Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
System-Biophysik Überblick
Life‘s Complexity Pyramid (Oltvai-Barabasi, Science 10/25/02) System Functional Modules Building Blocks Discuss the levels bottom – up Research focus has been on the bottom level – great successes of molecular biology, but to understand the „functions“ we need to move „up“ Underlying the system und sub-systems are complex networks of interaction – examples of subnetworks are gene regulatory networks, signal transduction networks, metabolic networks These are very large networks: for example, the bacterium E.Coli alone has over 4500 genes, around 2500 proteins,... Can one handle this level of complexity? How? Technological advances in production of high-throughput data (as expressed in many „omics“) One approach (pioneered by physicists like Strogatz, Barabasi,..) has been to analyze the topmost level (the large-scale structure) and develop the statistical mechanics of complex networks, including biological networks ....this work in the last few years has result many surprising insights into common structures between very different networks at this level (scale-free networks,...) But the third level is the biologically most relevant, and one key strategy is to look at key functional modules and discover the structure, dynamics, control methods and ways of (re-)designing and improving There is a related (but slightly different) approach-which is focussing on second level, looking for „network motifs“ or „building blocks“ -- Eric Davidson (a Caltech ´biologist) has studied the gene regulation network of the sea urchin and formulated the hypothesis that despite the apparent complexity, he thinks these are made up of a small number of such building blocks Components
 System. Functional. Modules. Building. Blocks. Discuss the levels bottom – up. Research focus has been on the bottom level – great successes of molecular biology, but to understand the „functions we need to move „up Underlying the system und sub-systems are complex networks of interaction – examples of subnetworks are gene regulatory networks, signal transduction networks, metabolic networks. These are very large networks: for example, the bacterium E.Coli alone has over 4500 genes, around 2500 proteins,... Can one handle this level of complexity How Technological advances in production of high-throughput data (as expressed in many „omics ) One approach (pioneered by physicists like Strogatz, Barabasi,..) has been to analyze the topmost level (the large-scale structure) and develop the statistical mechanics of complex networks, including biological networks ....this work in the last few years has result many surprising insights into common structures between very different networks at this level (scale-free networks,...) But the third level is the biologically most relevant, and one key strategy is to look at key functional modules and discover the structure, dynamics, control methods and ways of (re-)designing and improving. There is a related (but slightly different) approach-which is focussing on second level, looking for „network motifs or „building blocks -- Eric Davidson (a Caltech ´biologist) has studied the gene regulation network of the sea urchin and formulated the hypothesis that despite the apparent complexity, he thinks these are made up of a small number of such building blocks. Components.")
2
Zum Begriff „Bio-System“
Input Out- put Eigenschaften * Komponenten (Spezien) * Netzwerkartige Verknüpfungen (kinetische Raten) * Substrukturen (Knoten,Module, Motive) * Funktionelle Input => Output Relation Ziel * Erforschung der „Bauprinzipen“ (reverse engineering) Vorsicht : Bauprinzip nicht „rational“ sondern Ergebnis eines Evolutionprozesses * Erstellung quantitativer Modelle zur Beschreibung des Systems
 * Netzwerkartige Verknüpfungen (kinetische Raten) * Substrukturen (Knoten,Module, Motive) * Funktionelle Input => Output Relation. Ziel. * Erforschung der „Bauprinzipen (reverse engineering) Vorsicht : Bauprinzip nicht „rational sondern Ergebnis eines Evolutionprozesses. * Erstellung quantitativer Modelle zur Beschreibung des Systems.")
3
Boehring-Mennheim Large Metabolic Networks: the „usual“ view

5
Network Measures

6
Network Measures

7
Network Measures

8
Network Measures

9
Network Types Random Scale-Free Hierarchical

10
Network Types Random Scale-Free Hierarchical

11
Network Types Random Scale-Free Hierarchical

12
Metabolic networks at different levels of description

13
Metabolic networks: Rather Hierarchical than Scale-free

15
g=2.2 g=2.2 Jeong et al Nature Oct 00

16
Scale-free complex networks

17
Highly clustered „small worlds“
Nature June 4, 1998 Aug 1999

18
19 degrees of separation: “The WWW is very big but not very wide”
3 l15=2 [1,2,5] l17=4 [1,3,4,6,7] … < l > = ?? 6 1 4 7 5 2 < l > Finite size scaling: create a network with N nodes with Pin(k) and Pout(k) < l > = log(N) nd.edu 19 degrees of separation R. Albert et al Nature (99) based on 800 million webpages [S. Lawrence et al Nature (99)] A. Broder et al WWW9 (00) IBM
 and Pout(k) < l > = log(N) nd.edu. 19 degrees of separation R. Albert et al Nature (99) based on 800 million webpages [S. Lawrence et al Nature (99)] A. Broder et al WWW9 (00) IBM.")
19
Nature July 27, 2000

20
Yeast protein interaction network
Topological robustness 10% proteins with k<5 are lethal BUT 60% proteins with k>15 are lethal red = lethal, green = non-lethal orange = slow growth yellow = unknown

21
Construction of Scale-free networks
These scale-free networks do not arise by chance alone. Erdős and Renyi (1960) studied a model of growth for graphs in which, at each step, two nodes are chosen uniformly at random and a link is inserted between them. The properties of these random graphs are not consistent with the properties observed in scale-free networks, and therefore a model for this growth process is needed. The scale-free properties of the Web have been studied, and its distribution of links is very close to a power law, because there are a few Web sites with huge numbers of links, which benefit from a good placement in search engines and an established presence on the Web. Those sites are the ones that attract more of the new links. This has been called the winners take all phenomenon. The mostly widely accepted generative model is Barabasi and Albert's (1999) rich get richer generative model in which each new Web page creates links to existent Web pages with a probability distribution which is not uniform, but proportional to the current in-degree of Web pages. This model was originally discovered by Derek de Solla Price in 1965 under the term cumulative advantage, but did not reach popularity until Barabasi rediscovered the results under its current name. According to this process, a page with many in-links will attract more in-links than a regular page. This generates a power-law but the resulting graph differs from the actual Web graph in other properties such as the presence of small tightly connected communities. More general models and networks characteristics have been proposed and studied (for a review see the book by Dorogovtsev and Mendes). A different generative model is the copy model studied by Kumar et al. (2000), in which new nodes choose an existent node at random and copy a fraction of the links of the existent node. This also generates a power law. However, if we look at communities of interests in a specific topic, discarding the major hubs of the Web, the distribution of links is no longer a power law but resembles more a normal distribution, as observed by Pennock et al. (2002) in the communities of the home pages of universities, public companies, newspapers and scientists. Based on these observations, the authors propose a generative model that mixes preferential attachment with a baseline probability of gaining a link. en.wikipedia.org
 studied a model of growth for graphs in which, at each step, two nodes are chosen uniformly at random and a link is inserted between them. The properties of these random graphs are not consistent with the properties observed in scale-free networks, and therefore a model for this growth process is needed. The scale-free properties of the Web have been studied, and its distribution of links is very close to a power law, because there are a few Web sites with huge numbers of links, which benefit from a good placement in search engines and an established presence on the Web. Those sites are the ones that attract more of the new links. This has been called the winners take all phenomenon. The mostly widely accepted generative model is Barabasi and Albert s (1999) rich get richer generative model in which each new Web page creates links to existent Web pages with a probability distribution which is not uniform, but proportional to the current in-degree of Web pages. This model was originally discovered by Derek de Solla Price in 1965 under the term cumulative advantage, but did not reach popularity until Barabasi rediscovered the results under its current name. According to this process, a page with many in-links will attract more in-links than a regular page. This generates a power-law but the resulting graph differs from the actual Web graph in other properties such as the presence of small tightly connected communities. More general models and networks characteristics have been proposed and studied (for a review see the book by Dorogovtsev and Mendes). A different generative model is the copy model studied by Kumar et al. (2000), in which new nodes choose an existent node at random and copy a fraction of the links of the existent node. This also generates a power law. However, if we look at communities of interests in a specific topic, discarding the major hubs of the Web, the distribution of links is no longer a power law but resembles more a normal distribution, as observed by Pennock et al. (2002) in the communities of the home pages of universities, public companies, newspapers and scientists. Based on these observations, the authors propose a generative model that mixes preferential attachment with a baseline probability of gaining a link. en.wikipedia.org.")
22
The origin of the scale-free topology and hubs in biological networks
Evolutionary origin of scale-free networks

23
The origin of the scale-free topology and hubs in biological networks
Evolutionary origin of scale-free networks

25
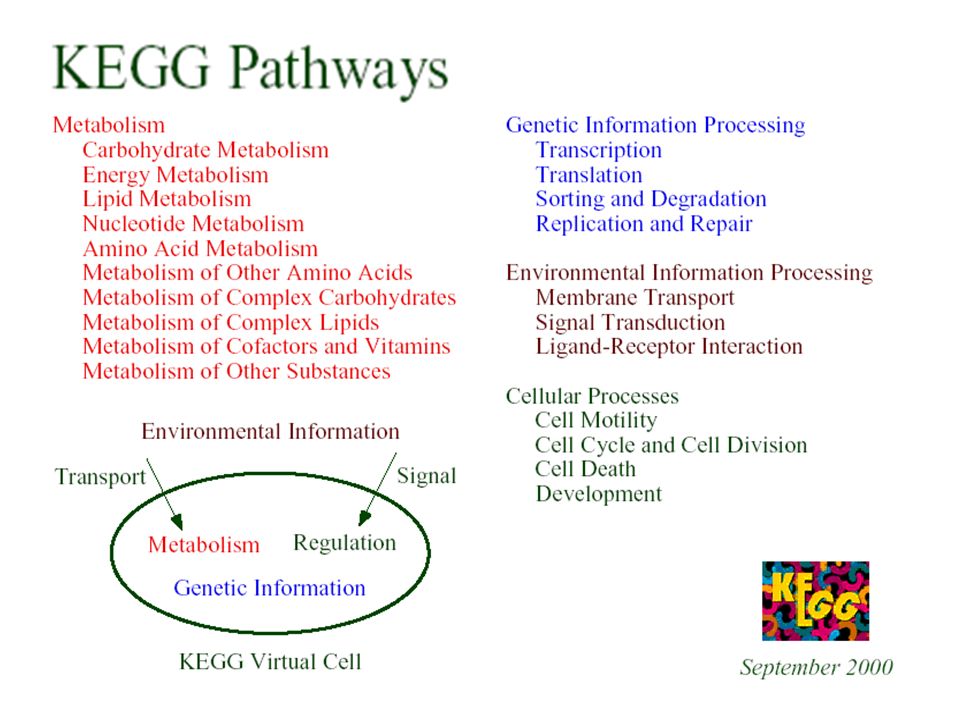
http://www.genome.jp/kegg/pathway.html#cellular -> MCP, CheY

26
Zusammenfassung Biologische Netzwerke
Netzwerke haben eine hierachische Struktur - Komponenten, Blöcke, funktionelle Module, System Universelle Eigenschaften komplexer Netzwerke * „small world property“ (kurze Verbindungswege) * skaleninvarianz (Verteilung der „connectivity“) * Starke Tendenz zu Clustern Große Zahl und inhomogene Komponenten Experimenteller Input durch: * Hochdurchsatztechniken / Datenbanken * Systematische Literaturanalyse (data-mining)
 * skaleninvarianz (Verteilung der „connectivity ) * Starke Tendenz zu Clustern. Große Zahl und inhomogene Komponenten. Experimenteller Input durch: * Hochdurchsatztechniken / Datenbanken. * Systematische Literaturanalyse (data-mining)")
Ähnliche Präsentationen















 Bluetooth Mobilkommunikation: Drahtlose LANs>")



>")

