Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Datenanalyse und Visualisierung in der Bioinformatik
Lehrveranstaltung Sommersemester 2004 W. Kurth, G.H. Buck-Sorlin, O.Kniemeyer Datenanalyse und Visualisierung in der Bioinformatik (Praktikum, 1 SWS Präsenzveranstaltung + 4 SWS praktische Taetigkeit (betreutes Arbeiten) )
 )")
2
“Bioinformatik ist die Entwicklung und Anwendung von
Was ist Bioinformatik? “Bioinformatik ist die Entwicklung und Anwendung von Computeranwendungen für die Analyse, Interpretation, Simulation und Vorhersage von biologischen Systemen und korrespondierenden experimentellen Methoden in den Naturwissenschaften”. Steffen Schulze-Kremer (RZPD Deutsches Ressourcenzentrum für Genomforschung GmbH) "Bioinformatik ist die computerunterstützte Analyse biologischer Systeme." Thomas Dandekar (EMBL Heidelberg) "Bioinformatik besteht darin, biologische Gesetzmäßigkeiten der Entwicklung neuer Algorithmen zugrunde zu legen und auf diese Weise zu synergistischen Effekten zu kommen, die weder in der Biologie noch in der Informatik alleine möglich wären." Thomas Werner (CEO Genomatix Software GmbH München) aus Hofestädt & Schnee (2002)
 Bioinformatik ist die computerunterstützte Analyse biologischer Systeme. Thomas Dandekar (EMBL Heidelberg) Bioinformatik besteht darin, biologische Gesetzmäßigkeiten der Entwicklung neuer Algorithmen zugrunde zu legen und auf diese Weise zu synergistischen Effekten zu kommen, die weder in der Biologie noch in der Informatik alleine möglich wären. Thomas Werner (CEO Genomatix Software GmbH München) aus Hofestädt & Schnee (2002)")
3
Was ist Bioinformatik? 1. Bio-Informatik = Probleme aus der Biologie + Methoden aus der Informatik; 2. Bio-Informatik = Probleme aus der Informatik + Methoden aus der Biologie. Rolf Backofen (Institut für Informatik, LMU München) aus Hofestädt & Schnee (2002) a. Schwerpunkt auf biologischer Fragestellung, Informatikwerkzeuge nach Bedarf eingesetzt b. Schwerpunkt auf Informatikmethoden, Biologie nur entfernte Motivation für untersuchte Probleme c. wirklich interdisziplinärer Ansatz: untersuchte Fragestellung und verwendete Informatikmethoden werden in ständigem Prozess adaptiert. Notwendig, da die Problemformalisierung nur eine Abstraktion des ursprünglichen Problems sein kann. Feinunterscheidung (nach Michael Waterman):
 aus Hofestädt & Schnee (2002) a. Schwerpunkt auf biologischer Fragestellung, Informatikwerkzeuge nach Bedarf eingesetzt. b. Schwerpunkt auf Informatikmethoden, Biologie nur entfernte Motivation für untersuchte Probleme. c. wirklich interdisziplinärer Ansatz: untersuchte Fragestellung und verwendete Informatikmethoden werden in ständigem Prozess adaptiert. Notwendig, da die Problemformalisierung nur eine Abstraktion des ursprünglichen Problems sein kann. Feinunterscheidung (nach Michael Waterman):")
4
aus Hofestädt & Schnee (2002)
")
5
Drei Integrationsachsen in der Computerbiologie
Gen Protein Makromolekularer Komplex Organelle Zelle Netzwerk Gewebe Organ System Organismus Drei Integrationsachsen in der Computerbiologie Empirische Daten Ontologien Statistische Modellierung System- analyse Vorhersagende Physiko-chemische erste Prinzipien Mathematische Theorie funktional regulatorisch Wachs- tum Metabolik elektrisch mechanisch Transport strukturell zwischen Daten und Theorie nach McCULLOCH & HUBER (2002), verändert
, verändert.")
6
Herausforderungen: funktional Systembiologie
nach McCULLOCH & HUBER (2002), verändert
, verändert.")
7
Herausforderungen: Zentrales Ziel der Systembiologie:
Funktional integrierte biologische Modellierung datenbezogen datenintensiv funktional nach McCULLOCH & HUBER (2002), verändert
, verändert.")
8
Herausforderungen: funktional Systembiologie Computational Biology
strukturell nach McCULLOCH & HUBER (2002), verändert
, verändert.")
9
Herausforderungen: funktional Systembiologie Computational Biology:
strukturell integriert (z.B. Molekulare Dynamik, Vorhersage der Proteinstruktur) gesteuert durch physico- chemische 1. Prinzipien berechnungsintensiv strukturell nach McCULLOCH & HUBER (2002), verändert
 gesteuert durch physico- chemische 1. Prinzipien. berechnungsintensiv. strukturell. nach McCULLOCH & HUBER (2002), verändert.")
10
Physico-chemische Erste Prinzipien:
Problem der Proteinfaltung Massengleichgewicht bei Analysen metabolischer Flüsse (auch bei sink-source-Modellen) nach McCULLOCH & HUBER (2002), verändert
 nach McCULLOCH & HUBER (2002), verändert.")
11
Beispiele für Schnittstellen zwischen strukturell und funktionell
integrierter Computational Biology: Kopplung zwischen biochemischen Netzwerken und räumlich gekoppelten Netzwerken Nutzung physiko-chemischer Beschränkungen zur Optimierung genomischer Systemmodelle des Zellmetabolismus Entwicklung kinetischer Modelle der Zellsignalübertragung in Verbindung mit physiologischen Targets wie z.B. Energiestoff- wechsel, Ionenflüsse oder Zellmotilität Nutzung empirischer Beschränkungen zur Optimierung von Vorhersagen der Proteinfaltung Integration von Systemmodellen der Zelldynamik in Kontinuum- modelle der Gewebe- und Organphysiologie nach McCULLOCH & HUBER (2002), verändert
, verändert.")
12
Das Zentrale Dogma „The central dogma states that once 'information' has passed into a protein it cannot get out again. The transfer of information from nucleic acid to nucleic acid, or from nucleic acid to protein, may be possible, but transfer from protein to protein, or from protein to nucleic acid, is impossible. Information here means the precise determination of sequence, either of bases in the nucleic acid or of amino acid residues in the protein" Francis Crick (1958). aus Waterman (1995)
. aus Waterman (1995)")
13
Bioinformatik-Probleme
Probleme, die mit dem zentralen Dogma assoziiert sind: Alle Probleme, die direkt mit einem spezifischen Level von Information (Sequenz, Struktur, Funktion) assoziiert sind oder aber mehrere Levels umfassen. Beispiele: Alignierungsverfahren (sequence alignment, structural alignment); Proteinstrukturvorhersage Probleme der Datenhaltung: Fragestellungen der Speicherung, Wiedergewinnung und Analyse der Daten. Beispiele: Aufbau von biologischen Datenbanken; data mining (Gewinnung neuen Wissens aus der Ansammlung der Daten) Simulation biologischer Systeme: Vorhersage des dynamischen Verhaltens eines biologischen Systems auf der Basis seiner Komponenten. Beispiel: Untersuchung metabolischer Netzwerke. Rolf Backofen (Institut für Informatik, LMU München) aus Hofestädt & Schnee (2002)
 assoziiert sind oder aber mehrere Levels umfassen. Beispiele: Alignierungsverfahren (sequence alignment, structural alignment); Proteinstrukturvorhersage. Probleme der Datenhaltung: Fragestellungen der Speicherung, Wiedergewinnung und Analyse der Daten. Beispiele: Aufbau von biologischen Datenbanken; data mining (Gewinnung neuen Wissens aus der Ansammlung der Daten) Simulation biologischer Systeme: Vorhersage des dynamischen Verhaltens eines biologischen Systems auf der Basis seiner Komponenten. Beispiel: Untersuchung metabolischer Netzwerke. Rolf Backofen (Institut für Informatik, LMU München) aus Hofestädt & Schnee (2002)")
14
Allgemeine Literatur:

15
Allgemeine Literatur:
Hofestädt, R., Schnee, R. (2002): Studien- und Forschungsführer Bioinformatik. Spektrum-Verlag. 234 S. Rashidi, H., Bühler, L.K. (2001): Grundriss der Bioinformatik. Spektrum-Verlag. 215 S. Hansen, A. (2001): Bioinformatik. Ein Leitfaden für Naturwissenschaftler. Birkhäuser-Verlag. 112 S. Waterman, M.S. (1995): Introduction to Computational Biology. Maps, sequences and genomes. Chapman & Hall, London. 431 S. Mount, D.W. (2001): Bioinformatics. Sequence and Genome Analysis. Cold Spring Harbor Laboratory Press. 564 S.
: Studien- und Forschungsführer Bioinformatik. Spektrum-Verlag. 234 S. Rashidi, H., Bühler, L.K. (2001): Grundriss der Bioinformatik. Spektrum-Verlag. 215 S. Hansen, A. (2001): Bioinformatik. Ein Leitfaden für Naturwissenschaftler. Birkhäuser-Verlag. 112 S. Waterman, M.S. (1995): Introduction to Computational Biology. Maps, sequences and genomes. Chapman & Hall, London. 431 S. Mount, D.W. (2001): Bioinformatics. Sequence and Genome Analysis. Cold Spring Harbor Laboratory Press. 564 S.")
16
Projekt T1: Erstellung einfacher genetisch-metabolischer Regelungsnetzwerke mit Hilfe der java-basierten Modellierplattform GroIMP Stark vereinfachtes Netzwerkmodell des Metabolismus einer Zelle von E.coli. Ein Teilaspekt des Stoffwechsels (z.B. Atmung, N-Fixierung) wird modelliert, Umfang des Modells: Komponenten Komponentenklassen: Gene, kodierte Peptide, Enzyme, Reaktionen (Metabolite). Regelungsnetzwerke anzufertigen und zu visualisieren in der Modellierumgebung GroIMP: Growth grammar related Interactive Modelling Platform; Formalisierung als Relational Growth Grammars (erweiterte L-Systeme: Kniemeyer, Buck-Sorlin, und Kurth 2003) . GroIMP: arbeitet mit RGGs: java-basierte Modelliersprache, daher formal sehr ähnlich zu Java. Einbettung von Java-Klassen in den XL-Code erlaubt. Support: Ole Kniemeyer
 wird modelliert, Umfang des Modells: Komponenten. Komponentenklassen: Gene, kodierte Peptide, Enzyme, Reaktionen (Metabolite). Regelungsnetzwerke anzufertigen und zu visualisieren in der Modellierumgebung GroIMP: Growth grammar related Interactive Modelling Platform; Formalisierung als Relational Growth Grammars (erweiterte L-Systeme: Kniemeyer, Buck-Sorlin, und Kurth 2003) . GroIMP: arbeitet mit RGGs: java-basierte Modelliersprache, daher formal sehr ähnlich zu Java. Einbettung von Java-Klassen in den XL-Code erlaubt. Support: Ole Kniemeyer.")
17
Projekt T1: Regelungsnetzwerke mit GroIMP
Beispiel: ABC-Modell der Blüten-Morphogenese (Portierung eines in "transsys" implementierten Modells von Jan T. Kim (2001) nach XL) XL erlaubt: • die Modellierung der (Konzentrations-) Dynamik eines Genregulationsnetzwerkes f:Factor(c, d) ::> {f.concentration +:= -c * d;}; f:Factor <+ g:Gene(ct) ::> {f.concentration +:= Math.max(0, sum((* Factor(c2,) Activate(s,m) g *), m * c2 / (s + c2)) + ct);}; • die Modellierung der Genexpression und m:Meristem (* -factors-> Factor(a,) Factor(b,) Factor(c,) *) ==> ShootPiece((b > 80) ? ((c > a) ? STAMEN : PETAL) : (a > 80) ? ((c > 80) ? SHOOT : SEPAL) : (c > 80) ? CARPEL : PEDICEL) m; ShootPiece(type) ==> ... graphical representation ...;
 nach XL) XL erlaubt: • die Modellierung der (Konzentrations-) Dynamik eines. Genregulationsnetzwerkes. f:Factor(c, d) ::> {f.concentration +:= -c * d;}; f:Factor <+ g:Gene(ct) ::> {f.concentration +:= Math.max(0, sum((* Factor(c2,) Activate(s,m) g *), m * c2 / (s + c2)) + ct);}; • die Modellierung der Genexpression. und. m:Meristem (* -factors-> Factor(a,) Factor(b,) Factor(c,) *) ==> ShootPiece((b > 80) ((c > a) STAMEN : PETAL) : (a > 80) ((c > 80) SHOOT : SEPAL) : (c > 80) CARPEL : PEDICEL) m; ShootPiece(type) ==> ... graphical representation ...;")
18
Projekt T1: Regelungsnetzwerke mit GroIMP
Beispiel: ABC-Modell der Blüten-Morphogenese zugrundegelegtes Netzwerk (nach Kim 2001): resultierende Konzentrationsdynamik:
: resultierende Konzentrationsdynamik:")
19
Projekt T2: Morphologisches Modell der sich entwickelnden Raps-Pflanze
Modellierung der Morphologie der Raps-Pflanze mittels relationaler Wachstumsgrammatiken unter GroIMP, Verknüpfung biometrischer Parameter mit genetischer Information, Modellierung von Dominanz und Rezessivität. Grundlage: parametrische RGGs Vorgaben: Fotos und einige biometrische Messungen/Erfassungen (Organgrössen, Winkel, ...) Abschätzen der anderen Parameter bzw. aus der Literatur Individuenmodell, Auflösung: Organebene (Blatt, Spross, Wurzel) Einbau genetischer Modellparameter aus der Literatur Visualisierung mit GroIMP
 Abschätzen der anderen Parameter bzw. aus der Literatur. Individuenmodell, Auflösung: Organebene (Blatt, Spross, Wurzel) Einbau genetischer Modellparameter aus der Literatur. Visualisierung mit GroIMP.")
20
Projekt T2: Beispiel Entwicklungsstudie Raps, durchgeführt mit cpfg/L-Studio

21
Projekt T3: 3D-Visualisierungs-/Animationstool für zellbiologische Anwendungen
Schaffung ein Visualisierungstool für die Anwendung in der Zellbiologie auf der Basis von Java3D zum interaktiven Erstellen von deskriptiven Graphiken und Animationen Eignung für die Erklärung von Methoden und Hypothesen v.a. im zellbiologischen Bereich im Rahmen von Präsentationen. Erwünschte Eigenschaften: Interaktives Modellfenster, in dem das Modell in 2D und eventuell in 3D darstellbar (und – falls 3D - möglichst drehbar) ist. Eine Toolbox mit einem baumartig strukturierten Katalog von vorgefertigten biologischen Grundobjekten (Bsp.: ‚Pilz’ ‚Spore’, ‚Hyphe’, ‚Haustorium’; oder ‚Zelle’ ‚Zellkern’, ‚Golgi-Apparat’, ‚ER’, etc.). Möglichkeit, Grundobjekte zu editieren (Farbe etc.) sowie Tool-Elemente vor einen importierten Hintergrund („Szene") zu stellen.
 ist. Eine Toolbox mit einem baumartig strukturierten Katalog von vorgefertigten. biologischen Grundobjekten (Bsp.: ‚Pilz’ ‚Spore’, ‚Hyphe’, ‚Haustorium’; oder ‚Zelle’ ‚Zellkern’, ‚Golgi-Apparat’, ‚ER’, etc.). Möglichkeit, Grundobjekte zu editieren (Farbe etc.) sowie Tool-Elemente vor. einen importierten Hintergrund („Szene ) zu stellen.")
22
Projekt T3: 3D-Visualisierungs-/Animationstool für zellbiologische Anwendungen
Optionale Eigenschaften: Interaktive Erstellung (und Import in die Toolbox) weiterer Grundobjekte Drehbuch für Animationen Import von Pixelgrafiken in die Szene, Möglichkeit der Verknüpfung mit dem Modell Ausgabeschnittstelle für gängige Animationsformate Objektkatalog baumförmig (hierarchisch) Anwendungsbeispiel: Wirt-Parasiten-System Gersten-Mehltau (Blumeria graminis hordei - Bgh) – Gerstenblattoberfläche (Hordeum vulgare) Visualisiert werden soll der Entwicklungszyklus der Konidien (asexuellen Sporen) von Blumeria graminis hordei.
 weiterer Grundobjekte. Drehbuch für Animationen. Import von Pixelgrafiken in die Szene, Möglichkeit der Verknüpfung mit. dem Modell. Ausgabeschnittstelle für gängige Animationsformate. Objektkatalog baumförmig (hierarchisch) Anwendungsbeispiel: Wirt-Parasiten-System Gersten-Mehltau (Blumeria graminis hordei - Bgh) – Gerstenblattoberfläche (Hordeum vulgare) Visualisiert werden soll der Entwicklungszyklus der Konidien (asexuellen. Sporen) von Blumeria graminis hordei.")
23
Blumeria graminis anamorph ...eine wichtige Getreide- krankheit.
teleomorph

24
24 h nach Inokulation

25
72 h nach Inokulation

26
Schema eines frühen Entwicklungsstadiums:
Hyphe anamorph Konidie Haustorium Epidermiszelle Mesophyllzelle teleomorph

27
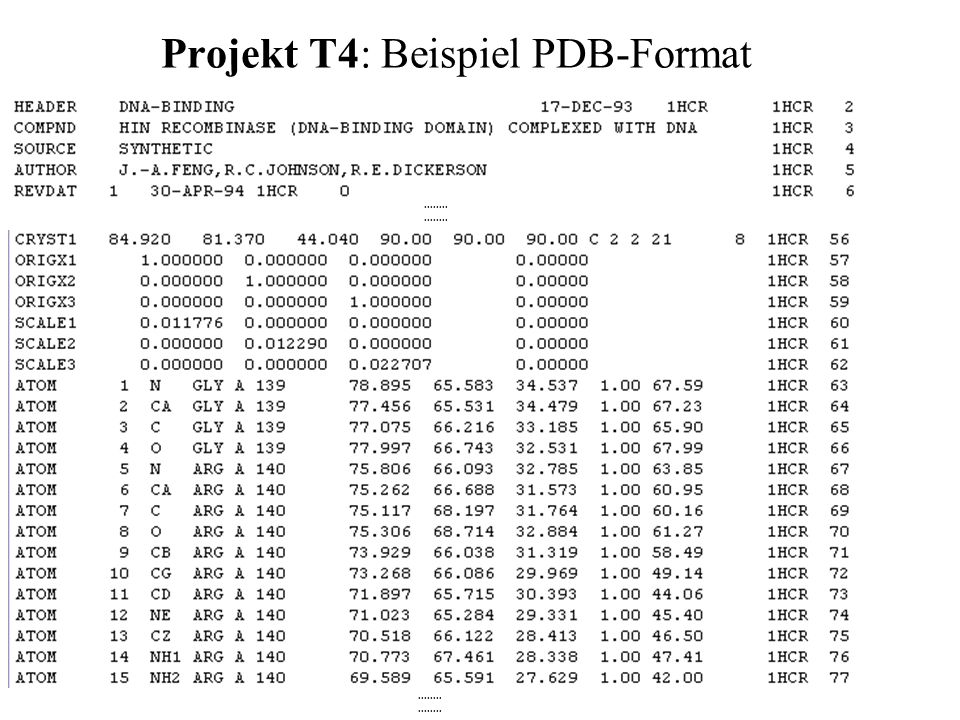
Projekt T4: Visualisierung von Proteinstrukturen
Visualisierung von Proteinstrukturen aus einer Proteinstruktur- Datenbank mittels GroIMP. Eingabeformat: PDB (Protein Data Bank, Gibt Topologie und Geometrie (u.a.) aller beteiligten Atome vor. Direkte Visualisierung in GroIMP durch Interpretation der vor- gegebenen Strukturinformation. Ausgabe: interaktives Makromolekülmodell als 'C-Backbone', Cartoon, Kalottenmodell oder "Ball and Stick".
 aller beteiligten Atome vor. Direkte Visualisierung in GroIMP durch Interpretation der vor- gegebenen Strukturinformation. Ausgabe: interaktives Makromolekülmodell als C-Backbone , Cartoon, Kalottenmodell oder Ball and Stick .")
28
Projekt T4: Beispiel PDB-Format
29
Projekt T4: Beispiele für graphische Ausgaben
backbone (Kohlenstoff- skelett) stick Kalotten- modell cartoon
 stick. Kalotten- modell. cartoon.")
30
Projekt T5: Übersetzung von Root Typ in eine Relationale Wachstumsgrammatik
Wurzelarchitekturmodell RootTyp: (Loic Pagès, INRA Avignon, Frankreich). Simuliert das Wachstum und die Verzweigung von Wurzeln verschiedener botanischer Arten (Getreide, Unkräuter...) unter Berücksichtigung eines eindimensionalen Bodenprofils. Simulierte Prozesse: Wurzelbildung, axiales und radiales (Dicken)Wachstum, sequentielle Verzweigung, Reiteration, Übergang, Verfaulen und Abwurf. Aufgabe: Übersetzung des Programms von C in ein durch GroIMP darstellbares kompaktes RGG-Regelsystem mit entsprechender Visualisierung
. Simuliert das Wachstum und die Verzweigung von. Wurzeln verschiedener botanischer Arten (Getreide, Unkräuter...) unter Berücksichtigung eines eindimensionalen Bodenprofils. Simulierte Prozesse: Wurzelbildung, axiales und radiales. (Dicken)Wachstum, sequentielle Verzweigung, Reiteration, Übergang, Verfaulen und Abwurf. Aufgabe: Übersetzung des Programms von C in ein durch GroIMP. darstellbares kompaktes RGG-Regelsystem mit. entsprechender Visualisierung.")
31
Graphische Ausgabe des Modells RootTyp:
links Original (Zeichnung), rechts Simulation
, rechts Simulation.")
Ähnliche Präsentationen



















