Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Marcel Riedel, Marcus Zelend, Danny Christl
Clustertools Marcel Riedel, Marcus Zelend, Danny Christl

2
Aufgabenstellung Recherche von Tools für einen massiv-parallelen Clusterrechner

3
Was ist ein Cluster? Vernetzung mehrerer Einzelrechner
Knoten meist über schnelles Netz verbunden erscheinen in vielen Fällen nach außen als ein einziger Rechner Zweck des Clusterings: Erhöhung der Rechenkapazität Erhöhung der Verfügbarkeit

4
Homogene vs. heterogene Cluster
Homogene Cluster: gleiche Hardware gleiches Betriebssystem auf allen Knoten Heterogene Cluster: Es kommen Knoten mit unter- schiedlicher Hardware und/oder unterschiedlichen Betriebssystemen zum Einsatz

5
Begriffe: MPI „Message Passing Interface“
Programmierschnittstelle für den Nachrichtenaustausch zwischen Knoten eines verteilten Systems mehrere Prozesse arbeiten an einem Problem und schicken sich dabei gegenseitig Nachrichten Nachrichtenaustausch z.B. über TCP oder gemeinsamen Hauptspeicher Implementierungen z.B. in C++, Java, Python

6
Begriffe: SMP „Symmetric MultiProcessing“
Multiprozessor-Computerarchitektur 2 oder mehrere identische CPUs teilen sich gemeinsamen Hauptspeicher für massiv-parallele Cluster ungeeignet andere Multiprozessorarchitekturen: NUMA (Non-Uniform Memory Access) ASMP (Asymmetric Multiprocessing)
 ASMP (Asymmetric Multiprocessing)")
7
Begriffe: SSI „Single System Image“

8
High Performance Computing Cluster
Hohe Rechenleistung durch gemeinsame, parallele Verarbeitung zu verarbeitender Jobs durch die Knoten Rechenleistung des Clusters = Summe der Leistung der einzelnen Knoten Schnellster Cluster: BCN Supercomputer-Center, Spanien Knoten bringen 62,6TFLOPS Schnellster Cluster IBM BladeCenter JS21 Cluster Platz 5 auf der TOP500 (500 schnellsten Rechnersysteme) Zum Vergleich: IBM BlueGene L Supercomputer im Lawrence Livermore National Lab, USA bringt 280,6TFLOPS und besitzt Das schnellste deutsche Clustersystem steht im Forschungszentrum Jülich und besitzt eine Leistung von 37,3TFLOPS, was weltweit Platz 13 bedeutet. Zum Vergleich – ein derzeit gängiges Desktopsystem hat eine Maximalleistung < 10GFLOPS
 Zum Vergleich: IBM BlueGene L Supercomputer im Lawrence Livermore National Lab, USA bringt 280,6TFLOPS und besitzt Das schnellste deutsche Clustersystem steht im Forschungszentrum Jülich und besitzt eine Leistung von 37,3TFLOPS, was weltweit Platz 13 bedeutet. Zum Vergleich – ein derzeit gängiges Desktopsystem hat eine Maximalleistung < 10GFLOPS.")
9
High Performance Computing Cluster
Verwendung: Berechnung, Modellierung und Simulation komplexer Systeme z.B. Wettervorhersage, Klimamodelle Verarbeitung riesiger Messdatenmengen Erstellung komplexer 3D-Modelle und Animationsfilme

10
Hardwarekonzept Homogener Knotenaufbau
Ein Master-Node und beliebig viele Compute-Nodes Distributed Memory-Architektur Einzelnen Knoten enthalten nur essentielle Komponenten Vernetzung über Hochgeschwindigkeitsnetz z.B. Inifiniband Homogen gleichartiger Aufbau, erleichtert Administration und geringere Störanfälligkeit Master-Node kann seperater Rechner sein, der mit dem Cluster vernetzt ist oder wenn Compute-Nodes entsprechend ausgestattet wird einer zum Master-Node gemacht Komponenten Neben Board + CPU + RAM + Netzwerkkarte(n) maximal noch Festplatte theoretisch Betrieb ohne Graka möglich Vernetzung je größer die Knotenzahl desto schneller muss das Netz sein sonst Flaschenhals; aber: aufgrund Distributed Memory geringere Datentransfers
 maximal noch Festplatte theoretisch Betrieb ohne Graka möglich. Vernetzung je größer die Knotenzahl desto schneller muss das Netz sein sonst Flaschenhals; aber: aufgrund Distributed Memory geringere Datentransfers.")
11
Softwarekonzept Als OS fast ausschließlich Linux im HPC-Bereich
Dateisystem NFS für kleine und mittlere Cluster CXFS, Lustre, Polyserve für große Cluster Boot-From-LAN-Konzept für Compute-Nodes Clustertools übernehmen Verwaltung Linux hohe Kompatibilität im HPC-Bereich, Spezielle Serverdistributionen nicht nötig Derzeit gängig: Kernel 2.6 mit voller 64Bit-Unterstützung Boot-From-LAN: Compute-Nodes erhalten Boot-Image mit dem OS vom Master-Node über das Netzwerk (Voraussetzung: PXE-fähige Netzwerkkarte sendet beim Booten ein Broatcast ans Netzwerk) Clustertools übernehmen Power-Management, Zu- und Abschalten einzelner Knoten, Suche nach neuen Knoten, Job-Management mit Queueing usw.
 Clustertools übernehmen Power-Management, Zu- und Abschalten einzelner Knoten, Suche nach neuen Knoten, Job-Management mit Queueing usw.")
12
Softwarekonzept Clustertools übernehmen Verwaltung Power-Management
Automatische Suche nach neuen Knoten Job-Management, Batch-Queue-System MPI-Implementierung Power-Management Schonendes Anschalten des Clusters zur Vermeidung von Stromspitzen, Zuschalten von Knoten bei Bedarf Batch-Queue-System stellt sicher, dass die einzelnen Knoten gleichmäßig und konstant mit Arbeit versorgt werden MPI – Programmierschnittstelle für paralleles Rechnen und den Nachrichtenaustausch zwischen den Knoten auf verteilten Computersystemen

13
Funktionsweise Dekomposition: Zerlegung komplexer Aufgaben in Teilaufgaben Job-Management-System auf Master-Node erledigt Zuteilung und Queueing der Teilaufgaben für die Compute-Nodes Abarbeitung der Teilaufgaben auf den Compute-Nodes Zusammenfügen der Ergebnisse auf dem Master-Node Kommunikation zwischen den einzelnen Knoten erfolgt über MPI Dekomposition kann durch spezielle Software erledigt werden oder von vorn herein über entsprechende parallele Programmierung Queueing-Arten eine Queue für alle Rechner-Knoten und/oder eine Queue je Rechner-Knoten, nach den bekannten Queueing-Verfahren (FCFS, RoundRobin, Shortest Job Next) Kommunikation z.B. Austausch von Zwischenergebnissen
 Kommunikation z.B. Austausch von Zwischenergebnissen.")
14
Hochverfügbarkeits-cluster (HA-Cluster)
Stellen ständig Daten und Dienste zur Verfügung 2 Arten: Aktiv-/Aktiv-Cluster Aktiv-/Passiv-Cluster Festplatten – und Serverausfälle minimieren Zusätzliche Rechner im System Keine Verringerung der Systemleistung, dafür hohe Kosten und etwas längere Ausfallzeit

15
Verwendung in Servern, gekoppelt mit einem NAS (Network Attached Storage ), die Dienste (Web-, Datenbank-, FTP- und Mail-Server ) Ausfall Internetpräsenz bedeutet: hoher wirtschaftlicher Schaden und Imageverlust

16
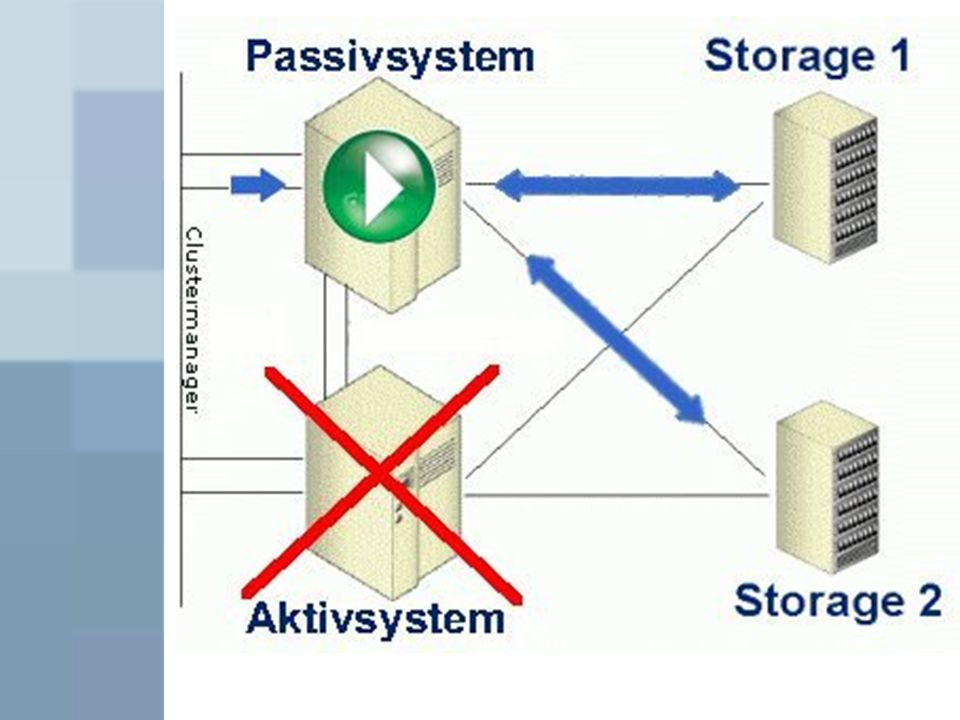
Aktiv-/ Passiv-Cluster
Ersatzknoten ohne Funktion (StandBy) Bei Ausfall: Deaktivierung des Hauptsystems (Reparatur) und Aktivierung des Ersatzsystems Clustermanager verteilt Aufgaben neu
 Bei Ausfall: Deaktivierung des Hauptsystems (Reparatur) und Aktivierung des Ersatzsystems. Clustermanager verteilt Aufgaben neu.")
18
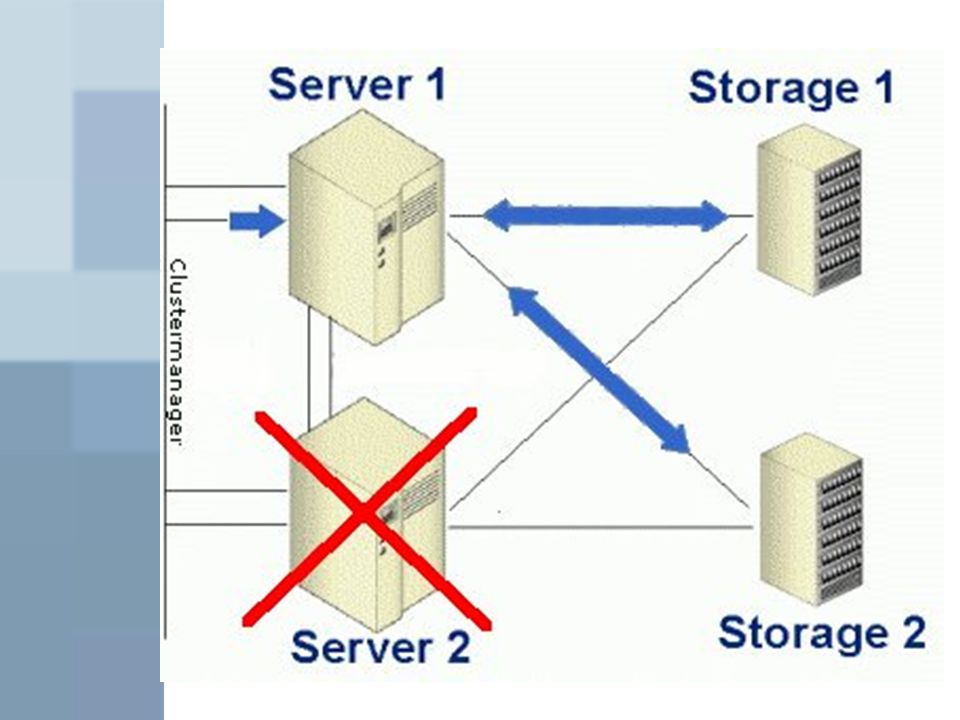
Aktiv-/ Aktiv-Cluster
Alle Knoten teilen sich Aufgabe Bei Ausfall: Entfernen des defekten Rechners logisch aus dem System Restliche Knoten teilen sich die Aufgaben des Ausfallrechners, gesteuert durch den Clustermanager (evtl. Neustarten der Prozesse) Verringerung der Systemleistung, aber sehr kleine Ausfallzeit
 Verringerung der Systemleistung, aber sehr kleine Ausfallzeit.")
20
Clustermanager für HA-Cluster
Microsoft Cluster Service Veritas Cluster Manager Red Hat Cluster Manager (Linux)
")
21
Shared Memory

22
Shared Memory Alle Knoten greifen auf gemeinsamen Speicher zu
Verbindungsnetz stellt nötige Protokolle für gleichzeitigen Speicherzugriff verschiedener Knoten bereit Zugriffsweise aller Knoten ist identisch Latenzzeit stets gleich Verbindungsnetzwerk wird Flaschenhals bei hoher Knotenzahl Kann über PVM als ein großer Parallelrechner angesprochen werden Bei einem Shared Memory System greifen alle Knoten auf einen gemeinsamen Arbeitsspeicherbereich zu. Ein Verbindungsnetzwerk stellt die Mittel zur Verfügung, die nötig sind um Daten aus dem gemeinsamen Speicher zu den Prozessoren zu übertragen. Gewöhnlich ist dabei die Zugriffsweise aller Knoten auf den Speicher identisch, sodass die Latenz der Speicherzugriffe für alle Knoten gleich ist. Mit steigender Knotenanzahl erweist sich jedoch selbst das schnellste Verbindungsnetzwerk als Flaschenhals, sodass für Cluster mit hoher Knotenzahl eine Architektur mit Distributed Memory zu favorisieren ist. Der Vorteil: Bei Verwendung von PVM kann diese Cluster-Architektur als ein großer Parallelrechner angesprochen werden, sodass kein großer Programmieraufwand bei der Parallelisierung von Software entsteht. (natürlich geht’s auch per MPI)
")
23
Verwendung von Shared Memory
Verwendung der Shared Memory Architektur bei: Cluster mit geringer Knotenzahl Aufgaben mit geringem Datenaufkommen Programmen, deren Parallelisierung zu aufwändig ist

24
Distributed Memory

25
Distributed Memory Jeder Knoten besitzt eigenen Arbeitsspeicher
Kein Zugriff auf „fremden“ Speicher Informationsaustausch über Nachrichten über MPI Nachteil: erhöhter Programmieraufwand, da explizites Ansprechen und Verwaltung der verteilten Ressourcen notwendig Bei Architekturen mit Distributed Memory besitzt jeder Knoten einen eigenen Arbeitsspeicher. Somit wird der Flaschenhals der Verbindung zum Speicher aufgelöst. Die einzelnen Knoten greifen nicht auf fremde Speicher zu, sondern tauschen Informationen über Prozesse mittels Nachrichten aus. Über das Netzwerk werden also nun nur noch Steuerdaten sowie Eingabe- und Ergebnisdaten transferiert. Somit eignet sich diese Architektur für Cluster mit einer hohen Knotenzahl, sodass für HPC-Cluster diese Variante zu favorisieren ist. Der Nachteil dieser Architektur ist der erhöhte Aufwand bei der Parallelisierung von Software, da die verteilten Ressourcen explizit vom Programmierer angesprochen und verwaltet werden müssen.

26
Verwendung von Distributed Memory
Verwendung der Distributed Memory Architektur bei: Cluster mit hoher Knotenzahl Aufgaben mit hohem Datenaufkommen Parallelisierte Programme bereits vorhanden bzw. Neuentwicklung

27
Beowulf-Cluster HPC-Cluster mit folgenden Eigenschaften:
Knoten sind einfache vernetzte Desktop-PCs Kommunikation über TCP/IP Betriebssystem: Linux / BSD Beowulf-Cluster ist die Bezeichnung für Cluster, die unter dem freien Betriebssystem Linux oder BSD laufen. Außerdem gibt es auch spezielle Linux-Versionen für derartige Cluster. Beowulf-Cluster zeichnen sich durch ihren Aufbau aus – sie bestehen aus gewöhnlichen, miteinander vernetzten Desktop-PCs. Diese kommunizieren über das TCP/IP-Protokoll miteinander; die Aufteilung der Aufgaben auf die einzelnen Rechner übernimmt auch hier MPI oder PVM (Parallele virtuelle Maschine – ein freies Softwarepaket für verteilte Anwendungen).
.")
28
Beowulf-Cluster

29
Vor- und Nachteile von Beowulf-Cluster
Vorteile: Problemlose Skalierbarkeit Lösen komplexer Aufgaben mit billiger COTS-Hardware Austausch defekter Rechnerknoten im laufenden Betrieb möglich Nachteile: Hoher Platzbedarf Hoher Energieverbrauch Hohe Wärmeentwicklung Vorteil dieser Cluster-Architektur bietet die problemlose Skalierbarkeit – durch Hinzufügen weiterer Rechner lässt sich Leistungsfähigkeit erhöhen. Somit lassen sich anspruchsvolle Rechenaufgaben mithilfe billiger COTS Hardware (COTS – commercial off-the-shelf – Serienprodukte) lösen; eine Anschaffung von anwendungsbezogener Hardware ist unnötig. Außerdem ist es beim Ausfall einzelner Rechnerknoten möglich, dass diese, während die anderen Knoten weiterlaufen, ausgetauscht werden können.
 lösen; eine Anschaffung von anwendungsbezogener Hardware ist unnötig. Außerdem ist es beim Ausfall einzelner Rechnerknoten möglich, dass diese, während die anderen Knoten weiterlaufen, ausgetauscht werden können.")
30
Beowulf-Cluster CLiC Die TU-Chemnitz betreibt seit dem Jahr 2000 den Beowulf-Cluster „CLiC“, welcher aus 528 Rechnerknoten, zwei Server-Rechner und einem Infrastruktur-Server-Rechner besteht. Die Rechnerknoten haben die folgende Konfiguration: Intel Pentium III, 800 MHz ASUS-Mainboard CUBX 512 MB SDRAM PC100 Festplatte Seagate Barracuda II 20,4 GB Floppy Grafikkarte ATI 3D Carger 4MB 2 x Netzwerkkarte Level One FNC 0108TX Tabelle 2: Konfiguration eines CLiC-Rechnerknotens Im CLiC sind drei Netzwerke vorhanden, wobei zwei davon die Knoten verbinden und eines ein internes Netzwerk darstellt, welches hauptsächlich für die Steuerung der Infrastruktur (u.a. der Stromzufuhr) der einzelnen Knoten reserviert ist. Die beiden "Knotennetzwerke" sind ein für die Nutzer zugängliches Servicenetzwerk und ein nur innerhalb des Clusters nutzbares Kommunikationsnetzwerk. Somit ist es möglich, dass die Knoten trotz hohem Datenaufkommen für die Systemverwaltung problemlos zumindest auf einem Netzwerk kommunizieren sollten
 der einzelnen Knoten reserviert ist. Die beiden Knotennetzwerke sind ein für die Nutzer zugängliches Servicenetzwerk und ein nur innerhalb des Clusters nutzbares Kommunikationsnetzwerk. Somit ist es möglich, dass die Knoten trotz hohem Datenaufkommen für die Systemverwaltung problemlos zumindest auf einem Netzwerk kommunizieren sollten.")
31
OpenMosix (ClusterKnoppix)
")
33
Kernelpatch für Linux Userland Tools (zur Administration) Arbeitet als SSI-Cluster (Single System Image) Clusterrechner und normale Personal- Computer können verwendet werden Betrieb ohne HDD möglich (PXE-fähig) Kein Master oder Serverrechner (Nodes gleichberechtigt) Auslastung erreicht durch regelmäßige Multicast-Messages Erscheint für den Nutzer als Multi-CPU- System
 Kein Master oder Serverrechner (Nodes gleichberechtigt) Auslastung erreicht durch regelmäßige Multicast-Messages. Erscheint für den Nutzer als Multi-CPU- System.")
34
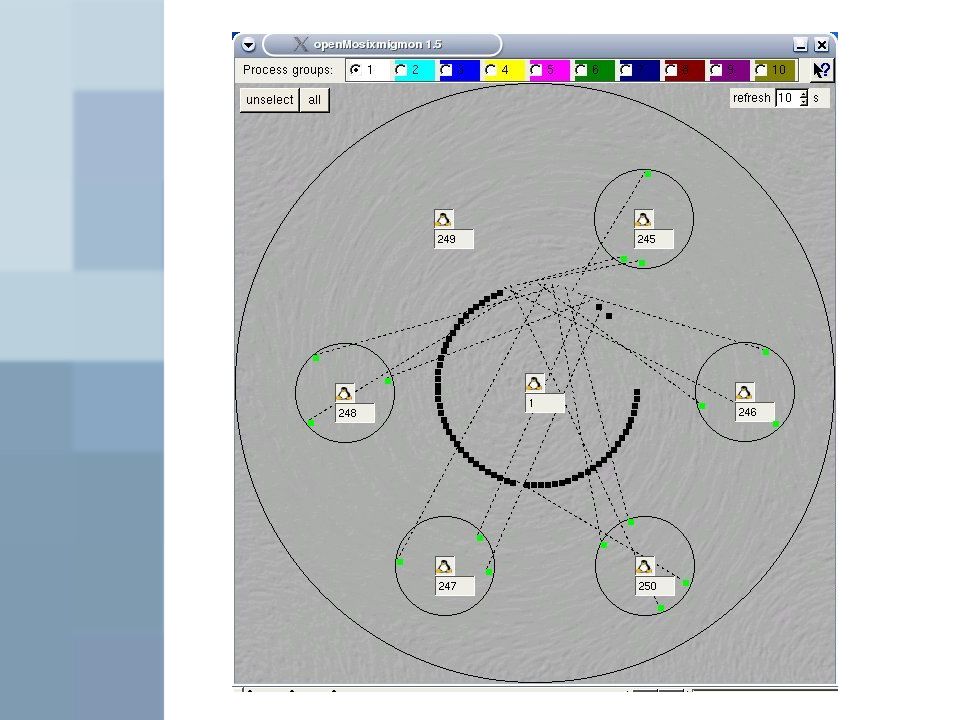
Prozessbearbeitung: Prozess wird auf einem System gestartet (Home Node) Prozess überschreitet Lastgrenze (einstellbar) Rechner prüft auf nicht ausgelastete Nodes im Cluster Gefunden-> Migration des Prozesses auf den gefunden Rechner Speicherseiten des Home Nodes werden kopiert und über das Netz an den gefundenen Rechner geschickt Kernel kopiert Seiten in den RAM

35
Prozess wird auf Rechner fortgesetzt
Auf Home Node bleibt Deputy (Sheriff) zurück -> zum Abfangen der Systemaufrufe des Prozesses
 zurück -> zum Abfangen der Systemaufrufe des Prozesses.")
37
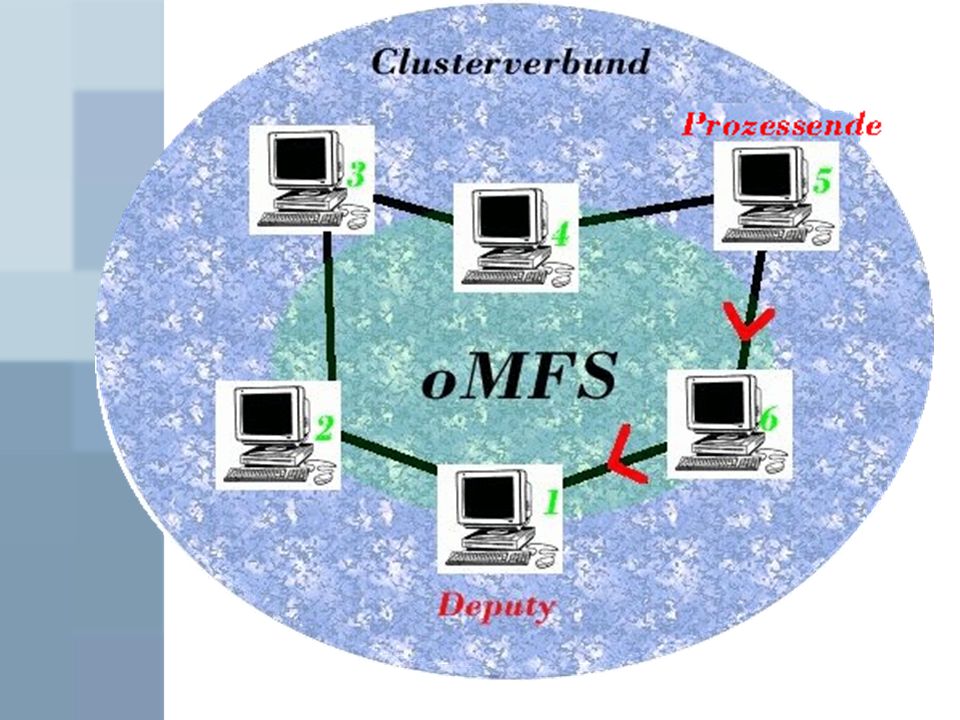
oMFS (openMosix File-System)
Prozesse mit ständigen Zugriff auf Daten müssten jedes Mal auf den Home Node zurück migriert werden Starke Zunahme der Netzwerklast und starke Performanceeinbußen oMFS macht Daten clusterweit bekannt In aktueller openMosix-Version ersetzt durch GFS (Global File System )
")
38
Fazit: Ungeeignet für vorherrschendes System, da zu viele Knoten
Unüberschaubar Starke Performanceeinbußen durch erhöhte Netzwerklast (Multicast- Messages)
")
39
Kerrighed SSI-Betriebssystem für Cluster (Modulpaket, Linux-Kernelpatch) Verbund herkömmlicher PCs zu symmetrischem Multiprozessor- system (SMP) speziell für wissenschaftliche numerische Berechnungen

40
Kerrighed Clusterweites Prozessmanagment
Unterstützung für clusterweites Shared Memory Cluster File System Transparentes Prozess- Checkpointing Hohe Verfügbarkeit der User- Anwendungen Einstellbare SSI-Features

41
Kerrighed Fazit: Systeme mit SMP-Architektur sind für massiv-parallele Rechner (mehr als 16 CPUs) nicht geeignet Online-Dokumentation wenig aussagekräftig

42
ParallelKnoppix

43
ParallelKnoppix vor allem für Cluster-Neulinge geeignet (ausführliches Tutorial) Einsatz von Live-CD, Master- Knoten auch in virtueller Maschine keine Software-Installation auf den Client-Knoten nötig mehrere MPI-Implementierungen (openMP, LAM-MPI, MPICH)
")
44
OSCAR Open Source Cluster Application Resources
Projekt der OpenClusterGroup Sammlung von Softwarepakten zum einfachen Aufbau von Clustern auf Basis von PVM / MPI mit umfangreichen Werkzeugen für Clustermanagement und Analyse OSCAR steht für Open Source Cluster Application Resources. Es ist eine Sammlung von Softwarepaketen zum einfachen Aufbau von Clustern auf Basis von PVM/MPI. Sie enthält umfangreiche Werkzeuge zum Clustermanagement sowie zur Analyse. OSCAR ist ein Projekt der Open Cluster Group, welche versucht, die Entwicklungen rund um freie Software für den Clustereinsatz zu koordinieren und neue Entwicklungen anzustoßen. Es hat zum Ziel, die Ressourcen für einen einfach zu installierenden, einfach zu wartenden und einfach zu gebrauchenden Cluster bereit zu stellen. OSCAR implementiert die aktuellen „best-knownpractices“ für High-Performance Cluster. OSCAR ist für verschiedene Linux-Distributionen benutzbar. Das Paket besteht aus RPMs, Perl-Scripts, Bibliotheken und einigen Werkzeugen, die benötigt werden, um einen Cluster mittlerer Größe zu erstellen. Die Clustergröße sollte idealerweise zwischen vier und 100 Knoten liegen. Der große Vorteil von OSCAR besteht darin, dass man nicht selbst alle Tools im Internet zusammensuchen muss. OSCAR wird ständig weiterentwickelt, so dass man nicht mit veralteten Tools zurückgelassen wird. OSCAR ist für all diejenigen das perfekte Tool, die nicht eine spezielle Clusterinstallation oder mehr als 100 Knoten betreiben möchten. Es ermöglicht einen relativ einfachen Einstieg ins Cluster-Computing, auch weil es die Fähigkeit besitzt, in heterogenen Umgebungen zu laufen, da PVM mitgeliefert wird.

45
OSCAR Implementierung der aktuellen „best- known practices“ für HPC-Cluster ständige Weiterentwicklung Nutzbar unter verschiedenen Linuxdistributionen Geeignet für nichtspezialisierte HPC- Cluster mit Knotenanzahl zwischen 4 und 100 Durch PVM auch in heterogenen Umgebungen lauffähig OSCAR steht für Open Source Cluster Application Resources. Es ist eine Sammlung von Softwarepaketen zum einfachen Aufbau von Clustern auf Basis von PVM/MPI. Sie enthält umfangreiche Werkzeuge zum Clustermanagement sowie zur Analyse. OSCAR ist ein Projekt der Open Cluster Group, welche versucht, die Entwicklungen rund um freie Software für den Clustereinsatz zu koordinieren und neue Entwicklungen anzustoßen. Es hat zum Ziel, die Ressourcen für einen einfach zu installierenden, einfach zu wartenden und einfach zu gebrauchenden Cluster bereit zu stellen. OSCAR implementiert die aktuellen „best-knownpractices“ für High-Performance Cluster. OSCAR ist für verschiedene Linux-Distributionen benutzbar. Das Paket besteht aus RPMs, Perl-Scripts, Bibliotheken und einigen Werkzeugen, die benötigt werden, um einen Cluster mittlerer Größe zu erstellen. Die Clustergröße sollte idealerweise zwischen vier und 100 Knoten liegen. Der große Vorteil von OSCAR besteht darin, dass man nicht selbst alle Tools im Internet zusammensuchen muss. OSCAR wird ständig weiterentwickelt, so dass man nicht mit veralteten Tools zurückgelassen wird. OSCAR ist für all diejenigen das perfekte Tool, die nicht eine spezielle Clusterinstallation oder mehr als 100 Knoten betreiben möchten. Es ermöglicht einen relativ einfachen Einstieg ins Cluster-Computing, auch weil es die Fähigkeit besitzt, in heterogenen Umgebungen zu laufen, da PVM mitgeliefert wird.

46
Komponenten von OSCAR C3 – Cluster Command Control LAM/MPI PVM
Maui PBS Scheduler OpenSSH OpenSSL SIS – System Installation Suite

47
C3 – Cluster Command Control
Interface zum Management von Cluster Enthält Kommandozeilen-Tools zur schnellen, effektiven Cluster- Verwaltung C3 ist ein Interface zum Management von Cluster. Es wurde ursprünglich zur Verwaltung des HighTORC-Linux-Clusters (Oak Ridge) entwickelt. Es enthält die folgenden kommandozeilenbasierte Tools, die das Cluster-Management effektiver und schneller machen sollen Das aktuelle Release C3 V4.x unterstützt Multithreading und wurde so konzeptioniert, dass es auch größere Cluster effektiv verwalten kann.
 entwickelt. Es enthält die folgenden kommandozeilenbasierte Tools, die das Cluster-Management effektiver und schneller machen sollen. Das aktuelle Release C3 V4.x unterstützt Multithreading und wurde so konzeptioniert, dass es auch größere Cluster effektiv verwalten kann.")
48
LAM/MPI LAM – eine spezielle MPI- Implementierung
Unterstützt MPI V1.2 und Teile von MPI V2 sowie aktives Debugging Volle Kompatibilität zu anderen MPI- Implementierungen Unterstützte Funktionen: Checkpoint/Restart, High Performance Communication, Integration von PBS, Easy Application Debugging LAM ist eine MPI-Implementierung (MPI – Message Passing Interface) zur Entwicklung von Programmen für Clustersysteme. Es unterstützt MPI V1.2 vollständig und große Teile von MPI V2. Zusätzlich wird noch Debugging ermöglicht. Mit LAM entwickelte Programme sind außerdem voll kompatibel zu anderen MPI-Implementierungen. Folgende Funktionen werden von LAM unterstützt (Auswahl): Checkpoint/Restart Anwendungen können angehalten werden und die aktuellen Daten auf Festplatte ausgelagert werden, sodass sie zu einem späteren Zeitpunkt fortgesetzt werden können High Performance Communication Die Kommunikation zwischen den Knoten kann so eingestellt werden, dass sie eine geringe Latenzzeit bietet und mit einem Minimum an Overhead auskommt – und das bei Geschwindigkeiten im GigabitEthernet-Bereich. Integration with PBS (Portable Batch System) Mithilfe von OpenPBS bzw. PBS Pro können die Jobs entsprechend einer vorherigen Priorisierung in eine oder mehrere Job-Queues aufgenommen werden. Dafür stehen verschiedene Algorithmen bereit. Easy Application Debugging LAM bietet Unterstützung für parallel arbeitende Debugger, selbst für komplizierte MPI-Anwendungen.
 zur Entwicklung von Programmen für Clustersysteme. Es unterstützt MPI V1.2 vollständig und große Teile von MPI V2. Zusätzlich wird noch Debugging ermöglicht. Mit LAM entwickelte Programme sind außerdem voll kompatibel zu anderen MPI-Implementierungen. Folgende Funktionen werden von LAM unterstützt (Auswahl): Checkpoint/Restart Anwendungen können angehalten werden und die aktuellen Daten auf Festplatte ausgelagert werden, sodass sie zu einem späteren Zeitpunkt fortgesetzt werden können. High Performance Communication Die Kommunikation zwischen den Knoten kann so eingestellt werden, dass sie eine geringe Latenzzeit bietet und mit einem Minimum an Overhead auskommt – und das bei Geschwindigkeiten im GigabitEthernet-Bereich. Integration with PBS (Portable Batch System) Mithilfe von OpenPBS bzw. PBS Pro können die Jobs entsprechend einer vorherigen Priorisierung in eine oder mehrere Job-Queues aufgenommen werden. Dafür stehen verschiedene Algorithmen bereit. Easy Application Debugging LAM bietet Unterstützung für parallel arbeitende Debugger, selbst für komplizierte MPI-Anwendungen.")
49
Weitere Komponenten SIS – System Installation Suite
Ermöglicht automatisierte Installation und Konfiguration von HPC-Cluster Nachträgliche Änderung der Einstellungen leicht möglich PVM (Parallel Virtual Machine) Alternative zu MPI Parallelrechner wird emuliert Maui PBS Scheduler Erweiterter Job-Scheduler mit verschiedene Queue-Richtlinien, dynamische Job-Prioritäten Gleichbereichtigungsalgorithmen PVM – Parallel Virtual Machine PVM stellt eine Alternative zu MPI dar. Mithilfe von PVM kann ein Cluster als ein Parallelrechner verwendet werden. Diese Umgebung wird von PVM emuliert und setzt diese auf die Cluster-Architektur auf. Maui PBS Scheduler Maui ist ein erweiterter Job-Scheduler für Cluster und Supercomputer. Er ist so optimiert und konfigurierbar, dass sich verschiedene Queue-Richtlinien, dynamische Job-Prioritäten und Gleichberechtigungsalgorithmen einstellen lassen. Das Job-Management wird wie folgt durchgeführt: OpenSSH OpenSSH ist eine freie SSH-Implementierung, welche durch Verschlüsselung eine sichere Kommunikation in offenen Netzwerken, wie z.B. TCP/IP bietet. OpenSSL OpenSSL ist ein freiverfügbares Toolkit, mit dem durch Implementierung von SSL- (Secure Sockets Layer) und TLS- (Transport Layer Security) Protokollen sowie einer allgemeinen Kryptografie-Bibliothek ein sicherer Datentransfer möglich wird. SIS – The System Installation Suite SIS eine Toolsammlung, die eine automatisierte Installation und Konfiguration von HPC-Clustern ermöglicht. Auch Aktualisierungen sind mittels SIS leicht möglich.
 Alternative zu MPI. Parallelrechner wird emuliert. Maui PBS Scheduler. Erweiterter Job-Scheduler mit. verschiedene Queue-Richtlinien, dynamische Job-Prioritäten. Gleichbereichtigungsalgorithmen. PVM – Parallel Virtual Machine PVM stellt eine Alternative zu MPI dar. Mithilfe von PVM kann ein Cluster als ein Parallelrechner verwendet werden. Diese Umgebung wird von PVM emuliert und setzt diese auf die Cluster-Architektur auf. Maui PBS Scheduler Maui ist ein erweiterter Job-Scheduler für Cluster und Supercomputer. Er ist so optimiert und konfigurierbar, dass sich verschiedene Queue-Richtlinien, dynamische Job-Prioritäten und Gleichberechtigungsalgorithmen einstellen lassen. Das Job-Management wird wie folgt durchgeführt: OpenSSH OpenSSH ist eine freie SSH-Implementierung, welche durch Verschlüsselung eine sichere Kommunikation in offenen Netzwerken, wie z.B. TCP/IP bietet. OpenSSL OpenSSL ist ein freiverfügbares Toolkit, mit dem durch Implementierung von SSL- (Secure Sockets Layer) und TLS- (Transport Layer Security) Protokollen sowie einer allgemeinen Kryptografie-Bibliothek ein sicherer Datentransfer möglich wird. SIS – The System Installation Suite SIS eine Toolsammlung, die eine automatisierte Installation und Konfiguration von HPC-Clustern ermöglicht. Auch Aktualisierungen sind mittels SIS leicht möglich.")
50
Maui PBS Scheduler

51
Beurteilung von OSCAR geeignet für vorliegendes System
Enthält alle nötigen Tools zur Einrichtung, Wartung und Betrieb Aber: Clustergröße bereits am oberen Ende der von OSCAR unterstützten Cluster Keine Angabe zu Power Management, evtl. Zusatztools nötig

52
Fazit Keine zufriedenstellende Lösung gefunden
für spezielle Problem ist eine “Massen”-Lösung im OpenSource/Freeware-Bereich unmöglich Anpassung von Clustersoftware über kommerzielle Firmen stellt sich als beste Lösung heraus

Ähnliche Präsentationen







>")











