Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Was ist Statistik? Statistik die Wissenschaft von Massenerscheinungen Phänomene, die in wohldefinierter Form und Weise in Masse auftreten, gehorchen bestimmten empirischen Gesetzen. Im Gegensatz zu Einzelereignissen können diese Gesetze mathematisch erfasst werden. deskriptive (beschreibende) Statistik : Darstellung großer Datenmengen sinnvoll mit Hilfe von Tabellen, Graphiken oder Piktogrammen. Charakterisierung dieser Datenmengen durch bestimmte Parameter und Ermöglichen von Vergleichen und Aufstellen von Beziehungen mit den anderen Datensätzen. analytische (beurteilende) Statistik: Schluss von Stichprobeneigenschaften auf Eigenschaften der Grundgesamtheit
 Statistik : Darstellung großer Datenmengen sinnvoll mit Hilfe von Tabellen, Graphiken oder Piktogrammen. Charakterisierung dieser Datenmengen durch bestimmte Parameter und Ermöglichen von Vergleichen und Aufstellen von Beziehungen mit den anderen Datensätzen. analytische (beurteilende) Statistik: Schluss von Stichprobeneigenschaften auf Eigenschaften der Grundgesamtheit.")
2
Kombinationen von Graphiken (Bevölkerungspyramiden, Flussdiagramme)
DARSTELLUNGEN VON DATEN Tabellen: leicht herzustellen, sehr vielfältig in der Anwendung, Daten genau dargestellt. Nachteil: Überblicke sind nicht so schnell zu erzielen. Graphiken: Geben raschen Überblick, Unterschiede (Größenvergleiche) sind er„sichtlich“. Nachteil: oft aufwendig zu gestalten, leicht manipulierbar. Stabdiagramme Kreis- und Streifendiagramme (zur Darstellung von Anteilen (Prozenten)) Piktogramme Liniendiagramme (Darstellung von Zeitreihen, Interpolation zwischen den gemessenen Daten nur für Bestandsdaten, nicht aber für Bewegungsdaten möglich z.B. Firmenkapital ist Bestandsdatum, jährlicher Umsatz ist Bewegungsdatum) Kombinationen von Graphiken (Bevölkerungspyramiden, Flussdiagramme)
 sind er„sichtlich . Nachteil: oft aufwendig zu gestalten, leicht manipulierbar. Stabdiagramme. Kreis- und Streifendiagramme (zur Darstellung von Anteilen (Prozenten)) Piktogramme. Liniendiagramme (Darstellung von Zeitreihen, Interpolation zwischen den gemessenen Daten nur für Bestandsdaten, nicht aber für Bewegungsdaten möglich. z.B. Firmenkapital ist Bestandsdatum, jährlicher Umsatz ist Bewegungsdatum) Kombinationen von Graphiken (Bevölkerungspyramiden, Flussdiagramme)")
3
Manipulationsmöglichkeiten von Graphiken
• farbige Gestaltung • geschickte Anordnung (falls das sinnvoll möglich ist!) der Stäbe oder Sektoren – ein kleiner Stab zwischen zwei großen Stäben schaut noch kleiner aus. • Abschneiden oder Unterbrechen der Stäbe • Weglassen der Standlinie bzw. Verwendung von nicht waagrechten oder nicht geraden Standlinien • perspektivische Verzerrungen ausnützen • in Piktogrammen weiß man oft nicht, ob die dargestellten Größen als Länge, Fläche oder Volumen der entsprechenden Figuren dargestellt werden • Änderung der Maßstäbe auf den Koordinatenachsen, auch in Verbindung mit Verschiebungen des Nullpunktes auf der Ordinaten- und/oder der Abszissenachse • Auswahl spezieller Daten
 der Stäbe oder Sektoren – ein kleiner Stab zwischen zwei großen Stäben schaut noch kleiner aus. • Abschneiden oder Unterbrechen der Stäbe. • Weglassen der Standlinie bzw. Verwendung von nicht waagrechten oder nicht geraden Standlinien. • perspektivische Verzerrungen ausnützen. • in Piktogrammen weiß man oft nicht, ob die dargestellten Größen als Länge, Fläche oder Volumen der entsprechenden Figuren dargestellt werden. • Änderung der Maßstäbe auf den Koordinatenachsen, auch in Verbindung mit Verschiebungen des Nullpunktes auf der Ordinaten- und/oder der Abszissenachse. • Auswahl spezieller Daten.")
6
Grundgesamtheit, Stichprobe, Merkmal
Grundgesamtheit (Gesamtpopulation) : Menge aller möglichen Untersuchungseinheiten; real oder fiktiv gegeben; Grundgesamtheit kann endlich oder als unendlich angenommen werden. Stichprobe: Teilmenge aus der Grundgesamtheit Stichprobenumfang: Anzahl der Untersuchungseinheiten der Stichprobe; Gesamterhebung Merkmal (Variable) X: eine qualitativ oder quantitativ messbare Eigenschaft der einzelnen Untersuchungseinheiten. x1, x2,..., xs bezeichnen die n Ausprägungen von X (theoretisch kann X auch unendlich viele Ausprägungen haben).
 : Menge aller möglichen Untersuchungseinheiten; real oder fiktiv gegeben; Grundgesamtheit kann endlich oder als unendlich angenommen werden. Stichprobe: Teilmenge aus der Grundgesamtheit. Stichprobenumfang: Anzahl der Untersuchungseinheiten der Stichprobe; Gesamterhebung. Merkmal (Variable) X: eine qualitativ oder quantitativ messbare Eigenschaft der einzelnen Untersuchungseinheiten. x1, x2,..., xs bezeichnen die n Ausprägungen von X (theoretisch kann X auch unendlich viele Ausprägungen haben).")
7
Grundgesamtheit oder Stichprobe
Untersuchungsobjekt 1 Grundgesamtheit oder Stichprobe UO 3 UO 4 UO 5 UO 2 x1 = 5,1 x2 = 2,4 x3 = 3 x4 = 2,4 x5 = 5,1 Messung Merkmalsausprägungen Stichprobenwerte

8
Skalen: Nichtmetrische Merkmale nominal qualitative Unterschiede Nationalität ordinal Rangordnung Noten, Güteklassen rangskaliert Metrisch Merkmale Intervallskala Abstände zwischen Rängen Temperatur Verhältnisskala Quotienten der Abstände Länge

9
Ausprägungen Häufigkeit relative Häufigkeit x1 h1 f1 x2 h2 f2 .... ... xs hs fs ∑ n 1 fj = hj/n ∑hj = n ∑fj = 1 Achtung: Mit x1, x2, x3,…,xn werden einmal die Merkmalswerte der n Untersuchungseinheiten bezeichnet (die xi müssen nicht alle verschieden sein), mit x1, x2, x3,…,xs werden aber auch die untereinander verschieden Ausprägungen des Merkmals bezeichnet (also gilt insbesondere n ≥ s)
, mit x1, x2, x3,…,xs werden aber auch die untereinander verschieden Ausprägungen des Merkmals bezeichnet (also gilt insbesondere n ≥ s)")
10
Beispiel „Häufigkeiten“

11
Häufigkeitsverteilung:
Zusammenhang zwischen Ausprägung und absoluter bzw. relativer Häufigkeit Darstellung tabellarisch oder graphisch, z.B. als Stabdiagramm – x-Achse: Ausprägungen (falls Merkmal ordinal, Rangordnung beachten; falls das Merkmal metrisch, Abstände zwischen den einzelnen Ausprägungen beachten) y-Achse: absolute bzw. relative Häufigkeiten für entsprechende Ausprägung
 y-Achse: absolute bzw. relative Häufigkeiten für entsprechende Ausprägung.")
12
Gruppierte Daten, Histogramm
Messung der Merkmalsausprägungen für die einzelnen Untersuchungseinheiten zu genau! Komprimierung der Stichprobenwerte durch Gliederung in Klassen (Gruppen) Klassen sowohl für nominale als auch ordinale und metrische Merkmale Bei metrischen Daten Klassen von der Form: {x: a < x ≤ b} nach links halboffenes Intervall; a und b heißen Klassengrenzen (obere bzw. untere), die Differenz b - a heißt Klassenbreite, 1/2 ( a + b ) - Mittelpunkt des Intervalls - die Klassenmitte Achtung: Vereinbarung: untere Klassengrenze gehört nicht zur Klasse, obere aber schon. Für benachbarte Klassen gilt: obere KG der einen ist untere KG der anderen Klasse d.h. es gibt keine Zwischenräume zwischen benachbarten Klassen Histogramm als Darstellungsmittel: über den Klassenintervallen werden Rechtecke gebildet, deren Fläche gleich der absoluten Klassenhäufigkeit, d.h. der Anzahl der zur Klasse gehörigen Stichprobenwerte ist Rechteckshöhe = Klassenhäufigkeit der Klasse / Klassenbreite
 Klassen sowohl für nominale als auch ordinale und metrische Merkmale. Bei metrischen Daten Klassen von der Form: {x: a < x ≤ b} nach links halboffenes Intervall; a und b heißen Klassengrenzen (obere bzw. untere), die Differenz b - a heißt Klassenbreite, 1/2 ( a + b ) - Mittelpunkt des Intervalls - die Klassenmitte. Achtung: Vereinbarung: untere Klassengrenze gehört nicht zur Klasse, obere aber schon. Für benachbarte Klassen gilt: obere KG der einen ist untere KG der anderen Klasse d.h. es gibt keine Zwischenräume zwischen benachbarten Klassen. Histogramm als Darstellungsmittel: über den Klassenintervallen werden Rechtecke gebildet, deren Fläche gleich der absoluten Klassenhäufigkeit, d.h. der Anzahl der zur Klasse gehörigen Stichprobenwerte ist Rechteckshöhe = Klassenhäufigkeit der Klasse / Klassenbreite.")
14
Kriterien für Klassenbildung:
• Anhäufungen (Cluster) zu Klassen zusammenfassen, wobei die Klassengrenzen die Mitte der Lücken gelegt werden sollen. Nicht zu viele Daten in eine Klasse legen (mehr als 40% aller Daten in einer Klasse ist in der Regel ungünstig). Nicht weniger als 3 und nicht mehr als 10 Klassen bilden • als Klassengrenzen möglichst „runde“ Zahlen wählen und nicht zu viele verschiedene Klassenbreiten • Klassengrenzen so legen, dass innerhalb der Klassen die Daten möglichst gleichmäßig verteilt sind Andere Autoren geben andere Kriterien (z.B. E. Kreyszig): • Die Klassenbreiten wähle man gleich lang • Die Klassenmitten sollen möglichst „runde“ Zahlen darstellen • In der Praxis wählt man meist 10 bis 20 Klassen
 zu Klassen zusammenfassen, wobei die Klassengrenzen die Mitte der Lücken gelegt werden sollen. Nicht zu viele Daten in eine Klasse legen (mehr als 40% aller Daten in einer Klasse ist in der Regel ungünstig). Nicht weniger als 3 und nicht mehr als 10 Klassen bilden. • als Klassengrenzen möglichst „runde Zahlen wählen und nicht zu viele verschiedene Klassenbreiten. • Klassengrenzen so legen, dass innerhalb der Klassen die Daten möglichst gleichmäßig verteilt sind. Andere Autoren geben andere Kriterien (z.B. E. Kreyszig): • Die Klassenbreiten wähle man gleich lang. • Die Klassenmitten sollen möglichst „runde Zahlen darstellen. • In der Praxis wählt man meist 10 bis 20 Klassen.")
16
Zentralmaße, Mittelwerte
Modus die am häufigst vorkommende Merkmalsausprägung; nicht eindeutig; immer ermittelbar; keine große Aussagekraft Median jener Wert, der eine geordnete Folge von Stichprobenwerten genau in zwei Hälften Merkmal mindest rangskalierte, M robust gegenüber Ausreißern

17
Arithmetisches Mittel
Merkmal metrisch, hoher Informationsgehalt Eigenschaften Median: M minimiert den Ausdruck Arithmetisches Mittel: minimiert den Ausdruck Geometrisches Mittel Zuwachsraten Vorsicht bei der Ermittlung von Zentralwerten für Prozentsätze!!!

18
Klassierte Daten Bildung von Zentralmaße für klassierte Daten: Man nehme an, dass sämtliche Daten in den jeweiligen Klassenmitten konzentriert sind und verfahre in gewohnter Weise. Der bei in Klassen zusammengefassten Daten auftretende Informationsverlust bewirkt Fehler in der Berechnung von Zentralmaßen. Korrekturverfahren finden sich in der Literatur

19
Streuungs- oder Dispersionsmaße
Angabe, wie sehr die Stichprobenwerte um das Zentralmaß streuen wie dicht die Daten um das Zentralmaß konzentriert liegen Zentralmaß Streuungsmaß Modus Spannweite Median Quartilabstand QA = 5 50% der Daten liegen innerhalb von 5 Werten um M Arithm. Mittel Standardabweichung x = 5 im Schnitt beträgt das Abstands- Quadrat der Daten vom arith. Mittel 5

20
Berechnung der Quartile
Allgemein: p-Quantil

21
Kastenschaubild (Box-Plot-Diagramm)
xmax xmin UQ M OQ

22
Andere Streuungsmaße:
Mittlere lineare Abweichung Variationskoeffizient 3s-Regel: Im Abstand von s Einheiten um das arithmetische Mittel liegen 68% der Daten, im Abstand von 2s 95,5% und im Abstand von 3s 99,7%. Standardisierung

23
Multivariate Statistik
Von den Untersuchungseinheiten werden mehrere Merkmale gleichzeitig gemessen (verbundene Merkmale). Resultat der Messung ist mehrdimensional. Univariate Statistik Darstellung der Häufigkeitsverteilung Punktwolke Stabdiagramm Kontingenztabelle
. Resultat der Messung ist mehrdimensional. Univariate Statistik. Darstellung der Häufigkeitsverteilung. Punktwolke. Stabdiagramm. Kontingenztabelle.")
24
hik Häufigkeit des gleichzeitigen Auftretens der Merkmalsausprägungen xi und yk
hxi Häufigkeit des Auftretens der Merkmalsausprägung xi (gleich, welche Ausprägung dabei das Merkmal Y annimmt) hyk Häufigkeit des Auftretens der Merkmalsausprägung yk (gleich, welche Ausprägung dabei das Merkmal X annimmt) hxi bzw. hyk sind die Häufigkeitsverteilungen von X bzw. Y ; Randverteilungen (Marginalverteilungen) von (X,Y)
 hyk Häufigkeit des Auftretens der Merkmalsausprägung yk (gleich, welche Ausprägung dabei das Merkmal X annimmt) hxi bzw. hyk sind die Häufigkeitsverteilungen von X bzw. Y ; Randverteilungen (Marginalverteilungen) von (X,Y)")
25
Zweidimensionale Häufigkeitsverteilung (Kontingenztabelle)
X Y y1 y2 y3 ..... yk ys x1 h11 h12 h13 h1k h1s hx1 x2 h21 h22 h23 h2k h2s hx2 x3 h31 h32 h33 h3k h3s hx3 xi hi1 hi2 hi3 hik his hxi xr hr1 hr2 hr3 hrk hrs hxr hy1 hy2 hy3 hyk hys n

26
Lineare Regression Problem: Punktwolke optimal durch eine Gerade approximieren

27
Minimalisierung der Quadrate der Vertikalabstände. 1
Minimalisierung der Quadrate der Vertikalabstände 1. Regrssionsgerade Minimalisierung der Quadrate der Horizontalabstände 2. Regrssionsgerade

28
1. Regressionsgerade 2. Regressionsgerade Dabei ist sxy die Kovarianz

29
Wahrscheinlichkeit Zufallsexperiment: Stringenz der Definition (insb. alle möglichen Ausgänge bekannt) Wiederholbarkeit (potentiell unendlich oft) Unabhängigkeit des Ausgangs eines ZE von früheren Ausgängen des ZE Empirische Definition von Wahrscheinlichkeit (empirisches. Gesetz der großen Zahlen) Achtung: d.h. nicht, dass Die Differenz zwischen der Anzahl des tatsächlichen Auftretens und der des zu erwartenden Auftretens von x ( = nP(x)) kann bei wachsendem n durchaus beliebig groß werden!
 Unabhängigkeit des Ausgangs eines ZE von früheren Ausgängen des ZE. Empirische Definition von Wahrscheinlichkeit (empirisches. Gesetz der großen Zahlen) Achtung: d.h. nicht, dass. Die Differenz zwischen der Anzahl des tatsächlichen Auftretens und der des zu erwartenden Auftretens von x ( = nP(x)) kann bei wachsendem n durchaus beliebig groß werden!")
30
Klassische Definition von Wahrscheinlichkeit
(vorausgesetzt, die Chance für das Auftreten jedes möglichen Falles ist immer dieselbe) Beispiel: Wie groß ist die Ws, dass bei 5 Würfen genau dreimal eine 6 gewürfelt wird? Anzahl der möglichen Fälle: 6x6x6x6x6 = 7776 Anzahl der günstigen Fälle: (6,6,6,*,*) (6,6,*,6,*), (6,6,*,*,6) (6,*,6,6,*), (6,*,6,*,6), (6,*,*,6,6) (*,6,6,6,*), (*,6,6,*,6), (*,6,*,6,6) (*,*,6,6,6) 10x25 = 250 P(x) = 250/7776 = 0,03
 Beispiel: Wie groß ist die Ws, dass bei 5 Würfen genau dreimal eine 6 gewürfelt wird Anzahl der möglichen Fälle: 6x6x6x6x6 = Anzahl der günstigen Fälle: (6,6,6,*,*) (6,6,*,6,*), (6,6,*,*,6) (6,*,6,6,*), (6,*,6,*,6), (6,*,*,6,6) (*,6,6,6,*), (*,6,6,*,6), (*,6,*,6,6) (*,*,6,6,6) 10x25 = 250. P(x) = 250/7776 = 0,03.")
31
Axiomatische Definition von Wahrscheinlichkeit
= {x1, x2,..., xn} sei eine endliche Menge (Menge der Elementarereignisse (ZE-Ausgänge)) P sei eine Funktion von mit Werten zwischen 0 und 1, die folgende Eigenschaft besitzt: heißt endlicher Wahrscheinlichkeitsraum und die Funktion P Wahrscheinlichkeitsmaß oder Wahrscheinlichkeitsverteilung. ACHTUNG: In der Literatur findet sich meist eine verallgemeinerungfähigere Definition, wobei auch unendlich sein kann; P ist nicht auf , sondern auf allen Teilmengen von mit Werten zwischen 0 und 1 definiert und besitzt folgende Eigenschaften: In unserer Definition müsste P eigentlich auf den Mengen {xi} statt auf den Elementen xi definiert werden. Beispiel: = {x1, x2}, P(x1) = P(x2) = ½ x1 ist das Ereignis Münze zeigt Zahl x2 ist das Ereignis Münze zeigt Wappen
) P sei eine Funktion von mit Werten zwischen 0 und 1, die folgende Eigenschaft besitzt: heißt endlicher Wahrscheinlichkeitsraum und die Funktion P Wahrscheinlichkeitsmaß oder Wahrscheinlichkeitsverteilung. ACHTUNG: In der Literatur findet sich meist eine verallgemeinerungfähigere Definition, wobei auch unendlich sein kann; P ist nicht auf , sondern auf allen Teilmengen von mit Werten zwischen 0 und 1 definiert und besitzt folgende Eigenschaften: In unserer Definition müsste P eigentlich auf den Mengen {xi} statt auf den Elementen xi definiert werden. Beispiel: = {x1, x2}, P(x1) = P(x2) = ½ x1 ist das Ereignis Münze zeigt Zahl. x2 ist das Ereignis Münze zeigt Wappen.")
32
Zufallsvariable (ZV) Definition: ZV X ist eine Funktion von einem Wahrscheinlichkeitsraum in die reellen Zahlen. Beispiel: = {1, 2, 3, 4, 5, 6} Augenzahl beim Wurf eines Würfels X() = 6 – 2 Interpretation: Falls gewürfelt wird, erhält man X() Geldeinheiten als Gewinn bzw. Verlust Wahrscheinlichkeitsverteilung einer ZV X Sei X: {x1,..., xr} eine ZV auf dem Wraum mit dem Wmaß P. Dann heißt das Wmaß PX auf {x1,..., xr} die Wverteilung von X, wobei Erwartungswert E(X) einer ZV X Beispiel: X: {1, 2, 3, 4, 5, 6} {4, 2, 0, -2, -4, -6} E(X) = 1/6 ( ) = -1, d.h. à la longue ist mit einem durchschnittlichen Gewinn von –1 Geldeinheiten zu rechnen (also kein faires Spiel)
 = 6 – 2 Interpretation: Falls gewürfelt wird, erhält man X() Geldeinheiten als Gewinn bzw. Verlust. Wahrscheinlichkeitsverteilung einer ZV X. Sei X: {x1,..., xr} eine ZV auf dem Wraum mit dem Wmaß P. Dann heißt das Wmaß PX auf {x1,..., xr} die Wverteilung von X, wobei. Erwartungswert E(X) einer ZV X. Beispiel: X: {1, 2, 3, 4, 5, 6} {4, 2, 0, -2, -4, -6} E(X) = 1/6 ( ) = -1, d.h. à la longue ist mit einem durchschnittlichen Gewinn von –1 Geldeinheiten zu rechnen (also kein faires Spiel)")
33
Varianz Var(X) einer ZV X
Beispiel: X: {1, 2, 3, 4, 5, 6} {4, 2, 0, -2, -4, -6}, E(X) = -1 = Var(X) = 1/6( ) – 1 = 76/6 – 1 = 11,67
 = -1. = Var(X) = 1/6( ) – 1 = 76/6 – 1 = 11,67.")
34
Zweidimensionale ZV X: R, Y: R seien ZV auf dem Wraum (, P) mit X() = {xi1 < i < r} und Y() = {yk1 < k < s}. X Y: R R heißt zweidimensionale ZV, deren gemeinsame Wverteilung gegeben ist durch Es gilt:
 mit X() = {xi1 < i < r} und Y() = {yk1 < k < s}. X Y: R R heißt zweidimensionale ZV, deren gemeinsame Wverteilung gegeben ist durch. Es gilt:")
35
Kovarianz zweier ZV, stochastische Unabhängigkeit
X und Y heißen (stochastisch) unabhängig genau dann, wenn für alle i und k gilt: Falls X und Y stochastisch unabhängig sind, gilt: E(XY) = E(X)E(Y) d.h. Cov(X,Y) = 0
 unabhängig genau dann, wenn für alle i und k gilt: Falls X und Y stochastisch unabhängig sind, gilt: E(XY) = E(X)E(Y) d.h. Cov(X,Y) = 0.")
36
Stochastische Modelle
Empirische Erhebung (Realität) Stochastisches Modell Grundgesamtheit Wahrscheinlichkeitsraum Untersuchungseinheit Elementarereignis Merkmal Zufallsvariable Relative Häufigkeit Wahrscheinlichkeit Häufigkeitsverteilung Wahrscheinlichkeitsverteilung Arithmetisches Mittel Erwartungswert Empirische Varianz Varianz Ziehen von Stichproben Zufallsstichprobe aus Grundgesamtheit (Modell ziehen von Kugeln aus einer Urne – mit Zurücklegen oder ohne Zurücklegen)
 Stochastisches Modell. Grundgesamtheit. Wahrscheinlichkeitsraum. Untersuchungseinheit. Elementarereignis. Merkmal. Zufallsvariable. Relative Häufigkeit. Wahrscheinlichkeit. Häufigkeitsverteilung. Wahrscheinlichkeitsverteilung. Arithmetisches Mittel. Erwartungswert. Empirische Varianz. Varianz. Ziehen von Stichproben. Zufallsstichprobe aus Grundgesamtheit (Modell ziehen von Kugeln aus einer Urne – mit Zurücklegen oder ohne Zurücklegen)")
37
Urne mit N verschiedenartigen Kugeln (n1, n2, …, nk)
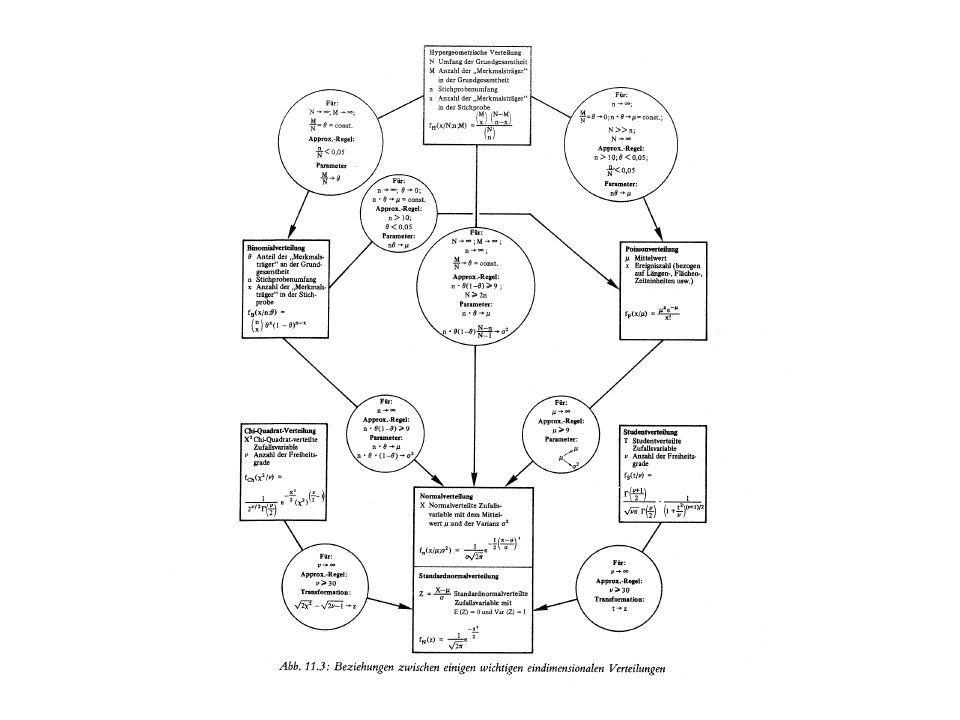
Urnenmodelle Urne mit N verschiedenartigen Kugeln (n1, n2, …, nk) P(Kugel j-ter Sorte) = nj/N n-maliges Ziehen mit Zurücklegen (2 Sorten): n-maliges Ziehen ohne Zurücklegen Ziehungen nicht mehr unabhängig Hypergeometrische Verteilung Falls N>60, n/N<0,1, lässt sich die hypergeometrische Verteilung durch eine B(n1/N, n)-Verteilung ersetzen
 P(Kugel j-ter Sorte) = nj/N. n-maliges Ziehen mit Zurücklegen (2 Sorten): n-maliges Ziehen ohne Zurücklegen. Ziehungen nicht mehr unabhängig. Hypergeometrische Verteilung. Falls N>60, n/N<0,1, lässt sich die hypergeometrische Verteilung durch eine B(n1/N, n)-Verteilung ersetzen.")
38
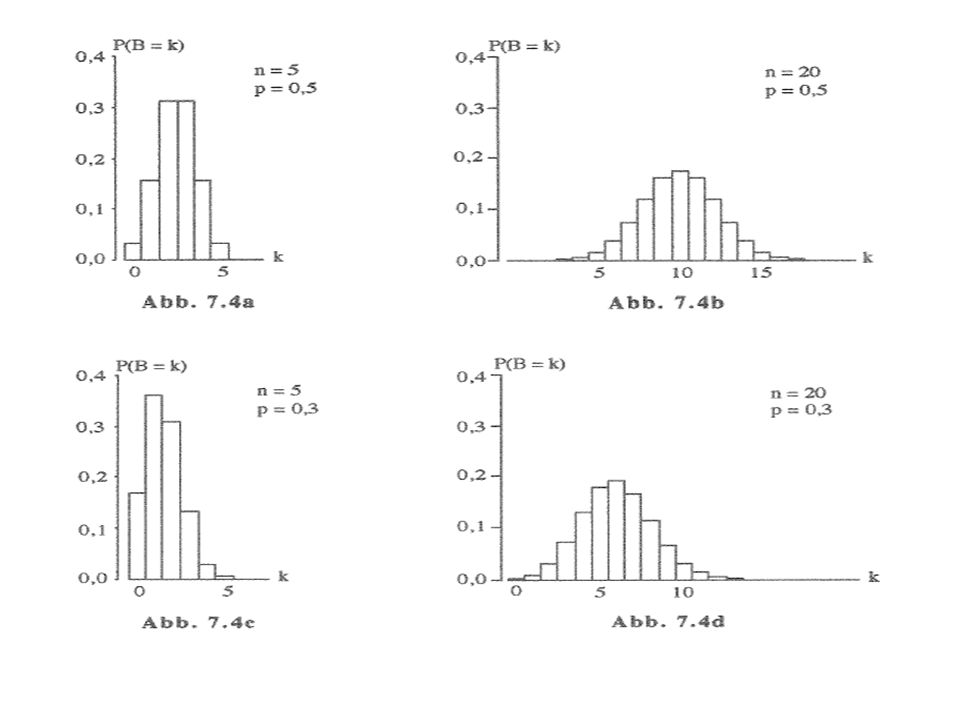
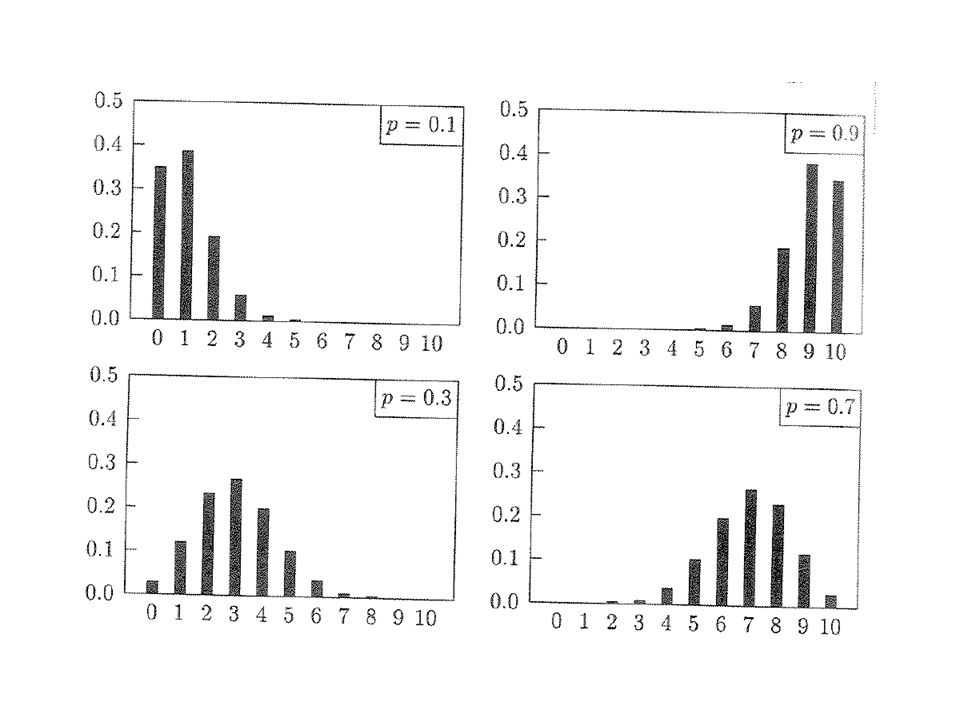
Bernoulliverteilung

42
Normalverteilung Wenn X eine B(n,p)-binomial verteilte ZV ist, dann hat die standardisierte ZV Mittelwert 0 und Standardabweichung 1. Für große n nähert sich die Verteilung von X* immer besser der Gaußschen Glockenkurve ist die standardisierte Glockenkurve, die Dichtefunktion der Standardnormalverteilung

43
Eigenschaften der Normalverteilung
ist bezüglich der x-Achse symmetrisch hat bei x=0 ein Maximum hat die x-Achse als Asymptote (für x) ist monoton steigend erfüllt die folgende Beziehungen:
 ist monoton steigend. erfüllt die folgende Beziehungen:")
44
Grenzwertsätze Zentraler Grenzwertsatz von de Moivre - Laplace:
Sei X eine B(n,p)-binomial verteilte Zufallsvariable, dann gilt für 0<p<1: In der Praxis lässt sich also jede Binomialverteilung durch die Normalverteilung ersetzen, falls die sogenannte Laplace-Bedingung np(1-p) ≥ 9 erfüllt ist. Zentraler Grenzwertsatz von Lindenberg - Lévy Seien X1, X2,..., Xn stochastisch unabhängige und identisch verteilte ZV, wobei E(Xi) = und Var(Xi) = s2 gilt, dann gilt für die ZV Sn = X1+X2+...+Xn : (Dabei heißen zwei ZV X und Y (stochastisch) unabhängig, wenn P(X=x, Y=y) = P(X=x).P(Y=y) für alle x und y gilt.)
-binomial verteilte Zufallsvariable, dann gilt für 0<p<1: In der Praxis lässt sich also jede Binomialverteilung durch die Normalverteilung ersetzen, falls die sogenannte Laplace-Bedingung np(1-p) ≥ 9 erfüllt ist. Zentraler Grenzwertsatz von Lindenberg - Lévy. Seien X1, X2,..., Xn stochastisch unabhängige und identisch verteilte ZV, wobei. E(Xi) = und Var(Xi) = s2 gilt, dann gilt für die ZV Sn = X1+X2+...+Xn : (Dabei heißen zwei ZV X und Y (stochastisch) unabhängig, wenn P(X=x, Y=y) = P(X=x).P(Y=y) für alle x und y gilt.)")
47
Übungen Angenommen zwei Personen A und B spielen ein faires Spiel, d.h. in jeder Spielrunde besitzen beide die gleiche Gewinnchance. Wer zuerst 6 Spielrunden gewonnen hat, erhält den gesamten Spieleinsatz von € 20,-. Das Spiel muss unterbrochen werden, nachdem A 5 und B 3 Runden gewonnen haben. Man finde eine gerechte Teilung des Spieleinsatzes. Mögliche Spielverläufe: A gewinnt bei folgenden Möglichkeiten: B gewinnt nur bei: A oder BA oder BBA BBB Wahrscheinlichkeiten: P(A gewinnt) = P(A) + P(BA) + P(BBA) = ½ + ¼ + 1/8 = 7/8 P(B gewinnt) = P(BBB) = 1/8 Teilung 7:1 € 17,50 erhält A, B € 2,50
 = P(A) + P(BA) + P(BBA) = ½ + ¼ + 1/8 = 7/8. P(B gewinnt) = P(BBB) = 1/8. Teilung 7:1 € 17,50 erhält A, B € 2,50.")
48
Würden sie folgendes Spiel einen Abend lang spielen
Würden sie folgendes Spiel einen Abend lang spielen? Eine Münze wird 4 mal geworfen. Erscheint Adler viermal erhalten sie € 20,-. Erscheint dagegen Adler genau dreimal, erhalten sie € 10,-. Der Spieleinsatz pro Spiel beträgt € 4,-. = {AAAA, AAAZ, AAZA, AZAA, ZAAA, AAZZ, AZAZ, AZZA, ZAAZ, ZAZA, ZZAA, AZZZ, ZAZZ, ZZAZ, ZZZA, ZZZZ} P(****) = 1/16 ZV X = Gewinn X(AAAA) = 16 X(AAAZ) = X(AAZA) = X(AZAA) = X(ZAAA) = 6 X(sonst) = -4 Erwartungswert von X E(X): E(X) = 16.1/ /16 + (-4).11/16 = ( – 44)/16 = -1/4
 = 1/16. ZV X = Gewinn. X(AAAA) = 16. X(AAAZ) = X(AAZA) = X(AZAA) = X(ZAAA) = 6. X(sonst) = -4. Erwartungswert von X E(X): E(X) = 16.1/ /16 + (-4).11/16 = ( – 44)/16 = -1/4.")
49
Laut offizieller Statistik sind 0,3% aller ÖsterreicherInnen mit AIDS infiziert. Ein HIV-Test zeigt mit 100% Sicherheit ein positives Resultat, falls die getestete Person tatsächlich erkrankt ist. Mit 99% Sicherheit zeigt der Test ein negatives Resultat, falls die Person nicht an AIDS erkrankt ist. Angenommen jemand wird in Kenntnis gesetzt, dass sein HIV-Test positiv ist. Wie hoch sind Chancen, dass diese Person tatsächlich an AIDS erkrankt ist? Genaue Abzählung (Annahme: Population = ) Real Test positiv negativ infiziert 24.000 gesund 79.760 P(tatsächlich infiziert unter der Voraussetzung „Test positiv“) = / = 0,23
 Real Test. positiv. negativ. infiziert gesund P(tatsächlich infiziert unter der Voraussetzung „Test positiv ) = / = 0,23.")
50
Die Fakultät für Wirtschaftswissenschaften und Informatik veranstaltet ein Fest, auf dem jede/r Teilnehmer/in die Chance hat, eine Reise zu gewinnen. Es sind 52 weibliche und 46 männliche Angehörige der Wirtschaftswissenschaften bzw. 42 weibliche und 48 männliche Angehörige der Informatik zugegen. Wie groß ist die Wahrscheinlichkeit, dass eine Informatikerin den Preis gewinnt, bzw. ein Mann gewinnt? St G männlich weiblich Informatik 48 42 90 Wirtschaft 46 52 98 94 188 P(Informatikerin) = 42/188 = 0,22 P(Mann) = 94/188 = 0,5
 = 42/188 = 0,22. P(Mann) = 94/188 = 0,5.")
51
Testen Problem: Wie lassen sich Vermutungen über die Grundgesamtheit überprüfen? Lösungsprinzip: Konstruktion eines wahrscheinlichkeitstheoretischen Modells unter der Annahme, dass die Vermutung gilt - Ziehen einer Stichprobe - Unter Bezugnahme auf das Modell Bestimmung der Wahrscheinlichkeit dieser Stichprobe – Verwerfen der Annahme bei zu geringer Wahrscheinlichkeit Achtung: Beim Testen werden die Hypothesen logisch nicht bewiesen! Keine Verifizierung, sondern Falsifizierung!

52
Testen von Hypothesen über Anteile
H0 Nullhypothese H1 Alternative Irrtumswahrscheinlichkeit, Fehler 1.Art, Signifikanz(niveau)
")
53
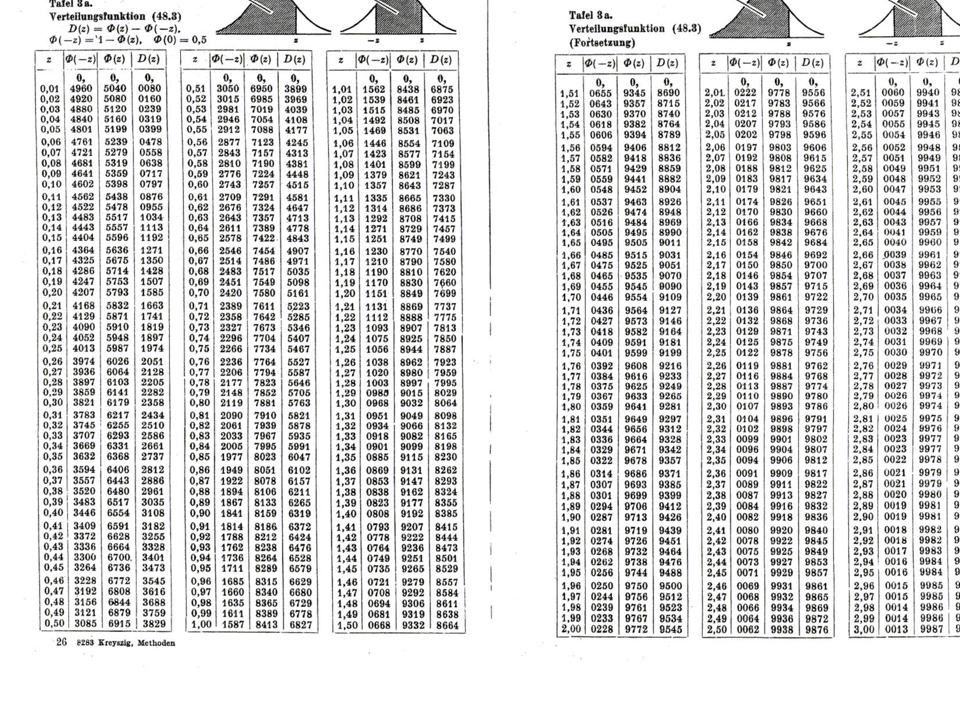
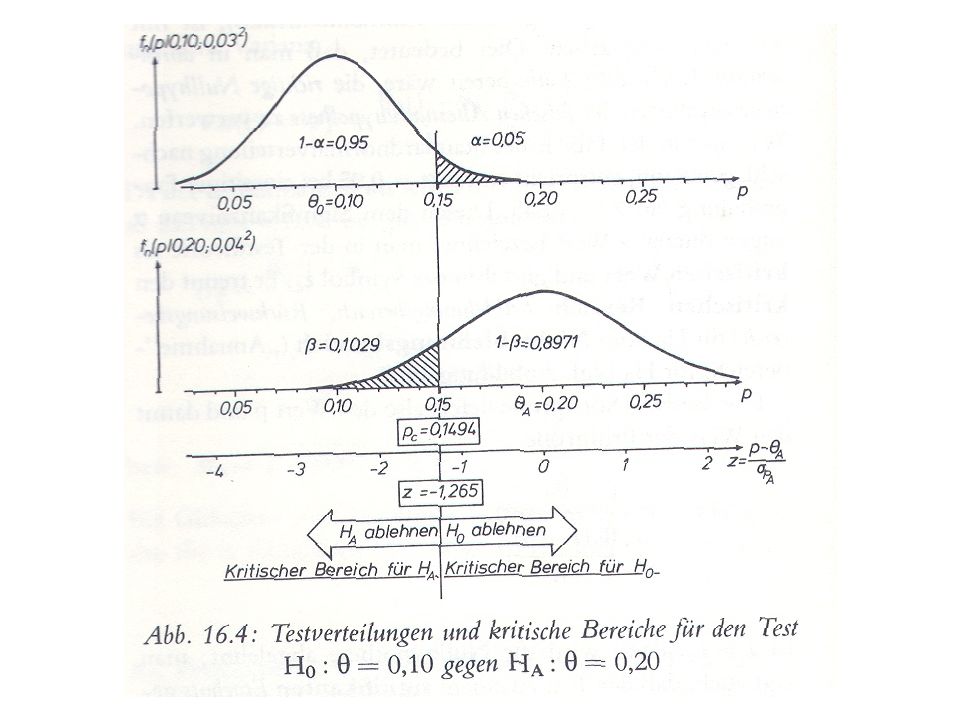
Beispiel Testen der Hypothese, dass Wähleranteil 40% beträgt, zur Alternative, dass er nur 30% beträgt. Signifikanzniveau ist 5%. Eine Stichprobe vom Umfang 100 enthält 33 WählerInnen. H0 p = 0,4 H1 p = 0,3 = 5% Stichprobe: n = 100 1. LB überprüfen 2. Bestimmung des kritischen Bereichs (jener Bereich K, für den P0(K) = und K = = {v | v < k})
 = und K = = {v | v < k})")
54
z=-1,645, also Da die Stichprobe 33 WählerInnen enthält, liegt die Anzahl der „Hits“, also der WählerInnen, nicht im kritischen Bereich K (31,9 < 33). Die Hypothese kann also nicht verworfen werden! Hätte die Stichprobe nur 31 oder noch weniger WählerInnen enthalten, dann hätte die Hypothese mit einer Irrtumswahrscheinlichkeit von = 0,05 (das ist die Ws unter der Annahme von H0, dass eine Stichprobe mit einer Anzahl kleiner als 31,1 auftritt) verworfen werden müssen. Fehler 1. und 2. Art H0 verwerfen H0 nicht verwerfen H0 wahr -Fehler, Fehler1.Art - H0 falsch -Fehler, Fehler 2. Art
. Die Hypothese kann also nicht verworfen werden! Hätte die Stichprobe nur 31 oder noch weniger WählerInnen enthalten, dann hätte die Hypothese mit einer Irrtumswahrscheinlichkeit von = 0,05 (das ist die Ws unter der Annahme von H0, dass eine Stichprobe mit einer Anzahl kleiner als 31,1 auftritt) verworfen werden müssen. Fehler 1. und 2. Art. H0 verwerfen. H0 nicht verwerfen. H0 wahr. -Fehler, Fehler1.Art. - H0 falsch. -Fehler, Fehler 2. Art.")
55
Fehler 2. Art Fehler 2. Art: H0 wird nicht verworfen – d.h. die Stichprobe darf nicht im kritischen Bereich liegen - obwohl sie falsch, also H1 richtig ist. ist Ws unter der Annahme H1, dass die Stichprobe nicht im kritischen Bereich liegt. Mit 33,72% Wahrscheinlichkeit wird die Nullhypothese nicht verworfen, obwohl sie falsch ist.

56
Weitere Parametertests für p
Einseitiger Test H0 : p < po H1 : p > po kritischer Bereich: {X > k} H0 : p > po H1 : p < po kritischer Bereich: {X < k} Zweiseitiger Test H0 : p = po H1 : p po kritischer Bereich: {X < k1} {X > k2}

57
Beispiel Von einem Produkt ist der Bekanntheitsgrad 25%. Nach einer Werbekampagne behauptet der Verkaufsleiter, sie sei erfolglos gewesen. Worauf in einer Blitzumfrage festgestellt wird, dass von 500 Personen 151 das Produkt kennen. War die Werbekampagne erfolglos? H0 : p=0,25 H1 : p>0,25 = 0,01 (0,05) n = 500 Kritischer Bereich: X>k LB: 500.0,25.0,75 = 93,75 > 9
 n = 500. Kritischer Bereich: X>k. LB: 500.0,25.0,75 = 93,75 > 9.")
58
Die Annahme, die Werbekampagne sei erfolglos gewesen, muss mit 1% Irrtumswahrscheinlichkeit verworfen werden. Der Redakteur eines Magazins behauptet, dass sich seine Leserschaft aus gleich vielen Frauen und Männern zusammensetzt. Aus einer statistischen Erhebung folgt, dass von 420 Personen, die sich als LeserInnen des Magazin deklarieren, 232 Männer (und 188 Frauen) sind. Gilt die Behauptung des Redakteurs (=0,05)? H0 : p=0, H1 : p≠0,5 n = 420 = 0,05 Kritischer Bereich: {X < k1} {X > k2} LB: 420.0,5.0,5 = 105
 sind. Gilt die Behauptung des Redakteurs (=0,05) H0 : p=0,5 H1 : p≠0,5. n = 420. = 0,05. Kritischer Bereich: {X < k1} {X > k2} LB: 420.0,5.0,5 = 105.")
59
232 > k2 = 230,08 (188 < k1 <189,92) Die Aussage des Redakteurs ist mit einer Irrtumswahrscheinlichkeit von 5% abzulehnen.
 Die Aussage des Redakteurs ist mit einer Irrtumswahrscheinlichkeit von 5% abzulehnen.")
61
2-Verteilung Die Verteilung der Summe der Quadrate von n unabhängig standardnormalverteilten ZV heißt 2-Verteilung mit Freiheitsgrad n.

62
Verteilungstests (2-Test)
Nullhypothese bezieht sich auf die Art der Verteilung (Normalverteilung, Binomialverteilung, etc.) oder auf Unabhängigkeit der Verteilung von anderen. 2-Unabhängigkeitstest: Nullhypothese: ZV X und Y sind unabhängige ZV Alternative: X und Y sind abhängige ZV X und Y sind unabhängig P(X = xi, Y = yk) = P(X = xi).P(Y = yk) Annahme X und Y unabhängig Ziehen einer Stichprobe vom Umfang n – Ergebnis: Häufigkeiten der Messwerte: X = xi Y = yk hik Unter der Annahme „X und Y unabhängig“ müssten die zu erwartenden Häufigkeiten eik der Stichprobe folgende Bedingung erfüllen:
 oder auf Unabhängigkeit der Verteilung von anderen. 2-Unabhängigkeitstest: Nullhypothese: ZV X und Y sind unabhängige ZV. Alternative: X und Y sind abhängige ZV. X und Y sind unabhängig P(X = xi, Y = yk) = P(X = xi).P(Y = yk) Annahme X und Y unabhängig. Ziehen einer Stichprobe vom Umfang n – Ergebnis: Häufigkeiten der Messwerte: X = xi Y = yk hik. Unter der Annahme „X und Y unabhängig müssten die zu erwartenden Häufigkeiten eik der Stichprobe folgende Bedingung erfüllen:")
63
Abweichung der Häufigkeiten der Stichprobenwerte von den zu erwartenden Häufigkeiten:
Die Prüfgröße 2 ist eine ZV, die einer speziellen Verteilung unterliegt, nämlich der 2 – Verteilung mit (r-1)(s-1) Freiheitsgraden. Falls 2 groß ist, dann Verwerfung der Nullhypothese „X und Y unabhängig“, wobei die Irrtumswahrscheinlichkeit = P(2 > k) ist.
(s-1) Freiheitsgraden. Falls 2 groß ist, dann Verwerfung der Nullhypothese „X und Y unabhängig , wobei die Irrtumswahrscheinlichkeit = P(2 > k) ist.")
64
Beispiel Eig Aus X Y Informatik BWL MK Randv. X geeignet 14 10 16 40 ungeeignet 25 19 60 Randv. Y 30 35 100 Falls X und Y unabhängig Eig Aus X Y Informatik BWL MK Randv. X geeignet 12 14 40 ungeeignet 18 21 60 Randv. Y 30 35 100

65
Anzahl der Freiheitsgrade: (r-1)(s-1) = (2-1)(3-1) = 2
Signifikanzniveau: = 0,05 Kritischer Bereich: 2 > k Tabelle: P(2 > k) = 0,05 k = 5,99 (P(2 > k) = 0,01 k = 9,21) 2 - Wert der Stichprobe: 2,937 2,937 < k Unabhängigkeit von X und Y wird nicht verworfen.
 = 0,05 k = 5,99 (P(2 > k) = 0,01 k = 9,21) 2 - Wert der Stichprobe: 2,937 2,937 < k Unabhängigkeit von X und Y wird nicht verworfen.")
66
Beispiel (4-Felder-Tafel):
Erfolg Methoden Gut Schlecht Methode 1 41 26 67 Methode 2 53 30 83 94 56 150 a b a+b c d c+d a+c b+d ist sehr nahe bei 0, also sind die Ergebnisse von den Methoden unabhängig

Ähnliche Präsentationen




![Definition [1]: Sei S eine endliche Menge und sei p eine Abbildung von S in die positiven reellen Zahlen Für einen Teilmenge ES von S sei p definiert.](/1/209241/big_thumb.jpg "Definition [1]: Sei S eine endliche Menge und sei p eine Abbildung von S in die positiven reellen Zahlen Für einen Teilmenge ES von S sei p definiert.>")
 Algorithmen hängt von gewissen zufälligen Ereignissen ab (Beispiel Quicksort). Um die Laufzeiten dieser.>")
 Wozu legt man Klassen an? Überblick>")






 Konzentrationsmaße Kennwert für die wirtschaftliche Konzentration Typische Beispiele: Verteilung des.>")



 der reellen Zahlen zugeordnet Niveau Dabei ist die Wahrscheinlichkeit,>")
 Ort:Hörsaal Loefflerstraße Übungen.>")



 findet heute um 14:30 Uhr im Hörsaal Loefflerstraße 70 statt.>")
