Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

0
Algorithmen und Datenstrukturen
Vorlesung Algorithmen und Datenstrukturen Materialien G. Pomberger

1
profil des vortragenden gustav pomberger
ing. für elektrotechnik, dipl.-ing. für informatik, dr. der technischen wissenschaften. 1968 bis 1976 konstrukteur im elektromaschinenbau bis wissenschaftlicher assistent am institut für informatik der universität linz forschungs-aufenthalt bei prof. n. wirth an der eth-zürich bis 1987 professor für informatik an der universität zürich. seit professor für wirtschaftsinformatik und in-stitutsvorstand an der johannes kepler universität in linz bis 1999 leiter des christian doppler laboratoriums für software engineering. seit 1988 gastprofessor an der universität zürich. mitbegründer des fachhochschullehrgangs software engineering in hagenberg. seit 2001 mitglied des senates der christian doppler gesellschaft. leiter verschiedenster informatik-projekte in industrie und forschung. autor zahlreicher publikationen und bücher.

2
literaturhinweise wirth, n.:
algorithmen und datenstrukturen mit modula-2 teubner verlag, 1996 algorithmen und datenstrukturen, pascal-version teubner verlag, 1999 knuth, d.e.: the art of computer programming: fundamental algorithms vol.I, 3rd. edition, addison wesley, 1997 seminumerical algorithms vol. II, 3rd. edition, addison wesley, 1997 sorting and searching vol. III, 2nd. edition, addison wesley, 1998 sedgewick, r.: algorithmen addison-wesley, 1995 rechenberg, p., pomberger, g. (eds.): handbuch der informatik, 3. erw. auflage carl hanser verlag, 2002 pomberger, g., blaschek, g.: software engineering, 2. Auflage carl hanser verlag, 1996
: handbuch der informatik, 3. erw. auflage. carl hanser verlag, pomberger, g., blaschek, g.: software engineering, 2. Auflage. carl hanser verlag,")
3
hinweise zur vorlesungsabwicklung
der vorlesungsstoff wird so vorgetragen, dass die lehrgangsteilnehmer die möglichkeit haben, den stoff vollständig mitzuschreiben. ergänzungen dazu finden sich auf den folgenden seiten und werden gegebenenfalls ergänzt.

4
die algorithmenbeschreibungssprache jana
jana (java-based abstract notation for algorithms) jana ist eine beschreibungssprache zur formulierung von algorithmen. sie ist an die programmiersprache java angelehnt. jana ist weitgehend frei von syntaktischem ballast, kommt mit wenigen konstruktionen aus und läßt dem benutzer formulierungsfreiheiten. algorithmen jeder algorithmus (prozedur) hat einen namen, parameter und anweisungen. anweisungen umfassen deklarationen und aktionen. beispiel: search (list l int len int x int i) { Anweisungen } bei den parametern wird jeweils der typ des parameters vor dessen namen angegeben. spielt der typ für die lösung des algorithmus keine rolle oder ist es eindeutig, welcher typ gemeint ist, kann er auch weggelassen werden. search (l len x int i) { // die typen von l, len und x sind // unspezifiert, i ist vom typ int Anweisungen
 jana ist eine beschreibungssprache zur formulierung von algorithmen. sie ist an die programmiersprache java angelehnt. jana ist weitgehend frei von syntaktischem ballast, kommt mit wenigen konstruktionen aus und läßt dem benutzer formulierungsfreiheiten. algorithmen. jeder algorithmus (prozedur) hat einen namen, parameter und anweisungen. anweisungen umfassen deklarationen und aktionen. beispiel: search (list l int len int x int i) { Anweisungen. } bei den parametern wird jeweils der typ des parameters vor dessen namen angegeben. spielt der typ für die lösung des algorithmus keine rolle oder ist es eindeutig, welcher typ gemeint ist, kann er auch weggelassen werden. search (l len x int i) { // die typen von l, len und x sind // unspezifiert, i ist vom typ int Anweisungen.")
5
die algorithmenbeschreibungssprache jana (2)
pfeile werden verwendet, um zwischen eingangs- (), aus- gangs-() und übergangsparamter() zu unterscheiden. die pfeile können weggelassen werden, wenn nur eingangspara- meter vorkommen. dann müssen die parameter allerdings durch beistriche getrennt werden. bei algorithmen mit rück- gabewerten (funktionen) wird der typ des rückgabewerts dem algorithmennamen vorangestellt: int search (list l int len int x) { Anweisungen return i } auch beim aufruf eines algorithmus müssen die pfeile ange-geben werden, wenn ausgangs- und/oder übergangs-parameter vorkommen: search(l n x idx) kommentare kommentare beginnen mit zwei schrägstrichen und erstrecken sich über den rest einer zeile: // dieser kommentar erstreckt // sich über zwei zeilen
, aus- gangs-() und übergangsparamter() zu unterscheiden. die pfeile können weggelassen werden, wenn nur eingangspara- meter vorkommen. dann müssen die parameter allerdings durch beistriche getrennt werden. bei algorithmen mit rück- gabewerten (funktionen) wird der typ des rückgabewerts dem algorithmennamen vorangestellt: int search (list l int len int x) { Anweisungen return i. } auch beim aufruf eines algorithmus müssen die pfeile ange-geben werden, wenn ausgangs- und/oder übergangs-parameter vorkommen: search(l n x idx) kommentare. kommentare beginnen mit zwei schrägstrichen und erstrecken sich über den rest einer zeile: // dieser kommentar erstreckt // sich über zwei zeilen.")
6
die algorithmenbeschreibungssprache jana (3)
operatoren zuweisung: = gleichheit: == sonst ist die benutzung von operatoren freigestellt. es können, soweit sinnvoll, auch die java-operatoren verwendet werden (!=, <, >, >=, <=, *, /, %, +, -, !, &&, ||, usw.) anweisungen es gibt folgende arten von anweisungen: zuweisungen, pro- zeduraufrufe, anweisungen zur ablaufsteuerung und text-an- weisungen. anweisungen können zur besseren lesbarkeit mit strichpunkten abgeschlossen werden, müssen es aber nicht. variable= ausdruck // zuweisung write(line) // prozeduraufruf line= readF(file) // funktionsaufruf
 anweisungen. es gibt folgende arten von anweisungen: zuweisungen, pro- zeduraufrufe, anweisungen zur ablaufsteuerung und text-an- weisungen. anweisungen können zur besseren lesbarkeit mit strichpunkten abgeschlossen werden, müssen es aber nicht. variable= ausdruck // zuweisung write(line) // prozeduraufruf line= readF(file) // funktionsaufruf.")
7
die algorithmenbeschreibungssprache jana (4)
zur ablaufsteuerung stehen if-, switch-, while-, for-, repeat-, und return-anweisungen zur verfügung. geschweifte klammern zur kennzeichnung von blöcken müssen verwendet werden. if (ausdruck) { Anweisungen } if (ausdruck1) { Anweisungen1 } else if (ausdruck2) { Anweisungen2 } else { Anweisungen3 } switch (ausdruck) { case ausdruck1: { Anweisungen1 } case ausdruck2: { Anweisungen2 } default: { Anweisungenn } }
 { Anweisungen } if (ausdruck1) { Anweisungen1 } else if (ausdruck2) { Anweisungen2 } else { Anweisungen3 } switch (ausdruck) { case ausdruck1: { Anweisungen1 } case ausdruck2: { Anweisungen2 } ... default: { Anweisungenn } }")
8
die algorithmenbeschreibungssprache jana (5)
auf ein case kann nicht nur eine konstante, sondern ein beliebig komplexer ausdruck folgen. der default-zweig kann auch wegfallen. zu beachten ist ferner, daß es (im unterschied zu java) keine break-anweisung gibt. nach der abarbeitung eines case-zweiges wird die switch-anweisung immer verlassen. switch (zahl) { case 0: { return "0"} case <0: { return "negative" } case >0: { return "positive" } } schleifen: while (ausdruck) { Anweisungen } repeat { Anweisungen } until (ausdruck)
 keine break-anweisung gibt. nach der abarbeitung eines case-zweiges wird die switch-anweisung immer verlassen. switch (zahl) { case 0: { return 0 } case <0: { return negative } case >0: { return positive } } schleifen: while (ausdruck) { Anweisungen } repeat { Anweisungen } until (ausdruck)")
9
die algorithmenbeschreibungssprache jana (6)
mögliche schreibweisen einer for-schleife: // iteriert von i=1 bis n for (i=1 .. n) { Anweisungen } // i nimmt nacheinander alle werte der menge an for (i ) { Anweisungen } // iteriert über 2er-potenzen for (int i=2, 4, 8, 16, .., n) { Anweisungen } // absteigende schleife (i=n, n-1, n-2, …, 0) for (i=n, n-1, .., 0) { Anweisungen } die anwendung der for-schleife ist sehr frei. wichtig ist, daß mit hilfe einer laufvariablen über einen bestimmten wertebereich iteriert wird. die laufvariable selbst kann im kopf der for-schlei- fe deklariert werden und ist nur innerhalb der for-schleife gültig. return-anweisungen: return return ausdruck
 { Anweisungen } // i nimmt nacheinander alle werte der menge an for (i ) { Anweisungen } // iteriert über 2er-potenzen for (int i=2, 4, 8, 16, .., n) { Anweisungen } // absteigende schleife (i=n, n-1, n-2, …, 0) for (i=n, n-1, .., 0) { Anweisungen } die anwendung der for-schleife ist sehr frei. wichtig ist, daß mit hilfe einer laufvariablen über einen bestimmten wertebereich iteriert wird. die laufvariable selbst kann im kopf der for-schlei- fe deklariert werden und ist nur innerhalb der for-schleife gültig. return-anweisungen: return return ausdruck.")
10
die algorithmenbeschreibungssprache jana (7)
textanweisungen sind freie prosatexte, die eine aktion oder einen ausdruck beschreiben, z.b.: if (statistische Rohdaten sind vorhanden) { berechne Mittelwert und Varianzen } in ausdrücken können arithmetische und boolesche operatoren, sowie konstanten, variablen und funktionsaufrufe verwendet werden. elementare datentypen als elementare typen stehen ganze zahlen, gleitkommazahlen, zeichen und boolesche werte zur verfügung: int ..., -1, 0, 1, 2, ... float ..., 0.0, ... char 'a', 'b', 'c', ... boolean true, false bei variablendeklarationen wird der typ den namen der zu deklarierenden variablen oder konstanten vorangestellt, z.b.: int i boolean a,b bei konstanten werden zusätzlich deren werte und das schlüsselwort final angegeben, z.b.: final int i= 5 final boolean a= true, b= false
 { berechne Mittelwert und Varianzen } in ausdrücken können arithmetische und boolesche operatoren, sowie konstanten, variablen und funktionsaufrufe verwendet werden. elementare datentypen. als elementare typen stehen ganze zahlen, gleitkommazahlen, zeichen und boolesche werte zur verfügung: int ..., -1, 0, 1, 2, ... float ..., 0.0, ... char a , b , c , ... boolean true, false. bei variablendeklarationen wird der typ den namen der zu deklarierenden variablen oder konstanten vorangestellt, z.b.: int i boolean a,b. bei konstanten werden zusätzlich deren werte und das schlüsselwort final angegeben, z.b.: final int i= 5 final boolean a= true, b= false.")
11
die algorithmenbeschreibungssprache jana (8)
statische variablen (gedächtnisvariablen) werden durch das schlüsselwort static spezifiziert. statischen variablen muß in der deklaration ein anfangswert zugewiesen werden. static boolean start= true felder gruppen von gleichartigen elementen werden in feldern zusammengefaßt. dabei sind folgende regeln zu beachten: es kann eine untergrenze und eine obergrenze pro dimension angegeben werden. wenn nur die feldgröße n angegeben wird, erstreckt sich der indexbereich von 0 bis n-1. größen/indexgrenzen können weggelassen werden, wenn sie nicht benötigt werden. größenangabe/indexgrenzen können auf die typbezeichnung oder den namen folgen. dimensionen werden innerhalb einer eckigen klammer durch kommas getrennt. int[1:n] feld1 // eindimensionales int-feld von 1 bis n int feld1[1:n] // äquivalent zu obiger deklaration char feld2[n] // char-feld (zeichenkette) von 0 bis n-1
 werden durch das schlüsselwort static spezifiziert. statischen variablen muß in der deklaration ein anfangswert zugewiesen werden. static boolean start= true. felder. gruppen von gleichartigen elementen werden in feldern zusammengefaßt. dabei sind folgende regeln zu beachten: es kann eine untergrenze und eine obergrenze pro dimension angegeben werden. wenn nur die feldgröße n angegeben wird, erstreckt sich der indexbereich von 0 bis n-1. größen/indexgrenzen können weggelassen werden, wenn sie nicht benötigt werden. größenangabe/indexgrenzen können auf die typbezeichnung oder den namen folgen. dimensionen werden innerhalb einer eckigen klammer durch kommas getrennt. int[1:n] feld1 // eindimensionales int-feld von 1 bis n. int feld1[1:n] // äquivalent zu obiger deklaration char feld2[n] // char-feld (zeichenkette) von 0 bis n-1.")
12
die algorithmenbeschreibungssprache jana (9)
int feld3[] // int-feld, größe unbestimmt, unterer // index 0 int feld4[-2:] // int-feld, größe unbestimmt, unterer // index –2 int feld5[:k] // int-feld, größe unbestimmt, oberer // index k int [0:k, 0:z] matrix // zweidimensionales int-feld der elementtyp eines feldes muß nicht unbedingt spezifiziert werden. man verwendet dann die schreibweise “variablen- name []”. liste[0:k] // eindimensionales feld von 0 bis k, // elementtyp beliebig auf einzelne elemente wird durch indizierung (index in eckigen klammern []) zugegriffen, z. b. int getSum(int[1:n] feld int n) { int sum= 0; for (int i= 1 .. n) { sum= sum+feld[i]; } return sum; }
 zugegriffen, z. b. int getSum(int[1:n] feld int n) { int sum= 0; for (int i= 1 .. n) { sum= sum+feld[i]; } return sum; }")
13
die algorithmenbeschreibungssprache jana (10)
zeichenketten zeichenketten werden wie char-felder behandelt. über die art der speicherung (vorangestellte längenangabe oder abschluß- zeichen) ist nichts spezifiziert. die vordefinierte funktion strlen() liefert die länge einer zeichenkette. zum lexikalischen vergleich von zeichenketten können die vergleichsoperatoren verwendet werden, genauso der zuweisungsoperator zum kopieren von zeichenketten. benutzerdefinierte datentypen neben den elementaren typen sind auch benutzerdefinierte datentypen erlaubt. diese werden mit dem schlüsselwort type gekennzeichnet. typdefinitionen sind z.b.: type Person= { // verbundtyp int id char[1:n] lastName, firstName } type Day= ( Mo, Tu, We, Th, Fr, Sa, Su) // aufzählungstyp type Matrix= int[7, 3] // matrix mit // grenzen // und type Month= (1..12) // Bereichstyp
 ist nichts spezifiziert. die vordefinierte funktion strlen() liefert die länge einer zeichenkette. zum lexikalischen vergleich von zeichenketten können die vergleichsoperatoren verwendet werden, genauso der zuweisungsoperator zum kopieren von zeichenketten. benutzerdefinierte datentypen. neben den elementaren typen sind auch benutzerdefinierte datentypen erlaubt. diese werden mit dem schlüsselwort type gekennzeichnet. typdefinitionen sind z.b.: type Person= { // verbundtyp int id char[1:n] lastName, firstName } type Day= ( Mo, Tu, We, Th, Fr, Sa, Su) // aufzählungstyp type Matrix= int[7, 3] // matrix mit // grenzen 0..6 // und 0..2 type Month= (1..12) // Bereichstyp.")
14
die algorithmenbeschreibungssprache jana (11)
verwendung: Person p Day d Matrix m Month month p.id= 5 p.lastName= "Maier" p.firstName= "Christine" d=Fr m[2, 1]=5 month=11 // nicht erlaubt: month=13 namenskonventionen es ist nützlich, bei der namensgebung gewisse konventionen einzuhalten, um die lesbarkeit zu erhöhen. variablen- und prozedurnamen sollen mit kleinbuchstaben, namen von be- nutzerdefinierten typen mit großbuchstaben beginnen. Inner- halb der namen kann groß- und kleinschreibung zur struk- turierung verwendet werden. weitere schreibweisen werden zusätzliche konstruktionen zur beschreibung von algorithmen gebraucht, so sollten diese an die programmier- sprache java angelehnt und, wenn erforderlich, erläutert werden.

15
die algorithmenbeschreibungssprache jana (12)
standardfunktionen irgendeiner programmiersprache sollten nicht verwendet bzw. zumindest erläutert werden. folgende funktionen können immer ohne erläuterung verwendet werden: read(value boolean eof) // generische funktion zum lesen // vom eingabemedium; eof gibt // an, ob das ende // des eingabestroms erreicht // wurde, eof kann auch wegge // lassen werden write(value) // Schreiben auf das Ausgabe- // medium; der Typ von value ist // beliebig writeLn() // zeilenvorschub auf dem // ausgabemedium int ord(char ch) // liefert den ordinalwert des // zeichens ch (z.b. ascii-code) char chr(int v) // liefert das zeichen mit dem // ordinalwert v (z.b. ascii- // zeichen) int strLen(char[] str) // liefert die länge der zeichen- // kette str
 // generische funktion zum lesen // vom eingabemedium; eof gibt // an, ob das ende // des eingabestroms erreicht // wurde, eof kann auch wegge- // lassen werden. write(value) // Schreiben auf das Ausgabe- // medium; der Typ von value ist // beliebig. writeLn() // zeilenvorschub auf dem // ausgabemedium. int ord(char ch) // liefert den ordinalwert des // zeichens ch (z.b. ascii-code) char chr(int v) // liefert das zeichen mit dem // ordinalwert v (z.b. ascii- // zeichen) int strLen(char[] str) // liefert die länge der zeichen- // kette str.")
16
die algorithmenbeschreibungssprache jana (13)
referenzdatentypen referenzdatentypen beschreiben dynamisch verwaltete datenobjekte, die ausschließlich über referenzen (zeiger) angesprochen werden können. diese werden mit dem schlüsselwort reftype gekennzeichnet, z. b. reftype Node= { int info Node left, right } mit dem schlüsselwort new gefolgt von einem referenz-typna- men kann ein datenobjekt dieses typs erzeugt, d.h. speicher allokiert werden, z.b.: Node root // ein zeiger auf ein daten // objekt wird deklariert. root= new Node // ein neues datenobjekt vom typ // n wird erzeugt. Node n= new Node // deklaration und erzeugung // eines neuen datenobjektes ein datenzugriff über referenzvariablen erfolgt mittels punktnotation. zur verdeutlichung der dereferenzierung kann auch der operator ^ verwendet werden, z.b.: root^.info= 5; // alternative schreibweise: // root.info= 5; root^.left= n; // nach der zuweisung verweisen // root.left und n auf dasselbe // datenobjekt
 angesprochen werden können. diese werden mit dem schlüsselwort reftype gekennzeichnet, z. b. reftype Node= { int info Node left, right } mit dem schlüsselwort new gefolgt von einem referenz-typna- men kann ein datenobjekt dieses typs erzeugt, d.h. speicher allokiert werden, z.b.: Node root // ein zeiger auf ein daten- // objekt wird deklariert. root= new Node // ein neues datenobjekt vom typ // n wird erzeugt. Node n= new Node // deklaration und erzeugung // eines neuen datenobjektes. ein datenzugriff über referenzvariablen erfolgt mittels punktnotation. zur verdeutlichung der dereferenzierung kann auch der operator ^ verwendet werden, z.b.: root^.info= 5; // alternative schreibweise: // root.info= 5; root^.left= n; // nach der zuweisung verweisen // root.left und n auf dasselbe // datenobjekt.")
17
die algorithmenbeschreibungssprache jana (14)
bei der zuweisung von referenzvariablen werden keine werte kopiert sondern nur die referenzen selbst. null ist ein spezieller wert für referenzvariablen, die noch auf kein datenobjekt verweisen. root^.right= null; mit dem schlüsselwort delete wird ein “datenobjekt” gelöscht, d.h. der reservierte speicherbereich wieder freigegeben, z.b.: delete n // löschen eines datenobjektes weiteres beispiel: Node search(Node root int x) { if (root==null) { return null } if (root.info==x) { return root } Node y= search(root.left x) if (y==null) { return search(root.right x) } return y } hinweis: bei der verwendung von referenzvariablen als eingangsparameter sind änderungen der übergebenen datenobjekte nach außen wirksam (vorsicht!).
 { if (root==null) { return null } if (root.info==x) { return root } Node y= search(root.left x) if (y==null) { return search(root.right x) } return y } hinweis: bei der verwendung von referenzvariablen als eingangsparameter sind änderungen der übergebenen datenobjekte nach außen wirksam (vorsicht!).")
18
die algorithmenbeschreibungssprache jana (15)
datentypen mit algorithmen oft gehören mehrere algorithmen logisch zusammen und ver- wenden gemeinsame daten, die zwischen aufrufen dieser algorithmen erhalten bleiben, z.b. algorithmen mit gedächtnis. eine solche gruppe von algorithmen wird gemeinsam mit ihren daten benannt und zu einem “typ” zusammengefaßt. alle algorithmen eines typs können auf variablen dieses typs zu- greifen. aufrufe der in den typen definierten prozeduren sind jeweils an ein bestimmtes datenobjekt gebunden. dieses datenobjekt muß dem prozedurnamen bei aufruf vorangestellt werden. algorithmen können sowohl für verbundtypen als auch für referenzdatentypen angegeben werden. beispiel mit verbundtyp: type Stack= { int top,size,stack[1..size] init() {...} push(int x) {...} int pop() {...} write() {...} }
 {...} push(int x) {...} int pop() {...} write() {...} }")
19
die algorithmenbeschreibungssprache jana (16)
verwendung: Stack s1, s2 s1.init() s2.init() s1.push(5) s2.push(10) int i= s1.pop() s2.write() beispiel mit referenzdatentyp: reftype BinaryTree= { Node root init() {root= null} add(int x) {...} Node search (int x) {...} write() {...} } BinaryTree tree= new BinaryTree tree^.init() // alternative schreib // weise: tree.init() tree^.add(5) Node n= tree^.search(3) tree^.write()
 s2.init() s1.push(5) s2.push(10) int i= s1.pop() s2.write() beispiel mit referenzdatentyp: reftype BinaryTree= { Node root init() {root= null} add(int x) {...} Node search (int x) {...} write() {...} } BinaryTree tree= new BinaryTree tree^.init() // alternative schreib- // weise: tree.init() tree^.add(5) Node n= tree^.search(3) tree^.write()")
20
zum algorithmenbegriff
1. algorithmen sind problemlösungsverfahren, die sich aus einzelnen schritten (aktionen) zusammensetzen, die aktionen beziehen sich in der regel auf objekte (siehe punkt 6) 2. jede aktion hat einen effekt, der eine änderung der werte von objekten bewirken kann (aber nicht muß) und (implizit oder explizot) bestimmt, welche aktion als nächste ausgeführt werden soll. beispiele (1) die aktion “setze x gleich der summe von a und b“ ändert den zustand des objekts x und bestimmt implizit, dass als nächstes die (im text) folgende aktion des algorithmus ausgeführt werden soll. (2) die aktion “verzweige zu aktion 3“ bestimmt nur, welche aktion als nächste ausgeführt werden soll (unter der annahme, die aktionen seien numeriert), läßt aber alle objekte des algorithmus unverändert. 3. jede aktion muß eindeutig interpretierbar sein. die ein- deutigkeit bezieht sich dabei auf den prozessor, der den algorithmus ausführen soll; für ihn darf es keinen inter- pretationsspielraum geben.
 zusammensetzen, die aktionen beziehen sich in der regel auf objekte (siehe. punkt 6) 2. jede aktion hat einen effekt, der eine änderung der werte von objekten bewirken kann (aber nicht muß) und (implizit oder explizot) bestimmt, welche aktion als nächste ausgeführt werden soll. beispiele. (1) die aktion setze x gleich der summe von a und b ändert den zustand des objekts x und bestimmt implizit, dass als nächstes die (im text) folgende aktion des algorithmus ausgeführt werden soll. (2) die aktion verzweige zu aktion 3 bestimmt nur, welche aktion als nächste ausgeführt werden soll (unter der annahme, die aktionen seien numeriert), läßt aber alle objekte des algorithmus unverändert. 3. jede aktion muß eindeutig interpretierbar sein. die ein- deutigkeit bezieht sich dabei auf den prozessor, der den algorithmus ausführen soll; für ihn darf es keinen inter- pretationsspielraum geben.")
21
zum algorithmenbegriff (2)
beispiel (1) die aktion “gehe bis zur nächsten kreuzung und biege ab“ ist unter umständen nicht eindeutig, nämlich dann nicht, wenn es darauf ankommt, ob nach links oder nach rechts abgebogen werden soll. 4. jede aktion muß ausführbar sein, d. h., sie muß so geartet sein, dass der prozessor, der den algorithmus ausführen soll, auch dazu in der lage ist. 5. jeder algorithmus muß statisch endlich sein, d. h. seine formulierung muß mit endlich vielen zeichen möglich sein. anders verhält es ich mit der dynamischen endlichkeit bzw. unendlichkeit. die meisten algorithmen (in dem hier ge- meinten sinn) enden natürlich in endlicher zeit, aber es gibt auch prozesse, die endlos sind. beispiele dafür sind algorithmen zur ampelsteuerung oder zur steuerung eines dialogs zwischen einem computer und einem benutzer. wenn wir diese prozesse als algorithmen auffassen, müssen algorithmen nicht notwedigerweise enden. die dynamische endlichkeit ist deshalb kein besonderes kennzeichen für unseren algorithmusbegriff.
 die aktion gehe bis zur nächsten kreuzung und biege ab ist unter umständen nicht eindeutig, nämlich dann nicht, wenn es darauf ankommt, ob nach links oder nach rechts abgebogen werden soll. 4. jede aktion muß ausführbar sein, d. h., sie muß so geartet sein, dass der prozessor, der den algorithmus ausführen soll, auch dazu in der lage ist. 5. jeder algorithmus muß statisch endlich sein, d. h. seine formulierung muß mit endlich vielen zeichen möglich sein. anders verhält es ich mit der dynamischen endlichkeit bzw. unendlichkeit. die meisten algorithmen (in dem hier ge- meinten sinn) enden natürlich in endlicher zeit, aber es gibt auch prozesse, die endlos sind. beispiele dafür sind algorithmen zur ampelsteuerung oder zur steuerung eines dialogs zwischen einem computer und einem benutzer. wenn wir diese prozesse als algorithmen auffassen, müssen algorithmen nicht notwedigerweise enden. die dynamische endlichkeit ist deshalb kein besonderes kennzeichen für unseren algorithmusbegriff.")
22
zum algorithmenbegriff (3)
6. algorithmen besitzen in der regel objekte, deren werte vor der ausführung des algorithmus festgelegt werden - wir nennen sie eingangsobjekte -, und solche, die während der ausführung einen bestimmten wert zugewiesen bekom- men. ein teil der objekte (d. h. ihre werte) bilden das ergebnis des algorithmus - wir nenne sie ausgangs- oder ergebnisobjekte. alle übrigen objekte bezeichnen wir als lokale hilfsobjekte. es gibt aber auch algorithmen, die keine eingangsobjekte besitzen. ein beispiel dafür ist ein algorithmus, der die aufgabe “bestimme die ersten 1000 primzahlen“ löst. er benötigt kein eingangsobjekt. es gibt auch algorithmen, die keine ausgangsobjekte besitzen. ein beispiel dafür ist ein algorithmus, der die aufgabe “warte, bis eine taste gedrückt ist“ löst. dieser algorithmus kann ohne ausgangsobjekte formuliert werden, und wir können auch nichts darüber aussagen, ob und wann der algorithmus endet. die frage, ob eine algorithmus ein- und/oder ausgangs- objekte besitzt, ist also von seiner spezifikation abhängig. das vorhandensein von ein- und/oder ausgangsobjekten ist daher kein spezifisches kennzeichen des algorithmus, wie wir ihn verstehen wollen.
 bilden das ergebnis des algorithmus - wir nenne sie ausgangs- oder ergebnisobjekte. alle übrigen objekte bezeichnen wir als lokale hilfsobjekte. es gibt aber auch algorithmen, die keine eingangsobjekte besitzen. ein beispiel dafür ist ein algorithmus, der die aufgabe bestimme die ersten 1000 primzahlen löst. er benötigt kein eingangsobjekt. es gibt auch algorithmen, die keine ausgangsobjekte besitzen. ein beispiel dafür ist ein algorithmus, der die aufgabe warte, bis eine taste gedrückt ist löst. dieser algorithmus kann ohne ausgangsobjekte formuliert werden, und wir können auch nichts darüber aussagen, ob und wann der algorithmus endet. die frage, ob eine algorithmus ein- und/oder ausgangs- objekte besitzt, ist also von seiner spezifikation abhängig. das vorhandensein von ein- und/oder ausgangsobjekten ist daher kein spezifisches kennzeichen des algorithmus, wie wir ihn verstehen wollen.")
23
zum algorithmenbegriff (4)
wir wollen unter hinweis auf die oben angeführten erläuter- ungen definieren: ein algorithmus ist eine präzise, d. h. in einer festgelegten sprache abgefaßte, endliche beschreibung eines schritt- weisen problemlösungsverfahrens zur ermittlung gesuchter objekte, in dem jeder schritt aus einer anzahl ausführbarer eindeutiger aktionen und einer angabe über den nächsten schritt besteht. ein algorithmus heißt abbrechend, wenn er die gesuchten objekten nach endlich vielen schritten liefert, andernfalls heißt der algorithmus nicht abbrechend. diese definition ist für unsere zwecke hinreichend klar und präzise. Sie ist jedoch nicht präzise im mathematischen sinn und unterscheidet sich von anderen definitionen dadurch, dass sie keine aussagen über die dynamische endlichkeit und die zahl der ein/ausgangsobjekte enthält.

24
Darstellungsarten v. Algorithmen Ablaufdiagramm

25
Darstellungsarten v. Algorithmen Symbole f. Ablaufdiagramme
Ablaufdiagrammkonstruktionen

26
Darstellungsarten v. Algorithmen Struktogramm

27
Darstellungsarten v. Algorithmen Algorithmen-Entwurfssprache
suche (int liste [1in] int n,x int i) { i=1 while ((i n) and (liste[i]x) { i=i+1 } if (i>n) {i=0 }
 { i=1. while ((i n) and (liste[i]x) { i=i+1. } if (i>n) {i=0 }")
28
Darstellungsarten v. Algorithmen Programmiersprache
Suche (liste: ARRAY OF INTEGER; n, x: INTEGER; VAR i: INTEGER); BEGIN i:=1; WHILE (i <=n) AND (liste [i]<>x) DO INC (i); END; IF i>n THEN i:=0 END; END Suche.
; BEGIN. i:=1; WHILE (i <=n) AND (liste [i]<>x) DO. INC (i); END; IF i>n THEN i:=0 END; END Suche.")
29
Algorithmus-Entwurf (Mensch)
Aufgabe Algorithmus-Entwurf (Mensch) Algorithmus z.B. in Pseudocode Programmierung (Mensch) Programm in höherer Programmiersprache Übersetzung (Maschine) Programm in Maschinensprache Gegebene Größen Programmausführung Ergebnisse (Maschine)
 Algorithmus. z.B. in Pseudocode. Programmierung (Mensch) Programm in höherer. Programmiersprache. Übersetzung (Maschine) Programm. in Maschinensprache. Gegebene Größen. Programmausführung. Ergebnisse. (Maschine)")
30
aufgabenstellung für beispiel mailverwaltung
ein strom von einlaufenden mails ist vor verteilung zu statistischen und dokumentationszwecken zu verarbeiten. jede mail wird durch die zeichenfolge ‘zzzz‘ abgeschlossen. der mail-strom ist beendet, wenn eine leere mail, gefolgt von der zeichenfolge ‘zzzz‘, eintrifft. die mails sollen ohne das abschließende ‘zzzz‘ zeilenweise mit 100 bis 120 zeichen pro zeile ausgegeben werden. die wörter jeder mail sollen gezählt, wörter mit mehr als n zeichen sollen außerdem extra gezählt werden. nach der ausgabe einer mail sollen auf einer neuen zeile die anzahlen der wörter insgesamt und der wörter mit mehr als n zeichen ausgegeben werden. das längste zugelassene wort hat y zeichen; längere wörter sollen zum abbruch des dokumentationsalgorithmus führen.

31
Mailverwaltung, ergebnis beispiel
inputparameter: n = 12, y = 20 inputstrom: stefan eberharter wird den ski-weltcup gewinnen zzzz ausbruch des kilimandscharo befürchtet zzzz auftakt der budgetberatungen im nationalrat: bei der ersten lesung zum budget vorbringen zzzz zzzz . (insges zeichen) ergebnis: stefan eberharter wird den ski-weltcup gewinnen 6 wörter 0 überlang ausbruch des kilimandscharo befürchtet 4 wörter 1 überlang auftakt der budgetberatungen vorbringen 52 wörter 8 überlang
 ergebnis: stefan eberharter wird den ski-weltcup gewinnen. 6 wörter 0 überlang. ausbruch des kilimandscharo befürchtet. 4 wörter 1 überlang. auftakt der budgetberatungen vorbringen. 52 wörter 8 überlang.")
32
Partiell geordnete Menge
6 4 5 8 7 9 10 2 1 3 Partiell geordnete Menge

33
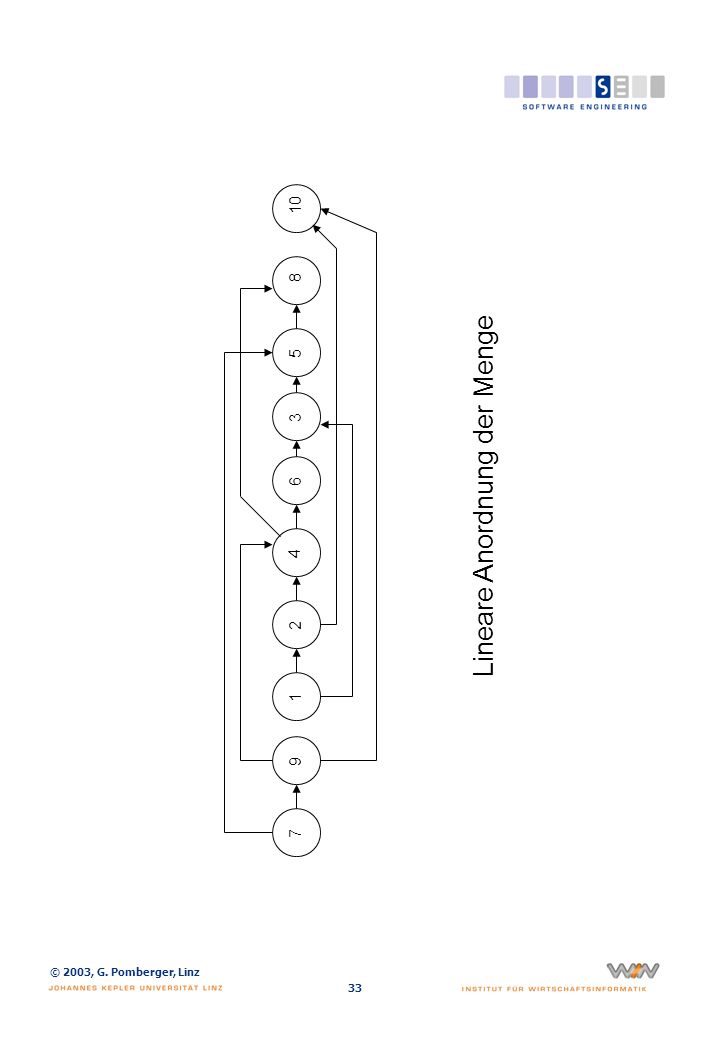
Lineare Anordnung der Menge
7 9 1 2 4 6 8 10 5 3 Lineare Anordnung der Menge

Ähnliche Präsentationen

>")




, von Mitte November an nur im Netz Abgabe der Lösungen jeweils 1 Woche später, 5 Minuten vor der.>")


 Java Einführung Mittwoch, 21.05.2003. Heute Ziel: erstes Java-Programm erstellen Von der Aufgabenstellung bis zur Lösung Grundlagen Einfache.>")



 Prof. Dr. Th. Ottmann.>")

 Tobias Lauer.>")
 Prof. Dr. Th. Ottmann.>")

>")
