Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Wissen im Web: Semantic Web Mining und die Motivation Freiwilliger
Bettina Berendt Humboldt University Berlin, Institute of Information Systems volle A4-Größe: 1,2,3, 20, 21, 22 2-auf-1: 4;8, 5;9, 6;10, 7;11, 12;16, 13;17, 14;18, 15;19 Optional volle A4-Größe: 23-26 result is translated into DiML. All processing and Cardona, M., & Marx, W. (2004).Verwechselt,vergessen,wiedergefunden. Referenzen–das fehlerhafte Gedächtnis[...] Physik Journal, 3 (11),
.Verwechselt,vergessen,wiedergefunden. Referenzen–das fehlerhafte Gedächtnis[...] Physik Journal, 3 (11),")
2
Dank an ... meine KoautorInnen (die auf den folgenden Folien gewürdigt sind) und die Seminargruppen, die am EDOC-Projekt mitgearbeitet haben und mitarbeiten: Hanna Brekenfeld, Noppawan Bunyongasena, Thomas Dammeier, Gebhard Dettmar, Kai Dingel, Michael Ferber, Christoph Hanser, Oleg Ishenko, Beate Krause, Altug Kul, Toni Lohde, Egor Nikitin, Thomas Posner, Derya Saki, Mert Sengüner, Daniel Trümper

3
Semantic Web Mining =

4
Agenda Makrokosmos Begriffe. Semantic Web Mining. Semantic Web Mining
Agenda Makrokosmos Begriffe Semantic Web Mining Semantic Web Mining Semantic Web Mining Mikrokosmos Beispiele Semantics Mining Semantics Mining

5
“Makrokosmos World Wide Web”
Ab hier ist es problemorientiert – vorher war es Begriffsklärung

6
Das Potenzial

7
Sehr viel Wissen, für Menschen zugänglich.

8
Die Probleme

9
Sehr viel Wissen, für Menschen zugänglich.

10
Web Mining

11
Formen Knowledge discovery (aka Data mining):
Web structure mining Web usage mining Knowledge discovery (aka Data mining): “the non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data.” 1 Web Mining: die Anwendung von Data-Mining-Techniken auf Inhalt, (Hyperlink-) Struktur und Nutzung von Webressourcen. Sagen: Grundidee ist es, die Intelligenz zu nutzen, die schon drin ist im Web Web content: clustering in Suchmaschinen wie kartoo, LSI in Suchmaschinen wie Google; Web structure: PageRank; Web usage: Amazon Webmining-Gebiete: Web content mining 1 Fayyad, U.M., Piatetsky-Shapiro, G., Smyth, P., & Uthurusamy, R. (Eds.) (1996). Advances in Knowledge Discovery and Data Mining. Boston, MA: AAAI/MIT Press
: the non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data. 1. Web Mining: die Anwendung von Data-Mining-Techniken auf Inhalt, (Hyperlink-) Struktur und Nutzung von Webressourcen. Sagen: Grundidee ist es, die Intelligenz zu nutzen, die schon drin ist im Web. Web content: clustering in Suchmaschinen wie kartoo, LSI in Suchmaschinen wie Google; Web structure: PageRank; Web usage: Amazon. Webmining-Gebiete: Web content mining. 1 Fayyad, U.M., Piatetsky-Shapiro, G., Smyth, P., & Uthurusamy, R. (Eds.) (1996). Advances in Knowledge Discovery and Data Mining. Boston, MA: AAAI/MIT Press.")
12
Web Mining: Beispiele Webmining-Gebiete: Web content mining
Web structure mining Web usage mining

13
Das Hauptproblem des Web Mining
Mütter museum: proper name of the founder – shows: simple lexical processing can lead astray! “Syntax ist eben doch nicht Semantik” Schraube + Mutter fehlt ganz "Live 8": Die Mutter aller Popkonzerte - Kultur - SPIEGEL ONLINE ...Zwei Millionen Menschen haben "das größte Konzert aller Zeiten" live erlebt, Milliarden verfolgten das Multimusikspektakel im Fernsehen, Radio oder im Ähnliche Seiten (auf S. 2) klingeltoene.de - Die Mutter aller KlingeltoeneKlingeltne, Polyphon, Handylogos fr alle , SMS, Midi, Real, MP3, Betreiberlogos, Gratislogos k - 8. Juli Im Cache - Ähnliche Seiten
 klingeltoene.de - Die Mutter aller KlingeltoeneKlingeltne, Polyphon, Handylogos fr alle , SMS, Midi, Real, MP3, Betreiberlogos, Gratislogos k - 8. Juli Im Cache - Ähnliche Seiten.")
14
Das Wikipedia 300 Component Model, generiert mit diskreter PCA Common phrases of selected components0 process; water; air; pressure; gas; body of water; natural gas; high pressure; hot water; fresh water;1 Mark; Gospel; Matthew; Luke; Rose; Virgin; Virgin Mary; Gospel of John; Gospel of Mark; Gospel of Luke;2 part; text; Britannica; entry; Encyclopedia Britannica; Encyclop~¦dia Britannica; Encyclopaedia Britannica; domain Encyclop~¦dia Britannica; public domain Encyclop~¦dia Britannica; public domain text;3 property; theorem; elements; proof; subset; axioms; proposition; natural numbers; fundamental theorem; mathematical logic;4 Dove; AMD; Dove Streptopelia; imperial crown; Imperial army; imperial court; imperial family; Collared Dove Streptopelia; Imperial Russia;5 side; feet; long time; long period; right side; left side; long distances; different types; short distance; opposite side;6 David; bill; Bob; Jim; Allen; Dave; Current stars; former members; Bill Clinton; former President;7 magazine; newspaper; political parties; public domain text; public opinion; political career; public schools; own right; political life; public service;8 way; things; boy; cat; long time; same way; same thing; only way; different ways; good thing;11 problems; zero; sum; digits; ~~; natural numbers; positive integer; mathematical analysis; decimal digits; natural logarithm;12 population density; couples; races; total area; makeup; Demographics; median age; income; density; housing units; Torres; Iraqi KASUMI KHAZAD Khufu; Granada; Spa; Fra; General information; General Public License; General Bernardo; New Granada; Torres Strait; love; Me; Rolling Stones; love songs; Rolling Stone magazine; Love Me; Fall in Love; Meet Me; love story; professional wrestler; Zusammenfassend – Schwächen rein statistischer Ansätze: Interpretation der Resultate? Existenz von Resultaten? Korrektheit? Inferenzen?

15
Semantic Web

16
Das Semantic Web “The Semantic Web is an extension of the current web in which information is given well-defined meaning, better enabling computers and people to work in co-operation.” 1 “The Semantic Web provides a common framework that allows data to be shared and reused across application, enterprise, and community boundaries. It is a collaborative effort led by W3C with participation from a large number of researchers and industrial partners. It is based on the Resource Description Framework (RDF), which integrates a variety of applications using XML for syntax and URIs for naming.” 2 1 Berners-Lee, T., Hendler, J., & Lassila, O. (2001). The Semantic Web. Sci. American, May. 2 3 Berners-Lee, T. (2000). Semantic Web XML
, which integrates a variety of applications using XML for syntax and URIs for naming Berners-Lee, T., Hendler, J., & Lassila, O. (2001). The Semantic Web. Sci. American, May Berners-Lee, T. (2000). Semantic Web XML")
17
Semantic Web: Beispiel
Category structure: <RDF xmlns:r=" xmlns:d=" xmlns=" <Topic r:id="Top"> <tag catid="1"/> <d:Title>Top</d:Title> <narrow r:resource="Top/Arts"/> .... </Topic> <Topic r:id="Top/Arts"> <tag catid="2"/> <d:Title>Arts</d:Title> <narrow r:resource="Top/Arts/Books"/> ... <narrow r:resource="Top/Arts/Artists"/> <symbolic r:resource="Typography:Top/Computers/Fonts"/> </RDF> Resources: <RDF xmlns:r=" xmlns:d=" xmlns=" ... <Topic r:id="Top/Arts"> <tag catid="2"/> <d:Title>Arts</d:Title> <link r:resource=" </Topic> <ExternalPage about=" .html"> <d:Title>John phillips Blown glass</d:Title> <d:Description>A small display of glass by John Phillips</d:Description> </ExternalPage> <Topic r:id="Top/Computers"> <tag catid="4"/> <d:Title>Computers</d:Title> <link r:resource=" <link r:resource=” </RDF> Semantic Web: Beispiel

18
Warum Semantic Web? Bsp. strukturierte Suche (1) – Metadaten gemäß DC
 – Metadaten gemäß DC")
19
Semantische Suche: Bsp. 2 – Metadaten gem. DC + Domänenontologie
Hierzu muss man evt. erstmal den ICD-9 zeigen (damit klar wird, dass subject aus einem kontrollierten Vokabular schöpft); dann kann man außerdem ka2portal zeigen! - hierzu eine Ontologie zeichnen? – in Verbindung bringen mit den SW-Folien, die zeigen, wie DC eingebaut wird
; dann kann man außerdem ka2portal zeigen! - hierzu eine Ontologie zeichnen – in Verbindung bringen mit den SW-Folien, die zeigen, wie DC eingebaut wird.")
20
Was ist eine Ontologie? An ontology is „an explicit specification of a shared conceptualisation.“ (Gruber, 1993) Gruber, T.R. (1993). Towards principles for the design of ontologies used for knowledge sharing. In N. Guarino & R. Poli (Eds.), Formal Ontologies in Conceptual Analysis and Knowledge Representation Deventer, NL: Kluwer. Bozsak, Ehrig, Handschuh, Hotho, Maedche, Motik, Oberle, Schmitz, Staab, Stojanovic, Stojanovic, Studer, Stumme, Sure,Tane, Volz, & Zacharias (2002). KAON - Towards a Large Scale Semantic Web. In Kurt Bauknecht, A. Min Tjoa, & Gerald Quirchmayr (Eds.), E-Commerce and Web Technologies, Third International Conference, EC-Web 2002, Aix-en-Provence, France, September 2-6, 2002, Proceedings (pp ). Springer: LNCS 2455
. Towards principles for the design of ontologies used for knowledge sharing. In N. Guarino & R. Poli (Eds.), Formal Ontologies in Conceptual Analysis and Knowledge Representation Deventer, NL: Kluwer. Bozsak, Ehrig, Handschuh, Hotho, Maedche, Motik, Oberle, Schmitz, Staab, Stojanovic, Stojanovic, Studer, Stumme, Sure,Tane, Volz, & Zacharias (2002). KAON - Towards a Large Scale Semantic Web. In Kurt Bauknecht, A. Min Tjoa, & Gerald Quirchmayr (Eds.), E-Commerce and Web Technologies, Third International Conference, EC-Web 2002, Aix-en-Provence, France, September 2-6, 2002, Proceedings (pp ). Springer: LNCS")
21
Website-Modellierung
cooperateswith(X,Y) cooperateswith(Y,X) Ontologie-basierte Website-Modellierung OBJECT NAME PERSON PERSON TITLE PROJECT COOPERATES COOPERATES -- -- WITH WITH Ontology WORKS-IN RESEARCHER RESEARCHER Semantic Web Mining Andreas Hotho WORKS-IN URI-SWMining DAMLPROJ - Relational Metadata URI-AHO WORKS-IN COOPERATES COOPERATES - - WITH WITH URI-GST WWW
 cooperateswith(Y,X) Ontologie-basierte. Website-Modellierung. OBJECT. NAME. PERSON. PERSON. TITLE. PROJECT. COOPERATES. COOPERATES WITH. WITH. Ontology. WORKS-IN. RESEARCHER. RESEARCHER. Semantic Web Mining. Andreas Hotho. WORKS-IN. URI-SWMining. DAMLPROJ. - Relational. Metadata. URI-AHO. WORKS-IN. COOPERATES. COOPERATES. - - WITH. WITH. URI-GST. WWW.")
22
Das Hauptproblem des Semantic Web
“Wer soll das alles machen?” <HTML><HEAD> <META NAME="DC.Creator" CONTENT="(Scheme=Freetext) Thomas Seilnacht <META NAME="DC.Title" CONTENT="(Scheme=Freetext) 10 Schritte zum Bau der eigenen Homepage"> <META NAME="DC.Date.Created" CONTENT="(Scheme=Freetext) "> <META NAME="DC.Form" CONTENT="(Scheme=IMT) text/html"> <META NAME="DC.Identifier" CONTENT="(Scheme=URL) <META NAME="DC.Description" CONTENT="(Scheme=Freetext) Anleitung zum Bau einer Homepage mit dem Netscape Communicator"> <META NAME="DC.Subject.Keywords" CONTENT="(Scheme=Freetext) Homepage, HTML, Internet, FTP, Polyview, Programmieren, Frames, JavaScript, CGI-Script, Grundbegriffe, Grafik, Freeware, INFORMATISCHE GRUNDBILDUNG"> <META NAME="DC.Type" CONTENT="Kurs/Onlinekurs/Virtuelles Seminar"> <META NAME="DC.Language" CONTENT="Deutsch"> <META NAME="DC.Description" CONTENT="(Scheme=URL)
 Thomas Seilnacht > <META NAME= DC.Title CONTENT= (Scheme=Freetext) 10 Schritte zum Bau der eigenen Homepage > <META NAME= DC.Date.Created CONTENT= (Scheme=Freetext) > <META NAME= DC.Form CONTENT= (Scheme=IMT) text/html > <META NAME= DC.Identifier CONTENT= (Scheme=URL) > <META NAME= DC.Description CONTENT= (Scheme=Freetext) Anleitung zum Bau einer Homepage mit dem Netscape Communicator > <META NAME= DC.Subject.Keywords CONTENT= (Scheme=Freetext) Homepage, HTML, Internet, FTP, Polyview, Programmieren, Frames, JavaScript, CGI-Script, Grundbegriffe, Grafik, Freeware, INFORMATISCHE GRUNDBILDUNG > <META NAME= DC.Type CONTENT= Kurs/Onlinekurs/Virtuelles Seminar > <META NAME= DC.Language CONTENT= Deutsch > <META NAME= DC.Description CONTENT= (Scheme=URL) Id=7915&KATEGORIE=medien >")
23
Strategien zur Schaffung des Semantic Web
“institutionell”: Zwang / extrinsische Motivation “sozial”: Verteilte Autorenschaft à la Open Source (example: dmoz.org) / intrinsische Motivation “informatisch / HCI”: Tool-Support “informatisch / Informationsverarbeitung” … Erfordernis: Interesse an gemeinsamem Wissen / Aufbau Bildung? Medizin? Wirtschaft? “ökonomisch”: kritische Masse (ex. EDI ?!) SCORM / DARPA nur erwähnen – die haben wiederum ihre eigenen Standards:
 / intrinsische Motivation. informatisch / HCI : Tool-Support. informatisch / Informationsverarbeitung … Erfordernis: Interesse an gemeinsamem Wissen / Aufbau. Bildung Medizin Wirtschaft ökonomisch : kritische Masse (ex. EDI !) SCORM / DARPA nur erwähnen – die haben wiederum ihre eigenen Standards:")
24
... Semantic Web Mining

25
Semantic Web Mining: Eine Definition
Mining of the Semantic Web Mining for the Semantic Web The iterative process of (1) and (2), in which the semantics obtained by mining are re-used for mining again. Evt. nach den beiden anderen Berendt, Stumme, & Hotho, Proc. ISWC 2002; Stumme, G., Hotho, A., & Berendt, B. (submitted). Semantic Web Mining – State of the Art and Future Directions.
 and (2), in which the semantics obtained by mining are re-used for mining again. Evt. nach den beiden anderen. Berendt, Stumme, & Hotho, Proc. ISWC 2002; Stumme, G., Hotho, A., & Berendt, B. (submitted). Semantic Web Mining – State of the Art and Future Directions.")
26
“Mikrokosmos EDOC” Ab hier ist es problemorientiert – vorher war es Begriffsklärung

27
Wissensbeiträge: Daten und Metadaten
<BIBLIOGRAPHY><FLOAT><PAGENUMBER>136</PAGENUMBER></FLOAT> <HEAD>Literaturverzeichnis</HEAD> ... <CITATION WORKTYPE="journal" PUBLISHED="PUBLISHED"> <CUT ID="bib-45-">[2] </CUT><WORKAUTHOR>Albrecht, T. F.; Bott, K.; Meier, T.; Schulze, A.; Koch, M.; Cundiff, S. T.; Feldmann, J.; Stolz, W.; Thomas, P.; Koch, S. W.; Göbel; E. O.</WORKAUTHOR> <ARTICLETITLE>Disorder mediated biexcitonic beats in semiconductor quantum wells</ARTICLETITLE>, <WORKTITLE>Phys. Rev. B</WORKTITLE>, <PUBDATE>1996</PUBDATE>, <NUMBER>54</NUMBER>, <PAGES>4436</PAGES>, </CITATION> ...

28
Dissertation Markup Language DiML http://edoc. hu-berlin
... <!ELEMENT citation (#PCDATA | | url | note | workauthor | worktitle | articletitle | serialtitle | address | editor | publisher | edition | volume | number | version | pages | pubdate | bible | court | law | cut | pagenumber)*> <!ATTLIST citation id ID #IMPLIED label CDATA #IMPLIED workType (Book | Journal | Misc) #IMPLIED published (yes|no) 'yes'> <!ELEMENT note (#PCDATA | em | u | strong | br | sup | tt | sub | link | name | | organization | term | foreign | url | footnote | endnote | glossref | indexref | pagenumber | q | citation | imath | im)*> <!ATTLIST note id ID #IMPLIED> <!ELEMENT workauthor (#PCDATA | given | surname | suffix | organization)*> <!ATTLIST workauthor role CDATA #IMPLIED ref IDREF #IMPLIED <!ELEMENT worktitle (#PCDATA | em | u | strong | br | sup | tt | sub | pagenumber)*> <!ATTLIST worktitle type CDATA #IMPLIED > <!ELEMENT articletitle (#PCDATA | em | u | strong | br | sup | tt | sub | pagenumber)*> <!ATTLIST articletitle
*> <!ATTLIST citation. id ID #IMPLIED. label CDATA #IMPLIED. workType (Book | Journal | Misc) #IMPLIED. published (yes|no) yes > <!ELEMENT note (#PCDATA | em | u | strong | br | sup | tt | sub | link | name | | organization | term | foreign | url | footnote | endnote | glossref | indexref | pagenumber | q | citation | imath | im)*> <!ATTLIST note. id ID #IMPLIED> <!ELEMENT workauthor (#PCDATA | given | surname | suffix | organization)*> <!ATTLIST workauthor. role CDATA #IMPLIED. ref IDREF #IMPLIED. <!ELEMENT worktitle (#PCDATA | em | u | strong | br | sup | tt | sub | pagenumber)*> <!ATTLIST worktitle. type CDATA #IMPLIED. > <!ELEMENT articletitle (#PCDATA | em | u | strong | br | sup | tt | sub | pagenumber)*> <!ATTLIST articletitle.")
29
Das Potenzial

30
Wenn es diese Daten und Metadaten einmal gibt ...
... dann unterstützen sie leistungsfähige Suchen in verteilten Archiven (z.B.) elektr. Abschlussarbeiten u. Dissertationen (ETDs) i.d.R. mit OAI-Metadaten-Harvesting Beispiele: z.Z. 154 Mitglieder / Repositorien z.Z. 27 Mitglieder / Repositorien Vorteile für die Autoren: Kostenfreie Publikation, hochwertige Archivierung Garantie der langfristigen Lesbarkeit (50 Jahre) Authentizität & Integrität Semantische Durchsuchbarkeit
 elektr. Abschlussarbeiten u. Dissertationen (ETDs) i.d.R. mit OAI-Metadaten-Harvesting. Beispiele: z.Z. 154 Mitglieder / Repositorien. z.Z. 27 Mitglieder / Repositorien. Vorteile für die Autoren: Kostenfreie Publikation, hochwertige Archivierung. Garantie der langfristigen Lesbarkeit (50 Jahre) Authentizität & Integrität. Semantische Durchsuchbarkeit.")
31
... aber wie bekommt man die (Meta)Daten?
Daten")
32
Die Probleme

33
Befragung

34
Problem 1: Es ist nicht einfach (und es macht keinen Spaß)
Seit Beginn von EDOC (1997): Anteil der Online-Diss. ~20% (13% incl. Medizinische Fakultät) Befragung aller DoktorandInnen und HabilitandInnen (knapp 2500 Personen, 12-14% antworteten) Hauptergebnisse bzgl. Bekanntheit und Nutzung von EDOC-Diensten: Probleme im Informationsfluss Marketing und Service Die Erstellung der Metadaten wird als mühselig und schwierig empfunden – insbesondere die I.d.R. nachträglich vorgenommene Literatur-Formatierung [Berendt, Brenstein, Li, & Wendland, Proc. ETD 2003; Berendt, Proc. AAAI Spring Symposium KCVC, 2005]
: Anteil der Online-Diss. ~20% (13% incl. Medizinische Fakultät) Befragung aller DoktorandInnen und HabilitandInnen (knapp 2500 Personen, 12-14% antworteten) Hauptergebnisse bzgl. Bekanntheit und Nutzung von EDOC-Diensten: Probleme im Informationsfluss Marketing und Service. Die Erstellung der Metadaten wird als mühselig und schwierig empfunden – insbesondere die I.d.R. nachträglich vorgenommene Literatur-Formatierung. [Berendt, Brenstein, Li, & Wendland, Proc. ETD 2003; Berendt, Proc. AAAI Spring Symposium KCVC, 2005]")
35
… und das hat Folgen <BIBLIOGRAPHY><FLOAT><PAGENUMBER>136</PAGENUMBER></FLOAT> <HEAD>Literaturverzeichnis</HEAD> <CITATION WORKTYPE="journal" PUBLISHED="PUBLISHED"> <CUT ID="bib-15-">[1] </CUT><WORKAUTHOR>Agarwal, R.; Krueger, B. P.; Scholes, G. D.; Yang, M.; Yom, J.; Mets, L.; Fleming, G. R.</WORKAUTHOR>U<ARTICLETITLE>ltrafast energy transfer in LHC-II revealed by three-pulse photon echo peak shift measurements</ARTICLETITLE>, <WORKTITLE>J. Phys. Chem. B</WORKTITLE>, <PUBDATE>2000</PUBDATE>, <NUMBER>104</NUMBER>, <PAGES>2908</PAGES>, </CITATION> ...

36
Warum ist das ein Problem?
Cardona, M., & Marx, W. (2004).Verwechselt,vergessen,wiedergefunden. Referenzen–das fehlerhafte Gedächtnis[...] Physik Journal, 3 (11),
.Verwechselt,vergessen,wiedergefunden. Referenzen–das fehlerhafte Gedächtnis[...] Physik Journal, 3 (11),")
37
Semantics Mining / usage mining

38
Q: Wissensbereitstellung als Nebeneffekt anderer Aktivitäten?
(hier: Websuche) Ein 3. Hauptergebnis der Befragung: weitgehend unbekannt und ungenutzt sind strukturiertes Schreiben strukturierte Suche Frage: Macht die Site Leser zu Autoren? Daten aus dem Webserver-Log 10,992 Sessions (210,655 Seiten) aus einer Woche 2003 (gegen Ende der ersten Befragung) Methoden: semantische Anreicherung, Assoziationsregel- und Sequenzmining (Tools: WEKA, WUM); Clustering, Klassifikation Exploiting: web usage
 Ein 3. Hauptergebnis der Befragung: weitgehend unbekannt und ungenutzt sind. strukturiertes Schreiben. strukturierte Suche. Frage: Macht die Site Leser zu Autoren Daten aus dem Webserver-Log. 10,992 Sessions (210,655 Seiten) aus einer Woche 2003 (gegen Ende der ersten Befragung) Methoden: semantische Anreicherung, Assoziationsregel- und Sequenzmining (Tools: WEKA, WUM); Clustering, Klassifikation. Exploiting: web usage.")
39
Non-semantic Web Usage Mining
[29/Mar/2003:00:02: ] "GET /favicon.ico HTTP/1.1" "-" "Mozilla/5.0 (Windows; U; Win 9x 4.90; de-DE; rv:1.0.1) Gecko/ Netscape/7.0" [29/Mar/2003:00:02: ] "GET /dissertationen/style/did.css HTTP/1.1" " "Mozilla/5.0 (Windows; U; Win 9x 4.90; de-DE; rv:1.0.1) Gecko/ Netscape/7.0" [29/Mar/2003:00:02: ] "GET /../projekte/epdiss/kolloqu/schu/slide4.html HTTP/1.0" "-" "Mozilla/5.0 (Slurp/cat; [29/Mar/2003:00:03: ] "GET /humboldt-vl/hofmann-hasso/PDF/Hofmann.pdf HTTP/1.1" "-" "Mozilla/4.0 (compatible; MSIE 6.0; Windows 98; Q312461)" [29/Mar/2003:00:04: ] "GET /dissertationen/biologie/kernekewisch-michaela/HTML/kernekewisch-vita.html HTTP/1.0" "-" "Mozilla/5.0 (Slurp/cat; [29/Mar/2003:00:04: ] "GET /download/kume/r-lailach-hesse.PDF HTTP/1.0" "-" "Googlebot/2.1 + [29/Mar/2003:00:07: ] "GET /dissertationen/radspieler-alexander /HTML/radspieler-ch2.html HTTP/1.1" "-" "Firefly/1.0 (compatible; Mozilla 4.0; MSIE 5.5)" Problem: URLs sind nicht semantisch. Eine Analyse der Daten in dieser Form bringt keine Erkenntnis!
 Gecko/ Netscape/ [29/Mar/2003:00:02: ] GET /dissertationen/style/did.css HTTP/ Mozilla/5.0 (Windows; U; Win 9x 4.90; de-DE; rv:1.0.1) Gecko/ Netscape/ [29/Mar/2003:00:02: ] GET /../projekte/epdiss/kolloqu/schu/slide4.html HTTP/ Mozilla/5.0 (Slurp/cat; [29/Mar/2003:00:03: ] GET /humboldt-vl/hofmann-hasso/PDF/Hofmann.pdf HTTP/ Mozilla/4.0 (compatible; MSIE 6.0; Windows 98; Q312461) [29/Mar/2003:00:04: ] GET /dissertationen/biologie/kernekewisch-michaela/HTML/kernekewisch-vita.html HTTP/ Mozilla/5.0 (Slurp/cat; [29/Mar/2003:00:04: ] GET /download/kume/r-lailach-hesse.PDF HTTP/ Googlebot/ [29/Mar/2003:00:07: ] GET /dissertationen/radspieler-alexander /HTML/radspieler-ch2.html HTTP/ Firefly/1.0 (compatible; Mozilla 4.0; MSIE 5.5) Problem: URLs sind nicht semantisch. Eine Analyse der Daten in dieser Form bringt keine Erkenntnis!")
40
Ontologie-basierte Verhaltensmodellierung: URLs und Anwendungsereignisse
Webseite mit Inhalt Gewünschter Dienst Erhaltener Inhalt Berendt, B., Stumme, G., & Hotho, A. (2004). Usage mining for and on the Semantic Web. In H. Kargupta, A. Joshi, K. Sivakumar, & Y. Yesha (Eds.), Data Mining: Next Generation Challenges and Future Directions. Menlo Park, CA: AAAI/MIT Press.
. Usage mining for and on the Semantic Web. In H. Kargupta, A. Joshi, K. Sivakumar, & Y. Yesha (Eds.), Data Mining: Next Generation Challenges and Future Directions. Menlo Park, CA: AAAI/MIT Press.")
41
Datenvorbereitung: Semantische Anreicherung
TOP AUTHOR SEARCH HOME DOC OTHER HINWEISE OAI FULLTEXT META RESULT DISS OTHER DOC OTHER PROJECT ADVICE LIST MASTER … DNB ABSTRACT … TEMPLATE … AUTHOR ACCESS README KEYWORD CONFERENCE ABSTRACT … FAQ ACCESS … … LATEX PUBLIC READ regexpr.txt: mapping from URLs to concepts HOME edoc\.hu-berlin\.de\/$ AUTHOR-START \/e_autoren_en\/$ DISS-ABSTRACT \/abstract\.php3\/habilitationen\/ AUTHOR-ADVICE \/e_autoren\/hinweise\.php\?nav=.* AUTHOR-ADVICE \/e_rzm\/hinweise\.php.* ... … DIML … … STUDY … … CMS

42
Resultat der Datenvorbereitung: Datenmodellierung
Ein Zugriff (request) entspricht [dem Interesse an] einem Konzept einer (Multi-)Menge von Konzepten einer strukturierten Menge von Konzepten Ein Merkmalsträger ist eine Session, betrachtet als eine (Multi-)Menge von Zugriffen eine Session, betrachtet als eine Sequenz von Zugriffen eine Session, betrachtet als ein Graph von Zugriffen ein Nutzer, modelliert durch (ggf. aggregierte) Attribute seiner Session(s) + ggf. andere Attribute (z.B. Wohnort, Einkommen, Transaktionshistorie) A B C A B C A B A C A B C
 entspricht [dem Interesse an] einem Konzept. einer (Multi-)Menge von Konzepten. einer strukturierten Menge von Konzepten. Ein Merkmalsträger ist. eine Session, betrachtet als eine (Multi-)Menge von Zugriffen. eine Session, betrachtet als eine Sequenz von Zugriffen. eine Session, betrachtet als ein Graph von Zugriffen. ein Nutzer, modelliert durch. (ggf. aggregierte) Attribute seiner Session(s) + ggf. andere Attribute (z.B. Wohnort, Einkommen, Transaktionshistorie) A. B. C. A. B. C. A. B. A. C. A. B. C.")
43
Semantic Web Usage Mining – Schritt 2: Musterentdeckung – Bsp
Semantic Web Usage Mining – Schritt 2: Musterentdeckung – Bsp. Sequenzmining “Find out pages that are usually visited together and inspect the navigation paths between them.” Sequence miner WUM ( select t from node as a b, template # _ a * b as t where a.accesses > 100 and a.support > 100 and b.accesses > 50 and b.support > 50 and ( b.support / a.support ) > 0.5 - only paths starting from author-relevant content and a.url startswith “AUTHOR”
 > only paths starting from author-relevant content. and a.url startswith AUTHOR")
44
Beliebte Eintrittspunkte und 1. Schritte
Bilder und Statistiken von WUM Erwähnung der Teilweg-Problematik; Hinweis auf STRATDYN Visitors move from top-level to list to individual pages When visitors enter pages that are not related to reading (diss, master, etc.), they stay in their areas. For example, visitor of other-other, stay in other-other. When visitors enter pages that are related to reading (diss, master, etc.), they move down the hierarchy when they navigate the site. “Leser“ gehen direkt zu Dissertationen u. bleiben dort.
, they stay in their areas. For example, visitor of other-other, stay in other-other. When visitors enter pages that are related to reading (diss, master, etc.), they move down the hierarchy when they navigate the site. Leser gehen direkt zu Dissertationen u. bleiben dort.")
45
Pfade zur Formatvorlage
“Autoren“ bleiben bei Autoren-Inhalten.

46
Leser und Autoren sind unterschiedliche Gruppen; Leser werden nicht zu Autoren (jedenfalls nicht in einer Session) Nur wenige Besucher nutzen die interne Suchmaschine, und sie erfahren die strukturierte Suche nicht als effektive oder effiziente Suchoption. Eine separate Fragebogenstudie unterstützt diesen Befund. Die Nutzung externer Suchmaschinen macht den Zugang zu Dissertations-Volltexten wahrscheinlicher. M SW ist hier sehr indirekt: die Resultate des Mining waren Anlass, das alles zu verbessern (also das, was jetzt kommt) Problem 2: Wissensbereitstellung ergibt sich nicht als Nebeneffekt anderer Aktivitäten (hier: Websuche)
 Problem 2: Wissensbereitstellung ergibt sich nicht als Nebeneffekt anderer Aktivitäten (hier: Websuche)")
47
Exkurs: Analyse bei gegebener Domänen-Ontologie: ka2portal. aifb
Exkurs: Analyse bei gegebener Domänen-Ontologie: ka2portal.aifb.uni-karlsruhe.de Gibt es verschiedene “Suchtypen” in diesem Onlinekatalog? Welche (Kombinationen von) Suchoptionen sind populär? Was signalisiert dieses über das inhaltliche Interesse der Nutzer?
 Suchoptionen sind populär Was signalisiert dieses über. das inhaltliche Interesse der Nutzer")
48
Semantics of requests Step 1: Domain ontology
community portal ka2portal.aifb.uni-karlsruhe.de ontology-based: Knowledge base in F-Logic Static pages: annotations Dynamic pages: generated from queries Queries also in F-Logic Logs contain these queries affiliation Titel = What does a user request mean? ERKLÄREN: die grünen Striche [Oberle, Berendt, Hotho, & Gonzalez, Proc. AWIC 2003]

49
Semantics of requests Step 2: Modelling requests and sessions-as-sets
RESEARCHER PERSON PROJECT PUBLICATION RESEARCHTOPIC EVENT ORGANIZATION RESEARCHINTEREST LASTNAME TITLE ISABOUT EVENTS EVENTTITLE WORKSATPROJECT AUTHOR AFFILIATION ISWORKEDONBY PROGRAMCOMMITTEE EMPLOYS NAME RESEARCHGROUPS An example query with concepts and relations: FORALL N,PEOPLE <-PEOPLE: Employee[affiliation->> " and PEOPLE:Person[lastName->>N]. Query = feature vector of concepts + relations Session = feature vector of concepts + relations, summed over all queries in the session Modelling user queries as atomic application events! ... Aufpassen mit requests! Application: Cluster analysis for identifying user groups Personalization Sequence analysis for identifying search strategies site improvement Clustering, Association rules, Classification, ...

50
Der Lösungsansatz

51
Mach es einfacher

52
Semantics Mining / content mining

53
Welche Art von Programmen und Nutzungsschnittstellen unterstützen Autoren und motivieren sie zur Mitarbeit? ... Und wie können weitere Daten gesammelt werden, um den Schreibprozess zu verstehen und zu unterstützen? Ein intelligentes Autorentool zur Schaffung von Semantik Prototyp: Fokus auf Bibliographie-Annotation Kern & fehleranfälligster Teil der Formatvorlagen-Benutzung in EDOC Basierend auf Informationsextraktion How can authors be assisted by computational means, and how can further data be gained for understanding the authoring process? [Berendt, Proc. AAAI Spring Symposium KCVC, 2005]

54
System-Architektur citeseer paratools TTT Web service VBA macro
other WS and info. sources Web service VBA macro

55
Nutzungsschnittstelle
„Wir haben einen Prototyp implementiert und wollen ihn zu einem Service machen“ Die neue Architektur; TTT / Paratools / citeseer –Extraktion eine Folie (Beispiele, wo es funktioniert hat aus meinen Set..txt) corrected, XML annotated, and formatted
 corrected, XML annotated, and formatted.")
56
Informationsextraktion: Referenz-Parsing in 3 Tools

57
Paratools-Zitations-Parsing http://paracite.eprints.org
Eine Datenbank von Templates der Form '_AUTHORS_ (_YEAR_). _TITLE_. _PUBLICATION_,_VOLUME_(_ISSUE_):_PAGES_' jedes _XXX_ ist assoziiert mit einem regulären Ausdruck Bsp.: _YEAR_ ([[:digit:]]{4}) 2 Gewichtungsfaktoren reliability: „syntaktische Festgelegtheit“ eines regulären Ausdrucks Ex.: _URL_ > _TITLE_ concreteness = Anzahl fixierter Symbole Ex.: '_AUTHORS_,_PUBLICATION_, in press' > '_AUTHORS_, _PUBLICATION_' Templates werden gegen die Referenz gematcht. Wähle das Template mit der höchsten reliability, oder (wenn diese gleich sind) mit der höchsten concreteness.
. _TITLE_. _PUBLICATION_,_VOLUME_(_ISSUE_):_PAGES_ jedes _XXX_ ist assoziiert mit einem regulären Ausdruck. Bsp.: _YEAR_ ([[:digit:]]{4}) 2 Gewichtungsfaktoren. reliability: „syntaktische Festgelegtheit eines regulären Ausdrucks. Ex.: _URL_ > _TITLE_. concreteness = Anzahl fixierter Symbole. Ex.: _AUTHORS_,_PUBLICATION_, in press > _AUTHORS_, _PUBLICATION_ Templates werden gegen die Referenz gematcht. Wähle das Template mit der höchsten reliability, oder (wenn diese gleich sind) mit der höchsten concreteness.")
58
Mach es lohnender

59
Semantics Mining / content + structure mining: RDI – Rosetta
Bradshaw, S. (2003). Reference Directed Indexing: Redeeming Relevance for Subject Search in Citation Indexes. In Proceedings of the 7th European Conference on Research and Advanced Technology for Digital Libraries. Bradshaw, S., & Hammond, K. (2000). Guiding people to information: Providing an interface to a digital library using Reference as a basis for indexing. In Proceedings of the Fifth International ACM Conference on Intelligent User Interfaces.
. Reference Directed Indexing: Redeeming Relevance for Subject Search in Citation Indexes. In Proceedings of the 7th European Conference on Research and Advanced Technology for Digital Libraries. Bradshaw, S., & Hammond, K. (2000). Guiding people to information: Providing an interface to a digital library using. Reference as a basis for indexing. In Proceedings of the Fifth International ACM Conference on Intelligent User Interfaces.")
60
Reference Directed Indexing: Redeeming Relevance for Subject Search in Citation Indexes, Proceedings of the 7th European Conference on Research and Advanced Technology for Digital Libraries, 2003.

61
Versteh es richtig

62
Semantics Mining / content + structure mining: SSI
R. Navigli & P. Velardi. Structural Semantic Interconnections: a knowledge-based approach to word sense disambiguation. IEEE Transactions on Pattern Analysis and Machine Intelligence (27-7), July, 2005.
, July,")
65
Basic idea: graphs of meanings induced by WordNet
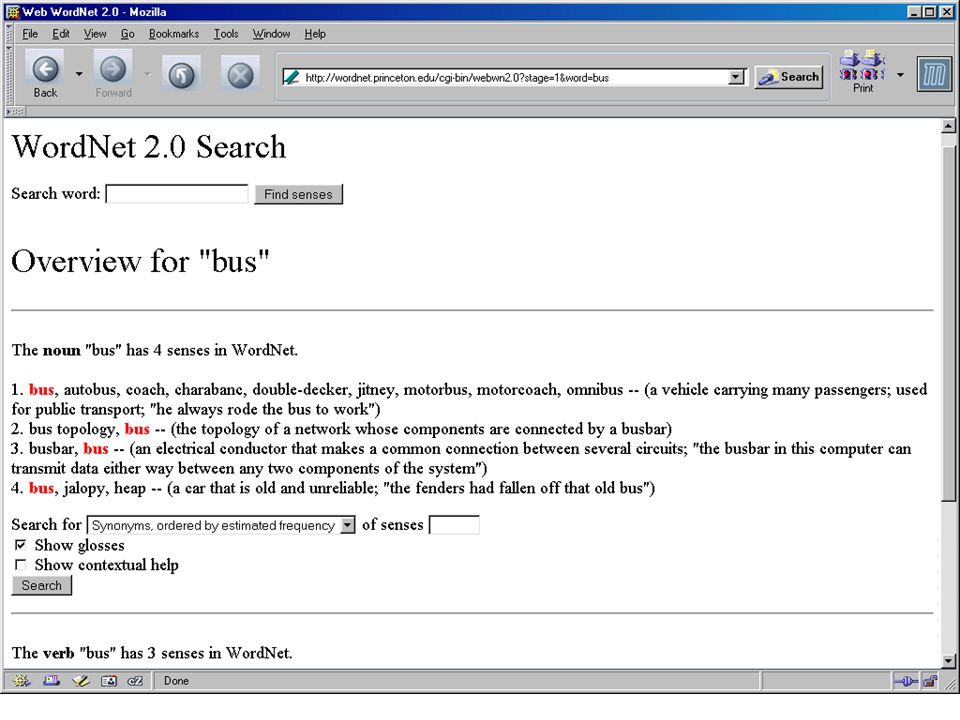
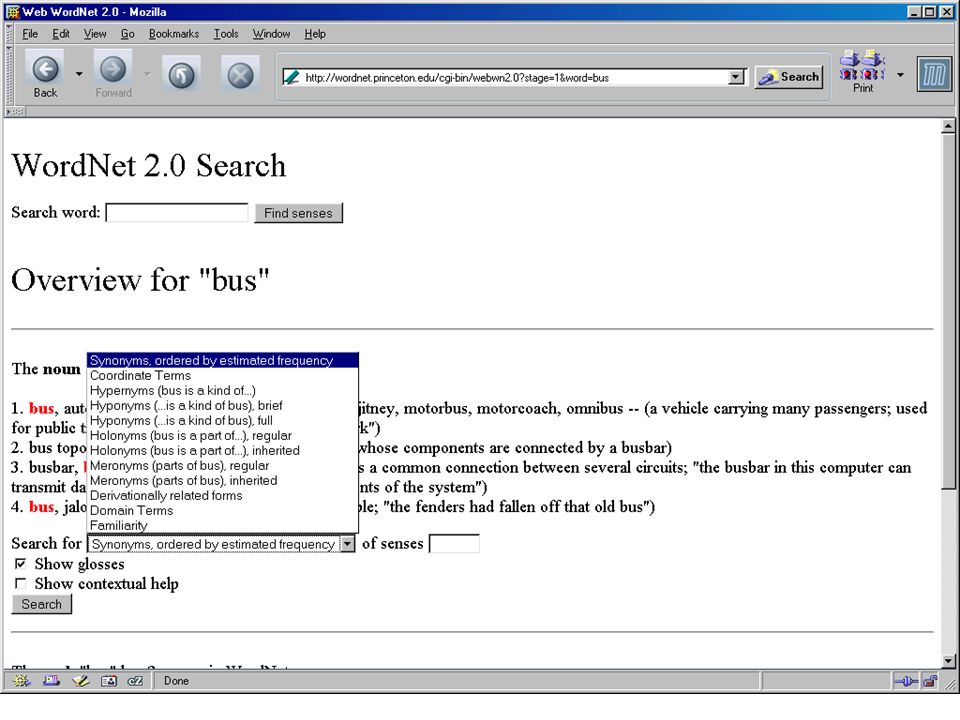
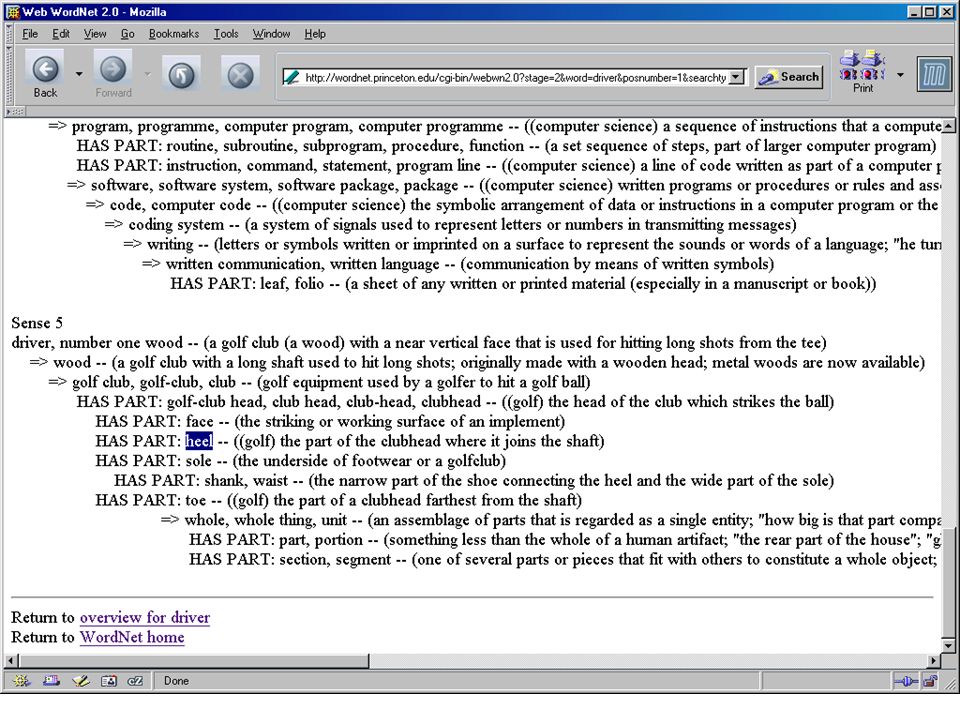
Using SSI for word sense disambiguation (“The driver turned on his heel and went back to the truck.“)
")
67
Zusammenfassung und Ausblick
Um Freiwillige zu motivieren, müssen informatische, motivationale und institutionelle Aspekte berücksichtigt werden! Erweiterung des Intelligenten Autoren-Tools: Erweiterung der Leistungsfähigkeit (Zitationsstile, ...) Integration weiterer Information-Retrieval- und Mining-Verfahren Laborstudien zur ersten Evaluation Usage-Mining zur fortlaufenden Evaluation Verstärkung des Community-Elements!
 Integration weiterer Information-Retrieval- und Mining-Verfahren. Laborstudien zur ersten Evaluation. Usage-Mining zur fortlaufenden Evaluation. Verstärkung des Community-Elements!")
68
Ausblick 1: Stärkere Einbeziehung der Community

69
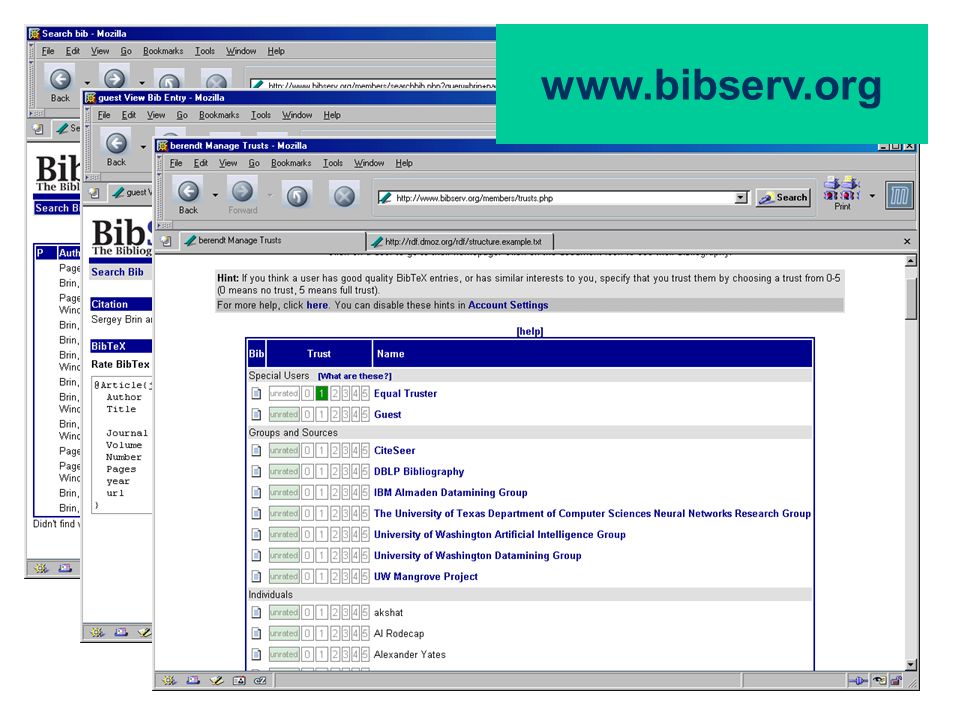
bibster.semanticweb.org Recommendations based on items‘ semantics and their ... similarity to the user‘s expertise measured by previous externalisations (content of personal database) ... similarity to relevant items measured by previous internalisations (answers to a query) and combinations (addition to the personal database) lift(X -> Y) = lift(Y -> X) = P(X and Y)/(P(X)P(Y)) = conf(X -> Y)/supp(Y) = conf(Y -> X)/supp(X) (originally called interest) Haase, Ehrig, Hotho, & Schnizler, 2004
 ... similarity to relevant items measured by previous internalisations (answers to a query) and combinations (addition to the personal database) lift(X -> Y) = lift(Y -> X) = P(X and Y)/(P(X)P(Y)) = conf(X -> Y)/supp(Y) = conf(Y -> X)/supp(X) (originally called interest) Haase, Ehrig, Hotho, & Schnizler,")
71
Ausblick 2: Spaß!

75
Danke für die Aufmerksamkeit!

Ähnliche Präsentationen