Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Oracle Data Warehouse Implementierung dimensionaler Modelle ”Star - Modell” Alfred Schlaucher, Oracle Deutschland

2
Data Warehouse Technik im Fokus
Themenübersicht Data Warehouse Technik im Fokus Ausgangssituation Architekturüberlegungen Startpunkt Anwender Namensregelungen Das physische Modell Verteilung auf Schichten Schlüssel und Indizierung Compression Partitionierung Statistiken Storage-Bedarf Materialized Views

3
Schneller Mehr Flexibler Genauer Operativer
Was Anwender bewegt Umfassende Sichten auf Kunden Einheitliche Informationen standardisierte und Daten Flexible und reichhaltige Auswertestrukturen Immer kürzere Auswertezyklen Schneller Mehr Flexibler Genauer Operativer Was hat uns bisher interessiert? In heutigen Business Intelligence und Data Warehouse Systemen messen und monitoren wir den geschäftlichen Erfolg unserer Unternehmen: Umsatzzahlen, Verbräuche, Gewinne und Verluste. Diese Informationen beziehen wir direkt aus den Daten der Online-IT-System, wandeln sie entsprechend um und ziehen unsere Schlüssel daraus. In der Regel sind dies Transaktionen in Datenbanken als Folge von Buchungen bzw. elektronischen Erfassungsvorgängen über Bildschirmmasken. Dies ist eine seit Jahrzehnten etablierte Vorgehensweise und gilt als höchst standardisiert.

4
Potentielle Informationsschätze
Alle Kundenkontaktpunkte Alle Geschäftsbeziehungen zu dem Kunden Alle historischen Daten Alle öffentlich verfügbaren Kundendaten Plus soziographische Informationen (Referenzdaten) Ergeben ein vollständiges Bild + neue Geschäftsoptionen 360°
 Ergeben ein vollständiges Bild. + neue Geschäftsoptionen. 360°")
5
Informationsdrehscheibe für alle (!) Sachgebiete
Standardisierte Berichte Advanced Analytics Ad-hoc Query & Reporting Modelle Simulation Data Warehouse Data Integration Layer Enterprise Information Layer User View Layer Referenzdaten Stammdaten Bewegungsdaten

6
Informationsdrehscheibe für alle (!) Sachgebiete
Harmonisieren Einheitliche verbundene Stammdaten Einheitliches Verständnis über Sachverhalte Standardisierte Kennzahlen Standardisierte Berichte Advanced Analytics Ad-hoc Query & Reporting Modelle Simulation Data Integration Layer Enterprise Information Layer User View Layer Referenzdaten Stammdaten Bewegungsdaten Stammdaten Referenzdaten Bewegungsdaten Neutrale Sicht auf alle Unternehmens- Bereiche Flexibel für alle Endebenutzer zugänglich

7
Analyseverfahren schon im Data Warehouse vorbereiten
User View Layer Alle Modellformen in einem System Umfangreichste R-Unterstützung Integriertes Data Mining Multidimensionale Speicherung als Add On zum Star Star Schema und 3 NF Standardisierte Berichte Advanced Analytics Ad-hoc Query & Reporting Modelle Simulation Mining- Struktur Oracle R Enterprise Oracle Data Miner Würfel Oracle OLAP Relational Any SQL

8
Wachsende DWH-Informationslandschaft
1. Informations- bedarfsanalyse Informationsbedürfnisse der Endanwender stehen am Anfang Auflistung aller benötigten Kennzahlen Sachgebiets-/ Aspekt-/ Teilprozess- Bezogene Vorgehens- weise Data Integration Layer Enterprise Information Layer User View Layer T R R S D D T S S F D Wachsendes Informations- modell B T B D B B D F D B B D T: Transfertabellen R: Referenztabellen S: Stammdaten B: Bewgungsdaten D: Dimensionen F: Fakten F D Strategische Daten Taktische Daten

9
Wachsende DWH-Informationslandschaft
2. Analyse- / Geschäftsobjekt- / Konzeptionelles Modell Eine zusammenhängende Auswerteschicht wird entworfen Daraus leiten sich alle Informationsobjekte in dem gesamten DWH ab. Sachgebiets-/ Aspekt-/ Teilprozess- Bezogene Vorgehens- weise Data Integration Layer Enterprise Information Layer User View Layer T R R S D D T S S F D Wachsendes Informations- modell B T B D B B D F D B B D T: Transfertabellen R: Referenztabellen S: Stammdaten B: Bewgungsdaten D: Dimensionen F: Fakten F D Strategische Daten Taktische Daten

10
Wachsende DWH-Informationslandschaft
3. Das DWH wächst Nach und nach entsteht ein unternehmensweit reichendes zusammenhängendes Informationmodell (Enterprise Layer) Sachgebiets-/ Aspekt-/ Teilprozess- Bezogene Vorgehens- weise Data Integration Layer Enterprise Information Layer User View Layer T R R S D D T S S F D Wachsendes Informations- modell B T B D B B D F D B B D T: Transfertabellen R: Referenztabellen S: Stammdaten B: Bewgungsdaten D: Dimensionen F: Fakten F D Strategische Daten Taktische Daten
 Sachgebiets-/ Aspekt-/ Teilprozess- Bezogene. Vorgehens- weise. Data Integration Layer. Enterprise Information Layer. User View Layer. T. R. R. S. D. D. T. S. S. F. D. Wachsendes. Informations- modell. B. T. B. D. B. B. D. F. D. B. B. D. T: Transfertabellen. R: Referenztabellen. S: Stammdaten. B: Bewgungsdaten. D: Dimensionen. F: Fakten. F. D. Strategische Daten. Taktische Daten.")
11
Exemplarische Fragestellungen der Anwender
Kennzahlen aus dem Vertrieb Kennzahlen aus dem Marketing Umsatz_Pro_Produkt_Segment Top 3 Produkte pro Segment Verhältnis von Handelsware zu Vermittlungsdiensten Personalaufwand / Investition pro Segement Umsatz_Verhältnis: Privat-/Firmenkunde Verhältnis von Umsatz mit und ohne Kundenkarte Umsatz pro spezifischem Kundensegment Berufsgruppe Altersgruppe Gehaltsgruppe Umsatz pro Produkt- und Kundensegment Kennzahlen aus dem Controlling Abgleich zwischen Einkaufs- und Verkaufszahlen Kennzahlen aus der Buchhaltung Abgleich zwischen Bestell- und Liefervorgängen

12
Data Warehouse Technik im Fokus
Themenübersicht Data Warehouse Technik im Fokus Ausgangssituation Architekturüberlegungen Startpunkt Anwender Namensregelungen Das physische Modell Verteilung auf Schichten Schlüssel und Indizierung Compression Partitionierung Statistiken Storage-Bedarf Materialized Views

13
Das physische Modell - Betrachtungshorizont
Datenarten Referenzdaten Stammdaten Bewegungsdaten Fakten Dimensionen Enterprise Information Layer User View Layer

14
Flexibles Informationsangebot + Schnelligkeit
Schichten-übergreifender Abfragebereich schafft Schnelligkeit Durchgängige Schichten Verbundmodelle Zusätzliche Referenzdaten Schnelligkeit bei der Aufbereitung der Daten Enterprise Information Layer User View Layer R S R S D D F F D MJ A C Q L D schafft Flexibilität B B D F D Zusammenhängender Abfragebereich A D B D F F D D D B B B Selbstpflegendes Kennzahlensystem

15
Namensvergaben hilft bei der Orientierung
Ziel: Die Wartbarkeit des Modells Prefixe für die unterschiedlichen Datenarten Fakten -> F_ Dimensionen -> D_ Referenzdaten -> R_ Stammdaten -> S_ Temporäre Daten -> tmp_ Bewegungsdaten -> B_ Suffixe für die unterschiedlichen Feld-Arten PK_/Schlüsselfelder -> _ID FK- Felder -> _ID (gleiche Namen wie PK-Fleder) Allgemeine Nummerierungen / Zählfelder > _NR Datumsfelder -> _Dat / _Datum
 Allgemeine Nummerierungen / Zählfelder -> _NR. Datumsfelder -> _Dat / _Datum.")
16
Wortstammanalyse hilft bei der Klassifizierung von Column-Namen
Hauptwort Eigenschafts- benennung Basistyp Kunden_Wohnart_Nr Information zu einem Kunden wird beschrieben Die Art und Weise, wie ein Kunde wohnt wird beschrieben unter- schiedliche Wohnungs- arten sind durch- nummeriert Bezugsobjekt Beschreibende Information Charakter des Attributes

17
Basistypgruppe Feldyp und Art des Wertes Rolle in Ab-hängigkeits-be-ziehung Sind NULLs erlaubt Muss Eindeutigkeit vorliegen Identifikatoren und bezeichnende Begriffe meist numerisch LHS nein ja Beschreibungen, Erzählungen, Texte meist Text , beliebige Zeichen RHS ja nein Klassifikatoren alphanumerisch, in Bezug setzende Begriffe, oft wenige Werte RHS eher nicht, eine Klassifizierung sollte für alle Sätze gelten nein Zustände meist Text , beliebige Zeichen RHS eher nicht, denn Zustände sollten für alle Sätze gelten, nein Zeiten Date / Time RHS ja nein Sequenzen, Aufzählungen Zählwerte) meist numerisch, oft versteckte Schlüsselkandidaten LHS nein ja
 meist numerisch, oft versteckte Schlüsselkandidaten. LHS. nein. ja.")
18
Mengen meist numerisch, einfache Zahlenwerte ohne weitere Angaben RHS nein, wenn etwas gezählt wird, sollte es immer gezählt warden ja Operatoren und abgeleitete Größen meist Text , beliebige Zeichen RHS nein ja Werte meist numerisch, einfache Zahlenwerte ohne weitere Angaben (brauchen i. d. R. eine relativierende Bezugsgröße z. B. Preis -> Währung) RHS nein ja (brauchen i. d. R. eine relativierende Bezugsgröße z. B. Preis -> Währung) Maße, Bezugsgrößen, Einheiten meist Text , beliebige Zeichen RHS nein ja
 RHS. nein. ja. (brauchen i. d. R. eine relativierende Bezugsgröße z. B. Preis -> Währung) Maße, Bezugsgrößen, Einheiten. meist Text , beliebige Zeichen. RHS. nein. ja.")
19
Hilfsmittel Feldliste
select substr(table_name,1,20) Tab, substr(column_name,1,20) Col, substr(data_type,1,8) Typ, substr(data_length,1,3) Len From dba_tab_columns WHERE owner = 'SV' and (table_name like 'F_%' or table_name like 'D_%') order by col / Über alle Tabellen Alphabetisch sortiert nach Spaltennamen Hilft beim Erkennen von Homonymen und Synonymen Hilft bei der Bewertung der Tauglichkeit von Spaltennamen Erlaubt Vorahnungen von Schlüsselkandidaten
 Tab, substr(column_name,1,20) Col, substr(data_type,1,8) Typ, substr(data_length,1,3) Len. From dba_tab_columns. WHERE. owner = SV and. (table_name like F_% or. table_name like D_% ) order by col. / Über alle Tabellen. Alphabetisch sortiert nach Spaltennamen. Hilft beim Erkennen von Homonymen und Synonymen. Hilft bei der Bewertung der Tauglichkeit von Spaltennamen. Erlaubt Vorahnungen von Schlüsselkandidaten.")
20
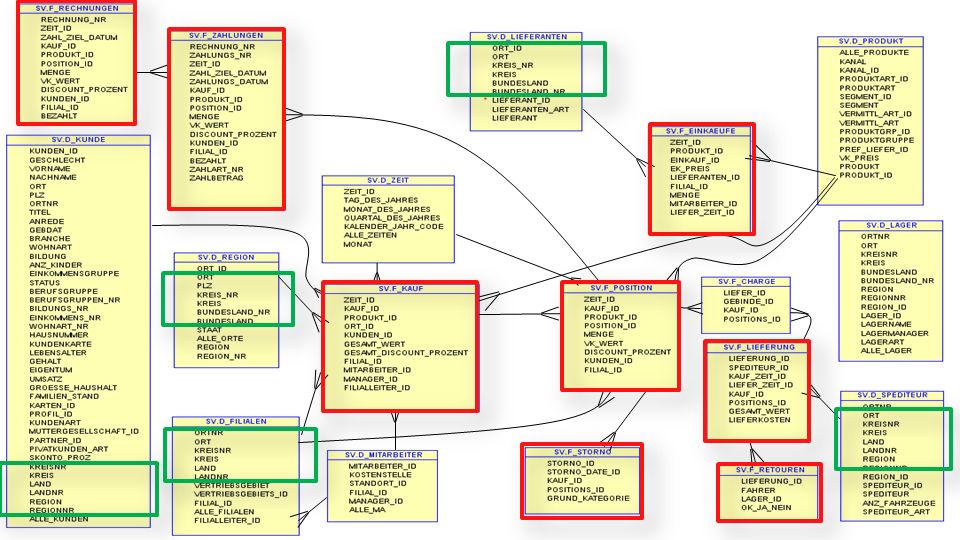
Die Feldliste (Beispiel)
TAB COL TYP LEN D_FILIALEN ALLE_FILIALEN VARCHAR D_KUNDE ALLE_KUNDEN VARCHAR D_LAGER ALLE_LAGER VARCHAR D_MITARBEITER ALLE_MA VARCHAR D_REGION ALLE_ORTE CHAR D_PRODUKT ALLE_PRODUKTE VARCHAR D_ZEIT ALLE_ZEITEN CHAR D_KUNDE ANREDE VARCHAR D_SPEDITEUR ANZ_FAHRZEUGE NUMBER D_KUNDE ANZ_KINDER VARCHAR D_ARTIKEL ARTIKEL_ID NUMBER D_ARTIKEL ARTIKEL_NAME VARCHAR D_KUNDE BERUFSGRUPPE VARCHAR D_KUNDE BERUFSGRUPPEN_NR NUMBER F_ZAHLUNGEN BEZAHLT VARCHAR F_ZAHLUNGEN_PARTITIO BEZAHLT VARCHAR D_KUNDE BILDUNG VARCHAR D_KUNDE BILDUNGS_NR NUMBER D_KUNDE BRANCHE VARCHAR D_REGION BUNDESLAND VARCHAR D_LAGER BUNDESLAND VARCHAR D_LIEFERANTEN BUNDESLAND VARCHAR D_LAGER BUNDESLAND_NR NUMBER D_LIEFERANTEN BUNDESLAND_NR NUMBER D_REGION BUNDESLAND_NR NUMBER F_POSITION DISCOUNT_PROZENT NUMBER Die Feldliste (Beispiel)
")
21
Die Modellfirma: SERVICE GmbH
Ursprungsgeschäft Baumärkte Erweiterungen Vermittlung von Handwerker-Service- Leistungen Vermittlung von Finanzdienstleitungen rund um das Bauen Direktes Endkundengeschäft über Internet Lieferservice direkt ins Haus Unterscheidung Privat- / Firmenkunden SERVICE GmbH

22
Erwartungen aus dem Unternehmen
Buchhaltung: Es fehlen Daten Warum sind die Spediteursrechnungen so hoch? Sind alle Bestellungen korrekt bezahlt worden? Wie hoch sind die Versandkosten pro Lieferung? Was wurde storniert? Marketing: Absatzzahlen sind nicht aussagefähig Wie viel Kunden gibt es? Lohnt die Kundenkarte? Welche Segmentierung gibt es? Controlling: Vergleichbarkeit fehlt Was sind rentable Sparten? Wie rentabel sind einzelne Produkte? Was kosten Produkte im Einkauf? Wie teuer wurden Produkte verkauft? SERVICE GmbH Vertrieb: wünscht leichtere Auswertungen Was sind wichtige Produkte? Was sind rentable Sparten? Hat sich der Servicebereich gelohnt? Management: Kennzahlen fehlen Wie hoch sind die liquiden Mittel? Wie hoch sind die Außenstände? Vertrieb Marketing Buchhaltung Management Controlling 22

23
Data Warehouse Technik im Fokus
Themenübersicht Data Warehouse Technik im Fokus Ausgangssituation Architekturüberlegungen Startpunkt Anwender Namensregelungen Das physische Modell Verteilung auf Schichten Schlüssel und Indizierung Compression Partitionierung Statistiken Storage-Bedarf Materialized Views

24
Referenzdaten Referenzdaten

25
Stammdaten

26
Das Auswerte- Schema

27
Das Szenario und die Mengen 67.840.000 100 67.840.000 305 220.000 5479
100024 10 16461 37 34 1999

28
Schlüssel im Star Dim_Artikel
Artikelsparte_Langname Levelschlüssel Artikelsparte Sparte Master Detail – Schlüssel: Numerische Felder Zwischen Zeit-Tabelle und Fakten-Tabelle DATE- Format FK-Constraint nicht nötig aber für den Optimizer bei Abfragen sinnvoll I.d.R. Keine PKs auf den Faktentabellen Parent Aggregation Artikelgruppe_Langtext Levelschlüssel Artikelgruppe Hierarchie Parent Aggregation Artikel_Langtext Levelschlüssel/ Objektname Artikel Business Key Artikel_Schlüssel Konsolidierungslevel Betrachtungslevel Künstlicher Dimension Key Dim_Schlüssel Fakten-FKs Fakten (Umsatz) 28
 28.")
29
PK PK FKs PK PK PK PK

30
Data Warehouse Technik im Fokus
Themenübersicht Data Warehouse Technik im Fokus Ausgangssituation Architekturüberlegungen Startpunkt Anwender Namensregelungen Das physische Modell Verteilung auf Schichten Schlüssel und Indizierung Compression Partitionierung Statistiken Storage-Bedarf Materialized Views

31
Design-Prinzip - Ziel: Leichte Auswertbarkeit Verteilung der Daten in den Schichten
Schichten-übergreifender Abfragebereich schafft Schnelligkeit ? Enterprise Information Layer User View Layer R S R S D D F F D D schafft Flexibilität B B D F D Zusammenhängender Abfragebereich D B D F F D D D B B B

32
Design-Prinzip - Ziel: Leichte Auswertbarkeit Verteilung der Daten in den Schichten
Schichten-übergreifender Abfragebereich schafft Schnelligkeit Gleiche Daten an mehreren Stellen In unterschiedlichen Dimensionen Redundante (konvergente) Fakten- Daten Synchronisierung über Zentrale Stamm- und Referenzdaten Standardisierten ETL-Prozess Enterprise Information Layer User View Layer R S R S D D F F D D schafft Flexibilität B B D F D Zusammenhängender Abfragebereich D B D F F D D D B B B
 Fakten- Daten. Synchronisierung über. Zentrale Stamm- und Referenzdaten. Standardisierten ETL-Prozess. Enterprise Information. Layer. User View Layer. R. S. R. S. D. D. F. F. D. D. schafft Flexibilität. B. B. D. F. D. Zusammenhängender Abfragebereich. D. B. D. F. F. D. D. D. B. B. B.")
33
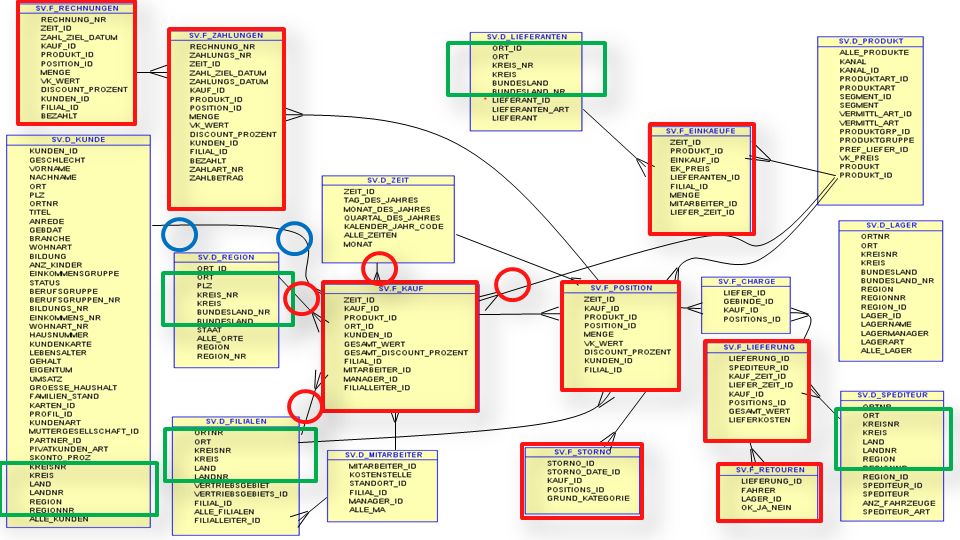
Sich überschneidende Dimensionen Einzelne Attribute sind gleich
Region Bundesland Kreis Wohnort Name Kunden_NR Kunde Region Bundesland Kreis Ort Filial_Kategorie Filial_NR Filiale Artikel_NR Menge Kunden_NR Preis Filial_Nr Umsatz 33

36
Standardisieren über einheitliche Referenzdaten
Enterprise Information Layer User View Layer Referenzdaten

37
Master Detail – Fakten Tabellen

38
Die Wechselwirkung zwischen Master Detail Fakten-Tabellen

39
Konvergente Fakten-Felder

40
Data Warehouse Technik im Fokus
Themenübersicht Data Warehouse Technik im Fokus Ausgangssituation Architekturüberlegungen Startpunkt Anwender Namensregelungen Das physische Modell Verteilung auf Schichten Schlüssel und Indizierung Compression Partitionierung Statistiken Storage-Bedarf Materialized Views

41
Wo und wie wird im DWH indiziert
Lade-Aktivitäten Lese-Aktivitäten Data Integration Layer Enterprise Information Layer User View Layer Process neutral / 3 NF Keine Indexe B*tree für Eindeutigkeit und als Primary Key Bitmaps Bitmaps B*tree für Primary Keys In den Dimensionen Tabellen

42
Bitmap-Index-Definitionen in Fakten-Tabellen
CREATE bitmap index idx_BM_KAUF_ZEIT_ID on F_KAUF_Partition(ZEIT_ID) local; CREATE bitmap index idx_BM_KAUF_PRODUKT_ID on F_KAUF_Partition(PRODUKT_ID) local; CREATE bitmap index idx_BM_KAUF_ORT_ID on F_KAUF_Partition(ORT_ID) local; CREATE bitmap index idx_BM_KAUF_KUNDEN_ID on F_KAUF_Partition(KUNDEN_ID) local; CREATE bitmap index idx_BM_KAUF_FILIAL_ID on F_KAUF_Partition(FILIAL_ID) local; CREATE bitmap index idx_BM_KAUF_MITARBEITER_ID on F_KAUF_Partition(MITARBEITER_ID) local; CREATE bitmap index idx_BM_KAUF_MANAGER_ID on F_KAUF_Partition(MANAGER_ID) local; CREATE bitmap index idx_BM_KAUF_FILIALLEITER_ID on F_KAUF_Partition(FILIALLEITER_ID) local; Bitmap-Indexe auf alle Fremdschlüssel-Felder der gößeren Fakten-Tabellen (Ausnahme KAUF_ID) Bei partitionierten Fakten- Tabellen:LOCAL Index Komprimierung erfolgt automatisch Regelmäßiges Löschen und Neuanlegen der Indexe Star Query-Transformation
 local; CREATE bitmap index idx_BM_KAUF_PRODUKT_ID on F_KAUF_Partition(PRODUKT_ID) local; CREATE bitmap index idx_BM_KAUF_ORT_ID on F_KAUF_Partition(ORT_ID) local; CREATE bitmap index idx_BM_KAUF_KUNDEN_ID on F_KAUF_Partition(KUNDEN_ID) local; CREATE bitmap index idx_BM_KAUF_FILIAL_ID on F_KAUF_Partition(FILIAL_ID) local; CREATE bitmap index idx_BM_KAUF_MITARBEITER_ID on F_KAUF_Partition(MITARBEITER_ID) local; CREATE bitmap index idx_BM_KAUF_MANAGER_ID on F_KAUF_Partition(MANAGER_ID) local; CREATE bitmap index idx_BM_KAUF_FILIALLEITER_ID on F_KAUF_Partition(FILIALLEITER_ID) local; Bitmap-Indexe auf alle Fremdschlüssel-Felder der gößeren Fakten-Tabellen (Ausnahme KAUF_ID) Bei partitionierten Fakten- Tabellen:LOCAL Index. Komprimierung erfolgt automatisch. Regelmäßiges Löschen und Neuanlegen der Indexe. Star Query-Transformation.")
43
Umgang mit Bitmap-Indexe
Rowid Name Abschluss Rating AAAHfVAAJAAAKOKAAA Meier Klasse_10 5 AAAHfVAAJAAAKOKAAB Schubert Abitur AAAHfVAAJAAAKOKAAC Klaus-Gustav AAAHfVAAJAAAKOKAAD Schmidt Diplom AAAHfVAAJAAAKOKAAE Langbein Doktor AAAHfVAAJAAAKOKAAF Hund AAAHfVAAJAAAKOKAAG Vogel AAAHfVAAJAAAKOKAAH Messner Abschluss= Klasse_10 Abschluss= Abitur Abschluss= Diplom Abschluss= Doktor 1 Feststellen, für welche Spalten Indexe nötig sind Selektivität der Werte in den betroffenen Spalten Prüfen Platzverbrauch im Blick haben Regelmäßig neu machen SELECT Name FROM KD_Table WHERE Abschluss=‘Diplom‘;

44
Platzverbrauch Bitmap-Indexe
SQL> SELECT index_name,index_type blevel, (leaf_blocks*8/1000) MB, NUM_ROWS, distinct_keys FROM user_indexes; INDEX_NAME BLEVEL MB NUM_ROWS DISTINCT_KEYS IDX_BM_LIEFERUNG_KAUF_ZEIT_ID BITMAP IDX_BM_ZAHLUNGEN_ZEIT_ID BITMAP IDX_BM_ZAHLUNGEN_PRODUKT_ID BITMAP IDX_BM_ZAHLUNGEN_KUNDEN_ID BITMAP IDX_BM_ZAHLUNGEN_FILIAL_ID BITMAP IDX_BM_POSITION_ZEIT_ID BITMAP IDX_BM_POSITION_PRODUKT_ID BITMAP IDX_BM_POSITION_KUNDEN_ID BITMAP IDX_BM_POSITION_FILIAL_ID BITMAP IDX_BM_KAUF_ZEIT_ID BITMAP IDX_BM_KAUF_PRODUKT_ID BITMAP IDX_BM_KAUF_ORT_ID BITMAP IDX_BM_KAUF_KUNDEN_ID BITMAP IDX_BM_KAUF_FILIAL_ID BITMAP IDX_BM_KAUF_MITARBEITER_ID BITMAP IDX_BM_KAUF_MANAGER_ID BITMAP IDX_BM_KAUF_FILIALLEITER_ID BITMAP GB
 MB, NUM_ROWS, distinct_keys FROM user_indexes; INDEX_NAME BLEVEL MB NUM_ROWS DISTINCT_KEYS IDX_BM_LIEFERUNG_KAUF_ZEIT_ID BITMAP IDX_BM_ZAHLUNGEN_ZEIT_ID BITMAP IDX_BM_ZAHLUNGEN_PRODUKT_ID BITMAP IDX_BM_ZAHLUNGEN_KUNDEN_ID BITMAP IDX_BM_ZAHLUNGEN_FILIAL_ID BITMAP IDX_BM_POSITION_ZEIT_ID BITMAP IDX_BM_POSITION_PRODUKT_ID BITMAP IDX_BM_POSITION_KUNDEN_ID BITMAP IDX_BM_POSITION_FILIAL_ID BITMAP IDX_BM_KAUF_ZEIT_ID BITMAP IDX_BM_KAUF_PRODUKT_ID BITMAP IDX_BM_KAUF_ORT_ID BITMAP IDX_BM_KAUF_KUNDEN_ID BITMAP IDX_BM_KAUF_FILIAL_ID BITMAP IDX_BM_KAUF_MITARBEITER_ID BITMAP IDX_BM_KAUF_MANAGER_ID BITMAP IDX_BM_KAUF_FILIALLEITER_ID BITMAP GB.")
45
select sum(k. gesamt_wert), p. segment, r. bundesland, z
select sum(k.gesamt_wert), p.segment, r.bundesland, z.Kalender_jahr_code from F_Kauf_PARTITION K, d_Zeit Z, d_region R, d_produkt P where to_date(K.zeit_id,'DD-MON-YY') = to_date(Z.zeit_id,'DD-MON-YY') and K.ort_id = R.ort_id and K.produkt_id = p.produkt_id group by p.segment, r.bundesland, z.Kalender_jahr_code | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | 0 | SELECT STATEMENT | | | | (1)| 00:00:01 | 1 | HASH GROUP BY | | | | (1)| 00:00:01 |* 2 | HASH JOIN | | | | (1)| 00:00:01 |* 3 | HASH JOIN | | | | (1)| 00:00:01 | 4 | NESTED LOOPS | | | | | | 5 | NESTED LOOPS | | | | (1)| 00:00:01 | 6 | TABLE ACCESS FULL | D_PRODUKT | | | (0)| 00:00:01 | 7 | PARTITION RANGE ALL | | | | | | 8 | BITMAP CONVERSION TO ROWIDS | | | | | |* 9 | BITMAP INDEX SINGLE VALUE | IDX_BM_KAUF_PRODUKT_ID | | | | | 10 | TABLE ACCESS BY LOCAL INDEX ROWID| F_KAUF_PARTITION | | | (1)| 00:00:01 | 11 | TABLE ACCESS FULL | D_ZEIT | | 117K| (0)| 00:00:01 | 12 | TABLE ACCESS FULL | D_REGION | | 305K| (0)| 00:00:01
, p.segment, r.bundesland, z.Kalender_jahr_code. from F_Kauf_PARTITION K, d_Zeit Z, d_region R, d_produkt P. where. to_date(K.zeit_id, DD-MON-YY ) = to_date(Z.zeit_id, DD-MON-YY ) and. K.ort_id = R.ort_id and. K.produkt_id = p.produkt_id. group by p.segment, r.bundesland, z.Kalender_jahr_code. | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | 0 | SELECT STATEMENT | | 1 | 106 | (1)| 00:00:01. | 1 | HASH GROUP BY | | 1 | 106 | (1)| 00:00:01. |* 2 | HASH JOIN | | 1 | 106 | (1)| 00:00:01. |* 3 | HASH JOIN | | 1 | 87 | (1)| 00:00:01. | 4 | NESTED LOOPS | | | | | | 5 | NESTED LOOPS | | 1 | 65 | (1)| 00:00:01. | 6 | TABLE ACCESS FULL | D_PRODUKT | 305 | 5185 | 6 (0)| 00:00:01. | 7 | PARTITION RANGE ALL | | | | | | 8 | BITMAP CONVERSION TO ROWIDS | | | | | |* 9 | BITMAP INDEX SINGLE VALUE | IDX_BM_KAUF_PRODUKT_ID | | | | | 10 | TABLE ACCESS BY LOCAL INDEX ROWID| F_KAUF_PARTITION | 1 | 48 | (1)| 00:00:01. | 11 | TABLE ACCESS FULL | D_ZEIT | 5479 | 117K| 12 (0)| 00:00:01. | 12 | TABLE ACCESS FULL | D_REGION | | 305K| 71 (0)| 00:00:")
46
Data Warehouse Technik im Fokus
Themenübersicht Data Warehouse Technik im Fokus Ausgangssituation Architekturüberlegungen Startpunkt Anwender Namensregelungen Das physische Modell Verteilung auf Schichten Schlüssel und Indizierung Compression Partitionierung Statistiken Storage-Bedarf Materialized Views

47
Partitioning senkt Verwaltungs-/Betriebskosten
24/7 Online Aktualisierung Index Aktualisierung Statistiken In Memory Komprimierung Kollektive Sicht (alle Tabellendaten) Storage Backup Archivierung Mai ja sehr günstig Partition- bezogene Sicht Juni nein Juli günstig nein nein August nein September Oktober ja High end ETL-Prozess November November ja ja
 Storage. Backup. Archivierung. Mai. ja. sehr. günstig. Partition- bezogene. Sicht. Juni. nein. Juli. günstig. nein. nein. August. nein. September. Oktober. ja. High end. ETL-Prozess. November. November. ja. ja.")
48
Partitionierung Welche Tabellen werden wie partitioniert
Große Tabellen (ab mehrere Millionen Sätze) Meist die Fakten-Tabellen Meist RANGE auf Zeit-Spalte Effekte bei Sub-partitionierung Range -> 70%- 80% Performance-Optimierung
 Meist die Fakten-Tabellen. Meist RANGE auf Zeit-Spalte. Effekte bei Sub-partitionierung. Range -> 70%- 80% Performance-Optimierung.")
49
Partitioniert Partitioniert Partitioniert Partitioniert

50
Beispiel F_KAUF_PARTITION
create table f_kauf_partition ( zeit_id date, Kauf_id number, Produkt_id number, ort_id number, Kunden_id number, Gesamt_Wert number, Gesamt_Discount_Prozent number, Filial_id number, Mitarbeiter_ID number, Manager_ID number, Filialleiter_ID number) PARTITION BY RANGE (ZEIT_ID) ( PARTITION jan10 VALUES LESS THAN (TO_DATE(' ','SYYYY-MM-DD')), PARTITION feb10 VALUES LESS THAN (TO_DATE(' ','SYYYY-MM-DD')), PARTITION mar10 VALUES LESS THAN (TO_DATE(' ','SYYYY-MM-DD')), PARTITION apr10 VALUES LESS THAN (TO_DATE(' ','SYYYY-MM-DD')), PARTITION mai10 VALUES LESS THAN (TO_DATE(' ','SYYYY-MM-DD')), PARTITION jun10 VALUES LESS THAN (TO_DATE(' ','SYYYY-MM-DD')), PARTITION jul10 VALUES LESS THAN (TO_DATE(' ','SYYYY-MM-DD')), ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ PARTITION nov13 VALUES LESS THAN (TO_DATE(' ','SYYYY-MM-DD')), PARTITION dec13 VALUES LESS THAN (TO_DATE(' ','SYYYY-MM-DD')), PARTITION next_month VALUES LESS THAN (MAXVALUE)); ;
 PARTITION BY RANGE (ZEIT_ID) ( PARTITION jan10 VALUES LESS THAN (TO_DATE( , SYYYY-MM-DD )), PARTITION feb10 VALUES LESS THAN (TO_DATE( , SYYYY-MM-DD )), PARTITION mar10 VALUES LESS THAN (TO_DATE( , SYYYY-MM-DD )), PARTITION apr10 VALUES LESS THAN (TO_DATE( , SYYYY-MM-DD )), PARTITION mai10 VALUES LESS THAN (TO_DATE( , SYYYY-MM-DD )), PARTITION jun10 VALUES LESS THAN (TO_DATE( , SYYYY-MM-DD )), PARTITION jul10 VALUES LESS THAN (TO_DATE( , SYYYY-MM-DD )), ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ PARTITION nov13 VALUES LESS THAN (TO_DATE( , SYYYY-MM-DD )), PARTITION dec13 VALUES LESS THAN (TO_DATE( , SYYYY-MM-DD )), PARTITION next_month VALUES LESS THAN (MAXVALUE)); ;")
51
Beispielabfrage select sum(k.gesamt_wert) Wert, p.segment segment,
r.bundesland land, z.Kalender_jahr_code Jahr from F_Kauf_PARTITION K, d_Zeit Z, d_region R, d_produkt P where to_date(K.zeit_id,'DD-MON-YY') = to_date(Z.zeit_id,'DD-MON-YY') and K.ort_id = R.ort_id and K.produkt_id = p.produkt_id and Z.monat_des_Jahres = and Z.KALENDER_JAHR_CODE = 2012 group by p.segment, r.bundesland, z.Kalender_jahr_code [F_Kauf K,]
 = to_date(Z.zeit_id, DD-MON-YY ) and. K.ort_id = R.ort_id and. K.produkt_id = p.produkt_id and. Z.monat_des_Jahres = 1 and. Z.KALENDER_JAHR_CODE = group by p.segment, r.bundesland, z.Kalender_jahr_code. [F_Kauf K,]")
52
Mit Partitioning Elapsed: 00:00:08.90 Execution Plan
Plan hash value: | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop | | 0 | SELECT STATEMENT | | | | (1)| 00:00:01 | | | | 1 | HASH GROUP BY | | | | (1)| 00:00:01 | | | |* 2 | HASH JOIN | | | | (1)| 00:00:01 | | | |* 3 | HASH JOIN | | | | (1)| 00:00:01 | | | | 4 | NESTED LOOPS | | | | | | | | | 5 | NESTED LOOPS | | | | (1)| 00:00:01 | | | | 6 | TABLE ACCESS FULL | D_PRODUKT | | | (0)| 00:00:01 | | | | 7 | PARTITION RANGE ALL | | | | | | | | | 8 | BITMAP CONVERSION TO ROWIDS | | | | | | | | |* 9 | BITMAP INDEX SINGLE VALUE | IDX_BM_KAUF_PRODUKT_ID | | | | | | | | 10 | TABLE ACCESS BY LOCAL INDEX ROWID| F_KAUF_PARTITION | | | (1)| 00:00:01 | | | |* 11 | TABLE ACCESS FULL | D_ZEIT | | | (0)| 00:00:01 | | | | 12 | TABLE ACCESS FULL | D_REGION | | 305K| (0)| 00:00:01 | | |
| Time | Pstart| Pstop | | 0 | SELECT STATEMENT | | 1 | 119 | (1)| 00:00:01 | | | | 1 | HASH GROUP BY | | 1 | 119 | (1)| 00:00:01 | | | |* 2 | HASH JOIN | | 1 | 119 | (1)| 00:00:01 | | | |* 3 | HASH JOIN | | 1 | 100 | (1)| 00:00:01 | | | | 4 | NESTED LOOPS | | | | | | | | | 5 | NESTED LOOPS | | 1 | 65 | (1)| 00:00:01 | | | | 6 | TABLE ACCESS FULL | D_PRODUKT | 305 | 5185 | 6 (0)| 00:00:01 | | | | 7 | PARTITION RANGE ALL | | | | | | 1 | 49 | | 8 | BITMAP CONVERSION TO ROWIDS | | | | | | | | |* 9 | BITMAP INDEX SINGLE VALUE | IDX_BM_KAUF_PRODUKT_ID | | | | | 1 | 49 | | 10 | TABLE ACCESS BY LOCAL INDEX ROWID| F_KAUF_PARTITION | 1 | 48 | (1)| 00:00:01 | 1 | 1 | |* 11 | TABLE ACCESS FULL | D_ZEIT | 31 | 1085 | 12 (0)| 00:00:01 | | | | 12 | TABLE ACCESS FULL | D_REGION | | 305K| 71 (0)| 00:00:01 | | |")
53
Ohne Partitioning Elapsed: 00:00:30.10 Execution Plan
Plan hash value: | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | | 0 | SELECT STATEMENT | | | | (2)| 00:00:01 | | 1 | HASH GROUP BY | | | | (2)| 00:00:01 | |* 2 | HASH JOIN | | | | (2)| 00:00:01 | | 3 | VIEW | VW_GBC_13 | | | (2)| 00:00:01 | | 4 | HASH GROUP BY | | | | (2)| 00:00:01 | |* 5 | HASH JOIN | | 4680K| 321M| (2)| 00:00:01 | | 6 | TABLE ACCESS FULL | D_PRODUKT | | | (0)| 00:00:01 | |* 7 | HASH JOIN | | 4680K| 245M| (2)| 00:00:01 | |* 8 | TABLE ACCESS FULL| D_ZEIT | | | (0)| 00:00:01 | | 9 | TABLE ACCESS FULL| F_KAUF | 15M| 287M| (1)| 00:00:01 | | 10 | TABLE ACCESS FULL | D_REGION | | 305K| (0)| 00:00:01 |
| Time | | 0 | SELECT STATEMENT | | 80 | 4960 | (2)| 00:00:01 | | 1 | HASH GROUP BY | | 80 | 4960 | (2)| 00:00:01 | |* 2 | HASH JOIN | | 154 | 9548 | (2)| 00:00:01 | | 3 | VIEW | VW_GBC_13 | 154 | 6622 | (2)| 00:00:01 | | 4 | HASH GROUP BY | | 154 | | (2)| 00:00:01 | |* 5 | HASH JOIN | | 4680K| 321M| (2)| 00:00:01 | | 6 | TABLE ACCESS FULL | D_PRODUKT | 305 | 5185 | 6 (0)| 00:00:01 | |* 7 | HASH JOIN | | 4680K| 245M| (2)| 00:00:01 | |* 8 | TABLE ACCESS FULL| D_ZEIT | 31 | 1085 | 12 (0)| 00:00:01 | | 9 | TABLE ACCESS FULL| F_KAUF | 15M| 287M| (1)| 00:00:01 | | 10 | TABLE ACCESS FULL | D_REGION | | 305K| 71 (0)| 00:00:01 |")
54
Data Warehouse Technik im Fokus
Themenübersicht Data Warehouse Technik im Fokus Ausgangssituation Architekturüberlegungen Startpunkt Anwender Namensregelungen Das physische Modell Verteilung auf Schichten Schlüssel und Indizierung Compression Partitionierung Statistiken Storage-Bedarf Materialized Views

55
Statistiken sammeln- auch für Partitioen
Aktualität der Statistiken Skripte mit allen Partitionen EXEC DBMS_STATS.GATHER_TABLE_STATS ('SV','F_KAUF',estimate_percent=>20); EXEC DBMS_STATS.GATHER_TABLE_STATS ('SV','F_Kauf_partition', estimate_percent=>20, GRANULARITY => 'PARTITION');
; EXEC DBMS_STATS.GATHER_TABLE_STATS. ( SV , F_Kauf_partition , estimate_percent=>20, GRANULARITY => PARTITION );")
56
Storage-Bedarf Regelmäßige Kontrolle der verbrauchten Ressourcen
select substr(segment_name,1,25) Segment, round((bytes/ ),2) GB,bytes, blocks,extents from user_segments where segment_type = 'TABLE‘ and segment like ‘F%’; SEGMENT GB BYTES BLOCKS EXTENTS F_KAUF F_LIEFERUNG F_POSITION F_ZAHLUNGEN F_CHARGE F_STORNO F_EINKAEUFE F_RETOUREN
 Segment, round((bytes/ ),2) GB,bytes, blocks,extents from user_segments where segment_type = TABLE‘ and segment like ‘F%’; SEGMENT GB BYTES BLOCKS EXTENTS F_KAUF F_LIEFERUNG F_POSITION F_ZAHLUNGEN F_CHARGE F_STORNO F_EINKAEUFE F_RETOUREN")
57
Platzverbrauch von partitionierten Tabellen
SELECT table_name, sum(num_rows), sum(blocks), round(sum(((blocks*8192)/ )),2) GB FROM user_tab_partitions group by table_name order by table_name TABLE_NAME SUM(NUM_ROWS) SUM(BLOCKS) GB F_KAUF_PARTITION F_LIEFERUNG_PARTITION F_POSITION_PARTITION F_ZAHLUNGEN_PARTITION
, sum(blocks), round(sum(((blocks*8192)/ )),2) GB. FROM user_tab_partitions. group by table_name order by table_name. TABLE_NAME SUM(NUM_ROWS) SUM(BLOCKS) GB F_KAUF_PARTITION F_LIEFERUNG_PARTITION F_POSITION_PARTITION F_ZAHLUNGEN_PARTITION")
58
Komprimierung alter table TMP_KAUF_POSITION move compress;
Einfache Tabellen Partitionierte Tabellen alter table TMP_KAUF_POSITION move compress; ALTER TABLE F_KAUF_PARTITION MOVE PARTITION APR10 COMPRESS FOR ALL OPERATIONS NOLOGGING;

59
Datenmengen ohne Partitionierung
Vorher Nachher Komp-Zeit Anz. Zeilen F_ZAHLUNGEN 6.44 4.1 2:23.47 TMP_KAUF_POSITION 2,55 1.48 1:45.19 F_POSITION 3.36 1.95 1:18.92 F_LIEFERUNG 3.78 2.58 1:31.57 F_KAUF 0.87 0.63 0:17.95

60
Datenmengen mit Partitionierung
Ohne Part Nachher Komp-Zeit Anz. Zeilen F_ZAHLUNGEN 6.57 6.44 3 TMP_KAUF_POSITION 2,55 F_POSITION 3.44 3.36 4 F_LIEFERUNG 3.91 3.78 F_KAUF 1,03 0.87 1.03 4:17.95

61
Data Warehouse Technik im Fokus
Themenübersicht Data Warehouse Technik im Fokus Ausgangssituation Architekturüberlegungen Startpunkt Anwender Namensregelungen Das physische Modell Verteilung auf Schichten Schlüssel und Indizierung Compression Partitionierung Statistiken Storage-Bedarf Materialized Views

62
Automatisches Summenmanagement Materialized Views
Level 4 Regionen Regionen_ID Transparanz: Abfragen nur auf die Original-Tabellen Flexibel: Alle Felder einer Dimensionstabelle sind abfragbar Stale: Stellt selbst fehlende Aktualität fest ETL-Effizient: Aktualisiert sich selbst Level 3 Bundesland Bundesland_ID Level 2 Regionen Dimension Kreise Kreise_ID Level 1 Orte Orte_ID PLZ Query Rewrite Parallel eingesetzte Techniken Materialized Views Query Rewrite Verwendung von Dimension Tables Fakten Tabelle Materialized View

63
Materialized Views sparen Plattenplatz und minimieren die Objektanzahl
Top/Alle_Artikel Summe pro Segement Segement Summe pro Sparte Artikelsparte Query Review Summe pro Gruppe Artikelgruppe Summe pro Artikel Artikel Summe pro Charge Artikelcharge Summe pro Charge Menge Umsatz

64
Nested Materialized Views nutzen bereits ausgeführte IO-Leistung
Materialized View Level 4 Aufwendige Join-Operation DIM_Zeit FAKT_Umsatz DIM_Produkte Umsatz Prod.Gr A Umsatz Prod. Gr B relativ zum Gesamtjahresumsatz Summierung/Monat Summierung/Jahr Umsatz Prod.Gr B Materialized View Level 3 Materialized View Level 2 Materialized View Level 1 Basistabellen IO

65
Anwendung: Auswertungen über Ein-/Verkäufe
Level 1: Getrennte MAVs mit Monats-Aggregat pro Produkt auf Einkaufs-Fakten auf Verkaufs-Fakten Level 2: Zusammenführen der Ein-/Verkaufs-Aggregation mit Mengenvergleiche und Berechnungen Level 3: Basierend auf den Mengen von Level 2 werden Finanzberechnungen gemacht Level 3: Zusätzliche Berechnungen Aggregation pro Produktgruppe / Segment usw

66
Produktgruppen-Sicht
Level 4 Mv_EA_Finanz_Kum_Gruppe_Monat Produktgruppen-Sicht Finanz-Sicht / Berechnungen LFD_Bestands_Wert / Produkt / Monat LFD_Saldo / Produkt / Monat Kumulierter EK / Produkt Kumulierter VK / Produkt Kumuliertes Saldo Level 3 Mv_EA_Finanz_Kum_Monat Jahres-Sicht Bestands-/Lager-Sicht / Berechnungen LFD_Bestands_Menge / Produkt / Monat VK_Menge / Produkt / Monat EK_Menge / Produkt / Monat Kumulierte EK Menge / Produkt Kumulierte VK Menge / Produkt Mav_Einkauf_Verkauf_Diff_Jahr Mv_EA_Menge_Kum_Monat Level 2 Mav_Produkt_Monat_einkaeufe Level 1 Mav_Produkt_Monat_Verkaeufe EA: Einkauf/Verkauf Kum: kumuliert F_EINKAEUFE F_POSITION F_KAUF

67
Das Materialized View Konzept
Optionen beim Anlegen Option BUILD DEFERRED Option REFRESH FORCE ON DEMAND Option ENABLE QUIRY REWRITE Sprechende Namen wählen Definition nur auf dem untersten Level der verbundenen Dimensionen Immer COUNT() in die SELECT-Definition dbms_mview.pmarker(u.rowid) – Funktion mit einbauen Dimension-Table Definitionen einbauen
 in die SELECT-Definition. dbms_mview.pmarker(u.rowid) – Funktion mit einbauen. Dimension-Table Definitionen einbauen.")
68
Materialized View Beispiel
create MATERIALIZED VIEW Mav_Zeit_Region_Produkt_kauf BUILD DEFERRED REFRESH FORCE ON DEMAND ENABLE QUERY REWRITE as select sum(k.gesamt_wert), p.Produkt_ID, r.ort_id, z.zeit_id, COUNT(*) from F_Kauf K, d_Zeit Z, d_region R, d_produkt P where K.zeit_id = Z.zeit_id and K.ort_id = R.ort_id and K.produkt_id = p.produkt_id group by p.Produkt_ID, r.ort_id, z.zeit_id
, p.Produkt_ID, r.ort_id, z.zeit_id, COUNT(*) from F_Kauf K, d_Zeit Z, d_region R, d_produkt P. where. K.zeit_id = Z.zeit_id and. K.ort_id = R.ort_id and. K.produkt_id = p.produkt_id. group by p.Produkt_ID, r.ort_id, z.zeit_id.")
69
Dimension (Beispiel) CREATE DIMENSION d_produkt
LEVEL Produkt IS d_produkt.PRODUKT_ID LEVEL Produktgruppe IS d_produkt.PRODUKTGRP_ID LEVEL Segment is d_produkt.SEGMENT_ID LEVEL Vermittlungs_Art IS d_produkt.VERMITTL_ART_ID LEVEL Produktart IS d_produkt.PRODUKTART_ID LEVEL Kanal IS d_produkt.KANAL_ID LEVEL Alle_Produkte IS d_produkt.ALLE_PRODUKTE HIERARCHY H_Produkt_SEGment (Produkt CHILD OF Produktgruppe CHILD OF Segment CHILD OF Produktart CHILD OF Kanal CHILD OF Alle_Produkte ) HIERARCHY H_Produkt_Vermittlungs_art (Produkt CHILD OF Produktgruppe CHILD OF Vermittlungs_Art CHILD OF Produktart CHILD OF Kanal CHILD OF Alle_Produkte ) ATTRIBUTE att_Produkt LEVEL Produkt DETERMINES (d_produkt.PRODUKT, d_produkt.VK_PREIS,d_produkt.PREF_LIEFER_ID) ATTRIBUTE att_Produktgruppe LEVEL Produktgruppe DETERMINES d_produkt.PRODUKTGRUPPE ATTRIBUTE att_Segment LEVEL Segment DETERMINES d_produkt.SEGMENT ATTRIBUTE att_Vermittlungs_Art LEVEL Vermittlungs_Art DETERMINES d_produkt.VERMITTL_ART ATTRIBUTE att_Vermittlungs_Art LEVEL Produktart DETERMINES d_produkt.PRODUKTART ATTRIBUTE att_KANAL LEVEL Kanal DETERMINES d_produkt.KANAL ;
 HIERARCHY H_Produkt_Vermittlungs_art. (Produkt CHILD OF Produktgruppe CHILD OF Vermittlungs_Art CHILD OF Produktart CHILD OF Kanal CHILD OF Alle_Produkte ) ATTRIBUTE att_Produkt LEVEL Produkt DETERMINES. (d_produkt.PRODUKT, d_produkt.VK_PREIS,d_produkt.PREF_LIEFER_ID) ATTRIBUTE att_Produktgruppe LEVEL Produktgruppe DETERMINES d_produkt.PRODUKTGRUPPE. ATTRIBUTE att_Segment LEVEL Segment DETERMINES d_produkt.SEGMENT. ATTRIBUTE att_Vermittlungs_Art LEVEL Vermittlungs_Art DETERMINES d_produkt.VERMITTL_ART. ATTRIBUTE att_Vermittlungs_Art LEVEL Produktart DETERMINES d_produkt.PRODUKTART. ATTRIBUTE att_KANAL LEVEL Kanal DETERMINES d_produkt.KANAL. ;")
70
Data Warehouse Technik im Fokus
Themenübersicht Data Warehouse Technik im Fokus Ausgangssituation Architekturüberlegungen Startpunkt Anwender Namensregelungen Das physische Modell Verteilung auf Schichten Schlüssel und Indizierung Compression Partitionierung Statistiken Storage-Bedarf Materialized Views Die Abfragen und die erreichten Kennzahlen

71
Umsatz pro Segment UMSATZ SEGMENT ---------- ----------------------
Select sum(kp.vk_wert) Umsatz, p.segment from f_position kp, d_produkt p where p.produkt_id = kp.produkt_id group by p.segment; UMSATZ SEGMENT Erstellungsleistung Baumarktware Buergschaft Finanzgeschaeft IT-Ware Darlehensvermittlung Planungsleistung
 Umsatz, p.segment from f_position kp, d_produkt p where p.produkt_id = kp.produkt_id group by p.segment; UMSATZ SEGMENT Erstellungsleistung Baumarktware Buergschaft Finanzgeschaeft IT-Ware Darlehensvermittlung Planungsleistung.")
72
Top 3 Produkte pro Segment
select * from (select rank() over (partition by p.segment order by sum(kp.vk_wert) desc ) as rangfolge, p.produkt, p.segment, round(sum(kp.vk_wert),0) as umsatz from f_position_partition kp, d_produkt p where p.produkt_id = kp.produkt_id group by p.segment,p.produkt order by p.segment) where rangfolge < 4 RANGFOLGE PRODUKT SEGMENT UMSATZ 1 Universal_Wagenheber Baumarktware 2 Bohrmaschine 800 Watt Baumarktware 3 Duschbecken Baumarktware 1 Absicherungsbuergschaft Buergschaft 1 Kapitalvermittlung Darlehensvermittlung 1 Bauleitung Erstellungsleistung 2 Elektorarbeiten Erstellungsleistung 3 Maurerarbeiten Erstellungsleistung 1 Investitionsdarlehen Finanzgeschaeft 2 Hyothekendarlehen Finanzgeschaeft 3 Kleinkredit Finanzgeschaeft 1 GRX_GRUMOR IT-Ware 2 SUN_AZOR_BIG IT-Ware 3 XT_MM IT-Ware 1 Architektenplan Planungsleistung 2 Statikplan Planungsleistung
 over (partition by p.segment order by sum(kp.vk_wert) desc ) as rangfolge, p.produkt, p.segment, round(sum(kp.vk_wert),0) as umsatz. from. f_position_partition kp, d_produkt p. where. p.produkt_id = kp.produkt_id. group by p.segment,p.produkt. order by p.segment) where rangfolge < 4. RANGFOLGE PRODUKT SEGMENT UMSATZ Universal_Wagenheber Baumarktware Bohrmaschine 800 Watt Baumarktware Duschbecken 80 Baumarktware Absicherungsbuergschaft Buergschaft Kapitalvermittlung Darlehensvermittlung Bauleitung Erstellungsleistung Elektorarbeiten Erstellungsleistung Maurerarbeiten Erstellungsleistung Investitionsdarlehen Finanzgeschaeft Hyothekendarlehen Finanzgeschaeft Kleinkredit Finanzgeschaeft GRX_GRUMOR IT-Ware SUN_AZOR_BIG IT-Ware XT_MM IT-Ware Architektenplan Planungsleistung Statikplan Planungsleistung")
73
Verhältnis Handelsware / Vermittlungsleistung
Select sum(kp.vk_wert) Umsatz_pro_Prod_Art, p.produktart from f_position kp, d_produkt p where p.produkt_id = kp.produkt_id group by p.produktart UMSATZ_PRO_PROD_ART PRODUKTART Vermittlung Handelsware
 Umsatz_pro_Prod_Art, p.produktart from f_position kp, d_produkt p where p.produkt_id = kp.produkt_id group by p.produktart. UMSATZ_PRO_PROD_ART PRODUKTART Vermittlung Handelsware.")
74
Weitere Kennzahlen (Ausschnitt) (Marketing)
Kunden-Mengenverhältnis Privat-Kunden Firmen-Kunden Umsatz-Verhältnis Privat-Kunden Firmen-Kunden Verhältnis Umsatz mit und ohne Kundenkarte select count(status), status from d_kunde group by status; select sum(ka.GESAMT_WERT) Umsatz, kd.kundenkarte * from f_kauf ka, d_kunde kd where ka.kunden_id = kd.kunden_id group by kd.kundenkarte select round(sum(ka.VK_WERT),0) Umsatz, p.segment from f_position ka, d_Produkt P where ka.produkt_id = p.produkt_id group by p.segment * order by umsatz
, status from d_kunde group by status; select sum(ka.GESAMT_WERT) Umsatz, kd.kundenkarte * from f_kauf ka, d_kunde kd where ka.kunden_id = kd.kunden_id group by kd.kundenkarte. select round(sum(ka.VK_WERT),0) Umsatz, p.segment from f_position ka, d_Produkt P where ka.produkt_id = p.produkt_id group by p.segment * order by umsatz.")
75
Bestell- und Liefervorgänge (Buchhaltung)
SQL> select * from (select count(kauf_id) Anz_Lieferungen from f_lieferung), (select sum(Gesamt_wert) Lieferwert from f_lieferung), (select sum(Lieferkosten) Kosten_Lieferungen from f_lieferung), (select count(kauf_id) Anz_Positionen from f_position), (select count(kauf_id) Anz_Kaeufe from f_kauf), (select count(kauf_id) Anz_Lieferfreie_Kaeufe from f_kauf where produkt_id != 0), (select count(*) Anz_Stornos from (select distinct Kauf_ID, Positions_ID from f_storno)), (select sum(p.VK_Wert) Wert_Stornos from f_position p,f_storno s where p.kauf_id = s.kauf_id and p.position_id = s.positions_id) ANZ_LIEFERUNGEN LIEFERWERT KOSTEN_LIEFERUNGEN ANZ_POSITIONEN ANZ_KAEUFE ANZ_LIEFERFREIE_KAEUFE ANZ_STORNOS WERT_STORNOS
 Anz_Lieferungen from f_lieferung), (select sum(Gesamt_wert) Lieferwert from f_lieferung), (select sum(Lieferkosten) Kosten_Lieferungen from f_lieferung), (select count(kauf_id) Anz_Positionen from f_position), (select count(kauf_id) Anz_Kaeufe from f_kauf), (select count(kauf_id) Anz_Lieferfreie_Kaeufe from f_kauf where produkt_id != 0), (select count(*) Anz_Stornos. from. (select distinct Kauf_ID, Positions_ID from f_storno)), (select sum(p.VK_Wert) Wert_Stornos. from f_position p,f_storno s. where p.kauf_id = s.kauf_id and p.position_id = s.positions_id) ANZ_LIEFERUNGEN LIEFERWERT KOSTEN_LIEFERUNGEN ANZ_POSITIONEN ANZ_KAEUFE ANZ_LIEFERFREIE_KAEUFE ANZ_STORNOS WERT_STORNOS")
76
Umsatz, Einkauf, Gewinn pro Produkt Controlling
select a.Produkt,a.Umsatz_pro_Prod,b.einkauf_pro_Prod, (a.Umsatz_pro_Prod-b.einkauf_pro_Prod) Gewinn_pro_Prod from (select round(sum(kp.vk_wert),0) Umsatz_pro_Prod, p.produkt Produkt from f_position kp, d_produkt p where p.produkt_id = kp.produkt_id group by p.produkt) a, (select round(sum(e.menge*e.ek_preis),0) einkauf_pro_Prod, p.produkt Produkt from f_einkaeufe e, d_produkt p where p.produkt_id = e.produkt_id group by p.produkt) b where a.produkt = b.produkt order by a.Umsatz_pro_Prod PRODUKT UMSATZ_PRO_PROD EINKAUF_PRO_PROD GEWINN_PRO_PROD Luesterklemmen 1, Muffe 15mm Reinigungstuecher Eimer_10l Sitzauflage Schrauben_M Schrauben_M Bindeseil
 Gewinn_pro_Prod. from (select round(sum(kp.vk_wert),0) Umsatz_pro_Prod, p.produkt Produkt. from f_position kp, d_produkt p. where p.produkt_id = kp.produkt_id. group by p.produkt) a, (select round(sum(e.menge*e.ek_preis),0) einkauf_pro_Prod, p.produkt Produkt. from f_einkaeufe e, d_produkt p. where p.produkt_id = e.produkt_id. group by p.produkt) b. where a.produkt = b.produkt. order by a.Umsatz_pro_Prod. PRODUKT UMSATZ_PRO_PROD EINKAUF_PRO_PROD GEWINN_PRO_PROD Luesterklemmen 1, Muffe 15mm Reinigungstuecher Eimer_10l Sitzauflage Schrauben_M Schrauben_M Bindeseil")
77
DATA WAREHOUSE

Ähnliche Präsentationen



>")

 U N I V E R S I T Ä T H A M B U R G November 2011.>")
 U N I V E R S I T Ä T H A M B U R G November 2011.>")
Media Landesanstalt für Kommunikation Baden-Württemberg (LFK) Landeszentrale für Medien und Kommunikation.>")






![IS: Datenbanken, © Till Hänisch 2000 CREATE TABLE Syntax: CREATE TABLE name ( coldef [, coldef] [, tableconstraints] ) coldef := name type [länge], [[NOT]NULL],](/1/649894/big_thumb.jpg "IS: Datenbanken, © Till Hänisch 2000 CREATE TABLE Syntax: CREATE TABLE name ( coldef [, coldef] [, tableconstraints] ) coldef := name type [länge], [[NOT]NULL],>")




