Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Qualitative und quantitative Textanalyse PageRank

2
Problemstellung und Motivation Wer wir sind, was wir machen und der ganze Rest

3
Wir... ● Alexandra Danilkina, Fabian Fier und Thomas Krause ● alle Informatiker ● Linguist?

5
Unser Thema ● „irgendwas mit PageRank“ ● „mit Linguisten zusammensetzen und mögliches konkretes Thema finden“

6
Unser Thema ● Problem: PageRank bezieht sich nur auf die Links, nicht auf sprachliche Elemente ● Korpus enthält keine Links ● nach langer Suche doch noch fündig geworden

7
Unser Thema Neologismus [Pl. Neologismen; griech. néos "neu", lògos "Wort"] (1) Neugebildeter sprachlicher Ausdruck (Wort oder Wendung), der zumindest von einem Teil der Sprachgemeinschaft, wenn nicht im allgemeinen, als bekannt empfunden wird, zur Bezeichnung neuer Sachverhalte, sei es in der Technik oder Industrie, oder neuer Konzepte, etwa in Politik, Kultur und Wissenschaft. [...] (zitiert nach wortwarte.de, wiederum entnommen von Hadumod Bußmann; Lexikon der Sprachwissenschaft, 2. Auflage 1990)
 Neugebildeter sprachlicher Ausdruck (Wort oder Wendung), der zumindest von einem Teil der Sprachgemeinschaft, wenn nicht im allgemeinen, als bekannt empfunden wird, zur Bezeichnung neuer Sachverhalte, sei es in der Technik oder Industrie, oder neuer Konzepte, etwa in Politik, Kultur und Wissenschaft. [...] (zitiert nach wortwarte.de, wiederum entnommen von Hadumod Bußmann; Lexikon der Sprachwissenschaft, 2. Auflage 1990).")
8
Unser Thema Neologism en Verlinkung ?

9
Unser Thema ● Arbeitshypothese: Die Verlinkung und die Entwicklung neuer Worte auf Webseiten könnten zusammenhängen ● PageRank als Maß für die Wichtigkeit einer Seite und damit möglicher Indikator für den Ursprung eines Begriffes

10
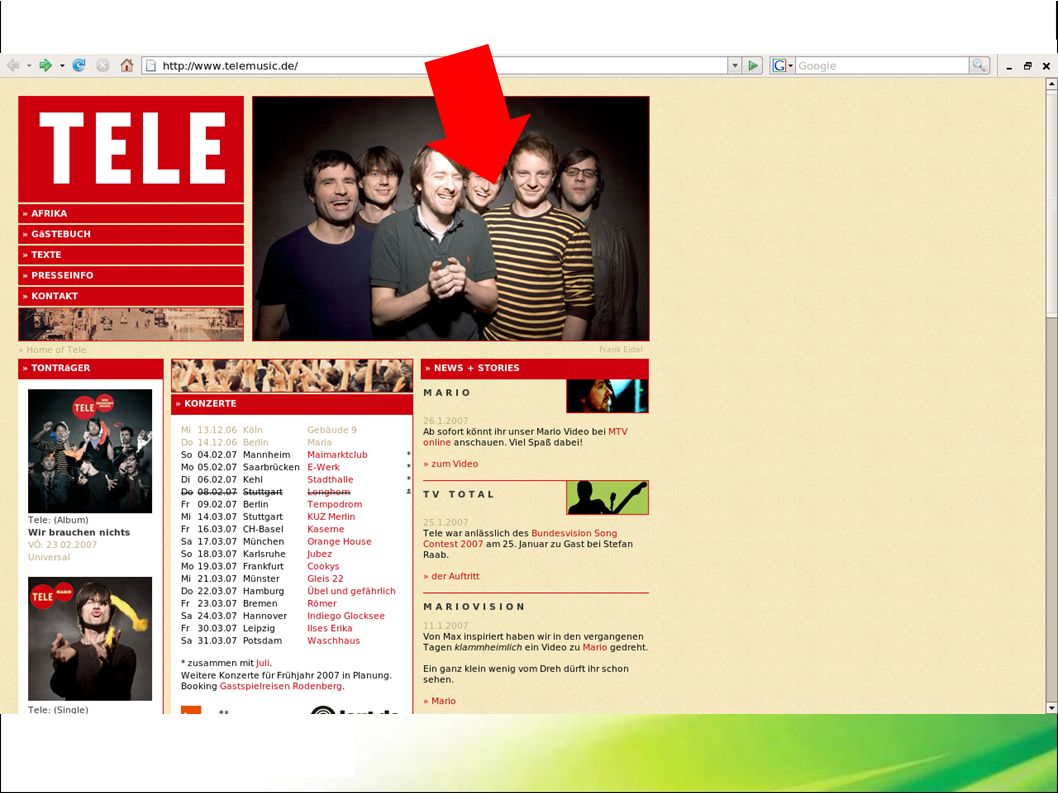
Unser Thema ● Verbreitung neuer Worte kann denen von Epidemien ähneln ● Einfluss anderer Sprachen ● Was bewegt die Menschen gerade? ● Was für Worte halten sich, welche sind Eintagsfliegen? ● wortwarte.de von der Universität Tübingen

11
Unser Thema ● Idee: Suche nach neuen Wörtern bei Google und Auswertung der Suchergebnisse ● PageRank berechnen und graphische Aufarbeitung ● Visualisierung der Verlinkungsstruktur

12
Ein wenig Geschichte Oder wie Google das wurde was es heute ist

13
Google Geschichte ● Gründer: Larry Page und Sergey Brin ● Studenten in Stanford ● innovative Suchmaschine BackRub (1996): berücksichtigt zum ersten mal „back links“ (später mehr dazu)
: berücksichtigt zum ersten mal „back links (später mehr dazu)")
14
Google Geschichte ● Wahlmöglichkeiten zu dieser Zeit: – entweder sehr spezieller Suchbegriff: Suchmaschine (AltaVista und Co.) – oder bei allgemeineren Begriffen: Verzeichnisse (Yahoo,...)
 – oder bei allgemeineren Begriffen: Verzeichnisse (Yahoo,...)")
15
Google Geschichte ● Verzeichnisse wurden manuell von Menschen gepflegt: lange Latenzzeiten beim Eintragen ● Suchmaschinen lieferten (zu) viele unspezifische Ergebnisse ● Überladene Portalseiten mit Nachrichten, Gewinnspielen und massiver Werbung, auch wenn man „nur“ mal suchen möchte
 viele unspezifische Ergebnisse ● Überladene Portalseiten mit Nachrichten, Gewinnspielen und massiver Werbung, auch wenn man „nur mal suchen möchte")
16
Google Geschichte ● Googles Vorteile: – bis dato unschlagbare Heuristik (allem voran PageRank): wichtige Seiten erscheinen schon unter den ersten Treffern – simple Oberfläche – hochaktuell und enorme Anzahl indexierter Seiten: erreicht durch (fast) vollständige Automatisierung
: wichtige Seiten erscheinen schon unter den ersten Treffern – simple Oberfläche – hochaktuell und enorme Anzahl indexierter Seiten: erreicht durch (fast) vollständige Automatisierung")
17
Google Geschichte ● aus „BackRub“ wird Google ● 1998: Einstieg des ersten Investors (Andy Bechtolsheim, Sun Mitbegründer) ● Juni 1999: weitere Investoren, insgesamt 25 Mio. USD Startkapital ● September 1999: beta-Status wird aufgegeben

18
Google Geschichte ● wie verdient so eine Suchmaschine Geld? ● Lizensierung der Suche durch andere Web- Firmen ● seit 2000: AdWords: – unauffällige suchwortabhängige kleine Werbetexte – seit 2002: cost-per-click Bezahlmodell – Anzeigen stehen untereinander in Konkurrenz

19
Google Geschichte ● und Google verdient gut... ● seit 4. Quartal 2001 mit Gewinn ● Einkaufstouren und Expansion, eine kleine Auswahl – Usenet-Archiv Deja.com – Bildersuche – Google E-Mail – Google News

20
Google Geschichte – blogger.com – Google Toolbar und Deskbar – Picasa – Google Earth – Google Video und Youtube ● enorme Vielfalt und Reichweite ● Börsengang, 24.10.2006 Marktwert von 147 Mrd. $ (IBM 139 Mrd. $)
.")
21
Google Geschichte ● „don't be evil“ ● Campus-Charakter der Google Inc. ● Forschung und Innovation ● z.B. Peter Norvig als „Director of Research“ (sehr bekannt in der Künstlichen Intelligenz- Forschung)
.")
22
Google Geschichte ● zensierte Ergebnisse in Ländern wie China ● „Datensammelwut“ ● automatische Auswertung von privaten Daten (z.B. bei Google E-Mail) ● Größe macht unheimlich
 ● Größe macht unheimlich.")
23
Zwischenfazit ● vom Campus-Projekt zum Giganten (in wenigen Jahren) ● Innovation und Benutzerfreundlichkeit ● Expansion ● viel Licht, viel Schatten
 ● Innovation und Benutzerfreundlichkeit ● Expansion ● viel Licht, viel Schatten")
24
PageRank Theorie

25
● Suchmaschinenproblematik ● Situation aus Sicht der Benutzer, Suchmaschinen ● Ranking, PageRank ● Random-Surfer-Modell ● Dangling Links

26
Situation aus der Benutzersicht ● Unüberschaubare Menge an Webseiten ● Unterschiedliche Qualität und Zielgruppen der Seiten ● Siehe Beispiel Autoverkauf

27
Situation aus der Sicht der Suchmaschinen ● Es gibt mehrere Milliarden Webpages ● Mehrere Hundert Millionen verschiedene Themen müssen indiziert werden ● Pro Tag müssen hundert Millionen Suchanfragen beantwortet werden

28
Lösungsansatz ● Möglicher Ansatz: Trennung zwischen relevanten und nicht-relevanten Seiten ● aber: reicht nicht aus ● Entscheidend: Reihenfolge bei Präsentation der Treffer

29
Klassische Heuristiken der Suchmaschinen ● viele Suchbegriffe tauchen im Titel auf ● Suchbegriff kommt oft im Inhalt der Seite vor ● URL ist nicht lang → Seite ist relevant

30
Ranking allgemein ● Mechanismus zur Relevanzbewertung von Suchergebnissen ● Suchergebnisse werden in der Regel in absteigender Reihenfolge dargestellt

31
PageRank PageRank ist eine Methode die Webseiten maschinell, effektiv und abhängig vom menschlichen Interesse nach Wichtigkeit und Relevanz einzuordnen.

32
PageRank: Idee ● Internet als gerichteter Graph ● Webpages - Knoten ● Links – Kanten ● PageRank – eine Zahl für Sortierung der Ergebnisse

33
Web als gerichteter Graph A A B B C C A und B sind Backlinks (eingehende) von C C ist ein ForwardLink von A u. B Unterscheidung von Links wichtig

34
Annahmen ● Links als implizite Aussage über (subjektive) hohe Meinung von Seiten, auf die Links verweisen ● viele Verweise auf eine Seite →Seite ist „wichtig“ ● Seite hat wenige Links→Jeder Link ist „wichtig“ ● Link kommt von einer „wichtigen“ Seite→Link ist „wichtig“
 hohe Meinung von Seiten, auf die Links verweisen ● viele Verweise auf eine Seite →Seite ist „wichtig ● Seite hat wenige Links→Jeder Link ist „wichtig ● Link kommt von einer „wichtigen Seite→Link ist „wichtig")
35
Beschreibung vom Algorithmus 1. Jeder Knoten (Seite) kriegt einen Startwert (z.B. 1/# Knoten) WIEDERHOLE bis Knotengewichte konvergiert sind: 2.Gewichte der Kanten Bestimmen als Gewicht des Knotens / # Links 3.Berechne Knotengewichte aus den Backlinks neu als ∑ Kantengewichte
 WIEDERHOLE bis Knotengewichte konvergiert sind: 2.Gewichte der Kanten Bestimmen als Gewicht des Knotens / # Links 3.Berechne Knotengewichte aus den Backlinks neu als ∑ Kantengewichte.")
36
PageRank mathematisch (etwas vereinfacht) u - eine Webseite B u - Menge der Seiten, die Links auf u enthalten N u – Anzahl Links in u Faktor c < 1
 u - eine Webseite B u - Menge der Seiten, die Links auf u enthalten N u – Anzahl Links in u Faktor c < 1")
37
Nachteil der vereinfachten Definition ● Rank Sinks - zyklisch verlinkte Seiten mit einem Eingang, aber ohne Ausgang (genauer später) ● PageRank erhöht sich innerhalb des Zyklus, ohne nach „außen“ abgegeben zu werden ∞ ∞ ∞
 ● PageRank erhöht sich innerhalb des Zyklus, ohne nach „außen abgegeben zu werden ∞ ∞ ∞")
38
Lösung – Rank Source Rank Source - Vektor E, der jeder Seite bei jeder Iteration einen gewissen konstanten „Bonus“ gibt

39
Matrixnotation (1) A: quadratische Matrix, in der Spalten und Zeilen Webseitenentsprechend gefüllt sind:
 A: quadratische Matrix, in der Spalten und Zeilen Webseitenentsprechend gefüllt sind:")
40
Matrixnotation (2) 1 2 3 5 4 = A Pagerank ausrechnen: R = cAR
 = A Pagerank ausrechnen: R = cAR")
41
Random-Surfer-Modell (1) ● Zufalls-Surfer befindet sich mit einer bestimmten Wahrscheinlichkeit auf einer Website (aus PageRank berechnet) ● P(Verfolgung von Links nicht abgebrochen ≡ weiterklicken) = Dämpfungsfaktor ● Es ergibt sich eine Kette von verlinkten besuchten Seiten ● „Langeweile“ → Unterbrechung der Kette, (= Aufruf einer komplett neuen Seite )
 ● Zufalls-Surfer befindet sich mit einer bestimmten Wahrscheinlichkeit auf einer Website (aus PageRank berechnet) ● P(Verfolgung von Links nicht abgebrochen ≡ weiterklicken) = Dämpfungsfaktor ● Es ergibt sich eine Kette von verlinkten besuchten Seiten ● „Langeweile → Unterbrechung der Kette, (= Aufruf einer komplett neuen Seite )")
42
Random-Surfer-Modell (2) ● Gewicht einer Seite als Wahrscheinlichkeit, dass ein zufälliger Surfer sich auf dieser Seite befindet ● Rank Source die Wahrscheinlichkeit für die Wahl einer best. Seite als neuer Startseite ● Surfer bleibt nicht in einem Rank Sink hängen

43
Dangling Links ● Links, die auf eine Seite, die keine ausgehende Links hat, zeigen ● → PageRank Sick ● Diese Einträge (Dangling Links) entfernen bis PageRank ausgerechnet ist, danach Werte den Seiten zuweisen Iteration 1 Iteration 2 A A B B C C
 entfernen bis PageRank ausgerechnet ist, danach Werte den Seiten zuweisen Iteration 1 Iteration 2 A A B B C C")
44
Implementation

45
Warum Java? ● Einfach ● Plattformübergreifend ● bereits vertraut Ideal für einen kleinen Prototyp

46
Aufbau

47
DataStructure Repräsentiert eine Internetseite: ● ID / URL ● PageRank ● LinkIDs / LinkURLs ● next

48
DataStructure ● diverse getter- / setter-Methoden ● toString für einfache Ausgabe Einfach verkettete lineare Struktur (linearisierter Graph -> Algorithmus)
")
49
AdvancedCrawler Eingabe: Suchwort Ausgabe: DataStructure, die die Suchergebnisse repräsentiert => Parsen der HTML-Ausgaben max. 800-900 Suchergebnisse (von „ungefähr 955.000.000“)
.")
50
HTTPCrawler Eingabe: URL Ausgabe: String der korrespondierenden Internetseite wget: problematisch (Google blockiert, zuverlässig aber langsam) Greedy (enge Timeouts) Benutzt: Apache Commons HTTPClient
 Greedy (enge Timeouts) Benutzt: Apache Commons HTTPClient")
51
LinkParser Eingabe: HTML-Seiten Ausgabe: Liste der darin enthaltenen Links, möglichst keine PDFs oder (Google- )Suchergebnisse Reguläre Ausdrücke: ]*href=\"?http://[^(>| )]*\"?[^>]*>
![LinkParser Eingabe: HTML-Seiten Ausgabe: Liste der darin enthaltenen Links, möglichst keine PDFs oder (Google- )Suchergebnisse Reguläre Ausdrücke: ]*href=\ )]*\ [^>]*>](http://images.slideplayer.org/40/11230211/slides/slide_51.jpg "LinkParser Eingabe: HTML-Seiten Ausgabe: Liste der darin enthaltenen Links, möglichst keine PDFs oder (Google- )Suchergebnisse Reguläre Ausdrücke: ]*href=\ )]*\ [^>]*>")
52
PageRankAlgorithm initialisiert die DataStructure (URLs -> IDs, linkURLs -> linkIDs) berechnet den "Quell"-PageRank jeder Seite (0,15/#Seiten) = zufälliger Surfer Berechnet einmalig (Verlinkungs-)Matrix T
 berechnet den Quell -PageRank jeder Seite (0,15/#Seiten) = zufälliger Surfer Berechnet einmalig (Verlinkungs-)Matrix T")
53
PageRankAlgorithm Methode makeAnIteration: - Berechnet neuen PageRank und speichert ihn in die vorliegende DataStructure - gibt delta zurück: Differenz zwischen altem und neuem PageRank (könnte man als Abbruchkriterium verwenden)
")
54
Demonstration

55
Wortwarte

59
Implementierung: Kritik ● Duplikate? Anker? Interne Links? ● Threads ● Effizienz ● Google-Optimierungen: Enthalten die Seiten die Begriffe überhaupt? ● Google als Blackbox benutzt, aber eigener Suchindex viel zu aufwendig ● nur erste Tiefe der Suchergebnisse untersucht

Ähnliche Präsentationen








>")




 Wege Prof. Dr. Th. Ottmann.>")

 Prof. Th. Ottmann.>")




