Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Das Informationsextraktions- System ANNIE Anna Mazhayskaya Anna Vinenko 09.07.2007

2
Informationsextraktion Informationsextraktion versucht, spezifische Informationen aus textuellen Dokumenten zu extrahieren und in datenbankartigen Schemata abzulegen. Die Information wird dabei gemäß fest vorgegebenen Spezifikationen ausgewählt. 1 1 vgl. http://www.uni-trier.de/uni/fb2/ldv/ldv_wiki/index.php/Informationsextraktion

3
GATE- General Architecture for Text Engineering ist eine Entwicklung der Sheffield University (Dept. of Natural Language Processing) enthält eine Klassenbibliothek (alle Schnittstellen sind in Java realisiert) bietet eine Entwicklungsumgebung mit graphischer Oberfläche http://gate.ac.uk/
 enthält eine Klassenbibliothek (alle Schnittstellen sind in Java realisiert) bietet eine Entwicklungsumgebung mit graphischer Oberfläche")
4
enthält drei Typen von Komponenten: LanguageResources (LRs) : Lexika, Korpora und Ontologien ProcessingResources (PRs): algorithmische Ressourcen wie Parser, Generatoren oder n-Gram-Modellierer VisualResources (VRs): zur Visualisierung und zum Editieren in GUIs vgl. GATE User guide, http://gate.ac.uk/sale/tao GATE

5
Aufbau der Processing Resources in GATE Komponenten der Processing Resources können sein: JAVA-Klassen (Sentence) Listen (Gazetter) JAPE-Regeln (Semantik Tagger)
 Listen (Gazetter) JAPE-Regeln (Semantik Tagger)")
6
JAPE - Java Annotation Patterns Engine ermöglicht Grammatiken für reguläre Sprachen in einer systemunabhängigen Spezifikation linke Seite (LHS): Muster rechte Seite (RHS): Aktion zur Ausführung der JAPE-Regeln erzeugt GATE einen Transduktor
: Muster rechte Seite (RHS): Aktion zur Ausführung der JAPE-Regeln erzeugt GATE einen Transduktor")
7
Algorithmen für die JAPE-Regeln 1. Algorithmus: Bildung eines FSM a) Bau eines NFSM mit Hilfe von LHS und RHS Abbildung 1: A nondeterministic FSM nach GATE User guide, Appendix B, JAPE: Implementation, http://gate.ac.uk/sale/tao
 Bau eines NFSM mit Hilfe von LHS und RHS Abbildung 1: A nondeterministic FSM nach GATE User guide, Appendix B, JAPE: Implementation,")
8
Algorithmen für die JAPE-Regeln 1 2 n! … b) Abbildung 2: Umwandlung eines NFSM in ein FSM
 Abbildung 2: Umwandlung eines NFSM in ein FSM")
9
Algorithmen für die JAPE-Regeln 2. Algorithmus bearbeitete Daten als Input neue Annotationen als Output Abbildung 3: An annotation graph nach GATE User guide, Appendix B, JAPE: Implementation, http://gate.ac.uk/sale/tao

10
ANNIE: a Nearly-New Information Extraction System Eine Teilmenge der Komponenten von GATE bildet das Informationsextraktionssystem ANNIE Abbildung 4: ANNIE and LaSIE nach GATE User guide, Ch. 8, ANNIE: a Nearly-New Information Extraction System, http://gate.ac.uk/sale/tao

11
Komponenten von ANNIE Tokeniser Gazetteer Sentence Splitter POS-Tagger Semantic Tagger Orthographic Coreference Pronominal Coreference vgl. GATE User guide, http://gate.ac.uk/sale/tao

12
Komponenten von ANNIE Tokeniser Zerlegt den Text in elementare Token wie Zahlen, Interpunktion und Wörter verschiedenen Typs z.B. Wörter mit Grossbuchstaben unterscheiden sich von den Wörtern mit Kleinbuchstaben Das Ziel ist, den Leistungsumfang für maximale Effizienz einzuschränken vgl. GATE User guide, http://gate.ac.uk/sale/tao

13
folgende Tokenarten sind möglich: word number symbol punctuation SpaceToken Komponenten von ANNIE Tokeniser vgl. GATE User guide, http://gate.ac.uk/sale/tao

14
Komponenten von ANNIE Regeln für den Tokeniser jede Regel hat eine linke und eine rechte Seite der reguläre Ausdruck auf der linken Seite wird mit der Eingabe abgeglichen die rechte Seite beschreibt die Annotationen, die zum AnnotationSet hinzugefügt werden sollen vgl. GATE User guide, http://gate.ac.uk/sale/tao

15
Komponenten von ANNIE Regeln für den Tokeniser Beispiel einer Regel für Wörter, die mit einem einzelnen Grossbuchstaben beginnen "UPPERCASE_LETTER" "LOWERCASE_LETTER"* > Token;orth=upperInitial;kind=word; vgl. GATE User guide, http://gate.ac.uk/sale/tao

16
Komponenten von ANNIE English Tokeniser passt die Ausgabe des generischen sprachunabhängigen Tokenisers den Erfordernissen des Part-of-Speech-Taggers für Englisch an Beispiel: dont aus drei Token: don,, t werden zwei: do undnt vgl. GATE User guide, http://gate.ac.uk/sale/tao

17
Komponenten von ANNIE Gazetteer die sog. Gazetteer-Listen sind Text-Dateien mit nur einem Eintrag pro Zeile für Firmen-, Personen-, Ortsnamen u.v.a.m. auf die Listen wird über eine Index-Datei (lists.def) zugegriffen aus diesen Listen werden endliche Automaten (zur Erkennung der Listenelemente) kompiliert vgl. GATE User guide, http://gate.ac.uk/sale/tao
 zugegriffen aus diesen Listen werden endliche Automaten (zur Erkennung der Listenelemente) kompiliert vgl. GATE User guide,")
18
Komponenten von ANNIE Gazetteer Die Einträge in der Index-Datei bestehen aus: dem Listentitel einem Haupttyp (major type) für die Listeneinträge einem Nebentyp (minor type) vgl. GATE User guide, http://gate.ac.uk/sale/tao

19
Komponenten von ANNIE Sentence Splitter ein Transduktor, der den Text in einzelne Sätze zerlegt verwendet eine Gazetterliste von Abkürzungen jeder Splitter ist anwendungs- und spracheunabhängig vgl. GATE User guide, http://gate.ac.uk/sale/tao

20
Komponenten von ANNIE Part-of-Speech-Tagger Erkennung von Wortarten (Verb, Substantiv, Präposition…) Verwendet ein Lexikon und ein Set von Regeln, trainiert auf dem Korpus aus dem Wall Street Journal vgl. GATE User guide, http://gate.ac.uk/sale/tao

21
Komponenten von ANNIE Semantic Tagger Beruht auf den Regeln in der JAPE-Sprache enthält Regeln, die auf den Annotationen aus den vorangegangenen Phasen arbeiten vgl. GATE User guide, http://gate.ac.uk/sale/tao

22
Komponenten von ANNIE Orthographic Coreference (OrthoMatcher) fügt Identitätsrelationen hinzu zwischen NEs (named entities), die vom semantischen Tagger bestimmt wurden benutzt eine Tabelle der Bezeichnungen der gleichen Entitäten in alternative Schreibweisen z. B.: IBM vs. Big Blue, Coca-Cola vs. Coke verwendet auch eine Liste mit leicht verwechselbaren Namen z. B.: BT Wireless vs. BT Cellnet vgl. GATE User guide, http://gate.ac.uk/sale/tao

23
Komponenten von ANNIE Pronominal Coreference wird in ANNIE nicht automatisch geladen, kann aber als sog. Processing Resource hinzugefügt werden besteht aus drei Submodulen: – Modul für Textstücke in Anführungszeichen (quoted text module) – Modul für sog. pleonastisches it (pleonastic it module) – Modul für Pronomenauflösung (pronominal resolution module) vgl. GATE User guide, http://gate.ac.uk/sale/tao
 – Modul für sog. pleonastisches it (pleonastic it module) – Modul für Pronomenauflösung (pronominal resolution module) vgl. GATE User guide,")
24
Komponenten von ANNIE Pronominal Coreference Das Modul setzt die Annotationen der vorangegangenen Module voraus dazu gehören: – Token (English Tokenizer) – Sentence (Sentence Splitter) – Split (Sentence Splitter) – Location (NE Transducer, OrthoMatcher) – Person (NE Transducer, OrthoMatcher) – Organization (NE Transducer, OrthoMatcher) vgl. GATE User guide, http://gate.ac.uk/sale/tao

25
Komponenten von ANNIE Pronominal Coreference: Modul für Textstücke in Anführungszeichen Modul identifiziert im Text Fragmente, die in Anführungszeichen stehen für diese Fragmente gelten im 3. Modul besondere Regeln für die Auflösung solcher Pronomen wie I, me, my… Das Modul bildet Quoted Text-Annotationen Das Modul ist ein JAPE-Transduktor auf der Basis einer JAPE-Grammatik vgl. GATE User guide, http://gate.ac.uk/sale/tao

26
Komponenten von ANNIE Pronominal Coreference Vorverarbeitung der Textdatei: Bestimme Sätze Bestimme Geschlecht der Personen Listen der Annotationen von Organisationen, Orten, Personen für jedes Pronomen suche nach den möglichen Antezedenten und wähle den besten aus bilde sog. Koreferenzketten (coreference chains) vgl. GATE User guide, http://gate.ac.uk/sale/tao
 vgl. GATE User guide,")
27
Komponenten von ANNIE Pronominal Coreference Alle Pronomina haben Annotationen vom Typ Token mit den Werten PRP oder PRP$ für das Merkmal category Kategorie PRP: Possesivpronomen my, your, his, her… Kategorie PRP$: Personalpronomen, Reflexivpronomen vgl. GATE User guide, http://gate.ac.uk/sale/tao

28
Dokumentformate für GATE: Plain Text HTML SGML XML RTF Email PDF Microsoft Word vgl. GATE User guide, http://gate.ac.uk/sale/tao

29
Documents: Content plus Annotations plus Features Annotationen sind in Graphen zusammengefasst, die als Java sets of Annotation modelliert sind. Annotationen haben Anfangsknoten und Endknoten, ID, Typ and FeatureMap. Nodes haben Pointer auf die Dokumentquelle. Result of annotation on a single sentence Tabelle 1: Result of annotation on a single sentence nach GATE User guide, Ch. 6, http://gate.ac.uk/sale/tao

30
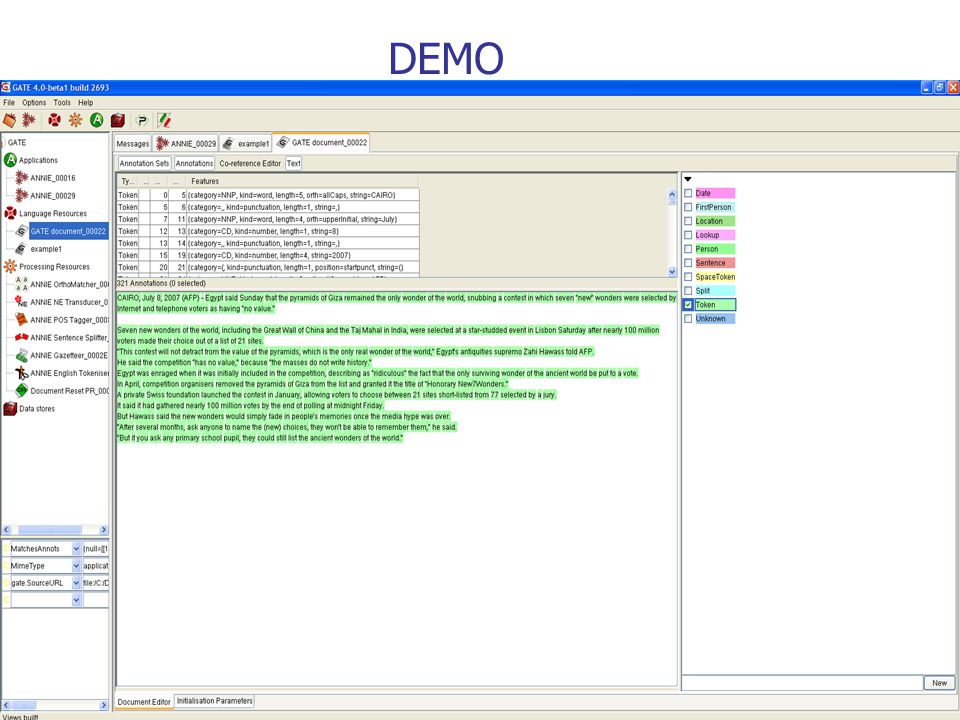
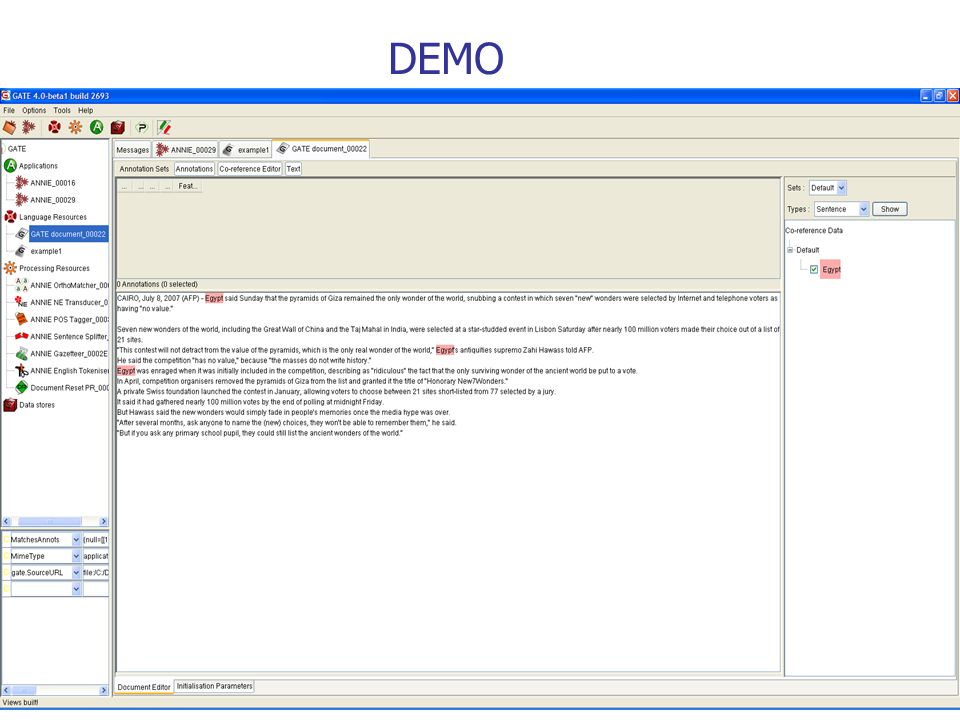
DEMO

33
Quellenangaben H.Cunningham, D.Maynard, K.Bontcheva,V.Tablan, C. Ursu, M.Dimitrov, M.Dowman, N.Aswani, I.Roberts, Y. Li, A.Shafirinc (2001-2006). Developing Language Processing Components with GATE Version 4 (a User Guide) For GATE version 4.0-beta1. The University of Sheffield (April 2007). http://gate.ac.uk/
. Developing Language Processing Components with GATE Version 4 (a User Guide) For GATE version 4.0-beta1. The University of Sheffield (April 2007).")
Ähnliche Präsentationen













 einer Zeichenkette Eine Grammatik definiert nicht die.>")

>")



