Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Kapitel V Adversiale Suche

2
Wahrscheinlichkeiten
KI Suchen Lernen/Schließen Anwendungen (un-)informiert Logik Computer Vision lokal Wahrscheinlichkeiten Robotik adversial Überwacht Ethik und Risiken Mit Unsicherheit Unüberwacht
informiert. Logik. Computer Vision. lokal. Wahrscheinlichkeiten. Robotik. adversial. Überwacht. Ethik und Risiken. Mit Unsicherheit. Unüberwacht.")
3
Suche nach einer „intelligenten“ Lösung

4
Suche nach einer „intelligenten“ Lösung
Bisher Unveränderlicher (statischer) Suchraum: Nachfolgerzustände nur vom aktuellen Zustand / Knoten abhängig „Intelligenter“ Suche mit „Gegenspieler“, Suchende beeinflussen den Suchraum: Schnellster Weg von Lübeck nach Berlin von anderen Autofahrern abhängig: Staugefahr! Je nach Verkehrsaufkommen unterschiedliche Strecken optimal (geringste Kosten = Fahrzeit)
 Suchraum: Nachfolgerzustände nur vom aktuellen Zustand / Knoten abhängig. „Intelligenter Suche mit „Gegenspieler , Suchende beeinflussen den Suchraum: Schnellster Weg von Lübeck nach Berlin von anderen Autofahrern abhängig: Staugefahr! Je nach Verkehrsaufkommen unterschiedliche Strecken optimal (geringste Kosten = Fahrzeit)")
5
Vorerst Beschränkung auf (besondere) Spiele
Zweipersonenspiele Vorerst Beschränkung auf (besondere) Spiele Endlich Deterministisch Zweipersonen(spiele) Nullsummen(spiele) Mit vollständiger Information “2-player zero-sum discrete finite determi-nistic games of perfect information”
 Spiele. Endlich. Deterministisch. Zweipersonen(spiele) Nullsummen(spiele) Mit vollständiger Information. 2-player zero-sum discrete finite determi-nistic games of perfect information")
6
Zweipersonenspiele 2-player zero-sum discrete finite deterministic games of perfect information Two player: … Zero-sum: in any outcome of any game, Player A’s gains equal player B’s losses Discrete: game states / decisions = discrete values Finite: only a finite number of states / decisions Deterministic: no chance (no die rolls) Perfect information: Both players can see the state, each decision made sequentially Andrew W. Moore,
 Perfect information: Both players can see the state, each decision made sequentially. Andrew W. Moore,")
7
Zweipersonenspiele 2-player zero-sum discrete finite deterministic games of perfect information? Hidden Information One player Not finite Stochastic Multiplayer Andrew W. Moore,

8
Ausgangssituation Zweipersonenspiele Zustände (je nach Spiel)
Nachfolgerfunktion (gemäß Spielregeln) Startzustand (gemäß Spielregeln) Zielzustände (gemäß Spielregeln) Bewertung der Zustände, Nutzenfunktion
 Startzustand (gemäß Spielregeln) Zielzustände (gemäß Spielregeln) Bewertung der Zustände, Nutzenfunktion.")
9
Ausgangssituation Ziel Zweipersonenspiele
Zweipersonenspiel: Spieler A, Spieler B Nullsummenspiel: Nutzen(A) = -Nutzen(B) Vollständige Information: alle möglichen Züge des Gegners sind bekannt Ziel jeder Spieler sucht nach einem Pfad im Suchbaum (Strategie) maximiere eigenen Nutzen – egal wie der andere Spieler agiert Wie? Unterstelle, Gegenspieler wählt stets die beste Alternative!
 = -Nutzen(B) Vollständige Information: alle möglichen Züge des Gegners sind bekannt. Ziel. jeder Spieler sucht nach einem Pfad im Suchbaum (Strategie) maximiere eigenen Nutzen – egal wie der andere Spieler agiert. Wie Unterstelle, Gegenspieler wählt stets die beste Alternative!")
10
Suche nach einer „intelligenten“ Lösung
Beispiel NIM Spielregel: Beide Spieler nehmen abwechselnd ein, zwei oder drei Streich- hölzer aus einer Reihe. Ziel des Spiels: wer das letzte Streichholz nimmt, hat gewonnen.

11
Suche nach einer „intelligenten“ Lösung
Beispiel NIM Was tun?

12
Ablauf: MINIMAX Sei Spieler 𝑨 zuerst am Zug, dann
Sucht 𝑨 nach einem Zug, so dass 𝐍𝐮𝐭𝐳𝐞𝐧(𝑨) maximal wird Sucht 𝑩 anschliessend einem Zug, so dass 𝐍𝐮𝐭𝐳𝐞𝐧(𝑩) maximal wird Wegen Nutzen(𝐴) = −Nutzen(𝐵) minimiert 𝑩 𝐍𝐮𝐭𝐳𝐞𝐧(𝑨) Wir betrachten nur noch den Nutzen von 𝑨
 maximal wird. Sucht 𝑩 anschliessend einem Zug, so dass 𝐍𝐮𝐭𝐳𝐞𝐧(𝑩) maximal wird. Wegen Nutzen(𝐴) = −Nutzen(𝐵) minimiert 𝑩 𝐍𝐮𝐭𝐳𝐞𝐧(𝑨) Wir betrachten nur noch den Nutzen von 𝑨.")
13
Ablauf: MINIMAX Die MINIMAX-Funktion ist definiert als
NUTZEN(𝑛) falls 𝑛 ein Endzustand max 𝑆∈nf 𝑛 MINIMAX 𝑆 falls Spieler 𝐴 am Zug min 𝑠∈nf 𝑛 MINIMAX 𝑆 falls Spieler 𝐵 am Zug nf(𝑛) ist Nachfolgerfunktion
 falls 𝑛 ein Endzustand. max 𝑆∈nf 𝑛 MINIMAX 𝑆 falls Spieler 𝐴 am Zug. min 𝑠∈nf 𝑛 MINIMAX 𝑆 falls Spieler 𝐵 am Zug. nf(𝑛) ist Nachfolgerfunktion.")
14
Ablauf am Beispiel (tic-tac-toe)
MINIMAX Ablauf am Beispiel (tic-tac-toe) Wohin kann A Stein platzieren? Wohin kann B dann Stein platzieren? Wohin kann A dann Stein platzieren? Welches Suchverfahren liegt zugrunde? Welche Konsequenzen hinsichtlich Laufzeit und Platzbedarf? Russell / Norvig: : Artificial Intelligence - A Modern Approach, 2nd edition. © Pearson Education, 2003
 Wohin kann A Stein platzieren Wohin kann B dann Stein platzieren Wohin kann A dann Stein platzieren Welches Suchverfahren liegt zugrunde Welche Konsequenzen hinsichtlich Laufzeit und Platzbedarf Russell / Norvig: : Artificial Intelligence - A Modern Approach, 2nd edition. © Pearson Education,")
15
Beispiel Suchbaum der Höhe 2
MINIMAX Beispiel Suchbaum der Höhe 2 3 3 2 2

16
Beispiel Suchbaum der Höhe 2
MINIMAX Beispiel Suchbaum der Höhe 2

17
Beispiel II-NIM MINIMAX Variation: wer zuletzt zieht hat verloren
Symmetrische Zustände für Spielverlauf irrelevant Andrew W. Moore,

18
Beispiel II-NIM MINIMAX Variation: wer zuletzt zieht hat verloren
Zustände Startzustand Nachfolger- funktion Zielzustände Nutzenfunktion Andrew W. Moore,

19
II-Nim Game Tree (ii ii) A (i ii) B (- ii) B (- ii) A (i i) A (- i) A
Andrew W. Moore,

20
II-Nim Game Tree (ii ii) A (i ii) B (- ii) B (- ii) A (i i) A (- i) A
Andrew W. Moore,

21
II-Nim Game Tree (ii ii) A (i ii) B (- ii) B (- ii) A (i i) A (- i) A
Andrew W. Moore,

22
II-Nim Game Tree (ii ii) A (i ii) B (- ii) B (- ii) A +1 (i i) A +1
Andrew W. Moore,

23
II-Nim Game Tree (ii ii) A (i ii) B -1 (- ii) B -1 (- ii) A +1
Andrew W. Moore,

24
II-Nim Game Tree Was tun? Egal ... (ii ii) A -1 (i ii) B -1
Andrew W. Moore,

25
Erweiterung auf mehrere Spieler
MINIMAX Erweiterung auf mehrere Spieler Jeder maximiert seinen Nutzen max max max

26
Zusammenfassung MINIMAX
Führt Tiefensuche durch den gesamten Zustandsraum durch Ist in der einfachsten Form auf Zweipersonen-spiele anwendbar, kann aber auf 𝑛-Personenspiele erweitert werden (jeder Spieler maximiert dann seinen Teil der Nutzenfunktion)
")
27
Zusammenfassung MINIMAX Algorithmus:
fmax(Zustand Z): falls Z = Endzustand, gib Nutzen(Z) zurück sonst gib das Maximum über alle fmin der Nachfolger von Zustand Z zurück fmin(Zustand Z): falls Z = Endzustand, gib Nutzen(Z) zurück sonst gib das Minimum über alle fmax der Nachfolger von Zustand Z zurück Minimax(Startzustand S) gib eine Aktion zurück, so dass der Nutzen des damit verbundenen Nachfolgezustandes = fmax(S)
: falls Z = Endzustand, gib Nutzen(Z) zurück sonst gib das Maximum über alle fmin der Nachfolger von Zustand Z zurück. fmin(Zustand Z): falls Z = Endzustand, gib Nutzen(Z) zurück sonst gib das Minimum über alle fmax der Nachfolger von Zustand Z zurück. Minimax(Startzustand S) gib eine Aktion zurück, so dass der Nutzen des damit verbundenen Nachfolgezustandes = fmax(S)")
28
MINIMAX Russell / Norvig: : Artificial Intelligence - A Modern Approach, 2nd edition. © Pearson Education, 2003

29
Eigenschaften MINIMAX Vollständigkeit: Optimalität:
ja, für endlichen Suchbaum Optimalität: Ja, gegen optimalen Gegner Zeitkomplexität: O(bm) Alle Knoten bewerten ... Raumkomplexität: O(bm) Tiefensuche Oft sehr groß, z.B. Schach mit 35 be-trachteten Möglich-keiten je Zug und 100 Halbzügen: (> 10154) Knoten
 Alle Knoten bewerten ... Raumkomplexität: O(bm) Tiefensuche. Oft sehr groß, z.B. Schach mit 35 be-trachteten Möglich-keiten je Zug und 100 Halbzügen: (> 10154) Knoten.")
30
Suchraum sehr, sehr, sehr groß …
Alpha-Beta-Pruning Suchraum sehr, sehr, sehr groß …

31
Spiel gegen „optimalen Gegner“
Alpha-Beta-Pruning Spiel gegen „optimalen Gegner“ Je nach Spieler wird immer Minimum / Maximum der Optionen gewählt Idee: Werte geben obere (Minimum) bzw. untere (Maximum) Schranke für den Nutzen an Vergleich mit den Schranken Größere (Minimum) / kleinere (Maximum) Unterbäume werden „abgeschnitten“ Branch-and-bound
 bzw. untere (Maximum) Schranke für den Nutzen an. Vergleich mit den Schranken. Größere (Minimum) / kleinere (Maximum) Unterbäume werden „abgeschnitten Branch-and-bound.")
32
Beispiel Suchbaum der Höhe 2
Alpha-Beta-Pruning Beispiel Suchbaum der Höhe 2 3 min(2,…) 3 > 2 ≥ …
 3 > 2 ≥ …")
33
Alpha-Beta-Pruning Beispiel (Spielbaum der Höhe 2)
")
34
Algorithmus nutzt zwei Parameter
Alpha-Beta-Pruning Algorithmus nutzt zwei Parameter = den besten (maximalen) Wert für einen Zug von Spieler A = den besten (minimalen) Wert für einen Zug von Spieler B und werden ständig aktualisiert Wenn ≥ gibt es einen anderen Pfad für Spieler A, der genauso gut oder besser ist! (B wählt Pfad zu , A wählt Pfad zu )
 Wert für einen Zug von Spieler A. = den besten (minimalen) Wert für einen Zug von Spieler B. und werden ständig aktualisiert. Wenn ≥ gibt es einen anderen Pfad für Spieler A, der genauso gut oder besser ist! (B wählt Pfad zu , A wählt Pfad zu )")
35
Algorithmus: Alpha-Beta-Pruning
fmax(Zustand Z, , ): falls Z = Endzustand, gib Nutzen(Z) zurück sonst bestimme sukzessive Das Maximum über alle fmin der Nachfolger von Zustand Z Falls ein fmin >= (d.h. der Wert des aktuellen Knoten ist größer als der kleinste in das Minimum einfließende Wert eines Knotens), gib den aktuellen Wert des Maximums zurück (RETURN) aktualisiere Nach jedem Knoten testen!
: falls Z = Endzustand, gib Nutzen(Z) zurück sonst bestimme sukzessive. Das Maximum über alle fmin der Nachfolger von Zustand Z. Falls ein fmin >= (d.h. der Wert des aktuellen Knoten ist größer als der kleinste in das Minimum einfließende Wert eines Knotens), gib den aktuellen Wert des Maximums zurück (RETURN) aktualisiere Nach jedem Knoten testen!")
36
Algorithmus: Alpha-Beta-Pruning
fmin(Zustand Z, , ): falls Z = Endzustand, gib Nutzen(Z) zurück sonst bestimme sukzessive Das Minimum über alle fmax der Nachfolger von Zustand Z Falls ein fmax <= (d.h. der Wert des aktuellen Knoten ist kleiner als der größte in das Maximum einfließende Wert eines Knotens), gib den aktuellen Wert des Minimums zurück (RETURN) aktualisiere Nach jedem Knoten testen!
: falls Z = Endzustand, gib Nutzen(Z) zurück sonst bestimme sukzessive. Das Minimum über alle fmax der Nachfolger von Zustand Z. Falls ein fmax <= (d.h. der Wert des aktuellen Knoten ist kleiner als der größte in das Maximum einfließende Wert eines Knotens), gib den aktuellen Wert des Minimums zurück (RETURN) aktualisiere Nach jedem Knoten testen!")
37
Algorithmus Alpha-Beta-Pruning
Alpha-beta-search(Startzustand S) gibt eine Aktion zurück, so dass der Nutzen des Nachfolgezustandes = fmax(S, -, +)
 gibt eine Aktion zurück, so dass der Nutzen des Nachfolgezustandes = fmax(S, -, +)")
38
Alpha-Beta-Pruning Russell / Norvig: : Artificial Intelligence - A Modern Approach, 2nd edition. © Pearson Education, 2003

39
Alpha-Beta-Pruning Russell / Norvig: : Artificial Intelligence - A Modern Approach, 2nd edition. © Pearson Education, 2003

40
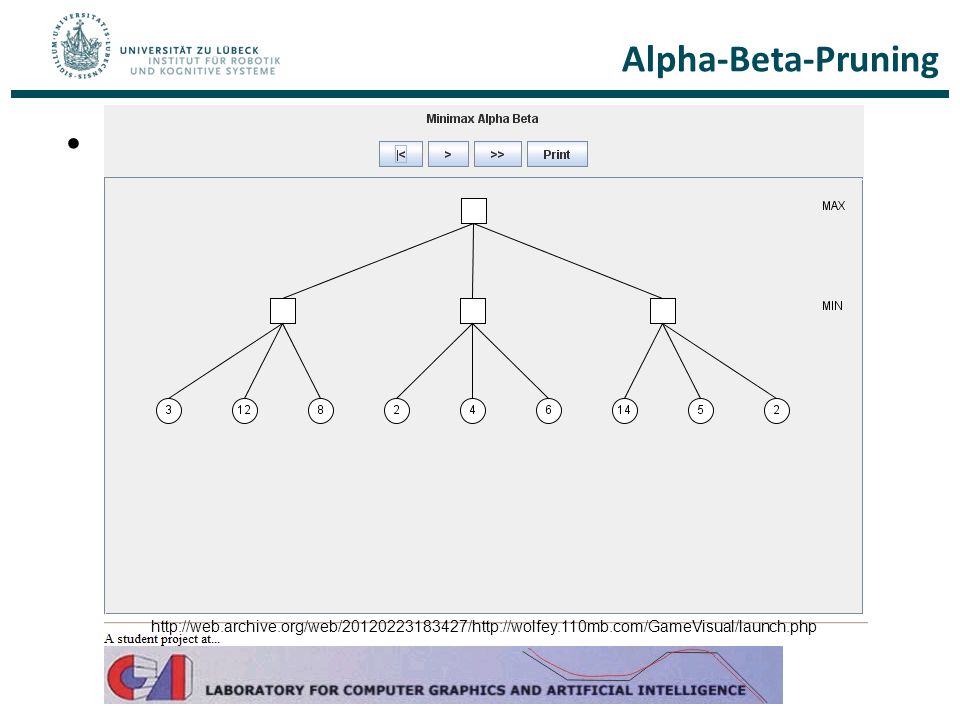
Beispiel Alpha-Beta-Pruning min-Knoten: 𝑣=2≤𝛼=3
[max{- , 3}, +] [max{3, 2}, +] [max{3, 2}, +] [- , min{+, 3}] [3, min{+, 2}] [3, min{+, 14}] 3 [- , min{3, 12}] [3, min{2, 4}] [3, min{14, 5}] [- , min{3, 8}] [3, min{2, 6}] [3, min{5, 2}] min-Knoten: 𝑣=2≤𝛼=3 Andere Implementierung: erst 𝛽=2, dann Bedingung 𝛼<𝛽 verletzt

41
Alpha-Beta-Pruning Beispiel

42
Beispiel Alpha-Beta-Pruning
43
Läßt sich diese Idee ausbauen?
Alpha-Beta-Pruning Zusammenfassung: Alpha-Beta-Pruning kann Anzahl der betrachteten Knoten erheblich reduzieren Reihenfolge der Nachfolgerknoten hat Einfluss auf Laufzeit – Nachfolgerknoten so sortieren, dass die beste Knoten zuerst untersucht (Heuristik) Kann durch Speichern bereits betrachteter Zustände (z.B. in einer ‚hash-table‘) verbessert werden (wie GRAPH-SEARCH) Datenstruktur bei Spielen auch als ‚transposition table‘ bezeichnet Läßt sich diese Idee ausbauen?
 Kann durch Speichern bereits betrachteter Zustände (z.B. in einer ‚hash-table‘) verbessert werden (wie GRAPH-SEARCH) Datenstruktur bei Spielen auch als ‚transposition table‘ bezeichnet. Läßt sich diese Idee ausbauen")
44
Rechenzeit in Sekunden
Alpha-Beta-Pruning Beispiel Schachstellung, konstante Suchtiefe von vier Halbzügen (jeder Spieler zieht zweimal) Algorithmus Bewertungen Cutoffs Anteil der Cutoffs Rechenzeit in Sekunden Minimax 0,00 % 134,87 s AlphaBeta 91,50 % 9,88 s AlphaBeta + Zugsortierung 27.025 99,28 % 0,99 s
 Algorithmus. Bewertungen. Cutoffs. Anteil der Cutoffs. Rechenzeit in Sekunden. Minimax ,00 % 134,87 s. AlphaBeta ,50 % 9,88 s. AlphaBeta + Zugsortierung ,28 % 0,99 s.")
45
Dynamische Programmierung
Suchraum sehr, sehr groß …

46
Dynamische Programmierung
Idee: Für viele Probleme gilt: „optimale Lösungen enthalten optimale Teillösungen“ (Richard Bellman) Bei Spielen Verschiedene Zugfolgen führen zur gleichen Spielsituation Wenn Ergebnis für Spielsituation bekannt („optimal gelöst“) und gespeichert ist, kann das bekannte Ergebnis verwendet werden ohne erneut zu suchen
 Bei Spielen. Verschiedene Zugfolgen führen zur gleichen Spielsituation. Wenn Ergebnis für Spielsituation bekannt („optimal gelöst ) und gespeichert ist, kann das bekannte Ergebnis verwendet werden ohne erneut zu suchen.")
47
Dynamische Programmierung
Beispiel (Textabgleich, siehe Luger) String 1: BAADDCABDDA String 2: BBADCBA Kosten 0 Buchstaben gleich, Position gleich 1 Position um 1 verschoben 2 Buchstaben ungleich und verschoben
 String 1: BAADDCABDDA. String 2: BBADCBA. Kosten. 0 Buchstaben gleich, Position gleich. 1 Position um 1 verschoben. 2 Buchstaben ungleich und verschoben.")
48
Dynamische Programmierung
Beispiel (Textabgleich, siehe Luger) Kosten in (x,y) setzen sich aus den Kosten zu einem “Vor-gängerzustand” und den Kosten in (x,y) zusammen a = Kosten in (6,2)+1 (wg. 1xSchieben) Kosten in (6,3) = min(a, b, c) b = Kosten in (5,3)+1 (wg. 1xSchieben) c = Kosten in (5,2) + “Einzelkosten” in (6,3) beide geschoben, gleich := 0; ungleich := 2 Luger: Artificial Intelligence, 6th edition. © Pearson Education Limited, 2009
 Kosten in (x,y) setzen sich aus den Kosten zu einem Vor-gängerzustand und den Kosten in (x,y) zusammen. a = Kosten in (6,2)+1 (wg. 1xSchieben) Kosten in (6,3) = min(a, b, c) b = Kosten in (5,3)+1 (wg. 1xSchieben) c = Kosten in (5,2) + Einzelkosten in (6,3) beide geschoben, gleich := 0; ungleich := 2. Luger: Artificial Intelligence, 6th edition. © Pearson Education Limited,")
49
Dynamische Programmierung
Beispiel (Textabgleich, siehe Luger) 1 ? 2 ? 3 ? 1 ? ? 2 3 ? ? 2 1 ? 2 ? ? Luger: Artificial Intelligence, 6th edition. © Pearson Education Limited, 2009
 Luger: Artificial Intelligence, 6th edition. © Pearson Education Limited,")
50
Dynamische Programmierung
Beispiel (Textabgleich, siehe Luger) Was nun? Eine optimale Lösung läßt sich ausgehend vom Zielzustand finden. Wie? Luger: Artificial Intelligence, 6th edition. © Pearson Education Limited, 2009
 Was nun Eine optimale Lösung läßt sich ausgehend vom Zielzustand finden. Wie Luger: Artificial Intelligence, 6th edition. © Pearson Education Limited,")
51
Dynamische Programmierung
Beispiel (Textabgleich, siehe Luger) Wähle jeweils die Vorgänger mit minimalen Kosten! (optimale Lösung = optimale Teillösungen …) Luger: Artificial Intelligence, 6th edition. © Pearson Education Limited, 2009
 Wähle jeweils die Vorgänger mit minimalen Kosten! (optimale Lösung = optimale Teillösungen …) Luger: Artificial Intelligence, 6th edition. © Pearson Education Limited,")
52
Dynamische Programmierung
Beispiel (Textabgleich, siehe Luger) String 1: B A A D D C A B D D A String 2: B B A D C B A
 String 1: B A A D D C A B D D A. String 2: B B A D C B A.")
53
DP for Chess Endgames Suppose one has only, say, 4 pieces in total left on the board. With enough compute power you can compute, for all such positions, whether the position is a win for Black, White, or a draw. Assume N such positions. With each state, associate an integer. A state code, so there’s a 1-1 mapping between board positions and integers from 0…N-1. Make a big array (2 bits per array entry) of size N. Each element in the array may have one of three values: ?: We don’t know who wins from this state W: We know white’s won from here B: We know black’s won from here Andrew W. Moore,
 of size N. Each element in the array may have one of three values: : We don’t know who wins from this state. W: We know white’s won from here. B: We know black’s won from here. Andrew W. Moore,")
54
DP for Chess Endgames Mark all terminal states with their values (W or B) Look through all states that remain marked with ?. For states in which W is about to move: If all successor states are marked B, mark the current state as B. If any successor state is marked W, mark the current state as W. Else leave current state unchanged. For states in which B is about to move: If all successor states are marked W, mark the current state as W. If any successor state is marked B, mark the current state as B. Else leave current state unchanged Goto 4, but stop when one whole iteration of 4 produces no changes. Any state remaining at “?” is a state from which no-one can force a win. Andrew W. Moore,

55
Suche mit Bewertungsfunktionen
Suchraum sehr groß …

56
Suche mit Bewertungsfunktionen
Beobachtung Ähnlich wie bei uninformierter Suche werden auch bei Alpha-Beta-Pruning und bei Minimax Pfade bis zu Endknoten verfolgt „Dynamische Programmierung“ kann die Suche verkürzen, wird aber schnell aufwendig Kann in Analogie zu Heuristiken kann auch bei Spielen eine „Bewertungsfunktion“ zur Nutzen-abschätzung der Züge herangezogen werden? Ja ...

57
Suche mit Bewertungsfunktionen
Anforderungen an Bewertungsfunktionen Die Endknoten werden in der gleichen Weise sortiert wie von der „echten“ Nutzenfunktion Die Berechnung der Bewertungsfunktion kann effizient erfolgen Für alle Knoten die keine Endknoten sind, sollte die Bewertungsfunktion „stark mit den Gewinnchancen korrelieren“

58
Suche mit Bewertungsfunktionen
können z.B. „features“ (Merkmale) des aktuellen Zustands berechnen Bsp. (Schach): Anzahl der Bauern, Besitz der Dame … Zustände anhand der „features“ kategorisieren Je Kategorie / Äquivalenzklasse von Zuständen über viele Spiele die Wahrscheinlichkeit für Spiel-ausgang berechnen, (z.B.) jeweils für Gewinn Verlust Unentschieden
 des aktuellen Zustands berechnen. Bsp. (Schach): Anzahl der Bauern, Besitz der Dame … Zustände anhand der „features kategorisieren. Je Kategorie / Äquivalenzklasse von Zuständen über viele Spiele die Wahrscheinlichkeit für Spiel-ausgang berechnen, (z.B.) jeweils für. Gewinn. Verlust. Unentschieden.")
59
Suche mit Bewertungsfunktionen
Alternativ jedem „feature“ Gewicht zugeordnen Wert der gewichteten linearen Funktion als Bewertung des Zustandes interpretieren Beispiel (Schach): Bauer = 1 Springer, Läufer = 3 Turm = 5 Dame = 9
: Bauer = 1. Springer, Läufer = 3. Turm = 5. Dame = 9.")
60
Suche mit Bewertungsfunktionen
Beispiel (Schach): Andere „features“ (Stellung, etc.) in „Bauernwerten“ ausgedrücken und in Zielfunktion zusammengefassen: EVAL(s) = w1f1(s) + w2f2(s) + … + wnfn(s) EVAL(s) = 1*Bauern(s) + 3*Springer(s) + … + 9*Dame(s) Woher kommen die Gewichte? Aus Erfahrung (humane Intelligenz) Durch maschinelles Lernen (später mehr ...) Nichtlineare und sich im Zeitverlauf ändernde Funktionen können sinnvoll sein
: Andere „features (Stellung, etc.) in „Bauernwerten ausgedrücken und in Zielfunktion zusammengefassen: EVAL(s) = w1f1(s) + w2f2(s) + … + wnfn(s) EVAL(s) = 1*Bauern(s) + 3*Springer(s) + … + 9*Dame(s) Woher kommen die Gewichte Aus Erfahrung (humane Intelligenz) Durch maschinelles Lernen (später mehr ...) Nichtlineare und sich im Zeitverlauf ändernde Funktionen können sinnvoll sein.")
61
Suche mit Bewertungsfunktionen
Pruning (Beschneiden) des Suchbaums Normaler Ablauf der Alpha-Beta Suche bis zur Tiefenschranke 𝑑 Für Zustände 𝑆 in Tiefe 𝑑 wird statt des durch Suche ermittelten Nutzens nun der Wert der Bewertungsfunktion Eval(𝑆) verwendet
 des Suchbaums. Normaler Ablauf der Alpha-Beta Suche bis zur Tiefenschranke 𝑑. Für Zustände 𝑆 in Tiefe 𝑑 wird statt des durch Suche ermittelten Nutzens nun der Wert der Bewertungsfunktion Eval(𝑆) verwendet.")
62
Suche mit Bewertungsfunktionen
Probleme (Beispiel Schach, siehe AIMA) + 9 = 12 Dame sicher, echter Vorteil für Schwarz. Weiß kann Dame schlagen, Bewertung?
 + 9 = 12. Dame sicher, echter Vorteil für Schwarz. Weiß kann Dame schlagen, Bewertung")
63
Suche mit Bewertungsfunktionen
Pruning (Beschneiden) des Suchbaums Feste Tiefenbeschränkung kann zu fehlerhafter Bewertung führen Warum? – Bewertung kann sich schnell ändern Verbesserung Möglichkeit schneller Änderungen berücksichtigen Tiefenbeschränkung nur für „stabile Zustände“ (‚quiescent positions‘ ) verwenden (z.B. keine wertvollen Figuren im nächsten Zug gefährdet) Entsprechende Variante der heuristischen Alpha-Beta-Suche auch als ‚quiescence search‘ bezeichnet
 des Suchbaums. Feste Tiefenbeschränkung kann zu fehlerhafter Bewertung führen. Warum – Bewertung kann sich schnell ändern. Verbesserung. Möglichkeit schneller Änderungen berücksichtigen. Tiefenbeschränkung nur für „stabile Zustände (‚quiescent positions‘ ) verwenden (z.B. keine wertvollen Figuren im nächsten Zug gefährdet) Entsprechende Variante der heuristischen Alpha-Beta-Suche auch als ‚quiescence search‘ bezeichnet.")
64
Suche mit Bewertungsfunktionen
Probleme (Beispiel Schach, siehe AIMA) Schwarz am Zug, was sind die nächsten Züge?
 Schwarz am Zug, was sind die nächsten Züge")
65
Suche mit Bewertungsfunktionen
Probleme (Beispiel Schach, siehe AIMA) 2 3 1 14 13 12
")
66
Suche mit Bewertungsfunktionen
Pruning (Beschneiden) des Suchbaums Horizont-Effekt: unvermeidbare Ereignisse, die über den aktuellen Betrachtungshorizont (Tiefen-beschränkung) hinaus vermieden werden können, werden als „vermeidbar“ betrachtet Im Beispiel wird Weiß mit Sicherheit eine Dame bekommen, aber die Tiefenschranke schneidet u.U. vorher den Suchbaum ab (auch für Weiß!) Ggf. den „besten Zug“ über Tiefenschranke hinaus betrachten (Tiefensuche mit bestem Zug)
 des Suchbaums. Horizont-Effekt: unvermeidbare Ereignisse, die über den aktuellen Betrachtungshorizont (Tiefen-beschränkung) hinaus vermieden werden können, werden als „vermeidbar betrachtet. Im Beispiel wird Weiß mit Sicherheit eine Dame bekommen, aber die Tiefenschranke schneidet u.U. vorher den Suchbaum ab (auch für Weiß!) Ggf. den „besten Zug über Tiefenschranke hinaus betrachten (Tiefensuche mit bestem Zug)")
67
Viele Spiele haben zufällige Komponente
EXPECTIMINIMAX Viele Spiele haben zufällige Komponente Das Auftreten verschiedener Spielzüge ist nicht deterministisch sondern unterliegt einer Wahrscheinlichkeitsverteilung Die in den Knoten berechneten Werte stellen keine „sichere Bewertung“, sondern einen Erwartungswert dar Im Suchbaum wird dies durch „Zufallsknoten“ dargestellt

68
Beispiel Backgammon (siehe AIMA)
EXPECTIMINIMAX Beispiel Backgammon (siehe AIMA)
")
69
Beispiel Backgammon (siehe AIMA)
EXPECTIMINIMAX Beispiel Backgammon (siehe AIMA)
")
70
Die EXPECTIMINIMAX-Funktion
Definition (Nf = Nachfolger; n,s sind Zustände) NUTZEN(n) falls n Endzustand MaxsNf(n) EXPECTIMINIMAX(s) falls Spieler A am Zug MinsNf(n) EXPECTIMINIMAX(s) falls Spieler B am Zug sNf(n) P(s)*EXPECTIMINIMAX(s) falls n Zufallsknoten Laufzeit: O(bmnm) wobei b = branching factor n = Anzahl möglicher Ergebnisse des Zufallsereignisses
 NUTZEN(n) falls n Endzustand. MaxsNf(n) EXPECTIMINIMAX(s) falls Spieler A am Zug. MinsNf(n) EXPECTIMINIMAX(s) falls Spieler B am Zug. sNf(n) P(s)*EXPECTIMINIMAX(s) falls n Zufallsknoten. Laufzeit: O(bmnm) wobei. b = branching factor. n = Anzahl möglicher Ergebnisse des Zufallsereignisses.")
71
Achtung: Nutzenfunktion „richtig“ wählen!
EXPECTIMINIMAX Achtung: Nutzenfunktion „richtig“ wählen! Gleiche Reihenfolge in der Bewertung Unterschiedliche Gewichtung / Nutzen

72
Anmerkungen EXPECTIMINIMAX
Standard Alpha-Beta-Pruning ist nicht sinnvoll Erweiterung: Wertebereich berücksichtigen und Grenze für den Mittelwert für die Bewertung verwenden

73
Deterministic games in practice
Checkers: Chinook ended 40-year-reign of human world champion Marion Tinsley in Used a precomputed endgame database defining perfect play for all positions involving 8 or fewer pieces on the board, a total of 444 billion positions. Chess: Deep Blue defeated human world champion Garry Kasparov in a six-game match in Deep Blue searches 200 million positions per second, uses very sophisticated evaluation, and undisclosed methods for extending some lines of search up to 40 ply. Othello: human champions refuse to compete against computers, who are too good. Go: human champions refuse to compete against computers, who are too bad. In go, b > 300, so most programs use pattern knowledge bases to suggest plausible moves. Othello/Reversi: Logistello 1997, gewinnt alle Spiele (6) gegen Weltmeister 19 x 19 Linien bei Go, also 361 Schnittpunkte, Bewertungsfunktion für Go schwierig
 gegen Weltmeister. 19 x 19 Linien bei Go, also 361 Schnittpunkte, Bewertungsfunktion für Go schwierig.")
Ähnliche Präsentationen
>")



>")
 Kein Graffiti in der Schule!>")
>")
, leere Liste falls n=0 Listenelemente besitzen.>")











