Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Data Mining

2
© Prof. T. Kudraß, HTWK Leipzig 2 Data Mining ist, wenn man vorher nicht so genau weiß, wonach man eigentlich sucht! Definition des Data Mining: nicht triviale Entdeckung gültiger, neuer, potentiell nützlicher und verständlicher Muster in großen Datenbeständen [Fayyad] besteht, aus mathematisch-statistischen Rechenverfahren, kombiniert mit selbstlernenden Systemen intelligente Anwendung auf Basis einer Data Warehouse- Architektur Analyseziel: Finde Gold in Deinen Daten! Was bedeutet Data Mining?

3
© Prof. T. Kudraß, HTWK Leipzig 3 Klassisches Data Mining – Strukturierte Daten (z.B. relationale Datenbanken) Multimedia Mining – Text Mining – Image Mining – Audio Mining – Video Mining Web Mining Spatial Data Mining (Geodaten) Data Mining Facetten
 Multimedia Mining – Text Mining – Image Mining – Audio Mining – Video Mining Web Mining Spatial Data Mining (Geodaten) Data Mining Facetten.")
4
© Prof. T. Kudraß, HTWK Leipzig 4 Evolution / Geschichte

5
© Prof. T. Kudraß, HTWK Leipzig 5 Drastischer Anstieg des Datenvolumens – Alle 18 Jahre verdoppelt sich Speicherkapazität im Unternehmen [IBM 2009] Dauerhafte Speicherung von Daten wird immer günstiger steigende Anzahl an Data-Warehouse-Anwendungen riesige Datenfriedhöfe in Wissenschaft und Wirtschaft manuelle Sichtung unmöglich Unzufriedenheit mit existierenden Analysemethoden (mehr Automatismus) SQL-,OLAP-Queries nicht ausreichend, da die Datenqualität oft nicht hoch ist Ausgangssituation
 SQL-,OLAP-Queries nicht ausreichend, da die Datenqualität oft nicht hoch ist Ausgangssituation.")
6
© Prof. T. Kudraß, HTWK Leipzig 6 Aussagen über Grundgesamtheit treffen, wenn nur eine zufällige Stichprobe zur Verfügung steht gewachsene Strukturen ausschöpfen Aufdeckung latenter Zusammenhänge zwischen Daten, Daten Wissen aus Daten Informationen gewinnen (meist Wettbewerbs- vorteile) und Entscheidungen schneller treffen – Kundenzufriedenheit – Marktkenntnis – Vorsprung vor der Konkurrenz – Erschließung neuer Vertriebskanäle Motivation
 und Entscheidungen schneller treffen – Kundenzufriedenheit – Marktkenntnis – Vorsprung vor der Konkurrenz – Erschließung neuer Vertriebskanäle Motivation.")
7
© Prof. T. Kudraß, HTWK Leipzig 7 Data Mining vs. KDD Data Mining – Teilschritt des KDD-Prozesses – besteht aus Algorithmen die in akzeptabler Rechenzeit aus einer vorgegebenen Datenbasis eine Menge von Mustern liefern. Knowledge Discovery in Databases (KDD) – nichttrivialen Prozess der Identifikation valider, neuartiger, potentiell nützlicher und klar verständlicher Muster in Daten
 – nichttrivialen Prozess der Identifikation valider, neuartiger, potentiell nützlicher und klar verständlicher Muster in Daten.")
8
© Prof. T. Kudraß, HTWK Leipzig 8 Der Prozess des KDD (Knowledge Discovery in Databases)
")
9
© Prof. T. Kudraß, HTWK Leipzig Auswahl (Selektion) Auswahl der zu analysierenden Daten aus einer Rohdatenmenge Zusammenfügen von Daten aus mehreren Quellen, z.B. in ein Data Warehouse Problem: heterogene Daten – Redundanzen – Wie kann man sicher sein, dass einzelne Attribute denselben Inhalt haben? (z.B. cust_id und cust_number )
 Auswahl der zu analysierenden Daten aus einer Rohdatenmenge Zusammenfügen von Daten aus mehreren Quellen, z.B. in ein Data Warehouse Problem: heterogene Daten – Redundanzen – Wie kann man sicher sein, dass einzelne Attribute denselben Inhalt haben. (z.B. cust_id und cust_number ).")
10
© Prof. T. Kudraß, HTWK Leipzig Vorverarbeitung (1) Warum Vorverarbeitung? – 10% des Zeitaufwandes im KDD entfallen auf die Ausführung von Data-Mining-Methoden – 90% des Aufwandes für Datenaufbereitung und Nachbearbeitung – Untersuchungen belegen Fehlerwahrscheinlichkeit in Rohdaten von bis zu 30% [Cabena u.a. 1997] Ziel: einheitliche Struktur und Format, Steigerung der Datenqualität besonders bei heterogenen Quellen

11
© Prof. T. Kudraß, HTWK Leipzig Vorverarbeitung (2) Semantische Probleme – Synonyme, Homonyme Lösung mit Hilfe von Metadaten und bereichsspezifischem Wissen Syntaktische Probleme – Verschiedene Schreibweisen Nutzung eines einheitlichen Schemas und von Katalogen (z.B. Straßenverzeichnis) Redundanzen Fehlende Werte (unbestimmbar bzw. unbestimmt) Säubern (verschiedene Varianten …) Falsche Werte Transformation Zu genaue Werte Aggregation
 Semantische Probleme – Synonyme, Homonyme Lösung mit Hilfe von Metadaten und bereichsspezifischem Wissen Syntaktische Probleme – Verschiedene Schreibweisen Nutzung eines einheitlichen Schemas und von Katalogen (z.B. Straßenverzeichnis) Redundanzen Fehlende Werte (unbestimmbar bzw. unbestimmt) Säubern (verschiedene Varianten …) Falsche Werte Transformation Zu genaue Werte Aggregation.")
12
© Prof. T. Kudraß, HTWK Leipzig Transformation Glättung. d.h. Ausreißer entfernen – Nützlich für Entscheidungsbäume, Hierarchien Erzeugen abgeleiteter Attribute (z.B. Aggregationen für bestimmte Dimensionen, Umsatzänderungen) Diskretisierung numerischer Attribute (Aufteilung von Wertebereichen in Intervalle, z.B. Altersgruppen) Normierung - Vergleichbarkeit herstellen Datenreduktion – Dimensionalität – Werteanzahl – Beispiel: Land Bundesland Stadt Straße 3 16 2076 392.466
 Diskretisierung numerischer Attribute (Aufteilung von Wertebereichen in Intervalle, z.B. Altersgruppen) Normierung - Vergleichbarkeit herstellen Datenreduktion – Dimensionalität – Werteanzahl – Beispiel: Land Bundesland Stadt Straße")
13
© Prof. T. Kudraß, HTWK Leipzig Data Mining Verfahren Clustering Zusammenfassen ähnlicher Objekte Assozationsanalyse Auffinden von Regeln ( Ausführliches Anwendungsbeispiel) Klassifikation Zuordnen von Datenobjekten zu vorgegebenen Klassen Anomalieentdeckung Auffinden von Ausreißern
 Klassifikation Zuordnen von Datenobjekten zu vorgegebenen Klassen Anomalieentdeckung Auffinden von Ausreißern.")
14
© Prof. T. Kudraß, HTWK Leipzig 14 Ziel: Objekte einer Eingabedatenmenge zu (vorgegebenen) Klassen zuzuordnen (lernt anhand von Daten) Problem: Merkmale der Objekte in einen funktionalen Zusammenhang bringen, dass deren Abbildung auf eine Klasse möglich wird Schritte: Training - Lernen der Kriterien zur Zuordnung von Objekten Anwendung - Zuordnung von Objekten zu Klassen … Beispiel: Kreditwürdigkeit Klassifikation
 Klassen zuzuordnen (lernt anhand von Daten) Problem: Merkmale der Objekte in einen funktionalen Zusammenhang bringen, dass deren Abbildung auf eine Klasse möglich wird Schritte: Training - Lernen der Kriterien zur Zuordnung von Objekten Anwendung - Zuordnung von Objekten zu Klassen … Beispiel: Kreditwürdigkeit Klassifikation.")
15
© Prof. T. Kudraß, HTWK Leipzig Klassifikation – Beispiel Beispiel: Kreditwürdigkeit von Bankkunden feststellen – Entscheidungsbäume – Nearest Neighbour – …. Berufstätig? 30 < Alter < 45Vermögen Einkommen < 100.000 Schulden > 250.000 Kein Kredit … … … …… JN J J J N N N N J

16
© Prof. T. Kudraß, HTWK Leipzig Clustering – Beispiel Gruppeneinteilung von Kunden Anzahl Ferngespräche Anzahl Ortsgespräche

17
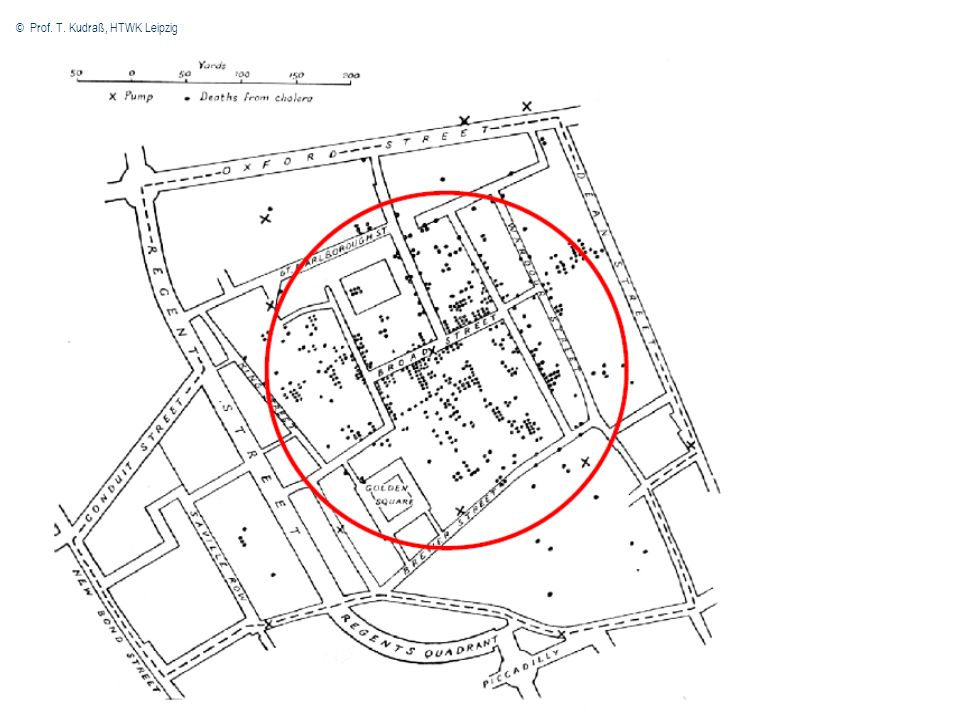
© Prof. T. Kudraß, HTWK Leipzig Spatial Data Mining - Beispiel im Jahr 1854 kam es in London zu einer Cholera- Epidemie der englische Arzt John Snow fand mittels Spatial Data Mining-Methoden die Ursache für diese Krankheit

18
© Prof. T. Kudraß, HTWK Leipzig

22
Spatial Data Mining – Beispiel (Forts.) Trinkwasserbrunnen in der Broad Street
 Trinkwasserbrunnen in der Broad Street")
23
© Prof. T. Kudraß, HTWK Leipzig Assoziationsanalyse - Beispiel Definition Assoziationsanalyse: – Auffinden von Assoziationsregeln, die das Auftreten eines Items in Abhängigkeit vom Auftreten anderer Items vorhersagen. Anwendung: Warenkorbanalyse Beispiele für Assoziationsregeln: {Käse} {Butter} (s = 0.6, k = 0.75) {Brot} {Käse, Butter, Eier} (s = 0.2, k = 0.25) {Butter, Brot} {Wurst}(s = 0.2, k = 0.5)
 {Brot} {Käse, Butter, Eier} (s = 0.2, k = 0.25) {Butter, Brot} {Wurst}(s = 0.2, k = 0.5).")
24
© Prof. T. Kudraß, HTWK Leipzig Assoziationsanalyse - Grundbegriffe Item-Menge Kollektion von einem oder mehreren Items, z.B. {Milch, Brot, Wurst} k-Item-Menge: Item-Menge mit k Elementen Support-Anzahl einer Item-Menge absolute Häufigkeit des Auftretens dieser Menge Support s einer Item-Menge relative Häufigkeit, z.B. s ({Brot,Wurst}) = 3/5 Assoziationsregel X Y mit X, Y als Item-Mengen Support s der Assoziationsregel X Y: s(X Y):= (X Y) / |T| relative Häufigkeit der Transaktionen, in denen beide Item-Mengen X und Y auftreten Konfidenz k der Assoziationsregel X Y: k(X Y):= (X Y) / (X) Häufigkeit des Auftretens von Items in Y in den Transaktionen, die X enthalten
 = 3/5 Assoziationsregel X Y mit X, Y als Item-Mengen Support s der Assoziationsregel X Y: s(X Y):= (X Y) / |T| relative Häufigkeit der Transaktionen, in denen beide Item-Mengen X und Y auftreten Konfidenz k der Assoziationsregel X Y: k(X Y):= (X Y) / (X) Häufigkeit des Auftretens von Items in Y in den Transaktionen, die X enthalten.")
25
© Prof. T. Kudraß, HTWK Leipzig A-Priori-Algorithmus A-Priori-Prinzip: Ist eine Item-Menge häufig auftretend, dann sind es auch alle ihre Teilmengen A-Priori-Algorithmus k=1 Generiere häufig auftretende Item-Mengen der Länge 1 Wiederhole bis keine häufig auftretenden Item-Mengen mehr identifiziert werden: Generiere aus den häufig auftretenden k-Item-Mengen Kandidaten Item-Mengen Länge k+1 Entferne Kandidaten Item-Mengen, die nicht häufig auftretende Teilmengen der Länge k enthalten Ermittle den Support jedes Kandidaten Entferne Kandidaten, die nicht häufig vorkommend sind

26
© Prof. T. Kudraß, HTWK Leipzig A-Priori-Algorithmus (Beispiel) Zum Vergleich: 6 1-Item-Mengen + 15 2-Item-Mengen + 20 3-Item-Mengen = 41 zu untersuchende Mengen (wäre Brute-Force- Algorithmus) 1-Item-Mengen 2-Item-Mengen (keine Kombinationen mit Milch und Eiern mehr bilden) 3-Item-Mengen Annahme: Minimale Support-Anzahl 3
 Zum Vergleich: 6 1-Item-Mengen Item-Mengen Item-Mengen = 41 zu untersuchende Mengen (wäre Brute-Force- Algorithmus) 1-Item-Mengen 2-Item-Mengen (keine Kombinationen mit Milch und Eiern mehr bilden) 3-Item-Mengen Annahme: Minimale Support-Anzahl 3.")
27
© Prof. T. Kudraß, HTWK Leipzig 27 Ablauf Visualisierungen der gefundenen Muster Einordnung/Bewertung der Muster Handelt es sich um bekannte oder überraschende Muster? Verallgemeinerung für zukünftige Daten möglich? Vorhersagekraft steigt mit Größe und Repräsentativität der Stichprobe! schlechte Bewertung: erneutes Data Mining mit anderem Verfahren, anderen Parametern oder anderen Daten gute Bewertung: Integration des gefundenen Wissens in die Wissensbasis und Nutzung für zukünftige KDD- Prozesse Interpretation

28
© Prof. T. Kudraß, HTWK Leipzig Anwendungen in der Industrie (Beispiel)
")
29
© Prof. T. Kudraß, HTWK Leipzig 29 Einzelhandel oft gemeinsam gekaufte Produkte treue Kunden, Premium-Kunden und Schnäppchen- Jäger Spezifische Interessensgruppen Erfolg einer Marketing-Aktion Absatzchancen neuer Produktsegmente Cross-Selling (Partnerschaft mit anderen Anbietern) Bestandsplanung: Wann kaufen Kunden wieviel wovon? Anwendungsbeispiele (1)
 Bestandsplanung: Wann kaufen Kunden wieviel wovon. Anwendungsbeispiele (1).")
30
© Prof. T. Kudraß, HTWK Leipzig 30 Banken Finden von Kriterien für die Kreditwürdigkeit von Kunden Prognose von Aktienkursen Wissenschaft Wirksamkeit von Medikamenten Zusammenhang von Umwelteinflüssen und Krankheiten Finden von Genen in DNA-Strängen Anwendungsbeispiele (2)
.")
31
© Prof. T. Kudraß, HTWK Leipzig 31 Web (Clickstream Analysis) Identifikation von Web-Transaktionen Häufigkeit des Seitenbesuchs Verweildauer auf einer Seite Häufige Navigationspfade durch Web-Site Welche Faktoren führen zu Abbruch? Welche Navigationspfade führen zu erfolgreichen Abschlüssen? Profiling in Social Networks Ansätze: Inhaltsanalyse - Web Content Mining Strukturanalyse - Web Structure Mining Nutzungsanalyse - Web Usage Mining Anwendungsbeispiele (3)
 Identifikation von Web-Transaktionen Häufigkeit des Seitenbesuchs Verweildauer auf einer Seite Häufige Navigationspfade durch Web-Site Welche Faktoren führen zu Abbruch. Welche Navigationspfade führen zu erfolgreichen Abschlüssen. Profiling in Social Networks Ansätze: Inhaltsanalyse - Web Content Mining Strukturanalyse - Web Structure Mining Nutzungsanalyse - Web Usage Mining Anwendungsbeispiele (3).")
32
© Prof. T. Kudraß, HTWK Leipzig 32 Behauptung: Data Mining diene dazu, Zusammenhänge automatisch zu entdecken, an die bisher noch nicht einmal jemand gedacht hat, und Fragen zu beantworten, die nicht einmal noch jemand gestellt hat. verständlicher Wunsch… z.B. Nutzung der riesigen Datenbestände einer Firma Problem hierbei: Qualität der gefundenen Muster Probleme (1)
.")
33
© Prof. T. Kudraß, HTWK Leipzig 33 Verständlichkeit – keine Zahlenkolonnen, Visualisierungen wichtig Interessantheit / Trivialität – keine Trivialitäten, die auch durch Datenbankabfragen oder Statistiken zu erhalten wären Bedeutungslosigkeit – Aussage bezieht sich auf 1 Element, keine Repräsentativität Bekanntheit – Aussage ist einem Benutzer mit Fachwissen längst bekannt Irrelevanz – unbeeinflussbare Faktoren (z.B. Exportzölle) Effizienz – Rechenzeit Probleme (2)
 Effizienz – Rechenzeit Probleme (2).")
34
© Prof. T. Kudraß, HTWK Leipzig 34 Data Mining Tools ProduktHersteller SPSSSPSS Scenario, 4ThougthCognos Enterprise MinerSAS MS SQL Server (Analytics Services)Microsoft Intelligent Miner for DataIBM Data Mining Suite (Darwin)Oracle Teradata Warehouse MinerNCR Waikato (WEKA) mit Schwerpunkt Maschinelles LernenOpen Source RapidMiner Open Source (ehemals YALE, Uni Dortmund)
Microsoft Intelligent Miner for DataIBM Data Mining Suite (Darwin)Oracle Teradata Warehouse MinerNCR Waikato (WEKA) mit Schwerpunkt Maschinelles LernenOpen Source RapidMiner Open Source (ehemals YALE, Uni Dortmund).")
35
© Prof. T. Kudraß, HTWK Leipzig 35 Als Data Mining bezeichnet man die softwaregestützte Ermittlung bisher unbekannter Zusammenhänge, Muster und Trends in sehr großen Datenbanken. Dabei kann der Benutzer bestimmte Ziele vorgeben, für die das System angemessene Beurteilungskriterien ableitet und damit die Objekte der Datenbank(en) analysiert. zahlreiche Nutzungsmöglichkeiten: Kundensegmentierung, Vorhersage des Kundenverhaltens, Warenkorbanalyse, … Problem: Interpretation der Ergebnisse nicht immer einfach zunehmende Unterstützung durch kommerzielle DBS, z.B. über MS-SQL Server 2005 mit Data Mining Funktionalität Zusammenfassung
 analysiert. zahlreiche Nutzungsmöglichkeiten: Kundensegmentierung, Vorhersage des Kundenverhaltens, Warenkorbanalyse, … Problem: Interpretation der Ergebnisse nicht immer einfach zunehmende Unterstützung durch kommerzielle DBS, z.B. über MS-SQL Server 2005 mit Data Mining Funktionalität Zusammenfassung.")
36
© Prof. T. Kudraß, HTWK Leipzig 36 Was Data Mining nicht ist… SQL / Ad Hoc Queries / Reporting Softwareagentensystem Online Analytical Processing (OLAP) Datenvisualisierung Verzicht auf exakte Kenntnis der zugrundeliegenden Daten (Semantik) Datenschutz Vorsicht ;)
 Datenvisualisierung Verzicht auf exakte Kenntnis der zugrundeliegenden Daten (Semantik) Datenschutz Vorsicht ;).")
Ähnliche Präsentationen


















.>")

 Prof. Th. Ottmann.>")
