Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Programmierungstechnik
© Günter Riedewald Die Folien sind eine Ergänzung zur Vorlesung und nur für den internen Gebrauch konzipiert.

2
Vorbemerkungen Rolle einer Vorlesung: Grundstruktur für Selbststudium
Ermöglichung der selbständigen Nutzung der Literatur Hinweis auf Probleme und Gesamtzusammenhänge

3
Vorbemerkungen Rolle von Übungen:
Ergänzung der Vorlesung durch umfangreichere Beispiele Dialog von Übungsleiter und Student zur Beseitigung von Unklarheiten Aktive Mitarbeit als Voraussetzung der aktiven Auseinandersetzung mit dem Stoff

4
Vorbemerkungen Vorlesungshilfsmittel: Tafel
- Schreibarbeit für beide Seiten + Hören-Sehen-Schreiben in Kombination erleichtert Verständnis und Merkfähigkeit + Ableitungen besser darstellbar

5
Vorbemerkungen Folien +- Vermittlung von mehr Stoff
+- Schreibarbeit entfällt - Höherer Aufwand zur Einprägung des Stoffes

6
Vorbemerkungen Multimedia - Hoher Entwicklungs- und Wartungsaufwand
- Bisher kein Nachweis eines deutlich höheren Lerneffekts + Darstellung dynamischer Vorgänge Hier: Kombination von Tafel und Folien

7
Vorbemerkungen Literaturstudium:
Ausführliche Beschäftigung mit dem Stoff Andere Sichten Mehrmaliges Lesen: 1. Diagonal Überblick 2. Durcharbeiten gründliches Verständnis

8
Vorbemerkungen Prüfungen:
Nachweis von Wissen und Fähigkeit der aktiven Nutzung (Verstehen Wiedergabe Anwendung) Prüfungsvorbereitung führt zur Verknüpfung von Teilgebieten und mit anderen Lehrgebieten
 Prüfungsvorbereitung führt zur Verknüpfung von Teilgebieten und mit anderen Lehrgebieten.")
9
Vorbemerkungen Abschlüsse und Bedingungen:
Studiengang Informatik (Fachprüfung Praktische Informatik): 1. Sem.: schriftliche Prüfung (ca. 150 min) 2. Sem.: benoteter Leistungsnachweis 3. Sem.: mündliche Prüfung (ca. 20 min) über PT und SWT (Vor.: Benoteter Leistungsnachweis)
: 1. Sem.: schriftliche Prüfung (ca. 150 min) 2. Sem.: benoteter Leistungsnachweis. 3. Sem.: mündliche Prüfung (ca. 20 min) über PT und SWT (Vor.: Benoteter Leistungsnachweis)")
10
Vorbemerkungen Studiengang IT/TI:
1. Sem.: schriftliche Prüfung (ca. 150 min) 2. Sem.: mündliche Prüfung (ca. 30 min)
 2. Sem.: mündliche Prüfung (ca. 30 min)")
11
Vorbemerkungen Studiengang WIN/BIN: 2. Sem.: benoteter Leistungsschein
3. Sem.: mündliche Prüfung (ca. 30 min) zu PT und SWT
 zu PT und SWT.")
12
Vorbemerkungen Rolle der Theorie:
Schnelles Veralten von Wissen zu konkreten Systemen Langlebige und allgemeingültige Erkenntnisse in der Theorie Theorie als Basis (Befähigung zur) Weiterbildung
 Weiterbildung.")
13
Vorbemerkungen Theorie als Basis der Automatisierung von Prozessen der IV Schnelle Einsatzbereitschaft von Absolventen erfordert Praxiserfahrungen Realitätsnahe Ausbildung an HS schwer zu verwirklichen Ausbildung als Mix von Theorie und Praxis

14
Vorbemerkungen Rolle der Theorie nach J. Nievergelt (Informatik-Spektrum, 18(6), S , 1995) Anwendungsmethodik Problemlösungen Systemrealisierung Programmsysteme Algorithmik Programmierung Theorie abstrakte math. Fakten

15
Literatur Alagic’, S., Arbib, M.A.: The Design of Well-Structured and Correct Programs, Springer-Verlag, 1978 Appelrath, H.-J., Ludewig, J.: Skriptum Informatik - eine konventionelle Einführung, B.G. Teubner Stuttgart, 1991

16
Literatur Bauer, F.L., Goos, G.: Informatik - eine einführende Übersicht Heidelberger Taschenbücher, Sammlung Informatik, Springer-Verlag, Teile 1+2, 3. Auflage, 1982, 1984, 4. Auflage 1991 Berman, K.A., Paul, J.L.: Fundamentals of Sequential and Parallel Algorithms, PWS Publishing Company, 1997

17
Literatur Forbrig, P.: Introduction to Programming by Abstract Data Type Fachbuchverlag Leipzig, 2001 Goldschlager, L., Lister, A.: Informatik - Eine moderne Einführung, Hanser Verlag, Prentice-Hall International, 3. Auflage 1990

18
Literatur Hotz, G.: Einführung in die Informatik, B.G. Teubner Stuttgart, 1990 Kröger, F.: Einführung in die Informatik - Algorithmenentwicklung, Springer-Lehrbuch, Springer-Verlag, 1991

19
Literatur Myers, G.J.: The Art of Software Testing, Wiley-Interscience Publication 1979 oder: Methodisches Testen von Programmen, Oldenbourg Verlag, 4. Auflage, 1991 Pomberger, G.: Softwaretechnik und Modula-2, Hanser Verlag, 1984

20
Literatur Sedgewick, R.: Algorithmen, Addison-Wesley Publ. Company, 1992, Auflage Sedgewick, R.: Algorithmen in Java Addison-Wesley Publ. Comp., 2003 Sedgewick, R.: Algorithmen in C++ Addison-Wesley Publ. Comp., 2002

21
Literatur Weitere Literatur: z. B. von den Autoren Broy, Gruska, Kerner, Wilhelm Siehe auch Lehrbücher zu konkreten Programmiersprachen

22
Inhalt 1. Einleitung 2. Grundbegriffe 3. Algorithmenentwurf und Programmentwicklung 3.1 Einleitung 3.2 Programmierungstechniken 3.3 Techniken der Algorithmenentwicklung (Iteration, Rekursion, nichtdeterministische Algorithmen, Backtracking, parallele Algorithmen)
")
23
3.4 Korrektheit, Zuverlässigkeit
3.4.1 Programmteste 3.4.2 Korrektheitsbeweise (Verifikation) Deduktive Methode Model Checking 3.5 Datenstrukturen 3.5.1 Einleitung 3.5.2 Mathematische Grundlagen 3.5.3 Fehlerbehandlung 3.5.4 Datenstrukturen und ihre Implementation
 Deduktive Methode Model Checking. 3.5 Datenstrukturen Einleitung Mathematische Grundlagen Fehlerbehandlung Datenstrukturen und ihre Implementation.")
24
4. Existenz und Durchführbarkeit von Algorithmen 4
4. Existenz und Durchführbarkeit von Algorithmen 4.1 Berechenbarkeit, Terminiertheit, Durchführbarkeit 4.2 Komplexität 4.3 Nichtprozedurale Algorithmen 5. Ausgewählte Algorithmen 5.1 Sortierverfahren Adressenorientiertes Sortieren Assoziatives Sortieren

25
5. 2 Suchverfahren 5. 2. 1 Einleitung 5. 2
5.2 Suchverfahren Einleitung Suchalgorithmen auf der Basis von Adressberechnungen (Hashing, perfektes Hashing, digitale Suchbäume, Tries) Assoziatives Suchen (Suchen in geordneten Mengen) Suchverfahren Gewichtete Bäume Balancierte Bäume (gewichtsbalanciert, höhenbalanciert)
 Assoziatives Suchen (Suchen in geordneten Mengen) Suchverfahren Gewichtete Bäume Balancierte Bäume (gewichtsbalanciert, höhenbalanciert)")
26
5. 3 Heuristische Algorithmen 5. 4 Evolutionsalgorithmen 6
5.3 Heuristische Algorithmen 5.4 Evolutionsalgorithmen 6. Funktionales Programmieren 6.1 Funktionen in der Mathematik 6.2 Datentypen und Programmierung

27
Problem 1 Anwendung 1 Problem 2 Mathe
Problem 1 Anwendung 1 Problem 2 Mathe. Software Modell Problem n Anwendung m Abstraktion Spezialisierung

28
Datenverarbeitung: = (N, I), : D D N Nachricht Nachricht´ Information Information´ I d D d´ D
, : D D N Nachricht Nachricht´ Information Information´ I d D d´ D")
29
Spezifikation Algorithmus in mathematischer Notation Algorithmus in höherer Programmierung Programmiersprache Algorithmus in Übersetzung Maschinensprache

30
Flussbilder - Grundelemente
Verarbeitungsblock <Anweisungs- x := x + 1 folge> y := 0 Bedingung nein ja nein ja x < 0

31
Flussbilder - Grundelemente
Konnektoren <Zahl> <Zahl> Gerichtete Kanten

32
Motto Bevor ein Zimmermann ein Haus baut, muss er einen Plan dafür erarbeiten. Eine Hundehütte kann er jederzeit auch ohne große Vorbereitung bauen.

33
Schrittweise Verfeinerung – Beispiel 1
Zubereitung einer Tasse Kaffee Koche Wasser Kaffee in Tasse Wasser in Tasse Wasser in Einschalten Warten bis Kessel zum Kochen

34
Schrittweise Verfeinerung – Beispiel 2
Sortieren einer Folge F zu F´ Zerlegung Sortierung Mischen in F1 und F2 von F1 zu F1´ von F1´ und von F2 zu F2´ F2´ zu F´

35
Schrittweise Verfeinerung Beispiel 3
program ggt( (*a,b*)); (*Vereinbarungen*) begin (* Eingabe a,b *) x := a; y := b; while y<>0 do begin (* Verkleinerung von y; Änderung von x *) end ; (* Ausgabe ggt(a,b)*) end.
); (*Vereinbarungen*) begin (* Eingabe a,b *) x := a; y := b; while y<>0 do begin (* Verkleinerung von y; Änderung von x *) end ; (* Ausgabe ggt(a,b)*) end.")
36
Struktogramme Verarbeitungsblock <Anweisungen> Lies N Block mit Bezeichnung <Name> Maxberech

37
Struktogramme Reihung zweier Blöcke Lies m, k y := m * k Wiederholung (abweisender Zyklus) <Bedingung> x > 0 <Anwei- x := x * 1 sungen> y := y + 2
 <Bedingung> x > 0 <Anwei- x := x * 1 sungen> y := y + 2")
38
Struktogramme Wiederholung (nichtabweisender Zyklus) <Anwei- x := x – 1 sungen> y := y + 2 <Bedingung> x < 0 Wiederholung (Zählzyklus) v=a,e,s i=1, 10, 2 <Anweisungen> s := s + 1
 <Anwei- x := x – 1 sungen> y := y + 2 <Bedingung> x < 0 Wiederholung (Zählzyklus) v=a,e,s i=1, 10, 2 <Anweisungen> s := s + 1")
39
Struktogramme Wiederholung (ohne Bedingung) <Anweisungen> Temperatur- messung Alternative (einfach) <Bedingung> x > 0 true false true false <Anw> <Anw> z := 1 z := 0
 <Anweisungen> Temperatur- messung Alternative (einfach) <Bedingung> x > 0 true false true false <Anw> <Anw> z := 1 z := 0")
40
Struktogramme Fallabfrage (mehrfache Alternative) <Ausdruck> s W1 W2 ... Wn A1 A2 ... An x := 0 y := 0 z := 0

41
Struktogramme Abbruchanweisung <Name> S1 B1 B2 true false A1 S1 A2 S2

42
Beziehungen Dienstmodul - Kundenmodul
Datenmodul Dienstmodul Definitionsmodul: Datentypen, Konstanten, Variablen Implementationsmodul: leer Kundenmodul Nutzung der Daten

43
Beziehungen Dienstmodul - Kundenmodul
Funktionsmodul Dienstmodul Definitionsmodul: Prozedur/Funktionsköpfe Implementationsmodul: Prozedur/Funktionsrümpfe Kundenmodul Lokale Daten und Prozedur/Funktionsaufrufe

44
Beziehungen Dienstmodul - Kundenmodul
Datenkapsel Dienstmodul Definitionsmodul: Prozedur/Funktionsköpfe Implementationsmodul: Prozedur/Funktionsrümpfe und Daten Kundenmodul Prozedur/Funktionsaufrufe (keine eigenen Daten)
")
45
Beziehungen Dienstmodul - Kundenmodul
Abstrakter Datentyp Dienstmodul Definitionsmodul: Prozedur/Funktionsköpfe, Datentyp Implementationsmodul: Struktur des Datentyps, Prozedur/Funktionsrümpfe Kundenmodul Prozedur/Funktionsaufrufe, Daten zum Datentyp

46
DEFINITION MODULE Dateimanager;
(*Dateimanipulationsroutinen*) CONST Endnr = 65535; (* groesste Kontonr*) TYPE Kontonr = CARDINAL; PROCEDURE AddiereWert; (*addiert Wert des letzten Bewegungsdatensatzes zum Datensatz im Ausgabepuffer*) PROCEDURE SchliesseDateien; (*schliesst alle Dateien*) PROCEDURE AusNeuStamm; (*schreibt Ausgabepuffer in neue Stammdatei*) PROCEDURE EinBewegung(VAR Bewnr: Kontonr); (*liefert einen Datensatz der Bewegungsdatei und seine Nummer*) ... END Dateimanager.
 CONST Endnr = 65535; (* groesste Kontonr*) TYPE Kontonr = CARDINAL; PROCEDURE AddiereWert; (*addiert Wert des letzten Bewegungsdatensatzes zum Datensatz im Ausgabepuffer*) PROCEDURE SchliesseDateien; (*schliesst alle Dateien*) PROCEDURE AusNeuStamm; (*schreibt Ausgabepuffer in neue Stammdatei*) PROCEDURE EinBewegung(VAR Bewnr: Kontonr); (*liefert einen Datensatz der Bewegungsdatei und seine Nummer*) ... END Dateimanager.")
47
IMPLEMENTATION MODULE Zufall;
(*Zufallszahlen nach der Kongruenzmethode*) FROM InOut IMPORT WriteString, WriteLn, WriteCard, ReadCard; CONST Modulus = 2345; Faktor = 3; Inkrement = 7227; VAR Seed: CARDINAL; PROCEDURE RandomCard(A, B: CARDINAL): CARDINAL; VAR random: REAL; BEGIN Seed := (Faktor*Seed+Inkrement) MOD Modulus; random := FLOAT(Seed)/FLOAT(Modulus); random := random*(FLOAT(B)-FLOAT(A)+1.0)+FLOAT(A); RETURN TRUNC(random) END RandomCard; WriteString(‘Zufallszahlen’); WriteLn; WriteString(‘Startwert?’); ReadCard(Seed); WriteLn END Zufall.
 FROM InOut IMPORT WriteString, WriteLn, WriteCard, ReadCard; CONST Modulus = 2345; Faktor = 3; Inkrement = 7227; VAR Seed: CARDINAL; PROCEDURE RandomCard(A, B: CARDINAL): CARDINAL; VAR random: REAL; BEGIN. Seed := (Faktor*Seed+Inkrement) MOD Modulus; random := FLOAT(Seed)/FLOAT(Modulus); random := random*(FLOAT(B)-FLOAT(A)+1.0)+FLOAT(A); RETURN TRUNC(random) END RandomCard; WriteString(‘Zufallszahlen’); WriteLn; WriteString(‘Startwert ’); ReadCard(Seed); WriteLn. END Zufall.")
48
DEFINITION MODULE Konserve;
TYPE tName = ARRAY [0..79] OF CHAR; tWochentag = (Montag, Dienstag, Mittwoch, Donnerstag, Freitag, Samstag, Sonntag); tMonat = (Januar, Februar, Maerz, April, Mai, Juni, Juli, August, September, Oktober, November, Dezember); tDatum = RECORD Tag:[1..31]; Monat: tMonat; Jahr: CARDINAL END; VAR Datum: tDatum; Konto: RECORD Name: tName; Kontonr: CARDINAL; datum: tDatum; wert: RECORD mod: (soll, haben); mark: CARDINAL; pfg: CARDINAL CONST MaxCard = 65535; MaxInt = 32767; MinInt = (-32767) - 1 END Konserve.
; tMonat = (Januar, Februar, Maerz, April, Mai, Juni, Juli, August, September, Oktober, November, Dezember); tDatum = RECORD. Tag:[1..31]; Monat: tMonat; Jahr: CARDINAL. END; VAR Datum: tDatum; Konto: RECORD. Name: tName; Kontonr: CARDINAL; datum: tDatum; wert: RECORD mod: (soll, haben); mark: CARDINAL; pfg: CARDINAL. CONST MaxCard = 65535; MaxInt = 32767; MinInt = (-32767) - 1. END Konserve.")
49
DEFINITION MODULE Stapel;
(*fuer Cardinalzahlen*) VAR Fehler: BOOLEAN; (*Fehler, falls versucht wird, ein Element von einem leeren Stapel zu entnehmen oder ein Element auf einen vollen Stapel abzulegen*) PROCEDURE leererStapel; (*Initialisierung eines Stapels*) PROCEDURE push(c: CARDINAL); (*Zahl auf einen Stapel*) PROCEDURE pop(VAR c: CARDINAL); (*Zahl vom Stapel*) END Stapel.
 VAR Fehler: BOOLEAN; (*Fehler, falls versucht wird, ein Element von einem leeren Stapel zu entnehmen oder ein Element auf einen vollen Stapel abzulegen*) PROCEDURE leererStapel; (*Initialisierung eines Stapels*) PROCEDURE push(c: CARDINAL); (*Zahl auf einen Stapel*) PROCEDURE pop(VAR c: CARDINAL); (*Zahl vom Stapel*) END Stapel.")
50
DEFINITION MODULE ADTPuffer;
TYPE Puffer; PROCEDURE leere(VAR R: Puffer); PROCEDURE leer(R: Puffer): BOOLEAN; PROCEDURE voll(R: Puffer): BOOLEAN; PROCEDURE push(VAR R: Puffer; El: CARDINAL); PROCEDURE pop(VAR R: Puffer); PROCEDURE gen(VAR R: Puffer) END ADTPuffer.
; PROCEDURE leer(R: Puffer): BOOLEAN; PROCEDURE voll(R: Puffer): BOOLEAN; PROCEDURE push(VAR R: Puffer; El: CARDINAL); PROCEDURE pop(VAR R: Puffer); PROCEDURE gen(VAR R: Puffer) END ADTPuffer.")
51
IMPLEMENTATION MODULE ADTPuffer;
(*Ringpuffer*) IMPORT... FROM... CONST G = 8; (* G-1 Groesse des Ringpuffers*) TYPE Puffer = POINTER TO Ring; Ring = RECORD rng: ARRAY[1..G] OF CARDINAL; kopf, ende: [1..G] END; ... END ADTPuffer.
 IMPORT... FROM... CONST G = 8; (* G-1 Groesse des Ringpuffers*) TYPE Puffer = POINTER TO Ring; Ring = RECORD rng: ARRAY[1..G] OF CARDINAL; kopf, ende: [1..G] END; ... END ADTPuffer.")
52
MODULE Ablage; ... FROM ADTPuffer IMPORT Puffer, gen, leer, voll, push, pop; VAR Ordner1, Ordner2: Puffer; END Ablage.

53
OOP - Beispiel CLASS Complex(x,y); REAL x,y; BEGIN REAL re,im; REAL PROCEDURE RealPart; BEGIN RealPart := re; END RealPart; REAL PROCEDURE ImaginaryPart; BEGIN ImaginaryPart := im; END ImaginaryPart; PROCEDURE Add(y); REF (COMPLEX) y; BEGIN re := re + y.RealPart; im := im + y.ImaginaryPart; END Add;
; REAL x,y; BEGIN REAL re,im; REAL PROCEDURE RealPart; BEGIN RealPart := re; END RealPart; REAL PROCEDURE ImaginaryPart; BEGIN ImaginaryPart := im; END ImaginaryPart; PROCEDURE Add(y); REF (COMPLEX) y; BEGIN re := re + y.RealPart; im := im + y.ImaginaryPart; END Add;")
54
... re := x; im := y; END COMPLEX; REF (COMPLEX) C1, C2, C3; C1 :- NEW COMPLEX(-1,1); C2 :- NEW COMPLEX(1,-1); C1.Add(C2);
 C1, C2, C3; C1 :- NEW COMPLEX(-1,1); C2 :- NEW COMPLEX(1,-1); C1.Add(C2); .")
55
OOP - Klassenhierarchie
Geometrisches Objekt Farbe, Zeichne,... Lineares Objekt 2D-Objekt 3D-Objekt

56
Beispiel: Türme von Hanoi
1 Turm ti: Bausteine 1 - i n-1 n (1) (2) (3)
 (2) (3)")
57
Reihenberechnung Eingabe x, Anfangswerte für Summand T und Summe S
S, T Abbruchtest p(T,S) nicht erfüllt erfüllt Ausgabe
 nicht erfüllt. erfüllt. Ausgabe.")
58
Reihenberechnung für sin x
Eingabe x, I:=1; T:=x; S:=0; xq:=-x*x |T|< Ausgabe S erfüllt nicht erfüllt S:=S+T; T:=T*xq/((I+1)*(I+2)); I:=I+2
*(I+2)); I:=I+2.")
59
Vollständige Induktion
Vor.: p:N0 Boolean (Prädikat), N0 = {0,1,..} Induktionsanfang: Zu beweisen: p(0) = WAHR (kürzer: p(0)) Induktionsvoraussetzung: Für alle n N0 ist zu beweisen: p(n) = WAHR p(n+1)= WAHR Induktionsschluss: Für alle n N0 gilt p(n) = WAHR.
, N0 = {0,1,..} Induktionsanfang: Zu beweisen: p(0) = WAHR (kürzer: p(0)) Induktionsvoraussetzung: Für alle n N0 ist zu beweisen: p(n) = WAHR p(n+1)= WAHR. Induktionsschluss: Für alle n N0 gilt. p(n) = WAHR.")
60
Allgemeine Induktion Vor.: p: M Boolean, M induktiv definiert
Induktionsanfang: Für die Basiselemente xM ist zu beweisen p(x) = WAHR. Induktionsvoraussetzung: Für alle Konstruktoren C und alle Elemente x1,...,xnM ist zu beweisen: p(xi) = WAHR, i=1,...,n p(C(x1,...,xn)) = WAHR Induktionsschluss: Für alle Elemente xM gilt p(x) = WAHR.
 = WAHR. Induktionsvoraussetzung: Für alle Konstruktoren C und alle Elemente x1,...,xnM ist zu beweisen: p(xi) = WAHR, i=1,...,n p(C(x1,...,xn)) = WAHR. Induktionsschluss: Für alle Elemente xM gilt p(x) = WAHR.")
61
Struktogramm - Hornerschema
i := 1; k := a1 i= 2, n+1 k := k * x + ai

62
Kantorovič-Baum für Polynome
a1 x a2 * + x a3 * ... an+1 +

63
Labyrinth - Beispiel

64
Polynom: a1x4 + a2x3 + a3x2 + a4x + a5 a4 x x * * a5 a3 x + * * a2 x a1 + * +

65
Paralleles Sortieren – Beispiel
Jochen Karin Franz Bernd Sepp Jim Maria Pos Jochen Karin Franz Bernd Sepp Jim Maria

66
Korrektheit Intuitive Vorstellungen Formal spezifizierte
über Eigenschaften Eigenschaften der der Software Software Durch Software realisierte Eigenschaften

67
Entwicklung von „funktionstreuer“ Software
Korrekte Software: a) Anwendung korrekter Werkzeuge auf Spezifikation b) Verifikation nach Softwareentwicklung c) Softwareentwicklung gekoppelt mit Beweisverfahren Softwareteste zur Fehlerentdeckung (auch fehlende Fälle) Simulation bei Echtzeitsoftware
 Anwendung korrekter Werkzeuge auf Spezifikation. b) Verifikation nach Softwareentwicklung. c) Softwareentwicklung gekoppelt mit Beweisverfahren. Softwareteste zur Fehlerentdeckung (auch fehlende Fälle) Simulation bei Echtzeitsoftware.")
68
Aussage zu Testen Es gibt keinen Algorithmus, der für ein beliebiges Programm eine solche Testdatenmenge erzeugen könnte, dass ein korrekter Test für die Testdaten auch die Korrektheit für beliebige andere Daten garantieren würde. (Beweis durch Rekursionssatz)
")
69
Testmethoden Kriterium Methoden
Art des Test- Durchsicht von Test lauffähiger Program- objekts Dokumenten me durch Ausführung Art der Test- statisch dynamisch (Abarbeitung ausführung (Inspektion) mit Testdaten) Kenntnisse Strukturtest Funktionstest (Struktur über Test- (bekannte unbekannt) objekt Struktur) Komponen- Modultest (einzelner Modul) tenart Integrationstest (Modulverbindung) Systemtest (Gesamtsystem mit BS)
 mit Testdaten) Kenntnisse Strukturtest Funktionstest (Struktur. über Test- (bekannte unbekannt) objekt Struktur) Komponen- Modultest (einzelner Modul) tenart Integrationstest (Modulverbindung) Systemtest (Gesamtsystem mit BS)")
70
Auswahl von Testdaten – Programmbeispiel
0 (A>1) (B=0) ja nein 1 X:=X/A 2 3 (A=2) (X>1) ja nein 4 X:=X+1 5 6
 (B=0) ja nein. 1 X:=X/A 2. 3 (A=2) (X>1) ja nein. 4 X:=X")
71
Äquivalenzmethode Bedingung Normalfälle Fehlerfälle
Daten aus (im Intervall) 2 („vor“ und Intervall „hinter“ Intervall) Daten sind (erlaubte 2 (zu kleine und zu Anzahl Anzahl) große Anzahl) Daten einer (aus Menge) 1 (nicht aus Menge) Menge
 2 („vor und. Intervall „hinter Intervall) Daten sind 1 (erlaubte 2 (zu kleine und zu. Anzahl Anzahl) große Anzahl) Daten einer 1 (aus Menge) 1 (nicht aus Menge) Menge.")
72
Vor- und Nachteile von Testmethoden
Funktionales Testen: + unabhängig von der Implementation + Entwicklung der Testfälle parallel zur Codierung - Redundanz in den Testdaten möglich, aber nicht ausschließbar - evtl. werden Programmteile nicht getestet - Definition von Überdeckungsmaßen schwierig

73
Vor- und Nachteile von Testmethoden - Fortsetzung
Strukturelles Testen: + wenig Redundanz in den Testdaten + alle Programmteile werden erreicht - Testdatenauswahl erst nach Codierung möglich - ausschließlicher Test des programmierten Verhaltens

74
Ein- und Ausgabeverhalten – Beispiel {x0y0} P {x=q*y+r0ry}
Programm Eigenschaften Voraussetzung: x 0, y > 0, x,y ganzzahlig q := 0; r := x; r 0 , y > 0, x = q*y + r WHILE r y DO r y, y > 0, r 0, x = q*y + r r := r - y; q := q + 1 r 0, y > 0, x = q*y + r OD; Nach der Schleife: x = q*y + r, 0 r < y

75
Korrektheit {Q} P {R} bedeutet: Wenn die Aussage Q vor der Abarbeitung des Teilprogrammes P wahr ist und die Abarbeitung von P terminiert, dann ist die Aussage R nach der Abarbeitung wahr (partielle Korrektheit). oder Wenn die Aussage Q vor der Abarbeitung des Teilprogrammes P wahr ist, dann terminiert die Abarbeitung von P und die Aussage R ist wahr (totale Korrektheit).
. oder Wenn die Aussage Q vor der Abarbeitung des Teilprogrammes P wahr ist, dann terminiert die Abarbeitung von P und die Aussage R ist wahr (totale Korrektheit).")
76
Axiome und Schlussregeln (Auszug) Axiom für die Wertzuweisung V := E (V Variable, E Ausdruck): {P’} V := E {P} , wobei P’ aus P durch Ersetzen der nichtquantifizierten Auftreten von V durch E entsteht (P’ ist die schwächste Vorbedingung)
 Axiom für die Wertzuweisung V := E (V Variable, E Ausdruck): {P’} V := E {P} , wobei P’ aus P durch Ersetzen der nichtquantifizierten Auftreten von V durch E entsteht (P’ ist die schwächste Vorbedingung)")
77
Axiome und Schlussregeln (Auszug) Verkettungsregel {P} A1 {Q}, {Q} A2 {R} {P} A1; A2 {R} Regel für die while-Anweisung {PB} A {P} {P} while B do A od {P not B}
 Verkettungsregel {P} A1 {Q}, {Q} A2 {R} {P} A1; A2 {R} Regel für die while-Anweisung {PB} A {P} {P} while B do A od {P not B}")
78
Axiome und Schlussregeln (Auszug) Implikationsregeln {P} S {Q}, Q R {P} S {R} P R, {R} S {Q} {P} S {Q}
 Implikationsregeln {P} S {Q}, Q R {P} S {R} P R, {R} S {Q} {P} S {Q}")
79
Pfadformeln E F p E G p p

80
Pfadformeln (Fortsetzung)
A F p A G p p p p p p p p p p p

81
Model Checking – Railroad (1)
")
82
Model Checking – Railroad (2)
")
83
Model Checking – Railroad (3)
")
84
Model Checking – Railroad (4)
")
85
Model Checking – Railroad (5)
Beispiellauf (Zugautomat):
:")
86
Betrachtungsebenen von Datenstrukturen
Datenstrukturen als abstrakte Objekte: Darstellung von Eigenschaften und Wirkungsweise von Operationen Konkrete Repräsentation Implementation in höherer Programmiersprache Implementation in Maschinensprache

87
Vorteile der Abstraktion
Konzentration auf Wesentliches Unabhängigkeit von Repräsentation und Programmiersprache Austauschbarkeit von Implementationen bei gleicher Schnittstelle Wiederverwendbarkeit der Implementationen Nutzerfreundlichkeit durch Verwendung des Problemniveaus

88
Algebraische Vorgehensweise der Softwareentwicklung
Anforderungsdefinition (informal) Formalisierung Test, Plausibilität Algebraische Spezifikation (Prototyping) Verfeinerung Verifikation Algorithmische Spezifikation Transformation Imperatives Programm
 Formalisierung Test, Plausibilität. Algebraische Spezifikation (Prototyping) Verfeinerung Verifikation. Algorithmische Spezifikation. Transformation. Imperatives Programm.")
89
Algebra ganzer Zahlen Trägermenge der Algebra: = {...,-2,-1,0,1,2,...} Operationen der Algebra: Addition, Subtraktion, Multiplikation, Division, Vergleiche Funktionalität (Profil) der Operationen: _+_: x _*_: x _/_: x _-_: x _<_: x ( steht für Boolean) ...
 der Operationen: _+_: x _*_: x _/_: x _-_: x _<_: x ( steht für Boolean) ...")
90
Algebra ganzer Zahlen - Fortsetzung
Eigenschaften der Operationen: · Addition, Multiplikation: kommutativ, assoziativ, distributiv a + b = b + a a * b = b * a (a + b) + c = a + (b + c) (a * b) * c = a * (b * c) (a + b) * c = (a * c) + (b * c) a,b,c · Subtraktion als Umkehrung zur Addition ...
 + c = a + (b + c) (a * b) * c = a * (b * c) (a + b) * c = (a * c) + (b * c) a,b,c · Subtraktion als Umkehrung zur Addition ...")
91
ADT Ganze Zahlen (Ganz)
Datensorten: INT Operationssymbole: + - pred succ 0 (für spätere Operationen Addition, Subtraktion, Vorgänger, Nachfolger, Konstante 0) Funktionalität: _+_: INT x INT INT _-_: INT x INT INT 0 : INT Signatur (Syntax) pred: INT INT succ: INT INT
 Funktionalität: _+_: INT x INT INT _-_: INT x INT INT 0 : INT Signatur (Syntax) pred: INT INT succ: INT INT")
92
ADT Ganze Zahlen (Ganz) - Fortsetzung
pred(succ(x)) = x succ(pred(x)) = x Termgleichungen x + 0 = x (Semantik) x + succ(y) = succ(x + y) x + pred(y) = pred(x + y) x - 0 = x x - succ(y) = pred(x - y) x - pred(y) = succ(x - y) x + y = y + x
) = x succ(pred(x)) = x Termgleichungen x + 0 = x (Semantik) x + succ(y) = succ(x + y) x + pred(y) = pred(x + y) x - 0 = x x - succ(y) = pred(x - y) x - pred(y) = succ(x - y) x + y = y + x")
93
Algebra Ganze Binärzahlen
Sorte: INT Trägermenge: {...,-11,-10,-1,0,1,10,11,...} Operator: + Operation: +B Addition von Binärzahlen Operator: succ Operation: +B 1 Operator: pred Operation: -B 1

94
Termalgebra Sorte: INT Trägermenge: alle Terme Operator: +
Operation: +T „Addition“ von Termen, d.h. t1 +T t2 = t1 + t2 Operator: succ Operation: succT(t) = succ(t) Operator: pred Operation: predT(t) = pred(t)
 = succ(t) Operator: pred. Operation: predT(t) = pred(t)")
95
Eigenschaften von Termgleichungen
Notation: - X: t1 = t2 bezeichnet eine Termgleichung mit der Variablenmenge X - x: s bezeichnet eine Variable der Sorte s Eigenschaften: Reflexivität: X: t = t Symmetrie: X: t1 = t2 X: t1 = t2 Transitivität: X1: t1 = t2, X2: t2 = t3 X1 X2: t1 = t3

96
Eigenschaften von Termgleichungen - Fortsetzung
Substituierbarkeit: X1 {xs}: t1 = t2, X2: t3 = t4, xs: S, t3 Ts, t4 Ts X1 X2: t5 = t6, t5 = t1[xs/t3], t6 = t1[xs/t4] Abstraktion: X: t1 = t2, xs: S, xs X X {xs}: t1 = t2 Konkretisierung: X {xs}: t1 = t2, t1 ...xs... t2, Menge der variablenfreien Terme der Sorte s ist nicht leer X: t1 = t2

97
Strukturelle Induktion
Voraussetzungen: Signatur mit Sortenmenge S, p Prädikat auf den Termen von Induktionsschritte: Basis: Beweis für p(t) = WAHR für alle nullstelligen Operationssymbole und Variablen Schritt: Beweis für Für alle Operationssymbole , alle Terme t1,...,tn und (t1,...,tn) gilt: p(ti) = WAHR, i = 1,...,n p((t1,...,tn)) = WAHR Schlussfolgerung: p(t) = WAHR für alle Terme t
 = WAHR für alle nullstelligen Operationssymbole und Variablen Schritt: Beweis für Für alle Operationssymbole , alle Terme t1,...,tn und (t1,...,tn) gilt: p(ti) = WAHR, i = 1,...,n p((t1,...,tn)) = WAHR Schlussfolgerung: p(t) = WAHR für alle Terme t")
98
Definition eines abstrakten Datentyps
Einführung von Sorten Einführung von Operationssymbolen Definition der Funktionalität der Operationssymbole Definition der Eigenschaften der Operationen (Termgleichungen, Termersetzungsregeln) Schnelles Prototyping Umsetzung (Implementation) in höhere Programmiersprache mit Verifikation
 Schnelles Prototyping. Umsetzung (Implementation) in höhere Programmiersprache mit Verifikation.")
99
Modulares Programmieren, objektorientiertes Programmieren und Theorie der Algebren im Vergleich
Datenkapsel: Daten – Operationen – Import/Export Abstrakter Datentyp: Datentyp – Operationen – Import/Export Beschreibung durch Definitionsmodul (Schnittstelle) und Implementationsmodul
 und Implementationsmodul.")
100
Modulares Programmieren, objektorientiertes Programmieren und Theorie der Algebren im Vergleich (Forts.) Objektorientiertes Programmieren Objekt: Daten (Attribute, Instanzvariablen) – Operationen (Methoden) Klasse (Objektbeschreibung): Datentypen – Operationen- Vererbung Beschreibung durch Schnittstelle und Implementation
 – Operationen (Methoden) Klasse (Objektbeschreibung): Datentypen – Operationen- Vererbung. Beschreibung durch Schnittstelle und Implementation.")
101
Modulares Programmieren, objektorientiertes Programmieren und Theorie der Algebren im Vergleich (Forts.) Theorie der Algebren Algebra: Trägermengen – Operationen – Import/Export Abstrakter Datentyp: Signatur (Sorten, Operationssymbole, Funktionalität) – Operationseigenschaften (Termgleichungen) – Import/Export
 – Operationseigenschaften (Termgleichungen) – Import/Export.")
102
Fehlerbehandlung - Beispiel
Datensorte: Nat Operationssymbole und ihre Funktionalität: zero: Nat succ: Nat Nat pred: Nat Nat add: Nat x Nat Nat mult: Nat x Nat Nat

103
Fehlerbehandlung – Beispiel (Forts.)
Termgleichungen: pred(succ(x)) = x add(zero, x) = x add(succ(x), y) = succ(add(x, y)) mult(zero, x) = zero mult(succ(x), y) = add(y, mult(x, y))
) = x add(zero, x) = x add(succ(x), y) = succ(add(x, y)) mult(zero, x) = zero mult(succ(x), y) = add(y, mult(x, y))")
104
Fehlerbehandlung – Beispiel (Forts.)
==> Ergänzung der Spezifikation: error: Nat succ(error) = error pred(error) = error add(error, x) = error add(x, error) = error mult(error, x) = error mult(x, error) = error pred(zero) = error
 = error pred(error) = error add(error, x) = error add(x, error) = error mult(error, x) = error mult(x, error) = error pred(zero) = error")
105
Fehlerbehandlung – Beispiel (Forts.)
Operationssymbole: zero: Nat succ: Nat Nat pred: Nat Nat add: Nat x Nat Nat error: Nat safe: Nat Bool

106
Fehlerbehandlung – Beispiel (Forts.)
Termgleichungen: succ(error) = error safe(zero) = true safe(succ(x)) = safe(x) safe(error) = false pred(error) = error pred(succ(x)) = x pred(zero) = error
 = error safe(zero) = true safe(succ(x)) = safe(x) safe(error) = false pred(error) = error pred(succ(x)) = x pred(zero) = error")
107
Fehlerbehandlung – Beispiel (Forts.)
add(zero, x) = x add(succ(x), y) = succ(add(x, y)) add(error, x) = error mult(zero, x) = if safe(x) then zero else error fi mult(succ(x), y) = add(y, mult(x, y)) mult(error) = error
 = x add(succ(x), y) = succ(add(x, y)) add(error, x) = error mult(zero, x) = if safe(x) then zero else error fi mult(succ(x), y) = add(y, mult(x, y)) mult(error) = error")
108
Spezifikation eines ADT
type <Name> ==<Exportliste> based on <Importliste> sorts <Namenliste> decl <Variablenliste> constructors <kanonische Operationssymbole mit Funktionalität> operations <restliche Operationssymbole mit Funktionalität> axioms <Termgleichungen> end of type

109
Beispiel – ADT BOOL type BOOL == bool, T, F, , based on sorts bool decl B:bool, B1:bool constructors T: bool; F : bool operations : bool bool; __: bool x bool bool axioms T = F; (B)) = B; T B = B; F B = F; B B1 = B1 B end of type
) = B; T B = B; F B = F; B B1 = B1 B end of type")
110
Beispiel – ADT BOOL Abgeleitete Operationen
B B1 = (B B1) B B1 = B B1 B B1 = (B B1) (B1 B)
 B B1 = B B1. B B1 = (B B1) (B1 B)")
111
Transformation arithmetischer Ausdrücke in IPN
Voraussetzungen: zu transformierender Ausdruck wird mit einem Endezeichen beendet und Operatoren haben Prioritäten · „(„ wird im Keller abgelegt · „)“ entkellert alle Operatoren bis einschließlich der zugehörigen öffnenden Klammer mit anschließender Beseitigung beider Klammern und Einfügen der Operatoren in die IPN
 entkellert alle Operatoren bis einschließlich der zugehörigen öffnenden Klammer mit anschließender Beseitigung beider Klammern und Einfügen der Operatoren in die IPN")
112
Transformation arithmetischer Ausdrücke in IPN (Fortsetzung)
· Variablen und Konstanten gehen sofort in die IPN über · Operatoren entkellern alle Operatoren mit größerer oder gleicher Priorität und werden anschließend gekellert; die entkellerten Operatoren werden der IPN hinzugefügt · Entkellerung aller Operatoren durch Endezeichen „!“ mit Löschen des Zeichens

113
Transformation arithmetischer Ausdrücke in IPN (Fortsetzung)
Prioritäten: 1 2 3 4 5 = / * 8 **

114
Abstrakter Datentyp Keller – Signatur
erelement init push element stack erstack top pop

115
Keller – Eigenschaften der Operationen
a) Aus einem nichtleeren Keller kann nur das zuletzt hinzugefügte Element entfernt werden. b) Von einem nichtleeren Keller kann nur das zuletzt hinzugefügte Element gelesen werden. c) Im Falle eines leeren Kellers kann weder ein Element entfernt noch gelesen werden. In beiden Fällen erfolgt eine Fehlermeldung.
 Aus einem nichtleeren Keller kann nur das zuletzt hinzugefügte Element entfernt werden. b) Von einem nichtleeren Keller kann nur das zuletzt hinzugefügte Element gelesen werden. c) Im Falle eines leeren Kellers kann weder ein Element entfernt noch gelesen werden. In beiden Fällen erfolgt eine Fehlermeldung.")
116
Kellerspezifikation type Keller1 == stack, push, pop, top, init, erstack based on ELEMENT sorts stack decl e: element, s: stack; constructors init: stack; push: element x stack stack; erstack: stack operations pop: stack stack; top: stack element

117
Kellerspezifikation (Fortsetzung)
axioms pop(push(e, s)) = s top(push(e, s)) = e pop(init) = erstack top(init) = erelement end of type
) = s top(push(e, s)) = e pop(init) = erstack top(init) = erelement end of type")
118
Abstrakter Datentyp Keller (erweitert) – Signatur
max erelement init nat push over lng = element stack erstack empty top pop bool full

119
Keller – Eigenschaften der neuen Operationen
a) lng gibt die Anzahl der Elemente eines Kellers an, wobei der leere Keller die Anzahl 0 hat und durch jedes in den Keller abgespeicherte Element die Anzahl um 1 vergrößert wird. b) Ein Keller ist leer, wenn die Anzahl seiner Elemente 0 ist. Ein Keller ist gefüllt, wenn die Anzahl eine vorgegebene Größe max erreicht hat.
 lng gibt die Anzahl der Elemente eines Kellers an, wobei der leere Keller die Anzahl 0 hat und durch jedes in den Keller abgespeicherte Element die Anzahl um 1 vergrößert wird. b) Ein Keller ist leer, wenn die Anzahl seiner Elemente 0 ist. Ein Keller ist gefüllt, wenn die Anzahl eine vorgegebene Größe max erreicht hat.")
120
Keller – Eigenschaften der neuen Operationen (Fortsetzung)
c) Der Initialisierungskeller ist leer. d) Die Abspeicherung eines Elements in einen vollen Keller führt zu einem Fehler.
 Der Initialisierungskeller ist leer. d) Die Abspeicherung eines Elements in einen vollen Keller führt zu einem Fehler.")
121
Kellerspezifikation (erweitert)
type Keller2 == stack, push, pop, top, init, erstack, full, empty, lng, max, over based on NAT, BOOL, ELEMENT sorts stack decl e:element, s:stack constructors init: stack; push: element x stack stack; erstack: stack; over: stack

122
Kellerspezifikation (erweitert) - Fortsetzung
operations pop: stack stack; top: stack element; lng: stack nat; max: nat; empty: stack bool; full: stack bool; _=_: nat x nat bool

123
Kellerspezifikation (erweitert) - Fortsetzung
axioms push(e, s) = if full(s) then over else push(e, s) fi pop(push(e, s)) = s top(push(e, s)) = e pop(init) = erstack top(init) = erelement lng(init) = 0 lng(push(e,s)) = lng(s) + 1 empty(init) = T empty(push(e, s)) = F full(s) = (lng(s) = max) end of type
 = if full(s) then over else push(e, s) fi pop(push(e, s)) = s top(push(e, s)) = e pop(init) = erstack top(init) = erelement lng(init) = 0 lng(push(e,s)) = lng(s) + 1 empty(init) = T empty(push(e, s)) = F full(s) = (lng(s) = max) end of type")
124
Abstrakter Datentyp Schlange – Signatur
max erelement init nat over insert length = element queue erqueue qempty front remove bool qfull

125
Schlange – Eigenschaften der Operationen
Eine nur initialisierte Schlange ist leer und hat die Länge 0. Mit jedem hinzugefügten Element wächst die Länge um 1. Eine Schlange mit mindestens 1 Element ist nicht leer. Eine volle Schlange hat die maximale Länge erreicht. Es kann dann kein Element hinzugefügt werden.

126
Schlange – Eigenschaften der Operationen (Fortsetzung)
Einer leeren Schlange kann kein Element entnommen werden. Elemente werden bei einer nichtleeren Schlange vorn weggenommen. Das Anfügen von Elementen geschieht am Ende der Schlange. Gelesen werden kann grundsätzlich nur das erste Element und das nur bei nichtleeren Schlangen.

127
Schlange - Spezifikation
type Schlange == queue, front, insert, remove, init, erqueue, over, qempty, qfull, length based on NAT, BOOL, ELEMENT sorts queue decl e:element, q:queue constructors init: queue; erqueue: queue; over: queue; insert: element x queue queue

128
Schlange – Spezifikation (Forts.)
operations front: queue element; remove: queue queue; length: queue nat; max: nat; qempty: queue bool; qfull: queue bool; _=_: nat x nat bool axioms length(init) = 0 length(insert(e, q)) = length(q) + 1
 = 0 length(insert(e, q)) = length(q) + 1")
129
Schlange – Spezifikation (Forts.)
qempty(init) = T qempty(insert(e, q)) = F qfull(q) = (length(q) = max) front(init) = erelement front(insert(e, q)) = if qempty(q) then e else front(q) fi insert(e, q) = if qfull(q) then over else insert(e, q) fi remove(init) = erqueue remove(insert(e, q)) = if qempty(q) then init else insert(e, remove(q)) fi end of type
 = T qempty(insert(e, q)) = F qfull(q) = (length(q) = max) front(init) = erelement front(insert(e, q)) = if qempty(q) then e else front(q) fi insert(e, q) = if qfull(q) then over else insert(e, q) fi remove(init) = erqueue remove(insert(e, q)) = if qempty(q) then init else insert(e, remove(q)) fi end of type")
130
Abstrakter Datentyp Tabelle – Signatur
isdef bool key read erelement delete add, update full element empty table = size init over ertable nat max

131
Abstrakter Datentyp Tabelle – Signatur (andere Variante – unvoll.)
element add mentry entry table key

132
Tabelle – Eigenschaften der Operationen
- Eine nur initialisierte Tabelle ist leer und hat den Umfang 0. Mit jeder Eintragung wächst ihr Umfang um 1. - Die Aktualisierung einer leeren Tabelle ist ohne Effekt. Hingegen ist das Lesen einer Eintragung aus einer leeren Tabelle ein Fehler. - In eine gefüllte Tabelle kann keine weitere Eintragung vorgenommen werden.

133
Tabelle - Spezifikation
type TABLE == key, table, read, add, update, delete, isdef, empty, full,init, over, ertable, size based on NAT, ELEMENT, BOOL sorts key, table decl k:key, l:key,t:table,e:element,f:element constructors init: table; over: table; ertable: table; add: table x key x element table

134
Tabelle – Spezifikation (Forts.)
operations read: table x key element; update: table x key x element table; delete: table x key table; __: key x key bool; isdef: table x key bool; empty: table bool; full: table bool; _=_: nat x nat bool; size: table nat; max: nat

135
Tabelle – Spezifikation (Forts.)
axioms delete(init, k) = ertable delete(add(t, k, e), l) = if k l then t else add(delete(t, l), k, e) fi isdef(init, k) = F isdef(add(t, k, e), l) = if k l then T else isdef(t, l) fi add(t, k, e) = if full(t) then over else if isdef(t, k) then ertable else add(t, k, e) fi fi
 = ertable delete(add(t, k, e), l) = if k l then t else add(delete(t, l), k, e) fi isdef(init, k) = F isdef(add(t, k, e), l) = if k l then T else isdef(t, l) fi add(t, k, e) = if full(t) then over else if isdef(t, k) then ertable else add(t, k, e) fi fi")
136
Tabelle – Spezifikation (Forts.)
update(init, k, e) = init update(add(t, k, e), l, f) = if k l then add(t, k, f) else add(update(t, l, f), k, e) fi read(init, k) = erelement read(add(t, k, e), l) = if k l then e else read(t, l) fi size(init) = 0 size(add(t, k, e) = 1 + size(t) empty(t) = (size(t) = 0) full(t) = (size(t) = max) end of type
 = init update(add(t, k, e), l, f) = if k l then add(t, k, f) else add(update(t, l, f), k, e) fi read(init, k) = erelement read(add(t, k, e), l) = if k l then e else read(t, l) fi size(init) = 0 size(add(t, k, e) = 1 + size(t) empty(t) = (size(t) = 0) full(t) = (size(t) = max) end of type")
137
Liste – informale Beschreibung
· Modellierung eines Karteikastens (Folge von Karteikarten) · Kennzeichnung der bearbeiteten Karte durch Einschub einer Spezialkarte (Markierungskarte) und damit Unterteilung der Karten in Karten des vorderen und hinteren Teils des Karteikastens · Einfügen und Entfernen von Karten stets vor der Markierungskarte
 · Kennzeichnung der bearbeiteten Karte durch Einschub einer Spezialkarte (Markierungskarte) und damit Unterteilung der Karten in Karten des vorderen und hinteren Teils des Karteikastens · Einfügen und Entfernen von Karten stets vor der Markierungskarte")
138
Liste – informale Beschreibung (Fortsetzung)
· Verschiebung der Markierungskarte um 1 Position nach vorn oder hinten oder nach ganz vorn bzw. ganz hinten · Lesen der Karte vor der Markierungskarte hinten Markierungskarte vorn

139
Liste - Signatur max mlist erlist over nat erelement read init element list = insert length delete, first, bool last, next, prev empty, full, atbeg, atend

140
Liste - Operationen insert Einfügen einer Karte vor der Markierungskarte delete Entfernen der Karte vor der Markierungskarte read Lesen der Karte vor der Markierungskarte init Initialisierung der Kartei (nur Markierungskarte vorhanden)
")
141
Liste – Operationen (Forts.)
first,last Setzen der Markierungskarte auf Anfang bzw. Ende next, prev 1 Karte nach hinten bzw. vorn length Anzahl der Karteikarten max maximale Kartenanzahl empty, full Ist der Karteikasten leer bzw voll? atbeg,atend Ist die Markierungskarte am Anfang bzw. Ende des Kastens?

142
Liste – Eigenschaften von Operationen (Auszug)
Befindet sich die Markierungskarte am Anfang des Kastens, so ist weder Lesen noch das Entfernen einer Karte möglich. Die Anwendung der prev-Operation ist dann nicht gestattet und die first-Operation hat keine Wirkung. Steht die Markierungskarte am Ende des Kastens, dann ist die next-Operation nicht erlaubt und die last-Operation ohne Wirkung.

143
Liste - Signaturänderung
element cons seq list clist nil

144
Beispiel – kanonischer Term
a b & c d Kanonischer Term – alte Form prev(prev(insert(d, insert(c, insert(b, insert(a, init)))))) Kanonischer Term – neue Form clist(cons(b, cons(a, nil)), cons(c, cons(d, nil)))
))))) Kanonischer Term – neue Form clist(cons(b, cons(a, nil)), cons(c, cons(d, nil)))")
145
Liste - Spezifikation type LIST == list, read, insert, mlist, init, erlist, over, delete, first, last, next, prev, length, empty, full, atbeg, atend based on ELEMENT, NAT, BOOL sorts list, seq decl e:element, f:seq, b:seq, l:list constructors mlist: list; erlist: list; over: list; nil: seq;

146
Liste – Spezifikation (Forts.)
cons: element x seq seq; clist: seq x seq list operations init: list; insert: element x list list; delete: list list; first: list list; last: list list; next: list list; prev: list list;

147
Liste – Spezifikation (Forts.)
read: list element; length: list nat; empty: list bool; full: list bool; atbeg: list bool; atend: list bool; max: nat; _=_: nat x nat bool

148
Liste – Spezifikation (Forts.)
axioms init = clist(nil, nil) insert(e, clist(f, b)) = if full(clist(f, b)) then over else clist(cons(e, f), b) fi delete(clist(nil, b)) = erlist delete(clist(cons(e, f), b)) = clist(f, b) read(clist(nil, b)) = erelement read(clist(cons(e, f), b)) = e
 insert(e, clist(f, b)) = if full(clist(f, b)) then over else clist(cons(e, f), b) fi delete(clist(nil, b)) = erlist delete(clist(cons(e, f), b)) = clist(f, b) read(clist(nil, b)) = erelement read(clist(cons(e, f), b)) = e")
149
Liste – Spezifikation (Forts.)
last(clist(f, nil)) = clist(f, nil) last(clist(f, cons(e, b))) = last(clist(cons(e, f), b)) first(clist(nil, b)) = clist(nil, b) first(clist(cons(e, f), b)) = first(clist(f, cons(e, b))) next(clist(f, nil)) = mlist next(clist(f, cons(e, b))) = clist(cons(e, f), b) prev(clist(nil, b)) = mlist prev(clist(cons(e, f), b) = clist(f, cons(e, b)) length(init) = 0
) = clist(f, nil) last(clist(f, cons(e, b))) = last(clist(cons(e, f), b)) first(clist(nil, b)) = clist(nil, b) first(clist(cons(e, f), b)) = first(clist(f, cons(e, b))) next(clist(f, nil)) = mlist next(clist(f, cons(e, b))) = clist(cons(e, f), b) prev(clist(nil, b)) = mlist prev(clist(cons(e, f), b) = clist(f, cons(e, b)) length(init) = 0")
150
Liste – Spezifikation (Forts.)
length(clist(cons(e, f), b)) = 1 + length(clist(f, b)) length(clist(nil, cons(e, b))) = 1 + length(clist(nil, b)) empty(l) = (length(l) = 0) full(l) = (length(l) = max) atbeg(clist(nil, b)) = T atbeg(clist(cons(e, f), b)) = F atend(clist(f, nil)) = T atend(clist(f, cons(e, b))) = F end of type
, b)) = 1 + length(clist(f, b)) length(clist(nil, cons(e, b))) = 1 + length(clist(nil, b)) empty(l) = (length(l) = 0) full(l) = (length(l) = max) atbeg(clist(nil, b)) = T atbeg(clist(cons(e, f), b)) = F atend(clist(f, nil)) = T atend(clist(f, cons(e, b))) = F end of type")
151
Baumdurchlaufalgorithmen
Inorder PROCEDURE inorder(t: IN tree); IF NOT null(t) THEN BEGIN inorder(left(t)); write(root(t)); inorder(right(t)) END FI END inorder
; IF NOT null(t) THEN BEGIN inorder(left(t)); write(root(t)); inorder(right(t)) END FI END inorder")
152
Baumdurchlaufalgorithmen
Präorder PROCEDURE preorder(t: IN tree); IF NOT null(t) THEN BEGIN write(root(t)); preorder(left(t)); preorder(right(t)) END FI END preorder
; IF NOT null(t) THEN BEGIN write(root(t)); preorder(left(t)); preorder(right(t)) END FI END preorder")
153
Baumdurchlaufalgorithmen
Postorder PROCEDURE postorder(t: IN tree); IF NOT null(t) THEN BEGIN postorder(left(t)); postorder(right(t)); write(root(t)) END FI END postorder
; IF NOT null(t) THEN BEGIN postorder(left(t)); postorder(right(t)); write(root(t)) END FI END postorder")
154
Treesort PROCEDURE treesort(x:IN array[1..n] of Elem);
{x ist die zu sortierende Folge} VAR t, q, help, tree, y, z:Elem; i:1..n; {t Gesamtbaum; help und q sind Unterbäume zur Bestimmung der Stelle, wo ein neuer Knoten angehangen werden soll} t := leaf(x[1]); {erstes Element wird zum Baum} FOR i:= 2 TO n DO {weitere Elemente werden in den Baum einsortiert} BEGIN y := x[i]; {einzusortierendes Element} help := t;
![Treesort PROCEDURE treesort(x:IN array[1..n] of Elem);](http://slideplayer.org/slide/5126446/16/images/154/Treesort+PROCEDURE+treesort%28x%3AIN+array%5B1..n%5D+of+Elem%29%3B.jpg "{x ist die zu sortierende Folge} VAR t, q, help, tree, y, z:Elem; i:1..n; {t Gesamtbaum; help und q sind Unterbäume zur Bestimmung der Stelle, wo ein neuer Knoten angehangen werden soll} t := leaf(x[1]); {erstes Element wird zum Baum} FOR i:= 2 TO n DO. {weitere Elemente werden in den Baum einsortiert} BEGIN y := x[i]; {einzusortierendes Element} help := t;")
155
Treesort (Forts.) WHILE NOT null(help) DO {Abwärtshangeln im Baum}
q := help; {Merken des Ausgangsknotens} z := root(help); {Bestimmung des Elements an der Wurzel von help} IF keyof(y) < keyof(z) THEN help := left(help) ELSE help := right(help) FI {Fortsetzung im linken oder rechten Unterbaum} OD;
; {Bestimmung des Elements an der Wurzel von help} IF keyof(y) < keyof(z) THEN help := left(help) ELSE help := right(help) FI. {Fortsetzung im linken oder rechten Unterbaum} OD;")
156
Treesort (Forts.) IF keyof(y) < keyof(z) THEN setleft(q, leaf(y))
ELSE setright(q, leaf(y)) FI {Anhängen eines Elements} OD; inorder(t); {Durchlauf durch t in Inorder} END treesort
) FI. {Anhängen eines Elements} OD; inorder(t); {Durchlauf durch t in Inorder} END treesort.")
157
Suche in einem treesort-Baum
FUNCTION find(t:IN tree; k:IN key): Boolean; VAR p:tree; found:Boolean; x:Elem; found := FALSE; p := t; WHILE (NOT null(p)) AND (NOT found) DO root(p, x); IF k = keyof(x) THEN found := true ELSE IF k < keyof(x) THEN p := left(p) ELSE p := right(p) FI OD; find := found END find
: Boolean; VAR p:tree; found:Boolean; x:Elem; found := FALSE; p := t; WHILE (NOT null(p)) AND (NOT found) DO. root(p, x); IF k = keyof(x) THEN found := true. ELSE IF k < keyof(x) THEN p := left(p) ELSE p := right(p) FI. OD; find := found. END find.")
158
Binärbaum - Signatur max setleft,setright nat leaf left, right noden = elem tree null, maxtree root over, ertree, empty bool cons setroot

159
Binärbaum - Operationen
root liefert Element der Wurzel setroot, setright, setleft Aktualisierung der Baum- komponenten noden liefert Knotenanzahl eines Baumes left (right) linker (rechter) Unterbaum wird geliefert cons Konstruktion eines Baumes aus Wurzelelement, linkem und rechtem Unterbaum
 linker (rechter) Unterbaum wird geliefert cons Konstruktion eines Baumes aus Wurzelelement, linkem und rechtem Unterbaum")
160
Binärbaum – Operationen (Forts.)
leaf ein Element wird zu einem Baum, bestehend aus einem Blatt (wird eigentlich nicht benötigt, ergibt aber kürzere Darstellungen) null Test auf leeren Baum maxtree Test auf maximale Knotenanzahl empty Bauminitialisierung
 null Test auf leeren Baum maxtree Test auf maximale Knotenanzahl empty Bauminitialisierung")
161
Binärbaum - Spezifikation
type B-TREE == tree, root, leaf, left, right, empty, cons, over, ertree, setroot, setleft, setright, noden, null, maxtree based on NAT, BOOL, ELEM sorts tree decl w:elem, r:tree, l:tree, e:elem, t:tree constructors empty: tree; over: tree; ertree: tree; cons: elem x tree x tree tree;

162
Binärbaum – Spezifikation (Forts.)
leaf: tree operations root: tree elem; left: tree tree; right: tree tree; setleft: tree x tree tree; setright: tree x tree tree; setroot: tree x elem tree; null: tree bool; maxtree: tree bool;

163
Binärbaum – Spezifikation (Forts.)
noden: tree nat; max: nat; _=_: nat x nat bool axioms root(empty) = erelem right(empty) = ertree left(empty) = ertree leaf(w) = cons(w, empty, empty) root(cons(w, l, r)) = w
 = erelem right(empty) = ertree left(empty) = ertree leaf(w) = cons(w, empty, empty) root(cons(w, l, r)) = w")
164
Binärbaum – Spezifikation (Forts.)
left(cons(w, l, r)) = l right(cons(w, l, r)) = r setleft(empty, t) = ertree setright(empty, t) = ertree setroot(empty, e) = ertree setleft(cons(w, l, r), t) = cons(w, t, r) setright(cons(w, l, r), t) = cons(w, l, t) setroot(cons(w, l, r), e) = cons(e, l, r)
) = l right(cons(w, l, r)) = r setleft(empty, t) = ertree setright(empty, t) = ertree setroot(empty, e) = ertree setleft(cons(w, l, r), t) = cons(w, t, r) setright(cons(w, l, r), t) = cons(w, l, t) setroot(cons(w, l, r), e) = cons(e, l, r)")
165
Binärbaum – Spezifikation (Forts.)
null(t) = (noden(t) = 0) noden(empty) = 0 noden(leaf(w)) = 1 noden(cons(w, l, r)) = 1 + noden(l) + noden(r) maxtree(t) = (noden(t) = max) cons(w, l, r) = if noden(cons(w, l, r)) > max then over else cons(w, l, r) fi end of type
 = (noden(t) = 0) noden(empty) = 0 noden(leaf(w)) = 1 noden(cons(w, l, r)) = 1 + noden(l) + noden(r) maxtree(t) = (noden(t) = max) cons(w, l, r) = if noden(cons(w, l, r)) > max then over else cons(w, l, r) fi end of type")
166
Beispielbaum T / T1 + / T3 a T2 * a c b c
right(T) = cons(/, leaf(a), leaf(c)) left(left(T)) = left( cons(+, leaf(a), cons(*, leaf(b), leaf(c)))) = leaf(a)
 = cons(/, leaf(a), leaf(c)) left(left(T)) = left( cons(+, leaf(a), cons(*, leaf(b), leaf(c)))) = leaf(a)")
167
Beispielbaum – Implementierung
Index Wert lr rr / 2 4 * 6 7 / 8 9 5 a 6 b 7 c 8 a 9 c

168
Beispiel – Freispeicherkette
Index Wert lr rr 1 besetzter Speicher 3 5 Anfang der Frei- speicherkette 8 nil

169
Fragen zu Algorithmen Existiert (im mathematischen Sinn) zu einer gegebenen Aufgabe ein Lösungsalgorithmus? Welche Ressourcen benötigt er und ist er überhaupt durchführbar (Komplexität)? Wie beeinflusst ein gegebenes Rechnersystem die effiziente Ausführung eines Algorithmus? In welcher Programmiersprache kann der Algorithmus am besten notiert werden?
 Wie beeinflusst ein gegebenes Rechnersystem die effiziente Ausführung eines Algorithmus In welcher Programmiersprache kann der Algorithmus am besten notiert werden")
170
Church-Turing-These Alle (existierenden) „vernünftigen“ Definitionen des Begriffs „Algorithmus“ sind gleichwertig. (Formale Beweise der Äquivalenz der Formalisierungen existieren.) Jede (neue) „vernünftige“ Definition des Begriffs ist gleichwertig mit den obigen.
 Jede (neue) „vernünftige Definition des Begriffs ist gleichwertig mit den obigen.")
171
Bemerkungen Intuitive Vorstellungen über Algorithmen lassen sich durch Turingmaschine, Markovalgorithmen usw. formalisieren. Ein Beweis der Äquivalenz ist allerdings nicht möglich. Die Formalisierungen des Algorithmenbegriffs kommen ohne den Rechnerbegriff aus. Demzufolge muss ein Algorithmus prinzipiell auf jedem Rechner ausführbar sein. Algorithmen können in Software oder Hardware umgesetzt werden.

172
Fermatsche Vermutung Stoppt der nachfolgende Algorithmus? Eingabe n; Für a = 1, 2, 3,... Für b = 1, 2,..., a Für c = 2, 3,..., a + b Wenn an + bn = cn, dann gib a, b, c und n aus und stoppe.

173
Totalitätsproblem Äquivalenzproblem
Gibt es einen Algorithmus, der für ein beliebiges Programm P feststellen kann, ob P für alle Eingaben D stoppt oder nicht stoppt? Äquivalenzproblem Gibt es einen Algorithmus, der für beliebige zwei Programme feststellen kann, ob sie die gleiche Aufgabe lösen.

174
Beispiel: Suchproblem
Gegeben: endliche Folge F von Elementen einer Menge S F = A1,..., An, Element a S Gesucht: Position von a in der Folge Algorithmus: FUNCTION LinSu(F: IN ARRAY [1..n] OF real; a: IN real): natural; FOR i := 1 TO n DO IF a = F[i] THEN RETURN(i) FI OD; RETURN(0) END LinSu
: natural; FOR i := 1 TO n DO IF a = F[i] THEN RETURN(i) FI OD; RETURN(0) END LinSu.")
175
O/Ω/Θ-Notation g(n) = O(f(n)) bedeutet: Es existieren eine positive Konstante M und eine Konstante n0, so dass (n n0) |g(n)| M*|f(n)|. g(n) = (f(n)) bedeutet: Es existieren eine positive Konstante M und eine Konstante n0, so dass (n n0) |g(n)| M*|f(n)|. g(n) = (f(n)) bedeutet: Es existieren eine positive Konstante M und eine Konstante n0, so dass (n n0) |f(n)|/M |g(n)| M*|f(n)|.
 = (f(n)) bedeutet: Es existieren eine positive Konstante M und eine Konstante n0, so dass (n n0) |g(n)| M*|f(n)|. g(n) = (f(n)) bedeutet: Es existieren eine positive Konstante M und eine Konstante n0, so dass (n n0) |f(n)|/M |g(n)| M*|f(n)|.")
176
Rechenregeln für die O-Notation
f(n) = O(f(n)) O(O(f(n))) = O(f(n)) c*O(f(n)) = O(f(n)) O(f(n))*O(g(n)) = O(f(n)*g(n)) O(f(n)*g(n)) = O(f(n))*O(g(n)) O(f(n)*g(n)) = f(n)*O(g(n))
 = O(f(n)) O(O(f(n))) = O(f(n)) c*O(f(n)) = O(f(n)) O(f(n))*O(g(n)) = O(f(n)*g(n)) O(f(n)*g(n)) = O(f(n))*O(g(n)) O(f(n)*g(n)) = f(n)*O(g(n))")
177
Beispiel Eine Operation benötige 0,000001 sec
Anzahl der Asymptotischer Zeitbedarf bei Eingabedaten Komplexität n log2 n n n2 2n , , ,0001 0,001 sec sec sec sec , , ,01 1014 sec sec sec Jhd. , , sec sec sec , , ,7 sec sec min , , ,8 sec sec h

178
Häufig auftretende Komplexitäten (in wachsender Reihenfolge)
O(1) konstant O(log n) logarithmisch O(n) O(n) linear O(n*log n) O(n2) quadratisch O(nk), k konstant polynomial O(kn), k konstant exponentiell O(n*2n) O(n!)
 konstant O(log n) logarithmisch O(n) O(n) linear O(n*log n) O(n2) quadratisch O(nk), k konstant polynomial O(kn), k konstant exponentiell O(n*2n) O(n!)")
179
Menge M mit Halbordnung (partieller Ordnung) R:
R M x M, R binäre Relation auf M, wobei gilt R ist reflexiv: (x M) (xRx) R ist transitiv: (x, y, z M) (xRy yRz xRz) R ist antisymmetrisch: (x, y M) (xRy yRx x = y) R ist eine (totale) Ordnung, wenn zusätzlich gilt: (x, y M) (xRy yRx)
 (xRx) R ist transitiv: (x, y, z M) (xRy yRz xRz) R ist antisymmetrisch: (x, y M) (xRy yRx x = y) R ist eine (totale) Ordnung, wenn zusätzlich gilt: (x, y M) (xRy yRx)")
180
Sortierproblem: Gegeben: U Universum mit Ordnung R M = {a1,
Sortierproblem: Gegeben: U Universum mit Ordnung R M = {a1,..., an}, ai U Gesucht: Permutation P = (p1,..., pn) von (1, ...,n), so dass apiRapi+1, i = 1,...,n-1 Beispiel: U = {0, 1, 2,...}, M = {5, 4, 8, 2} = {a1,...,a4} P = (4, 2, 1, 3), da a4 a2 a1 a3
 von (1, ...,n), so dass apiRapi+1, i = 1,...,n-1 Beispiel: U = {0, 1, 2,...}, M = {5, 4, 8, 2} = {a1,...,a4} P = (4, 2, 1, 3), da a4 a2 a1 a3")
181
Grad der Unsortiertheit einer Menge: Anzahl der Inversionen der Menge Inversion: M = {a1,..., an} (ai, aj), wobei ai > aj und i < j Maximale Anzahl: (n2 – n)/2 Beispiel: Im obigen Beispiel: (5, 4), (5, 2), (4, 2), (8, 2)
, wobei ai > aj und i < j Maximale Anzahl: (n2 – n)/2 Beispiel: Im obigen Beispiel: (5, 4), (5, 2), (4, 2), (8, 2)")
182
Klassifikation von Sortierverfahren: 1
Klassifikation von Sortierverfahren: 1. Nach der Art der Elemente: - Elementsortierung - Schlüsselsortierung Schlüssel Assoziierte Information Element Argument Wert Sortieren mit vollständiger Umspeicherung der Elemente oder nur mit Schlüsselumspeicherung (siehe auch Implementation des ADT Tabelle)
")
183
Stabile Sortierung: relative Ordnung zwischen zwei gleichen Schlüsseln bleibt erhalten Beispiel: Eine alphabetisch geordnete Liste von Prüfungsnoten wird nach den Noten geordnet. Dann sind alle Namen zur gleichen Note immer noch in alphabetischer Reihenfolge.

184
2. Nach dem Speicher: - Innere Sortierverfahren: Sortieren auf dem Hauptspeicher - Externe Sortierverfahren: Sortieren von Daten auf externen Speichern unter Nutzung innerer Verfahren für kleine Datenportionen 3. Nach der Rechnerarchitektur: Sequentielles und paralleles Sortieren 4. Nach der zeitlichen Komplexität 5. Nach den Methoden: adressenorientiert, assoziativ, hybrid

185
Adressenorientiertes Sortieren

186
Adressenorientiertes Sortieren Grundalgorithmus
Voraussetzung: U = {u1,..., um} Universum, M = {a1,..., an}, ai U, zu sortierende Menge Algorithmusschritte: 1) Initialisierung: Anlegen von m leeren Listen (zugeordnet zu den Elementen des Universums) 2) Verteilung: Abarbeitung von M von links nach rechts und Anhängen des Indexes i an die Liste j, wenn ai = uj. 3) Verkettung: Verbindung des Endes der i. Liste mit dem Anfang der (i+1). Liste ==> Indizes der Elemente der sortierten Folge bezogen auf ursprüngliche Folge
 Initialisierung: Anlegen von m leeren Listen (zugeordnet zu den Elementen des Universums) 2) Verteilung: Abarbeitung von M von links nach rechts und Anhängen des Indexes i an die Liste j, wenn ai = uj. 3) Verkettung: Verbindung des Endes der i. Liste mit dem Anfang der (i+1). Liste ==> Indizes der Elemente der sortierten Folge bezogen auf ursprüngliche Folge")
187
Adressenorientiertes Sortieren Beispiel
U = {0, 1, 2, 3, 4, 5, 6} = {u1,..., u7} M = {5, 4, 3, 4, 5, 0, 2, 1} = {a1,..., a8} Listen: Liste(Element) 1(0) 2(1) 3(2) 4(3) 5(4) 6(5) 7(6) 4 5 M sortiert: {a6, a8, a7, a3, a2, a4, a1, a5} = {0, 1, 2, 3, 4, 4, 5, 5}
 1(0) 2(1) 3(2) 4(3) 5(4) 6(5) 7(6) M sortiert: {a6, a8, a7, a3, a2, a4, a1, a5} = {0, 1, 2, 3, 4, 4, 5, 5}")
188
Adressenorientiertes Sortieren Eigenschaften
Komplexität: Zeitlich: - Typische Operationen: Einsortieren eines Elements in eine Liste (c1*n), Listen-verknüpfung (c2* (m – 1)) c3* (n + m) O(n+m) O(n) Speicher: O(n*m) O(n) Stabilität: ja
, Listen-verknüpfung (c2* (m – 1)) c3* (n + m) O(n+m) O(n) Speicher: O(n*m) O(n) Stabilität: ja.")
189
Adressenorientiertes Sortieren Lexikographisches Sortieren
Lexikographische Ordnung: U = {u1,..., un}, ui Zahlen gleicher Länge bestehend aus den Ziffern 0, 1,..., m-1 Dabei gilt: ui < uj, i < j, ui = a1...ak, uj = b1...bk l: (1 l k) (ar = br, r=1,...,l-1) (al < bl) Eine analoge Definition gilt für Wörter.
 (ar = br, r=1,...,l-1) (al < bl) Eine analoge Definition gilt für Wörter.")
190
Adressenorientiertes Sortieren Lexikographisches Sortieren
Algorithmusschritte: 1) Initialisierung: Anlegen von m leeren Listen (m Anzahl der Ziffern bzw. Buchstaben) 2) k Durchläufe: i. Durchlauf: · Verteilung: Zahlen (Wörter) des letzten Durchlaufs werden gemäß i. Ziffer (Buchstaben) einer Zahl (eines Wortes) von rechts betrachtet in die Listen einsortiert · Verkettung: Verbindung des Endes der i. Liste mit dem Anfang der (i+1). Liste
 Initialisierung: Anlegen von m leeren Listen (m Anzahl der Ziffern bzw. Buchstaben) 2) k Durchläufe: i. Durchlauf: · Verteilung: Zahlen (Wörter) des letzten Durchlaufs werden gemäß i. Ziffer (Buchstaben) einer Zahl (eines Wortes) von rechts betrachtet in die Listen einsortiert · Verkettung: Verbindung des Endes der i. Liste mit dem Anfang der (i+1). Liste")
191
Beispiel U = {affe, alf_, duo_, elch, esel, maus, tanz, tor_, zart, zoo_} S = {zoo_, affe, tor_, maus, alf_} _ a e f l m o r s t u z zoo_ affe maus tor_ alf_ alf_ zoo_ tor_ maus affe maus affe alf_ zoo_ affe maus tor_ zoo_

192
Adressenorientiertes Sortieren Lexikographisches Sortieren
Komplexität: Zeitlich: O(k * (m + n)) O(n) Speicher: O(n * m) O(n)
) O(n) Speicher: O(n * m) O(n)")
193
Assoziatives Sortieren
Prinzip: Vergleich der Elemente untereinander Grundmethode (rekursive Beschreibung): 1. Analyse: Überführung des ursprünglichen Sortierproblems in Sortierprobleme geringeren Umfangs 2. Rekursion: Lösung der kleineren Probleme gemäß 1.-3. 3. Synthese: Zusammensetzung der Lösungen der kleineren Probleme zur Lösung des Gesamtproblems
: 1. Analyse: Überführung des ursprünglichen Sortierproblems in Sortierprobleme geringeren Umfangs. 2. Rekursion: Lösung der kleineren Probleme gemäß Synthese: Zusammensetzung der Lösungen der kleineren Probleme zur Lösung des Gesamtproblems.")
194
Assoziatives Sortieren Sortieren durch Einfügen (INSERTSORT)
Algorithmus (rekursive Version): 1. Analyse: Zerlegung von M = {a1,..., an} in M1 = {a1,..., an-1} und M2 ={an} 2. Rekursion: Sortieren von M1 nach mit Ergebnis M1’ 3. Synthese: Einfügen von an an die richtige Stelle in M1’
: 1. Analyse: Zerlegung von M = {a1,..., an} in M1 = {a1,..., an-1} und M2 ={an} 2. Rekursion: Sortieren von M1 nach mit Ergebnis M1’ 3. Synthese: Einfügen von an an die richtige Stelle in M1’")
195
Beispiel: Sortieren von M = {4, 5, 0, 2, 1}
Zerlegung {4, 5, 0, 2, 1} {4, 5, 0, 2} {1} {0, 1, 2, 4, 5} {4, 5, 0} {2} {0, 2, 4, 5} {4, 5} {0} {0, 4, 5} {4} {5} {4, 5} Einsortierung

196
Assoziatives Sortieren Sortieren durch Einfügen (INSERTSORT)
Komplexität: Typische Operationen: Vergleich zweier Elemente, Verschiebung eines Elements um 1 Platz Zeitlich: O(n2) Speicher: O(n)
 Speicher: O(n)")
197
Sortieren durch Einfügen (INSERTSORT) Iterative Version
procedure insertion(a : array of integer); var i, j, v: integer; begin for i := 2 to N do v := a[i]; j := i; while a[j – 1] > v do begin a[j] := a[j – 1]; j := j – 1 end; a[j] := v end
; var i, j, v: integer; begin. for i := 2 to N do. v := a[i]; j := i; while a[j – 1] > v do. begin a[j] := a[j – 1]; j := j – 1 end; a[j] := v. end.")
198
Sortieren durch Einfügen (INSERTSORT) Iterative Version
Beispiel: a0 a1 a2 a3 a4 a5 - 4 - 4 5 -

199
Sortieren durch Einfügen (INSERTSORT) Eigenschaften
n Wegen der quadratischen zeitlichen Komplexität ist es ungeeignet für große Mengen, aber sehr wohl anwendbar für kleine. n Ist die zu sortierende Menge gut vorsortiert, dann sind auch große Mengen gut sortierbar (Annäherung an minimale Komplexität). n Es ist gut für on-line Sortierung geeignet. n Der durch den Algorithmus zusätzlich benötigte Speicherplatz ist unabhängig von der Größe der zu sortierenden Menge konstant. n Das Verfahren ist stabil.
. n Es ist gut für on-line Sortierung geeignet. n Der durch den Algorithmus zusätzlich benötigte Speicherplatz ist unabhängig von der Größe der zu sortierenden Menge konstant. n Das Verfahren ist stabil.")
200
Sortieren durch Einfügen (INSERTSORT) Verbesserungen
Beginn der Suche der Einfügungsstelle ca. von der Mitte der sortierten Menge an Beginn des Aufbaues der sortierten Menge von der Mitte her

201
Sortieren durch Einfügen (INSERTSORT) Verbesserungen
Beispiel: S = {4, 5, 0, 2, 1, 6} Aufbau der sortierten Menge: 4

202
Assoziatives Sortieren Sortieren durch Auswahl (SELECTSORT)
Algorithmus (rekursive Version): 1. M = {a1,..., an} wird zerlegt in M1 = {a11,..., a1n-1} = M - M2 und M2 = {min(M)} bzw. M2 = {max(M)} 2. Sortieren von M1 nach den Schritten mit der Ergebnismenge M1’ 3. M’ = M2 M1’ bzw. M’ = M1’ M2
: 1. M = {a1,..., an} wird zerlegt in M1 = {a11,..., a1n-1} = M - M2 und M2 = {min(M)} bzw. M2 = {max(M)} 2. Sortieren von M1 nach den Schritten mit der Ergebnismenge M1’ 3. M’ = M2 M1’ bzw. M’ = M1’ M2")
203
Sortieren durch Auswahl (SELECTSORT) Rekursive Variante
Beispiel: Sortieren mit Minimum {4, 5, 0, 2, 1} Zerlegung {4, 5, 2, 1} {0} {0, 1, 2, 4, 5} {4, 5, 2} {1} {4, 5} {2} {5} {4} Aneinanderreihung

204
Sortieren durch Auswahl (SELECTSORT) Iterative Variante
Beispiel: M = {4, 5, 0, 2, 1} Schritt Sortierte Menge Restmenge

205
Assoziatives Sortieren Sortieren durch Vertauschen (BUBBLESORT)
Prinzip: Vergleich von unmittelbar benachbarten Elementen mit anschließender Vertauschung bei falscher Reihenfolge

206
Sortieren durch Vertauschen (BUBBLESORT)
Beispiel: M = {4, 5, 0, 2, 1, 6} Vertauschungsschritte:

207
Sortieren durch Vertauschen (BUBBLESORT)
Verbesserungen: 1. Auslassen der Vergleiche von der Stelle an, von der im letzten Durchlauf die letzte Vertauschung stattfand (Elemente sind bereits in richtiger Reihenfolge) 2. Vergleich mit alternierender Richtung und Verbesserung 1. (SHEAKSORT)
 2. Vergleich mit alternierender Richtung und Verbesserung 1. (SHEAKSORT)")
208
Sortieren durch Vertauschen (BUBBLESORT)
3. Idee von D. L. Shell (1959): i. Sortierschritt auf der Basis des Vergleichs von Elementen, die hi Elemente voneinander entfernt liegen, wobei hi > hi+1, hk = 1 Empfehlung von Knuth: hi = 3*hi (..., 40, 13, 4, 1)
: i. Sortierschritt auf der Basis des Vergleichs von Elementen, die hi Elemente voneinander entfernt liegen, wobei hi > hi+1, hk = 1 Empfehlung von Knuth: hi = 3*hi (..., 40, 13, 4, 1)")
209
Sortieren durch Vertauschen (BUBBLESORT)
Beispiel: SHELLSORT für {4, 5, 0, 2, 1, 6} Vergleich und Vertauschung mit h1 = 4

210
Vergleich und Vertauschung mit h2 = Vergleich und Vertauschung mit h3 =

211
Assoziatives Sortieren Sortieren durch Mischen (MERGESORT)
Algorithmus: 1. M = {a1,..., an} wird zerlegt in M1 und M2, die von gleicher Größe sein sollten 2. Sortieren von M1 und M2 gemäß ; Ergebnismengen M1’ und M2’ 3. Mischen der Mengen M1’ und M2’ zur sortierten Menge unter Verwendung des nachfolgenden Algorithmus’

212
Assoziatives Sortieren Sortieren durch Mischen (MERGESORT)
Mischalgorithmus: Gegeben: Sortierte Mengen M1’ und M2’ Gesucht: Sortierte Menge M’ bestehend aus den Elementen von M1’ und M2’ Schritte: Initialisierung von M’: M’ := Solange M1’ und M2’ beide nicht leer sind, führe aus: Übernahme des kleineren der beiden ersten Elemente von M1’ und M2’ nach M’ und Entfernung aus M1’ bzw. M2’. Ist M1’ oder M2’ leer, dann Übernahme der anderen Menge nach M’.

213
Sortieren durch Mischen (MERGESORT)
Beispiel: Zerlegung {4, 5, 0, 2, 1, 6} {4, 5, 0} {2, 1, 6} {4, 5} {0} {2, 1} {6} {4} {5} {2} {1}

214
Mischung: {0, 1, 2, 4, 5, 6} {0, 4, 5} {1, 2, 6} {4, 5} {0} {1, 2} {6}

215
Assoziatives Sortieren QUICKSORT
Verbesserung von MERGESORT zu QUICKSORT (Hoare 1961): 1. Auswahl eines Pivotelements P aus M = {a1,..., an} und Zerlegung von M in zwei Mengen M1 und M2, wobei M1 alle Elemente aus M enthält, die kleiner als P sind. 2. Sortieren von M1 und M2 gemäß den Schritten mit den Ergebnismengen M1’ und M2’ 3. M’ = M1’ . {P} . M2’
: 1. Auswahl eines Pivotelements P aus M = {a1,..., an} und Zerlegung von M in zwei Mengen M1 und M2, wobei M1 alle Elemente aus M enthält, die kleiner als P sind. 2. Sortieren von M1 und M2 gemäß den Schritten mit den Ergebnismengen M1’ und M2’ 3. M’ = M1’ . {P} . M2’")
216
Beispiel: M = {207, 095, 646, 198, 809, 376, 917, 534, 310} Zerlegung
{376} {207, 095, 198, 310} {646, 809, 917, 534} {198} {646} {095} {207, 310} {534} {809, 917} {207} {809} {310} {917}

217
Verkettung {095, 198, 207, 310, 376, 534, 646, 809, 917} {095, 198, 207, 310} {376} {534, 646, 809, 917} {095} {198} {207, 310} {534} {646} {809, 917} {207} {310} {809} {917}

218
Assoziatives Sortieren Sortieren durch Zählen (COUNTSORT)
Prinzip: · Zu jedem Element von M = {a1,..., an} wird festgestellt, wie viel Elemente kleiner als dieses Element sind. · Die Anzahl der Elemente, die kleiner als ein gegebenes Element sind, gibt die Stellung des Elements in der sortierten Folge an.

219
Assoziatives Sortieren Sortieren durch Zählen (COUNTSORT)
Beispiel: Menge M = {4, 5, 0, 1, 2, 6} Kleinere Elemente Sortierte M´ = {0, 1, 2, 4, 5, 6} Menge Position

220
Assoziatives Sortieren Heapsort
Vollständiger Binärbaum: Auf jedem Niveau, bis evtl. auf das letzte, sind alle Knoten vorhanden. Auf dem letzten Niveau dürfen Knoten nur am rechten Rand lückenlos fehlen.

221
Assoziatives Sortieren Heapsort
Heap: Vollständiger Binärbaum, wobei der Schlüssel jeden Knotens größer oder gleich den Schlüsseln der Nachfolgerknoten ist. Lineare Darstellung eines Heaps: Anordnung der Elemente in einem Vektor entsprechend Baumebenen beginnend mit der 0. Ebene

222
Assoziatives Sortieren Heapsort
Beispiel: Heap Lineare Darstellung:

223
Assoziatives Sortieren Heapsort
Positionsbestimmung: Vorgänger zu Knoten j: Position j div 2 Direkte Nachfolger zu Knoten j: Positionen 2*j und 2*j + 1

224
Assoziatives Sortieren Heapsort
Algorithmus: 1. Aufbau eines Heap aus den Elementen der zu sortierenden Menge M: Wiederholung folgender Schritte beginnend mit einem 1-elementigen Heap 1.1 Anfügen des nächsten Elements aus M an gegebenen Heap 1.2 Überprüfung der Heapeigenschaft mit Korrektur, wenn nötig

225
2. Konstruktion der sortierten Menge M´: Wiederholung folgender Schritte bis zur Erreichung eines leeren Heaps: 2.1 Übernahme des Wurzelelements des Heaps nach M´(von links nach rechts) 2.2 Ersetzen des Wurzelelements im Heap durch letztes Heapelement (letzte Ebene, rechter Rand) 3.2 Überprüfung der Heapeigenschaft mit Korrektur, wenn nötig
 2.2 Ersetzen des Wurzelelements im Heap durch letztes Heapelement (letzte Ebene, rechter Rand) 3.2 Überprüfung der Heapeigenschaft mit Korrektur, wenn nötig .")
226
Beispiel: M = {550, 917, 613, 320, 809, 646, 412, 534} 1. Konstruktion des Heap 917 Erfüllt Heapeigenschaft nicht 550

227
Heap zu M

228
2. Konstruktion der sortierten Menge M´ Auslesen der Wurzel: 917 Ersetzen der Wurzel durch letztes Element:

229
Überprüfung der Heapeigenschaft:
809
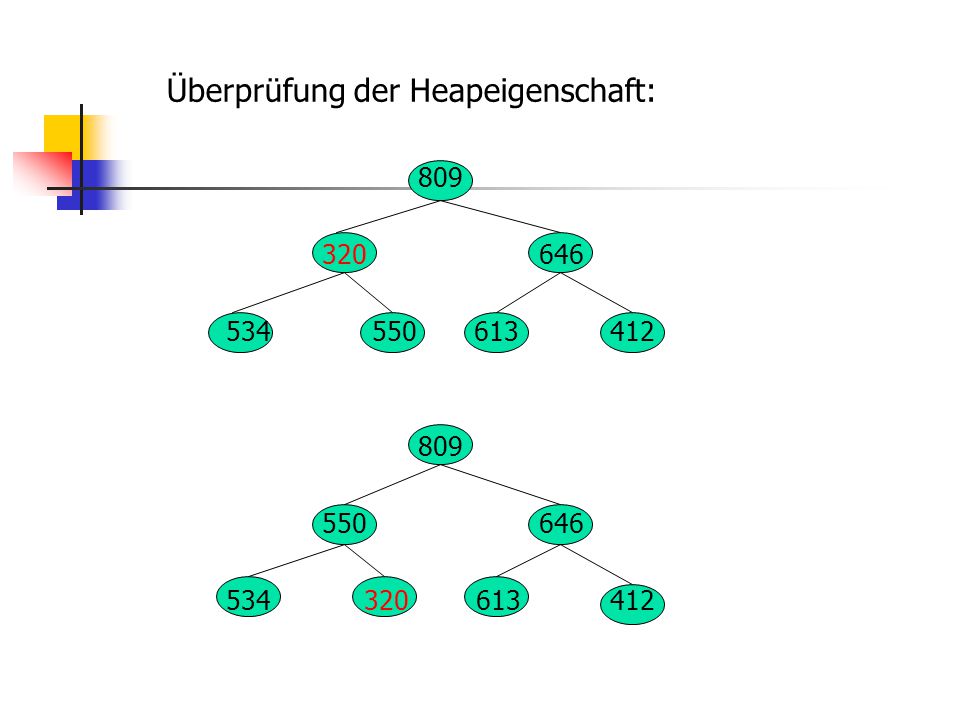
230
Auslesen und Ersetzen der Wurzel:
412 Endergebnis: M´= {320, 412, 534, 550, 613, 646, 809, 917}

231
Hybrides Sortieren Algorithmus: M = {a1,..., an}, amin minimales Element, amax maximales Element von M Schritte: 1. Unterteilung von <amin, amax+1) in m Teilintervalle <xi, xi+1), i=0,...,m-1, x0 = amin, xm = amax Verteilung der Elemente auf Intervalllisten 3. Assoziatives Sortieren in den Listen und Listenverkettung
 in m Teilintervalle <xi, xi+1), i=0,...,m-1, x0 = amin, xm = amax Verteilung der Elemente auf Intervalllisten 3. Assoziatives Sortieren in den Listen und Listenverkettung")
232
Beispiel: M = {207, 095, 646, 198, 809, 376, 918, 534, 310, 209, 181, 595, 799, 694, 344, 522, 139} xmin = 095 xmax + 1 = 919 m = 8 Intervalle Elemente Elemente sortiert <095, 198) Sortierte <198, 301) Menge <301, 404) <404, 507) <507, 610) <610, 713) <713, 816) <816, 919) 918
 Sortierte. <198, 301) Menge. <301, 404) <404, 507) <507, 610) <610, 713) <713, 816) <816, 919) 918 918.")
233
Suchverfahren Suchproblem: Ein Suchproblem ist gegeben durch 1) die Mengen U Universum (Elemente, aus denen der Suchraum bestehen kann), A Menge der Anfragen, X Menge der Antworten 2) und eine Beziehung zwischen den angeführten Mengen Q: A x 2U X Q(a, S) mit a A, S 2U bezeichnet eine Antwort aus X zu einer Anfrage a an einen Suchraum S aus dem Universum U.
 die Mengen U Universum (Elemente, aus denen der Suchraum bestehen kann), A Menge der Anfragen, X Menge der Antworten 2) und eine Beziehung zwischen den angeführten Mengen Q: A x 2U X Q(a, S) mit a A, S 2U bezeichnet eine Antwort aus X zu einer Anfrage a an einen Suchraum S aus dem Universum U.")
234
Suchverfahren Algebraische Formulierung
Statisches Suchproblem: Der Suchraum wird einmal aufgebaut und bleibt dann unverändert. Statisches Q X Lexikon init build A insert,delete 2U U

235
Suchverfahren Algebraische Formulierung
Dynamisches Suchproblem: ständige Änderung des Suchraums durch Hinzufügen und Entfernen von Elementen Dynamisches Q X Lexikon init A insert delete U

236
Suchverfahren Operationen: init Initialisierung des Suchraums mit einer leeren Menge insert Aufnahme eines Elements aus U in den Suchraum delete Entfernung eines Elements aus dem build Strukturierung des Suchraums

237
Suchverfahren Typische Suchprobleme
Zugehörigkeit eines Elements zu einer Menge: U = A beliebige Menge (nach jedem Element des U kann in S gefragt werden), X = {true, false}, S U true, a S Q(a, S) = false, a S S Wörterbuch mit der Anfrageoperation (Mitglied, member) und im dynamischen Fall zusätzlich mit den Operationen insert (Einfügen) und delete (Streichen, Entfernen)
, X = {true, false}, S U. true, a S. Q(a, S) = false, a S. S Wörterbuch mit der Anfrageoperation (Mitglied, member) und im dynamischen Fall zusätzlich mit den Operationen insert (Einfügen) und delete (Streichen, Entfernen)")
238
Suchverfahren Typische Suchprobleme
·Minimum (Maximum) einer geordneten Menge: U = X (potenziell jedes Element aus U kommt in Frage), A ohne Bedeutung Q(_, S) = min S (Q(_, S) = max S), S U Dynamischer Fall: Prioritätsschlange
 einer geordneten Menge: U = X (potenziell jedes Element aus U kommt in Frage), A ohne Bedeutung Q(_, S) = min S (Q(_, S) = max S), S U Dynamischer Fall: Prioritätsschlange")
239
Suchverfahren Typische Suchprobleme
Mehrdimensionale Suchprobleme (partial match searching): E beliebige Menge U = Ek Menge aller k-Tupel von Elementen aus E, k 1 A = (E {*})k Menge aller k-Tupel, deren Elemente * oder aus E sein können, * E X = 2U Q(a, S) = {b S| j (1 j k) (aj = bj aj = *)}, S Ek Menge aller k-Tupel, deren Komponenten mit denen von a = (a1,..., ak) übereinstimmen, wenn sie kein * sind
: E beliebige Menge. U = Ek Menge aller k-Tupel von Elementen aus E, k 1. A = (E {*})k Menge aller k-Tupel, deren Elemente * oder aus E sein können, * E. X = 2U. Q(a, S) = {b S| j (1 j k) (aj = bj aj = *)}, S Ek Menge aller k-Tupel, deren Komponenten mit denen von. a = (a1,..., ak) übereinstimmen, wenn sie kein * sind.")
240
Suchverfahren Typische Suchprobleme
·Problem des nächsten Nachbarn (Postamtproblem): A = U = E2, X = 2U, S E2 E2 zweidimensionaler Euklidischer Raum mit Metrik Q(a, S) = {b S| (c S) ((a, b) (a, c)} (Für eine Postsendung mit gegebenem Zielort ist das nächstliegende Postamt zu bestimmen.)
: A = U = E2, X = 2U, S E2. E2 zweidimensionaler Euklidischer Raum mit Metrik Q(a, S) = {b S| (c S) ((a, b) (a, c)} (Für eine Postsendung mit gegebenem Zielort. ist das nächstliegende Postamt zu bestimmen.)")
241
Suchverfahren Klassifizierungen
Klassifizierung der Suchalgorithmen: 1. Algorithmen mit Adressberechnung: Der Platz des gesuchten Elements im Suchraum wird ausgehend vom Wert des Elements berechnet. 2. Assoziative Algorithmen: Die Positionsbestimmung geschieht durch Vergleich des gesuchten Elements mit anderen Elementen des Suchraumes, wobei im Universum eine Ordnung vorgegeben sein muss. Weitere Klassifizierung: parallele Algorithmen, sequentielle Algorithmen

242
Suchverfahren Komplexitätsmaße
Voraussetzung: n Größe des Suchraumes P(n, k) zeitliche Komplexität der Konstruktion der Datenstruktur (Suchstruktur), in der gesucht wird (k-dimensionale Menge vom Umfang n) S(n, k) Speicherkomplexität der Suchstruktur Q(n, k) zeitliche Komplexität der Realisierung einer Anfrage über der Suchstruktur
 zeitliche Komplexität der Konstruktion der Datenstruktur (Suchstruktur), in der gesucht wird (k-dimensionale Menge vom Umfang n) S(n, k) Speicherkomplexität der Suchstruktur Q(n, k) zeitliche Komplexität der Realisierung einer Anfrage über der Suchstruktur")
243
Suchverfahren Komplexitätsmaße
U(n,k) zeitliche Komplexität jeder Aktualisie- rungsoperation für S I(n, k) zeitliche Komplexität einer insert- Operation im dynamischen Fall D(n, k) zeitliche Komplexität einer delete-
 zeitliche Komplexität jeder Aktualisie- rungsoperation für S I(n, k) zeitliche Komplexität einer insert- Operation im dynamischen Fall D(n, k) zeitliche Komplexität einer delete-")
244
Suchverfahren Algorithmen mit Adressberechnungen
Verwendung eines charakteristischen Vektors Voraussetzung: |U| = N, U = {1, 2,..., N}, N nicht zu groß Repräsentation von S U durch einen charakteristischen Vektor (Bitvektor) A: array [1..N] of Boolean, wobei A[i] = true genau dann, wenn das i. Element von U in S ist
 A: array [1..N] of Boolean, wobei A[i] = true genau dann, wenn das i. Element von U in S ist")
245
Suchverfahren unter Verwendung eines charakteristischen Vektors
Beispiel: U = {rot, blau, grün, gelb, schwarz}, S = (blau, gelb) type Farbe = ...; S: array [Farbe] of Boolean => S[blau] = true = S[gelb], S[rot] = S[grün] = S[schwarz] = false rot blau grün gelb schwarz false true false true false
 type Farbe = ...; S: array [Farbe] of Boolean => S[blau] = true = S[gelb], S[rot] = S[grün] = S[schwarz] = false rot blau grün gelb schwarz false true false true false")
246
Suchverfahren Algorithmen mit Adressberechnungen
Hashing Voraussetzung: großes (evtl. unendliches) Universum U und relativ kleine Menge S U, |S| m Verwendung einer Hashtabelle A[0..m-1] und einer Hashfunktion h: U {0,..., m-1} Wenn x S, dann wird x auf A[h(x)] oder „in der Nähe“ abgespeichert.
 Universum U und relativ kleine Menge S U, |S| m Verwendung einer Hashtabelle A[0..m-1] und einer Hashfunktion h: U {0,..., m-1} Wenn x S, dann wird x auf A[h(x)] oder „in der Nähe abgespeichert.")
247
Suchverfahren Hashing
Kollission: x, y S, x y, und h(x) = h(y) Abspeicherung von x und y auf unterschiedlichen Plätzen „in der Nähe“ von h(x); unterschiedliche Bestimmung der „Nähe“ Verkettung oder offene Adressierung
 = h(y) Abspeicherung von x und y auf unterschiedlichen Plätzen „in der Nähe von h(x); unterschiedliche Bestimmung der „Nähe Verkettung oder offene Adressierung")
248
Suchverfahren Hashing
1. Hashing mit Verkettung Alle Elemente von S mit der gleichen Hashadresse h(x) werden zu einer Kette verbunden, deren Anfang in A[h(x)] abgespeichert ist.
 werden zu einer Kette verbunden, deren Anfang in A[h(x)] abgespeichert ist.")
249
Suchverfahren Hashing mit Verkettung
Beispiel: U = {0, 1, 2,...}, S = (1, 3, 4, 7, 10, 17, 21}, m = 3 Hashfunktion: h(x) = x mod 3 A 2 17
 = x mod 3. A")
250
Suchverfahren Hashing
2. Hashing mit offener Adressierung Idee: Zu jedem Element x U gehört eine Folge von Tabellenpositionen h(x, i), i = 0, 1,... , auf denen sich x befinden könnte. Mögliche Hashfunktion: h(x, i) = [h1(x) + h2(x)*i] mod m
, i = 0, 1,... , auf denen sich x befinden könnte. Mögliche Hashfunktion: h(x, i) = [h1(x) + h2(x)*i] mod m.")
251
Suchverfahren Hashing mit offener Adressierung
Beispiel: m = 7, h1(x) = x mod 7, h2(x) = 1 + (x mod 4) S = (3, 17, 6, 9, 15, 13, 10) h(3, i) = [3 + 4*i] mod 7, i = 0 möglich Abspeicherung von 3 auf A[3] h(17, i) = [3 + 2*i] mod 7, i = 1 möglich Abspeicherung von 17 auf A[5] ...
 = x mod 7, h2(x) = 1 + (x mod 4) S = (3, 17, 6, 9, 15, 13, 10) h(3, i) = [3 + 4*i] mod 7, i = 0 möglich Abspeicherung von 3 auf A[3] h(17, i) = [3 + 2*i] mod 7, i = 1 möglich Abspeicherung von 17 auf A[5] ... ")
252
Suchverfahren Hashing
3. Perfektes Hashing Perfekte Hashfunktion: U = {0, 1,..., N - 1}, S U, h: {0, 1,..., N - 1} {0, 1,..., m-1} h heißt perfekt, wenn für alle x, y S, x y, gilt h(x) h(y). Eine Menge H von Hashfunktionen heißt (N, m, n)-perfekt, wenn es für jede Teilmenge S, |S| = n, ein h H gibt, so dass h für S eine perfekte Hashfunktion ist.
 h(y). Eine Menge H von Hashfunktionen heißt. (N, m, n)-perfekt, wenn es für jede Teilmenge S, |S| = n, ein h H gibt, so dass h für S eine perfekte Hashfunktion ist.")
253
Suchverfahren Perfektes Hashing
Praktische Methode (Cormack, Horspool, Kaiserwerth): Verwendung von zwei Tabellen: - Tabelle D (directory) - Tabelle T (Elementetabelle) Aufspaltung des Suchraums S in Gruppen Si, i=1,...,m, wobei gilt: x und y aus S gehören genau dann in die gleiche Gruppe, wenn ihr Hashwert gemäß primärer Hashfunktion h gleich ist
: Verwendung von zwei Tabellen: - Tabelle D (directory) - Tabelle T (Elementetabelle) Aufspaltung des Suchraums S in Gruppen Si, i=1,...,m, wobei gilt: x und y aus S gehören genau dann in die gleiche Gruppe, wenn ihr Hashwert gemäß primärer Hashfunktion h gleich ist.")
254
h(x,s) = a = h(y, s) bedeutet (|D| = s):
hk(e,r) ist eine sekundäre Hashfunktion für das Auffinden der Elemente aus Sk im Abschnitt [, +r-1] der Tabelle T, wobei hk(x,r) = u und hk(y,r) = t , |Sk| = r Tabelle D Tabelle T a k r +u x +t y +r-1
 ist eine sekundäre Hashfunktion für das Auffinden der Elemente aus Sk im Abschnitt. [, +r-1] der Tabelle T, wobei. hk(x,r) = u und hk(y,r) = t , |Sk| = r. Tabelle D Tabelle T. a k r +u x. +t y. +r-1.")
255
Suchverfahren Hashing
4. Digitale Suchbäume Idee: Kombination von Hashing und Suchbaum Hashwert: Binärzahl Interpretation des Hashwertes: - Durchlaufe den Wert von links nach rechts bis zum Auffinden des Elements oder eines freien Speicherplatzes zur Elementablage - 0: gehe nach links - 1: gehe nach rechts

256
Suchverfahren Digitale Suchbäume
Beispiel: S = {s1, s2, s3, s4, s5, s6} Hashfunktion: i h s s s s2 1001 s s s s s4 s s s6 1111

257
Suchverfahren Hashing
5. Tries (Retrieval trees) Tries haben eine analoge Struktur zu den digitalen Suchbäumen mit folgenden Änderungen: a) Die Elemente sind Blätter des Baumes. b) Als Hashwert wird die binäre Darstellung eines Elements verwendet. c) Die Kanten im Baum sind mit 0 (linke Kante) oder 1 (rechte Kante) bezeichnet. Der Hashwert eines Elements beschreibt dann eine Kantenfolge, die zum gesuchten Element führt.
 Tries haben eine analoge Struktur zu den digitalen Suchbäumen mit folgenden Änderungen: a) Die Elemente sind Blätter des Baumes. b) Als Hashwert wird die binäre Darstellung eines Elements verwendet. c) Die Kanten im Baum sind mit 0 (linke Kante) oder 1 (rechte Kante) bezeichnet. Der Hashwert eines Elements beschreibt dann eine Kantenfolge, die zum gesuchten Element führt.")
258
Suchverfahren Tries Beispiel: S = {0010, 1001, 1101, 0111, 0011, 1111}
s1 s5 s s s s6

259
Assoziatives Suchen Verfahren
Voraussetzungen: U linear geordnetes Universum (Menge mit totaler Ordnung) S = (x1,..., xn) mit xi xi+1 sei im Vektor S[1..n] abgespeichert, wobei S[i] = xi a U in S gesuchtes Element
 S = (x1,..., xn) mit xi xi+1 sei im Vektor S[1..n] abgespeichert, wobei S[i] = xi a U in S gesuchtes Element")
260
Grundalgorithmus: S Schritte:
S[1] S[unten] S[naechster]=e S[oben] S[n] Schritte: a) Vergleiche a mit einem Element e aus S. b) 1. e ist a Halt 2. a < e Suche im unteren Teil von S 3. a > e Suche im oberen Teil von S Erfolgloser Abbruch, wenn bei 2. bzw. 3. der jeweilige Bereich von S nur aus einem Element besteht und dieses Element nicht a ist.
 Vergleiche a mit einem Element e aus S. b) 1. e ist a Halt. 2. a < e Suche im unteren Teil von S. 3. a > e Suche im oberen Teil von S. Erfolgloser Abbruch, wenn bei 2. bzw. 3. der jeweilige Bereich von S nur aus einem Element besteht und dieses Element nicht a ist.")
261
Bestimmung des Suchabschnittes in S: 1
Bestimmung des Suchabschnittes in S: 1. Initialisierung: unten := 1; oben := n; naechster := aus [unten..oben] ausgewählter Index (des Elements e); 2. Solange oben > unten und a S[naechster], führe folgende Schritte aus: Wenn a < S[naechster], dann oben := naechster - 1, sonst unten := naechster + 1. naechster := aus [unten..oben] ausgewählter Index; 3. Wenn a = S[naechster], dann wurde a gefunden, sonst ist a nicht in S. Halt.
; 2. Solange oben > unten und a S[naechster], führe folgende Schritte aus: Wenn a < S[naechster], dann oben := naechster - 1, sonst unten := naechster + 1. naechster := aus [unten..oben] ausgewählter Index; 3. Wenn a = S[naechster], dann wurde a gefunden, sonst ist a nicht in S. Halt.")
262
Der Index von e (naechster) kann durch unterschiedliche Strategien ausgewählt werden: a) lineare Suche: naechster := unten b) binäre Suche: naechster := (oben + unten)/2 - Intervallhalbierung (x bedeutet: kleinste ganze Zahl größer oder gleich x) c) Interpolationssuche: zusätzlich werden S[0] und S[n + 1] eingeführt naechster := (unten - 1) + (a - S[unten - 1])*(oben - unten + 2)/ (S[oben + 1] - S[unten - 1])
![Der Index von e (naechster) kann durch unterschiedliche Strategien ausgewählt werden: a) lineare Suche: naechster := unten b) binäre Suche: naechster := (oben + unten)/2 - Intervallhalbierung (x bedeutet: kleinste ganze Zahl größer oder gleich x) c) Interpolationssuche: zusätzlich werden S[0] und S[n + 1] eingeführt naechster := (unten - 1) + (a - S[unten - 1])*(oben - unten + 2)/ (S[oben + 1] - S[unten - 1])](http://slideplayer.org/slide/5126446/16/images/262/Der+Index+von+e+%28naechster%29+kann+durch+unterschiedliche+Strategien+ausgew%C3%A4hlt+werden%3A+a%29+lineare+Suche%3A+naechster+%3A%3D+unten+b%29+bin%C3%A4re+Suche%3A+naechster+%3A%3D+%EF%83%A9%28oben+%2B+unten%29%2F2%EF%83%B9+-+Intervallhalbierung+%28%EF%83%A9x%EF%83%B9+bedeutet%3A+kleinste+ganze+Zahl+gr%C3%B6%C3%9Fer+oder+gleich+x%29+c%29+Interpolationssuche%3A+zus%C3%A4tzlich+werden+S%5B0%5D+und+S%5Bn+%2B+1%5D+eingef%C3%BChrt+naechster+%3A%3D+%28unten+-+1%29+%2B+%EF%83%A9%28a+-+S%5Bunten+-+1%5D%29%2A%28oben+-+unten+%2B+2%29%2F+%28S%5Boben+%2B+1%5D+-+S%5Bunten+-+1%5D%29%EF%83%B9.jpg "Der Index von e (naechster) kann durch unterschiedliche Strategien ausgewählt werden: a) lineare Suche: naechster := unten b) binäre Suche: naechster := (oben + unten)/2 - Intervallhalbierung (x bedeutet: kleinste ganze Zahl größer oder gleich x) c) Interpolationssuche: zusätzlich werden S[0] und S[n + 1] eingeführt naechster := (unten - 1) + (a - S[unten - 1])*(oben - unten + 2)/ (S[oben + 1] - S[unten - 1])")
263
Beispiel: S = (3, 8, 12, 16, 21, 27, 32), a = 12 Binäre Suche
unten naechster oben erster Suchabschnitt naechster oben zweiter Suchabschnitt unten + naechster dritter Suchabschnitt

264
Interpolationssuche Zusätzliche Elemente: S[0] = 0 S[8] = S unten naechster oben erster Suchabschnitt
![Interpolationssuche Zusätzliche Elemente: S[0] = 0 S[8] = S unten naechster oben erster Suchabschnitt](http://slideplayer.org/slide/5126446/16/images/264/Interpolationssuche+Zus%C3%A4tzliche+Elemente%3A+S%5B0%5D+%3D+0+S%5B8%5D+%3D+S+unten+naechster+oben+erster+Suchabschnitt.jpg "Interpolationssuche Zusätzliche Elemente: S[0] = 0 S[8] = S unten naechster oben erster Suchabschnitt")
265
Binärer Suchbaum S = (x1,..., xn) mit xi < xi+1, i=1,...,n-1 T Binärbaum mit den Knoten v1,..., vn und der Markierungsfunktion Label: {v1,..., vn } S , wobei gilt: vk sei die Wurzel eines beliebigen Unterbaums Tk von T. vi bzw. vj seien beliebige Knoten im linken bzw. rechten Unterbaum von Tk. Dann Label(vi) < Label(vk) < Label(vj)
 < Label(vk) < Label(vj)")
266
Suchbaum mit symmetrischer Ordnung:
- Markierung der inneren Knoten mit Elementen aus S. - Markierung der Blätter mit offenen Intervallen, die alle Elemente umfassen, die nicht im Suchbaum auftreten.

267
Beispiel: S = (3, 8, 12, 16, 21, 27, 32) 16 ( , 3) (3, 8) (16, 21) (21, 27) (8, 12) (12, 16) (27, 32) (32, )
 (3, 8) (16, 21) (21, 27) (8, 12) (12, 16) (27, 32) (32, )")
268
Algorithmus für den Zugriff zu einem Element a im Baum T: 1
Algorithmus für den Zugriff zu einem Element a im Baum T: 1. Initialisierung: v := Wurzel von T; 2. Solange v kein Blatt ist und Label(v) a, wiederhole: Ist a kleiner als Label(v), dann v := linker Sohn von v, sonst v := rechter Sohn von v. 3. Wenn v ein innerer Knoten ist, dann wurde a gefunden, sonst ist a nicht im Baum vorhanden.
 a, wiederhole: Ist a kleiner als Label(v), dann v := linker Sohn von v, sonst v := rechter Sohn von v. 3. Wenn v ein innerer Knoten ist, dann wurde a gefunden, sonst ist a nicht im Baum vorhanden.")
269
Algorithmus zum Einfügen eines neuen Knotens a mit xi0 < a < xi0+1 und S = (..., xi0, xi0+1,...): 1. Auffinden des Blattes mit der Markierung (xi0, xi0+1) 2. Ersetzen des Blattes durch einen Baum a (xi0, a) (a, xi0+1)
 2. Ersetzen des Blattes durch einen Baum a (xi0, a) (a, xi0+1) .")
270
Assoziatives Suchen Gewichtete Bäume
Zugriffsverteilung (0, 1, 1,..., n, n): S = (x1,..., xn) mit x1 < x2 < ... < xn i Wahrscheinlichkeit, dass das Zugriffselement a identisch mit xi ist j Wahrscheinlichkeit, dass das Zugriffselement a im Intervall (xj, xj+1) liegt i + j = 1
: S = (x1,..., xn) mit x1 < x2 < ... < xn i Wahrscheinlichkeit, dass das Zugriffselement a identisch mit xi ist j Wahrscheinlichkeit, dass das Zugriffselement a im Intervall (xj, xj+1) liegt i + j = 1")
271
Assoziatives Suchen Gewichtete Bäume
Tiefe eines Baumknotens v eines Baumes T: 1. v sei die Wurzel von T: Tiefe(v, T) = 0 2. Es sei T = <w, T1,..., Tm> und v sei ein Knoten im Teilbaum Ti: Tiefe(v, T) = 1 + Tiefe(v, Ti) T w T Ti vk Tm v
 = Es sei T = <w, T1,..., Tm> und v sei ein Knoten im Teilbaum Ti: Tiefe(v, T) = 1 + Tiefe(v, Ti) T w. T1 Ti vk Tm. v.")
272
Assoziatives Suchen Gewichtete Bäume
Gewichtete Pfadlänge PT eines Baumes T: PT = i*(1 + biT) + j*ajT biT Tiefe des Knotens xi im Baum T ajT Tiefe des Blattes (xj, xj+1) im Baum T
 + j*ajT biT Tiefe des Knotens xi im Baum T ajT Tiefe des Blattes (xj, xj+1) im Baum T")
273
Beispiel: x3 1/8 x2 1/8 x4 0 x1 1/24 (x2, x3) (x3, x4) (x4, x5)
x / x x / (x2, x3) (x3, x4) (x4, x5) / /12 (x0, x1) (x1, x2 ) 1/ PT = (1/24*3 + 1/8*2 + 1/8) + (1/6*3 + 1/8*2 + 5/12*2)
 (x3, x4) (x4, x5) 0 1/8 5/12. (x0, x1) (x1, x2 ) 1/6 0. PT = (1/24*3 + 1/8*2 + 1/8) + (1/6*3 + 1/8*2 + 5/12*2)")
274
Assoziatives Suchen Balancierte Bäume
1. Gewichtsbalancierte Bäume Wurzelbalance eines Baumes T: Voraussetzungen: - T hat einen linken Unterbaum Tl und einen rechten Unterbaum Tr - |T| bedeutet die Anzahl der Blätter von T Wurzelbalance: (T) = |Tl|/|T| = 1 - |Tr|/|T|
 = |Tl|/|T| = 1 - |Tr|/|T|")
275
Assoziatives Suchen Gewichtsbalancierte Bäume
Baum T von beschränkter Balance (T BB[]): Für jeden Unterbaum T’ von T gilt (T’) 1 - . Bedeutung der Bäume aus BB[]: Sie besitzen logarithmische Tiefe und im Mittel logarithmische mittlere Pfadlängen (für ¼ < /2/2).
: Für jeden Unterbaum T’ von T gilt (T’) 1 - . Bedeutung der Bäume aus BB[]: Sie besitzen logarithmische Tiefe und im Mittel logarithmische mittlere Pfadlängen (für ¼ < /2/2).")
276
Beispiel: 5/14 2/5 4/9 1/2 2/3 1/2 2/5 ( ) ( ) 1/2 ( ) 1/2 1/2 1/2 2/3
/ /9 1/ / / /5 ( ) ( ) 1/ ( ) 1/ / / /3 ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) 1/2 ( ) ( ) ( ) Für 1/3 ist der Baum aus BB[].
 ( ) 1/2 ( ) 1/2 1/2 1/2 2/3. ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) 1/2 ( ) ( ) ( ) Für 1/3 ist der Baum aus BB[].")
277
Operation Rotation nach links
x y 1 y x 2 a c b c a b 1 = 1 + (1 - 1)*2 2 = 1/(1 + (1 - 1)*2)
*2. 2 = 1/(1 + (1 - 1)*2)")
278
Operation Doppelrotation nach links
x z 1 y x y 3 a z 3 d a b c d b c 1 = 1 + (1 - 1)*2*3 2 = 1/(1 + (1 - 1)*2*3) 3 = 2*(1 - 3)/(1 - 2*3)
*2*3. 2 = 1/(1 + (1 - 1)*2*3) 3 = 2*(1 - 3)/(1 - 2*3)")
279
Assoziatives Suchen Balancierte Bäume
2. Höhenbalancierte Bäume (a, b)-Baum: Voraussetzungen: a, b ganze Zahlen, a 2, b 2*a - 1 (v) Anzahl der Söhne des Knotens v T ist ein (a, b)-Baum, wenn gilt: 1. Alle Blätter von T haben die gleiche Tiefe. 2. Alle Knoten v von T erfüllen die Bedingung (v) b. 3. Alle Knoten v, außer der Wurzel, erfüllen die Bedingung (v) a. 4. Die Wurzel r hat die Eigenschaft (r) 2.
-Baum: Voraussetzungen: a, b ganze Zahlen, a 2, b 2*a - 1. (v) Anzahl der Söhne des Knotens v. T ist ein (a, b)-Baum, wenn gilt: 1. Alle Blätter von T haben die gleiche Tiefe. 2. Alle Knoten v von T erfüllen die Bedingung (v) b. 3. Alle Knoten v, außer der Wurzel, erfüllen die Bedingung (v) a. 4. Die Wurzel r hat die Eigenschaft (r) 2.")
280
Abspeicherung einer Menge S als Baum T (Mehlhorn): 1
Abspeicherung einer Menge S als Baum T (Mehlhorn): 1. Die Elemente von S werden als Blätter von T von links nach rechts in aufsteigender Ordnung abgespeichert. 2. Jeder innere Knoten v wird mit k1(v) : k2(v) : ...: k(v)-1 markiert, ki(v) < kj(v) für i < j und ki(v), kj(v) U, wobei gilt: a) Für alle Blätter w des ersten Unterbaumes von v: Label(w) k1(v). b) Für alle Blätter des (v). Unterbaumes von v: Label(w) > k(v)-1. c) Für die Blätter w des i. Unterbaumes von v, 1 < i < (v): ki-1(v) < Label(w) ki(v).
: 1. Die Elemente von S werden als Blätter von T von links nach rechts in aufsteigender Ordnung abgespeichert. 2. Jeder innere Knoten v wird mit k1(v) : k2(v) : ...: k(v)-1 markiert, ki(v) < kj(v) für i < j und ki(v), kj(v) U, wobei gilt: a) Für alle Blätter w des ersten Unterbaumes von v: Label(w) k1(v). b) Für alle Blätter des (v). Unterbaumes von v: Label(w) > k(v)-1. c) Für die Blätter w des i. Unterbaumes von v, 1 < i < (v): ki-1(v) < Label(w) ki(v).")
281
Beispiel: (2, 4)-Baum 4 2 7 : 8 : 9 1 3 7 8 9 10 a : b : c
: 8 : 9 a : b : c bedeutet eine Elementeaufteilung in folgende Bereiche a (a, b] (b, c] c <

282
Beispiel: Rebalancierung nach Einfügen 4
: 7 : 8 : 9 Kein (2, 4)-Baum! Rebalanciert: : 7 : 9
-Baum! Rebalanciert: 4 : :")
283
Beispiel: Rebalancierung nach Streichen
4 : 7 : 9 Kein (2, 4)-Baum! Rebalanciert: 4 : 8
-Baum! Rebalanciert: 4 :")
284
Komplexitäten Sortieralgorithmen
Vorraussetzungen: U Universum, S Sortiermenge, |U| = m (im endlichen Fall), |S| = n Adressenorientiertes Sortieren: - Zeit: O(n + m) - Speicher: O(n * m) Lexikographisches Sortieren (k Stellenanzahl der sortierten Wörter, m Anzahl unterschiedlicher Zeichen): - Zeit: O(k * (m + n))
, |S| = n. Adressenorientiertes Sortieren: - Zeit: O(n + m) - Speicher: O(n * m) Lexikographisches Sortieren (k Stellenanzahl der sortierten Wörter, m Anzahl unterschiedlicher Zeichen): - Zeit: O(k * (m + n))")
285
Insersort, Selectsort, Bubblesort:
- Zeit: O(n2) - Speicher: O(n) Mergesort: - Zeit: O(n * log2 n) - Speicher: O(n) (2 * n) Quicksort: - Zeit: O(n2) , durchschnittlich ca. (n * log2 n) Countsort: - Speicher: O(n) (3 * n)
 - Speicher: O(n) Mergesort: - Zeit: O(n * log2 n) - Speicher: O(n) (2 * n) Quicksort: - Zeit: O(n2) , durchschnittlich ca. (n * log2 n) Countsort: - Speicher: O(n) (3 * n)")
286
Hybrides Sortieren: - Zeit: O(n * log2 n), durchschnittlich ca. (n) - Speicher: O(n) (2 * n) Heapsort: - Zeit: O(n * log2 n) - Speicher: O(n) Shellsort: Zeit: O(n1,5) (hängt entscheidend von den gewählten Abständen ab und ist schwer ermittelbar)
 - Speicher: O(n) Shellsort: Zeit: O(n1,5) (hängt entscheidend von den gewählten Abständen ab und ist schwer ermittelbar)")
287
Ausgewählte Komplexitäten Suchverfahren
Vorraussetzungen: U Universum, S Suchraum, |S| = n, m Anzahl möglicher Eintragungen in einer Hashtabelle Charakteristischer Vektor: Anfrage und Aktualisierung O(1) Hashing mit Verkettung: Anfrage, Einfügen, Löschen im schlechtesten Fall (n) Hashing mit offener Adressierung: durchschnittliche Suchzeit bei Belegungsfaktor =n/m ca. (1/)*log2 (1/(1-))
 Hashing mit Verkettung: Anfrage, Einfügen, Löschen im schlechtesten Fall (n) Hashing mit offener Adressierung: durchschnittliche Suchzeit bei Belegungsfaktor =n/m. ca. (1/)*log2 (1/(1-))")
288
Digitale Suchbäume: O(l) mit l Anzahl der Bit, aber durchschnittlich ca. (log2 n)
Tries: O(l) mit l Länge des Hashwertes Binäre Suche: Anfrage O(log2 n), Einfügen und Löschen O(n) Binärer Suchbaum: O(T) mit T Tiefe des Suchbaums Interpolationssuche: O(n) , durchschnittlich ca. (log2 log2 n) BB[], (1/4, 1 – 21/2/2]: O(log2 n) (a, b)-Baum: Suche, Einfügen, Löschen O(log2 n)
 mit l Länge des Hashwertes. Binäre Suche: Anfrage O(log2 n), Einfügen und Löschen O(n) Binärer Suchbaum: O(T) mit T Tiefe des Suchbaums. Interpolationssuche: O(n) , durchschnittlich. ca. (log2 log2 n) BB[], (1/4, 1 – 21/2/2]: O(log2 n) (a, b)-Baum: Suche, Einfügen, Löschen O(log2 n)")
289
Evolutionsalgorithmen
Charakterisierung: Such- und Optimierungsstrategien nach dem Vorbild der Evolution in der Natur Ingenieurtechnisch ist Evolution - ein Suchprozess im Raum genetischer Informationen bzw. Erbanlagen - mit dem Ziel des Findens bester Erbanlagen Verwendung schwacher Strategien (nicht problemabhängig; keine spezielle Bewertung)
")
290
Durchlauf durch den Suchraum:
Bestimmung des nächsten Suchpunktes ausgehend von durchlaufenen Suchpunkten und aktuellem Suchpunkt unter Nutzung von Bewertungskriterien Durchlaufstrategien: Feste Strategien Wissensbasierte Strategien

291
Evolutionsalgorithmen:
Genetische Algorithmen Genetische Programmierung Evolutionsstrategien Evolutionäre Programmierung

292
Anwendungen: Ältere Anwendungen: 1967 Entwicklung von Spielstrategien, Mustererkennung, Simulation lebender Zellen, 1975 Optimierung der Form von Kühlrippen, 1975 Gewichtsoptimierung eines Stabtragwerkes Neuere Anwendungen: Data Mining, automatische Programmerzeugung, Berechnung optimaler Linsenformen, Strukturevolution neuronaler Netze

293
Genetische Algorithmen
Genetische Algorithmen bilden eine Analogie zur natürlichen Auswahl und Evolution. Charakterisierung: 1. Wahl eines geeigneten Kodierungsmechanismus’ für Problemlösungen als „Chromosomen“ (i.d.R. Bitvektoren für Individuen) 2. Mechanismus zur Erzeugung der initialen Lösungspopulation (Generation 0)
 2. Mechanismus zur Erzeugung der initialen Lösungspopulation (Generation 0)")
294
Genetische Algorithmen (Fortsetzung)
3. Wiederholung nachfolgender Schritte bis zum Erreichen einer zufriedenstellenden Bewertung oder einer Abbruchbedingung: - Bewertung der aktuellen Population gemäß Bewertungs- oder Fitnessfunktion (Bewertung: Nähe zum Optimum; Fitness: Wahrscheinlichkeit des Überlebens und der Teilnahme an der Reproduktion Abbruch oder Fortsetzung mit nächstem Punkt)
")
295
Genetische Algorithmen (Fortsetzung)
- Selektion von Subpopulationen gemäß Heiratsschema und Erzeugung von Nachkommen der aktuellen Generation mittels Rekombination - Mutation der Nachkommen - Bestimmung der neuen Generation gemäß Ersetzungsschema - Aktualisierung der Abbruchbedingung

296
Beispiel: Problem des Handelsreisenden
Naiver Lösungsprozess: Bestimmung aller möglichen Routen ((n-1)!) und Auswahl der kürzesten praktisch nicht durchführbar Lösung durch genetischen Algorithmus: 1. Kodierung der Routen: a) graphisch: Städte als Knoten, Reisestrecken als bewertete Kanten Beispiel: C B D E A F
!) und Auswahl der kürzesten praktisch. nicht durchführbar. Lösung durch genetischen Algorithmus: 1. Kodierung der Routen: a) graphisch: Städte als Knoten, Reisestrecken als bewertete Kanten. Beispiel: C. B D E. A F.")
297
b) Vektor, dessen Komponenten den direkten Städteverbindungen entsprechen:
1 Verbindung vorhanden 0 Verbindung nicht vorhanden Probleme: n geschlossene Wegstrecken sind schlecht erkennbar n schwere Realisierbarkeit vernünftiger Rekombinations- und Mutationsoperatoren c) Vektor S mit k Komponenten (Indizes 0,1,...,k-1), k Anzahl der Städte: Jedem Element aus {0,1,...,k-1} entspricht eine Stadt. Die Vektorkomponenten führen die besuchten Städte kodiert und in der Besuchsreihenfolge an.
 Vektor S mit k Komponenten (Indizes 0,1,...,k-1), k Anzahl der Städte: Jedem Element aus {0,1,...,k-1} entspricht eine Stadt. Die Vektorkomponenten führen die besuchten Städte kodiert und in der Besuchsreihenfolge an.")
298
Beispiel: Zuordnung: A 0, B 1, C 2, D 3, E 4, F 5 S für obigen Weg: (0, 1, 3, 2, 4, 5) 2. Festlegung von Bewertungs- und Abbruchkriterien 3. Festlegung von Rekombinations- und Auswahlstrategien

299
Beispiele: Rekombinationsstrategien Kreuzung: Eltern Kinder Mutation: Löschen - Nachschieben - Einsetzen

300
Genetische Programmierung
Genetische Programmierung kann als genetische Algorithmen auf abstrakten Syntaxbäumen von Programmen betrachtet werden Ziel: Es sollen Programme erzeugt werden, die bestimmten Kriterien genügen Vorgehensweise: siehe genetische Algorithmen

301
Genetische Programmierung (Fortsetzung)
Beispiel: Programm in LISP-Notation: (MUL (ADD X (DIV Y 1.5)) (SUB Z 0.3)) Y/1.5 Z X + Y/1.5 (X + Y/1.5) * (Z - 0.3)
) (SUB Z 0.3)) Y/1.5 Z X + Y/1.5 (X + Y/1.5) * (Z - 0.3)")
302
Genetische Programmierung (Fortsetzung)
Abstrakter Syntaxbaum: MUL ADD SUB X DIV Z 0.3 Y 1.5

303
Algorithmusschritte: 1. Erzeugung einer initialen Programmpopulation 2
Algorithmusschritte: 1. Erzeugung einer initialen Programmpopulation 2. Wiederholung folgender Schritte bis zum Erreichen von Abbruchkriterien: a) Bewertung der aktuellen Population Abbruch bzw. Fortsetzung mit b) b) Erzeugung neuer Programme durch übliche genetische Operationen (z.B. Austausch von Baumteilen, Ersetzen von Baumteilen), die auch typgesteuert sein können
 Bewertung der aktuellen Population Abbruch bzw. Fortsetzung mit b) b) Erzeugung neuer Programme durch übliche genetische Operationen (z.B. Austausch von Baumteilen, Ersetzen von Baumteilen), die auch typgesteuert sein können")
304
c) Bestimmung der neuen Generation Programm-
population Programm- Eltern- test auswahl Neue Programme

305
Evolutionsstrategien
Ziel: Verbesserung von Verhalten durch Evolution Population: Vektoren reeller Zahlen Vektorkomponenten entsprechen Verhaltensmerkmalen Vorgehensweise: analog zu genetischen Algorithmen

306
Evolutionäre Programmierung
Keine Beschränkungen für Populationen! Erzeugung neuer Populationen durch Mutation

307
Komponenten prozeduraler (imperativer) Programmiersprachen (1)
· Ausdrucksmittel zur Darstellung des Steuerungsflusses (Iteration, Sequenz, Alternative, Parallelität) · Prozedurabstraktion (Zusammenfassung von Anweisungsfolgen zu einer, evtl. parametrisierten, Programmeinheit, die an verschiedenen Programmstellen aufgerufen werden kann)
 · Prozedurabstraktion (Zusammenfassung von Anweisungsfolgen zu einer, evtl. parametrisierten, Programmeinheit, die an verschiedenen Programmstellen aufgerufen werden kann)")
308
Komponenten prozeduraler (imperativer) Programmiersprachen (2)
· Programmvariablen als Modell für Speicherplätze: - Charakterisierung durch Name (Bezeichnung im Programm), Referenz (Adresse des zugeordneten Speicherplatzes), Wert (Inhalt des zugeordneten Speicherplatzes), Typ (Art des Inhaltes des zugeordneten Speicherplatzes)
, Referenz (Adresse des zugeordneten Speicherplatzes), Wert (Inhalt des zugeordneten Speicherplatzes), Typ (Art des Inhaltes des zugeordneten Speicherplatzes)")
309
Komponenten prozeduraler (imperativer) Programmiersprachen (3)
- Möglichkeit der Wertänderung - unterschiedliche Arten der Parametervermittlung (z.B. Referenzaufrufe, Werteaufrufe) - Nebeneffekte (side effect) von Prozeduren bei Wertänderung von nichtlokalen Variablen
 - Nebeneffekte (side effect) von Prozeduren bei Wertänderung von nichtlokalen Variablen.")
310
Komponenten prozeduraler (imperativer) Programmiersprachen (4)
- Möglichkeit der Mehrfachreferenz (Aliasnamen) - Sprachkonzepte zur Speicherverwaltung (z.B. Erzeugung und Beseitigung von Speicherplatz) - Lebensdauer und Gültigkeitsbereiche Lebensdauer: Dauer der Existenz eines Objekts; z.B. während der Existenz eines Prozedurkörpers existieren alle dort deklarierten Variablen. Gültigkeitsbereich: gibt Zugriffsmöglichkeiten zum Objekt an
 - Sprachkonzepte zur Speicherverwaltung (z.B. Erzeugung und Beseitigung von Speicherplatz) - Lebensdauer und Gültigkeitsbereiche Lebensdauer: Dauer der Existenz eines Objekts; z.B. während der Existenz eines Prozedurkörpers existieren alle dort deklarierten Variablen. Gültigkeitsbereich: gibt Zugriffsmöglichkeiten zum Objekt an")
311
Komponenten prozeduraler (imperativer) Programmiersprachen (5)
· Datentypkonzept: - Datentyphierarchie alle elementar strukturiert aufzählbar nicht aufzählbar rekursiv endliche kartesisches Vereinigung (Zeiger) Abbildung Produkt (union) (Array) (Record) - Typkontrollen, Typäquivalenz
 Abbildung Produkt (union) (Array) (Record) - Typkontrollen, Typäquivalenz")
312
Komponenten funktionaler Sprachen
· Menge einfacher Datenobjekte (z.B. Listen) · Menge vordefinierter elementarer Funktionen (z.B. zur Listenbearbeitung) · Regeln zur Komposition von Funktionen (z.B. Verkettung) · Bezeichnungsregeln für Funktionen im Zusammenhang mit Deklarationen · Anwendungsoperator für Funktionen (Funktionsaufruf)
 · Menge vordefinierter elementarer Funktionen (z.B. zur Listenbearbeitung) · Regeln zur Komposition von Funktionen (z.B. Verkettung) · Bezeichnungsregeln für Funktionen im Zusammenhang mit Deklarationen · Anwendungsoperator für Funktionen (Funktionsaufruf)")
313
Beispiel % Sortierfunktion DEF sort([]) = []
DEF sort([a|R]) = a insert sort(R) % [a|R] bezeichnet eine Liste mit dem Kopfelement % a und der nachfolgenden Restliste R % Einfuegefunktion DEF x insert [] = [x] DEF x insert [a|R] = IF x a THEN [x|[a|R]] ELSE [a|(x insert R)] FI
![Beispiel % Sortierfunktion DEF sort([]) = []](http://slideplayer.org/slide/5126446/16/images/313/Beispiel+%25+Sortierfunktion+DEF+sort%28%5B%5D%29+%3D+%5B%5D.jpg "DEF sort([a|R]) = a insert sort(R) % [a|R] bezeichnet eine Liste mit dem Kopfelement. % a und der nachfolgenden Restliste R. % Einfuegefunktion. DEF x insert [] = [x] DEF x insert [a|R] = IF x a THEN [x|[a|R]] ELSE [a|(x insert R)] FI.")
314
Sortieren von {17, 5, 7, 1} sort([17|[5, 7, 1]]) 7 insert sort([1])
17 insert sort([5, 7, 1]) sort([1|]) sort([5|7, 1]) 1 insert sort([]) 5 insert sort([7, 1]) 1 insert [] sort([7|1]) [1]
![Sortieren von {17, 5, 7, 1} sort([17|[5, 7, 1]]) 7 insert sort([1])](http://slideplayer.org/slide/5126446/16/images/314/Sortieren+von+%7B17%2C+5%2C+7%2C+1%7D+sort%28%5B17%7C%5B5%2C+7%2C+1%5D%5D%29+7+insert+sort%28%5B1%5D%29.jpg "17 insert sort([5, 7, 1]) sort([1|]) sort([5|7, 1]) 1 insert sort([]) 5 insert sort([7, 1]) 1 insert [] sort([7|1]) [1]")
315
Sortieren von {17, 5, 7, 1} (Fortsetzung)
7 insert [1] = 7 insert [1|] insert [1, 5,7] [1|7 insert []] [1|17 insert [5, 7]] [1|[7]] = [1, 7] [1|[5|17 insert [7]]] 5 insert [1, 7] [1|[5|[7|17 insert []]]] [1|5 insert [7]] [1|[5|[7|[17]]]] = [1|[5|7 insert []]] = [1, 5, 7] [1, 5, 7, 17]

316
Sprachelemente von Prolog
· Klausel (Hornklausel): A B1,...,Bq q 0, A, B1,...,Bq Atome Bedeutung: x1,...,xk (B1’ ... Bq’) A’ x1,...,xk alle Variablen der Klausel A’, B1’,...,Bq’ Aussagen, entstanden aus A, B1,...,Bq Fakt: A. verkürzte Form von A . · Atom: p(t1,..., tn), p n-stelliges Prädikatsymbol, t1,..., tn Terme
: A B1,...,Bq. q 0, A, B1,...,Bq Atome. Bedeutung: x1,...,xk (B1’ ... Bq’) A’ x1,...,xk alle Variablen der Klausel. A’, B1’,...,Bq’ Aussagen, entstanden aus A, B1,...,Bq. Fakt: A. verkürzte Form von A . · Atom: p(t1,..., tn), p n-stelliges Prädikatsymbol, t1,..., tn Terme.")
317
Sprachelemente von Prolog (Fortsetzung)
· Programm: P = <p, f, r, g> p endliche Menge von Prädikatsymbolen f endliche Menge von Funktionssymbolen r endliche Menge von Klauseln unter Verwendung von p und f g Anfrageklausel der Form goal B1,...,Bq. oder ?- B1,...,Bq.

318
Beispiel insertsort([], []).
%Die leere Liste sortiert ergibt wiederum die % leere Liste. insertsort([A|R], S) :- insertsort(R, SR), insert(A, SR, S). %Ist eine Liste nicht leer, so wird erst die % Restliste sortiert und anschliessend das %Kopfelement in die sortierte Restliste auf % den richtigen Platz eingefuegt.
![Beispiel insertsort([], []).](http://slideplayer.org/slide/5126446/16/images/318/Beispiel+insertsort%28%5B%5D%2C+%5B%5D%29..jpg "%Die leere Liste sortiert ergibt wiederum die. % leere Liste. insertsort([A|R], S) :- insertsort(R, SR), insert(A, SR, S). %Ist eine Liste nicht leer, so wird erst die. % Restliste sortiert und anschliessend das. %Kopfelement in die sortierte Restliste auf. % den richtigen Platz eingefuegt.")
319
Beispiel (Fortsetzung)
insert(X, [A|R], [A|S]) :- gt(X, A), !, insert(X, R, S). %Ist das einzufuegende Element X groesser als % das Kopfelement der Liste, so muss es in die % Restliste R eingefuegt werden. insert(X, S, [X|S]). %Ist das einzufuegende Element X kleiner oder %gleich dem Kopfelement, so wird es als neues %Kopfelement verwendet und die alte Liste S % bildet die neue Restliste.
 :- gt(X, A), !, insert(X, R, S). %Ist das einzufuegende Element X groesser als. % das Kopfelement der Liste, so muss es in die. % Restliste R eingefuegt werden. insert(X, S, [X|S]). %Ist das einzufuegende Element X kleiner oder. %gleich dem Kopfelement, so wird es als neues. %Kopfelement verwendet und die alte Liste S. % bildet die neue Restliste.")
320
Beispiel (Fortsetzung) Anfrage. - insertsort([17, 5, 7, 1], S)
Beispiel (Fortsetzung) Anfrage ?- insertsort([17, 5, 7, 1], S). Systemantwort yes S = [1, 5, 7, 17]
![Beispiel (Fortsetzung) Anfrage. - insertsort([17, 5, 7, 1], S)](http://slideplayer.org/slide/5126446/16/images/320/Beispiel+%28Fortsetzung%29+Anfrage.+-+insertsort%28%5B17%2C+5%2C+7%2C+1%5D%2C+S%29.jpg "Beispiel (Fortsetzung) Anfrage - insertsort([17, 5, 7, 1], S). Systemantwort yes S = [1, 5, 7, 17]")
321
Logische Programmierung mit Einschränkungen (Constraint logic programming) - Beispiel
%Zusammenstellung einer kalorienarmen Mahlzeit lightmeal(Vorspeise, Hauptmahlzeit, Nachspeise):- I > 0, J > 0, K > 0, I + J + K <= 10, %Die gesamte Mahlzeit darf nicht mehr als 10 %Kalorien enthalten. vor(Vorspeise, I), haupt(Hauptmahlzeit, J), nach(Nachspeise, K). %Erster Parameter ist Speise, zweiter ist Kalorien
:- I > 0, J > 0, K > 0, I + J + K <= 10, %Die gesamte Mahlzeit darf nicht mehr als 10. %Kalorien enthalten. vor(Vorspeise, I), haupt(Hauptmahlzeit, J), nach(Nachspeise, K). %Erster Parameter ist Speise, zweiter ist Kalorien.")
322
Beispiel (Fortsetzung)
%Vorspeisen vor(rettich, 1). vor(nudeln, 6). %Hauptmahlzeit haupt(H, I) :- fleisch(H, I). haupt(H, I) :- fisch(H, I). fleisch(bulette, 6). fleisch(schwein, 7). fisch(seezunge, 2). fisch(thun, 4). %Nachspeise nach(obst, 2). nach(eis, 6).
. vor(nudeln, 6). %Hauptmahlzeit. haupt(H, I) :- fleisch(H, I). haupt(H, I) :- fisch(H, I). fleisch(bulette, 6). fleisch(schwein, 7). fisch(seezunge, 2). fisch(thun, 4). %Nachspeise. nach(obst, 2). nach(eis, 6).")
323
Beispiel (Fortsetzung) Anfrage. - lightmeal(V, H, N)
Beispiel (Fortsetzung) Anfrage ?- lightmeal(V, H, N). Antwort des Systems V = rettich, H = bulette, N = obst.
 Anfrage - lightmeal(V, H, N). Antwort des Systems V = rettich, H = bulette, N = obst.")
324
Funktionales Programmieren Funktionen in der Mathematik
Definition (Funktion, Abbildung): D und W seien Mengen und f eine binäre, linkseindeutige Relation f D x W. Dann heißt f Funktion mit dem Definitionsbereich D und dem Wertebereich W. f bildet den Argumentwert x D auf den Resultatswert y W genau dann ab, wenn (x, y) f (Notation: f(x) = y. f(x) bezeichnet demzufolge die Anwendung von f auf x.).
: D und W seien Mengen und f eine binäre, linkseindeutige Relation f D x W. Dann heißt f Funktion mit dem Definitionsbereich D und dem Wertebereich W. f bildet den Argumentwert x D auf den Resultatswert y W genau dann ab, wenn (x, y) f (Notation: f(x) = y. f(x) bezeichnet demzufolge die Anwendung von f auf x.).")
325
D W ist der Typ (Funktionalität, Profil) von f
D W ist der Typ (Funktionalität, Profil) von f. f heißt partiell (total), wenn die Projektion von f auf D eine Teilmenge von D (die Menge D) ist, d.h. 1(f) D (1(f) = D). Definition (Totalisierung einer partiellen Funktion): Es sei f eine partielle Funktion mit dem Definitionsbereich D und dem Wertebereich W. Außerdem gelte D = D {} und W = W {}. Dann ist f eine totale Funktion mit dem Definitionsbereich D sowie dem Wertebereich W und y, f(x) = y, x D f(x) = , f(x) ist nicht definiert, x D , x =
 von f. f heißt partiell (total), wenn die Projektion von f auf D eine Teilmenge von D (die Menge D) ist, d.h. 1(f) D (1(f) = D). Definition (Totalisierung einer partiellen Funktion): Es sei f eine partielle Funktion mit dem Definitionsbereich D und dem Wertebereich W. Außerdem gelte D = D {} und W = W {}. Dann ist f eine totale Funktion mit dem Definitionsbereich D sowie dem Wertebereich W und y, f(x) = y, x D f(x) = , f(x) ist nicht definiert, x D , x = ")
326
Funktionales Programmieren -Terme
Definition (-Terme): -Terme sind 1. Variablen, Konstanten , Funktionssymbole 2. Terme der Form v.l (-Abstraktion) mit der Variablen v und dem -Term l; v heißt gebundene Variable in l. 3. Terme der Form (m n) (-Applikation) mit den -Termen m und n. m steht in Funktionsposition und n in Argumentposition.
: -Terme sind 1. Variablen, Konstanten , Funktionssymbole 2. Terme der Form v.l (-Abstraktion) mit der Variablen v und dem -Term l; v heißt gebundene Variable in l. 3. Terme der Form (m n) (-Applikation) mit den -Termen m und n. m steht in Funktionsposition und n in Argumentposition.")
327
Beispiele (Infixnotation statt Präfixnotation): · (x. 1 + x) · ((x
Beispiele (Infixnotation statt Präfixnotation): · (x. 1 + x) · ((x. 1 + x) 2) 3 · (x. ((y. ((x. x * y) 2)) x) x + y) 2 * y 2 * x 2 * (x + y)
: · (x. 1 + x) · ((x. 1 + x) 2) 3 · (x. ((y. ((x. x * y) 2)) x) x + y) 2 * y 2 * x 2 * (x + y)")
328
Konversionen ( Reduktion, Abstraktion):
1. Alpha-Konversion: (x. E) E[y/x] (Einsetzen von y anstelle von x in E; Umbenennung von Variablen ) 2. Beta-Konversion: ((x. E) F) E[F/x] Die Reduktion ist analog zum Ersetzen formaler Parameter durch aktuelle Parameter bei Prozeduraufrufen imperativer Sprachen. Zu beachten sind Namenskonflikte, die durch den Ersetzungsprozess entstehen können. 3. Eta-Konversion: (x. (E x)) E
 E[y/x] (Einsetzen von y anstelle von x in E; Umbenennung von Variablen ) 2. Beta-Konversion: ((x. E) F) E[F/x] Die Reduktion ist analog zum Ersetzen formaler Parameter durch aktuelle Parameter bei Prozeduraufrufen imperativer Sprachen. Zu beachten sind Namenskonflikte, die durch den Ersetzungsprozess entstehen können. 3. Eta-Konversion: (x. (E x)) E.")
329
Problem der Reihenfolge der Auswertung bei -Reduktion:
Erst Auswertung von F und dann Einsetzen für x – applikative oder strikte Auswertung (eager evaluation) Erst Einsetzen von F für x und anschließend Auswertung – normalisierende Auswertung (normal-order evaluation); Auswertung erfolgt nur, wenn sie benötigt wird – verzögerte Auswertung (lazy evaluation)
 Erst Einsetzen von F für x und anschließend Auswertung – normalisierende Auswertung (normal-order evaluation); Auswertung erfolgt nur, wenn sie benötigt wird – verzögerte Auswertung (lazy evaluation)")
330
Beispiel: (((b1. (b2. IF b1 THEN b2 ELSE FALSE FI)) n 0) t/n 0
Beispiel: (((b1. (b2. IF b1 THEN b2 ELSE FALSE FI)) n 0) t/n 0.5) n sei 0: Strikte Auswertung: Im zweiten Argumentterm tritt eine Division durch 0 auf und somit kann dieser Term nicht ausgewertet werden. Verzögerte Auswertung: IF n 0 THEN t/n 0.5 ELSE FALSE FI FALSE Diesmal wird der Term nicht benötigt und daher nicht berechnet.
) n 0) t/n 0.5) n sei 0: Strikte Auswertung: Im zweiten Argumentterm tritt eine Division durch 0 auf und somit kann dieser Term nicht ausgewertet werden. Verzögerte Auswertung: IF n 0 THEN t/n 0.5 ELSE FALSE FI FALSE Diesmal wird der Term nicht benötigt und daher nicht berechnet.")
331
Funktionale Programmierung Datentypen
Elementare Datentypen: z.B. int, real, bool, string Zusammengesetzte Datentypen: z.B. Tupel (Untermengen kartesischer Produkte), Verbunde (Tupel mit Selektoren), Listen (Tupel mit Elementen vom gleichen Typ), Funktionstypen
, Verbunde (Tupel mit Selektoren), Listen (Tupel mit Elementen vom gleichen Typ), Funktionstypen")
332
Ausgewählte Programmkonstrukte: - Wertedefinition val Identifikator = Ausdruck Dem Identifikator wird der Ausdruck als Bedeutung zugeordnet. - Funktionsabstraktion fun (Identifikator:Typ) Ausdruck Dies entspricht dem -Term Identifikator.Ausdruck, wobei der Identifikator (Variable) zusätzlich einen Typ bekommen hat.
 Ausdruck Dies entspricht dem -Term Identifikator.Ausdruck, wobei der Identifikator (Variable) zusätzlich einen Typ bekommen hat.")
333
- Funktionsdefinition val Name der Funktion = Funktionsabstraktion
- Funktionsdefinition val Name der Funktion = Funktionsabstraktion oder fun Name der Funktion (Identifikator:Typ) = Ausdruck, wobei Identifikator, Typ und Ausdruck aus der Funktionsabstraktion stammen.
 = Ausdruck, wobei. Identifikator, Typ und Ausdruck aus der Funktionsabstraktion stammen.")
334
Beispiele: Typvereinbarung für Binärbäume mit real-Zahlen als Markierungen: datatype tree = nil | tree of (real * tree * tree) (Typgleichung: tree = unit + (real x tree x tree) ) Musterbasierte Funktionsdefinition: Summe der real-Zahlen des Baumes fun sum(nil) = 0.0 | sum(tree(N, L, R)) = N + sum(L) + sum(R)
 ) Musterbasierte Funktionsdefinition: Summe der real-Zahlen des Baumes. fun sum(nil) = 0.0. | sum(tree(N, L, R)) = N + sum(L) + sum(R)")
335
1. 0 -3. 5 7. 7 -5. 7 5. 7 8. 0 sum(tree(1. 0, tree(-3. 5, tree(-5
sum(tree(1.0, tree(-3.5, tree(-5.7, nil, nil), nil), tree(7.7, tree(5.7, nil, nil), tree(8.0, nil, nil)))) = 13.2
, nil), tree(7.7, tree(5.7, nil, nil), tree(8.0, nil, nil)))) = 13.2")
336
Einsortieren einer int-Zahl in einen Binärbaum mit int-Zahlen als Markierungen:
datatype tree = nil | node of (tree * int * tree) fun insert(newitem, nil) = node(nil, newitem, nil) | insert(newitem, node(left, olditem, right)) = if newitem = olditem then node(insert(newitem, left), olditem, right) else node(left, olditem, insert(newitem, right))
 fun insert(newitem, nil) = node(nil, newitem, nil) | insert(newitem, node(left, olditem, right)) = if newitem = olditem. then node(insert(newitem, left), olditem, right) else node(left, olditem, insert(newitem, right))")
337
Typvereinigung von line, triangle und circle zu Figure
datatype Figure = line of (point * point) | triangle of (point * point * point) | circle of (point * real) (Typgleichung: Figure = line + triangle + circle mit line = point x point, triangle = point x point x point, circle = point x real)
 | triangle of (point * point * point) | circle of (point * real) (Typgleichung: Figure = line + triangle + circle. mit line = point x point, triangle = point x point x point, circle = point x real)")
338
Parametrisierte Datentypen:
z.B. type pair = * definiert Paare von Elementen eines beliebigen Typs .

339
Datentypen Listentyp · datatype list = nil| cons of ( * list)
fun hd(l: list) = case l of nil ... (*Fehler*) |cons(h,t) h and tl(l: list) = |cons(h,t) t and length(l: list) = case l of nil 0 |cons(h,t) 1 + length(t)
 = case l of nil ... (*Fehler*) |cons(h,t) h. and tl(l: list) = |cons(h,t) t. and length(l: list) = case l of nil 0. |cons(h,t) 1 + length(t)")
340
Eine Liste ist eine Folge von Elementen des gleichen Typs
Eine Liste ist eine Folge von Elementen des gleichen Typs. Definiert sind Funktionen zur Bestimmung des Listenkopfs (hd), des Listenrests (tl) und ihrer Länge (length). (Typgleichung: -list = unit + ( x -list) ) Notation: cons(h, t) oder h::t bezeichnen eine Liste mit dem Kopf h und dem Rest t.
, des Listenrests (tl) und ihrer Länge (length). (Typgleichung: -list = unit + ( x -list) ) Notation: cons(h, t) oder h::t bezeichnen eine Liste mit dem Kopf h und dem Rest t.")
341
Listentyp Operationen
Beispiele: · Summe der Elemente einer Liste ganzer Zahlen fun sum(nil) = 0 |sum(n::ns) = n + sum(ns) · Produkt der Elemente einer Liste ganzer Zahlen fun product(nil) = 1 | product(n::ns) = n * product(ns) · Liste der ganzen Zahlen von m bis n ([m, n]) fun op through(m,n) = if m n then nil else m:: (m + 1 through n) op bedeutet, der folgende Operator kann als Infixoperator verwendet werden.
 = 0. |sum(n::ns) = n + sum(ns) · Produkt der Elemente einer Liste ganzer Zahlen. fun product(nil) = 1. | product(n::ns) = n * product(ns) · Liste der ganzen Zahlen von m bis n ([m, n]) fun op through(m,n) = if m n then nil else m:: (m + 1 through n) op bedeutet, der folgende Operator kann als Infixoperator verwendet werden.")
342
Definition der Berechnung von bn 1. Variante (gewöhnlich):
Currying im Beispiel: Definition der Berechnung von bn 1. Variante (gewöhnlich): fun power(n, b) = if n=0 then 1.0 else b*power(n-1, b) Funktionalität: nat x integer integer 2. Variante (Currying): fun powerc(n) (b) = if n = 0 then 1.0 else b * powerc(n - 1) ( b) Funktionalität: nat (integer integer) Wenn val sqr = powerc(2) , dann liefert sqr das Quadrat zu einer integer-Zahl.
: fun power(n, b) = if n=0 then 1.0. else b*power(n-1, b) Funktionalität: nat x integer integer. 2. Variante (Currying): fun powerc(n) (b) = if n = 0 then 1.0. else b * powerc(n - 1) ( b) Funktionalität: nat (integer integer) Wenn val sqr = powerc(2) , dann liefert sqr das Quadrat zu einer integer-Zahl.")
343
Funktion als Argument im Beispiel:
1. Variante: fun twice(f: ) = fun (x: ) f(f(x)) Funktionalität: () () twice hat als Parameter eine Funktion und liefert selbst wieder eine Funktion. Daher könnte die vierte Potenz so definiert werden: val fourth = twice(sqr) 2. Variante: Definition der Verkettung zweier Funktionen: fun op (f: , g: ) = fun (x:) f(g(x)) Funktionalität: () x () () fun twice(f:) = f f
 = fun (x: ) f(f(x)) Funktionalität: () () twice hat als Parameter eine Funktion und liefert selbst wieder eine Funktion. Daher könnte die vierte Potenz so definiert werden: val fourth = twice(sqr) 2. Variante: Definition der Verkettung zweier Funktionen: fun op (f: , g: ) = fun (x:) f(g(x)) Funktionalität: () x () () fun twice(f:) = f f.")
344
Listentyp Allgemeine Operationen
Filteroperationen: Alle Elemente einer Liste, die eine gegebene Eigenschaft besitzen (ausgedrückt durch ein Prädikat p), sollen in eine neue Liste übernommen werden. filter p [] = [] x:: filter p xs, wenn p x filter p (x::xs) = filter p xs, sonst Funktionalität: ( bool) (-list -list) Beispiel: filter(odd) beseitigt alle geraden Zahlen aus einer Liste ganzer Zahlen
, sollen in eine neue Liste übernommen werden. filter p [] = [] x:: filter p xs, wenn p x filter p (x::xs) = filter p xs, sonst Funktionalität: ( bool) (-list -list) Beispiel: filter(odd) beseitigt alle geraden Zahlen aus einer Liste ganzer Zahlen")
345
Abbildung: Auf jedes Element einer Liste wird die gleiche Funktion angewendet. map f [] = [] map f (x::xs) = f x:: map f xs Funktionalität: () (-list -list) Beispiel: map(sqr) liefert auf eine integer-Liste angewendet eine Liste der Quadrate der Listenelemente bzw. map(odd) liefert eine Liste logischer Werte in Abhängigkeit davon, ob ein Listenelement ungerade (true) oder gerade (false) war.
 = f x:: map f xs Funktionalität: () (-list -list) Beispiel: map(sqr) liefert auf eine integer-Liste angewendet eine Liste der Quadrate der Listenelemente bzw. map(odd) liefert eine Liste logischer Werte in Abhängigkeit davon, ob ein Listenelement ungerade (true) oder gerade (false) war.")
346
faltr f a [x1,...,xn] = f x1 (f x2 (...(f xn a)...))
· Faltung: Diesen Operator gibt es als rechte und linke Faltung. Die Faltung bedeutet, dass alle Elemente einer Liste ausgehend von einem wählbaren Startwert durch eine zweistellige Operation verknüpft werden, z.B. durch Addition. faltr f a [x1,...,xn] = f x1 (f x2 (...(f xn a)...)) f ist eine zweistellige Operation und a ist der Startwert. Die Anwendung von f geschieht von rechts. Funktionalität: () []
![faltr f a [x1,...,xn] = f x1 (f x2 (...(f xn a)...))](http://slideplayer.org/slide/5126446/16/images/346/faltr+f+a+%5Bx1%2C...%2Cxn%5D+%3D+f+x1+%28f+x2+%28...%28f+xn+a%29...%29%29.jpg "· Faltung: Diesen Operator gibt es als rechte und linke Faltung. Die Faltung bedeutet, dass alle Elemente einer Liste ausgehend von einem wählbaren Startwert durch eine zweistellige Operation verknüpft werden, z.B. durch Addition. faltr f a [x1,...,xn] = f x1 (f x2 (...(f xn a)...)) f ist eine zweistellige Operation und a ist der Startwert. Die Anwendung von f geschieht von rechts. Funktionalität: () [] ")
347
Rechte Faltung in der Sprache ML: fun reduce(binaryop, unity) = let fun f(nil) = unity |f(x::xs) = binaryop(x, f(xs)) in f end Definition der Summe bzw. des Produkts der Elemente einer Liste von integer-Zahlen: reduce(op +, 0) bzw. reduce(op *, 1)
 bzw. reduce(op *, 1) .")
348
Potenziell unendlich lange Listen und verzögerte Auswertung
Beispiel: näherungsweise Berechnung der Quadratwurzel durch yn+1 = (yn + x/yn)/2 Lösungsidee: Berechnung der Elemente der unendlichen Folge gemäß Formel Abbruch der Berechnung der Folge, wenn sich zwei aufeinander folgende Elemente um nicht mehr als unterscheiden
/2. Lösungsidee: Berechnung der Elemente der unendlichen Folge gemäß Formel. Abbruch der Berechnung der Folge, wenn sich zwei aufeinander folgende Elemente um nicht mehr als unterscheiden.")
349
Berechnung der Listenelemente: fun approxsqrts(x) =
let fun from(approx) = approx:: from(0.5 * (approx x/approx)) in from(1.0) end Überprüfung der Abbruchbedingung für die ersten beiden Elemente einer Liste: fun absolute(eps) (approx1::approx2::approxs) = if abs(approx1 - approx2) = eps then approx2 else absolute(eps) (approx2::approxs)
 = approx:: from(0.5 * (approx + x/approx)) in from(1.0) end. Überprüfung der Abbruchbedingung für die ersten beiden Elemente einer Liste: fun absolute(eps) (approx1::approx2::approxs) = if abs(approx1 - approx2) = eps. then approx2. else absolute(eps) (approx2::approxs)")
350
Kombination der obigen Funktionen zur Lösungsfunktion:
val sqrt = absolute(0.0001)approxsqrts Listenelemente werden durch approxsqrts nur solange berechnet, wie sie für den Test absolute(0.0001) benötigt werden.
approxsqrts. Listenelemente werden durch approxsqrts nur solange berechnet, wie sie für den Test absolute(0.0001) benötigt werden.")
351
Andere Vorgehensweise (nicht in ML-Notation):
Verbesserung eines Näherungswertes y gemäß Formel (für x ist die Quadratwurzel zu berechnen): verbessern x y = (y + x/y)/2 Überprüfung der Abbruchbedingung für zwei Werte x und y: erfüllt x y = abs(y^2 - x) eps
: verbessern x y = (y + x/y)/2. Überprüfung der Abbruchbedingung für zwei Werte x und y: erfüllt x y = abs(y^2 - x) eps.")
352
Berechnung eines Funktionswertes der Funktion f mit dem Argument x in Abhängigkeit von der Bedingung p: x, wenn p x bis p f x = bis p f(f x), sonst Kombination obiger Funktionen: wurzel x y = bis (erfüllt x) (verbessern x) y
, sonst. Kombination obiger Funktionen: wurzel x y = bis (erfüllt x) (verbessern x) y.")
353
Beispiele: Sortierfunktionen in der Sprache OPAL OPAL-QUICKSORT
DEF sort() == DEF sort(a::R) == LET Small == (_ a) R Medium == a:: (_= a) R Large == (_ a) R IN sort(Small) :: Medium :: sort(Large) liefert zu einer Liste alle Elemente, die eine bestimmte Bedingung erfüllen, in Form einer Liste. vertritt die leere Liste.
 == DEF sort(a::R) == LET Small == (_ a) R. Medium == a:: (_= a) R. Large == (_ a) R. IN sort(Small) :: Medium :: sort(Large) liefert zu einer Liste alle Elemente, die eine bestimmte Bedingung erfüllen, in Form. einer Liste. vertritt die leere Liste.")
354
OPAL-INSERTSORT DEF sort() == DEF sort(a :: R) == a insert sort(R)
FUN insert: x seq[] seq[] DEF x insert == x :: DEF x insert (a :: R) == IF x a THEN x :: (a :: R) ELSE a :: (x insert R) FI
 == IF x a THEN x :: (a :: R) ELSE a :: (x insert R) FI.")
Ähnliche Präsentationen










>")

>")
, leere Liste falls n=0 Listenelemente besitzen.>")





