transform IFFT Inverse fast Fourier transform LAG Lag LEAD Lead MA Centered moving averages PMA Prior moving averages RMED Running medians SDIFF Seasonal difference T4253H Smoothing

124
Befehl COMPUTE ACHTUNG, ganz WICHTIG!!!
COMPUTE bezieht sich dagegen fast – aber leider nicht immer – wie folgt auf die Zeilen: Befehl COMPUTE

125
COMPUTE target variable=expression Example COMPUTE newvar1=var1+var2.
ABS(arg) Absolute value. ABS(SCALE) is 4.7 when SCALE equals 4.7 or –4.7. RND(arg) Round the absolute value to an integer and reaffix the sign. RND(SCALE) is –5 when SCALE equals –4.7. TRUNC(arg) Truncate to an integer. TRUNC(SCALE) is –4 when SCALE equals –4.7. MOD(arg,arg) Remainder (modulo) of the first argument divided by the second. When YEAR equals 1983, MOD(YEAR,100) is 83. SQRT(arg) Square root. SQRT(SIBS) is 1.41 when SIBS equals 2. EXP(arg) Exponential. e is raised to the power of the argument. EXP(VARA) is 7.39 when VARA equals 2. LG10(arg) Base 10 logarithm. LG10(VARB) is 0.48 when VARB equals 3. LN(arg) Natural or Naperian logarithm (base e). LN(VARC) is 2.30 when VARC equals 10. LNGAMMA(arg) Logarithm (base e) of complete Gamma function. ARSIN(arg) Arcsine. (Alias ASIN.) The result is given in radians. ARSIN(ANG) is 1.57 when ANG equals 1. ARTAN(arg) Arctangent. (Alias ATAN.) The result is given in radians. ARTAN(ANG2) is 0.79 when ANG2 equals 1. SIN(arg) Sine. The argument must be specified in radians. SIN(VARD) is 0.84 when VARD equals 1. COS(arg) Cosine. The argument must be specified in radians. COS(VARE) is 0.54 when VARE equals 1. COMPUTE COMPUTE target variable=expression Example COMPUTE newvar1=var1+var2. COMPUTE newvar2=RND(MEAN(var1 to var4). COMPUTE logicalVar=(var1>5). STRING newString (A10). COMPUTE newString=CONCAT((RTRIM(stringVar1), stringVar2). Functions and operators available for COMPUTE are described in “Transformation Expressions” on p. 44.
 Absolute value. ABS(SCALE) is 4.7 when SCALE equals 4.7 or –4.7. RND(arg) Round the absolute value to an integer and reaffix the sign. RND(SCALE) is. –5 when SCALE equals –4.7. TRUNC(arg) Truncate to an integer. TRUNC(SCALE) is –4 when SCALE equals –4.7. MOD(arg,arg) Remainder (modulo) of the first argument divided by the second. When YEAR. equals 1983, MOD(YEAR,100) is 83. SQRT(arg) Square root. SQRT(SIBS) is 1.41 when SIBS equals 2. EXP(arg) Exponential. e is raised to the power of the argument. EXP(VARA) is when VARA equals 2. LG10(arg) Base 10 logarithm. LG10(VARB) is 0.48 when VARB equals 3. LN(arg) Natural or Naperian logarithm (base e). LN(VARC) is 2.30 when VARC equals. 10. LNGAMMA(arg) Logarithm (base e) of complete Gamma function. ARSIN(arg) Arcsine. (Alias ASIN.) The result is given in radians. ARSIN(ANG) is when ANG equals 1. ARTAN(arg) Arctangent. (Alias ATAN.) The result is given in radians. ARTAN(ANG2) is when ANG2 equals 1. SIN(arg) Sine. The argument must be specified in radians. SIN(VARD) is 0.84 when. VARD equals 1. COS(arg) Cosine. The argument must be specified in radians. COS(VARE) is 0.54 when. VARE equals 1. COMPUTE. COMPUTE target variable=expression. Example. COMPUTE newvar1=var1+var2. COMPUTE newvar2=RND(MEAN(var1 to var4). COMPUTE logicalVar=(var1>5). STRING newString (A10). COMPUTE newString=CONCAT((RTRIM(stringVar1), stringVar2). Functions and operators available for COMPUTE are described in Transformation Expressions on p. 44.")
126
The following arithmetic operators are available: + Addition
COMPUTE - Befehle SUM(arg list) Sum of the nonmissing values across the argument list. MEAN(arg list) Mean of the nonmissing values across the argument list. SD(arg list) Standard deviation of the nonmissing values across the argument list. VARIANCE(arg list) Variance of the nonmissing values across the argument list. CFVAR(arg list) Coefficient of variation of the nonmissing values across the argument list. The coefficient of variation is the standard deviation divided by the mean. MIN(arg list) Minimum nonmissing value across the argument list. MAX(arg list) Maximum nonmissing value across the argument list. The following arithmetic operators are available: + Addition – Subtraction * Multiplication / Division ** Exponentiation
 Sum of the nonmissing values across the argument list. MEAN(arg list) Mean of the nonmissing values across the argument list. SD(arg list) Standard deviation of the nonmissing values across the argument list. VARIANCE(arg list) Variance of the nonmissing values across the argument list. CFVAR(arg list) Coefficient of variation of the nonmissing values across the argument list. The coefficient of variation is the standard deviation divided by the mean. MIN(arg list) Minimum nonmissing value across the argument list. MAX(arg list) Maximum nonmissing value across the argument list. The following arithmetic operators are available: + Addition. – Subtraction. * Multiplication. / Division. ** Exponentiation.")
127
1993 US Sozialerhebung (Teilmenge).sav Mehl Fake.sav
Aufgabe 1: Stellen Sie eine neue Datei zusammen, die Variablen enthält, die die Anzahl von 1, 2 und 3 Kindern in den Dateien 1991 US Sozialerhebung.sav 1993 US Sozialerhebung (Teilmenge).sav Mehl Fake.sav wiedergeben: oder: Ein_Kind_1991 Zwei_Kind_1991 Drei_Kind_1991 …. 29 4 34 Jahr Ein_Kind Zwei_Kinder Drei_Kinder 1991 29 4 34 1993
.sav. Mehl Fake.sav. wiedergeben: oder: Ein_Kind_1991. Zwei_Kind_1991. Drei_Kind_1991. … Jahr. Ein_Kind. Zwei_Kinder. Drei_Kinder")
128
Probleme: Wie muss die Grobstruktur des Programms aussehen?
Makrodefinition (2 Loops) Erste Schleife (Jahr) Adden (cases hinzufügen) Um cases erweiterte Datei ablegen Ende der zweiten Schleife Zweite Schleife (Anzahl Kinder) Variablenauswahl, Werteselektion Berechnen Sortieren Renamen Matchen (Variablen hinzufügen) Im Zwischenspeicher ablegen Ende der ersten Schleife Makroende
 Erste Schleife (Jahr) Adden (cases hinzufügen) Um cases erweiterte Datei ablegen. Ende der zweiten Schleife. Zweite Schleife (Anzahl Kinder) Variablenauswahl, Werteselektion. Berechnen. Sortieren. Renamen. Matchen (Variablen hinzufügen) Im Zwischenspeicher ablegen. Ende der ersten Schleife. Makroende.")
129
Regeln für die Vergabe von Variablennamen:
Variablennamen können aus Buchstaben und Ziffern gebildet werden. Erlaubt sind ferner die Sonderzeichen _ (underscore), . (Punkt) sowie die #, $ Nicht erlaubt sind Leerzeichen sowie spezifische Zeichen, wie !, ?, » und *. Der Variablenname muss mit einem Buchstaben beginnen. Erlaubt ist ferner das Das letzte Zeichen darf kein Punkt und sollte kein _ (underscore) sein, um Konflikte mit speziellen Variablen, die von SPSS-Prozeduren angelegt werden, zu vermeiden. Der Variablenname darf (ab der Version 12) max 64 Zeichen lang sein. Variablennamen sind nicht case-sensitive, d.h. die Groß- und Kleinschreibung ist nicht relevant. Variablennamen dürfen nicht doppelt vergeben werden. Reservierte Schlüsselwörter können nicht als Variablennamen verwendet werden. Zu den reservierten Schlüsselwörtern zählen: ALL, AND, BY, EQ, GE, GT, LE, LT, NE, NOT, OR, TO, WITH. Beispiele für ungültige Variablennamen: 1mal1 Bühl&Zöfel Stand 94 Wagen!
, . (Punkt) sowie die #, $ Nicht erlaubt sind Leerzeichen sowie spezifische Zeichen, wie !, , » und *. Der Variablenname muss mit einem Buchstaben beginnen. Erlaubt ist ferner das Das letzte Zeichen darf kein Punkt und sollte kein _ (underscore) sein, um Konflikte mit speziellen Variablen, die von SPSS-Prozeduren angelegt werden, zu vermeiden. Der Variablenname darf (ab der Version 12) max 64 Zeichen lang sein. Variablennamen sind nicht case-sensitive, d.h. die Groß- und Kleinschreibung ist nicht relevant. Variablennamen dürfen nicht doppelt vergeben werden. Reservierte Schlüsselwörter können nicht als Variablennamen verwendet werden. Zu den reservierten Schlüsselwörtern zählen: ALL, AND, BY, EQ, GE, GT, LE, LT, NE, NOT, OR, TO, WITH. Beispiele für ungültige Variablennamen: 1mal1 Bühl&Zöfel Stand 94 Wagen!")
130
Kommen wir jetzt auf das Eingangs-Beispiel d² - Test zurück:
Wie lässt sich für jedes Feld der %-Anteil einer fehlerhaften Bearbeitung berechnen? Ein erster Schritt wäre es, eine Datei mit allen Fällen der einzelnen Dateien zusammenzustellen, die vollständige Id‘s enthält Dann, Spalte für Spalte, alle Zeilen einzeln aller Bearbeitungen zu betrachten und zusammenzuzählen, wie oft dort eine 1 (fehlerfrei) oder eine 2 (Fehler) ein- getragen wurde. Schließlich wird die Summe aller Werte > 1 und die Summe aller Werte = 2 ermittelt Auf dieser Grundlage ergibt sich dann der %-Anteil
 oder eine 2 (Fehler) ein- getragen wurde. Schließlich wird die Summe aller Werte > 1 und die Summe aller Werte = 2 ermittelt. Auf dieser Grundlage ergibt sich dann der %-Anteil.")
131
/* Makro zum Ersetzen/Ausfüllen der Id-Nummern
/* SET PRINTBACK=ON MPRINT=ON . CD 'C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\D_Zwei' . ERASE FILE = 'SPEICHER01.sav' . DEFINE !Vervollstaendigen (LISTE = !CHAREND ('/')) . !DO !Datei !IN (!LISTE) . GET FILE= !Datei . EXECUTE . RECODE ID (MISSING=0) . IF ((Zeile > 0) & ($casenum > 1)) Id = Id + Lag(Id, 1) . ADD FILES /FILE=* /FILE='SPEICHER01.sav' . SAVE OUTFILE= 'SPEICHER01.sav' . !DOEND . !ENDDEFINE . !Vervollstaendigen Liste = 'Daten-Mi-10.sav' 'Daten-Mi-11.sav' 'Daten-Mi-12.sav' 'Daten-Mi-13.sav' 'Daten-Mi-14.sav' 'Daten-Mi-15.sav' 'Daten-Mi-16.sav' 'Daten-Mi-17.sav' 'Daten-Mi-18.sav' 'Daten-Mo-01.sav' 'Daten-Mo-02.sav' / .
) . !DO !Datei !IN (!LISTE) . GET. FILE= !Datei . EXECUTE . RECODE. ID (MISSING=0) . IF ((Zeile > 0) & ($casenum > 1)) Id = Id + Lag(Id, 1) . ADD FILES /FILE=* /FILE= SPEICHER01.sav . SAVE OUTFILE= SPEICHER01.sav . !DOEND . !ENDDEFINE . !Vervollstaendigen. Liste = Daten-Mi-10.sav Daten-Mi-11.sav Daten-Mi-12.sav Daten-Mi-13.sav Daten-Mi-14.sav Daten-Mi-15.sav Daten-Mi-16.sav Daten-Mi-17.sav Daten-Mi-18.sav Daten-Mo-01.sav Daten-Mo-02.sav / .")
132
Datei der Daten aller Bearbeitungen
Anhand dieser Datei aller Bearbeitungen gilt es jetzt eine Struktur wie die folgende zu erstellen: Spalte S_01, Zeile 1 des ersten Testteilnehmers Spalte S_01, Zeile 1 des zweiten Testteilnehmers Datei der Daten aller Bearbeitungen Spalte S_01, Zeile 1 des letzten Testteilnehmers

133
Sind auf diese Art und Weise die Werte Zeile 1, Spalte S_01 zusammengestellt, gilt es die Werte ‚1‘ und ‚2‘ zu erfassen und zusammenzuzählen, etwa auf diesem Weg: COUNT F_S = S_01 (2) . EXECUTE . R_S = S_ (1) . O_S = S_ (0) . S_01 F_S R_S O_S . 1 2
 . EXECUTE . R_S = S_01 (1) . O_S = S_01 (0) . S_01. F_S. R_S. O_S")
134
Um die Summe der F_S, R_S und O_S zusammenzuaddieren gibt es – wie immer – verschiedene Wege. Zunächst müssen die Missing Values in die Werte ‚0‘ umkodiert werden: RECODE F_S R_S O_S (MISSING=0) . EXECUTE . Dann kann mit dem Befehl: CREATE Fall = CSUM(Fall) . CREATE F_S = CSUM(F_S) . CREATE R_S = CSUM(R_S) . CREATE O_S = CSUM(O_S) . oder
 . EXECUTE . Dann kann mit dem Befehl: CREATE Fall = CSUM(Fall) . CREATE F_S = CSUM(F_S) . CREATE R_S = CSUM(R_S) . CREATE O_S = CSUM(O_S) . oder.")
135
IF ($casenum > 1) F_S = LAG(F_S, 1) + F_S . EXECUTE .
Mit der Anweisung: IF ($casenum > 1) F_S = LAG(F_S, 1) + F_S . EXECUTE . gearbeitet werden. Ihnen ist sicher das Aufaddieren einer Variablen ‚Fall‘ aufgefallen – die zuvor auf den Wert ‚1‘ gesetzt wurde. Diese Variable dient dazu, die letzte Zeile in der Datei zu bestimmen, um den Sortierbefehl richtig anwenden zu können. Dieser Befehl lautet: S_01 F_S R_S O_S . 1 2
 F_S = LAG(F_S, 1) + F_S . EXECUTE . gearbeitet werden. Ihnen ist sicher das Aufaddieren einer Variablen ‚Fall‘ aufgefallen – die zuvor auf den Wert ‚1‘ gesetzt wurde. Diese Variable dient dazu, die letzte Zeile in der Datei zu bestimmen, um den Sortierbefehl richtig anwenden zu können. Dieser Befehl lautet: S_01. F_S. R_S. O_S")
136
SORT CASES BY Fall (D) . SELECT IF ($casenum = 1) . EXECUTE . Mit der ersten Zeile werden die Werte von Fall absteigend (D) sortiert, so dass die höchsten Werte alle in der ersten Zeile stehen. Dann wird die erste Zeile ausgewählt – die anderen sind in diesem Moment verschwunden! Die gewünschte Berechnung erfolgt durch diesen Befehl: COMPUTE Proz_F = (100 * F_S) / (F_S + R_S) . Damit haben wir den Prozentanteil der Fehler beim Bearbeiten der ersten Zeile der Spalte S_01 berechnet.
 sortiert, so dass die höchsten Werte alle in der ersten Zeile stehen. Dann wird die erste Zeile ausgewählt – die anderen sind in diesem Moment verschwunden! Die gewünschte Berechnung erfolgt durch diesen Befehl: COMPUTE Proz_F = (100 * F_S) / (F_S + R_S) . Damit haben wir den Prozentanteil der Fehler beim Bearbeiten der ersten Zeile der Spalte S_01 berechnet.")
137
Damit ist aber noch nicht das Ende erreicht
Damit ist aber noch nicht das Ende erreicht. Um zu markieren, welchen Wert wir jetzt berechnet haben, nennen wir die Variable Proz_F um in die Variable ProzF_S_01 – die Variable Proz_F ist damit nicht mehr im Bestand der Datei!! Schließlich speichern wir in einer Zwischendatei den berechneten Wert und werfen mit DROP alle Variablen raus, die wir nicht benötigen: RENAME VARIABLES (Proz_F = !CONCAT(ProzF_, !Spalte)) . EXECUTE . MATCH FILES /FILE=* /FILE='SPEICHER02.sav' /DROP = Id, Fall, R_S, O_S, F_S, !Spalte . SAVE OUTFILE='SPEICHER02.sav' .
) . EXECUTE . MATCH FILES /FILE=* /FILE= SPEICHER02.sav /DROP = Id, Fall, R_S, O_S, F_S, !Spalte . SAVE OUTFILE= SPEICHER02.sav .")
144
Variablen: Marker = M: Outermarker = 2; Middlemarker = 3 Höhe = MSL (Mean Sea Level) oder AGL = (Above Ground Level)
 oder AGL = (Above Ground Level)")
145
Aufgabe: Einlesen von *.log resp. *.txt Dateien Abspeichern in *.sav Dateien Berechnung der Mittelwerte Höhe (MSL) bei Überflug eines Markers (Outer-Marker und Middle-Marker) Vergleich der Mittelwerte bei Vpn. und Flügen [Vergleich Kaffee an bestimmten Tagen, zu bestimmten Zeiten, zwischen bestimmten Zeiten] und dann: Berechnung des höchsten MSL-Wertes und des niedrigsten MSL-Wertes beim Überflug OM + MM
 bei Überflug eines Markers (Outer-Marker und Middle-Marker) Vergleich der Mittelwerte bei Vpn. und Flügen. [Vergleich Kaffee an bestimmten Tagen, zu bestimmten Zeiten, zwischen bestimmten Zeiten] und dann: Berechnung des höchsten MSL-Wertes und des niedrigsten MSL-Wertes beim Überflug OM + MM.")
146
Vorsicht! Es gibt auch Marker beim Abflug aus Hamburg-Finkenwerder, die registriert werden. Also: Abschnitte bestimmen, der relevant ist, bspw. mit Hilfe LAT/LON (Positionsangaben), siehe Scatterplott ↑.
, siehe Scatterplott ↑..")
147
Eine von vielen Vereinfachungsmöglichkeiten:
Da ein Dateibezug beim Einlesen der Dateien oft sehr lang und umständlich ist (siehe unsere bisherigen Dateien), kann ein Programm sehr schnell unüber- sichtlich werden. Abhilfe (1): CD 'C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\Komplexe Daten' . GET FILE = 'MEHL---EDHI23-EDDH sav' /KEEP = M, MSL, AGL, LAT, LON, vp, flug . EXECUTE. SELECT IF (M = 2 & LON > 9.87) . EXECUTE . ……… „CD“ legt das aktuelle Arbeitsverzeichnis fest, mit dem in allen weiteren Schritten gearbeitet wird. Bei allen nachfolgenden Befehlen wird direkt auf dieses Verzeichnis zugegriffen.
, kann ein Programm sehr schnell unüber- sichtlich werden. Abhilfe (1): CD C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\Komplexe Daten . GET FILE = MEHL---EDHI23-EDDH sav /KEEP = M, MSL, AGL, LAT, LON, vp, flug . EXECUTE. SELECT IF (M = 2 & LON > 9.87) . EXECUTE . ……… „CD legt das aktuelle Arbeitsverzeichnis fest, mit dem in allen weiteren Schritten gearbeitet wird. Bei allen nachfolgenden Befehlen wird direkt auf dieses Verzeichnis zugegriffen.")
148
Eine weitere Möglichkeit (2):
FILE HANDLE quelle01 /NAME = 'C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\Komplexe Daten\MEHL---EDHI23-EDDH sav ' . GET FILE = quelle01 /KEEP = M, MSL, AGL, LAT, LON, vp, flug . EXECUTE. SELECT IF (M = 2 & LON > 9.87) . EXECUTE . ………. Mit dem Befehl „FILE HANDLE“ wird ein frei wählbarer Kurzname festgelegt, der in allen folgenden Befehlen als „Ersatzbezeichnung“ für die ursprüngliche, vollständige, längere Angabe des Arbeits- verzeichnisses und des Dateinamens genutzt werden kann.
 . EXECUTE . ………. Mit dem Befehl „FILE HANDLE wird ein frei wählbarer Kurzname festgelegt, der in allen folgenden Befehlen als „Ersatzbezeichnung für die ursprüngliche, vollständige, längere Angabe des Arbeits- verzeichnisses und des Dateinamens genutzt werden kann.")
149
Die folgenden Seiten zeigen zur Übersicht und zum Vergleich drei Berechnungsvarianten:

150
/* MACRO Berechnen_01_Einfach Berechnen von Mittel-Werten innerhalb bestimmter Abschnitte mit Vereinfachungen CD 'C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\Komplexe Daten' . GET FILE = 'MEHL---EDHI23-EDDH sav' /KEEP = M, MSL, AGL, LAT, LON, vp, flug . EXECUTE. SELECT IF (M = 2 & LON > 9.87) . EXECUTE . COMPUTE Fall = 1 . CREATE SUMFall = CSUM(Fall) . CREATE SUMMSL = CSUM(MSL) . SORT CASES BY SUMfall (D) . SELECT IF ($casenum = 1) . COMPUTE MeanMSL = SUMMSL/SUMFall . SAVE OUTFILE='SPEICHER01.sav' /DROP = Fall, SUMFall, SUMMSL, M, AGL, MSL, LAT, LON . DEFINE !Berechnen1 (PLATZ = !charend ('§') ) . GET FILE = !QUOTE(!PLATZ) - Nächste Seite - Variante „Save“: Daten werden zunächst abgespeichert (erster Durchgang) um die Datei sicher nur mit den errechneten Daten zu füllen. Erst danach beginnt das MACRO
 . EXECUTE . COMPUTE Fall = 1 . CREATE SUMFall = CSUM(Fall) . CREATE SUMMSL = CSUM(MSL) . SORT CASES BY SUMfall (D) . SELECT IF ($casenum = 1) . COMPUTE MeanMSL = SUMMSL/SUMFall . SAVE OUTFILE= SPEICHER01.sav /DROP = Fall, SUMFall, SUMMSL, M, AGL, MSL, LAT, LON . DEFINE !Berechnen1 (PLATZ = !charend ( § ) ) . GET FILE = !QUOTE(!PLATZ) - Nächste Seite - Variante „Save : Daten werden zunächst abgespeichert (erster Durchgang) um die Datei sicher nur mit den errechneten Daten zu füllen. Erst danach beginnt das MACRO.")
151
- Fortsetzung - COMPUTE Fall = 1 . EXECUTE . CREATE SUMFall = CSUM(Fall) . CREATE SUMMSL = CSUM(MSL) . SORT CASES BY SUMfall (D) . SELECT IF ($casenum = 1) . COMPUTE MeanMSL = SUMMSL/SUMFall . ADD FILES /FILE=* /FILE= 'SPEICHER01.sav' /DROP = Fall, SUMFall, SUMMSL, M, AGL, MSL, LAT, LON . SAVE OUTFILE='SPEICHER01.sav' . !ENDDEFINE . !Berechnen1 PLATZ = MEHL---EDHI23-EDDH sav § . PLATZ = MEHL---EDHI23-EDDH sav § . PLATZ = GÖPEL---EDHI23-EDDH sav § . PLATZ = GÖPEL---EDHI23-EDDH sav § . PLATZ = GRÜN---EDHI23-EDDH sav § .
 . SELECT IF ($casenum = 1) . COMPUTE MeanMSL = SUMMSL/SUMFall . ADD FILES /FILE=* /FILE= SPEICHER01.sav /DROP = Fall, SUMFall, SUMMSL, M, AGL, MSL, LAT, LON . SAVE OUTFILE= SPEICHER01.sav . !ENDDEFINE . !Berechnen1. PLATZ = MEHL---EDHI23-EDDH sav § . PLATZ = MEHL---EDHI23-EDDH sav § . PLATZ = GÖPEL---EDHI23-EDDH sav § . PLATZ = GÖPEL---EDHI23-EDDH sav § . PLATZ = GRÜN---EDHI23-EDDH sav § .")
152
Also Vorsicht!!! Zuvor Dateien löschen!!
/* MACRO Berechnen_02_ mit Fehler!!!! Berechnen von Mittel-Werten innerhalb bestimmter Abschnitte mit Vereinfachungen SET PRINTBACK=ON MPRINT=ON . DEFINE !Berechnen1 (PLATZ = !CHAREND ('§')/ LISTE1 = !charend ('§')/LISTE2 = !charend ('§') ) . CD 'C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\Komplexe Daten' . !DO !ORT !IN (!PLATZ) . !DO !MARKER !IN (!LISTE1) . GET FILE = !ORT /KEEP = M, MSL, AGL, LAT, LON, vp, flug . EXECUTE. SELECT IF (M = !MARKER & LON > 9.87) . EXECUTE . COMPUTE Fall = 1 . CREATE SUMFall = CSUM(Fall) . CREATE SUMMSL = CSUM(MSL) . SORT CASES BY SUMFall (D) . SELECT IF ($casenum = 1) . COMPUTE MeanMSL = SUMMSL/SUMFall . RENAME VARIABLES (MeanMSL = !CONCAT(MEAN_, !MARKER)) . ADD FILES /FILE=* /FILE= 'SPEICHER01.sav' /DROP = Fall, SUMFall, SUMMSL, M, AGL, MSL, LAT, LON . SAVE OUTFILE = 'SPEICHER01.sav' . !DOEND . !ENDDEFINE . !Berechnen1 PLATZ = 'MEHL---EDHI23-EDDH sav' 'MEHL---EDHI23-EDDH sav' 'MEHL---EDHI23-EDDH sav' 'GÖPEL---EDHI23-EDDH sav' 'GÖPEL---EDHI23-EDDH sav' 'GRÜN---EDHI23-EDDH sav' § LISTE1 = 2 3 § LISTE2 = OUTERMARKER MIDDLEMARKER § . Variante „Unsave“ (zudem mit Fehler): MACRO beginnt sofort, Probleme entstehen, wenn Datei für Speicher bereits besteht und möglicherweise Daten enthält, da dann diese dort noch vorhandenen Daten mit aufgenommen werden. Also Vorsicht!!! Zuvor Dateien löschen!!
/ LISTE1 = !charend ( § )/LISTE2 = !charend ( § ) ) . CD C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\Komplexe Daten . !DO !ORT !IN (!PLATZ) . !DO !MARKER !IN (!LISTE1) . GET FILE = !ORT. /KEEP = M, MSL, AGL, LAT, LON, vp, flug . EXECUTE. SELECT IF (M = !MARKER & LON > 9.87) . EXECUTE . COMPUTE Fall = 1 . CREATE SUMFall = CSUM(Fall) . CREATE SUMMSL = CSUM(MSL) . SORT CASES BY SUMFall (D) . SELECT IF ($casenum = 1) . COMPUTE MeanMSL = SUMMSL/SUMFall . RENAME VARIABLES (MeanMSL = !CONCAT(MEAN_, !MARKER)) . ADD FILES /FILE=* /FILE= SPEICHER01.sav /DROP = Fall, SUMFall, SUMMSL, M, AGL, MSL, LAT, LON . SAVE OUTFILE = SPEICHER01.sav . !DOEND . !ENDDEFINE . !Berechnen1. PLATZ = MEHL---EDHI23-EDDH sav MEHL---EDHI23-EDDH sav MEHL---EDHI23-EDDH sav GÖPEL---EDHI23-EDDH sav GÖPEL---EDHI23-EDDH sav GRÜN---EDHI23-EDDH sav § LISTE1 = 2 3 § LISTE2 = OUTERMARKER MIDDLEMARKER § . Variante „Unsave (zudem mit Fehler): MACRO beginnt sofort, Probleme entstehen, wenn Datei für Speicher bereits besteht und möglicherweise Daten enthält, da dann diese dort noch vorhandenen Daten mit aufgenommen werden. Also Vorsicht!!! Zuvor Dateien löschen!!")
153
Also Vorsicht!!! Zuvor Dateien löschen!!
Variante „Unsave“ (diesmal ohne Fehler): MACRO beginnt sofort, Probleme entstehen, wenn Datei für Speicher bereits besteht und möglicherweise Daten enthält, da dann diese dort noch vorhandenen Daten mit aufgenommen werden. Also Vorsicht!!! Zuvor Dateien löschen!! /* MACRO Berechnen_02_Ohne Fehler von Mittel-Werten innerhalb bestimmter Abschnitte mit Vereinfachungen /* ACHTUNG! ACHTUNG! ACHTUNG! /* (1) Die Dateien Speicher01 und Speicher02 dürfen zu Beginn nicht vorhanden sein!!! /* (2) Die ausgewählten Bereiche müssen vorhanden sein, sonst doppelte Werte!!! /*SET PRINTBACK=ON MPRINT=ON . DEFINE !Berechnen1 (PLATZ = !CHAREND ('§')/ LISTE1 = !charend ('§')/LISTE2 = !charend ('§') ) . CD 'C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\Komplexe Daten' . !DO !ORT !IN (!PLATZ) . !DO !MARKER !IN (!LISTE1) . GET FILE = !ORT /KEEP = M, MSL, AGL, LAT, LON, vp, flug . EXECUTE. SELECT IF (M = !MARKER & LON > 9.87) . EXECUTE . COMPUTE Fall = 1 . - Nächste Seite -
: MACRO beginnt sofort, Probleme entstehen, wenn Datei für Speicher bereits besteht und möglicherweise Daten enthält, da dann diese dort noch vorhandenen Daten mit aufgenommen werden. Also Vorsicht!!! Zuvor Dateien löschen!! /* MACRO Berechnen_02_Ohne Fehler von Mittel-Werten innerhalb bestimmter Abschnitte mit Vereinfachungen. /* ACHTUNG! ACHTUNG! ACHTUNG! /* (1) Die Dateien Speicher01 und Speicher02 dürfen zu Beginn nicht vorhanden sein!!! /* (2) Die ausgewählten Bereiche müssen vorhanden sein, sonst doppelte Werte!!! /*SET PRINTBACK=ON MPRINT=ON . DEFINE !Berechnen1 (PLATZ = !CHAREND ( § )/ LISTE1 = !charend ( § )/LISTE2 = !charend ( § ) ) . CD C:\Dokumente und Einstellungen\Klaus Mehl\Eigene Dateien\Daten\Komplexe Daten . !DO !ORT !IN (!PLATZ) . !DO !MARKER !IN (!LISTE1) . GET FILE = !ORT. /KEEP = M, MSL, AGL, LAT, LON, vp, flug . EXECUTE. SELECT IF (M = !MARKER & LON > 9.87) . EXECUTE . COMPUTE Fall = Nächste Seite -")
154
- Fortsetzung - CREATE SUMFall = CSUM(Fall) . EXECUTE . CREATE SUMMSL = CSUM(MSL) . SORT CASES BY SUMFall (D) . SELECT IF ($casenum = 1) . COMPUTE MeanMSL = SUMMSL/SUMFall . RENAME VARIABLES (MeanMSL = !CONCAT(MEAN_, !MARKER)) . MATCH FILES /FILE=* /FILE= 'SPEICHER01.sav' /DROP = Fall, SUMFall, SUMMSL, M, AGL, MSL, LAT, LON . SAVE OUTFILE = 'SPEICHER01.sav' . !DOEND . ADD FILES /FILE=* /FILE= 'SPEICHER02.sav' . SAVE OUTFILE = 'SPEICHER02.sav' . !ENDDEFINE . !Berechnen1 PLATZ = 'MEHL---EDHI23-EDDH sav' 'MEHL---EDHI23-EDDH sav' 'MEHL---EDHI23-EDDH sav' 'GÖPEL---EDHI23-EDDH sav' 'GÖPEL---EDHI23-EDDH sav' 'GRÜN---EDHI23-EDDH sav' § LISTE1 = 3 2 § LISTE2 = OUTERMARKER MIDDLEMARKER § .
 . COMPUTE MeanMSL = SUMMSL/SUMFall . RENAME VARIABLES (MeanMSL = !CONCAT(MEAN_, !MARKER)) . MATCH FILES /FILE=* /FILE= SPEICHER01.sav /DROP = Fall, SUMFall, SUMMSL, M, AGL, MSL, LAT, LON . SAVE OUTFILE = SPEICHER01.sav . !DOEND . ADD FILES /FILE=* /FILE= SPEICHER02.sav . SAVE OUTFILE = SPEICHER02.sav . !ENDDEFINE . !Berechnen1. PLATZ = MEHL---EDHI23-EDDH sav MEHL---EDHI23-EDDH sav MEHL---EDHI23-EDDH sav GÖPEL---EDHI23-EDDH sav GÖPEL---EDHI23-EDDH sav GRÜN---EDHI23-EDDH sav § LISTE1 = 3 2 § LISTE2 = OUTERMARKER MIDDLEMARKER § .")
155
Ein wichtiges Problem, dass unbedingt Beachtung benötigt, kann entstehen, wenn aufgrund nicht vorhandener Daten keine Berechnungen durchgeführt werden können, zugleich durch den „MATCH“-Befehl, in Kombination mit den „SAVE“-Befehl die Zwischenspeicherdatei aber belegt werden soll. Es wird dann a) keine Berechnung durchgeführt, weil keine Daten vorhanden sind b) die in der Speicherdatei gelisteten Werte werden erneut gespeichert und schließlich c) durch den „ADD“-Befehl als vermeintliche Berechnung des neuen Falles abgespeichert. Was ist zu tun? Wichtig ist die Prüfung auf vorhandene Daten in der jeweiligen Datei, bspw. durch den Befehl: FREQUENCIES VARIABLES=M /STATISTICS=SUM /ORDER= ANALYSIS . der zuverlässig die Anzahl der Werte (hier die der Variable M) zählt.
 zählt.")
156
Eine andere Option ist die folgende: COMPUTE Fall = 0 .
EXECUTE . IF (M = 2) Fall = 1 . CREATE SUMFall = CSUM(Fall) . SORT CASES BY SUMFall (D) . SELECT IF ($casenum = 1) . Hier passiert folgendes: Die Variable „FALL“, mit der die Anzahl vorhandener Werte gezählt werden soll, wird zunächst auf 0 gesetzt. D.h. wenn die aufgerufene Datei überhaupt vorhanden ist, gibt es so immer eine Variable mit den Werten 0. Jetzt wird durch „IF (M=2) FALL = 1 .„ für die Fälle, bei denen die zu zählende Variable den Wert 2 aufweist, der Wert der Variable FALL auf 1 gesetzt und kann dann im nächsten Schritt gezählt werden. Wenn kein Wert 2 der Variablen M vorhanden ist, ergibt sich beim Zusammenzählen 0. Würde man hier mit „SELECT IF (M=2) .“ arbeiten, konnten keine Berechnungen vorgenommen werden, wenn der Wert M=2 im Datensatz nicht vorhanden ist.
 Fall = 1 . CREATE SUMFall = CSUM(Fall) . SORT CASES BY SUMFall (D) . SELECT IF ($casenum = 1) . Hier passiert folgendes: Die Variable „FALL , mit der die Anzahl vorhandener Werte gezählt werden soll, wird zunächst auf 0 gesetzt. D.h. wenn die aufgerufene Datei überhaupt vorhanden ist, gibt es so immer eine Variable mit den Werten 0. Jetzt wird durch „IF (M=2) FALL = 1 .„ für die Fälle, bei denen die zu zählende Variable den Wert 2 aufweist, der Wert der Variable FALL auf 1 gesetzt und kann dann im nächsten Schritt gezählt werden. Wenn kein Wert 2 der Variablen M vorhanden ist, ergibt sich beim Zusammenzählen 0. Würde man hier mit „SELECT IF (M=2) . arbeiten, konnten keine Berechnungen vorgenommen werden, wenn der Wert M=2 im Datensatz nicht vorhanden ist.")
157
Was den Ort des „COMPUTE Fall = 0
Was den Ort des „COMPUTE Fall = 0 .“ angeht, so muss er unbedingt vor jedem „SELECT IF …“ eingefügt werden, um seine eben beschriebene Funktionalität erfüllen zu können. Ersichtlich ist die eben besprochene Gefahr dadurch, dass in hintereinander liegenden Fällen exakt die selben Werte stehen. Wenn Sie so etwas bemerken: Kontrollieren!

158
Bitte beherzigen Sie den zentralen Leit- und Merksatz:
Garbage in, Garbage out

159
„Wie geht Erkenntnisgewinn?“ Ein erster, flüchtiger Blick
Transformation Interpretation Data Mining Vorbereitete Daten Transformierte Daten Wissen/ Modelle Muster

160
Kelchlänge Kelchbreite Blattlänge Blattbreite Iristyp 1 5 3,3 1,4 0,2 Setosa 2 6,4 2,8 5,6 2,2 Virginic 3 6,5 4,6 1,5 Versicol 4 6,7 3,1 2,4 6,3 5,1 6 3,4 0,3 7 6,9 2,3 8 6,2 4,5 9 5,9 3,2 4,8 1,8 10 3,6 11 6,1 12 2,7 1,6 13 5,2 14 2,5 3,9 1,1 15 5,5 16 5,8 1,9 17 6,8 18 1,7 0,5 19 5,7 1,3 20 5,4 21 7,7 3,8 22 4,7 23 24 7,6 6,6 2,1 25 4,9 Fisher (1936) Irisdaten: Länge und Breite von Blättern und Kelchen für 3 Iristypen
 Irisdaten: Länge und Breite von Blättern und Kelchen für 3 Iristypen.")
161
CART (classification and regression trees)
Kategoriale Werte (gut/schlecht) Metrische Werte (1, 2, 3, 4, ..) [Nominale, Ordinale Werte] CART (classification and regression trees) Split: Welche Variable trennt am besten bei welchem Wert?
 Metrische Werte (1, 2, 3, 4, ..) [Nominale, Ordinale Werte] CART (classification and regression trees) Split: Welche Variable trennt am besten bei welchem Wert")
172
Fehlklassifikationsmatrix Lernstichprobe (Irisdat) Matrix progn
Fehlklassifikationsmatrix Lernstichprobe (Irisdat) Matrix progn. (Zeile) x beob. (Spalte) Lernstichprobe N = 150 Klasse - Setosa Klasse - Versicol Klasse - Virginic Setosa Versicol 4 Virginic 2 Prognost. Klasse x Beob. Klasse n's (Irisdat) Matrix progn. (Zeile) x beob. (Spalte) Lernstichprobe N = 150 Klasse - Setosa Klasse - Versicol Klasse - Virginic Setosa 50 Versicol 48 4 Virginic 2 46
 Matrix progn. (Zeile) x beob. (Spalte) Lernstichprobe N = 150. Klasse - Setosa. Klasse - Versicol. Klasse - Virginic. Setosa. Versicol. 4. Virginic. 2. Prognost. Klasse x Beob. Klasse n s (Irisdat) Matrix progn. (Zeile) x beob. (Spalte) Lernstichprobe N = 150. Klasse - Setosa. Klasse - Versicol. Klasse - Virginic. Setosa. 50. Versicol Virginic")
173
Split-Bedingung (Irisdat) Split-Bedingung je Knoten
Split - Konst. Split - Variable 1 -2,09578 Blattlänge 2 3 -1,64421 Blattbreite

177
Aufbau der Datenmatrix, um einen Kausalbaum, eine Kreuztabelle zu erstellen:
V1 V2 V3 V4 V5 V6 Person/Bedingung Vgut_schlecht 345 232 234 336 767 787 A G 564 887 236 454 B 665 897 C S 789 123 567 D 459 456 E 981 F 438 341 657 656 H 447 I

178
Aufbau der Datenmatrix, um eine Korrelationsanalyse zu erstellen:
V1 V2 V3: Gefahrene Kilometer V4: Gartengröße V5: Wohnraum V6: Gehalt 345 232 234 336 767 787 564 887 236 454 665 897 789 123 567 459 456 981 438 341 657 656 447

179
Zwei, von vielen Problemen:
Feature Choise Overfitting, Underfitting

180
Zwei, von vielen Problemen:
Feature Choise Overfitting, Underfitting

181
Kategoriale Splits Bivariate Splits Multivariate Splits a b < 0,5
> 0,5 Multivariate Splits < 0,5 > 0,5, < 1,8 > 1,8

182
Phasen des Data Mining

185
Daten Trainings-daten Daten teilen Validierungs-daten Modell- bewertung

186
Disagreement table for observed variable (Compute Best Predicted Classification from all Models) Observed variable: Kreditwürdigkeit PMML_GDA3Pred for Kreditwürdig-keit - % Incorrect PMML_CTrees4Pred for Kreditwürdig-keit - % Incorrect PMML_CCHAID5Pred for Kreditwürdig-keit - % Incorrect VotedPrediction for Kreditwürdig-keit - % Incorrect Nein 8,40401 15,11180 9,17502 11,71935 Ja 21,50350 11,80070 24,82517 17,91958

189
Disagreement table for observed variable (Compute Best Predicted Classification from all Models) Observed variable: Kreditwürdigkeit PMML_GDA3Pred for Kreditwürdig-keit - % Incorrect PMML_CTrees4Pred for Kreditwürdig-keit - % Incorrect PMML_CCHAID5Pred for Kreditwürdig-keit - % Incorrect VotedPrediction for Kreditwürdig-keit - % Incorrect Nein 8,40401 15,11180 9,17502 11,71935 Ja 21,50350 11,80070 24,82517 17,91958

192
Auf den folgenden Folien wird exemplarisch (bitte nicht „blind“ als Rezept für alle anderen Vorgehensweisen benutzen!!) eine Analyse anhand der Daten „Speicher02.por“ Schritt für Schritt in einer von vielen möglichen Varianten vorgeführt. Dabei werden die (relativ) wenigen Daten durch ein sog. „Stratified Random Sampling“ auf jeweils annährend 50 Fälle für die Variable „gut/schlecht“ durch mehrfaches Ziehen aus dem Datensatz aufgestockt. Danach wird der Datensatz zu jeweils 50% in einen Teil für das Training der Modelle und in einen zur Validierung unter- teilt. Nach der Berechnung eines Klassifikationsbaumes (es könnten in derselben Manier x-weitere berechnet werden) erfolgt eine Bewertung des (hier nur einen) Modells.
 erfolgt eine Bewertung des (hier nur einen) Modells.")
193
So sieht als ein Beispiel die zu generierende Workflow-Oberfläche aus.
Teilergebnis auf Folien 162 und 164 Teilergebnis auf Folien 163 So sieht als ein Beispiel die zu generierende Workflow-Oberfläche aus. Die Daten sind im Knoten ganz links und müssen hinsichtlich abhängiger und unabhängiger (numerischer oder kategorialer) Variablen zugeordnet werden. Siehe nächste Folie
 Variablen zugeordnet werden. Siehe nächste Folie.")
194
In diesem Knoten werden für das Sampling jeweils 50 Fälle festgelegt.

195
Wollen Sie sich das Resultat an dem Daten-Zwischen-Knoten anschauen, so müssen Sie bspw. wie hier gezeigt ein Balkendiagramm mit Hilfe des entsprechenden Knotens aus dem Node Browser einfügen.

198
Mit Hilfe dieses Knotens wird der Sampling-Datensatz zu jeweils 50%/50% in einen Datensatz für das Training des Klassifikators und in einen für die Validierung unterteilt. Alternativ lässt sich auch die Anzahl der Fälle angeben.

199
Wichtig ist hier, die bereits durch den Training/Testing-Knoten festgelegte, Spezifikation dieses Datensatzes als „for deployed project“!!!!. Sollte Sie in anderen Fällen, unter einem anderen Projektaufbau keinen Knoten Test/Training verwenden, dann müssen Sie vor einer Aktivierung einer Bewertung diese kleine Box markieren!!

206
Hinweise, Verweise, Datenquellen:
(daten des socio-economic panel) (Bildungsdaten, bspw. PISA Daten) StatSoft.de StatSoft.com SPSS.de SPSS.com
 (Bildungsdaten, bspw. PISA Daten) StatSoft.de StatSoft.com. SPSS.de SPSS.com.")
Ähnliche Präsentationen

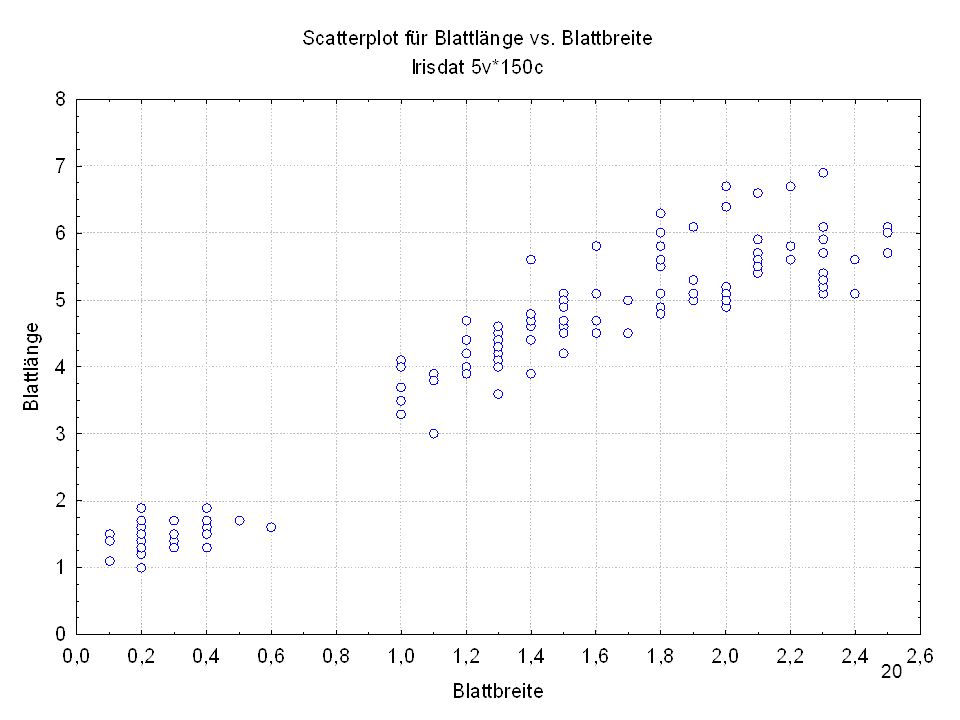

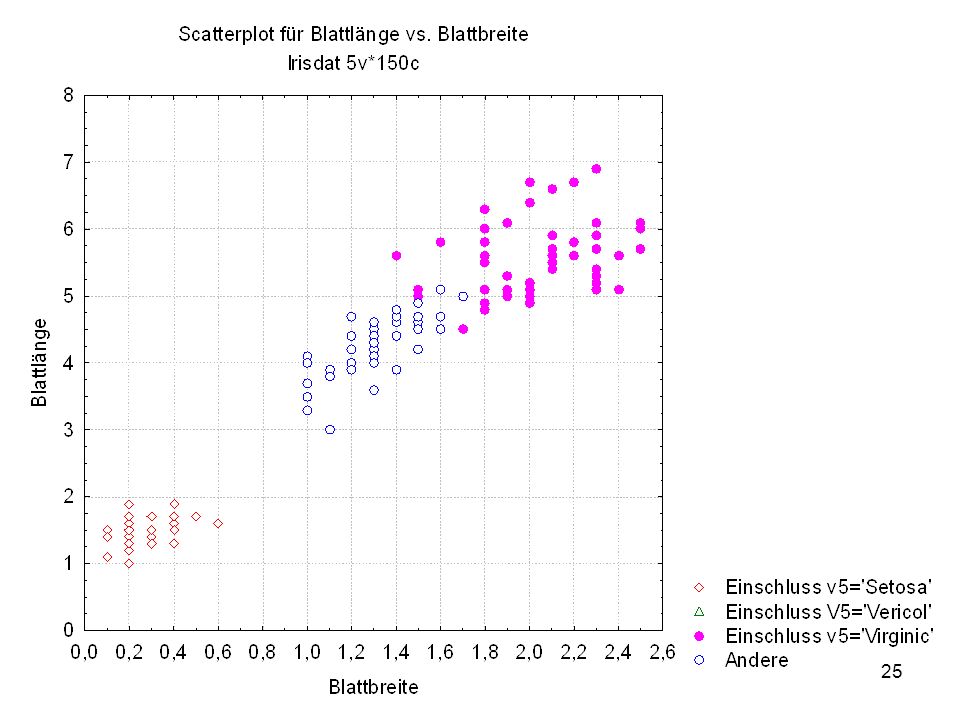
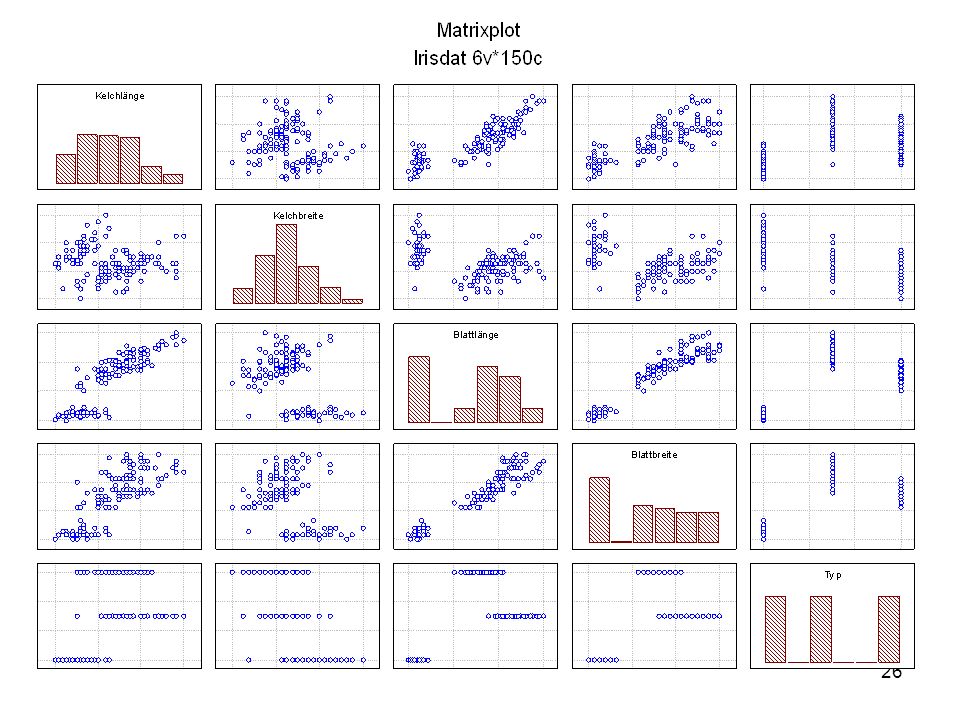
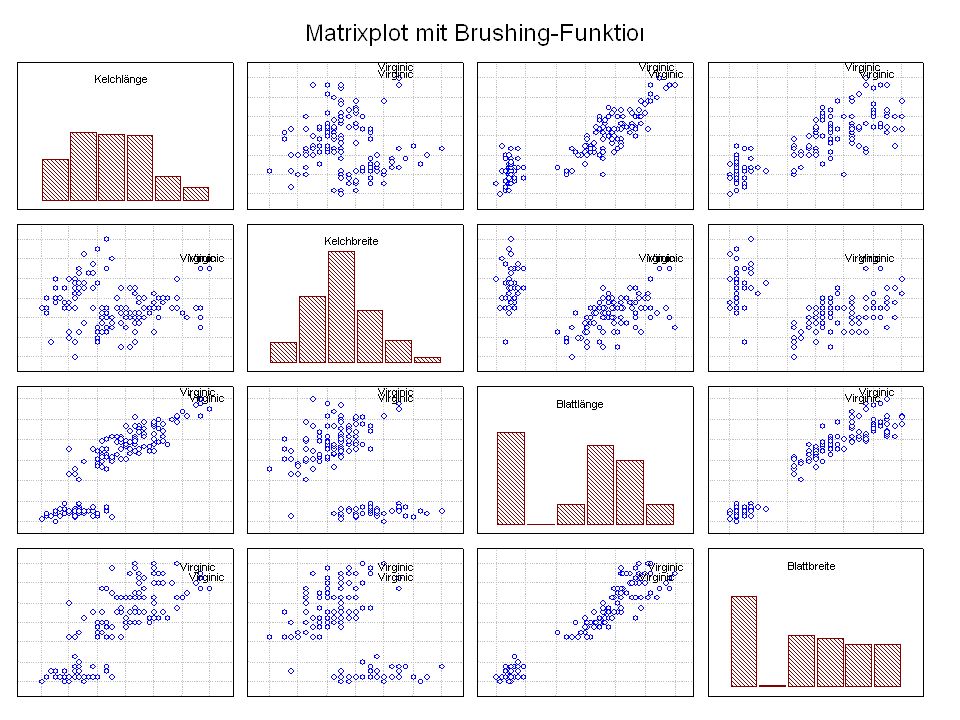
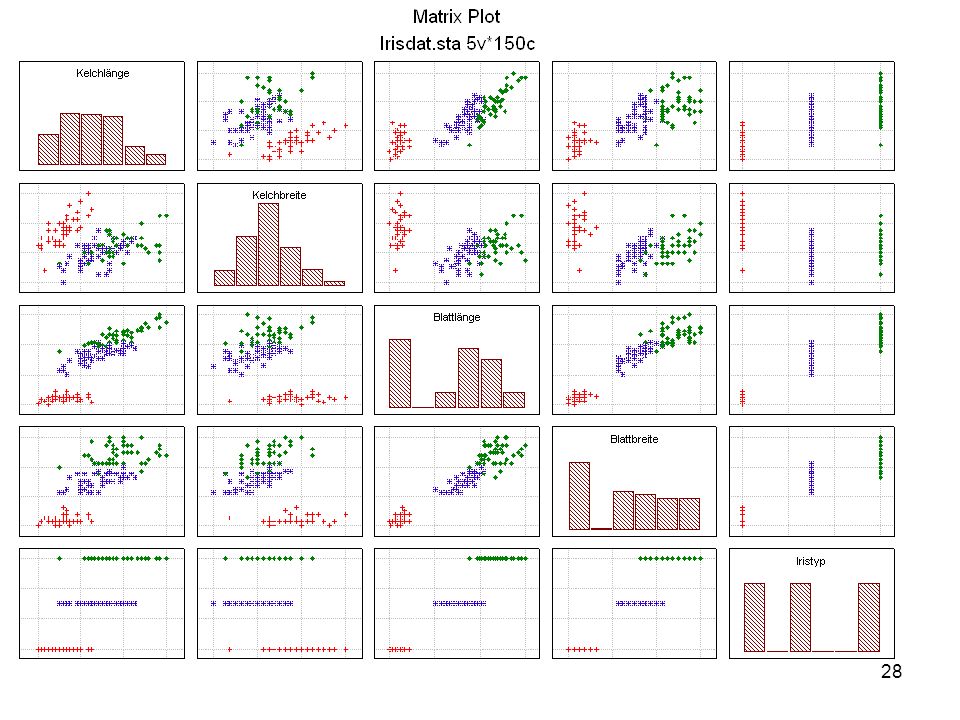
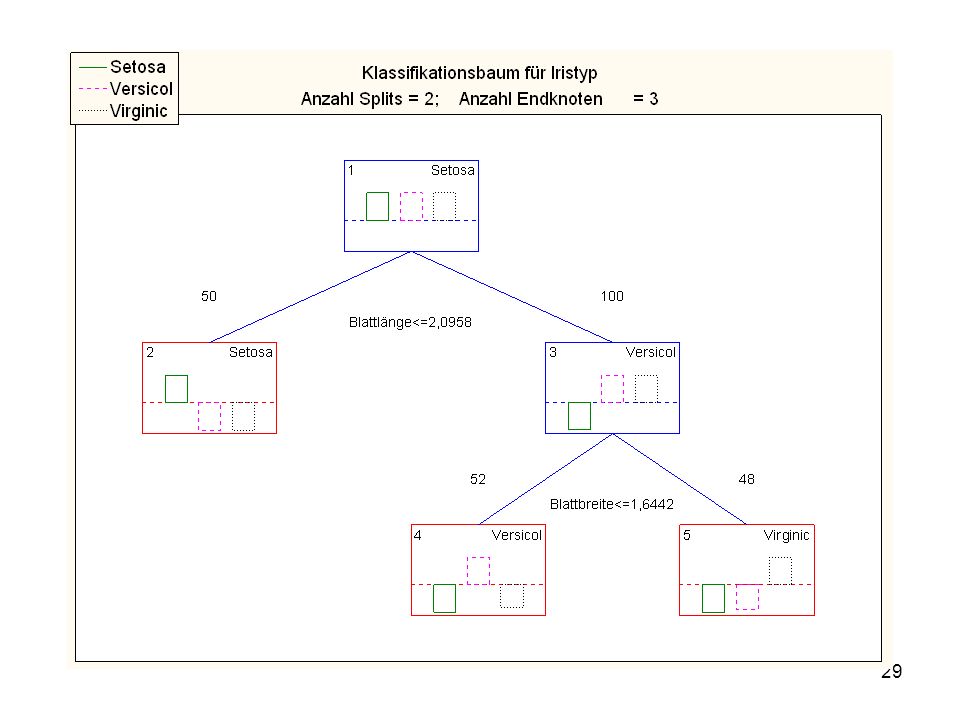
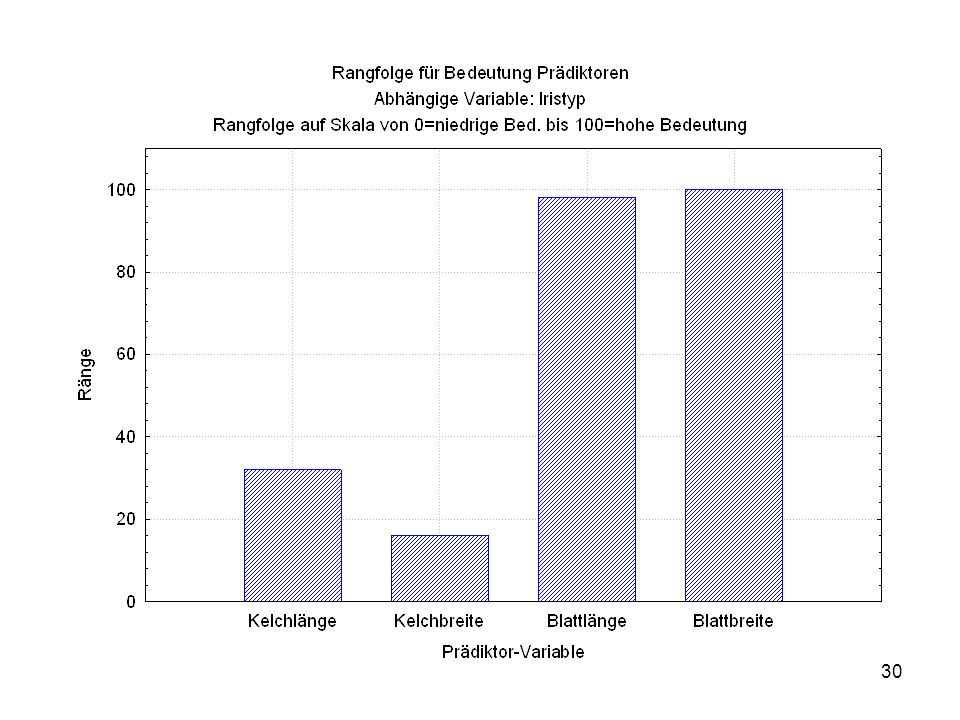
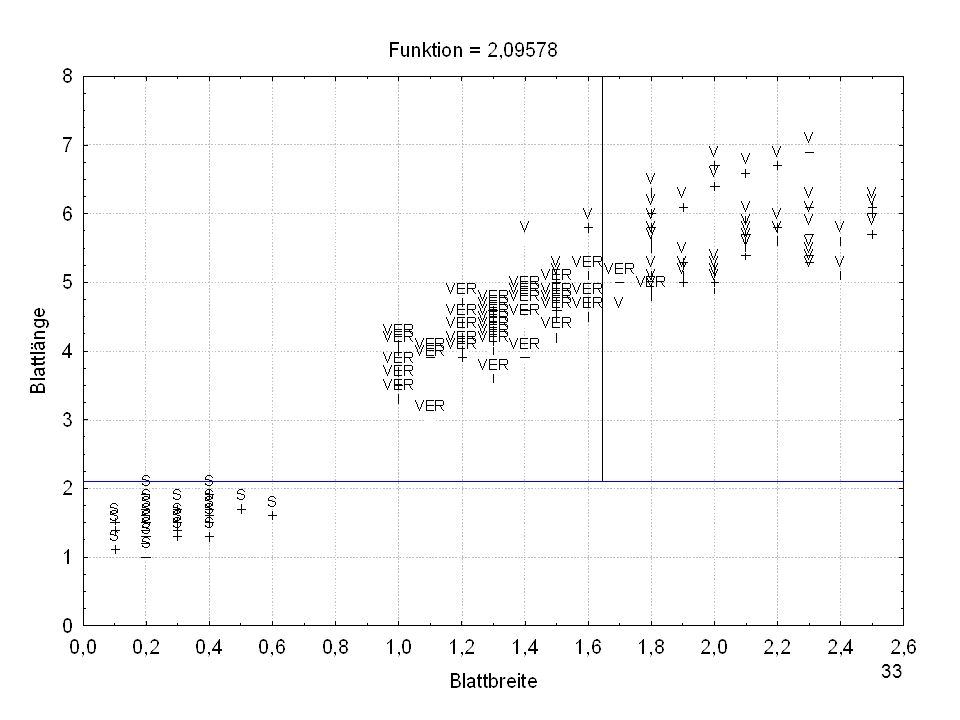
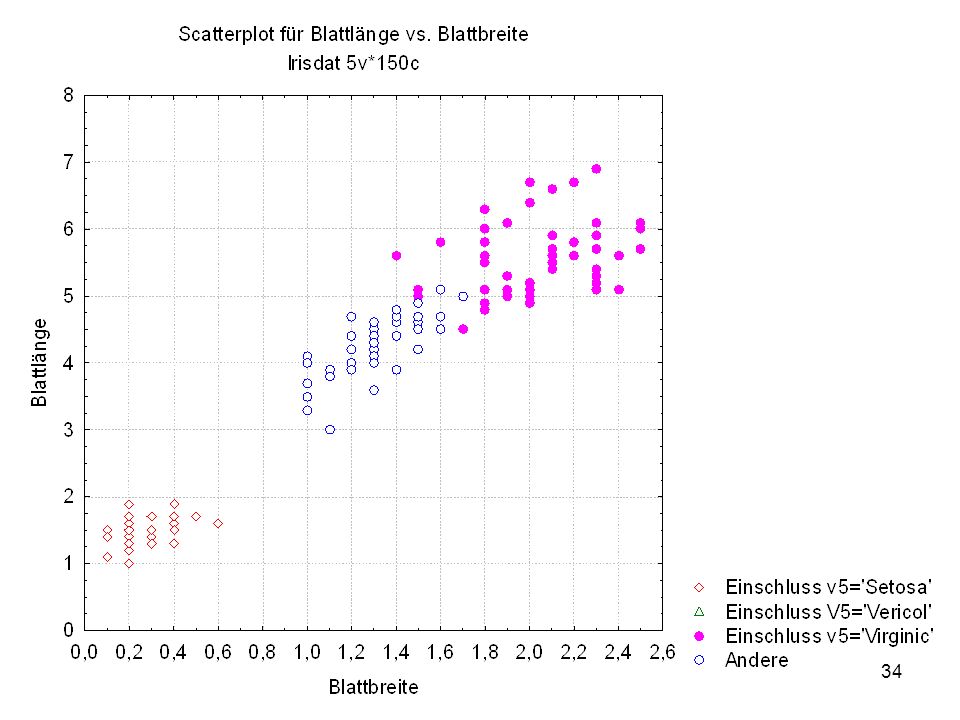
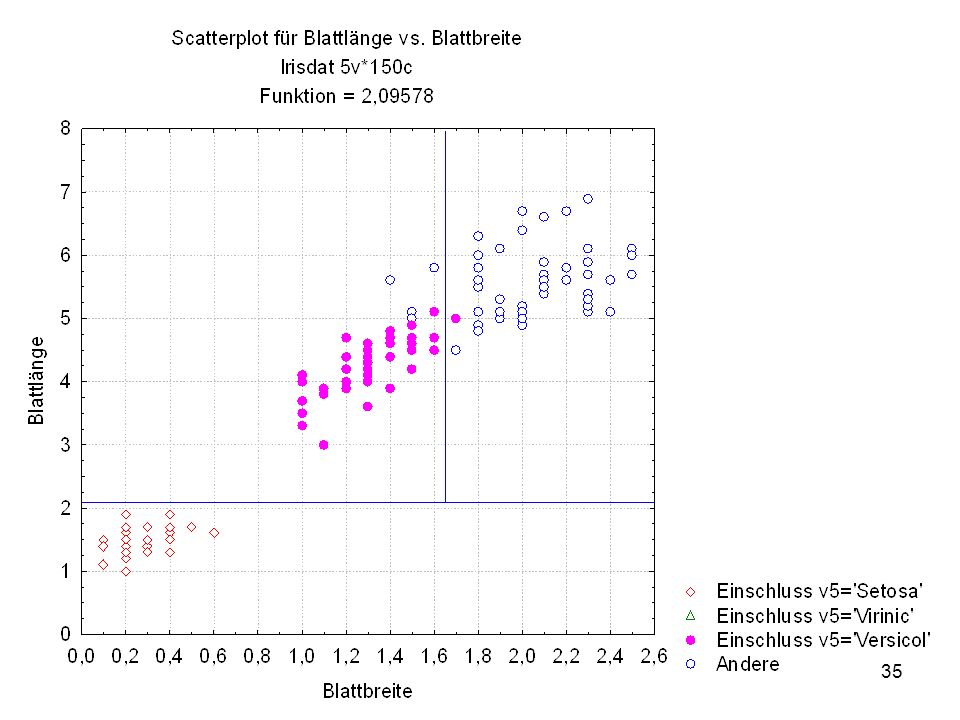

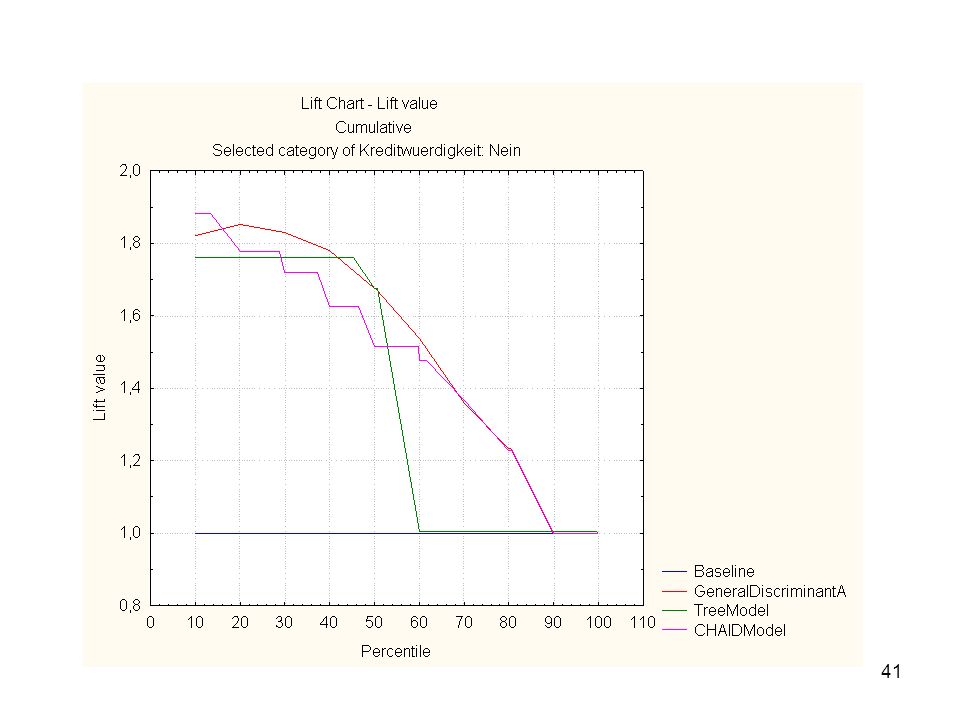







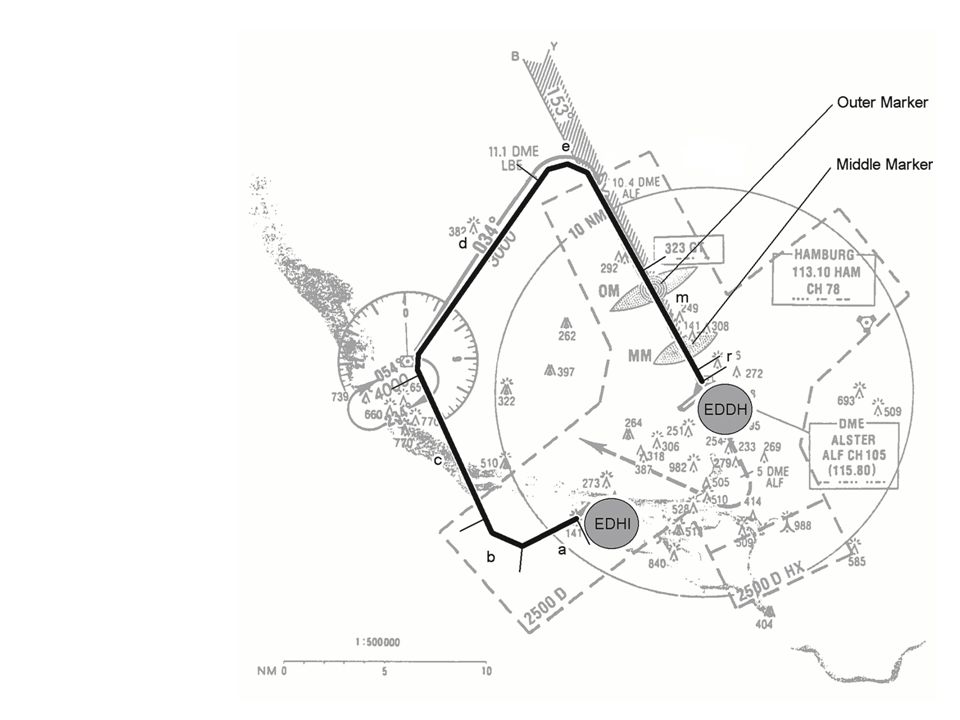
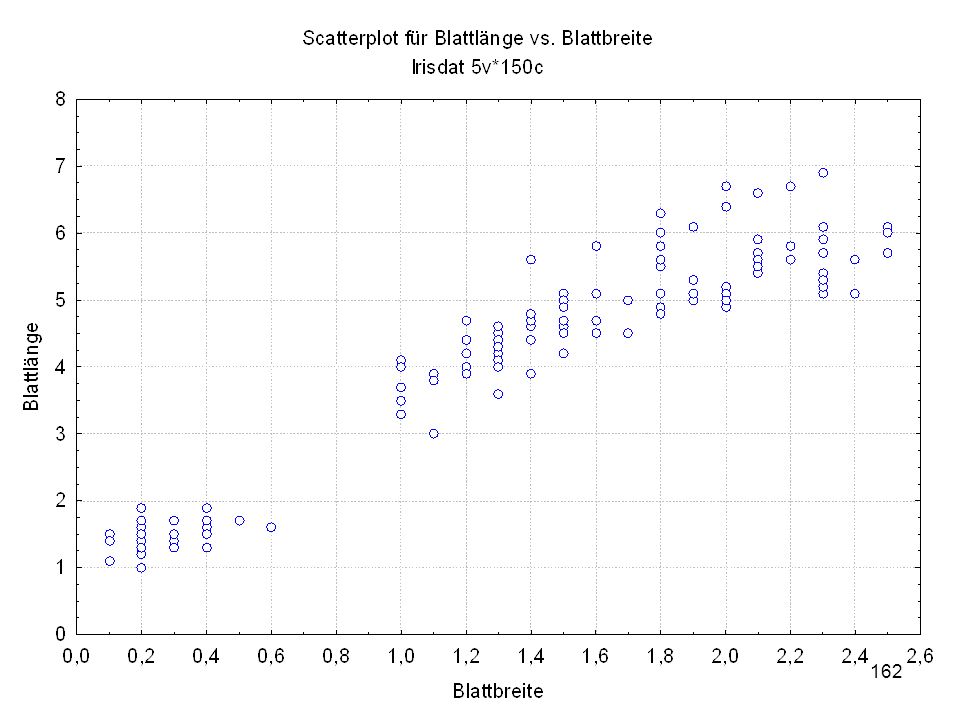
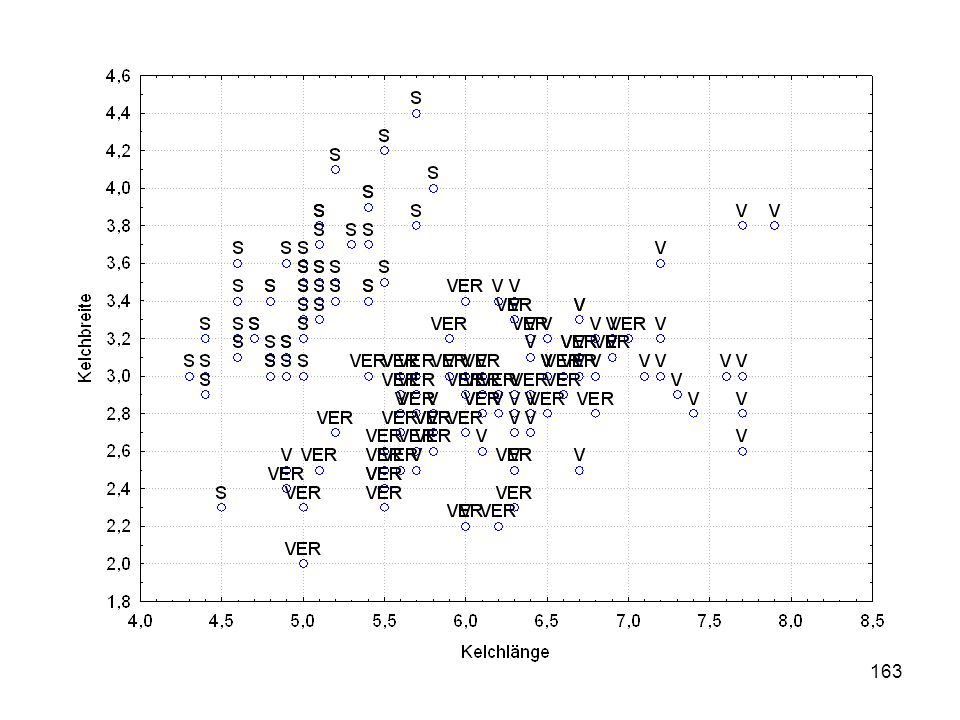
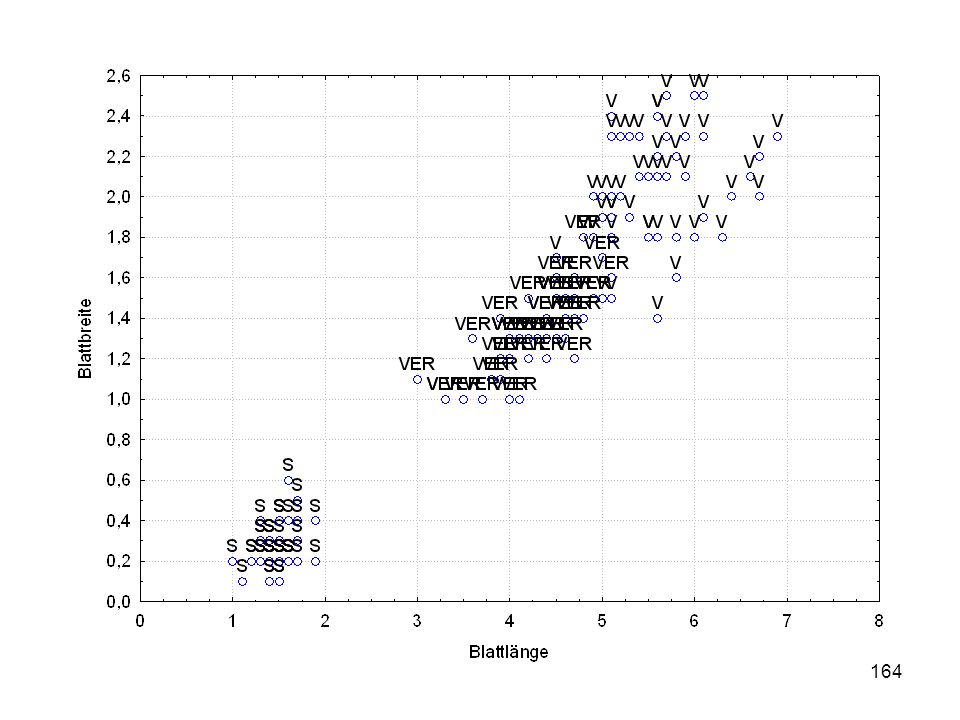
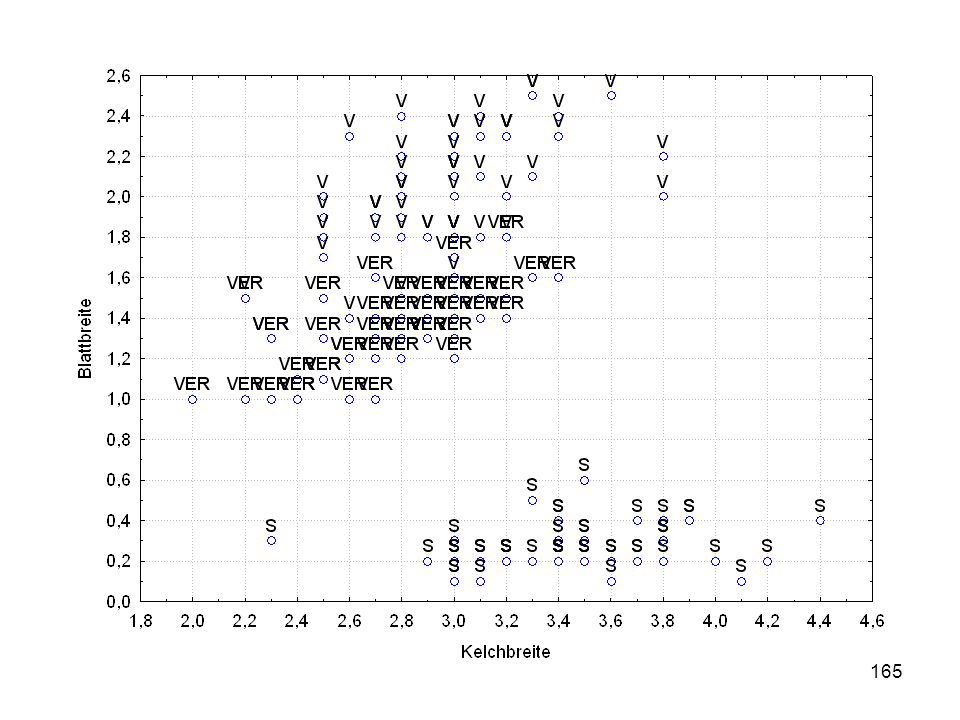
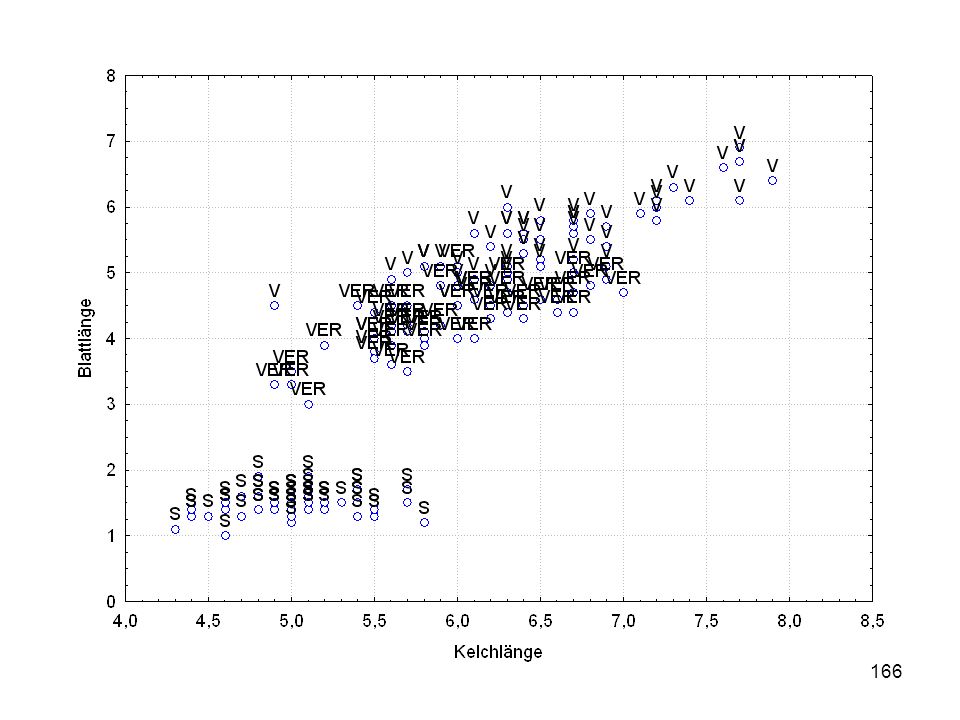
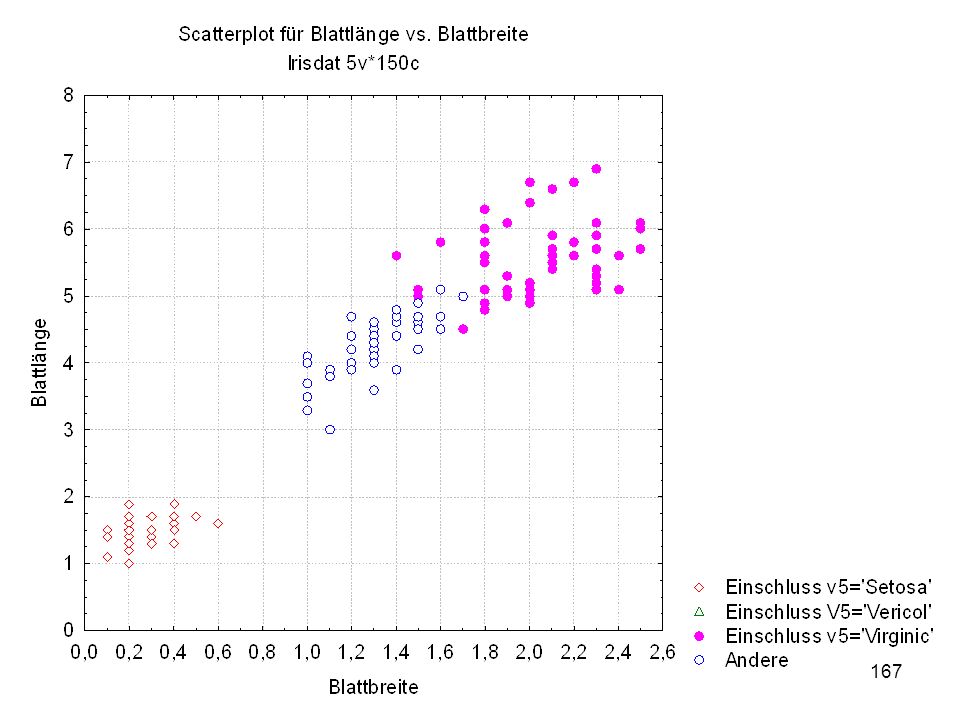
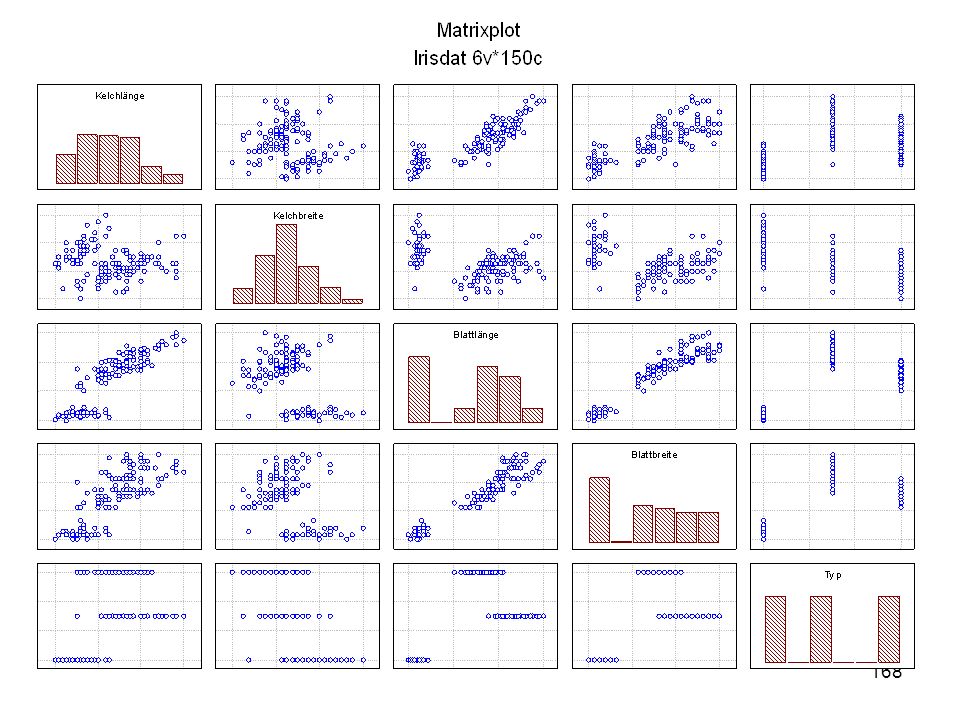


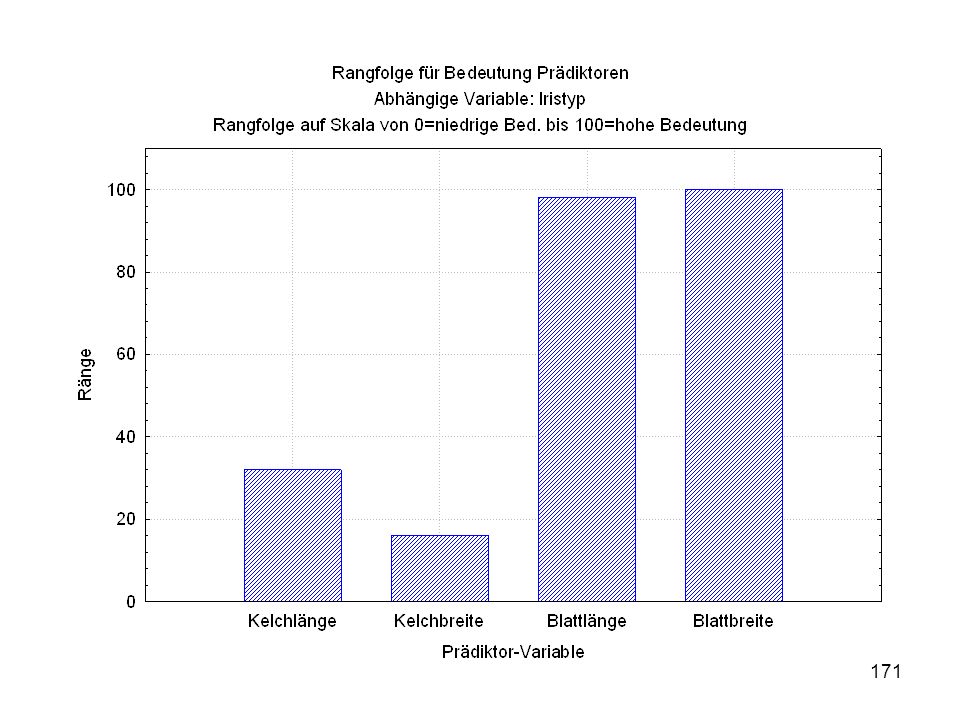

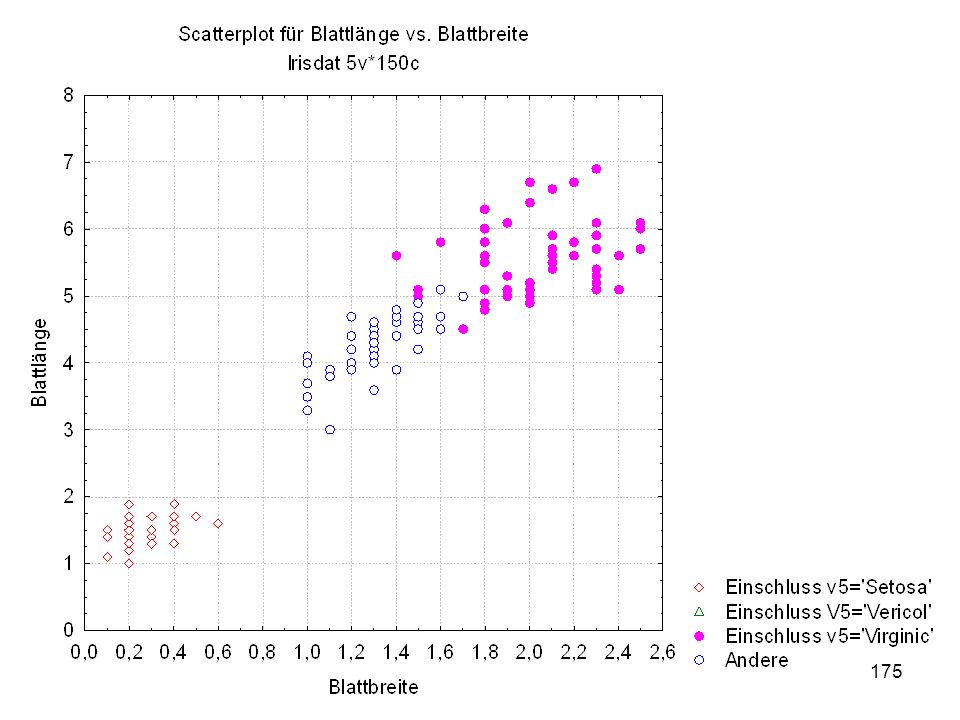
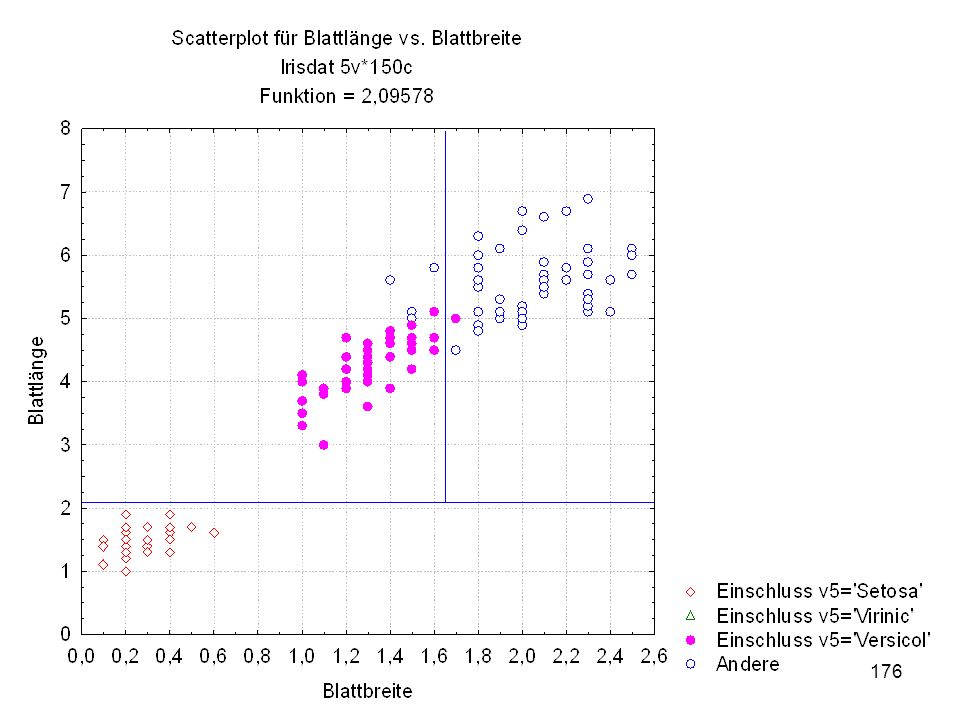


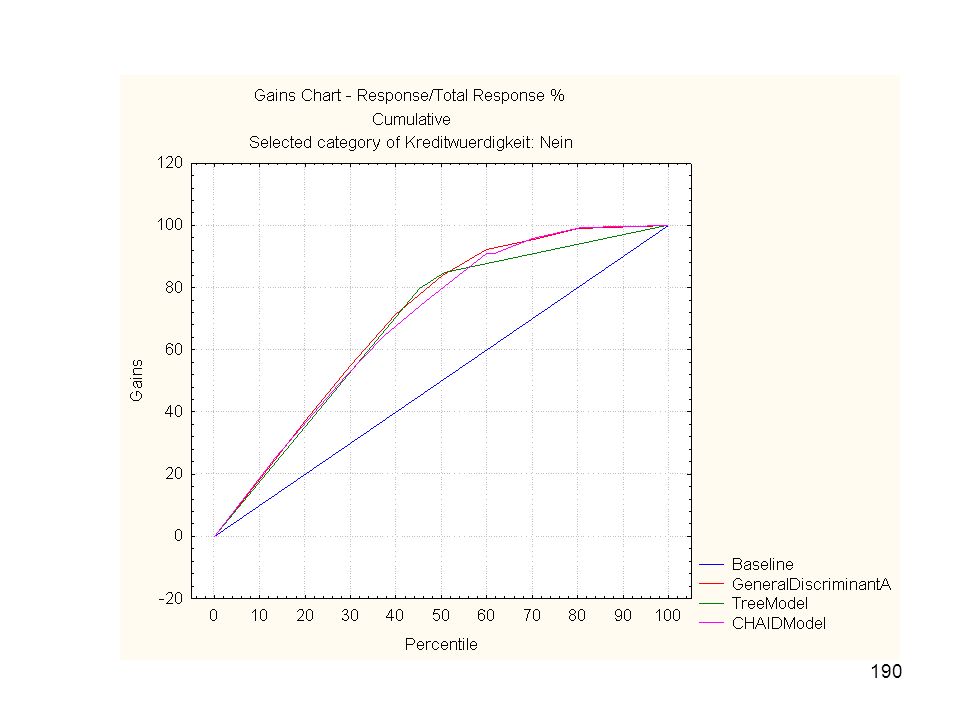
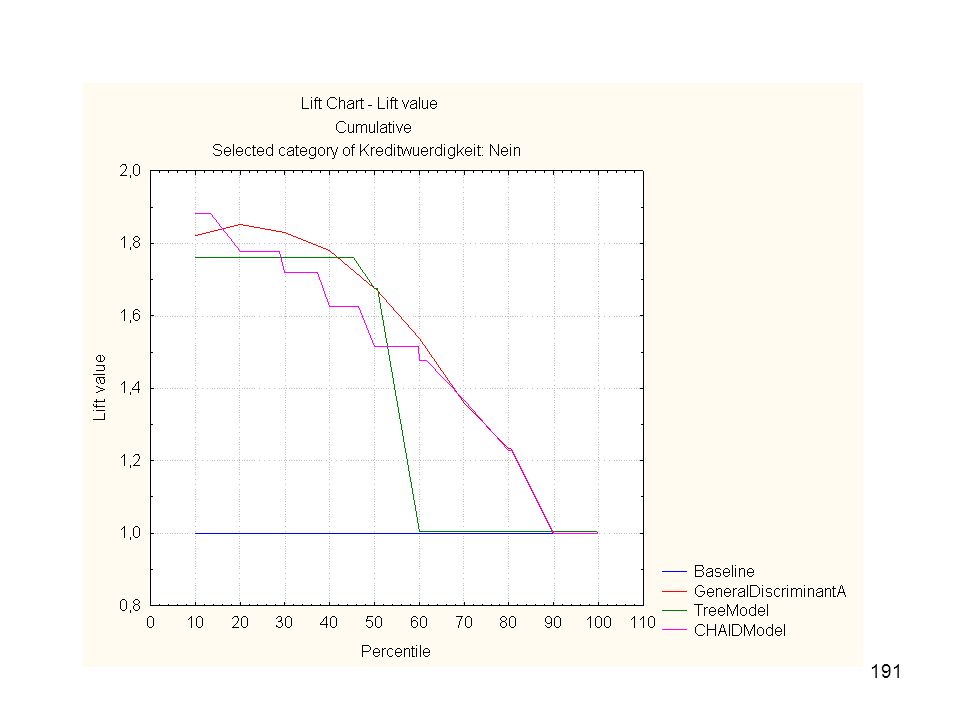

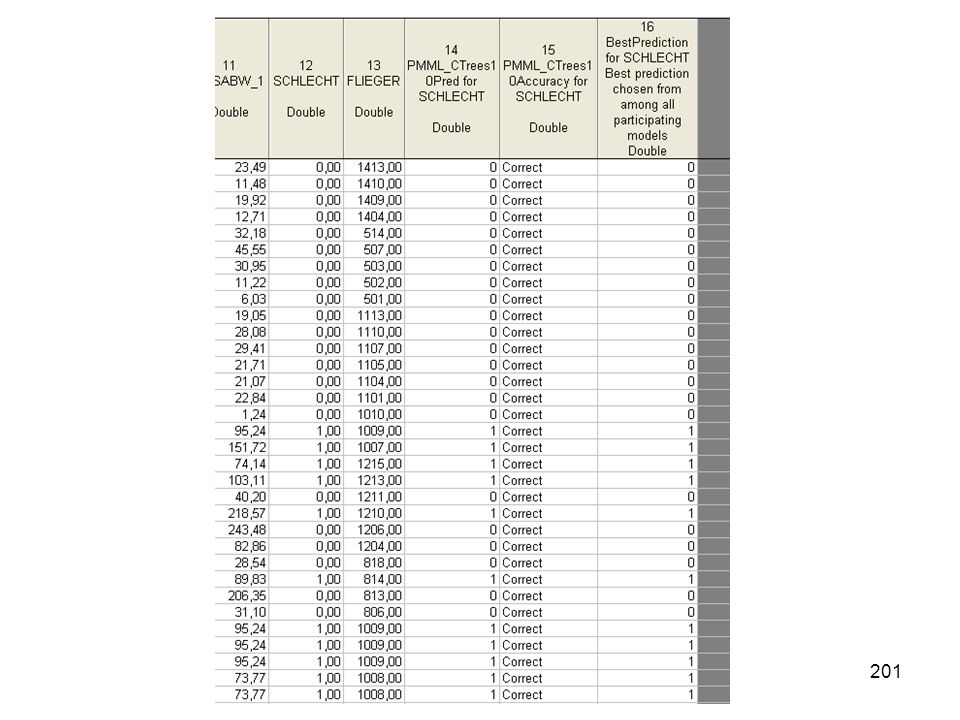
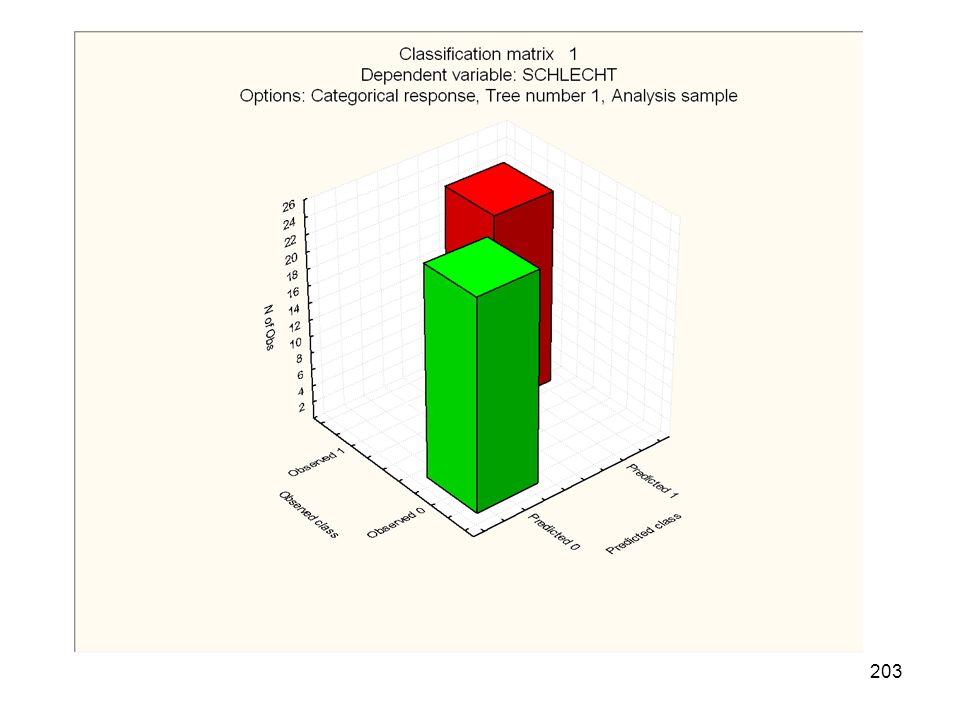
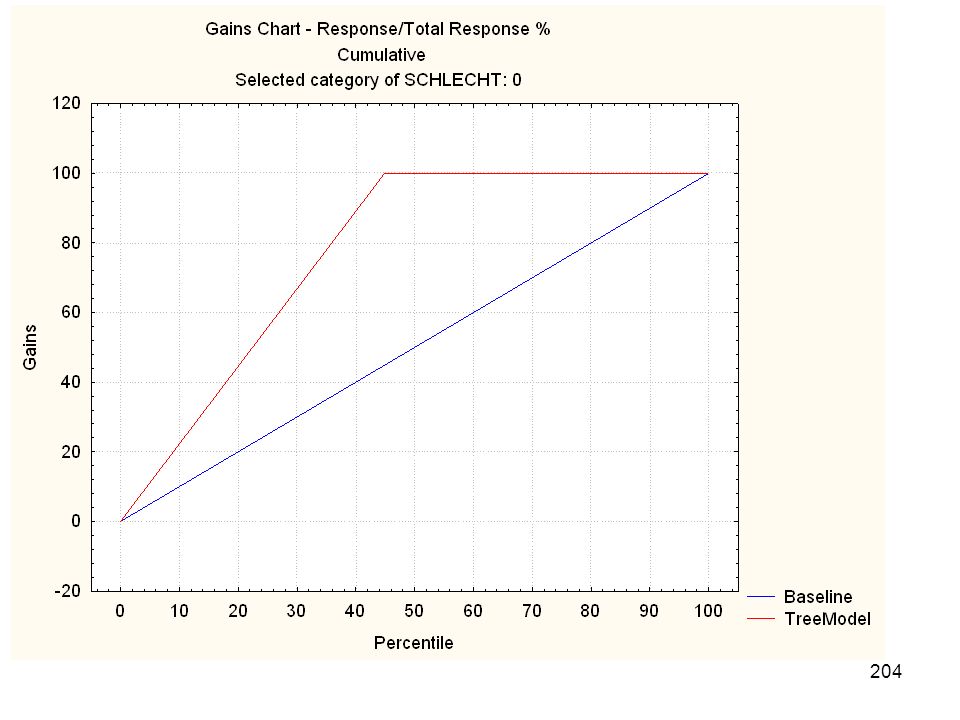






>")
>")

 U N I V E R S I T Ä T H A M B U R G November 2011.>")

Media Landesanstalt für Kommunikation Baden-Württemberg (LFK) Landeszentrale für Medien und Kommunikation.>")








