Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Teil I Informationsdarstellung in Rechenanlagen
1.1 Code und Codierung Themen Grundlegende Begriffe: – Code, Codierung, Codewörter, Dekodierung – Eigenschaften von Codes, Code-Klassen – Fehlererkennung und Fehlerkorrektur Codierungsverfahren zur Datenkompression – Wozu Datenkompression? – Komprimierungsarten – Lauflängencodierung

2
Wozu braucht man Codierungen?
Es gibt eine Vielzahl möglicher Typen zu verarbeitender Daten: Zahlen: Nat, Int, Real Wahrheitswerte: {T, F} Texte: Zeichenketten über festem Alphabet Audio: Sprache, Musik Bilder Video . . . Anwendungs-problem Anwendungsbereich „Welt“ analysieren, modellieren, codieren anwenden, interpretieren, decodieren Gesucht sind geeignete Darstellungen der Daten: kompakt/platzsparend einfache Codierung und Dekodierung einfach maschinell zu verarbeiten für Menschen lesbar . . . Daten Daten verarbeiten, übertragen, speichern, modifieren, löschen, verschlüsseln

3
Code und Codierung Beispiel: Morsecodierung (nach Samuel Morse)
c : {A, B, ... Z, 0, 1, ..., 9, Ä, Ö, Ü, CH} -> { , - }* Code-Tabelle:

4
Code und Codierung
Beispiel: Morsecodierung Darstellung der Code-Tabelle als Code- Baum Problem: Bei der Dekodierung gibt es Mehrdeutigkeiten. So hat z.B. das Codewort „_ _ _ _ _“ mehrere Urbilder: „0“, „MMT“ ...

5
Grundbegriffe: Zeichenvorrat, Alphabet
Zeichenvorrat Z Eine endliche Menge mit unterschiedlichen Zeichen zur Bildung von sog. Datenwörtern heißt Zeichenvorrat. Häufig verwendete Zeichenvorräte: {0,1}, {F, T}, {ja, nein}, {, } usw. {0,1, ..., 9}, {0,1, ..., 9, ., E, +, - , *, /, =}, {0,1, ..., 9, #}, {, , , } {A, ..., Z, a, ..., z}, {0,1, ..., 9, _, A, ..., Z, a, ..., z}, ASCII, Latin1, Latin9, UTF Alphabet (= Zeichenvorrat mit Ordnungsrelation) Die Elemente des Zeichenvorrats Z lassen sich gemäß einer Ordnungsrelation „“ in anordnen. Beispiele: - „Natürliche“ Ordnung der Ziffernmenge Z = {0,1, ..., 9} mit 0 1 2 9 - Telefon-Ordnung der Ziffernmenge Z = {0,1, ..., 9} mit 1 2 9 0 - Farben beim Skatspiel: Digitale Daten Digitale Daten sind Träger diskreter Information und werden durch Zeichen oder Zeichenketten über einem endlichen Alphabet dargestellt. Als Zeichenvorrat dient eine binäre Menge, meist die Menge {0,1}. 5
 Die Elemente des Zeichenvorrats Z lassen sich gemäß einer. Ordnungsrelation „ in anordnen. Beispiele: - „Natürliche Ordnung der Ziffernmenge Z = {0,1, ..., 9} mit 0 1 2 9. - Telefon-Ordnung der Ziffernmenge Z = {0,1, ..., 9} mit 1 2 9 0. - Farben beim Skatspiel: Digitale Daten. Digitale Daten sind Träger diskreter Information und werden durch Zeichen oder Zeichenketten über einem endlichen Alphabet dargestellt. Als Zeichenvorrat dient eine binäre Menge, meist die Menge {0,1}. 5.")
6
Grundbegriffe: Wörter, , Zn, Z+, Z*
Wort, Zeichenkette, String Es sei Z ein Zeichenvorrat. Eine Zeichenkette w = z1z2...zn mit zi Z bezeichnet man als ein Wort, Zeichenkette oder String gebildet über dem Zeichenvorrat Z. Kurzbezeichnung: Z-Wort, Z-String Das leere Wort („lambda“) enhält kein Zeichen. Wortlänge Es sei w = z1z2...zn ein Wort gebildet über Z. Dann bezeichnet „n“ die Wortlänge von w, d.h. die Anzahl der Zeichen, aus denen w besteht. Notation: |w| = n, falls w =z1z2...zn | | = 0 Zn, Z+, Z* Zn ist die Menge aller Wörter der Länge n: Zn = {w: w = z1...zn, zi Z} Z0 = {} Z+ ist die Menge aller Wörter, die man mit Zeichen aus Z bilden kann: Z+ = Z1 Z2 Z3 Z4 Z5 … Z* ist die Menge aller Wörter, die man mit Zeichen aus Z bilden kann einschließlich des leeren Wortes: Z+ = Z0 Z1 Z2 Z3 Z4 Z5 … 6
 enhält kein Zeichen. Wortlänge. Es sei w = z1z2...zn ein Wort gebildet über Z. Dann bezeichnet „n die Wortlänge von w, d.h. die Anzahl der Zeichen, aus denen w besteht. Notation: |w| = n, falls w =z1z2...zn. | | = 0. Zn, Z+, Z* Zn ist die Menge aller Wörter der Länge n: Zn = {w: w = z1...zn, zi Z} Z0 = {} Z+ ist die Menge aller Wörter, die man mit Zeichen aus Z bilden kann: Z+ = Z1 Z2 Z3 Z4 Z5 … Z* ist die Menge aller Wörter, die man mit Zeichen aus Z bilden kann einschließlich des leeren Wortes: Z+ = Z0 Z1 Z2 Z3 Z4 Z5 … 6.")
7
auff Linien und Ziphren in allerley Hanthierung
Wörter: Beispiele Adam Ries: Adam Risen Rechenbuch auff Linien und Ziphren in allerley Hanthierung Geschäfften unnd Kauffmanschafft 7

8
ein Zahlwort, d.h. ein Wort über Z: 2009 noch eines: 004982155863475
Wörter: Beispiele Z = {0, ..., 9} ein Zahlwort, d.h. ein Wort über Z: 2009 noch eines: kein Z-Wort, aber ein ASCII-Wort: 0821/5586 ̺ ( ̺ Z, /Z) In den meisten Programmiersprachen werden Strings durch Anführungszeichen (bzw. Zollzeichen) begrenzt: Java, C++, …: "wort", SQL: 'wort' Leerer String = = "" (Java und Co.) = '' (SQL) Leerzeichen = ̺ = " " (Java und Co.) = ' ' (SQL) 8
 In den meisten Programmiersprachen werden Strings. durch Anführungszeichen (bzw. Zollzeichen) begrenzt: Java, C++, …: wort , SQL: wort Leerer String = = (Java und Co.) = (SQL) Leerzeichen = ̺ = (Java und Co.) = (SQL) 8.")
9
Grundbegriffe: Konkatenantion
Verkettung von Wörtern (Konkatenation) Als Konkatenation oder Verkettung bezeichnet man diejenige Operation, die zwei Wörter zu einem Wort zusammenfügt. Formale Notation Seien Z ein Zeichenvorrat, w1 , w2 Z* zwei Wörter über Z, dann bildet die Operation : Z* x Z* Z* w1 und w2 durch w1 w2 auf die Zeichenkette w1w2 ab. (Formal muss man dies induktiv definieren.) Beispiele Leeres Wort: 123 = 123 = 123 Formal: 0821 5586 3475 = Java und Co.: "0821" + "5586" + "3475" = " " SQL: '0821' || '5586' || '3475' = ' ' 9
 Als Konkatenation oder Verkettung bezeichnet man diejenige Operation, die zwei Wörter zu einem Wort zusammenfügt. Formale Notation. Seien Z ein Zeichenvorrat, w1 , w2 Z* zwei Wörter über Z, dann bildet die Operation : Z* x Z* Z* w1 und w2 durch w1 w2 auf die Zeichenkette w1w2 ab. (Formal muss man dies induktiv definieren.) Beispiele. Leeres Wort: 123 = 123 = 123. Formal: 0821 5586 3475 = Java und Co.: = SQL: 0821 || 5586 || 3475 =")
10
Codierung, Code und Codewort
Definition: Codierung, Code und Codewort Seien A und B Zeichenvorräte (bzw. Alphabete). Eine Funktion c: A ® B+ heißt Zeichencodierung oder (kurz) Codierung. Der Wertebereich (Bildbereich) c(A) Í B+ mit c(A) := {c(a) Î B+ | a Î A } heißt Code. Jedes Element b Î c(A) heißt Codewort. Die Anzahl |b| Î Nat der Zeichen eines Codeworts b wird als Codewortlänge von b bezeichnet. 5. Eine Funktion c: A* ® B* heißt Wortcodierung. Anmerkungen: Codierungen sind Funktionen, die Zeichen bzw. Wörter über einen Zeichenvorrat auf Wörter über einem anderen Zeichenvorrat abbilden. Die Abbildungsvorschrift kann in unterschiedlicher Form vorliegen, z.B. als Tabelle oder als Rechenvorschrift. Jede Zeichencodierung c kann auf natürliche Weise einer Wortcodierung c* erweitert werden: c*(z1z2…zn) := c(z1)c(z2)…c(zn).
. Eine Funktion c: A ® B+ heißt Zeichencodierung oder (kurz) Codierung. Der Wertebereich (Bildbereich) c(A) Í B+ mit c(A) := {c(a) Î B+ | a Î A } heißt Code. Jedes Element b Î c(A) heißt Codewort. Die Anzahl |b| Î Nat der Zeichen eines Codeworts b wird als Codewortlänge von b bezeichnet. 5. Eine Funktion c: A* ® B* heißt Wortcodierung. Anmerkungen: Codierungen sind Funktionen, die Zeichen bzw. Wörter über einen Zeichenvorrat auf Wörter über einem anderen Zeichenvorrat abbilden. Die Abbildungsvorschrift kann in unterschiedlicher Form vorliegen, z.B. als Tabelle oder als Rechenvorschrift. Jede Zeichencodierung c kann auf natürliche Weise einer Wortcodierung c* erweitert werden: c*(z1z2…zn) := c(z1)c(z2)…c(zn).")
11
Code und Codierung Beispiel: Zählcodierung (z.B. Impulswahlverfahren beim Telefon) c : {0, 1, ..., 9} {Low, High}* Code-Tabelle: 1 = HL 6 = HHHHHHL 2 = HHL 7 = HHHHHHHL 3 = HHHL 8 = HHHHHHHHL 4 = HHHHL 9 = HHHHHHHHHL 5 = HHHHHL 0 = HHHHHHHHHHL Anmerkung: Im Gegensatz zur Morsecodierung gibt es bei der Zählcodierung keine Probleme bei der Dekodierung der zugehörigen Wortcodierung, da kein Codewort mit dem Anfang eines anderen Codeworts übereinstimmt: HHHHHHHHHHLHHHHHHHHLHHLHL = 0821 11 11

12
Codierung von Wörtern Frage: Wie codiert man ganze Wörter w aus einer Menge A*? Definition: Natürliche Fortsetzung Seien A und B Zeichenvorräte (bzw. Alphabete) und c: A ® B+ eine Zeichencodierung. Dann definiert man als natürliche Fortsetzung von c die Wortcodierung c* : A* ® B* durch: 1. c*() = ( ist das leere Wort, d.h. = "") 2. c*(wa) c*(w)c(a) für w Î A* und a Î A Beispiel: Sei c : {0, 1, ..., 9} -> {L, H}* die Zählkodierung c*(123) = c*(12) c(3) = c*(1) c(2) c(3) = c*() c(1) c(2) c(3) = HL HHL HHHL = HLHHLHHHL zu codierendes Wort "123" Î {O, ... 9}* das entstandene Codewort Î {L, H}* 12 12
 und c: A ® B+ eine Zeichencodierung. Dann definiert man als natürliche Fortsetzung von c die Wortcodierung c* : A* ® B* durch: 1. c*() = ( ist das leere Wort, d.h. = ) 2. c*(wa) c*(w)c(a) für w Î A* und a Î A. Beispiel: Sei c : {0, 1, ..., 9} -> {L, H}* die Zählkodierung. c*(123) = c*(12) c(3) = c*(1) c(2) c(3) = c*() c(1) c(2) c(3) = HL HHL HHHL. = HLHHLHHHL. zu codierendes Wort 123 Î {O, ... 9}* das entstandene Codewort Î {L, H}*")
13
Codierungsklassen Definition
Seien A und B Zeichenvorräte (bzw. Alphabete). a) c: A ® B (B ohne Stern) heißt Chiffrierung und c(A) ist ein Chiffre b) c: Z ® B+ (wobei Z eine Menge von Ziffern ist) heißt Zifferncodierung c) c: A ® Bn mit festem n Î Nat heißt Blockcodierung d) c: A ® Bool+ heißt Binärcodierung e) c: A ® Booln mit festem n Î Nat heißt n-Bit-Codierung Beispiele ad a) Chiffrierung: Sei c: A={0,1,2, ...9} ® A={0,1,2, ...9} mit c(0) = 2, c(1) = 3, c(2) = 4, c(3)= 5, ..., c(7)=9, c(8)=0, c(9)=1 ad c) Blockcodierung: Sei c: {0,1,2, ..., 9} ® {a,b,c}2 mit c(0) = aa, c(1) = ab, c(2)=ac, c(3)=ba, c(4)=bb, ..., c(9)=cc ad d) Binärcodierung: Sei c: {Augsburg, Berlin, Stuttgart} ® {0, 1}+ mit c(Augsburg)=0 , c(Berlin)=1, c(Stuttgart)=01
. a) c: A ® B (B ohne Stern) heißt Chiffrierung und c(A) ist ein Chiffre. b) c: Z ® B+ (wobei Z eine Menge von Ziffern ist) heißt Zifferncodierung. c) c: A ® Bn mit festem n Î Nat heißt Blockcodierung. d) c: A ® Bool+ heißt Binärcodierung. e) c: A ® Booln mit festem n Î Nat heißt n-Bit-Codierung. Beispiele. ad a) Chiffrierung: Sei c: A={0,1,2, ...9} ® A={0,1,2, ...9} mit c(0) = 2, c(1) = 3, c(2) = 4, c(3)= 5, ..., c(7)=9, c(8)=0, c(9)=1. ad c) Blockcodierung: Sei c: {0,1,2, ..., 9} ® {a,b,c}2. mit c(0) = aa, c(1) = ab, c(2)=ac, c(3)=ba, c(4)=bb, ..., c(9)=cc. ad d) Binärcodierung: Sei c: {Augsburg, Berlin, Stuttgart} ® {0, 1}+ mit c(Augsburg)=0 , c(Berlin)=1, c(Stuttgart)=01.")
14
Grundbegriffe im Zusammenhang mit Binärkodierungen
Bit (Binary Digit) Ein Zeichen aus einem 2-elementigen Alphabet A. Zum Beispiel: A = {0, 1} somit gilt für zA entweder z = 0 oder z = 1 A = {nein, ja} A = {aus, ein} A = {low, high} A = {dunkel, hell} .... Technisch können die Werte des Alphabets {0, 1} dargestellt werden z.B. als: – elektrische Ladungen: 0 = ungeladen 1 = geladen – elektrische Spannungen: 0 = 0 Volt 1 = 5 Volt – Magnetisierungen: 0 = unmagnetisiert 1 = magnetisiert – Spinzustände von Atomkernen (Qubits): 0 = + ½ 1 = -½ 14 14
 Ein Zeichen aus einem 2-elementigen Alphabet A. Zum Beispiel: A = {0, 1} somit gilt für zA entweder z = 0 oder z = 1. A = {nein, ja} A = {aus, ein} A = {low, high} A = {dunkel, hell} .... Technisch können die Werte des Alphabets {0, 1} dargestellt werden z.B. als: – elektrische Ladungen: 0 = ungeladen. 1 = geladen. – elektrische Spannungen: 0 = 0 Volt. 1 = 5 Volt. – Magnetisierungen: 0 = unmagnetisiert. 1 = magnetisiert. – Spinzustände von Atomkernen (Qubits): 0 = + ½. 1 = -½")
15
Grundbegriffe im Zusammenhang mit Binärcodierungen
Bitstring Ein binäres Wort, d.h. ein Wort über dem Alphabet {0,1} heißt Bitstring. Es gibt genau 2n mögliche Bitstring der Länge n. Byte/Oktett Ein Byte ist ein Bitstring der Länge 8 (ein Oktett von Bits). Es gibt genau 28 = 256 unterschiedliche Bytes. Datenwort Ein Datenwort ist eine im Speicher einer Rechenanlage abgelegte Bitfolge zur Repräsentation eines Datums. Meist haben Datenwörter die Länge 2n. Entwicklung der Prozessoren: 4-/8-/16-/32-/64-/128-Bit-Architektur Die Anzahl der Bits steht für die Größe der Wörter, die der Prozessor in einem Arbeitsschritt verarbeiten kann. 15
. Es gibt genau 28 = 256 unterschiedliche Bytes. Datenwort. Ein Datenwort ist eine im Speicher einer Rechenanlage abgelegte Bitfolge zur Repräsentation eines Datums. Meist haben Datenwörter die Länge 2n. Entwicklung der Prozessoren: 4-/8-/16-/32-/64-/128-Bit-Architektur. Die Anzahl der Bits steht für die Größe der Wörter, die der Prozessor in einem Arbeitsschritt verarbeiten kann. 15.")
16
Weitere spezielle Binärwörter
– Byte/Oktett = Bit – Nibble/Halbbyte = Bit (to nibble = to take half a bite) – Word = 16 Bit = 2 Byte – Double Word = 32 Bit = 4 Byte (auch Dword) – Quadruple Word = 64 Bit = 8 Byte (auch Qword) – Octuple Word = 128 Bit = 16 Byte (auch Oword) 16
 – Word = 16 Bit = 2 Byte. – Double Word = 32 Bit = 4 Byte (auch Dword) – Quadruple Word = 64 Bit = 8 Byte (auch Qword) – Octuple Word = 128 Bit = 16 Byte (auch Oword) 16.")
17
Codelineal Ein Codelineal ist eine grafische Darstellungsform, bei der die einzelnen Bit-Positionen farblich gekennzeichnet werden. Beispiel: Codelineal des Gray-Codes Der Gray-Code ist ein einschrittiger Blockcode. Jedes Codewort unterscheidet sich von seinem Vorgänger (Nachfolger) dadurch, dass jeweils genau ein Bit „gekippt“ wird.
 dadurch, dass jeweils genau ein Bit „gekippt wird.")
18
Eigenschaften von Codes
Da es unzählige Möglichkeiten gibt, Information zu codieren, benötigt man Kriterien, anhand derer man bewerten kann, wie gut sich eine Codierung bzw. ein Code für einen bestimmten Zweck eignet. Typische Fragestellungen: Ist die Zeichencodierung injektiv? Das heißt, ist eine Zeichen-Dekodierung möglich? Kommt es vor, dass sich Codewörter vollständig überlappen? Das heißt, ist die der Zeichenkodierung zugeordnete Wortcodierung injektiv? Sind die entstehenden Codewörter hinreichend unterschiedlich, so dass auch kleinere „Schreibfehler“ erkannt werden können? Wie lang sind die entstehenden Codewörter, ginge es auch kürzer?

19
Dekodierung, Fano-Bedingung
Frage: Wann ist eine Codierung (oder ihre Fortsetzung) umkehrbar ? Definition: Dekodierung Es seien A und B Zeichenvorräte (bzw. Alphabete) und c: A ® B* eine Codierung. Falls c injektiv ist, dann heißt die Umkehrabbildung c-1 : c(A) ® A Dekodierung von c(A) Definition: Fano-Bedingung Seien A und B Zeichenvorräte und c: A ® B* eine Codierung. c erfüllt die Fano-Bedingung, falls gilt: Es gibt kein Codewort u, das Anfang eines anderen Codeworts w ist. Formal: " u,v Î c(A): t Î B+: v = ut Anmerkung: Für jede Codierung c: A ® B* gilt: Falls c* injektiv ist, dann ist auch c injektiv. Falls c injektiv und c erfüllt Fano, dann ist auch c* injektiv. Aber Vorsicht: Aus c injektiv folgt nicht unbedingt, dass c* injektiv ist. für Konkatenation
 umkehrbar Definition: Dekodierung. Es seien A und B Zeichenvorräte (bzw. Alphabete) und c: A ® B* eine Codierung. Falls c injektiv ist, dann heißt die Umkehrabbildung. c-1 : c(A) ® A Dekodierung von c(A) Definition: Fano-Bedingung. Seien A und B Zeichenvorräte und c: A ® B* eine Codierung. c erfüllt die Fano-Bedingung, falls gilt: Es gibt kein Codewort u, das Anfang eines anderen Codeworts w ist. Formal: u,v Î c(A): t Î B+: v = ut. Anmerkung: Für jede Codierung c: A ® B* gilt: Falls c* injektiv ist, dann ist auch c injektiv. Falls c injektiv und c erfüllt Fano, dann ist auch c* injektiv. Aber Vorsicht: Aus c injektiv folgt nicht unbedingt, dass c* injektiv ist. für Konkatenation.")
20
Dekodierung, Fano-Bedingung
Anmerkung Die Morsecodierung ist injektiv, nicht aber ihre natürliche Fortsetzung. Beispiel: Sei w = "_ _ _ _ _", u = "_ _ _ _ ", v = "_", dann ist w = u•v aber v {•, _}+, d.h. v . Möglichkeit zur Herstellung der Fano-Bedingung Füge ein Sonderzeichen # zum Abschluss eines Codeworts ein: c#: {A, ..., Z, Ä, Ö, Ü, CH, 1, ..., 9} {•, _, #}* c#(a) := c(a)# (a Î {A, ..., Z, Ä, Ö, Ü, CH, 1, ..., 9}) Es gilt: c# ist injektiv und erfüllt die Fano-Bedingung. => Die natürliche Fortsetzung c#* ist ebenfalls injektiv. Beispiel c*(ESEL) = • • • • • • _• • = c*(SEINE) c#*(ESEL) = • # • • • # • # • _• • # c#*(SEINE) = • • • # • # • • # _• # • #
 := c(a)# (a Î {A, ..., Z, Ä, Ö, Ü, CH, 1, ..., 9}) Es gilt: c# ist injektiv und erfüllt die Fano-Bedingung. => Die natürliche Fortsetzung c#* ist ebenfalls injektiv. Beispiel. c*(ESEL) = • • • • • • _• • = c*(SEINE) c#*(ESEL) = • # • • • # • # • _• • # c#*(SEINE) = • • • # • # • • # _• # • #")
21
Fehlererkennung und Korrektur
Wichtiges Kriterium für die Güte einer Codierung ist die Möglichkeit der Fehlerbehandlung. (Mit „Fehler“ meint man hierbei jede unbeabsichtigte Veränderung eines Zeichens im Codewort, z.B. durch Fehler bei der Übertragung/Codierung/...) Ziel: Auftretende Fehler sollen erkennbar und möglichst korrigierbar sein. Im Folgenden beschränken wir uns auf Blockcodierungen, d.h c: A ® Bn, insbesondere n-Bit-Codierungen c: A ® Booln. Definition: Hamming-Distanz c : A ® Bn sei eine Block-Codierung und es seien x, y Î c(A) mit x = x xn und y = y yn. Dann definiert man den Hamming-Abstand h(x,y) zwischen den Worten x und y, durch: h(x,y) := h(xi, yi) für 1 £ i £ n, wobei h(xi, yi) := 1 für xi ¹ yi 0 sonst D.h., h(x,y) zählt die Stellen, an denen sich x und y unterscheiden. 21 21 21
 Ziel: Auftretende Fehler sollen erkennbar und möglichst korrigierbar sein. Im Folgenden beschränken wir uns auf Blockcodierungen, d.h. c: A ® Bn, insbesondere n-Bit-Codierungen c: A ® Booln. Definition: Hamming-Distanz. c : A ® Bn sei eine Block-Codierung und es seien x, y Î c(A) mit. x = x xn und y = y yn. Dann definiert man den Hamming-Abstand h(x,y) zwischen den Worten x und y, durch: h(x,y) := h(xi, yi) für 1 £ i £ n, wobei h(xi, yi) := 1 für xi ¹ yi. 0 sonst. D.h., h(x,y) zählt die Stellen, an denen sich x und y unterscheiden")
22
Hamming-Abstand eines Codes
Definition Der Hamming-Abstand hc einer Codierung c: A ® Bn ist definiert als: hc := min { h(x,y) | x, y Î c(A) und x ¹ y } (hc ist der kleinste Hamming-Abstand zweier Codewörter) Beispiel: 1-aus-10 Codierung Code-Tabelle: Ziffer Code Es ist hc = 2, da für alle x, y Î c(A) mit x ¹ y gilt: h(x,y) = 2
 | x, y Î c(A) und x ¹ y } (hc ist der kleinste Hamming-Abstand zweier Codewörter) Beispiel: 1-aus-10 Codierung. Code-Tabelle: Ziffer Code Es ist hc = 2, da für alle x, y Î c(A) mit x ¹ y gilt: h(x,y) = 2.")
23
Fehler-Erkennbarkeit
Frage: Wann ist ein Fehler erkennbar? Antwort: Dann, wenn durch den Fehler kein anderes Codewort entstehen kann. Definition: k-Fehler-erkennbar Es seien c : A ® Booln eine n-Bit-Codierung und k Î Nat. c heißt k-Fehler-erkennbar, gdw. durch Verfälschung von bis zu k Stellen eines Codeworts kein anderes Codewort entstehen kann, d.h. der Hammingabstand von c ist größer als k (hc > k). Illustration: Jeder Kreis enthält die Wörter, die durch max. k Fehler ("gekippte Bits") aus dem Codewort im "Mittelpunkt" entstehen können. Folgerung: c ist k-Fehler-erkennbar gdw. kein Codewort liegt im Kreis eines anderen Codewortes. k y k x k z
. Illustration: Jeder Kreis enthält die Wörter, die durch max. k Fehler ( gekippte Bits ) aus dem Codewort im Mittelpunkt entstehen können. Folgerung: c ist k-Fehler-erkennbar gdw. kein Codewort liegt im Kreis eines anderen Codewortes. k. y. k. x. k. z.")
24
Beispiel Gegeben: Codierung c : {0,1,2} ® Bool3 mit: c(0)="001", c(1)="010", c(2)="100" Betrachte k = 1 c(2) c(0) 101 100 001 000 011 110 k =1 c(1) 010 Codewort 1-Fehler
 c(0) k =1. c(1) 010. Codewort. 1-Fehler.")
25
Fehlerkorrigierbare Codes
Frage: Wann ist ein Fehler korrigierbar? => Wenn ein erkannter Fehler durch genau ein Codewort entstanden sein kann. Definition: k-Fehler-korrigierbar Es seien c : A ® Booln eine n-Bit-Codierung und k Î Nat. c heißt k-Fehler-korrigierbar gdw. aus einem durch Verfälschung von bis zu k Stellen eines Codeworts entstandenen Wort kann das richtige Codewort eindeutig ermittelt werden: d.h. " x Î c(A) und " y Î Booln : falls h(x,y) £ k dann ist y c(A) Folgerung: c ist k -Fehler-korrigierbar gdw. alle k-Kreise disjunkt sind. k x y z
 und y Î Booln : falls h(x,y) £ k dann ist y c(A) Folgerung: c ist k -Fehler-korrigierbar gdw. alle k-Kreise disjunkt sind. k. x. y. z.")
26
Fehler-erkennbar vs. Fehler-korrigierbar
k-Fehler-erkennbar k-Fehler-korrigierbar k k y y k k x x z z k k Kein Codewort und kein „k-Fehler“ liegt im Kreis eines anderen Codewortes. Falls für Codierung c gilt 2k + 1 £ hc dann ist c k-Fehler-korrigierbar Jede Codierung c ist ((hc-1)/2)-fehler-korrigierbar. Kein Codewort (x, y, z) liegt im Kreis (mit Radius k) eines anderen Codewortes. Falls für Codierung c gilt k+1 £ hc dann ist c k-Fehler-erkennbar Jede Codierung c ist (hc-1)-fehler-erkennbar.
/2)-fehler-korrigierbar. Kein Codewort (x, y, z) liegt im Kreis (mit Radius k) eines anderen Codewortes. Falls für Codierung c gilt k+1 £ hc. dann ist c k-Fehler-erkennbar. Jede Codierung c ist. (hc-1)-fehler-erkennbar.")
27
Beispiele Codierung c' mit c' : {A, B, C, D} ® Bool5 , mit
c(B) = 10011 c(C) = 11100 c(D) = 01111 Es ist hc' = 3 und somit ist c': i) 2-Fehler-erkennbar ii) 1-Fehler-korrigierbar Anmerkung: zur Codierung der 4 Zeichen hätte ein 2-stelliger Code ausgereicht. Die zusätzlichen drei Stellen ermöglichen jedoch Fehler- Erkennung und -Korrektur. 1-aus-10 Codierung 0 -> 1 -> ...... 9 -> Es ist hc = 2 und somit ist c: i) nur 1-Fehler-erkennbar ii) nicht Fehler-korrigierbar Anmerkung: 1-aus-10 ist kein besonders "cleverer" Code: - benötigt lange Codewörter - aber keine Fehlerkorrektur
 = c(C) = c(D) = Es ist hc = 3 und somit ist c : i) 2-Fehler-erkennbar. ii) 1-Fehler-korrigierbar. Anmerkung: zur Codierung der 4 Zeichen hätte ein 2-stelliger Code ausgereicht. Die zusätzlichen drei Stellen ermöglichen jedoch Fehler- Erkennung und -Korrektur. 1-aus-10 Codierung. 0 -> > > Es ist hc = 2 und somit ist c: i) nur 1-Fehler-erkennbar. ii) nicht Fehler-korrigierbar. Anmerkung: 1-aus-10 ist kein besonders. cleverer Code: - benötigt lange Codewörter. - aber keine Fehlerkorrektur.")
28
Gängige Verfahren zur Code-Sicherung
Anmerkung: Wegen ihrer praktischen Bedeutung bei der Datenübermittlung wurden viele weitere fehlererkennende/fehlerkorrigierende Codes entwickelt und untersucht. Einen Überblick gibt u.a. W. Dankmeier: Codierung. Vieweg 1994. Beispiele 1. Anhängen eines Prüfbits (Parity-Bit) derart, dass die Anzahl der "1" in jedem Codewort einheitlich gerade oder ungerade ist. (odd / even parity check) Für eine solche Codierung c gilt stets: hc= 2 und somit ist c 1-fehler-erkennbar 2. Anhängen mehrerer Prüfbits. Jedes Prüfbit sichert gerade/ungerade Parität bestimmter Stellen des Codewortes. 3. Analogon bei dezimaler Codierung: Kontrollziffern (etwa bei Kontonr., Matrikelnr. (nicht an der HSA), ...).
 derart, dass die Anzahl der 1 in jedem Codewort einheitlich gerade oder ungerade ist. (odd / even parity check) Für eine solche Codierung c gilt stets: hc= 2 und somit ist c 1-fehler-erkennbar. 2. Anhängen mehrerer Prüfbits. Jedes Prüfbit sichert gerade/ungerade Parität bestimmter Stellen des Codewortes. 3. Analogon bei dezimaler Codierung: Kontrollziffern (etwa bei Kontonr., Matrikelnr. (nicht an der HSA), ...).")
29
Gängige Verfahren zur Code-Sicherung
Codespreizung Idee: Treten bei der Übertragung vor allem Blockfehler auf, so werden diese auf mehrere Codewörter „verteilt“. Prinzip: - Die zu übertragenden Codewörter werden als Zeilen in eine Matrix abgelegt. - Dann überträgt man die Matrix zum Empfänger spaltenweise. - Der Empfänger liest die Matrix wieder zeilenweise aus. Sender zum Empfänger

30
Online-Applets zur Codierung
Codeüberlagerung Idee: Mehrere verschiedene Codes werden überlagert. Die Informationsübertragung erfolgt über gemeinsame Codewörter. Empfänger filtert aus dem gemeinsamen Codewort die für ihn bestimmte Nachricht heraus. Anwendung: Zum Beispiel in Mobilfunknetzen. Unterschiedliche Teilnehmer erhalten unterschiedliche Codes, die überlagert übertragen werden Applet: (zum Buch „Mobile Computing“, Jörg Roth) 30
 30.")
31
Weitere Aspekte der Codierung
Fragestellungen: - Wann ist es sinnvoll mit einer variablen Codewortlänge zu arbeiten? - Wie lässt sich zu einem Codierungsproblem ein optimaler Code (= Code mit minimaler mittlerer Wortlänge) entwickeln? - Datenkompression als spezielle Codierungsaufgabe. - Codierungen zur Verschlüsselung von Information (Kryptologie). Im Folgenden: - Entwicklung einer minimalen Codierung mit dem Verfahren nach Huffman. - Datenkompression durch Lauflängencodierung.
 entwickeln - Datenkompression als spezielle Codierungsaufgabe. - Codierungen zur Verschlüsselung von Information (Kryptologie). Im Folgenden: - Entwicklung einer minimalen Codierung mit dem Verfahren nach Huffman. - Datenkompression durch Lauflängencodierung.")
32
Huffman-Codierung Aufgabe
Gegeben: Alphabet A = {a1 , ... , an } über dem Wörter gebildet werden können und Alphabet B = {b1 , ... , bk } zur Bildung von Codewörtern. Gesucht: eine Codierung c: A ® B* derart, dass die Länge der mit c codierten Wörter im Mittel minimal sind: c(a1) = ? c(a2 ) = ? .... c(an ) = ? Beobachtung In einer konkreten Anwendung ist es meist so, dass nicht alle Zeichen aus dem Alphabet A mit gleicher Häufigkeit in den zu codierenden Wörter vorkommen. Beispiel Die Buchstaben q, x, y kommen in deutschen Wörtern weit weniger häufig vor, als die Buchstaben a, b, oder e.
 = c(a2 ) = .... c(an ) = Beobachtung. In einer konkreten Anwendung ist es meist so, dass nicht alle Zeichen aus dem Alphabet A mit gleicher Häufigkeit in den zu codierenden Wörter vorkommen. Beispiel. Die Buchstaben q, x, y kommen in deutschen Wörtern weit weniger häufig vor, als die Buchstaben a, b, oder e.")
33
Huffman-Codierung Idee:
Man ermittelt, mit welcher Häufigkeit die einzelnen Zeichen aus A in den zu codierenden Wörtern vorkommen. Ordne dann den am häufigsten vorkommenden Zeichen kurze Codewörter aus B* zu, während weniger häufig verwendete Zeichen längere Codewörter erhalten. Umsetzung dieser Idee nach Huffman: Schritt1: Ermittle Häufigkeit h(ai) für alle ai Î A. Schritt2: Erstelle einen „Huffman-Codebaum“. Schritt3: Leite aus dem „Huffman-Codebaum“ die Codierungen c(a1), c(a2), ..., c(an) ab.
 für alle ai Î A. Schritt2: Erstelle einen „Huffman-Codebaum . Schritt3: Leite aus dem „Huffman-Codebaum die Codierungen. c(a1), c(a2), ..., c(an) ab.")
34
Huffman-Codierung Beispiel: Zu kodieren sei das Wort BETRIEBSSYSTEM .
Schritt 0: A ist somit die Zeichenmenge { B, E, I, M, R, S, T, Y } . Schritt1: Ermittle Häufigkeit h(ai) für alle ai Î A. Schritt2: Erstelle einen „Huffman-Codebaum“. Idee: 1. Beginne mit den beiden am wenigsten häufig vorkommenden Zeichen ai und ak und fasse diese zu einem neuen Knoten k zusammen. 2. Der neue Knoten k erhält die Häufigkeit h(k) = h(ai) + h(ak) 3. Wiederhole Schritt 1 und 2 solange, bis keine Knoten mehr zusammengefasst werden können.
 für alle ai Î A. Schritt2: Erstelle einen „Huffman-Codebaum . Idee: 1. Beginne mit den beiden am wenigsten häufig vorkommenden Zeichen ai und ak und fasse diese zu einem neuen Knoten k zusammen. 2. Der neue Knoten k erhält die Häufigkeit h(k) = h(ai) + h(ak) 3. Wiederhole Schritt 1 und 2 solange, bis keine Knoten mehr zusammengefasst werden können.")
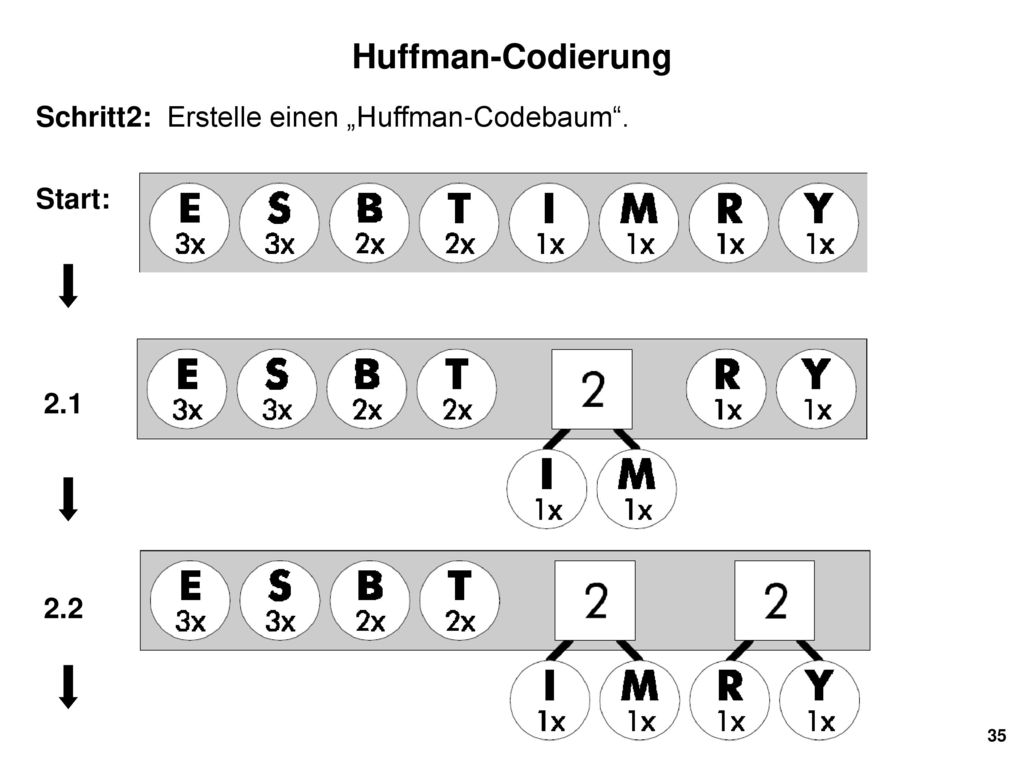
35
Huffman-Codierung Schritt2: Erstelle einen „Huffman-Codebaum“. Start:
2.1 2.2
36
Huffman-Codierung Schritt2: Erstelle einen „Huffman-Codebaum“. 2.3 2.4

37
Huffman-Codierung Schritt2: Erstelle einen „Huffman-Codebaum“. 2.5 2.6

38
Huffman-Codierung Schritt2: Erstelle einen „Huffman-Codebaum“. 2.7
Fertig: Es gibt kein weiteres, noch nicht zusammengefasstes Knotenpaar.

39
Huffman-Codierung Ergebnis von Schritt 2: „Huffman-Codebaum“
Schritt3: Leite aus dem „Huffman-Codebaum“ die Codierungen c(a1), c(a2), ..., c(an) ab. Dazu: Interpretiere jeden Weg im Baum vom Startknoten zu einem Blatt als „Wegebeschreibung“ mit folgender Bedeutung: 0: gehe nach links 1: gehe nach rechts
, c(a2), ..., c(an) ab. Dazu: Interpretiere jeden Weg im Baum vom Startknoten zu einem Blatt als „Wegebeschreibung mit folgender Bedeutung: 0: gehe nach links. 1: gehe nach rechts.")
40
Huffman-Codierung Ergebnis von Schritt3:
Binärcodierungen für die Zeichen aus A: c(E) = 00 c(S) = 01 c(B) = 100 c(T) = 101 c(I) = 1100 c(M) = 1101 c(R) = 1110 c(Y) = 1111 Hieraus ergibt sich dann die Codierung c*(BETRIEBSSYTEM) = (5 Byte)
 = 00. c(S) = 01. c(B) = 100. c(T) = 101. c(I) = c(M) = c(R) = c(Y) = Hieraus ergibt sich dann die Codierung. c*(BETRIEBSSYTEM) = (5 Byte)")
41
Anmerkungen zur Huffman-Codierung
Ein mit dem Huffman-Verfahren erzeugter Code erfüllt auch automatisch die Fano-Bedingung. Das heißt, kein Codewort ist Anfang eines anderen Codeworts. (Die Erfüllung der Fano-Bedingung folgt aus der Konstruktion des Baums: Jeder Pfad vom Start führt zu einem anderen Blatt.) Anstatt mit Zeichenhäufigkeiten h(ai) für ai Î A zu arbeiten, nimmt man oft auch die Auftrittswahrscheinlichkeit p(ai) eines Zeichens, wobei p(ai) einen Wert aus dem Intervall [0,..., 1] hat. Einsatzgebiet: „Huffman-Kompressor“ zur verlustfreien Datenkompression. Dient der Verringerung des Speicherplatzbedarfs elektronischer Dokumente.
 Anstatt mit Zeichenhäufigkeiten h(ai) für ai Î A zu arbeiten, nimmt man oft auch die Auftrittswahrscheinlichkeit p(ai) eines Zeichens, wobei p(ai) einen Wert aus dem Intervall [0,..., 1] hat. Einsatzgebiet: „Huffman-Kompressor zur verlustfreien Datenkompression. Dient der Verringerung des Speicherplatzbedarfs elektronischer Dokumente.")
42
Datenkompression Wozu Datenkompression/Datenkomprimierung? Die Größe elektronischer Medien/Dokumente wie Text, Grafik, Fotos, Audioclips, Videos, 3D-Modelle, Sensordaten usw. hängt wesentlich davon ab, wie diese Dokumente digital codiert sind. => Bedarf an Speicherplatz – Passt ein Dokument auf die Festplatte ? => Aufwand bei der Übertragung über eine Datenfernverbindung – Wie viele Bytes müssen übertragen werden, wie lange dauert ein Download? Beispiele: – Textseite (60 * 80 Zeichen, 1 Byte / Zeichen) bis zu 4,8 Kilobyte (kB) – Grafik, 640*480 Pixel mit 1 Byte Farbtiefe ca kB – 1 Sek. Audio in „Telfonqualität“ ca. 8 kB – 1 Min. unkomprimiertes Audio in CD-Qualität ca. 10 Megabyte (MB) – 1 Sek. unkomprimiertes Video, 25 Bilder/Sek., pro Bild 300KB 7,5 MB 42
 bis zu 4,8 Kilobyte (kB) – Grafik, 640*480 Pixel mit 1 Byte Farbtiefe ca. 300 kB. – 1 Sek. Audio in „Telfonqualität ca. 8 kB. – 1 Min. unkomprimiertes Audio in CD-Qualität ca. 10 Megabyte (MB) – 1 Sek. unkomprimiertes Video, 25 Bilder/Sek., pro Bild 300KB 7,5 MB. 42.")
43
Kompression Zur Archivierung und zum Transfer von digitalen Dokumenten hätte man gerne Datenformate (sprich Codierungen), die möglichst kompakt (sprich speicherplatzsparend) sind. Will man die Daten hingegen verarbeiten (z.B. ein Bild auf dem Bildschirm anzeigen), muss man die komprimierten Daten wieder „auspacken“. Komprimierung und Dekomprimierung sind spezielle Codierungen! komprimieren xxxxxx xxxxx 000011 010101 000101 001011 000011 010101 000101 001011 dekomprimieren originales Datenformat: + gut verarbeitbar (z.B. lesbar) große Datenmenge komprimiertes Datenformat: + geringere Datenmengegut – evtl. schlechter verarbeitbar (z.B. unlesbar für Mensch) 43
, die möglichst kompakt (sprich speicherplatzsparend) sind. Will man die Daten hingegen verarbeiten (z.B. ein Bild auf dem Bildschirm anzeigen), muss man die komprimierten Daten wieder „auspacken . Komprimierung und Dekomprimierung sind spezielle Codierungen! komprimieren. xxxxxx. xxxxx dekomprimieren. originales Datenformat: + gut verarbeitbar. (z.B. lesbar) große Datenmenge. komprimiertes Datenformat: + geringere Datenmengegut – evtl. schlechter verarbeitbar. (z.B. unlesbar für Mensch) 43.")
44
Datenkompression Zwei grundsätzliche Arten der Datenkompression
Verlustfreie Verfahren: Durch die Kompression geht keine Information verloren. Nach der Dekomprimierung liegt wieder das originale Datenformat vor. Beispiele: – Zip – GIF, TIFF etc. Verlustbehaftete Verfahren: Durch die Kompression geht mehr oder weniger viel Information verloren. Durch die Dekomprimierung gelingt nur noch eine Annäherung an das originale Datenformat. Idealerweise geht bei der Kompression nur „weniger wichtige“ Information verloren (z.B. Töne, die der Mensch ohnehin kaum hört) – JPG-Format für Bilder – MPG für Audio und Video
 – JPG-Format für Bilder. – MPG für Audio und Video.")
45
Verlustfreie Datenkompression
Universelle Verfahren – Verfahren arbeiten ohne Kenntnis der Daten Beispiel: Lauflängenkodierung (Run-length Encoding) Statistische Verfahren Prinzip: Verwende kürzere Kodierungen für häufiger vorkommende Zeichen. Beispiele: – Huffman-Kodierung – Arithmetische Kodierung Wörterbuchbasierte Verfahren Prinzip: Fasse Zeichen in der Eingabe zu Worten zusammen, ordne diesen Worten einen Index (Zahl) zu und lege das Paar (Wort, Zahl) in einem Wörterbuch ab. Beispiele: Lempel-Ziv-Algorithmus und Varianten davon (z.B. ZIP).
 Statistische Verfahren. Prinzip: Verwende kürzere Kodierungen für häufiger vorkommende Zeichen. Beispiele: – Huffman-Kodierung. – Arithmetische Kodierung. Wörterbuchbasierte Verfahren. Prinzip: Fasse Zeichen in der Eingabe zu Worten zusammen, ordne diesen Worten einen Index (Zahl) zu und lege das Paar (Wort, Zahl) in einem Wörterbuch ab. Beispiele: Lempel-Ziv-Algorithmus und Varianten davon (z.B. ZIP).")
46
3ABBBAACCCCAAADEEEF5AAA#B1111
Lauflängencodierung Prinzip Sei A ein Zeichenvorrat und w A* eine zu komprimierende Zeichenkette. Ersetze in w mehrere aufeinanderfolgende gleiche Zeichen durch ein einzelnes Zeichen mit Angabe der Anzahl aufeinanderfolgender Vorkommen. Beispiel Zu komprimieren sei das Wort: w = AAABBBAACCCCAAADEEEF5AAA#B Zeichen 3ABBBAACCCCAAADEEEF5AAA#B1111 3A3BAACCCCAAADEEEF5AAA#B1111 3A3B2ACCCCAAADEEEF5AAA#B1111 3A3B2A4CAAADEEEF5AAA#B1111 3A3B2A4C3ADEEEF5AAA#B Zeichen

47
3A3B2A4C3ADEEEF5AAA#B1111 25 Zeichen
Lauflängencodierung w = AAABBBAACCCCAAADEEEF5AAA#B Zeichen 3A3B2A4C3ADEEEF5AAA#B Zeichen Einzelne Zeichen verlängern die Kette! 3A3B2A4C3A1DEEEF5AAA#B Zeichen Ausweg: bei einem Zeichen keine Zahlangabe 3A3B2A4C3ADEEEF5AAA#B Zeichen 3A3B2A4C3AD3EF5AAA#B Zeichen 3A3B2A4C3AD3EF5AAA#B Zeichen 3A3B2A4C3AD3EF5AAA#B1111 Problem: w enthält selbst Ziffern => Verwechselungsgefahr

48
3A3B2A4C3AD3EF5AAA#B1111 24 Zeichen
Lauflängencodierung w = AAABBBAACCCCAAADEEEF5AAA#B Zeichen 3A3B2A4C3AD3EF5AAA#B Zeichen Ausweg: Alle Längenangaben mit Sonderzeichen markieren #3A#3B#2A#4C#3AD#3EF5AAA#B Zeichen #3A#3B#2A#4C#3AD#3EF5#3A#B Zeichen #3A#3B#2A#4C#3AD#3EF5#3A#B Zeichen Problem: w enthält selbst das zur Markierung gewählte Sonderzeichen. Ausweg: Doppelmarkierung mit ## #3A#3B#2A#4C#3AD#3EF5#3A##B Zeichen! #3A#3B#2A#4C#3AD#3EF5#3A##B Zeichen! #3A#3B#2A#4C#3AD#3EF5#3A##B# Zeichen!

49
Alternatives Run-length Encoding
Längere Folgen des Zeichens x werden durch x!<n> kodiert, wobei „!“ ein selten verwendetes Bytewort ist und n ∈ [4,259] (n ist mit einem Byte darstellbar). „!“ wird durch „!!“ dargestellt. ! → !!, !! → !!!!, !!! → !!!!!!, !!!! → !!!4, !!!!! → !!!5 … Beispiel Zu komprimieren sei das Wort: w = AAAABBBBBAACCCCAADEEEE!5!!!!!AAA#B Bytes wc = A!4B!5AAC!4AADE!4!!5!!!5AAA#B1! Bytes Anmerkung !37 = !! (da 33 der dezimale ASCII-Code von „!“ ist und 33+4=37) => 37 A´s müssen durch AA!36 dargestellt werden. Anstelle von „!“ sollte man das Byte verwenden. Es kommt in der Regel seltener vor. Hier gilt dann: Zeichen die zwischen 4 und 258 mal hintereinander vorkommen (n ∈ [4,258]) können kompakter dargestellt werden. 49
. „! wird durch „!! dargestellt. ! → !!, !! → !!!!, !!! → !!!!!!, !!!! → !!!4, !!!!! → !!!5 … Beispiel. Zu komprimieren sei das Wort: w = AAAABBBBBAACCCCAADEEEE!5!!!!!AAA#B Bytes. wc = A!4B!5AAC!4AADE!4!!5!!!5AAA#B1!4 32 Bytes. Anmerkung. !37 = !! (da 33 der dezimale ASCII-Code von „! ist und 33+4=37) => 37 A´s müssen durch AA!36 dargestellt werden. Anstelle von „! sollte man das Byte verwenden. Es kommt in. der Regel seltener vor. Hier gilt dann: Zeichen die zwischen 4 und 258 mal. hintereinander vorkommen (n ∈ [4,258]) können kompakter dargestellt werden. 49.")
50
Lauflängencodierung Überzeugenderes Beispiel: Komprimierung einer Grafik – jeder Bildpunkt b {0, 255} – insgesamt 19*51*1 Byte unkomprimiert ~ 969 Byte)
")
51
Lauflängencodierung Lauflängencodierung: 28S14B9S 6 Byte
19S3B26S3B 8 Byte 20S4B23S3BS 9 Byte .... S50B 3 Byte S2B46S2B Byte Komprimiertes Bild benötigt nur noch 1/12 des ursprünglichen Speicherplatzes (in Bytes) Summe: 78 Byte
 Summe: 78 Byte.")
52
Lauflängencodierung Anmerkung:
In Schwarz-Weißbildern kann man ausnützen, dass 0 und 1 abwechseln. Man braucht dann nur die Längen speichern. Zu Beginn des Bildes (im so genannten Header) muss noch die Bildbreite (= Anzahl der Bits pro Zeile) notiert werden. 2 Bytes reichen, um eine Bildbreite Bis zu Bit zu definieren. Codierung: 35 (Bildbreite) (= ) (= 12+7) 2 Bytes (Header) + 19 Bytes (Body) = 21 Bytes 52
 muss noch die Bildbreite. (= Anzahl der Bits pro Zeile) notiert werden. 2 Bytes reichen, um eine Bildbreite. Bis zu Bit zu definieren. Codierung: 35 (Bildbreite) (= ) (= 12+7) Bytes (Header) + 19 Bytes (Body) = 21 Bytes. 52.")
53
Die zu codierenden Daten enthalten „lange Läufe“, z.B.:
Lauflängencodierung Voraussetzungen für eine sich lohnende Kompression mit Lauflängencodierung: Die zu codierenden Daten enthalten „lange Läufe“, z.B.: lange Folgen von Leerzeichen in Texten viele führende Nullen in Tabellen mit Zahlen identische Farben in Bildern (Himmel, Wasser, weißer Hintergrund, ...) 53
 53.")
54
Wörterbuch-Codierungen
Idee Wiederkehrende längere Bitmuster erhalten „Namen“ oder „Nummern“ und werden in einer Art Wörterbuch notiert. Anstelle der Originaldaten überträgt man dann eine Sequenz von Namen sowie einmalig das Wörterbuch. Beispiel [1=A][2=B]…[G=7]…[L=12]…[O=15]…[26=Z] BLOGBLABLABLA = [27=2 12][28=27 1] 54

55
Wörterbuch-Codierungen
Anwendung Lempel-Ziv-Welch-Kompression (LZW, 1977) Hier wird das Wörterbuch (bei der Kodierung und Dekodierung) automatisch aus den Eingabedaten generiert. Wörterbuch: (0:A, 1:B, 2:C, 3:D, 4:AB, 5:B C, ...) Wird z.B. eingesetzt zur Kompression von Bilddaten GIF, TIFF, PNG etc. Patente auf LZW (GIF) => PNG als Open-Source-Format 55
 Hier wird das Wörterbuch (bei der Kodierung und Dekodierung) automatisch aus den Eingabedaten generiert. Wörterbuch: (0:A, 1:B, 2:C, 3:D, 4:AB, 5:B C, ...) Wird z.B. eingesetzt zur Kompression von Bilddaten GIF, TIFF, PNG etc. Patente auf LZW (GIF) => PNG als Open-Source-Format. 55.")
56
weitere Verfahren zur Datenkomprimierung
Arithmetische Codierung Eine Nachricht wird als Gleitkommazahl aus dem Intervall [0,1] kodiert. Dazu wird das Intervall aufgeteilt nach der Wahrscheinlichkeit der einzelnen Symbole. Jedes Intervall repräsentiert ein Zeichen. JPEG Verlustbehaftetes Verfahren zur Komprimierung von Bilddaten . Idee (stark vereinfacht): Pixel einer Bildzeile werden als Werte einer Schwingung s(t) angesehen. Die Funktion s(t) wird nun durch eine Superposition einfacher Schwingungen unterschiedlicher Frequenz angenähert (d.h. man schreibt s(t) als Summe von Basisschwingungen). Man überträgt dann im wesentlichen nur die Koeffizienten der Basisschwingung und spart eine Menge zu übertragender Daten ein. JPEG 2000 Verbesserung von JPEG. Anstatt von Schwingungen verwendet man so genannte Wavelets (= spezielle mathematische Funktionen). 56
: Pixel einer Bildzeile werden als Werte einer Schwingung s(t) angesehen. Die Funktion s(t) wird nun durch eine Superposition einfacher Schwingungen unterschiedlicher Frequenz angenähert (d.h. man schreibt s(t) als Summe von Basisschwingungen). Man überträgt dann im wesentlichen nur die Koeffizienten der Basisschwingung und spart eine Menge zu übertragender Daten ein. JPEG Verbesserung von JPEG. Anstatt von Schwingungen verwendet man so genannte Wavelets (= spezielle mathematische Funktionen)")
57
Literatur zum Thema Codierung
Werner, M. Information und Codierung: Grundlagen und Anwendungen Vieweg+Teubner; Auflage: 2.Auflage. 2008 Strutz, T.: Bilddatenkompression. Grundlagen, Codierung, Wavelets, JPEG, MPEG, H.264. Vieweg+Teubner; Auflage: 3, 2005 Roth J.: Mobile Computing: Grundlagen, Technik, Konzepte. Dpunkt Verlag, 2005 Gumm, H.-P., Sommer M.: Einführung in die Informatik, Oldenburg- Verlag, 2006, 7. Auflage (877 Seiten) Herold, H., Lurz, B., Wohlrab, J.: Grundlagen der Informatik Praktisch - Technisch – Theoretisch, Pearson Studium, 2006. Rechenberg, Peter; Pomberger, Gustav: Informatik-Handbuch Carl Hanser Verlag; 2006; 4. Auflage; (1251 Seiten) Schneider Uwe, Werner Dieter: Taschenbuch der Informatik. Fachbuchverlag Leipzig. 6. Auflage 2007.
 Herold, H., Lurz, B., Wohlrab, J.: Grundlagen der Informatik Praktisch - Technisch – Theoretisch, Pearson Studium, Rechenberg, Peter; Pomberger, Gustav: Informatik-Handbuch Carl Hanser Verlag; 2006; 4. Auflage; (1251 Seiten) Schneider Uwe, Werner Dieter: Taschenbuch der Informatik. Fachbuchverlag Leipzig. 6. Auflage")
Ähnliche Präsentationen


>")



 Prof. Th. Ottmann.>")
 Prof. Th. Ottmann.>")
 Definition: Eine Gruppe G ist eine Menge zusammen mit einer Verknüpfung, die jedem Paar (a,b) von Elementen aus G ein weiteres.>")










