Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Deskriptive Statistik und Explorative Datenanalyse
TU-Dresden Institut für Soziologie Lehrstuhl für Methoden der empirischen Sozialforschung Forschungsseminar Berufserfolg- und verläufe von Hochschulabsolventen Referentinnen: Betje Schulze, Anke Baron Deskriptive Statistik und Explorative Datenanalyse

2
Deskriptive Statistik
Die beschreibende (descriptive) Statistik versucht, große und unübersichtliche, experimentell sowie durch Beobachtung oder Befragung gewonnene Datenmengen durch graphische Darstellung auf einen Blick verständlich zu machen. Im Vordergrund stehen dabei Informationen über die Verteilung der Merkmalsausprägungen einzelner Merkmale – univariate Statistik – und der Kombinationen von Merkmalsausprägungen mehrerer Merkmale – bi- oder multivariate Statistik (Zusammenhänge, Abhängigkeiten). Die verwendeten Techniken hängen wesentlich vom Skalenniveau der einbezogenen Merkmale (Variablen) ab.
 Statistik versucht, große und unübersichtliche, experimentell sowie durch Beobachtung oder Befragung gewonnene Datenmengen durch graphische Darstellung auf einen Blick verständlich zu machen. Im Vordergrund stehen dabei Informationen über die. Verteilung der Merkmalsausprägungen einzelner Merkmale – univariate Statistik – und der Kombinationen von. Merkmalsausprägungen mehrerer Merkmale – bi- oder. multivariate Statistik (Zusammenhänge, Abhängigkeiten). Die verwendeten Techniken hängen wesentlich vom. Skalenniveau der einbezogenen Merkmale (Variablen) ab.")
3
Explorative Datenanalyse
Mittels einer guten Beschreibung, wird der Datensatz auf Besonderheiten hin analysiert Reduktion von hochdimensionalen Daten Wird oft der schließenden Statistik vorgeschaltet Man bekommt eine Idee davon, was man eventuell mit der schließenden Statistik beweisen möchte

4
Skalenniveaus Nominalskala: - Klassifikation von Objekten nach Gleichheit oder Verschiedenheit (Äquivalenzklassen) Ordinalskala: - es wird eine Rangordnung der Objekte bezüglich einer Eigenschaft vorausgesetzt (Rangskala) Intervallskala: - es wird nicht nur eine Aussage über die Rangfolge getroffen, zusätzlich informieren die Skalenwerte auch über die Abstände zwischen den Messwerten Verhältnisskala: - es werden Aussagen über Verhältnisse, d.h. Quotienten von Skalenwerten getroffen;
 Intervallskala: - es wird nicht nur eine Aussage über die Rangfolge getroffen, zusätzlich informieren die Skalenwerte auch über die Abstände zwischen den Messwerten. Verhältnisskala: - es werden Aussagen über Verhältnisse, d.h. Quotienten von Skalenwerten getroffen;")
5
Skalen- und Datenniveaus
Skalentyp Datenniveau Interpretation von Skalenwerten Mittelwert Streuungs-maße Beispiele Nominal-skala Nominal (qualitativ) gleich oder verschieden Modalwert Geschlecht, Kinder (ja/nein) Ordinals-kala Ordinal größer, kleiner oder gleich Median Quartil-abstand Schulab-schlüsse Intervall-skala Metrisch (quantitativ) Vergleichbar-keit von Differenzen Arith-metisches Mittel Standard-abweichung/ Varianz Temperatur Verhältnis-skala Gleichheit von Verhältnissen Arith-metisches Mittel Variations-koeffizient Einkommen
 gleich oder verschieden. Modalwert. Geschlecht, Kinder (ja/nein) Ordinals-kala. Ordinal. größer, kleiner oder gleich. Median. Quartil-abstand. Schulab-schlüsse. Intervall-skala. Metrisch. (quantitativ) Vergleichbar-keit von. Differenzen. Arith-metisches Mittel. Standard-abweichung/ Varianz. Temperatur. Verhältnis-skala. Gleichheit von Verhältnissen. Arith-metisches. Mittel. Variations-koeffizient. Einkommen.")
6
Univariate Datenanalyse
Pro Objekt i (i=1, …, n; n Stichprobenumfang) wird ein Merkmal X durch Messung, Befragung oder Beobachtung erhoben Z.B. Einkommen, Geschlecht, Adäquanz, Vollbeschäftigung Das Resultat ist jeweils ein Wert (Merkmalsausprägung) xi
 wird ein Merkmal X durch Messung, Befragung oder Beobachtung erhoben. Z.B. Einkommen, Geschlecht, Adäquanz, Vollbeschäftigung. Das Resultat ist jeweils ein Wert (Merkmalsausprägung) xi.")
7
Univariate Datenanalyse
Beschreibung der Häufigkeitsverteilung Ausprägung y(j) absolute Häufigkeit Nj relative Häufigkeit fj = Nj / N y (1) N1 f = N1 / N y (J) NJ fJ= NJ / N ∑Nj = N jεJ
 absolute Häufigkeit Nj relative Häufigkeit fj = Nj / N. y (1) N1 f = N1 / N y (J) NJ fJ= NJ / N. ∑Nj = N. jεJ.")
8
Beispiel an der Variable „Alter“
Ausprägung y(j) absolute relative kummulierte Häufigkeit Häufigkeit (%) Häufigkeit 21 – ,04 1,04 31 – ,41 22,45 41 – ,73 56,18 51 – ,44 84,62 61 – ,86 98,48 71 – ,48 99,96 81 – ,02 99,98 Gesamt ~100
 absolute relative kummulierte. Häufigkeit Häufigkeit (%) Häufigkeit. 21 – ,04 1, – ,41 22, – ,73 56, – ,44 84, – ,86 98, – ,48 99, – ,02 99,98. Gesamt ~100.")
9
Univariable Verteilung - Graphische Darstellung
univariate Plots: Untersuchung einzelner Variablen Interesse auf: Ausreißer, Häufungen von Beobachtungen in Teilen des Wertebereichs, Fehlen bestimmter Ausprägungen, Verteilungsform der Variablen

10
nominale und ordinale Daten
Stab- und Balkendiagramme (barcharts) sinnvoll nur für diskrete Merkmale i.d.R. auf X-Achse die Ausprägungen der Merkmale u. auf Y-Achse die Häufigkeit des Auftretens der Ausprägungen absolute Häufigkeiten geeignet für Darstellung der Untersuchungsergebnisse einer Population (Graphik 1); beim Vergleich mehrerer Populationen/ Subgruppen, mit unterschiedlich großem Stichprobenumfang – relative Häufigkeiten (Graphik 2) jeder Merkmalsausprägung wird ein Strich/ Balken zugeordnet -Anordnungsreihenfolge ist bei nominalen Merkmalen beliebig, bei ordinalen existiert eine „natürliche“ Anordnungsreihenfolge (Rangreihe) auch gruppierte metrische Daten können dargestellt werden (z.B. Häufigkeiten versch. Einkommensklassen)
 sinnvoll nur für diskrete Merkmale. i.d.R. auf X-Achse die Ausprägungen der Merkmale u. auf Y-Achse die Häufigkeit des Auftretens der Ausprägungen. absolute Häufigkeiten geeignet für Darstellung der Untersuchungsergebnisse einer Population (Graphik 1); beim Vergleich mehrerer Populationen/ Subgruppen, mit unterschiedlich großem Stichprobenumfang – relative Häufigkeiten (Graphik 2) jeder Merkmalsausprägung wird ein Strich/ Balken zugeordnet -Anordnungsreihenfolge ist bei nominalen Merkmalen beliebig, bei ordinalen existiert eine „natürliche Anordnungsreihenfolge (Rangreihe) auch gruppierte metrische Daten können dargestellt werden (z.B. Häufigkeiten versch. Einkommensklassen)")
12
ordinale Daten (und gruppierte metrische Daten)
Box-(Whisker-)Plot stellt Median, 25%- und 75%-Quantile (unteres und oberes Quartil), Extremwerte und Ausreißer dar untere bzw. obere Grenze der Box: unteres bzw. oberes Quartil (Hälfte der beobachteten Werte liegt in der Box); Länge der Box: Quartilsabstand; Linie innerhalb der Box: Median; Ausreißer: zw. 1,5 und 3 Box-Längen vom unteren/ oberen Rand der Box entfernt (dargestellt als °); Extremwerte: mehr als 3 Box-Längen entfernt (*); äußeren Striche – Zäune: kleinster und größter beobachteter Wert, der kein Ausreißer ist zwischen Median und unterem/ oberem Quartil immer 25% der Fälle – kleinere Flächen deuten nur auf starke Konzentration der Fälle in diesem Wertebereich hin ermöglicht Aussagen über Symmetrie, Schiefe sowie Zahl und Lage extremer Beobachtungen
Plot. stellt Median, 25%- und 75%-Quantile (unteres und oberes Quartil), Extremwerte und Ausreißer dar. untere bzw. obere Grenze der Box: unteres bzw. oberes Quartil (Hälfte der beobachteten Werte liegt in der Box); Länge der Box: Quartilsabstand; Linie innerhalb der Box: Median; Ausreißer: zw. 1,5 und 3 Box-Längen vom unteren/ oberen Rand der Box entfernt (dargestellt als °); Extremwerte: mehr als 3 Box-Längen entfernt (*); äußeren Striche – Zäune: kleinster und größter beobachteter Wert, der kein Ausreißer ist. zwischen Median und unterem/ oberem Quartil immer 25% der Fälle – kleinere Flächen deuten nur auf starke Konzentration der Fälle in diesem Wertebereich hin. ermöglicht Aussagen über Symmetrie, Schiefe sowie Zahl und Lage extremer Beobachtungen.")
14
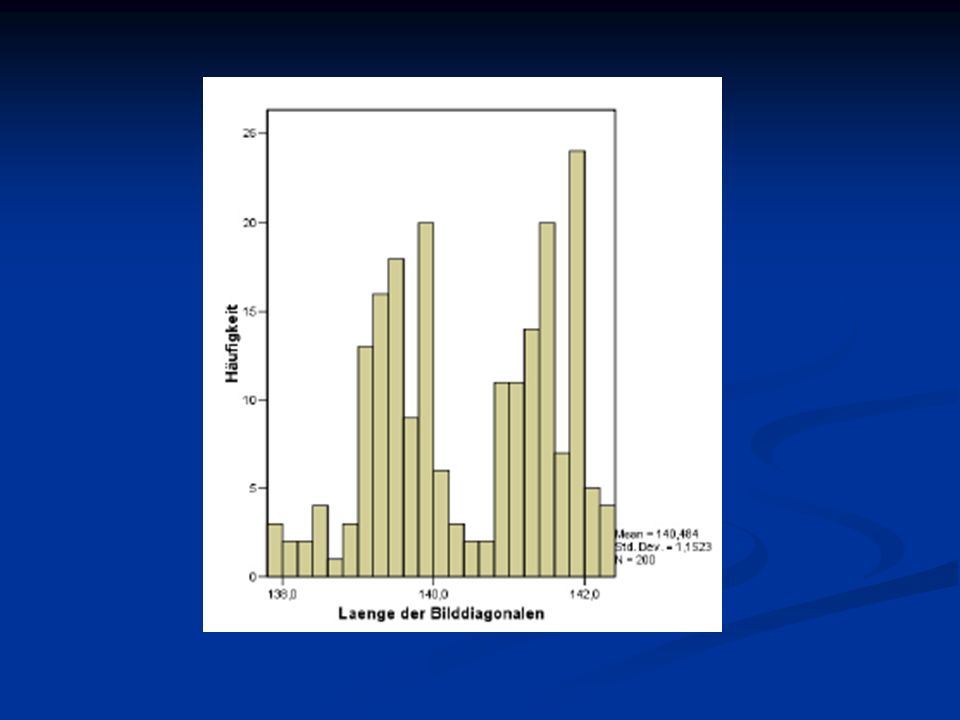
metrische Daten Histogramme
besonders geeignet, um vermutliche Verteilung in der Grundgesamtheit aufzudecken graphische Darstellung der Anzahl der Beobachtungen, die in die einzelnen Intervalle einer Klasseneinteilung von einer Variablen fallen zentral: Festlegung der Anzahl und Breite der Intervalle sowie des Ursprungs des Histogramms Bestimmung der Klasseneinteilung und des Beginns der Klasseneinteilung; hiervon hängt ab, welchen Eindruck man von einer Verteilung anhand des Histogramms gewinnt verschiedne Regeln zur Bestimmung der Anzahl und Breite der Intervalle

16
Averaged Shifted Histograms
m Histogramme mit gleicher Intervallbreite h erstellt, die aber jeweils um den Betrag h/m verschobene Ursprünge besitzen für ein ASH wird dann der Mittelwert der Beobachtungen im jeweiligen Intervall aller Histogramme an einem Punkt berechnet mit zunehmendem m erscheinen ASHs glatter; die Verteilung kann zuverlässiger dargestellt werden

18
Stem-and-Leaf-Display (Stamm-Blatt-Diagramm)
Verteilung einer Variablen durch die Länge von Zeilen wiedergegeben, wobei die Zeilen durch die Ziffern der Ausprägungen der Variablen gebildet werden die darzustellenden Ziffern werden hierbei in führende (stem) und restliche (leaves) Ziffern eingeteilt für jede führende Ziffer werden die zugehörigen restlichen Ziffern rechts neben der führenden Ziffer aufgeführt gleiche Merkmalsausprägungen werden direkt wiedergegeben zu beachten ist, dass die führenden Ziffern auch Werte wiedergeben müssen, die in den Daten nicht vorhanden sind (stem, aber kein dazugehöriges leave) links neben dem stem ist jeweils die Häufigkeiten der im Stamm und der entsprechenden Zeile angegebenen Merkmalsausprägung zu finden um aus dem Diagramm die Ursprungswerte ablesen zu können, muss noch die Einheit angegeben werden (stem width)
 und restliche (leaves) Ziffern eingeteilt. für jede führende Ziffer werden die zugehörigen restlichen Ziffern rechts neben der führenden Ziffer aufgeführt. gleiche Merkmalsausprägungen werden direkt wiedergegeben. zu beachten ist, dass die führenden Ziffern auch Werte wiedergeben müssen, die in den Daten nicht vorhanden sind (stem, aber kein dazugehöriges leave) links neben dem stem ist jeweils die Häufigkeiten der im Stamm und der entsprechenden Zeile angegebenen Merkmalsausprägung zu finden. um aus dem Diagramm die Ursprungswerte ablesen zu können, muss noch die Einheit angegeben werden (stem width)")
19
- gibt Aufschluss über Spannweite und Symmetrie der Verteilung
- zeigt Ausreißer, Lücken und Konzentrationen der Beobachtungen auf bestimmte Werte - liegt Interesse nicht in vermutlicher Verteilung der Grundgesamtheit, sondern in der Verteilung der Stichprobenwerte, ist das SLD dem Histogramm i.d.R. überlegen - am nützlichsten bei kleinen und mittleren Fallzahlen

20
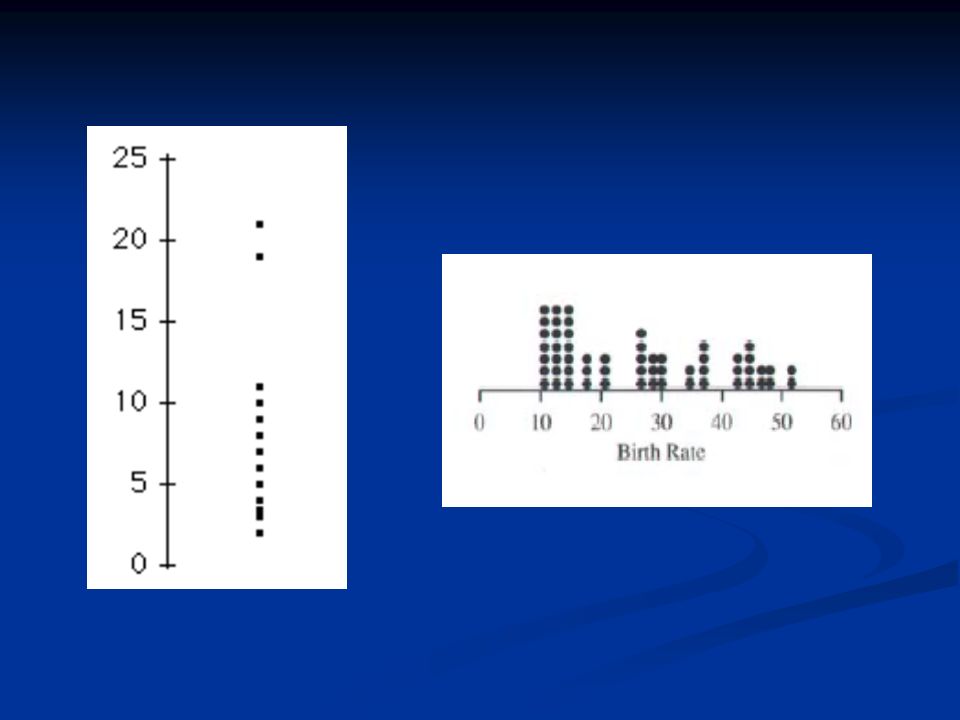
Eindimensionale Scatterplots
Dot-Plots erhält man, wenn man für jede Beobachtung einer kontinuierlichen Variablen auf einem Zahlenstrahl an der Variabelenausprägung der Beobachtung ein Plotsymbol plottet Eindimensionale Scatterplots stellen entlang einer Skala jeden vorkommenden Wert mit einem Kreis dar bieten für kleinere Fallzahlen (n<100) übersichtliche Darstellung Problem des Überdruckens bei Beobachtungen mit identischen Ausprägungen
 übersichtliche Darstellung. Problem des Überdruckens bei Beobachtungen mit identischen Ausprägungen.")
22
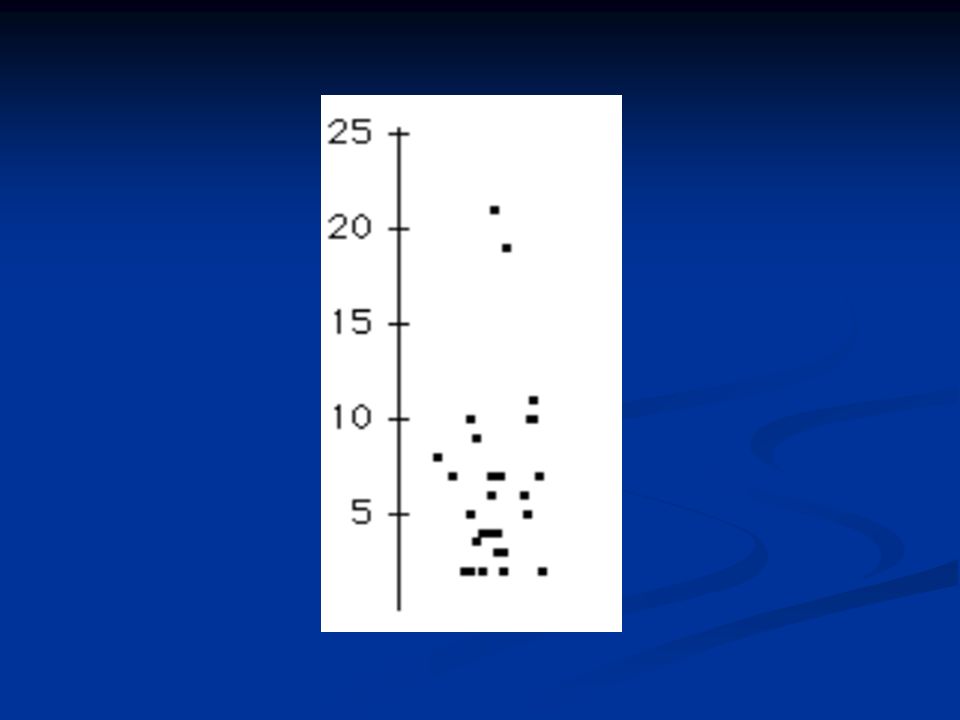
Stacked-Dot-Plots Plotsymbole für Beobachtungen mit identischen Ausprägungen werden nebeneinander dargestellt dies verhindert Überdrucken, schränkt aber die Anwendung für den Bereich der Fallzahlen (ca. n<300) ein – besonders bei starken Konzentrationen auf Teile des Wertebereichs
 ein – besonders bei starken Konzentrationen auf Teile des Wertebereichs.")
23
Jittered Dot-Plots die einzelnen Beobachtungen werden gegen gleichverteilte Zufallszahlen geplottet Beobachtungen mit identischer Ausprägung der interessierenden Variablen erhalten so unterschiedliche Plotpositionen in einer anderen Dimension des Plots (die jedoch nicht geplottet wird) auch für n>500
 auch für n>500.")
25
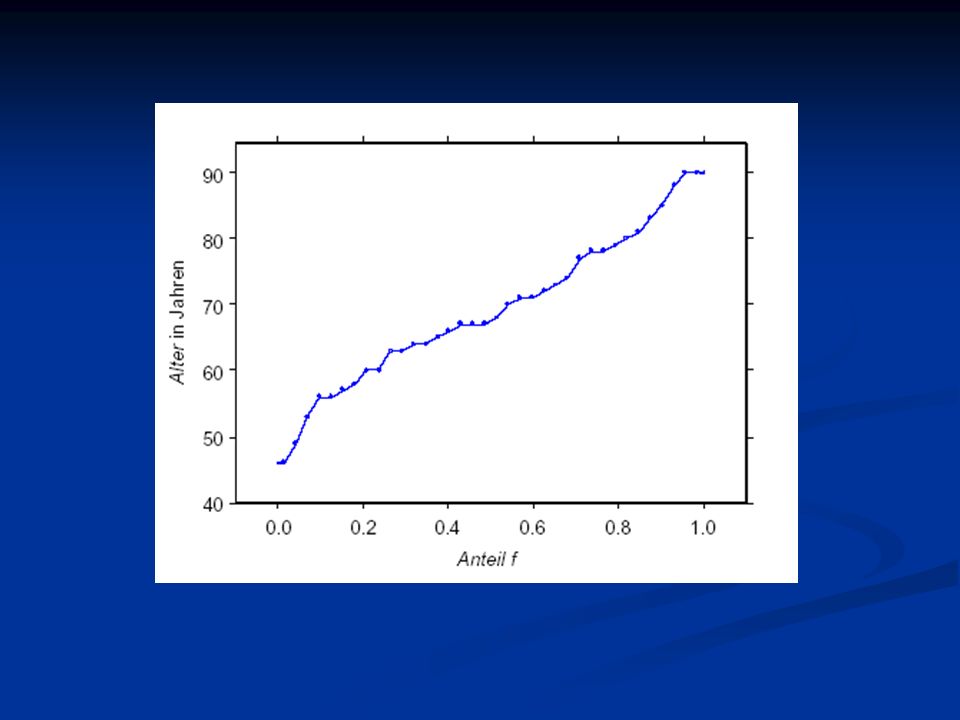
Q-Plots (Quantil-Plot)
plottet für jede Ausprägung der nach Größe sortierten Variablen das zugehörige Quantil (für jede Beobachtung wird also die Größe der Beobachtung gegen den Anteil der Beobachtungen geplottet, die kleiner als dieser Wert sind) man kann hier den Wert der Quantile direkt ablesen die Steilheit der durch die Punkte des Plots gebildeten Kurve gibt Aufschluss über die lokale Dichte: je steiler, desto stärker ist die lokale Dichte an diesen Punkten (mehrere identische Ausprägungen einer Variablen führen zu senkrechten Linien eine eingezeichnete Hilfslinie (Y=a+bX); lineare Regression der die beiden Achsen bildenden Größen) erleichtert Beurteilung der Steilheit und Erkennen einzelner Ausreißer
 man kann hier den Wert der Quantile direkt ablesen. die Steilheit der durch die Punkte des Plots gebildeten Kurve gibt Aufschluss über die lokale Dichte: je steiler, desto stärker ist die lokale Dichte an diesen Punkten (mehrere identische Ausprägungen einer Variablen führen zu senkrechten Linien. eine eingezeichnete Hilfslinie (Y=a+bX); lineare Regression der die beiden Achsen bildenden Größen) erleichtert Beurteilung der Steilheit und Erkennen einzelner Ausreißer.")
27
Plots für den Vergleich empirischer Verteilungen
Frage nach Unterschied zweier oder mehrerer Verteilungen und Art der Verteilungsunterschiede Back-to-Back-Stem-and-Leaf-Displays (metrische Daten) die Verteilung einer Variablen in zwei Gruppen wird in einem SLD „Rücken an Rücken“ dargestellt (ansonsten siehe SLD) Gruppierte Boxplots (ordinale und gruppierte metrische Daten) es wird für jede Ausprägung einer Gruppierungsvariablen ein Boxplot der abhängigen Variablen erstellt und gemeinsam dargestellt eignen sich für raschen Vergleich einer Variablen zwischen verschiedenen Gruppen
 die Verteilung einer Variablen in zwei Gruppen wird in einem SLD „Rücken an Rücken dargestellt (ansonsten siehe SLD) Gruppierte Boxplots. (ordinale und gruppierte metrische Daten) es wird für jede Ausprägung einer Gruppierungsvariablen ein Boxplot der abhängigen Variablen erstellt und gemeinsam dargestellt. eignen sich für raschen Vergleich einer Variablen zwischen verschiedenen Gruppen.")
28
● gruppierte Box-Dot-Plots
- Box-Dot-Plot: Kombination eines symmetrischen Dot-Plots mit einem Box-Plot; erlaubt einfache Feststellung multipler Ausreißer, ungewöhnlicher Konzentrationen in kleinen Wertebereichen und die direkte Wahrnehmung der Fallzahl pro Gruppe - zwei oder mehr dieser Box-Dot-Plots werden nebeneinander dargestellt; so werden die Gruppen vergleichbar - gruppierte Box-Dot-Plots empfehlen sich immer dann, wenn Mittelwertdiffernezen in verschiedenen Gruppen untersucht werden sollen

29
Q-Q-Plots die Quantile zweier empirischer Verteilungen werden direkt gegeneinander geplottet wären die Verteilungen in beiden Gruppen gleich, so müssten die Beobachtungen bei einem Q-Q-Plot auf einer Geraden liegen, die die identischen Ausprägungen der Variablen in den beiden Gruppen verbindet

30
Plots zum Vergleich empirischer und theoretischer Verteilungen
Frage ob eine empirische Verteilung mit einer theoretischen übereinstimmt Probability-Plots Quantile einer empirischen Verteilung werden gegen die Quantile einer theoretischen Verteilung geplottet am häufigsten wird als theoretische Verteilung die Normalverteilung verwendet (normal probability plots) die erwarteten Werte werden unter Annahme der Normalverteilung entlang der Y-Achse geplottet, die beobachteten Werte entlang der X-Achse liegen die Plotpunkte auf der Linie Y=X stimmen theoretische und empirische Verteilung überein graphische Darstellungen möglicher Verteilungen
 die erwarteten Werte werden unter Annahme der Normalverteilung entlang der Y-Achse geplottet, die beobachteten Werte entlang der X-Achse. liegen die Plotpunkte auf der Linie Y=X stimmen theoretische und empirische Verteilung überein. graphische Darstellungen möglicher Verteilungen.")
31
Plots für kategorisierte Variablen
Vergleich der Verteilung einer kategorisierten Variablen mit einer theoretischen Verteilung ● Überlagerte Histogramme Histogramm wird mit der Kurve der theoretisch erwarteten Häufigkeiten überlagert

32
Bivariate Datenanalyse
Pro Objekt i (i=1, …, n) werden zwei Merkmale X und Y gemeinsam erhoben Z.B. - Geschlecht und Einkommen - Familienstand und Einkommen Das Resultat ist ein Paar (xi, yi) von Merkmalsausprägungen
 werden zwei Merkmale X und Y gemeinsam erhoben. Z.B. - Geschlecht und Einkommen. - Familienstand und Einkommen. Das Resultat ist ein Paar (xi, yi) von Merkmalsausprägungen.")
33
Bivariate Datananalyse
Bivariate Daten werden meist in einer Kreuztabelle aufgezeigt Für eine korrekte und anschauliche Analyse bzw. Darstellung ist das Layout der Tabelle entscheidend: Hans Zeisels Regeln für die Darstellung von Daten in Kreuztabellen die erklärende Variable sollte im Kopf der Tabelle zu finden sein in Verbindung mit der Grundregel, Prozentwerte auf die erklärende Variable als Basis zu beziehen – Spaltenprozente

34
Bivariate Datenanalyse
es kann aus verschiedenen Gründen, z.B. viele Ausprägungen der erklärenden Variable, notwendig sein Zeilen- und Spalten der Kreuztabelle zu vertauschen und damit auch die Prozentuierungen das sollte allerdings für den Rezipienten erkenntlich gemacht werden

35
Beispiel: Layout von Tabellen

36
Layout von Tabellen

37
Bi- und Multivariate Verteilung – Graphische Darstellung
Scatterplots: Einschätzung der Art und Größe des Zusammenhangs zweier Variablen, die Identifikation ungewöhnlicher Beobachtungen, die Entdeckung von Clustern, ... die Wertepaare zweier Variablen werden dazu gegeneinander geplottet

38
● Informationsangereicherte Scatterplots
Scatterplot-Smoother Beurteilung der Art des Zusammenhanges zweier Variablen durch das Plotten von Hilslinien erleichtert häufig Regressionsgerade, die aber oft unangemessen ist die Beziehung zwischen zwei Variablen soll daher ohne Festlegung auf ein parametrisches Modell untersucht werden dazu dienen Scatterplot-Smoother: Median-Trace, Kernel-Smoothed-Quantile-Plots, K-NN-Smoother, Running-Line-Smoother, LOWESS-Smoother

39
Plots für drei- und mehrdimensionale Daten
Scatterplots für multivariate Daten/ Zusammenhänge zwischen drei oder mehr Variablen Scatterplots mit Icons Icons: bildliche Darstellung von Objekten, deren Eigenschaften durch die Ausprägung einer oder mehrerer Variablen gesteuert werden – Möglichkeit, im Scatterplot zusätzliche Dimensionen darzustellen für jeden Fall ein eigenes Icon geplottet ● Bubble-Plots: leere Kreise als Plotsymbol Größe gesteuert durch eine dritte Variable Nachteile: Beurteilung absoluter Größe der Bubbles fällt schwer leichter, wenn feste Bezugsgröße vorhanden...

40
● Rectangle-Plots: ● Arrow-Plots:
hier dienen Rechtecke innerhalb eines Rahmens als Icons Größe der Rechtecke durch die dritte Variable gesteuert ● Arrow-Plots: Möglichkeit, mehr als eine Dimension zusätzlich darzustellen geben eine Variable durch die Länge des Pfeils, eine andere durch die Richtung des Pfeils wieder

41
Bedingte Scatterplots
simultanes Aufstellen mehrerer Scatterplots derselben Variablen getrennt für Subgruppen der Beobachtungen eignen sich für: Vergleich der Art des Zusammenhangs in unterschiedlichen Teilgruppen, Entdeckung mehrdimensionaler Cluster, Untersuchung von Interaktionseffekten stetiger Variablen

42
Quellen Clauß, G./ Finze, F.-R./ Partzsch, L. (2002): Statistik. Für Soziologen, Pädagogen, Psychologen und Mediziner. Grundlagen. Wissenschaftlicher Verlag Harri Deutsch. Frankfurt am Main Schnell, Rainer (1994): Grafisch gestützte Datenanalyse. Oldenburgverlag. München Toutenburg, Helge (2000): Deskriptive Statistik. Springerverlag. Berlin Ludwig-Mayerhofer, W. (1994): Kleine Anmerkung, die Verbesserung der Darstellung von Kreuztabellen betreffend. Kölner Zeitschrift für Soziologie und Sozialpsychologie. 46. S
: Statistik. Für Soziologen, Pädagogen, Psychologen und Mediziner. Grundlagen. Wissenschaftlicher Verlag Harri Deutsch. Frankfurt am Main. Schnell, Rainer (1994): Grafisch gestützte Datenanalyse. Oldenburgverlag. München. Toutenburg, Helge (2000): Deskriptive Statistik. Springerverlag. Berlin. Ludwig-Mayerhofer, W. (1994): Kleine Anmerkung, die Verbesserung der Darstellung von Kreuztabellen betreffend. Kölner Zeitschrift für Soziologie und Sozialpsychologie. 46. S")
Ähnliche Präsentationen








 von letzter Stunde wiederholen>")










 Konzentrationsmaße Kennwert für die wirtschaftliche Konzentration Typische Beispiele: Verteilung des.>")

 Ort:Hörsaal Loefflerstraße.>")
