Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Bild I (Fortsetzung) 3.5 Farbdarstellung
Grundlagen des Grafikdrucks Halbtonverfahren Zur Darstellung von Graustufen bzw. Intensitäten eines Farbtons werden bei Rasterdruckern Halbtonverfahren (Halbton= Farbton in einem bestimmten Sättigungsgrad) eingesetzt. Man unterscheidet drei Verfahren: variable Farbsättigung der Rasterpunkte bei konstanter Punktgröße; z.B. bei Farblaserdruckern: Pixel der Farbe werden unterschiedlich dicht aufgetragen, Größe bleibt konstant variable Punktgröße bei konstanter Farbsättigung; z.B. kontinuierliche Tintenstrahler Simulation von Halbtönen im Dithering-Verfahren; z.B. Bubble-Jet Alle Verfahren liefern eine diskrete Skala von Halbtönen, da das menschliche Auge nur ca. 150 verschiedene Grau- bzw. Farbabstufungen unterscheiden kann.
 eingesetzt. Man unterscheidet drei Verfahren: variable Farbsättigung der Rasterpunkte bei konstanter Punktgröße; z.B. bei Farblaserdruckern: Pixel der Farbe werden unterschiedlich dicht aufgetragen, Größe bleibt konstant. variable Punktgröße bei konstanter Farbsättigung; z.B. kontinuierliche Tintenstrahler. Simulation von Halbtönen im Dithering-Verfahren; z.B. Bubble-Jet. Alle Verfahren liefern eine diskrete Skala von Halbtönen, da das menschliche Auge nur ca. 150 verschiedene Grau- bzw. Farbabstufungen unterscheiden kann.")
2
Bild I Echte Halbtondrucker, d.h. Geräte, die ohne Dithering auskommen, benötigen daher 8 Bit pro Pixel, um diese Auflösung zu erreichen.

3
Bild I 3.5.1.2 Dither-Techniken
Zur Simulation von Grau- und Farbabstufungen teilen die meisten Drucker das Bild in Halbtonzellen, d.h. kleine quadratische Arrays von Pixeln, auf. Zur Simulation eines Halbtonwertes wird eine geeignete Menge an Pixeln gedruckt. Hat ein Farbdrucker z.B. 5x5 große Halbtonzellen, so lassen sich 26 verschiedene Halbtöne bilden. Dies sind insgesamt Farben. Die Anordnung der gedruckten Pixel spielt für die Druckqualität eine große Rolle. Man unterscheidet verschiedene Verfahren, darunter: Dispersed Dithering Clustered Dithering Dithering mit Fehler-Diffusion

4
Bild I 3.5.1.3 Dispersed Dithering
gleichmäßige Verteilung der Pixel in der Halbtonzelle Bis auf ein Kontrastverhältnis von 50% (genau die Hälfte der Pixel werden gedruckt) führen alle anderen Abstufungen zu groben Strukturen und Moire-Effekten (Bildmusterung). Kleine (technisch bedingte) Abweichungen in der Punktgröße wirken sich negativ auf die Druckqualität aus.
 führen alle anderen Abstufungen zu groben Strukturen und Moire-Effekten (Bildmusterung). Kleine (technisch bedingte) Abweichungen in der Punktgröße wirken sich negativ auf die Druckqualität aus.")
5
Bild I 3.5.1.4 Clustered Dithering simuliert eine variable Punktgröße
Die zu druckenden Punkte einer Halbtonzelle werden vom Zentrum ausgehend spiralförmig angeordnet. Je mehr Punkte in der Halbtonzelle gedruckt werden, desto größer ist der einzelne Farbpunkt in der Mitte der Zelle.

6
3.5.1.5 Dithering mit Fehler-Diffusion
Dieses Verfahren benutzt keine Halbtonzellen, sondern durchläuft das Bild zeilenweise und ersetzen jedes Pixel aufgrund eines Schwellwertes durch ein Pixel mit 0% oder 100% Sättigung. Allerdings wird für jedes Pixel ein Abweichungsfehler berechnet und mit umgekehrtem Vorzeichen auf die noch nicht berechneten Nachbarpixel verteilt. Für unterschiedliche Grauwerte ergibt sich so eine unterschiedliche Streuung der Pixel. Man spricht deshalb von frequenzmoduliertem Dithering.

7
3.5.1.6 Auflösung geditherter Bilder
Die Bildung von Halbtonzellen zur Simulation von Sättigungswerten geht zu Lasten der maximalen Ortsauflösung. Man unterscheidet zwischen der Geräteauflösung eines Druckers und seiner Linienauflösung: Die Geräteauflösung gibt die maximale Auflösung an, die der Drucker aufgrund seines Pixelabstandes erreichen kann. Sie wird in dpi (dots per inch) gemessen. Die Zeilenauflösung oder Rasterfrequenz gibt an, welche Auflösung aufgrund der Größe der Halbtonzellen erreicht werden kann. Sie wird in lpi (lines per inch) gemessen. Der Zusammenhang zwischen Pixelauflösung und Linienauflösung ist gegeben durch die Beziehung Linienauflösung = Geräteauflösung / Kantenlänge der Halbtonzelle Ein Laserdrucker mit 600 dpi Geräteauflösung und Kantenlänge 16 erreicht 37,5 lpi.
 gemessen. Die Zeilenauflösung oder Rasterfrequenz gibt an, welche Auflösung aufgrund der Größe der Halbtonzellen erreicht werden kann. Sie wird in lpi (lines per inch) gemessen. Der Zusammenhang zwischen Pixelauflösung und Linienauflösung ist gegeben durch die Beziehung Linienauflösung = Geräteauflösung / Kantenlänge der Halbtonzelle. Ein Laserdrucker mit 600 dpi Geräteauflösung und Kantenlänge 16 erreicht 37,5 lpi.")
8
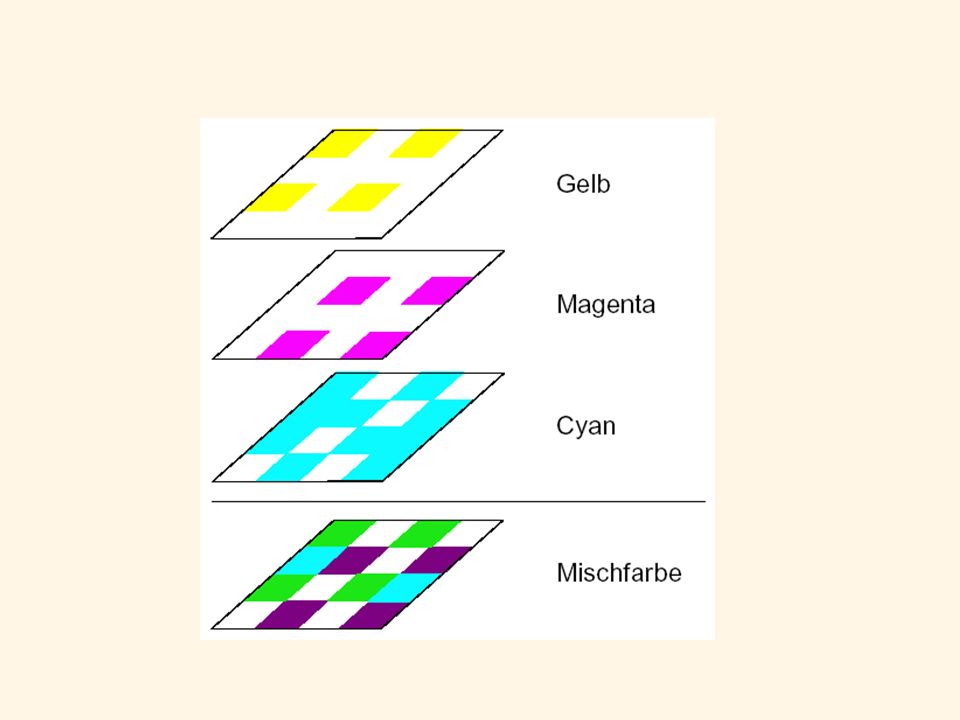
Drucken von Farbtönen Da Anwendungssysteme normalerweise mit RGB-Farben arbeiten, die Ausgabe am Drucker aber als CMY-Farben erfolgt, muss zunächst eine Transformation vorgenommen werden. Die subtraktive Mischung der Farben erfordert eigentlich die exakte Überlagerung beim Druck. Für das Auge ergibt sich allerdings der gleiche Eindruck, wenn die Farbpunkte sehr klein und dicht benachbart sind. Die einfachste Methode zur Mischung von Primärfarben ist es also, für jede Primärfarbe eine Dithermatrix nach der Methode des Dispersed Dithering zu erzeugen und dann diese Matrizen übereinander zu drucken. Damit lassen sich Grafiken mit geringen Anforderungen an die Anzahl der Mischtöne und Auflösung drucken.

10
3.5.2.1 Winkelversatz beim Druck
Um höhere Ansprüche zu erfüllen kann z.B die Winkelversatztechnik zum Einsatz kommen. Dabei werden Störeffekte bei geditherten Bildern aufgrund von mechanischen Ungenauigkeiten vermieden; Prinzip: Verdrehen und eventuelles Versetzen der Farbauszüge gegeneinander.

11
Bild II Kompression Grafik-Formate

12
Grundlegende Kompressionsverfahren
LZW RLE Huffman Da Rastergrafiken oftmals viel Speicherplatz benötigen, spielt für diese Formate die Datenkompression eine besonders große Rolle. Neben der Einsparung von Speicherplatz ist die Verringerung der notwendigen Übertragungsbandbreite ein wichtiges Ziel, besonders für die im Internet gebräuchlichen Formate JPEG, GIF, aber auch für Audio- oder Videoformate. Man unterscheidet: unkomprimierte Formate, Formate mit verlustloser Kompression (engl. lossless) , Formate mit verlustbehafteter Kompression (engl. lossy) . Bei verlustbehafteten Formaten ist die Bildqualität durch Parameter steuerbar.
 , Formate mit verlustbehafteter Kompression (engl. lossy) . Bei verlustbehafteten Formaten ist die Bildqualität durch Parameter steuerbar.")
13
1.1 LZW (Lempel-Ziv-Welch)
Charakteristik LZW gehört zur Familie der LZ-Algorithmen Der LZW (Lempel-Ziv-Welch) -Algorithmus ist ein Wörterbuch-basierter, substituierender Kompressionsalgorithmus. Der Algorithmus versucht, den zu komprimierenden Zeichenstrom in Teilketten zu zerlegen und diese in einer Tabelle zu speichern. Anschließend werden nur die Indizes in die betreffende Tabelle als Ausgangscode gespeichert. Anhand dieser Ausgangscodes läßt sich dann der ursprüngliche Zeichenstrom wieder generieren.
 -Algorithmus ist ein Wörterbuch-basierter, substituierender Kompressionsalgorithmus. Der Algorithmus versucht, den zu komprimierenden Zeichenstrom in Teilketten zu zerlegen und diese in einer Tabelle zu speichern. Anschließend werden nur die Indizes in die betreffende Tabelle als Ausgangscode gespeichert. Anhand dieser Ausgangscodes läßt sich dann der ursprüngliche Zeichenstrom wieder generieren.")
14
LZW-Kodierer Der Kodierer beginnt mit der Initialisierung des Wörterbuches durch z.B. alle Symbole des Alphabets. Bei herkömmlichen 8 Bit pro Zeichen ist das Wörterbuch z.B. zunächst 256 Einträge lang. Anschließend liest der Kodierer den Zeichenstrom der zu komprimierenden Datei Zeichen für Zeichen ein und akkumuliert die eingelesenen Zeichen im String I. Der so entstandene String I wird im Wörterbuch gesucht. Das nächste (erste) eingelesene Zeichen x wird im Wörterbuch gefunden. Solange I im Wörterbuch gefunden wird, wird das nächste Zeichen eingelesen und an den String angehängt. I = Ix Wird der String Ix im Wörterbuch nicht gefunden, gibt der Kodierer den Zeiger von I auf das Wörterbuch aus, schreibt den String Ix an die nächste freie Stelle im Wörterbuch und initialisiert den String I auf das zuletzt eingelesene Zeichen x.
 eingelesene Zeichen x wird im Wörterbuch gefunden. Solange I im Wörterbuch gefunden wird, wird das nächste Zeichen eingelesen und an den String angehängt. I = Ix. Wird der String Ix im Wörterbuch nicht gefunden, gibt der Kodierer den Zeiger von I auf das Wörterbuch aus, schreibt den String Ix an die nächste freie Stelle im Wörterbuch und. initialisiert den String I auf das zuletzt eingelesene Zeichen x.")
15
Beispiel

16
LZW-Dekodierer Der Dekodierer beginnt mit der Initialisierung des Wörterbuches durch z.B. alle Symbole des Alphabets. Anschließend liest der Dekodierer den Zeichenstrom der zu dekomprimierenden Datei Zeichen für Zeichen ein. Die Zeichen sind die Wörterbuch-Zeiger. Die eingelesenen Zeiger werden benutzt, um aus dem Wörterbuch die unkomprimierten Zeichen bzw. Strings auszulesen. Der Dekodierer bildet gleichzeitig das Wörterbuch in derselben Weise wie der Kodierer. Man bezeichnet Kodierer und Dekodierer als synchronisiert.

17
Beispiel abracadabra = 97,98,114,97,99,97,100,256,258 Wörterbuch: … a= 97 b=98 c=99 d=100 r=114

18
Beispiel abracadabra = 97,98,114,97,99,97,100,256,258 a Wörterbuch: unverändert

19
Beispiel abracadabra = 97,98,114,97,99,97,100,256,258 a b Wörterbuch: … neuer Eintrag: ab= 256

20
Beispiel abracadabra = 97,98,114,97,99,97,100,256,258 a b r Wörterbuch: … ab = 256 neuer Eintrag: br = 257

21
Beispiel abracadabra = 97,98,114,97,99,97,100,256,258 a b r a Wörterbuch: … ab = 256 br = 257 neuer Eintrag: ra= 258

22
Beispiel abracadabra = 97,98,114,97,99,97,100,256,258 a b r a c Wörterbuch: … ab = 256 br = 257 ra = 258 neuer Eintrag: ac = 259

23
Beispiel abracadabra = 97,98,114,97,99,97,100,256,258 a b r a c a Wörterbuch: … ab = 256 br = 257 ra = 258 ac = 259 neuer Eintrag: ca= 260

24
Beispiel abracadabra = 97,98,114,97,99,97,100,256,258 a b r a c a d Wörterbuch: … ab = 256 br = 257 ra = 258 ac = 259 ca= 260 neuer Eintrag: ad = 261

25
Beispiel abracadabra = 97,98,114,97,99,97,100,256,258 a b r a c a d ab Wörterbuch: … ab = 256 br = 257 ra = 258 ac = 259 ca = 260 ad = 261 neuer Eintrag: da = 262

26
da = 262 neuer Eintrag: abr = 263
Beispiel abracadabra = 97,98,114,97,99,97,100,256,258 a b r a c a d ab ra Wörterbuch: … ab = 256 br = 257 ra = 258 ac = 259 ca = 260 ad = 261 da = neuer Eintrag: abr = 263 br bereits vorhanden!

27
1.1.3 Probleme bei der LZW-Kompression
Gegeben sei die Zeichenfolge: aaaaaaaaaaaa; das Wörterbuch enthält als einzigen bekannten Eintrag a=0. Wie muß die Zeichenkette korrekt kodiert werden, damit der Dekodieralgorithmus den Code entschlüsseln kann? Die Codetabelle wird sich nur in den seltensten Fällen a priori bestimmen lassen. Lösung: Der Algorithmus muss die Tabelle bei der Komprimierung und Dekomprimierung selber aufbauen, denn sie wird nicht mit dem Code gespeichert. Die Tabelle müßte theoretisch unendlich groß sein, um alle Zeichenkombinationen aufzunehmen. Lösung: Die Größe der Tabelle wird limitiert.

28
1.2 RLE (Run Length Encoding)
Charakteristik RLE (dt. Lauflängenkodierung) nutzt lange Folgen sich wiederholender Zeichen oder Zeichenketten, sog. Läufe (runs) , aus. Bsp.: Statt AAAABBBCCCCDEEEEE könnte man auch 4A3B4CD5E schreiben. Problem: Treten im Eingabestrom z.B. nicht nur Buchstaben auf, muss ein Escape-Zeichen die Lauflängenangaben anzeigen. Es ergeben sich hierdurch häufig Zeichengruppen (Escapesequenzen) der Form: ESCrs wobei ESC=Escapezeichen, r=Lauflänge des Symbols, s=Symbol; Bsp.: Die Ziffern könnten durch einen Buchstaben ersetzt werden, wobei die Stelle des Buchstabens im Alphabet dem Ziffernwert entspricht (a=1, b=2, …) XDABBBXDCDXEE
 nutzt lange Folgen sich wiederholender Zeichen oder Zeichenketten, sog. Läufe (runs) , aus. Bsp.: Statt AAAABBBCCCCDEEEEE. könnte man auch 4A3B4CD5E. schreiben. Problem: Treten im Eingabestrom z.B. nicht nur Buchstaben auf, muss ein Escape-Zeichen die Lauflängenangaben anzeigen. Es ergeben sich hierdurch häufig Zeichengruppen (Escapesequenzen) der Form: ESCrs. wobei ESC=Escapezeichen, r=Lauflänge des Symbols, s=Symbol; Bsp.: Die Ziffern könnten durch einen Buchstaben ersetzt werden, wobei die Stelle des Buchstabens im Alphabet dem Ziffernwert entspricht (a=1, b=2, …) XDABBBXDCDXEE.")
29
1.2.2 Einfache Methoden zur Kompression von Binärdateien
Gegeben sei folgende binäre Zeichenfolge: Um in Binärdateien Daten zu komprimieren, kann man verschiedene Methoden anwenden, z.B. diese beiden: Methode 1: Man speichert jeweils eine Kombination aus dem Zeichen und seiner Lauflänge nach dem obigen Muster. Aus der Zeichenfolge oben wird so (3,0)(4,1)(5,0)(6,1). Wenn man zusätzlich festlegt, dass der erste Wert immer eine Null betreffen muss und sich danach 0 und 1 immer abwechseln, kann man die Kodierung abkürzen zu In der Regel steht eine feste Anzahl Bits für die Lauflängenangaben zur Verfügung. Falls die Blocklänge für diese Bitzahl zu groß sein sollte, muss der Block geteilt werden. Methode 2: Man speichert die Position und Länge der 1-Blöcke eines Bildes. Für das obige Beispiel erhält man die Ausgabe: (3,4)(12,6).
(4,1)(5,0)(6,1). Wenn man zusätzlich festlegt, dass der erste Wert immer eine Null betreffen muss und sich danach 0 und 1 immer abwechseln, kann man die Kodierung abkürzen zu In der Regel steht eine feste Anzahl Bits für die Lauflängenangaben zur Verfügung. Falls die Blocklänge für diese Bitzahl zu groß sein sollte, muss der Block geteilt werden. Methode 2: Man speichert die Position und Länge der 1-Blöcke eines Bildes. Für das obige Beispiel erhält man die Ausgabe: (3,4)(12,6).")
30
1.2.3 Kodierung mit variabler Länge
Diese Art der Lauflängenkodierung ist z.B. für Textdateien oder für detailreiche Bilder nicht besonders effizient. Besonders bei Textdateien ist es geschickter, nicht jedes Zeichen gleichmäßig mit 7, 8 oder gar 16 Bit darzustellen, sondern für Zeichen, die häufig vorkommen, wenige Bits zu benutzen, für Zeichen, die selten vorkommen mehr.

31
Beispiel Gegeben sei die Buchstabenfolge ABRACADABRA; Jeder Buchstabe des Alphabets wird mit 5-stelligem Bitcode repräsentiert und die Stelle im Alphabet entspricht dem dezimalen Wert der Binärzahl; dadurch ergibt sich regulär:

32
Beispiel Gegeben sei die Buchstabenfolge ABRACADABRA; Jeder Buchstabe des Alphabets wird mit 5-stelligem Bitcode repräsentiert und die Stelle im Alphabet entspricht dem dezimalen Wert der Binärzahl; dadurch ergibt sich regulär: Wenn A = 0, B = 1, R = 01, C = 10 und D = 11, so ergibt sich als Gesamtkodierung

33
Beispiel Gegeben sei die Buchstabenfolge ABRACADABRA; Jeder Buchstabe des Alphabets wird mit 5-stelligem Bitcode repräsentiert und die Stelle im Alphabet entspricht dem dezimalen Wert der Binärzahl; dadurch ergibt sich regulär: Wenn A = 0, B = 1, R = 01, C = 10 und D = 11, so ergibt sich als Gesamtkodierung Mängel: Die Begrenzungszeichen (hier: Leerstellen) müssen mit kodiert werden. In diesem Beispiel wird „optimal kodiert“; d.h. wir kennen die Häufigkeiten der Buchstaben und kodieren nur die im String vorhandenen Wann können die Begrenzer wegfallen?
 müssen mit kodiert werden. In diesem Beispiel wird „optimal kodiert ; d.h. wir kennen die Häufigkeiten der Buchstaben und kodieren nur die im String vorhandenen. Wann können die Begrenzer wegfallen")
34
Ein Code braucht dann keine Begrenzer, wenn jedes Zeichen eindeutig kodiert wird.
Beispielsweise ließe sich das mit der Kodierung A = 11, B = 00, C = 010, D = 10 und R = 011. (Es gibt immer mehrere gültige eindeutige Möglichkeiten der Kodezuweisung)
")
35
Ein Code braucht dann keine Begrenzer, wenn jedes Zeichen eindeutig kodiert wird.
Beispielsweise ließe sich das mit der Kodierung A = 11, B = 00, C = 010, D = 10 und R = 011. (Es gibt immer mehrere gültige eindeutige Möglichkeiten der Kodezuweisung) Die Zeichenkette läßt sich dann nur auf eine einzige Weise dekodieren.
 Die Zeichenkette läßt sich dann nur auf eine einzige Weise dekodieren.")
36
Binärbaum Die beste Struktur, diese Kodierung zu speichern, ist ein Binärbaum (B[inary]-Tree) . Der Binärbaum zeichnet sich dadurch aus, dass jeder Knoten genau zwei Kinder hat. Der Code für jedes Zeichen wird durch den Pfad von der Wurzel zu diesem Zeichen (dem sog. Blatt) bestimmt, wobei "nach links gehen" mit einer 0 kodiert wird, "nach rechts gehen" mit einer 1.
![Binärbaum Die beste Struktur, diese Kodierung zu speichern, ist ein Binärbaum (B[inary]-Tree) .](http://slideplayer.org/slide/637862/1/images/36/Bin%C3%A4rbaum+Die+beste+Struktur%2C+diese+Kodierung+zu+speichern%2C+ist+ein+Bin%C3%A4rbaum+%28B%5Binary%5D-Tree%29+..jpg "Der Binärbaum zeichnet sich dadurch aus, dass jeder Knoten genau zwei Kinder hat. Der Code für jedes Zeichen wird durch den Pfad von der Wurzel zu diesem Zeichen (dem sog. Blatt) bestimmt, wobei nach links gehen mit einer 0 kodiert wird, nach rechts gehen mit einer 1.")
37
1.3 Huffman-Kodierung Charakteristik Das allgemeine Verfahren zur Bestimmung des variablen Codes ist 1952 von D. Huffman entwickelt worden und wird deshalb Huffman-Kodierung genannt. Jeder beliebige Baum mit M äußerem Knoten kann benutzt werden, um jede beliebige Zeichenfolge mit M verschiedenen Zeichen zu kodieren. Welches ist aber der ideale Baum, um die Zeichenfolge zu kodieren?

38
Beispiel Gegeben sei folgender Beispielstring:
"A simple string to be encoded using a minimal number of bits". Im ersten Schritt wird die Häufigkeit jedes Zeichens in der zu kodierenden Zeichenfolge ermittelt.

39
Beispiel Gegeben sei folgender Beispielstring:
"A simple string to be encoded using a minimal number of bits". Im ersten Schritt wird die Häufigkeit jedes Zeichens in der zu kodierenden Zeichenfolge ermittelt. Als nächstes wird der Baum entsprechend der Häufigkeiten der Zeichen gebaut.

40
Beispiel Gegeben sei folgender Beispielstring:
"A simple string to be encoded using a minimal number of bits". Im ersten Schritt wird die Häufigkeit jedes Zeichens in der zu kodierenden Zeichenfolge ermittelt. Als nächstes wird der Baum entsprechend der Häufigkeiten der Zeichen gebaut. Während seiner Erzeugung wird der zu bauende Baum als binärer Baum betrachtet, mit Knoten, die Häufigkeiten speichern.

41
Beispiel Gegeben sei folgender Beispielstring:
"A simple string to be encoded using a minimal number of bits". Im ersten Schritt wird die Häufigkeit jedes Zeichens in der zu kodierenden Zeichenfolge ermittelt. Als nächstes wird der Baum entsprechend der Häufigkeiten der Zeichen gebaut. Während seiner Erzeugung wird der zu bauende Baum als binärer Baum betrachtet, mit Knoten, die Häufigkeiten speichern. Die beiden Knoten mit den kleinsten Häufigkeiten werden ausgewählt und es wird ein neuer Knoten erzeugt, der die beiden Knoten als Nachfolger hat. Die Häufigkeit des so entstandenen Knotens entspricht der Summe der Häufigkeiten seiner beiden Kinder.

42
Beispiel Gegeben sei folgender Beispielstring:
"A simple string to be encoded using a minimal number of bits". Im ersten Schritt wird die Häufigkeit jedes Zeichens in der zu kodierenden Zeichenfolge ermittelt. Als nächstes wird der Baum entsprechend der Häufigkeiten der Zeichen gebaut. Während seiner Erzeugung wird der zu bauende Baum als binärer Baum betrachtet, mit Knoten, die Häufigkeiten speichern. Die beiden Knoten mit den kleinsten Häufigkeiten werden ausgewählt und es wird ein neuer Knoten erzeugt, der die beiden Knoten als Nachfolger hat. Die Häufigkeit des so entstandenen Knotens entspricht der Summe der Häufigkeiten seiner beiden Kinder. Bei jedem Schritt verringert sich die Zahl der Knoten um 1 (zwei Konten werden durch einen ersetzt), solange bis alle Knoten durch einen einzigen Baum verbunden sind.
, solange bis alle Knoten durch einen einzigen Baum verbunden sind.")
43
Beispiel (Fortsetzung)
Aus der Verteilung der Häufigkeiten kann beispielsweise dieser Baum erzeugt werden:

44
Beispiel (Fortsetzung)
")
45
Beispiel (Fortsetzung)
Dieser Baum ist nur einer von mehreren möglichen Bäumen. Am Ende befinden sich Zeichen mit geringen Häufigkeiten unten im Baum, Zeichen mit großen Häufigkeiten aber oben

46
Die Buchstaben werden den Häufigkeitswerten zugeordnet
Im nächsten Schritt werden alle Pfade links mit 0 kodiert, alle rechts abgehenden mit 1 Nun können die Codes für die Zeichen ermittelt werden

47
Dateiformate für Bildinformationen
2.1 TIFF (Tagged Image File Format) 2.1.1 Charakteristik/ Basisstruktur Das TIFF (Tag[ged] Image File Format) geht auf eine gemeinsame Definition verschiedener Firmen (Aldus, HP, Microsoft etc.) zurück. Das TIFF-Format unterstützt u.a. LZW und Huffman-Kodierung (modifiziert) zur Komprimierung. Version: 6.0 . Eine TIFF-Datei besteht aus einem Header und einer variablen Zahl von Datenblöcken mit unterschiedlicher Länge, die über Zeiger adressiert werden. Die Struktur der Datei wird im wesentlichen durch die als IFD (Image File Directory) bezeichneten Blöcke geprägt. Diese IFDs bilden eine verkettete Liste innerhalb der Datei und enthalten (Meta-)Informationen bezüglich der gespeicherten Datentypen, der Bilddaten, des Grafikmodus, etc. Aus den IFDs verweisen Zeiger auf die eigentlichen Datenblöcke.
 Charakteristik/ Basisstruktur. Das TIFF (Tag[ged] Image File Format) geht auf eine gemeinsame Definition verschiedener Firmen (Aldus, HP, Microsoft etc.) zurück. Das TIFF-Format unterstützt u.a. LZW und Huffman-Kodierung (modifiziert) zur Komprimierung. Version: Eine TIFF-Datei besteht aus einem Header und einer variablen Zahl von Datenblöcken mit unterschiedlicher Länge, die über Zeiger adressiert werden. Die Struktur der Datei wird im wesentlichen durch die als IFD (Image File Directory) bezeichneten Blöcke geprägt. Diese IFDs bilden eine verkettete Liste innerhalb der Datei und enthalten (Meta-)Informationen bezüglich der gespeicherten Datentypen, der Bilddaten, des Grafikmodus, etc. Aus den IFDs verweisen Zeiger auf die eigentlichen Datenblöcke.")
48
Die Bilddaten werden in freien Bereichen innerhalb der Datei gespeichert.
Der Aufbau der TIFF-Datei ist somit sehr flexibel und es können z.B. mehrere Bilder oder verschiedene Varianten eines Bildes innerhalb einer Datei gespeichert werden.

49
TIFF-Header Der Header besitzt ein festes Format und belegt immer die ersten 8 Bytes der Datei.

50
Image File Directory Innerhalb der TIFF-Datei können die Daten beliebig angeordnet sein. Der Bezug darauf wird durch die IFDs vorgenommen. Das IFD funktioniert dabei als Inhaltsverzeichnis und Header auf die eigentlichen Datenbereiche. Beginnend mit dem Header sind alle IFDs durch Zeiger verkettet. Die Länge eines IFDs ist variabel und wird durch die Anzahl der Tag-Einträge bestimmt.

51
Struktur der Tags Das Tag enthält Informationen über Bilddaten wie z.B. Bildabmessungen, Auflösung etc. Passen nicht alle Angaben in das Tag, werden die Reste in freie Bereiche innerhalb der Datei ausgelagert. Ein Zeiger weist auf diesen Datenbereich.

52
2.2 GIF (Graphics Interchange Format)
Charakteristik GIF ist ein Rastergrafik-Format, das eine Farbtiefe von 8 Bit haben kann. Das GIF-Format liegt in zwei Spezifikationen vor: GIF-87a ist die 1987 entwickelte Standardversion. GIF-89a erlaubt zusätzlich zu GIF-87a Transparenz. Auch GIF-Dateien werden mit dem LZW-Verfahren komprimiert. GIF-Dateien können im Interlacing-Verfahren gespeichert werden. Das GIF-Format ist ein Copyright der Firma Compuserve. Interlacing-Verfahren die Formate GIF, JPEG und PNG kennen das Interlacing-Verfahren als Alternative zum zeilenweisen Aufbau der Grafik. Das Bild wird dabei unmittelbar in voller Größe, allerdings nur schemenhaft, aufgebaut. Fortlaufend werden immer mehr Daten nachgeladen (interlaced), wodurch die Grafik an Schärfe gewinnt. Der Speicherbedarf erhöht sich um ca. 10%.
, wodurch die Grafik an Schärfe gewinnt. Der Speicherbedarf erhöht sich um ca. 10%.")
53
2.3 PNG (Portable Network Graphics)
Das PNG-Format ist entwickelt worden, da es rund um das GIF-Format immer wieder Copyright-Probleme gegeben hat. PNG ist ein Rastergrafik-Format, das eine Farbtiefe von 48 Bit bei RGB-Bildern und 16 Bit bei Graustufenbildern haben kann. PNG-Dateien lassen sich ebenfalls interlaced speichern. PNG unterstützt u.a. Huffman-Kodierung.

54
Aufbau einer PNG-File Eine PNG-Datei hat einen blockweisen Aufbau, der aus sogenannten chunks (Blöcke) besteht. Die Zahl der chunks ist abhängig vom gespeicherten Bild. Struktur von CHUNKs

55
CHUNK-Typen Die PNG-Definition unterscheidet zwischen kritischen CHUNKs und untergeordneten (ancillary) CHUNKs. Kritische CHUNKs müssen von jedem Programm beherrscht werden, welches eine PNG-Datei liest oder schreibt. Die Namen kritischer CHUNKs beginnen mit einem Großbuchstaben. Die Namen untergeordneter CHUNKs beginnen mit einem Kleinbuchstaben. Header-CHUNK Der Header-CHUNK enthält Informationen über die Daten, die in der PNG-Datei gespeichert werden. Der CHUNK muss sofort nach den 8 Byte der Signatur auftreten. Als Signatur wird der Name IHDR benutzt.

56
Header-CHUNK

57
2.3.2.4 Textual Data-CHUNK (tEXt)
Der Textual Data-CHUNK erlaubt es, lesbare Texte in einer PNG-Datei mit abzulegen. Zur Zeit sind folgende Begriffe definiert: Title, Author, Description, Copyright, Creation Time, Software, Disclaimer, Warning, Source, Comment. Als Signatur wird der Name tEXt benutzt.

58
2.4 JPEG (Joint Photographics Expert Group)
Charakteristik JPEG ist eher eine Kompressionsmethode denn ein richtiges Bildformat: Um Kompressionsraten von bis zu 90% bei akzeptabler Bildqualität zu erreichen, werden verschiedene Methoden kombiniert eingesetzt, darunter auch Huffman, RLE oder DCT. JPEG-Dateien beschreiben Bilder als Rastergrafik, das eine Farbtiefe von 24 Bit haben kann. Dem Interlacing-Verfahren beim GIF entspricht das progressive JPEG. JPEG ist in ISO DIS definiert. Die Definition von JPEG erlaubt allerdings viele Freiheiten, so dass der Austausch von JPEG-Bilddaten zwischen verschiedenen Anwendungen und Plattformen relativ problematisch ist. Als minimaler Standard für den Austausch wurde das JFIF (JPEG File Interchange-Format) -Format definiert.
 -Format definiert.")
59
JPEG-Farbmodell JPEG-Grafiken werden im YCbCr-Farbmodell gespeichert. Y ist ein Luminaz-Wert und gibt die Helligkeit eines Punktes an, Cb und Cr sind Crominanz-Werte, welche die Farben charakterisieren. RGB- und YCbCr-Farbmodelle lassen sich linear ineinander überführen: die Berechnung der YCbCr-Farbe geschieht gemäß der folgenden Werte: Dieses Farbmodell empfiehlt sich aufgrund der Tatsache, dass der Mensch Helligkeitsunterschiede stärker wahrnimmt als Farbunterschiede.

60
Aufgaben 1) Wiederholen Sie den Stoff dieser Sitzung bis zur nächsten Sitzung (siehe dazu den Link zur Sitzung auf der HKI-Homepage). Informieren Sie sich zusätzlich durch eigene Literaturrecherche! 2) Beantworten Sie die Fragen aus der Sammlung „beispielhafte Klausurfragen“ zum Bereich Bild (soweit in dieser Sitzung behandelt).
 Beantworten Sie die Fragen aus der Sammlung „beispielhafte Klausurfragen zum Bereich Bild (soweit in dieser Sitzung behandelt).")
Ähnliche Präsentationen







>")
>")









 Prof. Th. Ottmann.>")
 Prof. Th. Ottmann.>")