Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Algorithm Engineering Parallele Algorithmen Stefan Edelkamp

2
Übersicht Parallele Externe Suche Parallele Verspätete Duplikatselimination Parallele Expansion Verteilte Sortierung Parallele Strukturierte Duplikatselimination Disjunkte Duplikatserkennungsbereiche Schlöser Parallele Algorithmen Matrix-Multiplikation List Ranking Euler Tour

3
Verteilte Suche Distributed setting provides more space. Experiments show that internal time dominates I/O.

4
Exploiting Independence Since each state in a Bucket is independent of the other – they can be expanded in parallel. Duplicates removal can be distributed on different processors. Bulk (Streamed) transfers much better than single ones.
 transfers much better than single ones..")
5
Distributed Queue for Parallel Best- First Search P0 P1 P2 TOP Beware of the Mutual Exclusion Problem!!!

6
Multiple Processors - Multiple Disks Variant Sorted buffers w.r.t the hash val Sorted Files P1 P2 P3P4 Divide w.r.t the hash ranges Sorted buffers from every processor Sorted File h 0 ….. h k-1 h k ….. h l-1

7
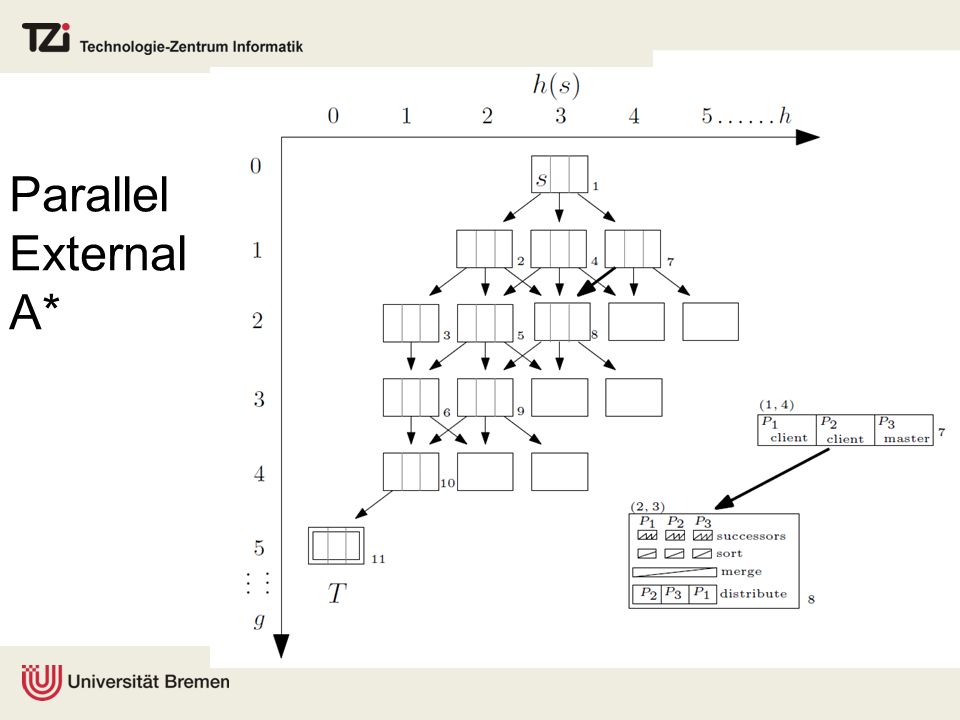
Parallel External A*

10
Distributed Heuristic Evaluation Assume one child processor for each tile one master processor B3B3 B1B1 B2B2 B8B8 B4B4 B5B5 B6B6 B7B7 B9B9 B 10 B 11 B 12 B 13 B 14 B 15 B0B0 B3B3 B1B1 B2B2 B8B8 B4B4 B5B5 B6B6 B7B7 B9B9 B 10 B 11 B 12 B 13 B 14 B 15 B0B0

11
Distributed Pattern Database Search Only pattern databases that include the client tile need to be loaded on the client Because multiple tiles in pattern, from birds eye PDB loaded multiple times In 15-Puzzle with corner and fringe PDB this saves RAM in the order of factor 2 on each machine, compared to loading all In 36-Puzzle with 6-tile pattern databases this saves RAM in the order of factor 6 on each machine, compared to loading all Extends to additive pattern databases

12
Distributed Heuristic Evaluation

13
Same bottleneck in external-memory search Bottleneck: Duplicate detection Duplicate paths cause parallelization overhead A C D B BCDDDD Internal memory External memory vs. fast slow A

14
Disjoint duplicate-detection scopes B1B1 B0B0 B4B4 B0B0 B3B3 B1B1 B2B2 B8B8 B4B4 B5B5 B6B6 B7B7 B9B9 B 10 B 11 B 12 B 13 B 14 B 15 B0B0 B1B1 B4B4 B3B3 B2B2 B7B7 B2B2 B3B3 B7B7 B 12 B8B8 B 13 B 15 B 14 B 11 B8B8 B 12 B 13 B 11 B 15 B 14

15
Finding disjoint duplicate-detection scopes B1B1 B0B0 B4B4 0000 0 0 000 00 1 0000 0 1 1 0 2 1 B2B2 B3B3 B7B7 0 1 0 B8B8 B 12 B 13 B 11 B 15 B 14 1 2 2 01 2 2 2 2 1 2 2 2 2 2 0 1 1 1 0 1 0 2 3 3 2 B1B1 B5B5 B6B6 B4B4 B9B9 2 3 3 4 3 3

16
Implementation of Parallel SDD Hierarchical organization of hash tables One hash table for each abstract node Top-level hash func. = state-space projection func. Shared-memory management Minimum memory-allocation size m Memory wasted is bounded by O(m #processors) External-memory version I/O-efficient order of node expansions I/O-efficient replacement strategy Benötigt nur ein Mutex Schloss B3B3 B1B1 B2B2 B8B8 B4B4 B5B5 B6B6 B7B7 B9B9 B 10 B 11 B 12 B 13 B 14 B 15 B0B0
 External-memory version I/O-efficient order of node expansions I/O-efficient replacement strategy Benötigt nur ein Mutex Schloss B3B3 B1B1 B2B2 B8B8 B4B4 B5B5 B6B6 B7B7 B9B9 B 10 B 11 B 12 B 13 B 14 B 15 B0B0.")
17
Parallelle Matrix- Multiplication

19
Parallele Matrix Multiplication

20
Exklusives Schreiben

21
Parallele Kopien

22
Fazit Matrix Multiplication

23
Paralleles List Ranking

24
List Ranking

25
Erster Algorithmus

26
Prinzip

27
Komplexität

28
Verbesserungen

29
Strategie

30
Unabhängige Mengen

31
2-Färbung

32
Reduktion

33
Restauration

34
Beispiel

35
Variablen

36
Beispiel (ctd.)
")
37
Pseudo Code

38
Nächster Schritt

39
Analyse

40
Backup

41
Algo

43
Speicher

44
Analyse

45
Ausblick: Randomisiert in O(n) whp?
 whp")
46
Probleme mit DFS

47
Idee Euler Tour

48
Parallel DFS

49
DFS Nummern

50
Allgemein

53
Beispiel

54
Ein Zyklus oder mehrere?

55
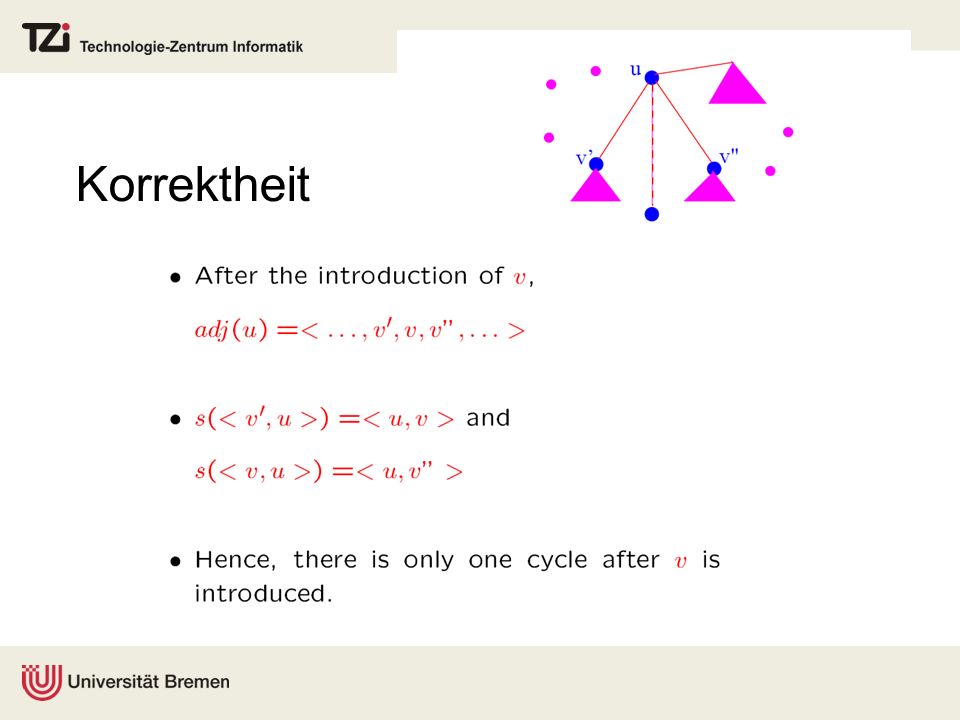
Korrektheit

57
Beispiel

58
Konstruktion Euler Tour

59
Fazit Euler Touren

60
GPU Architektur

61
Effektivität

62
Hierarchischer Speicher

63
Hash-based Partitioning

64
BFS

65
Kernel Functions

Ähnliche Präsentationen