Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Kapitel 7: Ausgewählte Algorithmen 7.1 Externes Suchen
7.2 Externes Sortieren 7.3 Teilstringsuche 7.4 Algorithmen der Computergraphik Nachtrag: Eine Webseite mit Animation zu AVL-Bäumen: Eine Webseite mit Animation zu Heapsort: (Diese Seite ist Teil eines Kurses, der noch weitere Animationen enthält.)
")
2
7.2 Externes Sortieren Problem: Sortieren großer Datenmengen, wie beim Externen Suchen gespeichert in Blöcken (Seiten). Effizienz: Zahl der Seitenzugriffe klein halten! Strategie: Sortieralgorithmus, der Daten sequentiell verarbeitet (kein häufiges Wechseln der Seiten): MergeSort!
: MergeSort!")
3
Problemstellung Beginn: n Datensätze in einem File g1,
unterteilt in Seiten der Größe b: Seite 1: s1,…,sb Seite 2: sb+1,…s2b … Seite k: s(k-1)b+1 ,…,sn ( k = [n/b]+ ) Bei sequentieller Verarbeitung: nur k Seitenzugriffe statt n.
b+1 ,…,sn. ( k = [n/b]+ ) Bei sequentieller Verarbeitung: nur k Seitenzugriffe statt n.")
4
Varianten von MergeSort für Externes Sortieren
MergeSort: Divide-and-Conquer-Algorithmus Für Externes Sortieren: ohne Divide-Schritt, nur noch Merge. Definition: Lauf := geordnete Teilfolge innerhalb eines Files. Strategie: durch Merge immer größere Läufe erzeugen, bis alles sortiert.

5
Algorithmus 1. Schritt: Erzeuge aus der Folge im Eingabefile g1
„Anfangsläufe“ und verteile sie auf zwei Files f1 und f2, gleich viele (1) auf jeden. (hierzu gibt es verschiedene Strategien, später). Nun: verwende vier Files f1, f2, g1, g2.
 auf jeden. (hierzu gibt es verschiedene Strategien, später). Nun: verwende vier Files f1, f2, g1, g2.")
6
2. Schritt (Hauptschritt):
Solange Zahl der Läufe > 1 wiederhole: { Mische je zwei Läufe von f1 und f2 zu einem doppelt so langen Lauf abwechselnd nach g1 und g2, bis keine Läufe auf f1 und f2 mehr übrig. Mische je zwei Läufe von g1 und g2 zu einem doppelt so langen Lauf abwechselnd nach f1 und f2, bis keine Läufe auf g1 und g2 mehr übrig. } Jede Schleife = zwei Phasen

7
Beispiel: Beginn: g1: 64, 17, 3, 99, 79, 78, 19, 13, 67, 34, 8, 12, 50 1. Schritt (hier Länge eines Anfangslaufs = 1): f1: 64 | 3 | 79 | 19 | 67 | 8 | 50 f2: 17 | 99 | 78 | 13 | 34 | 12 Hauptschritt, 1. Schleife, Teil 1 (1. Phase): g1: 17, 64 | 78, 79 | 34, 67 | 50 g2: 3, 99 | 13, 19 | 8, 12 1. Schleife, Teil 2 (2. Phase): f1: 3, 17, 64, 99 | 8, 12, 34, 67 | f2: 13, 19, 78, 79 | 50 |
: g1: 17, 64 | 78, 79 | 34, 67 | 50. g2: 3, 99 | 13, 19 | 8, Schleife, Teil 2 (2. Phase): f1: 3, 17, 64, 99 | 8, 12, 34, 67 | f2: 13, 19, 78, 79 | 50 |")
8
Beispiel Fortsetzung 1. Schleife, Teil 2 (2. Phase):
:")
9
Implementierung: Man hält von jedem der vier Files f1, f2, g1, g2 mindestens eine Seite im Hauptspeicher, am besten noch jeweils eine zweite Seite als Puffer. Gelesen/geschrieben wird immer nur seitenweise.

10
Aufwand Seitenzugriffe im 1. Schritt und in jeder Phase: O(n/b)
In jeder Phase Halbierung der Zahl der Läufe, also: Gesamtzahl der Seitenzugriffe: O((n/b) log n), wenn man mit Läufen der Länge 1 startet. Interne Rechenzeit im 1. Schritt und in jeder Phase: O(n). Gesamte interne Rechenzeit: O( n log n ).
 log n), wenn man mit Läufen der Länge 1 startet. Interne Rechenzeit im 1. Schritt und in jeder Phase: O(n). Gesamte interne Rechenzeit: O( n log n ).")
11
Zwei Varianten des 1. Schritts: Erzeugen von Anfangsläufen
Direktes Mischen Sortiere im Hauptspeicher („intern“) soviel wie möglich, z.B. m Datensätze Anfangsläufe der (festen!) Länge m, also r := n/m Anfangsläufe. Dann Gesamtzahl der Seitenzugriffe: O( (n/b) log(r) ).
 soviel wie möglich, z.B. m Datensätze. Anfangsläufe der (festen!) Länge m, also r := n/m Anfangsläufe. Dann Gesamtzahl der Seitenzugriffe: O( (n/b) log(r) ).")
12
Zwei Varianten des 1. Schritts: Erzeugen von Anfangsläufen
Natürliches Mischen erzeugt Anfangsläufe variabler Länge. Vorteil: man nutzt vorsortierte Teilfolgen aus Bemerkenswert: Anfangsläufe können durch Ersetzungs-Auswahl länger gemacht werden, als der Hauptspeicher groß ist!

13
Ersetzungs-Auswahl Lies m Datensätze vom Eingabefile in den Hauptspeicher. Wiederhole { Nenne alle Datensätze im Hauptspeicher „jetzt“. Beginne einen neuen Lauf. Solange noch ein „jetzt“ Datensatz im Hauptspeicher { Wähle aus den „jetzt“ Datensätzen im Hauptspeicher den kleinsten (d.h. mit kleinstem Schlüssel), gib ihn auf das aktuelle Ausgabefile aus, und fülle aus dem Eingabefile einen Datensatz nach (falls noch einer vorhanden), nenne ihn „jetzt“, falls er größer-gleich dem zuletzt ausgegebenen Datensatz ist; „nicht jetzt“, sonst. } bis keine Datensätze im Eingabefile mehr sind.
, gib ihn auf das aktuelle Ausgabefile aus, und fülle aus dem Eingabefile einen Datensatz nach (falls noch einer vorhanden), nenne ihn „jetzt , falls er größer-gleich dem zuletzt ausgegebenen Datensatz ist; „nicht jetzt , sonst. } bis keine Datensätze im Eingabefile mehr sind.")
14
Beispiel: Hauptspeicher mit Kapazität: 3 Datensätze.
Am Anfang im Eingabefile: 64, 17, 3, 99, 79, 78, 19, 13, 67, 34, 8, 12, 50 Im Hauptspeicher: („nicht jetzt“ Datensätze in Klammern) Läufe: 3, 17, 64, 78, 79, 99 | 13, 19, 34, 67 | 8, 12, 50 64 17 3 99 79 78 (19) (13) (67) 19 13 67 34 (8) (12) (50) 8 12 50
 Läufe: 3, 17, 64, 78, 79, 99 | 13, 19, 34, 67 | 8, 12, (19) (13) (67) (8) (12) (50)")
15
Implementierung: In einem Array: vorne: Heap für „jetzt“ Datensätze, Hinten: nachgefüllte „nicht jetzt“ Datensätze. Beachte: alle „jetzt“ Elemente kommen in den aktuell erzeugten Lauf.

16
Erwartete Länge der Anfangsläufe bei Ersetzungsauswahl:
2•m (m = Größe des Hauptspeichers = Zahl der Datensätze, die in den Hauptspeicher passen) bei zufälliger Schlüsselverteilung Noch größer bei Vorsortierung!
 bei zufälliger Schlüsselverteilung. Noch größer bei Vorsortierung!")
17
Vielweg-Mischen Statt je zwei Eingabefiles und Ausgabefiles (abwechselnd f1, f2 und g1, g2) je k Eingabefiles und Ausgabefiles: mische immer k Läufe zu einem. Dazu in jedem Schritt: Minimum unter den ersten Elementen aller k Läufe auf aktuellen Ausgabefile ausgeben.

18
Aufwand: In jeder Phase: Zahl der Läufe durch k dividiert, Also bei r Anfangsläufen nur logk(r) Phasen (statt log2(r)). Gesamtzahl der Seitenzugriffe: O( (n/b) logk(r) ). Interne Rechenzeit pro Phase: O(n log2 (k)) Gesamte interne Rechenzeit: O( n log2(k) logk(r)) = O( n log2(r) ).
). Gesamtzahl der Seitenzugriffe: O( (n/b) logk(r) ). Interne Rechenzeit pro Phase: O(n log2 (k)) Gesamte interne Rechenzeit: O( n log2(k) logk(r)) = O( n log2(r) ).")
19
Kapitel 7.3 Teilstringsuche nach Boyer und Moore
Positionsindex und Matchingrichtung ShiftRight als statische Funktion Bad Character Heuristik Good-Suffix Heuristik Algorithmen der Computergrafik Tracer Algorithmus Bresenham Algorithmus Schnelle Multiplikation und Fast-Fourier-Transformation

20
Teilstringsuche Problem: Prüfe, ob ein Suchwort s in einem Text t
vorkommt oder nicht. Schon bekannt: Algorithmus, der in Zeit O(|s| |t| ) arbeitet. Jetzt: bessere Algorithmen: von Knuth, Morris, Pratt (1977) von Boyer und Moore (1977).
 arbeitet. Jetzt: bessere Algorithmen: von Knuth, Morris, Pratt (1977) von Boyer und Moore (1977).")
21
Grundverfahren Aufwand des Grundverfahrens ist proportional zum Produkt aus Länge Suchstring und Teilstring. Zur Verbesserung sollte versucht werden, den Teilstring bei negativem Vergleichsergebnis möglichst weit nach rechts zu schieben: WIR KENNEN KEINEN NENNENSWERTEN FALL NENNEN -> +1 NENNEN (2fache Übereinst.) -> +? NENNEN -> +?
 -> + NENNEN -> +")
22
Naiver Algorithmus Operationen:
ohne1(String) String, anf1(String) char algorithmus präfix(s, t: String) Boolean { wenn (s leer) dann { ausgabe wahr; exit }; wenn (t leer) dann { ausgabe falsch; exit }; wenn anf1(s) = anf1(t) dann ausgabe präfix(ohne1(s),ohne1(t)) sonst ausgabe falsch } algorithmus TeilString(s, t: String) Boolean { res := falsch ; solange (t nicht leer) und (res=falsch) führe_aus { wenn präfix(s,t) dann res := wahr sonst t := ohne1(t) }; ausgabe res } Zeitaufwand: O( |s| • |t| )
 String, anf1(String) char. algorithmus präfix(s, t: String) Boolean { wenn (s leer) dann { ausgabe wahr; exit }; wenn (t leer) dann { ausgabe falsch; exit }; wenn anf1(s) = anf1(t) dann ausgabe präfix(ohne1(s),ohne1(t)) sonst ausgabe falsch } algorithmus TeilString(s, t: String) Boolean { res := falsch ; solange (t nicht leer) und (res=falsch) führe_aus { wenn präfix(s,t) dann res := wahr sonst t := ohne1(t) }; ausgabe res } Zeitaufwand: O( |s| • |t| )")
23
Varianten des Verfahrens
Einführung eines Positionsindex verhindert das zu weite Rechtsschieben des Suchstrings s, m=|s| , über den String t hinaus, n=|t|. Dabei wird das Verfahren O((n-m+1)•m). Ein Vergleich von links nach rechts ändert die Komplexität nicht. Schließlich kann die Funktion ShiftRight mit m-1 Werten im Voraus berechnet und tabelliert werden. Ab nun folgende Bezeichnungen: Suchstring als Array s[1..d], Textstring als Array t[1..l] Weiterhin werden noch die Präfixe von s mit sk= s[1]s[2]...s[k] (Konkatenation) und die Suffixe von s mit s[j d] = s[j+1]...s[d] notiert. Hierbei ist s[0] das leere Wort.
•m). Ein Vergleich von links nach rechts ändert die Komplexität. nicht. Schließlich kann die Funktion ShiftRight mit m-1 Werten im. Voraus berechnet und tabelliert werden. Ab nun folgende Bezeichnungen: Suchstring als Array s[1..d], Textstring als Array t[1..l] Weiterhin werden noch die Präfixe von s mit sk= s[1]s[2]...s[k] (Konkatenation) und die Suffixe von s mit s[j d] = s[j+1]...s[d] notiert. Hierbei ist s[0] das leere Wort.")
24
Algorithmus von Knuth, Morris, Pratt
Naives Verfahren und KMP-Algorithmus: Vergleiche s und t von links nach rechts. Naives Verfahren: bei Mismatch s um 1 Position nach rechts verschieben. KMP-Algorithmus: bei Mismatch s soweit wie möglich nach rechts verschieben (verschiedene Varianten möglich: neues gelesenes Zeichen miteinbeziehen oder noch nicht).
.")
25
Algorithmus von Knuth, Morris, Pratt (2)
Zweite Variante: neues gelesenes Zeichen wird miteinbezogen. Algorithmus für festes z durch endlichen Automaten darstellbar: Zustände 0 bis |s| mit Bedeutung: Zustand i i = max{ j | die j zuletzt in t gelesenen Zeichen stimmen mit dem Präfix der Länge j von s stimmt überein} Beim Lesen eines weiteren Zeichens in t geht der Automat in den entsprechenden neuen Zustand. Dieser Automat kann für gegebenes s im Voraus berechnet werden.

26
Algorithmus von Boyer und Moore
Ideen: Verschiebe das Wort s allmählich von links nach rechts, aber Vergleiche Wort s mit Text t im Wort s von rechts nach links. Zwei Heuristiken zum Verschieben des Suchstrings s. Bad-Character-Heuristik Good-Suffix-Heuristik Aufwand: auch O(|t|+|s|).
.")
27
Heuristiken

28
Erläuterungen zum Bild
In a) wird der Suchstring "reminiscence" von rechts nach links mit dem Text verglichen. Das Suffix "ce" stimmt überein, aber der "Bad-Character" "i" stimmt nicht mehr mit dem korrespondierenden "n" des Suchstrings überein. In b) wird der Suchstring nach der Bad-Character-Heuristik so weit nach rechts verschoben, bis der "Bad-Character" "i" mit dem am weitesten rechts auftretenden Vorkommen von "i" im Suchstring übereinstimmt. In c) wird nach der Good-Suffix-Heuristik das gefundene "Good-Suffix" "ce" mit dem Suchstring verglichen. Kommt dieses Suffix ein weiteres Mal im Suchstring vor, so kann der Suchstring so weit verschoben werden, dass dieses erneute Auftreten mit dem Text übereinstimmt.
 wird der Suchstring reminiscence von rechts nach links. mit dem Text verglichen. Das Suffix ce stimmt überein, aber der Bad-Character i stimmt nicht mehr mit dem. korrespondierenden n des Suchstrings überein. In b) wird der Suchstring nach der Bad-Character-Heuristik so. weit nach rechts verschoben, bis der Bad-Character i mit. dem am weitesten rechts auftretenden Vorkommen von i im Suchstring übereinstimmt. In c) wird nach der Good-Suffix-Heuristik das gefundene. Good-Suffix ce mit dem Suchstring verglichen. Kommt dieses Suffix ein weiteres Mal im Suchstring vor, so kann der Suchstring so weit verschoben werden, dass. dieses erneute Auftreten mit dem Text übereinstimmt.")
29
Die "Bad-Character Heuristik"
Matchfehler an der Stelle j mit s[j] t[pos+j], 1 j d (pos ist die Stelle vor dem aktuellen Beginn des Suchstrings) 1) Das falsche Zeichen t[pos+j] tritt im Suchstring nicht auf. Nun können wir ohne Fehler den Suchstring um j weiterschieben. 2) Das falsche Zeichen t[pos+j] tritt im Suchstring auf. Sei nun k der größte Index mit 1 k d, an dem s[k]=t[pos+j] gilt. Ist dann k<j, so wollen wir den Suchstring um j-k weiterschieben. Hier haben wir dann mindestens eine Übereinstimmung im Zeichen s[k] = t[pos+j]. Man kann den Wert k im voraus für jedes verschiedene Zeichen des Suchstrings als Funktion b(a) bestimmen, wobei a aus dem erlaubten Alphabet ist. b(a) gibt die Position des am weitesten rechts stehenden Auftreten vom Zeichen a im Suchstring an. Damit ist eine Verschiebung um j - k = j - b(t[pos + j]). zu machen. 3) Gilt allerdings k>j, so liefert die Heuristik einen negativen Shift j - k, der ignoriert wird, also Verschiebung um 1.
 1) Das falsche Zeichen t[pos+j] tritt im Suchstring nicht auf. Nun können wir ohne Fehler den Suchstring um j weiterschieben. 2) Das falsche Zeichen t[pos+j] tritt im Suchstring auf. Sei nun k der. größte Index mit 1 k d, an dem s[k]=t[pos+j] gilt. Ist dann k<j, so wollen wir den Suchstring um j-k weiterschieben. Hier haben wir dann mindestens eine Übereinstimmung im Zeichen. s[k] = t[pos+j]. Man kann den Wert k im voraus für jedes verschiedene. Zeichen des Suchstrings als Funktion b(a) bestimmen, wobei a aus. dem erlaubten Alphabet ist. b(a) gibt die Position des am weitesten. rechts stehenden Auftreten vom Zeichen a im Suchstring an. Damit ist. eine Verschiebung um j - k = j - b(t[pos + j]). zu machen. 3) Gilt allerdings k>j, so liefert die Heuristik einen negativen Shift j - k, der ignoriert wird, also Verschiebung um 1.")
30
Liste des rechtesten Wiedervorkommens im blauen Suchstring

31
Beispiel BCH Rechtestes Auftreten im Suchstring finden

32
"Good-Suffix Heuristik"
Angenommen, wir haben einen Matchfehler an der Stelle j mit s[j] t[pos+j], 0 j d gefunden (die weiter rechts liegenden Zeichen stimmen also überein, pos ist die aktuelle Position in t ). Gilt j= d, so schieben wir den Suchstring einfach um eine Position weiter. Gilt jedoch j<d, so haben wir d-j Übereinstimmungen. Das Suffix des Suchstrings s der Länge d-j und der passende Textstring t von der Stelle pos+1 an stimmen links von pos+d in d-j Zeichen überein. Nun berechnen wir die Größe g[j] := d- max{k: 0 k < d; (s[j d] ist Suffix von sk oder sk ist Suffix von s[j d])}. g heißt dann "Good-Suffix"-Funktion und kann im Vorhinein für alle 0 j d berechnet werden. Sie gibt die kleinste Anzahl von Zeichen an, um die wir den Suchstring s nach rechts schieben können, ohne Übereinstimmungen mit dem Text zu verlieren. s[1]s[2]s[3]s[4]s[5]s[6]=nennen s3 = nen, s4=nenn g[0]= 6-max{1,3}, g[1]=3, g[2]=3, g[3]=3, g[4]=3, g[5]=6-4
. Gilt j= d, so schieben wir den Suchstring einfach um eine Position weiter. Gilt jedoch j<d, so haben wir d-j Übereinstimmungen. Das Suffix des Suchstrings s der Länge d-j und der passende Textstring t von. der Stelle pos+1 an stimmen links von pos+d in d-j Zeichen überein. Nun berechnen wir die Größe. g[j] := d- max{k: 0 k < d; (s[j d] ist Suffix von sk oder sk ist Suffix von s[j d])}. g heißt dann Good-Suffix -Funktion und kann im Vorhinein für alle 0 j d. berechnet werden. Sie gibt die kleinste Anzahl von Zeichen an, um die wir den Suchstring s nach. rechts schieben können, ohne Übereinstimmungen mit dem Text zu verlieren. s[1]s[2]s[3]s[4]s[5]s[6]=nennen s3 = nen, s4=nenn. g[0]= 6-max{1,3}, g[1]=3, g[2]=3, g[3]=3, g[4]=3, g[5]=6-4.")
33
Good suffix alternativ
L'[ ] und l'[ ] für das Beispiel-Suchmuster: l'[pos] := Länge des längsten Suffix in Muster[pos..n], das auch Präfix ist. L'[pos] := Rechtes Ende der rechtesten Kopie von Muster[pos..n].

34
Good Suffix Beispiel Achtung – Verschiebung um 1 Länge d=11
Pos=0, j=6, g(6)=11-6=5 1. Fall Pos=7, j=5, g(5)=11-3=8 k<d, g(0)=11-3=8 Fazit: 11 Gesamtlänge. Die gegebene Heuristik arbeitet gut
=11-6=5 1. Fall. Pos=7, j=5, g(5)=11-3=8. k<d, g(0)=11-3=8. Fazit: 11 Gesamtlänge. Die gegebene Heuristik arbeitet gut.")
35
Weitere Beispiele: Wir kennen keinen nennenswerten Fall nennen Hier ist d=6, j=4 und der Buchstabe k tritt nicht im Suchstring auf. Wir können demnach den String nach der Bad-Charakter Heuristik um 4 Plätze weiterschieben. Good-Suffix-Heuristik: Das Good-Suffix ist en; Verschiebung: um 3 Positionen Nunmehr kommt der Mismatch-Buchstabe n im Suchstring viermal vor. Das maximale Vorkommen ist k=6. Wir müssen also die Good-Suffix Heuristik anwenden. Im Vorhinein haben wir g[5] = 6-4=2 berechnet und können den Suchstring um zwei Plätze nach rechts weiterschieben: Hier ist j=1. Die Bad-Character Heuristik ermöglicht uns lediglich, den String um eine Position nach rechts zu verschieben. Das Good-Suffix ist jedoch ennen, und das Präfix nen das Suchstrings ist ein Suffix des Good-Suffix. Wir haben also vorher schon g[1]= 6-3=3 berechnet. Die Good-Suffix Heuristik erlaubt uns also, den Suchstring um drei Positionen nach rechts weiterzuschieben.

36
Kapitel 7.4 Definition Bild R:= {(x,y)Z2, 0xa, 0yb}
B: R [0,255]3, RGB-Farbraum

37
Farbmodelle

38
Vier- und Achtnachbarntopologie

39
Tracer-Algorithmus

40
Streckenrasterung

41
Bresenham-Algorithmus
Algorithmus Bresenham_Haarstrecke_erster Oktant input (dx,dy) ; {Input Differenzen 0 £ dy £ dx} x := 0; y := 0 ; abweichung := - dx ; {Initialisierung} while ( abweichung < 0) and (x <= dx ) do begin { Zeichne das erste Linienstück mit Ordinate 0 } abweichung := abweichung + 2*dy ; plot (x,y) ; inc(x) ; end ; abweichung := abweichung - 2*dx ; inc(y); { Schleife für Ordinaten von 1 bis dy - 1 } while (y < dy ) do begin while (abweichung < 0) do { eine Ordinate abhandeln } begin abweichung := abweichung + 2*dy ; plot (x,y) ; inc(x) ; end ; abweichung := abweichung - 2*dx ; inc(y) ; end ; while ( x £ dx ) do begin { Zeichne das Linienstück mit Ordinate dy } abweichung := abweichung + 2*dy ; plot (x,y) ; inc(x); end ; end ;
 ; {Input Differenzen 0 £ dy £ dx} x := 0; y := 0 ; abweichung := - dx ; {Initialisierung} while ( abweichung < 0) and (x <= dx ) do begin. { Zeichne das erste Linienstück mit Ordinate 0 } abweichung := abweichung + 2*dy ; plot (x,y) ; inc(x) ; end ; abweichung := abweichung - 2*dx ; inc(y); { Schleife für Ordinaten von 1 bis dy - 1 } while (y < dy ) do begin. while (abweichung < 0) do { eine Ordinate abhandeln } begin abweichung := abweichung + 2*dy ; plot (x,y) ; inc(x) ; end ; abweichung := abweichung - 2*dx ; inc(y) ; end ; while ( x £ dx ) do begin { Zeichne das Linienstück mit Ordinate dy } abweichung := abweichung + 2*dy ; plot (x,y) ; inc(x); end ; end ;")
42
Erläuterungen

43
Bresenham Achtelkreis
Bresenham_Achtelkreis (r: integer {r Radius}); x := 0; y := r ; control := 1-r ; while x<= y do begin plot(x,y); inc(x); if control>=0 then begin dec(y) ; control := control - shl(y) end; control := control + shl(x) + 1; end; {while} end;
; x := 0; y := r ; control := 1-r ; while x<= y do begin. plot(x,y); inc(x); if control>=0 then. begin. dec(y) ; control := control - shl(y) end; control := control + shl(x) + 1; end; {while} end;")
44
Schnelle Multiplikation
„Klassische“ Algorithmen: O(n²) Rückführung auf die serielle Addition Durch Zerlegung „3M“: O(nld(3) ) O(n 1.585)) U = (Ahigh + Alow)(Bhigh + Blow) V = Ahigh * Bhigh; W = Alow * Blow A*B = V*22p + (U-W-V)*2p + W [Karatsuba, 1962] Drei kurze statt vier kurzen oder zwei langen Multiplikationen (Ausarbeitung Matthias Bogaczyk)
 Rückführung auf die serielle Addition. Durch Zerlegung „3M : O(nld(3) ) O(n 1.585)) U = (Ahigh + Alow)(Bhigh + Blow) V = Ahigh * Bhigh; W = Alow * Blow. A*B = V*22p + (U-W-V)*2p + W. [Karatsuba, 1962] Drei kurze statt vier kurzen oder zwei langen Multiplikationen. (Ausarbeitung Matthias Bogaczyk)")
45
Strassen-Algorithmus
Schnelle Multiplikation

46
Polynommultiplikation
A(x)=S0 k<n akxk , B(x)=S0 k<n bkxk , C(x)=S0 k<2n-1 ckxk entspricht genau der Faltung der beiden Vektoren A und B Beispiel für zwei Vektoren A und B der Länge n: c0 = a0b0 c1 = a0b1 + a1b0 c2 = a0b2 + a1b1 + a2b0 cn-1 = a0bn-1 + a1bn an-2b1 + an-1b0 cn = 0a0 + a1bn an-1b1 + 0b0 c2n-2 = an-1bn-1 Um das Produkt der beiden Polynome zu bestimmen, kann man auch die Polynome A und B an 2n-1 Stellen auswerten und dann C konstruieren.
=S0 k<n akxk , B(x)=S0 k<n bkxk , C(x)=S0 k<2n-1 ckxk. entspricht genau der Faltung der beiden Vektoren A und B. Beispiel für zwei Vektoren A und B der Länge n: c0 = a0b0. c1 = a0b1 + a1b0. c2 = a0b2 + a1b1 + a2b0. cn-1 = a0bn-1 + a1bn an-2b1 + an-1b0. cn = 0a0 + a1bn an-1b1 + 0b0. c2n-2 = an-1bn-1. Um das Produkt der beiden Polynome zu bestimmen, kann man auch die Polynome A und B an 2n-1 Stellen. auswerten und dann C konstruieren.")
47
Polynommultiplikation (2)
Die Konstruktion über das Hornerschema benötigt auch O(n2) Schritte. Daher muss man sich einen anderen Zugang überlegen und die Polynomauswertung anders darstellen.
 Schritte. Daher muss man sich einen anderen Zugang. überlegen und die Polynomauswertung anders darstellen.")
48
Polynomauswertung an Einheitswurzeln
Es ist also günstig, wenn man Es x0=w0; x1 = w1; x2 = w2; …; xn-1 = wn-1,,setzt wobei wn = 1, und wi i1‚ für 0 < i < n gilt. r 0 < i < n w ist die n-te komplexe Einheitswurzel exp(2pi/n).
.")
49
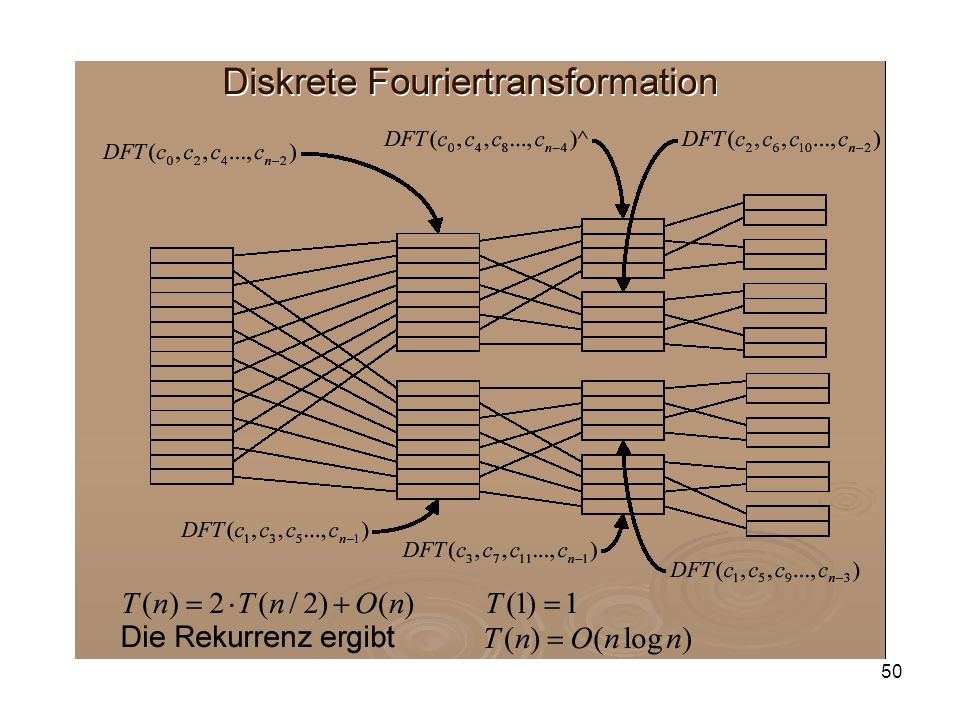
Diskrete Fouriertransformation

51
Die schnelle Fourier-Transformation
Bekanntlich kann die diskrete Fouriertransformation mit dem Teile und Herrsche–Prinzip mit einem Aufwand von O(N logN) Operationen unter Ausnutzung derselben Routine für die Hin– und Rücktransformation schnell implementiert werden. Ausgehend von dem Fourierpolynom einer 1–periodischen Funktion f(x) p(x) := 0kN-1 bk exp(i2πkx), w = exp(i2p/N) gilt p(k/N) = fk := f (k/N)= , k = 0, 1, ...,N-1 genau dann, wenn bk = 1/N 0lN-1 fl exp(-2πilk/N) , k = 0, ...,N-1.
 Operationen unter Ausnutzung derselben Routine. für die Hin– und Rücktransformation schnell implementiert. werden. Ausgehend von dem Fourierpolynom einer 1–periodischen. Funktion f(x) p(x) := 0kN-1 bk exp(i2πkx), w = exp(i2p/N) gilt. p(k/N) = fk := f (k/N)= , k = 0, 1, ...,N-1. genau dann, wenn. bk = 1/N 0lN-1 fl exp(-2πilk/N) , k = 0, ...,N-1.")
52
Die schnelle Fourier-Transformation 2
Wir schildern nun kurz den eindimensionalen FFT–Algorithmus von Cooley and Tukey nach Gauß und setzen N = 2n: Dazu führen wir die inverse Darstellung τ(k) zur Binärdarstellung einer ganzen Zahl k ein: k = a0 + a12 + a an-1 2n-1, ai {0, 1} τ(k) = an-1 + an , a0 2n-1. Nach der Initialisierung des Tableaus b[τ(k)] := f(k/N) kann der eindimensionale Grundalgorithmus folgendermaßen beschrieben werden:
 zur Binärdarstellung einer. ganzen Zahl k ein: k = a0 + a12 + a an-1 2n-1, ai {0, 1} τ(k) = an-1 + an , a0 2n-1. Nach der Initialisierung des Tableaus b[τ(k)] := f(k/N) kann der. eindimensionale Grundalgorithmus folgendermaßen beschrieben werden:")
53
Die schnelle Fourier-Transformation 3
for m := 1 to n do begin E := 1; for j := 0 to 2^(m-1) - 1 do for r := 0 to N-1 step 2^m do begin u := b[r+j]; v := b[r+j+2^(m-1)] * E; b[r+j] := u + v; b[r+j+2^(m-1)] := u - v; E := E * exp(-2 * pi * i / 2^m); end;
 - 1 do. for r := 0 to N-1 step 2^m do. begin. u := b[r+j]; v := b[r+j+2^(m-1)] * E; b[r+j] := u + v; b[r+j+2^(m-1)] := u - v; E := E * exp(-2 * pi * i / 2^m); end;")
54
Die schnelle Fourier-Transformation 4
Anschließend finden wir im Tableau b[k], 0 ≤ k ≤ 2n -1 die mit N multiplizierten Koeffizienten des komplexen Fourierpolynoms, die mittels der Korrespondenzen A0 := 2b0, Ak := bk + bN-k, Bk := i(bk – bN-k) in die Koeffizienten des reellen Fourierpolynoms umgerechnet werden können. Für die Rücktransformation wird die abschließende Division durch N unter- drückt und die letzte Zeile der Iteration in E := E · exp(2πi/2m) modifiziert. Die Berechnung der Transformation τ geschieht mit folgendem kleinen Programmfragment:
 in die Koeffizienten des reellen Fourierpolynoms umgerechnet werden. können. Für die Rücktransformation wird die abschließende Division durch N unter- drückt und die letzte Zeile der Iteration in E := E · exp(2πi/2m) modifiziert. Die Berechnung der Transformation τ geschieht mit folgendem kleinen. Programmfragment:")
55
Die schnelle Fourier-Transformation 5
m1 := N div 2; l := 0; for k := 0 to N-1 do begin read(Re(b[k]), Im(b[k])); If k > l then begin swap(Re(b[k]), Re(b[l])); swap(Im(b[k]), Im(b[l])); end; j := m1; while (j <= l) and (j > 0) do l := l - j; j := j div 2 l := l + j; Dieser Algorithmus überträgt sich auch auf den zweidimensionalen Fall.
, Im(b[k])); If k > l then. begin. swap(Re(b[k]), Re(b[l])); swap(Im(b[k]), Im(b[l])); end; j := m1; while (j <= l) and (j > 0) do. l := l - j; j := j div 2. l := l + j; Dieser Algorithmus überträgt sich auch auf den zweidimensionalen Fall.")
Ähnliche Präsentationen






 auf.>")






>")





