Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Kapitel 7. Sortier-Algorithmen
Vorbemerkungen: Sortierproblem: Gegeben Folge von Datensätzen (items) s1, s2, ... sn Jedes si besitzt Schlüssel ki (meist vom Typ integer). Gesucht: Permutation p, so daß kp(1) kp(2) ... kp(n) Interne Sortierverfahren: alle Datensätze im Hauptspeicher, sonst Nutzung des Externspeichers Maße für die Laufzeit: Anzahl der Schlüsselvergleiche C (Comparisons) und Anzahl der Zuweisungen von Datensätzen M (Moves). C min, C max, C mit jeweils M min, M max, M mit minimale, maximale, mittlere Anzahl
 s1, s2, ... sn. Jedes si besitzt Schlüssel ki (meist vom Typ integer). Gesucht: Permutation p, so daß kp(1) kp(2) ... kp(n) Interne Sortierverfahren: alle Datensätze im Hauptspeicher, sonst Nutzung des Externspeichers. Maße für die Laufzeit: Anzahl der Schlüsselvergleiche C (Comparisons) und Anzahl der Zuweisungen von Datensätzen M (Moves). C min, C max, C mit jeweils. M min, M max, M mit minimale, maximale, mittlere Anzahl.")
2
Klassifizierung von Sortiertechniken
Sortieren durch 1. Auswählen 2. Einfügen 3. Austauschen 4. Mischen 5. Streuen und Sammeln 6. Fachverteilen

3
Sortieren durch Auswahl (Selection Sort)
Methode: Finde zuerst das kleinste Element im Feld und tausche es gegen das an erster Stelle befindliche Element aus, finde danach das zweitkleinste Element und tausche es gegen das an zweiter Stelle befindliche Element aus und fahre in dieser Weise fort bis das gesamte Feld sortiert ist. Für jedes i von 1,..., N-1 tauscht es a[i] gegen das kleinste Element in a[i] , ... , a[N] aus: (Im folgenden ist a[i] immer der Wert des Schlüssels des i-ten Feldelementes. )
")
4
Funktion Selection_Sort
void selection_sort(int a [ ], int N ) { int i, j, min, t ; for ( i = 1 ; i < N ; i++ ) { min = i; for ( j = i+1; j <= N ; j++ ) if ( a [ j ] < a [ min ] ) min = j; t = a [ min ] ; a [ min ] = a [ i ] ; a [ i ] = t; } Analyse: Anzahl Schlüsselvergleiche: S i = N(N-1) / 2 = Q(N2) Anzahl Bewegungen von Sätzen: 3(N-1)
 { int i, j, min, t ; for ( i = 1 ; i < N ; i++ ) { min = i; for ( j = i+1; j <= N ; j++ ) if ( a [ j ] < a [ min ] ) min = j; t = a [ min ] ; a [ min ] = a [ i ] ; a [ i ] = t; } Analyse: Anzahl Schlüsselvergleiche: S i = N(N-1) / 2 = Q(N2) Anzahl Bewegungen von Sätzen: 3(N-1)")
5
Insertion Sort (Sortieren durch (direktes ) Einfügen):
(Beispiel: Einsortieren der Karten beim Kartenspiel) Methode: Betrachte die Elemente eines nach dem anderen und füge jedes an seinen richtigen Platz zwischen den bereits betrachteten ein (wobei diese sortiert bleiben). Das gerade betrachtete Element wird eingefügt, indem die größeren Elemente einfach um eine Position nach rechts bewegt werden und das Element dann auf dem frei gewordenen Platz eingefügt wird. Für jedes i von 2 bis N werden die Elemente a [1] ,..., a [i] sortiert, indem a [ i ] an die entsprechende Stelle in der sortierten Liste von Elementen in a[1] ,..., a[i-1] gesetzt wird.
 Methode: Betrachte die Elemente eines nach dem anderen und füge jedes an seinen richtigen Platz zwischen den bereits betrachteten ein (wobei diese sortiert bleiben). Das gerade betrachtete Element wird eingefügt, indem die größeren Elemente einfach um eine Position nach rechts bewegt werden und das Element dann auf dem frei gewordenen Platz eingefügt wird. Für jedes i von 2 bis N werden die Elemente a [1] ,..., a [i] sortiert, indem a [ i ] an die entsprechende Stelle in der sortierten Liste von Elementen in a[1] ,..., a[i-1] gesetzt wird.")
6
Funktion Insertion_Sort
void insertion_sort(int a [ ], int p[ ], int N ) { int i, j, v ; for ( i = 2 ; i <= N ; i++ ) { v = a [ i ] ; j = i; while ( a [ j-1 ] > v ) { a [ j ] = a [ j-1 ] ; j--; } a [ j ] = v ; } /* Programm läuft nur, wenn j>1*/
 { int i, j, v ; for ( i = 2 ; i <= N ; i++ ) { v = a [ i ] ; j = i; while ( a [ j-1 ] > v ) { a [ j ] = a [ j-1 ] ; j--; } a [ j ] = v ; } /* Programm läuft nur, wenn j>1*/")
7
Sortieren von Dateien mit großen Datensätzen
Ziel: Jedes Sortierverfahren so einzurichten, dass es nur N Austauschoperationen von vollständigen Datensätzen ausführt, indem man den Algorithmus indirekt (unter Verwendung eines Feldes von Indizes) mit der Datei arbeiten und das Umordnen dann nachträglich vornehmen lässt. Insbesondere, wenn das Feld a [ 1 ] , ... , a [ N ] aus umfangreichen Datensätzen besteht, zieht man es vor, mit einem „Indexfeld“ p [ 1 ] , ... , p [ N ] zu arbeiten, wobei ein Zugriff auf das Originalfeld nur für Vergleiche erfolgt. In C ist es zweckmäßig, eine auf dem gleichen Prinzip beruhende Implementierung zu entwickeln, die ein Feld von Maschinenadressen (Zeigern) verwendet.
 mit der Datei arbeiten und das Umordnen dann nachträglich vornehmen lässt. Insbesondere, wenn das Feld a [ 1 ] , ... , a [ N ] aus umfangreichen Datensätzen besteht, zieht man es vor, mit einem „Indexfeld p [ 1 ] , ... , p [ N ] zu arbeiten, wobei ein Zugriff auf das Originalfeld nur für Vergleiche erfolgt. In C ist es zweckmäßig, eine auf dem gleichen Prinzip beruhende Implementierung zu entwickeln, die ein Feld von Maschinenadressen (Zeigern) verwendet.")
8
Beispiel: Umordnen eines sortierten Feldes
Vor dem Sortieren k a [k] p [k] A O R T I N G E P S M X L Nach dem Sortieren k a [k] p [k] A O R T I N G E P S M X L Nach dem Permutieren k a [k] p [k] A E G I L M N S R P O T X

9
„Insertion sort“ unter Hinzufügung eines Indexfeldes
insertion ( int a [ ] , int p [ ], int N ) { int i, j, v ; for ( i = 0 ; i <= N ; i ++ ) p [ i ] = i ; for ( i = 2 ; i <= N ; i ++ ) v = p [ i ]; j = i ; while ( a [ p [j - 1]] > a [ v ]) { p [ j ] = p [j - 1] ; j-- ; } }
 { int i, j, v ; for ( i = 0 ; i <= N ; i ++ ) p [ i ] = i ; for ( i = 2 ; i <= N ; i ++ ) v = p [ i ]; j = i ; while ( a [ p [j - 1]] > a [ v ]) { p [ j ] = p [j - 1] ; j-- ; } }")
10
Funktion zum Umordnen einer Datei
insitu ( int a [ ], int p[ ], int N ) { int i , j , k , t ; for ( i = 1 ; i <= N ; i ++ ) if ( p [ i ] != i ) t = a [ i ] ; k = i; do { j = k ; a [ j ] = a [p [j ] ] ; k = p [ j ] ; p [ j ] = j ; } while ( k != i ); a [ j ] = t; }
 { int i , j , k , t ; for ( i = 1 ; i <= N ; i ++ ) if ( p [ i ] != i ) t = a [ i ] ; k = i; do. { j = k ; a [ j ] = a [p [j ] ] ; k = p [ j ] ; p [ j ] = j ; } while ( k != i ); a [ j ] = t; }")
11
„Insertion sort“ unter Verwendung eines Feldes von Zeigern
insertion ( int a [ ], int *p [ ], int N) { int i, j, *v; for (i = 0 ; i <= N ; i++ ) p [ i ] = & a [ i ] ; for (i = 2 ; i <= N ; i++ ) v = p [ i ]; j = i ; while ( *p[ j -1 ] > *v ) { p [ j ] = p [ j - 1 ] ; j -- ; } p [ j ] = v ; }
 { int i, j, *v; for (i = 0 ; i <= N ; i++ ) p [ i ] = & a [ i ] ; for (i = 2 ; i <= N ; i++ ) v = p [ i ]; j = i ; while ( *p[ j -1 ] > *v ) { p [ j ] = p [ j - 1 ] ; j -- ; } p [ j ] = v ; }")
12
Analyse Cmin(N) = N-1 Cmax(N) = S i=2..N i = Q(N2) Mmin(N) = 2(N-1) Mmax(N) = S i=2..N i+1 = Q(N2) Für die Abschätzung der Werte C mit und M mit kann man davon ausgehen, daß im Mittel die Hälfte der maximalen Vergleiche/Bewegungen ausgeführt werden müssen. Auch hier erhält man also Q(N2).
.")
13
Bubblesort Methode: Jeweils 2 benachbarte Schlüssel werden verglichen.
Ist a[i] > a[i+1] , so werden items vertauscht. Größtes Element steigt in jedem Durchgang ans Ende (wie Blase, engl. bubble, nach oben). Terminierung wenn keine Vertauschung mehr erfolgt ist, oder spätestens nach N-1 Durchläufen.
. Terminierung wenn keine Vertauschung mehr erfolgt ist, oder spätestens nach N-1 Durchläufen.")
14
Funktion bubblesort void bubble (int a[], int N) { int i, j,t,flag; for ( i = N ; i >= 1 ; i--) { flag = 1; for (j = 2; j <= i; j++ ) if ( a [j-1] > a [j] ) { flag = 0; t = a [j-1] ; a [j-1] = a [j] ; a [j] = t; } if (flag) break; } /* flag = 0 heißt Abbruch, da keine Vertauschung mehr erforderlich war. */
![Funktion bubblesort void bubble (int a[], int N) { int i, j,t,flag; for ( i = N ; i >= 1 ; i--) { flag = 1;](http://slideplayer.org/slide/633576/1/images/14/Funktion+bubblesort+void+bubble+%28int+a%5B%5D%2C+int+N%29+%7B+int+i%2C+j%2Ct%2Cflag%3B+for+%28+i+%3D+N+%3B+i+%3E%3D+1+%3B+i--%29+%7B+flag+%3D+1%3B.jpg "for (j = 2; j <= i; j++ ) if ( a [j-1] > a [j] ) { flag = 0; t = a [j-1] ; a [j-1] = a [j] ; a [j] = t; } if (flag) break; } /* flag = 0 heißt Abbruch, da keine Vertauschung mehr erforderlich war. */")
15
Analyse: Cmin(N) = N-1 Cmax(N) = (N-1) + (N-2) = N*(N-1) / 2 = Q(N2) Mmin(N) = 0 Mmax(N) = 3 * Cmax(N) = Q(N2) Dieselbe Abschätzung erhält man für die mittlere Laufzeit. Bubblesort asymmetrisch: gut, wenn viele Elemente in der richtigen Reihenfolge sind, schlecht sonst.

16
Quicksort erfahrungsgemäß eine der schnellsten Methoden
Divide and Conquer-Verfahren: Zerlege die Folge F= a[1],...,a[n] in zwei Folgen F1 und F2, so daß gilt: Für jeden Schlüsselwert ki1 der Folge F1 und jeden Schlüsselwert ki2 der Folge F2 gilt die Beziehung ki1 < ki2 , d. h. jedes Element der ersten Teilfolge ist kleiner als jedes Element der zweiten Teilfolge. Führe diese Zerlegung wiederum für beide Folgen F1 und F2 durch, usw. Das Verfahren bricht für eine Teilfolge ab, wenn diese einelementig ist. Nach dem Abbruch des Verfahrens ist dann die gesamte Folge sortiert. Wir beschreiben den Vorgang des Zerlegens und Zusammensetzens etwas genauer:

17
Zerlegung: (i) Wähle ein Element (Pivotelement) v aus der Folge a[1],...,a[n], etwa v:=a[1]; (ii) Durchsuche die Folge von links, bis ein Element a[i] mit v < a[i] gefunden wurde. (iii) Durchsuche die Folge von rechts, bis ein Element a[j] mit a[j] < v gefunden wurde. (iv) Vertausche beide Elemente (v) Wiederhole (ii), (iii) und (iv) so lange, bis i >= j gilt. Anschließend wird das Element v = a[1] mit a[j] vertauscht und es gilt für die neue Folge a[1],...,a[j-1], x, a[j+1],...,a[n]: a[i1] < v < a[i2], für alle i1 {1,...,j-1}, i2 {j+1,...,n} Daraufhin wird der gesamte Prozeß für die Teilfolgen a[1],...,a[j-1] und a[j+1],..., a[n] durchgeführt, und es ist kein Zusammensetzen der Ergebnisse mehr erforderlich.
![Zerlegung: (i) Wähle ein Element (Pivotelement) v aus der Folge a[1],...,a[n], etwa v:=a[1];](http://slideplayer.org/slide/633576/1/images/17/Zerlegung%3A+%28i%29+W%C3%A4hle+ein+Element+%28Pivotelement%29+v+aus+der+Folge+a%5B1%5D%2C...%2Ca%5Bn%5D%2C+etwa+v%3A%3Da%5B1%5D%3B.jpg "(ii) Durchsuche die Folge von links, bis ein Element a[i] mit. v < a[i] gefunden wurde. (iii) Durchsuche die Folge von rechts, bis ein Element a[j] mit. a[j] < v gefunden wurde. (iv) Vertausche beide Elemente. (v) Wiederhole (ii), (iii) und (iv) so lange, bis i >= j gilt. Anschließend wird das Element v = a[1] mit a[j] vertauscht und es gilt für die neue Folge a[1],...,a[j-1], x, a[j+1],...,a[n]: a[i1] < v < a[i2], für alle i1 {1,...,j-1}, i2 {j+1,...,n} Daraufhin wird der gesamte Prozeß für die Teilfolgen a[1],...,a[j-1] und a[j+1],..., a[n] durchgeführt, und es ist kein Zusammensetzen der Ergebnisse mehr erforderlich.")
18
Beispiel zu Quicksort:
Wir betrachten die Folge j i 44 55 12 42 94 6 18 67 und sortieren sie bezüglich der Ordnung <= . Zuerst haben wir das Vergleichselement v = a[1] = 44 gewählt. Mit der Variablen i sind wir von links so weit gelaufen, bis wir auf ein Element gestoßen sind, das größer ist als 44. Das gleiche geschah von rechts mit der Variablen j, bis ein Element gefunden wurde, das kleiner ist als v, a[i] und a[j] werden nun vertauscht und wir erhalten: i j 44 18 12 42 94 6 55 67

19
Mit i sind wir anschließend auf das Element a[5] = 94 und mit j auf a[6] = 6 gestoßen. Wiederum werden beide vertauscht: j i 44 18 12 42 6 94 55 67 Nachdem wir mit Hilfe von i und j die Folge weiter durchsucht haben, gilt jetzt i >= j, und damit ist das Abbruchkriterium der Zerlegung erreicht. Jetzt werden a[1] und a[j] vertauscht, und wir erhalten: 6 18 12 42 44 94 55 67 Jetzt gilt: Alle Elemente der linken Teilfolge sind kleiner oder gleich v, und jedes Element der rechten Teilfolge ist größer oder gleich v. Das Verfahren wird nun auf beide Teilfolgen angewendet: 6 18 12 42 und 94 55 67
![Mit i sind wir anschließend auf das Element a[5] = 94 und mit j auf a[6] = 6 gestoßen. Wiederum werden beide vertauscht:](http://slideplayer.org/slide/633576/1/images/19/Mit+i+sind+wir+anschlie%C3%9Fend+auf+das+Element+a%5B5%5D+%3D+94+und+mit+j+auf+a%5B6%5D+%3D+6+gesto%C3%9Fen.+Wiederum+werden+beide+vertauscht%3A.jpg "j. i Nachdem wir mit Hilfe von i und j die Folge weiter durchsucht haben, gilt jetzt i >= j, und damit ist das Abbruchkriterium der Zerlegung erreicht. Jetzt werden a[1] und a[j] vertauscht, und wir erhalten: Jetzt gilt: Alle Elemente der linken Teilfolge sind kleiner oder gleich v, und jedes Element der rechten Teilfolge ist größer oder gleich v. Das Verfahren wird nun auf beide Teilfolgen angewendet: und")
20
C-Programm zu Quicksort
void quicksort ( int a [ ] , int l , int r ) { /* ausgewähltes Element (Pivotelement) steht links. */ int v, i, j, t ; if ( r > l) { v = a [ l ] ; i = l; j = r + 1; /* v ist das Pivotelement*/ for ( ; ; ) { while ( a [++i] < v) ; /* s. Bemerkung unten */ while ( a [ - -j] > v ); if ( i >= j ) break; t = a[i] ; a[i] = a[j] ; a[j] = t; } t = a [ j ] ; a [ j ] = a [ l ]; a [ l ] = t; quicksort ( a , l , j -1 ) ; quicksort ( a , j +1 , r ) ; Bemerkung: Im Ausgangsfeld muss vor Start ein Stopper rechts vom letzten Element der Liste abgelegt werden, der beim ersten Durchlauf die while(a[++i] ... Schleife terminiert. In der Rekursion ist das nicht erforderlich, weil dann rechts der betrachtetenTeilliste Schlüssel > v stehen.
 { /* ausgewähltes Element (Pivotelement) steht links. */ int v, i, j, t ; if ( r > l) { v = a [ l ] ; i = l; j = r + 1; /* v ist das Pivotelement*/ for ( ; ; ) { while ( a [++i] < v) ; /* s. Bemerkung unten */ while ( a [ - -j] > v ); if ( i >= j ) break; t = a[i] ; a[i] = a[j] ; a[j] = t; } t = a [ j ] ; a [ j ] = a [ l ]; a [ l ] = t; quicksort ( a , l , j -1 ) ; quicksort ( a , j +1 , r ) ; Bemerkung: Im Ausgangsfeld muss vor Start ein Stopper rechts vom letzten Element der Liste abgelegt werden, der beim ersten Durchlauf die while(a[++i] ... Schleife terminiert. In der Rekursion ist das nicht erforderlich, weil dann rechts der betrachtetenTeilliste Schlüssel > v stehen.")
21
Analyse Quicksort worst case: sowohl Vergleiche wie Bewegungen quadratisch. Schlechtester Fall tritt ein, wenn Array bereits sortiert. (N + 1) + (N) + ( N - 1) Vergleiche best case: Folgen werden in gleichlange Teilfolgen aufgeteilt, Aufrufbaum hat Tiefe log N, auf jeder Ebene maximal N Vergleiche, damit Laufzeit Q(N log N). Mittlere Laufzeit fast so gut wie beste Laufzeit!! Annahmen: Schlüssel 1, ..., N, alle Permutationen gleich wahrscheinlich Average case Komplexität: O(N log N)
 + (N) + ( N - 1) Vergleiche. best case: Folgen werden in gleichlange Teilfolgen aufgeteilt, Aufrufbaum hat Tiefe log N, auf jeder Ebene maximal N Vergleiche, damit Laufzeit Q(N log N). Mittlere Laufzeit fast so gut wie beste Laufzeit!! Annahmen: Schlüssel 1, ..., N, alle Permutationen gleich wahrscheinlich. Average case Komplexität: O(N log N)")
22
Shellsort Methode: man sorgt dafür, daß Vertauschungen über größere Abstände möglich werden. Dazu wird abnehmende Folge von Inkrementen h t, ..., h1 definiert, so daß h1 = 1. Eine Folge k1,..., kN heißt h-sortiert, wenn für alle i, 1 i N-h, ki ki+h Array a wird nun mit Einfügesort ht sortiert, dann ht-1 sortiert usw. bis a 1-sortiert und damit sortiert ist.

23
Beispiel: Inkremente 4,2,1 : 4-Sortieren 3 Zuweisungen Zuweisungen : 2-Sortieren 3 Zuweisungen Zuweisungen : 1-Sortieren 3 Zuweisungen Zuweisungen Zuweisungen

24
Normalverfahren: Zuweisungen Zuweisungen Zuweisungen Zuweisungen Zuweisungen gezählt jeweils 1 Zuweisung an Hilfsspeicher, 1 Zuweisung pro Stelle mit neuem Wert. Problem: Wie wählt man Inkremente richtig? Bei geeigneter Wahl kann man Laufzeit O(N log2 N) erreichen.
 erreichen.")
25
Heapsort Ein Baum ist ein gerichteter Graph, d.h. eine Struktur bestehend aus Knoten und gerichteten Kanten (Pfeile) zwischen Knoten, so daß gilt: 1) genau ein Knoten besitzt keine eingehende Kante (Wurzel) 2) alle übrigen Knoten besitzen genau 1 eingehende Kante. Ein Baum heißt Binärbaum, wenn alle Knoten höchstens 2 ausgehende Kanten besitzen (Knoten ohne ausgehende Kanten heißen Blätter) und wenn zwischen dem linken und re. Sohn eines Knotens unterschieden wird. Ein Binärbaum heißt vollständig, wenn es keinen Binärbaum derselben Tiefe mit mehr Knoten gibt. Die Tiefe ist die Länge des längsten gerichteten Pfades in einem Baum. Definition: Ein Heap H (deutsch: Halde) ist ein Baum, für den folgendes gilt: 1) Sei n die Tiefe von H. Bis zur Tiefe n-1 ist H vollständiger Binärbaum. 2) Die Blätter der Tiefe n sind linksbündig im Baum angeordnet. 3) Knoten sind items. Der Schlüssel jedes Knotens ist größer als die Schlüssel seiner direkten Nachfolger (Söhne).
 genau ein Knoten besitzt keine eingehende Kante (Wurzel) 2) alle übrigen Knoten besitzen genau 1 eingehende Kante. Ein Baum heißt Binärbaum, wenn alle Knoten höchstens 2 ausgehende Kanten besitzen (Knoten ohne ausgehende Kanten heißen Blätter) und wenn zwischen dem linken und re. Sohn eines Knotens unterschieden wird. Ein Binärbaum heißt vollständig, wenn es keinen Binärbaum derselben Tiefe mit mehr Knoten gibt. Die Tiefe ist die Länge des längsten gerichteten Pfades in einem Baum. Definition: Ein Heap H (deutsch: Halde) ist ein Baum, für den folgendes gilt: 1) Sei n die Tiefe von H. Bis zur Tiefe n-1 ist H vollständiger Binärbaum. 2) Die Blätter der Tiefe n sind linksbündig im Baum angeordnet. 3) Knoten sind items. Der Schlüssel jedes Knotens ist größer als die Schlüssel seiner direkten Nachfolger (Söhne).")
26
Beispiel: 9 6 7 2 3 4 Idee für Sortieren:
Heaps lassen sich einfach als Arrays realisieren: Knoten werden einfach von der Wurzel beginnend auf jeder Ebene von links nach rechts durchnumeriert. Knoten a[i] hat Söhne a[2i] und a[2i+1]. Heap-Bedingung: a[i] > a[2i] und a[i] > a[2i+1] maximales Element eines Heaps: Wurzel Idee für Sortieren: Heap für zu sortierende Elemente herstellen, maximales Element entfernen, Heap-Bedingung wiederherstellen usw. Wie macht man das? 1) Mache letztes Element e zur Wurzel 2) Vertausche e jeweils mit seinem größten Sohn, bis Heap-Bedingung erfüllt ist (lasse e versickern)
 Mache letztes Element e zur Wurzel. 2) Vertausche e jeweils mit seinem größten Sohn, bis Heap-Bedingung. erfüllt ist (lasse e versickern)")
27
if (j<N && a[j] < a[j+1]) j++; if (v >= a[j]) break;
Versickere void downheap (a[], N, k) { int j, v; v= a[k]; while (k <= N/2) j=k+k; if (j<N && a[j] < a[j+1]) j++; if (v >= a[j]) break; a[k] = a[j]; k= j; } a[k] = v;
![if (j<N && a[j] < a[j+1]) j++; if (v >= a[j]) break;](http://slideplayer.org/slide/633576/1/images/27/if+%28j%3CN+%26%26+a%5Bj%5D+%3C+a%5Bj%2B1%5D%29+j%2B%2B%3B+if+%28v+%3E%3D+a%5Bj%5D%29+break%3B.jpg "Versickere. void downheap (a[], N, k) { int j, v; v= a[k]; while (k <= N/2) j=k+k; if (j<N && a[j] < a[j+1]) j++; if (v >= a[j]) break; a[k] = a[j]; k= j; } a[k] = v;")
28
Heapsort heapsort (int a[ ], int N) /*sortiert a[1] bis a[N] */ {
int k, t; /*wandle a[1] bis a[N] in Heap um*/ for (k=N/2; k>=1; k- -) downheap (a, N, k); while (N>1) /*vertausche a[1] und a[N] und laß a[1] versickern*/ t= a[1]; a[1]= a[N]; a[N] = t; downheap (a, - -N, 1); } Worst case Komplexität: Aufruf von downheap erzeugt höchstens log N Vertauschungen. N/2 + N-1 mal aufgerufen, damit also O(N log N). Zusätzlicher Speicherplatz konstant, also echtes in situ (in place) Verfahren.
![Heapsort heapsort (int a[ ], int N) /*sortiert a[1] bis a[N] */ {](http://slideplayer.org/slide/633576/1/images/28/Heapsort+heapsort+%28int+a%5B+%5D%2C+int+N%29+%2F%2Asortiert+a%5B1%5D+bis+a%5BN%5D+%2A%2F+%7B.jpg "int k, t; /*wandle a[1] bis a[N] in Heap um*/ for (k=N/2; k>=1; k- -) downheap (a, N, k); while (N>1) /*vertausche a[1] und a[N] und laß a[1] versickern*/ t= a[1]; a[1]= a[N]; a[N] = t; downheap (a, - -N, 1); } Worst case Komplexität: Aufruf von downheap erzeugt höchstens log N Vertauschungen. N/2 + N-1 mal aufgerufen, damit also O(N log N). Zusätzlicher Speicherplatz konstant, also echtes in situ (in place) Verfahren.")
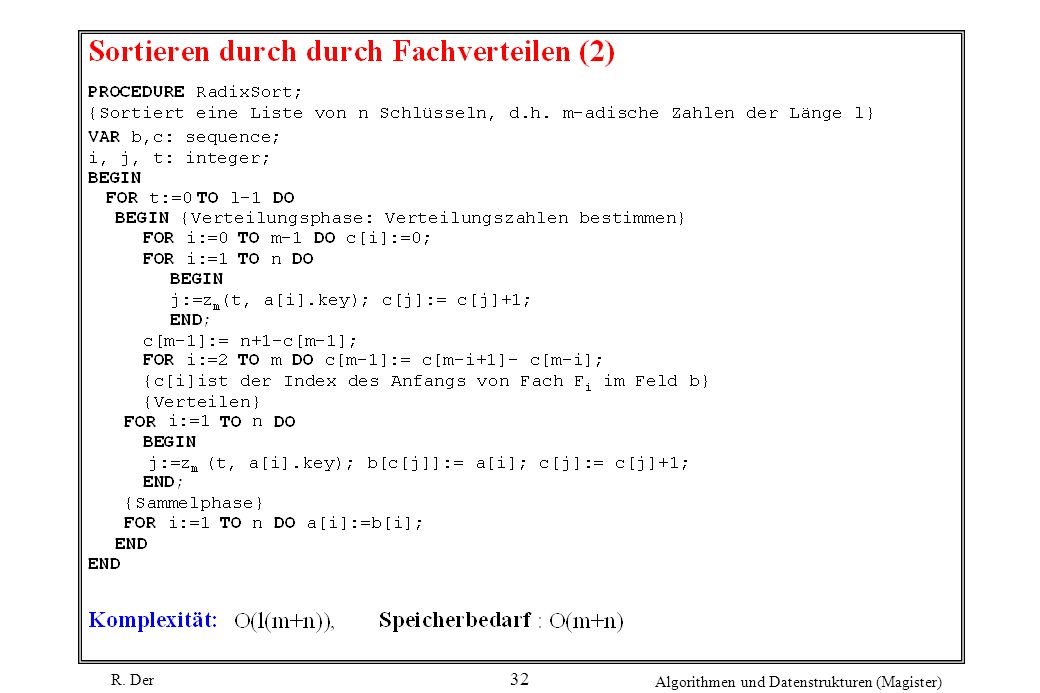
33
Mergesort John von Neumann, 1945 Algorithmus Mergesort (F)
Falls F leer oder einelementig -> Fertig. Sonst: Divide: Teile F in 2 möglichst gleichgroße Hälften F1, F2. Conquer: Sortiere L1 und L2 mittels Mergesort. Merge: Verschmelze die sortierten Teillisten zu sortierter Liste. Verschmelzen kann durch 2 Zeiger erfolgen, die die sortierten Teillisten durchwandern: Zeigen zunächst auf erstes Element, vergleichen Schlüssel, tragen kleineres item in konstruierte Liste ein und bewegen den Zeiger auf dieses Element um eine Position weiter.

34
Funktion mergesort mergesort (int a[], int l, int r) /*sortiert a[l] bis a[r] nach aufsteigenden Schlüsseln*/ { int i, j, k, m; if (r>1) /*Folge hat mindestens 2 Elemente*/ m= (r+l)/2; /*Mitte der Folge bestimmen*/ mergesort(a, l, m); mergesort(a, m+1, r); for (i=m+1; i>1; i--) b[i-1]= a[i-1]; for (j=m; j<r; j++) b[r+m-j]= a[j+1]; for (k=l;k<=r;k++) /*Zweiweg-Mischen*/ a[k]=(b[i]<b[j]) ? b[i++]: b[j--]; }}
![Funktion mergesort mergesort (int a[], int l, int r) /*sortiert a[l] bis a[r] nach aufsteigenden Schlüsseln*/](http://slideplayer.org/slide/633576/1/images/34/Funktion+mergesort+mergesort+%28int+a%5B%5D%2C+int+l%2C+int+r%29+%2F%2Asortiert+a%5Bl%5D+bis+a%5Br%5D+nach+aufsteigenden+Schl%C3%BCsseln%2A%2F.jpg "{ int i, j, k, m; if (r>1) /*Folge hat mindestens 2 Elemente*/ m= (r+l)/2; /*Mitte der Folge bestimmen*/ mergesort(a, l, m); mergesort(a, m+1, r); for (i=m+1; i>1; i--) b[i-1]= a[i-1]; for (j=m; j<r; j++) b[r+m-j]= a[j+1]; for (k=l;k<=r;k++) /*Zweiweg-Mischen*/ a[k]=(b[i]<b[j]) b[i++]: b[j--]; }}")
35
Komplexität: Beim Mischen werden Q(N) Schlüsselvergleiche gemacht. Rekursionstiefe logarithmisch beschränkt, insgesamt ergeben sich Q(N log N) Schlüsselvergleiche, denn C(N) = C(N/2) + C(N/2) + Q(N) = Q(N log N) Auch Anzahl der Bewegungen ist Q(N log N). nichtrekursive Varianten: Reines 2-Wege-Mergesort Es werden jeweils Teilfolgen der Länge 2, 4, 8 usw verschmolzen bis Folge sortiert ist. Dabei können kürzere Randstücke am rechten Rand übrigbleiben.
 Schlüsselvergleiche, denn. C(N) = C(N/2) + C(N/2) + Q(N) = Q(N log N) Auch Anzahl der Bewegungen ist Q(N log N). nichtrekursive Varianten: Reines 2-Wege-Mergesort. Es werden jeweils Teilfolgen der Länge 2, 4, 8 usw verschmolzen bis Folge sortiert ist. Dabei können kürzere Randstücke am rechten Rand übrigbleiben.")
36
Beispiel: 3 | 6 | 5 | 9 | 7 | 8 | 4 | 1 | 2 | 0 3 6 | 5 9 | 7 8 | 1 4 | 0 2 | | 0 2 | 0 2 Komplexität wie originales Mergesort

37
Natürliches 2-Wege-Mergesort
Verschmelzprozeß wird nicht mit einelementigen Listen begonnen, sondern mit möglichst langen bereits sortierten Teilfolgen. Jeweils zwei benachbarte Teilfolgen werden verschmolzen. Beispiel: 3 6 | | 1 8 | | Algorithmus nutzt Vorsortierung aus: falls Liste bereits sortiert, so wird das in O(N) Schritten festgestellt.
 Schritten festgestellt.")
38
Anmerkung: wie läßt sich Grad der Vorsortierung einer Folge F = k1,
Anmerkung: wie läßt sich Grad der Vorsortierung einer Folge F = k1,...,kn von Schlüsseln messen? Vorschlag 1: Zahl der Inversionen (Vertauschungen) von F inv(F) = |{(i,j) | 1 i < j n, ki > kj}| mißt so etwas wie Entfernungen zur richtigen Position Vorschlag 2: Anzahl der runs, d.h. der vorsortierten Teillisten (siehe oben) runs(F) = |{(i) | 1 i < n, ki+1 < ki}| + 1 Vorschlag 3: Länge der längsten sortierten Teilliste, las(F), bzw. rem(F) = n - las(F) (damit wie oben kleiner besser ist)
 von F. inv(F) = |{(i,j) | 1 i < j n, ki > kj}| mißt so etwas wie Entfernungen zur richtigen Position. Vorschlag 2: Anzahl der runs, d.h. der vorsortierten Teillisten (siehe oben) runs(F) = |{(i) | 1 i < n, ki+1 < ki}| + 1. Vorschlag 3: Länge der längsten sortierten Teilliste, las(F), bzw. rem(F) = n - las(F) (damit wie oben kleiner besser ist)")
39
Beispiele: F: inv(F): = = 5 runs(F): 3 6 | | 1 8 | | 0 3 | 2 5 | 4 7 | 6 9 | 8 rem(F): = = 8 Es gilt: 0 inv(F) n(n-1)/2 1 runs(F) n 0 rem(F) n-1
: | | 1 8 | | 0 3 | 2 5 | 4 7 | 6 9 | 8. rem(F): = = 8. Es gilt: 0 inv(F) n(n-1)/2. 1 runs(F) n. 0 rem(F) n-1.")
40
Zusammenfassung Sortierverfahren
best case average case worst case zus. Speicher Auswahl n n2 n2 1 Einfügen n n2 n2 1 Bubblesort n n2 n2 1 Quicksort n log n n log n n log n Heapsort n log n n log n n log n 1 Bucketsort n n n log n, n2 n Mergesort n log n n log n n log n n

Ähnliche Präsentationen






 auf.>")




>")

>")






>")
, leere Liste falls n=0 Listenelemente besitzen.>")
