Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Einführung in die Datenanalyse mit SPSS -Allgemeines -Dateneingabe -Datenbereinigung/ Auswahl -Datenbeschreibung und –exploration -Statistische Tests

2
Allgemeines Geschichtliches Lizenzen Installation Versionen Benutzeroberfläche Daten-Editor Viewer

3
Dateneingabe in SPSS Der Ihnen vorliegende Fragebogen soll mit SPSS ausgewertet werden. Bereiten Sie die Variablen für die Dateneingabe vor. Frage 1: Einfachantwort, man braucht eine Zeile in SPSS. Messung kategorisch, also Kategorie 1-5 möglich. Frage 2: Mehrfachantwort möglich, man braucht also pro Abfrage (hier: Stadt) eine Spalte in SPSS (hier 7). Antwortmöglichkeiten sind nein (=0) und ja (=1). Frage 3: beinhaltet 6 Abfragen mit jeweils 5 Antwortkategorien, es werden also 6 Zeilen in SPSS benötigt. Hier auch als Kodierung „1= trifft voll zu“ bis „5=trifft überhaupt nicht zu“. Frage 4: offene Antwort, Angabe ist metrisch, also Skalenniveau. Hiermit kann man am meisten rechnen, also Informationsgehalt am höchsten.
 eine Spalte in SPSS (hier 7). Antwortmöglichkeiten sind nein (=0) und ja (=1). Frage 3: beinhaltet 6 Abfragen mit jeweils 5 Antwortkategorien, es werden also 6 Zeilen in SPSS benötigt. Hier auch als Kodierung „1= trifft voll zu bis „5=trifft überhaupt nicht zu . Frage 4: offene Antwort, Angabe ist metrisch, also Skalenniveau. Hiermit kann man am meisten rechnen, also Informationsgehalt am höchsten..")
4
Dateneingabe in SPSS Frage 5: auch offene Antwort, aber nominal. Schwierig auszuwerten! Daten von 20 befragten Personen stehen in einer Excel- Datei zur Verfügung. Eine Möglichkeit der Dateneingabe in SPSS ist, in ein bestehendes Tabellenblatt per copy/ paste Daten aus Excel einzufügen. Aufgabe: Kopieren Sie die Daten der Excel Datei „Fragebogen_Daten.xlsx“ (Tabelle 1) in das bereits vorbereitete Datenblatt von SPSS.
 in das bereits vorbereitete Datenblatt von SPSS..")
5
Struktur der Datensätze In den Spalten stehen die einzelnen gemessenen Merkmale (Variablen), d.h. alle Messungen für das Gewicht stehen in einer Spalte In einer Zeile stehen alle stehen alle Messungen einer Beobachtungseinheit (z.B. Patient, Pflanze) Keine freien Zeilen zur besseren Übersichtlichkeit Werteeingaben immer einheitlich, also entweder nur Text oder nur Zahl (Empfehlung: immer als Zahl kodieren) Bei fehlenden Werten Zellen frei lassen Variablenname muss mit Buchstaben beginnen, keine Leer- und Sonderzeichen SPSS ist nicht „case-sensitiv“, d.h. Alter = alter = ALTER
 Keine freien Zeilen zur besseren Übersichtlichkeit Werteeingaben immer einheitlich, also entweder nur Text oder nur Zahl (Empfehlung: immer als Zahl kodieren) Bei fehlenden Werten Zellen frei lassen Variablenname muss mit Buchstaben beginnen, keine Leer- und Sonderzeichen SPSS ist nicht „case-sensitiv , d.h. Alter = alter = ALTER.")
6
Struktur der Datensätze GeschlechtGrößeGewicht m18078 m16686 m18680 m19188 m17985 m18895 m17570 m18677 m18086 m19090 w16153 w16158 w15759 w17075 w16657 w168 w16665 w17561 w16862 w17061 falschrichtig MännerFrauen GrößeGewichtGrößeGewicht 11807816153 21668616158 31868015759 41918817075 51798516657 618895168k.A. 71757016665 81867717561 91808616862 101909017061
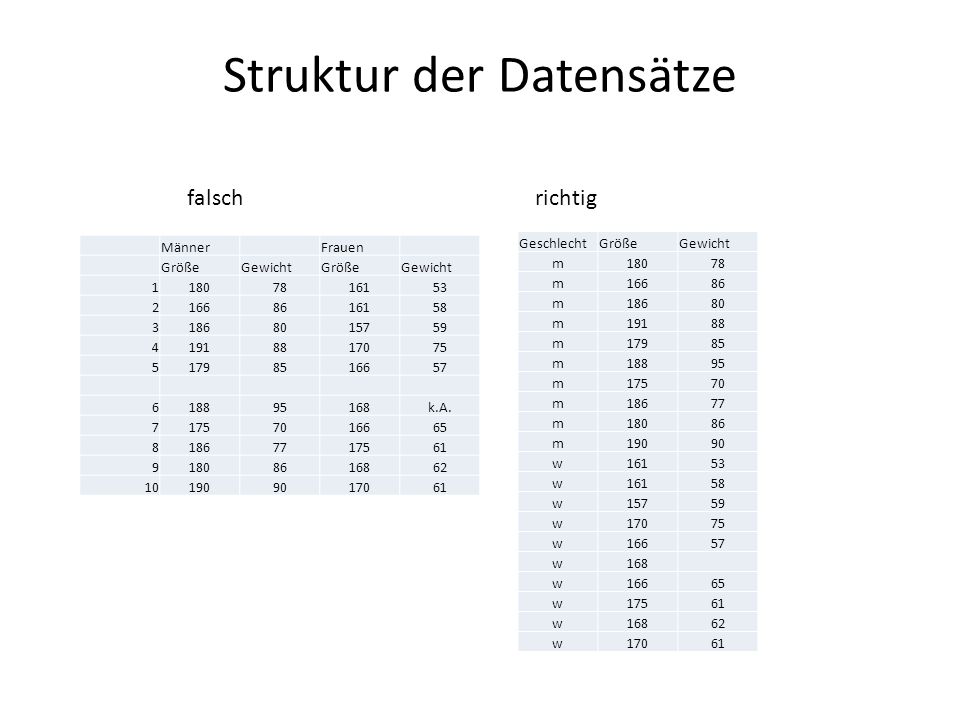
7
Datenerzeugung in SPSS Beispiel anhand des Datensatzes atemwege.xls (Quelle: http://www.statistik.lmu.de/service/datenarchiv/atem/atem.html) Laden einer Excel-Datei in SPSS: Datei Öffnen Daten Auswahl des Dateityps, hier.xls die gewünschte Datei kann ausgewählt werden. Dann Abfrage, ob in erster Zeile die Variablennamen stehen (in unserem Fall ist das so). Empfehlung: kurz visuell überprüfen, ob Daten sinnig sind. Angabe der Variablenlabels und Wertelabels Aufgabe: Vervollständigen Sie die Variablen- und Wertelabels gemäß den Angaben. Beachten: fehlende Werte! Tipp: gleiche Wertelabels können über copy & paste schneller eingegeben werden!
. Empfehlung: kurz visuell überprüfen, ob Daten sinnig sind. Angabe der Variablenlabels und Wertelabels Aufgabe: Vervollständigen Sie die Variablen- und Wertelabels gemäß den Angaben. Beachten: fehlende Werte. Tipp: gleiche Wertelabels können über copy & paste schneller eingegeben werden!.")
8
Datenbereinigung In vielen Fällen möchte man an den bestehenden Variablen noch etwas verändern bzw. neu Variablen erzeugen/ berechnen. Hierzu gibt es unter dem Menüpunkt Transformieren diverse Möglichkeiten: Variable berechnen : Man möchte in dem vorliegenden Datensatz eine Variable erhalten, die über die Anzahl der Vorerkran- kungen (Allergie, Kehlkopfent- zündung, Schnupfen, Husten) Auskunft gibt, also kann hier die neue Variable „Anz_Vorerkr“ durch Addition erzeugt werden.
 Auskunft gibt, also kann hier die neue Variable „Anz_Vorerkr durch Addition erzeugt werden..")
9
Datenbereinigung Bei dem Menüpunkt Variable berechnen besteht auch die Möglichkeit auf eine Vielzahl von Funktionen zurück zu greifen. Bei dem vorherigen Beispiel hätte man hier auch die Funktion SUM auswählen können.

10
Für die gleiche Aufgabe wäre auch ein andere Lösung möglich gewesen: Werte in Fällen zählen Unter dem Punkt „Werte definieren“ muss man dann noch den Wert „1“ eingeben. Bei dieser Funktion kann man sich jede Merkmals- ausprägung, fehlende Werte oder auch Bereiche durchzählen lassen! Datenbereinigung

11
Umkodieren von Variablen: Bei dieser Funktion (entweder Umkodieren in dieselben Variablen oder Umkodieren in andere Variablen ) können folgende Operationen durchgeführt werden: einfaches Umbenennen, z.B. sollen die mit „-1“ kodierten, fehlenden Werte in „99“ umgewandelt werden. Klassifizierung von Werten, z.B. möchte man Analysen nach Altersklassen durchführen, abgefragt wurde aber der Geburtsjahrgang. Bei der Variable „gebja“ treten Jahrgänge von 73 – 82 auf. Man möchte hier die Einteilung vornehmen von alt(1) und jung(2): 1: Jahrgänge 73 – 77 2: Jahrgänge 78 – 82 Name der neuen Variable: gebja_klass Bedingte Umkodierung von Fällen (s. nächstes Blatt)
 und jung(2): 1: Jahrgänge 73 – 77 2: Jahrgänge 78 – 82 Name der neuen Variable: gebja_klass Bedingte Umkodierung von Fällen (s. nächstes Blatt).")
12
Bedingte Umkodierung einer Variable Man möchte die Kinder in Größengruppen einteilen, die Grenzen setzt man aber je nach Geschlecht unterschiedlich an. 1 = „klein“ = Größe unterhalb des 25% Quartils 2 = „mittel“ = Größe zwischen 25% und 75% Quartil 3= „groß“ = Größe oberhalb des 75% Quartils Die Quartile für die Mädchen sind 25: 128,0050: 138,0075: 151,00 für die Jungen 25: 131,2550: 142,0075: 153,00 Transformieren Umkodieren in andere Variablen Im sich öffnenden Fenster Auswahl der Variable „gross“, Benennung der Ausgabevariable als „gross_klass“, Bezeichnung „Größe in Klassen nach Geschlecht“ Datenbereinigung

13
Durch Drücken der Schaltfläche „Alte und neue Werte“ öffnet sich ein weiteres Fenster, in das nacheinander die vorher festgelegten Bereiche zuerst für die Mädchen eingefügt werden. Durch Drücken von „Weiter“ kehrt man wieder zu dem vorherigen Fenster zurück.

14
Datenbereinigung Im nächsten Schritt muss man angeben, dass die eingegebenen Werte nur für die weiblichen Probanden gelten; dies geschieht durch Drücken des Feldes „Falls…“ und Eintragen der Bedingung „sex=2“, wie im neben stehenden Fenster gezeigt. Aufgabe: Führen Sie die Einteilung für die Jungen durch

15
Exkurs Syntax Man möchte eine Variable über die örtliche Belastung des Kindes einführen, dabei wird berücksichtigt – der Wohnort des Kindes (Variable zone) – ob die Mutter raucht (raumu) – ob der Vater raucht (rauva) Die neue Variable soll „belast“ heißen und soll folgende Werte annehmen können: 1: geringe Belastung (bei zone 2 raumu 0 rauva 0, 2 0 1, 2 1 0, 1 0 0, 3 0 0) 2: hohe Belastung (bei 2 1 1, 1 0 1, 1 1 0, 1 1 1, 3 0 1, 3 1 0, 3 1 1)
 – ob die Mutter raucht (raumu) – ob der Vater raucht (rauva) Die neue Variable soll „belast heißen und soll folgende Werte annehmen können: 1: geringe Belastung (bei zone 2 raumu 0 rauva 0, 2 0 1, 2 1 0, 1 0 0, 3 0 0) 2: hohe Belastung (bei 2 1 1, 1 0 1, 1 1 0, 1 1 1, 3 0 1, 3 1 0, 3 1 1)")
16
Exkurs Syntax Es besteht die Möglichkeit, diese Variable über das Menü zu erzeugen ( Transformieren Variable berechnen ), dies ist allerdings etwas umständlich! Möglich wäre auch der Weg über den Syntax ( Datei Neu Syntax ): IF (zone = 2 & raumu = 0 & rauva = 0)|(zone = 2 & raumu = 0 & rauva = 1)| (zone = 2 & raumu = 1 & rauva = 0)|(zone = 1 & raumu = 0 & rauva = 0)| (zone = 3 & raumu = 0 & rauva = 0) belast=1. IF (zone = 2 & raumu = 1 & rauva = 1)|(zone = 1 & raumu = 0 & rauva = 1)| (zone = 1 & raumu = 1 & rauva = 0)|(zone = 1 & raumu = 1 & rauva=1)| (zone = 3 & raumu = 1 & rauva = 0)|(zone = 3 & raumu = 0 & rauva = 1)| (zone = 3 & raumu = 1 & rauva = 1) belast=2. EXECUTE.
: IF (zone = 2 & raumu = 0 & rauva = 0)|(zone = 2 & raumu = 0 & rauva = 1)| (zone = 2 & raumu = 1 & rauva = 0)|(zone = 1 & raumu = 0 & rauva = 0)| (zone = 3 & raumu = 0 & rauva = 0) belast=1. IF (zone = 2 & raumu = 1 & rauva = 1)|(zone = 1 & raumu = 0 & rauva = 1)| (zone = 1 & raumu = 1 & rauva = 0)|(zone = 1 & raumu = 1 & rauva=1)| (zone = 3 & raumu = 1 & rauva = 0)|(zone = 3 & raumu = 0 & rauva = 1)| (zone = 3 & raumu = 1 & rauva = 1) belast=2. EXECUTE..")
17
Exkurs Syntax Vorteile zur Dokumentation der Analysen, z.B. bei Abschlussarbeiten Bei sich regelmäßig wiederholenden Analysen (Empfehlung: Kommentare schreiben) Nachteil es hat den Charakter einer Programmiersprache Öffnen des Syntax-Editors über Datei Neu „Syntax“ oder bei Durchführung einer Aufgabe durch Drücken der Schaltfläche „Einfügen“ (anstatt „OK“), der durchzuführende Befehl wird gleich in den Syntax-Editor eingetragen und kann jederzeit erneut durch geführt werden. Kommentare werden mit einem * gekennzeichnet.
 Nachteil es hat den Charakter einer Programmiersprache Öffnen des Syntax-Editors über Datei Neu „Syntax oder bei Durchführung einer Aufgabe durch Drücken der Schaltfläche „Einfügen (anstatt „OK ), der durchzuführende Befehl wird gleich in den Syntax-Editor eingetragen und kann jederzeit erneut durch geführt werden. Kommentare werden mit einem * gekennzeichnet..")
18
Datenauswahl Man möchte in einer Analyse nur die Kinder früherer Jahrgänge untersuchen. Von der selbst erstellten Variable gebja_klass sollen daher nur die Fälle „1“ ausgewählt werden. Daten Fälle auswählen Beachten: dieser „Filter“ bleibt auch nach Deaktivierung als eigene Variable erhalten Zur besseren Übersichtlichkeit sollen die Daten dann nach der Variable gebja_klass aufsteigend sortiert werden. Daten Fälle sortieren

19
Übung Sortieren Sie die Fälle zurück in die alte Ordnung. Setzen Sie einen Filter: wählen Sie die Fälle von männlichen Kindern aus, die als Anzahl an Vorerkrankungen (Anz_Vorerkr) mindestens 2 haben Erzeugen Sie eine Variable, die die Differenz zwischen fef50 und fef75 angibt, Name: diff_fef, Berechnung: fef50 – fef75 Erzeugen Sie eine Variable geb_jz (Jahreszeit Geburt) ausgehend von der Variable gebmo: 12, 1, 2 Winter 3-5 Frühjahr 6-8 Sommer 9-11 Herbst
 mindestens 2 haben Erzeugen Sie eine Variable, die die Differenz zwischen fef50 und fef75 angibt, Name: diff_fef, Berechnung: fef50 – fef75 Erzeugen Sie eine Variable geb_jz (Jahreszeit Geburt) ausgehend von der Variable gebmo: 12, 1, 2 Winter 3-5 Frühjahr 6-8 Sommer 9-11 Herbst.")
20
Hilfe Öffnen des Lernprogramms beim Start von SPSS Menüpunkt Hilfe Themen öffnet online-Hilfe sortiert nach Themen Fallstudien zu diversen Analysemethoden (Englisch) Statistik Assistent, ist quasi Ratgeber zur Auswahl des statistischen Verfahrens Arbeiten mit R Anleitung zur Integration von R Befehlen Befehlssyntax-Referenz Beschreibung der Syntaxsprache SPSS Community verbindet zu IBM Seite mit FAQ‘s Algorithmen Beschreibung der mathematischen Formeln, die den Prozeduren zugrunde liegen Hilfe zu Prozeduren: im Fenster findet sich eine Schaltfläche „Hilfe“, es öffnet sich online eine Beschreibung mit Beispielen. Benutzerhandbücher von SPSS beim Installationsmedium bei gelegt

21
Datenbeschreibung Menüpunkt Analysieren Deskriptive Statistik am Beispiel der Variable „Körpergröße“ In einem vorherigen Beispiel wurden die Quartile (25%, 50%, 75%) der Körpergröße von Mädchen und Jungen benötigt. Wie erhält man diese? Unter Analysieren Deskriptive Statistik Explorative Datenanalyse wird die Variable „gross“ als abhängige Variable ausgewählt, die Variable „sex“ in die Faktorenliste gesetzt. Im Fenster „Statistiken“ muss noch ein Häkchen bei den Perzentilen gesetzt werden, die Ausgabe sieht u.a. so aus:

22
Datenbeschreibung Pivot-Tabellen Die Formatvorlage kann verändert werden unter Bearbeiten Optionen „Pivot-Tabellen“. Die Pivot-Tabelle an sich kann durch Doppelklicken im Pivot- Tabellen-Editor bearbeitet werden, z.B. kann die eben gezeigte Tabelle noch etwas reduziert werden:

23
Datenbeschreibung Kreuztabellen ermöglichen eine zwei- bis mehrfache Aufteilung der Daten, einfache statistische Tests können auch verwendet werden. Beispiel: Besteht ein Einfluss der Umweltbelastung am Wohnort auf die Anzahl an Vorerkrankungen? Erstellen einer Kreuztabelle mit den Variab- len zone und Anz_Vorerkr. Analysieren Deskriptive Statistik Kreuztabel- len Bei der Schaltfläche „Zellen“ wurde bei Häufigkeiten „Beobachtet“ und „Erwartet“ ausgewählt sowie bei den Prozentwerten „Gesamtsumme“.

24
Datenbeschreibung Hat man bei der Schaltfläche „Statistiken“ ein Häkchen bei „Chi- Quadrat“ gesetzt, erhält man noch folgende Ausgabe. Beim Chi-Quadrat Test nach Pearson ist der p-Wert <0,05, d.h. es besteht ein signifikanter Einfluss der Umweltbelastung am Wohnort auf die Anzahl der Vorerkrankungen. Man kann auch noch eine weitere Aufschachtlung der Kreuztabelle vornehmen, z.B. das Geschlecht als Schichtvariable hinzu fügen.

25
Datenbeschreibung Bei der explorativen Datenanalyse können für Variablen mit Skalen- niveau (metrisch) auch diverse Diagramme mit erstellt werden, z.B. Boxplots und Normalverteilungsdiagramme (Q-Q-Plot) sowie statis- tische Tests zur Überprüfung der Normalverteilungsannahme durchgeführt werden. Dieses ist für die spätere Auswahl eines geeigneten Testverfahrens von Bedeutung ( Explorative Daten- analyse, „Diagramme“, Häkchen setzen bei „Normalverteilungstests mit Diagrammen“). Auch diese Diagramme können durch Doppelklicken im Diagramm- Editor geöffnet und bearbeitet werden, hierzu später. Eine Liste mit der Beschreibung aller Variablen und der möglichen Variablenwerte im Ausgabefenster (ähnlich der Variablenansicht) erhält man über die Syntax: display dictionary variable all.
 sowie statis- tische Tests zur Überprüfung der Normalverteilungsannahme durchgeführt werden. Dieses ist für die spätere Auswahl eines geeigneten Testverfahrens von Bedeutung ( Explorative Daten- analyse, „Diagramme , Häkchen setzen bei „Normalverteilungstests mit Diagrammen ). Auch diese Diagramme können durch Doppelklicken im Diagramm- Editor geöffnet und bearbeitet werden, hierzu später. Eine Liste mit der Beschreibung aller Variablen und der möglichen Variablenwerte im Ausgabefenster (ähnlich der Variablenansicht) erhält man über die Syntax: display dictionary variable all..")
26
Diagrammerstellung Mithilfe eines Balkendiagramms sollen die Häufigkeiten der Anzahlen an Vorerkrankungen dargestellt werden. Diagramme Diagrammerstellung. Per Drag and Drop wird die gewünschte Diagrammart und die Variable in das Vorschaufeld gezogen. Zum Bearbeiten des Diagramms doppelt klicken, es öffnet sich der Diagrammeditor. Durch Doppelklicken auf das zu ändernde Element (z.B. Balken) öffnet sich das Eigenschaften-Fenster
 öffnet sich das Eigenschaften-Fenster.")
27
Diagrammerstellung Aufgaben: - Ändern der Dicke der Balken - Ändern der Balken in 3D - Ändern der Hintergrundfarbe - Ändern der Schriftgröße der Achsenbeschriftungen - Verkleinern des y-Achsenabschnitts auf 0 bis 1050 - Fügen Sie eine Anmerkung ein

28
Einfache Testverfahren Auswahl eines geeigneten Tests zum Vergleich zweier Stichproben: - welcher Art sind die Daten (ordinal, metrisch,…) - kann man eine Verteilungsannahme machen (sind Daten normalverteilt?) - sind die Varianzen der beiden Stichproben homogen? Um bei metrischen Variablen die Normalverteilungsannahme zu untersuchen, verwendet man wie bereits vorgestellt Analysen Deskriptive Statistik Explorative Datenanalyse Die erstellten Boxplots sowie das Ergebnis des Shapiro-Wilk bzw. des Kolmogorov-Smirnov Tests geben einen Aufschluss über die Verteilungsannahme. Die Annahme der Varianzhomogenität (z.B. Levene Test) wird automatisch beim Durchführen eines T-Tests überprüft.
 wird automatisch beim Durchführen eines T-Tests überprüft..")
29
Einfache Testverfahren Die Tests zum Vergleich zweier Stichproben finden sich unter Analysen Mittelwerte vergleichen sowie unter Nichtparametrische Tests Beispiel: Es soll festgestellt werden, ob sich Jungen und Mädchen hinsichtlich des fef75 unterscheiden. Der fef75 ist eine metrische Variable, wir prüfen vorerst, ob diese normalverteilt ist. -> Boxplots -> Q-Q- Diagramm -> Teststatistiken Bei den Q-Q-plots zeigt sich eine deutliche Abweichung des fef75 von der Normalverteilung, das Ergebnis des Shapiro-Wilk Tests bestätigt dies (p- Wert < 0,05). Die Verteilung ist rechtsschief, dies kann man anhand eines Histogramms oder des „Schiefe“-Wertes, der deutlich größer als 0 ist, sehen. Die Verteilung ist auch „steilgipflig“, angezeigt durch den deutlich positiven „Kurtosis“-Wert. Ein weiterer Hinweis auf eine Abweichung von der Normalverteilung ist ein deutlicher Unterschied zwischen Mittelwert und Median.
. Die Verteilung ist rechtsschief, dies kann man anhand eines Histogramms oder des „Schiefe -Wertes, der deutlich größer als 0 ist, sehen. Die Verteilung ist auch „steilgipflig , angezeigt durch den deutlich positiven „Kurtosis -Wert. Ein weiterer Hinweis auf eine Abweichung von der Normalverteilung ist ein deutlicher Unterschied zwischen Mittelwert und Median..")
30
In diesem Fall würden wir also nicht von einer Normalverteilung ausgehen. Daher wählen wir einen nichtparametrischen Test: Analysieren Nichtparametrische Tests unabhängige Stichproben. SPSS verwendet den Mann-Whitney-U-Test für den Vergleich der zwei Stichproben. Dieser Test hat als Voraussetzung, dass die Verteilungen der beiden Stichproben gleich sind, was wir beim Betrachten der Boxplots bestätigen können (Levene-Test p-Wert 0,809). Ergebnis: Der p-Wert von 0,414 ist deutlich über dem Signifikanzniveau von 0,05, daher können keine geschlechterbedingten Unterschiede hinsichtlich des fef75 festgestellt werden. Einfache Testverfahren
. Ergebnis: Der p-Wert von 0,414 ist deutlich über dem Signifikanzniveau von 0,05, daher können keine geschlechterbedingten Unterschiede hinsichtlich des fef75 festgestellt werden. Einfache Testverfahren.")
31
Korrelation Untersucht, ob ein kausaler Zusammenhang zwischen zwei Variablen besteht. Beispiel: Es wird ein Zusammenhang zwischen der Vitalkapazität fvc und dem maximalen Ausatemstrom pef vermutet. Auch hier müssen die Variablen auf Normalverteilung untersucht werden, um das geeignete Verfahren auszuwählen. Beide Variablen folgen nicht der Normalverteilung, es kann daher nicht der Pearsonsche Korrelationskoeffizient verwendet werden, wir greifen daher auf den Spearman Rangkorrelations- koeffizienten zurück, der sich unter Analysieren Korrelation Bivariate Korrelationen findet. Als Ergebnis erhalten wir als Spearman-Rho-Wert 0,86, was eine starke, positive Korrelation anzeigt, die auf dem 1% Niveau signifikant ist.

32
Lineare Regression Erlaubt eine Aussage über den funktionalen Zusammenhang zweier metrischer, voneinander unabhängiger, (normalverteilter) und varianzhomogener Variablen. Wir möchten z.B. anhand des Gewichts der Kinder deren Körpergröße „vorhersagen“. Eine Korrelation zeigt einen starken positiven Zusammenhang dieser beiden Variablen auf (Spearman-rho= 0,923). Unter Analysieren Regression Linear erzeugen wir unser Regressionsmodell: abhängige Variable=Körpergröße, Unabhängige=Gewicht. Für die Bewertung des Modells sind folgende Angaben wichtig: das R² beträgt 0.794, d.h. fast 80% der Gesamtstreuung der Variable „Körpergröße“ werden durch unser Modell, also die Variable „Gewicht“ erklärt, die übrigen 20% ergeben die Residuen (nicht erklärte Streuung).
. Unter Analysieren Regression Linear erzeugen wir unser Regressionsmodell: abhängige Variable=Körpergröße, Unabhängige=Gewicht. Für die Bewertung des Modells sind folgende Angaben wichtig: das R² beträgt 0.794, d.h. fast 80% der Gesamtstreuung der Variable „Körpergröße werden durch unser Modell, also die Variable „Gewicht erklärt, die übrigen 20% ergeben die Residuen (nicht erklärte Streuung)..")
33
Unser Modell ist mit einem p-Wert<0.001 signifikant. Ausgehend von den Koeffizienten ergibt sich ein Regressions- modell mit folgenden Werten: (y = mx + b) gross = 1.081*gewi + 102.278 Anschließend muss aber noch untersucht werden, ob das Modell geeignet ist, um diesen Zusammenhang zu beschreiben. Hierzu müssen die Residuen folgende Bedingungen erfüllen: Lineare Regression
 gross = 1.081*gewi Anschließend muss aber noch untersucht werden, ob das Modell geeignet ist, um diesen Zusammenhang zu beschreiben. Hierzu müssen die Residuen folgende Bedingungen erfüllen: Lineare Regression.")
34
1. Unabhängig voneinander sein 2. Normalverteilt sein 3. Homogene Varianzen aufweisen Um dieses zu überprüfen, wählt man bei dem Diagrammfenster der Regression die Schaltfläche „Diagramme“ aus: Lineare Regression 1.Häkchen setzen bei „Histogramm“ und/ oder „Normalverteilungsdiagramm“ 2.Streudiagramm der standardisierten vorhergesagten Werte (ZPRED) und standardisierten Residuen (ZRESID) Zusätzlich unter Schaltfläche „Statistiken“ Auswahl des Durbin- Watson Tests.
 und standardisierten Residuen (ZRESID) Zusätzlich unter Schaltfläche „Statistiken Auswahl des Durbin- Watson Tests..")
35
Histogramm sowie Normalverteilungs- diagramm (rechts) zeigen eine Normalvertei- lung der standardisierten Residuen. Das Streudiagramm der stand. Residuen ge- gen die stand. geschätzten Werte (u.l.) zeigt keine extrem regelmäßige Verteilung der Punkte, die auf Autokorrelation hinweisen. Lineare Regression
 zeigt keine extrem regelmäßige Verteilung der Punkte, die auf Autokorrelation hinweisen. Lineare Regression.")
36
Der Durbin Watson Test auf Autokorrelation der Werte zeigt mit 1,665 einen unauffälligen Wert, es kann also davon ausgegangen werden, dass keine Autokorrelation der Werte vorliegt (hier werden Werte zwischen 1,5 und 2,5 als unauffällig angesehen). Allerdings zeigt sich eine leichte Krümmungstendenz der Punktwolke sowie ein größerer Abstand der Punkte zur Nulllinie bei größeren Werten. Beim „normalen“ Streudia- gramm wird das Problem deutlicher: Bei „leichten“ sowie bei sehr „schweren“ Kindern überschätzt das Modell deren Größe, darüber hinaus vergrößert sich die Streuung der Werte mit zunehmendem Körperge- wicht (je schwerer das Kind, desto ungenauer die Schätzung) Lineare Regression
 Lineare Regression.")
37
Man könnte versuchen, über eine Potenzfunktion eine Linearisierung zu erreichen. Man nimmt z.B. f(x)=ax b mit a und b als konstante reelle Zahlen und für x das Körpergewicht. Die Linearisierung erfolgt über log(f(x))=log(a)+b*log(x), für a und b wählt man z.B. 0,5 und 2, für x setzt man das Körpergewicht ein. In SPSS wählt man also Transformieren Variable berechnen Als neue Variable erhält man dann „log_gew“. Verwendet man diese in einem Streudia- gramm aufgetragen gegen die Größe erhält man eine offensichtlich „geradere“ Punktwolke (s. nächstes Blatt) Lineare Regression
=ax b mit a und b als konstante reelle Zahlen und für x das Körpergewicht. Die Linearisierung erfolgt über log(f(x))=log(a)+b*log(x), für a und b wählt man z.B. 0,5 und 2, für x setzt man das Körpergewicht ein. In SPSS wählt man also Transformieren Variable berechnen Als neue Variable erhält man dann „log_gew . Verwendet man diese in einem Streudia- gramm aufgetragen gegen die Größe erhält man eine offensichtlich „geradere Punktwolke (s. nächstes Blatt) Lineare Regression.")
38
Die lineare Regression liefert auch ein deutlich höheres R² (0,84, vorher 0,794), der Wert des Durbin-Watson Tests liegt mit 1,766 auch im unauffäl- ligen Bereich und das Streu- diagramm der standardisierten Lineare Regression Residuen gegen die stand. geschätzten Werte zeigt auch eine relativ gleichmäßige Punktwolke (li)
.")
39
Eine weitere Ungereimtheit wäre noch zu überprüfen: es existiert ein extremer Ausreißer: in dem nicht linearisierten Diagramm kann man ablesen, dass dieses Kind ca. 160cm groß und ca. 20kg schwer ist. Um diesen offensichtlich falschen Datenpunkt im Datensatz finden zu können, hilft Folgendes: Diagramm doppelt klicken, um den Diagrammeditor zu öffnen Im Diagrammeditor Elemente Datenbeschriftungsmodus, das erscheinende Viereck auf den betreffenden Punkt setzen und klicken, es wird die Zeilennummer des Punktes angezeigt, hier 302. Im Datensatz kann man dann in der Zeile 302 die Daten löschen bzw. korrigieren, direkt im Diagramm geht das nicht. Damit die Änderungen verarbeitet werden, muss das Diagramm erneut erzeugt werden, die erneute Durchführung der Regression ergibt dann auch ein R² von 0,845 (vorher 0,84). Lineare Regression
. Lineare Regression.")
Ähnliche Präsentationen
 von letzter Stunde wiederholen>")



 Das große 1 x 1 ( Berechnungen mit Namen, die Matrixformel ), Blattregister,>")













 2. Deskriptive Statistik (09.11.2010) 3. Ausgaben (16.11.2010) Wiederholung Tabellen,>")
