Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Oracle Warehouse Technologie Single-Engine-Based-Data-Warehouse

2
Performantes Data Warehouse
Effiziente, integrierte Data Warehouse Architekturen auf der Basis von Oracle 10 g Alfred Schlaucher Gerd Schoen Stichpunkte zu Ressourcen – schonenden Techniken mit dem Oracle – basierten Data Warehouse

3
Information Management und Agenda (Vormittag) Data Warehouse
10:00 – 11:00 Data Warehouse Herausforderungen / Trends Oracle Data Warehouse Architektur 11:00 – 11:15 Kaffeepause 11:15 – 12:30 Oracle DW Komponentenübersicht Operative Daten identifizieren und qualifizieren Data Profiling / Data Quality Das Data Warehouse modellieren mit Oracle Warehouse Builder Der OWB basierte ETL Prozess Das Warehouse automatisieren mit Oracle Workflow 12:30 – 13:30 Mittagspause Good morning, my name is _____________ and I’m pleased to be with you this morning. I’m responsible for ______________ within Oracle’s [Automotive] business. The Automotive industry is one of the largest market segments served by Oracle, you’ll see our customer list later in this presentation. Our Automotive customers keep over 600 Oracle employees very busy and after today’s visit I hope that you’ll see several opportunities where Oracle can help solve some of your problems Enough of that let’s get going

4
Agenda (Nachmittag) Information Management und Data Warehouse
13:30 – ca. 16:00 Optimale Datenbankmodelle / Kennzahlensysteme Datenbankbasiertes Laden Metadaten ILM (Information Lifecycle Management) Ausblick ca. 15:00 Kaffeepause Good morning, my name is _____________ and I’m pleased to be with you this morning. I’m responsible for ______________ within Oracle’s [Automotive] business. The Automotive industry is one of the largest market segments served by Oracle, you’ll see our customer list later in this presentation. Our Automotive customers keep over 600 Oracle employees very busy and after today’s visit I hope that you’ll see several opportunities where Oracle can help solve some of your problems Enough of that let’s get going
 Ausblick. ca. 15:00 Kaffeepause. Good morning, my name is _____________ and I’m pleased to be with you this morning. I’m responsible for ______________ within Oracle’s [Automotive] business. The Automotive industry is one of the largest market segments served by Oracle, you’ll see our customer list later in this presentation. Our Automotive customers keep over 600 Oracle employees very busy and after today’s visit I hope that you’ll see several opportunities where Oracle can help solve some of your problems. Enough of that let’s get going.")
5
Themen Information Management und Data Warehouse
Anforderungen und Architekturen Vorgehensweisen und Modelle Datenintegration Datenqualität Aufbau eines Data Warehouse Systems Optimierungen der Datenhaltung

6
Inkrementelles, ständiges Sammeln von Informationen
Das Data Warehouse Zentrale konsolidierte Sicht für qualitativ bessere Entscheidungen OLTP Transaktion Fokus Arbeits- plätze Markt Daten Call Center eCommerce Systeme Inkrementelles, ständiges Sammeln von Informationen BI-An- wendungen CRM Kampagnen Procurement Controlling Erklären Kombinieren Filtern Vervoll- ständigen Korrigieren Order Managmnt Sales Marketing Planung Kundenpflege/ -bindung Verwendung von Produkten Kundensegmentierung Kampagnen Mngt. Kaufverhalten . Die bekannte Aussage: Der geschäftliche Erfolg hängt heute mehr und mehr davon ab, wie gut wir unseren Kunden kennen und wie gut wir die Beziehungen zu dem Kunden pflegen können. Wir brauchen ein kundenzentrisches Unternehmen, mit der Ausrichtung aller Prozesse auf den Kunden. Kundenbestand sichern und an bestehende Kunden mehr verkaufen gebraucht wird ein mehrdimensionales Bild des Kunden, das einerseits die unterschiedlichen Prozesse im Unternehmen Unterstützt und andererseits Synergieeffekte über die Informationen entstehen läßt Synergien aus den unterschiedlichen Bereichen, in denen wir mit unseren Kunden in Kontakt treten, lassen neue Erkenntnisse über künftiges Verhalten des Kunden wachsen. Betrachten wir die Quellinformationen, so sehen wir, daß diese in einem ganz anderen Zusammenhang genutzt wurden und für eine andere Verwendung bestimmt waren. Um auswertbare Informationen zu erzeugen müssen diese Daten umgewandelt werden. (siehe Folientext). Warehouse Service Produkt Design ..... (1) Zentrale, (2) historische, (3) nach Themen sortierte, (4) separierte Daten + Referenzdaten + weiche Daten
. Warehouse. Service. Produkt Design (1) Zentrale, (2) historische, (3) nach Themen sortierte, (4) separierte Daten + Referenzdaten + weiche Daten.")
7
Bei allen Diskussionen nicht vergessen
Zentral zugreifbar Historische Sammlung nach Themen sortiert (Geschäftsobjekte) Daten separiert + Referenzdaten + weiche Daten (Entlastung op. Systeme)
 Daten separiert + Referenzdaten + weiche Daten (Entlastung op. Systeme)")
8
Data Warehouse Anforderungen
Klassisch Trends Anzahl Benutzer Anzahl Benutzergruppen Anzahl Schnittstellen Beispiel: Globus hat in seinem Data Warehouse 2000 Benutzer zu gelassen Ca. 200 – 300 sind zu bestimmten Zeiten gleichzeitig angemeldet. Bestimmte Berichte werden alle 30 Minuten aktualisiert. Benutzer fragen bis 10 mal täglich bestimmte aktualisierte Berichte ab. Kampagnen werden gefahren. In welchen Filialen laufen welche Kampagnenartikel besonders gut. Latenzzeit Granularität Datenmengen

9
Datenmengen anstatt Information
Oracle-Nutzer verwalten immer größere Datenmengen um 16:06 Uhr Auch wenn das auf der ersten Blick nach einer Binsenweisheit aussieht: Eine aktuelle Studie der US-amerikanischen Independent Oracle User Group (IOUG) erbrachte, dass 31 Prozent ihrer Mitglieder Datenbanken größer 1 Terabyte verwalten. Interessant ist das insbesondere vor dem Hintergrund, dass vor einem Jahr erst 13 Prozent mit solchen Datenmengen hantieren mussten. Für das wachsende Datenvolumen in den Oracle-Datenspeichern gibt es verschiedene Gründe – unter anderem das steigende Aufkommen unstrukturierter Daten (etwa Bilder, Videos und s) sowie von Daten aus Geschäfts- und Kundentransaktionen, neuen Geräten und Systemen sowie aufgrund von Compliance-Auflagen. Den DBAs bereitet das zunehmend Kopfzerbrechen. 60 Prozent der 335-köpfigen User Group mit Sitz in Chicago gaben zu Protokoll, ein Mangel an verfügbarem Massenspeicher habe ihre Datenbankleistung in Mitleidenschaft gezogen. Andere mussten mangels Speicher den Rollout von Applikationen verschieben. Die Aufgaben des Datebankverwalters überschneiden sich demnach auch zunehmend mit denen von Storage-Verantwortlichen (die zumindest in großen Unternehmen anzutreffen sind). Den größten Anstieg ihres Speicherbedarfs meldeten Datenbanker aus den Branchen Versorgungsunternehmen, Transportwesen, Energie und Telekommunikation. Generell gehen die für die Storage-Budgetierung Verantwortlichen inzwischen dazu über, zehn bis 25 Prozent Sicherheitsspanne für unerwartetes Wachstum mit einzukalkulieren. (tc)
 erbrachte, dass 31 Prozent ihrer Mitglieder Datenbanken größer 1 Terabyte verwalten. Interessant ist das insbesondere vor dem Hintergrund, dass vor einem Jahr erst 13 Prozent. mit solchen Datenmengen hantieren mussten. Für das wachsende Datenvolumen in den Oracle-Datenspeichern. gibt es verschiedene Gründe – unter anderem das steigende Aufkommen unstrukturierter Daten. (etwa Bilder, Videos und s) sowie von Daten aus Geschäfts- und Kundentransaktionen, neuen Geräten und Systemen sowie aufgrund von Compliance-Auflagen. Den DBAs bereitet das zunehmend Kopfzerbrechen. 60 Prozent der 335-köpfigen User Group mit. Sitz in Chicago gaben zu Protokoll, ein Mangel an verfügbarem Massenspeicher habe ihre. Datenbankleistung in Mitleidenschaft gezogen. Andere mussten mangels Speicher den Rollout von. Applikationen verschieben. Die Aufgaben des Datebankverwalters überschneiden sich demnach auch. zunehmend mit denen von Storage-Verantwortlichen (die zumindest in großen Unternehmen anzutreffen sind). Den größten Anstieg ihres Speicherbedarfs meldeten Datenbanker aus den Branchen Versorgungsunternehmen, Transportwesen, Energie und Telekommunikation. Generell gehen die für die Storage-Budgetierung. Verantwortlichen inzwischen dazu über, zehn bis 25 Prozent Sicherheitsspanne für unerwartetes. Wachstum mit einzukalkulieren. (tc)")
10
Informations- und Datenmanagement
Die richtigen Informationen zur richtigen Zeit an den richtigen Benutzer Datenüberfluss Daten sind vermengt, codiert, nicht lesbar Fehlerhafte Daten Unauffindbare Daten Wertlose Daten Sensible Daten Verteilte Daten Zu hohe Datenmengen und fehlende Information Datenaufbereitung, Datenintegration Datenaufbereitung, Datenextraktion, Datenintegration (ETL) Datenqualitätsmanagement Metadatenmanagement Information Lifecycle Management Security-Management Master Data Management (MDM) Datenintegration Data Warehouse Technologie
 Datenqualitätsmanagement. Metadatenmanagement. Information Lifecycle Management. Security-Management. Master Data Management (MDM) Datenintegration. Data Warehouse Technologie.")
11
Effiziente und ineffiziente Systeme
Abt. Kundenbetr. spezieller Infobedarf Beschränkte Ressourcen spezielle Vorlieben Abt. Risiko-Controll. Abt. Portfolio-Plan. Region Bundes- land Ort Kunde

12
Effiziente und ineffiziente Systeme
Reports Data Mart Ad hoc Anwendungsdaten Data Warehouse Staging Area Analyse Data Mart Clearing Datenvorhaltung Endbenutzer Daten WWW Mining Metadaten OWB

13
Kompromiss? . . . granulare, konsolidierte zentrale Daten (DWH)
operative Vorsysteme Reg Zeit Org. Linie Prod Auswerteschicht (Data Mart) Stage . Org. Linie Prod . Reg Org. Linie Prod .
 Stage. . Org. Linie. Prod. . Reg. Org. Linie. Prod. .")
14
Speichermodelle Select Umsatz P1 P2 P3 P4 P5 Region Produkt Reg Zeit
Org. Linie Prod

15
Ergebnis . . . granulare, konsolidierte zentrale Daten (DWH) operative
Vorsysteme Reg Zeit Org. Linie Prod Auswerteschicht (Data Mart) Stage . Org. Linie Prod . .
 Stage. . Org. Linie. Prod. . .")
16
Synergie-Effekte: ETL
operative Vorsysteme granulare, konsolidierte zentrale Daten (DWH) Auswerteschicht (Data Mart) Stage Vorgelagerte Transformationen Einzel- Transformationen
 Auswerteschicht (Data Mart) Stage. Vorgelagerte Transformationen. Einzel- Transformationen.")
17
Synergie-Effekte: ETL + RAC
operative Vorsysteme granulare, konsolidierte zentrale Daten (DWH) Auswerteschicht (Data Mart) Stage RAC Verbund
 Auswerteschicht (Data Mart) Stage. RAC Verbund.")
18
Konsolidierung Soft- und Hardware
Server 4 CPU Server 8 CPU Server 2 CPU Datenbank OLAP / Rep. ETL Server Server 6 CPU Datenbank Amazon konnte durch den Einsatz des Merge – Kommandos und einiger weiterer ETL Funktionen in der Datenbank Ein $ teueres ETL – Tool abschaffen. As Oracle developed more extensive ETL functionality Amazon used more and more Oracle functionality for its ETL. The final functionality enabling Amazon to use Oracle instead of 3rd party ETL tools was the MERGE statement's in Oracle9i. Once Amazon upgraded to Oracle9i there was no further need for a 3rd party ETL tool. (Abinitio) 16
 16.")
19
Architektonische Vorteile RAC und ETL
Voraussetzung ETL in der Datenbank Nur dieses bringt Last auf die RAC-Knoten Verteilung der Datenbank-basierten ETL-Jobs auf unterschiedliche Knoten Laufen keine ETL-Jobs Knoten frei für andere Datenbank-Aufgaben Geringere Hardware-Anschaffungskosten Wegfall Backup-Rechner Wegfall Netzlast Direkter ETL-Zugriff auf Daten der eigenen Datenbank und über schnelle Leitungen

20
Oracle DWH Referenzarchitektur
Master Data Hub Adapter Routing UDDI Enterprise Service Bus BPEL Process Manager Work- flow Nativ BPEL Rules BI Services Kunden Produkte Stage Prüfungen Data Warehouse Data Mart Top Level Management Kenn- zahlen- systeme Rules Rules ODS Beliebig komplexe Abfragen Rules Wahlfreie Positionierung ETL. Wahlfreie Analysenzugriffe Unified Repository Mitarbeiter operative Ebene operative und dispositive Metadaten Qualitätsstandards und Servives RAC Verbund

21
I n t e g r i e r t e D a t a W a r e h o u s e
Oracle DWH Plattform Experten/ Spezial- anwendung Austauschbare Frontends und Anwendungen Komplexe multidim. Generische Verwendung Standard Ad Hoc Data Mining Analyse- Komplexität Flexible Bereitstellung von Business Intelligence Informationen Kennzahlen Abonnement Fachspez. Kennzahlen Metadaten Fachspezifische Transformationen Vorgelagerte zentrale Transformationen und generische Kennzahlen Aspekte der Skalierung Vielfalt in den Analysemethoden und Verfahren Komplexität der Analyse Robustheit der Anwendung Option für breiten Einsatz in der Fläche Schnelligkeit beim Ausrollen in die Abteilungen Kosten von Einführungsprojekten Unterhaltungskosten Beherrschung der Vielfalt des Systems Data Quality Regelbausteine / abgebildete Business Rules I n t e g r i e r t e D a t a W a r e h o u s e P l a t t f o r m

22
Verteilung der Last in einem RAC-Verbund - Tagsüber
Options: RAC Verteilung der Last in einem RAC-Verbund - Tagsüber Load-Job 1 Interaktive Analysen Standard- Reporting Interaktive Analysen CPU CPU CPU CPU Knoten 1 Knoten 2 Knoten 3 Knoten 4 Eine Datenbank Schema CRM Schema Planung Schema Stamm- daten Schema DWH Schema Data Mining

23
Verteilung der Last in einem RAC-Verbund - Nachts
Options: RAC Verteilung der Last in einem RAC-Verbund - Nachts Load-Job 1 Load-Job 2 Standard- Reporting Load-Job 3 CPU CPU CPU CPU Knoten 1 Knoten 2 Knoten 3 Knoten 4 Eine Datenbank Schema CRM Schema Planung Schema Stamm- daten Schema DWH Schema Data Mining

24
Technologien und Verfahren zum Aufbau und zur Verwaltung von Data Warehouse-Umgebungen
Verwaltung und Dokumentation Metadaten Ownerschaften Grid Control Effiziente Datenhaltung Speichertechnik ILM Hardware ASM OLAP Datenintegration schnelles Bereitstellen DB-basiertes Laden MDM ETL-Option Qualitäts- management Data Profiling Data Auditing Daten-Zugriff Security Mandanten BI-Anwendungen Standard-Berichte Interaktive Berichte Data Mining Komplexe Analysen

25
Technologien und Verfahren
Oracle EE Compression Data Guard Verwaltung und Dokumentation Metadaten Ownerschaften Grid Control B&R Bitmapped Oracle Enterprise Edition Parallel Query Flashback Effiziente Datenhaltung Speichertechnik ILM Hardware ASM OLAP Streams Datenintegration schnelles Bereitstellen DB-basiertes Laden Master Data Management ETL-Option SAP Zugriff Enterprise-ETL RMAN Data Quality Option Qualitäts- management Data Profiling Data Auditing Data Rules Diagnostic Pack OBI SE Tuning Pack RAC Daten-Zugriff Security Mandanten OBI EE Repository (OWB) Partition SAP Connect BI-Anwendungen Standard-Berichte Interaktive Berichte Data Mining Komplexe Analysen OLAP Gateways Label Security Data Mining
 Partition. SAP Connect. BI-Anwendungen Standard-Berichte Interaktive Berichte Data Mining Komplexe Analysen. OLAP. Gateways. Label Security. Data Mining.")
26
Themen Datenintegration und Modellbasiertes ETL Komponenten
Information Management und Data Warehouse Themen Datenintegration und Modellbasiertes ETL Komponenten Good morning, my name is _____________ and I’m pleased to be with you this morning. I’m responsible for ______________ within Oracle’s [Automotive] business. The Automotive industry is one of the largest market segments served by Oracle, you’ll see our customer list later in this presentation. Our Automotive customers keep over 600 Oracle employees very busy and after today’s visit I hope that you’ll see several opportunities where Oracle can help solve some of your problems Enough of that let’s get going

27
Neue Anforderungen an Datenintegration und Datenmanagement
Immer mehr Anwender benutzen Daten Herausforderungen für Datenintegration und Datenmanagement Die Anzahl der Systeme und damit der Schnittstellen steigt Die Bereitsstellungszeit der Daten wird zunehmend kürzer Beispiel: Globus hat in seinem Data Warehouse 2000 Benutzer zu gelassen Ca. 200 – 300 sind zu bestimmten Zeiten gleichzeitig angemeldet. Bestimmte Berichte werden alle 30 Minuten aktualisiert. Benutzer fragen bis 10 mal täglich bestimmte aktualisierte Berichte ab. Kampagnen werden gefahren. In welchen Filialen laufen welche Kampagnenartikel besonders gut. Datenmengen wachsen

28
Datenintegrations- und Datenmanagementaufgaben
Zusammenführen von Daten aus heterogenen Systemen Korrigieren von Daten Garantieren von Datenqualität Datenmigration von System zu System Harmonisieren von Datenbeständen Inhaltliches Angleichen Synchronisieren z. B. Abstimmung von verschiedenen Schlüsseln Zuliefern von Daten Benutzergerechtes Bereitstellen Verwalten von Datenbeständen z. B. Historisieren / Archivieren / ILM

29
„Lösungen“ der Vergangenheit
Programmierung von Hand Zerstreute Programm-Sourcen Fehler bei der Entwicklung Unnötige Doppelarbeit Schlechte oder fehlende Dokumentation Schlechte Wartbarkeit Enorme Folgekosten Unkündbare „Inselexperten“ Immer wieder „Katastrophen“ im Echtbetrieb Wie war das nur?

30
Die Geschichte der ETL-Tools geht in Richtung integrierter Werkzeuge
1992 1996 2000 2005 Datenbankbasierte ETL-Werkzeuge Separate Engine-gestützte ETL-Werkzeuge Programm- generatoren Handprogrammierung

31
Es gibt 3 Hauptgründe für den Einsatz von OWB
Performance Effizientere Warehouse Architekturen (integriert in Oracle) Preis
 Preis.")
32
Oracle Warehouse Builder ist das ETL-Tool der Wahl in Oracle-Umgebungen!
Design des kompletten Data Warehouse Systems Logisches Design und Dokumentation Physisches Oracle Datenbank Design Fast alle Datenbankobjekte von Oracle 10g 100 % SQL 100 % PL / SQL - Generierung Bereitstellung der Datenbeschaffungsroutinen Laufzeit – System zur Fehlerkontrolle Universelles Metadaten-Repository Automatisiertes ETL durch Scriptsprache Data Quality / Data Profiling Hat bereits mehr Installationen als andere Mitbewerber

34
Enterprise Service Bus
Schnittstellenkomponenten Oracle Data Warehouse In Memory nn JCA COM+ SOAP WSIF & JBI Enterprise Service Bus Routing QOS BPEL Transform Rules FlatFile Oracle (Remote) Log XML FlatFile SAP Int. DB2 OS390, UDB Sybase, Informix, SQL-Server... PL/SQL Warehouse Datenbank Ext. Table XML Port FTP Port Streams tcp CDC Access/Excel Gateway UTL_FILE MessageBroker DB-Link XML ODBC Peoplesoft Queue DB-Link Adapter XML Queue Siebel Tabellen View SQL Loader Sequenz Index Cube Webservices MView Procedure Function FlatFile XML
 Log. XML. FlatFile. SAP Int. DB2 OS390, UDB. Sybase, Informix, SQL-Server... PL/SQL. Warehouse. Datenbank. Ext. Table. XML. Port. FTP. Port. Streams. tcp. CDC. Access/Excel. Gateway. UTL_FILE. MessageBroker. DB-Link. XML. ODBC. Peoplesoft. Queue. DB-Link. Adapter. XML. Queue. Siebel. Tabellen. View. SQL Loader. Sequenz. Index. Cube. Webservices. MView. Procedure. Function. FlatFile. XML. .")
35
Graphische Entwicklung des Datenbank-basierten ETL-Verfahrens mit OWB
Errortable-Verfahren Flashback-Verfahren Datenkomprimierung Faktor 2 – 4 SQL Partition-Exchange-Load Streams Change Data Capture Transport Tablespace External Tables Downstream Capture Table Functions Advanced Queuing Multi Table INSERT MERGE

36
Vorteile durch Generieren statt Programmieren
Vermindern von Fehlern durch Handprogrammierung Tabellen- und Spaltennamen müssen nicht mehr mühsam geschrieben werden Steuerung vieler Entwicklungsschritte durch Wizards Automatische Steuerung von Ziel- und Quellschemen Automatische Validierung (z. B. Typverträglichkeiten) Debugging der Laderoutinen Laufzeitumgebung steht bereit Dokumentation In der ETL – Tool – Diskussion ist immer darüber gestritten worden, ob es günstiger ist Laderoutinen von Hand zu programmieren oder Tools einzusetzen. Die Entscheidung ist längst gefallen, Tools haben sich durchgesetzt.
 Debugging der Laderoutinen. Laufzeitumgebung steht bereit. Dokumentation. In der ETL – Tool – Diskussion ist immer darüber gestritten worden, ob es günstiger ist Laderoutinen von. Hand zu programmieren oder Tools einzusetzen. Die Entscheidung ist längst gefallen, Tools haben sich durchgesetzt.")
37
OWB live

38
Themen Datenbankbasiertes Laden Information Management und Data
Warehouse Themen Datenbankbasiertes Laden Good morning, my name is _____________ and I’m pleased to be with you this morning. I’m responsible for ______________ within Oracle’s [Automotive] business. The Automotive industry is one of the largest market segments served by Oracle, you’ll see our customer list later in this presentation. Our Automotive customers keep over 600 Oracle employees very busy and after today’s visit I hope that you’ll see several opportunities where Oracle can help solve some of your problems Enough of that let’s get going

39
Datenbank – basiertes ETL
SQL basiert, d. h. die Oracle Datenbank wird ausgenutzt Möglichkeit primär mengenbasierte Operationen durchzuführen Wesentlich höhere Performance Automatisiertes Datenbankgeregelte Parallelisieren Datenbankgestütztes Ressources - Management Unterstützung aller aktuellen Datenbank – ETL – Funktionen wie Multiple Inserts Merge (Insert/Update) Direct Path Load Table Functions Partition Exchange and Load
 Direct Path Load. Table Functions. Partition Exchange and Load.")
40
Datenbank – basiertes ETL
Vollständige Hints – Bibliothek Verwendung aller Datenbank – Funktionen, z. B. auch analytische Funktionen Im Gegensatz zu den von 3. Herstellern nachgebildeten z. T. unvollständigen Funktionen (Beispiel SQL CASE, Decode) Datennahes Entwickeln Leichtes performantes und mengenbasiertes Updaten von Sätzen Ausnutzen temporärere Strukturen Temp – Tables Cache – Tables Ausnutzen besonders schneller Tabellen – Objekte Index – Based Tables Direkter Zugriff auf Tabelleninhalte
 Datennahes Entwickeln. Leichtes performantes und mengenbasiertes Updaten von Sätzen. Ausnutzen temporärere Strukturen. Temp – Tables. Cache – Tables. Ausnutzen besonders schneller Tabellen – Objekte. Index – Based Tables. Direkter Zugriff auf Tabelleninhalte.")
41
Datenbank - basiertes ETL
Nähe zu Katalogstrukturen Alle Informationen stehen sofort zur Verfügung Komplett – Definition aller physikalischen Objekte im Data Warehouse (Tables, Index, Materialised Views, Partitioning ...)
")
42
Datenbank – basiertes ETL im Zusammenhang mit OWB
ETL - Integriertes Data Quality Data Cleansing / Data Profiling ETL – Makro – Bildung / Experts Integrierte datenbankbasierte Workflow – Umgebung Web – basiertes Auswerten von Metadaten und Laufzeitergebnissen Unterstützung der Datenbank – Near Realtime – Funktionalität wie Queues, Streams, CDC, Web Services

43
Themen Workflow-Steuerung Information Management und Data Warehouse
Good morning, my name is _____________ and I’m pleased to be with you this morning. I’m responsible for ______________ within Oracle’s [Automotive] business. The Automotive industry is one of the largest market segments served by Oracle, you’ll see our customer list later in this presentation. Our Automotive customers keep over 600 Oracle employees very busy and after today’s visit I hope that you’ll see several opportunities where Oracle can help solve some of your problems Enough of that let’s get going

44
4 – Schichten Prozessverwaltung
Column Transformation Tabellen- Mapping Teil- Prozess Gesamt- Ein 4 – stufiges Workflow – Konzept sollte möglich sein. Auf der untersten Ebene sind es die auf Column – Ebene stattfindenden Prüfungen und Bearbeitungen. Das sind letztlich Funktionsbausteine. Die nächste Ebene sind Wandlungen auf dem Level ganzer Tabellen. Transformationen auf eine zusammenhängende Gruppen von Tabellen sind als Teilprozess zusammenzufassen. Der gesamte Befüllungsprozess für ein Warehouse muss über einen Gesamtprozess abgebildet werden.

45
Metadaten gestützte Steuerungslogik für das Data Warehouse
Repository Steuertabellen Variablen Variablen Workflow / BPEL

46
Themen Data Quality und Data Profiling Information Management und Data
Warehouse Themen Data Quality und Data Profiling Good morning, my name is _____________ and I’m pleased to be with you this morning. I’m responsible for ______________ within Oracle’s [Automotive] business. The Automotive industry is one of the largest market segments served by Oracle, you’ll see our customer list later in this presentation. Our Automotive customers keep over 600 Oracle employees very busy and after today’s visit I hope that you’ll see several opportunities where Oracle can help solve some of your problems Enough of that let’s get going

47
Ohne Daten kein Business Unternehmen funktionieren nur mit Daten
Information Chain Kunde Kunden- betreuer Logistik- system Stamm- daten Marketing Buch- haltung Lager Spedition Bedarf Adresse Kredit- daten Angebot Bestand Bestell- daten KD-Daten Kredit OK Order Adresse Werbung Verkaufs- daten Rechnung Bezahlung Reklamation Mahnung Liefer- schein Im Verlauf der Geschäftsprozesse entstehen ständig Daten. Kunden bestellen beim Kundenbetreuer und teilt eine Order und Adressdaten mit. Der Kundenbetreuer fragt in der Stammdatenhaltung nach der Gültigkeit der Adressdaten und die Kreditwürdigkeit nach. Die Stammdatenverwaltung liefert einen Kundenstammdatensatz. Der Kundenbetreuer fragt in der Logistik und im Lager nach der Verfügbarkeit nach. Bestandsdaten werden geliefert. Der Kunde erhält ein Angebot. Die Order geht in den Orderprozesse an Logistik, Lager und Buchhaltung. Lieferdaten gehen an den Spediteur. Eine Rechnung geht an den Kunden ... ...und eventuell wieder zurück, weil sie falsch ist. Aus den Kundenstamm- und Bestelldaten werden Marketingdaten. Werbeangebote gehen an den Kunden. -> es entsteht eine Informationskette über alle Prozesse hinweg -> Wenn zu Beginn bei der ersten Datenerfassung bereits kleine Fehler gemacht werde, pflanzt sich dieser Fehler in der ganzen Kette fort -> es kommen weitere Fehler hinzu. -> Fehler addieren sich Am Ende sind bis zu 20 % Daten im Unternehmen infiziert. Operative Prozesse

48
Datenqualität: Verschiedene Perspektiven im Unternehmen
Finanzwesen Produktion IT-Abteilung Marketing Kundensicht Nachverfolgung von Rechnungen Stornos Abweichende Zahlungen Kostet bis zu 5% des Umsatzes Mehrarbeit Zeitverzug Schlechte Produktivität Kostet bis zu 10% des Umsatzes Mehraufwand für Datenlieferung Fehlende Daten Synchronisation manuelle Pflege Daten nicht schnell genug Kostet bis zu 30% des IT-Budgets Richtige Daten für gezielte Werbung? Wie genau kennen wir den Kunden? Zielgerichtete Kunden-Daten: bessere Kampagnen Wie spricht mich das Unternehmen an? Arbeitet das Unternehmen korrekt? Vertrauens- verlust Image- schaden Zum Aufspüren von Datenqualitätsproblemen sollte man sich an die Stelle von verschiedenen Rollen im Unternehmen versetzen. Je nach Aufgabenstellung wirkt sich die Datenqualität unterschiedlich aus. Datenqualitätsprobleme sind oft nur Indizien für schlechte Prozesse.

49
Die Auswirkungen sind oft nur mittelbar zu erkennen
Vertrauens- schwund verzögerte Projektzeiten bis zu 10% weniger Umsatz Schlechte Daten- qualität Kunden Kosten DWH / IT bis zu 50% weniger Umsatz bei Service- Unternehmen Kosten Mitarbeiter- moral sinkt aufgrund unnützer Arbeit Die Auswirkungen schlechter Datenqualität sind in der Regel nur indirekt zu spüren. Z. B. wenn IT-Projekte zu lange Dauern wenn hochbezahlte Mitarbeiter sich mit weniger qualifizierten Tätigkeiten abgeben wenn Stammkunden wegbrechen wenn sich Partner beklagen .... Partner- organisationen Unternehmens- reporting dramatisch schwindendes Vertrauen Mitarbeiter- ressourcen fehlendes Vertrauen in die Berichtsdaten Einsatz von teueren hochqalifizierten Mitarbeitern für nicht Mehrwert schaffende Tätigkeiten

50
Der Prozess zur Verbesserung der Datenqualität
2. Fehlererkennung und Korrektur (ETL mit OWB*) Datenqualitätsprüfungen Verwalten von Domains Bilden von neuen Strukturen Korrigieren von Daten 1. Data Profiling (OWB*) Erkennen von Anomalien Domains Daten- strukturen generiert Fehler- bericht Feedback Daten Prozesse 3. Dokumentation der Qualitätsquoten (Metadaten Repository des OWB*) Dokumentation über Metadaten Datenqualität messen Daten-Owner / Nutzer Zusammenfassung zu dem Prozess der Verbesserung der Datenqualität Data Profiling ist nur ein Prozessbestandteil zum Erkennen und Messen von Schwachstellen mit Hilfe der Datenanalyse Die Fehlerkorrektur erfolgt programmtechnisch z. B. mit OWB – Mappings (diese werden aus dem OWB heraus generiert 4. Gelöst werden die Ursachen schlechter Datenqualität direkt in den operativen Prozessen 3. Zur Kontrolle des Fortschritts bei der Verbesserung der Datenqualität dient die Qualitätsfortschritts-Dokumentation mit Hilfe der Metadaten. Korrektur Trends 4. Ursachenbeseitung mit der Fachabteilung Optimieren Daten produzieren Fehlerquellen beseitigen *OWB: Data Quality Option Oracle Warehouse Builder
 Datenqualitätsprüfungen. Verwalten von Domains. Bilden von neuen Strukturen. Korrigieren von Daten. 1. Data. Profiling. (OWB*) Erkennen von Anomalien. Domains. Daten- strukturen. generiert. Fehler- bericht. Feedback. Daten. Prozesse. 3. Dokumentation. der Qualitätsquoten. (Metadaten Repository. des OWB*) Dokumentation über Metadaten. Datenqualität messen. Daten-Owner / Nutzer. Zusammenfassung zu dem Prozess der Verbesserung der Datenqualität. Data Profiling ist nur ein Prozessbestandteil zum Erkennen und Messen von Schwachstellen mit Hilfe der Datenanalyse. Die Fehlerkorrektur erfolgt programmtechnisch z. B. mit OWB – Mappings (diese werden aus dem OWB heraus generiert. 4. Gelöst werden die Ursachen schlechter Datenqualität direkt in den operativen Prozessen. 3. Zur Kontrolle des Fortschritts bei der Verbesserung der Datenqualität dient die Qualitätsfortschritts-Dokumentation mit Hilfe der Metadaten. Korrektur. Trends. 4. Ursachenbeseitung. mit der Fachabteilung. Optimieren. Daten produzieren. Fehlerquellen beseitigen. *OWB: Data Quality Option Oracle Warehouse Builder.")
51
Data Profiling Methodisches Vorgehen Domainanalyse / Dependancies / Pattern / Statistiken / .... Alle (!) Daten werden betrachtet Drill Down to Original Data Ermöglicht intuitive Betrachtungen Durch Visualisierung der Ergebnisse Gleichzeitiges Anzeigen unterschiedlicher Sichten Iterativer Prozess Data Profiling liefert ein Spiegelbild zu den operativen Unternehmensprozessen Selbstredend (The use of analytical techniques about data for the purpose of developing a thorough knowledge of its content, structure and quality)
")
52
Oracle-Komponenten im Rahmen des Data Quality-Managements
Oracle Warehouse Builder ETL / Transformationen Datenkorrekturen Data Profiling Methodisches und automatisiertes Feststellen von Daten-Anomalien Data Rules Beschreibung von Geschäftsregeln auf einer logisch / fachlichen Ebene Data Audits Monitoring von Datenqualitätsregeln Match/Merge Mapping Operator Abgleich und Zusammenführen von Stammdaten

53
Einsatz und Wirkung des Data Profiling
Metadaten Repository Data Quality Reporting Bekannte Geschäfts- regeln Custom Rule neue Geschäfts- regeln Mitarbeiter Know how Data Profiling Domains / Patterns / Dependencies Verletzte Geschäfts- regeln - Stammdaten - Bewegungsdaten Data Quality Audit / Monitoring Derived Rule Referenzdaten Korrigierte Stammdaten - Bewegungsdaten Correction

54
Einsatzgebiet Datenintegration
zunehmende Verflechtung von Prozessen unternehmensweite Sicht / erhöhter Informationsbedarf mehr als 50% der Aufwände v von Integrations- und Warehouse Projekten entfallen auf Datenfehler Mit Defekten hat man sich „arrangiert“ Daten werden öffentlich System A System C System B Defekte werden sichtbar

55
Datenqualitätsmanagement und Data Profiling
Regeln Anomalien Schwachstellen Methoden / Analysen / Statistiken Daten-Korrekturen Empfehlungen geänderte Prozesse Information Chain Kunde Kunden- betreuer Logistik- system Stamm- daten Marketing Buch- haltung Lager Spedition Bedarf Adresse Kredit- daten Angebot Bestand Bestell- daten KD-Daten Kredit OK Order Adresse Werbung Verkaufs- daten Rechnung Bezahlung Reklamation Mahnung Liefer- schein Data Profiling ist ein Bestandteil oder Teilschritt im Datenqualitätsmanagement. Innerhalb der Geschäftsprozesse werden Datenbestände identifiziert und diese dann den Profiling-Analysen unterzogen. Das Ergebnis können sein: Erkannte Geschäftsregeln, die von den bestehenden Verfahren abweichen Empfehlungen für neue Verfahrensweisen Datenkorrekturen Programme zur automatisierten Korrektur von Datenfehlern Die Ergebnisse fließen zurück in die Fachabteilungen und die Geschäftsprozesse.

56
Vorteile Der Oracle-Lösung
Integriert in die Datenbank und damit sehr schnell Integriert in ein ETL-Tool und damit sehr flexibel Schnell und intuitiv erlernbar Wesentlich kostengünstiger als andere Tools Data Profiling Data Quality Rules Rules Rules ETL Oracle Warehouse Builder

57
Data Profiling mit OWB Methoden Die operativen Daten Feintuning zu
den Analyse- methoden selbstredend Proto- kollierung laufende Analysen Drill Down zu den operativen Daten

58
Analyseumgebung Oracle Datenquellen Alle Gateway- lesbare Quellen
SAP-Daten Flat Files Adress-/LDAP- Verzeichnisse LDAP / DBMS_LDAP / Table Function Gateway / ODBC / FTP non Oracle Oracle 9i / 10g DB2, SQL Server Informix, Teradata SAP Source Schema Profiling Stage SAP Integrator Oracle Source Schema External Table Transportable Module RAC

59
Unterstützung von Software-Projekten
Durch den Feldnamen vermutet man rein numerische Inhalte Übereinstimmung von Feldname „...nr“ und Feldtyp Firmenrabatt ist in der Regel ein Rechenfeld Kundennr ist ein wichtiges Feld. Es sollte stimmig sein. ? sieht gut aus !

60
Unterstützung von Software-Projekten
Die Zahl 17 kommt häufig vor, hier muss es eine „systematische“ Ursache geben ? Felder sind nicht gepflegt kritisch! da es sich um einen Schlüssel- kandidaten handelt kritisch! weil doppelte Kundennummern ? OK

61
Metadatenmanagement

62
Daten-Ownerschaft Die Rolle von Metadaten
Wem gehören welche Daten? Wer nutzt welche Daten? Wer hat an welchen Daten welches Interesse? Wer hat welche Daten wie oft benutzt? Welche Prozesse sich auf welche Daten angewiesen? Welche Prozesse sind datenabhängig von anderen Prozessen?

63
Entity Data Set / Record (Name Location) Stakeholder Data Owner Role Abteilung Mitarbeiter Cost Subject Area Org

64
Impact / Lineage - Metadatenanalyse
Zurück

65
Aufbau eines DWH

66
Starschema Mviews Analytische Funktionen Mandantenfähigkeit Partitioning Transportable Tablespace Bitmap Indizierung Table Function

67
Ergebnis . . . granulare, konsolidierte zentrale Daten (DWH) operative
Vorsysteme Reg Zeit Org. Linie Prod Auswerteschicht (Data Mart) Stage . Org. Linie Prod . .
 Stage. . Org. Linie. Prod. . .")
68
Umsetzung in technische Lösungen - Dimensionale Sicht und relationale Datenbank
Einstiegspunkte für Abfragen V1 V2 V3 V4 Maier Müller Schmid Verkäufer Engel 1 : n Verkäufe Produkttabelle Zeit P1 P2 P3 P4 Prod1 Lief1 P1 P2 P3 P4 R1 R2 R3 R4 Z1 Z2 Z3 Z4 V1 V2 V3 V4 4 Z1 Z2 Z3 Z4 6.7.99 Q3 1 : n n : 1 Prod3 Lief4 4 7.7.99 Prod5 Lief5 9 8.7.99 Prod6 Lief9 8 9.7.99 N : 1 Starschema flexibel Graphisch auch für Business-User verständlich R1 R2 R3 R4 München Berlin Hamburg Regionen Frankfurt

69
Spielarten des Starschemas
Lieferant Gelieferte Teile Bestell- kosten Fakt Zeit Produkte Zentrale Fakt- Tabelle Connect by Parent Intersection- Table Teil von Fakt Umsatz Pro Verk. Verkäufer Verkaufs- anteil Ort Heterogenious Fact Kreis Land Hierarchie Drill Down Roll up Drill Across Slice / Dice Pivot Degenerate Facts Degenerate Dimensions Conforming Dimensions Factless Facts Slow changing dimensions

70
Die Datenbank für das Warehouse fit machen (Beispiele)
Dimension Ort Orte Regionen Länder Level 1 Definitionen Attribute Level 2 Definitionen Attribute Level 3 Definitionen Attribute Analytical- Functions Query Rewrite Materialized View Zeit Star-Transformation Bitmap-Index Parallel eingesetzte Techniken Materialized Views Query Rewrite Verwendung von Dimension Tables FK_Ort FK_Zeit FK_Produkt Partitions Umsätze Parallel+ Cluster Produkt Kunde

71
Mview

72
„Warum nicht andere arbeiten lassen“
Pflege von Aggregaten im Backend anstatt in den Analysetools (Materialized Views) Automatisierte Aggregatbildung Performance-Repository Spezielle Indizierung bei geringer Kardinalität „Aggregate Aware“ Zurück
 Automatisierte Aggregatbildung. Performance-Repository. Spezielle Indizierung bei geringer Kardinalität. „Aggregate Aware Zurück.")
73
Sich selbst aktualisierende Kennzahlen- Systeme Produktgruppen Umsatz
Verkaufsgebiete Kundengruppen Gewinn Deckungsbeitrag Fertigungsmaterial Variable Kosten Fertigungslöhne Var. Gemeinkosten Marketing+Vertriebl Spezielle Fixkosten Produktion Fremdkapital- Zinsen Fixe Kosten Materialwirtschaft Unternehmensleitung Allgemeine Fixkosten Finanz+Rech.wesen Allg. Verwaltung Konzessionen, Liz. Immaterielle Verm.Gegenst. Gesch.-Firmenwert Grundst. Gebäude Maschinen, Anl. Eigen- Kapital Anlage Vermögen Sachanlagen Fuhrpark Betriebs.+Geschausst. Beteilungen Finanzanlagen Ausleihungen Roh-Hilfsstffe Vorräte Halb-Fertigfabrikate Ford. Liefer+Leistung Fremd- Kapital Umlauf Vermögen Forderungen sonst. Ford. Kasse Liquide Mittel Bank Giro

74
Beispiel: Skalierung Auswertung Architekturbasierte Anwendergruppenunterstützung mit Materialized Views . Reg Zeit Top – Management (wenige hochverdichtete Kennzahlen) Aggregations- level 1 Aggregations- level 2 . . Mview Mview Sachmitarbeiter Planung / Marketing (Verdichtete Daten) Mview Materilized Views liefern zusätzliche Flexibilität bei den Auswertungen. Auch wenn nur eine beschränkte Anzahl von Tabellen physisch vorhanden ist, können wesentlich mehr Datenbestände simuliert werden. Materialized Views sind gespeicherte Sichte bzw. die gespeicherten Ergebnisse von vorformulierten Select – Abfragen. Materialized Views können auch wieder andere Materialized Views aufrufen. In einer ersten Materialized View –Schicht definiert man Abfragen auf den untersten Hierchieleveln der Dimensionen. Eine zweite Schicht von Materialized Views bildet dann zusätzliche Abfrage – Kombinationen auf der ersten Schicht. Dadurch entsteht ein extrem flexiblen System von Abfrageoptionen für Endbenutzer. Mview Mview . . . . Mitarbeiter Operative Ebene (Detaildaten auf dem Level von operativen Transaktionen) Org. Linie Prod Aggregat Summentabelle Summentabelle (Meier) Summentabelle (Müller)
 Aggregations- level 1. Aggregations- level Mview. Mview. Sachmitarbeiter. Planung / Marketing. (Verdichtete Daten) Mview. Materilized Views liefern zusätzliche Flexibilität bei den Auswertungen. Auch wenn nur eine beschränkte Anzahl von Tabellen physisch vorhanden ist, können wesentlich mehr Datenbestände simuliert werden. Materialized Views sind gespeicherte Sichte bzw. die gespeicherten Ergebnisse von vorformulierten. Select – Abfragen. Materialized Views können auch wieder andere Materialized Views aufrufen. In einer ersten Materialized View –Schicht definiert man Abfragen auf den untersten Hierchieleveln der. Dimensionen. Eine zweite Schicht von Materialized Views bildet dann zusätzliche Abfrage – Kombinationen auf der ersten Schicht. Dadurch entsteht ein extrem flexiblen System von Abfrageoptionen für Endbenutzer. Mview. Mview Mitarbeiter. Operative Ebene. (Detaildaten auf dem. Level von operativen. Transaktionen) Org. Linie. Prod. Aggregat. Summentabelle. Summentabelle (Meier) Summentabelle (Müller)")
75
Komponenten des Summary Managements / Materialized Views
Dimensions Materialized Views Refresh Query Rewrite SQL Access Advisor

76
Hilfsmittel rund um Materialized Views
DBMS_MVIEW.EXPLAIN_VIEW DBMS_ADVISOR.TUNE_VIEW DBMS_MVIEW.EXPLAIN_REWRITE DBMS_ADVISOR DBMS_STATS

77
Anwendungsarten Exact Match Join Back Rollup & Aggregate Rollup
Data Subset Multiple Materialized View (R2)
")
78
Analytische Funktionen / Kennzahlensysteme

79
Die Top 10 Artikel Artikel- Sparte Dimension Artikel Zeit
Artikelgruppe Artikel Umsatz Top 10 Artikel Parallel eingesetzte Techniken Materialized Views Query Rewrite Verwendung von Dimension Tables Select * from (select substr(A.Artikel,1,15),sum(U.umsatz) AS Wert, RANK() OVER (ORDER BY sum(U.umsatz) DESC ) AS Rangfolge from f_umsatz U,dim_artikel A where U.artikel_ID = A.artikel_ID group by a.Artikel) where rownum < 11; Region Kunde
,sum(U.umsatz) AS Wert, RANK() OVER (ORDER BY sum(U.umsatz) DESC ) AS Rangfolge. from f_umsatz U,dim_artikel A. where U.artikel_ID = A.artikel_ID group by a.Artikel) where rownum < 11; Region. Kunde.")
80
Die Top 3 Artikel pro Artikelgruppe
Artikel- Sparte Dimension Artikel Zeit Artikelgruppe Artikel Umsatz Top 3 Artikel pro Gruppe Parallel eingesetzte Techniken Materialized Views Query Rewrite Verwendung von Dimension Tables select substr(Artikel,1,25) as Artikel, substr(Artikelgruppe,1,25) as Artikelgruppe, Wert, Rangfolge FROM (select Artikel, Artikelgruppe, sum(U.umsatz) AS Wert, RANK() OVER (partition by a.Artikelgruppe ORDER BY sum(U.umsatz) DESC ) AS Rangfolge from f_umsatz U,dim_artikel A where U.artikel_ID = A.artikel_ID group by a.Artikelgruppe,a.Artikel order by A.Artikelgruppe) where Rangfolge < 4; Region Kunde
 as Artikel, substr(Artikelgruppe,1,25) as Artikelgruppe, Wert, Rangfolge. FROM. (select Artikel, Artikelgruppe, sum(U.umsatz) AS Wert, RANK() OVER (partition by a.Artikelgruppe ORDER BY sum(U.umsatz) DESC ) AS Rangfolge. from f_umsatz U,dim_artikel A where U.artikel_ID = A.artikel_ID group by a.Artikelgruppe,a.Artikel. order by A.Artikelgruppe) where Rangfolge < 4; Region. Kunde.")
81
Über Quartale kumulierte Umsätze pro Kunde
Dimension Kunde Zeit Q2_2002 Name Q1_2002 Jahr Quartal select substr(k.kunden_Name,1,25) as kunde, z.jahr, z.quartal_des_jahr as Quartal, sum(u.umsatz) as Umsatz, sum(sum(u.umsatz)) over (Partition By k.kunden_Name ORDER BY k.kunden_Name, z.jahr,z.quartal_des_jahr ROWS UNBOUNDED PRECEDING) as Umsatz_Summe from dim_kunde K,f_Umsatz U, dim_zeit Z where k.kunde_id = u.kunde_id and to_char(Z.Datum) = to_char(u.Datum) group by K.kunden_Name,z.jahr,z.quartal_des_jahr; Umsatz Parallel eingesetzte Techniken Materialized Views Query Rewrite Verwendung von Dimension Tables Region Kunde
 as kunde, z.jahr, z.quartal_des_jahr as Quartal, sum(u.umsatz) as Umsatz, sum(sum(u.umsatz)) over (Partition By k.kunden_Name. ORDER BY k.kunden_Name, z.jahr,z.quartal_des_jahr. ROWS UNBOUNDED PRECEDING) as Umsatz_Summe. from dim_kunde K,f_Umsatz U, dim_zeit Z. where. k.kunde_id = u.kunde_id and. to_char(Z.Datum) = to_char(u.Datum) group by K.kunden_Name,z.jahr,z.quartal_des_jahr; Umsatz. Parallel eingesetzte Techniken. Materialized Views. Query Rewrite. Verwendung von Dimension Tables. Region. Kunde.")
82
¼ der Kunden tragen zu ? % des Umsatzes bei?
1 Dimension Kunde Zeit 2 Name Buckets 3 4 select sum(umsatz), anteil, (sum(umsatz)*100/Gesamt_umsatz) as Prozent from (select substr(k.kunden_Name,1,25) as kunde, sum(u.umsatz) as Umsatz, ntile(4) over (order by sum(u.umsatz)) as Anteil from dim_kunde K,f_Umsatz U where k.kunde_id = u.kunde_id group by K.kunden_Name), (select sum(u.umsatz) as Gesamt_Umsatz from f_Umsatz U) group by anteil,Gesamt_umsatz; Umsatz Parallel eingesetzte Techniken Materialized Views Query Rewrite Verwendung von Dimension Tables 1 Region Kunde 2
, anteil, (sum(umsatz)*100/Gesamt_umsatz) as Prozent from. (select substr(k.kunden_Name,1,25) as kunde, sum(u.umsatz) as Umsatz, ntile(4) over (order by sum(u.umsatz)) as Anteil. from dim_kunde K,f_Umsatz U. where. k.kunde_id = u.kunde_id. group by K.kunden_Name), (select sum(u.umsatz) as Gesamt_Umsatz. from f_Umsatz U) group by anteil,Gesamt_umsatz; Umsatz. Parallel eingesetzte Techniken. Materialized Views. Query Rewrite. Verwendung von Dimension Tables. 1. Region. Kunde. 2.")
83
Durchschnittliche Bestellquote eines Kunden über 3 Monate
Dimension Kunde Zeit M2_2002 Name M1_2002 Jahr Monat select substr(k.kunden_Name,1,25) as kunde, z.jahr as Jahr, Monat_des_jahres as Mon, sum(u.umsatz) as Umsatz, avg(sum(u.umsatz)) over (order by K.kunden_Name, z.jahr, z.Monat_des_jahres Rows 2 Preceding) as Mov_3M_AVG from dim_kunde K,f_Umsatz U, dim_zeit Z where k.kunde_id = u.kunde_id and to_char(Z.Datum) = to_char(u.Datum) and k.kunden_name = 'Bauer' group by K.kunden_Name,z.jahr,z.Monat_des_jahres order by z.jahr,z.Monat_des_jahres; Umsatz Parallel eingesetzte Techniken Materialized Views Query Rewrite Verwendung von Dimension Tables Region Kunde
 as kunde, z.jahr as Jahr, Monat_des_jahres as Mon, sum(u.umsatz) as Umsatz, avg(sum(u.umsatz)) over (order by K.kunden_Name, z.jahr, z.Monat_des_jahres Rows 2 Preceding) as Mov_3M_AVG. from dim_kunde K,f_Umsatz U, dim_zeit Z. where. k.kunde_id = u.kunde_id and. to_char(Z.Datum) = to_char(u.Datum) and. k.kunden_name = Bauer group by K.kunden_Name,z.jahr,z.Monat_des_jahres. order by z.jahr,z.Monat_des_jahres; Umsatz. Parallel eingesetzte Techniken. Materialized Views. Query Rewrite. Verwendung von Dimension Tables. Region. Kunde.")
84
Das Bundesland mit dem stärksten Umsatz für jede Artikelgruppe
Dimension Artikel Region Bundesland Artikelgruppe Artikel Ort Region Kreis select ArtGr , Land ,Umsatz from (select ARTIKELGRUPPE as ArtGr , BUNDESLAND as Land , sum(umsatz) as Umsatz, max(sum(umsatz)) over (partition by ARTIKELGRUPPE) as Max_Ums_Land from dim_region R, dim_artikel A, f_umsatz U where R.ort_ID = U.ort_ID and A.Artikel_ID = U.artikel_ID group by ARTIKELGRUPPE ,BUNDESLAND order by ARTIKELGRUPPE ,BUNDESLAND ) where Umsatz = Max_Ums_Land ; Umsatz Parallel eingesetzte Techniken Materialized Views Query Rewrite Verwendung von Dimension Tables Region
 as Umsatz, max(sum(umsatz)) over (partition by ARTIKELGRUPPE) as Max_Ums_Land. from dim_region R, dim_artikel A, f_umsatz U. where. R.ort_ID = U.ort_ID and. A.Artikel_ID = U.artikel_ID. group by ARTIKELGRUPPE ,BUNDESLAND. order by ARTIKELGRUPPE ,BUNDESLAND ) where Umsatz = Max_Ums_Land ; Umsatz. Parallel eingesetzte Techniken. Materialized Views. Query Rewrite. Verwendung von Dimension Tables. Region.")
85
Vergleiche Umsätze mit Vorjahreszeitraum
Dimension Kunde Zeit M10_2002 Name M9_2002 M8_2002 M7_2002 M6_2002 M5_2002 M4_2002 M3_2002 Jahr M2_2002 M1_2002 Monat Umsatz select substr(k.kunden_Name,1,25) as kunde, z.jahr as Jahr, Monat_des_jahres as Mon, sum(u.umsatz) as Umsatz, lag(sum(u.umsatz),12) over (order by z.jahr,z.Monat_des_jahres) as vorjahr from dim_kunde K,f_Umsatz U, dim_zeit Z where k.kunde_id = u.kunde_id and to_char(Z.Datum) = to_char(u.Datum) and k.kunden_name = 'Bauer' group by K.kunden_Name,z.jahr,z.Monat_des_jahres order by z.jahr,z.Monat_des_jahres; Parallel eingesetzte Techniken Materialized Views Query Rewrite Verwendung von Dimension Tables Region Kunde
 as kunde, z.jahr as Jahr, Monat_des_jahres as Mon, sum(u.umsatz) as Umsatz, lag(sum(u.umsatz),12) over (order by. z.jahr,z.Monat_des_jahres) as vorjahr. from dim_kunde K,f_Umsatz U, dim_zeit Z. where. k.kunde_id = u.kunde_id and. to_char(Z.Datum) = to_char(u.Datum) and. k.kunden_name = Bauer group by K.kunden_Name,z.jahr,z.Monat_des_jahres. order by z.jahr,z.Monat_des_jahres; Parallel eingesetzte Techniken. Materialized Views. Query Rewrite. Verwendung von Dimension Tables. Region. Kunde.")
86
SQL Model Clause Select Land, Artikelgruppe, Jahr, Umsatz from
Artikel, Zeit, Region Land Artikelgruppe Jahr Umsatz Hessen KFZ-Zubehoer Hessen KFZ-Zubehoer Berlin Haushaltswaren Berlin Haushaltswaren Bayern KFZ-Zubehoer Bayern KFZ-Zubehoer Jahr Artikelgruppe Bundesland Umsatz

87
SQL Model Clause Partition Dimension Measures
<prior clauses of SELECT statement> MODEL [main] [reference models] [PARTITION BY (<cols>)] DIMENSION BY (<cols>) MEASURES (<cols>) [IGNORE NAV] | [KEEP NAV] [RULES ..... [ITERATE (n) [UNTIL <condition>] ] ( <cell_assignment> = <expression> ... ) Partition Dimension Measures Land Artikelgruppe Jahr Umsatz Hessen KFZ-Zubehoer Hessen KFZ-Zubehoer Berlin Haushaltswaren Berlin Haushaltswaren Bayern KFZ-Zubehoer Bayern KFZ-Zubehoer
] DIMENSION BY (<cols>) MEASURES (<cols>) [IGNORE NAV] | [KEEP NAV] [RULES [ITERATE (n) [UNTIL <condition>] ] ( <cell_assignment> = <expression> ... ) Partition. Dimension. Measures. Land Artikelgruppe Jahr Umsatz. Hessen KFZ-Zubehoer Hessen KFZ-Zubehoer Berlin Haushaltswaren Berlin Haushaltswaren Bayern KFZ-Zubehoer Bayern KFZ-Zubehoer")
88
SQL Model Clause – Beispiel
select bundesland,artikelgruppe,jahr,umsatz, wachstum_proz from sv MODEL RETURN UPDATED ROWS PARTITION BY (bundesland ) DIMENSION BY (artikelgruppe, jahr) MEASURES (umsatz, 0 wachstum_proz) RULES ( wachstum_proz[artikelgruppe,Jahr] = 100* (umsatz[CV(artikelgruppe), cv(jahr)] - umsatz[CV(artikelgruppe), cv(jahr) -1] ) / umsatz[CV(artikelgruppe), cv(jahr) -1] ) order by bundesland,artikelgruppe, jahr;
 DIMENSION BY (artikelgruppe, jahr) MEASURES (umsatz, 0 wachstum_proz) RULES ( wachstum_proz[artikelgruppe,Jahr] = 100* (umsatz[CV(artikelgruppe), cv(jahr)] - umsatz[CV(artikelgruppe), cv(jahr) -1] ) / umsatz[CV(artikelgruppe), cv(jahr) -1] ) order by bundesland,artikelgruppe, jahr;")
89
Partitioning

90
Fallbeispiel: 4 Terabyte Warehouse einer der grössten Banken Deutschlands
13 Tabellen Monatliches Ladevolumen von mehreren 100 GB Dez 02 Aug 02 View Ergebnisrechnung von Profitcentern 4 Mill. Kunden 8000 zugel. Nutzer tägl ReportServer- Zugriffe tägl Discoverer Zugriffe tägl. Ca 800 Plain SQL Auswertungen Jul 02 Jun 02 Mai 02 View Apr 02 Nov 02 Mar 02 Sep 02 View Feb 02 Okt 02 Jan 02

91
Partitioning Hauptgründe für das Partitioning Arten des Partitioning
Managebility Abfrageperformance Verfügbarkeit Arten des Partitioning Range List Hash Composite Range-Hash Composite Range-List

92
Geschickte Speicherung: Partitioning
Range 1996 1997 1998 1999 Hash 1 1000 2000 ... Sub-2 Sub-3 Sub-4 Sub-1 Composite Range Partitioning Erhöht Verfügbarkeit Daten noch zugreifbar nach Crash Parallel DML möglich leichtere Verwaltung (Backup/Recovery) Besseres I/O Balancing Range PartitioningErhöht Verfügbarkeit Besseres I/O Balancing CREATE TABLE sales… PARTITION BY RANGE (sale_year) (PARTITION p1 VALUES LESS THAN(1995) TABLESPACE tsa, PARTITION p2 VALUES LESS THAN(1996) TABLESPACE tsb…) Hash Partitioning Verteilt Zeilen automatisch gleichmäßig auf Partitionen (Hash Algorithm) Sinnvoll bei ungleichmäßiger Verteilung von Werten in den Schlüsselfeldern Beispiel: : 50 Treffer / : 500 Treffer Hohe Verteilung der Daten, sehr gut zu tunen Leicht zu implementieren, einfache Syntax Nicht einsetzbar bei historischen Daten und “Rolling Windows” List (9i) Nord / Sued / West / Ost
 Besseres I/O Balancing Range PartitioningErhöht Verfügbarkeit. Besseres I/O Balancing. CREATE TABLE sales… PARTITION BY RANGE (sale_year) (PARTITION p1 VALUES LESS THAN(1995) TABLESPACE tsa, PARTITION p2 VALUES LESS THAN(1996) TABLESPACE tsb…) Hash Partitioning. Verteilt Zeilen automatisch gleichmäßig auf Partitionen (Hash Algorithm) Sinnvoll bei ungleichmäßiger Verteilung von Werten in den Schlüsselfeldern Beispiel: : 50 Treffer / : 500 Treffer. Hohe Verteilung der Daten, sehr gut zu tunen. Leicht zu implementieren, einfache Syntax. Nicht einsetzbar bei historischen Daten und Rolling Windows List (9i) Nord / Sued / West / Ost.")
93
Range-Partitionierung
Jahr Zeit Quartal Monat Region Umsatz Parallel eingesetzte Techniken Materialized Views Query Rewrite Verwendung von Dimension Tables FK_Ort FK_Zeit FK_Produkt Qx9999 Artikel Kunde Q12000 Nach Quartalen und Jahren partitioniert Q22000 Q32000

94
Join-wise-Partitioning
Jahr Zeit Quartal Monat Region Umsatz FK_Ort FK_Zeit FK_Produkt Kunde Parallel eingesetzte Techniken Materialized Views Query Rewrite Verwendung von Dimension Tables Partition-Join 1:1 2:2 3:3 4:4 5:5 6:6 7:7 8:8 9:9 1 2 3 4 5 6 7 8 9 Artikel 1 2 3 4 5 6 Hash- Partition 7 8 9 Hash- Partition

95
Join-wise-Sub Partitioning
(Range und Hash) Jahr Zeit Quartal Monat Region Umsatz FK_Ort Artikel FK_Zeit FK_Produkt Kunde Parallel eingesetzte Techniken Materialized Views Query Rewrite Verwendung von Dimension Tables Partition-Join 1:1 2:2 3:3 4:4 5:5 6:6 7:7 8:8 9:9 1 2 3 4 5 6 7 8 9 Q22000 1 2 3 Range- Partition nach Zeit Hash- Partition Q32000 4 5 6 Q42000 7 8 9 Hash-Partition
 Jahr. Zeit. Quartal. Monat. Region. Umsatz. FK_Ort. Artikel. FK_Zeit. FK_Produkt. Kunde. Parallel eingesetzte Techniken. Materialized Views. Query Rewrite. Verwendung von Dimension Tables. Partition-Join. 1:1. 2:2. 3:3. 4:4. 5:5. 6:6. 7:7. 8:8. 9: Q Range- Partition nach Zeit. Hash- Partition. Q Q Hash-Partition.")
96
Beispielabfragen Beispieltabellen: Ca 7 Mio Sätze:
ohne Partitionierung - mit 12 Monatspartitionen – Verteilung zufällig

97
Arten der Indizierung bei der Partitionierung
Global Partitioned Index Global Non Partitioned Index Partitionierte Tabelle Local Index Partition 1 Partition 2 Partition 3 Partition 4 Partition 5 Partition 6

98
Beispiel: Partition-pruning
Warum mehr lesen als nötig? Lineitem Einzelpositionen/Fakttable Partitions Eliminierung = Reduktion der zu bearbeitenden Datenmenge week1 week2 week3 week4 week70 select a_group, sum(rev) from lineitem where ldate between ‘04.JAN.99’ and ‘07.JAN.99’ group by a_group
 from lineitem. where ldate between ‘04.JAN.99’ and ‘07.JAN.99’ group by a_group.")
99
Beispiel: Partition-wise-joining
Joins auf Fakten mit „abermillionen“ Zeilen? Zeit Produkte ArtikelNr,Artikelgruppe Tag/Woche_im_Jahr Monat/Quartal/Jahr Lineitem Einzelpositionen/Fakttable week1 week2 week3 week4 week70 Reduktion der zu bearbeitenden Datenmenge select lineitem.a_group, sum(rev) from lineitem where Zeit.ZeitID = Lineitem.ZeitID and Zeit.Woche = 20
 from lineitem. where Zeit.ZeitID = Lineitem.ZeitID and Zeit.Woche = 20.")
100
Beispiel: Verfügbarkeit im DW
Was passiert wenn es doch mal passiert? Wie groß ist die größte Datenmenge, die sie noch recovern können? week1 week4 Transaktionsverarbeitung Recovery week2 week3 Signifikante Verbesserung der Systemverfügbarkeit Unbeschädigte Partitionen bleiben zugänglich Beschädigte Partitionen können online wiederhergestellt werden Paralleles Wiederherstellen beeinträchtigter Partitionen

101
Laden mit Hilfe von Tablespace und Partitioning

102
Partition Exchange and Load (PEL)
Temp Table Financial Production New Month Human Ress P1 P2 P3 P4 4 8 9 Z1 Z2 Z3 Z4 Time Store Supplier Month 13 Index/Constraint free Parallel Direct Path Insert (Set Based) Create Table As Select .... (CTAS) Marketing Month 12 Service Month 11 Month 10 Region Fakttable
 Create Table As Select .... (CTAS) Marketing. Month 12. Service. Month 11. Month 10. Region. Fakttable.")
103
Warehouse Datenbank Apr Mai Jun Jul Jan Feb Mrz Aug ETL Prozess Archiv
Read-Only Read-Only Read-Only Apr Read-write Mai Read-write Jun Read-write Read-write Jul Read-write Jan Feb Mrz Partition Exchange and Load Aug Neue Daten Create Table As Select ... (CTAS) ETL Prozess Betriebssystem Copy Archiv Jan Archiv Feb Archiv Mrz Archiv Apr Archiv Mai Archiv Jun Archiv Jul Archiv Aug
 ETL Prozess. Betriebssystem. Copy. Archiv. Jan. Archiv. Feb. Archiv. Mrz. Archiv. Apr. Archiv. Mai. Archiv. Jun. Archiv. Jul. Archiv. Aug.")
104
Read-write Tablespace Read-write Tablespace
Alte Daten werden „eingefroren“ Nur aktuelle Daten bleiben Update - fähig Read-only Tablespace Read-write Tablespace Read-write Tablespace Dez Jan Feb Mar Apr May Jun Jul

105
Transportable Tablespace
1 CREATE TABLE temp_jan_umsatz NOLOGGING TABLESPACE ts_temp_umsatz AS SELECT * FROM ????????? WHERE time_id BETWEEN '31-DEC-1999' AND '01-FEB-2000'; Buchhaltung Produktion Personal Lager Lieferanten Marketing Service P1 P2 P3 P4 4 8 9 Z1 Z2 Z3 Z4 Index/Constraint free Parallel Direct Path Insert Set Based 2 ALTER TABLESPACE ts_temp_umsatz READ ONLY; 3 Kopieren des Tablespace zur Zielplattform; BS-Copy Daten EXP TRANSPORT_TABLESPACE=y TABLESPACES=ts_temp_umsatz FILE=jan_umsatz.dmp Meta daten 4

106
Transportable Tablespace
Meta daten 5 IMP TRANSPORT_TABLESPACE=y DATAFILES='/db/tempjan.f' TABLESPACES=ts_temp_umsatz FILE=jan_umsatz.dmp 6 ALTER TABLESPACE ts_temp_umsatz READ WRITE; 7 ALTER TABLE umsatz ADD PARTITION umsatz_00jan VALUES LESS THAN (TO_DATE('01-feb-2000','dd-mon-yyyy')); ALTER TABLE umsatz EXCHANGE PARTITION umsatz_00jan WITH TABLE temp_umsatz_jan INCLUDING INDEXES WITH VALIDATION; Neuer Monat 121999 111999 101999 091999 Fakttable Umsatz
); ALTER TABLE umsatz EXCHANGE PARTITION umsatz_00jan. WITH TABLE temp_umsatz_jan. INCLUDING INDEXES WITH VALIDATION; Neuer Monat Fakttable Umsatz.")
107
Bitmap Indizierung

108
Bitmap-Index Ausprägungen 1 Keine Ausbildung 2 Hauptschule
Ausprägungen 1 Keine Ausbildung 2 Hauptschule 3 Realschule 4 Gymnasium 5 Studium

109
Bitmap-Join-Index Umsatz Region Länder Regionen Orte Zeit Umsätze
Berlin 1 Umsatz Parallel eingesetzte Techniken Materialized Views Query Rewrite Verwendung von Dimension Tables FK_Ort Ulm 1 FK_Zeit FK_Produkt Umsätze Produkt Kunde

110
Fallbeispiel zur Lade- und Abfrageperformance

111
Customer 1.000.000 Products 10.000 Sales 292.282.479 Times 2.557
HP Proliant DL380 G3 6 GB RAM 2 CPU 3 GHz Sales Times 2.557 Promotions 1.001

112
Allgemeines zum Verfahren
300 Mio Sätze Index Insert into TGT Select * from SRC Temp Table

113
Jährliches Wachstum 20% Besonders viele Daten im November, Dezember, dafür weniger Daten im April, Juni, August (keine gleichmäßige Verteilung über alle Monate) Initial Load Jan 2002 – Nov 2004 External Tables ca. 27 Minuten für beide Varianten
 Initial Load Jan 2002 – Nov External Tables. ca. 27 Minuten für beide Varianten.")
114
Zeit für die Indexerzeugung Initial Load
Platzverbrauch für Bitmap Gesamtindex ca. 30 MB

115
Nachladen 1 Zeitscheibe Dezember 2004 Oracle 10G
ALTER TABLE sales ADD PARTITION sales_dec_2004 VALUES LESS THAN (TO_DATE('01-jan-2005','dd-mon-yyyy')); < 1 Sec < 1 Sec CREATE TABLE sales_temp_dec_2004 AS SELECT * FROM sales WHERE ROWNUM < 1; 2 3 INSERT INTO sales_temp_dec_2004 SELECT * FROM salesxt; 2 Min 6 Sec 4 CREATE BITMAP INDEX sales_cust_id_bix_dec_2004 ON sales_temp_dec_2004 (cust_id) NOLOGGING PARALLEL; 29 Sec ALTER TABLE sales EXCHANGE PARTITION sales_dec_2004 WITH TABLE sales_temp_dec_2004 INCLUDING INDEXES WITHOUT VALIDATION; 5 < 1 Sec 6 < 1 Sec Drop Partition
); < 1 Sec. < 1 Sec. CREATE TABLE sales_temp_dec_2004 AS. SELECT * FROM sales WHERE ROWNUM < 1; INSERT INTO sales_temp_dec_2004. SELECT * FROM salesxt; 2 Min 6 Sec. 4. CREATE BITMAP INDEX sales_cust_id_bix_dec_2004. ON sales_temp_dec_2004 (cust_id) NOLOGGING PARALLEL; 29 Sec. ALTER TABLE sales EXCHANGE PARTITION sales_dec_2004 WITH TABLE sales_temp_dec_2004 INCLUDING INDEXES WITHOUT VALIDATION; 5. < 1 Sec. 6. < 1 Sec. Drop Partition.")
116
Nachladen 1 Zeitscheibe Dezember 2004 ohne 10G - Features
Drop auf alle Indexe wenige Sekunden 6 Minuten Laden neue Daten (parallel) mit External Table 2 3 Neuerzeugen des Index Platzverbrauch für Btree Gesamtindex ca MB insgesamt 800 Minuten
 mit External Table Neuerzeugen des Index. Platzverbrauch für Btree. Gesamtindex ca MB. insgesamt 800 Minuten.")
117
Löschen des alten Monats Januar 2002
Oracle 10g Traditionell ALTER TABLE SALES DROP PARTITION SALES_JAN_2002; ca. 1 Sec. DELETE FROM SALES WHERE TIME_ID < TO_DATE('01-FEB-2002','DD-MON-YYYY'); 7 Stunden 51 Minuten 28 Sekunden Rollbacksegment wird genutzt: ca 4000 MB Plattenplatz
; 7 Stunden 51 Minuten 28 Sekunden. Rollbacksegment wird genutzt: ca 4000 MB Plattenplatz.")
118
Abrageperformance Abfrage 1 Abfrage 2 SELECT p.prod_name,
SUM(s.amount_sold) FROM sales s, products p, channels ch, promotions pm WHERE s.prod_id = p.prod_id AND s.channel_id = ch.channel_id AND s.promo_id = pm.promo_id AND ch.channel_desc = 'Catalog' AND pm.promo_category = 'flyer' AND p.prod_subcategory = 'Shorts - Men' GROUP BY p.prod_name; select p.prod_name, sum(s.amount_sold) from sales s, products p, channels ch, promotions pm, times t where s.prod_id = p.prod_id and s.channel_id = ch.channel_id and s.promo_id = pm.promo_id and s.time_id = t.time_id and ch.channel_desc = 'Catalog' and pm.promo_category = 'flyer' and t.calendar_quarter_desc ='2000-Q2' and p.prod_subcategory = 'Shorts - Men' group by p.prod_name;
 FROM. sales s, products p, channels ch, promotions pm. WHERE. s.prod_id = p.prod_id AND. s.channel_id = ch.channel_id AND. s.promo_id = pm.promo_id AND. ch.channel_desc = Catalog AND. pm.promo_category = flyer AND. p.prod_subcategory = Shorts - Men GROUP BY p.prod_name; select p.prod_name, sum(s.amount_sold) from sales s, products p, channels ch, promotions pm, times t. where. s.prod_id = p.prod_id and. s.channel_id = ch.channel_id and. s.promo_id = pm.promo_id and. s.time_id = t.time_id and. ch.channel_desc = Catalog and. pm.promo_category = flyer and. t.calendar_quarter_desc = 2000-Q2 and p.prod_subcategory = Shorts - Men group by p.prod_name;")
119
Abrageperformance select count(*) from sales;
where promo_id = 714 and channel_id = 'S'; 3. select count(*) from sales time_id = to_date('20-MAY-2004','DD-MON-YYYY') and channel_id = 'S';
 from sales. time_id = to_date( 20-MAY-2004 , DD-MON-YYYY ) and channel_id = S ;")
120
Aus 5 mach 3 Verfahren einfach halten
Viele Auswertemodelle sind zu komplex für Endbenutzer (z. B. Snowflake) Komplizierte ETL-Prozesse Aufwendige Erstellung und Wartung Aus 5 mach 3 Verfahren einfach halten Quellen Stage Zusätzliche Verdichtungs- /Abfragelogik Summe SRC1 Inserts/ Updates SRC2 Summe Mart Quellen Stage Sich Selbstpflegende Materialized Views Modern Oracle 9i – Technik erlaubt den Ladeprozess eines Warehouses sehr stark zu vereinfachen. Wo früher noch 5 Schritte benötigt wurden, gelingt es heute komplette Ladeprozesse mit nur 3 Schritten abzubilden. Stage – Tabellen ersetzen wir durch den Einsatz der External Tables. Die Weiterverarbeitung beginnt beginnt bereits bei dem Lesen der Textdateien. Aggregate und Summentabellen werden zunehemend durch Materialized Views ersetzt. Multiple Inserts machen die Logik einfacher. Es können mehrere Tabellen gleichzeitig angegangen werden. SRC1 SRC2 External Tables / Multiple Inserts Merge... Mart
 Komplizierte ETL-Prozesse. Aufwendige Erstellung und Wartung. Aus 5 mach 3 Verfahren einfach halten. Quellen. Stage. Zusätzliche Verdichtungs- /Abfragelogik. Summe. SRC1. Inserts/ Updates. SRC2. Summe. Mart. Quellen. Stage. Sich Selbstpflegende Materialized Views. Modern Oracle 9i – Technik erlaubt den Ladeprozess eines Warehouses sehr stark zu vereinfachen. Wo früher noch 5 Schritte benötigt wurden, gelingt es heute komplette Ladeprozesse mit nur 3 Schritten abzubilden. Stage – Tabellen ersetzen wir durch den Einsatz der External Tables. Die Weiterverarbeitung beginnt beginnt bereits bei dem. Lesen der Textdateien. Aggregate und Summentabellen werden zunehemend durch Materialized Views ersetzt. Multiple Inserts machen die Logik einfacher. Es können mehrere Tabellen gleichzeitig angegangen werden. SRC1. SRC2. External Tables / Multiple Inserts Merge... Mart.")
121
Mandantenfähigkeit

122
Mandantenfähige Data Marts
Strukturen einmal definieren Daten unterschiedlich benutzen Data Marts müssen nicht aus Gründen der Zugriffssicherheit redundant vorgehalten werden. Unterschiedlichen Benutzer- gruppen kann innerhalb eines Data Marts unterschiedliche Sichten erteilt werden. Oft wurden Data Marts separat angelegt, um unberechtigten Datenzugriff zu verhindern. Das ist mit dem Oracle Data Warehouse nicht mehr nötig. Über das Label – Security – Verfahren kann ein und dieselbe Tabelle für verschiedene Benutzergruppen bereitgestellt werde, ohne dass ein Benutzer die für ihn nicht bestimmten Daten eines anderen Benutzers in derselben Tabelle lesen kann. Bereitstellung 1 Data Mart

123
Mandantenabhänginge Zugriffssteuerung
Daten Anwender Kunde / Umsatz Konzern Gesamt Periode n-1 ... Periode n Anwendung 1 Zugriffe ... I1 In I1 In ... I1 ... I9 In Zurück

124
Options: - Label-Security - Partition
Mandantenfähige Data Marts Anwendungsbeispiel: Label-Security / Partitioning Eine Kenn- zahlentabelle! Reg Zeit Org. Linie Prod Reg Zeit Mandant 1 (Abteilung A) Mandant1 Reg Zeit Org. Linie Prod Materilized Views liefern zusätzliche Flexibilität bei den Auswertungen. Auch wenn nur eine beschränkte Anzahl von Tabellen physisch vorhanden ist, können wesentlich mehr Datenbestände simuliert werden. Materialized Views sind gespeicherte Sichte bzw. die gespeicherten Ergebnisse von vorformulierten Select – Abfragen. Materialized Views können auch wieder andere Materialized Views aufrufen. In einer ersten Materialized View –Schicht definiert man Abfragen auf den untersten Hierchieleveln der Dimensionen. Eine zweite Schicht von Materialized Views bildet dann zusätzliche Abfrage – Kombinationen auf der ersten Schicht. Dadurch entsteht ein extrem flexiblen System von Abfrageoptionen für Endbenutzer. Mandant 2 (Abteilung B) Mandant 2 Mandant 3 Org. Linie Prod Reg Zeit Org. Linie Prod Mandant 3 (Abteilung C) Physische getrennt gespeichert (als Partition)
 Mandant1. Reg. Zeit. Org. Linie. Prod. Materilized Views liefern zusätzliche Flexibilität bei den Auswertungen. Auch wenn nur eine beschränkte Anzahl von Tabellen physisch vorhanden ist, können wesentlich mehr Datenbestände simuliert werden. Materialized Views sind gespeicherte Sichte bzw. die gespeicherten Ergebnisse von vorformulierten. Select – Abfragen. Materialized Views können auch wieder andere Materialized Views aufrufen. In einer ersten Materialized View –Schicht definiert man Abfragen auf den untersten Hierchieleveln der. Dimensionen. Eine zweite Schicht von Materialized Views bildet dann zusätzliche Abfrage – Kombinationen auf der ersten Schicht. Dadurch entsteht ein extrem flexiblen System von Abfrageoptionen für Endbenutzer. Mandant 2. (Abteilung B) Mandant 2. Mandant 3. Org. Linie. Prod. Reg. Zeit. Org. Linie. Prod. Mandant 3. (Abteilung C) Physische getrennt. gespeichert (als Partition)")
125
Information Lifecycle Management

126
Information Lifecycle Management (ILM)
")
127
Information Lifecycle Management (ILM) mit Oracle ASM
Aktiv Weniger Aktiv Historisch Archiv Dieser Monat Dieses Jahr Vorjahre Disk Gruppe L Disk Gruppe H Disk Gruppe P High End Storage $$$ Midrange Storage $$ Current Month Last 11 months Year and and 2000 Years Historisches Storage Low End Storage $ !

128
ILM Siehe dazu auch online:

129
ILM

130
Checkliste – Effizienter Betrieb DWH
Oracle Data Warehouse Mit den Anforderungen wachsen Verfahren und Techniken zum Aufbau und Verwalten von Data Warehouse Umgebungen Checkliste – Effizienter Betrieb DWH Alfred Schlaucher BU Database

131
Themen Sammlung von Effizienz steigernden Punkten im Data Warehouse
Information Management und Data Warehouse Themen Sammlung von Effizienz steigernden Punkten im Data Warehouse Good morning, my name is _____________ and I’m pleased to be with you this morning. I’m responsible for ______________ within Oracle’s [Automotive] business. The Automotive industry is one of the largest market segments served by Oracle, you’ll see our customer list later in this presentation. Our Automotive customers keep over 600 Oracle employees very busy and after today’s visit I hope that you’ll see several opportunities where Oracle can help solve some of your problems Enough of that let’s get going

132
Drei Bereiche in denen effizienter gearbeitet werden kann
Hardware Projekte Tools

133
Hardware Vor einer Hardware-Aufrüstung zunächst alle Software-gestützten Verfahren ausnutzen Investitionen hier veralten nicht Hardware bereits nach 1 Jahr 50% weniger wert Software-Verfahren Partitioning / Bitmapped-I. Mat. Views / Star Query Die Wahl der Platten an den tatsächlichen Bedürfnissen ausrichten Keine teueren Platten für weniger wichtige Daten ILM-Verfahren nutzen / Ownerschaften feststellen ASM Komprimierung nutzen -> weniger Plattenplatz Cluster-Technik statt Monoliten-Systeme

134
Effiziente Projektarbeit
Verwendung von Data Profiling-Tools schnelleres Auffinden von Schwachstellen Iterative Vorgehensweise Nacheinander-Realisieren von Data Marts bei gleichzeitiger Pflege von zentralen, synchronisierenden Strukturen Ersetzen handgeschriebener Lade-Routinen durch Modelle und generierten Code

135
Effiziente Architektur und Verfahren (1/3)
Mehr-Schichten-Architektur Trennung von Vorsystemen und Data Marts durch eine zentrale, synchronisierende (DWH-)Schicht Möglichst große Nähe zwischen DWH und operativen Vorsystemen Minimiert Ladeaufwand bei kürzeren Ladezyklen Keine 1:1 Kopien zwischen Vorsystemen und DWH (Stage) nach Möglichkeit bereits mit dem ersten Zugriff transformieren und filtern Keine Aggregat-Tabellen verwenden stattdessen sich selbst-aktualisierende Materialized Views -> spart ETL-Schritte
Schicht. Möglichst große Nähe zwischen DWH und operativen Vorsystemen. Minimiert Ladeaufwand bei kürzeren Ladezyklen. Keine 1:1 Kopien zwischen Vorsystemen und DWH (Stage) nach Möglichkeit bereits mit dem ersten Zugriff transformieren und filtern. Keine Aggregat-Tabellen verwenden. stattdessen sich selbst-aktualisierende Materialized Views -> spart ETL-Schritte.")
136
Effiziente Architektur und Verfahren (2/3)
ETL-Verfahren ganzheitlich sehen zwischen zentralen und nachgelagerten ETL-Schritten unterscheiden Keine separaten ETL-Server Datenbank-interne Lademechanismen nutzen, weil schneller und billiger Bedingtes Mehrfachschreiben in unterschiedliche Ziele bei nur einmaligem Extrakt aus Quell-Strukturen Automatisierte Insert/Update-Steuerung Automatisierte Regelprüfung und Protokollierung durch den Kern der Datenbank Verschieben kompletter Datenbereiche mit gleichen Merkmalen (sog. Partitions) Flash-Back-Verfahren zum Zurückrollen kompletter Ladeläufe Datentransport auf Datenbank-Block-Ebene Datenbank-gesteuertes Wiederholen von Ladeläufen ohne Entwicklungsaufwand (keine Unterscheidung von Initial- und Delta-Load)
 Flash-Back-Verfahren zum Zurückrollen kompletter Ladeläufe. Datentransport auf Datenbank-Block-Ebene. Datenbank-gesteuertes Wiederholen von Ladeläufen ohne Entwicklungsaufwand (keine Unterscheidung von Initial- und Delta-Load)")
137
Effiziente Architektur und Verfahren (3/3)
Sicherheitsanforderungen Tabellen-intern lösen nicht durch kopieren von Tabellen z. B. Label Security + Partitioning Zentrale Kennzahlen im Kern-DWH berechnen und nicht erst in den BI-Tools BI-Tools muss die Arbeit so leicht wie möglich gemacht werden Metadatendokumentation zu allen Objekten und Prozessen im DWH pflegen universelle Repositories verwenden

138
Tools Vor einer Tool-Auswahl auf die tatsächlichen Bedürfnisse achten
Gesamtsystem betrachten Vereinheitlichung von Tools Vermeiden von Tools-Inseln Administrationsaufwand bei isolierten Systemen ist oft sehr hoch

139
Oracle Warehouse Technologie Single-Engine-Based-Data-Warehouse

142
Information Management und Data Warehouse Themen Entwicklung multidimensionaler Modelle in der relationalen Datenbank Good morning, my name is _____________ and I’m pleased to be with you this morning. I’m responsible for ______________ within Oracle’s [Automotive] business. The Automotive industry is one of the largest market segments served by Oracle, you’ll see our customer list later in this presentation. Our Automotive customers keep over 600 Oracle employees very busy and after today’s visit I hope that you’ll see several opportunities where Oracle can help solve some of your problems Enough of that let’s get going

143
Umsetzung in technische Lösungen Dimensionale Sicht
Tage Produkte Welche Produkte werden an welchen Tagen wie oft verkauft? Spreadsheet (z. B. Excel) P1 P2 P3 T1 T2 T3 T4 T5 4 6 8 9 P1 P2 P3 T1 T2 T3 T4 T5 4 6 8 9 Produkte Welche Produkte werden an welchen Tagen in welcher Stadt wie oft verkauft? München Hamburg Berlin Mehrere Sichten mit mit Spreadsheets (z. B. Excel)
 P1. P2. P3. T1 T2 T3 T4 T P1. P2. P3. T1 T2 T3 T4 T Produkte. Welche Produkte werden an welchen Tagen in welcher Stadt wie oft verkauft München. Hamburg. Berlin. Mehrere Sichten mit mit Spreadsheets (z. B. Excel)")
144
Umsetzung in technische Lösungen Dimensionale Sicht
Komplexere Sichten mit mit Spreadsheets (z. B. Excel) stoßen an Grenzen P1 P2 P3 T1 T2 T3 T4 T5 4 6 8 9 Produkte München Hamburg Berlin Welche Verkäufer verkauften welche Produkte an welchen Tagen in welcher Stadt wie oft Meier P1 P2 P3 T1 T2 T3 T4 T5 4 6 8 9 Produkte München Hamburg Berlin Müller
 stoßen an Grenzen. P1. P2. P3. T1 T2 T3 T4 T Produkte. München. Hamburg. Berlin. Welche Verkäufer verkauften welche. Produkte an welchen Tagen in welcher Stadt wie oft. Meier. P1. P2. P3. T1 T2 T3 T4 T Produkte. München. Hamburg. Berlin. Müller.")
145
Umsetzung in technische Lösungen Dimensionale Sicht
Produkte P4 P3 P2 P1 T1 T2 T3 T4 T5 R1 R2 R3 R4 Zeit Region 10 Dimensionen umspannen einen Datenraum Angabe von x,y,z Koordinaten ergeben eindeutig die jeweiligen Werte. Die Achsen sind Einstiegspunkte für den Business-User Verkäufer Mathematisch lassen sich beliebig viele Dimensionen beschreiben f(x,y,z,w...) V1 V2 V3 V4 V5 8
 V1 V2 V3 V4 V5. 8.")
146
Umsetzung in technische Lösungen - Dimensionale Sicht und relationale Datenbank
Produkttabelle Zweidimensionale Darstellung P1 P2 P3 P4 4 6 8 9 Produkttabelle Verkäufe Auslagern der Werte P1 P2 P3 P4 Prod1 Lief1 P1 P2 P3 P4 4 1 : n Prod3 Lief4 4 Prod5 Lief5 9 Prod6 Lief9 8 Produkttabelle Verkäufe Zeit P1 P2 P3 P4 Prod1 Lief1 P1 P2 P3 P4 Z1 Z2 Z3 Z4 4 Z1 Z2 Z3 Z4 6.7.99 Q3 1 : n n : 1 Prod3 Lief4 4 7.7.99 Prod5 Lief5 9 8.7.99 Prod6 Lief9 8 9.7.99

147
Umsetzung in technische Lösungen - Dimensionale Sicht und relationale Datenbank
Einstiegspunkte für Abfragen V1 V2 V3 V4 Maier Müller Schmid Verkäufer Engel 1 : n Verkäufe Produkttabelle Zeit P1 P2 P3 P4 Prod1 Lief1 P1 P2 P3 P4 R1 R2 R3 R4 Z1 Z2 Z3 Z4 V1 V2 V3 V4 4 Z1 Z2 Z3 Z4 6.7.99 Q3 1 : n n : 1 Prod3 Lief4 4 7.7.99 Prod5 Lief5 9 8.7.99 Prod6 Lief9 8 9.7.99 N : 1 Starschema flexibel Graphisch auch für Business-User verständlich R1 R2 R3 R4 München Berlin Hamburg Regionen Frankfurt

148
Quellmodell

149
Struktur einer Dimension
Dim_Artikel Artikelsparte_Langname Levelschlüssel Artikelsparte Sparte Parent Artikelgruppe_Langtext Levelschlüssel Artikelgruppe Parent Artikel_Langtext Artikel Levelschlüssel Artikel_Schluessel Fakten

150
Themen RAC Information Management und Data Warehouse
Good morning, my name is _____________ and I’m pleased to be with you this morning. I’m responsible for ______________ within Oracle’s [Automotive] business. The Automotive industry is one of the largest market segments served by Oracle, you’ll see our customer list later in this presentation. Our Automotive customers keep over 600 Oracle employees very busy and after today’s visit I hope that you’ll see several opportunities where Oracle can help solve some of your problems Enough of that let’s get going

151
Herausforderung: “Insellösungen”
Limitierte Skalierbarkeit, keine Verteilung von Ressourcen Konfiguration für die Höchstlast und maximale Kapazität Single Point of Failure Schwierige Anpassung an neue Business Anforderungen 58% CPU 23 % CPU 100% CPU 3500 IO/Sec, 350 IO/Sec, 1000 IO/Sec GRID nicht nur CPUs sondern auch Plattenplatz The ad hoc infrastructure built up by IT over the years has created islands of computation. Each enterprise application has its own dedicated server and storage. As application demands fluctuate over time, one server can be at maximum usage while another server is sitting idle. To combat this, customers purchase extra server and storage capacity to meet peak demand. The HW is sized for the peak load of a particular application, which usually means one applications HW may be minimally used while another applications HW is maxed out. In fact, Giga Research says that the industry average for server utilization is about 30%. So that mean a lot of wasted capacity. And it’s not just the hardware. Software and labor cost more since they also must be configured for peak loads. Hardware (21%), software (24%) and system administrator/DBA labor (40%) consume 85% of the typical IT budget. And there is no inherent scalability here. That’s b/c with a large SMP box, when companies reach the capacity of their server, they need to purchase an entirely new larger SMP box to run their application. And then from an availability standpoint, running apps on an SMP box, means a single point of failure (as we can see from the supply chain example here), unless companies have a backup hardware in place. So, uptime or availability is often far less than optimal is these distributed environments. Security also suffers because every system must maintain its own secure infrastructure. The individual islands inevitably result in multiple passwords, inconsistent security policies and varying levels of security management expertise across the systems. 70% 30% Order Entry 95% Kapazität CRM Kapazität Kapazität DWH
, software (24%) and system administrator/DBA labor (40%) consume 85% of the typical IT budget. And there is no inherent scalability here. That’s b/c with a large SMP box, when companies reach the capacity of their server, they need to purchase an entirely new larger SMP box to run their application. And then from an availability standpoint, running apps on an SMP box, means a single point of failure (as we can see from the supply chain example here), unless companies have a backup hardware in place. So, uptime or availability is often far less than optimal is these distributed environments. Security also suffers because every system must maintain its own secure infrastructure. The individual islands inevitably result in multiple passwords, inconsistent security policies and varying levels of security management expertise across the systems. 70% 30% Order Entry. 95% Kapazität. CRM. Kapazität. Kapazität. DWH.")
152
Grid Computing mit Oracle 10g
Dynamisches Load Balancing Optimale Resourcen Auslastung Reduzierter HW Bedarf Weniger Oracle Lizenzen ! Kostengünstige Maschinen In der Summe billiger Mehr Ausfallsicherheit Leichtere Skalierung 100 % DWH CRM 60 % OE CPU Auslastung des GRID 65 % Kapazität

153
Themen SQL Advisor Information Management und Data Warehouse
Good morning, my name is _____________ and I’m pleased to be with you this morning. I’m responsible for ______________ within Oracle’s [Automotive] business. The Automotive industry is one of the largest market segments served by Oracle, you’ll see our customer list later in this presentation. Our Automotive customers keep over 600 Oracle employees very busy and after today’s visit I hope that you’ll see several opportunities where Oracle can help solve some of your problems Enough of that let’s get going

158
Themen Automatisches Error Logging Information Management und Data
Warehouse Themen Automatisches Error Logging Good morning, my name is _____________ and I’m pleased to be with you this morning. I’m responsible for ______________ within Oracle’s [Automotive] business. The Automotive industry is one of the largest market segments served by Oracle, you’ll see our customer list later in this presentation. Our Automotive customers keep over 600 Oracle employees very busy and after today’s visit I hope that you’ll see several opportunities where Oracle can help solve some of your problems Enough of that let’s get going

159
Fehlertabelle definieren
Massen-DML (Set-Based) Ohne Abbruch Fehlerhafte Eingabesätze werden separat protokolliert (analog SQL Loader und External Table) DBMS_ERRLOG.CREATE_ERROR_LOG ( dml_table_name IN VARCHAR2, err_log_table_name IN VARCHAR2 := NULL, err_log_table_owner IN VARCHAR2 := NULL, err_log_table_space IN VARCHAR2 := NULL, skip_unsupported IN BOOLEAN := FALSE);
 Ohne Abbruch. Fehlerhafte Eingabesätze werden separat protokolliert (analog SQL Loader und External Table) DBMS_ERRLOG.CREATE_ERROR_LOG ( dml_table_name IN VARCHAR2, err_log_table_name IN VARCHAR2 := NULL, err_log_table_owner IN VARCHAR2 := NULL, err_log_table_space IN VARCHAR2 := NULL, skip_unsupported IN BOOLEAN := FALSE);")
160
1 2 3 4 5 SQL> desc T3 Name Type
F NUMBER F NUMBER exec DBMS_ERRLOG.CREATE_ERROR_LOG ('T3') 3 SQL> desc ERR$_T3; Name Type ORA_ERR_NUMBER$ NUMBER ORA_ERR_MESG$ VARCHAR2(2000) ORA_ERR_ROWID$ ROWID ORA_ERR_OPTYP$ VARCHAR2(2) ORA_ERR_TAG$ VARCHAR2(2000) F VARCHAR2(4000) F VARCHAR2(4000) 4 insert into t3 values(1,2) LOG ERRORS INTO err$_T3 1* select substr(ora_err_number$,1,10) Nr,substr(ora_err_mesg$,1,50) Err from ERR$_T3 SQL> / NR ERR ORA-00001: unique constraint (DWH4.IDX_T3) violate 5
 3. SQL> desc ERR$_T3; Name Type ORA_ERR_NUMBER$ NUMBER. ORA_ERR_MESG$ VARCHAR2(2000) ORA_ERR_ROWID$ ROWID. ORA_ERR_OPTYP$ VARCHAR2(2) ORA_ERR_TAG$ VARCHAR2(2000) F1 VARCHAR2(4000) F2 VARCHAR2(4000) 4. insert into t3 values(1,2) LOG ERRORS INTO err$_T3. 1* select substr(ora_err_number$,1,10) Nr,substr(ora_err_mesg$,1,50) Err. from ERR$_T3. SQL> / NR ERR ORA-00001: unique constraint (DWH4.IDX_T3) violate. 5.")
161
Themen Tabellen-Komprimierung Information Management und Data
Warehouse Themen Tabellen-Komprimierung Good morning, my name is _____________ and I’m pleased to be with you this morning. I’m responsible for ______________ within Oracle’s [Automotive] business. The Automotive industry is one of the largest market segments served by Oracle, you’ll see our customer list later in this presentation. Our Automotive customers keep over 600 Oracle employees very busy and after today’s visit I hope that you’ll see several opportunities where Oracle can help solve some of your problems Enough of that let’s get going

162
Table Compression: Performance Impact
Example: TPC-H benchmark NOTE: This is NOT an official TPC-H result Based on 300 GB HP (Compaq) configuration: Composite metric w/o compression: 5976 Composite metric with compression: 5957 Compression had only a .3% impact on overall performance Performance of individual queries varied by +/- 15%
 configuration: Composite metric w/o compression: Composite metric with compression: Compression had only a .3% impact on overall performance. Performance of individual queries varied by +/- 15%")
163
Themen Real Application Cluster (RAC) Automatic Storage Manager (ASM)
Information Management und Data Warehouse Themen Real Application Cluster (RAC) Automatic Storage Manager (ASM) Good morning, my name is _____________ and I’m pleased to be with you this morning. I’m responsible for ______________ within Oracle’s [Automotive] business. The Automotive industry is one of the largest market segments served by Oracle, you’ll see our customer list later in this presentation. Our Automotive customers keep over 600 Oracle employees very busy and after today’s visit I hope that you’ll see several opportunities where Oracle can help solve some of your problems Enough of that let’s get going
 Automatic Storage Manager (ASM) Good morning, my name is _____________ and I’m pleased to be with you this morning. I’m responsible for ______________ within Oracle’s [Automotive] business. The Automotive industry is one of the largest market segments served by Oracle, you’ll see our customer list later in this presentation. Our Automotive customers keep over 600 Oracle employees very busy and after today’s visit I hope that you’ll see several opportunities where Oracle can help solve some of your problems. Enough of that let’s get going.")
164
Herausforderung: “Insellösungen”
Limitierte Skalierbarkeit, keine Verteilung von Ressourcen Konfiguration für die Höchstlast und maximale Kapazität Single Point of Failure Schwierige Anpassung an neue Business Anforderungen 58% CPU 23 % CPU 100% CPU 3500 IO/Sec, 350 IO/Sec, 1000 IO/Sec GRID nicht nur CPUs sondern auch Plattenplatz The ad hoc infrastructure built up by IT over the years has created islands of computation. Each enterprise application has its own dedicated server and storage. As application demands fluctuate over time, one server can be at maximum usage while another server is sitting idle. To combat this, customers purchase extra server and storage capacity to meet peak demand. The HW is sized for the peak load of a particular application, which usually means one applications HW may be minimally used while another applications HW is maxed out. In fact, Giga Research says that the industry average for server utilization is about 30%. So that mean a lot of wasted capacity. And it’s not just the hardware. Software and labor cost more since they also must be configured for peak loads. Hardware (21%), software (24%) and system administrator/DBA labor (40%) consume 85% of the typical IT budget. And there is no inherent scalability here. That’s b/c with a large SMP box, when companies reach the capacity of their server, they need to purchase an entirely new larger SMP box to run their application. And then from an availability standpoint, running apps on an SMP box, means a single point of failure (as we can see from the supply chain example here), unless companies have a backup hardware in place. So, uptime or availability is often far less than optimal is these distributed environments. Security also suffers because every system must maintain its own secure infrastructure. The individual islands inevitably result in multiple passwords, inconsistent security policies and varying levels of security management expertise across the systems. 70% 30% Order Entry 95% Kapazität CRM Kapazität Kapazität DWH
, software (24%) and system administrator/DBA labor (40%) consume 85% of the typical IT budget. And there is no inherent scalability here. That’s b/c with a large SMP box, when companies reach the capacity of their server, they need to purchase an entirely new larger SMP box to run their application. And then from an availability standpoint, running apps on an SMP box, means a single point of failure (as we can see from the supply chain example here), unless companies have a backup hardware in place. So, uptime or availability is often far less than optimal is these distributed environments. Security also suffers because every system must maintain its own secure infrastructure. The individual islands inevitably result in multiple passwords, inconsistent security policies and varying levels of security management expertise across the systems. 70% 30% Order Entry. 95% Kapazität. CRM. Kapazität. Kapazität. DWH.")
165
Grid Computing mit Oracle 10g
Dynamisches Load Balancing Optimale Resourcen Auslastung Reduzierter HW Bedarf Weniger Oracle Lizenzen ! Kostengünstige Maschinen In der Summe billiger Mehr Ausfallsicherheit Leichtere Skalierung 100 % DWH CRM 60 % OE CPU Auslastung des GRID 65 % Kapazität

166
Konsolidierung Soft- und Hardware
Server 8 CPU Server 4 CPU Datenbank ETL Server Serv 2 CPU Server 6 CPU Datenbank Amazon konnte durch den Einsatz des Merge – Kommandos und einiger weiterer ETL Funktionen in der Datenbank Ein $ teueres ETL – Tool abschaffen. As Oracle developed more extensive ETL functionality Amazon used more and more Oracle functionality for its ETL. The final functionality enabling Amazon to use Oracle instead of 3rd party ETL tools was the MERGE statement's in Oracle9i. Once Amazon upgraded to Oracle9i there was no further need for a 3rd party ETL tool. (Abinitio) 16
 16.")
167
Verteilung der Last in einem RAC-Verbund - Tagsüber
Options: RAC Verteilung der Last in einem RAC-Verbund - Tagsüber Load-Job 1 Interaktive Analysen Standard- Reporting Interaktive Analysen CPU CPU CPU CPU Knoten 1 Knoten 2 Knoten 3 Knoten 4 Eine Datenbank Schema CRM Schema Planung Schema Stamm- daten Schema DWH Schema Data Mining

168
Verteilung der Last in einem RAC-Verbund - Nachts
Options: RAC Verteilung der Last in einem RAC-Verbund - Nachts Load-Job 1 Load-Job 2 Standard- Reporting Load-Job 3 CPU CPU CPU CPU Knoten 1 Knoten 2 Knoten 3 Knoten 4 Eine Datenbank Schema CRM Schema Planung Schema Stamm- daten Schema DWH Schema Data Mining

169
RAC senkt die Hardware-Kosten im Data Warehouse massiv!
Options: RAC RAC senkt die Hardware-Kosten im Data Warehouse massiv! Geringere Anschaffungskosten weil kleine Maschine im Vergleich zu den großen Monoliten Wegfall Backup-Maschine die RAC-Knoten sichern sich gegenseitig Minimierte Anforderung an Rechenkapazität weil ETL- und Abfragelasten flexibler verteilt werden können „Extrem“-Referenz: Amazon Beispiel in Deutschland: Quelle

170
Dispositive Anwendungen gemeinsam verwalten
ETL Data Mart Planung Neutrales Data Warehouse Mining Rechner DW Anwendungen 1 ETL, Planung Rechner DW Anwendungen 2 (DWH, BI, Mining) Cache Fusion Eine Datenbank SAN Storage Instanz 1 Instanz 2 Schema CRM Schema Planung Schema Stamm- daten Schema DWH Schema Data Mining
 Cache Fusion. Eine Datenbank. SAN Storage. Instanz 1. Instanz 2. Schema. CRM. Schema Planung. Schema Stamm- daten. Schema DWH. Schema Data. Mining.")
171
Automatic Storage Management (ASM)
DWH A DWH B Automatic Storage Management Datenbank Management Dateisystemmanagement Volumemanagement SAN SAN Management Minimierung von Komplexität und Kosten nicht verschiedene Tools kein teueres Veritas Storage Management

172
ORACLE ASM Nutzen / Vorteile durch ORACLE ASM:
Vereinfachtes Storagemanagement (weniger administrative Schritte) Kein Volumemanager notwendig manuelles IO-Tuning entfällt höhere Performance (ca. 15 %) durch „SAME“ und „Redistribute“ weniger „Verschnitt“ durch freie Bereiche Ein Storage für alle Datenbank-Objekte (DataFiles,ArchiveLogs …) Spiegelung der Datenbereiche auf bis zu 3 Ziele automatische „Reparatur“ durch Rebalance (via redundantem Storage) verringerte Downtimes (geplant und ungeplant)
 Kein Volumemanager notwendig. manuelles IO-Tuning entfällt. höhere Performance (ca. 15 %) durch „SAME und „Redistribute weniger „Verschnitt durch freie Bereiche. Ein Storage für alle Datenbank-Objekte (DataFiles,ArchiveLogs …) Spiegelung der Datenbereiche auf bis zu 3 Ziele. automatische „Reparatur durch Rebalance (via redundantem Storage) verringerte Downtimes (geplant und ungeplant)")
173
GRID nicht nur CPUs sondern auch Plattenplatz
ASM Verwendung Amazon / Verwendung von billigen Plattensystemen Clusterfähigen Volume-Manager ist nötig (ansonsten teuer mit Veritas) Ermöglicht hohe IO-Leistung 8 GB Durchsatz
 Ermöglicht hohe IO-Leistung. 8 GB Durchsatz.")
Ähnliche Präsentationen



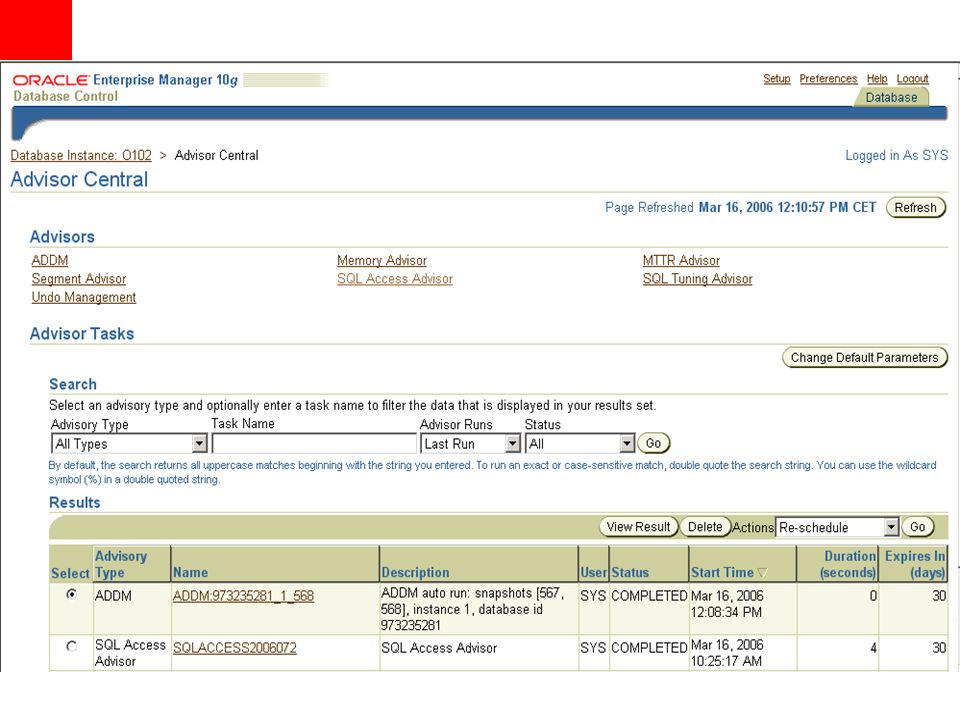
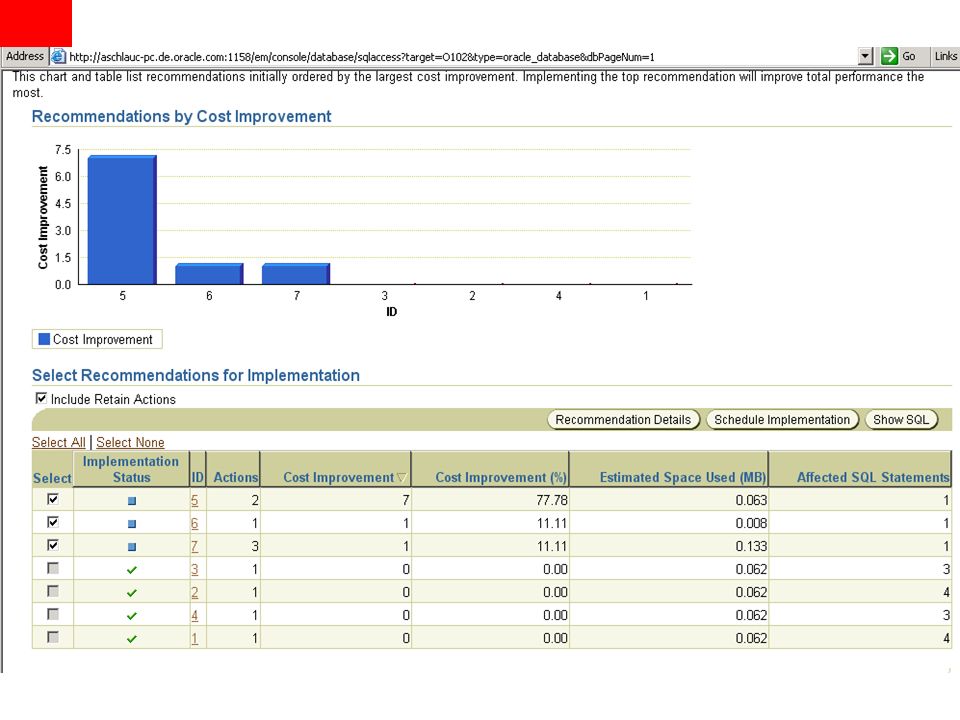

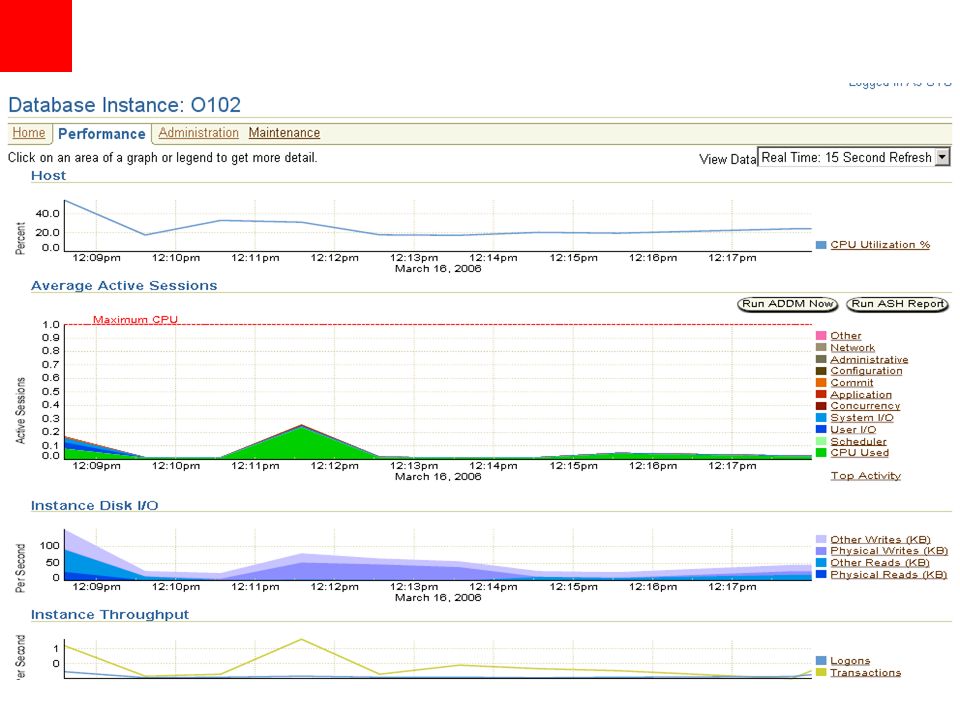











![IS: Datenbanken, © Till Hänisch 2000 CREATE TABLE Syntax: CREATE TABLE name ( coldef [, coldef] [, tableconstraints] ) coldef := name type [länge], [[NOT]NULL],](/1/649894/big_thumb.jpg "IS: Datenbanken, © Till Hänisch 2000 CREATE TABLE Syntax: CREATE TABLE name ( coldef [, coldef] [, tableconstraints] ) coldef := name type [länge], [[NOT]NULL],>")







