Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Kohonennetze für Information Retrieval mit User Feedback
Georg Ruß Otto-von-Guericke-Universität Magdeburg

2
Gliederung Motivation der präsentierten Datenverarbeitungsmethode
Kohonennetze / Self Organizing Maps (SOM) Information Retrieval am Beispiel von -Sammlungen User Feedback Zusammenfassung der Ergebnisse
 Information Retrieval am Beispiel von -Sammlungen. User Feedback. Zusammenfassung der Ergebnisse.")
3
Einleitung / Motivation
- großes Datenaufkommen in digitaler Form (Datenbanken, -Sammlungen, Newsgroups, ...) - zunehmende Unübersichtlichkeit → Methode zur Klassifikation und Filterung der Informationen notwendig → gewünschte Eigenschaften: 1. Verständlich 2. Fehlerfrei 3. Automatisch → Growing Self-Organizing Maps als Methode, die die gewünschten Eigenschaften aufweist -scannerkassen, Usenet-Diskussionen, Instant Messaging,... - -sammlungen kursiv, weil als Beispiel im Vortrag verwendet -automatisch fauler user, ich kann/will ja nicht ständig dem programm sagen, was es machen soll -fehlerfrei wird von jedem programm erwartet aus richtigem wissen sollte man nichts falsches schlußfolgern, nur weil das Programm etwas falsch macht -verständlich was nutzt mir generiertes wissen, mit dem ich nichts anfangen kann, weil ich es nicht verstehe Information mining: Wissensentdeckung in Datenbanken ist der nichttriviale Prozeß der Identifikation gültiger, neuer, potentiell nützlicher und schlußendlich verständlicher Muster in Datenbeständen (wert auf „verständlich“)
 - zunehmende Unübersichtlichkeit. → Methode zur Klassifikation und Filterung der Informationen notwendig. → gewünschte Eigenschaften: 1. Verständlich 2. Fehlerfrei. 3. Automatisch. → Growing Self-Organizing Maps als Methode, die die gewünschten Eigenschaften aufweist. -scannerkassen, Usenet-Diskussionen, Instant Messaging, sammlungen kursiv, weil als Beispiel im Vortrag verwendet automatisch. fauler user, ich kann/will ja nicht ständig dem programm sagen, was es machen soll. -fehlerfrei. wird von jedem programm erwartet. aus richtigem wissen sollte man nichts falsches schlußfolgern, nur weil das Programm etwas falsch macht. -verständlich. was nutzt mir generiertes wissen, mit dem ich nichts anfangen kann, weil ich es nicht verstehe. Information mining: Wissensentdeckung in Datenbanken ist der nichttriviale Prozeß der Identifikation gültiger, neuer, potentiell nützlicher und schlußendlich verständlicher Muster in Datenbeständen (wert auf „verständlich )")
4
Self-Organizing Maps (1)
1. Verständlich - bilden hochdimensionalen Eingaberaum in zweidimensionale Karte ab - Ähnlichkeitsbeziehungen werden durch Nachbarschaften dargestellt - Anpassungen des Netzes durch Gewichtsänderungen (Output nicht zwangsläufig zweidimensional, aber sinnvoll in diesem Fall) Aufgrund von Ähnlichkeitsmaßen wird der Eingaberaum in den Ausgaberaum abgebildet. Zu jedem hochdimensionalen Input-Vektor wird ein zweidimensionaler Output-Vektor generiert, der in einer Karte dargestellt werden kann. Nachbarschaftserhaltende Abbildung, d.h. ähnliche s sind auch in der Karte benachbart. So wie ich z.B. ähnliche s in denselben Ordner stecke, sind ähnliche s auch in der Karte dicht beieinander. Am Beispiel Klassifikation von s: Wie sollen s diesen Input Layer darstellen? -> Preprocessing bzw. Datenvorverarbeitung ist notwendig, damit das neuronale Netz einen passenden Input erhält. Preprocessing in mehreren Schritten. -> nächste Folie
 Aufgrund von Ähnlichkeitsmaßen wird der Eingaberaum in den Ausgaberaum abgebildet. Zu jedem hochdimensionalen Input-Vektor wird ein zweidimensionaler Output-Vektor generiert, der in einer Karte dargestellt werden kann. Nachbarschaftserhaltende Abbildung, d.h. ähnliche s sind auch in der Karte benachbart. So wie ich z.B. ähnliche s in denselben Ordner stecke, sind ähnliche s auch in der Karte dicht beieinander. Am Beispiel Klassifikation von s: Wie sollen s diesen Input Layer darstellen -> Preprocessing bzw. Datenvorverarbeitung ist notwendig, damit das neuronale Netz einen passenden Input erhält. Preprocessing in mehreren Schritten. -> nächste Folie.")
5
Self-Organizing Maps (2)
2. Fehlerfrei - Verfahren basiert auf Voronoi-Zerlegung → „fehlerminimale“ Zerlegung des Eingaberaums in eine endliche Anzahl von Zuständigkeitsgebieten → hexagonales Grid als Optimum zwischen lückenlos und fehlerminimal Nicht ganz fehlerfrei, aber fehlerminimal

6
Self-Organizing Maps (3)
3. Automatisch - “self-organizing“ als Begriff - modellhafte Nachbildung von neuronalen Strukturen - Lernen als automatisierter Prozeß - Paradigma des „unsupervised learning“ - einfache mathematische Vektor-Methoden Self-organizing als Begriff sagt schon aus, dass der Prozeß weitgehend automatisch abläuft -Mensch lernt auch automatisch -Lernen aufgrund von Inputs - -weitere Paradigmen: supervised/teacher || Reinforcement/Reward Learning

7
Information Retrieval (1)
Definition: Information Retrieval ist ein Prozeß zur 1. Gewinnung, 2. Speicherung und 3. Pflege von Informationen. Visualisierung kommt noch hinzu im Folgenden an einem „Text-Mining“-Beispiel

8
Information Retrieval (2)
zu 1. Informationsgewinnung - filtering (Entfernen von Stop-Words) - stemming (Bilden der Wortstämme) - indexing (Bildung von Gruppen von Wörtern, die in ähnlichem Kontext auftauchen, „buckets“) - Erstellen von Kontextvektoren für jedes Wort - Erstellen von charakteristischen n-dimensionalen Vektoren für jedes Dokument, sog. „fingerprints“ Filtering: Entfernen solcher Wörter, die nicht zur Unterscheidung zwischen Dokumenten beitragen -> Präpositionen, Artikel, Konjunktionen ... -> sehr seltene Wörter (z.B. Vertipper) -> sehr häufige Wörter (Informationsgehalt umgekehrt proportional zur Auftretenswahrscheinlichkeit (Shannon‘scher Informationsbegriff)) -> kann mit vordefinierten Stop-Lists geschehen (Beispiel einer Stop-List) Effekte: -> beeinträchtigt nicht den Prozeß des Information Retrieval -> beschleunigt weitere Verarbeitung -> spart Speicherplatz Stemming: Bilden der Wortstämme -> Entfernung von Suffixen und Präfixen -> z.B. durch Angeben einer Grammatik mit Produktionsregeln Indexing: Vorstellbar als eine Art „Einsortieren von ähnlichen Wörtern in Eimer oder Behälter“ Fingerprints: N-dimensionale Vektoren, für jeden Eimer zähle ich, wieviele Wörter aus dem Dokument in diesen einsortiert werden, Anzahl steht im Vektor Ein beispiel sagt mehr als tausend Worte, also kommt jetzt eins.
 - stemming (Bilden der Wortstämme) - indexing (Bildung von Gruppen von Wörtern, die in ähnlichem Kontext auftauchen, „buckets ) - Erstellen von Kontextvektoren für jedes Wort. - Erstellen von charakteristischen n-dimensionalen Vektoren für jedes Dokument, sog. „fingerprints Filtering: Entfernen solcher Wörter, die nicht zur Unterscheidung zwischen Dokumenten beitragen. -> Präpositionen, Artikel, Konjunktionen ... -> sehr seltene Wörter (z.B. Vertipper) -> sehr häufige Wörter (Informationsgehalt umgekehrt proportional zur Auftretenswahrscheinlichkeit (Shannon‘scher Informationsbegriff)) -> kann mit vordefinierten Stop-Lists geschehen (Beispiel einer Stop-List) Effekte: -> beeinträchtigt nicht den Prozeß des Information Retrieval. -> beschleunigt weitere Verarbeitung. -> spart Speicherplatz Stemming: Bilden der Wortstämme. -> Entfernung von Suffixen und Präfixen. -> z.B. durch Angeben einer Grammatik mit Produktionsregeln Indexing: Vorstellbar als eine Art „Einsortieren von ähnlichen Wörtern in Eimer oder Behälter Fingerprints: N-dimensionale Vektoren, für jeden Eimer zähle ich, wieviele Wörter aus dem Dokument in diesen einsortiert werden, Anzahl steht im Vektor. Ein beispiel sagt mehr als tausend Worte, also kommt jetzt eins.")
9
Information Retrieval (3)
")
10
Information Retrieval (4)
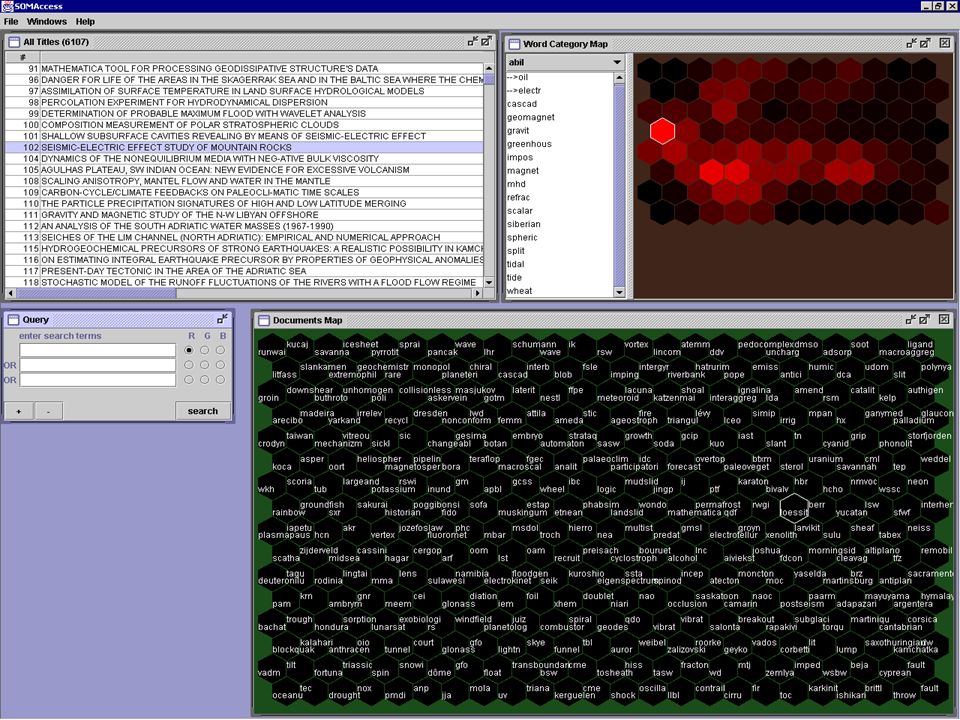
zu 2. Speicherung (mit Visualisierung) - Worte, die in ähnlichem Kontext auftauchen, sind selbst ähnlich zueinander → ähnliche Worte werden in der Wortkarte („word category map“) benachbart sein → Aufbau der Wortkarte erfolgt sukzessive
 - Worte, die in ähnlichem Kontext auftauchen, sind selbst ähnlich zueinander. → ähnliche Worte werden in der Wortkarte („word category map ) benachbart sein. → Aufbau der Wortkarte erfolgt sukzessive.")
11
Information Retrieval (5)
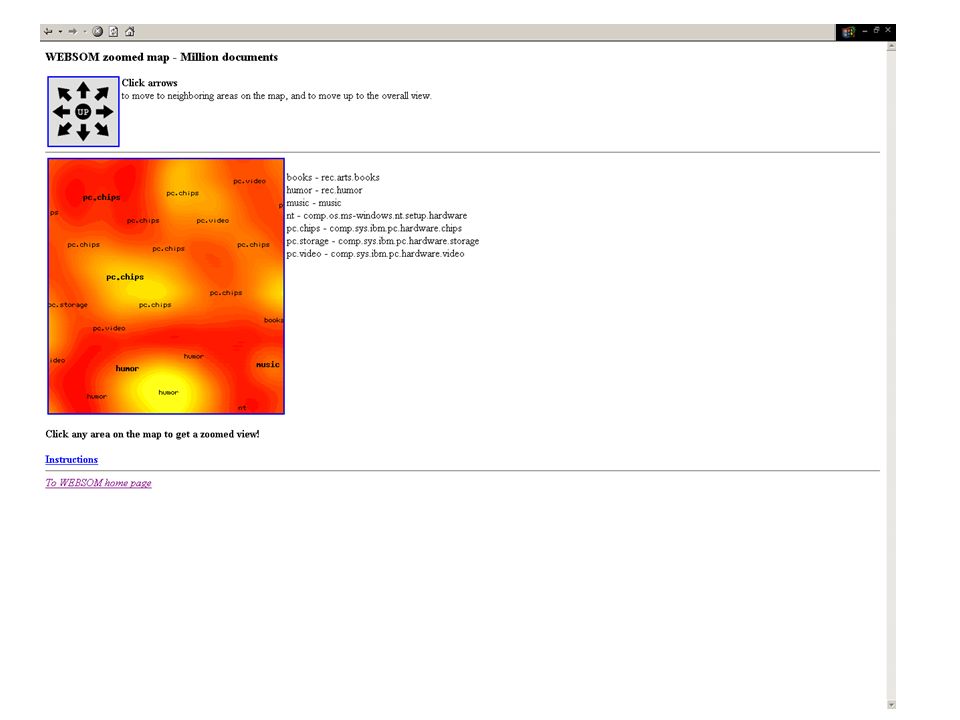
zu 2. Speicherung (mit Visualisierung) - ähnliche Dokumente besitzen ähnliche Vektoren → ähnliche Dokumente werden in der Karte benachbart sein (bzw. im selben „bucket“) → Aufbau der Dokumentenkarte erfolgt sukzessive → zukünftige Veränderungen (z.B. neue „buzz words“) können durch ein erneutes Anlernen der Karte berücksichtigt werden
 - ähnliche Dokumente besitzen ähnliche Vektoren. → ähnliche Dokumente werden in der Karte benachbart sein (bzw. im selben „bucket ) → Aufbau der Dokumentenkarte erfolgt sukzessive. → zukünftige Veränderungen (z.B. neue „buzz words ) können durch ein erneutes Anlernen der Karte berücksichtigt werden.")
12
User Feedback Problem:
- Dokumente könnten in mehrere Cluster der Karte gut passen Lösung: - Einbeziehung der oft guten Intuition des Nutzers - z.B. Abfrage per Drag-and-Drop - Anpassung des gewünschten Ähnlichkeitsmaßes (d.h. Änderung von Prioritäten einzelner Features)
")
13
Ergebnisse / Nutzen (1) Ergebnis: mehr Möglichkeiten einer Datenbankanfrage - herkömmliche Suche nach Keyword visuelle Suche auf den erstellten Karten i) auf der Wortkarte (Finden neuer Keywords) ii) auf der Dokumentenkarte (Finden ähnlicher Dokumente) - Content Based Search (Query by Example)
 auf der Wortkarte (Finden neuer Keywords) ii) auf der Dokumentenkarte (Finden ähnlicher Dokumente) - Content Based Search (Query by Example)")
14
Ergebnisse / Nutzen (2) Ablauf einer Suche:
1. Herkömmliche Keyword-Suche 2. Anzeige der Treffer auf der Wort- / Dokumentenkarte Wortkarte: 3a. Inspizieren der Wortkarte zum Finden neuer Keywords Dokumentenkarte: 3b. Inspizieren der Dokumentenkarte zum Finden weiterer relevanter Dokumente

15
Ergebnisse / Nutzen (3) Content Based Search / Classification / Query by Example a) als Vorlage für die Suche nach ähnlichen s: - Berechnung des Fingerprints - Anzeige auf der Dokumentenkarte - Ergebnis: ähnliche s b) Automatische Klassifikation von eingehenden s: - Einsortieren in die Dokumentenkarte, wobei die Buckets in diesem Fall „echte“ Mail-Ordner sein können
 Automatische Klassifikation von eingehenden s: - Einsortieren in die Dokumentenkarte, wobei die Buckets in diesem Fall „echte Mail-Ordner sein können.")
21
Zusammenfassung Der Einsatz von Self-Organizing Maps innerhalb von Dokumentensammlungen bringt erhebliche Vorteile: - automatisches Lernen sowie Visualisierung großer Dokumentsammlungen - mehr Möglichkeiten zur Suche - intuitive Verständlichkeit des Systems - Möglichkeit zur Einbeziehung des Nutzers - Flexibilität ohne großen Aufwand Prototypen: SOMAccess auf DUST-2 CD-ROM Websom (

22
Vielen Dank für Ihre Aufmerksamkeit !

Ähnliche Präsentationen




![Webinar für [Name der Gruppe] [Name des Institutes]](/1/204123/big_thumb.jpg "Webinar für [Name der Gruppe] [Name des Institutes]>")

















