Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Statistical issues with financial market data
A: Cross-Section Data: - deviations from multivariate normality - “tail dependence” - copulas - default predictions B: Time series data - heavy tails - chaos? - structural change in patterns of dependence - Integration and Cointegration - ARCH- and GARCH-effects - Long memory and structural change Themen, zu den gerade an meinem Lehrstuhl Doktoarbeiten laufen, oder gerade gelaufen sind. Speziell RGS: Pavel Stoimenov zu Copulas< Christoph Hanck zu Cointegration Alesia Khudnizkaja zu Kreditausfällen Alle Fertig Aktuell: Marten van kampen: structural change in patterns of dependence Heute. Zwei Themen rausgreifen .

2
Fangen wir an mit Kreditausfällen.
Um was geht es da? Wahrscheinlichkeitsprognosen. Jeder von Ihnen nach einem Jahr: P(Promotion binnen 3 Jahren) = ? Zwei Problemkreise: 1. Wie kommen Prognosen zustande? 2. Wie mißt man die Qualität von Prognosen? In zwei Kontexten 1. Privatkreditgeschäft bei Geschäftsbanken („Credit scoring“) 2. Ausfallprognosen für Firmen oder ganze Staaten („Rating“) Im weiteren; 2 + 2: Wer ist „besser“: Moody‘s oder S+P? Warum wichtig?
 = Zwei Problemkreise: 1. Wie kommen Prognosen zustande 2. Wie mißt man die Qualität von Prognosen In zwei Kontexten 1. Privatkreditgeschäft bei Geschäftsbanken („Credit scoring ) 2. Ausfallprognosen für Firmen oder ganze Staaten („Rating ) Im weiteren; 2 + 2: Wer ist „besser : Moody‘s oder S+P Warum wichtig")
3
Nicht nur Moody’s

4
Selected bond rating agencies
Name in business since Moody’s investors service (“Moody’s”) 1900 Fitch investor service (“Fitch”) 1922 Standard and Poors’ Corporation (“S&P”) 1923 Thomson Bank Watch 1974 Dominion bond rating service (“DBRS”) 1976 Japanese bond rating institute 1977 Duff and Phelps Credit Rating 1986 . Alle tun mehr oder weniger das gleiche. Wer ist der beste? How to rate the raters?
 Fitch investor service ( Fitch ) Standard and Poors’ Corporation ( S&P ) Thomson Bank Watch Dominion bond rating service ( DBRS ) Japanese bond rating institute Duff and Phelps Credit Rating Alle tun mehr oder weniger das gleiche. Wer ist der beste How to rate the raters")
6
Correspondence between selected S+P-grades and default probabilities
rel. frequencies of default (%) AAA - AA 0,01 A 0,04 BBB 0,21 BB+ 0,75 BB- 1,14 B 5,16 CCC 10,00 CC 20,00 D 100,00 1. Schritt: Übersetzen von Buchstaben in Ausfallwahrscheinlichkeiten. Wichtig (und oft übersehen): A heißt nicht: Kredit ist sicher. 4 von fallen trotzdem aus. Prominente Beispiele: (from M. Carey: “Some evidence on the consistency of banks’ internal credit ratings,” Federal Reserve Board 2001, Table 1, page 7 )
 AAA - AA. 0,01. A. 0,04. BBB. 0,21. BB+ 0,75. BB- 1,14. B. 5,16. CCC. 10,00. CC. 20,00. D. 100, Schritt: Übersetzen von Buchstaben in Ausfallwahrscheinlichkeiten. Wichtig (und oft übersehen): A heißt nicht: Kredit ist sicher. 4 von fallen trotzdem aus. Prominente Beispiele: (from M. Carey: Some evidence on the consistency of banks’ internal credit ratings, Federal Reserve Board 2001, Table 1, page 7 )")
7
Rated A by S+P, Sept. 9, 2008 Default, Sep. 15, 2008

8
Filed for bancruptcy Dec. 1
Filed for bancruptcy Dec Was rated investment status by both Moody‘s and S+P 1 month before Formerly Worldcom; defaults on credit payments in July 2002, rated A by S+P In April 2002. Formerly the world's biggest dairy product producer, had its credit rating cut to junk after missing a payment in Dec. 2003; rated A a couple of months before

9
Evaluating and comparing probability forecasters (=rating agencies)
Case 1: Raters A and B rate different obligors at different points in time (“skill scores”) Case 2: Raters A and B rate identical obligors at identical points in time Damit zur Sache. Zwei Problemkreise Im weiteren: 1 Ist natürlich nur dann interessant, wenn ein Unternehmen oder ein Staat mehrere Rating hat und die Ratings differieren, Tun sie das?
 Case 2: Raters A and B rate identical obligors at identical points in time. Damit zur Sache. Zwei Problemkreise. Im weiteren: 1. Ist natürlich nur dann interessant, wenn ein Unternehmen oder ein Staat mehrere Rating hat und die Ratings differieren, Tun sie das")
10
Credit ratings Rated the same by Moody’ and S&P
Sovereign Corporate AA/Aa or above 67% 53% Other investment grade 56% 36% Below investment grade 29% 41% Sources: Moody’s; Federal Reserve Bank of New York

11
Predicted Default probability
Example: Assigning default probabilities to 800 borrowers Predicted Default probability Distribution of borrowers across default probabilities according to different probability forecasters A B C D 0,5% 200 (1) 160 1% 400 (4) 200 1,5% 400 (6) 2% 800(16) 3% 400(12) 440 4,5% 200 (9) Konkretes Zahlenbeispiel: 4 Ratingagenturen bewerten 800 Schuldner. 16 Ausfälle. Gesamtausfallw.keit = 16/800 = 2% B macht sich Leben einfach: alle kriegen Prognose 2%! Kalibiriert! („well calibrated“) Aber trivial A schon besser. Ebenfalls kalibriert A besser als B im Sinn der “Verfeinerungsordnung“ (“refinement ordering“): B-Prognose läßt sich aus A-Prognose ableiten. A wiederum läßt sich aus C und D ableiten. C und D nicht vergleichbar :
 % 400 (4) ,5% 400 (6) 2% 800(16) 3% 400(12) ,5% 200 (9) Konkretes Zahlenbeispiel: 4 Ratingagenturen bewerten 800 Schuldner. 16 Ausfälle. Gesamtausfallw.keit = 16/800 = 2% B macht sich Leben einfach: alle kriegen Prognose 2%! Kalibiriert! („well calibrated ) Aber trivial. A schon besser. Ebenfalls kalibriert. A besser als B im Sinn der Verfeinerungsordnung ( refinement ordering ): B-Prognose läßt sich aus A-Prognose ableiten. A wiederum läßt sich aus C und D ableiten. C und D nicht vergleichbar. :")
12
Likewise for non-defaults
Default ordering (S. Vardemann and G. Meeden, Journal of the American Statistical Society 1983): A is better than B if its cumulated percentage of defaults (with cumulation starting in the good grades) is nowhere above that of B‘s. Likewise for non-defaults In normalem Deutsch: A bewertet Ausfälle systematisch schlechter als B. Leicht herzustellen. Wie schlage ich S+P? S+P gibt AAA. Ich gebe AAa S+P gibt AAa. Ich gebe A usw. Damit schlage ich S+P im Sinn der Ausfallordnung! Aber: s+p schlägt mich in sSnn der Anti-Ausfallordnung! Bewertet Nicht-Ausfälle systematisch besser!!! Im weiteren: beides! Zusammenhang mit Verfeinerungsordnung?
: A is better than B if its cumulated percentage of defaults (with cumulation starting in the good grades) is nowhere above that of B‘s. Likewise for non-defaults. In normalem Deutsch: A bewertet Ausfälle systematisch schlechter als B. Leicht herzustellen. Wie schlage ich S+P S+P gibt AAA. Ich gebe AAa. S+P gibt AAa. Ich gebe A usw. Damit schlage ich S+P im Sinn der Ausfallordnung! Aber: s+p schlägt mich in sSnn der Anti-Ausfallordnung! Bewertet Nicht-Ausfälle systematisch besser!!! Im weiteren: beides! Zusammenhang mit Verfeinerungsordnung")
13
Theorem 1 (Vardeman/Meeden 1983): If A and B are both well calibrated, and A dominates B in the default ordering, then A is more refined than B. Hat mich einen Monat meines Lebens gekostet! Beispiel? Keins gefunden Grund:

14
Theorem 2 (Krämer 2005): Let A and B be both well calibrated
Theorem 2 (Krämer 2005): Let A and B be both well calibrated. Then A and B cannot be ordered according to the Vardeman/ Meeden default ordering. Damit Theorem 1 trivial: Wenn-Teil ist falsch. Wenn A dann B: Falls A falsch ist, kann man für B einsetzen was man will, der Satz bleibt immer richtig! Neues Theorem: wenn …, dann ist 2+2 = 5! Also: bei kalibrierten Prognosen Ausfallordnung wenig hilfreich (bei nicht kalibrierten Prognosen aber schon) Letzte Halbordnung: Lorenzordnung
: Let A and B be both well calibrated. Then A and B cannot be ordered according to the Vardeman/ Meeden default ordering. Damit Theorem 1 trivial: Wenn-Teil ist falsch. Wenn A dann B: Falls A falsch ist, kann man für B einsetzen was man will, der Satz bleibt immer richtig! Neues Theorem: wenn …, dann ist 2+2 = 5! Also: bei kalibrierten Prognosen Ausfallordnung wenig hilfreich (bei nicht kalibrierten Prognosen aber schon) Letzte Halbordnung: Lorenzordnung.")
15
Lorenz-curve, power curve, cumulative accuracy profile
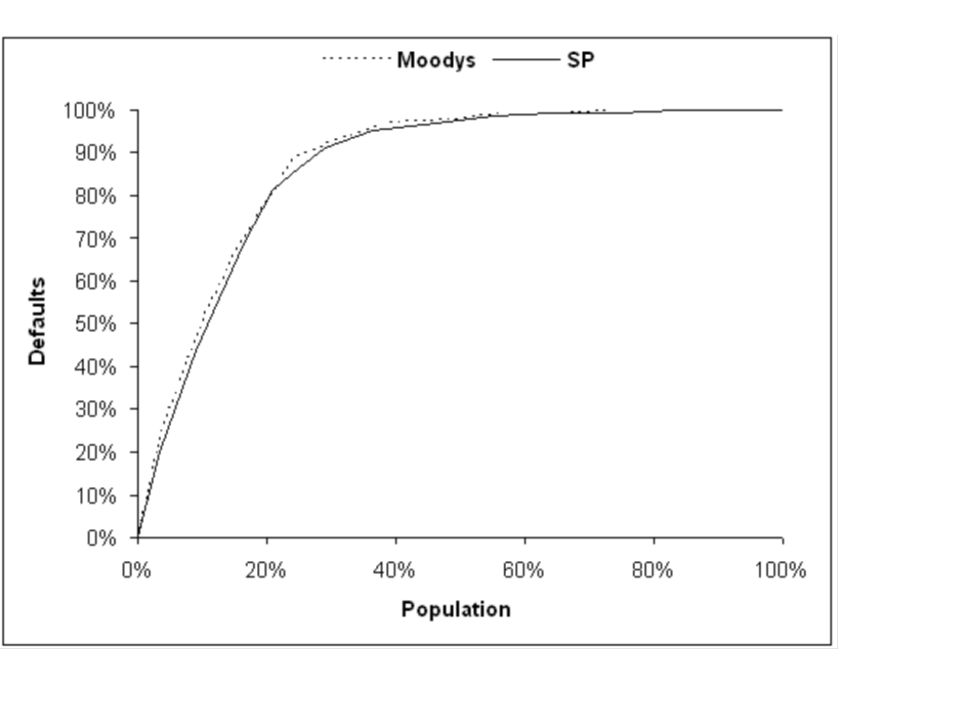
1000 Kreditnehmer; 10% fallen aus. 3 Ratingklassen. Grundidee: Sortiere Kreditnehmer auf waagerechter Achse von schlecht nach gut, trage auf senkrechter Achse Anteil an Gesamtausfällen ab, der auf diese Kreditnehmer entfällt. ->:Lorenzkurve („power curve“) Im Beispiel auf die 10% schlechtesten entfallen 50% aller Ausfälle, Auf die 80% schlechtesten entfallen 95% aller Ausfälle. Optimale Prognose: Alle Ausfälle in die schlechteste Klasse Naher Verwandter der Lorenzkurve: ROC-Kurve. Auf waagerechter Achse nur die Nichtausfälle. Rückt Ordinatenwerte nach links: 90% Nichtausfälle. Wieviel % in der schlechtesten Klasse? 50/900 = 5,6% overall Defaults bad 10% 50% medium 70% 45% good 20% 5%
 Im Beispiel auf die 10% schlechtesten entfallen 50% aller Ausfälle, Auf die 80% schlechtesten entfallen 95% aller Ausfälle. Optimale Prognose: Alle Ausfälle in die schlechteste Klasse. Naher Verwandter der Lorenzkurve: ROC-Kurve. Auf waagerechter Achse nur die Nichtausfälle. Rückt Ordinatenwerte nach links: 90% Nichtausfälle. Wieviel % in der schlechtesten Klasse 50/900 = 5,6% overall. Defaults. bad. 10% 50% medium. 70% 45% good. 20% 5%")
16
Theorem (independently by various authors):
Consider all possible pairs of defaults and non-defaults. The accuracy ratio (=area underneath the ROC-curve) is then equal to the probability that in one such randomly chosen pair, the non-default is ranked higher than the default Als nächstes: wie hängen diese Qualitätskriterien zusammen?
 is then equal to the probability that in one such randomly chosen pair, the non-default is ranked higher than the default. Als nächstes: wie hängen diese Qualitätskriterien zusammen")
17
Theorem: Let A and B be (semi-)calibrated probability forecasters
Theorem: Let A and B be (semi-)calibrated probability forecasters. Then we have: A dominates B in the Vardeman/ Meeden default ordering sense => A is more refined than B (sufficient for) A’s ROC and power curves are nowhere below those of B Kalibriert: prognostizierte Ausfallw-keit = E(wahrer Ausfallanteil) Semi-Kalibriert: E(wahrer Ausfallanteil) = monoton steigende Funktion der prognostizierten A-W-keit The converse does not hold
calibrated probability forecasters. Then we have: A dominates B in the Vardeman/ Meeden default ordering sense. => A is more refined than B. (sufficient for) A’s ROC and power curves are nowhere below those of B. Kalibriert: prognostizierte Ausfallw-keit = E(wahrer Ausfallanteil) Semi-Kalibriert: E(wahrer Ausfallanteil) = monoton steigende Funktion der prognostizierten A-W-keit. The converse does not hold.")
18
Anwendung:

19
California Edison: rated A+ in 1999, default 2001
(has recovered in the meantime)
")
21
W. Krämer: Strukturbruchtests bei Renditekorrelationen
Gemeinsame Arbeiten mit „Korrelation“ steht hier vor allem als pars pro toto für Abhängigkeitsmaße allgemein. Bestens bekannt: Korrelationen im Sinn von Bravais Pearson sind zwar das am weitesten verbreitete, aber trotzdem nur eines von vielen und in vielen Anwendungen noch nicht einmal das beste Maß für Abhängigkeiten. Speziell bei Kapitalmarktrenditen sind gewöhnliche Korrelationen dezidiert suboptimal. Auf der anderen Seite sind natürlich Korrelationen das in der Praxis mit Abstand häufigste Abhängigkeitsmaß überhaupt; viele Anwender kennen überhaupt nichts anderes, und allein schon deshalb erscheint es durchaus lohnend, auch einmal den statistischen Eigenschaften dieses Maßes näher hinterher zu spüren. Maarten van Kampen Jonas Kaiser Dominik Wied

22
Wertentwicklung globaler Aktienmärkte im Jahr 2007 USA + 6,4 % Japan
- 11,1 % Deutschland + 22,3 % GB + 3,8 % Frankreich + 1,3 % Spanien + 7,3 % Italien - 7,0 % China + 96,7 % Indien + 47,1 % Damit zum Thema. Um was geht es hier? Sehen Sie sich einmal diese Tabelle an: Aktienmärkte 2007 Im großen und ganzen bergauf. Aber: Durchaus ungleichmäßig. Und hier zum Vergleich das Jahr 2008:

23
Wertentwicklung der gleichen Aktienmärkte 2008
USA (DJIA) - 32,7 % Japan (Nikkei 225) - 29,7 % Deutschland (DAX) - 39,5 % GB (FTSE 100) - 30,9 % Frankreich (CAC40) - 42,0 % Spanien (IBEX 35) - 38,7 % Italien (S+P Mib) - 48,8 % China (Shanghai Comp.) - 65,4 % Indien (Sensex 30) - 52,9 % Aktienmärkte 2008 Da braucht man keinen formalen Test: die Abhängigkeit hat zugenommen. Und zu allem Überfluß auch noch dann, wenn man es am wenigsten braucht: Diversifikationseffekt. Also: dass Abhängigkeitsmuster auf Kapitalmärken im Zeitablauf konstant bleiben, glaubt heute kein Mensch. Darauf kann man im wesentlichen auf zweierlei Weise reagieren: 1. Man läßt von vornherein in den einschlägigen statistischen Modellen zeitvariable Abhängigkeiten zu 2. Man unterstellt zumindest zeitweise Konstanz, und testet auf Strukturbruch. Auf die relativen Meriten dieser Vorgangsweisen will ich hier nicht eingehen. Ich betrachte im weiteren vor allem die Strategie Nr. 2, d.h. Strukturbruchtests. Davor kurze Übersicht über verwandte Themen, als Anregung für mögliche Dissertationen
 - 32,7 % Japan (Nikkei 225) - 29,7 % Deutschland (DAX) - 39,5 % GB (FTSE 100) - 30,9 % Frankreich (CAC40) - 42,0 % Spanien (IBEX 35) - 38,7 % Italien (S+P Mib) - 48,8 % China (Shanghai Comp.) - 65,4 % Indien (Sensex 30) - 52,9 % Aktienmärkte Da braucht man keinen formalen Test: die Abhängigkeit hat zugenommen. Und zu allem Überfluß auch noch dann, wenn man es am wenigsten braucht: Diversifikationseffekt. Also: dass Abhängigkeitsmuster auf Kapitalmärken im Zeitablauf konstant bleiben, glaubt heute kein Mensch. Darauf kann man im wesentlichen auf zweierlei Weise reagieren: 1. Man läßt von vornherein in den einschlägigen statistischen Modellen zeitvariable Abhängigkeiten zu. 2. Man unterstellt zumindest zeitweise Konstanz, und testet auf Strukturbruch. Auf die relativen Meriten dieser Vorgangsweisen will ich hier nicht eingehen. Ich betrachte im weiteren vor allem die Strategie Nr. 2, d.h. Strukturbruchtests. Davor kurze Übersicht über verwandte Themen, als Anregung für mögliche Dissertationen.")
24
Modellierung zeitvariabler Abhängigkeiten
Dynamische bedingte Korrelationen: R. Engle: „Dynamic conditional correlation: A simple class of multivariate generalized autoregressive conditional heteroskedasticity models,“ Journal of Business and Economic Statistics 20, 2002, „Markov-Switching“: D. Pelletier: „Regime switching for dynamic correlations,“ Journal of Econometrics, 2006, M. Haas: „Covariance forecasts and long-run correlations in a Markov-switching model for dynamic correlations“, Finance Research Letters, 7, 2010, 86-97 Dynamische Copulas: A. Patton: „Modelling asymmetric exchange rate dependence,“ International Economic Review 47, 2006, D. Totouom: Dynamic Copulas: Applications to finance and economics, Paris E. Giacomini, W. Härdle, und V. Spokoiny: „Inhomogeneous dependency modelling with time varying copulae,“ Journal of Business and Economic Statistics 27, 2009, D. Guegan und J. Zhang: Change analysis of a dynamic copula for measuring dependende in multivariate data,“ Quantitative Finance 10, 2010, Multivariate ARCH-Garch Modelle. Nicht nur bedingte Varianz, auch bedingte Kovarianzen hängen von der Historie des Prozesses ab Parameter Ausprägungen eines Markov-Prozesses Copulas ändern sich im Zeitverlauf Was ist eine Copula?

25
Was ist eine Copula? Ausgangspunkt ist folgendes ebenso zentrale wie elementare Resultat der W-Theorie: Sei X stetige Zve mit Verteilungsfunktion F. Dann ist die neue Zve U:= F(X) auf [0,1] gleichverteilt Def: die gemeinsame Verteilung von U=F(X) und V=G(Y) heißt Copula von von X und Y Satz: Die gemeinsame Verteilung von X und Y ist durch die Copula und die beiden Randverteilungen eindeutig festgelegt , Copulas ändern ich nicht bei monotonen Transformationen. X,Y >0: Copula von ln(X) und ln(Y) gleich wie Copula von X und Y. Damit ideale Basis für alle Abhängigkeitsmaße, die unter monotonen Transformationen invariant sind. Spearman rho, Kendalls tau usw. In diesem Sinn Faktorisierung der gemeinsamen Verteilung
 auf [0,1] gleichverteilt. Def: die gemeinsame Verteilung von U=F(X) und V=G(Y) heißt Copula von von X und Y. Satz: Die gemeinsame Verteilung von X und Y ist durch die Copula und die beiden Randverteilungen eindeutig festgelegt. , Copulas ändern ich nicht bei monotonen Transformationen. X,Y >0: Copula von ln(X) und ln(Y) gleich wie Copula von X und Y. Damit ideale Basis für alle Abhängigkeitsmaße, die unter monotonen Transformationen invariant sind. Spearman rho, Kendalls tau usw. In diesem Sinn Faktorisierung der gemeinsamen Verteilung.")
26
Randabhängigkeit („tail dependence“): Links: 3000 tägliche BMW- und VW-Renditen, Rechts: 3000 bivariat normalverteilte Zufallsvektoren Weiters Promotionsthema: Randabhängigkeiten. Beispiel: Zwei bivariate Datensätze mit der gleichen Korrelation. Folie Randabhängigkeit Korrelation in beiden Fällen gleich. Aber: gemeinsame Extremereignisse bei realen Daten viel häufiger als bei bivariater Normalität zu erwarten. Allgemein: Randabhängigkeit bei elliptischen Verteilungen nur dann, wenn die Verteilung der erzeugenden Variablen regulär variierende Ränder hat (Rafael Schmidt 2002). Damit Randabhängigkeit bei Normalverteilung ausgeschlossen. Inzwischen riesige Literatur zum Modellieren, Schätzen und Testen solcher Randabhängigkeiten: = ?
. Damit Randabhängigkeit bei Normalverteilung ausgeschlossen. Inzwischen riesige Literatur zum Modellieren, Schätzen und Testen solcher Randabhängigkeiten: =")
27
Ausgewählte Literatur zu Randabhängigkeiten
Longin/Solnik: „Extreme Correlation of international equity markets,“ Journal of Finance 2001 R. Schmidt: „Tail dependence for elliptically contoured distributions,“ Math. Meth. Oper. Research 2002 Falk/Michel: „Testing for tail dependence in extrem value models,“ AISM 2006 Hüsler/Li: „Testing asymptotic independence in bivariate extremes,“ Journal of Statistical Planning and Inference 2009 F.Schmid/R.Schmidt/ J.Penzer: „Measuring Large Comovements in Financial Markets“, erscheint in Quantitative Finance 2010. Bücher/Dette/Volgushev: „A new estimator of the Pickands dependence function and a test for extrem-value correlation,“ Dortmund 2010 (SFB 823 Diskussionspapier).
.")
28
Signifikanztests auf konstante Abhängigkeitsstruktur
A): endogene Brüche: mögliche Muster unter der Alternative sind dateninduziert („truncated correlations“, „excess correlations“) B): exogene Brüche: Aufspaltung der Stichprobe nach potentiell unterschiedlichen Abhängigkeitsmustern ohne Ansicht der realisierten Werte von (X, Y) Nächstes Thema: Signifikanztests auf konstante Abhängigkeitsstruktur. Zwei Klassen: 2 Klassen Klasse A: Beliebte Alternative: “Abhängigkeiten sind in Zeiten hoher Volatilitäten größer as sonst”. Sehr beliebt: „truncated correlations“. Auch hier führt der Korrelationskoeffizient leicht in die Irre:
: endogene Brüche: mögliche Muster unter der Alternative sind dateninduziert („truncated correlations , „excess correlations ) B): exogene Brüche: Aufspaltung der Stichprobe nach potentiell unterschiedlichen Abhängigkeitsmustern ohne Ansicht der realisierten Werte von (X, Y) Nächstes Thema: Signifikanztests auf konstante Abhängigkeitsstruktur. Zwei Klassen: 2 Klassen. Klasse A: Beliebte Alternative: Abhängigkeiten sind in Zeiten hoher Volatilitäten größer as sonst . Sehr beliebt: „truncated correlations . Auch hier führt der Korrelationskoeffizient leicht in die Irre:")
29
In beiden Fällen die Frage: Wie kann aus solchen bedingten Korrelationen auf die unbedingten K. zurückschließen? Oder anders ausgedrückt: sind die gestiegenen empirischen Korrelationen Ausdruck eines Strukturbruchs im datenerzeugenden Prozess, oder ein Artefakt der Bedingung? Bei Normalverteilung schöne Formel:

30
bedingte Korrelation von X und Y, gegeben X A
Bei bivariater Normalverteilung gilt (Boyer et al. (1999) „Pitfalls in tests for changes in correlations“, International Finance Discussion Papers Number 597): Auf die Details der Formel will ich nicht eingehen. Was man aber sehr schön sieht: Die bedingte Korrelation ist genau dann größer als die unbedingte Korrelation, wenn die bedingte Varianz größer ist als die unbedingte Varianz. Letzteres ist etwa bei Bedingung auf große Absolutwerte von X ganz klar der Fall. Problem: Abweichung von Normalverteilung. In Literatur speziell untersucht: bivariate t-Verteilung (Campbell u. a. , Empirical Finance 2008).
 „Pitfalls in tests for changes in correlations , International Finance Discussion Papers Number 597): Auf die Details der Formel will ich nicht eingehen. Was man aber sehr schön sieht: Die bedingte Korrelation ist genau dann größer als die unbedingte Korrelation, wenn die bedingte Varianz größer ist als die unbedingte Varianz. Letzteres ist etwa bei Bedingung auf große Absolutwerte von X ganz klar der Fall. Problem: Abweichung von Normalverteilung. In Literatur speziell untersucht: bivariate t-Verteilung (Campbell u. a. , Empirical Finance 2008).")
31
Theorem: E(XZ|X A) = 0
 = 0")
32
Gemeinsame Verteilung
konstant? Copula konstant? Dias/Embrechts 2004 R lard/Scaillet 2009 Zweite Momente konstant? Bartlett 1949 Aue et al. 2009 Copula constant in einem Punkt? Harvey/Busetti 2009 Krämer/v.Kampen 2010 Spearman ρ, Kendall τ konstant? Dobric/Frahm Schmid 2007 Schmid/Gaisser 2010 Varianzen konstant? Riesige Literatur Korrelationen konstant? Kullback 1967 Jennrich 1970 Fischer 2007 Wied 2009 Wied/Krämer/ Dehling 2010 Als nächstes: exogene Brüche in der Korrelation bzw. von Abhängigkeiten ganz allgemein im Zeitverlauf Mögliche Nullhypothesen (in absteigender Allgemeinheit. Folie Nullhypothesen. Ganz oben: riesige Literatur zu Verteilungstests Im weiteren: unten links und unten rechts

33
Copula von X und Y an der Stelle (τ, τ) =: C(τ, τ)
 =: C(τ, τ)")
34
Grundidee (Busetti & Harvey 2009): Betrachte empirische Copula C
Grundidee (Busetti & Harvey 2009): Betrachte empirische Copula C*(τ, τ) und 1 (sowohl Xt wie Yt links vom IT,t(τ, τ) := empirischen τ-Quantil sonst Unter H0:
: Betrachte empirische Copula C*(τ, τ) und. 1 (sowohl Xt wie Yt links vom IT,t(τ, τ) := empirischen τ-Quantil 0 sonst. Unter H0:")
35
Typische Zeitverläufe der Teststatistik

36
Grundidee: Lehne Ho ab bei extremer Fluktuation von
Emp. Korrelation unter Nutzung aller Datenpunke = Approximation für wahres ρ Unten rechts: Bisherige Ansätze: unter Alternative entweder nur ein und dazu noch ein bekannter Bruchzeitpunkt (Jennrich) oder parametrisch (t-Verteilung und restriktive Fluktuation unter H1 bei Fischer) Neu: Nichtparametrische Alternative Grundidee die gleiche: betrachte kumulierte Abweichungen sukzessiver geschätzter Korrelationen von der „endgültigen“ Korrelation: Grundidee wie bei den meisten Tests vergleichsweise offensichtlich und trivial; Schwierig dagegen – ebenfalls wie bei den meisten Tests - ist die Ableitung der Nullverteilung. Und die hat es tatsächlich in sich. war auch das zentrale Resultat der Diss. von Dominik Wied, auf der alles weitere beruht. empirische Korrelation der Datenpaare 2, …, t
 oder parametrisch (t-Verteilung und restriktive Fluktuation unter H1 bei Fischer) Neu: Nichtparametrische Alternative. Grundidee die gleiche: betrachte kumulierte Abweichungen sukzessiver geschätzter Korrelationen von der „endgültigen Korrelation: Grundidee wie bei den meisten Tests vergleichsweise offensichtlich und trivial; Schwierig dagegen – ebenfalls wie bei den meisten Tests - ist die Ableitung der Nullverteilung. Und die hat es tatsächlich in sich. war auch das zentrale Resultat der Diss. von Dominik Wied, auf der alles weitere beruht. empirische Korrelation der Datenpaare 2, …, t.")
37
Für Details siehe: J. Kaiser, W. Krämer (2010): “A cautionary note on computing conditional from unconditional correlations”. Erscheint in Economics Letters. W. Krämer, M. van Kampen (2010): „A simple nonparametric test for structural change in joint tail probabilities“, Erscheint in Economics Letters). Dominik Wied: „A generalized functional delta method,“ Dortmund 2010 (SFB 823 Diskussionspapier). D. Wied, W. Krämer, H. Dehling. "Testing for a change in correlation at an unknown point in time", 2010, zur Veröffentlichung eingereicht. M. van Kampen, D. Wied. "A nonparametric constancy test for copulas under mixing conditions", Dortmund 2010 (SFB 823 Diskussionspapier). M. Arnold, N. Bissantz, D. Wied, D. Ziggel. "A new online-test for changes in correlations between assets", Dortmund 2010 (SFB 823 Diskussionspapier).
: A cautionary note on computing conditional from unconditional correlations . Erscheint in Economics Letters. W. Krämer, M. van Kampen (2010): „A simple nonparametric test for structural change in joint tail probabilities , Erscheint in Economics Letters). Dominik Wied: „A generalized functional delta method, Dortmund 2010 (SFB 823 Diskussionspapier). D. Wied, W. Krämer, H. Dehling. Testing for a change in correlation at an unknown point in time , 2010, zur Veröffentlichung eingereicht. M. van Kampen, D. Wied. A nonparametric constancy test for copulas under mixing conditions , Dortmund 2010 (SFB 823 Diskussionspapier). M. Arnold, N. Bissantz, D. Wied, D. Ziggel. A new online-test for changes in correlations between assets , Dortmund 2010 (SFB 823 Diskussionspapier).")
38
Verallgemeinerungen auf höhere Dimensionen
Copula-Based Measures of Multivariate Association (with T. Blumentritt, S. Gaißer, M. Ruppert, R. Schmidt), In: F. Durante, W. Härdle, P. Jaworski, T. Rychlik (eds.) Workshop on Copula Theory and its Applications. Springer, 2010. Nonparametric inference on multivariate versions of Blomqvist's beta and related measures of tail-dependence (with R. Schmidt), Metrika, Vol. 66, , Multivariate conditional versions of Spearman's rho and related measures of tail dependence (with R. Schmidt), Journal of Multivariate Analysis, Vol. 98, No. 6, , 2007. Multivariate Extensions of Spearman's Rho and Related Statistics (with R. Schmidt), Statistics and Probability Letters, Vol. 77, No. 4, 2007.
, In: F. Durante, W. Härdle, P. Jaworski, T. Rychlik (eds.) Workshop on Copula Theory and its Applications. Springer, Nonparametric inference on multivariate versions of Blomqvist s beta and related measures of tail-dependence (with R. Schmidt), Metrika, Vol. 66, , 2007 Multivariate conditional versions of Spearman s rho and related measures of tail dependence (with R. Schmidt), Journal of Multivariate Analysis, Vol. 98, No. 6, , Multivariate Extensions of Spearman s Rho and Related Statistics (with R. Schmidt), Statistics and Probability Letters, Vol. 77, No. 4,")
Ähnliche Präsentationen







 Natural Sources SNAP11.>")












 Trackball. Joystick.>")