Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
4 Sortierverfahren 4.1 Einführung 4.2 Naive Sortierverfahren
InsertionSort (Sortieren durch Einfügen) BubbleSort (Aufsteigen von Blasen) SelectionSort (Sortieren durch Auswählen) Vergleich der naiven Sortierverfahren 4.3 Effiziente Sortierverfahren "divide and conquer" MergeSort QuickSort Vergleich verschiedener Sortierverfahren 4.4 Ein untere Schranke für Sortierverfahren
 BubbleSort (Aufsteigen von Blasen) SelectionSort (Sortieren durch Auswählen) Vergleich der naiven Sortierverfahren. 4.3 Effiziente Sortierverfahren divide and conquer MergeSort QuickSort Vergleich verschiedener Sortierverfahren. 4.4 Ein untere Schranke für Sortierverfahren.")
2
4.1 Einführung Zuerst: Verfahren, die keine besondere Datenstruktur erfordern, sondern nur Array oder lineare Liste. Das Sortierproblem: Gegeben: eine Menge X von Elementen xi (i = 1, ... , n) und eine Abbildung k: X -> C ("key" / Schlüssel), wobei auf dem Bildbereich C eine Ordnungsrelation "<<" definiert ist. Gesucht: eine Anordnung der Elemente von X als xi', so dass für alle i < j: k(xi') << k(xj').
 und. eine Abbildung k: X -> C ( key / Schlüssel), wobei auf dem Bildbereich C eine Ordnungsrelation << definiert ist. Gesucht: eine Anordnung der Elemente von X als xi , so dass für alle i < j: k(xi ) << k(xj ).")
3
Die Menge X wird in der Regel als
Array [1..n] of El oder List of El repräsentiert, wobei El der Typ der zu sortierenden Elemente ist. El kann selbst zusammengesetzt sein (z.B. Verbundtyp oder Class). Vereinfachung (reicht zur Erläuterung von Sortieralgorithmen): die Elemente von X sind selbst Zahlen mit der üblichen Ordnung. Also: X[i] < X[j] anstelle von k(xi) << k(xj).
. Vereinfachung (reicht zur Erläuterung von. Sortieralgorithmen): die Elemente von X sind selbst Zahlen. mit der üblichen Ordnung. Also: X[i] < X[j] anstelle von k(xi) << k(xj).")
4
Allgemeiner Lösungsansatz
Viele Sortierverfahren sind Variationen des folgenden Grundmusters: Solange es Indexpaare (i,j) mit 1 i < j n und X[i] > X[j] gibt, vertausche X[i] mit X[j]. Daher benötigt: Grundoperationen für paarweisen Vergleich zweier Elemente sowie für das Vertauschen. Dies geschieht im Array üblicherweise mittels einer Vertauschoperation swap(Array, i, j), die als destruktive (nicht kopierende) Prozedur realisiert wird. Das Sortieren von Listen wird meist funktional implementiert, wobei der Listenparameter jeweils kopiert wird. Grundoperationen (Funktionen) sind hier: isempty(List) -> Boolean first(List) -> El butFirst(List) -> List insertFirst(El, List) -> List (statt insertFirst auch: cons(El, List))
 mit 1 i < j n und X[i] > X[j] gibt, vertausche X[i] mit X[j]. Daher benötigt: Grundoperationen für. paarweisen Vergleich zweier Elemente sowie für das. Vertauschen. Dies geschieht im Array üblicherweise mittels einer Vertauschoperation swap(Array, i, j), die als destruktive (nicht kopierende) Prozedur realisiert wird. Das Sortieren von Listen wird meist funktional implementiert, wobei der Listenparameter jeweils kopiert wird. Grundoperationen (Funktionen) sind hier: isempty(List) -> Boolean. first(List) -> El. butFirst(List) -> List. insertFirst(El, List) -> List. (statt insertFirst auch: cons(El, List))")
5
Bemerkung zur Indizierung
In der obigen Definition des Sortierproblems ist zur Ablage der Menge X von einem Feld Array[1..n] ausgegangen worden. In Programmiersprachen wie C oder Java werden allerdings Felder mit n Elementen von 0 bis n-1 indiziert. Dies ist bei der Verwendung dieser Programmiersprachen in der Definition entsprechend anzupassen (vgl. auch die Beispiele in Java; dort wird auf das Element s[0] zugegriffen!).
.")
6
Terminologie Sortieren in situ (am Ort): Die zu sortierenden Datensätze werden in einem Array gehalten und nicht kopiert. Stabiles Sortierverfahren: Elemente mit gleichem Schlüssel werden nicht vertauscht. Internes vs. externes Sortieren: Die Daten liegen vollständig im Hauptspeicher vor bzw. nicht. (Externes Sortieren ist - obwohl hier zunächst nicht behandelt - von größerer praktischer Bedeutung!) Allgemeingültige und spezielle Verfahren: Erstere beruhen auf dem paarweisen Vergleich von Elementen (d.h. ihrer Schlüssel) und machen - im Gegensatz zu den speziellen - keine Annahmen über den Wertebereich und die Struktur der Elemente.
 Allgemeingültige und spezielle Verfahren: Erstere beruhen auf dem paarweisen Vergleich von Elementen (d.h. ihrer Schlüssel) und machen - im Gegensatz zu den speziellen - keine Annahmen über den Wertebereich und die Struktur der Elemente.")
7
4.2 Naive Sortierverfahren
Drei „naive“ Sortierverfahren“: InsertionSort (Sortieren durch Einfügen) BubbleSort (Aufsteigen von Blasen) SelectionSort (Sortieren durch Auswählen) Effizienzanalyse jeweils: günstigster Fall (best case), ungünstigster Fall (worst case) und durchschnittlicher Fall (average case: "av").
 BubbleSort (Aufsteigen von Blasen) SelectionSort (Sortieren durch Auswählen) Effizienzanalyse jeweils: günstigster Fall (best case), ungünstigster Fall (worst case) und. durchschnittlicher Fall (average case: av ).")
8
4.2.1 InsertionSort (Sortieren durch Einfügen)
Zu sortieren: eine Folge x1, ..., xn. Idee: Für i=2 bis n do /** Annahme: die Teilfolge x1, ..., xi-1 ist sortiert */ füge xi an der richtigen Stelle in die Teilfolge x1, ..., xi-1 ein. InsertionSort ist ein stabiles in situ-Verfahren.

9
algorithm InsertionSort(s: List of El) -> List of El {
wenn isempty(s) dann rückgabe s; rückgabe insert(first(s), insertionSort(butFirst(s)) } function insert(x: El, s: List of El) -> List of El { wenn isempty(s) dann rückgabe list(x); wenn x < first(s) dann rückgabe insertFirst(x,s) sonst rückgabe insertFirst(first(s), insert(x, butFirst(s)) } Die Funktion insert(x: El, s: List) setzt s als vorsortierte Liste voraus.
 dann rückgabe s; rückgabe insert(first(s), insertionSort(butFirst(s)) } function insert(x: El, s: List of El) -> List of El { wenn isempty(s) dann rückgabe list(x); wenn x < first(s) dann rückgabe insertFirst(x,s) sonst rückgabe insertFirst(first(s), insert(x, butFirst(s)) } Die Funktion insert(x: El, s: List) setzt s als vorsortierte Liste voraus.")
10
Implementierung in Java:
/** Sortieren durch Einfuegen */ void InsertionSort(int[] s) { for (int i=1; i < s.length; i++) for (int j=i; (j > 0) && (s[j] < s[j-1]); j--) Swap(s,j,j-1); }
 { for (int i=1; i < s.length; i++) for (int j=i; (j > 0) && (s[j] < s[j-1]); j--) Swap(s,j,j-1); }")
11
Effizienzanalyse: günstigster Fall (best case),
hier: aufsteigende Vorsortierung, ungünstigster Fall (worst case), hier: absteigende Vorsortierung, durchschnittlicher Fall (average case: "av"). Zahl der Vergleiche: C(n) (comparisons) Zahl der Vertauschungen: S(n) (swaps). Sbest = = O(1) Sav = n(n-1) / 4 = O(n²) Sworst = n (n-1) / 2 = O(n²) Cbest = n = O(n) Cav = Sav + (n-1) = n (n-1) / 4 + (n-1) = O(n²) Cworst = n (n-1) / 2 = O(n²)
, hier: absteigende Vorsortierung, durchschnittlicher Fall (average case: av ). Zahl der Vergleiche: C(n) (comparisons) Zahl der Vertauschungen: S(n) (swaps). Sbest = 0 = O(1) Sav = n(n-1) / 4 = O(n²) Sworst = n (n-1) / 2 = O(n²) Cbest = n-1 = O(n) Cav = Sav + (n-1) = n (n-1) / 4 + (n-1) = O(n²) Cworst = n (n-1) / 2 = O(n²)")
12
4.2.2 BubbleSort (Aufsteigen von Blasen)
Zu sortieren: eine Folge x1, ..., xn. Idee: Durchlaufe das Feld von hinten nach vorne und vertausche zwei benachbarte Elemente, wenn sie nicht in der korrekten Reihenfolge stehen. In jedem Einzelschritt rückt das kleinere zweier benachbarter Elemente nach links. Nach einem Durchlauf ist sichergestellt, dass das kleinste Elemente ganz links steht; nach i Durchläufen stehen die i kleinsten Elemente (aufsteigend) an den Positionen 0 bis i-1. BubbleSort ist ein stabiles in situ-Verfahren.
 an den Positionen 0 bis i-1. BubbleSort ist ein stabiles in situ-Verfahren.")
13
Implementierung in Java:
/** BubbleSort */ void bubbleSort(int[] s) { for (int i=0; i < s.length-1; i++) for (int j=s.length-1; j>i; j--) if (s[j] < s[j-1]) Swap(s,j,j-1); }
 { for (int i=0; i < s.length-1; i++) for (int j=s.length-1; j>i; j--) if (s[j] < s[j-1]) Swap(s,j,j-1); }")
14
Namenserklärung „Bubble“-Sort: Bei umgekehrtem Durchlaufen:
„Aufsteigen von Blasen“ (engl. bubble): Größere Blasen steigen solange auf, bis sie durch eine noch größere Blase aufgehalten werden, die ihrerseits wieder aufsteigt.
: Größere Blasen steigen solange auf, bis sie durch eine noch größere Blase aufgehalten werden, die ihrerseits wieder aufsteigt.")
15
Effizienzanalyse: Zahl der Vergleiche: C(n) (comparisons)
Zahl der Vertauschungen: S(n) (swaps). Cbest = n (n-1) / 2 = O(n²) Cav = n (n-1) / 2 = O(n²) Cworst = n (n-1) / 2 = O(n²) Sbest = = O(1) Sav = n (n-1) /4 = O(n²) Sworst = n (n-1) / 2 = O(n²)
 (swaps). Cbest = n (n-1) / 2 = O(n²) Cav = n (n-1) / 2 = O(n²) Cworst = n (n-1) / 2 = O(n²) Sbest = 0 = O(1) Sav = n (n-1) /4 = O(n²) Sworst = n (n-1) / 2 = O(n²)")
16
4.2.3 SelectionSort (Sortieren durch Auswählen)
Zu sortieren: eine Folge x1, ..., xn. Idee: Schritt: ermittle das kleinste Element der Folge und setze es an die erste Stelle. Schritt: bestimme das kleinste Element der verbleibenden Folge mit n-1 Elementen und setze es an die zweite Stelle. Etc. Nach n Schritten ist die Folge sortiert.

17
Vergleich InsertionSort und SelectionSort
Bei InsertionSort Auswahl: leicht. Das erste (beliebige) Element aus dem unsortierten Teil des Arrays ausgewählt; Einfügen in den sortierten Teil: aufwändig. Bei SelectionSort Auswahl: aufwändig. Einfügen: leicht. Dadurch ist die Zahl der Swap-Operationen minimal (immer n-1).
 Element aus dem unsortierten Teil des Arrays ausgewählt; Einfügen in den sortierten Teil: aufwändig. Bei SelectionSort. Auswahl: aufwändig. Einfügen: leicht. Dadurch ist die Zahl der Swap-Operationen minimal (immer n-1).")
18
Funktionale Implementierung
algorithm selectionSort(s: List of El) -> List of El { wenn isempty(s) dann rückgabe s; rückgabe insertFirst(min(s), selectionSort(butFirst(replace(s,min(s),first(s)))) } function replace(s: List of El, x: El, y: El) -> List of El { wenn x = first(s) dann rückgabe insertFirst(y, butFirst(s)); rückgabe insertFirst(first(s), replace(butFirst(s), x, y))
 -> List of El { wenn isempty(s) dann rückgabe s; rückgabe insertFirst(min(s), selectionSort(butFirst(replace(s,min(s),first(s)))) } function replace(s: List of El, x: El, y: El) -> List of El { wenn x = first(s) dann rückgabe insertFirst(y, butFirst(s)); rückgabe insertFirst(first(s), replace(butFirst(s), x, y))")
19
Implementierung in Java:
/** Auswahl-Sortieren */ void selectionSort(int[] s) { for (int i=0; i < s.length-1; i++) { int min_index = i; for (int j=i+1; j < s.length; j++) if (s[j] < s[min_index]) min_index = j; Swap(s,i,min_index); }
 { for (int i=0; i < s.length-1; i++) { int min_index = i; for (int j=i+1; j < s.length; j++) if (s[j] < s[min_index]) min_index = j; Swap(s,i,min_index); }")
20
Effizienzanalyse: Cbest = n (n-1) / 2 = O(n2) Cav = n (n-1) /2 = O(n2) Cworst = n (n-1) / 2 = O(n2) Sbest = n-1 = O(n) Sav = n-1 = O(n) Sworst = n-1 = O(n)
 Sav = n-1 = O(n) Sworst = n-1 = O(n)")
21
4.2.4 Vergleich der naiven Sortierverfahren
Insertion Sort Bubble Sort Selection Sort Vergleiche: best O(n) O(n²) average worst Swaps: O(1)
 O(n²) average. worst. Swaps: O(1)")
22
4.3 Effiziente Sortierverfahren "divide and conquer"
Prinzip "divide and conquer" (teile und herrsche): Teile (divide) die zu sortierende Folge solange weiter auf, bis triviale Fälle entstehen. diese direkt behandeln (conquer), dann zusammenfügen (merge). Führt zu verzweigt rekursiven Verfahren.
: Teile (divide) die zu sortierende Folge solange weiter auf, bis triviale Fälle entstehen. diese direkt behandeln (conquer), dann zusammenfügen (merge). Führt zu verzweigt rekursiven Verfahren.")
23
MergeSort: QuickSort Aufwand in Aufwand in merge-Phase divide-Phase:

24
4.3.1 MergeSort (Sortieren durch Verschmelzen)
algorithm mergeSort(s: List of El) -> List of El { n: int; r, t, r', t': List of El; n := länge(s); wenn n ≤ 1 dann rückgabe s; r := <s1, ... , s[n/2] >; t := <s[n/2]+1, ... , sn>; r' := mergeSort(r); t' := mergeSort(t); rückgabe merge(r',t') } function merge(r: List of El, s: List of El) -> List of El { wenn isempty(r) dann rückgabe s; wenn isempty(s) dann rückgabe r; wenn first(r) < first(s) dann rückgabe insertFirst(first(r),merge(butFirst(r),s) sonst rückgabe insertFirst(first(s),merge(r,butFirst(s)) }
 -> List of El. { n: int; r, t, r , t : List of El; n := länge(s); wenn n ≤ 1 dann rückgabe s; r := <s1, ... , s[n/2] >; t := <s[n/2]+1, ... , sn>; r := mergeSort(r); t := mergeSort(t); rückgabe merge(r ,t ) } function merge(r: List of El, s: List of El) -> List of El. { wenn isempty(r) dann rückgabe s; wenn isempty(s) dann rückgabe r; wenn first(r) < first(s) dann rückgabe insertFirst(first(r),merge(butFirst(r),s) sonst rückgabe insertFirst(first(s),merge(r,butFirst(s)) }")
25
Eigenschaften MergeSort: beliebt für externes Sortieren.
Vorteil gegenüber QuickSort (später): gleichmäßige Aufteilung (divide) leicht möglich.
: gleichmäßige Aufteilung (divide) leicht möglich.")
26
Effizienzanalyse: Zuerst von merge:
function merge(r: List of El, s: List of El) -> List of El { wenn isempty(r) dann rückgabe s; wenn isempty(s) dann rückgabe r; wenn first(r) < first(s) dann rückgabe insertFirst(first(r),merge(butFirst(r),s) sonst rückgabe insertFirst(first(s),merge(r,butFirst(s)) } Komplexität von merge: O(n+m), wobei n und m die entsprechenden Längen der Listen sind.
 -> List of El. { wenn isempty(r) dann rückgabe s; wenn isempty(s) dann rückgabe r; wenn first(r) < first(s) dann rückgabe insertFirst(first(r),merge(butFirst(r),s) sonst rückgabe insertFirst(first(s),merge(r,butFirst(s)) } Komplexität von merge: O(n+m), wobei n und m die entsprechenden Längen der Listen sind.")
27
Effizienzanalyse: Je nach Implementierung erhält man für die Komplexität von MergeSort folgende Rekursionsgleichung (n = Zahl der Listenelemente): T(n) = O(n) + 2 * T(n/2) + O(n) bei Implementierung als Liste mit divide in O(n) T(n) = O(1) + 2 * T(n/2) + O(n) bei Implementierung als Array mit divide in O(1) Dies lässt sich zu einer Rekursionsgleichung verallgemeinern, die für viele Verfahren mit "balancierter Zerlegung" in zwei Teilprobleme gilt: T(n) = a (konst.) für n = 1 T(n) = 2 * T(n/2) + f(n) + c sonst
: T(n) = O(n) + 2 * T(n/2) + O(n) bei Implementierung als Liste mit divide in O(n) T(n) = O(1) + 2 * T(n/2) + O(n) bei Implementierung als Array mit divide in O(1) Dies lässt sich zu einer Rekursionsgleichung verallgemeinern, die für viele Verfahren mit balancierter Zerlegung in zwei Teilprobleme gilt: T(n) = a (konst.) für n = 1 T(n) = 2 * T(n/2) + f(n) + c sonst.")
28
Lösung der Rekursionsgleichung
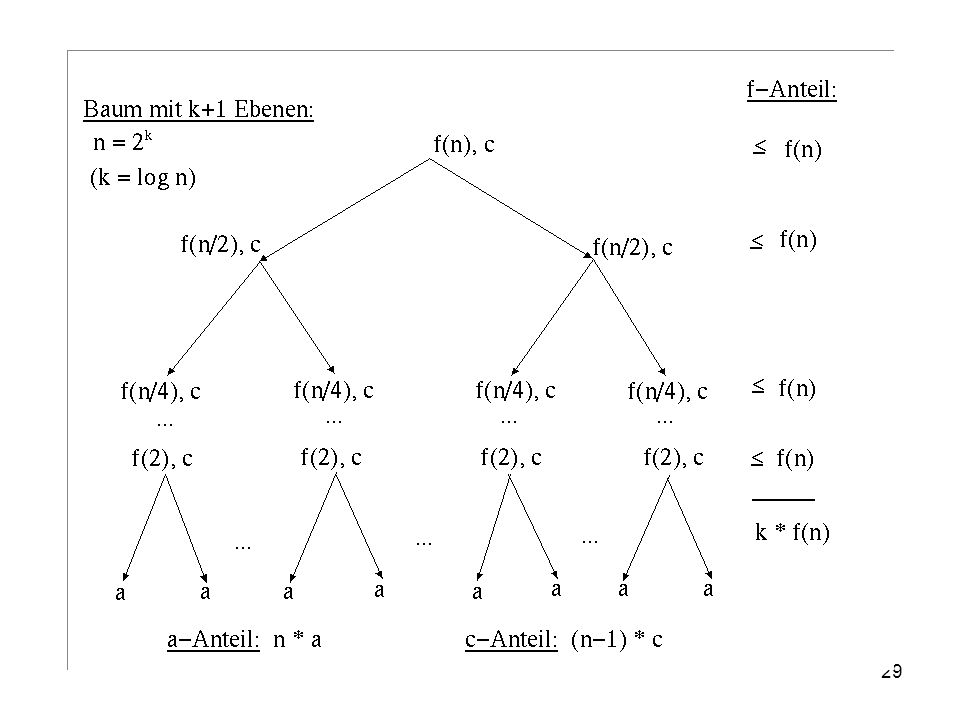
T(1) = a (konst.) T(n) = 2 • T(n/2) + f(n) + c für n >1 Annahme: i f(n/i) f(n) Gilt z.B. für f(n) = nk • log(n) j (k 1, j 0). Lösung der Rekursionsgleichung: ersichtlich aus Anordnung der f(n) in einem Binärbaum mit k = log n Ebenen: T(n) = O(n) falls f(n) = 0 T(n) = O(n log n) falls f(n) = b • n T(n) = O(n log² n) falls f(n) = b • n • log n
 = a (konst.) T(n) = 2 • T(n/2) + f(n) + c für n >1. Annahme: i f(n/i) f(n) Gilt z.B. für f(n) = nk • log(n) j. (k 1, j 0). Lösung der Rekursionsgleichung: ersichtlich aus Anordnung der f(n) in einem Binärbaum mit k = log n Ebenen: T(n) = O(n) falls f(n) = 0 T(n) = O(n log n) falls f(n) = b • n T(n) = O(n log² n) falls f(n) = b • n • log n.")
30
QuickSort (1) Das algorithmische Prinzip von QuickSort in funktionaler Darstellung: algorithm quickSort(s: List of El) -> List of El { wenn länge(s) ≤ 1 dann rückgabe s; ("partitioniere" s in r und t, sodass r ≤ t elementweise); r' := quickSort(r); t' := quickSort(t); rückgabe concat(r',t') } Aufwand O(n log n) (average case)
 ≤ 1 dann rückgabe s; ( partitioniere s in r und t, sodass r ≤ t elementweise); r := quickSort(r); t := quickSort(t); rückgabe concat(r ,t ) } Aufwand O(n log n) (average case)")
31
QuickSort (2) Problem: Gleichmäßige Aufteilung der Listen
Dazu wählt man Pivot p mit r ≤ p ≤ t Beim Sortieren werden Teillisten als Sub-Arrays dargestellt. Es wird ein Pivot-Wert gewählt, der auch wirklich im Array vorkommt. Dies geschieht in einer Funktion pivot_index, die den Index des Pivot-Wertes im Array zurückgibt. partition wird als Funktion realisiert, die den Index der Nahtstelle mit dem Pivot-Element zurückliefert. Das Pivot-Element selbst wird mittels zweier zusätzlicher "Swaps" aus dem Vergleichprozess herausgehalten. Sortierroutine (QuickSort) verzweigt rekursiv. Kleine Restlisten werden mit InsertSort zu Ende sortiert
 verzweigt rekursiv. Kleine Restlisten werden mit InsertSort zu Ende sortiert.")
32
Java-Implementation (1)
/** QuickSort */ void quickSort(int[] s, int li, int re) { System.out.print("["+li+","+re+"]: "); printArray(s); int m = partition(s,li,re); if ((m-li) > 1) quickSort(s,li,m-1); if ((re-m) > 1) quickSort(s,m+1,re); } int partition(int[] s, int li, int re) // wichtig: li < re { / / if (li == re-1) // { if (s[li] > s[re]) Swap(s,li,re); // return li; } int p = pivot_index(s,li,re); int pivot = s[p]; Swap(s,p,li); // bringe Pivot-Element an den Anfang int i = li+1; // NICHT li++ !!! int j = re;
 { System.out.print( [ +li+ , +re+ ]: ); printArray(s); int m = partition(s,li,re); if ((m-li) > 1) quickSort(s,li,m-1); if ((re-m) > 1) quickSort(s,m+1,re); } int partition(int[] s, int li, int re) // wichtig: li < re. { / / if (li == re-1) // { if (s[li] > s[re]) Swap(s,li,re); // return li; } int p = pivot_index(s,li,re); int pivot = s[p]; Swap(s,p,li); // bringe Pivot-Element an den Anfang. int i = li+1; // NICHT li++ !!! int j = re;")
33
Java-Implementation (2)
do { while ((i <= re) && (s[i] <= pivot)) i++; while ((j >= li+1) && (pivot <= s[j])) j--; if (i < j) Swap(s,i,j); } while (i < j); // jetzt gilt: j =< i ! Swap(s,li,j); // bringe Pivot-Element an Nahtstelle return j; } int pivot_index(int[] s, int li, int re) { double m = (s[li] + s[re]) / 2.0; double d = Math.abs(s[li] - m); int p = li; for (int i=li+1; i<=re; i++) if (Math.abs(s[i]-m) < d) { p = i; d = Math.abs(s[i]-m); } return p; /* --- alternative Implementierung { return (li + re) / 2; } --- */
 && (s[i] <= pivot)) i++; while ((j >= li+1) && (pivot <= s[j])) j--; if (i < j) Swap(s,i,j); } while (i < j); // jetzt gilt: j =< i ! Swap(s,li,j); // bringe Pivot-Element an Nahtstelle return j; } int pivot_index(int[] s, int li, int re) { double m = (s[li] + s[re]) / 2.0; double d = Math.abs(s[li] - m); int p = li; for (int i=li+1; i<=re; i++) if (Math.abs(s[i]-m) < d) { p = i; d = Math.abs(s[i]-m); } return p; /* --- alternative Implementierung. { return (li + re) / 2; } --- */")
34
Untere Schranke für Sortierverfahren
Sortieren von 3 Elementen: Für jede Permutation von x, y, z existiert (mindestens) ein Blatt des Entscheidungsbaumes
 ein Blatt des Entscheidungsbaumes.")
35
Untere Schranke für Sortierverfahren 2
Benutze nun die folgende Abschätzung: n! > n(n-1) (n/2) = (n/2) n/2 log n! > (n/2)(log n – log 2) Die Höhe eines binären Baumes mit m Blättern ist aber mindestens log2 m . Damit ist klar, dass es für mindestens eine Anfangskonstellation nötig ist, einen Pfad der Länge > C n log n zu durchlaufen, um die Menge basierend auf Vergleichen zu sortieren. Eine bessere Abschätzung für n! liefert übrigens die Stirlingsche Formel log n! 0.5 log (2n) + n (log n – 1)
 (n/2) = (n/2) n/2. log n! > (n/2)(log n – log 2) Die Höhe eines binären Baumes mit m Blättern ist aber mindestens. log2 m . Damit ist klar, dass es für mindestens eine Anfangskonstellation nötig ist, einen Pfad der Länge > C n log n zu durchlaufen, um die Menge basierend. auf Vergleichen zu sortieren. Eine bessere Abschätzung für n! liefert übrigens die Stirlingsche Formel. log n! 0.5 log (2n) + n (log n – 1)")
Ähnliche Präsentationen







 Prof. Th. Ottmann.>")

 T. Lauer.>")









