Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Methoden der Politikwissenschaft Regressionsanalyse Siegfried Schumann

2
Prognosegleichung Backhaus-Formel für den Regressionskoeffizienten (S. 16) äquivalent zum Grundkurs! aber: Rohwerte! in SPSS: B Backhaus-Formel für die Regressionskonstante (S. 16) wie im Grundkurs aber Benennung: b0! in SPSS: CONST
 wie im Grundkurs. aber Benennung: b0! in SPSS: CONST.")
3
Standardisierte Regressionskoeffizienten
ˆ bei Backhaus: → Standardisierung entspricht dem Koeffizienten für z-standardisierte Variablen! Sinn: Vergleichbarkeit innerhalb einer Gleichung herstellen! In SPSS: BETA

4
Arbeitsblatt 1: Eine unabhängige Variable
r aus Gleichungen u. 2 errechenbar? Konstante = ? SYCDU x 10 1 Jahr (Alter) Jahre
 10 Jahre.")
5
Multiple Regression Regressionsgleichung:
Zielfunktion der multiplen Regressionsfunktion: e = Residuum

6
Arbeitsblatt 1: y-Werte für Gleichung y = 2x1 + x2 - 4
Lego-Modell!

7
Demonstration am Modell:
Regressionsgerade → Regressionsebene Regressionskoeffizienten: Steigung unabhängig von den übrigen UVs! Interpretationen: Regressionskoeffizienten Regressionskonstante analog zum bivariaten Modell

8
Arbeitsblatt 1: z-Standardisierung / Unabhängigkeit
Hätte R2 auch kleiner sein können als in vorhergehender Tabelle? bereits bekannt? Nächste Zeile: Welche Werte sind bekannt?

9
Wdh: Bestimmtheitsmaß R2 – Zerlegung eines Werts
Regressionsgerade

10
Wdh: Zerlegung eines y-Wertes
x Abweichung vom arithmetischen Mittel Regressionsgerade arithmetisches Mittel Werte für Beispiel 2 (Grundkurs)
")
11
Wdh: Berechnung von R2

12
Bestimmtheitsmaß R2 Prüfung der Regressionsfunktion insgesamt
Backhaus: R2 → r2 R2 wird beeinflusst von: Zahl der Regressoren Größe der Stichprobe Korrigiertes Bestimmtheitsmaß: Bei großen Fallzahlen kaum bedeutsam. Beispiel: N=K=1000, J=5: r2 = 0.81 → r2korr = r2 = 0.49 → r2korr = r2 = 0.09 → r2korr = Anmerkung: R = r = Multipler Korrelationskoeffizient J = Anzahl der Regressoren K = Zahl der Beobachtungen ?

13
Prüfung des Bestimmtheitsmaßes
F-Test: Hat sich R2emp ≠ 0 zufällig ergeben, (Backhaus: r2emp ≠ 0) obwohl in der Grundgesamtheit R2 gleich „0“ ist? H0: Kein Zusammenhang zwischen der AV und den UVs (in der Grundgesamtheit) H1: Zusammenhang zwischen der AV und den UVs (in der Grundgesamtheit) Testgröße: F-Verteilung: (Dichte) Zähler- bzw. Nennerfreiheitsgrade J = Anzahl der Regressoren K = Zahl der Beobachtungen ––––––––– df. Zähler: df. Nenner: 5 df. Zähler: 10 df. Nenner: 10 nach Bortz 1989: 107
 obwohl in der Grundgesamtheit R2 gleich „0 ist H0: Kein Zusammenhang zwischen der AV und den UVs (in der Grundgesamtheit) H1: Zusammenhang zwischen der AV und den UVs (in der Grundgesamtheit) Testgröße: F-Verteilung: (Dichte) Zähler- bzw. Nennerfreiheitsgrade. J = Anzahl der Regressoren. K = Zahl der Beobachtungen. ––––––––– df. Zähler: 1 df. Nenner: df. Zähler: 10 df. Nenner: 10. nach Bortz 1989: 107.")
14
F-Tabelle - Vertrauenswahrscheinlichkeit 0.95 / 0.99
Beispiel: J = 1 K = 10 Femp = 4.23 → n.s. f1 = J: Anzahl der UVs f2 = K - J - 1: Fallzahl - Anzahl der UVs - 1 aus: Clauß u.a. 1994: 366 f. (Tabellen in Backhaus: S. 576ff.; Auszug: S. 27)
")
15
Weiteres Gütemaß Standardfehler der Schätzung Im Beispiel:
Bezogen auf den Mittelwert von Y (1806.8) beträgt der Standardfehler der Schätzung 21% was nicht als gut bewertet werden kann (Backhaus u.a : 73) Gibt an, welcher mittlere Fehler bei der Verwendung der Regressionsfunktion zur Schätzung der AV gemacht wird. (Backhaus u.a. 2006: 73)
 beträgt der Standardfehler der Schätzung 21% was nicht als gut bewertet werden kann. (Backhaus u.a : 73) Gibt an, welcher mittlere Fehler bei der Verwendung der Regressionsfunktion zur Schätzung der AV gemacht wird. (Backhaus u.a. 2006: 73)")
16
Prüfung der Regressionskoeffizienten
Für jede der unabhängigen Variablen (UV) ist H0 gegen H1 zu prüfen: H0: Der Regressionskoeffizient hat in der Grundgesamtheit den Wert „0“ (kein „Einfluss“ der betreffenden UV auf die AV!) H1: Der Regressionskoeffizient hat in der Grundgesamtheit einen Wert ≠ „0“ („Einfluss“ der betreffenden UV auf die AV!) Testgröße: T-Verteilung (Dichte) (aus: Bleymüller u.a. 1992: 63)
 ist H0 gegen H1 zu prüfen: H0: Der Regressionskoeffizient hat in der Grundgesamtheit den Wert „0 (kein „Einfluss der betreffenden UV auf die AV!) H1: Der Regressionskoeffizient hat in der Grundgesamtheit einen Wert ≠ „0 („Einfluss der betreffenden UV auf die AV!) Testgröße: T-Verteilung. (Dichte) (aus: Bleymüller u.a. 1992: 63)")
17
Kritische Werte der t-Verteilung (Wdh.)
df.: K-J-1 J = Anzahl der Regressoren K = Zahl der Beobachtungen Beispiel: K = 10 J = 1 α = 0.05 → SNV Tafel 4 aus: Clauß u.a. 1994:

18
Konfidenzintervalle für Regressionskoeffizienten
Berechnung des Konfidenzintervalls (KI): mit: = Regressionskoeffizient des j-ten Regressors = Standardfehler des j-ten Regressionskoeffizienten t = t-Wert für gewählte Vertrauenswahrscheinlichkeit Interpretation? Intervall liegt mit einer Wahrscheinlichkeit von [Vertrauenswahrscheinlichkeit] so, dass es den Regressionskoeffizienten in der Grundgesamtheit umschließt. Je größer das KI, desto unsicherer die Schätzung der Steigung des Regressionskoeffizienten. Gilt insbesondere bei Vorzeichenwechsel innerhalb des KI!
: mit: = Regressionskoeffizient des j-ten Regressors. = Standardfehler des j-ten Regressionskoeffizienten. t = t-Wert für gewählte Vertrauenswahrscheinlichkeit. Interpretation Intervall liegt mit einer Wahrscheinlichkeit von [Vertrauenswahrscheinlichkeit] so, dass es den Regressionskoeffizienten in der Grundgesamtheit umschließt. Je größer das KI, desto unsicherer die Schätzung der Steigung des Regressionskoeffizienten. Gilt insbesondere bei Vorzeichenwechsel innerhalb des KI!")
19
Prämissen / Prämissenverletzungen (PV) linearen Regressionsmodell
beim linearen Regressionsmodell

20
Annahmen des linearen Regressionsmodells
Das Modell ist richtig spezifiziert. Es ist linear in den Parametern βj. Es enthält die relevanten UVs (und nur diese!). Zahl der zu schätzenden Parameter (J+1) < Zahl der Beobachtungen (K). Die Störgrößen haben den Erwartungswert Null. Keine Korrelation zwischen den UVs und der Störgröße Störgrößen haben eine konstante Varianz (Homoskedaszidität) Störgrößen sind unkorreliert (keine Autokorrelation) Keine lineare Abhängigkeit zwischen den UVs (keine perfekte Multikollinearität). Die Störgrößen sind normalverteilt. (→ relevant bei statistischen Tests!) Praktisches Problem: Ausreichende Varianz der UVs in der Stichprobe! nach Backhaus u.a. 2006: 79
. Zahl der zu schätzenden Parameter (J+1) < Zahl der Beobachtungen (K). Die Störgrößen haben den Erwartungswert Null. Keine Korrelation zwischen den UVs und der Störgröße. Störgrößen haben eine konstante Varianz (Homoskedaszidität) Störgrößen sind unkorreliert (keine Autokorrelation) Keine lineare Abhängigkeit zwischen den UVs (keine perfekte Multikollinearität). Die Störgrößen sind normalverteilt. (→ relevant bei statistischen Tests!) Praktisches Problem: Ausreichende Varianz der UVs in der Stichprobe! nach Backhaus u.a. 2006: 79.")
21
PV: Nicht lineare Regressionsbeziehung
PV = Prämissenverletzung! PV: Nicht lineare Regressionsbeziehung oder: Strukturbruch? Lineare Regressionsfunktion Y = β0 + β1 · X Nichtlineare Regressionsfunktion Y = β0 + β1 · X0.5 nach Backhaus u.a. 2006: 82

22
PV: Nicht lineare Regressionsbeziehung II
Strukturbruch: Niveauänderung Strukturbruch: Trendänderung nach Backhaus u.a. 2006: 82

23
PV: nicht alle relevanten UVs im Modell enthalten
Sympathie J. Fischer Sympathie J. Trittin „Irak“ gerechtfertigt Zuzug Ausländer ↓ AKWs „abschalten“ Zufried. Grüne in Koalition NEO-FFI: OE NEO-FFI: GW Links-Rechts Selbsteinstufung Erklärte Varianz R2: Abhängige Variable (AV) jeweils: Sympathie für die Grünen Zahlenwerte: standardisierte Regressionskoeffizienten nicht signifikant (unter Signifikanzniveau „.05“) - - - - + - - +
 jeweils: Sympathie für die Grünen. Zahlenwerte: standardisierte Regressionskoeffizienten. nicht signifikant (unter Signifikanzniveau „.05 )")
24
PV: Nicht konstante Varianz der Störgrößen
Homoskedaszidität: Alle bedingten Verteilungen der ui haben Erwertungswert 0 und konstante Varianz σu (Bleymüller, 1992: 149) Heteroskedaszidität I Heteroskedaszidität II Relevant vor allem bei Zeitreihen! nach Backhaus u.a. 2006: 87
 Heteroskedaszidität I. Heteroskedaszidität II. Relevant vor allem bei Zeitreihen! nach Backhaus u.a. 2006: 87.")
25
PV: Nicht unkorrelierte Störgrößen (Autokorrelation)
Positive Autokorrelation Negative Autokorrelation Relevant vor allem bei Zeitreihen! nach Backhaus u.a. 2006: 87

26
Erkennen von Autokorrelation (Zeitreihen!)
Optische Inspektion (Residuen) Durbin-Watson-Test = + Beziehung? Berechnung? : (Standardfehler der Residuen in der Grundgesamtheit!) (aus Backhaus u.a. 2006: 101)
 Durbin-Watson-Test. = + Beziehung Berechnung : (Standardfehler der Residuen in der Grundgesamtheit!) (aus Backhaus u.a. 2006: 101)")
27
Test auf Autokorrelation (Durbin-Watson-Formel)
Kritische Werte (Tabelle!) ? Empirischer Wert der Prüfgröße „d“
 Empirischer Wert der Prüfgröße „d")
28
Durbin-Watson Tabelle
Vertrauenswahrscheinlichkeit: einseitig 0.975, zweiseitig 0.95 K = Zahl der Beobachtungen J = Zahl der Regressoren d+u = unterer Grenzwert des Unschärfebereichs d+o = unterer Grenzwert Beispiel: aus Backhaus u.a. 2006: 820

29
Test auf Autokorrelation (Durbin-Watson-Formel)
Beispiel: d+u (hier: du) = 1.21 d+o (hier: do) = 1.56 4 - do = 2.44 4 - du = 2.79 d = 2.02 Ho „keine Auto-korrelation“ kann nicht zurückge-wiesen werden! 1.21 1.56 2.44 2.79 d = 2.02
 = d+o (hier: do) = do = du = d = Ho „keine Auto-korrelation kann nicht zurückge-wiesen werden! d =")
30
Test auf Autokorrelation: Beispiel 1
d = Indexwert für die Prüfung auf Autokorrelation ek = Residualgröße für den Beobachtungswert in Periode k (k = 1, 2, …, K) ?
")
31
Test auf Autokorrelation: Beispiel 2
d = Indexwert für die Prüfung auf Autokorrelation ek = Residualgröße für den Beobachtungswert in Periode k (k = 1, 2, …, K) ?
")
32
Keine perfekte Multikollinearität
PV: Starke d.h. Forderung: Keine perfekte lineare Abhängigkeit der UVs Prüfung auf Multikollinearität: 1. Prüfung: Korrelationsmatrix der UVs 2. multiple Korrelation R2 1 – R2 (Toleranz) Variance Inflation Factor (VIF) = Kehrwert der Toleranz Abhilfemöglichkeiten: Variablen (UVs) entfernen Ersetzung von Variablen durch Faktoren
 Variance Inflation. Factor (VIF) = Kehrwert der Toleranz. Abhilfemöglichkeiten: Variablen (UVs) entfernen. Ersetzung von Variablen durch Faktoren.")
33
Beispiele für Regressionsmodelle

34
Bivariates Modell: Lineare Einfachregression
/MISSING LISTWISE /STATISTICS COEFF OUTS CI R ANOVA TOL /CRITERIA=PIN(.05) POUT(.10) /NOORIGIN /DEPENDENT fr4_3 /METHOD=ENTER fr9_5 /CASEWISE DEPENDENT PRED RESID OUTLIRE (0) 0,000 : = Zusammenhang?
 POUT(.10) /NOORIGIN. /DEPENDENT fr4_3. /METHOD=ENTER fr9_5. /CASEWISE DEPENDENT PRED RESID OUTLIRE (0) 0,000. : = Zusammenhang")
35
t-Verteilung → Standardnormalverteilung
z = 1.96 γ = 0.05 z = 2.58 γ = 0.01 0.0035 0.0035 z = γ = 0.007 SPSS z = γ = 0.007

36
Multiple Regression – Modell 1 (Ausgangsmodell)
/MISSING LISTWISE /STATISTICS COEFF OUTS CI R ANOVA TOL /CRITERIA=PIN(.05) POUT(.10) /NOORIGIN /DEPENDENT fr4_3 /METHOD=ENTER fr6_2 fr9_ fr29_4 fr29_10 fr40_24 /RESIDUALS HIST(ZRESID). ? Y: erklärte Streuung K=2262 ? ? ? Y: nicht erklärte Streuung : J = Quotient : K-J-1 = K-1 Y: Gesamt- Streuung SAQy
 POUT(.10) /NOORIGIN. /DEPENDENT fr4_3. /METHOD=ENTER fr6_2 fr9_5 fr29_4 fr29_10 fr40_24. /RESIDUALS HIST(ZRESID). Y: erklärte Streuung. K=2262. Y: nicht erklärte Streuung. : J. = Quotient. : K-J-1. = K-1. Y: Gesamt- Streuung SAQy.")
37
Fs.: Multiple Regression – Modell 1

38
Fs.: Multiple Regression – Modell 1
Normalverteilung der Residuen?

39
Fs.: Multiple Regression – Modell 1

40
Multiple Regression – Modell 2 (+ LIRE)
vorher: .113 vorher: .000 vorher: .259 .090 -.136

41
Multiple Regression – Modell 3 (+ Symp. CDU)
vorher: .173 vorher: .000 .043 .001

42
Multiple Regression – Modell 4 (+ Symp. CSU)
vorher: .434 rCDU CSU = .86 ?

43
Multiple Regression – Modell 4

44
Zusammenfassung / Überblick zu den Modellen

45
linearen Regressionsmodell
Produktvariablen im linearen Regressionsmodell

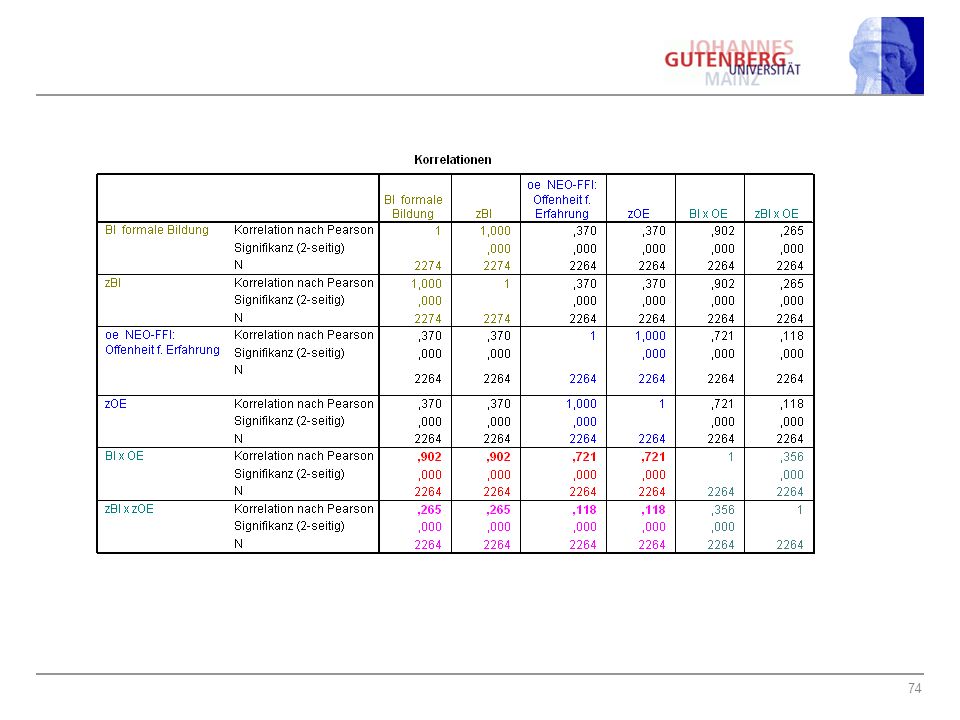
46
Produktvariablen - 1 Interaktion: Offenheit x Bildung? R2 = .281
Ausgangsmodell R2 = .281 Interaktion: Offenheit x Bildung? R2 = .285 nur: Produktvariable

47
Korrelationsmatrix symmetrisch!
Produktvariablen - 2 Korrelationsmatrix symmetrisch! BI und OE sind korreliert ! „Explodieren“ des Zusammenhangs durch Produktbildung Abhilfe: Mittelwert herausnehmen (zentrieren reicht!)
")
48
Produktvariablen - 3 x2 Werte der z-standardisierten Produktvariablen x1 · x2 Für z-standardisierte Varaiblen: x1

49
Produktvariablen - 4 R2 = .281 R2 = .285 Ausgangsmodell
Ausgangsmodell mit z-standardisierter Produktvariable R2 = .285 z - Produktvariable

50
Interpretation des Interaktionseffekts I
(extrem) rechte Einstellungen Produktvariable negative Werte: ∙ Bildung, keine OE ∙ keine Bildung, OE positive Werte: ∙ Bildung, OE ∙ keine Bildung, keine OE
 rechte Einstellungen. Produktvariable. negative Werte: ∙ Bildung, keine OE. ∙ keine Bildung, OE. positive Werte: ∙ Bildung, OE. ∙ keine Bildung, keine OE.")
51
Interpretation des Interaktionseffekts II
Gruppenmittelwerte (empirisch ermittelt) OFFENHEIT über Mittelwert unter Mittelwert 2.67 2.69 (n = 353) 2.32 2.30 (n = 758) Geschätzte Werte (aus Modell ohne Interaktionseffekt) 2.94 2.93 (n = 689) 2.72 2.75 (n = 464) unter Mittelwert über Mittelwert BILDUNG
 OFFENHEIT. über Mittelwert. unter Mittelwert (n = 353) (n = 758) Geschätzte Werte (aus Modell ohne Interaktionseffekt) (n = 689) (n = 464) unter Mittelwert über Mittelwert BILDUNG.")
52
Dichotome unabhängige Variablen linearen Regressionsmodell
im linearen Regressionsmodell

53
Vorstellung der Variablen
NBL = 1 ABL = 0 hohe Werte: Rechts dichotome Variable Umfrage 2003 ABL NBL

54
Modell 1: AV = LIX, UV = NBL LIX 0 (ABL) 1 (NBL) NBL Interpretation?
 1 (NBL) NBL Interpretation")
55
Modell 2: AV = LIX,UV = LIRE (getrennt: ABL,NBL)
Weiteres Vorgehen: LIX Ein Modell? leichter Interaktionseffekt? 1-5 LIRE 1-11 ABL R2=.035 NBL R2=.073

56
Modell 3: AV = LIX, UV = LIRE und NBL
Interaktion? LIX LIX LIX 1-5 NBL 1 LIRE 1-5 1-11 LIRE LIRE 1-11 ABL + NBL R2=.035 + R2=.073 R2=.230

57
Modell 4: AV = LIX, UV = LIRE und NBL + Interaktion

58
Dummyvariablen als unabhängige Variablen linearen Regressionsmodell
im linearen Regressionsmodell

59
Bildung der Dummyvariablen
Ausgangsvariable nachfolgende Berechnungen: Daten aus der Studie 2003 AV: Sympathie für die CSU (-5 … +5)
")
60
Lineare Abhängigkeit der Dummyvariablen
Katholiken: kath = 1 ev = 0 NoKo = → Σ = 1 Protestanten: kath = 0 ev = 1 NoKo = → Σ = 1 keine Konf.: kath = 0 ev = 0 NoKo = → Σ = 1

61
Bivariate Regressionen

62
AV: Sympathie CSU, UV: 2 der 3 Dummyvariablen

63
Umrechnung der unstandardisierten Koeffizienten

64
Empirische Ergebnisse zum Vergleich (Wdh.)
")
65
Dummyvariablen zentriert

66
Dummyregression zentriert

67
Dummyvariablen zentriert (Wdh.)
")
68
Dummyvariablen z-standardisiert

69
Dummyregression z-standardisiert – Teil I

70
Dummyregression z-standardisiert – Teil II
zentrierte Werte SDs dividieren!

71
Dummyvariablen z-standardisiert (Wdh.)
")
72
(SPSS) AV: Sympathie CSU; UVs: ev, kath, NoKo
REGRESSION /MISSING LISTWISE /STATISTICS COEFF OUTS R ANOVA TOL /CRITERIA=PIN(.05) POUT(.10) /NOORIGIN /DEPENDENT fr5_3 (Sympathie/Antipathie CSU) /METHOD=ENTER ev kath NoKo /RESIDUALS HIST(ZRESID).
 POUT(.10) /NOORIGIN. /DEPENDENT fr5_3 (Sympathie/Antipathie CSU) /METHOD=ENTER ev kath NoKo. /RESIDUALS HIST(ZRESID).")
73
Vielen Dank für Ihre Aufmerksamkeit!

Ähnliche Präsentationen



>")

 U N I V E R S I T Ä T H A M B U R G November 2011.>")
Media Landesanstalt für Kommunikation Baden-Württemberg (LFK) Landeszentrale für Medien und Kommunikation.>")












