Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Seminar parallele Programmierung SS 2003
Graphalgorithmen Seminar parallele Programmierung SS 2003 Bernd Kruthoff und Jochen Olejnik

2
Gliederung 1. Motivation 2. Verbundene Komponenten
- Hirschbergs Algorithmus 3. Minimal Spannender Baum - Kruskals Algorithmus - Sollins Algorithmus 4. Kürzeste Pfade von einem Knoten ausgehend - Moores Algorithmus 5. Zusammenfassung

3
1. Motivation Probleme der Praxis werden komplexer
Lassen sich häufig durch Graphen darstellen Herkömmliche Algorithmen stoßen an Grenzen Lösung: Parallelisierung bekannter Algorithmen

4
Verbundene Komponenten
Finden aller verbundenen Komponenten in einem ungerichteten Graphen 3 mögliche Ansätze: A. Suchalgorithmen durch Breiten- bzw. Tiefensuche durch den kompletten Graphen

5
Verbundene Komponenten
B. Transitive Hülle Grundlage: Adjazenzmatrix Bestimmen der transitiven Hülle durch Plus-Min-Multiplikationen Plus-Min-Multiplikation ist Matrixmultiplikation bei der Skalamultiplikationen durch Additionen und Additionen durch Minimumoperationen ersetzt werden => Strukturanalogie zur Matrixmultiplikation: => Laufzeit: für eine Plus-Min-Multiplikation => für log n Plus-Min-Multiplikationen

6
C. Hirschbergs Algorithmus
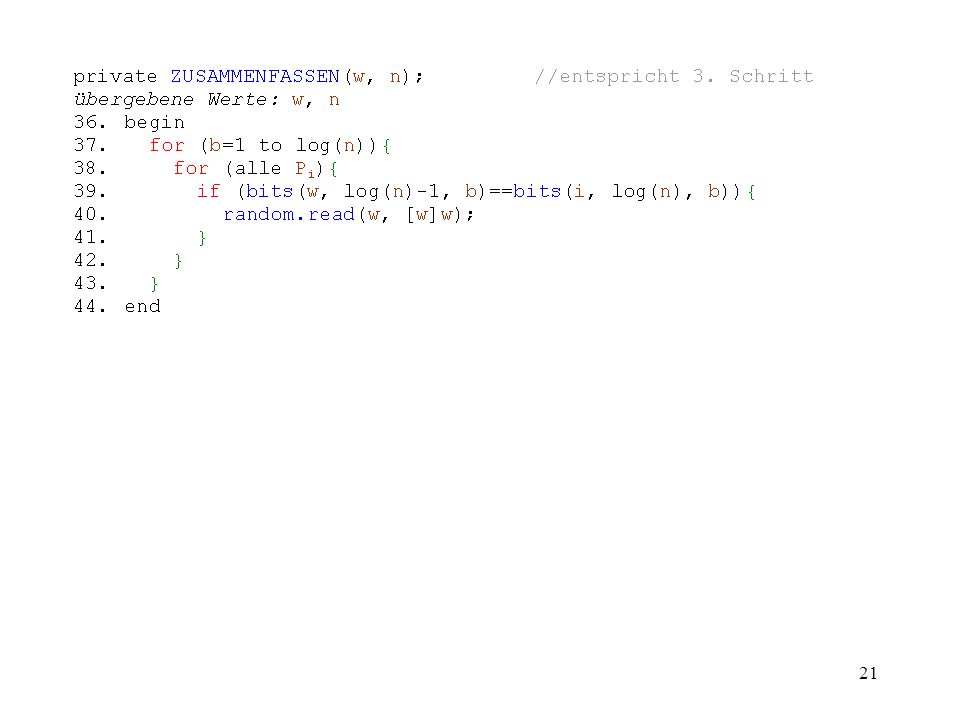
Grundidee: Knoten zu Knotengruppen zusammenfassen bis kein weiteres Zusammenfassen mehr möglich ist Jeder Knoten gehört zu genau einer Knotengruppe Knotengruppen werden durch Wurzel (hier: kleinstes Element) identifiziert Der Algorithmus: 1. Schritt: Zu jedem Knoten wird die angrenzenden Knotengruppe mit der kleinsten Wurzel gesucht 2. Schritt: Verbinden der Wurzeln der in Schritt 1 gefundenen Knotengruppen 3. Schritt: Die in Schritt 2 gefundenen Knotengruppen werden zu einer Knotengruppe zusammengefasst Endet, wenn es in Schritt 1 keine angrenzende Knotengruppe mehr gibt
 identifiziert. Der Algorithmus: 1. Schritt: Zu jedem Knoten wird die angrenzenden Knotengruppe mit der kleinsten Wurzel gesucht. 2. Schritt: Verbinden der Wurzeln der in Schritt 1 gefundenen Knotengruppen. 3. Schritt: Die in Schritt 2 gefundenen Knotengruppen werden zu einer Knotengruppe zusammengefasst. Endet, wenn es in Schritt 1 keine angrenzende Knotengruppe mehr gibt.")
7
Ein Beispiel: Die Ausgangssituation: Knoten 1 2 3 4 5 6 7 8 9 10 11
Knoten-gruppe

8
Beispiel: 1. Iteration 1. Schritt: Zu jedem Knoten wird die angrenzende Knotengruppe mit der kleinsten Wurzel gesucht

9
Beispiel: 1. Iteration 2. Schritt: Verbinden der Wurzeln der in Schritt 1 gefundenen Knotengruppen

10
Beispiel: 1. Iteration 3. Schritt: Die in Schritt 2 gefundenen Knotengruppen werden zu einer Knotengruppe zusammengefasst

11
Beispiel: 1. Iteration Ergebnis
Knoten 1 2 3 4 5 6 7 8 9 10 11 Knoten-gruppe

12
Beispiel: 2. Iteration Letzte Iteration: Startgraph:
1. Schritt: Zu jedem Knoten wird die angrenzenden Knotengruppe mit kleinster Wurzel gesucht

13
Beispiel: 2. Iteration 2. Schritt: Verbinden der Wurzeln der in Schritt 1 gefundenen Knotengruppen

14
Beispiel: 2. Iteration 3. Schritt: Die in Schritt 2 gefundenen Knotengruppen werden zu einer Knotengruppe zusammengefasst

15
Beispiel: 2. Iteration Ergebnis
Knoten 1 2 3 4 5 6 7 8 9 10 11 Knoten-gruppe

16
Komplexität Der Algorithmus benötigt Iterationen weil sich die Anzahl der Knotengruppen mit jeder Iteration mindestens halbiert Es werden n2 Prozessoren benötigt, weil maximal n benachbarte Knotengruppen pro Knoten verglichen werden müssen. => Gesamtkomplexität

17
Verbesserungen Betrachten von Brents Theorem:
Es reichen Prozessoren aus um n Elemente anzusprechen und deren Minimum in Zeit zu finden. Jeder Prozessor kann log n Elemente anstatt nur einem ansprechen oder das Minimum aus log n Elementen berechnen, anstatt nur das Minimum aus zwei Elementen ohne die Zeitkomplexität zu verändern. Der Algorithmus benötigt also Zeit bei Prozessoren.

18
Eine Implementierung Implementierung von Hirschbergs Algorithmus auf das 2D Mesh SIMD Rechnermodell (Nassimi, Sahni) 3 neue Befehle: random.read(a,[b]c) liest den Wert der Variablen c im Bereich von Prozess b in die Variable a ein random.write(a,[b]c) schreibt den Wert der Variablen a in die Variable c im Bereich von Prozess b Laufzeit dieser Operationen ist nur vom Rechner abhängig => konstant in Bezug auf die Anzahl der Elemente bits(i,j,k) gibt den Wert der Stellen j bis k der Zahl i zurück z. B. bits (9,3,2) : 9 ist binär 0101 zweite und dritte Stelle: 01 also wird 1 zurückgegeben Ist j<k wird 0 zurückgegeben
 liest den Wert der Variablen c im Bereich von Prozess b in die Variable a ein. random.write(a,[b]c) schreibt den Wert der Variablen a in die Variable c im Bereich von Prozess b. Laufzeit dieser Operationen ist nur vom Rechner abhängig => konstant in Bezug auf die Anzahl der Elemente. bits(i,j,k) gibt den Wert der Stellen j bis k der Zahl i zurück. z. B. bits (9,3,2) : 9 ist binär 0101 zweite und dritte Stelle: 01 also wird 1 zurückgegeben. Ist j<k wird 0 zurückgegeben.")
22
Laufzeit dieser Implementierung

23
Loop (Zeilen 5-18) wird log n mal durchlaufen
In innerem Loop (Zeilen 9-13) wird d mal die Minimumoperation angewendet, welche O(n) Zeit verbraucht
 wird d mal die Minimumoperation angewendet, welche O(n) Zeit verbraucht.")
24
Laufzeit dieser Implementierung
Loop (Zeilen 5-18) wird log n mal durchlaufen In innerem Loop (Zeilen 9-13) wird d mal die Minimumoperation angewendet, welche O(n) Zeit verbraucht Auf dem 2D mesh-SIMD-Rechner mit n Prozessoren und n=2k Knoten und Maximalwert d hat dieser Algorithmus eine Komplexität von
 wird log n mal durchlaufen. In innerem Loop (Zeilen 9-13) wird d mal die Minimumoperation angewendet, welche O(n) Zeit verbraucht. Auf dem 2D mesh-SIMD-Rechner mit n Prozessoren und n=2k Knoten und Maximalwert d hat dieser Algorithmus eine Komplexität von .")
25
Minimal Spannender Baum
Finden des Minimal Spannenden Baumes in einem ungerichteten verbundenen gewichteten Graphen Kruskals Algorithmus Idee: Alle Knoten sind anfangs Bäume Pro Iteration wird nun die kleinste noch nicht im Minimal Spannenden Baum vorhandene Kante eingefügt, falls dadurch kein Zyklus entstünde

26
Beispiel Kruskals Algorithmus

27
Beispiel Kruskals Algorithmus

28
Der Heap als Datenstruktur
Parallelisierung durch geschickte Wahl der Datenstruktur Hier bietet sich der Heap an! => Gute Laufzeiteigenschaften Hier wird der Heap mit -wertigen Knoten zu einem vollständigen Binärbaum ausgebaut Lemma: Man kann mit einer UMA-Multiprozessormaschine mit log nProzessoren ein Element aus einer n-elementigen Menge in konstanter Zeit aus dem Heap auslesen.

29
Der Heap als Datenstruktur
Jede Ebene hat Flag mit Wert => voll wenn alle Knoten belegt => leer wenn es leere Knoten in Ebene gibt Wert empty_node zeigt pro Ebene Knoten, in dem Wert fehlt Jeder Prozessor ist für eine Ebene zuständig. Wird ein Knoten leer so füllt ihn der zuständige Prozessor aus dem kleinsten Element der Kinder dieses Knotens wieder auf Wird ein Blatt leer, so wird der Wert eingetragen Heapaufbau kann durch Prescheduling parallelisiert werden

30
Ein Beispielheap E Heap F EN 1 Voll kein 2 Leer 3 6 4

31
Der Gesamtalgorithmus
Aufbauen des Heap Prozess entnimmt fortlaufend Knoten aus dem Heap und überprüft, ob sie zum Minimal Spannenden Baum gehören Die restlichen Prozesse stellen währenddessen den Heap wieder her Terminiert, wenn ausgelesen wird Laufzeit: Wiederaufbau des Heap und Überprüfung auf Zyklus (Find und Union) geschieht in konstanter Zeit Entnahme der Knoten in konstanter Zeit möglich =>Gesamtalgorithmus benötigt O(n) Zeit
 geschieht in konstanter Zeit. Entnahme der Knoten in konstanter Zeit möglich. =>Gesamtalgorithmus benötigt O(n) Zeit.")
32
Wechsel....

Ähnliche Präsentationen





 Weg>")




>")






>")


 Wege Prof. Dr. Th. Ottmann.>")
