Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
„schlecht“ „gut“

2
Unterschiede messen Median ist der Punkt, bei dem die eine Hälfte der Werte oberhalb und die andere unterhalb dieses Punktes liegt Median Mean Der Mittelwert wird berechnet durch die Summe aller Werte geteilt durch die Anzahl der Werte

3
∑ ∑ Mathematisch wird die Berechnung des Mittelwertes so dargestellt:
X = ∑ xi n X ausgesprochen: X Strich oder x quer ist das Symbol für den Mittelwert ∑ dies ist der griechische Großbuchstabe für Sigma und das sog. Summenzeichen, d.h. alle Messwerte müssen addiert werden xi dieses Zeichen steht für sämtliche Einzelmesswerte n und n steht schließlich für die Anzahl der durchgeführten Messungen

4
Unterschiede messen Zwei weit verbreite, einfache Methoden:
Zwischen zwei Klassen unterscheiden: Gut ↔ Schlecht Zwischen vier (oder einer anderen Anzahl von) Perzentilen unterscheiden
 Perzentilen unterscheiden.")
5
Einfache Aussage über Reihenfolge
1 Rangreihe: Einfache Aussage über Reihenfolge Hohe Reliabilität, etwa durch Paarvergleich Keine Informationen über Abstände Vergleichbarkeit nur bei identischen N‘s 2 3 4 5 6 7 8

6
Grobe Aussage über die Stellung in einer Reihe
Quartile: Grobe Aussage über die Stellung in einer Reihe Hohe Reliabilität, weil recht ‚simpel‘ Sehr grobe Informationen über Abstände Einfache Vergleichbarkeit über verschiedene Bereiche hinweg 1 I. Quartil 2 3 II. Quartil 4 5 III. Quartil 6 7 VI. Quartil 8

7
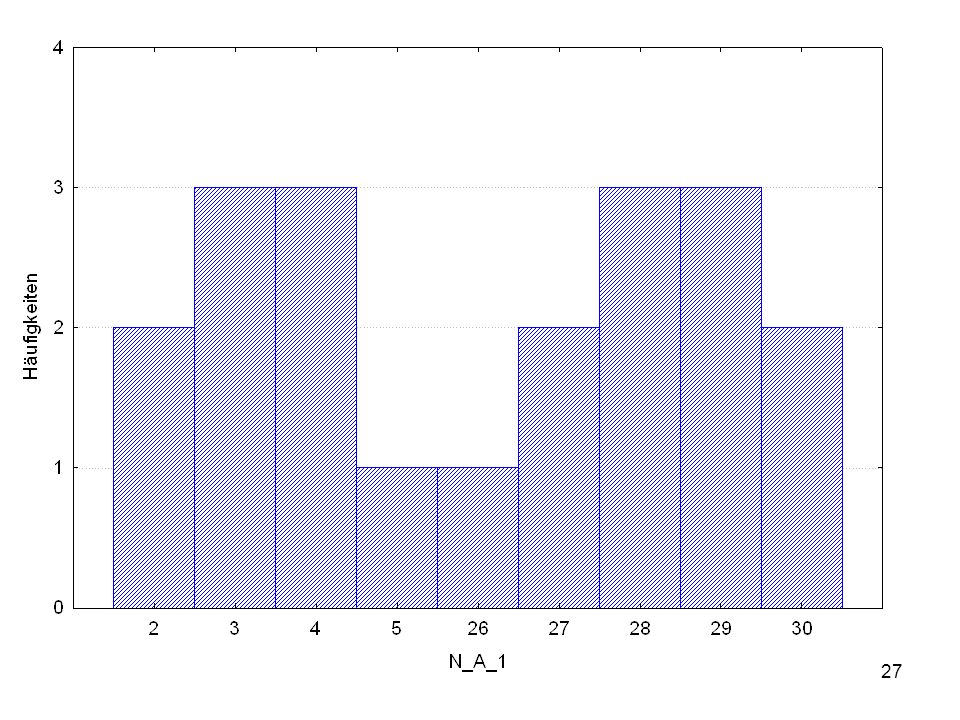
Werte Quartil Prozentrang 30 4 100,00 28 90,00 21 3 80,00 16 70,00 12 60,00 11 2 50,00 6 40,00 5 30,00 1 20,00 10,00 Prozentrang („RANG“): Aussage über die Stellung in einer Reihe Reliabilität von der Messung abhängig Keine Informationen über Abstände Einfache Vergleichbar- keit über verschiedene Bereiche hinweg
: Aussage über die Stellung in einer Reihe. Reliabilität von der Messung abhängig. Keine Informationen über Abstände. Einfache Vergleichbar- keit über verschiedene Bereiche hinweg.")
8
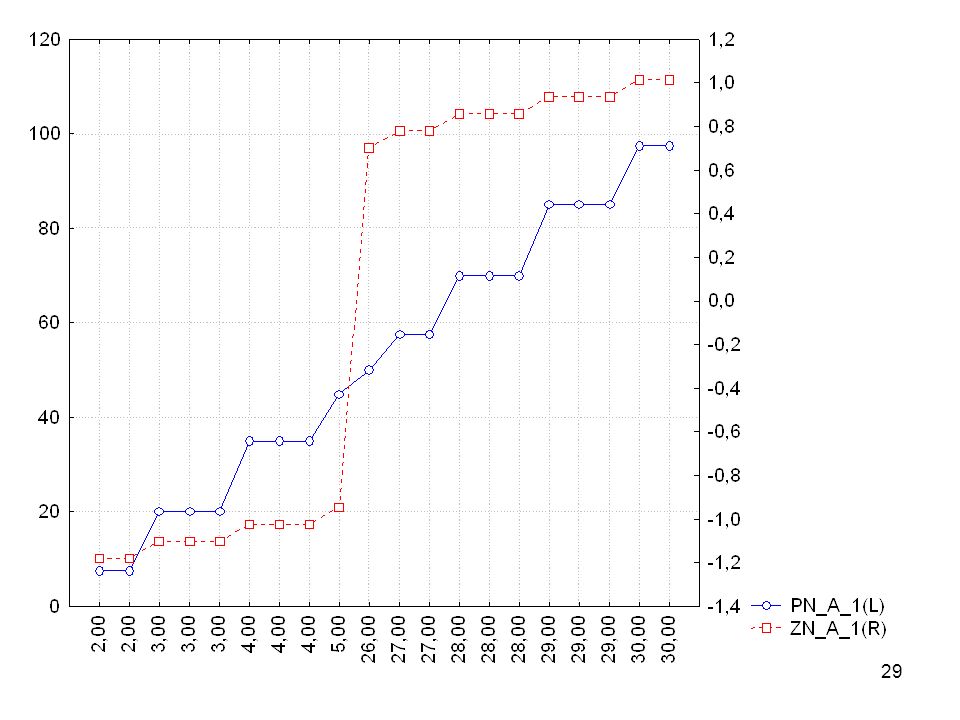
Relativer Prozentrang
Werte Relativer Prozentrang 30 100,00 28 93,33 21 70,00 16 53,33 12 40,00 11 36,67 6 20,00 5 16,67 1 3,33 ,00 Relativer Prozentrang: (100*Wert)/MaxWert Genaue Aussage über die Stellung in einer Reihe Reliabilität von der Messung abhängig Informationen über Abstände Einfache Vergleichbar- keit über verschiedene Bereiche hinweg
/MaxWert. Genaue Aussage über die Stellung in einer Reihe. Reliabilität von der Messung abhängig. Informationen über Abstände. Einfache Vergleichbar- keit über verschiedene Bereiche hinweg.")
10
Werte Rel. % Z-Werte Note 30 100,00 1,59844 2 28 93,33 1,41039 21 70,00 ,75221 3 16 53,33 ,28208 12 40,00 -,09403 4 11 36,67 -,18805 6 20,00 -,65818 5 16,67 -,75221 1 3,33 -1,12831 ,00 -1,22234

11
Unterschiede messen Keine Variation vorhanden

12
Erste Ebene: Spannbreite (R für range)
Unterschiede messen In welchem Maß ist Variation vorhanden? Erste Ebene: Spannbreite (R für range) R = Xmax – Xmin
 R = Xmax – Xmin.")
13
Zweite Ebene: Summe der quadrierten Fehler (Abweichungen)
Unterschiede messen In welchem Maß ist Variation vorhanden? Zweite Ebene: Summe der quadrierten Fehler (Abweichungen) ∑ ( ) 2 xi - X σ² = n - 1 Mean
 ∑ ( ) 2. xi. - X. σ² = n - 1. Mean.")
14
Dritte Ebene: Standardabweichung
Unterschiede messen In welchem Maß ist Variation vorhanden? Dritte Ebene: Standardabweichung √ ∑ ( ) 2 xi - X σ = n - 1 Mean
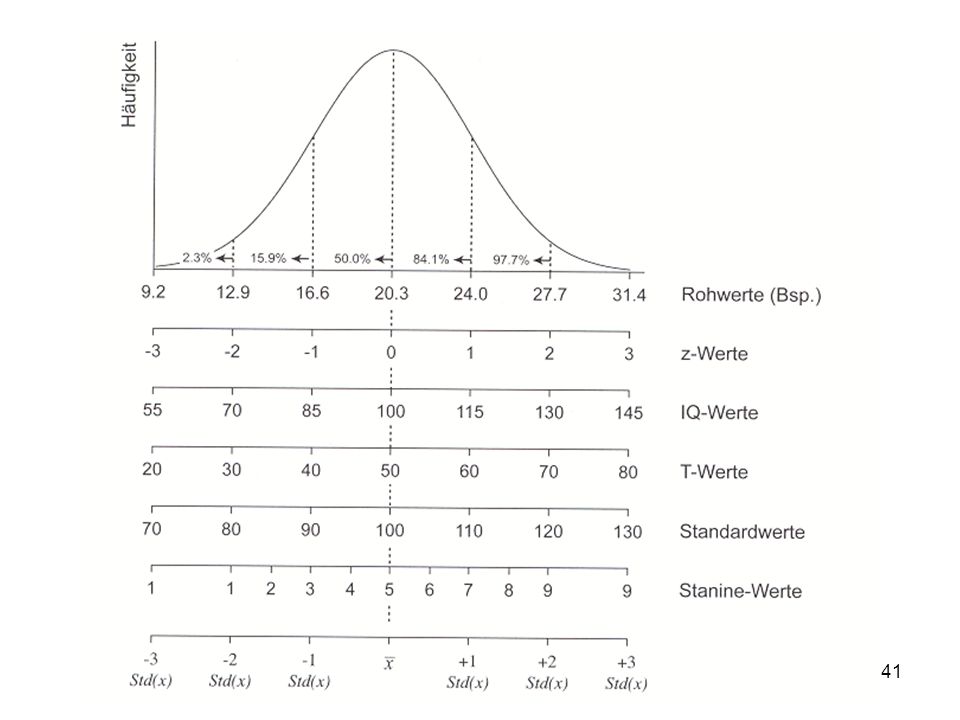
 2. xi. - X. σ = n - 1. Mean.")
15
z = σx xi Unterschiede messen In welchem Maß ist Variation vorhanden?
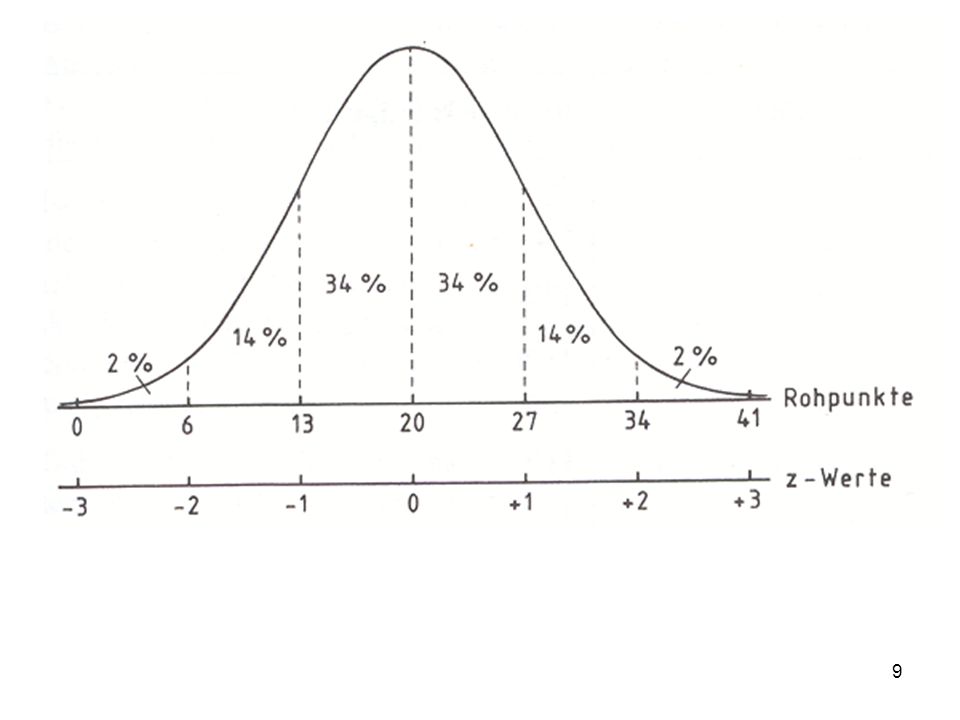
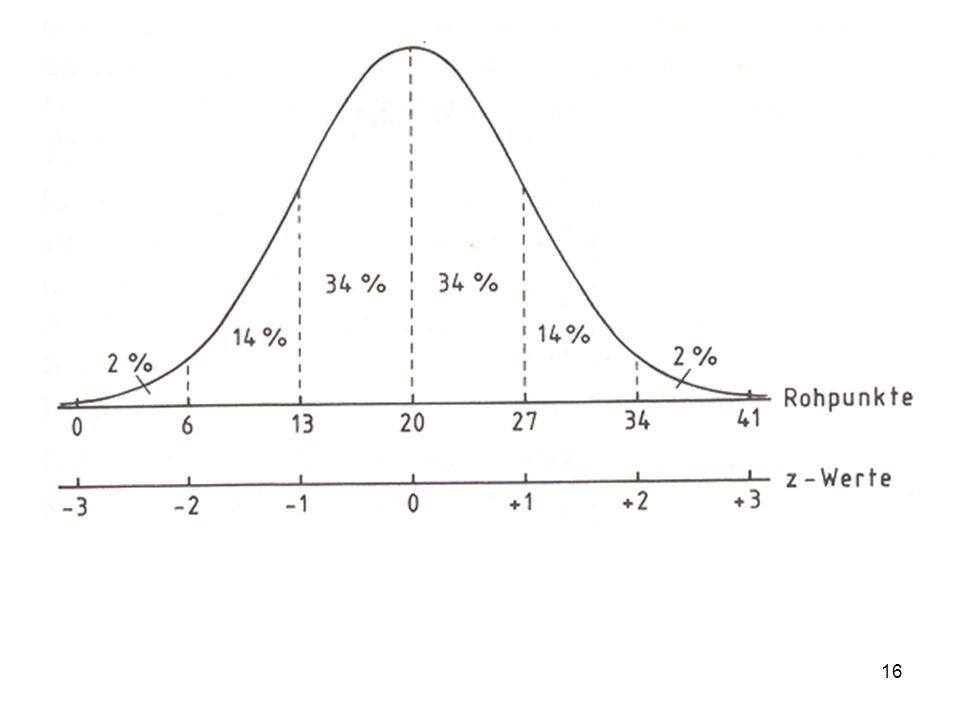
Vierte Ebene: z-Transformation Abstand jeder Messung zum Mittelwert, geteilt durch die Standardabweichung xi - X z = σx Mean 0 Mean 0 Alle Mittewerte werden Null, die Abstände werden standardisiert; die relative Lage jeder Messung kann verglichen werden

17
(leicht hinkender Vergleich)
Sie wollen verschieden formatige, verschieden große Bilder auf eine Seite bringen

18
(leicht hinkender Vergleich)
Sie wollen verschieden formatige, verschieden große Bilder auf eine Seite bringen

19
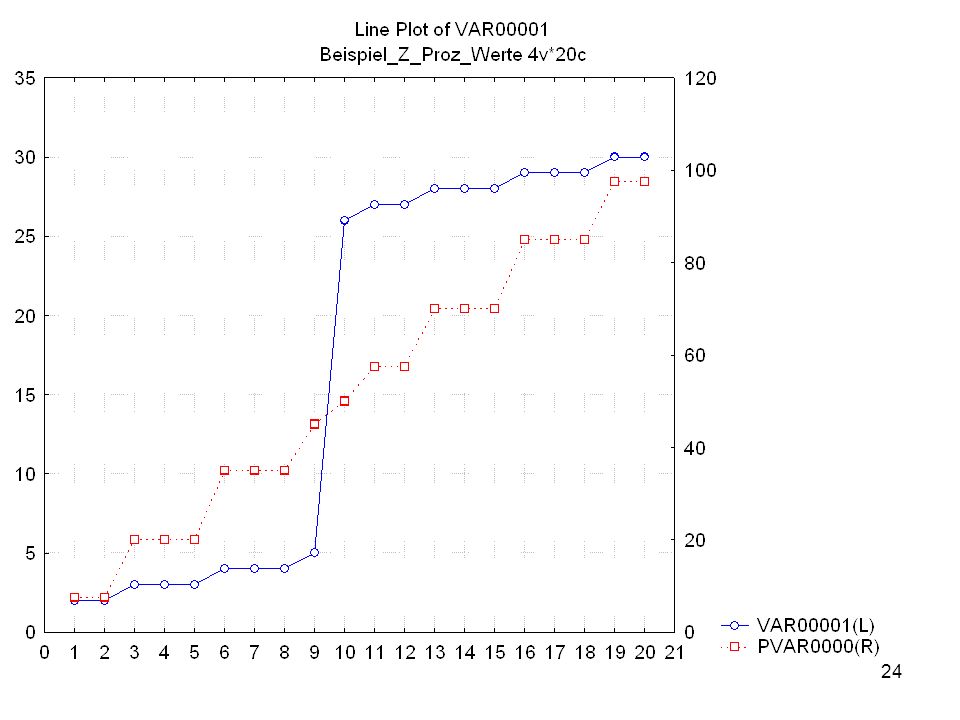
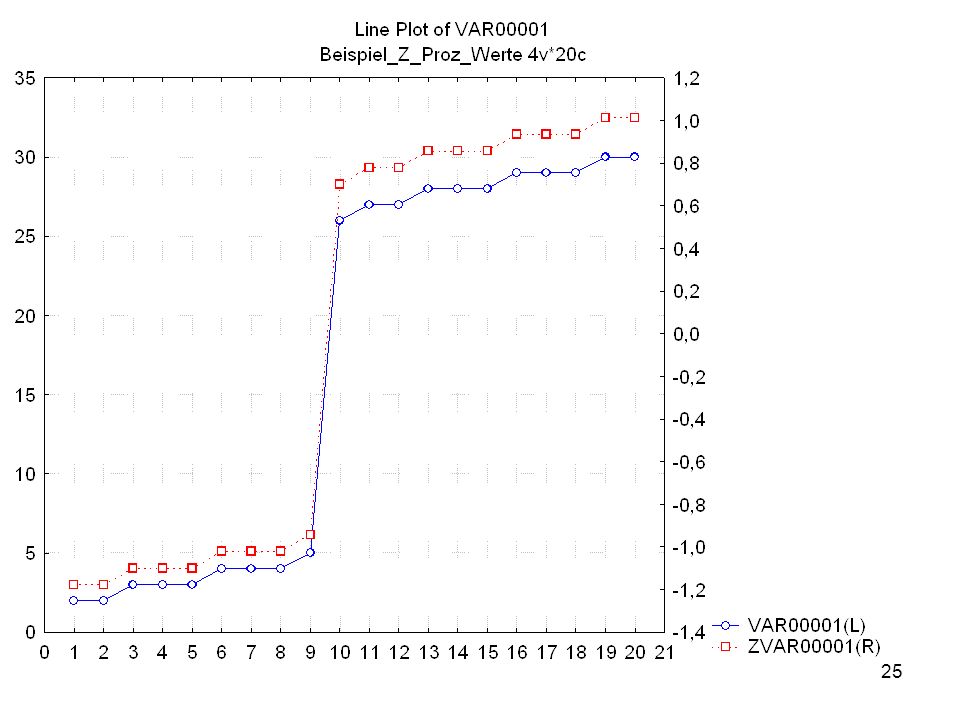
Mittelwerte: 64, ,26 Std.-Abw.: 11, ,831

20
Wirkung der Z-Transformation:

21
Mit Hilfe dieser Grafik wird erkennbar, was die Prozentränge im Unterschied zu den Z-standardisierten Werten angeben: Am linken Rand sind die Rohwerte abgetragen, am oberen Rand die Prozentränge und am unteren Rand die z-standardisierten Werte. Wie ersichtlich, hat der höchste Rohwert den Prozentrang 100 und den Z-Wert +3. Der niedrigste Rohwert hingegen den Prozentrang 1,25 und den Z-Wert -2.

22
Prozentränge cum f cum f % = 100 N (N = 300) Rohwert Fälle f cum f
80 .. 5 25 98 4 18 73 24,3 24 3 19 55 18,3 2 15 36 12,0 12 1 21 7,0 7 9 3,0 300 = 100 % 9 = x %

23
sog. ‚Absoluter Rangwert‘: 1. Rang + 2. Rang/2 = 1,5
Werte mal 100/Max-Wert: 2*100 = 200/30 = 6,66666 Relative Rangfolge in %: 20 = 100 % 1,5 = x % Z-Transformation

36
Umwandlung eines numerischen Wertes in einen kategorialen Wert

37
Deskriptive Statistik (School perfomance)
Gült. N Mittelw. Median Minimum Maximum Stdabw. WRITING 80 99,82004 99,56863 93,51375 109,1118 3,377652 Deskriptive Statistik (School perfomance)
")
38
Mittelwert: Arithmetisches Mittel = Summe aller beobachteten Merkmalswerte dividiert durch die Anzahl der Beobachtungen Median (auch Zentral- oder 50% Wert): Der Median ist der Wert für den gilt, dass 50% aller Werte größer oder gleich sind. Der Median halbiert die Stichprobenverteilung
: Der Median ist der Wert für den gilt, dass 50% aller Werte größer oder gleich sind. Der Median halbiert die Stichprobenverteilung.")
39
Deskriptive Statistik (School perfomance)
Gült. N Mittelw. Median Minimum Maximum Stdabw. WRITING 90 121,5067 100,1944 93,51375 410,0000 66,48269 Deskriptive Statistik (School perfomance)
")
40
Gült. N Mittelw. Median Minimum Maximum Stdabw. WRITING 80 99,82004 99,56863 93,51375 109,1118 3,377652 Gült. N Mittelw. Median Minimum Maximum Stdabw. WRITING 90 121,5067 100,1944 93,51375 410,0000 66,48269

42
Umwandlung eines numerischen Wertes in einen kategorialen Wert

43
Deskriptive Statistik (School perfomance)
Gült. N Mittelw. Median Minimum Maximum Stdabw. WRITING 80 99,82004 99,56863 93,51375 109,1118 3,377652 Deskriptive Statistik (School perfomance)
")
44
Mittelwert: Arithmetisches Mittel = Summe aller beobachteten Merkmalswerte dividiert durch die Anzahl der Beobachtungen Median (auch Zentral- oder 50% Wert): Der Median ist der Wert für den gilt, dass 50% aller Werte größer oder gleich sind. Der Median halbiert die Stichprobenverteilung
: Der Median ist der Wert für den gilt, dass 50% aller Werte größer oder gleich sind. Der Median halbiert die Stichprobenverteilung.")
45
Deskriptive Statistik (School perfomance)
Gült. N Mittelw. Median Minimum Maximum Stdabw. WRITING 90 121,5067 100,1944 93,51375 410,0000 66,48269 Deskriptive Statistik (School perfomance)
")
46
Gült. N Mittelw. Median Minimum Maximum Stdabw. WRITING 80 99,82004 99,56863 93,51375 109,1118 3,377652 Gült. N Mittelw. Median Minimum Maximum Stdabw. WRITING 90 121,5067 100,1944 93,51375 410,0000 66,48269

48
Gruppenzugehörigkeit: A
Gruppenzugehörigkeit: B Gruppenzugehörigkeit: C

49
Gibt es „Muster“ in der Verteilung?

53
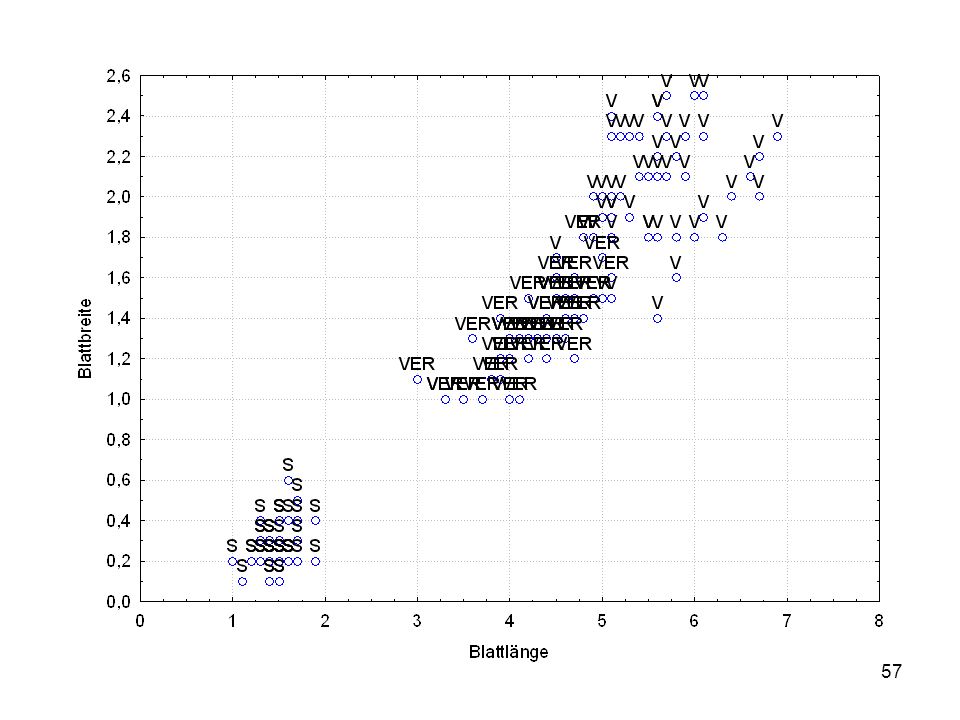
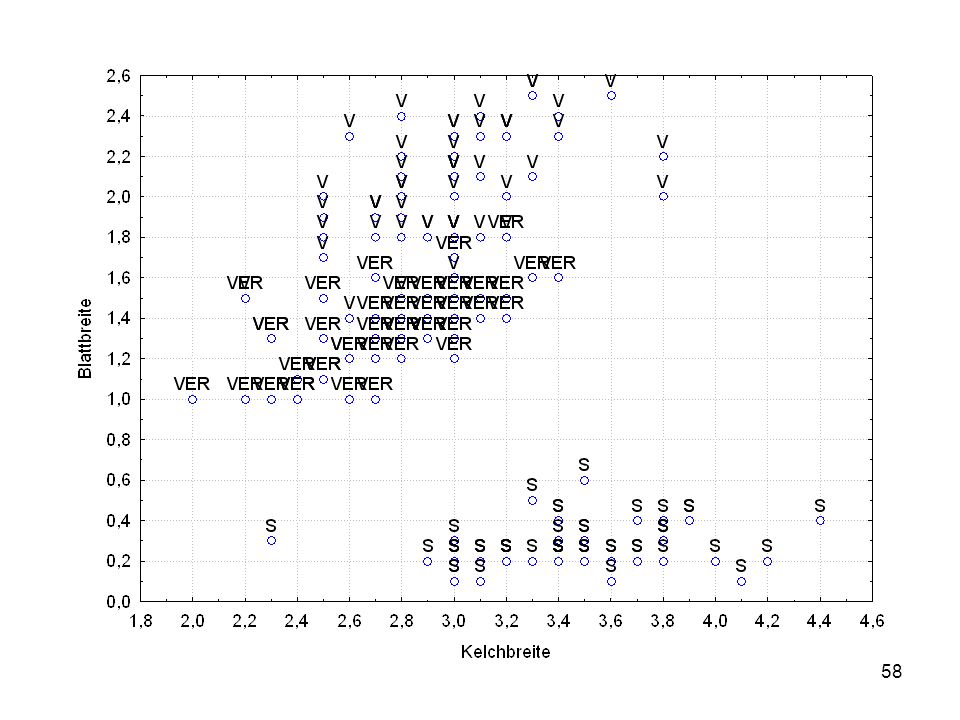
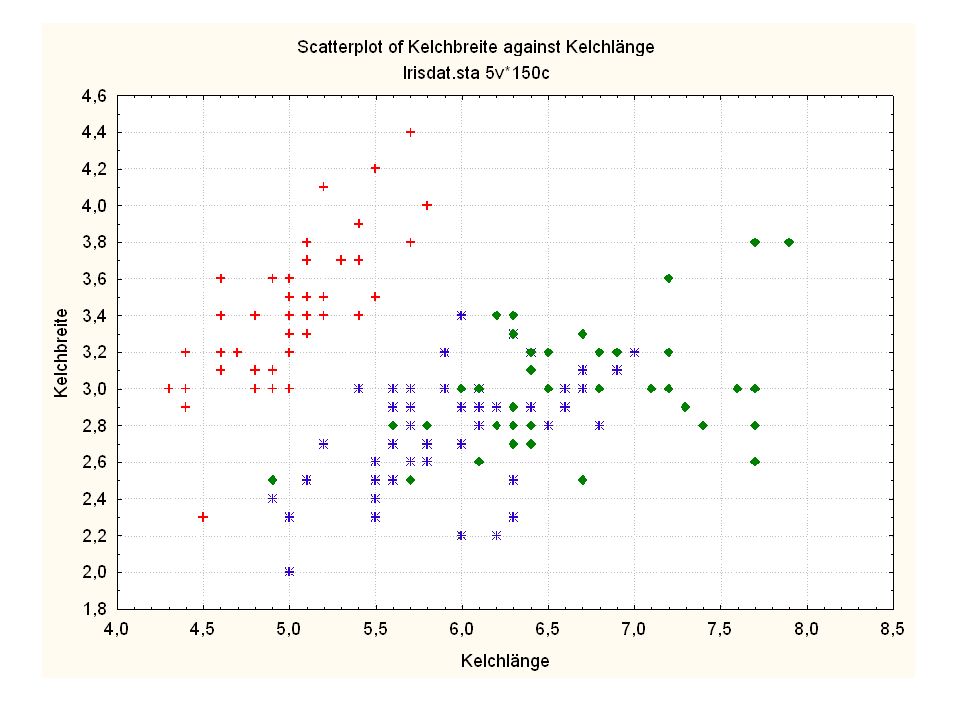
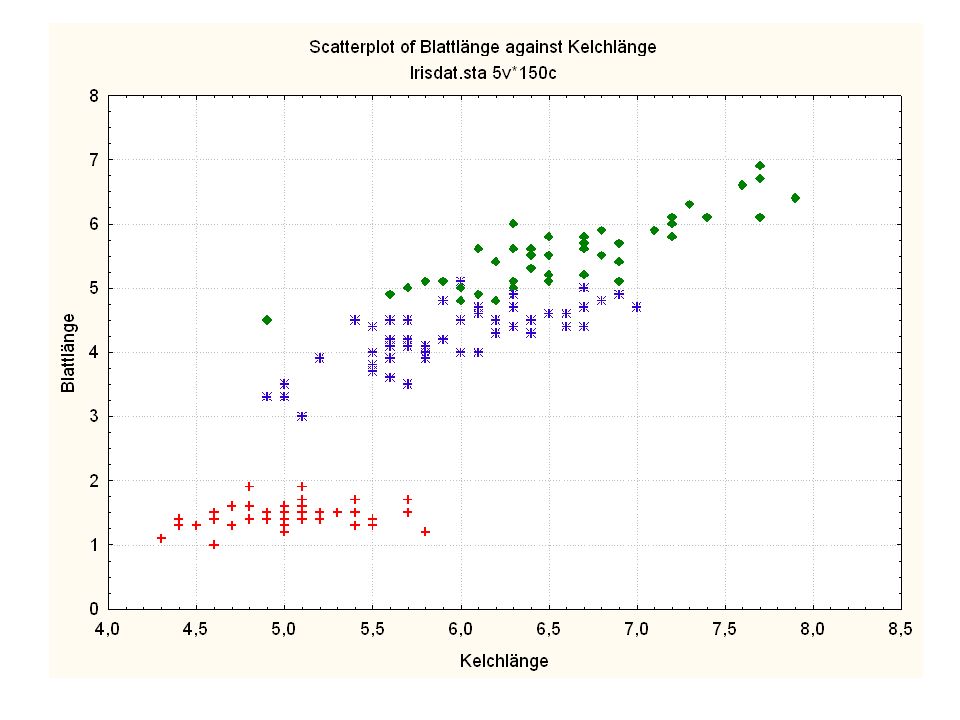
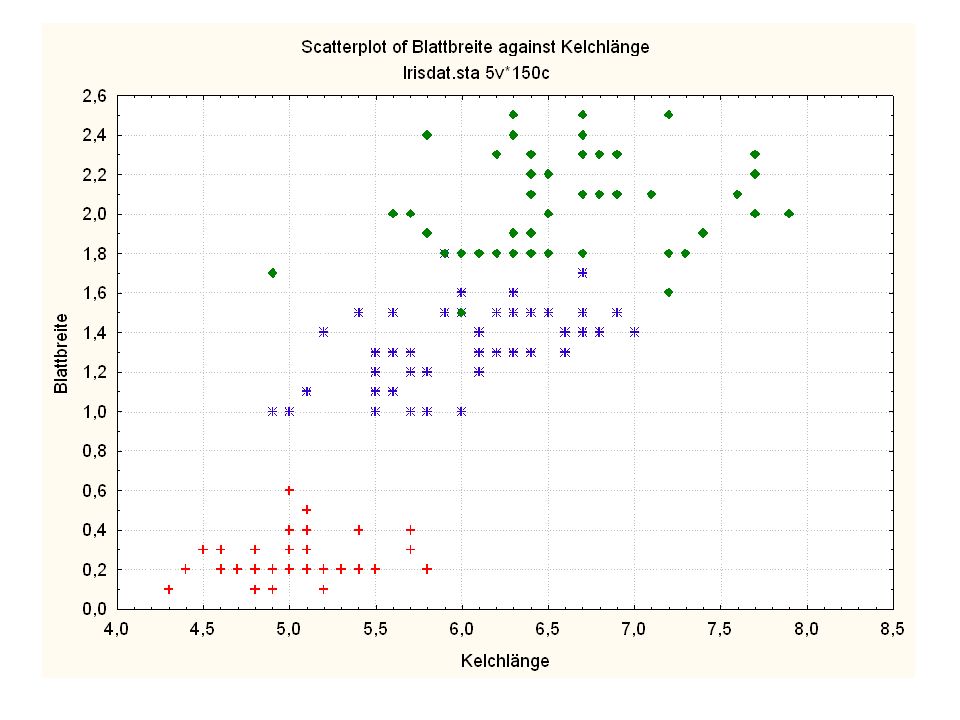
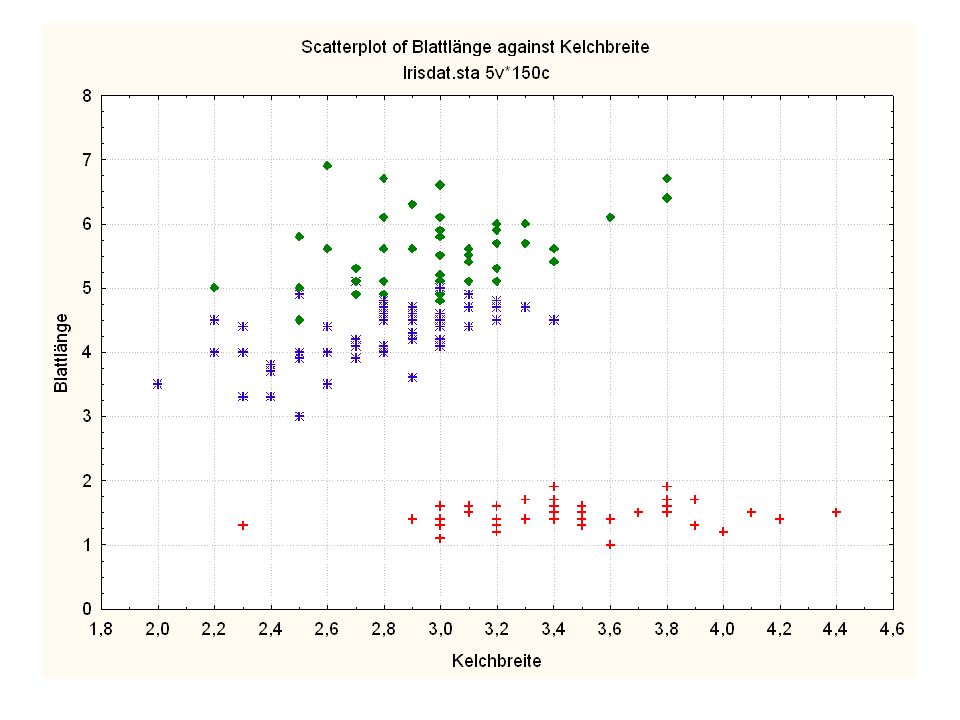
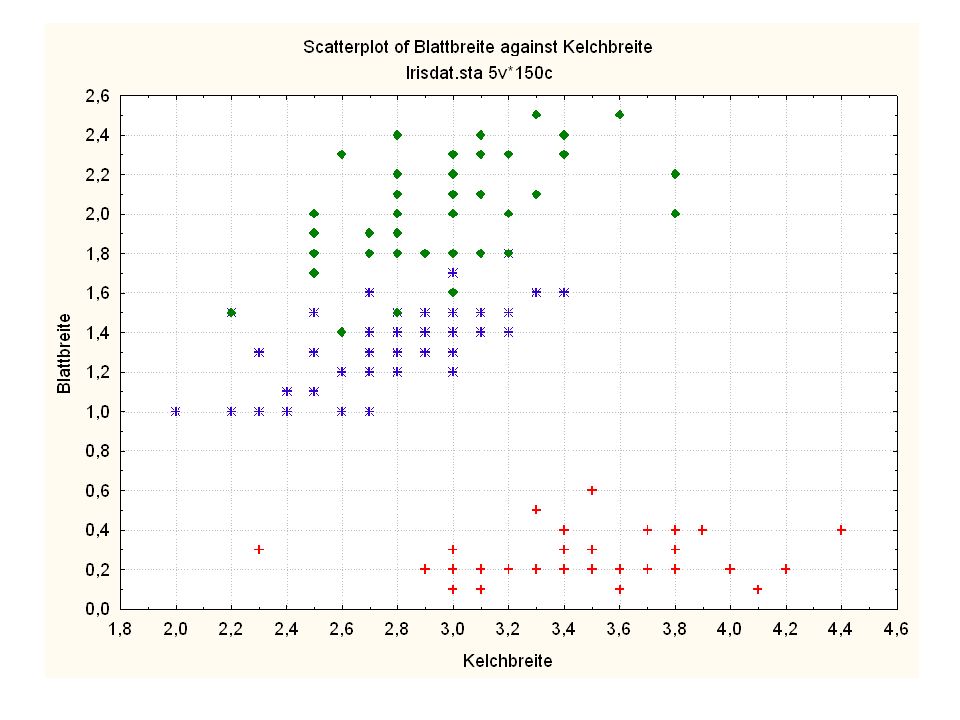
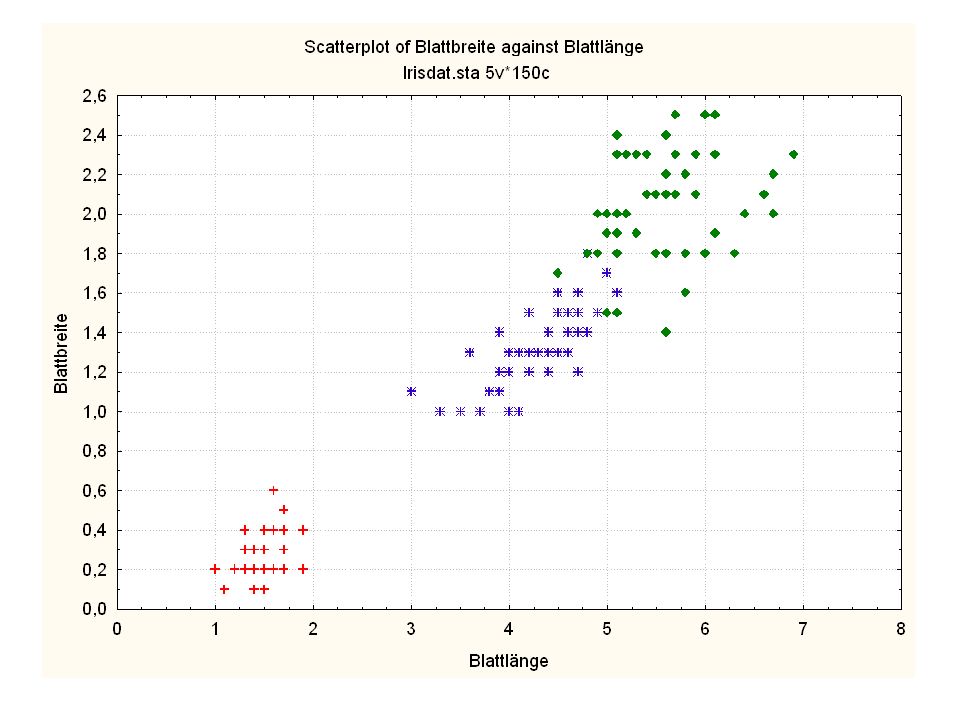
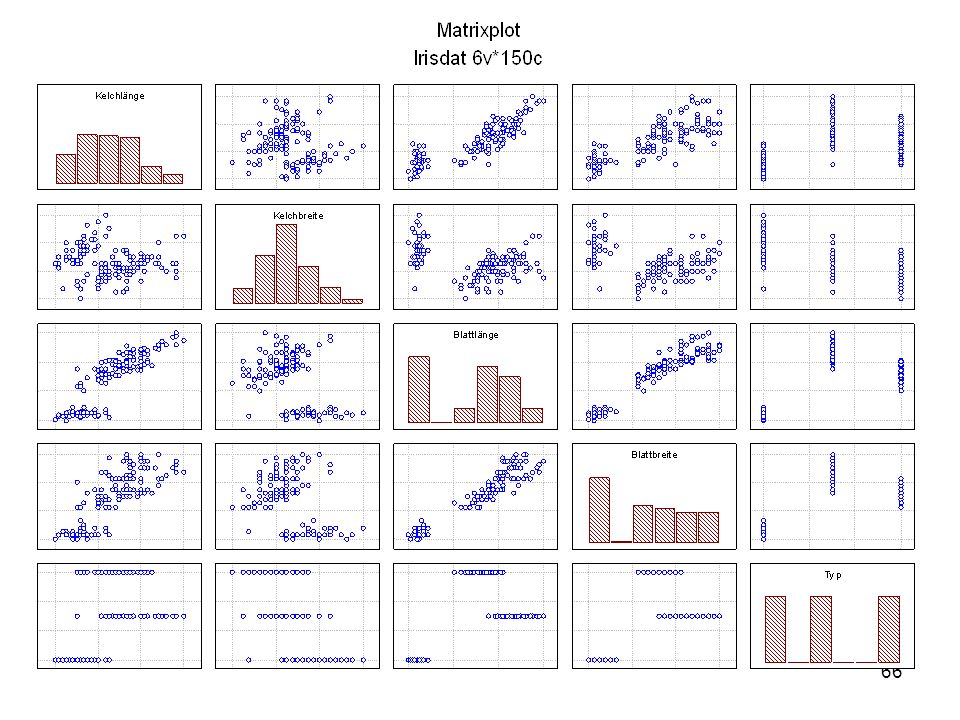
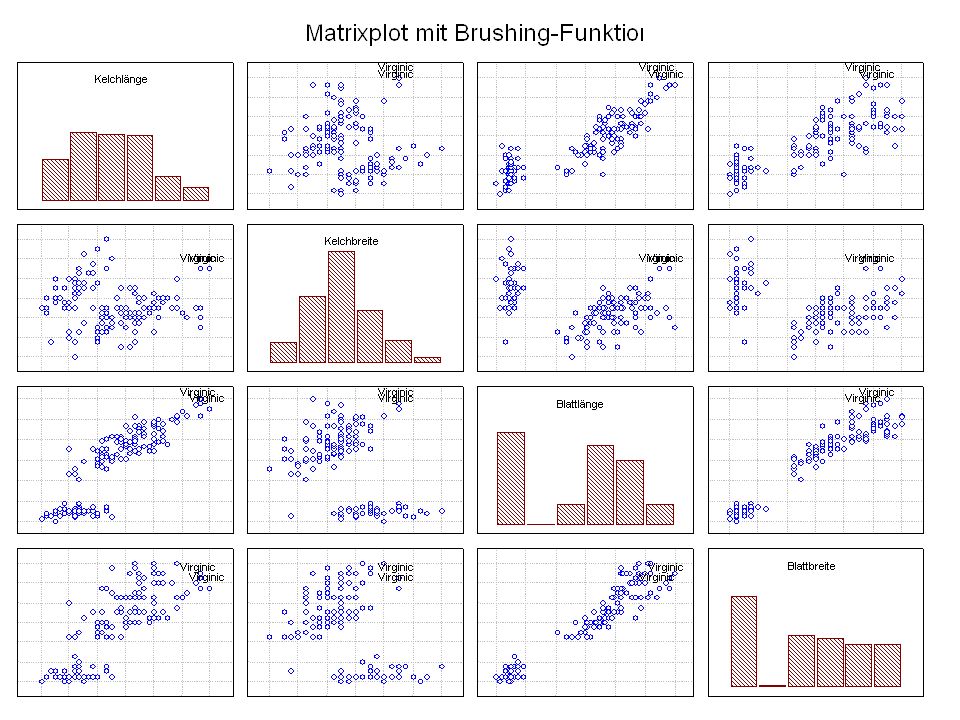
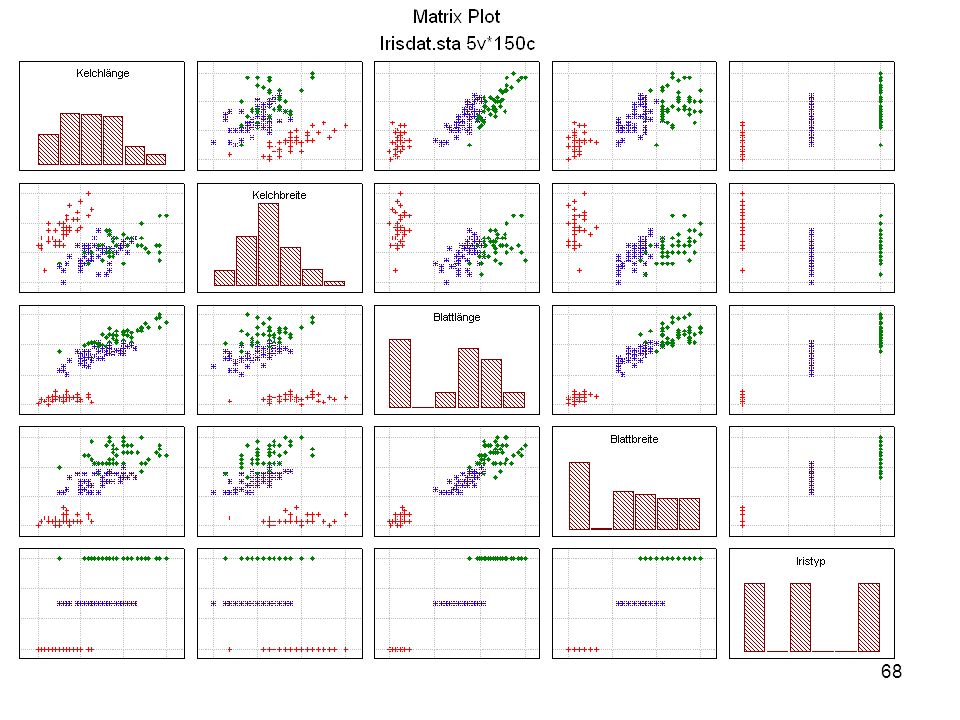
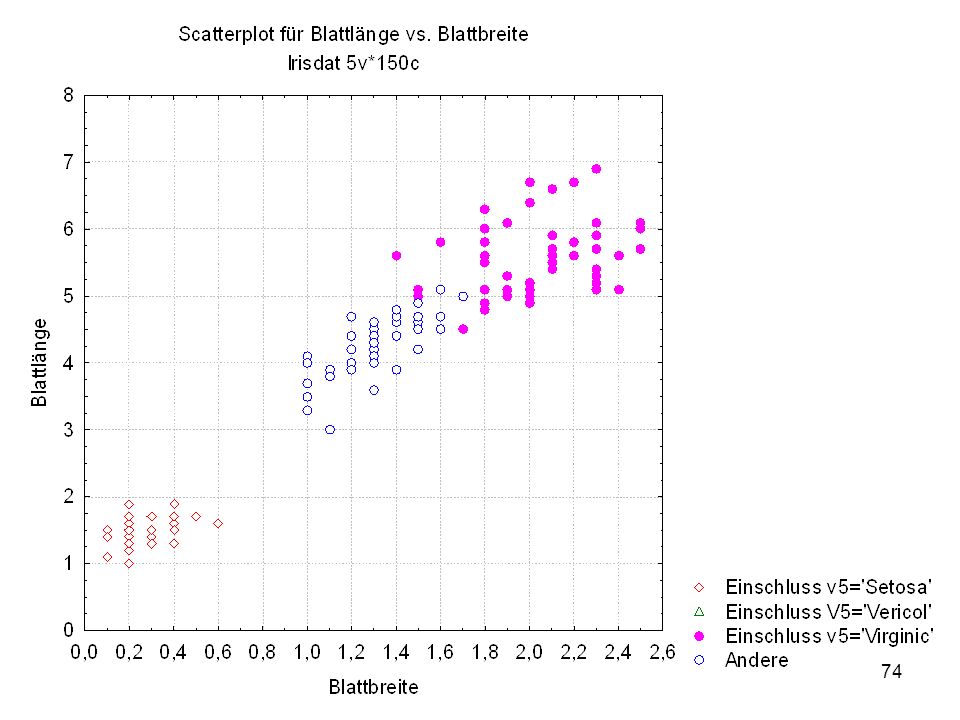
Durch was unterscheiden sich die drei Iristypen?
Kelchlänge Kelchbreite Blattlänge Blattbreite Iristyp 1 5 3,3 1,4 0,2 Setosa 2 6,4 2,8 5,6 2,2 Virginic 3 6,5 4,6 1,5 Versicol 4 6,7 3,1 2,4 6,3 5,1 6 3,4 0,3 7 6,9 2,3 8 6,2 4,5 9 5,9 3,2 4,8 1,8 10 3,6 11 6,1 12 2,7 1,6 13 5,2 14 2,5 3,9 1,1 15 5,5 16 5,8 1,9 17 6,8 18 1,7 0,5 19 5,7 1,3 20 5,4 21 7,7 3,8 22 4,7 23 24 7,6 6,6 2,1 25 4,9 Fisher (1936) Irisdaten: Länge und Breite von Blättern und Kelchen für 3 Iristypen Durch was unterscheiden sich die drei Iristypen?
 Irisdaten: Länge und Breite von Blättern und Kelchen für 3 Iristypen. Durch was unterscheiden sich die drei Iristypen")
54
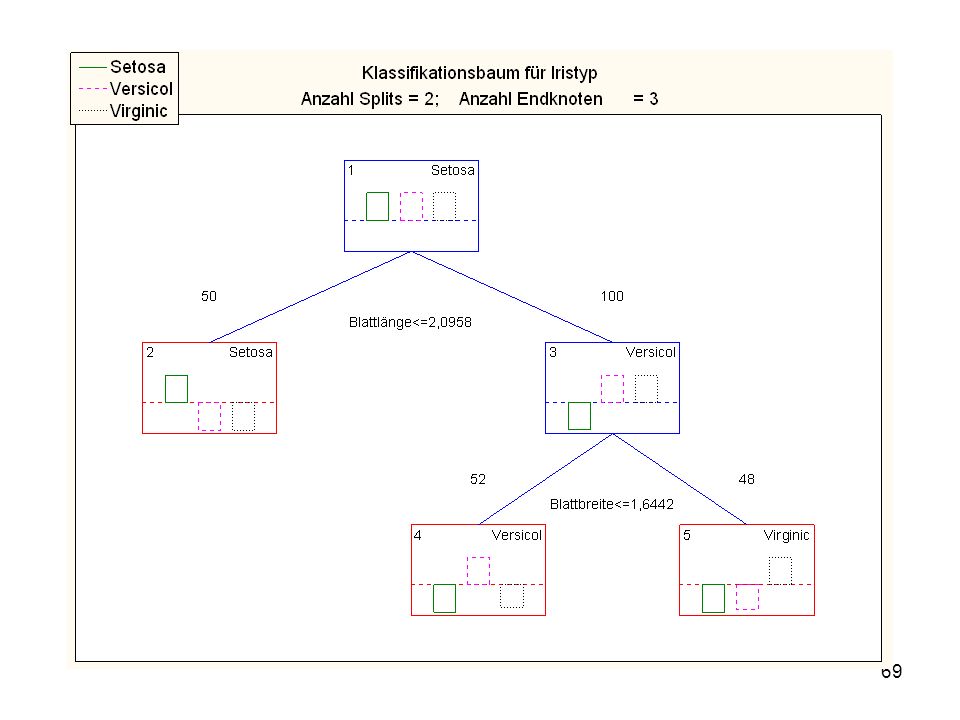
CART (classification and regression trees)
Kategoriale Werte (gut/schlecht) Metrische Werte (1, 2, 3, 4, ..) [Nominale, Ordinale Werte] CART (classification and regression trees) Split: Welche Variable trennt am besten bei welchem Wert?
 Metrische Werte (1, 2, 3, 4, ..) [Nominale, Ordinale Werte] CART (classification and regression trees) Split: Welche Variable trennt am besten bei welchem Wert")
71
Fehlklassifikationsmatrix Lernstichprobe (Irisdat) Matrix progn
Fehlklassifikationsmatrix Lernstichprobe (Irisdat) Matrix progn. (Zeile) x beob. (Spalte) Lernstichprobe N = 150 Klasse - Setosa Klasse - Versicol Klasse - Virginic Setosa Versicol 4 Virginic 2 Prognost. Klasse x Beob. Klasse n's (Irisdat) Matrix progn. (Zeile) x beob. (Spalte) Lernstichprobe N = 150 Klasse - Setosa Klasse - Versicol Klasse - Virginic Setosa 50 Versicol 48 4 Virginic 2 46
 Matrix progn. (Zeile) x beob. (Spalte) Lernstichprobe N = 150. Klasse - Setosa. Klasse - Versicol. Klasse - Virginic. Setosa. Versicol. 4. Virginic. 2. Prognost. Klasse x Beob. Klasse n s (Irisdat) Matrix progn. (Zeile) x beob. (Spalte) Lernstichprobe N = 150. Klasse - Setosa. Klasse - Versicol. Klasse - Virginic. Setosa. 50. Versicol Virginic")
72
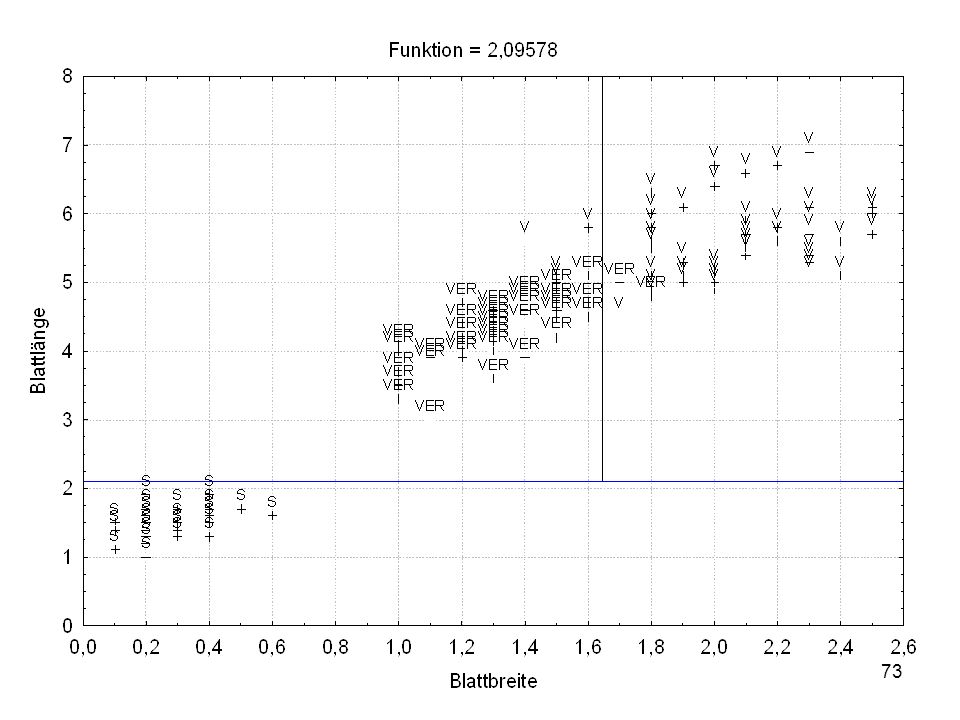
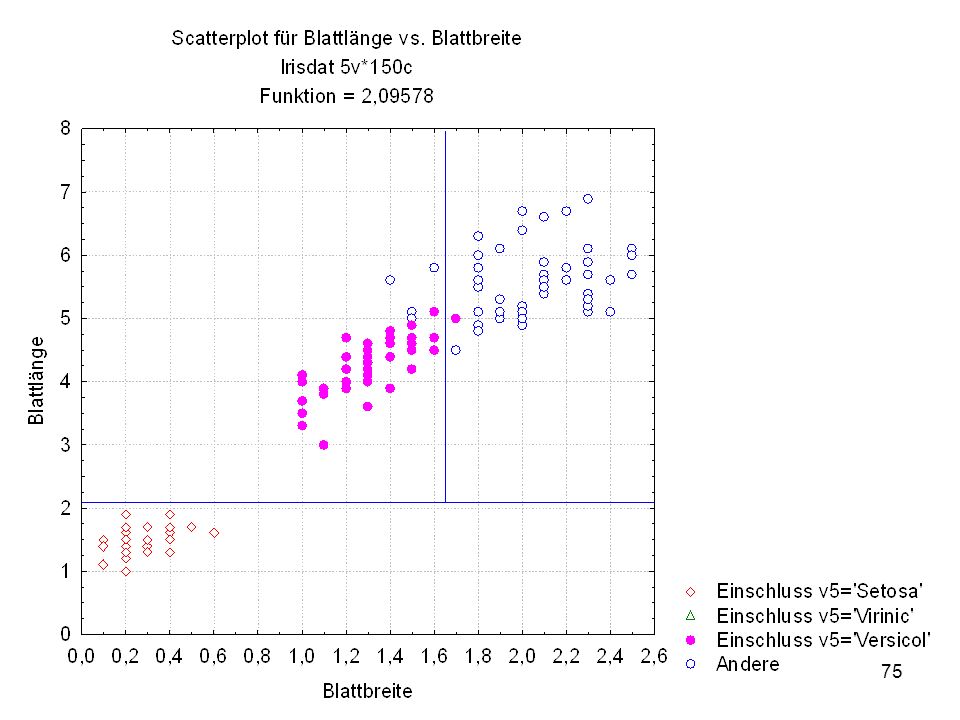
Split-Bedingung (Irisdat) Split-Bedingung je Knoten
Split - Konst. Split - Variable 1 -2,09578 Blattlänge 2 3 -1,64421 Blattbreite

76
Zwei, von vielen Problemen:
Feature Choise Overfitting, Underfitting

77
Zwei, von vielen Problemen:
Feature Choise Overfitting, Underfitting

78
Kategoriale Splits Bivariate Splits Multivariate Splits a b < 0,5
> 0,5 Multivariate Splits < 0,5 > 0,5, < 1,8 > 1,8

79
Analyse und Modellbildung
Wie kann man dieses Problem lösen? Etwa mit Hilfe einer sog. „Kreuzvalidierung“: Alle Daten Teilmenge Anwendung auf andere Teilmenge Analyse und Modellbildung

80
Daten Trainings-daten Daten teilen Validierungs-daten Modell- bewertung

81
Vierter Schritt: Wovon ist „gut“ oder „schlecht“ abhängig
Vierter Schritt: Wovon ist „gut“ oder „schlecht“ abhängig? Güte der erreichten Aufklärung überprüfen

83
Practical Significance
Statistical Significance

84
Was, wenn kein Zusammenhang?
Practical Significance 50% Datensatz Datensatz Modell/Zusammenhang 50% Datensatz Statistical Significance Modell/Zusammenhang = Zufall? Zufall Modell/Zusammenhang >/< Zufall? Was, wenn kein Zusammenhang?

85
Zusammenfassung der behandelten methodischen Ansätze:
Eine bislang unbehandelte Frage lautet: Wie aussagekräftig sind die jeweils gewonnenen Befunde?

86
H0 Person A besitzt keine hellseherischen Fähigkeiten
Folgende Hypothese soll geprüft werden: H0 Person A besitzt keine hellseherischen Fähigkeiten H1 Person A verfügt über hellseherische Fähigkeiten Unter welchen Bedingungen kann H0 bestätigt/verworfen werden? Unter welchen Bedingungen kann H1 bestätigt/verworfen werden? Es gibt Konventionen, die als Grundlage der Entscheidung genutzt werden können/sollten: Das Signifikanzniveau. Irrtumswahrscheinlichkeit Bedeutung Symbolisierung p > 0,05 nicht signifikant ns p <= 0,05 signifikant * p <= 0,01 sehr signifikant ** p <= 0,001 höchst signifikant ***

87
Wie groß ist die Wahrscheinlichkeit dreimal „Kopf“ zu erhalten, wenn drei mal eine Münze geworfen wird? Dazu müssen wir uns die Möglichkeiten vor Augen führen: (K = Kopf; W = Wappen) WWW, WWK, WKW, KWW, WKK, KWK, KKW und KKK Wir haben folglich 8 Möglichkeiten, davon erfüllt eine unsere Bedingung. Die Wahrscheinlichkeit p ist demnach 1/8 oder 0,125.
 WWW, WWK, WKW, KWW, WKK, KWK, KKW und KKK. Wir haben folglich 8 Möglichkeiten, davon erfüllt eine. unsere Bedingung. Die Wahrscheinlichkeit p ist demnach 1/8 oder 0,125.")
88
Wahrscheinlichkeit p bei drei Würfen

89
Wie groß ist die Wahrscheinlichkeit viermal „Kopf“ zu erhalten, wenn vier mal eine Münze geworfen wird? Dazu erneut die Möglichkeiten: (K = Kopf; W = Wappen) W W W W K K K K W W K K K W K W W W W K K K K W W K K W W K W K W W K W K K W K K K W W W K W W K W K K K W W K K W W W W K K K Wir haben folglich 16 Möglichkeiten, davon erfüllt eine unsere Bedingung. Die Wahrscheinlichkeit p ist demnach 1/16 oder 0,0625.
 W W W W K K K K W W K K K W K W. W W W K K K K W W K K W W K W K. W W K W K K W K K K W W. W K W W K W K K K W W K K W W W W K K K. Wir haben folglich 16 Möglichkeiten, davon erfüllt eine. unsere Bedingung. Die Wahrscheinlichkeit p ist demnach 1/16 oder 0,0625.")
90
Signifikanzstufen Irrtumswahrscheinlichkeit Bedeutung Symbolisierung
p > 0,05 nicht signifikant ns p <= 0,05 signifikant * p <= 0,01 sehr signifikant ** p <= 0,001 höchst signifikant ***

91
„Ein Wert von p = 0.05 besagt unter der Annahme, dass kein Effekt existiert, dass – vereinfacht aus- gedrückt, puristische Methodiker mögen mit der Stirn runzeln – bei dieser Stichprobengröße ein mindestens so großer Effekt nur in 5% aller vergleichbar angelegter Studien beobachtet werden kann.“ Rost 2007, 81

92
Irrtumswahrscheinlichkeit: Ein p = 0,03 bedeutet:
Die Wahrscheinlichkeit, dass unter der Annahme, die Nullhypothese sei richtig, das gegebene Untersuchungsergebnis oder ein noch extremeres auftritt, beträgt 0,03 oder 3%. Signifikanzstufen p <= 0,05 signifikant * p <= 0,01 sehr signifikant ** p <= 0,001 höchst signifikant ***

93
Partner Partnerin Vorzeichen + - =
Ergebnis einer hypothetischen Studie, in der die Ausbildung von Paaren verglichen wird (aus: Sedlmeier & Renkewitz 2008, 370): Partner Partnerin Vorzeichen Studium Realschule + Gymnasium - = Es finden sich somit 7 positive Vorzeichen. Ist das Ergebnis auf dem 5% Niveau signifikant? Wie hoch ist die Wahrscheinlichkeit für 0, 1, 2 etc. positive Vorzeichen? Vorzeichentest nach Fischer
: Partner. Partnerin. Vorzeichen. Studium. Realschule. + Gymnasium. - = Es finden sich somit 7 positive Vorzeichen. Ist das Ergebnis auf dem 5% Niveau. signifikant Wie hoch ist die Wahrscheinlichkeit für 0, 1, 2 etc. positive Vorzeichen Vorzeichentest nach Fischer.")
95
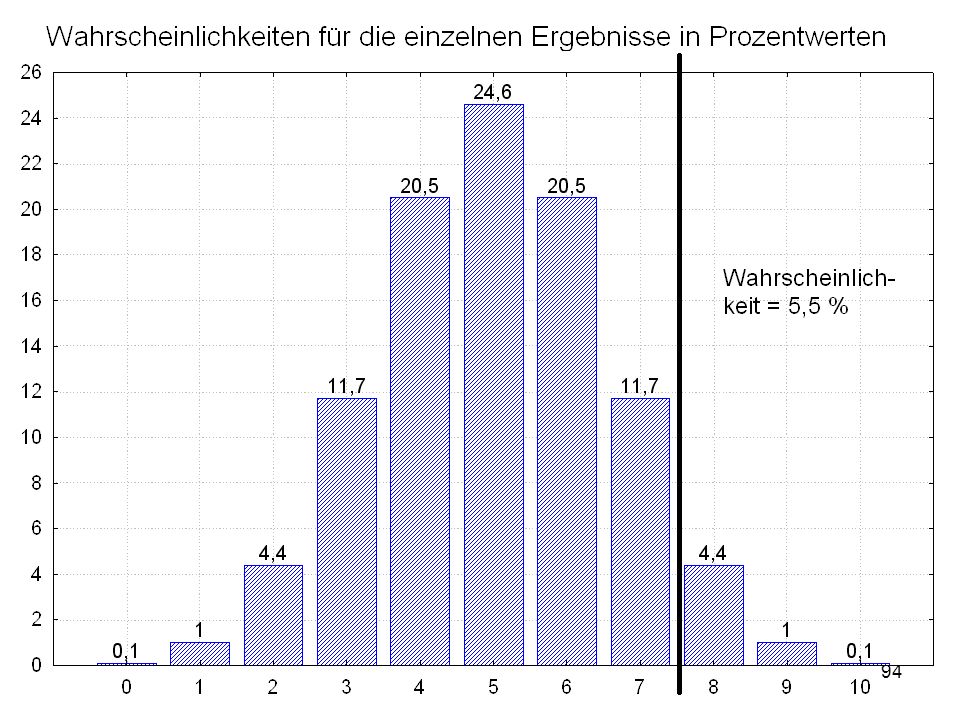
Wenn, wie im vorliegenden Fall, von zehn Paaren sieben ein positives Vorzeichen aufweisen (Bildungsabschluss des männlichen Partners höher als der des weiblich), dann liegt die Wahrscheinlichkeit dafür: 0,1 % + 1,0 % + 4,4 % + 11,7 % = 17,2 % Es wäre gemäß der Konvention also falsch, daraus irgendwelche Schlussfolgerungen zu ziehen, weil ns.

96
Erstellen einer einfachen Probedatei mit folgendem Inhalt:

97
Bei zwei Beobachtungen pro Schulform ergeben sich damit 3 mal 8 = 24 Kombinationsmöglichkeiten:
№ Schulform Abschluss 1 2 3 4 5 6 7 8

98
Die Wahrscheinlichkeit p ist demnach für eine ‚Abweichung‘ von
einem Fall bei sechs Beobachtungen 01/06 entspricht der Wahrscheinlichkeit vom 8/ p = 0,33333

108
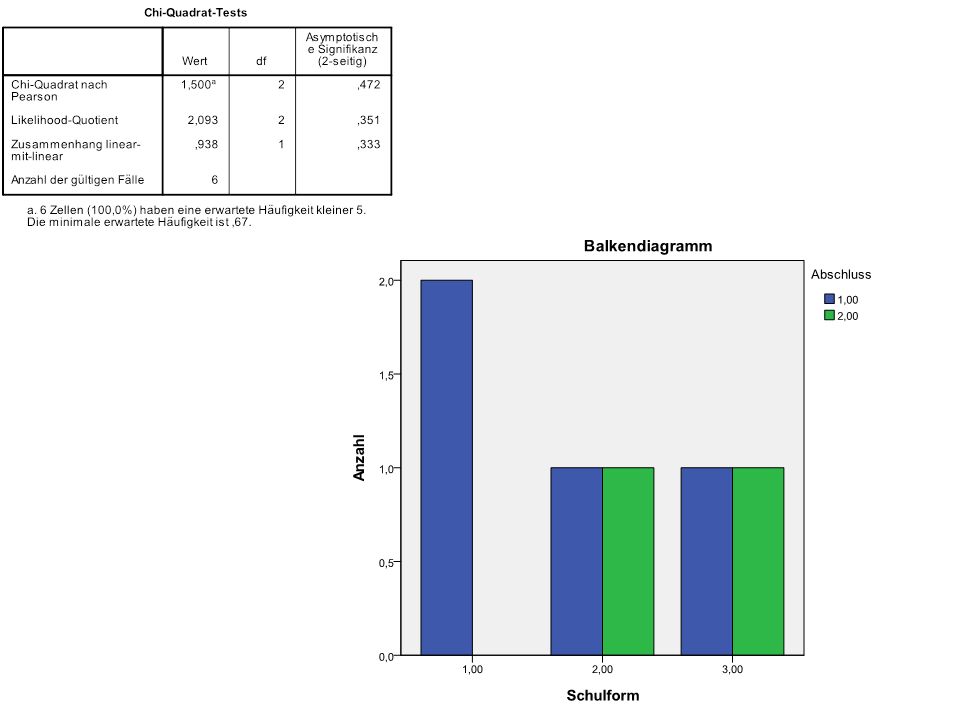
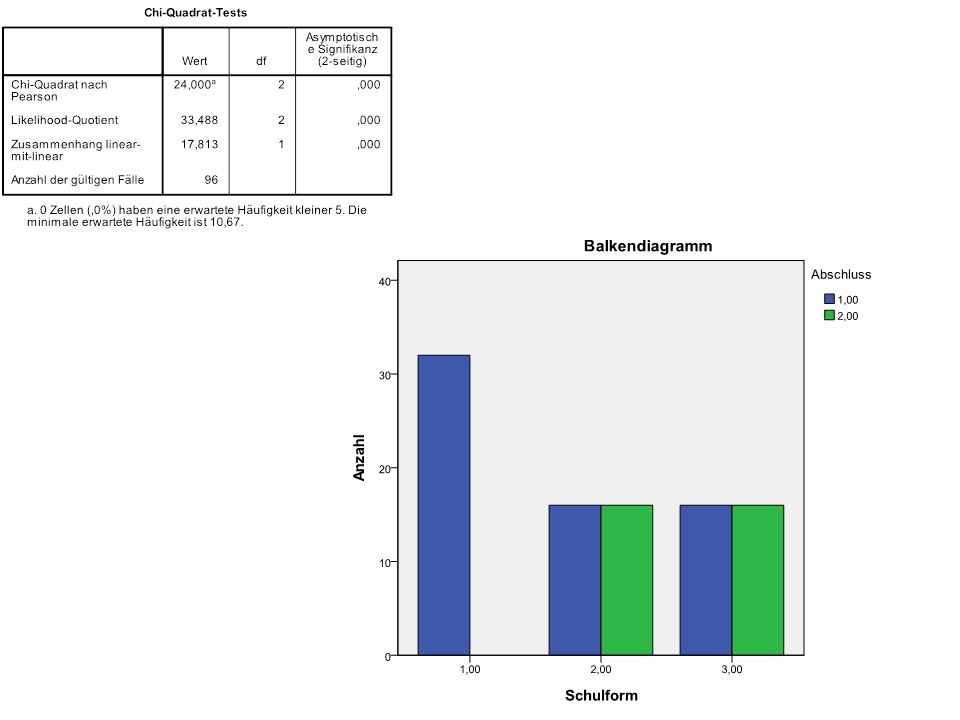
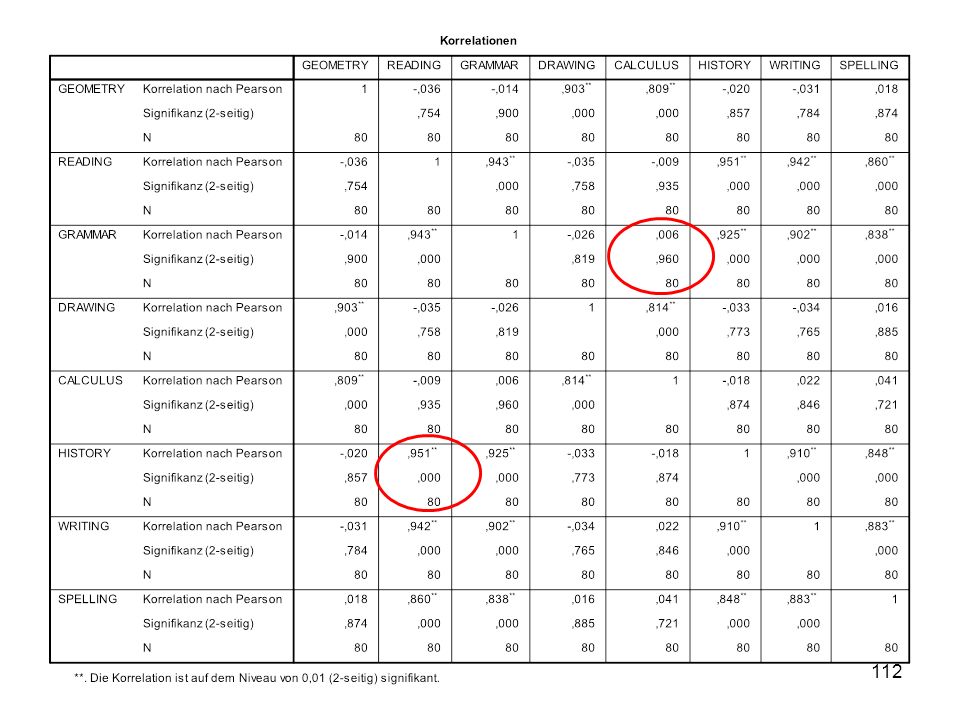
N = 80

109
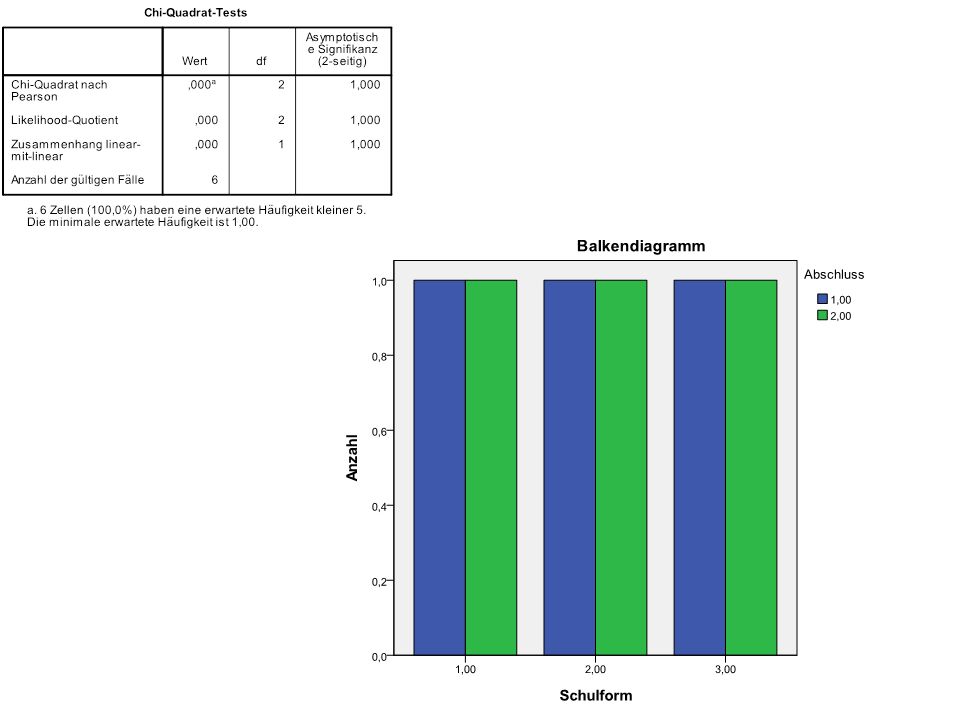
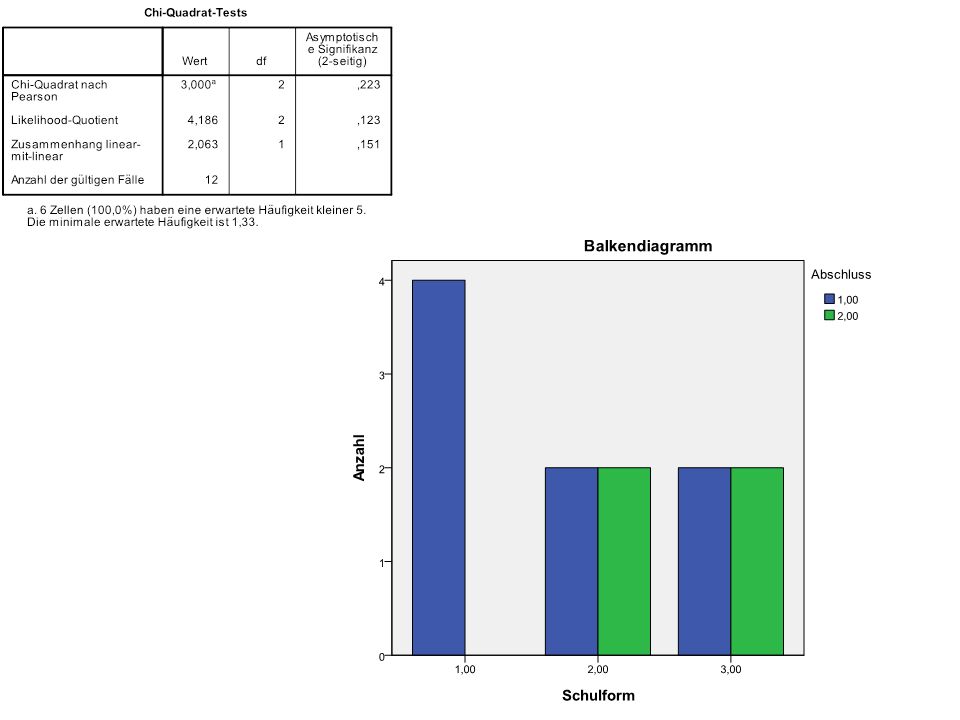
N = 4

110
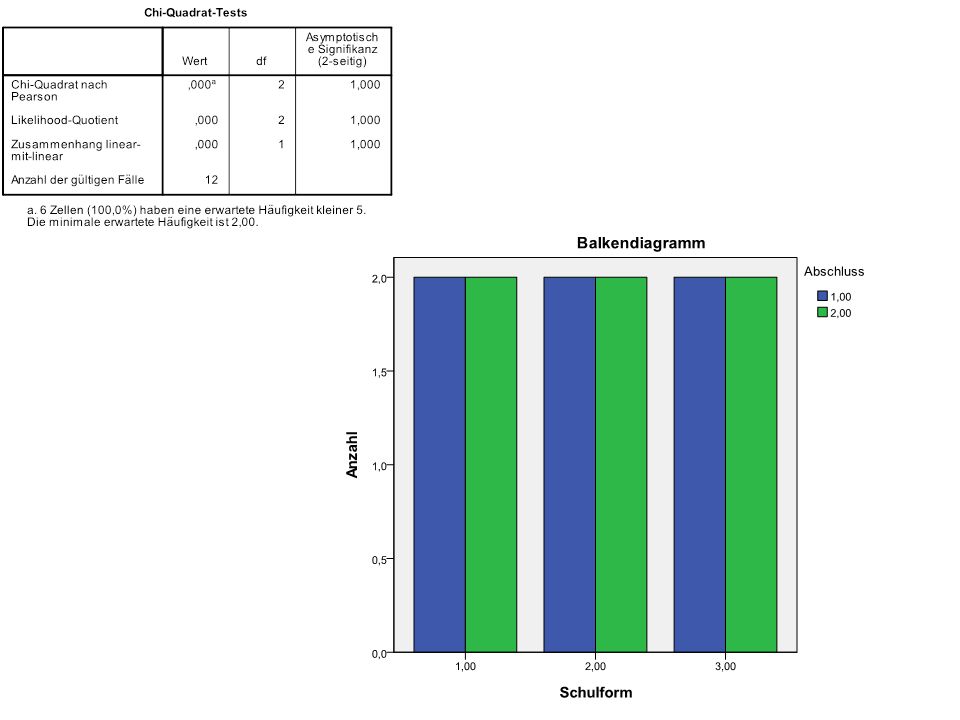
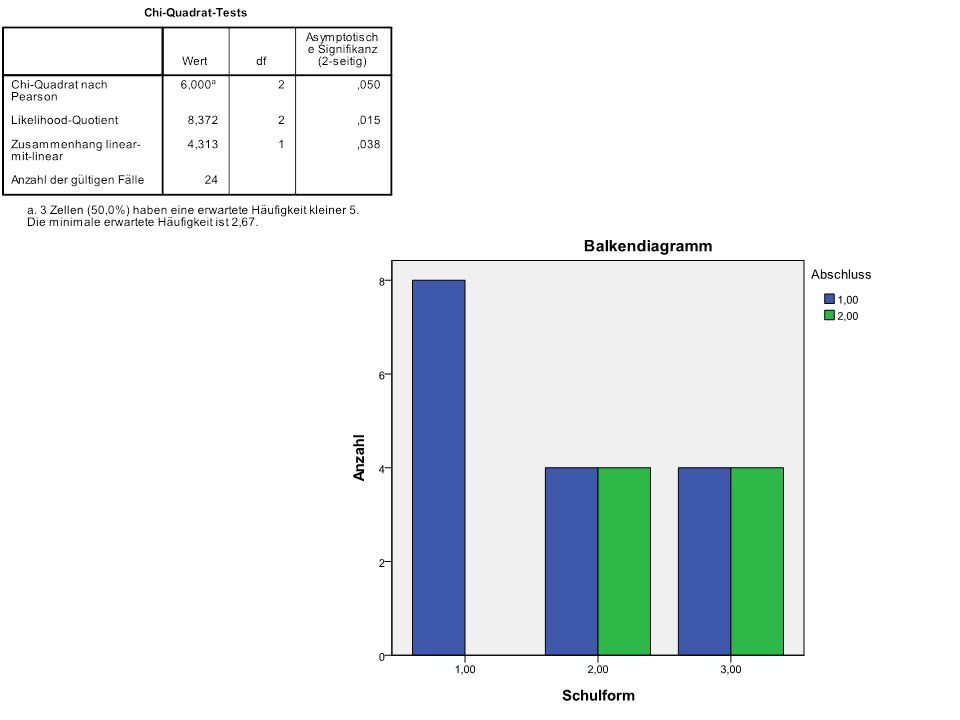
N = 8

111
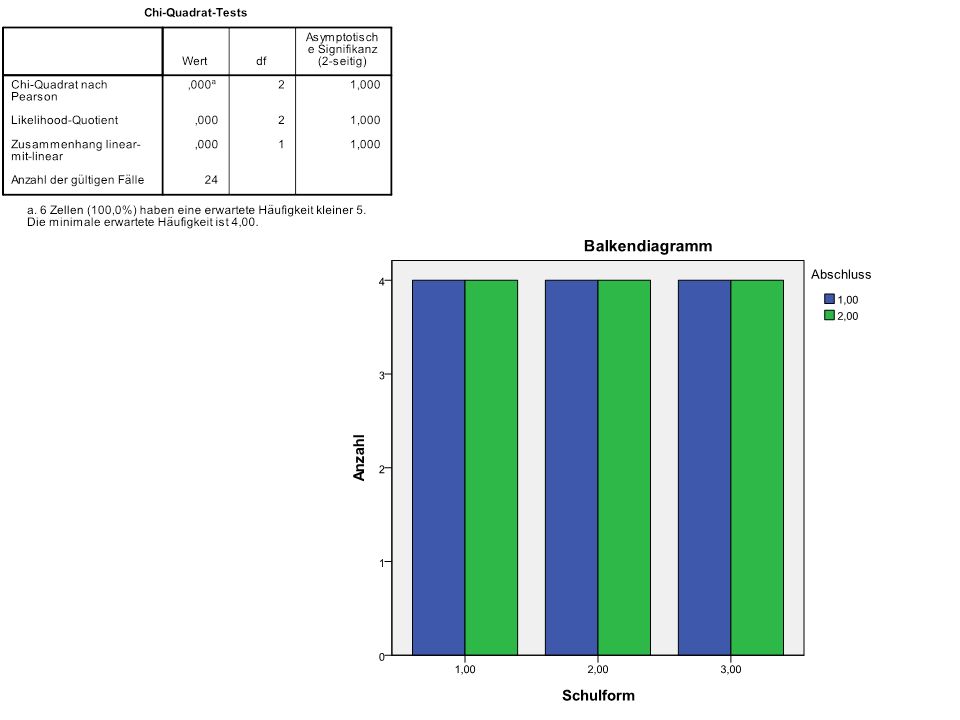
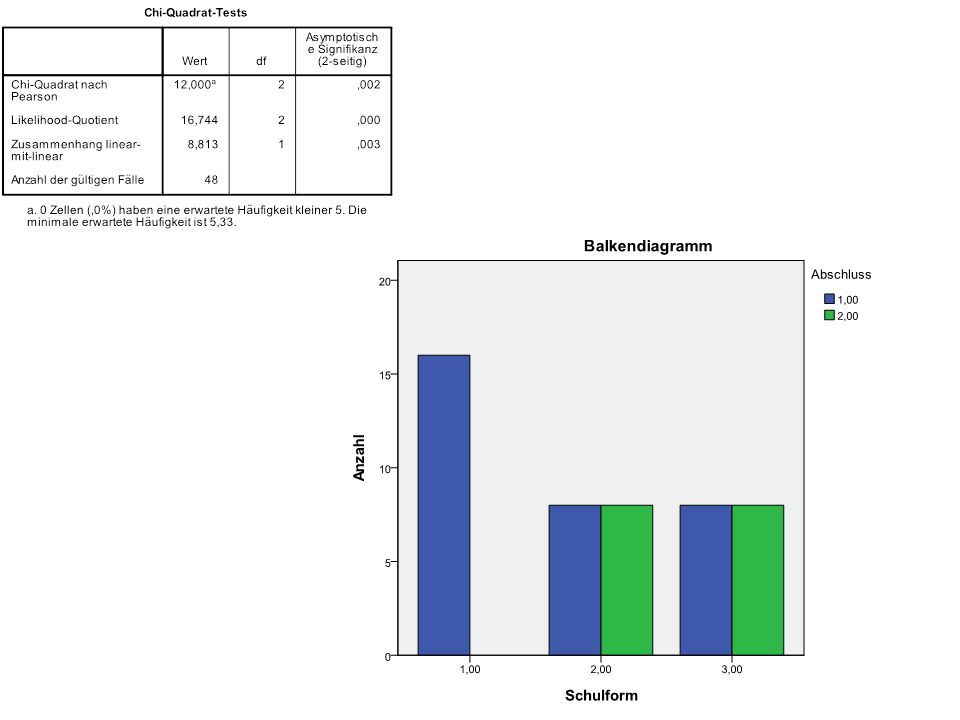
N = 16

113
N = 80

114
N = 4

115
N = 4

116
N = 8

117
N = 16

Ähnliche Präsentationen













>")


 U N I V E R S I T Ä T H A M B U R G November 2011.>")
 U N I V E R S I T Ä T H A M B U R G November 2011.>")
Media Landesanstalt für Kommunikation Baden-Württemberg (LFK) Landeszentrale für Medien und Kommunikation.>")









