Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Datenbanken und Informationssysteme - Data Warehouse, Data Mining, Business Intelligence -
Prof. Dr. K. Huckert, Projektgruppe Praxisorientierte Informatik, Hochschule für Technik und Wirtschaft des Saarlandes

2
Datenbanken und Informationssysteme
Inhalt: 1. Einführende Bemerkungen 2. Praxisbeispiel eines Data Warehouse 3. Grundlagen Data Warehouse 4. OLAP und SQL 5. Data Warehouse-Architektur 6. Praktikum 7. Data Mining 8. Praktikum

3
Datenbanken und Informationssysteme
Literatur: Azevedo, Pedro/Brosius, Gerhard/Dehnert, Stefan/Neumann, Berthold/Scheerer, Benjamin: Business Intelligence und Reporting mit dem SQL Server Microsoft Press 2006 Chamoni, Peter/Gluchowski, Peter (Hrsg.): Analytische Informationssysteme. Springer 3. Auflage 2006 Kemper, Hans-Georg/Mehanna, Walid/Unger, Carsten: Business Intelligence. Vieweg 2. Auflage 2006 Lusti, Markus: Data Warehousing und Data Mining: - Eine Einführung in entscheidungsunterstützende Systeme-. Springer 2. Auflage 2002 Sattler, Kai-Uwe/Saake, Gunter: Data-Warehouse-Technologien. Vorlesungsskript im WS 2006/2007,Internet-Quelle: bis dwt-11.pdf Vossen, Gottfried: Datenbanksysteme: - Datenintegration und –analyse -, Manuskripte zum Fernstudium Allgemeine Informatik, Koblenz 2.Auflage 2005
: Analytische Informationssysteme. Springer 3. Auflage Kemper, Hans-Georg/Mehanna, Walid/Unger, Carsten: Business Intelligence. Vieweg 2. Auflage Lusti, Markus: Data Warehousing und Data Mining: - Eine Einführung in entscheidungsunterstützende Systeme-. Springer 2. Auflage Sattler, Kai-Uwe/Saake, Gunter: Data-Warehouse-Technologien. Vorlesungsskript im WS 2006/2007,Internet-Quelle: bis dwt-11.pdf. Vossen, Gottfried: Datenbanksysteme: - Datenintegration und –analyse -, Manuskripte zum Fernstudium Allgemeine Informatik, Koblenz 2.Auflage")
4
Datenbanken und Informationssysteme
Einführende Bemerkungen

5
Datenbanken und Informationssysteme
Definition Informationsintegration: Unter Informationsintegration (Datenintegration) versteht man das Zusammenführen von Daten und Inhalten aus verschiedenen Quellen und Anwendungen zu einer einheitlichen Menge. Beispiele: Produktdatenmanagement Führungsinformationssystem CAD-Daten - Plandaten Marketinginformationen - operative Daten aus Vertrieb, ERP-Daten Produktion, Finanzwesen - externe Daten (volkswirtschaftl Daten, Branchendaten) Daten sind unterschiedlich repräsentiert (Darstellungsform, Dateien, Datenbanken, unterschiedliche Hardware)
 versteht man das Zusammenführen von Daten und Inhalten aus verschiedenen Quellen und Anwendungen zu einer einheitlichen Menge. Beispiele: Produktdatenmanagement Führungsinformationssystem. CAD-Daten - Plandaten. Marketinginformationen - operative Daten aus Vertrieb, ERP-Daten Produktion, Finanzwesen. - externe Daten (volkswirtschaftl. Daten, Branchendaten) Daten sind unterschiedlich repräsentiert (Darstellungsform, Dateien, Datenbanken, unterschiedliche Hardware)")
6
Datenbanken und Informationssysteme
Problematik Informationsintegration: Semantik Redundanz Heterogenität

7
Datenbanken und Informationssysteme
Formen von Datenintegration Virtuelle Systeme Materialisierte Systeme

8
Datenbanken und Informationssysteme Virtuelles System (anfrageorientierte Integration)
")
9
Datenbanken und Informationssysteme
Erläuterungen: Wrapper: Programm, das die Quelldaten in ein gemeinsames Datenmodell verpackt. Wirkungsweise ist die Informationsextraktion in ein bestimmtes Muster. Integrator: Programm, das unter Verwendung von Metadateninformationen, die unterschiedlichen Quelldaten zusammenführt. Stellt in der Regel auch Mechanismen zum Suchen, Lesen, Schreiben, Verdichten, Visualieren etc. bereit. Anstelle eines zentralen Integrators kann auch ein Mediator verwendet werden. Ein Mediator kombiniert und restrukturiert Daten, die vom Wrapper geliefert wird. Beispielsweise für bestimmte Clienten für bestimmte Anwendungen. Techniken: Eigenentwicklungen, ODBC (JDBC) , XML etc.
 , XML etc.")
10
Datenbanken und Informationssysteme
Materialisierte Systeme Unterschied zum virtuellen System: Es wird ein separater, integrierter Datenbestand dauerhaft („materialisiert“) aufgebaut. Unterklassifikation materialisierte Systeme: Universelles Datenbanksystem: Daten werden in einem weiteren Datenbanksystem materialisiert. Neben klassischen Daten häufig auch Bild-, Text- und Videodaten (XML-Daten). Datenlager (Data Warehouse): Daten werden aus den gegebenen Quellen aufbereitet (selektiert, aggregiert), um dann für statistische Auswertungen und Analysen verwendet zu werden. Vor allem für Decision Support Systeme von Interesse.
 aufgebaut. Unterklassifikation materialisierte Systeme: Universelles Datenbanksystem: Daten werden in einem weiteren Datenbanksystem materialisiert. Neben klassischen Daten häufig auch Bild-, Text- und Videodaten (XML-Daten). Datenlager (Data Warehouse): Daten werden aus den gegebenen Quellen aufbereitet (selektiert, aggregiert), um dann für statistische Auswertungen und Analysen verwendet zu werden. Vor allem für Decision Support Systeme von Interesse.")
11
Datenbanken und Informationssysteme Materialisiertes System

12
Datenbanken und Informationssysteme
Beispiel: Suchmaschinen Web

13
Datenbanken und Informationssysteme
Praxisbeispiel eines Data Warehouses der LARS Data GmbH

14
Data Warehouse - Verwendungszweck
Auswertung der Kennzahlen des Betriebes, Berichte, Analysen alle Kenngrößen schnell und umfassend überblicken Informationen topdown analysieren (Gesamtsumme -> Beleg) Abweichungen/ Aufälligkeiten erkennen Zusammenhänge/ Regeln/ Trends erkennnen Chancen und Risiken erkennen Anwender: Management, Controlling, ...
 Abweichungen/ Aufälligkeiten erkennen. Zusammenhänge/ Regeln/ Trends erkennnen. Chancen und Risiken erkennen. Anwender: Management, Controlling, ...")
15
Data Warehouse Architektur
Reporting, Analysen Operative Systeme Data Warehouse Relationale Datenstrukturen (Tabellen) Multidimensionale Datenstrukturen (Cubes) Extraktionstools DTS, Bodi, ...
 Multidimensionale. Datenstrukturen. (Cubes) Extraktionstools. DTS, Bodi, ...")
16
Multidimensionale Datenstrukturen
Gegenstand der Analyse/ Betrachtung: Mengen, Werte Betrachtung aus multidimensionaler Sicht (Dimensionen) Hierarchische Strukturen innerhalb der Dimensionen Verdichtung der Werte für jede beliebige Elementkombination aus jeder Hierarchie, Beispiele Stückzahl Artikel X in 2003 an Kunden Müller Wert Warengruppe A im Monat 02/2003 für Kundengruppe XYZ Stückzahl Artikel 4711 am an Kunde 123 Gesamtwert aller verkaufter Waren in 2002 und 2003 Dimension Zeit Hierachie Monat: Jahr ->Quartal -> Monat -> Tag Dimension Zeit Hierachie Woche: Jahr -> Woche -> Tag Dimension Produkt Hierarchie: Hauptgruppe -> Untergruppe -> Artikel Dimension Kunde Hierachie Kundengruppe -> Kunde Datum Artikelnr Kundennr Menge Wert 4711 123 5 100 4712 3 150 7 130 125 Faktentabelle Verkauf
 Hierarchische Strukturen innerhalb der Dimensionen. Verdichtung der Werte für jede beliebige Elementkombination aus jeder Hierarchie, Beispiele. Stückzahl Artikel X in 2003 an Kunden Müller. Wert Warengruppe A im Monat 02/2003 für Kundengruppe XYZ. Stückzahl Artikel 4711 am an Kunde 123. Gesamtwert aller verkaufter Waren in 2002 und Dimension Zeit. Hierachie Monat: Jahr ->Quartal -> Monat -> Tag. Dimension Zeit. Hierachie Woche: Jahr -> Woche -> Tag. Dimension Produkt. Hierarchie: Hauptgruppe -> Untergruppe -> Artikel. Dimension Kunde. Hierachie Kundengruppe -> Kunde. Datum. Artikelnr. Kundennr. Menge. Wert Faktentabelle Verkauf.")
17
Data Warehouse im Pressevertrieb
Die LaRS Data GmbH hat eine effiziente Data Warehouse Lösung für den Pressevertrieb entwickelt Das Produkt ist bisher bei 15 Pressegrossisten produktiv Ergänzend hat LaRS Data im Auftrag des Bundesverbandes Presse Grosso eine zentrale webbasierte Lösung realisiert Die standardisierten Strukturen und Verfahren sind auf andere Branchen direkt portierbar.

18
Data Warehouse im Pressevertrieb
Presse Großhändler bezieht Presseprodukte: Zeitschriften, Zeitungen von den Verlagen beliefert Einzelhändler: Kioske, Tankstellen, Märkte, ... ist Alleinauslieferer an die Einzelhändler in seinem Presse-Grosso-Gebiet hat Dispositionsrecht: Er entscheidet über das Sortiment beim Einzelhändler hat Remissionspflicht: Nicht verkaufte Ware nimmt er vom Einzelhändler zurück Ziele effiziente marktorientierte Verteilung der Produkte Minimierung der Remissionen bei nur geringen entgangenen Verkäufen Das Presse-Grosso-Informationssystem der LaRS Data GmbH bildet diesen Pressevertrieb in einer Business Intelligence Lösung ab.

19
Datenmodell Hauptgruppe (25) EVT-Jahr (3) Geschäftsart (10) 25 weitere Dimensionen Zeitdimensionen Verlage Erscheinungsweisen Nullverkäufe Ausverkäufe Kundenbetreuer Öffnungszeiten Schließzeiten, ... Untergruppe (190) EVT-Quartal 12 Untergruppe (50) Objekt (6.000) EVT-Woche (150) Kunde (3000) Heftfolge ( ) EVT-Datum (1100) Ca. 100 Kennzahlen des Pressevertriebs: Lieferungen, Remissionen, Verkauf, Umsatz, Quoten, … Granulat: Millionen Datensätze
 EVT-Quartal. 12. Untergruppe. (50) Objekt. (6.000) EVT-Woche. (150) Kunde. (3000) Heftfolge. ( ) EVT-Datum. (1100) Ca. 100 Kennzahlen des Pressevertriebs: Lieferungen, Remissionen, Verkauf, Umsatz, Quoten, … Granulat: Millionen Datensätze.")
20
Kennzahlen Kennzahlen im Presse-Grosso-Informationssystem, u.a.
Liefermengen: Hauptlieferung, Nachlieferung, Lieferberichtigungen, Remissionen Umsätze: Verlage, Grossist, Einzelhändler Roherlös, Nettowarenwert SQR-Remission, Soll-Remission Quoten: Remissionsquote, Nachlieferquote, Ausverkaufsquote,... Anzahl eingeschalteter Einzelhändler, Anzahl Heftfolgen,... Durchschnitte: durchschnittliche Mengen und Werte pro EH, pro Woche, pro Heftfolge Mengen und Werte bezogen auf soziodemografische Daten: Einwohner, Männer, Frauen, Haushalte für jede Kombination von Dimensions-Elementen abrufbar

21
Beispielauswertungen, Hardcopy 1

22
Beispielauswertungen, Hardcopy 2

23
Beispielauswertungen, Hardcopy 3

24
Nutzenpotentiale Kontrolle und Optimierung der Dispositionsverfahren
Argumentation in Verhandlungen/ Gesprächen mit Verlagen Unterstützung der Außendienstmitarbeiter und der Kundenbetreuer in der Kundenberatung Auffälligkeiten bei Reklamationen (Qualitätsmanagement) Optimierungspotentiale bei Nullverkäufen, Ausverkäufen Tendenzen der Geschäftsentwicklung Ablösung bisheriger individueller Controlling-Berichte
 Optimierungspotentiale bei Nullverkäufen, Ausverkäufen. Tendenzen der Geschäftsentwicklung. Ablösung bisheriger individueller Controlling-Berichte.")
25
Datenbanken und Informationssysteme
Weitere Beispiele für betriebswirtschaftliche Anwendungen

26
Datenbanken und Informationssysteme
Informationsbereitstellung - Kennzahlen für die Abwicklung von Geschäftsprozessen im Bereich Planung, Forecasting, Budgetierung Anwender: Führungskräfte, Controlling Formen der Bereitstellung Query-Ansätze (frei definierte Anfragen) Reporting (vordefinierte Berichte) Redaktionell aufbereitete, personalisierte Informationen Analyse (Business Intelligence) Detaillierte Analyse der Daten zur Untersuchung von Abweichungen oder Auffälligkeiten
 Reporting (vordefinierte Berichte) Redaktionell aufbereitete, personalisierte Informationen. Analyse (Business Intelligence) Detaillierte Analyse der Daten zur Untersuchung von Abweichungen oder Auffälligkeiten.")
27
Datenbanken und Informationssysteme
Weiteres kommerzielles Einsatzbeispiel Wal-Mart (Marktführer amerikanischer Einzelhandel) 2003: 300 TB Bis zu Anfragen pro Tag Sehr hoher Detaillierungsgrad (Artikelumsätze, Lagerbestand, Kundenverhalten) Standortanalysen Untersuchung von Marketing-Aktionen Auswertung von Kundenbefragungen Basis für Warenkorbanalyse, Kundenklassifizierung
 2003: 300 TB. Bis zu Anfragen pro Tag. Sehr hoher Detaillierungsgrad (Artikelumsätze, Lagerbestand, Kundenverhalten) Standortanalysen. Untersuchung von Marketing-Aktionen. Auswertung von Kundenbefragungen. Basis für Warenkorbanalyse, Kundenklassifizierung.")
28
Datenbanken und Informationssysteme
Beispiele für wissenschaftliche und technische Anwendungen

29
Datenbanken und Informationssysteme
Wissenschaftliche Anwendungen Beispiel: Project Earth Observing System (Klima- und Umweltforschung) täglich 1,9 TB meteorologischer Daten Aufbereitung und Analyse mit statistischen Methoden Technische Anwendungen: Öffentlicher Bereich: Umweltdaten (Wasseranalysen)
 täglich 1,9 TB meteorologischer Daten. Aufbereitung und Analyse mit statistischen Methoden. Technische Anwendungen: Öffentlicher Bereich: Umweltdaten (Wasseranalysen)")
30
Datenbanken und Informationssysteme

31
Datenbanken und Informationssysteme
Zusammenfassung Kennzeichen Data Warehouse (Quelle: Wikipedia) Integration von Daten aus unterschiedlich strukturierten und verteilten Datenbeständen, um eine globale Sicht auf die Quelldaten und damit übergreifende Auswertungen zu ermöglichen Ermittlung verborgener Zusammenhänge zwischen Daten durch Data Mining Schnelle und flexible Verfügbarkeit von Berichten, Statistiken und Kennzahlen, um z. B. Zusammenhänge zwischen Markt und Leistungsangebot erkennen zu können Umfassende Information über Geschäftsobjekte und Zusammenhänge Transparenz im Zeitablauf zu Geschäftsprozessen, Kosten und Ressourceneinsatz
 Integration von Daten aus unterschiedlich strukturierten und verteilten. Datenbeständen, um eine globale Sicht auf die Quelldaten und damit übergreifende Auswertungen zu ermöglichen. Ermittlung verborgener Zusammenhänge zwischen Daten durch Data Mining. Schnelle und flexible Verfügbarkeit von Berichten, Statistiken und Kennzahlen, um z. B. Zusammenhänge zwischen Markt und Leistungsangebot erkennen zu können. Umfassende Information über Geschäftsobjekte und Zusammenhänge. Transparenz im Zeitablauf zu Geschäftsprozessen, Kosten und Ressourceneinsatz.")
32
Datenbanken und Informationssysteme
Aufgaben: 1. Welche Anwendungen kann man sich vorstellen, bei denen eine Integration eine Rolle spielt? 2.Vorteile/Nachteile Virtualisierung und Materialisierung. 3. Wie würden Sie den Begriff Data Warehouse charakterisieren? 4. Lesen Sie in der Wikipedia den Artikel „Data Warehouse“ 5. Versandhandel Riemenschneider (aus Bachelor-Vorlesung Datenbanken) . Einsatz in 10 Filialen, die international agieren. Man konstruiere inhaltlich ein mögliches Data Warehouse.
 . Einsatz in 10 Filialen, die international agieren. Man konstruiere inhaltlich ein mögliches Data Warehouse.")
33
Datenbanken und Informationssysteme
Lösung zu 1. Produktdatenbanksysteme /Umsätze, Käufe in Internetshops, Umsätze Filialsysteme, firmenübergreifende Anwendungen (z.B. interne + externe Daten) wie Verbandslösungen, Entscheidungsunterstützungssysteme im Umweltbereich Lösung zu 2. Vorteile Virtualisierung: kein weiteres DB-System erforderlich Vorteile Materialisierung: Antwortzeiten sind besser, Aktualisierung billiger als ständige Neuzusammenstellung
 wie Verbandslösungen, Entscheidungsunterstützungssysteme im Umweltbereich. Lösung zu 2. Vorteile Virtualisierung: kein weiteres DB-System erforderlich. Vorteile Materialisierung: Antwortzeiten sind besser, Aktualisierung billiger als ständige Neuzusammenstellung.")
34
Datenbanken und Informationssysteme
Lösung zu 3. Zusammenfassung Kennzeichen Data Warehouse Integration von Daten aus unterschiedlich strukturierten und verteilten Datenbeständen, um eine globale Sicht auf die Quelldaten und damit übergreifende Auswertungen zu ermöglichen Ermittlung verborgener Zusammenhänge zwischen Daten durch Data Mining (Entscheidungsunterstützung) Schnelle und flexible Verfügbarkeit von Berichten, Statistiken und Kennzahlen, um z. B. Zusammenhänge zwischen Markt und Leistungsangebot erkennen zu können Umfassende Information über Geschäftsobjekte und Zusammenhänge Transparenz im Zeitablauf zu Geschäftsprozessen, Kosten und Ressourceneinsatz
 Schnelle und flexible Verfügbarkeit von Berichten, Statistiken und Kennzahlen, um z. B. Zusammenhänge zwischen Markt und Leistungsangebot erkennen zu können. Umfassende Information über Geschäftsobjekte und Zusammenhänge. Transparenz im Zeitablauf zu Geschäftsprozessen, Kosten und Ressourceneinsatz.")
35
Datenbanken und Informationssysteme
Lösung zu 5. Wichtig!! Zuerst überlegen, welche Auswertungen sinnvoll sind!! D.h. welche betriebswirtschaftlichen Kennzahlen sind interessant Gesamtumsatz, Regionumsatz, Quartalsumsatz, Jahresumsatz/Region/Unterregion, Artikelumsatz/Region/Zeit, Artikelgruppenumsatz, Kundenumsatz, Kundengruppe, Top 10 – Listen, Flop-Listen, Saisonlisten

36
Datenbanken und Informationssysteme
Lösung zu 5. (Unterscheidung Fakten zu Dimensionen) Fakten Dimension Filiale Gebiet (Total/Land/Region/Stadt) Land Zeit ( Jahr/Quartal/Monat/Woche/Datum) Bestellnummer Artikel (Gesamt/Hauptgruppe/Untergruppe/Artikel) Bestelldatum Kunden (Großhandel/Einzelhandel) (Lieferdatum) Kundennummer Kundenname Postleitzahl (Kundentyp) (Geschlecht) Artikelnummer Artikelbezeichnung Artikelkategorie Einzelpreis Menge Bestellwert (Beurteilung, Note)
 Fakten Dimension. Filiale Gebiet (Total/Land/Region/Stadt) Land Zeit ( Jahr/Quartal/Monat/Woche/Datum) Bestellnummer Artikel (Gesamt/Hauptgruppe/Untergruppe/Artikel) Bestelldatum Kunden (Großhandel/Einzelhandel) (Lieferdatum) Kundennummer. Kundenname. Postleitzahl. (Kundentyp) (Geschlecht) Artikelnummer. Artikelbezeichnung. Artikelkategorie. Einzelpreis. Menge. Bestellwert. (Beurteilung, Note)")
37
Datenbanken und Informationssysteme
Grundlagen Data Warehouse

38
Charakteristika operativer und dispositiver Daten

39
Datenbanken und Informationssysteme
Begriff OLTP/Data Warehouse OLTP = OnLine Transactional Processing Klassische operative Informationssysteme (z.B. ERP-Systeme) - Erfassung und Verwaltung von Daten - Transaktionale Verarbeitung: kurze Lese-/Schreibzugriffe auf wenige Datensätze - Verarbeitung durch jeweilige Fachabteilung Data Warehouse - Analyse im Mittelpunkt - lange Lesetransaktionen auf vielen Datensätzen - Integration, Konsolidierung und Aggregation der Daten
 - Erfassung und Verwaltung von Daten. - Transaktionale Verarbeitung: kurze Lese-/Schreibzugriffe auf wenige. Datensätze. - Verarbeitung durch jeweilige Fachabteilung. Data Warehouse. - Analyse im Mittelpunkt. - lange Lesetransaktionen auf vielen Datensätzen. - Integration, Konsolidierung und Aggregation der Daten.")
40
Datenbanken und Informationssysteme

41
Datenbanken und Informationssysteme

42
Datenbanken und Informationssysteme
Definition Begriff Data Warehouse „A data warehouse is a subject-oriented, integrated, time-variant, nonvolatile collection of data in support of management´s decision-making process.“ (Inmon (1996), S. 33) „Ein Data-Warehouse ist eine themenorientierte, integrierte, chronologisierte und persistente Sammlung von Daten, um das Management bei seinen Entscheidungsprozessen zu unterstützen.“
, S. 33) „Ein Data-Warehouse ist eine themenorientierte, integrierte, chronologisierte und persistente Sammlung von Daten, um das Management bei seinen Entscheidungsprozessen zu unterstützen.")
43
Datenbanken und Informationssysteme
Charakteristika Begriff Data Warehouse subject-oriented (Themenorientierung): Die Auswahl der in das Data-Warehouse zu übernehmenden Daten geschieht nach bestimmten Datenobjekten (Produkt, Kunde, Firma,...), die für die Analysen von Kennzahlen für Entscheidungsprozesse relevant sind, nicht hingegen nach operativen Prozessen. integrated (Vereinheitlichung): Im Data-Warehouse werden die in verschiedenen (operativen) Quellsystemen in meist heterogenen Strukturen vorliegenden ausgewählten Daten in vereinheitlichter Form gehalten. (interne und externe Quellen) time-variant (Zeitorientierung): Analysen über zeitliche Veränderungen und Entwicklungen sollen im Data-Warehouse ermöglicht werden; daher ist die langfristige Speicherung der Daten im Data-Warehouse nötig (Einführung der Dimension "Zeit"). Keine Änderungen der Daten im Data Warehouse. nonvolatile (Beständigkeit): Daten werden dauerhaft (nicht-flüchtig) gespeichert.
: Die Auswahl der in das Data-Warehouse zu übernehmenden Daten geschieht nach bestimmten Datenobjekten (Produkt, Kunde, Firma,...), die für die Analysen von Kennzahlen für Entscheidungsprozesse relevant sind, nicht hingegen nach operativen Prozessen. integrated (Vereinheitlichung): Im Data-Warehouse werden die in verschiedenen (operativen) Quellsystemen in meist heterogenen Strukturen vorliegenden ausgewählten Daten in vereinheitlichter Form gehalten. (interne und externe Quellen) time-variant (Zeitorientierung): Analysen über zeitliche Veränderungen und Entwicklungen sollen im Data-Warehouse ermöglicht werden; daher ist die langfristige Speicherung der Daten im Data-Warehouse nötig (Einführung der Dimension Zeit ). Keine Änderungen der Daten im Data Warehouse. nonvolatile (Beständigkeit): Daten werden dauerhaft (nicht-flüchtig) gespeichert.")
44
Datenbanken und Informationssysteme
Weitere Begriffe: Data-Warehouse-Prozess: alle Schritte der Datenbeschaffung (Extraktion, Transformation, Laden), des Speicherns und der Analyse Data Mart externe Teilsicht auf das Data Warehouse durch Kopieren anwendungsspezifisch
, des Speicherns und der Analyse. Data Mart. externe Teilsicht auf das Data Warehouse. durch Kopieren. anwendungsspezifisch.")
45
Datenbanken und Informationssysteme

46
Datenbanken und Informationssysteme

47
Datenbanken und Informationssysteme
Definition Business Intelligence (nach Kemper et al.) Unter Business Intelligence (BI) wird ein integrierter, unternehmensspezifischer, IT-basierter Gesamtansatz zur betrieblichen Entscheidungsunterstützung verstanden. BI-Werkzeuge dienen ausschließlich der Entwicklung von BI-Anwendungen BI-Anwendungssysteme bilden Teilaspekte des BI- Gesamtansatzes ab.
 Unter Business Intelligence (BI) wird ein integrierter, unternehmensspezifischer, IT-basierter Gesamtansatz zur betrieblichen Entscheidungsunterstützung verstanden. BI-Werkzeuge dienen ausschließlich der Entwicklung von. BI-Anwendungen. BI-Anwendungssysteme bilden Teilaspekte des BI- Gesamtansatzes ab.")
48
Einsatzfeld von BI-Anwendungssystemen

49
Datenbanken und Informationssysteme

50
Datenbanken und Informationssysteme
Historische Wurzeln 60er Jahre: MIS (Management Information System) - verdichtete extrakte kleiner Datenbestände - Aufbereitung statischer (vorgeplanter Berichte) - Mainframe 80er Jahre: EIS (Executive Information System), DSS (Decision Support System) - Berichtsgeneratoren - Einführung von Hierarchieebenen für Auswertung von Kennzahlen (Roll-up, Drill-down) - Modellierungskomponenten (Planungssprachen) - Client/Server, GUI 1992: Einführung Data Warehouse-Begriff durch W.H. Inmon 1993: Definition des Begriffes OLAP durch E.F.Codd
 - verdichtete extrakte kleiner Datenbestände. - Aufbereitung statischer (vorgeplanter Berichte) - Mainframe. 80er Jahre: EIS (Executive Information System), DSS (Decision Support System) - Berichtsgeneratoren. - Einführung von Hierarchieebenen für Auswertung von. Kennzahlen (Roll-up, Drill-down) - Modellierungskomponenten (Planungssprachen) - Client/Server, GUI. 1992: Einführung Data Warehouse-Begriff durch W.H. Inmon. 1993: Definition des Begriffes OLAP durch E.F.Codd")
51
Datenbanken und Informationssysteme

52
Datenbanken und Informationssysteme
OLAP (OnLine Analytical Processing) Der OLAP-Begriff wurde 1993 von Edgar F. Codd geprägt. Er formulierte zunächst 12 Regeln, die er bis zuletzt auf 18 Regeln erweitert hat. Diese Evaluierungsregeln stellten die erste Anforderungsliste an ein OLAP-System dar. Zwar werden diese Regeln noch gern aufgeführt, aber ihre Bedeutung für die Bewertung eines OLAP-Systems kann heute nicht mehr als besonders hoch eingestuft werden. Dies liegt im Besonderen an ihrer stark anwendungsbezogenen Ausrichtung und ihren teils umstrittenen Regeln.
 Der OLAP-Begriff wurde 1993 von Edgar F. Codd geprägt. Er formulierte zunächst 12 Regeln, die er bis zuletzt auf 18 Regeln erweitert hat. Diese Evaluierungsregeln stellten die erste Anforderungsliste an ein OLAP-System dar. Zwar werden diese Regeln noch gern aufgeführt, aber ihre Bedeutung für die Bewertung eines OLAP-Systems kann heute nicht mehr als besonders hoch eingestuft werden. Dies liegt im Besonderen an ihrer stark anwendungsbezogenen Ausrichtung und ihren teils umstrittenen Regeln.")
53
Datenbanken und Informationssysteme
Grundregeln von Codd: Multidimensionale konzeptionelle Sicht auf die Daten (wichtigstes Kriterium für OLAP) Transparenz (klare Trennung zwischen Benutzerschnittstelle und der zu Grunde liegenden Architektur) Zugriffsmöglichkeiten (Bezug der Basisdaten aus externen oder operationalen Datenbeständen) Konsistente Leistungsfähigkeit der Berichterstattung (möglichst schnelle Reportingfunktionalität) Client-Server-Architektur (auf den Verwendungszweck optimierte Lastverteilung) Generische Dimensionalität (alle Dimensionen in ihrer Struktur und Funktionalität einheitlich) Dynamische Handhabung dünn besetzter Matrizen (dynamische Speicherstrukturanpassung) Mehrbenutzerunterstützung Unbeschränkte kreuzdimensionale dimensionsübergreifende Operationen Intuitive Datenanalyse (direkte Navigation innerhalb der Datenwürfel) Flexibles Berichtswesen (Ergebnisse im Report frei anordnungsbar) Unbegrenzte Anzahl von Dimensionen und Konsolidierungsebenen (15 bis 20 Dimensionen mit beliebig vielen Aggregationsstufen)
 Transparenz (klare Trennung zwischen Benutzerschnittstelle und der zu Grunde liegenden Architektur) Zugriffsmöglichkeiten (Bezug der Basisdaten aus externen oder operationalen Datenbeständen) Konsistente Leistungsfähigkeit der Berichterstattung (möglichst schnelle Reportingfunktionalität) Client-Server-Architektur (auf den Verwendungszweck optimierte Lastverteilung) Generische Dimensionalität (alle Dimensionen in ihrer Struktur und Funktionalität einheitlich) Dynamische Handhabung dünn besetzter Matrizen (dynamische Speicherstrukturanpassung) Mehrbenutzerunterstützung. Unbeschränkte kreuzdimensionale dimensionsübergreifende Operationen. Intuitive Datenanalyse (direkte Navigation innerhalb der Datenwürfel) Flexibles Berichtswesen (Ergebnisse im Report frei anordnungsbar) Unbegrenzte Anzahl von Dimensionen und Konsolidierungsebenen (15 bis 20 Dimensionen mit beliebig vielen Aggregationsstufen)")
54
Datenbanken und Informationssysteme
Einige Anmerkungen (1): (Multidimensionale konzeptionelle Sicht auf die Daten) Entscheidungsrelevante Zahlengrößen müssen sich am mentalen Unternehmensbild betrieblicher Fach- und Führungskräfte orientieren und damit multidimensionaler Natur sein. Beispiel: Umsätze oder Kosten müssen sich entlang unterschiedlicher Dimensionen wie Zeit, Sparte, Produkt etc. aufgliedern lassen.
: (Multidimensionale konzeptionelle Sicht auf die Daten) Entscheidungsrelevante Zahlengrößen müssen sich am mentalen Unternehmensbild betrieblicher Fach- und Führungskräfte orientieren und damit multidimensionaler Natur sein. Beispiel: Umsätze oder Kosten müssen sich entlang unterschiedlicher Dimensionen wie Zeit, Sparte, Produkt etc. aufgliedern lassen.")
55
Datenbanken und Informationssysteme
Einige Anmerkungen (2): (“dünnbesetzte“ Matrizen) Nicht jedes Dimensionselement geht mit allen anderen Dimensionselementen eine Verbindung ein. Beispiel: Nicht jedes Produkt wird in jedem Land angeboten. Resultat: Andere Formen der Datenspeicherung (aus der Theorie “dünnbesetzter“ Matrizen)
: ( dünnbesetzte Matrizen) Nicht jedes Dimensionselement geht mit allen anderen Dimensionselementen eine Verbindung ein. Beispiel: Nicht jedes Produkt wird in jedem Land angeboten. Resultat: Andere Formen der Datenspeicherung (aus der Theorie dünnbesetzter Matrizen)")
56
Datenbanken und Informationssysteme
Einige Anmerkungen (3): (Unbeschränkte kreuzdimensionale dimensionsübergreifende Operationen) Über die verschiedenen Dimensionen hinweg werden Operationen für eine ausgereifte Datenanalyse benötigt, z.B. zur Kennzahlenberechnung. Neben der reinen Aggregation von Elementen innerhalb einer Dimension müssen Verfahren zur Verfügung stehen, die zur beliebigen Verknüpfung der Datenelemente innerhalb und zwischen Würfeln zur Verfügung stehen. Dies bedeutet eine vollständige, integrierte Datenmanipulationssprache (DML) Hinweis MDX (wird später kurz erläutert)
: (Unbeschränkte kreuzdimensionale dimensionsübergreifende Operationen) Über die verschiedenen Dimensionen hinweg werden Operationen für eine ausgereifte Datenanalyse benötigt, z.B. zur Kennzahlenberechnung. Neben der reinen Aggregation von Elementen innerhalb einer Dimension müssen Verfahren zur Verfügung stehen, die zur beliebigen Verknüpfung der Datenelemente innerhalb und zwischen Würfeln zur Verfügung stehen. Dies bedeutet eine vollständige, integrierte Datenmanipulationssprache (DML) Hinweis MDX (wird später kurz erläutert)")
57
Datenbanken und Informationssysteme
FASMI-Regeln nach Pendse und Creeth stellten sie unter dem Akronym FASMI „Fast Analysis of Shared Multidimensional Information“ fünf herstellerunabhängige Evaluierungsregeln auf, um damit das OLAP-Konzept zu beschreiben. Fast: Abfragen sollen durchschnittlich fünf Sekunden dauern dürfen. Dabei sollen einfache Abfragen nicht länger als eine Sekunde und nur wenige, komplexere Abfragen bis zu 20 Sekunden Verarbeitungszeit beanspruchen. Analysis: Ein OLAP-System soll jegliche benötigte Logik bewältigen können. Dabei soll die Definition einer komplexeren Analyseabfrage durch den Anwender mit wenig Programmieraufwand zu realisieren sein. Shared: Ein OLAP-System soll für den Mehrbenutzerbetrieb ausgelegt sein. Dies bedingt eine Verfügbarkeit geeigneter Zugriffsschutzmechanismen. Multidimensional: Als Hauptkriterium fordern Pendse und Creeth eine mehrdimensionale Strukturierung der Daten mit voller Unterstützung der Dimensionshierarchien. Information: Bei der Analyse sollen einem Anwender alle benötigten Daten transparent zur Verfügung stehen. Eine Analyse darf nicht durch Beschränkungen des OLAP-Systems beeinflusst werden.

58
Datenbanken und Informationssysteme
Anforderungen an OLAP-Werkzeuge Darstellung von Daten in aggregierter und summierter Form z.B. Gesamtverkaufszahl eines Produktes in einem Quartal in einem bestimmten Ort Grad der Aggregation kann variiert werden z.B. Zeit über Tage, Woche, Monat, Quartal, Jahr mehrdimensionale Sicht z.B. Verkäufe pro Produkt, pro Stadt, pro Quartal interaktive Abfragen im Sekundenbereich Analyse umfangreicher Datenbestände (Terrabyte)
")
59
Datenbanken und Informationssysteme
Exkurs:EXCEL

60
Datenbanken und Informationssysteme
Umsatzdaten sollen nach verschiedenen Merkmalen ausgewertet und verdichtet werden. (EXCEL/SQL) Livedemonstration Für Übung: Auf P steht EXCEL-Tabelle , Verzeichnis VORLESUNGSUNTERLAGEN, Bereich DATENBANKEN UND INFORMATIONSSYSTEME,Datei AUFTRAGSDATEN.XLS, auf dem Bereich PI_MASTER ist entsprechende Datenbank verfügbar. Vorteile/Nachteile ??
 Livedemonstration. Für Übung: Auf P steht EXCEL-Tabelle , Verzeichnis VORLESUNGSUNTERLAGEN, Bereich DATENBANKEN UND INFORMATIONSSYSTEME,Datei AUFTRAGSDATEN.XLS, auf dem Bereich PI_MASTER ist entsprechende Datenbank verfügbar. Vorteile/Nachteile")
61
Datenbanken und Informationssysteme
Pivottabellen Eine Pivot-Tabelle stellt aufgrund der verwendeten Aggregierung in den Datenfeldern die Ausgangsdaten in verdichteter, zusammengefasster Form dar. Das ist zwar mit Informationsverlust verbunden, aber andererseits ist genau das der Nutzen einer Pivot-Tabelle. Sie ist ein Hilfsmittel, um große Datenmengen auf überschaubare Größen zu reduzieren und einfache Auswertungen durchzuführen Eine Pivot-Tabelle besteht aus mehreren Bereichen, von denen jeder beliebige Felder (Spaltenüberschriften) der Originaldaten aufnehmen kann. Typischerweise werden die erforderlichen Felder bei Erstellung der Pivot-Tabelle aus einer Liste ausgewählt und mit der Maus in den gewünschten Bereich gezogen.
 der Originaldaten aufnehmen kann. Typischerweise werden die erforderlichen Felder bei Erstellung der Pivot-Tabelle aus einer Liste ausgewählt und mit der Maus in den gewünschten Bereich gezogen.")
62
Datenbanken und Informationssysteme

63
Datenbanken und Informationssysteme
Zeilenfelder Ein hierher gezogenes Feld bewirkt, dass die Ausgangsdaten nach diesem Feld gruppiert werden. Für jeden verschiedenen Feldinhalt, der in den Ausgangsdaten vorkommt, wird eine Zeile in der Pivot-Tabelle angelegt. Werden zwei Felder als Zeilenfelder ausgewählt, dann werden innerhalb jeder zum 1. Feld gehörigen Gruppe alle Gruppen, die zum 2. Feld gehören, in der Pivot-Tabelle dargestellt. Bei mehr als zwei Zeilenfeldern setzt sich diese Aufteilung entsprechend für alle Felder fort. Die Reihenfolge der Zeilenfelder ist relevant und wird vom Benutzer sinnvollerweise so gewählt, dass das Ergebnis möglichst übersichtlich ist. Spaltenfelder Bewirken analog wie Zeilenfelder eine Gruppierung; die verschiedenen Inhalte eines Spaltenfeldes werden jedoch nicht in Zeilen sondern in Spalten dargestellt. Verwendet der Benutzer zugleich Zeilen- und Spaltenfelder, hat er eine Kreuztabelle erstellt. Datenfelder Bestimmen, was im Schnittpunkt von Zeilen und Spalten dargestellt wird. Für jedes Datenfeld wird mittels einer Aggregationsfunktion (wie z. B. "Summe" oder "Anzahl der Datensätze") bewirkt, dass in jeder Zelle der Pivot-Tabelle genau ein Wert eingetragen wird, auch wenn es viele Datensätze gibt, die Mitglied in den zu der Zelle gehörigen Gruppen sind. Werden mehrere Datenfelder gewählt, kann der Benutzer entscheiden, ob die verschiedenen Datenfelder nebeneinander in Spalten oder untereinander in Zeilen dargestellt werden sollen (exakt wie für Spalten- und Zeilenfelder). Es kann auch dasselbe Feld mehrfach als Datenfeld verwendet werden (sinnvollerweise mit unterschiedlicher Aggregationsfunktion). Seitenfelder Erlauben eine Filterung, d. h. eine Einschränkung der Pivot-Tabelle auf jene Datensätze der Ausgangsmenge, die in den gewählten Seitenfeldern bestimmte Werte aufweisen.
 bewirkt, dass in jeder Zelle der Pivot-Tabelle genau ein Wert eingetragen wird, auch wenn es viele Datensätze gibt, die Mitglied in den zu der Zelle gehörigen Gruppen sind. Werden mehrere Datenfelder gewählt, kann der Benutzer entscheiden, ob die verschiedenen Datenfelder nebeneinander in Spalten oder untereinander in Zeilen dargestellt werden sollen (exakt wie für Spalten- und Zeilenfelder). Es kann auch dasselbe Feld mehrfach als Datenfeld verwendet werden (sinnvollerweise mit unterschiedlicher Aggregationsfunktion). Seitenfelder. Erlauben eine Filterung, d. h. eine Einschränkung der Pivot-Tabelle auf jene Datensätze der Ausgangsmenge, die in den gewählten Seitenfeldern bestimmte Werte aufweisen.")
64
Datenbanken und Informationssysteme
Die verschiedenen Typen von Feldern einer Pivot-Tabelle entsprechen bestimmten Teilen einer SQL-Abfrage: Zeilen- und Spaltenfelder von Pivot-Tabellen entsprechen Feldern in der GROUP-BY-Klausel. Datenfelder entsprechen Ausdrücken im Select-Teil des SQL-Befehls. Diese Ausdrücke enthalten notwendigerweise Aggregationsfunktionen wie z. B. die Summenfunktion. Seitenfelder entsprechen einfachen Bedingungen in der WHERE-Klausel des SQL-Befehls.

65
Datenbanken und Informationssysteme
Durch Doppelklick auf eine Zelle in einer Pivot-Tabelle werden Gruppen ein- und ausgeblendet ("Drill-down" und "Roll-up"), um mehr oder weniger Details darzustellen. Gehört die Zelle zu einem Datenfeld, werden nach dem Doppelklick alle einzelnen Datensätze aus den Originaldaten, die in die Berechnung dieser Zelle einflossen, auf einem separaten Tabellenblatt dargestellt. Pivot-Tabellen können nur für die Abfrage, nicht zur Änderung von Daten verwendet werden. Die Einträge einer Pivot-Tabelle sind entweder schreibgeschützt oder eine Änderung wirkt sich nicht auf die zugrundeliegenden Originaldaten aus.
, um mehr oder weniger Details darzustellen. Gehört die Zelle zu einem Datenfeld, werden nach dem Doppelklick alle einzelnen Datensätze aus den Originaldaten, die in die Berechnung dieser Zelle einflossen, auf einem separaten Tabellenblatt dargestellt. Pivot-Tabellen können nur für die Abfrage, nicht zur Änderung von Daten verwendet werden. Die Einträge einer Pivot-Tabelle sind entweder schreibgeschützt oder eine Änderung wirkt sich nicht auf die zugrundeliegenden Originaldaten aus.")
66
Datenbanken und Informationssysteme
Übungsblatt Pivot-Tabellen 1. Erzeugen Sie mit Hilfe von EXCEL mit der Datei AUFTRAGSDATEN.XLS folgende Pivottabellen eine Umsatztabelle nach Ländern Eine Umsatztabelle ohne Hessen und Rheinlandpfalz c eine entsprechende Graphik d. eine Umsatztabelle nach Ländern und Vk-Weg e. eine Tabelle nach Vk-Weg und Ländern f. wo liegen die Unterschiede zwischen c und d g. eine Tabelle nach Länder, Vk-Weg und Kategorie h. welches Land hat den größten Umsatz i. welche fünf Länder haben größte Umsatzwerte j. welches ist der größte Umsatz im Land mit dem größten Umsatz k. welche Länder liegen maximal 20% vom maximalen Umsatz entfernt 2. Wie lauten die entsprechenden SQL-Befehle 3. Unterschiede Tabellenkalkulation SQL

67
Datenbanken und Informationssysteme
Unterschiede SQL vs. Tabellenkalkulation Datenbankabfrageprogramme sind i. A. flexibler als Pivot-Tabellen, d. h. mit SQL können mehr Fragestellungen beantwortet werden. Die Abfrageprogramme bieten jedoch typischerweise weniger Möglichkeiten zur ansprechenden Aufbereitung der Ergebnisse und sind weniger komfortabel zu bedienen. Viele Programme können Datensätze nicht als Kreuztabelle ausgeben und spezielle Formatierungen sind nur in Handarbeit (d. h. ohne Assistenten und Steuerelemente) oder gar nicht möglich.
 oder gar nicht möglich.")
68
Datenbanken und Informationssysteme
--Folgende Fragestellungen sind in der Auftragsdatenbank von Interesse: --1. Ermittle nach Ländern innerhalb der verschiedenen Preiskategorien die Bruttoumsätze ---Erste Lösung SELECT Land, Preis, SUM(Brutto) FROM Auftragsdaten Group By Land, Preis ORDER By Land --Zweite Lösung --die Forderung der Ausgabe einer Zeile pro Land und Kategorie soll --fallengelassen werden. Es soll pro Land eine Zeile mit der --Preiskategorie Hoch, Mittel, Niedrig erzeugt werden. --(Kreuz- oder Pivottabelle) -- Lösung über CASE-Anweisung SELECT Land, sum (case (preis) when 'Hoch' then Brutto else 0 end) as [HOCH], sum (case (preis) when 'Mittel' then Brutto else 0 end) as [MITTEL], when 'Niedrig' then Brutto else 0 end) as [NIEDRIG] GROUP BY LAND ORDER BY Land
 FROM Auftragsdaten. Group By Land, Preis. ORDER By Land. --Zweite Lösung. --die Forderung der Ausgabe einer Zeile pro Land und Kategorie soll. --fallengelassen werden. Es soll pro Land eine Zeile mit der. --Preiskategorie Hoch, Mittel, Niedrig erzeugt werden. --(Kreuz- oder Pivottabelle) -- Lösung über CASE-Anweisung. SELECT Land, sum (case (preis) when Hoch then Brutto else 0 end) as [HOCH], sum (case (preis) when Mittel then Brutto else 0 end) as [MITTEL], when Niedrig then Brutto else 0 end) as [NIEDRIG] GROUP BY LAND. ORDER BY Land.")
69
Datenbanken und Informationssysteme
--Dritte Lösung über PIVOT SELECT Land, [HOCH] , [MITTEL], [NIEDRIG] FROM (SELECT LAND, PREIS, Brutto from Dbo.Auftragsdaten) AS p PIVOT ( SUM (BRUTTO) FOR PREIS IN ( [HOCH], [MITTEL], [NIEDRIG] ) ) AS pvt ORDER BY LAND --Entpivotisierung über UNPIVOT --Vierte Lösung über Cursor
 AS p. PIVOT. ( SUM (BRUTTO) FOR PREIS IN ( [HOCH], [MITTEL], [NIEDRIG] ) ) AS pvt. ORDER BY LAND. --Entpivotisierung über UNPIVOT. --Vierte Lösung über Cursor.")
70
Datenbanken und Informationssysteme

71
Datenbanken und Informationssysteme
Klassifikation Geschäftsdaten - Katalogdaten (z.B. Produktdaten, in der Regel statisch) - Operative Daten (Verkäufe, ändern sich laufend) Umsetzung in OLAP: Katalogdaten → Dimensionen (multidimensional) (Zeit, Ort, Produkt) Operative Daten → Fakten, jedes Faktum ist durch ein Maß (z.B. Verkaufsmenge) gekennzeichnet
 - Operative Daten (Verkäufe, ändern sich laufend) Umsetzung in OLAP: Katalogdaten → Dimensionen (multidimensional) (Zeit, Ort, Produkt) Operative Daten → Fakten, jedes Faktum ist durch ein Maß. (z.B. Verkaufsmenge) gekennzeichnet.")
72
Datenbanken und Informationssysteme
Definition Dimension Symbolisches, diskretes Attribut, das die Auswahl, Zusammenfassung und Navigation eines Faktums (z.B. Umsatz, Absatzmenge) erlaubt (Dimensionsbeispiele Region, Produkt, Periode) Definition Fakt Aggregierbares, meist numerisches und kontinuierliches Attribut, das die mehrdimensionale Messung eines betrieblichen Erfolgskriterium erlaubt (z.B. Gewinn, Kosten, Deckungsbeitrag)
 erlaubt (Dimensionsbeispiele Region, Produkt, Periode) Definition Fakt. Aggregierbares, meist numerisches und kontinuierliches Attribut, das die mehrdimensionale Messung eines betrieblichen Erfolgskriterium erlaubt (z.B. Gewinn, Kosten, Deckungsbeitrag)")
73
Multidimensionale Datenstrukturen
Gegenstand der Analyse/ Betrachtung: Mengen, Werte Betrachtung aus multidimensionaler Sicht (Dimensionen) Hierarchische Strukturen innerhalb der Dimensionen Verdichtung der Werte für jede beliebige Elementkombination aus jeder Hierarchie, Beispiele Stückzahl Artikel X in 2003 an Kunden Müller Wert Warengruppe A im Monat 02/2003 für Kundengruppe XYZ Stückzahl Artikel 4711 am an Kunde 123 Gesamtwert aller verkaufter Waren in 2002 und 2003 Dimension Zeit Hierachie Monat: Jahr ->Quartal -> Monat -> Tag Dimension Zeit Hierachie Woche: Jahr -> Woche -> Tag Dimension Produkt Hierarchie: Hauptgruppe -> Untergruppe -> Artikel Dimension Kunde Hierachie Kundengruppe -> Kunde Datum Artikelnr Kundennr Menge Wert 4711 123 5 100 4712 3 150 7 130 125 Faktentabelle Verkauf
 Hierarchische Strukturen innerhalb der Dimensionen. Verdichtung der Werte für jede beliebige Elementkombination aus jeder Hierarchie, Beispiele. Stückzahl Artikel X in 2003 an Kunden Müller. Wert Warengruppe A im Monat 02/2003 für Kundengruppe XYZ. Stückzahl Artikel 4711 am an Kunde 123. Gesamtwert aller verkaufter Waren in 2002 und Dimension Zeit. Hierachie Monat: Jahr ->Quartal -> Monat -> Tag. Dimension Zeit. Hierachie Woche: Jahr -> Woche -> Tag. Dimension Produkt. Hierarchie: Hauptgruppe -> Untergruppe -> Artikel. Dimension Kunde. Hierachie Kundengruppe -> Kunde. Datum. Artikelnr. Kundennr. Menge. Wert Faktentabelle Verkauf.")
74
Datenbanken und Informationssysteme
Beispiel: Datenlager Verkäufe Dimension(en): Quartal, Produkt, Ort x , y , z Fakt(Maß): Verkäufe Dimension und Fakt(Maß) lassen sich in einem dreidimensionalen Würfel (Data Cube, Datenwürfel darstellen). Dimensionen werden in Dimensionstabellen (hier Quartal, Produkt,Ort), Fakten (hier Verkäufe ergänzt um beschreibende Dimensionselemente) in einer Faktentabelle(n) gespeichert.
: Quartal, Produkt, Ort. x , y , z. Fakt(Maß): Verkäufe. Dimension und Fakt(Maß) lassen sich in einem dreidimensionalen Würfel (Data Cube, Datenwürfel darstellen). Dimensionen werden in Dimensionstabellen (hier Quartal, Produkt,Ort), Fakten (hier Verkäufe ergänzt um beschreibende Dimensionselemente) in einer Faktentabelle(n) gespeichert.")
75
Datenbanken und Informationssysteme

76
Datenbanken und Informationssysteme
Erläuterung: Verkäufe ( 4 Quartale, 4 Produkte, 4 Orte), 64 Zellen möglich Inhalt der Zelle ist adressierbar z.B. durch Verkäufe ( 2, Seife, Denver) = 65 Würfel ist mit vielen Regeln auswertbar
, 64 Zellen möglich. Inhalt der Zelle ist adressierbar z.B. durch Verkäufe ( 2, Seife, Denver) = 65. Würfel ist mit vielen Regeln auswertbar.")
77
Datenbanken und Informationssysteme

78
Datenbanken und Informationssysteme
Mögliche Auswertungen Projektion (Quartal x Produkt), liefert Verkäufe über alle Orte summiert Projektion (Quartal x Ort), liefert Verkäufe über Produkte Projektion (Quartal), liefert Verkäufe über Produkte und Orte Projektion (Ort) liefert Verkäufe Quartale und Produkte Gesamtverkaufszahlen entsteht durch „Kollabieren“ des Würfels Jede Projektion wird als ROLL-UP bezeichnet. Bei 3D-Würfeln existieren 8 Aggregationen. In SQL-3 kann mit einem CUBE-Operator alle ROLL-UPs simultan berechnet werden.
, liefert Verkäufe über alle Orte summiert. Projektion (Quartal x Ort), liefert Verkäufe über Produkte. Projektion (Quartal), liefert Verkäufe über Produkte und Orte. Projektion (Ort) liefert Verkäufe Quartale und Produkte. Gesamtverkaufszahlen entsteht durch „Kollabieren des Würfels. Jede Projektion wird als ROLL-UP bezeichnet. Bei 3D-Würfeln existieren 8 Aggregationen. In SQL-3 kann mit einem CUBE-Operator alle ROLL-UPs simultan berechnet werden.")
79
Datenbanken und Informationssysteme

80
Datenbanken und Informationssysteme
Operationen auf Würfeln: ROLL-UP (Projektion, Reduktion der Dimension), in SQL Elimination von Attributen in einer GROUP BY-Klausel DRILL-DOWN (Summen können detailliert werden, komplementär zu Roll-Up)
, in SQL Elimination von Attributen in einer GROUP BY-Klausel. DRILL-DOWN (Summen können detailliert werden, komplementär zu Roll-Up)")
81
Datenbanken und Informationssysteme

82
Datenbanken und Informationssysteme
SLICE-AND-DICE - Slice: entspricht der relationalen Projektion, schneidet aus Würfel „Scheiben“ - Dice: entspricht der relationalen Selektion, schneidet „Teilwürfel“ heraus

83
Datenbanken und Informationssysteme

84
Datenbanken und Informationssysteme
PIVOTING (Drehen des Würfels durch Vertauschen der Dimensionen, Daten können durch unterschiedliche Perspektiven betrachtet werden) RANKINGS (bildet Ranglisten z.B. Top 10)
 RANKINGS (bildet Ranglisten z.B. Top 10)")
85
Datenbanken und Informationssysteme

86
Datenbanken und Informationssysteme
Schemaformen in Data Warehouses Werte der Measures (Maße) sind in einer Faktentabelle gespeichert Elementwerte jeder Dimension werden in einer Tabelle vorgehalten. Diese Tabellen werden als Dimensionstabellen bezeichnet Primärschlüssel jeder Dimensionstabelle erscheint als Fremdschlüssel in der Faktentabelle. Technik der relationalen Datenbanken findet Anwendung
 sind in einer Faktentabelle gespeichert. Elementwerte jeder Dimension werden in einer Tabelle vorgehalten. Diese Tabellen werden als Dimensionstabellen bezeichnet. Primärschlüssel jeder Dimensionstabelle erscheint als Fremdschlüssel in der Faktentabelle. Technik der relationalen Datenbanken findet Anwendung.")
87
Datenbanken und Informationssysteme
Dimensionstabellen haben folgende Aufgabe: Beschreibung der Fakten, um sinnvolle Aussagen entstehen zu lassen In ihr sind Suchkriterien festgelegt, nach denen Fakten sinnvoll auswertbar sind Sie definieren Hierarchien, entlang derer die Verdichtungsstufen für die Auswertungen festgelegt werden können.

88
Datenbanken und Informationssysteme
Beispiel: Versandhandel (operatives System) 1. Relation Kunden (Kunden_Nr, Name,.., PLZ,.....,Wert) Relation Artikel (Artikel_Nr, Bezeichnung, Kategorie, Me, Bestand, Preis) 3. Relation Bestellungen (Bestell_Nr, Kunden_Nr, Bestelldatum, Lieferdatum, Betrag, Bemerkung) 4. Relation Bestelldaten (Bestell_Nr, Artikel_Nr, Anzahl) 5. Relation Mengeneinheiten (Me, Beschreibung) (ER-Diagramm siehe Teil 1 der Vorlesung)
 1. Relation Kunden (Kunden_Nr, Name,.., PLZ,.....,Wert) Relation Artikel (Artikel_Nr, Bezeichnung, Kategorie, Me, Bestand, Preis) 3. Relation Bestellungen (Bestell_Nr, Kunden_Nr, Bestelldatum, Lieferdatum, Betrag, Bemerkung) 4. Relation Bestelldaten (Bestell_Nr, Artikel_Nr, Anzahl) 5. Relation Mengeneinheiten (Me, Beschreibung) (ER-Diagramm siehe Teil 1 der Vorlesung)")
89
Datenbanken und Informationssysteme
Tansformation operatives System in Data-Warehouse (!!!!!!!) Überflüssige operative Daten weglassen (z.B. Bestand in Artikel, Bemerkung in Bestellung) 2. Integration von Zeitdimensionen (Aufnahme hierarchischer Zeitkategorien, Jahr, Quartal, Monat, Kalenderwoche) 3. Definition von Ableitungen (Ableitungen sind einfache Vorberechnungen wie Betrag = Menge * Einzelpreis, eine Verdichtung – zum Beispiel zeitliche oder geographische Aggregation - oder eine Umgruppierung) Einsparung von Verbundoperationen (hier Verbund Bestellung und Bestelldaten)
 Überflüssige operative Daten weglassen (z.B. Bestand in Artikel, Bemerkung in Bestellung) 2. Integration von Zeitdimensionen (Aufnahme hierarchischer. Zeitkategorien, Jahr, Quartal, Monat, Kalenderwoche) 3. Definition von Ableitungen (Ableitungen sind einfache. Vorberechnungen wie Betrag = Menge * Einzelpreis, eine. Verdichtung – zum Beispiel zeitliche oder geographische. Aggregation - oder eine Umgruppierung) Einsparung von Verbundoperationen (hier Verbund Bestellung und. Bestelldaten)")
90
Datenbanken und Informationssysteme
Data Warehouse Versandhandel Typische Fragestellungen: Welcher Umsatz wurde in den verschiedenen Kategorien pro Monat des Jahres 2006 mit weiblichen Kunden aus den verschiedenen Wohnorten erzielt? Wie hat sich der Umsatz mit einem bestimmten Kunden über einen gewissen Zeitraum entwickelt? Dimensionen: Bestellung (Bestell-Nr, Datum, Kunde…) Artikel (Artikel_Nr, Bezeichnung, Kategorie, Preis) Kunde (Kunden_Nr, Name, Anrede, Wohnort) Zeit (Bestelldatum, Monat, Quartal, Jahr) Faktentabelle: Bestell_Nr, Artikel_Nr, Kunden_Nr, Bestelldatum mit den Measures Anzahl und Gesamtpreis
 Artikel (Artikel_Nr, Bezeichnung, Kategorie, Preis) Kunde (Kunden_Nr, Name, Anrede, Wohnort) Zeit (Bestelldatum, Monat, Quartal, Jahr) Faktentabelle: Bestell_Nr, Artikel_Nr, Kunden_Nr, Bestelldatum mit den Measures Anzahl und Gesamtpreis.")
91
Datenbanken und Informationssysteme
Bild nicht aktuell !

92
Datenbanken und Informationssysteme

93
Datenbanken und Informationssysteme

94
Datenbanken und Informationssysteme
Erläuterung zum Star-Schema Jede Dimensionstabelle ist durch einen Schlüssel und beschreibende Attribute gekennzeichnet Normalisierung wird in der Regel vernachlässigt Die Schlüssel der einzelnen Dimensionen finden sich in der Faktentabelle wieder (referentielle Integrität), diese bilden in ihrer Gesamtheit den Primärschlüssel in der Faktentabelle Faktentabelle enthält weiterhin die Maße
, diese bilden in ihrer Gesamtheit den Primärschlüssel in der Faktentabelle. Faktentabelle enthält weiterhin die Maße.")
95
Datenbanken und Informationssysteme

96
Datenbanken und Informationssysteme
Problem: Zwischen Dimensionstabellen und Faktentabelle besteht eine 1:n –Beziehung (Primärschlüssel in Dimensionstabelle und dem Fremdschlüssel in der Faktentabelle). Faktentabelle kann daher nur mit solchen Dimensionen verbunden werden, für die sie auch Fremdschlüsselwerte enthält. Was geschieht, wenn zwei Maße nur mit einem Teil denselben Dimensionen verbunden sind, zum anderen Teil nicht?
. Faktentabelle kann daher nur mit solchen Dimensionen verbunden werden, für die sie auch Fremdschlüsselwerte enthält. Was geschieht, wenn zwei Maße nur mit einem Teil denselben Dimensionen verbunden sind, zum anderen Teil nicht")
97
Datenbanken und Informationssysteme
Beispiel (Chamoni/Gluchowski, S. 202) Datawarehouse für Marketing und Controlling Galaxie-Schema (vgl. nächste Folie)
 Datawarehouse für Marketing und Controlling. Galaxie-Schema (vgl. nächste Folie)")
98
Datenbanken und Informationssysteme

99
Datenbanken und Informationssysteme
Vorteile Star-Schema und Varianten Einfache und daher intuitive Datenmodelle Geringe Anzahl physischer Data Warehouse-Tabellen Geringe Anzahl Join-Operationen Geringer Aufwand im Rahmen der Data Warehouse-Wartung Nachteile Verschlechtertes Antwortzeitverhalten bei sehr großen Dimensionstabellen Redundanz innerhalb der Dimensionstabellen durch das mehrmalige Festhalten identischer Fakten Ein Problem des Sternschemas ist, dass Daten in den Dimensionstabellen über einen langen Zeitraum hinweg einen Bezug auf Daten in den Faktentabellen haben. Über die Zeit hinweg können aber auch Änderungen der Dimensionsdaten notwendig werden. Diese Änderungen dürfen sich aber in der Regel nicht auf Daten vor der Änderung auswirken. Wenn sich beispielsweise der Verkäufer für eine Produktgruppe ändert, dann darf der jeweilige Eintrag in der Dimensionstabelle nicht einfach überschrieben werden. Stattdessen muss ein neuer Eintrag generiert werden, da sonst die Verkaufszahlen des vorherigen Verkäufers nicht mehr feststellbar wären. Ein Konzept zur Vermeidung solcher Konflikte sind Slowly Changing Dimensions. (Quelle: Wikipedia)
")
100
Datenbanken und Informationssysteme
Schneeflocken-Schema

101
Datenbanken und Informationssysteme

102
Datenbanken und Informationssysteme
Vorige Abbildung heißt Schneeflocken-Schema modifizieren Star-Schema aus verschiedenen Gründen entsteht durch Attribut-Hierarchien entsteht durch Normalisierung (3.Normalform) Normalisierung von n:m Beziehungen durch explizite Verbindungstabellen (Sternschema bildet n:m- Beziehungen nicht explizit durch Verbindungstabellen ab, Faktentabelle enthält viel Redundanz)
 Normalisierung von n:m Beziehungen durch explizite. Verbindungstabellen (Sternschema bildet n:m- Beziehungen nicht explizit durch Verbindungstabellen ab, Faktentabelle enthält viel Redundanz)")
103
Datenbanken und Informationssysteme

104
Datenbanken und Informationssysteme
Aufgaben: 1. Lesen Sie in der Wikipedia die Artikel zu Data Warehouse, Data Mart, OLAP, CUBE, Sternschema, Schneeflockenschema. 2.Was versteht man unter einem Datenwürfel und warum ist eine Würfelsicht auf Daten im Zusammenhang mit OLAP angemessen? 3. Welche Operationen werden auf Datenwürfeln ausgeführt? 4.Was versteht man unter einer Fakten- und was unter einer Dimensionstabelle? 5.Was versteht man unter einem Stern- und was unter einem Schneeflockenschema.

105
Datenbanken und Informationssysteme
Aufgabe 6: Erstellen Sie aus dem folgendem ERM-Datenmodell (nächste Folie), das ein operatives System beschreibt, ein Sternschema für ein Data Warehouseprojekt. Ein Verkaufsleiter will Zeit-, Produkt-, Kunden-, Verkäufer- und Regionalvergleiche erstellen. Ausserdem möchte er wissen, ob das Kreditlimit, das Alter des Kunden oder der Zivilstand den Absatz beeinflussen. a. Tragen Sie die Fakten, Dimensionen und Kategorien (Dimensionsattribute) in ein Anforderungsdiagramm ein. Ordnen Sie die Dimensionstabellen um die Faktentabelle an und definieren Sie deren Beziehungen. Welche betriebswirtschaftlichen Fragestellungen sind von Interesse Aufgabe 7: Eigener Ausdruck (vgl. S:\DBS Master\Übungsaufgabe Modellierung Datawarehouse.doc bzw. P:\ )
, das ein operatives System beschreibt, ein Sternschema für ein Data Warehouseprojekt. Ein Verkaufsleiter will Zeit-, Produkt-, Kunden-, Verkäufer- und Regionalvergleiche erstellen. Ausserdem möchte er wissen, ob das Kreditlimit, das Alter des Kunden oder der Zivilstand den Absatz beeinflussen. a. Tragen Sie die Fakten, Dimensionen und Kategorien (Dimensionsattribute) in ein Anforderungsdiagramm ein. Ordnen Sie die Dimensionstabellen um die Faktentabelle an und definieren Sie deren Beziehungen. Welche betriebswirtschaftlichen Fragestellungen sind von Interesse. Aufgabe 7: Eigener Ausdruck (vgl. S:\DBS Master\Übungsaufgabe Modellierung Datawarehouse.doc bzw. P:\ )")
106
Datenbanken und Informationssysteme
1: enthält 2: ist enthalten 3: beinhaltet 4: haben 5: gehört

107
Datenbanken und Informationssysteme
Lösungen: 2. Ein Datenwürfel beschreibt den funktionalen Zusammenhang zwischen beispielsweise 3 Dimensionen und einem Fakt (Faktum) in der Form eines Würfels, der durch die Dimensionen aufgespannt wird und bei welchem jeder „Zelle“ ein Wert eines Faktums zugeordnet wird. Diese anschauliche Darstellung (Sicht), trägt der Unterscheidung zwischen Dimensionen und Fakten Rechnung, die im Rahmen von OLAP benötigt wird. Roll-Ups, Drill-Downs, Slice and Dice, Pivotisierung/ Rotation, Rankings. Roll-Ups sind Gruppierungen entlang der Dimensionen, Drill-Downs sind Degruppierungen. Slice and Dice dient der Selektion von Teilwürfeln, z.B. der Selektion horizontaler oder vertikaler Ebenen (2D-Projektionen oder einzelner Zellen, Rankings bilden Ranglisten z.B. Top 10. Pivoting bedeutet ein Drehen des Würfels durch Vertauschen der Dimensionen, Daten können durch unterschiedliche Perspektiven betrachtet werden.
 in der Form eines Würfels, der durch die Dimensionen aufgespannt wird und bei welchem jeder „Zelle ein Wert eines Faktums zugeordnet wird. Diese anschauliche Darstellung (Sicht), trägt der Unterscheidung zwischen Dimensionen und Fakten Rechnung, die im Rahmen von OLAP benötigt wird. Roll-Ups, Drill-Downs, Slice and Dice, Pivotisierung/ Rotation, Rankings. Roll-Ups sind Gruppierungen entlang der Dimensionen, Drill-Downs sind Degruppierungen. Slice and Dice dient der Selektion von Teilwürfeln, z.B. der Selektion horizontaler oder vertikaler Ebenen (2D-Projektionen oder einzelner Zellen, Rankings bilden Ranglisten z.B. Top 10. Pivoting bedeutet ein Drehen des Würfels durch Vertauschen der Dimensionen, Daten können durch unterschiedliche Perspektiven betrachtet werden.")
108
Datenbanken und Informationssysteme
Lösungen: Eine Dimensionstabelle enthält die Attribute (und die zugehörigen Werte) einer einzelnen Dimension, die in einem OLAP-Zusammenhang von Bedeutung ist, z.B. Produktinformationen, Orts- und Zeitinformation. Eine Faktentabelle enthält „Repräsentanten“ verschiedener Dimensionen (i.a. Schlüssel) und ordnet deren Kombination jeweils ein Faktum (Fakten) zu. 5. Bei einem Sternschema wird eine Faktentabelle zentral (als Mitte eines Stern) angeordnet, die zugehörigen Dimensionstabellen bilden die „Strahlen“ des Sterns. Die Faktentabelle steht dabei über Fremdschlüsselbeziehungen mit den Dimensionstabellen in Beziehung. Die Dimensionstabellen sind i.a. nicht normalisiert (z.B. nicht in 3NF). Falls man die Dimensionstabellen normalisiert, geht man über zu einem Schneeflockenschema.
 einer einzelnen Dimension, die in einem OLAP-Zusammenhang von Bedeutung ist, z.B. Produktinformationen, Orts- und Zeitinformation. Eine Faktentabelle enthält „Repräsentanten verschiedener Dimensionen (i.a. Schlüssel) und ordnet deren Kombination jeweils ein Faktum (Fakten) zu. 5. Bei einem Sternschema wird eine Faktentabelle zentral (als Mitte eines Stern) angeordnet, die zugehörigen Dimensionstabellen bilden die „Strahlen des Sterns. Die Faktentabelle steht dabei über Fremdschlüsselbeziehungen mit den Dimensionstabellen in Beziehung. Die Dimensionstabellen sind i.a. nicht normalisiert (z.B. nicht in 3NF). Falls man die Dimensionstabellen normalisiert, geht man über zu einem Schneeflockenschema.")
109
Datenbanken und Informationssysteme
Lösung zur Aufgabe 6:

110
Datenbanken und Informationssysteme
Sternenschema

111
Datenbanken und Informationssysteme
Lösung zu Aufgabe 7:

112
Datenbanken und Informationssysteme
OLAP /SQL/MDX

113
Datenbanken und Informationssysteme
Implementierungsansätze OLAP-Operationen SQL 3 (ROLLUP, CUBE, RANK, NTILE…..) MDX OLAP-Frontends (z.B. COGNOS, PANORAMA NOVAVIEW, EXCEL)
 MDX. OLAP-Frontends (z.B. COGNOS, PANORAMA. NOVAVIEW, EXCEL)")
114
Datenbanken und Informationssysteme
OLAP Operatoren von SQL:2003 (SQL3) ROLLUP-Operator - als Erweiterung der GROUP BY-Klausel realisiert Betrachte Zensus-Tabelle als Ausgangspunkt
 ROLLUP-Operator. - als Erweiterung der GROUP BY-Klausel realisiert. Betrachte Zensus-Tabelle als Ausgangspunkt.")
115
Datenbanken und Informationssysteme

116
Datenbanken und Informationssysteme
Select Bundesstaat, avg(Einkommen)as Durchschnittseinkommen From Zensus Group By Bundesstaat Ergebnis Bundesstaat Durchschnittseinkommen FL ,00 TX ,71
as Durchschnittseinkommen. From Zensus. Group By Bundesstaat. Ergebnis. Bundesstaat Durchschnittseinkommen. FL 35940,00. TX 36085,71.")
117
Datenbanken und Informationssysteme
ROLLUP erzeugte sogenannte Superaggregate für ausgewählte Gruppierungsspalten. Diese Supperaggregate sind eine Aggregation nach Dimensionen. Der ROLLUP-Operator eignet sich zum Generieren von Berichten, die Teilergebnisse und Gesamtwerte enthalten. Der ROLLUP-Operator generiert ein Resultset, das mit den vom CUBE-Operator generierten Resultsets vergleichbar ist. Unterschied Group By und Group By With Rollup durch nachstehendes Beispiel ersichtlich.

118
Datenbanken und Informationssysteme
Select Bundesstaat, avg(Einkommen)as Durchschnittseinkommen From Zensus Group By Bundesstaat With Rollup Ergebnis : Bundesstaat Durchschnittseinkommen FL ,00 TX ,71 NULL ,00 Generiert also alle Gruppen einschliesslich Gesamtwert (Nullprojektion)
as Durchschnittseinkommen. From Zensus. Group By Bundesstaat With Rollup. Ergebnis : Bundesstaat Durchschnittseinkommen. FL 35940,00. TX 36085,71. NULL 36000,00. Generiert also alle Gruppen einschliesslich Gesamtwert (Nullprojektion)")
119
Datenbanken und Informationssysteme
SELECT Bundesstaat, Landkreis, Ort, Count(*) as Bevölkerung, AVG(Einkommen) AS Durchschnittseinkommen FROM Zensus GROUP BY Bundesstaat, Landkreis, Ort Bundesstaat Landkreis Ort Bevölkerung Durchschnittseinkommen FL Dade NULL ,00 FL Dade Hialeh ,00 FL Dade Miami ,00 FL Orange Orlando ,00 FL Orange Taft ,00 TX Harris Baytown ,00 TX Harris Houston ,00 TX Travis NULL ,00 TX Travis Austin ,00 Gesamtzahl Gruppen 9
 as Bevölkerung, AVG(Einkommen) AS Durchschnittseinkommen. FROM Zensus. GROUP BY Bundesstaat, Landkreis, Ort. Bundesstaat Landkreis Ort Bevölkerung Durchschnittseinkommen. FL Dade NULL ,00. FL Dade Hialeh ,00. FL Dade Miami ,00. FL Orange Orlando ,00. FL Orange Taft ,00. TX Harris Baytown ,00. TX Harris Houston ,00. TX Travis NULL ,00. TX Travis Austin ,00. Gesamtzahl Gruppen 9.")
120
Datenbanken und Informationssysteme
Select Bundesstaat, Landkreis, Ort, Count(*) as Bevölkerung , AVG(Einkommen) AS Durchschnittseinkommen From Zensus Group By Bundesstaat, Landkreis, Ort WITH ROLLUP Bundesstaat Landkreis Ort Bevölkerung Durchschnittseinkommen FL Dade NULL ,00 (hier ist Ort = NULL) FL Dade Hialeh ,00 FL Dade Miami ,00 FL Dade NULL ,33 (Projektion in zwei Dimensionen) FL Orange Orlando ,00 FL Orange Taft ,00 FL Orange NULL ,00 FL NULL NULL ,00 (Projektion in eine Dimension) TX Harris Baytown ,00 TX Harris Houston ,00 TX Harris NULL ,00 TX Travis NULL ,00 TX Travis Austin ,00 TX Travis NULL ,66 TX NULL NULL ,71 NULL NULL NULL ,00 (Projektion in „keine“ Dimension) 16 Gruppen
 as Bevölkerung , AVG(Einkommen) AS Durchschnittseinkommen. From Zensus. Group By Bundesstaat, Landkreis, Ort WITH ROLLUP. Bundesstaat Landkreis Ort Bevölkerung Durchschnittseinkommen. FL Dade NULL ,00 (hier ist Ort = NULL) FL Dade Hialeh ,00. FL Dade Miami ,00. FL Dade NULL ,33 (Projektion in zwei Dimensionen) FL Orange Orlando ,00. FL Orange Taft ,00. FL Orange NULL ,00. FL NULL NULL ,00 (Projektion in eine Dimension) TX Harris Baytown ,00. TX Harris Houston ,00. TX Harris NULL ,00. TX Travis NULL ,00. TX Travis Austin ,00. TX Travis NULL ,66. TX NULL NULL ,71. NULL NULL NULL ,00 (Projektion in „keine Dimension) 16 Gruppen.")
121
Datenbanken und Informationssysteme
Problematik Erzeugt gleiche Zeilen bei Ort = Null und bei der Projektion in zwei Dimensionen Hilfe über die Grouping-Funktion

122
Datenbanken und Informationssysteme
GROUPING-Funktion Eine Aggregatfunktion, die die Ausgabe einer weiteren Spalte mit dem Wert 1 bewirkt, wenn die Zeile durch den CUBE- oder den ROLLUP-Operator hinzugefügt wird. Ist die Zeile nicht das Ergebnis des CUBE- oder ROLLUP-Operators, wird der Wert 0 ausgegeben. Die Gruppierung ist nur in der zu einer GROUP BY-Klausel zugeordneten Auswahlliste zulässig, die den CUBE- oder den ROLLUP-Operator enthält.

123
Datenbanken und Informationssysteme
Syntax am Beispiel SELECT Bundesstaat, Landkreis, Ort, Count(*) as Bevölkerung , AVG(Einkommen)as Durchschnittseinkommen, GROUPING(Ort) AS 'Grouping' FROM Zensus GROUP BY Bundesstaat, Landkreis, Ort WITH ROLLUP
 as Bevölkerung , AVG(Einkommen)as Durchschnittseinkommen, GROUPING(Ort) AS Grouping FROM Zensus. GROUP BY Bundesstaat, Landkreis, Ort WITH ROLLUP.")
124
Datenbanken und Informationssysteme
Bundesstaat Landkreis Ort Bevölkerung Durchschnittseinkommen Grouping FL Dade NULL , FL Dade Hialeh , FL Dade Miami , FL Dade NULL , FL Orange Orlando , FL Orange Taft , FL Orange NULL , FL NULL NULL , TX Harris Baytown , TX Harris Houston , TX Harris NULL , TX Travis NULL , TX Travis Austin , TX Travis NULL , TX NULL NULL , NULL NULL NULL , 16 Gruppen (7 Gruppen durch Rollup generiert)
")
125
Datenbanken und Informationssysteme
ROLLUP und COMPUTE BY-Befehl Select Bundesstaat, avg(Einkommen)as Durchschnittseinkommen From Zensus Group By Bundesstaat With Rollup Select Bundesstaat, Einkommen ORDER BY Bundesstaat Compute AVG (Einkommen) BY Bundesstaat Das Resultset einer ROLLUP-Operation verfügt über einen vergleichbaren Funktionsumfang wie das Resultset, das von einer COMPUTE BY-Operation zurückgegeben wird. ROLLUP weist jedoch die folgenden Vorteile auf: ROLLUP gibt ein einzelnes Resultset zurück, während COMPUTE BY mehrere Resultsets zurückgibt, was die Komplexität von Anwendungscode erhöht. ROLLUP kann in einem Servercursor verwendet werden, COMPUTE BY hingegen nicht. Teilweise kann der Abfrageoptimierer effizientere Ausführungspläne für ROLLUP als für COMPUTE BY generieren.
as Durchschnittseinkommen. From Zensus. Group By Bundesstaat With Rollup. Select Bundesstaat, Einkommen. ORDER BY Bundesstaat. Compute AVG (Einkommen) BY Bundesstaat. Das Resultset einer ROLLUP-Operation verfügt über einen vergleichbaren Funktionsumfang wie das Resultset, das von einer COMPUTE BY-Operation zurückgegeben wird. ROLLUP weist jedoch die folgenden Vorteile auf: ROLLUP gibt ein einzelnes Resultset zurück, während COMPUTE BY mehrere Resultsets zurückgibt, was die Komplexität von Anwendungscode erhöht. ROLLUP kann in einem Servercursor verwendet werden, COMPUTE BY hingegen nicht. Teilweise kann der Abfrageoptimierer effizientere Ausführungspläne für ROLLUP als für COMPUTE BY generieren.")
126
Datenbanken und Informationssysteme
CUBE-Operator Cube-Operator verallgemeinert ROLLUP-Operator, indem er ihn auf alle 2d Aggregationen für d gegebene Dimensionen simultan anwendet. Die Realisation lautet: SELECT FROM WHERE GROUP BY WITH CUBE Hinweis: Für den CUBE-Befehl Verwendung einer anderen Faktentabelle, die keine Nullwerte enthält.

127
Datenbanken und Informationssysteme

128
Datenbanken und Informationssysteme
SELECT Modell, Jahr, Farbe, SUM(Verkäufe) AS Verkäufe FROM Autoverkäufe GROUP BY Modell, Jahr, Farbe WITH CUBE Diese Formulierung ist die abkürzende Schreibweise für folgende Folgen von GROUP-BY-Befehlen
 AS Verkäufe. FROM Autoverkäufe. GROUP BY Modell, Jahr, Farbe WITH CUBE. Diese Formulierung ist die abkürzende Schreibweise für folgende Folgen von GROUP-BY-Befehlen.")
129
Datenbanken und Informationssysteme
Select Modell, Jahr, Farbe, Verkäufe From Autoverkäufe UNION Select Modell, Jahr, Sum(Verkäufe) As Verkäufe Group By (Modell, Jahr) Group By (Modell, Farbe) Group By (Jahr, Farbe) Group By (Modell)
 As Verkäufe. Group By (Modell, Jahr) Group By (Modell, Farbe) Group By (Jahr, Farbe) Group By (Modell)")
130
Datenbanken und Informationssysteme
UNION Select Modell, Jahr, Sum(Verkäufe) As Verkäufe From Autoverkäufe Group By (Jahr) Group By (Farbe) Select ‚Alle‘, ‚Alle‘, ‚Alle‘, sum (Verkäufe) As Verkäufe
 As Verkäufe. From Autoverkäufe. Group By (Jahr) Group By (Farbe) Select ‚Alle‘, ‚Alle‘, ‚Alle‘, sum (Verkäufe) As Verkäufe.")
131
Datenbanken und Informationssysteme
Hat die SELECT-Liste n Attribute der Kardinalität C1,..., Cn, so hat die resultierende Cube-Relation π (Ci +1) mit i = 1,..,n Im Beispiel also: 3 * 4 * 4 = 48 Zeilen
 mit i = 1,..,n. Im Beispiel also: 3 * 4 * 4 = 48 Zeilen.")
132
Datenbanken und Informationssysteme
Effiziente Speicherung von Faktentabellen (Bit-Map-Index) Betrachte Autoverkäufe: Unterstellt man, daß nur die Autos „Chevy“ und „Ford“ vorkommen, daß nur die Jahre 190,1991, 1992 existieren und nur die Farben „rot“, „weiß“, „blau“ bei den Autos als Lackierung zulässig sind, so kann man z.B. das Tupel (Chevy, 1990, rot) durch folgenden Bit-Vektor darstellen: (1,0,1,0,0,1,0,0)
 Betrachte Autoverkäufe: Unterstellt man, daß nur die Autos „Chevy und „Ford vorkommen, daß nur die Jahre 190,1991, 1992 existieren und nur die Farben „rot , „weiß , „blau bei den Autos als Lackierung zulässig sind, so kann man z.B. das Tupel (Chevy, 1990, rot) durch folgenden Bit-Vektor darstellen: (1,0,1,0,0,1,0,0)")
133
Datenbanken und Informationssysteme

134
Datenbanken und Informationssysteme
SELECT * FROM Verkäufe WHERE Jahr = 1991 AND Farbe = ‘Weiss‘ Wird übersetzt in Boolesches UND der Spalten 4 und 7, liefert dann die Tupel-Identifier (TID) 5 und 14
 5 und 14.")
135
Datenbanken und Informationssysteme
Übungsaufgabe: Betrachte folgenden View aus Versandhandel Riemenschneider ERWEITERTE_BESTELLDATEN mit folgenden Spalten Bestell-Nr, Artikel_Nr, Kunde, Kategorie, Anzahl SQL Befehl: Create View Erweiterte_Bestelldaten AS SELECT Bestelldaten.Bestell_Nr, Bestelldaten.Artikel_Nr, Kunden.Kunden_Nr, Artikel.Kategorie, Bestelldaten.Anzahl FROM Bestelldaten, Artikel, Kunden, Bestellungen WHERE Bestelldaten.Artikel_Nr = Artikel.Artikel_Nr AND Kunden.Kunden_Nr = Bestellungen.Kunden_Nr AND Bestelldaten.Bestell_Nr = Bestellungen.Bestell_Nr

136
Datenbanken und Informationssysteme
Aufgabe 1: Wie viele Artikel hat jeder Kunde bestellt? Aufgabe 2: Wie viele Artikel hat jeder Kunde und wie viele Artikel wurden insgesamt bestellt? Aufgabe 3: Wie viele Artikel hat jeder Kunde in den unterschiedlichen Kategorien bestellt. Aufgabe 4: Verdichtung nach allen Dimensionen

137
Datenbanken und Informationssysteme
SELECT Kunden_nr, SUM (Anzahl) FROM Erweiterte_Bestelldaten GROUP BY Kunden_nr ORDER BY Kunden_nr GROUP BY Kunden_nr WITH ROLLUP
 FROM Erweiterte_Bestelldaten. GROUP BY Kunden_nr. ORDER BY Kunden_nr. GROUP BY Kunden_nr WITH ROLLUP.")
138
Datenbanken und Informationssysteme
Select Kunden_nr, Kategorie, Artikel_Nr, Sum (anzahl) FROM Erweiterte_Bestelldaten Group By Kunden_nr, Kategorie, Artikel_Nr with Rollup ORDER BY Kunden_nr from Erweiterte_Bestelldaten Group By Kunden_nr, Kategorie, Artikel_Nr with cube
 FROM Erweiterte_Bestelldaten. Group By Kunden_nr, Kategorie, Artikel_Nr with Rollup. ORDER BY Kunden_nr. from Erweiterte_Bestelldaten. Group By Kunden_nr, Kategorie, Artikel_Nr with cube.")
139
Datenbanken und Informationssysteme
Wiederholung (Auftragsdatenbank): 1. Wie ist der Umsatzwert für jedes Land in jedem Preissegment und in jeder Kategorie 2. Wieviele Zeilen produziert diese Abfrage 3. Wieviele Zeilen wird der Rollup-Operator produzieren (Begründung!!!) 4. Wieviele Zeilen wird der CUBE-Operator produzieren, eine Abschätzung (Obere Schranke) genügt!! (Begründung!!!)
: 1. Wie ist der Umsatzwert für jedes Land in jedem Preissegment und in jeder Kategorie. 2. Wieviele Zeilen produziert diese Abfrage. 3. Wieviele Zeilen wird der Rollup-Operator produzieren (Begründung!!!) 4. Wieviele Zeilen wird der CUBE-Operator produzieren, eine Abschätzung (Obere Schranke) genügt!! (Begründung!!!)")
140
Datenbanken und Informationssysteme
Lösung SELECT Land, Preis, Kategorie, ROW_NUMBER OVER (ORDER BY, Land, Preis, Kategorie) FROM Auftragsdaten GROUP BY Land, Preis, Kategorie 97 97 + Kardinalität von {(Land, Preis)} + Kardinalität von { (Land)} + 1 (Nullprojektion) = 126 3a Begründung: Kardinalität von {(Land, Preis)} = 21, Kardinalität von { (Land)} = 7 97 + Produktformel aus Vorlesung (siehe CUBE-Operator) 4a hier: 8*4*8 (Anzahl Länder = 7, Anzahl Preis = 3, Anzahl Kategorie = 7), also hier = 256 (exakt sind es 196 Zeilen)
 FROM Auftragsdaten. GROUP BY Land, Preis, Kategorie Kardinalität von {(Land, Preis)} + Kardinalität von { (Land)} + 1 (Nullprojektion) = a Begründung: Kardinalität von {(Land, Preis)} = 21, Kardinalität von. { (Land)} = Produktformel aus Vorlesung (siehe CUBE-Operator) 4a hier: 8*4*8 (Anzahl Länder = 7, Anzahl Preis = 3, Anzahl Kategorie = 7), also hier = 256 (exakt sind es 196 Zeilen)")
141
Datenbanken und Informationssysteme
Rangfolgefunktionen Rangfolgefunktionen ermöglichen die Rückgabe eines Rangfolgewertes für jede Zeile im Abfrageergebnis. ROW_NUMBER (fügt dem Abfrageergebnis eine Spalte mit einer Zeilennummer hinzu) RANK (Abfrageergebnis kann mit einer Rangspalte versehen werden) DENSE_RANK NTILE (Abfrageergebnissen können Gruppennummern hinzugefügt werden) Beispielsdaten: Auftragsdatenbank (3300 Zeilen)
 RANK (Abfrageergebnis kann mit einer Rangspalte versehen werden) DENSE_RANK. NTILE (Abfrageergebnissen können Gruppennummern hinzugefügt werden) Beispielsdaten: Auftragsdatenbank (3300 Zeilen)")
142
Datenbanken und Informationssysteme
ROW-NUMBER SELECT Land, Preis, SUM(Brutto) AS Umsatz, ROW_NUMBER() OVER (ORDER BY SUM(BRUTTO) DESC) AS Rang FROM Auftragsdaten GROUP BY Land, Preis ORDER By Land ORDER By Rang
 AS Umsatz, ROW_NUMBER() OVER (ORDER BY SUM(BRUTTO) DESC) AS Rang. FROM Auftragsdaten. GROUP BY Land, Preis. ORDER By Land. ORDER By Rang.")
143
Datenbanken und Informationssysteme
RANK/DENSE_RANK: ROW_NUMBER nummeriert fortlaufend, nicht geeignet wenn Werte gleich sind. RANK() nimmt ein Ranking vor. Sind Werte gleich, so erhalten sie den gleichen Rangplatz. Sind beispielsweise drei Werte gleich, so erhält das darauffolgende Element den Rangplatz, der um (3 +1) weitergeschaltet ist. DENSE_RANK schaltet bei vorstehendem Beispiel nur um 1 weiter. SELECT Datum, Land,Kategorie, Einheiten, Listenpreis, RANK() OVER (ORDER BY Listenpreis) AS Rang FROM Auftragsdaten SELECT Datum, Land, Kategorie, Einheiten, Listenpreis, DENSE_RANK() OVER (ORDER BY Listenpreis) AS Dense_Rang
 nimmt ein Ranking vor. Sind Werte gleich, so erhalten sie den gleichen Rangplatz. Sind beispielsweise drei Werte gleich, so erhält das darauffolgende Element den Rangplatz, der um (3 +1) weitergeschaltet ist. DENSE_RANK schaltet bei vorstehendem Beispiel nur um 1 weiter. SELECT Datum, Land,Kategorie, Einheiten, Listenpreis, RANK() OVER (ORDER BY Listenpreis) AS Rang. FROM Auftragsdaten. SELECT Datum, Land, Kategorie, Einheiten, Listenpreis, DENSE_RANK() OVER (ORDER BY Listenpreis) AS Dense_Rang.")
144
Datenbanken und Informationssysteme
NTILE fasst Datensätze zu einer vorgegebenen Anzahl von Gruppen zusammen (nach Möglichkeit gleichgrosse Gruppen). SELECT NTILE(10) OVER (ORDER BY Listenpreis) AS Gruppe, Datum, Land,Kategorie, Einheiten, Listenpreis FROM Auftragsdaten
. SELECT NTILE(10) OVER (ORDER BY Listenpreis) AS Gruppe, Datum, Land,Kategorie, Einheiten, Listenpreis FROM Auftragsdaten.")
145
Datenbanken und Informationssysteme
MDX MultiDimensional eXpressions (MDX) ist eine spezielle Datenbanksprache für OLAP. Seit 1997 von Microsoft entwickelt, heute weitgehend als Standard etabliert. Leistungsumfang: MDX hat Skripting-Funktionalität MDX kann als Datenmanipulationssprache eingesetzt werden. 3. MDX kann als Datendefinitionssprache verwendet 4. MDX-Funktionen (ca. 100)
 ist eine spezielle Datenbanksprache für OLAP. Seit 1997 von Microsoft entwickelt, heute weitgehend als Standard etabliert. Leistungsumfang: MDX hat Skripting-Funktionalität. MDX kann als Datenmanipulationssprache eingesetzt. werden. 3. MDX kann als Datendefinitionssprache verwendet. 4. MDX-Funktionen (ca. 100)")
146
Datenbanken und Informationssysteme
Grundgerüst einer Abfrage Zeige im CUBE Aufträge für alle Länder in der Preiskategorie „Hoch“, „Mittel“, „Niedrig“ die kumulierten Bruttoumsatzzahlen. MDX SELECT { ( [DIM Region]. [Land ] ) } ON ROWS, { ( [DIM Artikel]. [Preiskategorie]. [HOCH]: [DIM Artikel]. [Preiskategorie]. [NIEDRIG] ) } ON COLUMNS, FROM Aufträge WHERE [MEASURES].[BRUTTO]
 } ON ROWS, { ( [DIM Artikel]. [Preiskategorie]. [HOCH]: [DIM Artikel]. [Preiskategorie]. [NIEDRIG] ) } ON COLUMNS, FROM Aufträge. WHERE [MEASURES].[BRUTTO]")
147
Datenbanken und Informationssysteme
MDX

148
Datenbanken und Informationssysteme
OLAP-Tutorium

149
Datenbanken und Informationssysteme Praktische Übungen zu Data Warehousing
Inhalte: Integration von Daten in eine SQL Server – Datenbank. Vorgehen bei der Erstellung eines Data Warehouse mittels Business Intelligence Development Studio. Erstellen eines Data Warehouse und Datenanalyse am Beispiel der Versandhandelsdatenbank und der Datenbank DW1fach.

150
Datenbanken und Informationssysteme Praktische Übungen zu Data Warehousing
Datenintegration Verwendung von INSERT XML-Datei SQL-Server Verwendung von ODBC und MS-Access EXCEL-Tabelle SQL-Server BLOB (.doc, .wav, .bmp, .mp3, .ppt, ….) SQL-Server Verwendung von OLEDB, ADODB, .NET, …. Verwendung von SSIS(DTS-Import-Assistent)
 SQL-Server. Verwendung von OLEDB, ADODB, .NET, …. Verwendung von SSIS(DTS-Import-Assistent)")
151
Datenbanken und Informationssysteme Praktische Übungen zu Data Warehousing
Datenintegration Übungsaufgabe 1: Datenintegration Übernehmen Sie die Daten der Datei Telefonliste.txt mittels ODBC in eine SQL-Server-Tabelle Telefonliste_xx der Datenbank PI_Master.

152
Aufbau eines Data Warehouse und Datenanalyse
Datenbanken und Informationssysteme Praktische Übungen zu Data Warehousing Aufbau eines Data Warehouse und Datenanalyse Erstellen eines Data Warehouse für SQL Server mittels Business Intelligence Development Studio Neues Projekt anlegen Datenquellen definieren Datenquellensicht definieren Cube erstellen Anpassen des Cubes mittels des Cube-Designers Bereitstellen des Cubes Auswerten des Cubes mittels des Cube-Browsers.

153
Aufbau eines Data Warehouse und Datenanalyse
Datenbanken und Informationssysteme Praktische Übungen zu Data Warehousing Aufbau eines Data Warehouse und Datenanalyse Der Cube wird in XML- und Binärdateien gespeichert. Über Management Studio werden die Rechte für den Zugriff auf den Cube vergeben. Ein Endanwender kann z.B. mittels EXCEL auf den Cube zugreifen und Datenanalysen durchführen.

154
Aufbau eines Data Warehouse und Datenanalyse
Datenbanken und Informationssysteme Praktische Übungen zu Data Warehousing Aufbau eines Data Warehouse und Datenanalyse Data Warehouse für die Versandhandelsdatenbank Typische Fragestellungen: Welcher Umsatz wurde in den verschiedenen Kategorien pro Monat des Jahres 2006 mit weiblichen Kunden aus den verschiedenen Wohnorten erzielt? Wie hat sich der Umsatz mit einem bestimmten Kunden über einen gewissen Zeitraum entwickelt? Dimensionen: Artikel (Artikel_Nr, Bezeichnung, Kategorie, Preis) Kunde (Kunden_Nr, Name, Anrede, Wohnort) Zeit (Bestelldatum, Monat, Quartal, Jahr) Faktentabelle: Bestell_Nr, Artikel_Nr, Kunden_Nr, Bestelldatum und den Measures Anzahl und Gesamtpreis
 Kunde (Kunden_Nr, Name, Anrede, Wohnort) Zeit (Bestelldatum, Monat, Quartal, Jahr) Faktentabelle: Bestell_Nr, Artikel_Nr, Kunden_Nr, Bestelldatum und den Measures Anzahl und Gesamtpreis.")
155
Aufbau eines Data Warehouse und Datenanalyse
Datenbanken und Informationssysteme Praktische Übungen zu Data Warehousing Aufbau eines Data Warehouse und Datenanalyse Data Warehouse für die Versandhandelsdatenbank Es ergibt sich offenbar ein Sternschema. Dabei basieren zwei Dimensionen auf Tabellen der relationalen Datenbank, die dritte wird bei der Realisierung als so genannte Serverzeitdimension erstellt. Die Faktentabelle wird mittels eines Joins über die Tabellen Bestelldaten, Bestellungen, Artikel, Kunden als Tabelle Fakten_Versandhandel erstellt.

156
Aufbau eines Data Warehouse und Datenanalyse
Datenbanken und Informationssysteme Praktische Übungen zu Data Warehousing Aufbau eines Data Warehouse und Datenanalyse Data Warehouse für die Versandhandelsdatenbank create table Fakten_Versandhandel (Bestell_Nr int not null, Artikel_Nr int not null, Kunden_Nr int not null, Bestelldatum smalldatetime not null, Anzahl smallint not null, Gesamtpreis money not null) insert into Fakten_Versandhandel select bd.artikel_nr,bd.bestell_nr,k.kunden_nr,bestelldatum,anzahl, anzahl*preis from bestelldaten bd,bestellungen b,kunden k,artikel a where bd.bestell_nr=b.bestell_nr and b.kunden_nr=k.kunden_nr and bd.artikel_nr=a.artikel_nr
 insert into Fakten_Versandhandel. select bd.artikel_nr,bd.bestell_nr,k.kunden_nr,bestelldatum,anzahl, anzahl*preis. from bestelldaten bd,bestellungen b,kunden k,artikel a. where bd.bestell_nr=b.bestell_nr and b.kunden_nr=k.kunden_nr and. bd.artikel_nr=a.artikel_nr.")
157
Aufbau eines Data Warehouse und Datenanalyse
Datenbanken und Informationssysteme Praktische Übungen zu Data Warehousing Aufbau eines Data Warehouse und Datenanalyse Data Warehouse für die Versandhandelsdatenbank Vorführung der Implementierung des Data Warehouse für die Versandhandelsdatenbank mittels Business Intelligence Development Studio. Vorführung der Datenanalyse mittels Cube-Browser. Vorführung der Datenanalyse mittels EXCEL.

158
Aufbau eines Data Warehouse und Datenanalyse
Datenbanken und Informationssysteme Praktische Übungen zu Data Warehousing Aufbau eines Data Warehouse und Datenanalyse Übungsaufgabe 2: Aufbau eines Data Warehouse für die Datenbank DW1fach Schritt 1: Machen Sie sich mit den Tabellen der Datenbank DW1fach vertraut. Sichten Sie die Tabellen. Identifizieren Sie die Primärschlüssel. Skizzieren Sie ein Diagramm, das die Beziehungen zwischen den Tabellen aufzeigt.

159
Aufbau eines Data Warehouse und Datenanalyse
Datenbanken und Informationssysteme Praktische Übungen zu Data Warehousing Aufbau eines Data Warehouse und Datenanalyse Übungsaufgabe 2: Aufbau eines Data Warehouse für die Datenbank DW1fach Schritt 2: Es soll ein Data Warehouse für DW1fach entworfen werden. Formulieren Sie typische Fragestellungen des Managements, die bei der Datenanalyse beantwortet werden sollen. Welche Dimensionen und Measures erscheinen Ihnen sinnvoll? Welche Faktentabelle(n) verwenden Sie? Welche Dimensionstabellen benutzen Sie, welche Attribute dieser Tabellen erscheinen für die zugehörige Dimension sinnvoll? Skizzieren Sie als Ergebnis Ihrer Überlegungen ein Schema, das Ihre Überlegungen widerspiegelt.
 verwenden Sie Welche Dimensionstabellen benutzen Sie, welche Attribute dieser Tabellen erscheinen für die zugehörige Dimension sinnvoll Skizzieren Sie als Ergebnis Ihrer Überlegungen ein Schema, das Ihre. Überlegungen widerspiegelt.")
160
Aufbau eines Data Warehouse und Datenanalyse
Datenbanken und Informationssysteme Praktische Übungen zu Data Warehousing Aufbau eines Data Warehouse und Datenanalyse Übungsaufgabe 2: Aufbau eines Data Warehouse für die Datenbank DW1fach Schritt 3: Das in Schritt 2 entworfene Data Warehouse soll implementiert werden. Implementieren Sie mittels Business Intelligence Development Studio ein Data Warehouse DW1fach_OLAPxx für DW1fach. Beantworten Sie einige typische Fragestellungen des Managements mit Hilfe des Cube-Browsers. Binden Sie den Cube in eine EXCEL-Tabelle ein und beantworten Sie einige typische Fragestellungen des Managements.

161
Aufbau eines Data Warehouse und Datenanalyse
Datenbanken und Informationssysteme Praktische Übungen zu Data Warehousing Aufbau eines Data Warehouse und Datenanalyse Übungsaufgabe 2: Aufbau eines Data Warehouse für die Datenbank DW1fach Lösungen zu Schritt 2: Fragestellungen: Wie hat sich der Umsatz für die Warengruppe Wein in den Jahren 2004 und 2005 pro Region entwickelt? Wie verhält sich der Jahresumsatz pro Mitarbeiter in den Jahren 2004 und 2005 zu dem entsprechenden Jahresgehalt? Schema(Galaxie): Nächste Folie.
: Nächste Folie.")
163
Datenbanken und Informationssysteme
Data Warehouse- Architektur

164
Datenbanken und Informationssysteme
1. Anforderungen an Data Warehousing 2. Referenzarchitektur

165
Datenbanken und Informationssysteme
Anforderungen des Data Warehousing - Unabhängigkeit zwischen Datenquellen und Analysesystem bezüglich Verfügbarkeit, Belastung, laufender Änderung - Dauerhafte Bereitstellung integrierter und abgeleiteter Daten - Mehrfachverwendung der bereitgestellten Daten - Möglichkeit der Durchführung prinzipiell beliebiger Auswertungen (Analysebedürfnisse der Nutzer)
")
166
Datenbanken und Informationssysteme
Anforderungen des Data Warehousing - Unterstützung individueller Sichten (bzgl. Zeithorizont, Struktur) - Möglichkeit der Integration neuer Datenquellen - Automation der Abläufe - Eindeutigkeit über Datenstrukturen, Zugriffsberechtigungen und Prozesse - Ausrichtung an den Geschäftszielen des Unternehmens
 - Möglichkeit der Integration neuer Datenquellen. - Automation der Abläufe. - Eindeutigkeit über Datenstrukturen, Zugriffsberechtigungen und Prozesse. - Ausrichtung an den Geschäftszielen des Unternehmens.")
167
Datenbanken und Informationssysteme
Geschäftsziele: Welche Geschäftsziele verfolgt die Abteilung, die das Data Warehouse einsetzen will Welche Indikatoren messen den Erfolg der Abteilung Welche Risiken sind mit der Geschäftstätigkeit verbunden Welche Merkmale dienen der Früherkennung von Risiken Wie innovativ ist die Geschäftstätigkeit?

168
Datenbanken und Informationssysteme
Analysebedürfnisse: Wie gross ist der Anteil der Routine- bzw. Ad hoc-Analysen? Wie gross ist der Anteil der historischen Auswertungen Welche Datenquellen haben die Abteilungen (informelle Quellen)
")
169
Datenbanken und Informationssysteme

170
Datenbanken und Informationssysteme
Referenzarchitektur

171
Datenbanken und Informationssysteme
Data-Warehouse-Manager - Zentrale Komponente eines Data Warehouse- Systems - Initiierung, Steuerung und Überwachung der einzelnen Prozesse - Initiierung des Datenbeschaffungsprozesses - in regelmäßigen Zeitabständen - bei Änderung einer Quelle - explizite Anforderung

172
Datenbanken und Informationssysteme
Data-Warehouse-Manager - Nach Auslösen des Ladeprozesses: - Überwachung weiterer Schritte - Koordination der Reihenfolge der Verarbeitung - Fehlerfall - Dokumentation von Fehlern - Wiederanlaufmechanismen - Zugriff auf Metadaten aus dem Repository

173
Datenbanken und Informationssysteme
Datenquellen - interne operative Daten - externe Daten (Internet, Branchendaten) Alle Daten, die in das Data Warehouse integriert werden müssen, unterliegen einem sogenannten Transformationsprozess (Schlagwort ETL mit E = Extract, T = Transformation, L = Loading). Der Transformationsprozess umfaßt dabei alle Aktivitäten zur Umwandlung der operativen Daten in betriebswirtschaftlich interpretierbare Daten. Dabei sind die nachstehenden Teilprozesse zu durchlaufen.
 Alle Daten, die in das Data Warehouse integriert werden müssen, unterliegen einem sogenannten Transformationsprozess (Schlagwort ETL mit E = Extract, T = Transformation, L = Loading). Der Transformationsprozess umfaßt dabei alle Aktivitäten zur Umwandlung der operativen Daten in betriebswirtschaftlich interpretierbare Daten. Dabei sind die nachstehenden Teilprozesse zu durchlaufen.")
174
Datenbanken und Informationssysteme Transformation der operativen Daten

175
Datenbanken und Informationssysteme

176
Datenbanken und Informationssysteme
Erste Transformationsschicht – Filterung

177
Datenbanken und Informationssysteme
Bereinigung und Filterung dient der Befreiung der extrahierten Daten sowohl von syntaktischen und semantischen Mängeln. Unter syntaktischen Mängeln sind formelle Mängel in der codetechnischen Darstellung zu verstehen. Semantische Mängel betreffen Mängel in den betriebswirtschaftlichen Inhalten der Daten

178
Datenbanken und Informationssysteme

179
Datenbanken und Informationssysteme
Harmonisierung Harmonisierung stellt die zweite Schicht der Transformation dar. Zwei Arten der Harmonisierung werden dabei unterschieden: Syntaktische Harmonisierung Betriebswirtschaftliche Harmonisierung Operative und externe Datenbestände weisen in der Regel eine hohe Heterogenität auf. Bei der syntaktischen Harmonisierung werden Schlüsseldisharmonien, Probleme unterschiedlicher Daten, Synonyme und Homonyme behandelt.

180
Datenbanken und Informationssysteme

181
Datenbanken und Informationssysteme

182
Datenbanken und Informationssysteme
Schlüsseldisharmonien entstehen durch unterschiedliche operative Anwendungssysteme, die meistens historisch zu unterschiedlichen Zeitpunkten entwickelt wurden. Lösung für voriges Beispiel: Entwicklung einer Zuordnungstabelle, die für jeden Kunden einen neuen künstlichen Primärschlüssel generiert und die Primärschlüssel der operativen Systeme mitführt, sodass übergreifende Auswertungen möglich sind.

183
Datenbanken und Informationssysteme

184
Datenbanken und Informationssysteme
Betriebswirtschaftliche Harmonisierung Hier werden die beiden Punkte Abgleich der betriebswirtschaftlichen Kennziffern sowie die Festlegung der gewünschten Granularität behandelt. Dies bedeutet Implementierung von Transformationsregeln, die das operative Datenmaterial in Bezug auf die betriebswirtschaftliche Bedeutung, die gebiets- und ressortspezifische Gültigkeit, die Währung oder die Periodenzuordnung in einheitliche Werte überführen.

185
Datenbanken und Informationssysteme
Betriebswirtschaftliche Harmonisierung (Fortsetzung) Granularität Granularität (Maß für die Feinkörnigkeit eines Systems, bei DWH Zeitraumbezug) Beispiel: Sollen beispielsweise tagesaktuelle Werte auf Basis von Produkt- bzw. Kundengruppen die detailliertesten Daten eines DWH bilden, sind sämtliche Einzelbelege über Aggregationsmechanismen zu tagesaktuellen, produktgruppen- und kundengruppenspezifischen Werten zusammenzufassen.
 Granularität. Granularität (Maß für die Feinkörnigkeit eines Systems, bei DWH Zeitraumbezug) Beispiel: Sollen beispielsweise tagesaktuelle Werte auf Basis von Produkt- bzw. Kundengruppen die detailliertesten Daten eines DWH bilden, sind sämtliche Einzelbelege über Aggregationsmechanismen zu tagesaktuellen, produktgruppen- und kundengruppenspezifischen Werten zusammenzufassen.")
186
Datenbanken und Informationssysteme
Aggregation Die dritte Transformationsschicht ist die Aggregation (vgl. nächste Folie). In dieser Phase werden die gefilterten und harmonisierten Daten um Verdichtungsstrukturen erweitert. Dazu werden Dimensionshiearchietabellen entwickelt. Beispiele: Kunde, Kundengruppe, Gesamt Produkt, Produktuntergruppe, Produkthauptgruppe,Gesamt Abteilungszugehörigkeit, Gesamt Generelle Problematik: Historische Änderungen z.B. Artikeländerungen, Kundennamenwechsel, Neue Abteilungen
. In dieser Phase werden die gefilterten und harmonisierten Daten um Verdichtungsstrukturen erweitert. Dazu werden Dimensionshiearchietabellen entwickelt. Beispiele: Kunde, Kundengruppe, Gesamt. Produkt, Produktuntergruppe, Produkthauptgruppe,Gesamt. Abteilungszugehörigkeit, Gesamt. Generelle Problematik: Historische Änderungen z.B. Artikeländerungen, Kundennamenwechsel, Neue Abteilungen.")
187
Datenbanken und Informationssysteme

188
Datenbanken und Informationssysteme

189
Datenbanken und Informationssysteme
Aktualisierungsproblematik Echtzeit-Aktualisierung Aktualisierung in periodischen Zeitabständen Aktualisierung in Abhängigkeit der Änderungsquantität Vorteile/Nachteile

190
Datenbanken und Informationssysteme
Überblick Integration Services im SQL Server 2005 (SSIS) Vorläufer DTS (Data Transformation Services) Verbindung zu operativen Systemen über OLE DB (ODBC, FTP) Implementierung von Workflowmodellen
 Vorläufer DTS (Data Transformation Services) Verbindung zu operativen Systemen über OLE DB (ODBC, FTP) Implementierung von Workflowmodellen.")
191
Datenbanken und Informationssysteme
Tools für Integration Services Import/Export-Assistent für Datenmigration DTSRun für Administratoren (Kommandozeilenmodus) DTSRunUI (Graphische Komponente) SQL-Agent zur zeitlichen Steuerung von Batch-Jobs
 DTSRunUI (Graphische Komponente) SQL-Agent zur zeitlichen Steuerung von Batch-Jobs.")
192
Datenbanken und Informationssysteme
Abschlussfallstudie aus Kemper et al. S.72 Unterlagen als Kopie auf Laufwerk P, Manuskriptname Fallstudie BI.PDF

193
Datenbanken und Informationssysteme
Data Mining

194
Datenbanken und Informationssysteme
Unter Data-Mining versteht man die Anwendung von (statistisch-mathematischen) Methoden auf einen Datenbestand mit dem Ziel der Mustererkennung. Dabei finden insbesondere solche Methoden Anwendung, die hervorragende asymptotische Laufzeiten haben, weshalb Data-Mining oft im Zusammenhang mit großen Datenbeständen genannt wird. Gleichwohl ergeben sich durch den Verzicht auf Modellannahmen über den Datenentstehungsprozess auch bei kleinen Datenbeständen interessante Anwendungsmöglichkeiten. In Abgrenzung zum Knowledge Discovery in Databases findet beim Data Mining keine Bewertung der Ergebnisse statt, etwa auf Bekanntheit von Mustern oder Trivialitäten. Daher kann Data Mining als ein (zentraler) Baustein im Knowledge Discovery in Databases gesehen werden . Quelle: Wikipedia
 Methoden auf einen Datenbestand mit dem Ziel der Mustererkennung. Dabei finden insbesondere solche Methoden Anwendung, die hervorragende asymptotische Laufzeiten haben, weshalb Data-Mining oft im Zusammenhang mit großen Datenbeständen genannt wird. Gleichwohl ergeben sich durch den Verzicht auf Modellannahmen über den Datenentstehungsprozess auch bei kleinen Datenbeständen interessante Anwendungsmöglichkeiten. In Abgrenzung zum Knowledge Discovery in Databases findet beim Data Mining keine Bewertung der Ergebnisse statt, etwa auf Bekanntheit von Mustern oder Trivialitäten. Daher kann Data Mining als ein (zentraler) Baustein im Knowledge Discovery in Databases gesehen werden . Quelle: Wikipedia.")
195
Datenbanken und Informationssysteme
Ziele von Data Mining Auswertung von Daten aus Data Warehouse mit dem Ziel des Entdeckens von neuen Zusammenhängen, Trends, Statistiken, Verhaltensmustern. Häufig weiß man am Anfang nicht, wonach man sucht Herausfinden nützlicher Informationen wie Kundenverhalten Klassifikation der Daten zum Zweck der Risikoabschätzung oder Entscheidungsfindung

196
Datenbanken und Informationssysteme
Begriff Muster (Synonyma Vorbild, Pattern) Sprachmuster Warenmuster Kaufmuster Bildmuster Textmuster Verhaltensmuster Prozessmuster Problemmuster
 Sprachmuster. Warenmuster. Kaufmuster. Bildmuster. Textmuster. Verhaltensmuster. Prozessmuster. Problemmuster.")
197
Datenbanken und Informationssysteme

198
Datenbanken und Informationssysteme
Anwendungen von Data Mining Direktmarketing - Mailing - Außendienst Kundenprofile - Erstellung von Kunden-Profilen - Top-Kunden-Analyse - Neukundengewinnung - Prävention von Kündigungen Handel - Warenkorbanalyse - E-Business

199
Datenbanken und Informationssysteme
Anwendungen von Data Mining Finanz – und Versicherungswirtschaft - Risikoanalyse - Missbrauchsentdeckung

200
Datenbanken und Informationssysteme
Data Mining ist Prozess, der in sechs Phasen verläuft und in dem verschiedene Methoden zum Einsatz kommen können. Grundlage des Prozesses sind die Daten im Data Warehouse.

201
Datenbanken und Informationssysteme

202
Datenbanken und Informationssysteme
Typisches Beispiel Optimierung des Direktmailings für ein Produkt Schritt 1: Erstellung Produktprofils, Nutzung von Erfahrungen aus früheren Aktionen (Responsedatenbank), bei neuen Produkten Testaktion (z.B – 20000) repräsentativer Kunden. Schritt 2: Qualifizierung der Kundendatenbank auf Basis der Responsedatenbank. Die gesamte Kundendatenbank in verschiedene Kundensegmente (vgl. nächste Folie) unterteilt. Jedes Segment hat Responsepotential. Damit auch der Kunde. Schätzung über Responseverhalten. Sortierung der Kundensegmente nach Responsepotential. Leiter des Direktmailings muß Entscheidung treffen, welches Segment in Mailing- Aktion einbezogen wird.
, bei neuen Produkten Testaktion (z.B – 20000) repräsentativer Kunden. Schritt 2: Qualifizierung der Kundendatenbank auf Basis der Responsedatenbank. Die gesamte Kundendatenbank in verschiedene Kundensegmente (vgl. nächste Folie) unterteilt. Jedes Segment hat Responsepotential. Damit auch der Kunde. Schätzung über Responseverhalten. Sortierung der Kundensegmente nach Responsepotential. Leiter des Direktmailings muß Entscheidung treffen, welches Segment in Mailing- Aktion einbezogen wird.")
203
Datenbanken und Informationssysteme
Kundensegmente in der Kundendatenbank können beispielsweise durch folgende Segmentbeschreibung klassifiziert werden.

204
Datenbanken und Informationssysteme
Benutzung Datensatz Die segmentierte Kundendatenbank dient nun als Eingabe für das Data Mining-Verfahren. Jeder qualifizierte Datensatz beschreibt einen Kunden, der angeschrieben werden soll. Typische Merkmale sind u.a.: Weitere Angaben sind Reaktionen auf Mailingaktionen.

205
Datenbanken und Informationssysteme
Bewertung Ergebnisse Soll-Ist-Vergleich Responserate Kosten-Umsatz-Relation Deckungsbeitragsrechnung

206
Datenbanken und Informationssysteme
Beispiel Versicherungen Fragestellungen: Charakterisierung Seniorenmarkt Änderung Kundenverhalten im Alter Charakterisierung von Vermittlern Untersuchung Zusammenhänge Autounfälle und dem Alter des Fahrers Diverse Anwendungen Vorhersage von Wirbelstürmen oder Erdbeben Analyse von Satellitenbildern

207
Datenbanken und Informationssysteme
Klassifikation Problem: Kreditkartengesellschaft will Verfahren zur Risikoabschätzung bei der Vergabe von Kreditkarten an Neukunden entwickeln. Gesellschaft verfügt über großen Datenbestand von Kunden, deren Kreditwürdigkeit aus der Zahlungshistorie abgeleitet werden kann. Ziel: Herleitung einer Klassifikation für alle in Frage kommenden Personen bzw. potentielle Kunden, so daß diejenigen mit exzellenter bzw. guter Krediteinschätzung auf Antrag eine Kreditkarte erhalten.

208
Datenbanken und Informationssysteme
Klassifikation Lösung: Finde in der Datenbank Bedingungen für ein erstes Attribut, die die Wertemenge der Datenbank disjunkt zerlegt. Überprüfe diese Einschätzung anhand der vorhandenen DB. Falls dies richtig ist, reicht diese Zerlegung bereits. Ansonsten suche Bedingung für ein weiteres Attribut. Iteriere, bis eine verläßliche Klassifikation gefunden wurde. Werbung nur an interessante Kunden. Was heißt interessant?

209
Datenbanken und Informationssysteme

210
Datenbanken und Informationssysteme
E i n e mögliche Klassifikationsregel lautet: Eine Person ist kreditwürdig, falls sie den Hochschulabschluss Master besitzt und ein Jahreseinkommen von mehr als hat.

211
Datenbanken und Informationssysteme
Klassifikationsaufgabe allgemein Eine feste Anzahl von Klassen Beispiele von Klasseninstanzen und deren Attributwerte (Trainings Set) Gesucht ist dann ein Profil für jede einzelne Klasse!
 Gesucht ist dann ein Profil für jede einzelne Klasse!")
212
Datenbanken und Informationssysteme
Algorithmen für Klassifikationsaufgaben Regressionsanalyse (siehe auch Wikipedia) Entscheidungsbaumverfahren Distanzbasierte Algorithmen Algorithmen für neuronale Netze
 Entscheidungsbaumverfahren. Distanzbasierte Algorithmen. Algorithmen für neuronale Netze.")
213
Datenbanken und Informationssysteme
Regressionsanalyse

214
Datenbanken und Informationssysteme
Ziel der Regressionsanalyse ist es, Beziehungen zwischen einer abhängigen und einer/mehrerer unabhängigen Variablen festzustellen. Einfache lineare Regression Die Daten (Datenbank) liegen in der Form (xi, yi) (i = 1,2,..n) vor. Als Modell wählt man: Yi = a + b*xi + εi a, b sind unbekannt, εi heiß Störgröße.
 liegen in der Form (xi, yi) (i = 1,2,..n) vor. Als Modell wählt man: Yi = a + b*xi + εi. a, b sind unbekannt, εi heiß Störgröße.")
215
Datenbanken und Informationssysteme
Beispiel: xi yi Nr. Preis Absatzmenge 1 20 2 16 3 15 7 4 5 13 6 10

216
Datenbanken und Informationssysteme
Vorgehensweise: Minimum-Quadrat-Methode oder Methode der kleinsten Quadrate. Man minimiert die summierten Quadrate der Residuen Hier: a = b= -0.98 d.h. lineare Gleichung: y = x (lineare Regressionsgerade) Exkurs: EXCEL
 Exkurs: EXCEL.")
218
Datenbanken und Informationssysteme
Übungsaufgabe Es seien die Absatzzahlen eines Produktes über 20 Monate in einer Datenbank festgehalten. Die folgende Tabelle enthalte die beobachteten Daten Wie lauten die Prognosewerte für den Monat. Benutzen Sie die eingebaute Regressionsanalyse als auch das Modell auf Laufwerk P. Wo versagt die Methode?? (Kritik)
")
219
Datenbanken und Informationssysteme
Zeit Menge 1 9 2 13 3 17 4 15 5 12 6 7 22 8 16 10 18 11 25 23 19 14 24 30 26 27 32 20

220
Datenbanken und Informationssysteme
Beispiele für Entscheidungsbäume

221
Datenbanken und Informationssysteme

222
Datenbanken und Informationssysteme

223
Datenbanken und Informationssysteme

224
Datenbanken und Informationssysteme

225
Datenbanken und Informationssysteme

226
Datenbanken und Informationssysteme

227
Datenbanken und Informationssysteme

228
Datenbanken und Informationssysteme

229
Datenbanken und Informationssysteme
Einfaches Modell zur Vorhersage des Studienerfolges mit Decision Trees Erstellung des Mining-Modelles (z.B. mit DMX) Training des Modelles Modellvorhersagen treffen
 Training des Modelles. Modellvorhersagen treffen.")
230
Datenbanken und Informationssysteme
Erstellung des Mining-Modelles (mit DMX) CREATE MINING MODEL Studienabschluss (MatNr Text Key, Geschlecht Text Discrete, Lebensalter Long Continuous, Elterneinkommen Long Continuous, Berufserfahrung Long Continuous Studienabschluss Long Discrete Predict) USING Microsoft_Decision_Trees
 CREATE MINING MODEL Studienabschluss. (MatNr Text Key, Geschlecht Text Discrete, Lebensalter Long Continuous, Elterneinkommen Long Continuous, Berufserfahrung Long Continuous. Studienabschluss Long Discrete Predict) USING Microsoft_Decision_Trees.")
231
Datenbanken und Informationssysteme
Modell trainieren INSERT INTO Studienabschluss (MatNr, Geschlecht, Lebensalter, Elterneinkommen, Berufserfahrung, Studienabschluss) OPEN QUERY (DM_Einf, “SELECT * FROM STUDIENABSCHLÜSSE“)
 OPEN QUERY (DM_Einf, SELECT * FROM STUDIENABSCHLÜSSE )")
232
Datenbanken und Informationssysteme
Modellvorhersage SELECT [Studienabschluss]. [Studienabschluss] PredictProbability ([Studienabschluss]. [Studienabschluss]) FROM [Studienabschluss] NATURAL PREDICTION JOIN OPENQUERY ([DM_EIN] , “SELECT [Geschlecht], [Lebensalter], [NoteSchulabschluss], [Elterneinkommen], [Berufserfahrung] FROM [dbo.][Studienabschlüsse]” AS t )
 FROM [Studienabschluss] NATURAL PREDICTION JOIN. OPENQUERY ([DM_EIN] , SELECT [Geschlecht], [Lebensalter], [NoteSchulabschluss], [Elterneinkommen], [Berufserfahrung] FROM [dbo.][Studienabschlüsse] AS t )")
233
Datenbanken und Informationssysteme
Cluster-Bildung (Siehe auch Wikipedia Clusteranalyse) Unter Clusteranalyse versteht man ein strukturentdeckendes, multivariates Analyseverfahren zur Ermittlung von Gruppen (Clustern) von Objekten, deren Eigenschaften oder ihre Ausprägungen bestimmte Ähnlichkeiten oder Unähnlichkeiten aufweisen. Die Clusteranalyse ist mit der Klassifikation verwandt. Wesentlicher Unterschied zur Klassifikation ist, daß bei einer Clusteranalyse die Gruppen nicht vordefiniert sind, sondern erst bestimmt werden müssen. Es sind Ähnlichkeiten zu finden, die mit Hilfe bestimmter Charakteristika zu finden sind.
 Unter Clusteranalyse versteht man ein strukturentdeckendes, multivariates Analyseverfahren zur Ermittlung von Gruppen (Clustern) von Objekten, deren Eigenschaften oder ihre Ausprägungen bestimmte Ähnlichkeiten oder Unähnlichkeiten aufweisen. Die Clusteranalyse ist mit der Klassifikation verwandt. Wesentlicher Unterschied zur Klassifikation ist, daß bei einer Clusteranalyse die Gruppen nicht vordefiniert sind, sondern erst bestimmt werden müssen. Es sind Ähnlichkeiten zu finden, die mit Hilfe bestimmter Charakteristika zu finden sind.")
234
Datenbanken und Informationssysteme
Beispiel: Gruppierung von Kunden (Ausschnitt)
")
235
Datenbanken und Informationssysteme
Je nach Zielsetzung sind nur bestimmte Attribute interessant. Beispiel: Kampagne für Kinderkleider. Möglicher Cluster (Werbung nur Personen mit Kinder)
")
236
Datenbanken und Informationssysteme
Fragen: 1. Was versteht man unter dem Bilden einer Klassifikation? 2. Welche Anwendungen sind für Klassifikationen denkbar? 3. Was versteht man unter dem Bilden von Clustern?

237
Datenbanken und Informationssysteme
Assoziationsregeln Die Assoziationsanalyse bezeichnet die Suche nach starken Regeln. Diese daraus folgenden Assoziationsregeln beschreiben Korrelationen zwischen gemeinsam auftretenden Dingen. Der Zweck einer Assoziationsanalyse besteht also darin, Items (Elemente einer Menge, wie z.B. einzelne Artikel eines Warenkorbs) zu ermitteln, die das Auftreten anderer Items innerhalb einer Transaktion implizieren. Eine solcherart aufgedeckte Beziehung zwischen zwei oder mehr Items kann dann als Regel der Form „Wenn Item(menge) A, dann Item(menge) B“ bzw. A → B dargestellt werden.
 zu ermitteln, die das Auftreten anderer Items innerhalb einer Transaktion implizieren. Eine solcherart aufgedeckte Beziehung zwischen zwei oder mehr Items kann dann als Regel der Form „Wenn Item(menge) A, dann Item(menge) B bzw. A → B dargestellt werden.")
238
Datenbanken und Informationssysteme
Warenkorb-Tabelle

239
Datenbanken und Informationssysteme
I:= {i1, i2,…,im} sei eine Menge von Dingen oder Items Hier I := {Füller, Tinte, Heft, Seife,….} Transaktion Tn I. (n = 1, 2, 3……) Hier T3 = {Füller, Heft} Gegenstand der Analyse ist “Datenbank” D ={ T1, T2 ,…,Tk}
 Hier T3 = {Füller, Heft} Gegenstand der Analyse ist Datenbank D ={ T1, T2 ,…,Tk}")
240
Datenbanken und Informationssysteme
Verdacht: Wenn Füller gekauft wird, dann auch Tinte. Wird auch Assoziationsregel genannt. Konsequenz: Plaziere beispielsweise in einem Kaufhausregal Füller neben Tinte oder mache gemeinsam Werbung für diese Dinge oder gib Kaufempfehlung (siehe Amazon). Assoziationsregeln werden auch in der Form R:LS → RS geschrieben, d.h. in unserem bisherigen Beispiel - wenn linke Seite gekauft wird, dann auch rechte Seite -, wobei LS und RS disjunkte Mengen von Dingen sind. Assoziationsregeln schreibt man in der Form R: LS → RS und es gilt LS, RS I sowie LS ∩ RS = { }
. Assoziationsregeln werden auch in der Form. R:LS → RS. geschrieben, d.h. in unserem bisherigen Beispiel - wenn linke Seite gekauft wird, dann auch rechte Seite -, wobei LS und RS disjunkte Mengen von Dingen sind. Assoziationsregeln schreibt man in der Form R: LS → RS und es gilt. LS, RS I sowie LS ∩ RS = { }")
241
Datenbanken und Informationssysteme
Definition von zwei „Maßen“ 1. Support: (anschaulich „Wichtigkeit“ einer Menge) Zu einer gegebenen Menge I von Dingen und gegebener Datenbank D von k Transaktionen sei J als Teilmenge von I eine Auswahl von Dingen. Der Support von J ist dann definiert als In Worten: Der Support von J gibt an, wieviel Prozent der Transaktionen J enthalten. Dieses Maß läßt sich sofort auf Assoziationsregeln übertragen.
 Zu einer gegebenen Menge I von Dingen und gegebener Datenbank D von k Transaktionen sei J als Teilmenge von I eine Auswahl von Dingen. Der Support von J ist dann definiert als. In Worten: Der Support von J gibt an, wieviel Prozent der Transaktionen J enthalten. Dieses Maß läßt sich sofort auf Assoziationsregeln übertragen.")
242
Datenbanken und Informationssysteme
Es gilt folgendes: Der Support einer Regel in der Form R: LS →RS ist definiert als: Beispiel zur Berechnung Support-Regel R: Füller → Tinte Besitzt den Support ¾ , da die Teile Füller und Tinte in drei der vier Transaktionen vorkommen. Support(Füller) = 4/4, Support(Tinte) = ¾. Anmerkung: Hat eine Regel die Form R: LS → RS und eine andere Regel R‘ die Form LS → RS, so gilt Supp(R) = Supp(R‘)
 = 4/4, Support(Tinte) = ¾. Anmerkung: Hat eine Regel die Form R: LS → RS und eine andere Regel R‘ die Form LS → RS, so gilt Supp(R) = Supp(R‘)")
243
Datenbanken und Informationssysteme
2. Maß „Confidence“ einer Regel („Stärke“ einer Regel) In Worten: Die Confidence einer Regel R: LS → RS bezeichnet den Prozentsatz der Transaktionen, die RS umfassen, falls sie auch alle Elemente von LS enthalten. Die Confidence einer Regel deutet den Grad der Korrelation zwischen Verkäufen von Mengen von Dingen in der Datenbanken an. Konfidenz und Support sind mathematisch nicht unabhängig voneinander. Beispiel zur Berechnung Confidence Regel R: Füller → Tinte Conf (R): = Supp({Füller, Tinte}) = ¾ / 4/4 = 0,75 / 1 = 0,75 Supp({Füller}) Dies bedeutet, daß der Grad der Korrelation relativ stark ist.
 In Worten: Die Confidence einer Regel R: LS → RS bezeichnet den Prozentsatz der Transaktionen, die RS umfassen, falls sie auch alle Elemente von LS enthalten. Die Confidence einer Regel deutet den Grad der Korrelation zwischen Verkäufen von Mengen von Dingen in der Datenbanken an. Konfidenz und Support sind mathematisch nicht unabhängig voneinander. Beispiel zur Berechnung Confidence Regel R: Füller → Tinte. Conf (R): = Supp({Füller, Tinte}) = ¾ / 4/4 = 0,75 / 1 = 0,75. Supp({Füller}) Dies bedeutet, daß der Grad der Korrelation relativ stark ist.")
244
Datenbanken und Informationssysteme
Beispiel: Gegeben sei eine Assoziationsregel Zahnbürste → Zahncreme Support: Mit dem Support wird berechnet, welcher Anteil aller Transaktion für die Regel Zahnbürste → Zahncreme gilt. Zur Berechnung wird die Anzahl der Transaktionen, in denen beide interessierenden Itemmengen vorkommen, durch die Anzahl aller Transaktionen geteilt. Confidence: Für welchen Anteil der Transaktionen, in den {Zahnbürste} vorkommt, kommt auch {Zahncreme} vor. Zur Berechnung der Confidence wird die Anzahl aller regelerfüllenden Transaktionen durch die Anzahl der Transaktionen, die {Zahnbürste} enthalten, geteilt. Lift: Angenommen 10% aller Kunden kaufen {Zahncreme}, aber 50% aller Kunden die {Zahnbürste} kaufen, kaufen auch {Zahncreme}. Dann hat die Regel einen 5-fachen Lift.

245
Datenbanken und Informationssysteme
Weiteres Beispiel: Regel R: Bier → Chips Ein Support dieser Regel von 0,8 bedeutet dann, daß in 80% der Transaktionen Bier und Chips gemeinsam vorkommen; unabhängig davon bedeutet eine Confidence von 0,5, daß die Hälfte der Leute, die Bier gekauft haben auch Chips dazu gekauft haben.

246
Datenbanken und Informationssysteme
In der realen Anwendung wir meistens so vorgegangen, daß für einen Mindestens-Support sowie eine Minimalkonfidenz vorgibt und sich dann nur für Regeln interessiert, welche beide enthalten. Dies kann z.B. mit einem Apriori-Algorithmus geschehen (siehe folgende Folien). Beispiel: Gegeben sei ein Mindest-Support von 0,5 und eine Minimal-Confidence von 0,5. Wie sehen dann gültige Regeln aus? TID Gekaufte Teile 200 1,2,3 100 1,3 400 1,4 500 2,5,6
. Beispiel: Gegeben sei ein Mindest-Support von 0,5 und eine Minimal-Confidence von 0,5. Wie sehen dann gültige Regeln aus TID. Gekaufte Teile ,2, , , ,5,6.")
247
Datenbanken und Informationssysteme
Lösung: Regel 1: → mit Support 2/4 = 0,5 und Confidence 2/3 = 0,67 Regel 2: 3 → mit Support 2/4 = 0,5 und Confidence 2/2 = 1

248
Datenbanken und Informationssysteme
Frage 1: Was versteht man unter einer Assoziationsregel Frage 2: Welche Maße verwenden Assoziationsregeln Frage 3: Geben Sie ein Beispiel an für eine Regel mit geringem Support aber hoher Konfidenz (denken Sie an gehobenen Lebensstil)
")
249
Datenbanken und Informationssysteme
Frage: Wie können Assoziationsregel konstruiert werden. Apriori-Verfahren Voraussetzung (Eingabedaten): Warenkorbtabelle, gebildet über einer festen Menge I Ein geforderter Mindest-Support σ Eine geforderte Mindestkonfidenz γ
: Warenkorbtabelle, gebildet über einer festen Menge I. Ein geforderter Mindest-Support σ. Eine geforderte Mindestkonfidenz γ.")
250
Datenbanken und Informationssysteme
Apriori-Verfahren (Fortsetzung) Man finde so genannte „häufige“ Mengen, d.h. Mengen J, die Teilmenge von I sind, deren Support Supp(J) > σ Man erzeuge potenzielle Assoziationsregeln R durch Aufteilen einer jeden häufigen Menge J in zwei Mengen LS und RS, so dass J = LS vereinigt RS gilt, ferner LS geschnitten RS = {} und R: LS → RS Man berechne die Konfidenz einer jeden in Schritt 2 erzeugten Regel R und gebe diejenigen aus mit der Confidence con(R) > γ Grundproblem ist Schritt 1
 Man finde so genannte „häufige Mengen, d.h. Mengen J, die Teilmenge von I sind, deren Support Supp(J) > σ. Man erzeuge potenzielle Assoziationsregeln R durch Aufteilen einer jeden häufigen Menge J in zwei Mengen LS und RS, so dass J = LS vereinigt RS gilt, ferner LS geschnitten RS = {} und R: LS → RS. Man berechne die Konfidenz einer jeden in Schritt 2 erzeugten Regel R und gebe diejenigen aus mit der Confidence con(R) > γ. Grundproblem ist Schritt 1.")
251
Datenbanken und Informationssysteme
Grundproblem: Wie ermittelt man häufige Mengen? Ermittle Häufigkeit der Einermengen und teste ob Supp(Einermenge) > σ. Das Ergebnis sei eine Menge M. Vergrößere schrittweise häufige Mengen, bis keine neuen Obermengen gefunden werden können
 > σ. Das Ergebnis sei eine Menge M. Vergrößere schrittweise häufige Mengen, bis keine neuen Obermengen gefunden werden können.")
252
Datenbanken und Informationssysteme
Warenkorb-Tabelle

253
Datenbanken und Informationssysteme
Beispiel: Support σ >= 0,7, d.h. wir interessieren uns nur für Assoziationsregeln, deren auf beiden Regelseiten vorkommenden Teile in mindestens 70% der Transaktionen enthalten sind. Schritt 1: Ermittle Häufigkeiten der Menge I = {Füller, Tinte, Heft, Seife} . Ergebnis: Die Einermengen {Füller}, {Tinte} und {Heft} sind häufig, da diese Produkte in ¾ oder mehr der Transaktionen vorkommen. {Seife} ist nicht häufig, kommt nur in der Hälfte der Transaktionen vor. M = {{Füller}, {Tinte} ,{Heft} }

254
Datenbanken und Informationssysteme
Schritt 2: Bilde Zweiermengen: {Füller, Tinte}, { Tinte, Heft}, { Füller, Heft} Häufig sind nur {Füller, Tinte}, { Füller, Heft} Bilde Dreiermengen {Füller, Tinte, Heft}, ist nicht häufig Es ergeben sich 4 potentielle Regeln Füller → Tinte Tinte → Füller Füller → Heft Heft → Füller

255
Datenbanken und Informationssysteme
Schritt 3: Es sei = 0,8 gefordert, dies ist für jede Regel zu überprüfen. Conf(Regel 1) = 0,75 Conf(Regel 2) = 1 Conf(Regel 3) = 0,75 Conf(Regel 4) = 1 Dies bedeutet, daß Regel 2 und Regel 4 als Assoziationsregeln gelten.
 = 0,75. Conf(Regel 2) = 1. Conf(Regel 3) = 0,75. Conf(Regel 4) = 1. Dies bedeutet, daß Regel 2 und Regel 4 als Assoziationsregeln gelten.")
256
Datenbanken und Informationssysteme
Aufgabe: Man berechne mindestens eine Assoziationsregel, die in beiden Maßen mindestens 0,6 aufweisen

257
Wurst, Käse, Butter, Milch
TID Items 1 Brot, Wurst 2 Brot, Käse, Butter, Eier 3 Wurst, Käse, Butter, Milch 4 Brot, Wurst, Käse, Butter 5 Brot, Wurst, Käse, Milch Item Anzahl Brot Milch Wurst Butter Käse Eier Brot, Butter Brot, Käse Wurst, Butter Wurst, Käse Butter, Käse Lösung: Häufigkeit Einer-Mengen Allgemein (theoretische Überlegungen): 6 Einermengen, 15 Zweiermengen, 20 Dreiermengen Annahme zusätzlich: Anzahl >= 3 Reduktion auf 4 Einermengen d.h. nur 6 Zweiermengen und 4 Dreiermengen untersucht zu werden
: 6 Einermengen, 15 Zweiermengen, 20 Dreiermengen. Annahme zusätzlich: Anzahl >= 3. Reduktion auf 4 Einermengen. d.h. nur 6 Zweiermengen und 4 Dreiermengen untersucht zu werden.")
258
Regel Käse → Wurst hat Maße Support = 0,6 und Confidence von 0,75
Regel {Wurst, Käse } → Butter hat Support =0,4 und Confidence 0,67

259
Datenbanken und Informationssysteme
Aufsatz von Microsoft zu Data Mining durcharbeiten (Laufwerk P)
")
Ähnliche Präsentationen
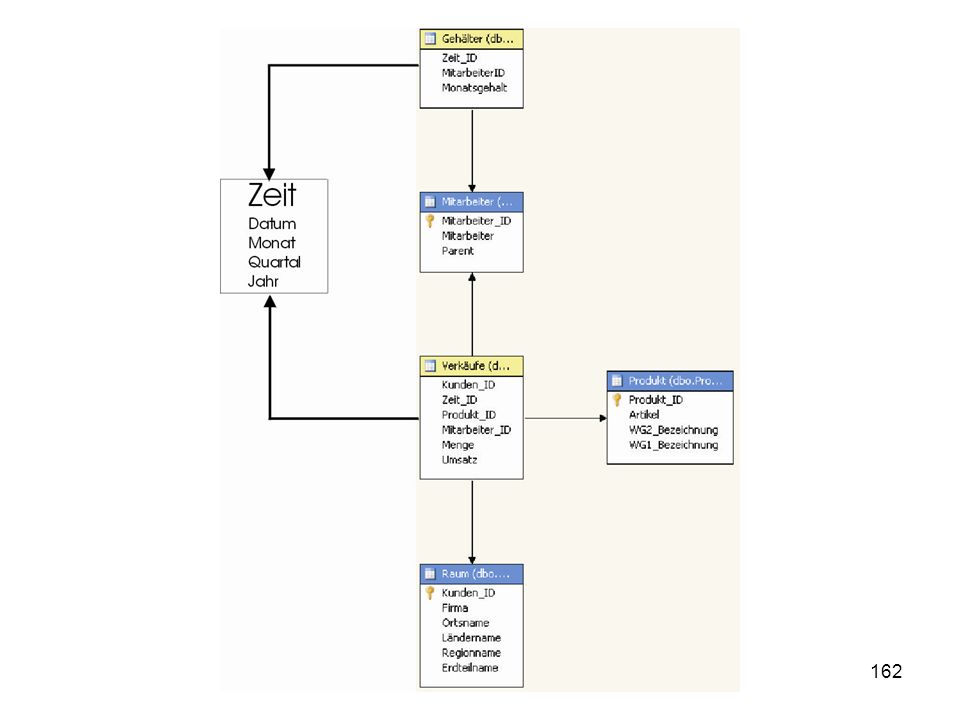







>")
>")



.>")






