Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Data Warehouses und Data Mining
Online Transaction Processing Data Warehouse-Anwendungen Data Mining

2
OLTP: Online Transaction Processing
Beispiele: Flugbuchungssystem Bestellungen in einem Handelsunternehmen Charakteristisch: Hoher Parallelitätsgrad Viele (1000+/sec) kurze Transaktionen Transaktionen bearbeiten nur ein kleines Datenvolumen "Mission-critical" für das Unternehmen Hohe Verfügbarkeit muss gewährleistet sein Normalisierte Relationen (möglichst wenig Update-Kosten) Nur wenige Indexe
 kurze Transaktionen. Transaktionen bearbeiten nur ein kleines Datenvolumen. Mission-critical für das Unternehmen. Hohe Verfügbarkeit muss gewährleistet sein. Normalisierte Relationen (möglichst wenig Update-Kosten) Nur wenige Indexe.")
3
Data Warehouse-Anwendungen: OLAP (Online Analytical Processing)
Im Gegensatz zu OLTP stehen bei OLAP etwa folgende Fragestellungen im Zentrum: Wie hat sich die Auslastung der Transatlantikflüge über die letzten zwei Jahre entwickelt? oder Wie haben sich besondere offensive Marketingstrategien für bestimmte Produktlinien auf die Verkaufszahlen ausgewirkt?

4
Sammlung und periodische Auffrischung der Data Warehouse-Daten
OLAP-Anfragen Decision Support Data Mining OLTP-Datenbanken und andere Datenquellen extract, transform, load Data Warehouse

5
Datenbank-Design für Data Warehouses: Stern-Schema
Stern-Schema eines Date Warehouse: Eine sehr große Faktentabelle: Alle Verkäufe der letzten drei Jahre Alle Telefonate des letzten Jahres Alle Flugreservierungen der letzten fünf Jahre Normalisiert Mehrere Dimensionstabellen: Zeit Filialen Kunden Produkt Oft nicht normalisiert

6
Das Stern-Schema: Handelsunternehmen
Produkte Kunden Filialen Verkäufe Fremdschlüssel- beziehungen Zeit Verkäufer

7
Das Stern-Schema: Krankenversicherung
Patienten Ärzte Krankenhäuser Behandlungen Zeit Krankheiten

8
Dimensionstabellen (relativ klein)
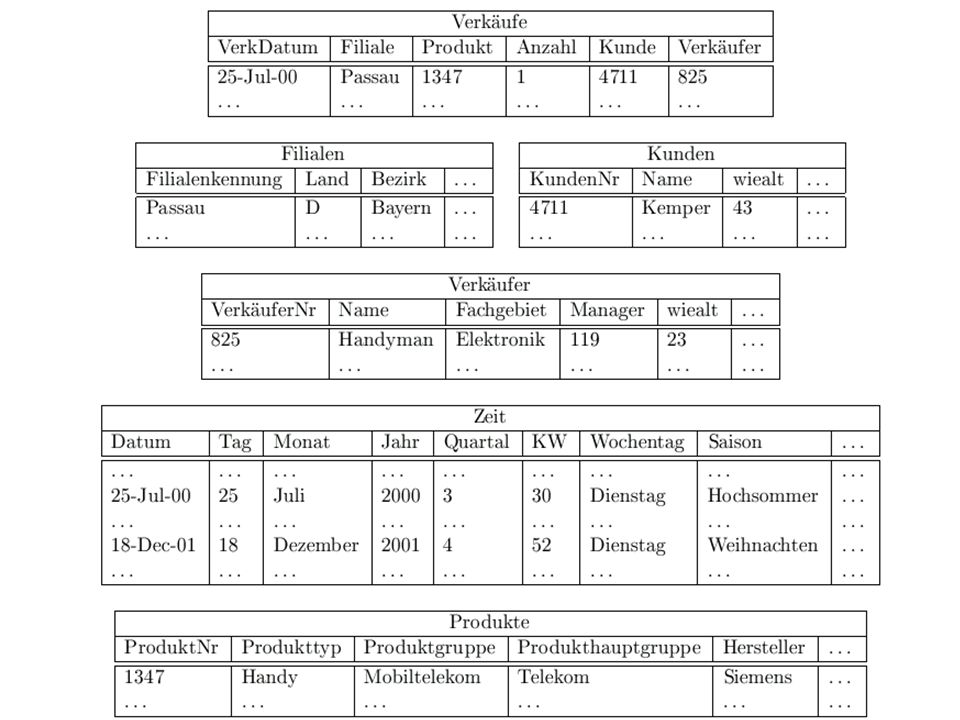
Stern-Schema Verkäufe VerkDatum Filiale Produkt Anzahl Kunde Verkäufer 25-Jul-00 Passau 1347 1 4711 825 ... Faktentabelle (typischerweise SEHR groß, Tupel) Filialen FilialenKennung Land Bezirk ... Passau D Bayern Kunden KundenNr Name wieAlt ... 4711 Kemper 43 Dimensionstabellen (relativ klein) Verkäufer VerkäuferNr Name Fachgebiet Manager wieAlt ... 825 Handyman Elektronik 119 23
 Filialen. FilialenKennung. Land. Bezirk. ... Passau. D. Bayern. Kunden. KundenNr. Name. wieAlt Kemper. 43. Dimensionstabellen (relativ klein) Verkäufer. VerkäuferNr. Name. Fachgebiet. Manager. wieAlt Handyman. Elektronik")
9
Stern-Schema (cont‘d)
Zeit Datum Tag Monat Jahr Quartal KW Wochentag Saison 25-Jul-00 25 7 2000 3 30 Dienstag Hochsommer ... 18-Dec-01 18 12 2001 4 52 Weihnachten Typische Tupel-Anzahl: 1000 (3 Jahre) Produkte ProduktNr Produkttyp Produktgruppe Produkthauptgruppe Hersteller .. 1347 Handy Mobiltelekom Telekom Siemens ... Typische Tupel-Anzahl: (Katalog)
 Produkte. ProduktNr. Produkttyp. Produktgruppe. Produkthauptgruppe. Hersteller Handy. Mobiltelekom. Telekom. Siemens. ... Typische Tupel-Anzahl: (Katalog)")
10
Nicht-normalisierte Dimensionstabellen: Hierarchische Klassifizierung
Zeit Datum Tag Monat Jahr Quartal KW Wochentag Saison 25-Jul-00 25 7 2000 3 30 Dienstag Hochsommer ... 18-Dec-01 18 12 2001 4 52 Weihnachten Geltende FDs: Datum Monat Quartal Produkte ProduktNr Produkttyp Produktgruppe Produkthauptgruppe Hersteller .. 1347 Handy Mobiltelekom Telekom Siemens ... ProduktNr Produkttyp Produktgruppe Produkthauptgruppe

11
Normalisierung führt zum Schneeflocken-Schema
Produkthaupt- gruppen Produktgruppen Filialen Kunden Produkttypen Verkäufe Produkte Zeit Verkäufer KWs Quartale

12
Typische Anfragen gegen Stern-Schemata: Analyse
"Wieviele Handys welcher Hersteller haben junge Kunden in den Bayerischen Filialen zu Weihnachten 2001 gekauft?" Verdichtung SELECT SUM(v.Anzahl), p.Hersteller FROM Verkäufe v, Filialen f, Produkte p, Zeit z, Kunden k WHERE z.Saison = 'Weihnachten' and z.Jahr = 2001 and k.wieAlt < 30 and p.Produkttyp = 'Handy' and f.Bezirk = 'Bayern' AND v.VerkDatum = z.Datum and v.Produkt = p.ProduktNr and v.Filiale = f.FilialenKennung and v.Kunde = k.KundenNr GROUP BY p.Hersteller; Einschränkung der Dimensionen Verdichtung Join-Prädikate
, p.Hersteller. FROM Verkäufe v, Filialen f, Produkte p, Zeit z, Kunden k. WHERE z.Saison = Weihnachten and. z.Jahr = 2001 and k.wieAlt < 30 and. p.Produkttyp = Handy and f.Bezirk = Bayern AND. v.VerkDatum = z.Datum and v.Produkt = p.ProduktNr and. v.Filiale = f.FilialenKennung and v.Kunde = k.KundenNr. GROUP BY p.Hersteller; Einschränkung. der Dimensionen. Verdichtung. Join-Prädikate.")
13
Algebra-Ausdruck (Star Join)
...(Produkte) ...(Filialen) Verkäufe ...(Zeit) ...(Kunden)
 ...(Filialen) Verkäufe. ...(Zeit) ...(Kunden)")
14
Grad der Verdichtung: Roll-up/Drill-Down
SELECT Jahr, Hersteller, SUM(v.Anzahl) FROM Verkäufe v, Produkte p, Zeit z WHERE v.Produkt = p.ProduktNr AND v.VerkDatum = z.Datum AND p.Produkttyp = 'Handy' GROUP BY p.Hersteller, z.Jahr; SELECT Jahr, SUM(v.Anzahl) GROUP BY z.Jahr; Roll-up Drill-down
 FROM Verkäufe v, Produkte p, Zeit z. WHERE v.Produkt = p.ProduktNr AND v.VerkDatum = z.Datum. AND p.Produkttyp = Handy GROUP BY p.Hersteller, z.Jahr; SELECT Jahr, SUM(v.Anzahl) GROUP BY z.Jahr; Roll-up. Drill-down.")
15
Analyse von Handyverkaufszahlen
nach verschiedenen Dimensionen

16
Analyse von Handyverkaufszahlen nach verschiedenen Dimensionen
Roll-up Analyse von Handyverkaufszahlen nach verschiedenen Dimensionen Down Drill-

17
Data Cubes (n-dim. Datenwürfel)
Die Darstellung derart verdichteter Information erfolgt in Decision-Support-Systemen oft spreadsheet-artig (cross tabulation): Dieser 2-dimensionale data cube fasst alle Anfrageergebnisse der vorhergenden Folie zusammen.
: Dieser 2-dimensionale data cube fasst alle Anfrageergebnisse. der vorhergenden Folie zusammen.")
18
Ultimative Verdichtung
Keine Gruppierung (keine GROUP BY-Klausel) alle Tupel bilden eine einzige Gruppe, bevor aggregiert wird: SELECT SUM(Anzahl) FROM Verkäufe v, Produkte p WHERE v.Produkt = p.ProduktNr AND p.Produkttyp = 'Handy';
 alle Tupel. bilden eine einzige Gruppe, bevor aggregiert wird: SELECT SUM(Anzahl) FROM Verkäufe v, Produkte p. WHERE v.Produkt = p.ProduktNr AND p.Produkttyp = Handy ;")
19
Materialisierung von Aggregaten
INSERT INTO Handy2DCube ( SELECT p.Hersteller, z.Jahr, SUM(v.Anzahl) FROM Verkäufe v, Produkte p, Zeit z WHERE v.Produkt = p.ProduktNr and p.Produkttyp = 'Handy' and v.VerkDatum = z.Datum GROUP BY z.Jahr, p.Hersteller ) UNION ( SELECT p.Hersteller, NULL, SUM(v.Anzahl) FROM Verkäufe v, Produkte p GROUP BY p.Hersteller ) UNION ( SELECT NULL, z.Jahr, SUM(v.Anzahl) GROUP BY z.Jahr ) UNION ( SELECT NULL, NULL, SUM(v.Anzahl) FROM Verkäufe v, Produkte p WHERE v.Produkt = p.ProduktNr and p.Produkttyp = 'Handy' );
 FROM Verkäufe v, Produkte p, Zeit z. WHERE v.Produkt = p.ProduktNr and p.Produkttyp = Handy and v.VerkDatum = z.Datum. GROUP BY z.Jahr, p.Hersteller ) UNION. ( SELECT p.Hersteller, NULL, SUM(v.Anzahl) FROM Verkäufe v, Produkte p. GROUP BY p.Hersteller ) UNION. ( SELECT NULL, z.Jahr, SUM(v.Anzahl) GROUP BY z.Jahr ) UNION. ( SELECT NULL, NULL, SUM(v.Anzahl) FROM Verkäufe v, Produkte p. WHERE v.Produkt = p.ProduktNr and p.Produkttyp = Handy );")
20
Relationale Struktur der Datenwürfel

21
Würfeldarstellung

22
Der CUBE-Operator (SQL:1999)
Die Materialisierung von Aggregaten führt zu aufwendigen Anfragen, deren Optimierung für das RDBMS schwierig ist: n Dimensionen 2n Unterfragen, verbunden durch UNION Aggregate könnten hierarchisch berechnet werden Folgender CUBE-Operator ersetzt 23 Unteranfragen: SELECT p.Hersteller, z.Jahr, f.Land, SUM(v.Anzahl) FROM Verkäufe v, Produkte p, Zeit z, Filialen f WHERE v.Produkt = p.ProduktNr AND p.Produkttyp = 'Handy' AND v.VerkDatum = z.Datum AND v.Filiale = f.Filialenkennung GROUP BY CUBE (z.Jahr, p.Hersteller, f.Land);
 FROM Verkäufe v, Produkte p, Zeit z, Filialen f. WHERE v.Produkt = p.ProduktNr AND p.Produkttyp = Handy AND v.VerkDatum = z.Datum AND v.Filiale = f.Filialenkennung. GROUP BY CUBE (z.Jahr, p.Hersteller, f.Land);")
23
Wiederverwendung von Teil-Aggregaten
Annahme: Folgende Verdichtung liegt in der Datenbank vorausberechnet vor (materialisiert): INSERT INTO VerkäufeProduktFilialeJahr ( SELECT v.Produkt, v.Filiale, z.Jahr, SUM(v.Anzahl) FROM Verkäufe v, Zeit z WHERE v.VerkDatum = z.Datum GROUP BY v.Produkt, v.Filiale, z.Jahr ); Dann läßt sich folgende Anfrage auf der vorausberechneten Verdichtung VerkäufeProduktFilialeJahr berechnen (anstatt auf die Faktentabelle Verkäufe zugreifen zu müssen): SELECT v.Produkt, v.Filiale, SUM(v.Anzahl) FROM Verkäufe v VerkäufeProduktFilialeJahr v GROUP BY v.Produkt, v.Filiale
: INSERT INTO VerkäufeProduktFilialeJahr. ( SELECT v.Produkt, v.Filiale, z.Jahr, SUM(v.Anzahl) FROM Verkäufe v, Zeit z. WHERE v.VerkDatum = z.Datum. GROUP BY v.Produkt, v.Filiale, z.Jahr ); Dann läßt sich folgende Anfrage auf der vorausberechneten Verdichtung VerkäufeProduktFilialeJahr berechnen (anstatt auf die Faktentabelle Verkäufe zugreifen zu müssen): SELECT v.Produkt, v.Filiale, SUM(v.Anzahl) FROM Verkäufe v VerkäufeProduktFilialeJahr v. GROUP BY v.Produkt, v.Filiale.")
24
Die Materialisierungs-Hierarchie
Teilaggregate T sind für eine Aggregation A wiederverwendbar wenn es einen gerichteten Pfad von T nach A gibt Also T ... A Man nennt diese Materialisierungshierarchie auch einen Verband (Engl. lattice)
")
25
Die Zeit-Hierarchie

26
Bitmap-Indexe Typische OLAP-Workloads lassen die Ausnutzung sehr
spezifischer Index-Strukuren zu. Hier: Index auf spezifische Werte eines Attributes mit kleiner diskreter Domäne: Optimierung durch Komprimierung der Bitmaps Ausnutzung der dünnen Besetzung, bspw. durch runlength-compression Speichere jeweils die Länge der Nullfolgen zwischen zwei Einsen

27
Bitmap-Indexe: Beispiel-Anfrage und Auswertung
Marketing-Aktion: Extrahiere junge, gerade volljährige Kundinnen: SELECT k.Name FROM Kunden k WHERE k.Geschlecht = 'w' AND k.wiealt BETWEEN 18 AND 19; Unterstützung der Anfrage durch folgende Operation auf Bitmap-Indizes: (w18 w19) Gw
 Gw.")
28
Bitmap-Operationen

29
Klassischer Join-Index
Bitmap-Indizes als Join-Indizes Klassischer Join-Index Bitmap-Join-Index Bitmap-Join-Index

30
(i,II)(ii,I)(iii,II)(iv,II)(v,I)(vi,II)... B-Baum TID-K
TID-V (i,II)(ii,I)(iii,II)(iv,II)(v,I)(vi,II)... B-Baum TID-K (I,i)(I,v)(II,i)(II,iii)(II,iv)(II,vi)...
(ii,I)(iii,II)(iv,II)(v,I)(vi,II)... B-Baum. TID-K. (I,i)(I,v)(II,i)(II,iii)(II,iv)(II,vi)...")
31
(i,II)(ii,I)(iii,II)(iv,II)(v,I)(vi,II)...
5 5 SELECT k.* FROM Verkäufe v, Kunden k WHERE v.ProduktID = 5 AND v.KundenNr = k.KundenNr B-Baum TID-V (i,II)(ii,I)(iii,II)(iv,II)(v,I)(vi,II)...
(ii,I)(iii,II)(iv,II)(v,I)(vi,II)...")
32
(I,i)(I,v)(II,i)(II,iii)(II,iv)(II,vi)...
B-Baum TID-K (I,i)(I,v)(II,i)(II,iii)(II,iv)(II,vi)... SELECT v.* FROM Verkäufe v, Kunden k WHERE k.KundenNr = 4711 AND v.KundenNr = k.KundenNr
(I,v)(II,i)(II,iii)(II,iv)(II,vi)... SELECT v.* FROM Verkäufe v, Kunden k. WHERE k.KundenNr = 4711 AND. v.KundenNr = k.KundenNr.")
34
Erinnerung: Star Join "Wieviele Handys welcher Hersteller haben junge Kunden in den Bayerischen Filialen zu Weihnachten 2001 gekauft?" SELECT SUM(v.Anzahl), p.Hersteller FROM Verkäufe v, Filialen f, Produkte p, Zeit z, Kunden k WHERE z.Saison = 'Weihnachten' and z.Jahr = 2001 and k.wieAlt < 30 and p.Produkttyp = 'Handy' and f.Bezirk = 'Bayern' AND v.VerkDatum = z.Datum and v.Produkt = p.ProduktNr and v.Filiale = f.FilialenKennung and v.Kunde = k.KundenNr GROUP BY p.Hersteller; Einschränkung der Dimensionen Join-Prädikate
, p.Hersteller. FROM Verkäufe v, Filialen f, Produkte p, Zeit z, Kunden k. WHERE z.Saison = Weihnachten and. z.Jahr = 2001 and k.wieAlt < 30 and. p.Produkttyp = Handy and f.Bezirk = Bayern AND. v.VerkDatum = z.Datum and v.Produkt = p.ProduktNr and. v.Filiale = f.FilialenKennung and v.Kunde = k.KundenNr. GROUP BY p.Hersteller; Einschränkung. der Dimensionen. Join-Prädikate.")
35
Illustration des Star Join

36
Bitmap-Indexe für die Dimensions-Selektion

37
Klassischer Join-Index
Bitmap-Indizes als Join-Indizes Klassischer Join-Index Bitmap-Join-Index Bitmap-Join-Index

38
Ausnutzung der Bitmap-Join-Indexe

39
Eine weitere Join-Methode: DiagJoin
Geeignet zur Verfolgung von 1:N-Beziehungen Daten sind geballt (clustered) durch zeitlich nahe Einfügung in beide beteiligten Tabellen Beispiel: Order (Bestellung) Lineitem (Bestellposition) Order Lineitem Die Lineitems einer Order kommen zeitlich kurz hintereinander Grundidee des DiagJoins besteht darin, synchron über die beiden Relationen zu laufen Die Orders werden in einem Fenster (sliding window) gehalten
 durch zeitlich nahe Einfügung in beide beteiligten Tabellen. Beispiel: Order (Bestellung) Lineitem (Bestellposition) Order Lineitem. Die Lineitems einer Order kommen zeitlich kurz hintereinander. Grundidee des DiagJoins besteht darin, synchron über die beiden Relationen zu laufen. Die Orders werden in einem Fenster (sliding window) gehalten.")
40
DiagJoin LineItem Order# Position Produkt Preis 4711 1 PC … 5645
Laptop 2 Drucker 3 Toner Hub 7765 Fax 4 Papier Handy Mixer 9876 Order Customer Order# Kemper 4711 Maier 5645 Müller 7765 Hummer 9876 Kaller 9965 Lola 3452 Junker 1232 …

41
DiagJoin LineItem Order# Position Produkt Preis 4711 1 PC … 5645
Laptop 2 Drucker 3 Toner Hub 7765 Fax 4 Papier Handy Mixer 9876 Order Customer Order# Kemper 4711 Maier 5645 Müller 7765 Hummer 9876 Kaller 9965 Lola 3452 Junker 1232 …

42
DiagJoin LineItem Order# Position Produkt Preis 4711 1 PC … 5645
Laptop 2 Drucker 3 Toner Hub 7765 Fax 4 Papier Handy Mixer 9876 Order Customer Order# Kemper 4711 Maier 5645 Müller 7765 Hummer 9876 Kaller 9965 Lola 3452 Junker 1232 …

43
DiagJoin LineItem Order# Position Produkt Preis 4711 1 PC … 5645
Laptop 2 Drucker 3 Toner Hub 7765 Fax 4 Papier Handy Mixer 9876 Order Customer Order# Kemper 4711 Maier 5645 Müller 7765 Hummer 9876 Kaller 9965 Lola 3452 Junker 1232 …

44
DiagJoin LineItem Order# Position Produkt Preis 4711 1 PC … 5645
Laptop 2 Drucker 3 Toner Hub 7765 Fax 4 Papier Handy Mixer 9876 5 Quirl Order Customer Order# Kemper 4711 Maier 5645 Müller 7765 Hummer 9876 Kaller 9965 Lola 3452 Junker 1232 …

45
DiagJoin LineItem Order# Position Produkt Preis 4711 1 PC … 5645
Laptop 2 Drucker 3 Toner Hub 7765 Fax 4 Papier Handy Mixer 9876 5 Quirl Order Customer Order# Kemper 4711 Maier 5645 Müller 7765 Hummer 9876 Kaller 9965 Lola 3452 Junker 1232 … Tupel muss zwischengespeichert und "nachbearbeitet" werden (temp file).
.")
46
Anforderungen an den DiagJoin
1:N-Beziehung zwischen beteiligten Tabellen Die "1"-er Tupel sind in etwa dersleben Reihenfolge gespeichert worden wie die "N"-er Tupel Die Tupel werden in der "time-of-creation"-Reihenfolge wieder von der Platte gelesen (full table scan) Die referentielle Integrität sollte gewährleistet sein (Warum?) Das Fenster muss so groß sein, daß nur wenige Tupel nachbearbeitet werden müssen Nachbearbeitung bedeutet: Tupel auf dem Hintergrundspeicher (temp file) speichern Den zugehörigen Joinpartner in Order via Index auffinden Dafür ist ein Index auf Order.Order# hierfür notwendig Kein Index nötig für die erste Phase des DiagJoins
 Die referentielle Integrität sollte gewährleistet sein (Warum ) Das Fenster muss so groß sein, daß nur wenige Tupel nachbearbeitet werden müssen. Nachbearbeitung bedeutet: Tupel auf dem Hintergrundspeicher (temp file) speichern. Den zugehörigen Joinpartner in Order via Index auffinden. Dafür ist ein Index auf Order.Order# hierfür notwendig. Kein Index nötig für die erste Phase des DiagJoins.")
47
Klassifikation Assoziationsregeln
Data Mining Klassifikation Assoziationsregeln

48
Data Mining : Klassifikationsregeln
Ziel des Data Mining: Durchsuchen großer Datenmengen nach bisher unbekannten Zusammenhängen (Knowledge discovery) Klassifikation: Treffe "Vorhersagen" auf der Basis bekannter Attributwerte Vorhersageattribute: V1, V2, ..., Vn Vorhergesagtes Attribut: A Klassifikationsregel: P1(V1) P2(V2) ... Pn(Vn) A = c Prädikate P1, P2, .., Pn Konstante c Beispiel für eine Klassifikationsregel: (wieAlt>35) (Geschlecht =`m´) (Autotyp=`Coupé´) (Risiko=´hoch')
 Klassifikation: Treffe Vorhersagen auf der Basis bekannter Attributwerte. Vorhersageattribute: V1, V2, ..., Vn. Vorhergesagtes Attribut: A. Klassifikationsregel: P1(V1) P2(V2) ... Pn(Vn) A = c. Prädikate P1, P2, .., Pn Konstante c. Beispiel für eine Klassifikationsregel: (wieAlt>35) (Geschlecht =`m´) (Autotyp=`Coupé´) (Risiko=´hoch )")
49
Klassifikations/Entscheidungsbaum
Jedes Blatt des Baumes entspricht einer Klassifikationsregel

50
Klassifikations/Entscheidungsbaum
(wieAlt>35) (Geschlecht =`m´) (Autotyp=`Coupé´) (Risiko=´hoch´)
 (Geschlecht =`m´) (Autotyp=`Coupé´) (Risiko=´hoch´)")
51
Erstellung von Entscheidungs-/ Klassifikationsbäume
Trainingsmenge Große Zahl von Datensätzen, die in der Vergangenheit gesammelt wurden Sie dient als Grundlage für die Vorhersage (= Klassifikation) von "neu ankommenden" Objekten Beispiel: neuer Versicherungskunde wird gemäß dem Verhalten seiner "Artgenossen" eingestuft Rekursives Partitionieren: Fange mit einem Attribut A an und spalte die Tupelmenge bzgl. ihrer A-Werte Jede dieser Teilmengen wird rekursiv weiter partitioniert Fortsetzen, bis nur noch gleichartige Objekte in der jeweiligen Partition sind
 von neu ankommenden Objekten. Beispiel: neuer Versicherungskunde wird gemäß dem Verhalten seiner Artgenossen eingestuft. Rekursives Partitionieren: Fange mit einem Attribut A an und spalte die Tupelmenge bzgl. ihrer A-Werte. Jede dieser Teilmengen wird rekursiv weiter partitioniert. Fortsetzen, bis nur noch gleichartige Objekte in der jeweiligen Partition sind.")
52
Data Mining : Assoziationsregeln
Beispielregel: Wenn jemand einen PC kauft, dann kauft er/sie auch einen Drucker Confidence Dieser Wert legt fest, bei welchem Prozentsatz der Datenmenge, bei der die Voraussetzung (linke Seite) erfüllt ist, die Regel (rechte Seite) auch erfüllt ist. Eine Confidence von 80% für unsere Beispielregel sagt aus, dass vier Fünftel der Leute, die einen PC gekauft haben, auch einen Drucker dazu gekauft haben. Support Dieser Wert legt fest, wieviele Datensätze überhaupt gefunden wurden, um die Gültigkeit der Regel zu verifizieren. Bei einem Support von 1% wäre also jeder Hundertste Verkauf ein PC zusammen mit einem Drucker.
 erfüllt ist, die Regel (rechte Seite) auch erfüllt ist. Eine Confidence von 80% für unsere Beispielregel sagt aus, dass vier Fünftel der Leute, die einen PC gekauft haben, auch einen Drucker dazu gekauft haben. Support. Dieser Wert legt fest, wieviele Datensätze überhaupt gefunden wurden, um die Gültigkeit der Regel zu verifizieren. Bei einem Support von 1% wäre also jeder Hundertste Verkauf ein PC zusammen mit einem Drucker.")
53
Verkaufstransaktionen Warenkörbe
TransID Produkt 111 Drucker Papier PC Toner 222 Scanner 333 444 555 Finde alle Assoziationsregeln L R mit einem Support größer als minsupp und einer Confidence von mindestens minconf Dazu sucht man zunächst die sogenannten frequent itemsets (FI), also Produktmengen, die in mindestens minsupp der Einkaufswägen/ Transaktionen enthalten sind Der A Priori-Algorithmus basiert auf der Erkenntnis, dass alle Teilmengen eines FI auch FIs sein müssen
, also Produktmengen, die in mindestens minsupp der Einkaufswägen/ Transaktionen enthalten sind. Der A Priori-Algorithmus basiert auf der Erkenntnis, dass alle Teilmengen eines FI auch FIs sein müssen.")
54
A Priori Algorithmus für alle Produkte p
überprüfe ob p ein frequent itemset (Kardinalität 1) ist, also in mindestens minsupp Einkaufswägen enthalten ist k := 1 iteriere solange für jeden frequent itemset Ik mit k Produkten generiere alle itemsets Ik+1 mit k+1 Produkten und Ik I k+1 lies alle Einkäufe einmal (sequentieller Scan auf der Datenbank) und überprüfe, welche der (k+1)-elementigen itemset- Kandidaten mindestens minsupp mal vorkommen k := k+1 bis keine neuen frequent itemsets gefunden werden
 ist, also in. mindestens minsupp Einkaufswägen enthalten ist. k := 1. iteriere solange. für jeden frequent itemset Ik mit k Produkten. generiere alle itemsets Ik+1 mit k+1 Produkten und Ik I k+1. lies alle Einkäufe einmal (sequentieller Scan auf der Datenbank) und überprüfe, welche der (k+1)-elementigen itemset- Kandidaten mindestens minsupp mal vorkommen. k := k+1. bis keine neuen frequent itemsets gefunden werden.")
55
VerkaufsTransaktionen
A Priori-Algorithmus VerkaufsTransaktionen TransID Produkt 111 Drucker Papier PC Toner 222 Scanner 333 444 555 Zwischenergebnisse FI-Kandidat Anzahl {Drucker} 4 {Papier} 3 {PC} {Scanner} 2 {Toner} {Drucker, Papier} {Drucker, PC} {Drucker, Scanner} {Drucker, Toner} {Papier, PC} {Papier, Scanner} {Papier, Toner} {PC, Scanner} {PC,Toner} {Scanner, Toner} Minsupp=3/5 Disqua-lifiziert

56
VerkaufsTransaktionen
A Priori-Algorithmus VerkaufsTransaktionen TransID Produkt 111 Drucker Papier PC Toner 222 Scanner 333 444 555 Zwischenergebnisse FI-Kandidat Anzahl {Drucker, Papier} 3 {Drucker, PC} {Drucker, Scanner} {Drucker, Toner} {Papier, PC} 2 {Papier, Scanner} {Papier, Toner} {PC, Scanner} {PC,Toner} {Scanner, Toner} {Drucker, Papier, PC} {Drucker, Papier, Toner} {Drucker, PC, Toner} {Papier, PC, Toner}

57
Ableitung von Assoziationsregeln aus den frequent itemsets
Betrachte jeden FI mit hinreichend viel support Bilde alle nicht-leeren Teilmengen L FI und untersuche die Regel L FI – L Die Confidence dieser Regel berechnet sich als: confidence(L FI – L) = support(FI) / support(L) Falls die Confidence > minconf ist, behalte diese Regel Betrachte FI = {Drucker, Papier, Toner}, L = {Drucker} support(FI) = 3/5 Regel: {Drucker} {Papier, Toner} confidence = support({Drucker, Papier, Toner}) / support({Drucker}) = (3/5) / (4/5 = ¾ = 75 %
 = support(FI) / support(L) Falls die Confidence > minconf ist, behalte diese Regel. Betrachte FI = {Drucker, Papier, Toner}, L = {Drucker} support(FI) = 3/5. Regel: {Drucker} {Papier, Toner} confidence. = support({Drucker, Papier, Toner}) / support({Drucker}) = (3/5) / (4/5 = ¾ = 75 %")
58
Erhöhung der Confidence
Vergrößern der linken Seite (dadurch Verkleinern der rechten Seite) führt zur Erhöhung der Confidence Formal: L L+ , R R- confidence(L R) <= confidence(L+ R - ) Beispiel-Regel: {Drucker} {Papier, Toner} confidence = support({Drucker, Papier, Toner}) / support({Drucker}) = (3/5) / (4/5) = ¾ = 75% Beispiel-Regel: {Drucker,Papier} {Toner} Confidence = support({Drucker,Papier,Toner}) / support({Drucker,Papier}) = (3/5) / (3/5) = 1 = 100%
 führt zur Erhöhung der Confidence. Formal: L L+ , R R- confidence(L R) <= confidence(L+ R - ) Beispiel-Regel: {Drucker} {Papier, Toner} confidence. = support({Drucker, Papier, Toner}) / support({Drucker}) = (3/5) / (4/5) = ¾ = 75% Beispiel-Regel: {Drucker,Papier} {Toner} Confidence = support({Drucker,Papier,Toner}) / support({Drucker,Papier}) = (3/5) / (3/5) = 1 = 100%")
Ähnliche Präsentationen






>")






.>")





