Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Data Mining Cup 2012 Wissensextraktion – Multimedia Engineering
deck using PDA or similar devices Fakultät für Ingenieurwissenschaften Jevgenij Jakunschin Christian Mewes

2
Gliederung Software Vorverarbeitung Analyse Algorithmen Verfeinerung
Auswahl

3
Software Daten wurden in .csv Format gespeichert
Excel für frühe Analysen und Umwandlung Knime + Weka + Math plugins für Datamining, Clusterung und die meisten Algorithmen Matlab für für Regression, Interpolation und Approximationverfahren Dropbox für Synchronisation

5
Vorverarbeitung Keine fehlenden Werte Keine Duplikate
Keine fehlerhaften Werte Rein syntaxisch her Daten komplett korrekt Allerdings...

6
Vorverarbeitung Allerdings... Starke Schwankungen, mit „Peaks“
Keine zusätzlichen/abgeleiteten Informationen (wie Wochentag oder Gewinn) Werte nicht normalisiert und/oder nominalisiert
 Werte nicht normalisiert und/oder nominalisiert.")
7
Vorverarbeitung Erstellen von CSV Dateien mit Zusätzlichen Informationen: -Gewinn,Wochentag, Durschnittlicher Gewinn (soweit) Zusätzliche nominalisierten und normalisierten Werte Durschnittswerte für Diagramme und Statistiken Strukturieren und Anlegen von Zwischentabellen/Resultaten Tabellen mit allen Wochenwerten in einer Zeile (pro Produkt)
")
9
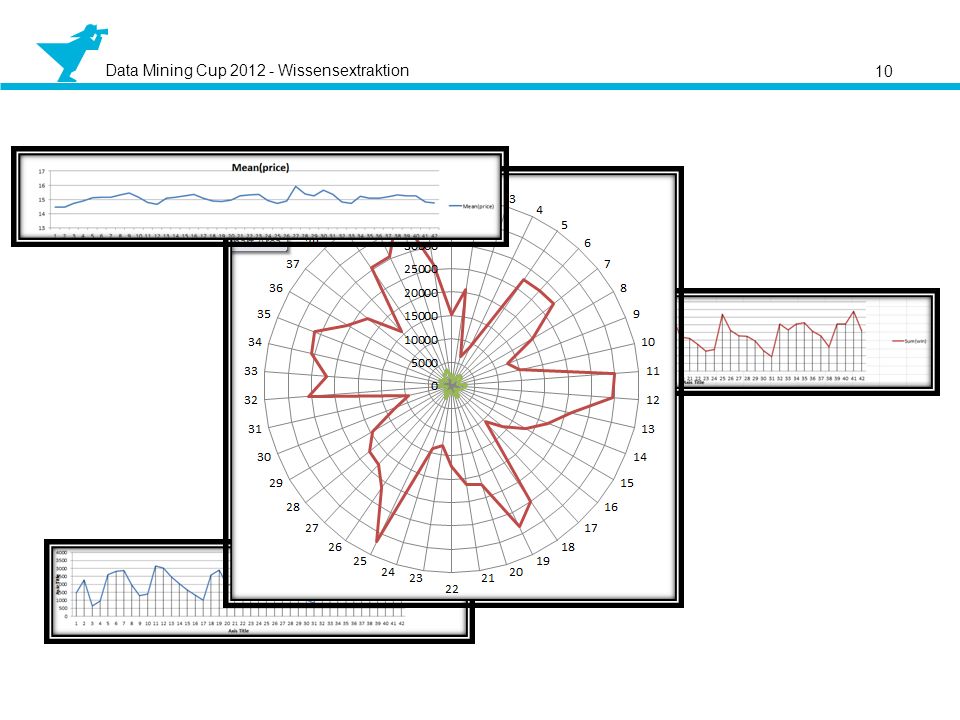
Analysis Erstellen von Tabellen mit Mittelwerten und Summen
Darstellen von Diagrammen Notieren von Abweichungen, Min/Max-Werten Überprüfen auf Auffälligkeiten durch gruppierte Tabellen Starker Exceleinsatz

11
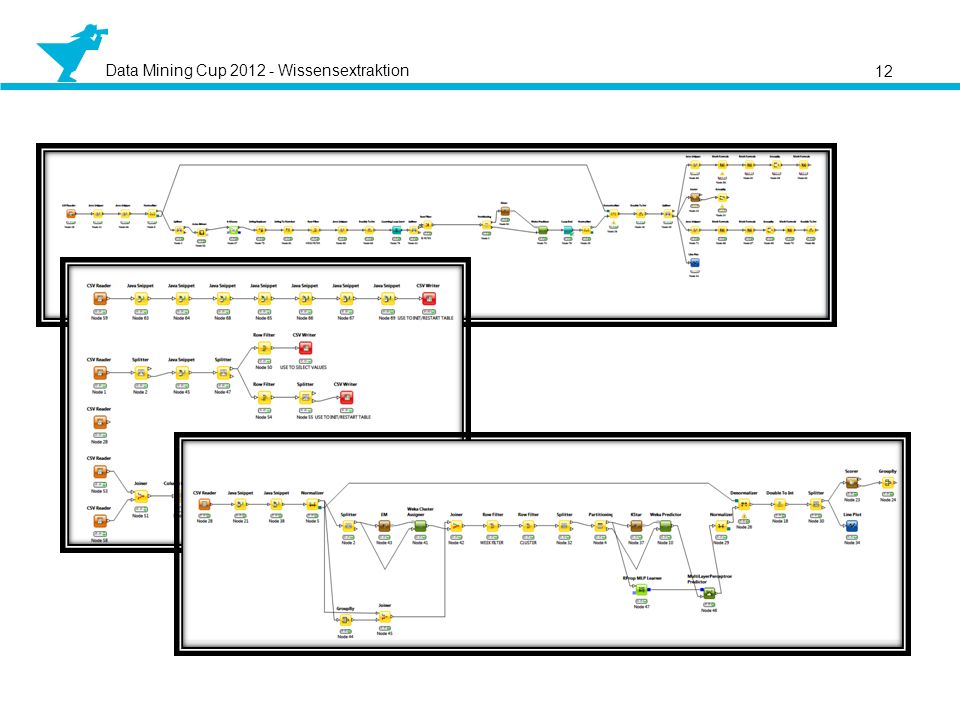
Algorithmen Erstellen von Matlab und Knime Umgebungen
Möglichkeiten schnell Module und Algorithmen zu tauschen Schnelles Anpassen der Daten... ... für Noralisieren, Partitonieren, Splitten, Clusterung... ...und schließlich Auswertung

13
Algorithmen: Regression (linear, logistic, polynom, WEKA versions)
Bayes (Naive, WEKA versions, Multinomial) Neuronal Network (MLP, PNN, WEKA Voted Perceptron Kstar, LWL Decission Trees Clustering: Kmeans, Xmeans .. (usw.)
 Neuronal Network (MLP, PNN, WEKA Voted Perceptron. Kstar, LWL. Decission Trees. Clustering: Kmeans, Xmeans. .. (usw.)")
14
Algorithmen: Regression (linear, logistic, polynom, WEKA versions)
Bayes (Naive, WEKA versions, Multinomial) Neuronal Network (MLP, PNN, WEKA Voted Perceptron Kstar, LWL Decission Trees Clustering: Kmeans, Xmeans .. (usw.)
 Neuronal Network (MLP, PNN, WEKA Voted Perceptron. Kstar, LWL. Decission Trees. Clustering: Kmeans, Xmeans. .. (usw.)")
15
Algorithmen Ergebnisse meist sehr ungenau (accuracy <<10%)
aber 2 Algorithmen waren klar im Vorteil: Kstar – WEKA plugin – ungenau aber erkennt Tendenz Regressionen (Polynom/Linear) Accuracy Werte bis zu 20% Beide trotzdem bei weitem nicht genau genug
 Accuracy Werte bis zu 20% Beide trotzdem bei weitem nicht genau genug.")
16
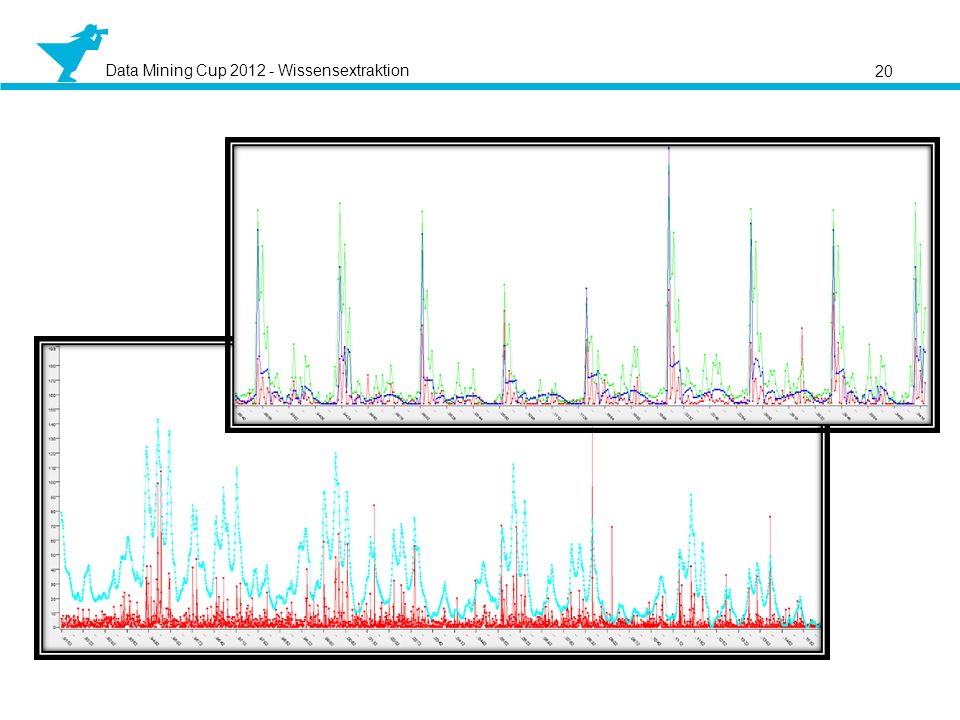
Verfeinerung Verbesserung der Resultate auf viele Weisen
Veränderung interner Variablen Clusterung nach Wochentagen verbessert Ergebnisse stark Zusätzliche Einbindung von Neuronalen Netzwerken Entfernen oder skalieren mancher Daten

17
Verfeinerung Größte Veränderung durch Sortierung nach Wochentagen
Durch mehr als 7 Cluster allerdings noch bessere Resultate Clustersuche schlägt sich vor K-means Relativ gute Ergebnisse bei Regression und Kstar

18
Das experementieren ging dann eine Weile weiter...

19
Testen - Knime 1) Allgemeiner Workflow und WEKA Workflow
2) Anwendungen meister Algorithmen 3) Entscheidung: Regression(Matlab) und Kstar(Knime) 4) Kstar – Anpassung der Variablen (++) 5) Kstar+MLP – Hinzufügen eines neuronalen Netzes (--) 6) Kstar – Clusterung nach Wochetagen (++) 7) Kstar+Kmeans – Automatische Clusterung (++) 8) Kstar+Kmeans – Skalierung/Filterung (++) Beste Kstar Ergebnisse in 600ter Bereich...
 Anwendungen meister Algorithmen. 3) Entscheidung: Regression(Matlab) und Kstar(Knime) 4) Kstar – Anpassung der Variablen (++) 5) Kstar+MLP – Hinzufügen eines neuronalen Netzes (--) 6) Kstar – Clusterung nach Wochetagen (++) 7) Kstar+Kmeans – Automatische Clusterung (++) 8) Kstar+Kmeans – Skalierung/Filterung (++) Beste Kstar Ergebnisse in 600ter Bereich...")
21
Verfeinern - Matlab 1. Durchschnitt Tag/Menge pro Produkt
2. DS Wochentag/Menge pro Produkt (~16%) 3. MIN, MAX statt DS (ca.30%) 4. Ausreißer beseitigen (+ca.1.5%) 5. Identische Datensätze (+ca.1.5%) 6. Durchschnittspreis (+ca.0.5%) 7. Approximation Menge (30-40%, aber E:NaN, M:NaN) (8.Clustering Menge) (9.Clustering Produkt) 10.Zusammenführung aller Ansätze
 3. MIN, MAX statt DS (ca.30%) 4. Ausreißer beseitigen (+ca.1.5%) 5. Identische Datensätze (+ca.1.5%) 6. Durchschnittspreis (+ca.0.5%) 7. Approximation Menge (30-40%, aber E:NaN, M:NaN) (8.Clustering Menge) (9.Clustering Produkt) 10.Zusammenführung aller Ansätze.")
23
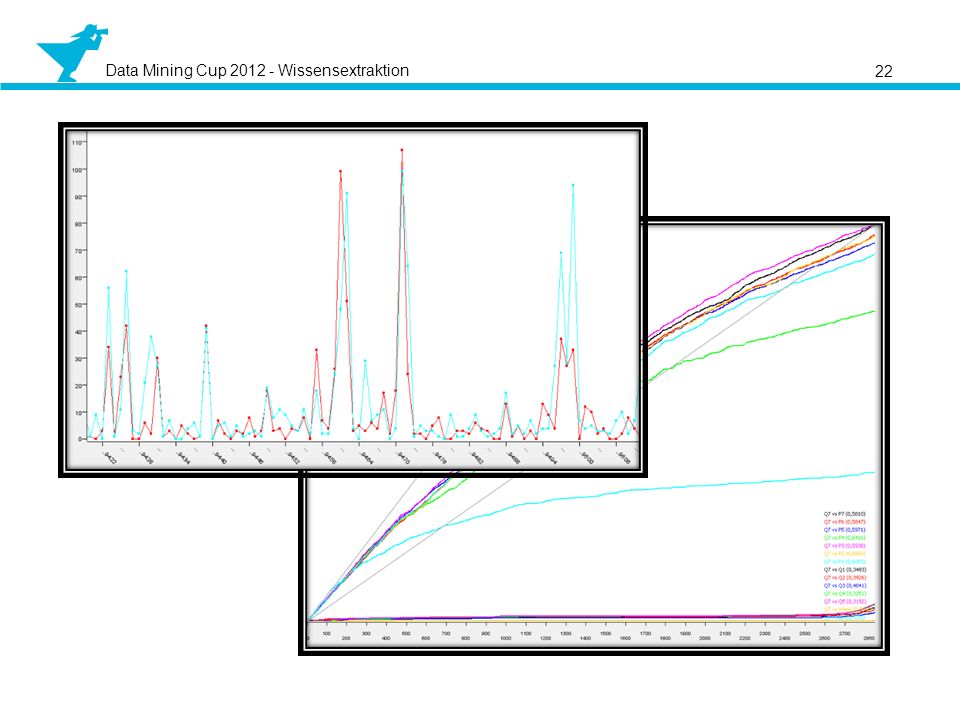
Auswahl Bis man zwischen Regression und Kstar wählen musste
(Bei Aufteilung 4:2 Wochen) Kstar: EuklD: 650, ManD: 20000, Accuracy bis 25% Regression: EuklD: 462, ManD: 20948, Accuracy bis 16.4% Regression kann konfiguriert werden, auf Kosten von der EuklD und ManD höhere Accuracy zu bekommen (30+) Endentscheidung: Regression
 Kstar: EuklD: 650, ManD: 20000, Accuracy bis 25% Regression: EuklD: 462, ManD: 20948, Accuracy bis 16.4% Regression kann konfiguriert werden, auf Kosten von der EuklD und ManD höhere Accuracy zu bekommen (30+) Endentscheidung: Regression.")
24
Quellen und Zusatzinformationen

25
Danke fürs Zuhören!

Ähnliche Präsentationen


 Die Schüler eignen sich Grundkenntnisse in der Arbeit mit einem.>")






 Zeilen- und Spaltenanzahl angeben Daten eingeben DiagrammEinfügen - Illustrationen - Diagramm.>")




>")






