Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Wissenschaftliches Datenmanagement Probleme in PByte-Klimadatenarchiven
Michael Lautenschlager World Data Center for Climate Max-Planck-Institut für Meteorologie / Modelle und Daten, Hamburg Jena,

2
Inhalt: Klimasystem und Modellierung Architektur am DKRZ
CERA Datenmodell IMDI und AFP Integrated Model and Data Infrastructure und Automatic Fill Process

3
Data Group maintaining the WDCC
Michael Kurtz Hannes Thiemann Peter Lenzen Hans Luthardt Hermann Winter Michael Lautenschlager Jörg Wegner Heinke Höck Frank Toussaint (Order: from left to right)
")
4
Klimasystem

5
Modellgleichungen Grundprinzip Erhaltung von Masse, Energie und Impuls
Beispiel: Gleichungen für Impuls, Temperatur und Feuchte im ECHAM-Modell

6
Flussdiagramm Globales Atmosphären- Modell ECHAM

7
Das Gitternetz im Atmosphärenmodell
Diskretisierung Das Gitternetz im Atmosphärenmodell

8
Nordeuropa im Klimamodell
T42 (300 km) T106 (120 km)
 T106 (120 km)")
9
Datenmengen Horizontalauflösung des Klimamodells
T42: 128 * 64 = 8192 Punkte pro Globalfeld T106: 160 * 320 = Punkte pro Globalfeld Erforderliche Speichereinheiten (GRIB Format 1) Horizontalfeld (Zugriffseinheit): 17.1 kB (T42) / kB (T106) Unix Filegröße für monatsweise akkumulierte Ergebnisse mit 12 Std. Speicherintervall (Physikalische Einheit): 120 MB (T42) / 750 MB (T106) 240 Jahre Modellintegration (Logische Einheit): 1/3 TB (T42) / 2 TB (T106) 1) machine independent, self-descriptive and compressive
 Horizontalfeld (Zugriffseinheit): 17.1 kB (T42) / kB (T106) Unix Filegröße für monatsweise akkumulierte Ergebnisse mit 12 Std. Speicherintervall (Physikalische Einheit): 120 MB (T42) / 750 MB (T106) 240 Jahre Modellintegration (Logische Einheit): 1/3 TB (T42) / 2 TB (T106) 1) machine independent, self-descriptive and compressive.")
10
Anwendung der WDCC Daten Oktober 1991

11
, 12:00 ECMWF-ERA40 Druckdifferenz: 60 hPa

13
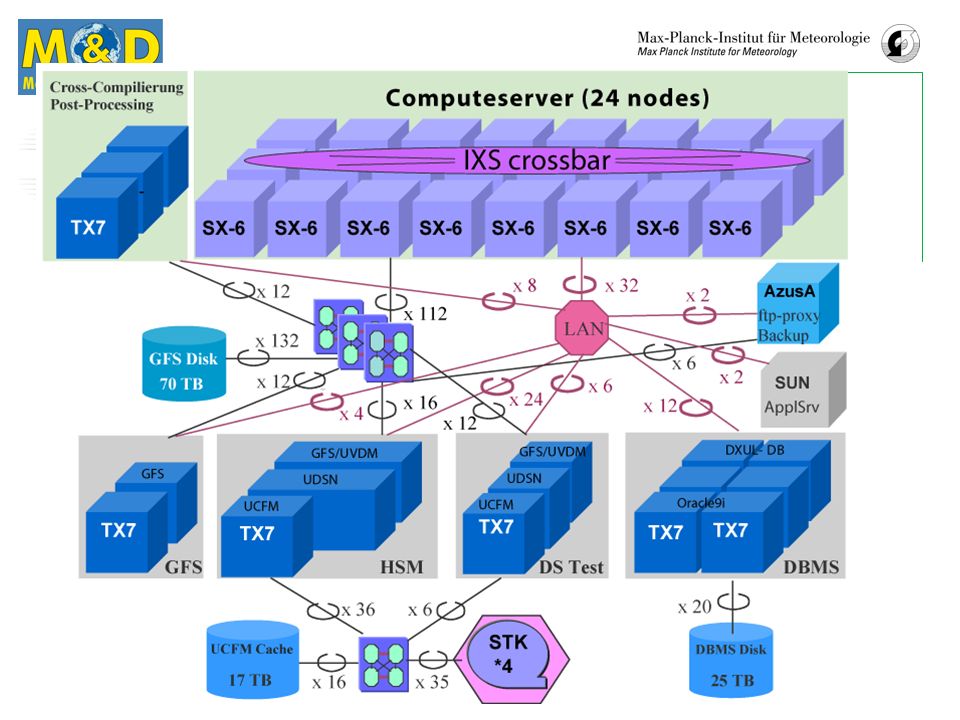
DKRZ Compute-Server Der HLRE Compute-Server besteht aus 24 NEC SX-6 Knoten. Die technischen Daten eines enzelnen Knotens sind in der folgenden Tabelle zusammengefasst. CPUs 8 Taktfrequenz Speicher und CPU (MHz) 500 Vektor Pipelines pro CU Funktionen der Vektoreinheit add/shift, multiply, divide, logical Vektor-Register pro Pipeline 72 Länge der Vektor-Register (words) 256 GFLOP/s pro CPU Hauptspeicher (GB) 64 Gesamte Bandbreite des Speichers (GB/s) Speicherbandbreite pro CPU (GB/s) 32
 500. Vektor Pipelines pro CU. Funktionen der Vektoreinheit. add/shift, multiply, divide, logical. Vektor-Register pro Pipeline. 72. Länge der Vektor-Register (words) 256. GFLOP/s pro CPU. Hauptspeicher (GB) 64. Gesamte Bandbreite des Speichers (GB/s) Speicherbandbreite pro CPU (GB/s) 32.")
14
DKRZ Compute-Server Peak (Rpeak) 1536 LINPACK Rmax 1484
Die 24 Knoten unserer Installation sind über den IXS (Inter-node Crossbar Switch) verbunden. Der IXS schaltet zwischen beliebigen Knoten Verbindungen mit einer Bandbreite von jeweils 8 GB/s. Die Gleitkomma-Leistung des Gesamtsystems in GFLOP/s ist in der untenstehenden Tabelle dargestellt. Peak (Rpeak) 1536 LINPACK Rmax 1484 Dauerhafte Leistung eines am DKRZ eingesetzten typischen Klimamodelles ca. 500
 verbunden. Der IXS schaltet zwischen beliebigen Knoten Verbindungen mit einer Bandbreite von jeweils 8 GB/s. Die Gleitkomma-Leistung des Gesamtsystems in GFLOP/s ist in der untenstehenden Tabelle dargestellt. Peak (Rpeak) LINPACK Rmax Dauerhafte Leistung eines am DKRZ eingesetzten typischen Klimamodelles. ca")
15
DKRZ – Earth Simulator (Japan)
TOP500 HPC-List (June 2004) DKRZ: Platz 148 mit 192 Proz. NEC-SX6 Earth Simulator, Japan: Platz 1 mit 5120 Proz. NEC-SX6 ES = 25 * DKRZ
 DKRZ: Platz 148 mit 192 Proz. NEC-SX6. Earth Simulator, Japan: Platz 1 mit 5120 Proz. NEC-SX6. ES = 25 * DKRZ.")
17
DKRZ Datenservice Prozessoren Intel Itanium2 Taktfrequenz 1 GHz Cache
3 MB (on-chip L3) Max. Anzahl CPUs 32 Max. Speicher 128 GB LINPACK Rmax (32 CPUs) GFLOP/s Einige Daten des gesamten Datenservers sind in der untenstehenden Tabelle zusammengefasst. Kapazität des Bandarchivs (TB) >3500 Festplattenkapazität (TB) ca 70 Bandbreite zwischen Compute-Server und Data-Server (MB/s) 450
 Max. Anzahl CPUs. 32. Max. Speicher. 128 GB. LINPACK Rmax (32 CPUs) GFLOP/s. Einige Daten des gesamten Datenservers sind in der untenstehenden Tabelle zusammengefasst. Kapazität des Bandarchivs (TB) >3500. Festplattenkapazität (TB) ca 70. Bandbreite zwischen Compute-Server und Data-Server (MB/s) 450.")
18
DKRZ Bandarchiv

19
HSM Archive Content: End of 2003: 1.3 PB End of 2004: 2.6 PB Prognose 2001:

20
CERA Konzept Datenkatalog Automatisierte Klimadatenspeicherung
Die „Gelben Seiten“ des Massenspeicherarchivs Metadaten in Tabellen des Datenmodells Automatisierte Klimadatenspeicherung Primärdaten-Processing synchron zum Modelllauf Anwendungsorientierte Speicherung erlaubt schnellen Zugriff Speicherung als BLOB-Tabelleneinträge Rohdaten als Zeiger ins Datenarchiv Transparenter Rohdatenzugriff Zeiger auf Unix-Files als B-File-Einträge in Tabelle (Oracle)
")
21
CERA-2 Data Model Blocks
Coverage Information on the volume of space-time covered by the data Reference Any publication related to the data togehter with the publication form Parameter Block describes data topic, variable and unit Metadata Entry This is the central CERA Block, providing information on the entry's title type and relation to other entries the project the data belong to a summary of the entry a list of general keywords related to data creation and review dates of the metadata Status Status information like data quality, processing steps, etc. Spatial Reference Information on the coordinate system used Distribution Distribution information including access restrictions, data format and fees if necessary Contact Data related to contact persons and institutes like distributor, investigator, and owner of copyright Additionally: Modules and Local Extensions Module DATA_ORGANIZATION (grid structure) Module DATA_ACCESS (physical storage) Local extension for specific information on (e.g.) data usage data access and data administration
 Module DATA_ACCESS (physical storage) Local extension for specific information on (e.g.) data usage. data access and data administration.")
23
Produktion (4D) und Zugriff (2D)
 und Zugriff (2D)")
24
Primäres Daten- Processing

25
CERA Data Structure Experiment Description Unix-Files Table / Pointer
Level 1 - Interface: Metadata entries (XML, ASCII) + Data Files Experiment Description Unix-Files Table / Pointer Dataset 1 Dataset n BLOB Data Table Level 2 – Interf.: Separate files containing BLOB table data in application adapted structure (time series of single variables)
 + Data Files. Experiment. Description. Unix-Files. Table / Pointer. Dataset 1. Dataset n. BLOB Data. Table. Level 2 – Interf.: Separate files. containing BLOB. table data in. application. adapted structure. (time series of. single variables)")
26
Web-Based User Interface
Catalogue Inspection Climate Data Retrieval CERA DB: Backbone of WDCC Internet Access Experiments: 400 Datensets: 53367 BLOBs: ca. 3.8 * 109 BLOB sizes GCM’s: 10 – 100 kB DB-Accounts: 500 Data retrievals: 1500 – / month Data volume: 250 – 2200 GB / month CERA Database: 133 TB ( ) *Data Catalogue *Processed Climate Data *Pointer to Raw Data files CERA Database System DKRZ Mass Storage Archive Mass Storage Archive 2.6 PB ( ) Web access to entire CERA DB content
 *Data Catalogue. *Processed Climate Data. *Pointer to Raw Data files. CERA Database System. DKRZ Mass. Storage Archive. Mass Storage Archive. 2.6 PB ( ) Web access to entire. CERA DB content.")
27
AFP M&D Integrated Model and Data Infrastructure Modellkomponenten
Modell-Computer-Matrix Codeverwaltung Userinterface: GUI + Scripting Laufumgebung: Jobskripten & Dateihandling Datenprocessing + Grafik Datenimport: Assimilation und Antrieb Randbedingungen Nutzerinterface: Datensuche und Download Processing und Grafik DKRZ-Archiv WDC Climate: CERA DB mit Katalog Datenprocessing Modellkomponenten Kopplungsumgebung: Modellintegration PRISM Modellanwendungen Archivföderation BADC (UK) WDC-Netzwerk Automatisiertes Füllen DB-Füllen: API und Scripten M&D AFP
 WDC-Netzwerk. Automatisiertes Füllen. DB-Füllen: API und Scripten. M&D AFP.")
28
Automatic Fill Process (AFP)
Creation of application-oriented data storage must be automatic !!!

29
Archive Data Flow per month
Global File System Mass Storage Archive Unix-Files 60 TB/month Compute Server Application Oriented Data Hierarchy Unix-Files 2004: 1 TB/day (peak) Application Oriented Data Hierarchy Important: Automatic fill process has to be performed before corresponding files migrate to mass storage archive. CERA DB System Metadata Initialisation
 Application. Oriented. Data Hierarchy. Important: Automatic fill process. has to be performed. before corresponding. files migrate to mass. storage archive. CERA. DB. System. Metadata. Initialisation.")
30
Automatic Fill Process
Steps and Relations DB-Server: Initialisation of CERA DB Metadata and BLOB data tables are created DB Server: BLOB data table input accessed from DB fill cache BLOB table injection and update of metadata Step 2 repeated until table partition is filled (BLOB table fill cache) Close partition, write corresponding DB files to HSM archive, open new partition and continue with 2) Close entire table and update metadata after end of model experiment Compute Server: Climate model calculation starts with 1. month Next model month starts and primary data processing of previous month BLOB table input is produced and stored in the dynamic DB fill cache Step 2 repeated until end of model experiment
 Close partition, write corresponding DB files to HSM archive, open new partition and continue with 2) Close entire table and update metadata after end of model experiment. Compute Server: Climate model calculation starts with 1. month. Next model month starts and primary data processing of previous month BLOB table input is produced and stored in the dynamic DB fill cache. Step 2 repeated until end of model experiment.")
31
WDCC User Access Pattern

32
Bewertung nach Vortrag:
Allgemeinen Teil kürzer und Schwerpunkt auf CERA Architektur: CERA-2 Datenmodell (Constraints + Trigger) und XML Interface BLOB Tabellen und HSM Anschluß Indexverwaltung BLOB Tabellen und Speicherbedarf B-Files als Pointer auf UNIX-Files (soweit realisiert) Sehr interessierte Zuhörer, Zeitbedarf war 70 min, also 2,2 min/Folie
 und XML Interface. BLOB Tabellen und HSM Anschluß. Indexverwaltung BLOB Tabellen und Speicherbedarf. B-Files als Pointer auf UNIX-Files (soweit realisiert) Sehr interessierte Zuhörer, Zeitbedarf war 70 min, also 2,2 min/Folie.")
Ähnliche Präsentationen