Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Oracle Data Warehouse – Datenbank basierte ETL-Prozesse Reduzieren Sie Ihre Ladezeiten! Organisieren Sie Ihre ETL-Prozesse! DATA WAREHOUSE

2
Datenbank-basierte ETL-Prozesse
Themenübersicht Datenbank-basierte ETL-Prozesse Anforderungen an den ETL-Prozess im Data Warehouse Speichermanagement und Grundlagentechniken Blöcke, Extents, Segmente, Tablespace Direct Path Load, Mengenbasiertes Laden Optimierungsszenario Hilfsmittel für schnelles Laden Prüftechniken mit SQL Szenario zum Prüfen von Daten Weitere Techniken und Tools 2

3
Das große Klagen Bzgl. System-Nutzen Bzgl. Maintenance und Technik
Lieferzeiten der Daten zu lange (Latenzen) Zu schwerfällig bei Änderungen Informationen mehrfach vorhanden Fehlende unternehmensweite Sichten Nicht die richtigen Informationen für die Anwender Anwender haben zu wenig unmittelbaren Einfluss auf die Daten Immer teuerer Maintenance-Aufwand zu hoch / Personal Explodierende Datenmengen -> Storage- / Ladezeitenthematik Bzgl. Maintenance und Technik
 Zu schwerfällig bei Änderungen. Informationen mehrfach vorhanden. Fehlende unternehmensweite Sichten. Nicht die richtigen Informationen für die Anwender. Anwender haben zu wenig unmittelbaren Einfluss auf die Daten. Immer teuerer. Maintenance-Aufwand zu hoch / Personal. Explodierende Datenmengen -> Storage- / Ladezeitenthematik. Bzgl. Maintenance und Technik.")
4
ETL ist mehr als nur Daten von A nach B kopieren nicht Point-To-Point sondern Informationsschaffend
Quellsystem DWH-System n-tier n-tier ETL? Application Server Application Server ETL? 4

5
? ? Die strategische Rolle der Warehouse-Schicht Strategische Daten
Enterprise Layer Core - DWH / Info Pool User View Layer Integration Layer Service Logistik Einkauf Vertrieb Controlling Marketing Service Logistik Einkauf Vertrieb Controlling Marketing Wunsch für unter- schiedliche Sichten auf die selben Geschäfts- objekte Die selben Geschäfts- objekte in unter- schiedlichen Prozessen ? Strategische Daten ? Wirkungsweite des Systems muss festgelegt sein Eindeutigkeit in der Kernschicht

6
„Breite“ der Datenmodelle
Was verdienen wir an gelben + bunten Fahrrädern? Logistik Enterprise Layer User View Integration Es geht um Gesamt- sichten: „Breite“ der Datenmodelle WARE Waren_Nr Gebinde Gewicht Hoehe Laenge Breite Verpackung Verpackungen LIEFERANT PK_Lieferanten_ID Lieferant_Name Gelagerte Artikel, Menge + Größe T_ARTIKEL PK_Artikel_ID Eink_Artikel_Nr Log_Waren_Nr Vert_Produkt_Nr Eink_Einheit Eink_Preis Lieferant Gebinde Gewicht Hoehe Laenge Breite Verpackung Vert_Einheit Farbe Vert_Preis S_ARTIKEL PK_Artikel_ID Eink_Artikel_Nr Log_Waren_Nr Vert_Produkt_Nr Eink_Einheit Eink_Preis FK_Lieferanten_ID Gebinde Gewicht PK_Verpackungs_ID Vert_Einheit FK_Farben_ID Vert_Preis Lager Lieferanten Einkauf Gekaufte Artikel, Menge + Preise ARTIKEL Artikel_Nr Einheit Preis Lieferant Zeit Artikel Vertrieb Verkaufte Artikel Menge + Preise PRODUKT Produkt_Nr Einheit Farbe Preis VERPACKUNGSART PK_Verpackungs_ID Hoehe Laenge Breite Gewinn = Verkaufspr. – Einkaufspr. – Lagerkosten FARBE PK_Farben_ID Farbe Aufschlag Rabatte Lieferanten- Discounts

7
Was verdienen wir an gelben + bunten Fahrrädern?
Logistik Enterprise Layer User View Integration WARE Waren_Nr Gebinde Gewicht Hoehe Laenge Breite Verpackung Verpackungen Lager LIEFERANT PK_Lieferanten_ID Lieferant_Name Es geht um Gesamt- sichten: „Breite“ der Daten- modelle D_ARTIKEL_LAGER PK_Artikel_ID Log_Waren_Nr Gebinde Gewicht Verpackung Gelagerte Artikel, Menge + Größe T_ARTIKEL PK_Artikel_ID Eink_Artikel_Nr Log_Waren_Nr Vert_Produkt_Nr Eink_Einheit Eink_Preis Lieferant Gebinde Gewicht Hoehe Laenge Breite Verpackung Vert_Einheit Farbe Vert_Preis S_ARTIKEL PK_Artikel_ID Eink_Artikel_Nr Log_Waren_Nr Vert_Produkt_Nr Eink_Einheit Eink_Preis FK_Lieferanten_ID Gebinde Gewicht PK_Verpackungs_ID Vert_Einheit FK_Farben_ID Vert_Preis Lieferanten Einkauf D_ARTIKEL_EINK PK_Artikel_ID Eink_Artikel_Nr Eink_Einheit Eink_Preis Lieferanten Farben Gekaufte Artikel, Menge + Preise ARTIKEL Artikel_Nr Einheit Preis Lieferant Zeit Vertrieb D_ARTIKEL_VERT PK_Artikel_ID Vert_Produkt_Nr Eink_Einheit Vert_Einheit Farben Vert_Preis Verkaufte Artikel Menge + Preise PRODUKT Produkt_Nr Einheit Farbe Preis VERPACKUNGSART PK_Verpackungs_ID Hoehe Laenge Breite FARBE PK_Farben_ID Farbe Aufschlag Rabatte Lieferanten- Discounts

8
Was definieren wir als ETL-Prozesse?
Data Integration Layer Enterprise Information Layer User View Layer OLTP + Data Warehouse + BI BI-Tool Server + Caches Latenz von bis 8

9
Es gibt Data Warehouse-spezifische Rahmenbedingungen
OLTP Data Warehouse Interaktion Lesen und Schreiben Eher nur Lesen / konzentriertes Mengen-Schreiben Verteilung der Aktionen Oft auf viele Tabellen verteilt Oft zentrisches Arbeiten auf wenigen Tabellen Art von Lese-/Schreib- Aktionen Verteilt und nur einzelne Sätze Konzentriert und viele Sätze gleichzeitig Satzorientiert in kleinen Blöcken Spaltenorientiert in sortieren Blöcken Art der physischen Speicherung Hoch Weniger Anzahl Benutzer

10
Was bedeutet das für die eingesetzte Technologie?
OLTP Data Warehouse Interaktion Lesen und Schreiben Eher nur Lesen / konzentriertes Mengen-Schreiben Gering Hoch Parallelisierung Hoch Eher gering Hochverfügbarkeit SAN Dedicated Storagesystem komplett selektiv Backup

11
Bei der Wahl von Mitteln immer berücksichtigen:
10 – 50 Tabellen 500 – Tabellen Große Tabellen Partitioniert Namentlich bekannt > 70 % des Datenvolumens KleineTabellen Nicht Partitioniert Unkenntliche Masse < 30 % des Datenvolumens 11

12
Datenbank-nahes Laden – Grundlage für Flexibilität und Performance
Daten dort laden, wo sie liegen Möglichst wenig Datenbewegung Mengenbasiertes Laden! ETL-Tools sollten Datenbank – Features mitnehmen Oracle Confidential – Restricted

13
Ziele und Aufgaben Was wird geladen
Bereitstellen von Daten in adäquater Weise Zeitlich passend Richtige Form Passende Inhalte Daten so ablegen, dass man sie wiederfindet Dokumentation Daten Ressourcen-ökonomisch speichern Berücksichtigung von Plattenplatz Was wird geladen Es sollte nur das geladen werden, was wirklich gebraucht wird Gibt es einen Auftrag für das Laden bestimmter Daten? Wer braucht die Daten? Welche Daten werden gebraucht? Sind die zu ladenden Daten in einem brauchbaren Zustand? Welche Anforderungen sind an Quelldaten zu stellen? Wer definiert die Anforderungen? Ladedokumentation: wann, von wem ... Nachvollziebarkeit 13

14
Hilfsmittel in der Datenbank (Auflistung)
Parallelisierung Partitioning / Partition Exchange Load (PEL) Direct Path Load Set-Based SQL Pipelined Table Functions Materialized Views External Tables / Loader Transportable Tablespace Data Pump Database Link Direkt FTP-Load
 Direct Path Load. Set-Based SQL. Pipelined Table Functions. Materialized Views. External Tables / Loader. Transportable Tablespace. Data Pump. Database Link. Direkt FTP-Load.")
15
Ziele eines effizienten ETL-Prozesses
Ressource-schonend Rechenzeit, Storage Schnell änderbar und pflegbar Kurze Laufzeiten Erzeugen von stimmigen Abfrage-Ergebnissen Erleichterung für BI-Tools ....

16
Allgemeine Regeln Schichtenmodell als Orientierung nutzen – ganzheitlich planen Transformationen so früh wie möglich im Verlauf des Schichtenmodells Auf die spezifischen Anforderungen und Situationen in den jeweiligen Schichten reagieren Alle Schichten innerhalb derselben Datenbank Daten nur dann bewegen, wenn sich qualitativ etwas verändert. Nur diejenigen Daten laden, die wirklich benötigt werden Eher selektieren als kopieren Prüfungen an wenigen Stellen konzentrieren Bei Data Marts prüfen, ob sie permanent bereit gehalten werden

17
Flexibilität und schnelles Bereitsstellen
Data Integration Layer Enterprise Information Layer User View Layer T R R D D S T S S F D B integrieren Zusammenhängender Abfragebereich T aufbereiten D B B B D F D B B D F D Operative Daten Strategische Daten Taktische Daten T: Transfertabellen R: Referenztabellen S: Stammdaten B: Bewgungsdaten D: Dimensionen F: Fakten 17

18
Die Organisation des ETL-Prozesses
Data Integration Layer Enterprise Information Layer User View Layer Richtig selektieren Die Masse aller Prüfungen Stamm- Referenzdaten aktualisieren Nur denormalisierende Joins Möglichst viele Kennzahlen in die Datenbank Repository (Glossar, alle Objekte) Für alle Aktionen den frühest möglichen Punkt finden 18
 Für alle Aktionen den frühest möglichen Punkt finden. 18.")
19
Angemessen in den Situationen agieren
Data Integration Layer Enterprise Information Layer User View Layer Keine Daten Referenzdaten Dimensionen Stammdaten Fakten Bewegungsdaten (granulare Transaktionsdaten) vor- berechnete Kennzahlen vor- berechnete Kennzahlen T: Transfertabellen R: Referenztabellen S: Stammdaten B: Bewgungsdaten D: Dimensionen F: Fakten 19
 vor- berechnete Kennzahlen. vor- berechnete Kennzahlen. T: Transfertabellen. R: Referenztabellen. S: Stammdaten. B: Bewgungsdaten. D: Dimensionen. F: Fakten. 19.")
20
Angemessen in den Situationen agieren
Data Integration Layer Enterprise Information Layer User View Layer Temporäre Daten 20% Volumen f. viele Kleine Tabellen Wieder herstellbare Daten 80% Volumen f. wenige große Tabellen => partitioniert 20

21
Lade-Aktivitäten an Schichtübergängen
Integration Enterprise User View Flüchtige Daten Persistent Kopien / teilpersistent dynamisch Clearing-Verfahren, technisches, logisches, semantisches Prüfen Denormalisieren z.T. Aggregieren Normalisieren (Granularisieren) Historisieren Generische Datenstrukturen (isolierte Tabellen, teil-ausgeprägte Datentypen) Keine Constraints 3 NF Datenstrukturen (ER-Tabellen, ausgeprägte Datentypen) Aktivierte Constraints Multidimensionale Modelle (ER-Tabellen, ausgeprägte Datentypen) Kopieren Selektieren Mengenbasiertes Prüfen ohne Constraints Umschlüsselung Lookups -> Referenz-/Stammdaten Joins Aufbauen von Distinct-Strukturen (Normalisieren) Lookups -> Dimensionsdaten Joins - Denormalisieren 21
 Historisieren. Generische Datenstrukturen (isolierte Tabellen, teil-ausgeprägte Datentypen) Keine Constraints. 3 NF Datenstrukturen (ER-Tabellen, ausgeprägte Datentypen) Aktivierte Constraints. Multidimensionale Modelle (ER-Tabellen, ausgeprägte Datentypen) Kopieren Selektieren. Mengenbasiertes Prüfen ohne Constraints. Umschlüsselung Lookups -> Referenz-/Stammdaten Joins Aufbauen von Distinct-Strukturen (Normalisieren) Lookups -> Dimensionsdaten Joins - Denormalisieren. 21.")
22
Verfahren für schnelles ETL in der Datenbank
Data Integration Layer Enterprise Information Layer User View Layer Selektieren Statt kopieren Direct Path in temporäre Tabellen Contraint- freies Prüfen mit Mengen- basiertem SQL Partition Exchange &LOAD in partit. Tabellen (PEL) Unveränderte Bewegungs- daten liegen lassen Große Fakten-Tab. über PEL. Kenn- zahlen aus- schließlich über MAV- Refresh Bekannte Kennzahlen in die DB weniger Koipien in BI-Tools
 Unveränderte Bewegungs- daten liegen lassen. Große Fakten-Tab. über PEL. Kenn- zahlen aus- schließlich über. MAV- Refresh. Bekannte Kennzahlen. in die DB. weniger Koipien in. BI-Tools.")
23
Datenbank-basierte ETL-Prozesse
Themenübersicht Datenbank-basierte ETL-Prozesse Anforderungen an den ETL-Prozess im Data Warehouse Speichermanagement und Grundlagentechniken Blöcke, Extents, Segmente, Tablespace Direct Path Load, Mengenbasiertes Laden Optimierungsszenario Hilfsmittel für schnelles Laden Prüftechniken mit SQL Szenario zum Prüfen von Daten Weitere Techniken und Tools 23

24
Zuordnung Datenobjekten und Speicher
Table Index Mview Partition DB-Objekte

25
Speicherobjekte

26
Die automatische Extent-Vergrößerung
Automatische Allokierung von weiteren Segmenten Exponentielles Vergrößerungs-Mass select t.TABLE_NAME, t.blocks,t.EMPTY_BLOCKS,t.AVG_SPACE,t.AVG_ROW_LEN,t.NUM_ROWS, t.pct_free, t.compression,s.EXTENTS,s.bytes seg_bytes,e.blocks ext_blks,e.bytes ext_bytes from user_segments s, user_tables t, user_extents e where t.TABLE_NAME = s.segment_name and e.SEGMENT_NAME = s.SEGMENT_NAME and t.TABLE_NAME = 'F_UMSATZ'; TABLE_NAME BLOCKS EMPTY_BLOCKS AVG_ROW_LEN NUM_ROWS PCT_FREE COMPRESS EXTENTS SEG_BYTES EXT_BLKS EXT_BYTES F_UMSATZ DISABLED F_UMSATZ DISABLED F_UMSATZ DISABLED F_UMSATZ DISABLED

27
Block- und Satzstruktur
Row header Column length Datenbank Block Column value

28
Empfehlungen bzgl. Spacemanagement
PCTFREE auf 0 setzen In der Regel sind keine späteren UPDATES nötig Spart gegenüber dem Default von 10% auch 10% IO und jede Verarbeitung ist um 10% schneller Sollten dennoch UPDATES gemacht werden müssen: Partitionieren der Tabelle Die jüngsten Partitionen mit separatem Tablespace definieren und PCTFREE auf gewünschten Wert setzen Wenn keine UPDATES mehr zu erwarten sind -> umkopieren auf eine Partition mit einem Tablespace mit PCTFREE=0 Blocksize hochsetzen 16K, 32K Wirkt sich bei Massen-Inserts bei einer gößeren Datenmenge positiv auf die Performnce aus

29
High Water Mark Nach INSERTS: Extent ID 0 1 2 3 4 Segment
Nach DELETES: Extent ID Segment Used block Unused block Free space after delete

30
Wie wird die „High Water Mark“ bestimmt
TOTAL_BLOCKS UNUSED_BLOCKS Extent ID Segment High-water mark LAST_USED_EXTENT_FILE_ID, LAST_USED_EXTENT_BLOCK_ID

31
Deallocate Space Extent ID 4 3 2 1 Before deallocation Segment
Before deallocation Segment ALTER TABLE tablename DEALLOCATE UNUSED; High-water mark Extent ID 4 3 2 1 Segment After deallocation Used block Unused block Free space after delete

32
Truncate Table TRUNCATE TABLE tablename Extent ID 0 1 Segment
Free space High-water mark

33
Direct Path Load INSERT /*+APPEND */ INTO DWH.F_UMSATZ NOLOGGING
SELECT * FROM OLTP.BESTELLUNGEN; Server process F_UMSATZ Segment High-water mark Used block Free space after delete Blocks used by inserted rows

34
Paralleler Direct Path Load
ALTER SESSION ENABLE PARALLEL DML; INSERT /*+APPEND PARALLEL(F_UMSATZ,2) */ INTO DWH.F_UMSATZ NOLOGGING SELECT * FROM OLTP.BESTELLUNGEN; Slave process Slave process F_UMSATZ Segment High-water mark Used block Free space after delete Temporary segments
 */ INTO DWH.F_UMSATZ NOLOGGING. SELECT * FROM OLTP.BESTELLUNGEN; Slave process. Slave process. F_UMSATZ. Segment. High-water mark. Used block. Free space after delete. Temporary segments.")
35
„Convential“ und „Direct Path“ - Load
Instance SGA Shared pool Array insert Extent management Conventional Data save Direct path Table High-water mark Space used only by conventional load

36
Direct Path / Convential Path
Commits Reuse Free Space in Blöcken Constraint Checks Immer Undo Data / Logging Daten zunächst immer in SGA Buffer Tabelle für andere Benutzer offen Convential Path SQL Loader External Table Insert Append CTAS Benutzer SQL Command Processing Space Management Get new extents Adjust High Water Mark Find partial blocks Fill partial blocks Buffer Cache Buffer Cache Management Manage queues - Manage contention Read Database Blocks Write Database Direct Path Database Oracle Server Direct Path Data Save Schreiben oberhalb der High Water Marks Keine Constraint Checks Nur PK, Not Null, Unique Key Kein Logging Daten nicht in SGA Buffer Tabelle gesperrt für andere Benutzer

37
Testfall F_Umsatz F_Umsatz_DP 51.100.000 Sätze 51.100.000 Sätze
ARTIKEL_ID KUNDEN_ID ZEIT_ID REGION_ID KANAL_ID UMSATZ MENGE UMSATZ_GESAMT ARTIKEL_ID KUNDEN_ID ZEIT_ID REGION_ID KANAL_ID UMSATZ MENGE UMSATZ_GESAMT Sätze Sätze SQL> insert into f_umsatz_DP select * from f_umsatz; Zeilen erstellt. Abgelaufen: 00:07:57.73 SQL> insert /*+ APPEND */ into f_umsatz_DP select * from f_umsatz; Abgelaufen: 00:00:27.24 SQL> insert /*+ APPEND PARALLEL(F_UMSATZ_DP,2) */ into f_umsatz_DP select * from f_umsatz; Abgelaufen: 00:00:20.68
 */ into f_umsatz_DP select * from f_umsatz; Abgelaufen: 00:00:")
38
Beliebte Fehler – Direct Path Load
Schreiben einzelner INSERTS mit APPEND Stattdessen INSERTS mit vielen Sätzen Create or Replace procedure ABC as ..... Cursor pos is select ..... .... Begin open pos; loop exit when pos%notfound; Insert /*+ APPEND */ into Ziel_Tabelle select ...... Commit; end loop; ..... End; Insert /*+ APPEND */ into ziel_Tabelle select Direct Path Load nur mit echten Mengen und nicht bei Einzel-Inserts

39
Beliebte Fehler – Direct Path Load
Batch-Lauf 1 (Session 1) Insert /*+ APPEND */ into F_UMSATZ select Batch-Lauf 2 (Session 2) Insert /*+ APPEND */ into F_UMSATZ select Tabelle BESTELLUNG Gegenseitiges Blockieren durch Direct Path Loads auf In unterschiedlichen Sessions auf die gleiche Tabelle
 Insert /*+ APPEND */ into. F_UMSATZ. select Batch-Lauf 2. (Session 2) Insert /*+ APPEND */ into. F_UMSATZ. select Tabelle. BESTELLUNG. Gegenseitiges Blockieren durch Direct Path Loads auf. In unterschiedlichen Sessions auf die gleiche Tabelle.")
40
Das Simulations-Szenario
Name Type F0 NUMBER F1 NUMBER F2 NUMBER F3 VARCHAR2(50) F4 DATE F5 VARCHAR2(50) F6 VARCHAR2(50) F7 NUMBER Tabelle T10 Name Type F0 NUMBER F1 NUMBER F2 NUMBER F3 VARCHAR2(50) F4 DATE F5 VARCHAR2(50) F6 VARCHAR2(50) F7 NUMBER Tabelle T20 ~ 10 Millionen Sätze 1, 6 GB, unkompr. F0 F1 F2 F F F F F7 IamPFnAz6qnhWZlqao1AHgaR9gQczm4SSvtJn9lU 27-JAN-11 upOLaDSvWuxmv4pFlZsgtEPqgi43uRgI1uQjF7kV x2AFYV3W2QIcxf5mPzl39MpErCZI7rc1eQMXuMs8 42 ESh7uiu6Hqo6cwqqk9B7D1w9biFR3QjCVDyNWjaq 01-MAY-08 Mcj4QZEVmiG5Qof4eoPwqARLFhlc1xpLmgrAzL5i jvuabLwH44YODTusRR3Huyz7sECCTrLFGZA5QJdD 12 PA2OpnqxTISxHoHsJ5BZrIJArDGhcKCIi1lAzJyj 17-DEC-10 ebU5ogfehM87oO1f8e1VVrFOjJBsZJEUQLcyOls7 GP5zpIb5EzAsPrT9EuL6tdcJ2BVGbFXtch3F4rkO 58 P4q95WqLs9yWOdx6yryAt7zNgO8YeGzqmXTLdHJe 26-NOV-09 eTsS6sZdjeZbRWSnjq2m3ivoACc29dQENlVYjtkK DTTfROusF1hU1LLGHNRXWWGwpFlO47zedJWgEdX5 55
 F4 DATE. F5 VARCHAR2(50) F6 VARCHAR2(50) F7 NUMBER. Tabelle T10. Name Type F0 NUMBER. F1 NUMBER. F2 NUMBER. F3 VARCHAR2(50) F4 DATE. F5 VARCHAR2(50) F6 VARCHAR2(50) F7 NUMBER. Tabelle T20. ~ 10 Millionen Sätze. 1, 6 GB, unkompr. F0 F1 F2 F3 F4 F5 F6 F IamPFnAz6qnhWZlqao1AHgaR9gQczm4SSvtJn9lU 27-JAN-11 upOLaDSvWuxmv4pFlZsgtEPqgi43uRgI1uQjF7kV x2AFYV3W2QIcxf5mPzl39MpErCZI7rc1eQMXuMs ESh7uiu6Hqo6cwqqk9B7D1w9biFR3QjCVDyNWjaq 01-MAY-08 Mcj4QZEVmiG5Qof4eoPwqARLFhlc1xpLmgrAzL5i jvuabLwH44YODTusRR3Huyz7sECCTrLFGZA5QJdD PA2OpnqxTISxHoHsJ5BZrIJArDGhcKCIi1lAzJyj 17-DEC-10 ebU5ogfehM87oO1f8e1VVrFOjJBsZJEUQLcyOls7 GP5zpIb5EzAsPrT9EuL6tdcJ2BVGbFXtch3F4rkO P4q95WqLs9yWOdx6yryAt7zNgO8YeGzqmXTLdHJe 26-NOV-09 eTsS6sZdjeZbRWSnjq2m3ivoACc29dQENlVYjtkK DTTfROusF1hU1LLGHNRXWWGwpFlO47zedJWgEdX")
41
Der ungünstigste Fall Einzelinserts – Simuliert über Cursor-Prozedur
CREATE OR REPLACE PROCEDURE PR_x AS CURSOR crs_T10 IS SELECT * FROM T10; bstnr number; V_F0 NUMBER; V_F1 NUMBER; V_F2 NUMBER; V_F3 VARCHAR2(50); V_F4 DATE; V_F5 VARCHAR2(50); V_F6 VARCHAR2(50); V_F7 NUMBER; BEGIN open crs_T10; loop FETCH crs_T10 into V_F0 ,V_F1,V_F2,V_F3,V_F4,V_F5,V_F6,V_F7; insert /*+ NOLOGGING */ into T20 values(V_F0,V_F1,V_F2,V_F3,V_F4,V_F5,V_F6,V_F7); EXIT WHEN crs_T10%NOTFOUND; END loop; END; Lese-Operation T10 Tabelle Datenbewegung über Variablen Schreibvorgang Laufzeit: 08:31 (Minuten : Sekunden) (8:12 System DWH)
; V_F4 DATE; V_F5 VARCHAR2(50); V_F6 VARCHAR2(50); V_F7 NUMBER; BEGIN. open crs_T10; loop. FETCH crs_T10 into V_F0 ,V_F1,V_F2,V_F3,V_F4,V_F5,V_F6,V_F7; insert /*+ NOLOGGING */ into T20 values(V_F0,V_F1,V_F2,V_F3,V_F4,V_F5,V_F6,V_F7); EXIT WHEN crs_T10%NOTFOUND; END loop; END; Lese-Operation T10 Tabelle. Datenbewegung über Variablen. Schreibvorgang. Laufzeit: 08:31 (Minuten : Sekunden) (8:12 System DWH)")
42
Der einfache INSERT Laufzeit: 01:46 (Minuten : Sekunden)
insert into t20 select * from t10; INSERT in leere Tabelle INSERT in gefüllte Tabelle INSERT in gefüllte Tabelle (Wiederholung) Laufzeit: 01:46 (Minuten : Sekunden) Laufzeit: 01:58 (Minuten : Sekunden) Laufzeit: 01:58 (Minuten : Sekunden)
 Laufzeit: 01:46 (Minuten : Sekunden) Laufzeit: 01:58 (Minuten : Sekunden) Laufzeit: 01:58 (Minuten : Sekunden)")
43
Umschalten der DB shutdown immediate; startup mount alter database archivelog; [alter database noarchivelog;] alter database open; Logging / Nologging INSERT im Archivelog-Modus INSERT mit NOLOGGING im ARCHIVE-Modus insert into t20 select * from t10; Laufzeit: 02:56 (Minuten : Sekunden) (3:10 System DWH) insert /*+ NOLOGGING */ into t20 select * from t10; Laufzeit: 01:48 (Minuten : Sekunden) (Hint nur zu Dokuzwecken. Steuerung des NOLOGGING-Zustands über ALTER DATABASE NOARCHIVELOG.)
![Umschalten der DB shutdown immediate; startup mount. alter database archivelog; [alter database noarchivelog;]](http://slideplayer.org/slide/11898625/67/images/43/Umschalten+der+DB+shutdown+immediate%3B+startup+mount.+alter+database+archivelog%3B+%5Balter+database+noarchivelog%3B%5D.jpg "alter database open; Logging / Nologging. INSERT im Archivelog-Modus. INSERT mit NOLOGGING im ARCHIVE-Modus. insert into t20 select * from t10; Laufzeit: 02:56 (Minuten : Sekunden) (3:10 System DWH) insert /*+ NOLOGGING */ into t20 select * from t10; Laufzeit: 01:48 (Minuten : Sekunden) (Hint nur zu Dokuzwecken. Steuerung des NOLOGGING-Zustands über ALTER DATABASE NOARCHIVELOG.)")
44
Logging / Nologging Wird der Archivelog-Modus benötigt oder nicht?
Relevant für Backup DataGuard / Golden Gate Flashback Wichtigster Punkt ist: BACKUP Abhängig vom Backup-Konzept

45
Auswirkungen auf das Backup-Konzept
Plattensicherung Oft einfach, weil eingespielte Verfahren Grosser Ressourcenverbrauch Alle (DWH-Bereiche) werden gesichtert -> großer Platzbedarf Teure Backup-Software Nicht immer sicher, weil korrupte Datenbank-Blöcke nicht erkannt werden können Man kann ohne Archivlog fahren -> ETL schneller und einfacher Sicherung mit RMAN Ressourcen-günstigstes Verfahren Man muss mit Archivlog fahren ETL etwas langsamer Massenloads mit Driect Path Load (NOLOGGING) -> separate Sicherung
 werden gesichtert -> großer Platzbedarf. Teure Backup-Software. Nicht immer sicher, weil korrupte Datenbank-Blöcke nicht erkannt werden können. Man kann ohne Archivlog fahren -> ETL schneller und einfacher. Sicherung mit RMAN. Ressourcen-günstigstes Verfahren. Man muss mit Archivlog fahren. ETL etwas langsamer. Massenloads mit Driect Path Load (NOLOGGING) -> separate Sicherung.")
46
RMAN- Backup-Verfahren: Was wird gesichert?
Data Integration Layer Enterprise Information Layer User View Layer R: Referenztabellen T R R D D T: Transfertabellen S: Stammdaten S B: Bewgungsdaten T S S F D D: Dimensionen B F: Fakten T D B Keine Sicherung Keine Sicherung, wenn Data Marts komplett neu aufgebaut Werden Inkremental Backup nur für Referenz- und Stammdaten große Bewegungsdatentabellen am besten nach Abschluss des ETL-Laufes sichern RMAN (Incremental) RMAN (Incremental) 46
 RMAN (Incremental) 46.")
47
Direct Path Load Create Table t20 as select * from t10;
Create Table As Select (CTAS) INSERT mit APPEND - Hint Create Table t20 as select * from t10; Laufzeit: 01:00 (Minuten : Sekunden) insert /*+ APPEND */ into t20 select * from t10; Laufzeit: 01:00 (Minuten : Sekunden)
 INSERT mit APPEND - Hint. Create Table t20 as select * from t10; Laufzeit: 01:00 (Minuten : Sekunden) insert /*+ APPEND */ into t20 select * from t10; Laufzeit: 01:00 (Minuten : Sekunden)")
48
Arbeiten mit Buffer-Caches
Wiederholtes Laden ohne zuvor die Buffer-Caches zu leeren Der SELECT-Teil läuft schneller 1. Verarbeitung insert /*+ APPEND */ into t20 select * from t10; Laufzeit: 01:00 (Minuten : Sekunden) 2. Verarbeitung insert /*+ APPEND */ into t20 select * from t10; Laufzeit: 00:25 (Minuten : Sekunden)
 2. Verarbeitung. insert /*+ APPEND */ into t20 select * from t10; Laufzeit: 00:25 (Minuten : Sekunden)")
49
Verlagern des Ladeprozesses auf SSD-Platten
Bestimmte Arbeitstabellen des ETL-Prozesses liegen auf gesonderten SSD-Platten Die aktiven Partitionen großer Tabellen Temporäre Tabellen Data Integration Layer Enterprise Information Layer User View Layer R: Referenztabellen CTAS 20% R R T S S S D D T: Transfertabellen SSD S: Stammdaten CTAS B: Bewgungsdaten T PEL F D D: Dimensionen SSD SSD SSD B SSD F: Fakten T A: Aggregate D SSD SSD A Partitionierte Tabellen B PEL T SSD PEL SSD SSD Prüfungen 80%

50
Verlagern des Ladeprozesses auf SSD-Platten
Test mit Direct Path Load CTAS mit SSD Create Table T20 as select * from t10; Laufzeit: 00:10 (Minuten : Sekunden) APPEND mit SSD insert /*+ APPEND */ into t20 select * from t10; Laufzeit: 00:10 (Minuten : Sekunden)
 APPEND mit SSD. insert /*+ APPEND */ into t20 select * from t10; Laufzeit: 00:10 (Minuten : Sekunden)")
51
Datenbank-basierte ETL-Prozesse
Themenübersicht Datenbank-basierte ETL-Prozesse Anforderungen an den ETL-Prozess im Data Warehouse Speichermanagement und Grundlagentechniken Blöcke, Extents, Segmente, Tablespace Direct Path Load, Mengenbasiertes Laden Optimierungsszenario Hilfsmittel für schnelles Laden Prüftechniken mit SQL Szenario zum Prüfen von Daten Weitere Techniken und Tools 51

52
Verfahren für schnelles ETL in der Datenbank
Data Integration Layer Enterprise Information Layer User View Layer Selektieren Statt kopieren Direct Path in temporäre Tabellen Contraint- freies Prüfen mit Mengen- basiertem SQL Partition Exchange &LOAD in partit. Tabellen (PEL) Unveränderte Bewegungs- daten liegen lassen Große Fakten-Tab. über PEL. Kenn- zahlen aus- schließlich über MAV- Refresh Bekannte Kennzahlen in die DB weniger Koipien in BI-Tools
 Unveränderte Bewegungs- daten liegen lassen. Große Fakten-Tab. über PEL. Kenn- zahlen aus- schließlich über. MAV- Refresh. Bekannte Kennzahlen. in die DB. weniger Koipien in. BI-Tools.")
53
Es gibt 6 Prüf-Kategorien
Attribut-bezogene Regeln Not Null / Pflichtfelder Formatangaben numeric Alphanumerisch Date Masken Div. Check Constraint Wertbereiche Ober-/Untergrenzen / Wertelisten Satz-bezogene Regeln Abhängigkeiten von Werten in anderen Attributen desselben Satzes Satz-übergreifende Regeln Primary Key / Eindeutigkeit Aggregat – Bedingungen Ober- Untergrenzen von Summen Anzahl Sätze pro Intervall usw. Rekursive Zusammenhänge Verweise auf andere Sätze derselben Tabelle (Relation) Tabellen-über greifende Regeln Foreign Key Child-Parent (Orphan) Parent-Child Aggregat – Bedingungen Ober- Untergrenzen von Summen Anzahl Sätze pro Intervall usw. Referenz-Zusammenhänge Verweise auf Sätze einer anderen Tabelle (Relation) Zeit-/ Zusammenhang-bezogene Regeln Zeitinvariante Inhalte (z. B. Anz. Bundesländer) Zeitabhängige Veränderungen Über die Zeit mit anderen Daten korrelierende Feldinhalte Verteilungs-/Mengen-bezogene Regeln Verteilung Arithmetische Mittel Varianz / Standardabweichungen Qualitätsmerkmale und Mengen A D B E C F
 Tabellen-über greifende Regeln. Foreign Key. Child-Parent (Orphan) Parent-Child. Aggregat – Bedingungen. Ober- Untergrenzen von Summen. Anzahl Sätze pro Intervall usw. Referenz-Zusammenhänge. Verweise auf Sätze einer anderen Tabelle (Relation) Zeit-/ Zusammenhang-bezogene Regeln. Zeitinvariante Inhalte (z. B. Anz. Bundesländer) Zeitabhängige Veränderungen. Über die Zeit mit anderen Daten korrelierende Feldinhalte. Verteilungs-/Mengen-bezogene Regeln. Verteilung. Arithmetische Mittel. Varianz / Standardabweichungen. Qualitätsmerkmale und Mengen. A. D. B. E. C. F.")
54
Mengen-basierte Prüfungen mit SQL
Attribut-bezogene Regeln Not Null / Pflichtfelder Formatangaben numeric Alphanumerisch Date Masken Div. Check Constraint Wertbereiche Ober-/Untergrenzen / Wertelisten Satz-bezogene Regeln Abhängigkeiten von Werten in anderen Attributen desselben Satzes Satz-übergreifende Regeln Primary Key / Eindeutigkeit Aggregat – Bedingungen Ober- Untergrenzen von Summen Anzahl Sätze pro Intervall usw. Rekursive Zusammenhänge Verweise auf andere Sätze derselben Tabelle (Relation) select bestellnr, case when -- wenn Feld BESTELLNR nicht numerisch REGEXP_LIKE(BESTELLNR, '[^[:digit:]]') then 1 else 0 End Num_Check_bestellnr from bestellung; A select CASE WHEN (F1 = 3 and F2 = F3 + F4) then 1 ELSE 0 end from fx B insert /*+ APPEND */ into err_non_unique_bestellung select bestellnr from (select count(bestellnr) n, bestellnr from bestellung group by bestellnr) where n > 1; C
 select. bestellnr, case. when -- wenn Feld BESTELLNR nicht numerisch. REGEXP_LIKE(BESTELLNR, [^[:digit:]] ) then 1. else 0. End Num_Check_bestellnr. from bestellung; A. select. CASE. WHEN (F1 = 3 and F2 = F3 + F4) then 1. ELSE 0. end. from fx. B. insert /*+ APPEND */ into err_non_unique_bestellung. select bestellnr from. (select. count(bestellnr) n, bestellnr. from bestellung. group by bestellnr) where n > 1; C.")
55
Umgang mit SQL und PL/SQL im DB-ETL
So nicht ... Aber z. B. so ... Create or replace procedure Proc_A V1 number; V2 number; V3 varchar2; V4 varchar2; .... Cursor CS as select s1,s2 from tab_src; Begin open CS; loop fetch CS into v1,v2,...; select f1 into v3 from tab1; select f1 into v4 from tab2; insert into Ziel _tab s1,s2,s3,s4 values(v1,v2,v3,v4); end; insert into ziel select f1, f2, f3, f4 from (with CS as select s1 v1,s2 v2 from tab_src Select tab1.f1 f1 ,tab2.f2 f2, CS.s1 f3,CS.s2 f4 from tab1,tab2,CS Where... );
; end; insert into ziel. select f1, f2, f3, f4 from. (with CS as. select s1 v1,s2 v2 from tab_src. Select tab1.f1 f1 ,tab2.f2 f2, CS.s1 f3,CS.s2 f4. from tab1,tab2,CS. Where... );")
56
Prüfungen Kategorie A Attribut-/Column-bezogene Regeln
Not Null / Pflichtfelder Formatangaben numeric Alphanumerisch Date Masken Div. Check Constraint Wertbereiche Ober-/Untergrenzen / Wertelisten

57
Prüfen mit oder Ohne Datenbank-Constraints
Constraints verlangsamen den Massen-Insert des ETL-Prozesses => Ohne Constraints arbeiten => Prüfen mit SQL-Mitteln => Prüfen mit DML-Errorlogging Nur bei wenigen Daten sinnvoll

58
Prüfkonzepte Fachliche Prüfungen kaum möglich Einfach implementierbar
Eventuell zusätzliche Prüfungen nötig Einfach implementierbar Bessere Performance Nur bei aktivierten Constraints Stage-Tabelle + Geprüfte Daten Statistik Routine Statistiken Date Number Varchar2() Kopieren Check Constraints Bad File Fehlerhafte Sätze DML Error Log 58
 Kopieren. Check Constraints. Bad File. Fehlerhafte Sätze. DML Error Log. 58.")
59
Error Logging Constraints Unique Key / Primary Key Foreign Key
Kunde Constraints Unique Key / Primary Key Foreign Key NOT NULL Check Constraint KUNDENNR VORNAME NACHNAME ORTNR STRASSE TELEFON INSERT INTO Kunde VALUES (......) LOG ERRORS INTO kunde_err('load_ ') Kunde_err KUNDENNR VORNAME NACHNAME ORTNR STRASSE TELEFON ORA_ERR_NUMBER$ ORA_ERR_MESG$ ORA_ERR_ROWID$ ORA_ERR_OPTYP$ ORA_ERR_TAG$ 59
 LOG ERRORS INTO kunde_err( load_ ) Kunde_err. KUNDENNR VORNAME NACHNAME ORTNR STRASSE TELEFON. ORA_ERR_NUMBER$ ORA_ERR_MESG$ ORA_ERR_ROWID$ ORA_ERR_OPTYP$ ORA_ERR_TAG$ 59.")
60
Testfall Bestellung Bestellung_Check UNIQUE- CONSTRAINT 1.100.000
BESTELLNR ORTNR KUNDENNR DATUM ANZAHLPOS BESTELLNR ORTNR KUNDENNR DATUM ANZAHLPOS Sätze doppelt Bestellung_Check_Errors BESTELLNR ORTNR KUNDENNR DATUM ANZAHLPOS ORA_ERR_NUMBER$ ORA_ERR_MESG$ ORA_ERR_ROWID$ ORA_ERR_OPTYP$ ORA_ERR_TAG$

61
Testfall begin dbms_errlog.create_error_log(
dml_table_name => 'BESTELLUNG_CHECK', err_log_table_name => 'BESTELLUNG_CHECK_ERRORS' ); end; SQL> insert into bestellung_check select * from bestellung 2 LOG ERRORS INTO bestellung_check_errors ('daily_load') REJECT LIMIT 3 ; Zeilen erstellt. Abgelaufen: 00:00:50.63
; end; SQL> insert into bestellung_check select * from bestellung. 2 LOG ERRORS INTO bestellung_check_errors ( daily_load ) REJECT LIMIT ; Zeilen erstellt. Abgelaufen: 00:00:")
62
Die Alternative Zusammen 00:00:03.15 1.
create table Bestellung_non_unique as select bestellnr from (select count(BESTELLNR) n, bestellnr from bestellung group by bestellnr) where n > 1; Tabelle wurde erstellt. Abgelaufen: 00:00:00.49 2. insert /*+ APPEND */ into bestellung_check select B.BESTELLNR,B.ORTNR,B.KUNDENNR,B.DATUM , B.ANZAHLPOS from bestellung B where B.BESTELLNR not in (select bestellnr from Bestellung_non_unique); Zeilen erstellt. Abgelaufen: 00:00:02.26 Zusammen :00:03.15
 n, bestellnr. from bestellung. group by bestellnr) where n > 1; Tabelle wurde erstellt. Abgelaufen: 00:00: insert /*+ APPEND */ into bestellung_check. select B.BESTELLNR,B.ORTNR,B.KUNDENNR,B.DATUM , B.ANZAHLPOS. from bestellung B. where B.BESTELLNR not in (select bestellnr from Bestellung_non_unique); Zeilen erstellt. Abgelaufen: 00:00: Zusammen 00:00:")
63
Check Constraint mit Regular Expressions
CREATE TABLE Check_KUNDE ( KUNDENNR NUMBER, GESCHLECHT NUMBER, VORNAME VARCHAR2(50), NACHNAME VARCHAR2(50), ANREDE VARCHAR2(10), GEBDAT DATE, ORTNR NUMBER, STRASSE VARCHAR2(50), TELEFON VARCHAR2(30) ); Regel: Im Kundennamen müssen Buchstaben vorkommen und keine reine Zahlenkolonne ALTER TABLE check_kunde ADD CONSTRAINT Ch_KD_Name CHECK(REGEXP_LIKE(NACHNAME, '[^[:digit:]]')); INSERT INTO check_kunde (Kundennr, Geschlecht, Vorname, Nachname, Anrede, Gebdat, Ortnr, Strasse, Telefon) VALUES (9,1,'Klaus','123','Herr',' ',2,'Haupstr.', ); FEHLER in Zeile 1: ORA-02290: CHECK-Constraint (DWH.CH_KD_NAME) verletzt Verwendung von Regular Expressions steigert die Performance bei Prüfungen 63
, NACHNAME VARCHAR2(50), ANREDE VARCHAR2(10), GEBDAT DATE, ORTNR NUMBER, STRASSE VARCHAR2(50), TELEFON VARCHAR2(30) ); Regel: Im Kundennamen müssen Buchstaben vorkommen und keine reine Zahlenkolonne. ALTER TABLE check_kunde ADD CONSTRAINT Ch_KD_Name CHECK(REGEXP_LIKE(NACHNAME, [^[:digit:]] )); INSERT INTO check_kunde (Kundennr, Geschlecht, Vorname, Nachname, Anrede, Gebdat, Ortnr, Strasse, Telefon) VALUES (9,1, Klaus , 123 , Herr , ,2, Haupstr. , ); FEHLER in Zeile 1: ORA-02290: CHECK-Constraint (DWH.CH_KD_NAME) verletzt. Verwendung von Regular Expressions steigert die Performance bei Prüfungen. 63.")
64
Beispiele Modus Zeichenklassen * Match 0 or more times
? Match 0 or 1 time + Match 1 or more times {m} Match exactly m times {m,} Match at least m times {m, n} Match at least m times but no more than n times \n Cause the previous expression to be repeated n times Modus [:alnum:] Alphanumeric characters [:alpha:] Alphabetic characters [:blank:] Blank Space Characters [:cntrl:] Control characters (nonprinting) [:digit:] Numeric digits [:graph:] Any [:punct:], [:upper:], [:lower:], and [:digit:] chars [:lower:] Lowercase alphabetic characters [:print:] Printable characters [:punct:] Punctuation characters [:space:] Space characters (nonprinting), such as carriage return, newline, vertical tab, and form feed [:upper:] Uppercase alphabetic characters [:xdigit:] Hexidecimal characters Zeichenklassen 64
 [:digit:] Numeric digits. [:graph:] Any [:punct:], [:upper:], [:lower:], and [:digit:] chars. [:lower:] Lowercase alphabetic characters. [:print:] Printable characters. [:punct:] Punctuation characters. [:space:] Space characters (nonprinting), such as carriage return, newline, vertical tab, and form feed. [:upper:] Uppercase alphabetic characters. [:xdigit:] Hexidecimal characters. Zeichenklassen. 64.")
65
Wichtiges Hilfsmittel für Einzelfeldprüfungen: CASE-Anweisung
SELECT CASE WHEN isnumeric('999') = 1 THEN 'numerisch' ‚ ELSE 'nicht numerisch'‚ END Ergebnis FROM dual; CREATE OR REPLACE FUNCTION isnumeric ( p_string in varchar2) return boolean AS l_number number; BEGIN l_number := p_string; RETURN 1; EXCEPTION WHEN others THEN RETURN 0; END; 65
 = 1 THEN numerisch ‚ ELSE nicht numerisch ‚ END Ergebnis FROM dual; CREATE OR REPLACE FUNCTION isnumeric ( p_string in varchar2) return boolean AS. l_number number; BEGIN. l_number := p_string; RETURN 1; EXCEPTION. WHEN others THEN RETURN 0; END; 65.")
66
Hilfsfunktion: Date_Check
BEGIN inDate:= trim(str); if dateCheck(inDate, 'mm-dd-yyyy') = 'false' AND dateCheck(inDate, 'mm-dd-yy') = 'false' AND dateCheck(inDate, 'yyyy-mm-dd') = 'false' AND dateCheck(inDate, 'yy-mm-dd') = 'false' AND dateCheck(inDate, 'yyyy-mon-dd') = 'false‚ AND dateCheck(inDate, 'yy-mon-dd') = 'false‚ AND dateCheck(inDate, 'dd-mon-yyyy') = 'false‚ AND dateCheck(inDate, 'dd-mon-yy') = 'false‚ AND dateCheck(inDate, 'mmddyy') = 'false‚ AND dateCheck(inDate, 'mmddyyyy') = 'false‚ AND dateCheck(inDate, 'yyyymmdd') = 'false' AND dateCheck(inDate, 'yymmdd') = 'false‚ AND dateCheck(inDate, 'yymmdd') = 'false' AND dateCheck(inDate, 'yymondd') = 'false‚ AND dateCheck(inDate, 'yyyymondd') = 'false‚ AND dateCheck(inDate, 'mm/dd/yyyy') = 'false' AND dateCheck(inDate, 'yyyy/mm/dd') = 'false‚ AND dateCheck(inDate, 'mm/dd/yy') = 'false' AND dateCheck(inDate, 'yy/mm/dd') = 'false‚ AND dateCheck(inDate, 'mm.dd.yyyy') = 'false' AND dateCheck(inDate, 'mm.dd.yy') = 'false' AND dateCheck(inDate, 'yyyy.mm.dd') = 'false' AND dateCheck(inDate, 'yy.mm.dd') = 'false' then return 'false'; else return 'true'; end if; exception --when others then return 'false'; END; create or replace function IsDate (str varchar2) return varchar2 is inDate varchar2(40); FUNCTION dateCheck (inputDate varchar2, inputMask varchar2) RETURN varchar2 IS dateVar date; BEGIN dateVar:= to_date(inputDate,inputMask); return 'true'; exception when others then return 'false'; END; In Verbindung mit der CASE-Anweisung 66
; if dateCheck(inDate, mm-dd-yyyy ) = false AND dateCheck(inDate, mm-dd-yy ) = false AND dateCheck(inDate, yyyy-mm-dd ) = false AND dateCheck(inDate, yy-mm-dd ) = false AND dateCheck(inDate, yyyy-mon-dd ) = false‚ AND dateCheck(inDate, yy-mon-dd ) = false‚ AND dateCheck(inDate, dd-mon-yyyy ) = false‚ AND dateCheck(inDate, dd-mon-yy ) = false‚ AND dateCheck(inDate, mmddyy ) = false‚ AND dateCheck(inDate, mmddyyyy ) = false‚ AND dateCheck(inDate, yyyymmdd ) = false AND dateCheck(inDate, yymmdd ) = false‚ AND dateCheck(inDate, yymmdd ) = false AND dateCheck(inDate, yymondd ) = false‚ AND dateCheck(inDate, yyyymondd ) = false‚ AND dateCheck(inDate, mm/dd/yyyy ) = false AND dateCheck(inDate, yyyy/mm/dd ) = false‚ AND dateCheck(inDate, mm/dd/yy ) = false AND dateCheck(inDate, yy/mm/dd ) = false‚ AND dateCheck(inDate, mm.dd.yyyy ) = false AND dateCheck(inDate, mm.dd.yy ) = false AND dateCheck(inDate, yyyy.mm.dd ) = false AND dateCheck(inDate, yy.mm.dd ) = false then return false ; else return true ; end if; --exception --when others then return false ; END; create or replace function IsDate (str varchar2) return varchar2 is inDate varchar2(40); FUNCTION dateCheck (inputDate varchar2, inputMask varchar2) RETURN varchar2. IS dateVar date; BEGIN dateVar:= to_date(inputDate,inputMask); return true ; exception when others then return false ; END; In Verbindung mit der CASE-Anweisung. 66.")
67
Abarbeitungslogik für Einzelfeldprüfung mit CASE
Gepruefte_Daten Stage-Tabelle Temp-Tabelle Date Number Varchar2() INSERT ALL WHEN Feld_1_is_null =1 into Error_Daten WHEN Feld_1_is_null=0 into Gepruefte_Daten Varchar2() Varchar2() INSERT INTO temp_table SELECT CASE .... FROM Stage_Table Feld1 Feld2 Feld3 Feld1 Feld2 Feld3 Feld1_is_null Feld1_is_numeric Feld2_is_numeric Kopieren Error_Daten Date Number Varchar2() Temporäre Tabelle ist optional Ist wesentlich übersichtlicher Erlaubt Kombination von unterschiedlichen Prüfkriterien 67
 INSERT ALL WHEN Feld_1_is_null =1 into Error_Daten. WHEN Feld_1_is_null=0 into Gepruefte_Daten. Varchar2() Varchar2() INSERT INTO temp_table. SELECT CASE .... FROM Stage_Table. Feld1 Feld2 Feld3. Feld1 Feld2 Feld3. Feld1_is_null Feld1_is_numeric Feld2_is_numeric. Kopieren. Error_Daten. Date. Number. Varchar2() Temporäre Tabelle ist optional. Ist wesentlich übersichtlicher. Erlaubt Kombination von unterschiedlichen Prüfkriterien. 67.")
68
Abarbeitungslogik mit CASE
OLTP_Kunden_tmp Bestellnr Menge Summe Name Ort BestDatum OLTP_Kunden INSERT INTO OLTP_Kunden_tmp SELECT Bestellnr,Menge,Summe,Name,Ort,BestDatum, CASE WHEN (Bestellnr is NULL) then 1 ELSE 0 END Bestellnr_isNull, CASE WHEN (isNumeric(Menge) = 1) END Menge_isNumeric, CASE WHEN (isNumeric(Summe) = 1) END Summe_isNumeric, CASE WHEN (Summe is NULL) END Summe_isNull, CASE WHEN (isDate(BestDatum) = 1) END BestDatum_isDate FROM OLTP_Kunden; Bestellnr Menge Summe Name Ort BestDatum Bestellnr_isNull Menge_isNumeric Summe_isNumeric Summe_isNull BestDatum_isDate ...
 then 1 ELSE 0. END Bestellnr_isNull, CASE WHEN (isNumeric(Menge) = 1) END Menge_isNumeric, CASE WHEN (isNumeric(Summe) = 1) END Summe_isNumeric, CASE WHEN (Summe is NULL) END Summe_isNull, CASE WHEN (isDate(BestDatum) = 1) END BestDatum_isDate. FROM OLTP_Kunden; Bestellnr. Menge. Summe. Name. Ort. BestDatum. Bestellnr_isNull. Menge_isNumeric. Summe_isNumeric. Summe_isNull. BestDatum_isDate. ...")
69
Prüfungen Kategorie B Satz-bezogene Regeln
Abhängigkeiten von Werten in anderen Attributen desselben Satzes Lösung: Analog zu Kategorie A über CASE F1 F2 F3 F4 1 select CASE WHEN (F1 = 3 and F2 = F3 + F4) then 1 ELSE 0 end from fx
 then 1. ELSE 0. end. from fx.")
70
Prüfungen Kategorie C Satz-übergreifende Regeln
Primary Key / Eindeutigkeit Aggregat – Bedingungen Ober- Untergrenzen von Summen Anzahl Sätze pro Intervall usw. Rekursive Zusammenhänge Verweise auf andere Sätze derselben Tabelle (Relation)
")
71
6. Eindeutigkeit / PK BESTELLUNG BESTELLPOSITION
BESTELLNR ORTNR KUNDENNR BESTELLDATUM ANZAHLPOS PK BESTELLNR POSITIONSNR MENGE ARTIKELNR DEPOTSTELLE RABATT FK PK FK FK Lösung: Mengenbasiertes Sammeln doppelter Sätze in Fehlertabelle insert /*+ APPEND */ into err_non_unique_bestellung select bestellnr from (select count(bestellnr) n, bestellnr from bestellung group by bestellnr) where n > 1;
 n, bestellnr. from bestellung. group by bestellnr) where n > 1;")
72
7. Aggregatbildung D_ARTIKEL F_UMSATZ ARTIKEL_NAME GRUPPE_NR
GRUPPE_NAME SPARTE_NAME SPARTE_NR ARTIKEL_ID 7. Aggregatbildung F_UMSATZ ARTIKEL_ID KUNDEN_ID ZEIT_ID REGION_ID KANAL_ID UMSATZ MENGE UMSATZ_GESAMT Anforderung: Wenn der Umsatz pro Artikel unter 20% des Artikelgruppen-Gesamtwertes fällt, dann ROT Lösung: Mit analytischen Funktionen: Auf Satzebene über Informationen von Satzgruppen verfügen FK PK FK FK FK FK select Artikelname, Artikelgruppe, Wert, sum(wert) over (partition by Artikelname) Artikelgesamtwert, sum(wert) over (partition by Artikelgruppe) Gruppengesamtwert, case when (round(((sum(wert) over (partition by Artikelname))/(sum(wert) over (partition by Artikelgruppe))*100),0) ) < 20 then 'ROT' ELSE 'GRUEN' end Prozent from Artikel
 over (partition by Artikelname) Artikelgesamtwert, sum(wert) over (partition by Artikelgruppe) Gruppengesamtwert, case. when. (round(((sum(wert) over (partition by Artikelname))/(sum(wert) over (partition by. Artikelgruppe))*100),0) ) < 20. then ROT ELSE GRUEN end Prozent. from Artikel.")
73
8. Rekursive Zusammenhänge
F_Key Parent Member Group _Value _Value Anforderung: Die Summe aller Member_Value-Werte pro Parent muss gleich dem Group_Value-Wert des Parent sein. Lösung: Über Sub-Select in dem nach Parent gruppiert und summiert wird. select distinct A.F_key from rk A, (select sum(member_value) sum_member, parent from rk where parent != 0 group by group_value, parent) B where A.member_value = 0 and A.group_value = B.sum_member;
 sum_member, parent. from rk. where parent != 0 group by group_value, parent) B. where A.member_value = 0 and. A.group_value = B.sum_member;")
74
Prüfungen Kategorie D Tabellen-übergreifende Regeln
Foreign Key Child-Parent (Orphan) Parent-Child Aggregat – Bedingungen Ober- Untergrenzen von Summen Anzahl Sätze pro Intervall usw. Referenz-Zusammenhänge Verweise auf Sätze einer anderen Tabelle (Relation)
 Parent-Child. Aggregat – Bedingungen. Ober- Untergrenzen von Summen. Anzahl Sätze pro Intervall usw. Referenz-Zusammenhänge. Verweise auf Sätze einer anderen Tabelle (Relation)")
75
9. Foreign Keys BESTELLUNG KUNDE
BESTELLNR ORTNR KUNDENNR BESTELLDATUM ANZAHLPOS PK KUNDENNR KUNDENNAME BERUFSGRUPPE SEGMENT KUNDENTYP PK FK Anforderung: Zu jeder Bestellung muss es einen Kunden geben. Lösung: Sub-Select in Where-Klausel. insert /*+ APPEND */ into err_orphan_Bestellung select bestellnr from bestellung where Kundennr not in (select Kundennr from kunde);
;")
76
10. Aggregatbedingungen Anzahl Sätze pro Einheit
BESTELLUNG BESTELLPOSITION Anforderung: Anzahl Positionen muss einen bestimmten Wert haben. Lösung: Sub-Select in FROM-Klausel. BESTELLNR ORTNR KUNDENNR BESTELLDATUM ANZAHLPOS PK BESTELLNR POSITIONSNR MENGE ARTIKELNR DEPOTSTELLE RABATT FK PK FK FK insert /*+APPEND */ into err_anz_pos_Bestellposition select BESTELLNR, anzahl_pos, bst_ANZAHLPOS from (select bestellnr, count(positionsnr) Anzahl_pos, ANZAHLPOS bst_anzahlpos from Best_Pos group by bestellnr,ANZAHLPOS) where Anzahl_pos <> bst_anzahlpos;
 Anzahl_pos, ANZAHLPOS bst_anzahlpos. from Best_Pos. group by bestellnr,ANZAHLPOS) where Anzahl_pos <> bst_anzahlpos;")
77
Szenario Regeln bzgl. der Bestellpositionen Qualitative Prüfungen
Regel bzgl. der Bestellungen Es darf keine Bestellung ohne Positionen geben. Bestellnummern müssen eindeutig sein. Es kann nur Bestellungen mit gültigen Kundennummern geben. Bestellungen müssen immer in einem Zeitraum +/- 10 Tage von dem Tagestadum liegen. Regeln bzgl. der Bestellpositionen Der durchschnittliche Wert einer Position muss > 5 sein. Positionsnummern müssen pro Bestellung lückenlos von 1 beginnend aufsteigen sein. Es darf nur Bestellpositionen mit einer gültigen Bestellnummer geben. Es darf nur Bestellpositionen mit einer gültigen Artikelnummer geben. Rabatt darf nur für Firmenkunden gegeben werden. Formatprüfungen: Feld Depostelle 3-stellig alphanumerisch und 3-stellig numerisch Feld Rabatt mus numerisch sein und mindestens den Wert 0 haben Feld Menge muss gefüllt sein (NotNull) und muss > 0 sein Qualitative Prüfungen Wenn der Gesamtwert pro Bestellung muss < 1000 beträgt, dann muss , wenn groesser, dann markieren. Der Gesamtumsatz ist i. d. R. in dem 4ten Quartal am höchsten. Bestellungen haben einen bestimmte Anzahl Positionen.
 und muss > 0 sein. Qualitative Prüfungen. Wenn der Gesamtwert pro Bestellung muss < 1000 beträgt, dann muss , wenn groesser, dann markieren. Der Gesamtumsatz ist i. d. R. in dem 4ten Quartal am höchsten. Bestellungen haben einen bestimmte Anzahl Positionen.")
78
Die Beispiel - Quellumgebung
PK Die Beispiel - Quellumgebung ARTIKEL ARTIKEL_NAME ARTIKEL_ID GRUPPE_NR PREIS ARTIKEL_GRUPPEN PK ARTIKEL_SPARTEN GRUPPE_NR GRUPPE_NAME SPARTE_NR PK FK SPARTE_NAME SPARTE_NR PK FK BESTELLUNG BESTELLPOSITION KUNDE BESTELLNR ORTNR KUNDENNR BESTELLDATUM ANZAHLPOS PK BESTELLNR POSITIONSNR MENGE ARTIKELNR DEPOTSTELLE RABATT FK PK KUNDENNR KUNDENNAME BERUFSGRUPPE SEGMENT KUNDENTYP PK FK FK 78

79
Beispielprüfungen

80
Beispielprüfungen

81
1. Schritt: Prüfungen von Tabellen-übergreifenden Beziehungen
ARTIKEL ARTIKEL_NAME ARTIKEL_ID GRUPPE_NR PREIS ARTIKEL_GRUPPEN PK ARTIKEL_SPARTEN GRUPPE_NR GRUPPE_NAME SPARTE_NR PK FK SPARTE_NAME SPARTE_NR PK FK 18 2 6 BESTELLUNG BESTELLPOSITION KUNDE BESTELLNR ORTNR KUNDENNR BESTELLDATUM ANZAHLPOS PK BESTELLNR POSITIONSNR MENGE ARTIKELNR DEPOTSTELLE RABATT FK PK KUNDENNR KUNDENNAME BERUFSGRUPPE SEGMENT KUNDENTYP PK FK 13 FK 21 81

82
2. Schritt: Prüfungen und Berechnungen von Satz-übergreifenden Abhängigkeiten
ARTIKEL ARTIKEL_NAME ARTIKEL_ID GRUPPE_NR PREIS ARTIKEL_GRUPPEN PK ARTIKEL_SPARTEN GRUPPE_NR GRUPPE_NAME SPARTE_NR PK FK SPARTE_NAME SPARTE_NR PK FK 1 13 18 2 6 BESTELLUNG BESTELLPOSITION KUNDE BESTELLNR ORTNR KUNDENNR BESTELLDATUM ANZAHLPOS PK BESTELLNR POSITIONSNR MENGE ARTIKELNR DEPOTSTELLE RABATT FK PK 14 KUNDENNR KUNDENNAME BERUFSGRUPPE SEGMENT KUNDENTYP PK FK 13 4 9 FK 10 21 82

83
3. Schritt: Feldprüfungen
ARTIKEL ARTIKEL_NAME ARTIKEL_ID GRUPPE_NR PREIS ARTIKEL_GRUPPEN PK ARTIKEL_SPARTEN GRUPPE_NR GRUPPE_NAME SPARTE_NR PK FK SPARTE_NAME SPARTE_NR PK FK 1 13 18 2 6 BESTELLUNG BESTELLPOSITION 5 12 11 KUNDE BESTELLNR ORTNR KUNDENNR BESTELLDATUM ANZAHLPOS PK BESTELLNR POSITIONSNR MENGE ARTIKELNR DEPOTSTELLE RABATT FK PK 14 KUNDENNR KUNDENNAME BERUFSGRUPPE SEGMENT KUNDENTYP PK FK 15 16 17 13 4 FK 18 9 10 6 19 20 8 21 83

84
Regeln bei der Ablauf-Planung
Alles was mengenbasiert prüfbar ist, kommt zuerst Feldbezogene Prüfungen sind nachgelagert Bei aufwendigen Joins abklären, ob diese mehrfach benötigt werden, wenn ja, dann Prüfen einer Join-Tabelle Nach Möglichkeit diese Prüfungen in eine zeitlich enge Abfolge bringen Aufwendige feldbezogene Prüfungen, Prüfungen mit Funktionen usw. werden in einer einzigen Transformation zusamengefasst Bei Datenübernahme aus Datenbanken ist zu prüfen, ob innerhalb der Zielumgebung noch geprüft werden muss Bei Text-Eingabe-Daten die External Table bzw. Loader – Prüfmittel nutzen

85
Anordnung und Gruppierung der Ladeschritte des Beispiel-Szenarios
err_non_unique_bestellung err_orphan_Bestellung err_childless_Bestellung err_orphan_Position err_orphan_PositionArtikel err_seq_pos_Bestellposition err_anz_pos_Bestellposition err_AVG_Pos_Wert err_maske_depotstelle err_Wert_Menge err_not_null_Menge err_not_Rabatt_Wert err_kd_Rabatt_ok BESTELLUNG BESTELLPOSITION KUNDE ARTIKEL BEST_POS Tmp_ BEST_POS Tmp2_ BEST_POS Hauptdatenfluss Beziehungsprüfungen

86
Umsetzung der Prüfungen
Siehe separaten Ausdruck

87
Umsetzung der Prüfungen
Siehe separaten Ausdruck

88
Umsetzung der Prüfungen
Siehe separaten Ausdruck

89
Umsetzung der Prüfungen
Siehe separaten Ausdruck

90
Auflistung der Laufzeiten für die einzelnen Prüfungen (unterschiedliche Massnamen)
")
91
Datenbank-basierte ETL-Prozesse
Themenübersicht Datenbank-basierte ETL-Prozesse Anforderungen an den ETL-Prozess im Data Warehouse Speichermanagement und Grundlagentechniken Blöcke, Extents, Segmente, Tablespace Direct Path Load, Mengenbasiertes Laden Optimierungsszenario Hilfsmittel für schnelles Laden Prüftechniken mit SQL Szenario zum Prüfen von Daten Weitere Techniken und Tools 91

92
Verfahren für schnelles ETL in der Datenbank
Data Integration Layer Enterprise Information Layer User View Layer Selektieren Statt kopieren Direct Path in temporäre Tabellen Constraint- freies Prüfen mit Mengen- basiertem SQL Partition Exchange &LOAD in partit. Tabellen (PEL) Unveränderte Bewegungs- daten liegen lassen Große Fakten-Tab. über PEL. Kenn- zahlen aus- schließlich über MAV- Refresh Bekannte Kennzahlen in die DB weniger Kopien in BI-Tools
 Unveränderte Bewegungs- daten liegen lassen. Große Fakten-Tab. über PEL. Kenn- zahlen aus- schließlich über. MAV- Refresh. Bekannte Kennzahlen. in die DB. weniger Kopien in. BI-Tools.")
93
Partition Exchange Loading (PEL)
Temporäre Tabelle Financial Production Neuer Monat Human Res. P1 P2 P3 P4 4 8 9 Z1 Z2 Z3 Z4 Zeit Store Supplier Monat 13 Marketing Parallel Direct Path INSERT (Set Based) CREATE TABLE AS SELECT (CTAS) CREATE Indizes / Statistiken anlegen EXCHANGE Tabelle Monat 12 Service Monat 11 Monat 10 Region DROP PARTITION Faktentabelle 93
 CREATE TABLE AS SELECT. (CTAS) CREATE Indizes / Statistiken anlegen EXCHANGE Tabelle. Monat 12. Service. Monat 11. Monat 10. Region. DROP PARTITION. Faktentabelle. 93.")
94
Partition Exchange Loading (PEL)
-- Leere Partition an Zieltabelle hinzufügen ALTER TABLE Bestellung ADD PARTITION "Nov08" VALUES LESS THAN (to_date('30-Nov-2008','dd-mon-yyyy')); -- Neue leere temporäre Tabelle erstellen CREATE TABLE Bestellung_temp AS SELECT * FROM Bestellung WHERE ROWNUM < 1; -- Inhalte laden INSERT /*+ APPEND */ INTO "PART"."BESTELLUNG_TEMP" (BESTELLNR, KUNDENCODE, BESTELLDATUM, LIEFERDATUM, BESTELL_TOTAL, AUFTRAGSART, VERTRIEBSKANAL) VALUES ('2', '3', TO_DATE('23.Nov.2008', 'DD-MON-RR'), to_date('23.Nov.2008', 'DD-MON-RR'), '44', 'Service', '6'); Commit; -- Erstellen Index auf temporäre Tabelle CREATE INDEX Ind_Best_Dat_Nov ON Bestellung_temp ("BESTELLNR") NOLOGGING PARALLEL; -- Temporäre Tabelle an die Zieltabelle anhängen ALTER TABLE Bestellung EXCHANGE PARTITION "Nov08" WITH TABLE Bestellung_temp INCLUDING INDEXES WITHOUT VALIDATION; 94
); -- Neue leere temporäre Tabelle erstellen. CREATE TABLE Bestellung_temp AS. SELECT * FROM Bestellung WHERE ROWNUM < 1; -- Inhalte laden. INSERT /*+ APPEND */ INTO PART . BESTELLUNG_TEMP (BESTELLNR, KUNDENCODE, BESTELLDATUM, LIEFERDATUM, BESTELL_TOTAL, AUFTRAGSART, VERTRIEBSKANAL) VALUES ( 2 , 3 , TO_DATE( 23.Nov.2008 , DD-MON-RR ), to_date( 23.Nov.2008 , DD-MON-RR ), 44 , Service , 6 ); Commit; -- Erstellen Index auf temporäre Tabelle. CREATE INDEX Ind_Best_Dat_Nov ON Bestellung_temp ( BESTELLNR ) NOLOGGING PARALLEL; -- Temporäre Tabelle an die Zieltabelle anhängen. ALTER TABLE Bestellung EXCHANGE PARTITION Nov08 WITH TABLE Bestellung_temp INCLUDING INDEXES WITHOUT VALIDATION; 94.")
95
PEL – Auswirkungen auf die DWH-Verwaltung und Konzepte
Angleichung des Partition-Kriteriums auf den Lade-Rythmus und damit die „Zeit“ Meist täglicher Load -> Tagespartitionen Späteres Merge auf Monatsebene möglich / nötig Zwang zum späteren Monats-Merge nutzen für Komprimierung Reorganisation ILM-Konzept Eine Partitionierungs-Ebene ist durch das PEL-Verfahren meist schon belegt Local-Indizierung (wenn überhaupt gebraucht) entstehen automatisch
 entstehen automatisch.")
96
Enterprise Information Alter table exchange partition
Data Integration Layer Enterprise Information Layer User View Layer Archivieren (drop partition) Älteste Mai Juni Juli Checks August September Oktober CTAS Alter table add partition Tmp_table November Direct Path Alter table exchange partition
 Älteste. Mai. Juni. Juli. Checks. August. September. Oktober. CTAS. Alter table add partition. Tmp_table. November. Direct Path. Alter table exchange partition.")
97
Aufbau Fakten-Tabellen
Data Integration Layer Enterprise Information Layer User View Layer Archivieren (drop partition) Älteste Fact-Table Mai Juni Juni Juli Juli August Checks August September September Oktober Tmp_table Oktober November CTAS Tmp_table November CTAS Direct Path Alter table exchange partition Tmp_table Alter table exchange partition
 Älteste. Fact-Table. Mai. Juni. Juni. Juli. Juli. August. Checks. August. September. September. Oktober. Tmp_table. Oktober. November. CTAS. Tmp_table. November. CTAS. Direct Path. Alter table. exchange partition. Tmp_table. Alter table exchange partition.")
98
Beispiele für Lösungen

99
Klassische PL/SQL Cursor – Verarbeitung (Negativ – Beispiel)
t_Ref_1 (z. B ) t_ref_2 (z. B. 5000) t_ref_3 (z. B. 50) t_ref_4 (z. B. 6000) t_Quelle_Stage_1 (z. B ) t_Quelle_Stage_2 (z. B. 5000) t_ref_5 (z. B. 8000) t_ref_6 (z. B. 400) t_ref_7 (z. B. 80) t_ref_8 (z. B ) t_ref_9 (z. B ) select cursor Faktentabelle Insert + Diverse Updates und Inserts auf Protokolltabellen Für alle Bewegeungs- sätze z. B. ) Loop (0,1 Sec / Lauf) 8,3 Std* Zur Verdeutlichung dieses Beispiel: In der klassischen prozeduralen Programmierung ( auch mit Oracle PL/SQL ) wurden Schleifen programmiert, um jeden Satz einzeln zu prüfen und zu laden. In dieses Schleifen sind fast immer zusätzliche SELECT – Befehle oder Referenzabgleiche abgesetzt worden. Selbst wenn ein Schleifendurchlauf nur 0,1 Sec an Zeit verbraucht, addiert sich diese Zeit bei einer entsprechenden Anzahl Sätzen auf Laufzeiten von Stunden. Das Beispiel ist typisch für satzweise, prozedurale Verarbeitung. * Wert aus einer Bank (2003), wäre heute wesentlich weniger
 t_ref_2 (z. B. 5000) t_ref_3 (z. B. 50) t_ref_4 (z. B. 6000) t_Quelle_Stage_1 (z. B ) t_Quelle_Stage_2 (z. B. 5000) t_ref_5 (z. B. 8000) t_ref_6 (z. B. 400) t_ref_7 (z. B. 80) t_ref_8 (z. B ) t_ref_9 (z. B ) select. cursor. Faktentabelle. Insert. + Diverse Updates und. Inserts auf. Protokolltabellen. Für alle. Bewegeungs- sätze z. B ) Loop. (0,1 Sec / Lauf) 8,3 Std* Zur Verdeutlichung dieses Beispiel: In der klassischen prozeduralen Programmierung ( auch mit Oracle PL/SQL ) wurden Schleifen programmiert, um jeden Satz einzeln zu prüfen und zu laden. In dieses Schleifen sind fast immer zusätzliche SELECT – Befehle oder Referenzabgleiche abgesetzt worden. Selbst wenn ein Schleifendurchlauf nur 0,1 Sec an Zeit verbraucht, addiert sich diese Zeit bei einer entsprechenden Anzahl Sätzen auf Laufzeiten von Stunden. Das Beispiel ist typisch für satzweise, prozedurale Verarbeitung. * Wert aus einer Bank (2003), wäre heute wesentlich weniger.")
100
Mengenbasierte Alternative (Performance – Optimierung bis zu Faktor 20 und mehr)
t_Ref_1 t_Ref_2 t_Ref_3 t_Ref_4 t_Ref_5 Outer Join Temp Table t_Ref_6 t_Ref_7 t_Ref_8 t_Ref_9 Cursor loop Satzweise Prüfung Protokoll Fakt Table Das Gegenbeispiel der mengenbasierten Verarbeitung nutzt die Mengenlehre – Algorithmen, die das relationale Datenbanksystem mittels SQL anbietet. Über einen Outer – Join und eine temporäre Zwischentabelle werden Referenzwerte (Lookups) gelesen. Die temporäre Tabelle kann zusätzlich separat geprüft werden. Ein letzter Ladeschritt schreibt die bereits geprüften Sätze in die Zieltabelle. Das Verfahren läuft im Verhältnis 1 : 10 schneller.
 gelesen. Die temporäre Tabelle kann zusätzlich separat geprüft werden. Ein letzter Ladeschritt schreibt die bereits geprüften Sätze in die Zieltabelle. Das Verfahren läuft im Verhältnis 1 : 10 schneller.")
101
Aufgabenstellung: Lookup-Argumente über Funktionen gewinnen
Mehrstufige Verarbeitung Über Funktionen Argumente gewinnen Argumente in Lookup-Aufrufe einbauen WITH-Verarbeitung

102
Insert into ziel select * from
(with lc as ( select level V_KAUF_ID, ran_M_N(0,2000) V_MITARBEITER_ID, ran_M_N(1,100024) V_KUNDEN_ID, sysdate-ran_M_N(20,1000) V_Kaufdatum, ran_M_N(999,1011) V_PRODUKT_ID, ran_M_N(0,4) V_GESAMT_DISCOUNT_PROZENT from Dual connect by level < 5) select L.V_KAUF_ID, L.V_MITARBEITER_ID, L.V_KUNDEN_ID, L.V_Kaufdatum, L.V_PRODUKT_ID, M.FILIAL_ID, M.MANAGER_ID, F.FILIALLEITER_ID, F.ORTNR, P.VK_PREIS-((P.VK_PREIS*1)*L.V_GESAMT_DISCOUNT_PROZENT)/100 Gesamt_wert, L.V_GESAMT_DISCOUNT_PROZENT from LC L, d_MITARBEITER M, d_filialen F, d_produkt P where L.V_MITARBEITER_ID = M.MITARBEITER_ID and M.FILIAL_ID = F.FILIAL_ID and L.V_ProdukT_id = P.produkt_id)
 V_MITARBEITER_ID, ran_M_N(1,100024) V_KUNDEN_ID, sysdate-ran_M_N(20,1000) V_Kaufdatum, ran_M_N(999,1011) V_PRODUKT_ID, ran_M_N(0,4) V_GESAMT_DISCOUNT_PROZENT. from Dual connect by level < 5) select. L.V_KAUF_ID, L.V_MITARBEITER_ID, L.V_KUNDEN_ID, L.V_Kaufdatum, L.V_PRODUKT_ID, M.FILIAL_ID, M.MANAGER_ID, F.FILIALLEITER_ID, F.ORTNR, P.VK_PREIS-((P.VK_PREIS*1)*L.V_GESAMT_DISCOUNT_PROZENT)/100 Gesamt_wert, L.V_GESAMT_DISCOUNT_PROZENT. from. LC L, d_MITARBEITER M, d_filialen F, d_produkt P. where L.V_MITARBEITER_ID = M.MITARBEITER_ID and. M.FILIAL_ID = F.FILIAL_ID and. L.V_ProdukT_id = P.produkt_id)")
103
Beschreiben einer Master/Detail - Beziehung
Ziel: Die Sätze in der Detail-Tabelle müssen immer einen Parent-Satz haben Lösung: Multiple Insert: Die Information aus einer Quelle steht immer zum Beschreiben von Parent- und Child-Tabelle zur Verfügung. Beide sind synchronisierbar BESTELLUNG BESTELLPOSITION BESTELLNR ORTNR KUNDENNR BESTELLDATUM ANZAHLPOS PK BESTELLNR POSITIONSNR MENGE ARTIKELNR DEPOTSTELLE RABATT FK PK FK FK

104
Multiple Inserts verarbeiten / pauschal
INSERT ALL WHEN 1=1‚ THEN INTO BESTELLUNG (KUNDENCODE,BESTELL_TOTAL,STATUS) VALUES (KUNDENCODE,BESTELL_TOTAL,STATUS) WHEN 1=1, THEN INTO BESTELLPOSITION (BESTELLMENGE,BESTELL_TOTAL,PRODUKT_NR) VALUES (BESTELLMENGE, BESTELL_TOTAL, PRODUKT_NR) SELECT WH_TRANSAKTIONEN.BESTELLMENGE BESTELLMENGE, WH_TRANSAKTIONEN.KUNDENCODE KUNDENCODE, WH_TRANSAKTIONEN.BESTELL_TOTAL BESTELL_TOTAL, WH_TRANSAKTIONEN.STATUS STATUS, WH_TRANSAKTIONEN.PRODUKT_NR PRODUKT_NR FROM WH_TRANSAKTIONEN WH_TRANSAKTIONEN ; 104
 VALUES (KUNDENCODE,BESTELL_TOTAL,STATUS) WHEN 1=1, THEN INTO BESTELLPOSITION (BESTELLMENGE,BESTELL_TOTAL,PRODUKT_NR) VALUES (BESTELLMENGE, BESTELL_TOTAL, PRODUKT_NR) SELECT WH_TRANSAKTIONEN.BESTELLMENGE BESTELLMENGE, WH_TRANSAKTIONEN.KUNDENCODE KUNDENCODE, WH_TRANSAKTIONEN.BESTELL_TOTAL BESTELL_TOTAL, WH_TRANSAKTIONEN.STATUS STATUS, WH_TRANSAKTIONEN.PRODUKT_NR PRODUKT_NR FROM WH_TRANSAKTIONEN WH_TRANSAKTIONEN ; 104.")
105
Multiple Inserts verarbeiten / selektiert
INSERT ALL WHEN STATUS = 'P'‚ THEN INTO WH_TRANS_PRIVAT (BESTELLMENGE,KUNDENCODE,BESTELL_TOTAL,STATUS) VALUES (BESTELLMENGE,KUNDENCODE,BESTELL_TOTAL,STATUS) WHEN STATUS = 'F'‚ THEN INTO WH_TRANS_FIRMA (BESTELLMENGE,KUNDENCODE,BESTELL_TOTAL,STATUS) VALUES (BESTELLMENGE,KUNDENCODE,BESTELL_TOTAL,STATUS) SELECT WH_TRANSAKTIONEN.BESTELLMENGE BESTELLMENGE, WH_TRANSAKTIONEN.KUNDENCODE KUNDENCODE, WH_TRANSAKTIONEN.BESTELL_TOTAL BESTELL_TOTAL, WH_TRANSAKTIONEN.STATUS STATUS FROM WH_TRANSAKTIONEN WH_TRANSAKTIONEN WHERE (WH_TRANSAKTIONEN.STATUS = 'P‚ /*SPLITTER.PRIVATKUNDEN*/) OR (WH_TRANSAKTIONEN.STATUS = 'F‚ /*SPLITTER.FIRMENKUNDEN*/); 105
 VALUES (BESTELLMENGE,KUNDENCODE,BESTELL_TOTAL,STATUS) WHEN STATUS = F ‚ THEN INTO WH_TRANS_FIRMA (BESTELLMENGE,KUNDENCODE,BESTELL_TOTAL,STATUS) VALUES (BESTELLMENGE,KUNDENCODE,BESTELL_TOTAL,STATUS) SELECT WH_TRANSAKTIONEN.BESTELLMENGE BESTELLMENGE, WH_TRANSAKTIONEN.KUNDENCODE KUNDENCODE, WH_TRANSAKTIONEN.BESTELL_TOTAL BESTELL_TOTAL, WH_TRANSAKTIONEN.STATUS STATUS FROM WH_TRANSAKTIONEN WH_TRANSAKTIONEN WHERE (WH_TRANSAKTIONEN.STATUS = P‚ /*SPLITTER.PRIVATKUNDEN*/) OR (WH_TRANSAKTIONEN.STATUS = F‚ /*SPLITTER.FIRMENKUNDEN*/); 105.")
106
Deltadaten Extrahieren
OLTP DWH 1 Table Änderungsdatum Table 2 Table Trigger Table Queue Deltabildung über MINUS 3 Table Table 4 LogFile Queue Table Logminer 5 LogFile Streams Table Queue 6 LogFile Golden Gate Queue Table

107
Herausforderungen beim Extrahieren
Unterschiedliche Namen in Quell- und Zielsystemen Bewahrung der Konsistenz Zeitpunkt des Ladens kann kritisch sein Vollständigkeit der Daten Unterschiedliche GRANTs der User Zusätzlicher Netzwerkverkehr Meist ist nur das Delta der geänderten Daten gewünscht Formate (Datum, Zeichensätze) 107
 107.")
108
Einlesetechniken Vorsysteme
EBCDIC ASCII SQL-Loader Direct Save External Table SQL Database Link SQL Oracle Transportable TS BS Copy BS Copy Datapump Oracle DWH Non Oracle ODBC SQL JDBC SQL Gateway SQL Applikation z. B. SAP R/3 API CALL API SQL

109
Die Quellen Selektieren statt kopieren
Nur die Daten laden, die gebraucht werden Keine 1:1 Kopien in die Integrations-Schicht Nach Möglichkeit vor Eintritt in die Datenbank Prüfungen durchführen Bereits geprüfte Daten nicht mehr prüfen Selektieren statt kopieren

110
Nicht so ....sondern 1:1 T 1:1 T T T 1:1 T 1:1 T Data Integration
Layer Data Integration Layer 1:1 T 1:1 CTAS T T T 1:1 T 1:1 T Warum? Logik so früh wie möglich

111
Techniken für Data Marts / User View Layer
Viele verstecke Aufwende Verlagerung von IT in die Fachabteilungen Redundanzen Ursache vieler nicht abgestimmter Kennzahlen

112
Enterprise Information
Minimales Bewegen Große unveränderte Tabellen liegen lassen Zugriff auf beide Schichten Security mit Bordmittel anstatt durch Kopieren lösen Enterprise Information Layer User View Layer D D F D B D B PEL

113
Kennzahlen User View Layer Kennzahlen nur als Materialized Views
Automatisches Refresh anstatt ETL Standardisierte und stimmige Kennzahlen Wiederverwenden von bereits aggregierten Daten L1 L2 L3 L4

114
BI-Tool Server + Caches
Der Weg in die BI-Tools User View Layer So So viel wie möglich in der DB vorbereiten Verhindert unnötiges Kopieren Keine Verlagerung von Pseudo-ETL in die BI-Tools Standardisierte Kennzahlen Millionen von Sätzen BI-Tool Server + Caches User View Layer Oder so WenigeSätze

115
Weitere Einflussfaktoren und Techniken
Parallelisierung -> abhängig von Hardware -> direktes Steuern über Hints Aktuelle Statistiken -> Source Tabellen -> auch während des ETL-Laufes Ausnutzen des Cache-Effektes -> Organisieren der Abarbeitungsreihenfolge -> Eventuell Query-Result-Cache nutzen Vermeiden von großen Join-Tabellen > eventuell kleine Join-Tabelle mit wenigen Spalten

116
Weitere Einflussfaktoren und Techniken
Schnelle mengen-basierte Prüfungen kommen zuerst, teuere Prüfungen (Feld-Prüfungen) zuletzt durchführen Möglichst viel Hauptspeicher für Join-Operationen mit großen Tabellen Sort-Area-Size hoch setzen Blocksize auf 16 bzw. 32 K PCTfree auf Null setzen Partition Change Tracking (PCT) für inkrementelles Refresh der MAVs
 zuletzt durchführen. Möglichst viel Hauptspeicher für Join-Operationen mit großen Tabellen. Sort-Area-Size hoch setzen. Blocksize auf 16 bzw. 32 K. PCTfree auf Null setzen. Partition Change Tracking (PCT) für inkrementelles Refresh der MAVs.")
117
Keine unnötige Daten-Transporte ...
User View Layer 1:1 Data Integration Layer Enterprise Information Layer Vorsystem Vorsystem mit Vorrechner User View Layer 1:1 1:1 1:1 User View Layer 1:1 Externe ETL-Server

118
... sondern kurze Wege Freie Wahlmöglichkeit für Ort und Art des ETL
Data Integration Layer Enterprise Information Layer User View Layer Vorsystem Process neutral / 3 NF Ein-Datenbank-Server Externe ETL-Server (Hauptsächlich zu Dokumentationszwecken)
")
119
Zusammenfassung der wichtigsten Techniken
Eine zusammenhängende Datenbank Data Integration Layer Enterprise Information Layer User View Layer R: Referenztabellen CTAS 20% R R T S S S D D T: Transfertabellen S: Stammdaten CTAS B: Bewgungsdaten T PEL F D D: Dimensionen B F: Fakten T A: Aggregate D Partitionierte Tabellen PEL T B PEL Prüfungen 80% A Aggregatbildung durch Materialized Views Vorgelagerte Prüfungen SQL-Mengen- basierte Prüfungen Vorbereitete temporäre Tabellen Partition Exchange Partition Exchange Denormalisierung (Joins) und Aggregate Konzentration aller Prüfungen CTAS : Create Table As Select PEL : Partition Exchange and Load 119
 und Aggregate. Konzentration aller Prüfungen. CTAS : Create Table As Select. PEL : Partition Exchange and Load")
120
Zusammenfassung der Techniken bezogen auf das Schichten-Modell
Data Integration Layer Enterprise Information Layer User View Layer R: Referenztabellen CTAS 20% R R T S S S D D T: Transfertabellen S: Stammdaten CTAS B: Bewgungsdaten T PEL F D D: Dimensionen B F: Fakten T A: Aggregate D A Partitionierte Tabellen T B PEL PEL PCT Prüfungen 80% Typ-/Format- Prüfungen für Texte Über Loader bzw. External Table- Prüfungen Temporäre Prüf- und Zwischentabellen mit Direct Path Load (CTAS) Partition Exchange Load als Weiterverarbeitung der External Tables Referenzieren von großen Faktentabellen in die Warehouse- Schicht hinein Kennzahlen- systeme mit Materialized Views Fast Refresh mit Partition Change Tracking (PCT)
 Partition Exchange Load als. Weiterverarbeitung der External Tables. Referenzieren. von großen. Faktentabellen in die Warehouse- Schicht hinein. Kennzahlen- systeme mit Materialized Views. Fast Refresh mit. Partition Change. Tracking (PCT)")
121
Lade-Transaktionssteuerung innerhalb der Datenbank

122
Aufgabenstellung der Lade-Transaktion
Betrachten des kompletten Ladelaufs als eine zusammenhängende Transaktion Entweder alle Sätze oder keine geladen Wie können abgebrochene Ladeläufe wieder rückgängig gemacht werden? 122

123
Transaktionssteuerung / -rücksetzung
Markieren von Sätzen eines Ladelaufs in zusätzlichen Feldern Ladelauf-Nummer, Ladelauf-Datum, ... Zurückrollen durch langsames Einzel-DELETE Arbeiten mit Partitioning Aufbau einer neuen Partition unabhängig von der Zieltabelle Schnelles DROP PARTITION im Fehlerfall Einfachste und schnellste Variante Flashback Database / Table / Query Transaktions-genaues Zurückrollen Flashback DB benötigt zusätzlichen Plattenplatz 3 2 1 123

124
Flashback Steuerung über ETL / ODI
SCN ( Sequence Change Number / Log Archiving) Zeit (Timestamp) Restore Point ETL / ODI Flashback Recovery Area Zeit SCN Restore Point Log
 Zeit (Timestamp) Restore Point. ETL / ODI. Flashback Recovery Area. Zeit. SCN. Restore Point. Log.")
125
Flashback Technologie in der Datenbank
Flashback table x to scn ; SELECT * FROM employees AS OF TIMESTAMP TO_TIMESTAMP(' :30:00', 'YYYY-MM-DD HH:MI:SS') WHERE last_name = 'Chung'; Flashback Table Flashback Drop Flashback Query Flashback Versions Query Flashback Transaction Query Flashback Database Flashback Data Archive SELECT versions_startscn, versions_starttime, versions_endscn, versions_endtime, versions_xid, versions_operation, last_name, salary FROM employees VERSIONS BETWEEN TIMESTAMP TO_TIMESTAMP(' :00:00', 'YYYY-MM-DD HH24:MI:SS') AND TO_TIMESTAMP(' :00:00', 'YYYY-MM-DD HH24:MI:SS') WHERE first_name = 'John'; SELECT xid, operation, start_scn, commit_scn, logon_user, undo_sql FROM flashback_transaction_query WHERE xid = HEXTORAW(' D'); Flashback Database to scn ; Flashback Database AS OF TIMESTAMP TO_TIMESTAMP(' :30:00', 'YYYY-MM-DD HH:MI:SS') ;
 WHERE last_name = Chung ; Flashback Table. Flashback Drop. Flashback Query. Flashback Versions Query. Flashback Transaction Query. Flashback Database. Flashback Data Archive. SELECT versions_startscn, versions_starttime, versions_endscn, versions_endtime, versions_xid, versions_operation, last_name, salary. FROM employees. VERSIONS BETWEEN TIMESTAMP. TO_TIMESTAMP( :00:00 , YYYY-MM-DD HH24:MI:SS ) AND. TO_TIMESTAMP( :00:00 , YYYY-MM-DD HH24:MI:SS ) WHERE. first_name = John ; SELECT xid, operation, start_scn, commit_scn, logon_user, undo_sql. FROM flashback_transaction_query. WHERE xid = HEXTORAW( D ); Flashback Database to scn ; Flashback Database AS OF TIMESTAMP. TO_TIMESTAMP( :30:00 , YYYY-MM-DD HH:MI:SS ) ;")
126
Flashback Database Flashback Database
Erstellen der Fast (Flash) Recovery Area Restart Database ( mount exclusive, wenn DB <11.2) SQL> ALTER DATASE FLASHBACK ON; SQL> ALTER SYSTEM SET db_flashback_retention_target = <number_of_minutes>; SQL> ALTER DATABASE OPEN; Restore Points (ab 11.2 im laufenden Betrieb) create restore point PRE_LOAD; create restore point PRE_LOAD guarantee flashback database; (impliziert das Anlegen von Flashback Logs) drop restore point PRE_LOAD; Anwendung eines Restores nur im DB Mount-Status flashback database to restore point PRE_LOAD; Ein Rücksetzpunkt funktioniert aber letztendlich nur wie eine benannte SCN. Das heißt, anstatt sich sich eine SCN zu merken und aufzuschreiben, wird ein Rücksetzpunkt gesetzt und man kann das Flashback der Datenbank mit dessen Namen ausführen. Die gesetzten Rücksetzpunkte mit SCN und verbrauchtem Flashback Platz kann man v$restore_points entnehmen.
 Recovery Area. Restart Database ( mount exclusive, wenn DB <11.2) SQL> ALTER DATASE FLASHBACK ON; SQL> ALTER SYSTEM SET db_flashback_retention_target = <number_of_minutes>; SQL> ALTER DATABASE OPEN; Restore Points (ab 11.2 im laufenden Betrieb) create restore point PRE_LOAD; create restore point PRE_LOAD guarantee flashback database; (impliziert das Anlegen von Flashback Logs) drop restore point PRE_LOAD; Anwendung eines Restores nur im DB Mount-Status. flashback database to restore point PRE_LOAD; Ein Rücksetzpunkt funktioniert aber letztendlich nur wie eine benannte SCN. Das heißt, anstatt sich sich eine SCN zu merken und aufzuschreiben, wird ein Rücksetzpunkt gesetzt und man kann das Flashback der Datenbank mit dessen Namen ausführen. Die gesetzten Rücksetzpunkte mit SCN und verbrauchtem Flashback Platz kann man v$restore_points entnehmen.")
127
Monitoring in der Datenbank

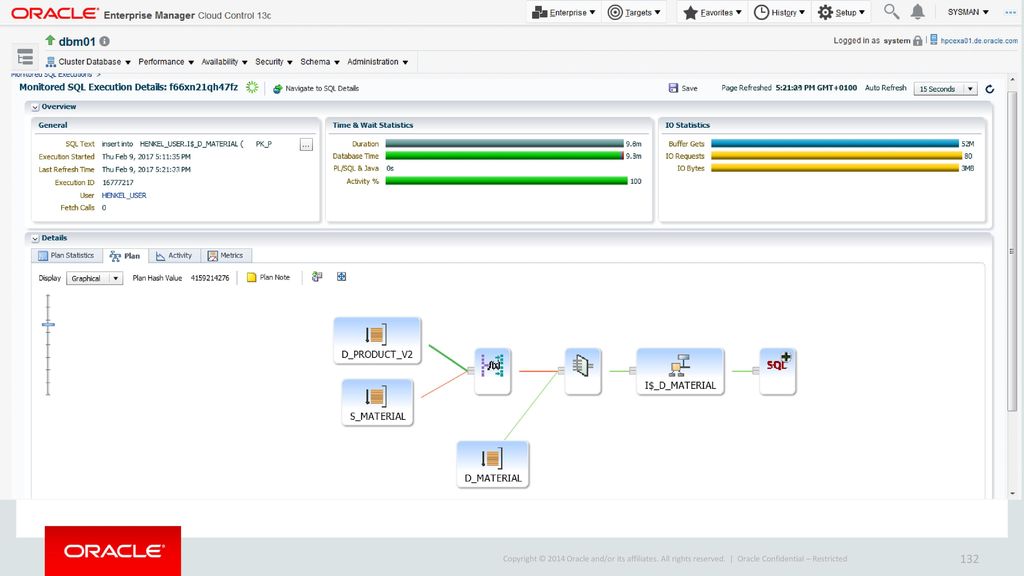
129
Oracle Confidential – Restricted

131
Oracle Confidential – Restricted

132
Oracle Confidential – Restricted

Ähnliche Präsentationen

>")












![IS: Datenbanken, © Till Hänisch 2000 CREATE TABLE Syntax: CREATE TABLE name ( coldef [, coldef] [, tableconstraints] ) coldef := name type [länge], [[NOT]NULL],](/1/649894/big_thumb.jpg "IS: Datenbanken, © Till Hänisch 2000 CREATE TABLE Syntax: CREATE TABLE name ( coldef [, coldef] [, tableconstraints] ) coldef := name type [länge], [[NOT]NULL],>")
. © Prof. T. Kudraß, HTWK Leipzig Open Database Connectivity (ODBC) Idee: – API für eine DBMS, das ein Call-Level-Interface.>")




