Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Proseminar Präsentation
Thomas Schnöller ICQ:

2
Themen der Präsentation
Einführung ins Transaction Management Distributed Concurrency Control Distributed DBMS Reliability

3
Einführung ins Transaction Management
Definitionen Eigenschaften Typen

4
Definition Transaktion: Besteht aus einer Sequenz von Lese- und Schreiboperationen auf eine Datenbank zusammen mit Berechnungsschritten Transaction management behandelt das Problem die Datenbank immer in einen konsistenten Zustand zu halten, auch wenn gleichzeitige Zugriffe und Fehler auftreten.

5
Eigenschaften von Transaktionen
Untrennbarkeit (=Atomicity) Konsistenz (=Consistency) Isolation Widerstandsfähigkeit (=Durability)
 Konsistenz (=Consistency) Isolation. Widerstandsfähigkeit (=Durability)")
6
Untrennbarkeit (=Atomicity)
Eine Transaktion wird als eine Einheit von Operationen angesehen Darum werden entweder alle Aktionen einer Transaktion beendet oder keine All-or-Nothing Prinzip

7
Konsistenz (=Consistency)
Richtigkeit einer Transaktion Ist ein korrektes Programm, dass einen konsistenten Datenbankstatus zu einem anderen mapped

8
Isolation Wird gebraucht, damit eine Transaktion die ganze Zeit über eine konsistente Datenbank sieht Eine ausführende Transaktion kann ihre Ergebnisse nicht anderen gleichzeitig ausführenden Transaktionen offenbaren, bis zu deren Einsatz

9
Widerstandsfähigkeit (=Durability)
Falls eine Transaktion einsetzt sind ihre Resultate permanent und können auch nicht aus der Datenbank gelöscht werden

10
Typen von Transaktionen
Kriterien zur Typeneinteilung: Dauer von Transaktionen Organisation der Lese- und Schreibzugriffe Struktur

11
Kriterium der Dauer von Transaktionen
Short-life Transaction: Kurze Ausführungs- und Antwortzeit Relative kleine Datenbank Banking, Fluglinien Reservierung, ... Long-life Transaction Gegenteil von Short-life CAD/CAM database, statistische Applikationen, komplexe Abfragen, image processing

12
Kriterium der Organisation der Lese- und Schreibaktionen
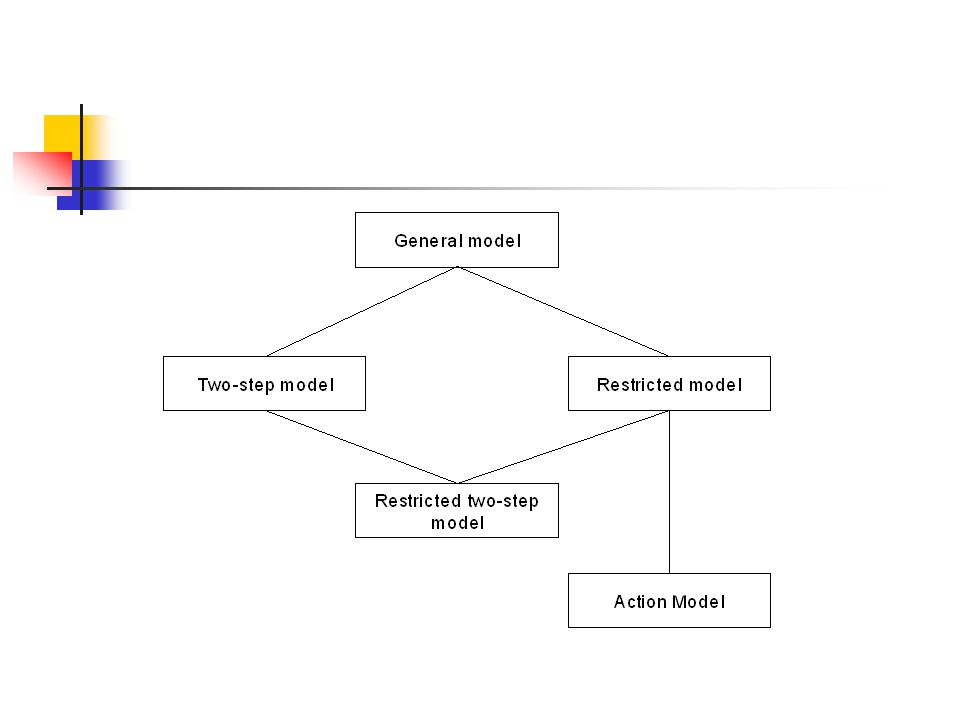
General Model Lese- und Schreibzugriffe haben keine bestimmte Reihenfolge Two-step Model Leseaktionen werden vor Schreibaktionen ausgeführt Restricted Model Daten müssen gelesen werden, bevor sie geschrieben werden

13
Restricted two-step Model Action Model
Vereint das two-step mit dem restricted Model Action Model Besteht aus dem Restricted Model, mit dem Unterschied, dass jedes <Lese und Schreib> Paar ausgeführt wird

15
Kriterium der Struktur
Flat Transactions Ein Startpunt und ein Endpunkt Meiste Arbeit im Transactionmanagement beruht auf Flat Transactions Nested Transactions (Open-Closed) Eine Transaktion ikludiert eine andere Workflows Neuer Typ. Wurde erstellt, da die alten Typen den Anforderungen komplexer Geschäftsmodelle nicht gerecht wurden
 Eine Transaktion ikludiert eine andere. Workflows. Neuer Typ. Wurde erstellt, da die alten Typen den Anforderungen komplexer Geschäftsmodelle nicht gerecht wurden.")
16
Distributed Concurrency Control
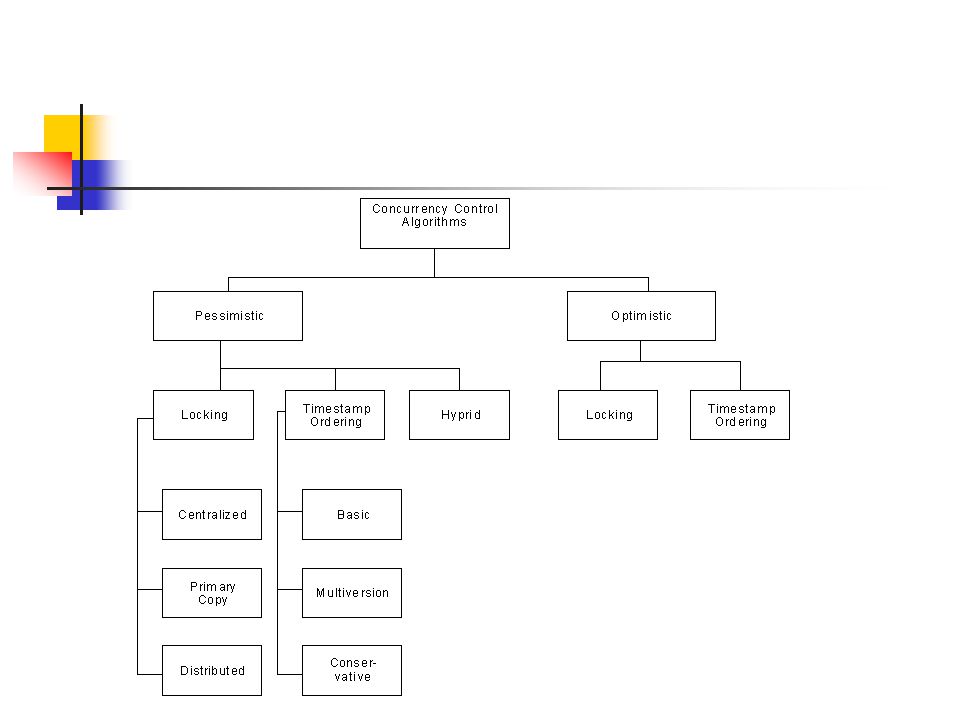
Klassifizierung von Concurrency (=Gleichzeitigkeits) Algorithmen Locking-Based Timestamp-Based
 Algorithmen. Locking-Based. Timestamp-Based.")
17
Klassifizierung Das weitverbreitetste Klassifizierungsmerkmal ist die Synchronisation Durchbruch in der Klassifizierung liegt aber in den: Locking based: Basieren auf den exklusiven Zugriff von gemeinsamen Daten Protocols: Ordnen die Ausführungen von Transaktionen auf Grund eines Rule-Set

18
Diese beiden Klassen können wiederum aus zwei Sichtweisen betrachtet werden:
Pessimistische Sicht: Viele Transaktionen werden einen Konflikt mit anderern Transaktionen haben Optimistische Sicht: Nicht viele Transaktionen werden Konflikte mit anderen Transaktionen haben

19
Optimistisch Pessimistisch

20
Auf Grund dieser Sichtweisen kann man die Concurrency Control Methods wieder in zwei Klassen einteilen: Pessimistic Algorithms: Synchronisieren die gleichzeitige Ausführung von Transaktionen schon früh im Lebenszyklus der Ausführungen Optimistic Algorithms: Verzögern die Synchronisation der Transaktionen bis zur Terminierung

22
Locking-Based Concurrency Control Algorithms
Grundidee: Es darf nur immer eine Operation auf gemeinsame Daten, auf die auch mehrere Operationen, die einen Konflikt verursachen können zugreifen können, zugreifen. Dies passiert durch einen sogenannten „Lock“ in jeder Einheit. 2 Typen von Locks: Read Lock Write Lock

23
Kompatibilität von Lock-Modes
Man spricht von Kompatibilität von Lock-Modes, wenn 2 Transaktionen die auf die selben Daten zugreifen, die Berechtigung für einen „Lock“ zur selben Zeit. Read Lock Write Lock compatible Not compatible

24
Timestamp-Based Algorithms
Einfaches Identifizierungsmittel für Transaktionen Einzigartig Monoton Verschiedene Möglichkeiten des Zuweisens: Global steigender Zähler Bei verteilten Systemen ein Problem Jede Seite verwendet meist einen eigenen lokalen Zähler

25
Distributed DBMS Reliability
Definition System, Status und Fehler Zuverlässigkeit und Verfügbarkeit Gründe für Fehler in verteilten Systemen Ansätze und Techniken zur Fehlervermeidung Fehler in verteilten DBMS

26
Definition Ein zuverlässiges DBMS ist eines, dass auch dann noch User-Requests bearbeiten kann, auch wenn das darunter liegende System unzuverlässig ist. In anderen Worten, wenn Komponenten der verteilten Umgebung Fehler haben, sollte ein zuverlässiges DBMS in der Lage sein weiter User-Requests zu bearbeiten ohne die Datenbankkonsistenz zu zerstören.

27
System, Status und Fehler
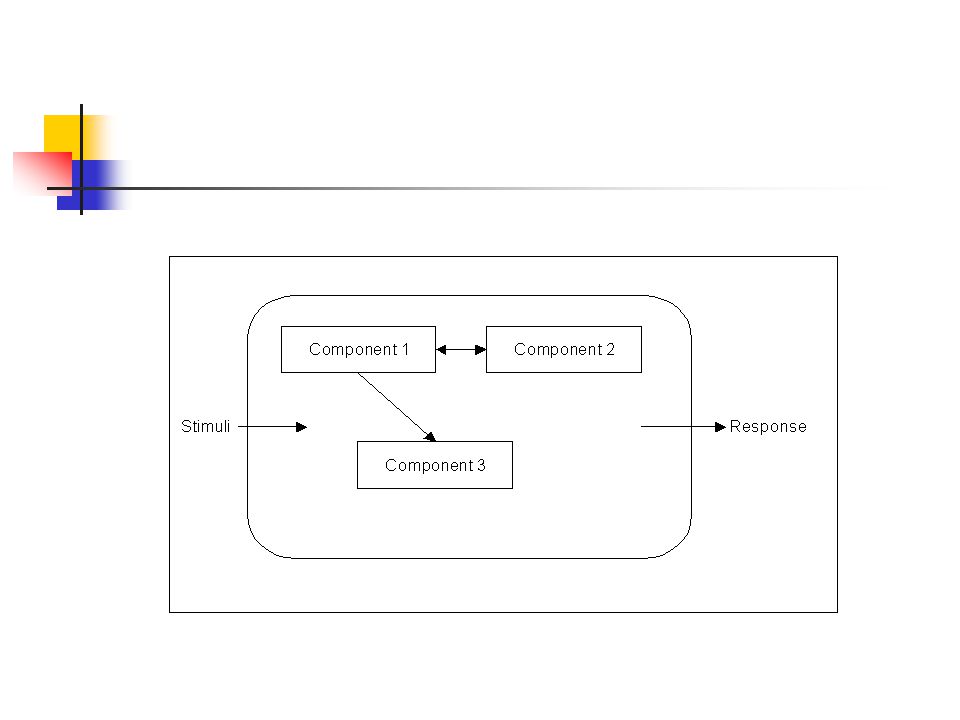
System: Besteht aus einer Sammlung von Komponenten und interagiert mit seiner Umwelt durch Antworten mit einem bestimmten Verhalten, die auf bestimmte Reize (=Stimuli) erfolgen. Jede Komponente stellt ebenfalls ein System dar die auch als Subsystem bezeichnet werden. Die Art wie die Komponenten eines Systems zusammengesetzt sind nennt man Design.
 erfolgen. Jede Komponente stellt ebenfalls ein System dar die auch als Subsystem bezeichnet werden. Die Art wie die Komponenten eines Systems zusammengesetzt sind nennt man Design.")
29
Externer Status: Kann die Antwort sein, die ein System auf einen externen Reiz gibt
Interner Status: Ist der externe Status der Komponenten des Systems. Spezifikation: Beinhaltet das gültige Verhalten, die ein System in einem bestimmten Status aufweist.

30
Es gibt 3 Arten von Fehlern:
Failure: Jedes abweichende Verhalten von der Spezifikation Error: Der Teil eines Status ist falsch Fault: Jeder Fehler in den internen states der Komponenten oder des Designs eines Systems Fault Error Failure

31
Zuverlässigkeit und Verfügbarkeit
Zuverlässigkeit bedeutet, dass in einem System, während eines bestimmten Zeitintervalls keine Fehler auftreten. Wird typischerweise für Systeme beschrieben, die nicht repariert werden können (z.B.: Weltraum-basierte Systeme), oder wo die Operation des Systems so kritisch ist, dass keine Zeit zum Reparieren toleriert werden kann.
, oder wo die Operation des Systems so kritisch ist, dass keine Zeit zum Reparieren toleriert werden kann.")
32
Verfügbarkeit hingegen bedeutet, dass ein System zu einem bestimmten Zeitpunkt genau das macht, was in der Spezifikation spezifiziert wurde. Eine bestimmte Anzahl an Fehlern kann auftreten, wenn diese aber beseitigt wurden, ist das System zu einem bestimmten Zeitpunkt wieder Verfügbar. Damit sieht man, dass sich Verfügbarkeit auf reparable Systeme bezieht.

33
1985: IBM/XA Operating System mit Stanford linear accelerator (SLAC) :
 :")
34
1985: Tandem Computers

35
Performance Studie des AT&T 5ESS digital Switch

36
Ansätze und Techniken zur Fehlervermeidung
2 fundamentale Ansätze zur Fehler Vermeidung sind die Toleranz und Prävention von Fehlern. Toleranz: Beruht auf den Designansätzen von Systemen, welche es in Betracht ziehen, dass Fehler auftreten können. Versucht Mechanismen in das System einzubaun, um Fehler zu entdecken, zu entfernen bzw zu kompensieren bevor Systemfehler auftreten Prävention: Implementierte System soll keine Fehler haben

37
Beispiele für Techniken
Redundanz in Systeme einbauen: Falls eine Komponente ausfällt übernimmt(=kompensieren) die redundante Komponente die Aufgaben. Modularer Aufbau des Systems: Modularität des Systems ermöglicht die Isolation von Fehlern in einer Komponente. Ist darum für Software- Hardwaresysteme wichtig.
 die redundante Komponente die Aufgaben. Modularer Aufbau des Systems: Modularität des Systems ermöglicht die Isolation von Fehlern in einer Komponente. Ist darum für Software- Hardwaresysteme wichtig.")
38
Fehler in verteilten DBMS
Transaction Failures (aborts) Site (system) Failures Media (disk) Failures Communication Failures
 Site (system) Failures. Media (disk) Failures. Communication Failures.")
39
Transaction Failures Incorrect input data deadlock

40
Site (System) Failures
Meist Hard- oder Softwarefehler Führt zu einem Verlust von Hauptspeicherinhalten jeder Inhalt der Datenbank der in einem Buffer des Hauptspeichers gelegen hat geht verloren In VS spricht man auch von Site Failure anderer Computer kann ausfallen Total Partiell

41
Media Failures Bei Secondary Storage Devices
Bei Betriebssystemfehlern oder Hardwarefehlern Alle Daten des DBMS die sekundär gespeichert wurden gehen verloren Abhilfe: Duplizieren und Archivieren des Sekundärmediums

42
Communication Failures
Treten nur in verteilten Systemen auf Verschiedene Ursachen: Fehler in Messages Unsachgemäß angeforderte Messages Lost Messages Line Failures Verlorene oder nicht lieferbare Messages sind meist Ursachen für einen Line Failure. Das Netzwerk kann dabei in zwei oder mehrere getrennte Gruppen zerfallen Network Partioning

Ähnliche Präsentationen

; 2.Reduziere.>")








; 2.Reduziere.>")

>")






