Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

2
Die Linusbank Problembeschreibung Projektplan Data Understanding Data Preparation Modeling Kampagnen-Management Fazit Literatur

3
Die Linusbank Allgemeine Marktübersicht
Höhere Preissensitivität Häufig 2 bis 4 Bankverbindungen Entwicklung kostenloser Girokonten: 2000: gesamt: 6 % 2005: gesamt: 10 % - 2 % Onlinekonten 2010: gesamt 20 % - 19 % Onlinekonten Allgemeine Demografie am Markt: 21 % jünger als 30 15 % älter als 70 Jahre 19 % zwischen 40 und 49 Andere Altersgruppen jeweils ca. 15 %

4
Die Linusbank Unternehmenssicht
Mittelgroße Filialbank mit Kunden 5 Produkte : Umfangreiches Data Warehouse mit historisierter Datenbasis Sowohl Online- als auch Filialgeschäft

5
Die Linusbank Problembeschreibung Was der Kunde sagt Projektplan
Was der Kunde will Projektplan Data Understanding Data Preparation Modeling …

6
Problembeschreibung Was der Kunde sagt
„Wir wollen den Produktbesitz und die Produktnutzung unserer Bestandskunden intensivieren, um dem Wettbewerbsdruck zu begegnen. Allerdings sind die Kosten unserer jeweils produktbezogenen Cross- und Up-Selling-Kampangen hoch, und zu häufig sollten die Kunden auch nicht angesprochen werden. Deshalb wollen wir mit unseren Kampagnen vorranging die wertvollsten Kunden adressieren. Leider können wir den Erfolg von Kampagnen nur schwer beurteilen. Anhand von Vergangenheitsdaten wissen wir, dass sich unsere Kunden hinsichtlich ihres Produktbesitzes, ihrer Produktnutzung sowie ihrer Reaktion auf Kampagnen zum Teil deutlich unterscheiden.“

7
Problembeschreibung Was der Kunde will
Kosten für Kampagnen sehr hoch Kunden nutzen wenige Produkte Keine Erfolgsmessung der Kampagnen Wertvolle Kunden unbekannt Ziele: Kundenzufriedenheit und Bindung erhöhen Wertvolle Kunden identifizieren Kosten reduzieren Erfolgsmessung für Marketingkampagnen einführen

8
Die Linusbank Problembeschreibung Projektplan Data Understanding
Projektablauf Koordination der Projektarbeit Data Understanding Data Preparation Modeling Kampagnenauswertung …

9
Projektplan Projektablauf
Orientierung des Projektablaufes an den Phasen des CRISP-DM Einarbeitung in Bankgeschäft und Daten der Linusbank Festlegen der Teilziele für Projektablauf Erarbeiten von Kennzahlen auf Basis der vorhandenen Daten Evaluation der erstellten Modelle und ableiten von Handlungsempfehlungen

10
Projektplan Kooperation der Projektarbeit
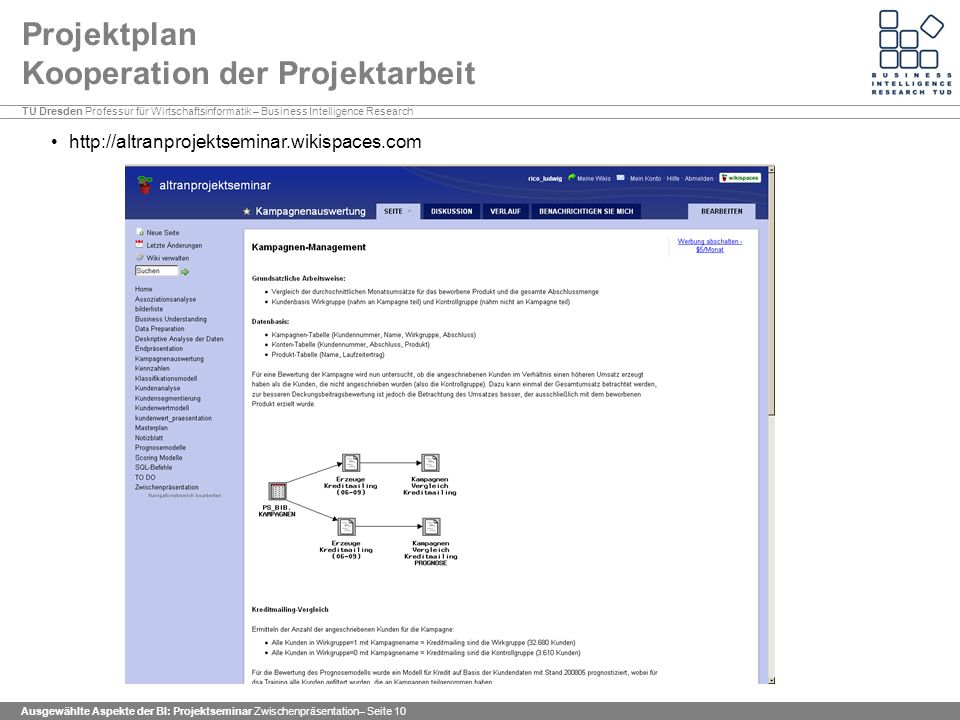
11
… Projektplan Data Understanding Data Preparation
Übersicht über vorhandene Daten Produktverteilung Produkterträge Kundenanalyse Kundenwertkonzept Data Preparation

12
Deskriptive Analyse Übersicht über vorhandene Daten

13
Deskriptive Analyse Produktverteilung (Gesamt)
Girokonto hat größten Produktanteil Kredit nur vergleichsweise geringer Anteil Anteil für Riester und Sparen minimal

14
Deskriptive Analyse Produktverteilung (im Monat Juni)
")
15
Deskriptive Analyse Produktverteilung (im Monat Dezember)
")
16
Deskriptive Analyse Produktverteilung
Deutliche Unterschiede in der Produktverteilung zwischen den Monaten Juni und Dezember erkennbar Zurückzuführen auf wirksame Marketingkampagnen Alle Informationen über erstes Halbjahr im Datensatz für Juni enthalten Juni - Datensatz stellt Basis unserer Annahmen und Berechnungen dar Später: Vergleich und Güteanalyse mit Daten des Dezembers

17
Deskriptive Analyse Produkterträge
Riester und Kredit haben die höchsten Anteile an den Erträgen Zins, Giro und Depot vergleichsweise niedriger Ertragsanteil Produkt Jahresertrag Laufzeitertrag Riester 530 € 1970 € Zins 140 € 290 € Giro 40 € 260 € Depot 25 € 90 € Kredit 450 € 570 €

18
… Projektplan Data Understanding Data Preparation
Übersicht über vorhandene Daten Produktverteilung Produkterträge Kundenanalyse Kundenwertkonzept Data Preparation

19
Deskriptive Analyse Kundenanalyse 1/4
Die absolute Zahl der Kunden, die 1, 2, 3, 4 oder 5 und mehr Produkte besitzen Die relativen Änderungen der Kunden mit einer bestimmten Anzahl an Produkten

20
Deskriptive Analyse Kundenanalyse 2/4
Umsatzanalyse nach Monaten sowie Zahl der Kunden, die einen Vertrag abgeschlossen haben und Zahl der abgeschlossenen Verträge.

21
Deskriptive Analyse Kundenanalyse 3/4
Übersicht über das Volumen von Kreditkunden abhängig von der Kreditwürdigkeit

22
Deskriptive Analyse Kundenanalyse 4/4
Mehr Filial- als Onlinekunden Kaum Unterschiede in der Altersstruktur im Vergleich Online/ Offline

23
Deskriptive Analyse Kundenwertkonzept 1/3
Motivation: Banken besitzen nur beschränkte Ressourcen für Aktivitäten der Kundenbindung Ziel ist es Kundensegmente zu identifizieren, die den Einsatz dieser Ressourcen rechtfertigen Ermöglichung einer spezifischen Art der Betreuung von Bestandkunden und potenziellen Neukunden Ausschöpfung von Cross- & Up-Selling-Potenzialen Mögliche Verfahren Qualitative Segmentierung ABC-Analysen Kundendeckungsbeitragsrechnung Kunden-Scoring-Modelle Kunden-Portfolio-Analyse Customer Lifetime Value Quelle:

24
Deskriptive Analyse Kundenwertkonzept 2/3
Kundenwert lässt sich über viele Faktoren bestimmen: Beziehungsdauer Kreditwürdigkeit Transaktionsvolumen Erwartete Kaufwahrscheinlichkeit für die Zukunft Generierter Umsatz Hohes Einkommen Durch welche Daten lassen sich solche Kunden erkennen? Kreditvolumen Einlagen - Netto - Volumen Einlagenvolumen Saldo Girokonto

25
Deskriptive Analyse Kundenwertkonzept 3/3
Versuchsansatz: Kunden unterteilen in A, B und C Kunden A Kunden sind wertvoll B Kunden haben keinen besonderen Wert, schädigen die Linusbank aber nicht C Kunden schädigen die Linusbank Mögliche einflussreiche Größen für Kundenwertbestimmung: Produktnutzung_X X ist die Menge an Produkten, welche einen besonders hohen Anteil am Umsatz/Gewinn der Linusbank haben Dauer_X Gewichtungsfaktor für die wichtigsten X Produkte der Linusbank Anzahl_X Gewichtungsfaktor für die wichtigsten X Produkte der Linusbank Volumen_X Gewichtungsfaktor für die wichtigsten X Produkte der Linusbank Kreditwürdigkeit Risikominimierung Vermögensausprägung viel Vermögen bedeutet viel Kapital für die Linusbank Beziehungsdauer Zeichen für Loyalität Cross-Selling_Potenzial_X Möglichkeit der Aufwertung des Kunden durch Kampagnen

26
… Data Understanding Data Preparation Modeling Kampagnen-Management Fazit Literatur

27
Data Preparation Datenbereinigung
Ausschluss von „toten“ Kunden, um eine saubere Datenbasis für die Folgemodelle zu erzeugen? Nur bedingt sinnvoll, da diese Kunden durch die Kampagnen reaktiviert werden Denkbarer Nutzen etwa bei Assoziationsanalyse für den Warenkorb, wobei Konten-Tabelle nur Kunden enthält, die mindestens ein Produkt besitzen Modelle arbeiten fehlerhaft, aber der gezielte Ausschluss (klar definierter) wertloser Kunden ist fehlerfrei, sodass das Endmodell eine höhere Güte aufweisen müsste Normierung der Datensätze erforderlich, da Daten sowohl metrisch skaliert vorliegen (z. B. Kredithöhe oder Beziehungsdauer) oder nominal bzw. ordinal (z. B. Geschlecht, Familienstand, Kreditwürdigkeit) Verbindung der Datensätze über die Kundennummer möglich (jeder Kunde hat eine eindeutige Kundennummer)
 wertloser Kunden ist fehlerfrei, sodass das Endmodell eine höhere Güte aufweisen müsste. Normierung der Datensätze erforderlich, da Daten sowohl metrisch skaliert vorliegen (z. B. Kredithöhe oder Beziehungsdauer) oder nominal bzw. ordinal (z. B. Geschlecht, Familienstand, Kreditwürdigkeit) Verbindung der Datensätze über die Kundennummer möglich (jeder Kunde hat eine eindeutige Kundennummer)")
28
Data Preparation Ausschluss von Datenmaterial
Produktnutzung_Giro und Dauer_Giro beinhalten die gleichen Fakten Wenn die Produktnutzung = 0 ist auch die Dauer_Giro = 0 Daraus folgt, dass Dauer_Giro überflüssig ist ebenso bei Zins, Kredit, Riester, Depot, Kreditkarte, Sparkarte, Baufinanzierung Ausschluss von Kreditkarte, Baufinanzierung und Termingeld, Sparkarte laut Aufgabenstellung (keine adäquaten Daten)
")
29
Data Preparation Transformierung von Datensätzen
Tabelle Konten und Kunden Verknüpfung der beiden Tabellen für jeden Monat mit den Informationen: Beziehungsdauer Alter Vertriebskanal Produktnutzungsdauer (Giro, Zins, Kredit, Riester, Depot, Sparkarte) Nutzen der Produkte wurde binär kodiert Kunde nutz Produkt 1 Kunde nutz Produkt nicht 0 Alter: bis 17: Minderjährig (wird ausgeschlossen) ab 60 Beziehungsdauer: 0-3: Neukunde 3-12: 1 Jahr 13-24: 2 Jahre 25-60: 3-5 Jahre : Jahre ab 121: mehr als 10 Jahre
 Nutzen der Produkte wurde binär kodiert. Kunde nutz Produkt 1. Kunde nutz Produkt nicht 0. Alter: bis 17: Minderjährig (wird ausgeschlossen) ab 60. Beziehungsdauer: 0-3: Neukunde 3-12: 1 Jahr 13-24: 2 Jahre 25-60: 3-5 Jahre : 6-10 Jahre ab 121: mehr als 10 Jahre.")
30
Data Preparation Kundenwert
Für eine erste Analyse genügt ein relativ einfacher Initialkundenwert, der auf Basis des Laufzeitertrags ermittelt wird. In weiteren Schritt kann anhand von den verschiedenen Prognosemodellen ein Score für jeden Kunden erzeugt werden, der in einen präziseren und feiner abgestimmten Kundenwert einfließt. Für die aktuelle Aufgabe genügt der Initialkundenwert. Kunden haben zu einem bestimmten Zeitpunkt ein eine Menge an Produkten mit unterschiedlichem Ertrag erworben Je nach Ertrag erzeugen diese Kunden einen höheren oder niedrigeren Umsatz Kunden werden anhand dieses Umsatzes in verschiedene Werte-Klassen eingeteilt

31
Data Preparation Kundenwert
Ermittlung des Kundenwertes abhängig von der Zielstellung, wobei Ziele nicht klar voneinander trennbar sind: Erhöhung der Kundenbindung? Steigerung der Produktdurchdringung je Kunde? Steigerung des durchschnittlichen Umsatzes? Verbesserung der Kundenzufriedenheit? Hier: Steigerung der Produktdurchdringung und erhöhen des Umsatzes (Cross Selling)
")
32
Data Preparation Kundenwert
Dazu: Ermittlung passender Kennzahlen notwendig. Möglich sind: Einlagenvolumen Kreditwürdigkeit Produktumsatz Beziehungsdauer ABER: Modell soll möglichst einfach gestaltet werden, sodass so viele Eigenschaften wie notwendig und so wenige wie möglich verwendet werden. Dafür bieten sich der Produktumsatz (Laufzeiterträge) und das erwartete Cross Selling Potential an (ermittelt anhand der Prognosemodelle)
 und das erwartete Cross. Selling Potential an (ermittelt anhand der Prognosemodelle)")
33
Data Preparation Kundenwert
Vorgehen zur Kundenwertbestimmung Zweistufiges Vorgehen: Schritt 1: Initialkundenwert besteht lediglich aus Produktumsatz, da Potential noch nicht bekannt ist Dieser Kundenwert fließt in Prognose-Modell ein Schritt 2: tatsächlicher Kundenwert erzeugt durch neuen Kundenwert aus Ergebnis des Prognose-Modells Berechnung anhand der Scores für die einzelnen Kaufwahrscheinlichkeiten der Produkte

34
Data Preparation Kundenwert
Berechnung Initialkundenwert: Summe der Laufzeiterträge der Kunden und Einteilung in Klassen A bis E Berechnung des tatsächlichen Kundenwertes: Summe der Einzelscores für die Kaufwahrscheinlichkeiten für die 5 Produkte (Maximal erreichbarer Wert: 5 Punkte) Beinhaltet durch Berücksichtigung des Initialkundenwertes bereits die jeweiligen Umsätze erneute Einteilung der Kunden in Klassen A bis E anhand der Höhe des Gesamtscores.
 Beinhaltet durch Berücksichtigung des Initialkundenwertes bereits die jeweiligen Umsätze. erneute Einteilung der Kunden in Klassen A bis E anhand der Höhe des. Gesamtscores.")
35
Data Preparation Kundenwert
Hilfsmittel: ABC-Analyse Klassische ABC-Analyse gruppiert Kunden prozentual in Klassen ein, die einen bestimmten Umsatzanteil ausmachen jedoch in SQL extrem komplex zu implementieren Abgewandelter Algorithmus sortiert Kunden absteigend nach Umsatz und ordnet absolute Mengen in die Klassen ein, sodass die ersten Kunden mit dem höchsten Umsatz Klasse A darstellen, die nächsten Kunden Klasse B usw. Die Mengen wurden so definiert, dass ca. 20 % der Kunden (A und B) 80 % des Umsatzes generieren A: B: – C: – D: – E Über
 80 % des Umsatzes generieren. A: B: – C: – D: – E Über")
36
Data Understanding Data Preperation Modeling Assoziationsanalyse …
Clusteranalyse Prognosemodelle

37
Modeling Assoziationsanalyse
Teil der Aufgabenstellung: Entwickeln Sie jeweils ein Produktbezogenes Data-Mining-Modell zur Prognose von Cross-Selling-Abschlüssen auf die Produkte Linuskredit, Linusdepot, Linusgiro, Linuszins und Linusriester. Ziel der Analyse Eindruck darüber gewinnen, welche Produkte häufig gemeinsam genutzt werden.

38
Assoziationsanalyse Vorbereitung der Daten für Assoziationsanalyse
Benötigter Datensatz: Konten Enthaltene Daten: Kundennummer als ID Produktnutzung (Kredit, Depot, Giro, Zins, Riester) binär 0 oder 1 Vermögensausprägung (negativ, ausgeglichen, positiv) nominal -1, 0 oder 1 Alter in 5 Stufen nominal Kreditwürdigkeit (gut, schlecht, unbekannt) nominal Beziehungsdauer Kanal (Online, Filiale) binär
 binär 0 oder 1. Vermögensausprägung (negativ, ausgeglichen, positiv) nominal -1, 0 oder 1. Alter in 5 Stufen nominal. Kreditwürdigkeit (gut, schlecht, unbekannt) nominal. Beziehungsdauer. Kanal (Online, Filiale) binär.")
39
Assoziationsanalyse Einstellungen
Der Datenfluss im Diagramm: Reduzieren der Werte, da Transaktionen wie Kredit oder Riester im verhältnis zur Gesamtzahl der Transaktionen relativ selten auftreten. Sie sollen aber trotzdem in der Analyse erscheinen Die Filtereinstellungen, um nicht zu berücksichtigende Produkte auszuschließen:

40
Assoziationsanalyse Ergebnis 1/2
Das Ergebnis der Analyse mit dem ermittelten Warenkorb. Hier zu sehen sind nur die Regeln, die auf der rechten Seite genau ein Ergebnis erzeugen.

41
Assoziationsanalyse Ergebnis 2/2
Überblick über alle erzeugten Regeln:

42
Assoziationsanalyse Fazit
Häufig zusammen gekauft werden Zins, Depot und Riester in allen möglichen Kombinationen. Macht Sinn, da alle drei Produkte im Kern Sparprodukte darstellen. Starken Lift erzeugen Riester-Produkte, die sowohl für Zins, als auch Zins Kombination mit Giro oder Depot häufig nachgefragt werden. Diese Produkte werden jedoch vergleichsweise selten verkauft. Handlungsmöglichkeiten: Kunden, die bereits ein oder mehrere Produkte besitzen, könnten entsprechend interessiert sein an den ermittelten Kombinationen. So bietet es sich an, Besitzer von Zins, die noch über kein Depot verfügen, ein Produktangebot vorzubereiten bzw. Depot-Besitzern auch Linuszins anzubieten.

43
Data Understanding Data Preperation Modeling Assoziationsanalyse …
Clusteranalyse Prognosemodelle Kampagnen-Management Fazit Literatur

44
Modeling Clusteranalyse
Teil der Aufgabenstellung: Entwickeln Sie jeweils ein Produktbezogenes Data-Mining-Modell zur Prognose von Cross-Selling-Abschlüssen auf die Produkte Linuskredit, Linusdepot, Linusgiro, Linuszins und Linusriester. Ziel der Analyse Eindruck über die Kundenstruktur gewinnen. Gibt es typische Nutzergruppen, die ähnliche Eigenschaften aufweisen?

45
Clusteranalyse Vorbereitung der Daten für Clusteranalyse
Benötigter Datensatz: Kunden_binary200812 Enthaltene Daten: Kundennummer als ID Produktnutzung (Kredit, Depot, Giro, Zins, Riester) binär 0 oder 1 Vermögensausprägung (negativ, ausgeglichen, positiv) nominal -1, 0 oder 1 Alter in 5 Stufen nominal Kreditwürdigkeit (gut, schlecht, unbekannt) nominal Beziehungsdauer Kanal (Online, Filiale) binär
 binär 0 oder 1. Vermögensausprägung (negativ, ausgeglichen, positiv) nominal -1, 0 oder 1. Alter in 5 Stufen nominal. Kreditwürdigkeit (gut, schlecht, unbekannt) nominal. Beziehungsdauer. Kanal (Online, Filiale) binär.")
46
Clusteranalyse Vorgehen
Nachdem der Clusternode keine zufriedenstellenden Ergebnisse hervorbrachte, kam der SOM/Kohonen-Node zum Einsatz. Vorgehen: Sampling-Node mit Simple-Random (12345) als Starteinstellung und 4x6 Clustern. Anschließend Beobachtung des Distance-Plots auf eine gleichmäßige Verteilung der Cluster und Prüfung der Clusterhäufigkeit in den Statistics. Schrittweise Reduzierung der Clusterzahl brachte bei 2x3 Clustern das erste gute Ergebnis, bei dem die Cluster gut verteilt waren und keine Häufung mehr auftrat. Als wichtige Variablen zeigt sich stets die Beziehungsdauer, die Vermögensausprägung, Giro, Depot, Zins, Kredit.
 als Starteinstellung und 4x6 Clustern. Anschließend Beobachtung des Distance-Plots auf eine gleichmäßige Verteilung der Cluster und Prüfung der Clusterhäufigkeit in den Statistics. Schrittweise Reduzierung der Clusterzahl brachte bei 2x3 Clustern das erste gute Ergebnis, bei dem die Cluster gut verteilt waren und keine Häufung mehr auftrat. Als wichtige Variablen zeigt sich stets die Beziehungsdauer, die Vermögensausprägung, Giro, Depot, Zins, Kredit.")
47
Clusteranalyse Ergebnis 1/5
Ergebnis der Clusteranalyse

48
Clusteranalyse Ergebnis 2/5
Das Ergebnis der Analyse mit dem ermittelten Distanzgraphen.

49
Clusteranalyse Ergebnis 3/5
Das Alter wurde nicht in die Cluster-Unterscheidung einbezogen.

50
Clusteranalyse Ergebnis 4/5
Die Verteilung der Produkte auf die verschiedenen Cluster

51
Clusteranalyse Ergebnis 5/5
Während Vermögensausprägung durchaus einen Einfluss hat, ist die Kreditwürdigkeit in allen Clustern gleich verteilt.

52
Clusteranalyse Fazit Es zeigen sich drei auffällige Cluster-Gruppierungen: So gibt es stets ein Cluster Kreditkunden, das einen erheblichen Anteil an Kreditkunden beinhaltet, die eine stark negative Vermögensausprägung aufweisen und eine mittlere Beziehungsdauer ab 3 Jahren erreichen. Die zweite Gruppe sind die Sparkunden mit positiver Vermögensausprägung, langer Bindungsdauer teils über 10 Jahre und allen drei Spar-Produkten Zins, Depot und Giro. Die dritte Gruppe umfasst die verbleibenden Cluster mit vorrangig ausgeglichenem Vermögen und häufig einem Girokonto oder Depot. Handlungsmöglichkeiten: Es lässt sich erkennen, dass im Cluster der Sparkunden die klassischen Sparprodukte häufig nachgefragt werden. Ein Ansatz wäre, Kunden zu finden, die ebenfalls vermögend sind, aber noch nicht alle Produkte besitzen. Zusätzlich ist eine Aktion denkbar, bei der Kunden, die alle Produkte besitzen, aber nur geringe Einlagen aufweisen, zusätzliches Geld überweisen, weil sie mit hoher Wahrscheinlichkeit noch woanders über Konten mit Spareinlagen verfügen.

53
Modeling Assoziationsanalyse Fazit … Clusteranalyse Prognosemodelle
Standardprognosemodelle Giro Kredit Riester Zins Depot Scores Fazit

54
Modeling Prognosemodelle
Teil der Aufgabenstellung: Entwickeln Sie jeweils ein produktbezogenes Data-Mining-Modell zur Prognose von Cross-Selling-Abschlüssen auf die Produkte linuskredit, linusdepot, linusgiro, linuszins und linusriester. Ziel der Modelle Klassifikation von Kunden, um Wahrscheinlichkeiten für Produktabschlüssen zu prognostizieren.

55
Modeling Vorbereitung der Daten für die Prognosemodelle
Benötigte Datensätze: Kundendaten_200806 Kundendaten_200812 Transformationen: Alter (nominal 5 Klassen) Vermögensausprägung (ordinal -1 0 und 1) Produktnutzung (binär für jedes Produkt) Beziehungsdauer (nominal 5 Klassen) Kundenwert (Initialwert): Klasse (nominal A bis E) Umsatz (metrisch) Ausgangsdaten: Kundennummer (id) Alter (nominal 5 Klassen) Kanal (binär) Kreditwürdigkeit (nominal 3 Klassen) Vermögensausprägung (ordinal -1 0 und 1) Giro (binär) Kredit (binär) Riester (binär) Zins (binär) Depot (binär) Beziehungsdauer (nominal 5 Klassen) Klasse (nominal 5 Klassen) Umsatz (interval )
 Vermögensausprägung (ordinal -1 0 und 1) Produktnutzung (binär für jedes Produkt) Beziehungsdauer (nominal 5 Klassen) Kundenwert (Initialwert): Klasse (nominal A bis E) Umsatz (metrisch) Ausgangsdaten: Kundennummer (id) Alter (nominal 5 Klassen) Kanal (binär) Kreditwürdigkeit (nominal 3 Klassen) Vermögensausprägung (ordinal -1 0 und 1) Giro (binär) Kredit (binär) Riester (binär) Zins (binär) Depot (binär) Beziehungsdauer (nominal 5 Klassen) Klasse (nominal 5 Klassen) Umsatz (interval )")
56
Erstellung von Standardprognosemodellen Vorgehen 1/2
Aufgrund der Daten in Kundendaten_ Modelle entwickeln, welche Prognosen für Produktabschlüsse erstellen Prognosen werden mit den tatsächlichen Daten aus Kundendaten_ verglichen und anhand der Misclassification Rate und dem Fehler zweiter Art bewertet FZA sollte möglichst klein sein, da er potentiellen Kunden angibt, die nicht angesprochen werden Um ein möglichst optimales Prognosemodell zu erhalten werden zunächst drei Standardmodelle erstellt und davon das geeignetste weiter optimiert Bevorzugt wird nach Möglichkeit der Entscheidungsbaum, da er viele positive Eigenschaften wie Verständlichkeit und hohe Performance besitzt Ausschluss von Kundendaten, welche bereits durch Kampagnen angesprochen wurden, um die Ergebnisse nicht zu verfälschen

57
Erstellung von Standardprognosemodellen Vorgehen 2/2
Anlegen zwei paralleler Datenstränge für je Trainings- bzw. Validierungsdaten aus Kundendaten_ und Testdaten aus Kundendaten_200812

58
Erstellung von Standardprognosemodellen Einstellungen 1/3
"Umsatz" aus Datensatz ausschließen, da indirekt im Kundenwert enthalten: Anlegen von fünf Pfaden (mit je zwei Datensträngen) für jedes Produkt Jeweiliges Produkt als Target definieren:
 für jedes Produkt. Jeweiliges Produkt als Target definieren:")
59
Erstellung von Standardprognosemodellen Einstellungen 2/3
Künstliches Angleichen der Verteilung in den Target-Variablen, um neutralen Trainingsdatensatz zu erhalten Gleichverteilung der Daten für Target, sodass keine Ausprägung der Variable dominiert

60
Erstellung von Standardprognosemodellen Einstellungen 3/3
Datenstränge für Training, Validierung und Test aufteilen: Standardmodelle des Künstlichen Neuronalen Netzes, der Regresion und des Entscheidungsbaums erstellen:

61
Erstellung von Standardprognosemodellen Vergleich
Standardmodelle im Assesment-Node vergleichen Besonders geeignetes Modell auswählen, welches weiter zu optimieren ist Auswahl anhand von Missclassifcation für Test Erkärung: Test: Vergleich des Modells mit Dezember Validation: Zur Optimierung Trainingsmodelle Bevorzugte Auswahl für Entscheidungsbaum, sofern er nicht wesentlich schlechter ist

62
Optimierungen Entscheidungsbaum Einstellungen
Wichtigstes Bewertungskriterium ist die Missclassifiation Rate im Testdatensatz und der prozentuale Fehler zweiter Art Wenn alle Standardmodelle auf ähnlichen Niveau sind wird der Entscheidungsbaum versucht zu optimieren Wenn sich größere Abweichungen ergeben werden zusätzlich zum Entscheidungsbaum auch andere Modelle optimiert Optimierung Entscheidungsbaum: Absenkung es Signifikanzlevels im Chi-Quadrat-Test Absenkung der minimalen Beobachtungen je Blattkonten Erhöhung der benötigten Beobachtungen für jede Split-Suche

63
Optimierungen Neuronales Netz Einstellungen
Modelauswahl Kriterium auf Misclassification Rate ändern Versteckte Neuronen erhöhen, direkte Verbindungen zulassen

64
Optimierungen Regression Einstellungen
Methode auf Backward ändern Validation Misclassification als Kriterium wählen

65
Modeling Assoziationsanalyse Fazit … Clusteranalyse Prognosemodelle
Standardprognosemodelle Giro Kredit Riester Zins Depot Scores Kampagnen-Management Fazit

66
Prognosemodelle Giro Die Misclassifikation Rates im Testdatensatz stellen sich wie folgt zusammen: Neuronal Network: Optimiert: Verschlechterung um 0,1 % Tree: Optimiert: Verbesserung um 1,2 % Regression: Neuronales Netz ist bestes Modell, konnte aber nicht weiter optimiert werden Entscheidungsbaum konnte auch mit Optimierungen nicht entsprechend verbessert werden Neuronales Netz wird als Prognosemodell für Grio genommen

67
Prognosemodelle Giro Fehler zweiter Art von 4,7 %

68
Prognosemodelle Kredit
Die Misclassifikation Rates im Testdatensatz stellen sich wie folgt zusammen: Neuronal Network: Tree: Optimiert: Verbesserung um 0,05 % Regression: Alle Modelle liegen nah beieinander auf sehr hohem Niveau Der Entscheidungsbaum konnte somit auch nicht mehr nennenswert optimiert werden. Optimierter Entscheidungsbaum wird als Prognosemodell für Kredit genommen

69
Prognosemodelle Kredit
Sehr geringer Fehler zweiter Art von nur 0,8 %

70
Prognosemodelle Kredit
Entscheidungsregeln im optimierten Entscheidungsbaum

71
Prognosemodelle Riester
Die Misclassifikation Rates im Testdatensatz stellen sich wie folgt zusammen: Neuronal Network: Optimiert: Verbesserung von 0,4 % Tree: Optimiert: Verbesserung um 12,9 % Regression: Entscheidungsbaum mit Abstand am schlechtesten Optimierungen bei anderen Modellen versprach kein Erfolg Optimierung bei Entscheidungsbaum verbessern Ergebnis signifikant, sodass Ergebnis vergleichbar wird mit anderen Modellen Optimierter Entscheidungsbaum wird als Prognosemodell für Riester genommen

72
Prognosemodelle Riester
extrem hoher Fehler zweiter Art von 47 %

73
Prognosemodelle Riester
Entscheidungsregeln im optimierten Entscheidungsbaum

74
Prognosemodelle Zins Die Misclassifikation Rates im Testdatensatz stellen sich wie folgt zusammen: Neuronal Network: Tree: Optimiert: Verbesserung um 0,5 % Regression: Entscheidungsbaum ist per se schon sehr gut, konnte aber nicht signifikant optimiert werden. Optimierter Entscheidungsbaum wird als Prognosemodell für Zins genommen

75
Prognosemodelle Zins extrem hoher Fehler zweiter Art von 44 %

76
Prognosemodelle Zins Entscheidungsregeln im optimierten Entscheidungsbaum

77
Prognosemodelle Depot
Die Misclassification Rates im Testdatensatz stellen sich wie folgt zusammen: Neuronal Network: Optimiert: Verschlechterung von 1,2 % Tree: Optimiert: Verbesserung von 5,4 % Regression: Der Entscheidungsbaum ist ein guter Ausgangspunkt für das Modell und liefert optimiert, die besten Ergebnisse. optimierter Entscheidungsbaum wird als Prognosemodell für Depot genommen

78
Prognosemodelle Depot
6,9 % Fehler zweiter Art

79
Prognosemodelle Depot
Entscheidungsregeln im optimierten Entscheidungsbaum

80
Prognosemodelle Scores
Extraktion der Scores: Entscheidungsregeln der Modelle werden extrahiert und über einen SAS-Code in Prognosewahrscheinlichkeiten für Kunden zu dem jeweiligen Produkt gespeichert. Aus dem Prognosewahrscheinlichkeiten und dem alten Kundenwert wird anschließend der neue Kundenwert berechnet

81
Modeling Assoziationsanalyse Fazit … Clusteranalyse Prognosemodelle
Standardprognosemodelle Giro Kredit Riester Zins Depot Scores Kampangen - Management Fazit

82
Kampagnen-Management Vorgehen 1/2
Grundsätzliche Arbeitsweise: Vergleich der durchschnittlichen Monatsumsätze für das beworbene Produkt und die gesamte Abschlussmenge Kundenbasis: Wirkgruppe (nahm an Kampagne teil) Kontrollgruppe (nahm nicht an Kampagne teil) Datenbasis: Kampagnen-Tabelle (Kundennummer, Name, Wirkgruppe, Abschluss) Konten-Tabelle (Kundennummer, Abschluss, Produkt) Produkt-Tabelle (Name, Laufzeitertrag)
 Kontrollgruppe (nahm nicht an Kampagne teil) Datenbasis: Kampagnen-Tabelle (Kundennummer, Name, Wirkgruppe, Abschluss) Konten-Tabelle (Kundennummer, Abschluss, Produkt) Produkt-Tabelle (Name, Laufzeitertrag)")
83
Kampagnen-Management Vorgehen 2/2
Für eine Bewertung der Kampagne wird nun untersucht, ob die angeschriebenen Kunden im Verhältnis einen höheren Umsatz erzeugt haben als die Kunden, die nicht angeschrieben wurden (also die Kontrollgruppe). Dazu kann der Gesamtumsatz betrachtet werden. Zur besseren Deckungsbeitragsbewertung ist jedoch die Betrachtung des Umsatzes besser, der ausschließlich mit dem beworbenen Produkt erzielt wurde.
. Dazu kann der Gesamtumsatz betrachtet werden. Zur besseren Deckungsbeitragsbewertung ist jedoch die Betrachtung des Umsatzes besser, der ausschließlich mit dem beworbenen Produkt erzielt wurde.")
84
Kampagnen-Management Kreditmailing-Vergleich
Ermitteln der Anzahl der angeschriebenen Kunden für die Kampagne: Alle Kunden in Wirkgruppe=1 mit Kampagnename = Kreditmailing sind die Wirkgruppe ( Kunden) Alle Kunden in Wirkgruppe=0 mit Kampagnename = Kreditmailing sind die Kontrollgruppe (3.610 Kunden) Für die Bewertung des Prognosemodells wurde ein Modell für Kredit auf Basis der Kundendaten mit Stand prognostiziert, wobei für das Training alle Kunden gefiltert wurden, die an Kampagnen teilgenommen haben. Die ermittelten Kunden mit einer Kreditkaufwahrscheinlichkeit werden anschließend nach Wahrscheinlichkeit gescored. Für eine Bewertung anhand der gemachten Kampagne wurden nur die Kunden angeschrieben, die sowohl in der Kampagne Kreditmailing aufgeführt waren als auch vom eigenen Prognosemodell als "Kaufkunden" bewertet wurden. Daraus ergibt sich eine Wirkgruppe mit Kunden. Die Kontrollgruppe bleibt gleich.
 Alle Kunden in Wirkgruppe=0 mit Kampagnename = Kreditmailing sind die Kontrollgruppe (3.610 Kunden) Für die Bewertung des Prognosemodells wurde ein Modell für Kredit auf Basis der Kundendaten mit Stand prognostiziert, wobei für das Training alle Kunden gefiltert wurden, die an Kampagnen teilgenommen haben. Die ermittelten Kunden mit einer Kreditkaufwahrscheinlichkeit werden anschließend nach Wahrscheinlichkeit gescored. Für eine Bewertung anhand der gemachten Kampagne wurden nur die Kunden angeschrieben, die sowohl in der Kampagne Kreditmailing aufgeführt waren als auch vom eigenen Prognosemodell als Kaufkunden bewertet wurden. Daraus ergibt sich eine Wirkgruppe mit Kunden. Die Kontrollgruppe bleibt gleich.")
85
Kampagnen-Management Kreditmailing-Vergleich
Umsatz Wirkgruppe (Zeitraum 6 bis 8) Kredit: EUR abzgl. Kosten * 1,20 = EUR Nettoumsatz EUR Durchschntl. Brutto-Umsatz: 39,87 EUR Durchschntl. Netto-Umsatz: 39,47 EUR Einbezogene Kunden über 3 Monate: Umsatz Wirkgruppe (Zeitraum 6 bis 8) mit eigenem Prognose-Modell Kredit auf Basis von Mai für August Kredit: abzgl. Kosten * 1,20 = ,6 Nettoumsatz Durchschntl. Brutto-Umsatz: 39,48 EUR Durchschntl. Netto-Umsatz: 39,08 EUR Einbezogene Kunden über 3 Monate:
 Kredit: EUR abzgl. Kosten * 1,20 = EUR Nettoumsatz EUR Durchschntl. Brutto-Umsatz: 39,87 EUR Durchschntl. Netto-Umsatz: 39,47 EUR Einbezogene Kunden über 3 Monate: Umsatz Wirkgruppe (Zeitraum 6 bis 8) mit eigenem Prognose-Modell Kredit auf Basis von Mai für August. Kredit: abzgl. Kosten * 1,20 = ,6 Nettoumsatz Durchschntl. Brutto-Umsatz: 39,48 EUR Durchschntl. Netto-Umsatz: 39,08 EUR Einbezogene Kunden über 3 Monate:")
86
Kampagnen-Management Ergebnis im Vergleich zur Kontrollgruppe 1/2
Kontrollgruppe (Zeitraum 6 bis 8): Umsatz Kredit 6 bis 8: EUR Durchschntl. Umsatz: 34,743 EUR Einbezogene Kunden über 3 Monate: Kampagnen-Ergebnisse im Vergleich zu Kontrollgruppe Lift der Kampagne mit Brutto- und Netto-Ergebnissen 39,866 EUR / 34,743 EUR = 14,75 % 39,466 EUR / 34,743 EUR = 13,59 % Lift der prognostizierten Kampagne mit Brutto- und Netto-Ergebnissen 39,482 EUR / 34,743 EUR = 13,64 % 39,082 EUR / 34,743 EUR = 12,48 %
: Umsatz Kredit 6 bis 8: EUR Durchschntl. Umsatz: 34,743 EUR Einbezogene Kunden über 3 Monate: Kampagnen-Ergebnisse im Vergleich zu Kontrollgruppe Lift der Kampagne mit Brutto- und Netto-Ergebnissen 39,866 EUR / 34,743 EUR = 14,75 % 39,466 EUR / 34,743 EUR = 13,59 % Lift der prognostizierten Kampagne mit Brutto- und Netto-Ergebnissen 39,482 EUR / 34,743 EUR = 13,64 % 39,082 EUR / 34,743 EUR = 12,48 %")
87
Kampagnen-Management Ergebnis im Vergleich zur Kontrollgruppe 2/2

88
Modeling Assoziationsanalyse Fazit Literatur … Clusteranalyse
Prognosemodelle Kampangen - Management Fazit Literatur

89
FAZIT 1/2 Assoziation Clustering Prognose für Produkte
Analyse zeigt guten Ersteindruck über das Kaufverhalten der Kunden Bietet hilfreiche Ergebnisse mit geringem Aufwand Bietet im Gegensatz zu teureren Kampagnen-Aktionen eine günstige Cross-Selling-Grundlage im direkten Verkaufsgespräch Clustering Ermöglichte Identifikation wesentlicher Kundengruppen in bestehender Kundenbasis Bietet guten Ansatz um Kampagnen speziell auf diese Kundengruppen wie Kreditkunden oder Sparkunden auszurichten Alternativ können auch neue Kampagnen entwickelt werden, um neue Kundengruppen abhängig von der Firmenstrategie aufzubauen Prognose für Produkte Prognose für Kredit, Depot und Giro liefert gute Ergebnisse Bei Zins und Riester verursacht der hohe Fehler zweiter Art hohe Opportunitätskosten, da Anteil positiver Kunden sehr gering ist

90
FAZIT 2/2 Scoring Kampagnen-Management Aufwändig zu ermitteln
Nutzen des Scores und Umfang der einbezogenen Attribute extrem abhängig vom Ziel der Kundenbewertung Für Produktprognose schon sehr einfacher Score auf Umsatzbasis ausreichend, da Modelle bereits über hohe Aussagekraft verfügen Kampagnen-Management Kampagnen sehr nützlich für Umsatzsteigerung je Kunde im Vergleich zur nicht angeschriebenen Kontrollgruppe Kampagnen-Ergebnisse mit Prognose-Modell erreichen vergleichbar gute Werte trotz eingeschränkter Datenauswahl

91
Literatur H. Hippner et: „Handbuch Data Mining im Marketing“
Randall Matignon: „Data Mining Using SAS Enterprise Miner“ (2007) ????
")
Ähnliche Präsentationen




>")

 U N I V E R S I T Ä T H A M B U R G November 2011.>")
 U N I V E R S I T Ä T H A M B U R G November 2011.>")
Media Landesanstalt für Kommunikation Baden-Württemberg (LFK) Landeszentrale für Medien und Kommunikation.>")










>")
>")