Präsentation herunterladen
Die Präsentation wird geladen. Bitte warten

1
Data Mining Spectral Clustering Junli Zhu SS 2005

2
Einleitung Motivation Algorithmen spectral clustering kernel k-means

4
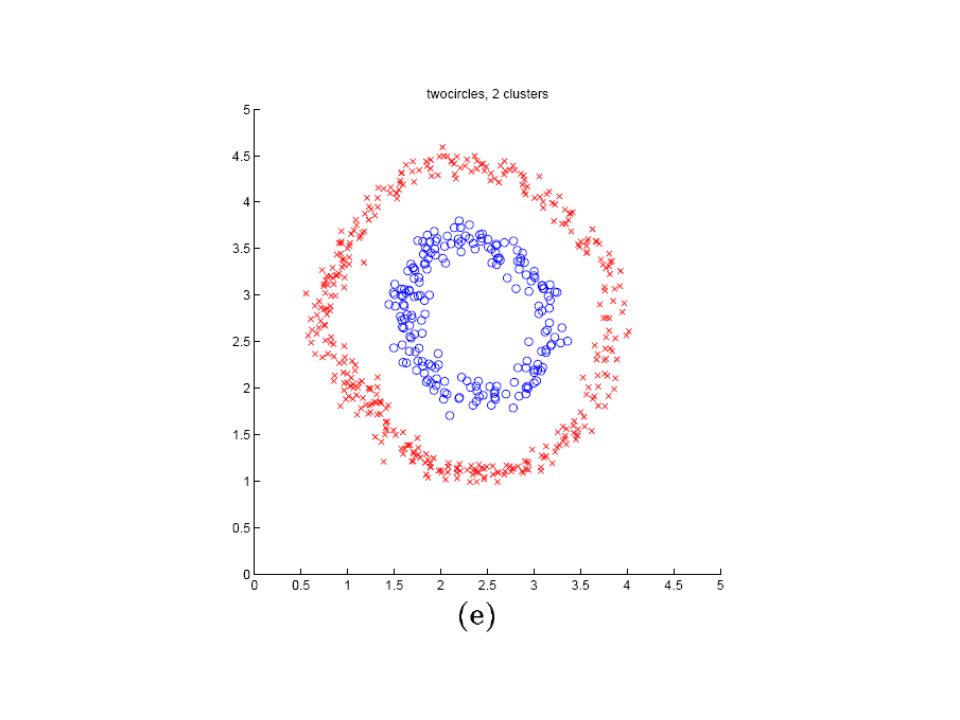
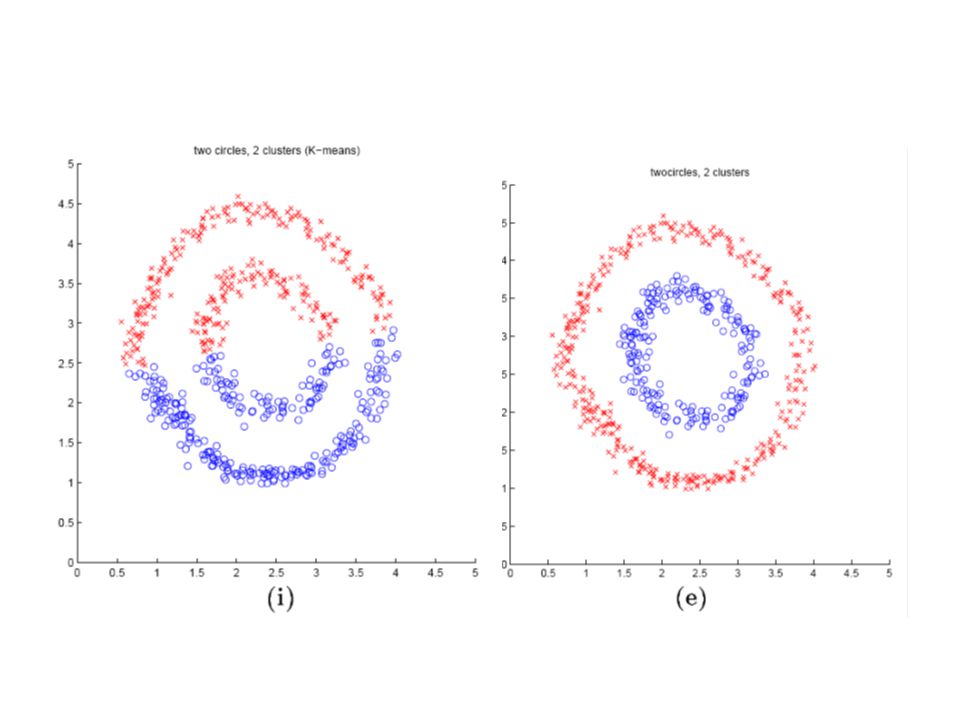
Spectral Clustering Algorithmus Gegeben sei eine Menge von Punkte S={s 1, …, s n }in 1.Sei affinity Matrix A ∈, definiere A ij =exp(- ), wenn i≠j ; sonst A ii =0 2. Sei D eine Diagonalmatrix, D ii =, und

5
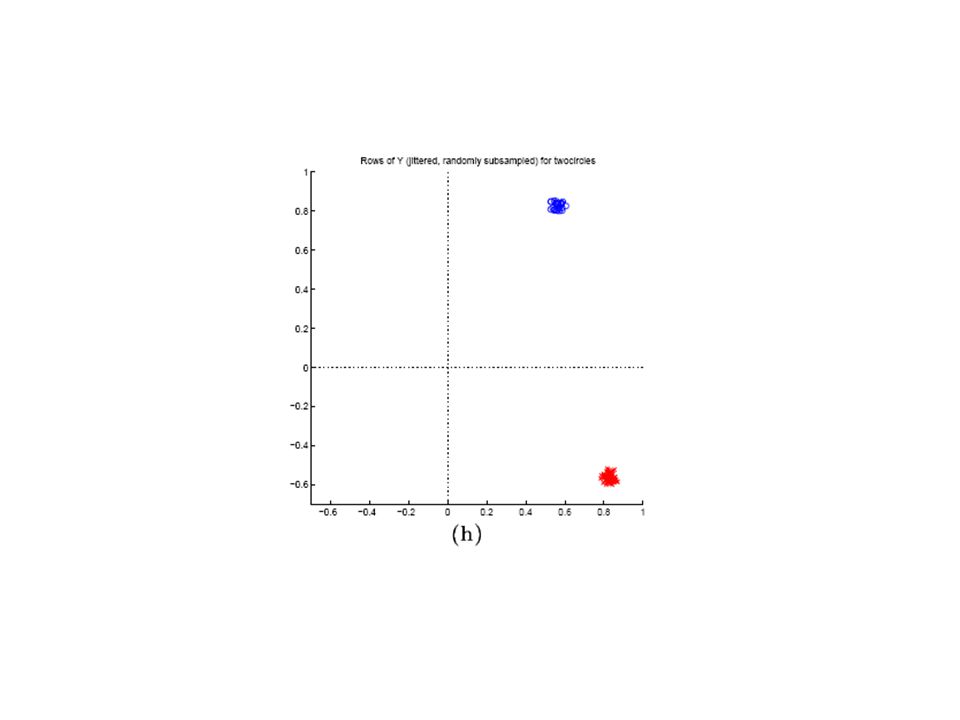
3. Finde die k groessten Eigenvektoren von L: x 1, x 2, …, x k, bilde Matrix X=[x 1 x 2… x k ] 4. Bilde die Matrix Y aus X, damit jeder Zeile von X normalisiert ist und die Laenge 1 hat 5. Behandle jede Zeile von Y als ein Punkt im Raum,verpacke sie in k clusters mit k-means oder einer anderer Methode 6. Zum Schluss ordne den originale Punkt s i zu Cluster j nur,wenn Zeile i der Matrix Y zu Cluster j zugeordnet ist.
![3. Finde die k groessten Eigenvektoren von L: x 1, x 2, …, x k, bilde Matrix X=[x 1 x 2… x k ] 4.](http://images.slideplayer.org/8/2486356/slides/slide_5.jpg "Bilde die Matrix Y aus X, damit jeder Zeile von X normalisiert ist und die Laenge 1 hat 5. Behandle jede Zeile von Y als ein Punkt im Raum,verpacke sie in k clusters mit k-means oder einer anderer Methode 6. Zum Schluss ordne den originale Punkt s i zu Cluster j nur,wenn Zeile i der Matrix Y zu Cluster j zugeordnet ist..")
6
Analysis Ideal case sei k=3,d.h. 3 clusters S 1, S 2, S 3, mit der Groesse n 1, n 2, n 3, sei = 0,wenn x i und x j in unterschiedliche cluster,sonst = A ij

8
Proposition 1 Let ’ s off-diagonal blocks,,be zero. Also assume that each cluster is connected. Then there exist k orthogonal vectors ( if i=j, 0 otherwise ) so that ’ s rows satisfy for all i = 1, …,k, j = 1, …, n i.
 so that ’ s rows satisfy for all i = 1, …,k, j = 1, …, n i..")
9
General Case Eigengap Assumption A 1. there exists δ>0 so that,for all i = 1,….,k, Assumption A 1.1 define the Cheeger constant of the cluster Si to be Where the outer minimum is over all index subsets. Assume that there exists δ>0 so that for all i.

10
Assumption A 2. there is some fixed є 1 > 0, so that for all i 1, i 2 ∈ {1, …,k}, i 1 ≠ i 2,we have that Assumption A 3. for some fixed є 2 >0, for every i=1, …,k, j ∈ S i, we have

11
Assumption A 4. there is some constant C>0 so that for every i = 1, …,k, j = 1, …, n i, we have

12
Theorem 2 let assumptions A1, A2, A3 und A4 hold. Set. if, then there exist k orthogonal vectors r 1,.., r k ( if i = j, 0 0therwise) so that Y ’ s rows satisfy
 so that Y ’ s rows satisfy.")
16
Kernel k-means Before clustering,points are mapped to a higher- dimensional feature space using a nonlinear function Weighted kernel k-means

17
Weighted Kernel k-means A weight for each poing a : w(a) Cluster, the partitioning of points, with the non-linear function, define the objektiv function where
 Cluster, the partitioning of points, with the non-linear function, define the objektiv function where")
18
Euklidische Abstand von zu m j

19
Algorithmus weighted-kernel-kmeans(K,k,w,C 1, …, C k ) Input: K: kernel matrix, k: number of clusters, w: weights for each point Output: C 1,.., C k :partitioning of the points 1.Initialize the k clusters: 2.Set t = 0. 3.For each point a,find its new cluster index as 4. Compute the updated clusters as 5. If not converged, set t=t+1 and go to Step 3; Otherweise, stop.

20
Spectral Clustering with Normalized Cuts Gegeben sei ein Graph G=( V, E, A), wobei V ist die Menge der Eckpunkten, E ist die Menge der Kanten zwischen die Punkten, A ist ein Matrix der Kanten, sei A, B ⊆ V,definiere links( A, B )= normlinkratio( A, B )=
, wobei V ist die Menge der Eckpunkten, E ist die Menge der Kanten zwischen die Punkten, A ist ein Matrix der Kanten, sei A, B ⊆ V,definiere links( A, B )= normlinkratio( A, B )=")
21
Sei D ein diagonale Matrix,mit, das normalized cut Kriterium minimize ist aber Äquivalent zu dem Problem maximize, wobei, X ist ein n*k indicator matrix, und

22
Sei, erleichtere die Anforderungen, so dass, X= maximize Um dieses Problem zu loesen, setzen wir den Matrix mit k Eigenvektoren von dem Matrix

23
Normalized cuts using Weighted Kernel k-means sei W=D und, die spur maximazation von weighted kernel k-means ist Äquivalent zu spur maximazation fuer normalized cut, wenn. Kernel k-means using Eigenvectors rechne die erste k Eigenvektoren von Matrix

24
Fazit Spectral Clustering Kernel k-means

Ähnliche Präsentationen