Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
GWDG – Kurs Parallelrechner-Programmierung mit MPI MPI Punkt-zu-Punkt-Kommunikation Oswald Haan ohaan@gwdg.de

2
Nachrichten- Inhalt : 31.03 – 01. 04. 2015Parallelrechner-Programmierung mit MPI2 Nachrichtenaustausch Daten : Aus lokalen Speicherzellen Absender Empfänger Identifikation Größe : 3 kB Absender Empfänger Identifikation Größe : 3 kB Daten : In lokale Speicherzellen Proz. 1 Netz Proz. 2 Umschlag : Lokaler Speicher:

3
Blockierendes Senden: MPI_SEND MPI_SEND(buf, count, datatype, dest, tag, comm) IN buf initial address of send buffer (choice) IN countnumber of elements in send buffer (non-negative integer) IN datatype datatype of each send buffer element (handle) IN dest rank of destination (integer) IN tag message tag (integer) IN comm communicator (handle) Parallelrechner-Programmierung mit MPI331.03 – 01. 04. 2015

4
Blockierendes Senden mit mpi4py comm.Send(buf, dest = 0, tag = 0) IN comm communicator (MPI comm) IN buf object to be sent (numpy array) IN dest rank of destination (integer) IN tag message tag (integer) comm.send(buf, dest = 0, tag = 0) IN comm communicator (MPI comm) IN buf object to be sent (python object) IN dest rank of destination (integer) IN tag message tag (integer) Parallelrechner-Programmierung mit MPI431.03 – 01. 04. 2015

5
MPI_SEND: Nachricht Die gesendete Nachricht besteht aus count aufeinanderfolgenden Speicherzellen, die jeweils ein Element vom Typ datatype enthalten, beginnend bei der durch buf gegebenen Speicheradresse. Die Länge der Nachricht in Byte ist deshalb: count * Länge in Byte eines Elementes vom Typ datatype MPI Datentypen entsprechen den Standard-Datentypen von Fortran und C Zusätzliche Datentypen: MPI_BYTEein Byte (uninterpretiert) MPI_PACKED mit MPI_PACK generiertes Datenpaket Implementationsabhängig können weitere Datentypen definiert sein Parallelrechner-Programmierung mit MPI531.03 – 01. 04. 2015
 MPI_PACKED mit MPI_PACK generiertes Datenpaket Implementationsabhängig können weitere Datentypen definiert sein Parallelrechner-Programmierung mit MPI –")
6
MPI-eigene Datentypen: Fortran MPI datatype Fortran datatype MPI_INTEGER INTEGER MPI_REAL REAL MPI_DOUBLE_PRECISION DOUBLE PRECISION MPI_LOGICAL LOGICAL MPI_CHARACTER CHARACTER MPI_COMPLEX COMPLEX Parallelrechner-Programmierung mit MPI631.03 – 01. 04. 2015

7
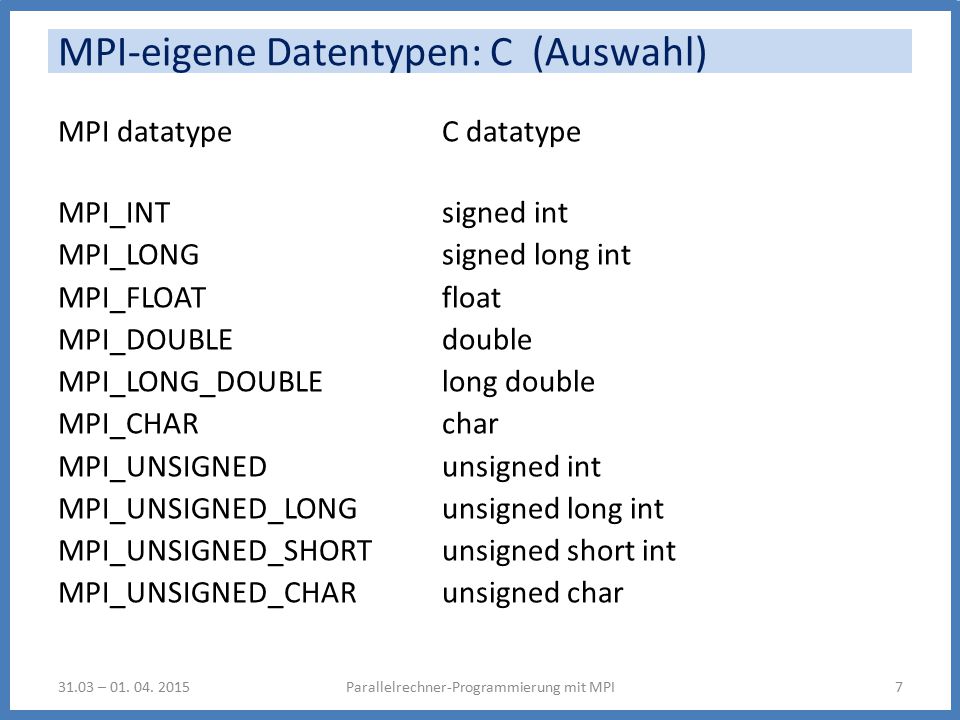
MPI-eigene Datentypen: C (Auswahl) MPI datatype C datatype MPI_INT signed int MPI_LONG signed long int MPI_FLOAT float MPI_DOUBLE double MPI_LONG_DOUBLE long double MPI_CHAR char MPI_UNSIGNED unsigned int MPI_UNSIGNED_LONG unsigned long int MPI_UNSIGNED_SHORT unsigned short int MPI_UNSIGNED_CHAR unsigned char Parallelrechner-Programmierung mit MPI731.03 – 01. 04. 2015
8
MPI-eigene Datentypen: mpi4py (Auswahl) MPI datatype mpi4py datatype MPI.INT signed int MPI.LONG signed long int MPI.FLOAT float MPI.DOUBLE double MPI.LONG_DOUBLE long double MPI.CHAR char Parallelrechner-Programmierung mit MPI831.03 – 01. 04. 2015

9
MPI_SEND: Nachrichten-Umschlag Parallelrechner-Programmierung mit MPI931.03 – 01. 04. 2015

10
Blockierendes Empfangen: MPI_RECV MPI_RECV (buf, count, datatype, source, tag, comm, status) OUT buf initial address of receive buffer (choice) IN count number of elements in receive buffer (non-negative integer) IN datatype datatype of each receive buffer element (handle) IN source rank of source or MPI_ANY_SOURCE (integer) IN tag message tag or MPI_ANY_TAG (integer) IN comm communicator (handle) OUT status status object (Status) Parallelrechner-Programmierung mit MPI1031.03 – 01. 04. 2015

11
Blockierendes Empfangen mit mpi4py comm.Recv(buf, source = 0, tag = 0, status = None) IN comm communicator (MPI comm) OUT buf object to be received (numpy array) IN source rank of source (integer) or MPI.ANY_SOURCE IN tag message tag (integer) or MPI.ANY_TAG OUT status status information (Status) buf = comm.recv(source = 0, tag = 0, status = None) IN comm communicator (MPI comm) OUT buf object to be received (python object) IN source rank of source (integer) or MPI.ANY_SOURCE IN tag message tag (integer) or MPI.ANY_TAG OUT status status information (Status) Parallelrechner-Programmierung mit MPI1131.03 – 01. 04. 2015

12
MPI_RECV: Nachricht Die empfangene Nachricht wird abgespeichert auf count aufeinanderfolgenden Speicherzellen, die jeweils ein Element vom Typ datatype erhalten, beginnend bei der durch buf gegebenen Speicheradresse. Die Länge der empfangenen Nachricht in Byte ist deshalb: count * Länge in Byte eines Elementes vom Typ datatype Die Länge der mit MPI_SEND gesendeten Nachricht darf die in MPI_RECV spezifizierte Länge der empfangenen Nachricht nicht überschreiten, sie kann aber kürzer sein. MPI_PROBE(source, tag, comm, status) mit identischen Argumenten wie MPI_RCV liefert über status Information über die zu empfangende Nachricht. Diese Information kann dann im eigentlichen MPI_RECV Aufruf verwendet werden, z.B. um einen genügend großen Empfangsbereich bereitzustellen Parallelrechner-Programmierung mit MPI1231.03 – 01. 04. 2015
 mit identischen Argumenten wie MPI_RCV liefert über status Information über die zu empfangende Nachricht. Diese Information kann dann im eigentlichen MPI_RECV Aufruf verwendet werden, z.B. um einen genügend großen Empfangsbereich bereitzustellen Parallelrechner-Programmierung mit MPI –")
13
Das Argument status in MPI_RECV Eigenschaften der empfangenen Nachricht können unbekannt sein, wenn MPI_ANY_SOURCE als Wert für source MPI_ANY_TAG als Wert für taggewählt wird und wenn die Länge der gesendeten Nachricht beim Empfänger nicht bekannt ist. Das Argument status stellt eine Struktur zur Verfügung, in der diese Eigenschaften hinterlegt sind. Die Abfrage des Status und der damit verbundene Aufwand wird vermieden, wenn als Argument für status MPI_STATUS_IGNORE verwendet wird. In mpi4py ist dieses Verhalten voreingestellt, wenn die Variable status nicht gesetzt wird. Parallelrechner-Programmierung mit MPI1331.03 – 01. 04. 2015

14
Das Argument status in MPI_RECV C: StrukturFORTRAN: Feld MPI_Status statusinteger status(MPI_STATUS_SIZE) status.MPI_SOURCEstatus(MPI_SOURCE) status.MPI_TAG status(MPI_TAG) status.MPI_ERROR status(MPI_ERROR) MPI_GET_COUNT(status, datatype, count) Berechnet aus den Anzahl der empfangenen Bytes die Zahl count der empfangenen Elemente vom Typ datatype Parallelrechner-Programmierung mit MPI1431.03 – 01. 04. 2015

15
Das Argument status in mpi4py mpi4py: status ist Struktur vom Typ Status status = MPI.Status() source = status.Get_source() tag = status.Get_tag() error = status.Get_error() count = status.Get_elements(mpi_datentyp) size = status.Get_count() count: Anzahl empfangener Elemente vom Typ mpi_datentyp size: Größe des empfangenen Objekts in Byte Parallelrechner-Programmierung mit MPI1531.03 – 01. 04. 2015

16
Nachricht vor Empfangen prüfen MPI_PROBE(MPI_ANY_SOURCE, MPI_ANY_TAG, comm, status) mpi4py: comm.Probe(source=MPI.ANY_SOURCE, tag=MPI.ANY_TAG, status=status) Parallelrechner-Programmierung mit MPI1631.03 – 01. 04. 2015

17
Verschiedene Modi für blockierendes Senden Gepuffertes Senden: MPI_BSEND(sbuf,... Puffer-Initialisierung: MPI_BUFFER_ATTACH(temp,size) endet, wenn sbuf nach temp kopiert ist: lokale Operation Synchrones Senden: MPI_SSEND(sbuf,... Endet, wenn sbuf nach rbuf kopiert ist: nichlokale Operation Sofortiges Senden: MPI_RSEND(sbuf,... Nur erlaubt, wenn MPI_RECV bereits gestartet ist Standard Implementierung: MPI_SEND(sbuf,... Kurze Nachrichten : in Puffer auf Empfängerseite Lange Nachrichten: synchrones Senden Aufruf von MPI_xSEND endet, wenn sbuf wieder verwendet werden kann Aufruf von MPI_RECV endet, wenn die Nachricht in rbuf abgespeichert ist. Parallelrechner-Programmierung mit MPI1731.03 – 01. 04. 2015
 endet, wenn sbuf nach temp kopiert ist: lokale Operation Synchrones Senden: MPI_SSEND(sbuf,... Endet, wenn sbuf nach rbuf kopiert ist: nichlokale Operation Sofortiges Senden: MPI_RSEND(sbuf,... Nur erlaubt, wenn MPI_RECV bereits gestartet ist Standard Implementierung: MPI_SEND(sbuf,... Kurze Nachrichten : in Puffer auf Empfängerseite Lange Nachrichten: synchrones Senden Aufruf von MPI_xSEND endet, wenn sbuf wieder verwendet werden kann Aufruf von MPI_RECV endet, wenn die Nachricht in rbuf abgespeichert ist. Parallelrechner-Programmierung mit MPI –")
18
Reihenfolge von Senden und Empfangen Mehrere Nachrichten werden in der Reihenfolge des Sendens empfangen: CALL MPI_COMM_RANK(comm, rank, ierr) IF (rank.EQ.0) THEN CALL MPI_SEND(buf1, count, MPI_INTEGER, 1, tag, comm, ierr) CALL MPI_SEND(buf2, count, MPI_REAL, 1, tag, comm, ierr) ELSE IF (rank.EQ.1) THEN CALL MPI_RECV(buf1, count, MPI_INTEGER, 0, tag, comm, status, ierr) CALL MPI_RECV(buf2, count, MPI_REAL, 0, tag, comm, status, ierr) END IF Parallelrechner-Programmierung mit MPI1831.03 – 01. 04. 2015

19
Reihenfolge: garantierter Deadlock CALL MPI_COMM_RANK(comm, rank, ierr) IF (rank.EQ.0) THEN CALL MPI_RECV(recvbuf, count, MPI_REAL, 1, tag, comm, status, ierr) CALL MPI_SEND(sendbuf, count, MPI_REAL, 1, tag, comm, ierr) ELSE IF (rank.EQ.1) THEN CALL MPI_RECV(recvbuf, count, MPI_REAL, 0, tag, comm, status, ierr) CALL MPI_SEND(sendbuf, count, MPI_REAL, 0, tag, comm, ierr) END IF Deadlock Parallelrechner-Programmierung mit MPI1931.03 – 01. 04. 2015

20
Reihenfolge: möglicher Deadlock CALL MPI_COMM_RANK(comm, rank, ierr) IF (rank.EQ.0) THEN CALL MPI_SEND(sendbuf, count, MPI_REAL, 1, tag, comm, ierr) CALL MPI_RECV(recvbuf, count, MPI_REAL, 1, tag, comm, status, ierr) ELSE IF (rank.EQ.1) THEN CALL MPI_SEND(sendbuf, count, MPI_REAL, 0, tag, comm, ierr) CALL MPI_RECV(recvbuf, count, MPI_REAL, 0, tag, comm, status, ierr) END IF Deadlock, wenn die Nachricht auf Senderseite nicht gepuffert wird Parallelrechner-Programmierung mit MPI2031.03 – 01. 04. 2015

21
Reihenfolge: garantiert kein Deadlock CALL MPI_COMM_RANK(comm, rank, ierr) IF (rank.EQ.0) THEN CALL MPI_SEND(sendbuf, count, MPI_REAL, 1, tag, comm, ierr) CALL MPI_RECV(recvbuf, count, MPI_REAL, 1, tag, comm, status, ierr) ELSE IF (rank.EQ.1) THEN CALL MPI_RECV(recvbuf, count, MPI_REAL, 0, tag, comm, status, ierr) CALL MPI_SEND(sendbuf, count, MPI_REAL, 0, tag, comm, ierr) END IF Zuerst: NachrichtTask 0 Task 1 Dann:Nachricht Task 1 Task 0 Parallelrechner-Programmierung mit MPI2131.03 – 01. 04. 2015

22
MPI_SENDRECV : kein Deadlock Parallelrechner-Programmierung mit MPI2231.03 – 01. 04. 2015 MPI_SENDRECV(sendbuf, sendcount, sendtype, dest, sendtag, recvbuf, recvcount, recvtype,source, recvtag, comm, status) IN sendbuf initial address of send buffer (choice) IN sendcount number of elements in send buffer (non-negative integer) IN sendtype type of elements in send buffer (handle) IN dest rank of destination (integer) IN sendtag send tag (integer) OUT recvbuf initial address of receive buffer (choice) IN recvcount number of elements in receive buffer (non-negative integer) IN recvtype type of elements in receive buffer (handle) IN source rank of source or MPI_ANY_SOURCE (integer) IN recvtag receive tag or MPI_ANY_TAG (integer) IN comm communicator (handle) OUT status status object (Status)
 IN sendbuf initial address of send buffer (choice) IN sendcount number of elements in send buffer (non-negative integer) IN sendtype type of elements in send buffer (handle) IN dest rank of destination (integer) IN sendtag send tag (integer) OUT recvbuf initial address of receive buffer (choice) IN recvcount number of elements in receive buffer (non-negative integer) IN recvtype type of elements in receive buffer (handle) IN source rank of source or MPI_ANY_SOURCE (integer) IN recvtag receive tag or MPI_ANY_TAG (integer) IN comm communicator (handle) OUT status status object (Status).")
23
Sendrecv mit mpi4py Parallelrechner-Programmierung mit MPI2331.03 – 01. 04. 2015 comm.Sendrecv (sendbuf, dest=0, sendtag=0, recvbuf=None, source=0, recvtag=0, status=None) IN comm communicator (MPI comm) IN sendbuf object to be sent (numpy array) IN dest rank of destination (integer) IN sendtag send tag (integer) OUT recvbuf object to be received (numpy array) IN source rank of source (integer) or MPI.ANY_SOURCE IN recvtag receive tag (integer) or MPI.ANY_TAG OUT status status information (Status)
 IN comm communicator (MPI comm) IN sendbuf object to be sent (numpy array) IN dest rank of destination (integer) IN sendtag send tag (integer) OUT recvbuf object to be received (numpy array) IN source rank of source (integer) or MPI.ANY_SOURCE IN recvtag receive tag (integer) or MPI.ANY_TAG OUT status status information (Status).")
24
fffs Nonblocking communication Parallelrechner-Programmierung mit MPI2431.03 – 01. 04. 2015 Overlapping of communication and computation bb isend data1 compute data2 Wait for completion of isend fffsbb isend data2 compute data1 Wait for completion of isend Task 0 fffsbb irecv data1 compute data2 Wait for completion of irecv fffsbb irecv data2 compute data1 Wait for completion of irecv Task 1

25
Example CALL MPI_COMM_RANK(comm, rank, ierr) IF (rank.EQ.0) THEN CALL MPI_ISEND(data1, count, MPI_REAL, 1, tag, comm, request1, ierr) CALL WORK(data2) CALL MPI_ISEND(data2, count, MPI_REAL, 1, tag, comm, request2, ierr) CALL MPI_WAIT(request1, status, ierr) CALL WORK(data1) CALL MPI_WAIT(request2, status, ierr)... ELSE IF (rank.EQ.1) THEN CALL MPI_IRECV(data1, count, MPI_REAL, 0, tag, comm, request1, ierr) CALL WORK(data2) CALL MPI_ISEND(data2, count, MPI_REAL, 0, tag, comm, request2, ierr) CALL MPI_WAIT(request1, status, ierr) CALL WORK(data1) CALL MPI_WAIT(request2, status, ierr)... END IF Parallelrechner-Programmierung mit MPI2531.03 – 01. 04. 2015
 THEN CALL MPI_IRECV(data1, count, MPI_REAL, 0, tag, comm, request1, ierr) CALL WORK(data2) CALL MPI_ISEND(data2, count, MPI_REAL, 0, tag, comm, request2, ierr) CALL MPI_WAIT(request1, status, ierr) CALL WORK(data1) CALL MPI_WAIT(request2, status, ierr)... END IF Parallelrechner-Programmierung mit MPI –")
Ähnliche Präsentationen
>")

 Funktionsaufruf kann.>")










 mit unterschiedlichen Datentypen (im Gegensatz zu Feldern) zusammengefaßt.>")





