Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Eine korpusbasierte Geschichte des deutschsprachigen Romans Göttingen, 15.8.2012 Fotis Jannidis

2
Ziel Monographische Darstellung (vulgo: Buch) Theoriebaustelle 1: Kritik an der (Literatur-)Geschichte Theoriebaustelle 2: Modelle historiographischer Präsentation Zwischenstand: Patchwork von Mikronarrativen; Hypertext?
 Theoriebaustelle 1: Kritik an der (Literatur-)Geschichte Theoriebaustelle 2: Modelle historiographischer Präsentation Zwischenstand: Patchwork von Mikronarrativen; Hypertext")
3
Komponenten (Mikronarrative) Epochen Gattungsentwicklungen (Bildungsroman usw.) Werkentwicklungen Narrative Muster Synchrone Feldanalyse Ausdiff. lit. Kommunikationssysteme, z.B. Populäre Lit. Einzeltextinterpretation …

4
Komponenten mit Korpusforschung Epochen Gattungsentwicklungen (Bildungsroman usw.) Werkentwicklungen Narrative Muster Synchrone Feldanalyse Ausdiff. lit. Kommunikationssysteme, z.B. Populäre Lit. Einzeltextinterpretation …

5
Forschungsstand: Material USA: Bsp: ca. 3.000 Romane des 19. Jh. D: 650 Romane (TextGridRep)
")
6
Forschungsstand: Methoden Ngram-Verlauf in der Zeit Stylometrie Regelbasierte Analyse Machinelles Lernen Topic Modeling

7
The method John Burrows: Delta Basis: most frequent words (mostly stopwords) A measure for the relative stilistic distance between texts „the mean of the absolute differences between the z-scores for a set of word-variables in a given text-group and the z-scores for the same set of word-variables in a target text“
 A measure for the relative stilistic distance between texts „the mean of the absolute differences between the z-scores for a set of word-variables in a given text-group and the z-scores for the same set of word-variables in a target text")
8
Z-score x is a raw score to be standardized μ is the mean of the population σ is the standard deviation of the population

9
Assigning authors of American novels (Hoover 2004)
")
10
Validity With texts longer than 2000 words Burrows‘ Delta is a good indicator for the correct author With shorter texts in 85% of all cases the correct author is one of the first five names

11
The tool R Script by Maciej Eder, Jan Rybicki

13
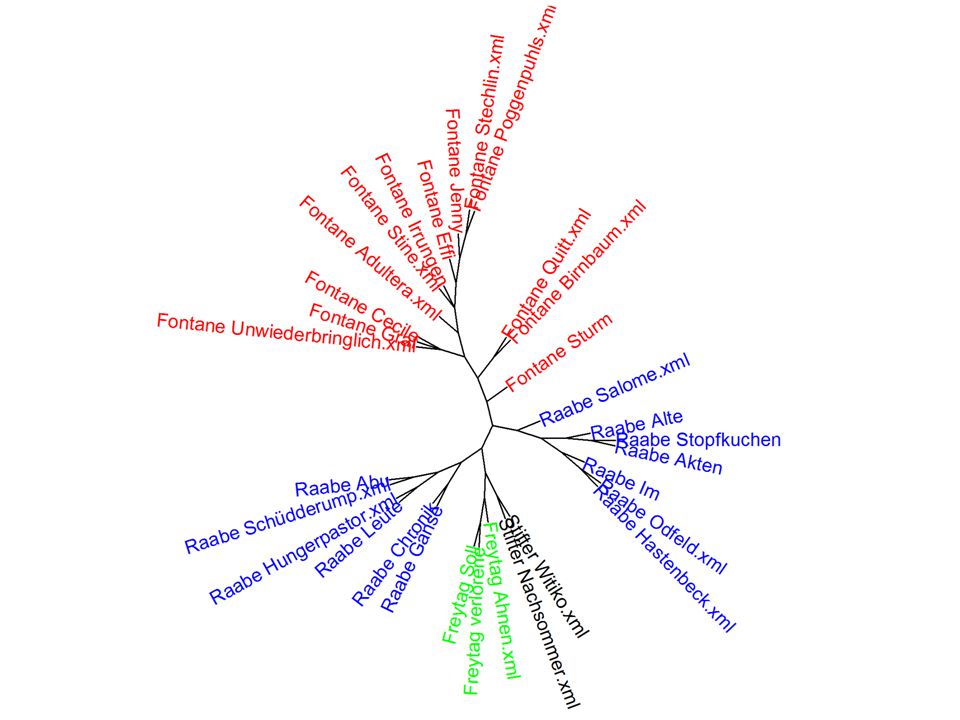
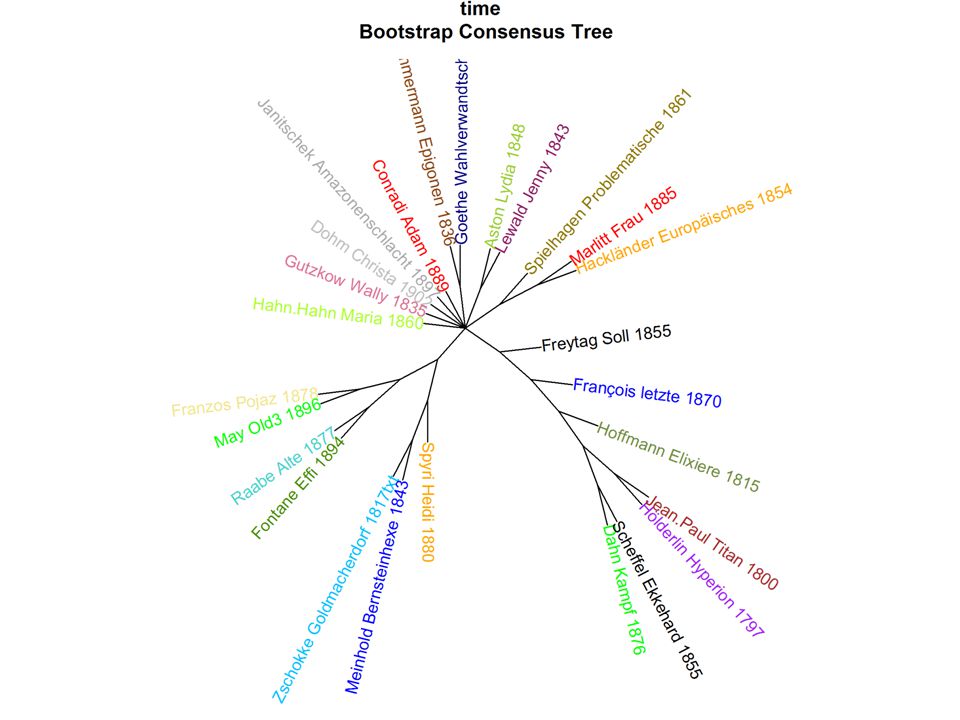
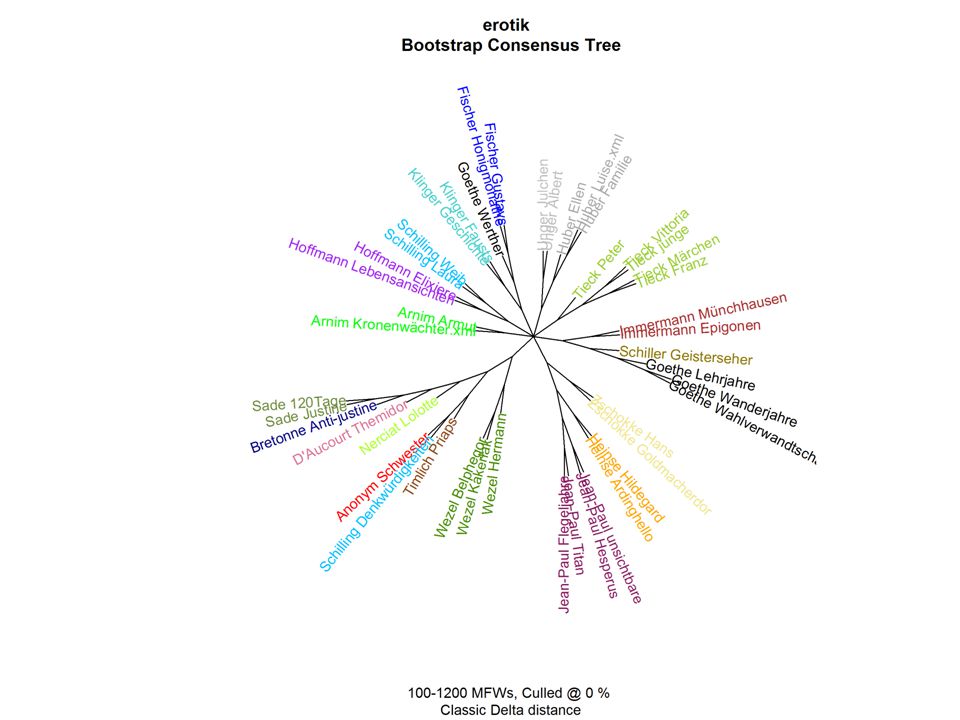
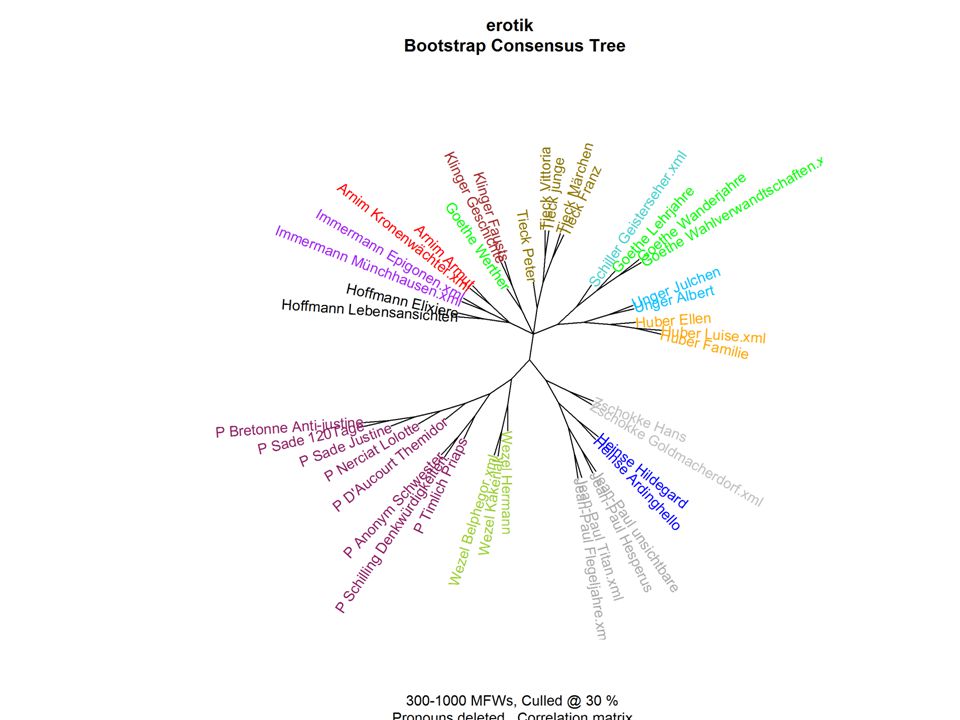
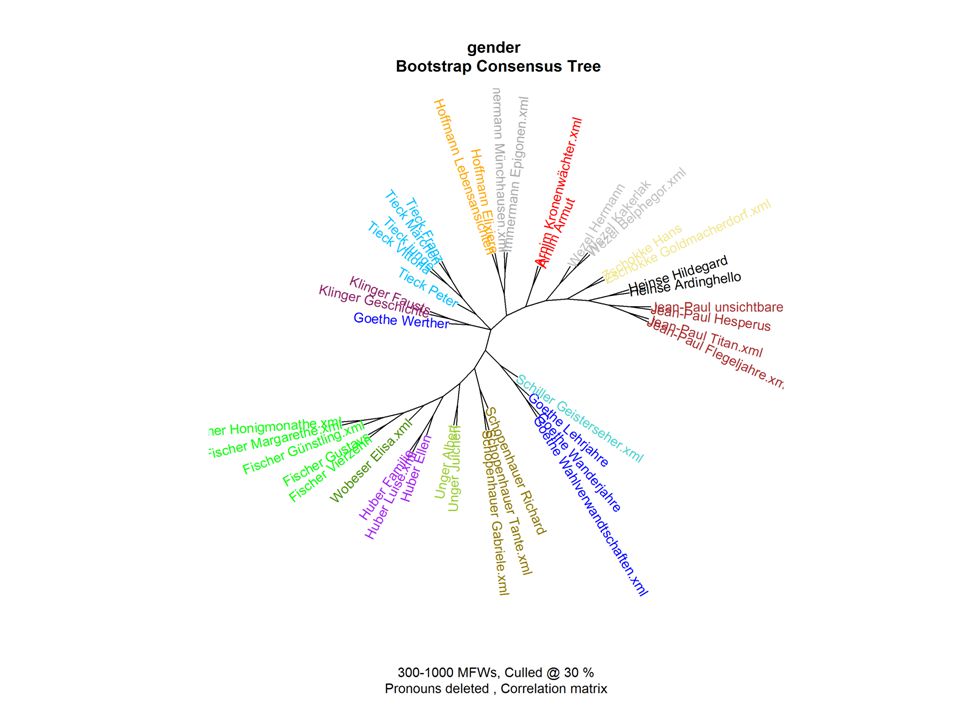
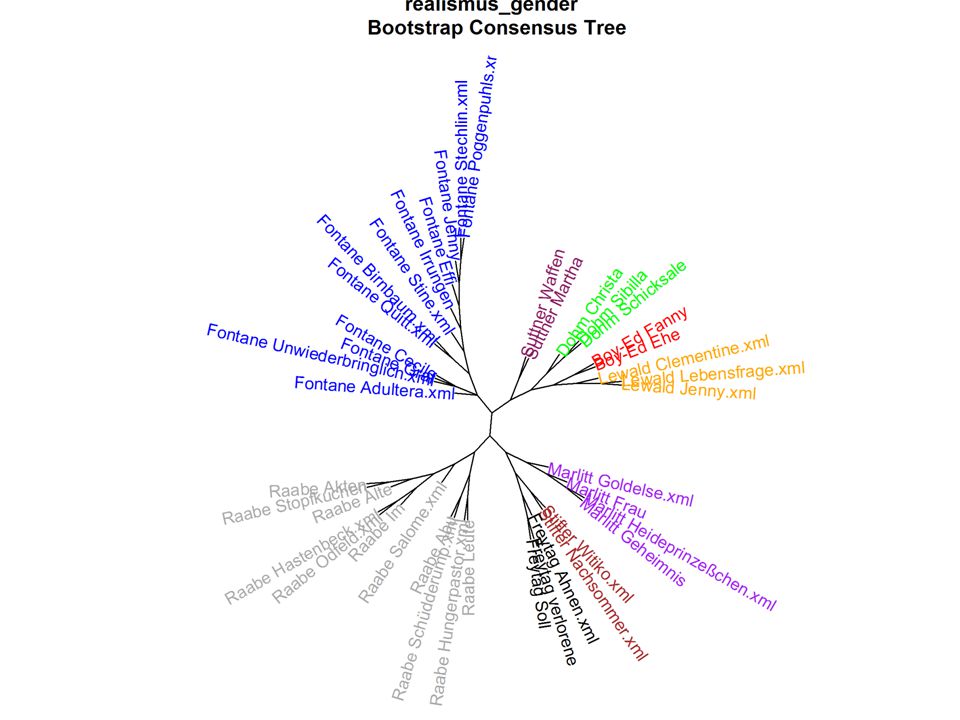
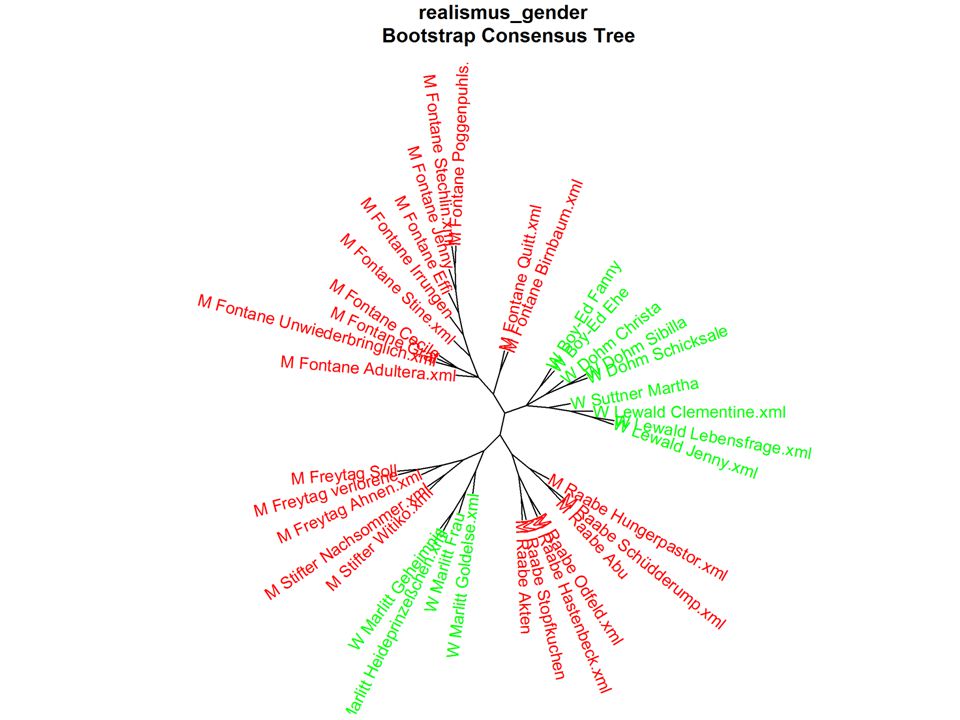
Some ‚results‘

23
Stand der Dinge: Eine Einschätzung Kalibrierung der Instrumente Fruchtbare Verwendungsformen Viel Platz zwischen Heilsversprechen und Verteufelung

24
Probleme quantitativer Textanalyse Typische Probleme: Mangelndes historisches Wissen, unbrauchbare Texte, falsche Indikatoren, unzulänglich gehandhabte statistische Verfahren Wahrscheinlichkeitsaussagen in den Geisteswissenschaften Trivial?

25
Mapping Models Genre und Gender Konzepte und die der zu sie ich er in den das sich mit nicht so ein dem von es auf war als wie Narrative, descriptions of erotic actions and tableaux, staging of bodies, language of seduction Bag of Words Most frequent words

26
Quantitative Verfahren und die Literaturwissenschaft Ersatz oder Ergänzung? Ein neues Paradigma? Empirische Psychologie und korpusbasierte Verfahren Vs. oder Koop

27
Quantitative Ansätze basieren auf sehr diversen Kompetenzen. Das problem der Interdisziplinarität

28
Literatur John Burrows: Delta: A Measure for Stylistic Difference and A Guide to Likely Authorship. In: LLC 17,3 (2002). TextGridRep http://textgridrep.de/repository.html The R Script for Stylometric Analyses https://sites.google.com/site/computationalstylistics/ Ryan Heuser, Long Le-Khac: A Quantitative Literary History of 2,958 Nineteenth-Century British Novels: The Semantic Cohort Method. Stanford LabReport May 2012. http://litlab.stanford.edu/LiteraryLabPamphlet4.pdf
. TextGridRep The R Script for Stylometric Analyses Ryan Heuser, Long Le-Khac: A Quantitative Literary History of 2,958 Nineteenth-Century British Novels: The Semantic Cohort Method. Stanford LabReport May")
Ähnliche Präsentationen




![Z-Transformation Die bilaterale Z-Transformation eines Signals x[n] ist die formale Reihe X(z): wobei n alle ganzen Zahlen durchläuft und z, im Allgemeinen,](/1/205073/big_thumb.jpg "Z-Transformation Die bilaterale Z-Transformation eines Signals x[n] ist die formale Reihe X(z): wobei n alle ganzen Zahlen durchläuft und z, im Allgemeinen,>")












 2.Kultur 3.Forming questions Heute ist Dienstag, der 3. September 2013 Hausaufgaben GH #1,#2.>")
 am Gymnasium Sulingen.>")


>")
