Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
From Bits to Information — Maschinelle Lernverfahren in Information Retrieval und Web Mining
Thomas Hofmann Department of Computer Science Brown University (Founder, CEO & Chief Scientist, RecomMind Inc., Berkeley & Rheinbach (!)) In Kollaboration mit: David Cohen, CMU & Burning Glass Jan Puzicha, UC Berkeley & RecomMind David Gondek & Ioannis Tsochantaridis, Brown University
) In Kollaboration mit: David Cohen, CMU & Burning Glass. Jan Puzicha, UC Berkeley & RecomMind. David Gondek & Ioannis Tsochantaridis, Brown University.")
2
Vortragsüberblick Einleitung Vektorraum-Modell für Textdokumente
Informationstheoretisches Retrieval Modell Probabilistic Latent Semantic Analysis Informationssuche und Textkategorisierung Hypermedia- & Web-Retrieval Kollaboratives Filtern Ausblick

3
Information Retrieval: Probleme & Herausforderungen
3

4
Robustes Information Retrieval — Jenseits der keyword-basierten Suche
“labour immigrants Germany” query match “German job market for immigrants” ? “foreign workers in Germany” “green card Germany” “labour immigrants Germany” query match “German job market for immigrants” query ? Fehlerbehaftete Transkription outrage sink Anchorage there warfare “green card Germany” query ? “foreign workers in Germany” query ? Akustisches Signal Automatische Spracherkennung

5
Hypermedia Retrieval — Linkanalyse und die Qualität von Informationsquellen
Linkanalyse mittels Markov-ketten Modell (Random Walk auf Web Graph) mittlere Aufenthaltswahr-scheinlichkeit entspricht PageRank
 mittlere Aufenthaltswahr-scheinlichkeit entspricht PageRank.")
6
Dokument-Klassifikation & Text Mining
Generierung & Wartung von Taxonomien Automatische Klassifikation und Annotation von Dokumenten M13 = MONEY MARKETS M132 = FOREX MARKETS MCAT = MARKETS Visualisierung von Taxonomien © Inxight

7
Kollaboratives Filtern — Jenseits der solipsistischen Suche
NN Benutzerprofil ? Empfehlung ? Benutzerprofil

8
Kollaboratives Filtern — Jenseits der solipsistischen Suche
Multimedia Dokumente User Community Datenbank mit Benutzerprofilen UserID ItemID Rating 10002 451 3 10221 647 4 10245 2 12344 801 5 … Rating

9
2. Vektorraum-Modell für Textdokumente
9

10
Dokument-Term Matrix = D = Dokumentensammlung W = Lexikon/Vokabular
intelligence Texas Instruments said it has developed the first 32-bit computer chip designed specifically for artificial intelligence applications [...] Dokument-Term Matrix ... artificial 1 intelligence interest artifact 2 t =

11
Dokument-Term Matrix (b)
Typisch: Zahl der Dokumente Vokabular Spärlichkeit < 0.1 % Dargestellt 1e-8 1 2

12
Vektorraum-Modell Retrieval Modell Ähnlichkeit zwischen
Dokument und Query Kosinus des Winkels zwischen Query und Dokument(en) Retrieval Modell Dokumente werde gemäß ihrer Ähnlichkeit zur Query sortiert Verwendung im SMART System und vielen kommerziellen Systemen (z.B. Verity) This may seem like a somewhat unserious example, the problem behind this, however, is very serious … There are more precisely two problems: Polysems […] and Homonyms […] 1’00’’ G. Salton, “The SMART Retrieval System – Experiments in Automatic Document Processing”, 1971.
 Retrieval Modell. Dokumente werde gemäß ihrer Ähnlichkeit zur Query sortiert. Verwendung im SMART System und vielen kommerziellen Systemen (z.B. Verity) This may seem like a somewhat unserious example, the problem behind this, however, is very serious … There are more precisely two problems: Polysems […] and Homonyms […] 1’00’’ G. Salton, The SMART Retrieval System – Experiments in Automatic Document Processing ,")
13
Vektorraum-Modell: Diskussion
Vorteile Partielles Matching von Anfragen und Dokumenten Ranking gemäß des Ähnlichkeitsmaßes Nachteile: Dimensionalität („curse of dimensionality”) Spärlichkeit (inneres Produkt ist rauschanfällig) Semantik: Auftreten von exakt identischen Termen gefordert, semantische Beziehungen zwischen Wörtern werden nicht modelliert Syntaktische/semantische Regularitäten bleiben unberücksichtigt
 Spärlichkeit (inneres Produkt ist rauschanfällig) Semantik: Auftreten von exakt identischen Termen gefordert, semantische Beziehungen zwischen Wörtern werden nicht modelliert. Syntaktische/semantische Regularitäten bleiben unberücksichtigt.")
14
3. Informationstheoretisches Retrieval-Modell
14

15
Lexikale Semantik – Synonymien und Polysemien
Mehrdeutigkeit von Wörtern (Polysemie) Wörter haben oftmals eine Vielzahl von Bedeutungen und verschiedenartige Gebrauchsformen (insbesondere für heterogene Datenbestände). Mars Planet röm. Gottheit Schokoriegel Semantische Ähnlichkeit (Synonymie) Verschiedene Wörter/Terme haben oft die identische oder sehr ähnliche Bedeutung (schwächer: Wörter aus dem gleichen Themengebiet). Galaxie Milchstraße Universum Kosmos
 Wörter haben oftmals eine Vielzahl von Bedeutungen und verschiedenartige Gebrauchsformen (insbesondere für heterogene Datenbestände). Mars. Planet. röm. Gottheit. Schokoriegel. Semantische Ähnlichkeit (Synonymie) Verschiedene Wörter/Terme haben oft die identische oder sehr ähnliche Bedeutung (schwächer: Wörter aus dem gleichen Themengebiet). Galaxie. Milchstraße. Universum. Kosmos.")
16
Dokumente als Informationsquellen
“Ideales” Dokument: (gedächtnislose) Informations-quelle D = Dokumentensammlung W = Lexikon/Vokabular andere Dokumente “Wirkliches” Dokument: empirische relative Wort-Häufigkeiten Stichprobe (sample) Again, we begin with representational issues. Suppose, we have given a collection of documents D and a vocabulary W. Ignoring word order (of course a very strong assumption, but very common in IR) the data can be represented by a table (term/document matrix). A document is then represented by a “vector” of word counts. (You may suspect that I would like to put the term “vector” in quotes, because it is actually an empirical distribution over words. 1’30’’
 Informations-quelle. D = Dokumentensammlung. W = Lexikon/Vokabular. andere Dokumente. Wirkliches Dokument: empirische relative Wort-Häufigkeiten. Stichprobe. (sample) Again, we begin with representational issues. Suppose, we have given a collection of documents D and a vocabulary W. Ignoring word order (of course a very strong assumption, but very common in IR) the data can be represented by a table (term/document matrix). A document is then represented by a vector of word counts. (You may suspect that I would like to put the term vector in quotes, because it is actually an empirical distribution over words. 1’30’’")
17
Das Sprachmodell-“Spiel”
US trade economic intellectual property development Beijing human rights free negotiations imports ? Gegeben ist ein Dokument („bag-of-words“ Repräsentation) in dem einige Wörter zugedeckt sind. intellectual property negotiations Zielsetzung: Vorhersage der zugedeckten Wörter basierend auf dem Kontext US trade economic development Beijing human rights free imports China Semantic model Grundidee: Gute Vorhersage-genauigkeit erfordert ein Modell das Wortsemantik berücksichtigt
 in dem einige Wörter zugedeckt sind. intellectual property. negotiations. Zielsetzung: Vorhersage der zugedeckten Wörter basierend auf dem Kontext. US. trade. economic. development. Beijing. human rights. free. imports. China. Semantic model. Grundidee: Gute Vorhersage-genauigkeit erfordert ein Modell das Wortsemantik berücksichtigt.")
18
Informationsquellen-Modell des Information Retrievals
Bayessche Regel: Wahrscheinlichkeit der Relevanz eines Dokuments bzgl. einer Anfrage A priori Relevanz- Wahrscheinlichkeit Generatives Query Modell Wahrscheinlichkeit daß q von d „erzeugt wurde” Sprach- modell J. Ponte & W.B. Croft, ”A Language Model Approach to Information Retrieval”, SIGIR 1998.

19
4. Probabilistic Latent Semantic Analysis
19

20
Probabilistic Latent Semantic Analysis
Problemstellung: Wie können dokument-spezfische “Sprachmodelle” gelernt werden? Datenmangel! Ansatz: pLSA Dimensionsreduktionstechnik für Kontingenztabellen Faktoranalyse für Zählvariablen (und kategorialen Variablen) Faktoren Konzepten / Themengebieten Dokument- “quellen” (Topic) Faktor- “quellen” Dokumentspezifische Mischproportionen Latente Variable z (“small” #states) T. Hofmann, “Probabilistic Latent Semantic Analysis”, UAI 1999. Z. Gilula, M.J. Evans, I. Guttman, "Latent Class Analysis of Two-Way Contingency Tables by Bayesian Methods" Biometrika, 1989.
 Faktoren Konzepten / Themengebieten. Dokument- quellen (Topic) Faktor- quellen Dokumentspezifische. Mischproportionen. Latente Variable. z ( small #states) T. Hofmann, Probabilistic Latent Semantic Analysis , UAI Z. Gilula, M.J. Evans, I. Guttman, Latent Class Analysis of Two-Way Contingency Tables by Bayesian Methods Biometrika,")
21
pLSA: Graphisches Modell
N w c(d) P(z|d) z shared by all words in a document shared by all documents in collection P(w|z) N w c(d) P(z|d) z P(w|z) collection N w c(d) P(z|d) z document collection single document in collection word occurrences in a z w c(d) Graphische Darstellung mittels „Plates”
 P(z|d) z. shared by all words. in a document. shared by all. documents in. collection. P(w|z) N. w. c(d) P(z|d) z. P(w|z) collection. N. w. c(d) P(z|d) z. document. collection. single document. in collection. word. occurrences. in a. z. w. c(d) Graphische Darstellung mittels „Plates")
22
pLSA: „Bottleneck“ Parametrisierung
Dokumente Terme

23
pLSA: „Bottleneck“ Parametrisierung
Latente Konzepte Dokumente Terme

24
pLSA: Positive Matrix-Zerlegung
Mischverteilung in Matrixnotation Randbedingungen (constraints) Nicht-negativität aller Matrizen Normalisierung gemäß der L1-Norm (keine Orthogonalität gefordert!) T. Hofmannn, „Probabilistic Lantent Semantic Analysis“, Uncertainty in Artificial Intelligence 1999. D.D. Lee & H.S. Seung, „Learning the parts of objects by non-negative matrix factorization”, Nature, 1999.
 Nicht-negativität aller Matrizen. Normalisierung gemäß der L1-Norm. (keine Orthogonalität gefordert!) T. Hofmannn, „Probabilistic Lantent Semantic Analysis , Uncertainty in Artificial Intelligence D.D. Lee & H.S. Seung, „Learning the parts of objects by non-negative matrix factorization , Nature,")
25
Vergleich: SVD Eigenschaften: Singulärwert-Zerlegung, Definition
: orthonormale Spalten : Diagonal mit Singulärwerten (geordnet) Eigenschaften: Existenz & Eindeutigkeit Schwellwertbildung über Singulärwerte resultiert in einer niederdimensionalen Approximation (im Sinne der Frobenius Norm) = X n X m n X k k X k k X m = X n X m n X n S. Deerwester, S. Dumais, G. Furnas, T. Landauer & R. Harshman. „Indexing by latent semantic analysis.“ Journal of the American Society for Information Science, 1990
 Eigenschaften: Existenz & Eindeutigkeit. Schwellwertbildung über Singulärwerte resultiert in einer niederdimensionalen Approximation (im Sinne der Frobenius Norm) = X. n X m. n X k. k X k. k X m. = X. n X m. n X n. S. Deerwester, S. Dumais, G. Furnas, T. Landauer & R. Harshman. „Indexing by latent semantic analysis. Journal of the American Society for Information Science,")
26
Expectation-Maximization-Algorithmus
Maximierung der (temperierten) Log-Likelihood mittels Expectation-Maximization Iterationen E-Schritt: Posterior-Wahrscheinlichkeiten der latenten Variablen) M-Schritt: Schätzung der Parameter basierend auf „vervollständigten Statistiken” Wahrsch. daß ein Term w in Dokument d durch Konzept z „erklärt“ wird
 Log-Likelihood mittels Expectation-Maximization Iterationen. E-Schritt: Posterior-Wahrscheinlichkeiten der latenten Variablen) M-Schritt: Schätzung der Parameter basierend auf „vervollständigten Statistiken Wahrsch. daß ein Term w in Dokument d durch Konzept z „erklärt wird.")
27
Beispiel: TDT1 News Stories
TDT1 = Dokumentensammlung mit >16,000 Kurznachrichten (Reuters, CNN, aus den Jahren 1994/95) Resultate basierend auf einer Zerlegung mit 128 Konzepten 2 dominante Faktoren für “flight“ und “love“ (wahrscheinlichsten Wörter) “flight” “love” plane airport crash flight safety aircraft air passenger board airline space shuttle mission astronauts launch station crew nasa satellite earth home family like just kids mother life happy friends cnn film movie music new best hollywood love actor entertainment star P(w|z)
 Resultate basierend auf einer Zerlegung mit 128 Konzepten. 2 dominante Faktoren für flight und love (wahrscheinlichsten Wörter) flight love plane. airport. crash. flight. safety. aircraft. air. passenger. board. airline. space. shuttle. mission. astronauts. launch. station. crew. nasa. satellite. earth. home. family. like. just. kids. mother. life. happy. friends. cnn. film. movie. music. new. best. hollywood. love. actor. entertainment. star. P(w|z)")
28
Beispiel: Science Magazine Artikel
Datensatz mit ca.12K Artikeln aus dem Science Magazine Ausgewählte Konzepte eines Modells mit K=200 P(w|z) P(w|z)
 P(w|z)")
29
5. Informationssuche & Textkategorisierung
29

30
Experiments: Precison-Recall
4 test collections (each with approx docs)
")
31
Experimentelle Auswertung
Zusammenfassung der quantitativen Auswertung Konsistente Verbesserung der Retrieval Genauigkeit Relative Verbesserung von 15-45% Average Precision Relative Gain in Average Prec.

32
Textkategorisierung Support-Vektor-Maschinen mit semantischen Kernfunktionen Standard-Textsammlung: Reuters21578 (5 Hauptkategorien), 5% Trainingsdaten mit Labels, 95% Hintergrunddaten Substantielle Ver-besserungen (ca.25%), falls zusätzliche ungelabelte Daten zur Verfügung stehen T. Hofmann, „An information-geometric approach to learning the similarity between documents”, Neural Information Processing Systems, 2000.
, 5% Trainingsdaten mit Labels, 95% Hintergrunddaten. Substantielle Ver-besserungen (ca.25%), falls zusätzliche ungelabelte Daten zur Verfügung stehen. T. Hofmann, „An information-geometric approach to learning the similarity between documents , Neural Information Processing Systems,")
33
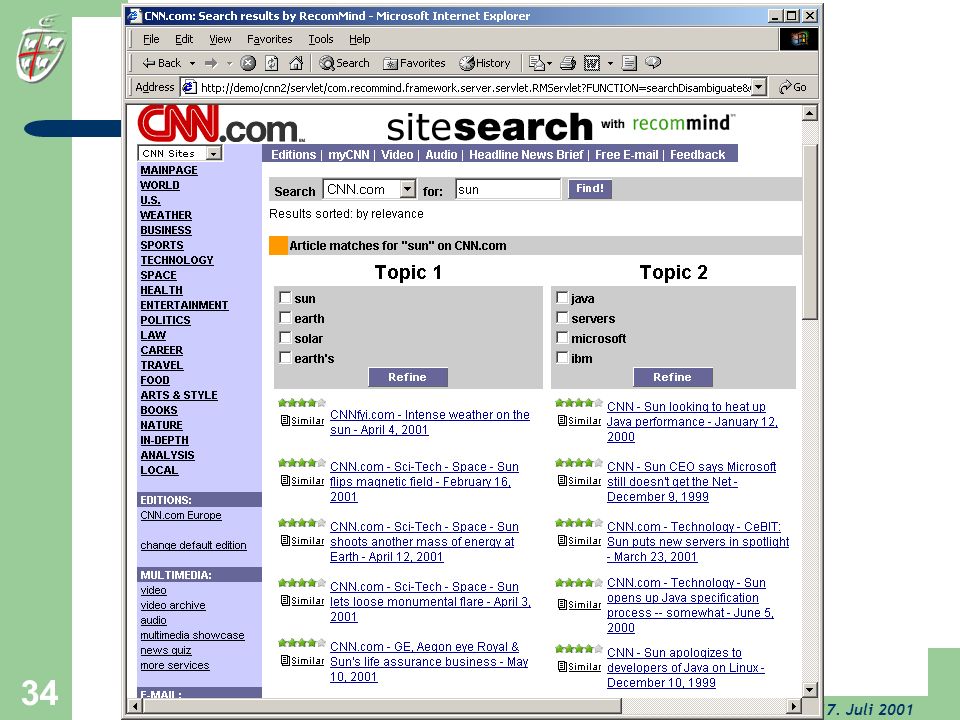
Robustes Retrieval in der Praxis

35
MedlinePlus: Gesundheits-Informationen für Jedermann

36
Amazon: Verbesserte Büchersuche
build your own search engine

37
Amazon: Verbesserte Büchersuche

38
6. Hypermedia Retrieval 38

39
Hyperlinks in Information Retrieval
Hyperlinks stellen zusätzliche Autor-Annotationen zur Verfügung Hyperlinks repräsentieren (typischerweise) eine implizite positive Bewertung der referenzierten Quelle Web-Graph spiegelt soziale Strukturen wider (cyber/virtual/Web communities) Link-Struktur erlaubt eine Einschätzung der Qualität der Dokumente (page authorithy) Überwindung von reinem inhaltsbasiertem Retrieval Erlaubt (potentiell) die Unterscheidung zwischen qualitativ hoch- und niederwertigen Web-Sites/Seiten
 eine implizite positive Bewertung der referenzierten Quelle. Web-Graph spiegelt soziale Strukturen wider (cyber/virtual/Web communities) Link-Struktur erlaubt eine Einschätzung der Qualität der Dokumente (page authorithy) Überwindung von reinem inhaltsbasiertem Retrieval. Erlaubt (potentiell) die Unterscheidung zwischen qualitativ hoch- und niederwertigen Web-Sites/Seiten.")
40
Random Walk auf Web Graphen
Fiktiver Surfer hüpft von Webseite zu Webseite Zufällige Wahl eines Outlinks in jedem Schritt Mit Wahrscheinlichkeit q Teleportation zu einer zufälligen Seite PageRank: numerischer Score für jede Seite Aufenthaltswahrscheinlichkeit des Surfers Intuition „Es ist gut viele Inlinks zu haben.“ „Es ist nicht gut in einer abgekapselten Komponente zu sein.“ Modellierung Homogene Markov-Kette PageRank: stationäre Verteilung; Random Walk nutzt Ergodizität, alternativ über Spektralzerlegung (dominanter Eigenvektor)
")
41
HITS (Hyperlink Induced Topic Search)
HITS (Jon Kleinberg und die Smart Gruppe in IBM) Schritt 1: Query-basiertes Retrieval von Resultaten Schritt 2: Generierung eines Kontextgraphen (Links und Backlinks) Schritt 3: Rescoring Methode mit Hub- und Authority-Gewichten unter Verwendung der Adjazenzmatrix des Kontextgraphen (Lösung: Linke/rechte Eigenvektoren (SVD)) Authority- Gewichte p q … Hub Gewichte q p … J. Kleinberg, “Authoritative Sources in a Hyperlinked Environment”, 1998.
 Schritt 1: Query-basiertes Retrieval von Resultaten. Schritt 2: Generierung eines Kontextgraphen (Links und Backlinks) Schritt 3: Rescoring Methode mit Hub- und Authority-Gewichten unter Verwendung der Adjazenzmatrix des Kontextgraphen. (Lösung: Linke/rechte Eigenvektoren (SVD)) Authority- Gewichte. p. q. … Hub. Gewichte. q. p. … J. Kleinberg, Authoritative Sources in a Hyperlinked Environment ,")
42
Semantisches Modell des WWW
Verstehen des Inhalts Probabilistic latent semantic analysis Automatische Identifikation von Konzepten und Themengebieten. Verstehen der Linkstruktur Probabilistisches Graphenmodell = prädiktives Modell für zusätzliche Links basierend auf vorhandenem Graph Schätzung der Entropie des Web Graphen (im Sinne eines stochastischen Prozesses) Basierend auf „Web communities” Probabilistische Version von HITS
 Basierend auf „Web communities Probabilistische Version von HITS.")
43
Latente Web Communities
Web Community: dichter bipartiter Teilgraph Source Knoten Target Knoten Probabilistisches Modell evtl. identisch D. Cohen & T. Hofmann, „The Missing Link – A Probabilistic Models of Document Content and Hypertext Connecivity“, NIPS*2001.

44
Dekomposition des Web-Graphen
Web Teilgraph Community 1 Links gehören zu genau einer Web Community (im probab. Sinne) Web Seiten können zu mehreren Communities gehören Community 2 Community 3
 Web Seiten können zu mehreren Communities gehören. Community 2. Community 3.")
45
Linking Hyperlinks and Content
Kombination von pLSA und pHITS (probab. HITS) in einem gemeinsamen Modell w z P(z|s) P(w|z) Konzept/Topic P(t|z) t Web Community
 in einem gemeinsamen Modell. w. z. P(z|s) P(w|z) Konzept/Topic. P(t|z) t. Web Community.")
46
“Ulysses” Webs: Space, War, and Genius (Helden unerwünscht!)
Basismenge generiert via Altavista mit Query “Ulysses” ulysses space page home nasa science solar esa mission ulysses.jpl.nasa.gov/ helio.estec.esa.nl/ulysses grant s ulysses online war school poetry president civil /presidents/ug18.html saints.css.edu/gppg.html page ulysses new web site joyce net teachers information /Joyce/Ulysses.htm /Fiction/joyce/ulysses T. Hofmann, SIGIR 2000.

47
6. Kollaboratives Filteren
47

48
Vorhersage von Benutzerpräferenzen und -aktionen
Benutzerprofil Dr. Strangelove Three Colors: Blue Fargo Pretty Woman Rating? Movie? .

49
Kollaboratives Filtern
Kollaboratives / Soziales Filtern Was tun, wenn Merkmalsextraktion problematisch ist? (Multimedia-Retrieval, e-Commerce, etc.) Rückgriff auf Gemeinsamkeiten und Ähnlichkeiten von Interessen zur Verbesserung von Vorhersagen Verwendung von Benutzerprofildaten (Web logs von Downloads, Transaktionen, Click-Streams, Ratings) Recommender Systeme – e-commerce Problemformalisierung Datenrepräsentation: dünn-besetzte Matrix mit impliziten und/oder expliziten Bewertungen
 Rückgriff auf Gemeinsamkeiten und Ähnlichkeiten von Interessen zur Verbesserung von Vorhersagen. Verwendung von Benutzerprofildaten (Web logs von Downloads, Transaktionen, Click-Streams, Ratings) Recommender Systeme – e-commerce. Problemformalisierung. Datenrepräsentation: dünn-besetzte Matrix mit impliziten und/oder expliziten Bewertungen.")
50
Kollaboratives Filtern via pLSA
Diskrete Bewertungsskala, z.B. Votes: (Zahl der Sterne) z v Bewertung v ist unabhängig von der Person u, gegeben den Zustand der latenten Variable z u y Jede Person ist durch eine spezifische W-Verteilung charakterisiert Analogie zum IR [Person=Dokument], [Item=Wort]
 z. v. Bewertung v ist unabhängig von der Person u, gegeben den Zustand der latenten Variable z. u. y. Jede Person ist durch eine spezifische W-Verteilung charakterisiert. Analogie zum IR [Person=Dokument], [Item=Wort]")
51
pLSA vs. Memory-basierte Techniken
Standard-Technik: Memory-basiert Gegeben einen „aktiven Benutzer“, berechne Korrelation mit allen Benutzerprofilen in der Datenbank (e.g., Pearson Koeffizienten) Transformation der Korrelation in relative Gewichte Gewichtete (additive) Vorhersage über alle Nachbarn pLSA Explizite Dekomposition der Benutzerpräferenzen: Interessen sind inhärent multidimensional keine globale Ähnlichkeitsfunktion zwischen Personen (es kommt auf die Hinsicht an!) Probabilistisches Modell erlaubt explizite Optimierung der gewünschten Kostenfunktion Data Mining: Exploration von Benutzer-Daten, Auffinden von Interessensgruppen
 Transformation der Korrelation in relative Gewichte. Gewichtete (additive) Vorhersage über alle Nachbarn. pLSA. Explizite Dekomposition der Benutzerpräferenzen: Interessen sind inhärent multidimensional keine globale Ähnlichkeitsfunktion zwischen Personen (es kommt auf die Hinsicht an!) Probabilistisches Modell erlaubt explizite Optimierung der gewünschten Kostenfunktion. Data Mining: Exploration von Benutzer-Daten, Auffinden von Interessensgruppen.")
52
EachMovie Datensatz EachMovie: >40K Benutzer, >1.6K Filme, >2M Ratings Experimentelle Auswertung: Vergleich mit Memory-basierten Methoden, leave-one-out Protokoll Vorhersagegenauigkeit

53
EachMovie Data Set (II)
Mittlere Absolute Abweichung Bewertung der Rangordnung: Gewichte fallen exponentiell mit dem Rang in einer Empfehlungsliste

54
Interessengruppen, Each Movie

55
Des-Interessengruppen, Each Movie

56
7. Ausblick 56

57
Zusammenfassung Techniken des maschinellen Lernens, insbesondere Verfahren der Matrix Dekomposition, als Grundlagentechnologie des Information Retrieval Zusammenhang zwischen Modellen mit latenten Variablen und semantischen Datenrepräsentationen Vielzahl von Anwendungsszenarien von der Informationssuche und der Kategorisierung bis hin zur Analyse von Benutzerprofilen Potentielle real-world Anwendungen Robustere und genauere Retrieval- und Suchmaschinen Automatische Kategorisierung von Dokumenten Recommender Systeme für e-commerce und für Information Portals

58
Laufende Forschungsprojekte
Intelligente Informationsagenten, fokusiertes Web-Crawling [DARPA-TASK Projekt ] Question-Answering Information Retrieval [NSF -Information Technology Research ] Kategorisierung von Multimedia Dokumenten [NSF - Information Technology Research ] Probabilistische Web-Graph Modelle [Internet Archiv] Generative Modelle zur Kombination von Text und Bildern [NSF – pending] Intelligente Mensch-Maschinen Schnittstellen zur effizienten Informations-Suche, Navigation und Visualisierung [in Vorbereitung] Lernen von Konzept-Hierarchien und Integration von existierenden Taxonomien [RecomMind] Personalisiertes Retrieval Interface: Kombination von Suche und kollaborativem Filtern [RecomMind] CS. BROWN. EDU RECOM MIND. COM

59
The End. 59

Ähnliche Präsentationen






 U N I V E R S I T Ä T H A M B U R G November 2012.>")
 U N I V E R S I T Ä T H A M B U R G November 2011.>")
 U N I V E R S I T Ä T H A M B U R G November 2011.>")

Media Landesanstalt für Kommunikation Baden-Württemberg (LFK) Landeszentrale für Medien und Kommunikation.>")
![Personalisierte Benutzeroberflächen BFD WS 12/13 Übung 6 Producing an end-user experience that is uniquely appropriate for each individual. [Sears]](/1/639535/big_thumb.jpg "Personalisierte Benutzeroberflächen BFD WS 12/13 Übung 6 Producing an end-user experience that is uniquely appropriate for each individual. [Sears]>")



: Umgang mit einfachen Datentypen Umgang mit Feldern Umgang mit Referenzen.>")



