Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Eigenschaften des Gehörs
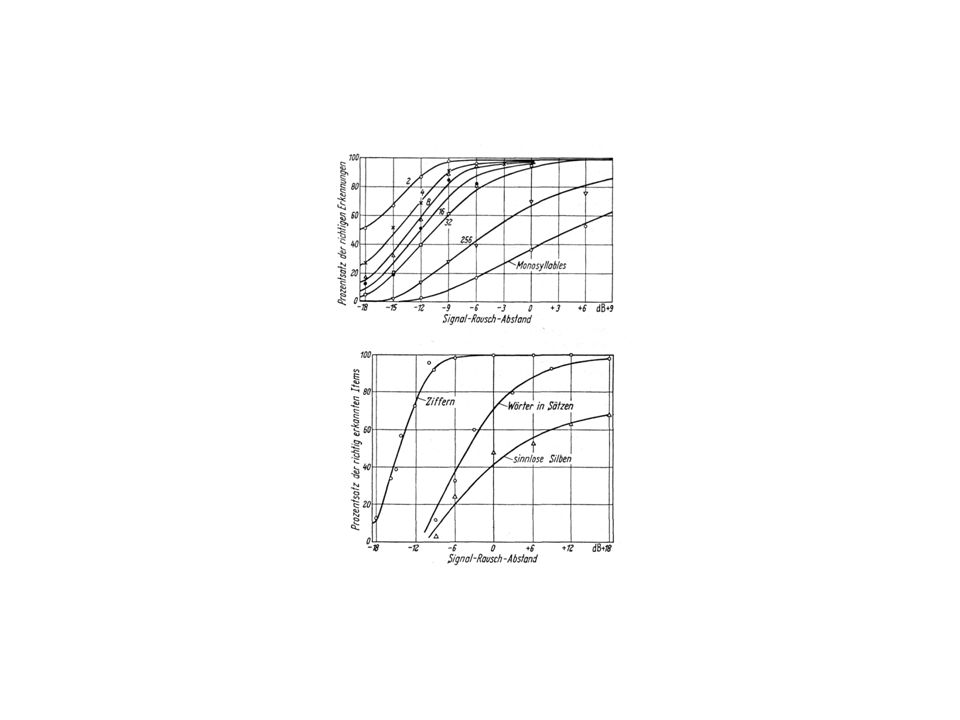
Das akustische Signal besteht aus Schallwellen. Wellen haben die Eigenschaften Frequenz (Anzahl der Schwingungen/sec ) und Amplitude (Stärke der Schwingung) Was können menschliche Hörer unterscheiden? Frequenzunterschiede: 20 Hz (1 Hz = 1 Schwingung /sec) Amplitudenunterschiede: 0.5 dB (Dezibel; 1 dB = 20 log Px/P0) (Flüstern = 20dB, Kinopublikum 45dB, Kaufhaus 60dB) Theoretisch mögliche Unterscheidungen: 250 Amplituden (0-125 dB) 1000 Frequenzen (10 – Hz) Kombinationen Tatsächlich benutzen Sprachen aber nur höchstens 80 Phoneme.
 und Amplitude (Stärke der Schwingung) Was können menschliche Hörer unterscheiden Frequenzunterschiede: 20 Hz (1 Hz = 1 Schwingung /sec) Amplitudenunterschiede: 0.5 dB (Dezibel; 1 dB = 20 log Px/P0) (Flüstern = 20dB, Kinopublikum 45dB, Kaufhaus 60dB) Theoretisch mögliche Unterscheidungen: 250 Amplituden (0-125 dB) 1000 Frequenzen (10 – Hz) Kombinationen. Tatsächlich benutzen Sprachen aber nur höchstens 80 Phoneme.")
2
Eigenschaften des Gehörs
Was können menschliche Hörer identifizieren (Pollack, 1952, 1953, 1954)? 5 verschiedene Frequenzkategorien 5-7 verschiedene Amplitudenkategorien 8-9 Kombinationen aus Frequenz und Amplitude 6 verschiedene Dimensionen zusammen erlauben etwa 32 identifizierbare Kategorien. Wir können also nicht alle unterscheidbaren akustischen Signale identifizieren, sondern nur eine viel geringere Anzahl von Kategorien. > Trade-off zwischen Menge der Information und Sicherheit der Erkennung. Wie viel Information kann damit übertragen werden?
 5 verschiedene Frequenzkategorien. 5-7 verschiedene Amplitudenkategorien. 8-9 Kombinationen aus Frequenz und Amplitude. 6 verschiedene Dimensionen zusammen erlauben etwa 32 identifizierbare Kategorien. Wir können also nicht alle unterscheidbaren akustischen Signale identifizieren, sondern nur eine viel geringere Anzahl von Kategorien. > Trade-off zwischen Menge der Information und Sicherheit der Erkennung. Wie viel Information kann damit übertragen werden")
3
Information Informationsgehalt eines bestimmten Ereignisses i , das mit der Wahrscheinlichkeit pi auftritt: Hi = log2 1/pi d.h. je wahrscheinlicher, desto weniger Information. Informationsübertragung ist nie perfekt. Störungen nennt man Rauschen. Signal-Rausch-Verhältnis gibt an, wie deutlich das Signal (also etwa die Buchstaben oder Phoneme) im Verhältnis zum Rauschen wahrzunehmen ist. Je weniger Informationen man überträgt, desto weniger deutlich muss das Signal sein.
 im Verhältnis zum Rauschen wahrzunehmen ist. Je weniger Informationen man überträgt, desto weniger deutlich muss das Signal sein.")
5
Phonemerkennung

7
Kategorielle Wahrnehmung
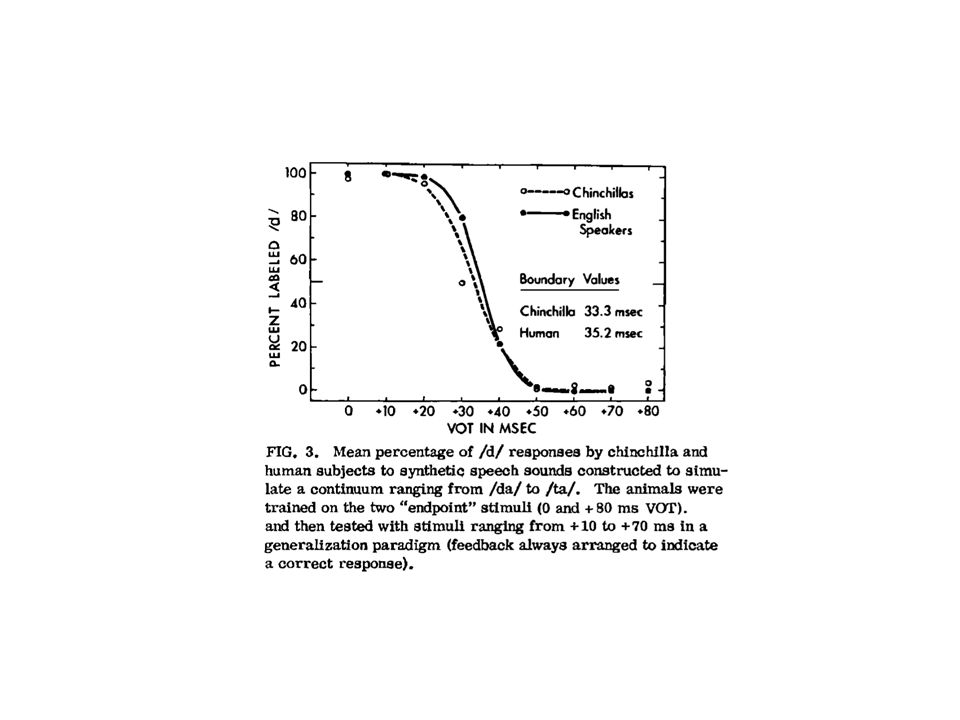
Phoneme werden kategoriell erkannt (categorical perception, Liberman, 1963) Identifikation Wenn man eine akustische Eigenschaft (z.B. VOT) in gleich großen Schritten variiert, wechselt die Wahrnehmung nicht kontinuierlich, sondern in Sprüngen zwischen Kategorien. Stimuli Wahrnehmung b / d / g Diskrimination Stimuluspaare, die einen akustisch identischen Unterschied aufweisen, können an Kategoriengrenzen besser unterschieden werden als innerhalb der Kategorien. (z.B. Stimuli 4 und 5 besser als 6 und 7).
 Identifikation. Wenn man eine akustische Eigenschaft (z.B. VOT) in gleich großen Schritten variiert, wechselt die Wahrnehmung nicht kontinuierlich, sondern in Sprüngen zwischen Kategorien. Stimuli Wahrnehmung b / d / g. Diskrimination. Stimuluspaare, die einen akustisch identischen Unterschied aufweisen, können an Kategoriengrenzen besser unterschieden werden als innerhalb der Kategorien. (z.B. Stimuli 4 und 5 besser als 6 und 7).")
8
Kategorielle Wahrnehmung
Kategoriengrenzen sind sprachspezifisch. Das bedeutet, dass Kinder entweder am Anfang einen akustischen Unterschied in einem Kontinuum überall gleich gut unterscheiden können und dies später unter dem Einfluss der Muttersprache verlernen (“acquired similarity”) oder am Anfang einen akustischen Unterschied in einem Kontinuum nicht (gut) wahrnehmen können und dies später unter dem Einfluss der Muttersprache an den Kategoriengrenzen lernen (“acquired distinctiveness”)
 oder. am Anfang einen akustischen Unterschied in einem Kontinuum nicht (gut) wahrnehmen können und dies später unter dem Einfluss der Muttersprache an den Kategoriengrenzen lernen ( acquired distinctiveness )")
9
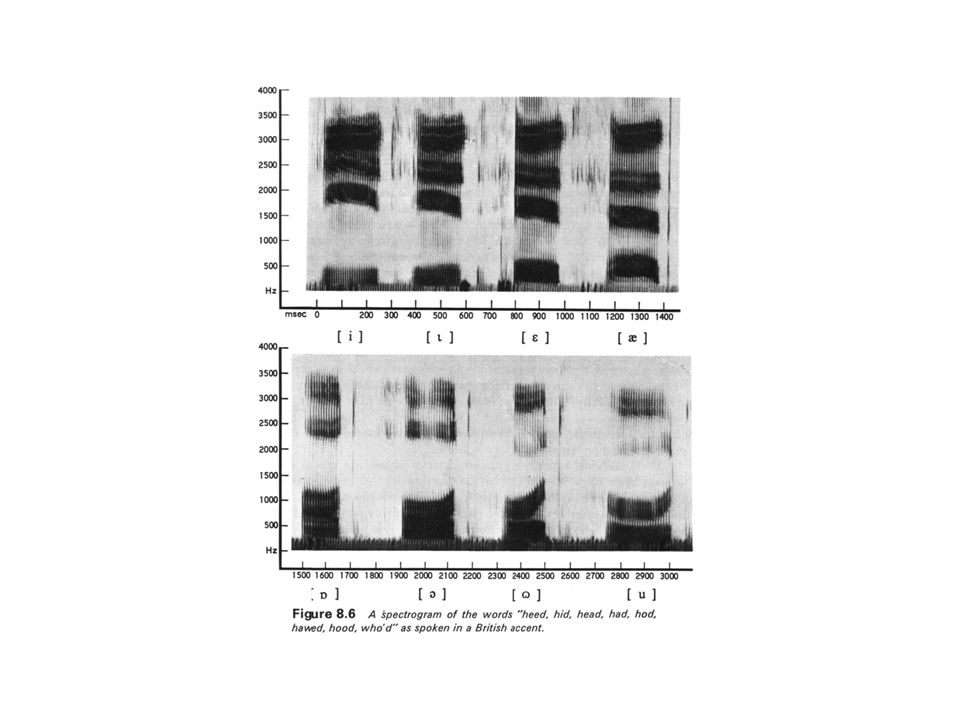
Durch Veränderung des Übergangs zum Vokalformanten wird die Konsonantenqualität kontinuierlich verändert. Im Englischen gibt es in diesem Kontinuum eine Grenze zwischen /b/ und /d/. Im Hindi gibt es zwei Grenzen, weil es zwei verschiedene /d/-Laute gibt.

11
Englische 6-8 monatige Säuglinge unterscheiden Laute
an einer Kategoriegrenze des Hindi besser als 11-13 monatige Säuglinge oder Erwachsene.

13
Konsonanten, in geringerem Maße auchVokale, werden also als Kategorien wie /p/, /d/, /m/ usw. wahrgenommen, innerhalb derer feine akustische Unterschiede nicht gut wahrgenommen werden. Das legt nahe, dass der akustische Input in eine abstraktere phonologische Repräsentation umgewandelt wird, auf Grundlage derer dann passende Lexikoneinträge gesucht werden. Bei dieser Repräsentation wären dann keine Informationen über den genauen Klang eines gehörten /p/ mehr vorhanden. Die meisten Spracherkennungsmodelle nehmen das tatsächlich an. Es gibt aber auch Theorien, die annehmen, das bei der Worterkennung noch viel mehr akustische Details genutzt werden (episodische Theorien der Worterkennung).
.")
14
Worterkennung und prälexikalische Repräsentation
Literatur: Frauenfelder & Floccia (1998) The recognition of spoken word. In: Friederici, A. (ed.) Language Comprehension: A biological perspective. Berlin, Heidelberg, New York. Springer. pp. 1-40 Grundprobleme der Worterkennung: a) Es gibt einige zehntausend teilweise sehr ähnliche Lexikoneinträge. b) Lexikalische Einbettung (Haus: Hau, Au, aus) c) Variabilität der konkreten Realisierung. Viele verschiedene ‚Tokens‘ einer Wortform müssen auf einen ‚Type‘, den Lexikoneintrag abgebildet werden. (abhängig von Sprecher, Sprechgeschwindigkeit, sprachlicher Umgebung: vgl. ‚du‘ in ‚du kannst‘ vs. ‚kannst du‘, ‚Haus und Hof‘ bei verschiedenen Sprechgeschwindigkeiten) d) Kontinuität der gesprochenen Sprache
 The recognition of spoken word. In: Friederici, A. (ed.) Language Comprehension: A biological perspective. Berlin, Heidelberg, New York. Springer. pp Grundprobleme der Worterkennung: a) Es gibt einige zehntausend teilweise sehr ähnliche Lexikoneinträge. b) Lexikalische Einbettung (Haus: Hau, Au, aus) c) Variabilität der konkreten Realisierung. Viele verschiedene ‚Tokens‘ einer Wortform müssen auf einen ‚Type‘, den Lexikoneintrag abgebildet werden. (abhängig von Sprecher, Sprechgeschwindigkeit, sprachlicher Umgebung: vgl. ‚du‘ in ‚du kannst‘ vs. ‚kannst du‘, ‚Haus und Hof‘ bei verschiedenen Sprechgeschwindigkeiten) d) Kontinuität der gesprochenen Sprache.")
15
Lexikalische Alignment-Mechanismen
Die lexikalische Suche hängt sehr davon ab, ob und wenn ja welche Einheiten im Input als mögliche Wortanfänge angenommen werden, d.h. welche Teile der Inputrepräsentation und der lexikalischen Repräsentationen miteinander verglichen werden. (Sind beim Input "Haus" nur die Lexikoneinträge 'Haus' und 'Hau' mögliche Kandidaten oder auch 'aus' und 'Au'?) In Analogie zu einem Textformat nennt man das 'Ausrichtung' oder 'Alignment'. Input: (Ich gehe ins) Haus. Lexikoneinträge: Hau Haus Au aus
 In Analogie zu einem Textformat nennt man das Ausrichtung oder Alignment . Input: (Ich gehe ins) Haus. Lexikoneinträge: Hau. Haus. Au. aus.")
16
In Theorien der Worterkennung finden sich folgende Alignment-Mechanismen:
Vollständiges Alignment b) Positionelles Alignment (Wortanfang wird als erkannt vorausgesetzt) ‚Landmark‘-Alignment (Hörer nutzen Hinweise, die Wortanfänge signalisieren.) Metrische Segmentierung (Cutler & Norris, 1988) Spezialfall des Landmark-Alignment: Wortanfänge werden z.B. im Englischen vor betonten Silben angenommen.
 Positionelles Alignment (Wortanfang wird als erkannt vorausgesetzt) ‚Landmark‘-Alignment (Hörer nutzen Hinweise, die Wortanfänge signalisieren.) Metrische Segmentierung (Cutler & Norris, 1988) Spezialfall des Landmark-Alignment: Wortanfänge werden z.B. im Englischen vor betonten Silben angenommen.")
17
Prälexikalische Inputrepräsentation
Die prälexikalische Inputrepräsentation vermittelt zwischen dem Sprachsignal und den Lexikoneinträgen. Die Art und Weise wie der Input vor dem Lexikonzugriff kodiert ist, entscheidet darüber, wie die o.g. Probleme gelöst werden können. Mögliche ‚Units‘ sind akustische Repräsentationen, phonologische Merkmale, Phoneme, Moren, Silben, andere prosodische Einheiten Was muß eine Unit leisten? (Cutler & Norris 1985) - erkennbar sein - jede mögliche Äußerung kodieren (transkribieren) können - auf lexikalische Einheiten abbildbar sein Kosten-Nutzen-Relationen Unmittelbarkeit des Lexikonzugriffs: je kleiner die Unit desto schneller. Silben teilweise schon zu lang ( vgl. ‚Herbst‘) Zuverlässigkeit: je länger desto zuverlässiger. Man verhört sich eher bei einem Phonem als bei einer Silbe. Aufwand bei der Kodierung: einige 10 Phoneme vs. einige tausend Silben
 - erkennbar sein. - jede mögliche Äußerung kodieren (transkribieren) können. - auf lexikalische Einheiten abbildbar sein. Kosten-Nutzen-Relationen. Unmittelbarkeit des Lexikonzugriffs: je kleiner die Unit desto schneller. Silben teilweise schon zu lang ( vgl. ‚Herbst‘) Zuverlässigkeit: je länger desto zuverlässiger. Man verhört sich eher bei einem Phonem als bei einer Silbe. Aufwand bei der Kodierung: einige 10 Phoneme vs. einige tausend Silben.")
18
Miller & Volaitis, 1989

19
Palmeri, Goldinger, & Pisoni, 1993

20
Experimentelle Befunde zur Inputrepräsentation
Miller & Volaitis, 1989 Technik: Phoneme categorisation Wird die Kategorisierung aufgrund von VOT durch die Sprechgeschwindigkeit beeinflusst? Ja. Bei langsamer Sprache werden auch /p/s mit längerer VOT als normal als /p/ kategorisert. > Phonemkategorisierung passt sich akustischen Veränderungen an. Unit = Phonem Palmeri, Goldinger, & Pisoni, 1993 Technik: Continuous recognition memory task VPs erkennen Wörter, die vorher in einer Liste präsentiert wurden, besser wieder, wenn sie vom gleichen Sprecher stammen. Akustische Besonderheiten wie eine bestimmte Stimme werden abgespeichert und bei der Worterkennung benutzt (allerdings ist nicht klar, wie lange der Effekt hält) Worterkennung benutzt akustische Repräsentation („Episodic trace“)
 Worterkennung benutzt akustische Repräsentation („Episodic trace )")
21
Experimentelle Befunde zur Inputrepräsentation
Mehler et al. 1981 Technik: ‚Fragment detection‘ Ist die Silbe /ba/ oder /bal/ in den Wörtern /ba.lance/ bzw. /bal.con/ Vps reagieren schneller bei Silbenübereinstimmung > Unit = Silbe Ergebnis erwies sich als sprach- und sprechgeschwindigkeitsabhängig. Möglicherweise mißt die Technik postlexikalische Prozesse. Radeau, Morais & Segui 1995 Technik: ‚Phonological Priming‘ Priming–Effekt wenn Prime und Target in den letzten beiden von 3 Phonemen übereinstimmten. Effekt war nicht abhängig von lexikalischer Frequenz. Unit = Rime

22
Kolinsky, Morais & Cluytens 1995
Technik: ‚Speech Migration‘ Den Vps werden zwei verschiedene Kunstwörter gleichzeitig rechts und links über Kopfhörer dargeboten (dichotische Darbietung). Sie müssen angeben, was sie gehört haben. Es werden dabei häufig existierende Wörter gehört, die aus einer Vermischung der dargebotenen Kunstwörter entstehen. dargeboten: ‚biton‘ und ‚cojou‘ gehört: ‚coton‘ (Baumwolle) oder ‚bijou‘ (Schmuckstück) Die ‚Wanderung‘ (migration) von Silben ist dabei häufiger als die anderer Einheiten. > spricht für Silben als Units Wiederholungsexperimente für Japanisch (Silben und Moren) und Portugiesisch (initiales Phonem) Units sprachspezifisch Insgesamt: verschiedene Units einschließlich akustischer Information > Worterkennung nutzt alle verfügbaren Informationen, aber mit sprachspezifischer Gewichtung
. Sie müssen angeben, was sie gehört haben. Es werden dabei häufig existierende Wörter gehört, die aus einer Vermischung der dargebotenen Kunstwörter entstehen. dargeboten: ‚biton‘ und ‚cojou‘ gehört: ‚coton‘ (Baumwolle) oder ‚bijou‘ (Schmuckstück) Die ‚Wanderung‘ (migration) von Silben ist dabei häufiger als die anderer Einheiten. > spricht für Silben als Units. Wiederholungsexperimente für Japanisch (Silben und Moren) und Portugiesisch (initiales Phonem) Units sprachspezifisch. Insgesamt: verschiedene Units einschließlich akustischer Information > Worterkennung nutzt alle verfügbaren Informationen, aber mit sprachspezifischer Gewichtung.")
23
Problem: wortinitiale Phonemabweichung (‚Figarette‘)
Kohortenmodell I Inputrepräsentation: Phoneme Alignment: Wort-Onset Laterale Inhibition: nein Worterkennung am ‚uniqueness point‘, definiert durch lexikalische Umgebung Input aktivierte Kohorte Input Kohorte Input Kohorte /kvi/ /kvit/ /kvitu/ quick quitt Quittung Quirl Quitte Quirlig Quittung Quirlen quittieren quitt quittieren Quittung Quitte Quitte Quiz Problem: wortinitiale Phonemabweichung (‚Figarette‘)
")
24
Experimente Marslen-Wilson & Zwitserlood, 1989 technique: cross-modal semantic priming neither mat nor dat (pseudoword) prime dog Connine, Blasko & Titone, 1993 gat (small phonological distance between the /g/ and the /k/ in cat) DOES prime dog to some extent > activation of initially slightly different competitors Zwitserlood 1989 stimuli: captain - captive the fragment /capt/ primes both ship and guard the fragment /capti/ no longer primes ship > competitors immediately drop out after non-initial mismatch > evidence for bottom-up inhibition
 DOES prime dog. to some extent. > activation of initially slightly different competitors. Zwitserlood stimuli: captain - captive. the fragment /capt/ primes both ship and guard. the fragment /capti/ no longer primes ship. > competitors immediately drop out after non-initial mismatch. > evidence for bottom-up inhibition.")
25
Shillcock 1990 technique: cross-modal semantic priming trombone primes rib but: Gow & Gordon 1995 tulips DID NOT prime kiss (associatively related to lips) Norris et al., 1995 technique: word spotting (does the stimulus contain a word?) stimulus: maskuk (contains mask) Subjects were slower to detect mask if there was a large set of words beginning with /sk/). > non-initial competitors are activated, size of set of non-initial competitors matters
 Norris et al., technique: word spotting (does the stimulus contain a word ) stimulus: maskuk (contains mask) Subjects were slower to detect mask if there was a large set of words beginning with /sk/). > non-initial competitors are activated, size of set of non-initial competitors matters.")
26
Kohortenmodell II Inputrepräsentation: distinktive Merkmale Alignment: Wort-Onset Weitere Unterschiede zu Kohortenmodell I Kohorten sind größer, da gewisses Maß an Nichtübereinstimmung toleriert wird. Kohortenmitglieder variieren im Aktivierungsniveau, abhängig von Frequenz und Qualität der Übereinstimmung Erkennungszeitpunkt hängt vom Aktivierungsgrad der Mitbewerber ab

Ähnliche Präsentationen









![FRIKATIVE Sitzung 9 Welche Konsonanten sind für sich alleine identifizierbar? -Alle Konsonanten ausser [pt] in tippt, weil das [p] nicht gelöst wird und.](/1/645849/big_thumb.jpg "FRIKATIVE Sitzung 9 Welche Konsonanten sind für sich alleine identifizierbar? -Alle Konsonanten ausser [pt] in tippt, weil das [p] nicht gelöst wird und.>")



 Carola Mook Nach einem Artikel von Patricia K. Kuhl.>")

>")




